Kettle数据集成实验指导书

Kettle数据集成
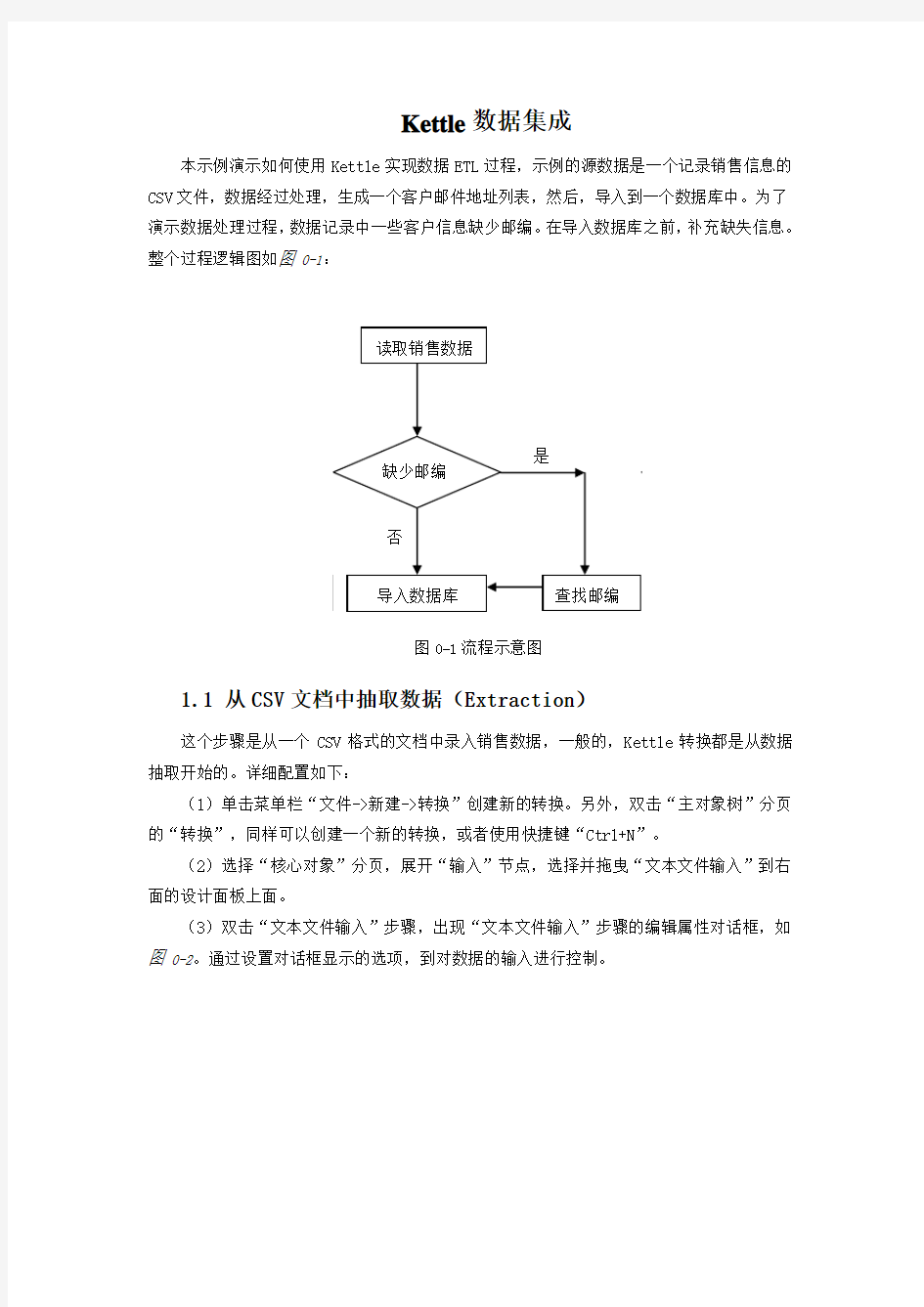
本示例演示如何使用Kettle实现数据ETL过程,示例的源数据是一个记录销售信息的CSV文件,数据经过处理,生成一个客户邮件地址列表,然后,导入到一个数据库中。为了演示数据处理过程,数据记录中一些客户信息缺少邮编。在导入数据库之前,补充缺失信息。整个过程逻辑图如图 0-1:
图 0-1流程示意图
1.1从CSV文档中抽取数据(Extraction)
这个步骤是从一个CSV格式的文档中录入销售数据,一般的,Kettle转换都是从数据抽取开始的。详细配置如下:
(1)单击菜单栏“文件->新建->转换”创建新的转换。另外,双击“主对象树”分页的“转换”,同样可以创建一个新的转换,或者使用快捷键“Ctrl+N”。
(2)选择“核心对象”分页,展开“输入”节点,选择并拖曳“文本文件输入”到右面的设计面板上面。
(3)双击“文本文件输入”步骤,出现“文本文件输入”步骤的编辑属性对话框,如图 0-2。通过设置对话框显示的选项,到对数据的输入进行控制。
图 0-2属性对话框
(4)在“步骤名”文本框中,输入“销售数据读取”。将步骤名更改为“销售数据读取”。
(5)单击“浏览”按钮定位到数据源文件sales_data.csv,例如:文件在E:\Kettle\sales_data.csv路径下面。定位到文件夹E:\Kettle\,选择文件sales_data.csv,单击“打开”按钮。
(6)单击“增加”按钮,添加文件路径到选中的文件列表中。单击“显示文件内容”按钮。可以查看文件内容的详细格式,使用了什么分隔符,是否有行首(列标)。例如:文件使用了逗号(,)作为分隔符,使用引号(“)作为文本限定符,以及包含一行标题。
(7)单击“文本文件输入”的“内容”分页,“内容”分页用来设置输入数据文件的格式。
(8)在“分隔符”文本框中,输入“,”(中英文逗号不同)。在“文本限定符”文本框中,输入“"”,因为文件“sales_data.csv”中有行首,选择“头部”,在“头部行数量”文本框中,输入“1”。如图 0-3所示。
图 0-3内容属性页
(9)单击“字段”分页,单击“获得字段”,从数据文件中读取字段。此时会弹出一个对话框,要求指定要扫描数据的行数,可以设置任意值,“0”表示扫描整个文件,网格中的每一行都允许定义字段的属性,例如,格式,长度和精度,是否允许有重复行出现。单击“确定”按钮,将显示定义格式下输入数据的汇总信息。通过扫描可以检查输入的数据是否正确,从而减少转换运行时错误。单击“取消”,不扫描数据文件。扫描完成后,单击“关闭”按钮,回到属性设置对话框。
(10)在“字段”分页下,找到“SALES”字段,“SALES”的字段类型显示为
“String”,kettle通过它来确定字段的数据类型,单击“String”,在下拉框中选择“Number”,可以更正数据类型为数字类型。单击“格式”列对应的单元格,输入“#.##”或“0.00”,定义要显示个数据格式。如图 0-4所示。
图 0-4字段属性页
(11)单击“预览记录”,查看指定行数的记录。以验证输入的数据格式是否正确。
1.2过滤邮编缺失的记录(Transformation)
资源文件中有许多缺少邮编的记录,使用过滤记录步骤过滤出这些记录,以便在下一个步骤中解决。
(1)添加“过滤记录”,到设计面板。
(2)创建一个连接在“销售数据输入”(文本文件输入)步骤和“过滤记录”步骤之间。连接表示数据在转换中的流向,创建连接,单击“销售数据输入”步骤,然后,长按Shift键,在“销售数据输入”图标上按着鼠标左键拖曳到过滤记录步骤。这样两个步骤之间显示一个箭头,表示数据的流向。如图 0-5所示。
图 0-5步骤设置
另外,把鼠标悬停在“销售数据输入”步骤上,过一会儿,会出现悬停窗口,拖曳步骤的向右指针按钮到“过滤记录”,同样可以创建一个连接。如图 0-6所示。
图 0-6添加连接
(3)双击“过滤记录”步骤,在属性设置对话框中编辑“过滤记录”的属性。
(4)在“步骤名”文本框中输入“过滤缺失邮编”
(5)在“条件”下面,点击
(6)在字段对话框中选择“POSTALCODE”,单击“确定”
(7)单击比较操作符(默认设置为“=”),选择IS NOT NULL,单击“确定”。单击“确定”按钮退出过滤字段属性对话框。
1.3加载数据到目标数据库(Loading)
将“POSTALCODE”不为空的记录加载到数据库中的表。
(1)在“核心对象”分页中,展开“输出”文件夹,
(2)单击并拖曳“表输出”步骤到设计面板,在“过滤缺失邮编”(过滤字段)和表输出步骤创建连接,选择“Result is TRUE”,如图 0-7所示。
图 0-7有选择的连接
(3)双击“表输入”步骤,打开属性对话框。
(4)重命名步骤名为“写入数据库”
(5)单击“数据库连接”文本框后面的“新建”按钮,弹出一个数据库连接对话框,配置属性,创建一个数据库连接。
(6)配置数据库连接参数
(7)单击“测试”,检验数据库配置是否正确。单击“确定”退出窗口
(8)单击“确定”,退出数据库连接对话框
(9)在“表输入”属性对话框中,选择“裁剪表”属性。
(10)在“目标表”文本框中,输入“SALES_DATA”,数据表在目标数据库中并不存在,Kettle提供根据输入字段生成DDL语句来创建表。但用户必须对数据库有足够的权限。
(11)单击“SQL”生成创建目标表的DDL语句。
(12)单击“执行”运行SQL语句。当一个SQL语句执行完成后,会有一个显示结果的对话框弹出,单击“确定”,关闭对话框。单击“关闭”关闭SQL编辑对话框,单击“确定”,关闭表输入编辑对话框。
最终的完整步骤如图 0-8:
图 0-8完整的转换
1.4运行和调试
转换有三种运行方式,适用于各种ETL项目的需求。
(1)在Spoon图形界面设计器上,单击执行按钮(用于执行转换或者作业),一个“执行转换”对话框出现。可以选择本地执行转换、远程执行转换或者集群环境下执行。这里选择“本地执行”。
(2)单击“启动”。转换开始执行,在设计面板下面是“执行结果”面板,“Step Metrics”页,显示转换中各个步骤的统计结果,包括读写记录和输入、输出及处理速度等相关信息的显示。如果某个步骤出错,该步骤的信息会高亮显示为红色。如图 0-9所示。
图 0-9结果统计窗口
数据挖掘实验三报告
实验三:基于Weka 进行关联规则挖掘 实验步骤 1.利用Weka对数据集contact-lenses.arff进行Apriori关联规则挖掘。要求: 描述数据集;解释Apriori 算法及流程;解释Weka 中有关Apriori 的参数;解释输出结果 Apriori 算法: 1、发现频繁项集,过程为 (1)扫描 (2)计数 (3)比较 (4)产生频繁项集 (5)连接、剪枝,产生候选项集 (6)重复步骤(1)~(5)直到不能发现更大的频集 2、产生关联规则 (1)对于每个频繁项集L,产生L的所有非空子集; (2)对于L的每个非空子集S,如果 P(L)/P(S)≧min_conf(最小置信度阈值) 则输出规则“S=>L-S” Weka 中有关Apriori 的参数:
1. car 如果设为真,则会挖掘类关联规则而不是全局关联规则。 2. classindex 类属性索引。如果设置为-1,最后的属性被当做类属性。 3.delta 以此数值为迭代递减单位。不断减小支持度直至达到最小支持度或产生了满足数量要求的规则。 4. lowerBoundMinSupport 最小支持度下界。 5. metricType 度量类型。设置对规则进行排序的度量依据。可以是:置信度(类关联规则只能用置信度挖掘),提升度(lift),杠杆率(leverage),确信度(conviction)。 在Weka中设置了几个类似置信度(confidence)的度量来衡量规则的关联程度,它们分别是: a)Lift :P(A,B)/(P(A)P(B)) Lift=1时表示A和B独立。这个数越大(>1),越表明A和B存在于一个购物篮中不是偶然现象,有较强的关联度. b)Leverage :P(A,B)-P(A)P(B) Leverage=0时A和B独立,Leverage越大A和B的关系越密切
大型数据库实验指导书
淮海工学院计算机科学系 大型数据库实验指导书 计算机网络教研室
实验1安装配置与基本操作 实验目的 1. 掌握Oracle9i服务器和客户端软件的安装配置方法。 2. 掌握Oracle9i数据库的登录、启动和关闭。 实验环境 局域网,windows 2000 实验学时 2学时,必做实验。 实验内容 1. 在局域网环境下安装配置Oracle9i服务器和客户端软件。 2. 练习Oracle9i数据库的登录、启动和关闭等基本操作。 实验步骤 1、将Oracle 9i的第1号安装盘放入光驱,双击setup,将弹出“Oracle Universal Installer:欢迎使用”对话框。 2、单击“下一步”按钮,出现“Oracle Universal Installer:文件定位”对话框。 在路径中输入“E:\Oracle\ora92”,其它取默认值。 3、启动第1号盘的安装程序setup,具体方法同安装Oracle 9i服务器,不同的是在 选择安装产品时选择“Oracle9i Client 9.2.0.1.0”选项; 4、安装结束后,弹出“Oracle Net Configuration Assistant:欢迎使用”对话框。取 默认值。 5、登录Oracle9i数据库:选择“开始”→“所有程序”→Oracle-OraHome92→Enterprise Manager Console ; 6、系统出现“登录”对话框。选择“独立启动”。 分析与思考 (1)简述启动Oracle9i数据库的一般步骤。 (2)简述启动Oracle9i模式中三个选项的区别? (3)简述关闭Oracle9i模式中四个选项的区别?
#(16课时)数据库实验指导书
《数据库原理及使用》实验指导书 (适用于计算机科学和技术、软件工程专业) 热风器4 计算机科学和技术学院 2011年12月 ⒈本课程的教学目的和要求 数据库系统产生于20世纪60年代末。30多年来,数据库技术得到迅速发展,已形成较为完整的理论体系和一大批实用系统,现已成为计算机软件领域的一个重要分支。数据库原理是计算科学和技术专业重要的专业课程。 本课程实验教学的目的和任务是使学生通过实践环节深入理解和掌握课堂教学内容,使学生得到数据库使用的基本训练,提高其解决实际问题的能力。 ⒉实验教学的主要内容 数据库、基本表、视图、索引的建立和数据的更新;关系数据库的查询,包括单表查询、连接查询、嵌套查询等;数据库系统的实现技术,包括事务的概念及并发控制、恢复、完整性和安全性实现机制;简单数据库使用系统的设计实现。 ⒊实验教学重点 本课程的实验教学重点包括: ⑴数据库、基本表、视图、索引的建立和数据的更新; ⑵SQL的数据查询; ⑶恢复、完整性和安全性实现机制; ⑷简单数据库使用系统的设计实现; 4教材的选用 萨师煊,王珊.数据库系统概论(第四版).北京:高等教育出版社.2006,5 实验1创建数据库(2学时) 实验目的 1.学会数据表的创建; 2.加深对表间关系的理解; 3.理解数据库中数据的简单查询方法和使用。 实验内容 一、给定一个实际问题,实际使用问题的模式设计中至少要包括3个基本表。使用问题是供应商给工程供应零件(课本P74)。 1.按照下面的要求建立数据库: 创建一个数据库,数据库名称可以自己命名,其包含一个主数据文件和一个事务日志文件。注意主数据文件和事务日志文件的逻辑名和操作系统文件名,初始容量大小为5MB,
数据分析实验报告
数据分析实验报告 文稿归稿存档编号:[KKUY-KKIO69-OTM243-OLUI129-G00I-FDQS58-
第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出: 统计量 全国居民 农村居民 城镇居民 N 有效 22 22 22 缺失 均值 1116.82 747.86 2336.41 中值 727.50 530.50 1499.50 方差 1031026.918 399673.838 4536136.444 百分位数 25 304.25 239.75 596.25 50 727.50 530.50 1499.50 75 1893.50 1197.00 4136.75 3画直方图,茎叶图,QQ 图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民 Stem-and-Leaf Plot Frequency Stem & Leaf 5.00 0 . 56788 数据分析实验报告 【最新资料,WORD 文档,可编辑修改】
2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689 1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下:(1)K—S检验
结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。 (2 )W 检验 结果:在Shapiro-Wilk 检验结果972.00 w ,p=0.174大于0.05 接受原假设,即数据来自正太总体。 习题1.5 5 多维正态数据的统计量 数据:
数据挖掘实验报告
《数据挖掘》Weka实验报告 姓名_学号_ 指导教师 开课学期2015 至2016 学年 2 学期完成日期2015年6月12日
1.实验目的 基于https://www.360docs.net/doc/ff1766435.html,/ml/datasets/Breast+Cancer+WiscOnsin+%28Ori- ginal%29的数据,使用数据挖掘中的分类算法,运用Weka平台的基本功能对数据集进行分类,对算法结果进行性能比较,画出性能比较图,另外针对不同数量的训练集进行对比实验,并画出性能比较图训练并测试。 2.实验环境 实验采用Weka平台,数据使用来自https://www.360docs.net/doc/ff1766435.html,/ml/Datasets/Br- east+Cancer+WiscOnsin+%28Original%29,主要使用其中的Breast Cancer Wisc- onsin (Original) Data Set数据。Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 3.实验步骤 3.1数据预处理 本实验是针对威斯康辛州(原始)的乳腺癌数据集进行分类,该表含有Sample code number(样本代码),Clump Thickness(丛厚度),Uniformity of Cell Size (均匀的细胞大小),Uniformity of Cell Shape (均匀的细胞形状),Marginal Adhesion(边际粘连),Single Epithelial Cell Size(单一的上皮细胞大小),Bare Nuclei(裸核),Bland Chromatin(平淡的染色质),Normal Nucleoli(正常的核仁),Mitoses(有丝分裂),Class(分类),其中第二项到第十项取值均为1-10,分类中2代表良性,4代表恶性。通过实验,希望能找出患乳腺癌客户各指标的分布情况。 该数据的数据属性如下: 1. Sample code number(numeric),样本代码; 2. Clump Thickness(numeric),丛厚度;
大数据库应用实验指导书(1,2)
《—数据库应用—》上机指导书 数据库课程组编写 前言
“数据库应用”是一门理论性和实践性都很强的专业课程, 通过本课程的学习,学生会使用SQL Server数据库管理系统并能进行实际应用。能熟练掌握Transact-SQL语言,能保证数据的完整性和一致性、数据库的安全,并能进行简单编程。 “数据库应用”课程上机的主要目标: 1)通过上机操作,加深对数据库系统理论知识的理解。 2)通过使用SQL SERVER2000,了解SQL SERVER 数据库管理系统的数据管理方式,并掌握其操作技术。 3)通过实际题目的上机,提高动手能力,提高分析问题和解决问题的能力。 “数据库应用”课程上机项目设置与内容 表3列出了”数据库应用”课程具体的上机项目和内容 上机组织运行方式:
⑴上机前,任课教师需要向学生讲清上机的整体要求及上机的目标任务;讲清上机安排和进度、平时考核内容、期末考试办法、上机守则及上机室安全制度;讲清上机操作的基本方法,上机对应的理论内容。 ⑵每次上机前:学生应当先弄清相关的理论知识,再预习上机内容、方法和步骤,避免出现盲目上机的行为。 ⑶上机1人1组,在规定的时间内,由学生独立完成,出现问题时,教师要引导学生独立分析、解决,不得包办代替。 ⑷该课程上机是一个整体,需要有延续性。机房应有安全措施,避免前面的上机数据、程序和环境被清除、改动等事件发生,学生最好能自备移动存储设备,存储自己的数据。 ⑸任课教师要认真上好每一堂课,上机前清点学生人数,上机中按要求做好学生上机情况及结果记录。 上机报告要求 上机报告应包含以下内容: 上机目的,上机内容及操作步骤、上机结果、及上机总结及体会。 上机成绩评定办法 上机成绩采用五级记分制,分为优、良、中、及格、不及格。按以下五个方面进行综合考核: 1、对上机原理和上机中的主要环节的理解程度; 2、上机的工作效率和上机操作的正确性; 3、良好的上机习惯是否养成; 4、工作作风是否实事求是; 5、上机报告(包括数据的准确度是否合格,体会总结是否认真深入等) 其它说明 1.在上机课之前,每一个同学必须将上机的题目、程序编写完毕,对运行中可能出 现的问题应事先作出估计;对操作过程中有疑问的地方,应做上记号,以便上机时给予注意。做好充分的准备,以提高上机的效率 2.所有上机环节均由每位同学独立完成,严禁抄袭他人上机结果,若发现有结果雷 同者,按上机课考核办法处理。 3.上机过程中,应服从教师安排。 4.上机完成后,要根据教师的要求及时上交作业。
福建工程学院《实验指导书(数据库系统原理及应用)》
数据库系统原理 实验指导书 (本科)
目录 实验一数据定义语言 (1) 实验二SQL Sever中的单表查询 (3) 实验三SQL Serve中的连接查询 (4) 实验四SQL Serve的数据更新、视图 (5) 实验五数据控制(完整性与安全性) (7) 实验六语法元素与流程控制 (9) 实验七存储过程与用户自定义函数 (11) 实验八触发器 (12)
实验一数据定义语言 一、实验目的 1.熟悉SQL Server2000/2005查询分析器。 2.掌握SQL语言的DDL语言,在SQL Server2000/2005环境下采用Transact-SQL实现表 的定义、删除与修改,掌握索引的建立与删除方法。 3.掌握SQL Server2000/2005实现完整性的六种约束。 二、实验内容 1.启动SQL Server2000/2005查询分析器,并连接服务器。 2.创建数据库: (请先在D盘下创建DB文件夹) 1)在SQL Server2000中建立一个StuDB数据库: 有一个数据文件:逻辑名为StuData,文件名为“d:\db\S tuDat.mdf”,文件初始大小为5MB,文件的最大大小不受限制,文件的增长率为2MB; 有一个日志文件,逻辑名为StuLog,文件名为“d:\db\StuLog.ldf”,文件初始大小为5MB,文件的最大大小为10MB,文件的增长率为10% 2)刷新管理器查看是否创建成功,右击StuDB查看它的属性。 3.设置StuDB为当前数据库。 4.在StuDB数据库中作如下操作: 设有如下关系表S:S(CLASS,SNO, NAME, SEX, AGE), 其中:CLASS为班号,char(5) ;SNO为座号,char(2);NAME为姓名,char(10),设姓名的取值唯一;SEX为性别,char(2) ;AGE为年龄,int,表中主码为班号+座号。 写出实现下列功能的SQL语句。 (1)创建表S; (2)刷新管理器查看表是否创建成功; (3)右击表S插入3个记录:95031班25号李明,男性,21岁; 95101班10号王丽,女性,20岁; 95031班座号为30,名为郑和的学生记录; (4)将年龄的数据类型改为smallint; (5)向S表添加“入学时间(comedate)”列,其数据类型为日期型(datetime); (6)对表S,按年龄降序建索引(索引名为inxage); (7)删除S表的inxage索引; (8)删除S表; 5.在StuDB数据库中, (1)按照《数据库系统概论》(第四版)P82页的学生-课程数据库创建STUDENT、COURSE 和SC三张表,每一张表都必须有主码约束,合理使用列级完整性约束和表级完整性。 并输入相关数据。 (2)将StuDB数据库分离,在D盘下创建DB文件夹下找到StuDB数据库的两个文件,进行备份,后面的实验要用到这个数据库。 6.(课外)按照《数据库系统概论》(第四版)P74页习题5的SPJ数据库。创建SPJ数据 库,并在其中创建S、P、J和SPJ四张表。每一张表都必须有主码约束,合理使用列级完整性约束和表级完整性。要作好备份以便后面的实验使用该数据库数据。 三、实验要求:
数据挖掘实验报告(一)
数据挖掘实验报告(一) 数据预处理 姓名:李圣杰 班级:计算机1304 学号:1311610602
一、实验目的 1.学习均值平滑,中值平滑,边界值平滑的基本原理 2.掌握链表的使用方法 3.掌握文件读取的方法 二、实验设备 PC一台,dev-c++5.11 三、实验内容 数据平滑 假定用于分析的数据包含属性age。数据元组中age的值如下(按递增序):13, 15, 16, 16, 19, 20, 20, 21, 22, 22, 25, 25, 25, 25, 30, 33, 33, 35, 35, 35, 35, 36, 40, 45, 46, 52, 70。使用你所熟悉的程序设计语言进行编程,实现如下功能(要求程序具有通用性): (a) 使用按箱平均值平滑法对以上数据进行平滑,箱的深度为3。 (b) 使用按箱中值平滑法对以上数据进行平滑,箱的深度为3。 (c) 使用按箱边界值平滑法对以上数据进行平滑,箱的深度为3。 四、实验原理 使用c语言,对数据文件进行读取,存入带头节点的指针链表中,同时计数,均值求三个数的平均值,中值求中间的一个数的值,边界值将中间的数转换为离边界较近的边界值 五、实验步骤 代码 #include
数据分析实验报告
《数据分析》实验报告 班级:07信计0班学号:姓名:实验日期2010-3-11 实验地点:实验楼505 实验名称:样本数据的特征分析使用软件名称:MATLAB 实验目的1.熟练掌握利用Matlab软件计算均值、方差、协方差、相关系数、标准差与变异系数、偏度与峰度,中位数、分位数、三均值、四分位极差与极差; 2.熟练掌握jbtest与lillietest关于一元数据的正态性检验; 3.掌握统计作图方法; 4.掌握多元数据的数字特征与相关矩阵的处理方法; 实验内容安徽省1990-2004年万元工业GDP废气排放量、废水排放量、固体废物排放量以及用于污染治理的投入经费比重见表6.1.1,解决以下问题:表6.1.1废气、废水、固体废物排放量及污染治理的投入经费占GDP比重 年份 万元工业GDP 废气排放量 万元工业GDP 固体物排放量 万元工业GDP废 水排放量 环境污染治理投 资占GDP比重 (立方米)(千克)(吨)(%)1990 104254.40 519.48 441.65 0.18 1991 94415.00 476.97 398.19 0.26 1992 89317.41 119.45 332.14 0.23 1993 63012.42 67.93 203.91 0.20 1994 45435.04 7.86 128.20 0.17 1995 46383.42 12.45 113.39 0.22 1996 39874.19 13.24 87.12 0.15 1997 38412.85 37.97 76.98 0.21 1998 35270.79 45.36 59.68 0.11 1999 35200.76 34.93 60.82 0.15 2000 35848.97 1.82 57.35 0.19 2001 40348.43 1.17 53.06 0.11 2002 40392.96 0.16 50.96 0.12 2003 37237.13 0.05 43.94 0.15 2004 34176.27 0.06 36.90 0.13 1.计算各指标的均值、方差、标准差、变异系数以及相关系数矩阵; 2.计算各指标的偏度、峰度、三均值以及极差; 3.做出各指标数据直方图并检验该数据是否服从正态分布?若不服从正态分布,利用boxcox变换以后给出该数据的密度函数; 4.上网查找1990-2004江苏省万元工业GDP废气排放量,安徽省与江苏省是 否服从同样的分布?
数据挖掘实验报告三
实验三 一、实验原理 K-Means算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。 在数据挖掘中,K-Means算法是一种cluster analysis的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。 算法原理: (1) 随机选取k个中心点; (2) 在第j次迭代中,对于每个样本点,选取最近的中心点,归为该类; (3) 更新中心点为每类的均值; (4) j<-j+1 ,重复(2)(3)迭代更新,直至误差小到某个值或者到达一定的迭代步 数,误差不变. 空间复杂度o(N) 时间复杂度o(I*K*N) 其中N为样本点个数,K为中心点个数,I为迭代次数 二、实验目的: 1、利用R实现数据标准化。 2、利用R实现K-Meams聚类过程。 3、了解K-Means聚类算法在客户价值分析实例中的应用。 三、实验内容 依据航空公司客户价值分析的LRFMC模型提取客户信息的LRFMC指标。对其进行标准差标准化并保存后,采用k-means算法完成客户的聚类,分析每类的客户特征,从而获得每类客户的价值。编写R程序,完成客户的k-means聚类,获得聚类中心与类标号,并统计每个类别的客户数
四、实验步骤 1、依据航空公司客户价值分析的LRFMC模型提取客户信息的LRFMC指标。
2、确定要探索分析的变量 3、利用R实现数据标准化。 4、采用k-means算法完成客户的聚类,分析每类的客户特征,从而获得每类客户的价值。
五、实验结果 客户的k-means聚类,获得聚类中心与类标号,并统计每个类别的客户数 六、思考与分析 使用不同的预处理对数据进行变化,在使用k-means算法进行聚类,对比聚类的结果。 kmenas算法首先选择K个初始质心,其中K是用户指定的参数,即所期望的簇的个数。 这样做的前提是我们已经知道数据集中包含多少个簇. 1.与层次聚类结合 经常会产生较好的聚类结果的一个有趣策略是,首先采用层次凝聚算法决定结果
数据库实训指导书
《数据库》实训计划 课程名称:数据库原理及应用 一、课程简介 《数据库原理及应用》课程是我院计算机科学与技术专业的一门重要专业课程,是一门理论性和实践性都很强的面向实际应用的课程,它是计算机科学技术中发展最快的领域之一。可以说数据库技术渗透到了工农业生产、商业、行政管理、科学研究、教育、工程技术和国防军事等各行各业。因此本课程的教学既要向学生传授一定的数据库理论基础知识,又要培养学生运用数据库理论知识和数据库技术解决实际应用问题的能力。 二.课程实验 实验题目 1.学籍管理系统 2.图书档案管理系统 3.企业人事管理系统 4.工资管理系统 5.用户和权限管理系统。 6.仓库管理系统。 7.企业进销存管理系统。 8、超市管理系统 10、酒店管理系统 11、旅游管理系统 12、高考成绩信息管理系统
13、医院信息管理系统 14、银行计算机储蓄系统 15、 ICU监护系统 16、可自拟题目 任选一题按照下列实验纲要进行设计。 实验纲要 1、实验目标 本课程实验教学的目的和任务是使学生通过实践环节深入理解和掌握课堂教学内容,使学生得到数据库应用的基本训练,提高其解决实际问题的能力。 2、实验内容 数据库的模式设计;数据库、表、视图、索引的建立与数据的更新;关系数据库的查询,包括嵌套查询、连接查询等;数据库系统的实现技术,包括事务的概念及并发控制、恢复、完整性和安全性实现机制;简单数据库应用系统的设计实现。 给定一实际问题,让学生自己完成数据库模式的设计,包括各表的结构(属性名、类型、约束等)及表之间的关系,在选定的DBMS上建立数据库表。用SQL命令和可视化环境分别建立数据库表,体会两种方式的特点。 3、实验教学重点 本课程的实验教学重点包括:⑴数据库的模式设计;⑵SQL的数据查询; ⑶并发控制、恢复、完整性和安全性实现机制;⑷简单数据库应用系统的设计实现; 实验1:数据库的创建
数据挖掘实验三
实验三设计并构造AdventureWorks数据仓库实例 【实验要求】 在SQL Server 平台上,利用AdventureWorks数据库作为商业智能解决方案的数据源,设计并构造数据仓库,建立OLAP和数据挖掘模型,并以输出报表的形式满足决策支持的查询需求。 【实验内容】 步骤1:需求分析:以决策者的视角分析和设计数据仓库的需求; 步骤2:根据所设计的需求,确定本数据仓库的主题和主题与边界; 步骤3:设计并构造逻辑模型; 步骤4:进行数据转换和抽取,建立数据仓库:创建数据源,,建立OLAP和挖掘模型,使用多维数据集进行分析,建立数据挖掘结构和数据挖掘模型,创建报表。 【实验平台】 Win7操作系统,SQL Server 2005 【实验过程】 一、创建Analysis Services 项目 1.打开Business Intelligence Development Studio。 2.在“文件”菜单上,指向“新建”,然后选择“项目”。 3.确保已选中“模板”窗格中的“Analysis Services 项目”。 4.在“名称”框中,将新项目命名为AdventureWorks。 5. 单击“确定”。 二、创建数据库和数据源 1.运行AdventureWorks sql server 2005示例数据库.msi,然后用SQL Server Management Studio 附加数据库AdventureWorks_Data.mdf 。 (1)运行AdventureWorks sql server 2005示例数据库.msi
(2)用SQL Server Management Studio附加数据库AdventureWorks_Data.mdf
ACCESS2010数据库技术实验指导书3
《ACCESS2010数据库技术及应用》 实验指导(3) 学号: 姓名: 班级: 专业:
实验三窗体 实验类型:验证性实验课时: 4 学时指导教师: 时间:201 年月日课次:第节教学周次:第周 一、实验目的 1. 掌握窗体创建的方法 2. 掌握向窗体中添加控件的方法 3. 掌握窗体的常用属性和常用控件属性的设置 二、实验内容和要求 1. 创建窗体 2. 修改窗体,添加控件,设置窗体及常用控件属性 三、实验步骤 案例一:创建窗体 1.使用“窗体”按钮创建“成绩”窗体。 操作步骤如下: (1)打开“教学管理.accdb”数据库,在导航窗格中,选择作为窗体的数据源“教师”表,在功能区“创建”选项卡的“窗体”组,单击“窗体”按钮,窗体立即创建完成,并以布局视图显示,如图3-1所示。 (2)在快捷工具栏,单击“保存”按钮,在弹出的“另存为”对话框中输入窗体的名称“教师”,然后单击“确定”按钮。 图3-1布局视图 2.使用“自动创建窗体”方式 要求:在“教学管理.accdb”数据库中创建一个“纵栏式”窗体,用于显示“教师”表中的信息。 操作步骤: (1)打开“教学管理.accdb”数据库,在导航窗格中,选择作为窗体的数据源“教师”表,在功能区“创建”选项卡的“窗体”组,单击“窗体向导”按钮。如图3-2所示。 (2)打开“请确定窗体上使用哪些字”段对话框中,如图3-3 所示。在“表和查询”下拉列表中光图3-2窗体向导按钮
标已经定位在所学要的数据源“教师”表,单击按钮,把该表中全部字段送到“选定字段”窗格中,单击下一步按钮。 (3)在打开“请确定窗体上使用哪些字”段对话框中,选择“纵栏式”,如图3-4所示。单击下一步按钮。 (4)在打开“请确定窗体上使用哪些字”段对话框中,输入窗体标题“教师”,选取默认设置:“打开窗体查看或输入信息”,单击“完成”按钮,如图3-5所示。 (5)这时打开窗体视图,看到了所创建窗体的效果,如图3-6所示。 图3-3“请确定窗体上使用哪些字”段对话框 图3-4“请确定窗体使用的布局”段对话框中
2016数据库原理实验指导书
信息工程学院 数据库原理实验指导书二零一六年五月
目录 实验一SQL SERVER 2005的安装与启动 (1) 实验二数据库的操作 (11) 实验三SQL SERVER2005查询编辑器 (23) 实验四SQL语言的DDL (31) 实验五SQL语言的DML初步 (34) 实验六DML的数据查询 (36) 实验七数据库综合设计 (40)
实验一SQL Server 2005的安装与启动 一、实验目的 SQL Server 2005是Mircosoft公司推出的关系型网络数据库管理系统,是一个逐步成长起来的大型数据库管理系统。 本次实验了解SQL Server 2005的安装过程,了解SQL Server 2005的启动,熟悉SQL Server 2005软件环境。学会安装SQL Server 2005。 二、实验内容 1.安装SQL Server 2005 (1)将SQL Server 2005(中文开发版)安装盘插入光驱后,SQL Server 2005安装盘将自动启动安装程序;或手动执行光盘根 目录下的Autorun.exe文件,这两种方法都可进行SQL Server 2005的安装。出现如下画面。 (2)选中“运行SQL Server Client 安装向导”进行安装,弹出【最终用户许可协议】界面。
(3)选中【我接受许可条款和条件】选项,单击【下一步】按钮,进入【安装必备组件】界面。 (4)组件安装完成后,单击【下一步】按钮,进入【欢迎使用Microsoft SQL Server 安装向导】界面。
(5)单击【下一步】按钮,进入【系统配置检查】界面。检查完毕将显示检查结果。 (6)检查如果没有错误,单击【下一步】按钮,进入【注册信息】界面。
数据分析实验报告
数据分析实验报告 【最新资料,WORD文档,可编辑修改】 第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出:
方差1031026.918399673.8384536136.444百分位数25304.25239.75596.25 50727.50530.501499.50 751893.501197.004136.75 3画直方图,茎叶图,QQ图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民Stem-and-Leaf Plot Frequency Stem & Leaf 9.00 0 . 122223344 5.00 0 . 56788 2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689
1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下:(1)K—S检验 单样本Kolmogorov-Smirnov 检验 身高N60正态参数a,,b均值139.00
标准差7.064 最极端差别绝对值.089 正.045 负-.089 Kolmogorov-Smirnov Z.686 渐近显着性(双侧).735 a. 检验分布为正态分布。 b. 根据数据计算得到。 结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。(2)W检验
数据挖掘实验报告1
实验一 ID3算法实现 一、实验目的 通过编程实现决策树算法,信息增益的计算、数据子集划分、决策树的构建过程。加深对相关算法的理解过程。 实验类型:验证 计划课间:4学时 二、实验内容 1、分析决策树算法的实现流程; 2、分析信息增益的计算、数据子集划分、决策树的构建过程; 3、根据算法描述编程实现算法,调试运行; 4、对所给数据集进行验算,得到分析结果。 三、实验方法 算法描述: 以代表训练样本的单个结点开始建树; 若样本都在同一个类,则该结点成为树叶,并用该类标记; 否则,算法使用信息增益作为启发信息,选择能够最好地将样本分类的属性; 对测试属性的每个已知值,创建一个分支,并据此划分样本; 算法使用同样的过程,递归形成每个划分上的样本决策树 递归划分步骤,当下列条件之一成立时停止: 给定结点的所有样本属于同一类; 没有剩余属性可以进一步划分样本,在此情况下,采用多数表决进行 四、实验步骤 1、算法实现过程中需要使用的数据结构描述: Struct {int Attrib_Col; // 当前节点对应属性 int Value; // 对应边值 Tree_Node* Left_Node; // 子树 Tree_Node* Right_Node // 同层其他节点 Boolean IsLeaf; // 是否叶子节点 int ClassNo; // 对应分类标号 }Tree_Node; 2、整体算法流程
主程序: InputData(); T=Build_ID3(Data,Record_No, Num_Attrib); OutputRule(T); 释放内存; 3、相关子函数: 3.1、 InputData() { 输入属性集大小Num_Attrib; 输入样本数Num_Record; 分配内存Data[Num_Record][Num_Attrib]; 输入样本数据Data[Num_Record][Num_Attrib]; 获取类别数C(从最后一列中得到); } 3.2、Build_ID3(Data,Record_No, Num_Attrib) { Int Class_Distribute[C]; If (Record_No==0) { return Null } N=new tree_node(); 计算Data中各类的分布情况存入Class_Distribute Temp_Num_Attrib=0; For (i=0;i 计算机科学学院《ORACLE数据库》实验指导书 《ORACLE数据库》实验指导书 实验一Oracle数据库安装配置以及基本工具的使用 1.实验的基本内容 实验室中oracle数据库安装后某些服务是关闭的(为了不影响其他课程的使用),所以在进入数据库前需要对oracle进行配置: (1)启动oracle OraHomeTNSLISTENER 和oracleserviceORACLE 两个服务 (2)修改listener.ora 和tnsnames.ora 两个文件的内容 (3)以用户名:system ,口令:11111 以“独立登录”的方式进入oracle 数据库系统 (4)熟悉数据库中可用的工具。 2.实验的基本要求 (1)掌握Oracle11g的配置以及登录过程。 (2)熟悉系统的实验环境。 3.实验的基本仪器设备和耗材 计算机 4.实验步骤 (1) 查看设置的IP地址是否与本机上的IP地址一致。若不一致则修改为本机IP地址。 (2) 启动oracle OraHomeTNSLISTENER 和oracleserviceORACLE 两个服务 控制面板/性能与维护/管理工具/服务/ oracle OraHomeTNSLISTENER(右击/启动)。 控制面板/性能与维护/管理工具/服务/ oracleserviceORACLE(右击/启动) (3) 修改listener.ora 和tnsnames.ora 两个文件的内容 D:\app\Administrator\product\11.1.0\db_1\NETWORK\ADMIN (用记事本方式打开),将HOST=“…..”内容修改为本机的IP地址,保存退出。 D:\app\Administrator\product\11.1.0\db_1\NETWORK\ADMIN (用记事本方式打开),将HOST=“…..”内容修改为本机的IP地址,保存退出。 (4) 启动oracle 数据库 数据库实验指导书 (试用版) 二零零六年三月 目录 引言 1 一、课程实验目的和基本要求 1 二、主要实验环境 1 三、实验内容 1 实验1 数据库模式设计和数据库的建立 2 一、教学目的和要求 2 二、实验内容 2 三、实验步骤 2 四、思考与总结 3 实验2 数据库的简单查询和连接查询 4 一、教学目的和要求 4 二、实验内容 4 三、实验步骤 4 四、思考与总结 5 实验3 数据库的嵌套查询和组合统计查询 6 一、教学目的和要求 6 二、实验内容 6 三、实验步骤 6 四、思考与总结 7 实验4 视图与图表的定义及数据完整性和安全性 8 一、教学目的和要求 8 二、实验内容 8 三、实验步骤 8 四、思考与总结 9 实验5 简单应用系统的实现 10 一、教学目的和要求 10 二、实验内容 10 三、实验步骤 10 四、思考与总结 10 附录1:数据库实验报告格式 11 附录2:SQL Server 2000使用指南 12 1 SQL Server 2000简介 12 2 SQL Server 2000的版本 12 3 SQL Server 2000实用工具 12 4 创建数据库 15 5 创建和修改数据表 17 6 创建索引 22 7 存储过程 23 8 触发器 25 9 备份和恢复 27 10 用户和安全性管理 28 引言 数据库技术是一个理论和实际紧密相连的技术,上机实验是数据库课程的重要环节,它贯穿于整个―数据库阶段‖课程教学过程中。 一、课程实验目的和基本要求 上机实验是本课程必不可少的实践环节。学生应在基本掌握各知识点内容的基础上同步进行相关实验,以加深对知识的理解和掌握,达到理论指导实践,实践加深理论的理解与巩固的效果。 数据库课程上机实验的主要目标是: 通过上机操作,加深对数据库系统理论知识的理解。 通过使用具体的DBMS,了解一种实际的数据库管理系统,并掌握操作技术。 通过实际题目的上机实验,提高动手能力,提高分析问题和解决问题的能力。 实验在单人单机的环境下,在规定的时间内,由学生独立完成。出现问题时,教师要引导学生独立分析、解决,不得包办代替。 上机总学时不少于12学时。 二、主要实验环境 操作系统为Microsoft Windows 2000/XP。 数据库管理系统可以选择:(1)Microsoft SQL Server 2000标准版或企业版 (2)Microsoft Access2000 (3)金仓数据库KingbaseES。 三、实验内容 本课程实验主要包括数据库的模式设计,数据库、表、视图、索引的建立与数据的更新;关系数据库的查询,包括连接查询、嵌套查询、组合查询等;数据库系统的实现技术,包括事务的概念及并发控制、完整性和安全性实现机制;简单数据库应用系统的设计与实现。实验1 数据库模式设计和数据库的建立 一、教学目的和要求 根据一个具体应用,独自完成数据库模式的设计。 熟练使用SQL语句创建数据库、表、索引和修改表结构。 熟练使用SQL语句向数据库输入数据、修改数据和删除数据的操作。 二、实验内容 对实际应用进行数据库模式设计(至少三个基本表)。 数据仓库与数据挖掘实验一任务书 多维数据集的建立以及数据的加载 一、目的和要求 (1)建立关系数据库,为多维数据集的建立做好准备。 (2)在没有数据源的情况下,创建一个多维数据集,熟悉多维数据集建立的过程。 (3)为创建的多维数据集添加数据源,并向关系架构加载数据。 二、实验内容 一)建立关系数据库 1.建立数据库my sales 数据库表如下 订单信息:订单号,订单日期,订单金额,商品号,单价,数量,客户号,员工号,付款状态 客户信息表:客户号,姓名,家庭地址,性别,联系电话,年龄,生日,文化程度商品信息表:商品号,商品名称,类别编号,大小范围,大小,颜色范围,颜色,照片,吊牌价,标准成本,开始销售日期,重量,销售状态 类别信息表:类别编号,类别名称,描述,小类别编号 小类别信息表:小类别编号,小类别名称,描述,大类别编号 大类别信息表:大类别编号,大类别名称,描述 2.建立外键关系,新建数据库关系图 3.输入数据库数据 二)根据分析需求收集数据源导入数据仓库并进行抽取,转换,集成。 1)打开Microsoft SQL Server Management Studio,创建一个新的数据库sales_DW. 2)右击数据源my sales,选择单击任务—导出数据,出现导出界面,单击“下一步”按钮,“选择数据源”页自动填入创建到my sales 的连接的数据源、服务器和数据库,单击“下一步”。 3)在“选择目标”页,从数据库下拉列表框中选择sales_DW. 4)在“指定表复制和查询”页可以选择“复制一个或多个表或视图的数据”,页可以选择“编写查询以指定要传输的数据”,如果选择后者,可以在下一步出现的对话框中输入“select……………from [数据表]”语句实现数据的抽取。也可以选择前者,出现如下的对话框,根据任务选择要复制的数据表。 《数据库技术及应用》实验指导书 实验环境 1.软件需求 (1)操作系统:Windows 2000 Professional,或者Windows XP (2)数据库管理系统:SQL Server2000 (3)应用开发工具:Delphi7.0 (4)其它工具:Word 2.硬件需求 (1)PC机 (2)网络环境 基本需求信息 一、对某商场采购销售管理进行调研后,得到如下基本需求信息: 该商场有多名工作人员(主要是采购员和销售员),主要负责从供应商处采购商品,而后将商品销售给客户。采购员主要负责根据商场的销售情况确定要采购的商品,并与供应商联系,签订采购单。销售员主要负责将采购来的商品销售给客户,显然一个客户一次可能购买多种商品。一个供应商可以向该商场供应多种商品,而一种商品也可以由多个供应商供应。 商场的管理者每个月需要对该月已采购的商品和已销售的商品进行分类统计,对采购员和销售员的业绩进行考核,对供应商和客户进行等级评定,并计算商场利润。 二、E-R图 三、需要建立的数据表如下 1.供应商表(supplier):供应商ID,供应商名称,地区,信誉等级 2.供应表(supplying):供应商ID,商品ID,商品单价 3.商品表(commodity):商品ID,商品名称,商品库存量,商品均价 4.采购单表(stock):采购单ID,采购员ID,供应商ID,采购总金额,签订日期 5.采购明细表(stockDetail):采购单ID,商品ID,采购数量,商品单价 6.销售单表(sale):销售单ID,销售员ID,客户ID,销售总金额,签订日期 7.销售明细表(saleDetail):销售ID,商品ID,销售数量,商品单价,单价折扣oracle数据库实验指导书
数据库实验指导书
数据挖掘实验1任务书
2012《数据库技术及应用》实验指导书