lab13.2_TinyLinker_小型链接器
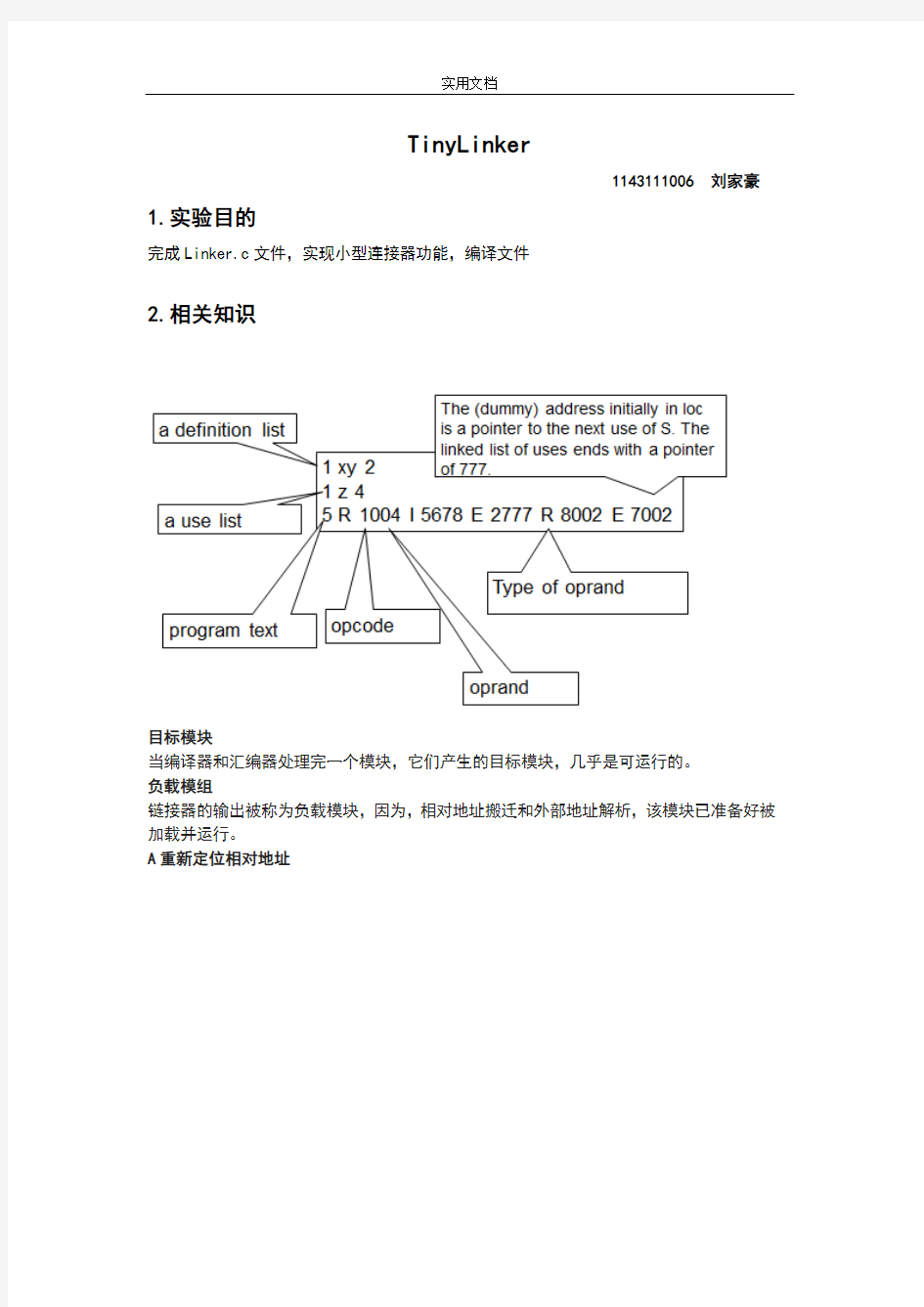
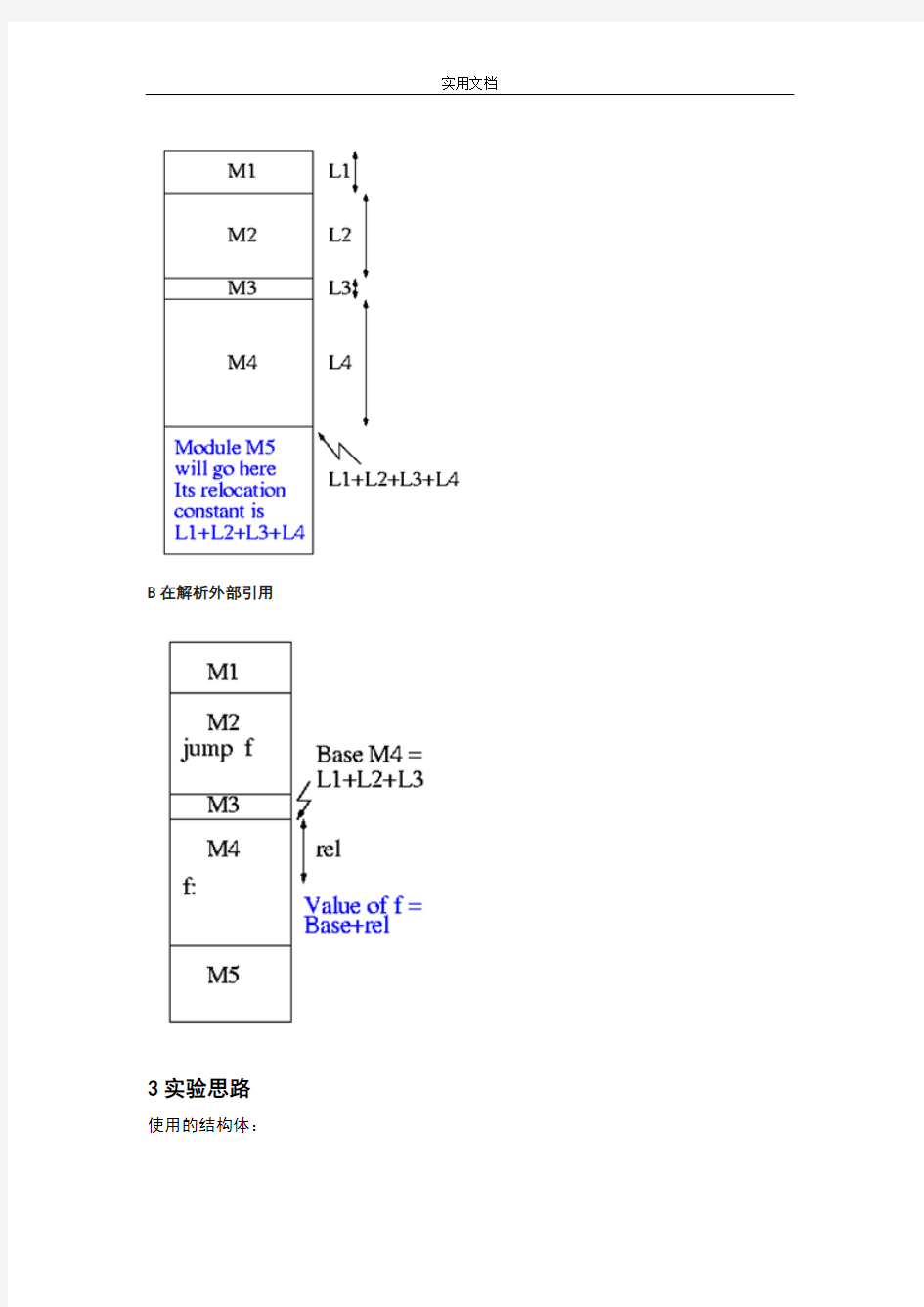
TinyLinker
1143111006 刘家豪1.实验目的
完成Linker.c文件,实现小型连接器功能,编译文件
2.相关知识
目标模块
当编译器和汇编器处理完一个模块,它们产生的目标模块,几乎是可运行的。
负载模组
链接器的输出被称为负载模块,因为,相对地址搬迁和外部地址解析,该模块已准备好被加载并运行。
A重新定位相对地址
B在解析外部引用
3实验思路
使用的结构体:
A提取file中的word
B 读取下一行
C通过两次process,对符号表和定义表进行遍历并修改,再寄地址上加偏移量,进行重定位
Process_one()用来建立符号表
process_two()用来重定位代码表,并修改代码的地址,以及打印错误情况
替换外部符号:
替换相对地址:
输出当前代码段以及打印相关错误(如果存在):
打印警告信息(如果有):
4.实验结果
测试9个输入文件输出9个output文件都满足要求:
5.Linker(linker.c源码)
#include
#include
#include
#include "linker.h"
FILE *in; //for read module
FILE *out; //for output link result
struct symbolMsg{
char sym[30];
int addr;
int module;
int errorCode;
}symbolTable[100];
struct CodeStr{
char type;
int opcode;
int errorCode;
char* symbol;
};
int offset;
void link(int test_num, const char *filename)
{
char outputfile[100];
char file[5000];
memset(outputfile, 0, 10);
sprintf(outputfile, "output-%d.txt", test_num);
in = fopen(filename, "r"); //open file for read,the file contains module that you should do with
out = fopen(outputfile, "w"); //open the "output" file to output link result
if(in==NULL||out==NULL)
{
fprintf(stderr, "can not open file for read or write\n");
exit(-1);
}
memset(symbolTable,0,sizeof(struct symbolMsg)*100);
memset(file,0,sizeof(file));
fread(file,sizeof(char),sizeof(file),in);
// printf("%s",file);
// return;
process_one(file);
process_two(file);
fclose(in);
fclose(out);
}
/*提取file中的word*/
char * nextWord(char* src,char* word,int wordsize)
{
int i=0,j=0;
memset(word,0,wordsize);
while(src[i] == ' ')i++;
for(j=0;src[i+j] != ' '&& src[i+j] != '\0' && j if (src[i+j] == '\n') { j++; break; } word[j] = src[i+j]; } return src+i+j; } char * nextLine(char* start) { int i=0; while(start[i] != '\n') i++; return &start[i +1]; } /*you must implement this function*/ void process_one(char* start) { char word[20]; int Index,k; int module = 1; char* errorMsg = NULL; Index=0; while(*start != '\0') { int num=0; start = nextWord(start,word,sizeof(word)); num = atoi(word); for(k=0;k { int i=0; start = nextWord(start,word,sizeof(word)); for(i=0;i if (i < Index) { // error: symbol is multiply defined, print an error message and use the value giveninthe first definition. symbolTable[i].errorCode = 2; continue; } strcpy(symbolTable[Index].sym,word); start = nextWord(start,word,sizeof(word)); symbolTable[Index].addr = atoi(word); symbolTable[Index++].module = module; } start = nextLine(start); start = nextWord(start,word,sizeof(word)); num = atoi(word); for(k=Index-1;symbolTable[k].module == module;k--) { // error: If an address appearing in a definition exceeds the size of the module, print an error message and treat the address given as 0(relative). if (symbolTable[k].addr >= num) { symbolTable[k].errorCode = 1; symbolTable[k].addr =0; } symbolTable[k].addr += offset; } offset += num; start = nextLine(start); start = nextLine(start); module++; // next module } fwrite("Symbol Table\n",sizeof(char),strlen("Symbol Table\n"),out); errorMsg = (char*)malloc(100); for(k=0;k { memset(errorMsg,0,100); if (1 == symbolTable[k].errorCode) { sprintf(errorMsg,"Error: The value of %s is outside module %d; zero (relative) used",symbolTable[k].sym,symbolTable[k].module); } else if(2 == symbolTable[k].errorCode) { sprintf(errorMsg,"Error: This variable is multiply defined; first value used."); } // output symbolTable & error msg fprintf(out,"%s=%d %s\n",symbolTable[k].sym,symbolTable[k].addr,errorMsg); } free(errorMsg); fwrite("\nMemory Map\n",sizeof(char),strlen("\nMemory Map\n"),out); fflush(out); } /*you must implement this function*/ void process_two(char* start) { char word[20]; struct CodeStr* code; char* useList; // 引用列表 char *errorMsg =NULL; int i=0; int memMapNumber =0; int num=0,codeCount; // num of codes in a module int curOffset; offset = 0; while(*start != '\0') { curOffset = offset; //第一行定义列表(eg: 1 xy 2) start = nextLine(start); //第二行引用列表 useList = start; start = nextLine(start); //第三行代码段(num type opcode type opcode ...) start = nextWord(start,word,sizeof(word)); codeCount = atoi(word); offset += codeCount ; code = (struct CodeStr*) malloc(sizeof(struct CodeStr)*codeCount); for(i=0;i { start = nextWord(start,word,sizeof(word)); code[i].type = *word; start = nextWord(start,word,sizeof(word)); code[i].opcode = atoi(word); code[i].errorCode =0; } // 第四行空行 start = nextLine(start); // 替换外部符号 useList = nextWord(useList,word,sizeof(word)); num = atoi(word); for(i=0; i { int lineOffset;//外部符号在该行中的偏移量 useList = nextWord(useList,word,sizeof(word));// symbol //从符号表查找相应符号以获得绝对地址 for(i=0;symbolTable[i].sym[0] !='\0' && strcmp(symbolTable[i].sym,word)!=0;i++); if (symbolTable[i].sym[0] != '\0') { symbolTable[i].addr |= (1<<8);//标记该符号已使用 /////////////////////////// } useList = nextWord(useList,word,sizeof(word));// offset lineOffset = atoi(word); //替换符号 while(lineOffset != 777) { int temp; temp = code[lineOffset].opcode %1000; code[lineOffset].opcode = (code[lineOffset].opcode/1000)*1000 + symbolTable[i].addr%(1<<8); if (code[lineOffset].type != 'E') { // error: If an address on a use list is not type E,print an error message and treat the address as type E code[lineOffset].errorCode =2; } else if (symbolTable[i].sym[0] == '\0') { // error: If a symbol is used but not defined, print an error message and use the value zero. code[lineOffset].errorCode =1; } else if (temp >= num) { // error: If an ddress appearing in a use list exceeds the size of the module, print an error message and treat the address as the sentinel ending the list. code[lineOffset].errorCode =4; break; } else code[lineOffset].errorCode = -1; // 标记该操作码出现在了使用链中code[lineOffset].symbol = symbolTable[i].sym; lineOffset = temp; } } //替换相对地址 for (i=0;i { if (0 ==code[i].errorCode && 'R' ==code[i].type) //替换相对地址 { code[i].opcode += curOffset; } } //检查是否有不在使用链中的e类型操作码将其视作立即数 for (i=0;i { if ('E' == code[i].type && 0 == code[i].errorCode) { // error: If a type E address is not on a use list, print an error message and treat the address as type I code[i].errorCode = 3; } } //输出当前代码段 errorMsg = (char *)malloc(100); for(i=0;i { memset(errorMsg,0,100); switch(code[i].errorCode) { case 1: //符号未定义 sprintf(errorMsg,"Error: %s is not defined; zero used.",code[i].symbol); break; case 2: //非e类型出现在使用链中 sprintf(errorMsg,"Error: %c type address on use chain; treated as E type.",code[i].type); break; case 3: //未出现在使用链中的e类型 strcpy(errorMsg,"Error: E type address not on use chain; treated as I type."); break; case 4: //符号偏移量超过模块大小 strcpy(errorMsg,"Error: Pointer in use chain exceeds module size; chain terminated."); break; } fprintf(out,"%d:\t%d %s\n",memMapNumber++,code[i].opcode,errorMsg); } free(errorMsg); free(code); } fprintf(out,"\n"); for(i=0; symbolTable[i].sym[0] != '\0';i++) { // If a symbol is defined but not used, print a warning message and continue if (0 == symbolTable[i].addr /(1<<8)) { fprintf(out,"Warning: %s was defined in module %d but never used.\n",symbolTable[i].sym,symbolTable[i].module); } } } 第9章 共享库 $Revision: 2.3 $ $Date: 1999/06/15 03:30:36 $ 程序库的产生可以追溯到计算技术的最早期,因为程序员很快就意识到通过重用程序 的代码片段可以节省大量的时间和精力。随着如Fortran and COBOL等语言编译器的发展,程序库成为编程的一部分。当程序调用一个标准过程时,如sqrt(),编译过的语言显式地使用库,而且它们也隐式地使用用于I/O、转换、排序及很多其它复杂得不能用内联代码解释的函数库。随着语言变得更为复杂,库也相应地变复杂了。当我在20年前写一个Fortran 7 7编译器时,运行库就已经比编译器本身的工作要多了,而一个Fortran 77库远比一个C++库要来得简单。 语言库的增加意味着:不但所有的程序包含库代码,而且大部分程序包含许多相同的 库代码。例如,每个C程序都要使用系统调用库,几乎所有的C程序都使用标准I/O库例程,如printf,而且很多使用了别的通用库,如math,networking,及其它通用函数。这就意 味着在一个有一千个编译过的程序的UNIX系统中,就有将近一千份printf的拷贝。如果所有那些程序能共享一份它们用到的库例程的拷贝,对磁盘空间的节省是可观的。(在一个没有共享库的UNIX系统上,单printf的拷贝就有5到10M。)更重要的是,运行中的程序如 能共享单个在内存中的库的拷贝,这对主存的节省是相当可观的,不但节省内存,也提高页交换。 所有共享库基本上以相同的方式工作。在链接时,链接器搜索整个库以找到用于解决 那些未定义的外部符号的模块。但链接器不把模块内容拷贝到输出文件中,而是标记模块来自的库名,同时在可执行文件中放一个库的列表。当程序被装载时,启动代码找到那些库,并在程序开始前把它们映射到程序的地址空间,如图1。标准操作系统的文件映射机制自动共享那些以只读或写时拷贝的映射页。负责映射的启动代码可能是在操作系统中,或在可执行体,或在已经映射到进程地址空间的特定动态链接器中,或是这三者的某种并集。 ---------------------------------------------------------------------------------------------图9-1:带有共享库的程序 可执行程序,共享库的图例 可执行程序main,app库,C库 不同位置来的文件 箭头展示了从main到app,main到C,app到C的引用 1.概论 先来阐述一下DLL(Dynamic Linkable Library)的概念,你可以简单的把DLL看成一种仓库,它提供给你一些可以直接拿来用的变量、函数或类。在仓库的发展史上经历了“无库-静态链接库-动态链接库”的时代。 静态链接库与动态链接库都是共享代码的方式,如果采用静态链接库,则无论你愿不愿意,lib中的指令都被直接包含在最终生成的EXE文件中了。但是若使用DLL,该DLL不必被包含在最终EXE文件中,EXE文件执行时可以“动态”地引用和卸载这个与EXE独立的DLL文件。静态链接库和动态链接库的另外一个区别在于静态链接库中不能再包含其他的动态链接库或者静态库,而在动态链接库中还可以再包含其他的动态或静态链接库。 对动态链接库,我们还需建立如下概念: (1)DLL 的编制与具体的编程语言及编译器无关 只要遵循约定的DLL接口规范和调用方式,用各种语言编写的DLL都可以相互调用。譬如Windows提供的系统DLL(其中包括了Windows的API),在任何开发环境中都能被调用,不在乎其是Visual Basic、Visual C++还是Delphi。 (2)动态链接库随处可见 我们在Windows目录下的system32文件夹中会看到kernel32.dll、user32.dll和gdi32.dll,windows的大多数API都包含在这些DLL中。kernel32.dll中的函数主要处理内存管理和进程调度;user32.dll中的函数主要控制用户界面;gdi32.dll中的函数则负责图形方面的操作。 一般的程序员都用过类似MessageBox的函数,其实它就包含在user32.dll这个动态链接库中。由此可见DLL对我们来说其实并不陌生。 (3)VC动态链接库的分类 Visual C++支持三种DLL,它们分别是Non-MFC DLL(非MFC动态库)、MFC Regular DLL(MFC规则DLL)、MFC Extension DLL(MFC扩展DLL)。 非MFC动态库不采用MFC类库结构,其导出函数为标准的C接口,能被非MFC或MFC编写的应用程序所调用;MFC规则DLL 包含一个继承自CWinApp的类,但其无消息循环;MFC扩展DLL采用MFC的动态链接版本创建,它只能被用MFC类库所编写的应用程序所调用。 由于本文篇幅较长,内容较多,势必需要先对阅读本文的有关事项进行说明,下面以问答形式给出。 问:本文主要讲解什么内容? 答:本文详细介绍了DLL编程的方方面面,努力学完本文应可以对DLL有较全面的掌握,并能编写大多数DLL程序。 问:如何看本文? 答:本文每一个主题的讲解都附带了源代码例程,可以随文下载(每个工程都经WINRAR压缩)。所有这些例程都由笔者编写并在VC++6.0中调试通过。 网站链接协议 本网站链接协议(以下简称“协议”)于 [日期] 签订并生效。 签订协议的一方:[贵公司的名称](简称“许可方”),根据 [省/市] 的法律成立和存续的公司,其总部位于: [贵公司的完整地址] 另一方:[被许可方的名称](简称“被许可方”),根据 [省/市] 的法律成立和存续的公司,其总部位于: [完整地址] 事实陈述 鉴于,许可方是一个互联网网站的所有者和运营者,该网站致力于[描述],其域名地址如下:[地址](“许可方网站”): 鉴于,被许可方是一个互联网网站的所有者和运营者,该网站致力于于 [描述],其域名地址如下: [地址](“被许可方网站”): 鉴于,被许可方想在许可方的网站上添加一个图形链接,从而使许可方网站的用户可以通过点击该链接访问被许可方网站; 在获取本协议中规定的补偿的情况下,许可方愿意向被许可方提供指向被许可方网站的链接。 因此,考虑到本协议包含的承诺和谅解,许可方和被许可方达成协议如下: 1.链接图形和链接位置 许可方应将被许可方的图像放置在许可方网站的首页,以便用户在标准的 VGA 监视器上以 [分辨率] 使用标准的行业浏览器(最新版的网景和微软 Internet Explorer)在全屏模式下,加载许可方的首页就能看见被许可方的链接图形。在此配置下,被许可方图形的尺寸不应小于 [数量] 像素 X [数量] 像素。当用户点击被许可方的图像时,会通过用户的 Web 浏览器将用户从许可方的网站导至被许可方的网站。 被许可方应使放置于许可方网站上的链接导向被许可方的首页,不应链接一个自动重新加载的页面或未与用户进一步交互就自动转向另一个页面。 1、运行地址<--->链接地址:他们两个是等价的,只是两种不同的说法。 2、加载地址<--->存储地址:他们两个是等价的,也是两种不同的说法。 运行地址:程序在SRAM、SDRAM中执行时的地址。就是执行这条指令时,PC应该等于这个地址,换句话说,PC等于这个地址时,这条指令应该保存在这个地址内。 加载地址:程序保存在Nand flash中的地址。 位置无关码:B、BL、MOV都是位置位置无关码。 位置有关码:LDR PC,=LABEL等类似的代码都是位置有关码。 下面我们来看看一个Makefile文件 sdram.bin : head.S leds.c arm-linux-gcc -c -o head.o head.S arm-linux-gcc -c -o leds.o leds.c arm-linux-ld -Ttext 0x30000000 head.o leds.o -o sdram_elf arm-linux-objcopy -O binary -S sdram_elf sdram.bin arm-linux-objdump -D -m arm sdram_elf > sdram.dis clean: rm -f sdram.dis sdram.bin sdram_elf *.o 我们可以看到sdram_elf的代码段是从0x30000000地址开始存放,这个地址我们称之为运行地址。为什么从这个地址开始存放,因为SDRAM的起始地址是0x30000000. 下面来看看一个启动代码 @************************************************************************* @ File:head.S @ 功能:设置SDRAM,将程序复制到SDRAM,然后跳到SDRAM继续执行 @************************************************************************* .equ MEM_CTL_BASE, 0x48000000 .equ SDRAM_BASE, 0x30000000 .text .global _start _start: 7.5 分散加载描述文件 在7.3节中已经简单介绍了映像的组成,也介绍了如何用命令选项来构建简单结构的映像。要构建映像的存储器映射,链接器必须有:描述节如何分组成区的分组信息、描述映像区在存储器映射中的放置地址的放置信息。 分散加载机制允许为链接器指定映像的存储器映射信息,可实现对映像组件分组和布局的全面控制。分散加载通常仅用于具有复杂存储器映射的映像(尽管也可用于简单映像),也就是适合加载和执行时内存映射中的多个区是分散的情况。本节将对armlink所使用的分散加载描述文件作详细介绍。 7.5.1 分散加载机制 7.5.1.1 何时使用分散加载机制 链接命令行选项提供了一些对数据和代码布局的控制,但如果要对布局进行全面控制则需要比命令行选项更详细的指令。对于以下一些情况,就需要或最好使用分散加载描述文件: 复杂存储器映射:代码和数据需要放在多个不同存储器区域,必须详细指明哪个节放在哪个存储器空间。 不同存储器类型:许多系统包含FLASH、ROM、SDRAM和快速SRAM。利用分散加载可将代码和数据放置在最适合的存储器类型中。例如,中断代码可能放在快 速SRAM中,以改进中断响应时间,而将不频繁使用的配置信息可能放在较慢的 FLASH中。 存储器映射I/O:分散加载机制可将数据节精确放在存储器的某个地址,便于访问外设映射内存。 固定位置的函数:可以将函数放在存储器中的一个固定位置,即使周围的应用程序已经被修改并重新编译。 使用符号识别堆和栈:链接程序时,分散加载机制可为堆和栈的位置定义符号。 在实现嵌入式系统时,通常会需要使用分散加载机制,因为这些系统一般都会使用ROM、RAM和存储器映射I/O。 注意,如果为Cortex-M3结构的处理器编译程序,此处理器结构有着一个固定的内存映射,可以使用分散加载文件来定义栈和堆。 链接时如要使用分散加载文件,则需使用链接命令选项--scatter description_file,详细内容参考7.2节。 7.5.1.2 为分散加载所定义的符号 当armlink使用分散加载描述文件创建映像时,它将创建一些区相关符号,在7.4节中已作详细介绍。仅当代码引用这些特殊符号时,链接器才创建它们。 当分散加载描述文件被使用时,7.4节中的符号Image$$RW$$Base、 Image$$RW$$Limit、Image$$RO$$Base、Image$$RO$$Limit、 Image$$ZI$$Base和Image$$ZI$$Limit不被定义。 若使用分散加载文件,但不指定任何区名并且不使用__user_initial_stackheap(),则库将生成一个错误信息。 练习1解答 下列哪个不是嵌入式系统的特点:()请选择一个答案: a. 专用性 b. 资源受限 c. 功耗约束 d. 常由外接交流电电源供电 题目2题干下列哪些不是嵌入式系统:()。请选择一个答案: a. 移动电话、手机 b. MP3 c. MID d. 深蓝超级计算机 题目3指令和数据共享同一总线的体系结构是()。请选择一个答案: a. 冯?诺依曼结构 b. 哈佛结构 c. RISC d. CISC 题目4下面不属于 ...嵌入式处理器的是:()。请选择一个答案: a. Intel Core(酷睿)处理器 b. Intel Atom处理器 c. MCS-51单片机 d. ARM处理器 题目5在嵌入式处理器与外部设备接口中,使用2根线实现多对多双向收发的是:()。 请选择一个答案: a. UART b. I2C c. SPI d. USB 题目6假设使用奇偶校验位,UART发送一个字节的数据,从idle状态开始(及数据线为高),到允许进行下一次发送动作态为止,至少需要()个时钟节拍。 请选择一个答案: a. 8 b. 9 c. 10 d. 11 题目7关于SIMD说法错误 ..的是:()。 请选择一个答案: a. SIMD通过复制ALU和寄存器组,共享取值、译码单元来获得计算并行。 b. SIMD是通过增加寄存器个数来提高数据处理的宽度。 c. SIMD中多个运算单元运行的是相同的指令。 d. Intel Atom的SSE指令属于SIMD指令 题目8 ARM7中如果需要实现形如 R0=R1+(R2<<3)的操作,最少可以用()条指令。 请选择一个答案: a. 1 b. 2 c. 3 d. 4 题目9交叉开发形成的可执行文件()。请选择一个答案: a. 直接在宿主机上运行 b. 下载到目标机上运行 c. 上载到宿主机上运行 d. 在宿主机和目标机任选一处运行 题目10 ____需要操作系统或加载程序将其加载到内存中才能执行,____加载器只能把它加载到固定的地址运行。() 请选择一个答案: a. 可重定位执行文件,可重定位执行文件 ELF 文件的加载和动态链接过程 本文的目的:大家对于Hello World 程序应该非常熟悉,随便使用哪一种语言,即使还不熟悉的语言,写出一个Hello World 程序应该毫不费力,但是如果让大家详细的说明这个程序加载和链接的过程,以及后续的符号动态解析过程,可能还会有点困难。本文就是以一个最基本的C 语言版本Hello World 程序为基础,了解Linux 下ELF 文件的格式,分析并验证ELF 文件和加载和动态链接的具有实现。 本文的实验平台: Ubuntu 7.04 Linux kernel 2.6.20 gcc 4.1.2 glibc 2.5 gdb 6.6 objdump/readelf 2.17.50 本文的组织: 第一部分大致描述ELF 文件的格式; 第二部分分析ELF 文件在内核空间的加载过程; 第三部分分析ELF 文件在运行过程中符号的动态解析过程; (以上各部分都是以Hello World 程序为例说明) 第四部分简要总结; 第五部分阐明需要深入了解的东西。 一、 ELF 文件格式 1. 概述 Executable and Linking Format(ELF)文件是x86 Linux 系统下的一种常用目标文件(object file)格式,有三种主要类型: 1) 适于连接的可重定位文件(relocatable file),可与其它目标文件一起创建可执行文件 和共享目标文件。 2) 适于执行的可执行文件(executable file),用于提供程序的进程映像,加载的内存执 行。 3) 共享目标文件(shared object file),连接器可将它与其它可重定位文件和共享目标文 件连接成其它的目标文件, 动态连接器又可将它与可执行文件和其它共享目标文件 (一)教学设计部分 ?教学内容分析 本课的主要内容与地位 网页的学名是HTML(即:超文本文件),从本质上说网页只是一个文本文件,超文本的意思即是含超级链接的文本文件。 HTML格式是文本文件,不嵌入任何非文本格式文件,网页中所有丰富的元素都是通过链接实现的,用一段文本文件告诉浏览器图片或者声音的位置,然后浏览器会自动加载到网页中显示,但网页本身仍然没有嵌入任何非文本的文件。 由此可见,超链接是网页赖以存在的基础。理解超链接的原理、熟练地使用超链接是一个合格的网站建设者必要条件。 本课与前后内容的关系 学习超链接的相关知识,是对前面几课制作的几个孤立网页的有机整合。只有通过超链接,由网页组成的集合才能被称作网站。 ?教学目标分析 知识目标/技能目标 知识目标 1.理解超链接的概念。 2.理解导航栏在网页设计中的重要性。 技能目标 1.掌握在网页中插入超链接的一般过程; 2.熟练掌握将链接指向站点内、站点外和电子邮箱的一般方法; 3.学会在网站内设置导航栏。 过程与方法目标 能够根据实际需要,选择不同的网页素材、建立不同的链接。 情感态度与价值观目标 体会万物皆有联系,加强与父母、老师和同学之间沟通和交流,虚心听取别人的意见,不至于在自己的成长过程中迷失方向。 本课的重难点 重点:“创建超链接”对话框;标签链接。 难点:导航栏的设置。 本课的课时分配建议 一课时 ?教学策略设计建议 教法建议 本课是第一单元的重点和难点,教学中建议采用将学生进行分组,不同级别的学生完成不同的探究任务。其中包括:站点内的超链接、到外部站点的超链接、到电子邮箱的链接和到应用程序或文档的链接,以及选择不同的网页素材(文字、图片)作为链接对象的操作方法。 在学生的学习过程中,教师应指导学生实时进行网页的预览,以体验不同链接的不同作用。对实践中遇到的如OutlookExpress的使用问题,教师可在讲解知识点时作以简单的介绍。 讲解设置导航栏部分时,教师可指导学生回顾第二课设置网页模板的相关知识。 ?教学资源与环境建议 教学环境准备建议 1.保证每台学生机能够连接Internet或虚拟网络环境; 2.学生机安装OutlookExpress。 ?教学评价建议 自评、互评、师评要注意的问题 在任务驱动、协作探究的教学过程中,学生是否顺利地建立了各种超链接; 在教师的指导下,各任务小组的学生能否相互协作。 ?教学过程参考案例 第一阶段:导入新课,明确学习目标 第二阶段:范例精讲,学生自主探究,完成范例。 1.操作系统对文件实行统一管理,最基本的是为用户提供( )功能。 A.按名存取B.文件共享C.文件保护D.提高文件的存取速度 2.按文件用途分类,编译程序是( )。 A.系统文件B.库文件C.用户文件D.档案文件 3.在随机存储方式中,用户以( )为单位对文件进行存取和检索。 A.字符串B.数据项C.字节D.逻辑记录 4. 采取哪种文件存取方式,主要取决于( )。 A.用户的使用要求B.存储介质的特性C.用户的使用要求和存储介质的特性D.文件的逻辑结构 5.文件系统的按名存取主要是通过( )实现的。 A.存储空间管理B.目录管理C.文件安全性管理D.文件读写管理 6.文件管理实际上是对( )的管理。 A.主存空间B.辅助存储空间C.逻辑地址空间D.物理地址空间 7. 如果文件系统中有两个文件重名,不应采用( )结构。 A.一级目录B.二级目录C.树形目录D.一级目录和二级目录 8.树形目录中的主文件目录称为( )。 A.父目录B.子目录C.根目录D.用户文件目录 9.绝对路径是从( )开始跟随的一条指向制定文件的路径。 A.用户文件目录B.根目录C.当前目录D.父目录 10. 逻辑文件可分为流式文件和( )两类。 A.索引文件B.链接文件C.记录式文件D.只读文件 11.由一串信息组成,文件内信息不再划分可独立的单位,这是指( )。 A.流式文件B.记录式文件C.连续文件D.串联文件 12.记录式文件内可以独立存取的最小单位是由( )组成的。 A.字B.字节C.数据项D.物理块 13. 下列文件中,( )的物理结构不便于文件的扩充。 A.顺序文件B.链接文件C.索引文件D.多级索引文件 14.( )的物理结构对文件随机存取时必须按指针进行,效率较低。 A.连续文件B.链接文件C.索引文件D.多级索引文件 15. 数据库文件的逻辑结构形式是( )。 A.链接文件B.流式文件C.记录式文件D.只读文件 16.文件的逻辑记录的大小是( )。 A.恒定的B.相同的C.不相同的D.可相同也可不同 17.能用来唯一标识某个逻辑记录的数据项为记录的( )。 A.主键B.次键C.索引D.指针 18. 链接文件解决了顺序结构中存在的问题,它( )。 A.提高存储空间利用率B.适合于随机存取方式 C不适用于顺序存取D.指针存入主存,速度快 19.文件系统可以为某个文件建立一张( ),其中存放每个逻辑记录存放位置的指针。A.位示图B.索引表C.打开文件表D.链接指针表 20. 在文件系统中设置一张( ),它利用二进制的一位表示磁盘中一个块的使用情况。A.空闲块表B.位示图c.链接指针表D.索引表 21.“打开文件”操作要在系统设置的( )中登记该文件的有关信息。 A.索引表B.链接指针表c.已开文件表D.空闲块表 网页加载提速之 - 优化网页图片文件你的网页一定有图片,加载一个网页往往图片的总尺寸是最大的,特别是那些颜色丰富的背景图片和大副广告图片。所以一般要在同等图片质量的情况下要尽可能地减小图片尺寸。在Photoshop中我们可以用保存为Web图片的选项试一下。图片也有几种常用的文件格式。如JPEG一般是用来存储照片或全彩色图片的,比如照片、屏幕截图等。GIF图片格式的颜色要比JPEG少,适合做小图,如制作按钮、Logo等,另外GIF支持动态效果。PNG跟GIF比较相似,但它的尺寸较大,支持的颜色也比GIF要多,并且PNG支持背景透明。我们可以试试使用一种不同的格式保存图片试下,如将PNG和JPEG 换成GIF试试。网页加载提速之 - 图片使用height和width属性你会给每个图片加上height和width属性吗?这两个属性可以让浏览器在加载图片之前就知道图片的长和宽,并预留出指定的长宽待图片加载后显示。如果没有这两个属性,浏览器还需要在读取图片成功后再处理一次页面布局样式,这无疑减慢了网页加载速度。所以在固定图片大小的情况下最好都使用上长和宽属性。网页加载提速之 - CSS 文件压缩瘦身 DIV+CSS是现在流利的网页布局方式,DIV定义了元素,CSS控制显示效果。所以往往我们会把CSS写到另外一个或多个外部链接CSS文件中,并且CSS文件代码也有很多行。我们可以使用一些CSS压缩工具来删除CSS文件中不必要的多余内容,如重复定义样式、空格等来瘦身。可以尝试使用一下CleanCSS工具来压缩你的CSS文件。网页加载提速之 - 目录地址后加上斜杠(/)如访客点击访问这样一个目录地址,去打开这个目录下的index.html文档。当服务器收到请求后它需要消耗一些时间来分析这是一个文件还是一个目录。但是如果我们在最后加上一个斜杠(/),服务器就知道你是在访问一个目录地址,然后就直接加载默认文档index.html或index.php就行了。这样服务器就不用花时间来分析这个地址,也起到了一定加速的作用。网页加载提速之 - 整合CSS、JS文件减少HTTP请求次数现在的网页都有多个图片、CSS外部文件链接、Javascript外部脚本链接。所以当访问一个网页时浏览器需要多次向服务器请求这些文件。在请求和加载之间会产生不少的时间差。特别是一些网页上有多个小图片、图标按钮的网页,有多少图片,浏览器就需要请求多少将这些小文件,多将请求这些小图片文件将明显影响网页的加载速度。所以我们应该尽可能将小图片拼合一个PNG大图片 Linux提供了一套API来动态装载库。下面列出了这些API: - dlopen,打开一个库,并为使用该库做些准备。 - dlsym,在打开的库中查找符号的值。 - dlclose,关闭库。 - dlerror,返回一个描述最后一次调用dlopen、dlsym,或dlclose的错误信 息的字符串。 C语言用户需要包含头文件dlfcn.h才能使用上述API。glibc还增加了两个POSIX标准中没有的API: - dladdr,从函数指针解析符号名称和所在的文件。 - dlvsym,与dlsym类似,只是多了一个版本字符串参数。 在Linux上,使用动态链接的应用程序需要和库libdl.so一起链接,也就是使用选项-ldl。但是,编译时不需要和动态装载的库一起链接。程序3-1是一个在Linux上使用dl*例程的简单示例。 延迟重定位(Lazy Relocation) 延迟重定位/装载是一个允许符号只在需要时才重定位的特性。这常在各UNIX 系统上解析函数调用时用到。当一个和共享库一起链接的应用程序几乎不会用到该共享库中的函数时,该特性被证明是非常有用的。这种情况下,只有库中的函数被应用程序调用时,共享库才会被装载,否则不会装载,因此会节约一些系统资源。但是如果把环境变量LD_BIND_NOW设置成一个非空值,所有的重定位操作都会在程序启动时进行。也可以在链接器命令行通过使用-z now链接器选项使 延迟绑定对某个特定的共享库失效。需要注意的是,除非重新链接该共享库,否则对该共享库的这种设置会一直有效。 初始化(initializing)和终止化(finalizing)函数 有时候,以前的代码可能用到了两个特殊的函数:_init和_fini。_init和_fini 函数用在装载和卸载某个模块(注释14)时分别控制该模块的构造器和析构器 (或构造函数和析构函数)。他们的C语言原型如下: void _init(void); void _fini(void); 当一个库通过dlopen()动态打开或以共享库的形式打开时,如果_init在该库中存在且被输出出来,则_init函数会被调用。如果一个库通过dlclose()动态关闭或因为没有应用程序引用其符号而被卸载时,_fini函数会在库卸载前被调用。当使用你自己的_init和_fini函数时,需要注意不要与系统启动文件一起链接。可以使用GCC选项 -nostartfiles 做到这一点。 但是,使用上面的函数或GCC的-nostartfiles选项并不是很好的习惯,因为这可能会产生一些意外的结果。相反,库应该使用__attribute__((constructor))和__attribute__((destructor))函数属性来输出它的构造函数和析构函数。如 l i n u x考试试题及答 案 Linux考试试题及答案 一、选择题 1、在/etc/fstab 文件中指定的文件系统加载参数中,那个参数一般用于CD-ROM 等移动设备(D ) A. defaults B. sw C. rw 和 ro D. noauto 2、Linux 文件权限一共 10 位长度,分成四段,第三段表示的内容是(C) A. 文件类型 B. 文件所有者的权限 C. 文件所有者所在组的权限 D. 其他用户的权限 3、在使用 mkdir 命令创建新的目录时,在其父目录不存在时先创建父目录的选项是(D) A. -m B. -d C. -f D. -p 4、一台主机要实现通过局域网与另一个局域网通信,需要做的工作是(C) A. 配置域名服务器 B. 定义一条本机指向所在网络的路由 C. 定义一条本机指向所在网络网关的路由 D. 定义一条本机指向目标网络网关的路由 5.下列提法中,不属于 ifconfig 命令作用范围的是(D) A. 配置本地回环地址 B. 配置网卡的 IP 地址 C. 激活网络适配器 D. 加载网卡到内核中 6、下列关于链接描述,错误的是(B) A. 硬链接就是让链接文件的 i 节点号指向被链接文件的 i 节点 B. 硬链接和符号连接都是产生一个新的 i 节点 C. 链接分为硬链接和符号链接 D. 硬连接不能链接目录文件 7、下列文件中,包含了主机DNS 配置信息的文件是(C ) A. /etc/host.conf B. /etc/hosts C. /etc/resolv.conf D. /etc/networks 8、那个命令可以从文本文件的每一行中截取指定内容的数据(D) A.cp B.dd C.fmt D.cut 对于.lds文件,它定义了整个程序编译之后的连接过程,决定了一个可执行程序的各个段的存储位置。虽然现在我还没怎么用它,但感觉还是挺重要的,有必要了解一下。 1、secname:段名 2、contents:决定哪些内容放在本段,可以是整个目标文件,也可以是目标文件中的某段(代码段、数据段等) 3、start:本段连接(运行)的地址,如果没有使用AT(ldadr),本段存储的地址也是start。GNU网站上说start可以用任意一种描述地址的符号来描述。 4、AT(ldadr):定义本段存储(加载)的地址。 看一个简单的例子:(摘自《2410完全开发》) 以上,head.o放在0x00000000地址开始处,init.o放在head.o后面,他们的运行地址也是0x00000000,即连接和存储地址相同(没有AT指定);main.o放在4096(0x1000,是AT指定的,存储地址)开始处,但是它的运行地址在0x30000000,运行之前需要从0 x1000(加载处)复制到0x30000000(运行处),此过程也就用到了读取Nand flash。 这就是存储地址和连接(运行)地址的不同,称为加载时域和运行时域,可以在.lds连接脚本文件中分别指定。 编写好的.lds文件,在用arm-linux-ld连接命令时带-Tfilename来调用执行,如 arm-linux-ld –Tnand.lds x.o y.o –o xy.o。也用-Ttext参数直接指定连接地址,如 arm-linux-ld –Ttext 0x30000000 x.o y.o –o xy.o。 既然程序有了两种地址,就涉及到一些跳转指令的区别,这里正好写下来,以后万一忘记了也可查看,以前不少东西没记下来现在忘得差不多了。。。 ARM汇编中,常有两种跳转方法:b跳转指令、ldr指令向PC赋值。 我自己经过归纳如下: ARM9系列处理器共有37个寄存器,其中31个属于通用寄存器,6个为ARM处理器。不同工作模式所设立的专用状态寄存器。通用寄存器都是32位的。 ARM总共有7种不同的处理器模式,分别是 用户模式(User):程序正常执行的模式、 快速中断模式(FIQ):用于高速数据传输和通道处理、 外部中断模式(IRQ):用于普通的外部中断请求处理、 管理模式(Supervisor):供操作系统使用的一种保护模式、 数据访问中止模式(Abort):用于虚拟存储和存储保护、 未定义指令中止模式(Undef):用于支持硬件协处理器的软件仿真、 系统模式(System):用于运行特权级的操作系统任务。 以上除了用户模式外,都叫特权模式,而在特权模式中,除系统模式外的其余五种被称为异常模式,不同模式间可以相互转换。 ARM9的6个状态寄存器包括1个当前程序状态寄存器(CPSR)和5个备份状态寄存器(SPSR),CPSR在所有模式下都是通用的,它包含了条件代码标志位、中断禁止位、当前处理器模式以及其他状态和控制信息。 SPSR是在处理器进入异常模式时用来保存CPSR寄存器内容的,当从异常退出时,用SPSR 来恢复CPSR的值。 R13:SP堆栈指针R14:LR链接寄存器R15:PC指令指针(指向下一条执行指令) FIQ和IRQ为例,异常处理代码: SUBS LR , LR , #4 STMFD SP! , {reglist , LR} ..... LDMFD SP! , {reglist , PC}^ 也可以在返回时修正LR,例如: STMFD SP! , {reglist , LR} ..... LDMFD SP! , {reglist , LR} SUBS PC , LR , #4 Thumb指令为16位,能完成的功能是32位ARM指令的子集。对应的这两类指令,ARM处理器支持两种运行状态:ARM状态和Thumb状态。 小端存储格式:数据低位放入低地址,高位放在高地址。 大端存储格式:数据低位放入高地址,高位放在低地址。 ARM状态和Thumb状态切换可以通过BX指令来实现。BX指令通过判断Rn所存储的目标地址的最后一位来判断要跳转到什么状态:若Rn[0]=0,则跳转到ARM状态,若Rn[0]=1,则跳转 For personal use only in study and research; not for commercial use U-Boot移植过程中的运行地址和装载地址的区别 uboot移植涉及到底层硬件的设置,因此需要掌握UART、系统时钟频率、NOR FLASH、NAND FLASH、SDRAM、网卡、存储控制器等硬件的功能及配置,这些都可以参照相应开发板的芯片手册来完成,没有什么大的问题。在移植过程中,一直困扰我的是PIC(代码无关性)问题,即运行地址和加载地址的区别,看过网上很多关于这两者的介绍,感觉懂一点,却一直不知所然。在参考大量的文献下,算是得了一点心得。 首先来了解下运行地址及加载地址的区别 运行地址:也叫链接地址,是程序定位的绝对地址,即在编译连接时确定的地址。如果程序中有位置相关指令,程序在运行时,程序必须在运行地址上。 加载地址:程序放置的位置。 运行地址和加载地址的值有时相等,有时却不相等,所以这给初学者带来很大的困扰。为了弄清楚这个问题,还得从NOR FLASH,NAND FLASH,S3C2440内部4KB RAM的映射说起。 左边表示从NOR FLASH启动时的映射,右边表示从NAND FLASH启动时的映射。 这里只讨论从NOR FLASH启动的情况,从图中可以看出NOR FLASH映射到了0X00000000的起始位置,假如UBOOT的代码存放在NOR FLASH上,即装载地址为0X00000000。再来看看UBOOT的链接地址,代码在board/smdk2410/U-Boot.lds里。 连接脚本文件lds中没有设置LMA,只是设置了VMA。VMA的设置是通过顶层目录下的config.mk文件中的LDFLAGS实现的 在board/smdk2410/config.mk定义了TEXT_BASE = 0x33F80000(SDRAM),即程序的运行地址查看u-boot.map文件,代码的连接地址是从0x33F80000开始的。 167 .text 0x33f80000 0x232c8 168 cpu/arm920t/start.o(.text) 169 .text 0x33f80000 0x4a0 cpu/arm920t/start.o 170 0x33f80048 _bss_start 171 0x33f8004c _bss_end U-Boot移植过程中的运行地址和装载地址的区别 uboot移植涉及到底层硬件的设置,因此需要掌握UART、系统时钟频率、NOR FLASH、NAND FLASH、SDRAM、网卡、存储控制器等硬件的功能及配置,这些都可以参照相应开发板的芯片手册来完成,没有什么大的问题。在移植过程中,一直困扰我的是PIC(代码无关性)问题,即运行地址和加载地址的区别,看过网上很多关于这两者的介绍,感觉懂一点,却一直不知所然。在参考大量的文献下,算是得了一点心得。 首先来了解下运行地址及加载地址的区别 运行地址:也叫链接地址,是程序定位的绝对地址,即在编译连接时确定的地址。如果程序中有位置相关指令,程序在运行时,程序必须在运行地址上。 加载地址:程序放置的位置。 运行地址和加载地址的值有时相等,有时却不相等,所以这给初学者带来很大的困扰。为了弄清楚这个问题,还得从NOR FLASH,NAND FLASH,S3C2440内部4KB RAM的映射说起。 左边表示从NOR FLASH启动时的映射,右边表示从NAND FLASH启动时的映射。 这里只讨论从NOR FLASH启动的情况,从图中可以看出NOR FLASH映射到了0X00000000的起始位置,假如UBOOT的代码存放在NOR FLASH上,即装载地址为0X00000000。再来看看UBOOT的链接地址,代码在board/smdk2410/U-Boot.lds里。 连接脚本文件lds中没有设置LMA,只是设置了VMA。VMA的设置是通过顶层目录下的config.mk文件中的LDFLAGS实现的 在board/smdk2410/config.mk定义了TEXT_BASE = 0x33F80000(SDRAM),即程序的运行地址查看u-boot.map文件,代码的连接地址是从0x33F80000开始的。 167 .text 0x33f80000 0x232c8 168 cpu/arm920t/start.o(.text) 169 .text 0x33f80000 0x4a0 1. 什么是lib文件,lib和dll的关系如何 (1)lib是编译时需要的,dll是运行时需要的。 如果要完成源代码的编译,有lib就够了。 如果也使动态连接的程序运行起来,有dll就够了。 在开发和调试阶段,当然最好都有。 (2)一般的动态库程序有lib文件和dll文件。lib文件是必须在编译期就连接到应用程序中的,而dll文件是运行期才会被调用的。如果有dll文件,那么对应的lib文件一般是一些索引信息,具体的实现在dll文件中。如果只有lib文件,那么这个lib文件是静态编译出来的,索引和实现都在其中。静态编译的lib文件有好处:给用户安装时就不需要再挂动态库了。但也有缺点,就是导致应用程序比较大,而且失去了动态库的灵活性,在版本升级时,同时要发布新的应用程序才行。 (3)在动态库的情况下,有两个文件,一个是引入库(.LIB)文件,一个是DLL文件,引入库文件包含被DLL导出的函数的名称和位置,DLL包含实际的函数和数据,应用程序使用LIB文件链接到所需要使用的DLL文件,DLL库中的函数和数据并不复制到可执行文件中,因此在应用程序的可执行文件中,存放的不是被调用的函数代码,而是DLL中所要调用的函数的内存地址,这样当一个或多个应用程序运行时再把程序代码和被调用的函数代码链接起来,从而节省了内存资源。从上面的说明可以看出,DLL和.LIB文件必须随应用程序一起发行,否则应用程序将会产生错误。 2、严重警告: (1) 用 extern "C" _declspec(dllexport) 只可以导出全局函数,不能导出类的成员函数 (2) 使用extern "C" _declspec(dllexport)输出的函数可以被c语言调用,否则则不可 (3) 注意标准调用约定的问题,输出与调用的函数约定应该一致,如当dll模块的函数输出采用标准调用约定_stdcall,则调用程序的导入函数说明也要用标准约定 (4) 用extern "C" _declspec(dllexport) 和 EXPOTRT导出的函数不改变函数名,可以给c++或c编写的exe调用. 假如没有extern "C",导出的函数名将会改变,只能给c++编写的exe调用 (5)在动态加载动态链接库函数时注意GetProcAddress(hInst,"add")中第二个参数是否为动态链接库导出的函数名,因为在生成动态库时可能会改变动态库导出函数的函数名,加上修饰符 (6)dll初始化全局变量时,全局变量要放在共享数据断,并且初始化每一个变量,在StartHook函数里初始化其值,记得一进函数就初始化 (7)调试时,编译器会自动查找其目录下(不含debug和release目录)的dll文件,所以dll文件应该放在主文件目录下,但生成的应用程序则只会在同一个目录下找dll(不需要lib文件),所以单纯的运行exe,不通过编译器,那就要把dll文件放在与exe相同的目 动态链接库(DLL) 一、相关概念 动态链接库(Dynamic Link Library): 动态链接库通常都不能直接运行,也不能接收消息。它们是一些独立的文件,文件后缀一般为.DLL,其中包含供其他可执行程序或其它DLL调用的函数。只有在其它模块调用动态链接库中的函数时,它才发挥作用。 例如,Windows API中的所有函数都包含在DLL中。其中有3个最重要的DLL,Kernel32.dll,它包含用于管理内存、进程和线程的各个函数;User32.dll,它包含用于执行用户界面任务(如窗口的创建和消息的传送)的各个函数;GDI32.dll,它包含用于画图和显示文本的各个函数。他们一般位于C:\windows\System32或类似的目录下。 通俗一点说,动态链接库就是将很多函数放到一起形成一个集合模块,注册后供其他应用程序运行时动态调用。 这许许多多的函数又可分为内部函数和导出函数。内部函数是用来在动态链接库内部调用的函数,主要用来实现动态链接库的实际功能;导出函数,顾名思义就是供外部模块或者应用程序在运行的时候调用的,是应用程序和动态链接库间的接口。导出函数包含在导出表中, 导出表包含动态链接库中所有可以被外部调用的函数名(对外的接口)。 顾名思义,动态链接库,是动态链接,它是相对于静态链接而言的。 静态库: 函数和数据被编译进一个二进制文件(通常扩展名为.LIB)。在其他程序使用静态库的情况下,在编译链接可执行文件时,链接器从库中复制这些函数和数据,并把它们和应用程序的其它模块组合起来创建最终的可执行文件(.EXE文件)。发布产品时,只需发布.EXE文件即可,不需要发布.LIB文件。 优点:无须包括函数库所包含的函数代码,应用程序可以利用标准的函数集; 缺点:两个应用程序运行时同时使用同一静态链接库中的函数,需要使用同一函数代码的两份拷贝,降低内存使用率。 动态库: 在其他程序使用动态库的时候,往往要用到DLL提供者提供的两个文件:一个引入库(.LIB)和一个DLL(.DLL)。但这里的.LIB文件和静态库中的.LIB文件有着本质的差别,这里的.LIB只包含导出的函数、变量的符号名,.DLL包含实际的函数和数据。在编译链接时,只需要链接.LIB,DLL中的函数代码和数据并不复制到可执行文件中,在运行的时候,才去加载DLL,并访问DLL中的导出函数。 优点:可以采用多种编程语言来编写;提供二次开发的平台;简化项目管理;可以节省磁盘空间和内存,等。 动态链接库DLL和可执行文件EXE的区别: 可执行文件运行起来后有自己的独立的进程空间,而动态链接库的导出函数被动态链接到应用程序的进程空间,这样多个应用程序可以共享一份代码副本。另外,动态链接库可以包括一个导出表,记录该动态链接库对外提供的函数接口。 二、DLL的开发、声明和调用链接器和加载器09
VC++动态链接库创建和调用全过程详解
网站链接协议
链接地址和运行地址
分散加载描述文件
嵌入式系统
ELF文件的加载和动态链接过程
第五课 建立超链接(教参)
操作系统原理试题
提高网页加载速度的5种方式.
dlopen及so动态加载原理
linux考试试题及答案讲课教案
链接文件中的运行域与加载域
嵌入式期末复习
运行地址和加载地址
运行地址和加载地址
动态链接库(dll)学习资料总结
动态连接库