数据挖掘机器学习

机器学习、数据挖掘的经典算法总结
1 决策树算法
机器学习中,决策树是一个预测模型;它代表的是对象属性值与对象值之间的一种映射关系。树中每个节点表示某个对象,每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应具有上述属性值的子对象。决策树仅有单一输出;若需要多个输出,可以建立独立的决策树以处理不同输出。
从数据产生决策树的机器学习技术叫做决策树学习, 通俗说就是决策树。
决策树学习也是数据挖掘中一个普通的方法。在这里,每个决策树都表述了一种树型结构,它由它的分支来对该类型的对象依靠属性进行分类。每个决策树可以依靠对源数据库的分割进行数据测试。这个过程可以递归式的对树进行修剪。当不能再进行分割或一个单独的类可以被应用于某一分支时,递归过程就完成了。另外,随机森林分类器将许多决策树结合起来以提升分类的正确率。
决策树同时也可以依靠计算条件概率来构造。决策树如果依靠数学的计算方法可以取得更加理想的效果。
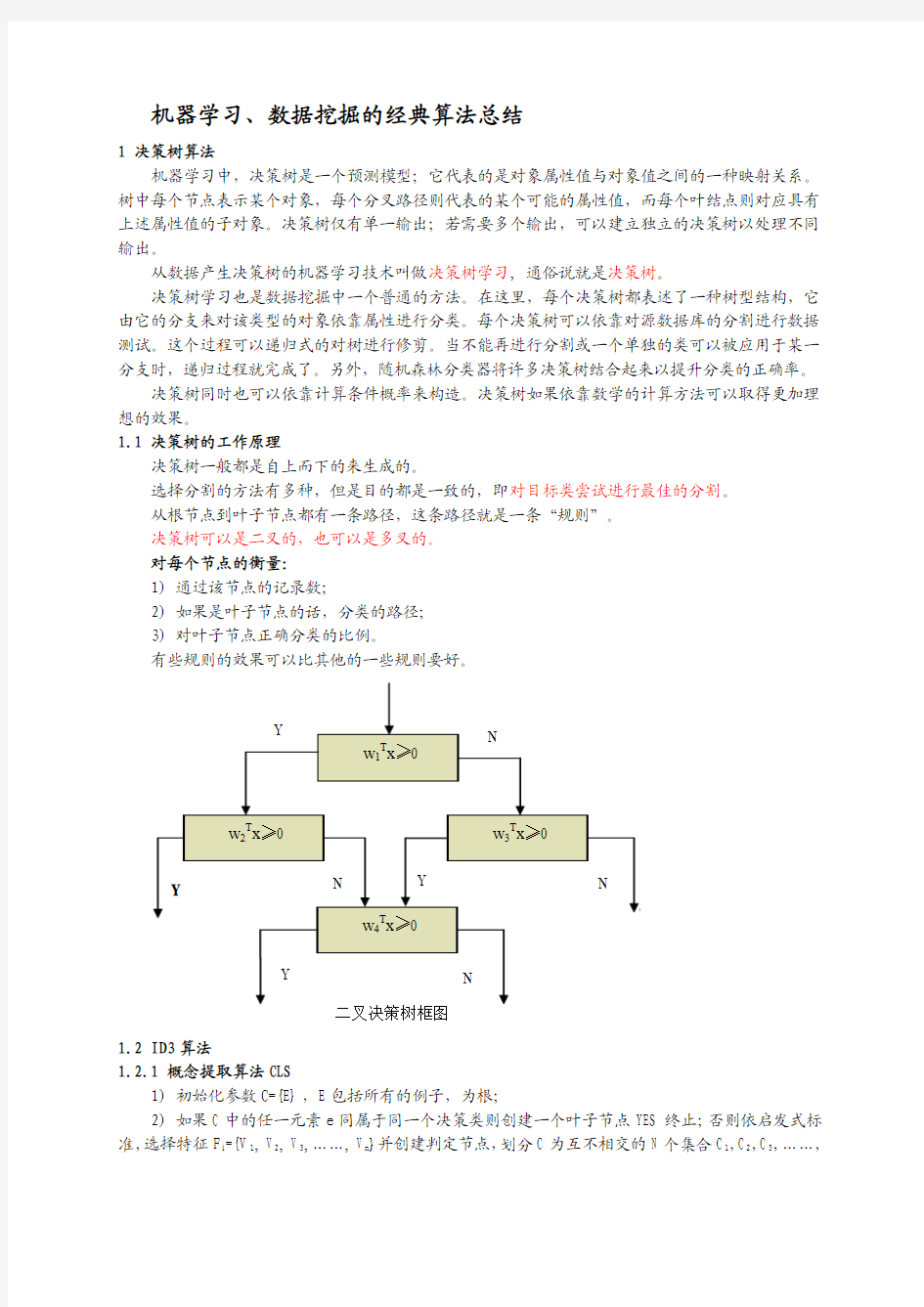
1.1 决策树的工作原理
决策树一般都是自上而下的来生成的。
选择分割的方法有多种,但是目的都是一致的,即对目标类尝试进行最佳的分割。
从根节点到叶子节点都有一条路径,这条路径就是一条“规则”。
决策树可以是二叉的,也可以是多叉的。
对每个节点的衡量:
1) 通过该节点的记录数;
2) 如果是叶子节点的话,分类的路径;
3) 对叶子节点正确分类的比例。
有些规则的效果可以比其他的一些规则要好。
1.2 ID3算法
1.2.1 概念提取算法CLS
1) 初始化参数C={E},E包括所有的例子,为根;
2) 如果C中的任一元素e同属于同一个决策类则创建一个叶子节点YES终止;否则依启发式标准,选择特征F i={V1, V2, V3,……, V n}并创建判定节点,划分C为互不相交的N个集合C1,C2,C3,……,
C n;
3) 对任一个C i递归。
1.2.2 ID3算法
1) 随机选择C的一个子集W (窗口);
2) 调用CLS生成W的分类树DT(强调的启发式标准在后);
3) 顺序扫描C搜集DT的意外(即由DT无法确定的例子);
4) 组合W与已发现的意外,形成新的W;
5) 重复2)到4),直到无例外为止。
启发式标准:
只跟本身与其子树有关,采取信息理论用熵来量度。
熵是选择事件时选择自由度的量度,其计算方法为:P=freq(C j,S)/|S|;INFO(S)=-SUM(P*LOG(P));SUM()函数是求j从1到n的和。Gain(X)=Info(X)-Infox(X);Infox(X)=SUM( (|T i|/|T|)*Info(X);
为保证生成的决策树最小,ID3算法在生成子树时,选取使生成的子树的熵(即Gain(S))最小的特征来生成子树。
ID3算法对数据的要求:
1) 所有属性必须为离散量;
2) 所有的训练例的所有属性必须有一个明确的值;
3) 相同的因素必须得到相同的结论且训练例必须唯一。
1.3 C4.5算法
由于ID3算法在实际应用中存在一些问题,于是Quilan提出了C4.5算法,严格上说C4.5只能是ID3的一个改进算法。
C4.5算法继承了ID3算法的优点,并在以下几方面对ID3算法进行了改进:
1) 用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;
2) 在树构造过程中进行剪枝;
3) 能够完成对连续属性的离散化处理;
4) 能够对不完整数据进行处理。
C4.5算法有如下优点:
产生的分类规则易于理解,准确率较高。
C4.5算法有如下缺点:
在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。此外,C4.5只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
分类决策树算法:
C4.5算法是机器学习算法中的一种分类决策树算法,其核心算法是ID3算法。
分类决策树算法是从大量事例中进行提取分类规则的自上而下的决策树。
决策树的各部分是:
根:学习的事例集;
枝:分类的判定条件;
叶:分好的各个类。
1.3.1 C4.5对ID3算法的改进
1) 熵的改进,加上了子树的信息。
Split_Infox(X)= -SUM( (|T|/|T i|)*LOG(|T i|/|T|));
Gain ratio(X)= Gain(X)/Split_Infox(X);
2) 在输入数据上的改进
①因素属性的值可以是连续量,C4.5对其排序并分成不同的集合后按照ID3算法当作离散量进行处理,但结论属性的值必须是离散值。
②训练例的因素属性值可以是不确定的,以?表示,但结论必须是确定的。
3) 对已生成的决策树进行裁剪,减小生成树的规模。
2 The k-means algorithm(k平均算法)
k-means algorithm是一个聚类算法,把n个对象根据它们的属性分为k个分割,k < n。它与处理混合正态分布的最大期望算法很相似,因为他们都试图找到数据中自然聚类的中心。它假设对象属性来自于空间向量,并且目标是使各个群组内部的均方误差总和最小。
假设有k个群组S i, i=1,2,...,k。μi是群组S i内所有元素x j的重心,或叫中心点。
k平均聚类发明于1956年,该算法最常见的形式是采用被称为劳埃德算法(Lloyd algorithm)的迭代式改进探索法。劳埃德算法首先把输入点分成k个初始化分组,可以是随机的或者使用一些启发式数据。然后计算每组的中心点,根据中心点的位臵把对象分到离它最近的中心,重新确定分组。继续重复不断地计算中心并重新分组,直到收敛,即对象不再改变分组(中心点位臵不再改变)。
劳埃德算法和k平均通常是紧密联系的,但是在实际应用中,劳埃德算法是解决k平均问题的启发式法则,对于某些起始点和重心的组合,劳埃德算法可能实际上收敛于错误的结果。(上面函数中存在的不同的最优解)
虽然存在变异,但是劳埃德算法仍旧保持流行,因为它在实际中收敛非常快。实际上,观察发现迭代次数远远少于点的数量。然而最近,David Arthur和Sergei Vassilvitskii提出存在特定的点集使得k平均算法花费超多项式时间达到收敛。
近似的k平均算法已经被设计用于原始数据子集的计算。
从算法的表现上来说,它并不保证一定得到全局最优解,最终解的质量很大程度上取决于初始化的分组。由于该算法的速度很快,因此常用的一种方法是多次运行k平均算法,选择最优解。
k平均算法的一个缺点是,分组的数目k是一个输入参数,不合适的k可能返回较差的结果。另外,算法还假设均方误差是计算群组分散度的最佳参数。
3 SVM(支持向量机)
支持向量机,英文为Support Vector Machine,简称SV机(论文中一般简称SVM)。它是一种监督式学习的方法,它广泛的应用于统计分类以及回归分析中。
支持向量机属于一般化线性分类器。它们也可以被认为是提克洛夫规范化(Tikhonov Regularization)方法的一个特例。这种分类器的特点是他们能够同时最小化经验误差与最大化几何边缘区。因此支持向量机也被称为最大边缘区分类器。
在统计计算中,最大期望(EM)算法是在概率(probabilistic)模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量(Latent Variable)。最大期望经常用在机器学习和计算机视觉的数据集聚(Data Clustering)领域。最大期望算法经过两个步骤交替进行计算,第一步是计算期望(E),也就是将隐藏变量像能够观测到的一样包含在内从而计算最大似然的期望值;另外一步是最大化(M),也就是最大化在 E 步上找到的最大似然的期望值从而计算参数的最大似然估计。M 步上找到的参数然后用于另外一个 E 步计算,这个过程不断交替进行。
Vapnik等人在多年研究统计学习理论基础上对线性分类器提出了另一种设计最佳准则。其原理也从线性可分说起,然后扩展到线性不可分的情况。甚至扩展到使用非线性函数中去,这种分类器被称为支持向量机(Support Vector Machine,简称SVM)。支持向量机的提出有很深的理论背景。支持向量机方法是在近年来提出的一种新方法,但是进展很快,已经被广泛应用在各个领域之中。
SVM的主要思想可以概括为两点:(1) 它是针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能;(2) 它基于结构风险最小化理论之上在特征空间中建构最优分割超平面,使得学习器得到全局最优化,并且在整个
样本空间的期望风险以某个概率满足一定上界。
在学习这种方法时,首先要弄清楚这种方法考虑问题的特点,这就要从线性可分的最简单情况讨论起,在没有弄懂其原理之前,不要急于学习线性不可分等较复杂的情况,支持向量机在设计时,需要用到条件极值问题的求解,因此需用拉格朗日乘子理论,但对多数人来说,以前学到的或常用的是约束条件为等式表示的方式,但在此要用到以不等式作为必须满足的条件,此时只要了解拉格朗日理论的有关结论就行。
支持向量机将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边建有两个互相平行的超平面。分隔超平面使两个平行超平面的距离最大化。假定平行超平面间的距离或差距越大,分类器的总误差越小。一个极好的指南是C.J.C Burges的《模式识别支持向量机指南》。van der Walt 和 Barnard 将支持向量机和其他分类器进行了比较。
有很多个分类器(超平面)可以把数据分开,但是只有一个能够达到最大分割。
我们通常希望分类的过程是一个机器学习的过程。这些数据点并不需要是中的点,而可以是
任意(统计学符号)中或者 (计算机科学符号) 的点。我们希望能够把这些点通过一个n-1维的超平面分开,通常这个被称为线性分类器。有很多分类器都符合这个要求,但是我们还希望找到分类最佳的平面,即使得属于两个不同类的数据点间隔最大的那个面,该面亦称为最大间隔超平面。如果我们能够找到这个面,那么这个分类器就称为最大间隔分类器。
设样本属于两个类,用该样本训练SVM得到的最大间隔超平面。在超平面上的样本点也称为支持向量。
SVM的优势:
由于支持向量机方法是建立在统计学习理论的VC维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度,Accuracy)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折衷,以期获得最好的推广能力(Generalizatin Ability)。支持向量机方法的几个主要优点是:
●可以解决小样本情况下的机器学习问题;
●可以提高泛化性能;
●可以解决高维问题;
●可以解决非线性问题;
●可以避免神经网络结构选择和局部极小点问题。
4 贝叶斯(Bayes)分类器
贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。目前研究较多的贝叶斯
分类器主要有四种,分别是:Naive Bayes、TAN、BAN和GBN。
贝叶斯网络是一个带有概率注释的有向无环图,图中的每一个结点均表示一个随机变量,图中两结点间若存在着一条弧,则表示这两结点相对应的随机变量是概率相依的,反之则说明这两个随机变量是条件独立的。网络中任意一个结点X 均有一个相应的条件概率表(Conditional Probability Table,CPT),用以表示结点X 在其父结点取各可能值时的条件概率。若结点X 无父结点,则X 的CPT 为其先验概率分布。贝叶斯网络的结构及各结点的CPT 定义了网络中各变量的概率分布。
贝叶斯分类器是用于分类的贝叶斯网络。该网络中应包含类结点C,其中C 的取值来自于类集合( c1 , c2 , ... , c m),还包含一组结点X = ( X1 , X2 , ... , X n),表示用于分类的特征。对于贝叶斯网络分类器,若某一待分类的样本D,其分类特征向量为x = ( x1 , x2 , ... , x n) ,则样本D 属于类别c i的概率为P( C = c i | X = x) = P( C = c i | X1 = x1 , X2 = x 2 , ... , X n = x n) ,( i = 1 ,2 , ... , m) 。
而由贝叶斯公式可得:P( C = c i | X = x) = P( X = x | C = c i) P( C = c i) / P( X = x) 其中,P( C = c i) 可由领域专家的经验得到,称为先验概率;而P( X = x | C = c i) 和P( X = x) 的计算则较困难;P( C = c i | X = x)称为后验概率。
应用贝叶斯网络分类器进行分类主要分成两阶段。第一阶段是贝叶斯网络分类器的学习,即从样本数据中构造分类器;第二阶段是贝叶斯网络分类器的推理,即计算类结点的条件概率,对分类数据进行分类。这两个阶段的时间复杂性均取决于特征值间的依赖程度,甚至可以是NP完全问题(世界七大数学难题之一),因而在实际应用中,往往需要对贝叶斯网络分类器进行简化。根据对特征值间不同关联程度的假设,可以得出各种贝叶斯分类器,Naive Bayes、TAN、BAN、GBN就是其中较典型、研究较深入的贝叶斯分类器。
4.1 朴素贝叶斯(Naive Bayes)分类器
分类是将一个未知样本分到几个预先已知类的过程。数据分类问题的解决是一个两步过程:第一步,建立模型,描述预先的数据集或概念集。通过分析由属性/特征描述的样本(或实例,对象等)来构造模型。假定每一个样本都有一个预先定义的类,由一个被称为类标签的属性确定。为建立模型而被分析的数据元组形成训练数据集,该步也称作有指导的学习。
4.1.1 决策树模型和朴素贝叶斯模型的比较
在众多的分类模型中,应用最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Bayesian Model,NBC)。决策树模型通过构造树来解决分类问题。首先利用训练数据集来构造一棵决策树,一旦树建立起来,它就可为未知样本产生一个分类。在分类问题中使用决策树模型有很多的优点,决策树便于使用,而且高效;根据决策树可以很容易地构造出规则,而规则通常易于解释和理解;决策树可很好地扩展到大型数据库中,同时它的大小独立于数据库的大小;决策树模型的另外一大优点就是可以对有许多属性的数据集构造决策树。决策树模型也有一些缺点,比如处理缺失数据时的困难,过度拟合问题的出现,以及忽略数据集中属性之间的相关性等。
和决策树模型相比,朴素贝叶斯模型发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。理论上,NBC模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,这给NBC模型的正确分类带来了一定影响。在属性个数比较多或者属性之间相关性较大时,NBC模型的分类效率比不上决策树模型。而在属性相关性较小时,NBC模型的性能最为良好。
朴素贝叶斯模型:
V map=arg max{P( V j | a1,a2...a n)}
V j属于V集合,其中j=1,2,…,N,即共有N类;
V map是给定一个example,得到的最可能的目标值;
a1...an是这个example里面的属性/特征,共有n个特征。
Vmap为目标值,就是后面计算得出的概率最大的一个,所以用max 来表示,它意味着该example 应该/最可能为得到最大后验概率的那个类,这与前面讲到的贝叶斯分类器是一致的。
将贝叶斯公式应用到 P( V j | a1,a2...a n)中,可得到:
V map= arg max{P(a1,a2...a n | V j ) P( V j ) / P (a1,a2...a n)}
又因为朴素贝叶斯分类器默认a1...an他们互相独立的,所以P(a1,a2...an)对于结果没有影响(因为所有的概率都要除同一个东西之后再比较大小)。于是可得到:
V map= arg max{P(a1,a2...a n | V j ) P( V j )}
然后,朴素贝叶斯分类器基于一个简单的假定:给定目标值时属性之间相互条件独立。换言之,该假定说明给定实例的目标值情况下,观察到联合的a1,a2...a n的概率正好是对每个单独属性的概率乘积:P(a1,a2...a n | V j ) = Πi P( a i| V j )。
因此,朴素贝叶斯分类器公式为:V nb =arg max{P( V j )Πi P ( a i | V j )}。
5 邻近算法(k-Nearest Neighbor algorithm,k最近邻算法)
下图中,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3(即实线圆内部),由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5(即虚线圆内),由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成正比。
该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。因此可以采用权值的方法(和该样本距离小的邻居权值大)来改进。该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
6 回归树分类器
如果要选择在很大范围的情形下性能都好的、同时不需要应用开发者付出很多的努力并且易于被终端用户理解的分类技术的话,那么Brieman, Friedman, Olshen和Stone(1984)提出的分类树方法是一个强有力的竞争者。
6.1 分类树
在分类树下面有两个关键的思想。第一个是关于递归地划分自变量空间的想法;第二个想法是用验证数据进行剪枝。
6.2 递归划分
让我们用变量Y表示因变量(分类变量),用X1, X2, X3,...,X p表示自变量。通过递归的方式把关于变量X的p维空间划分为不重叠的矩形。首先,一个自变量被选择,比如X i和X i的一个值x i,比方说选择x i把p维空间为两部分:一部分是p维的超矩形,其中包含的点都满足X i<=x i,另一个p 维的超矩形包含的所有点满足X i>x i。接着,这两部分中的一个部分通过选择一个变量和该变量的划分值以相似的方式被划分。这导致了三个矩形区域。随着这个过程的持续,我们得到的矩形越来越小。这个想法是把整个X空间划分为矩形,其中的每个小矩形都尽可能是同构的或“纯”的。“纯”的意思是(矩形)所包含的点都属于同一类。我们认为包含的点都只属于一个类(当然,这并不总是可能的,因为经常存在一些属于不同类的点,但这些点的自变量有完全相同的值)。
7 Adaboost分类器
Adaboost是adaptive boost的缩写,它是一种迭代算法。其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器 (强分类器)。其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,最后将每次训练得到的分类器融合起来,作为最后的决策分类器。使用Adaboost分类器可以排除一些不必要的训练数据特征,并将重点放在关键的训练数据上。
该算法其实是一个弱分类算法的提升过程,这个过程通过不断的训练,可以提高对数据的分类能力。
整个过程如下所示:
●先通过对N个数据的训练样本的学习得到第一个弱分类器;
●将分错的样本和其他的新数据一起构成一个新的N个数据的训练样本,通过对这个样本的
学习得到第二个弱分类器;
●将1.和2.都分错了的样本加上其他的新样本构成另一个新的N个数据的训练样本,通过对
这个样本的学习得到第三个弱分类器;
●最终经过提升的强分类器,即某个数据被分为哪一类要通过,……的多数表决。
对于boosting算法,存在两个问题:
●如何调整训练集,使得在训练集上训练的弱分类器得以进行;
●如何将训练得到的各个弱分类器联合起来形成强分类器。
针对以上两个问题,adaboost算法进行了调整:
●使用加权后选取的训练数据代替随机选取的训练样本,这样将训练的焦点集中在比较难分
的训练数据样本上;
●将弱分类器联合起来,使用加权的投票机制代替平均投票机制。让分类效果好的弱分类器
具有较大的权重,而分类效果差的分类器具有较小的权重。
Adaboost算法是Freund和Schapire根据在线分配算法提出的,他们详细分析了Adaboost算法错误率的上界,以及为了使强分类器达到要求的错误率,算法所需要的最多迭代次数等相关问题。与Boosting算法不同的是,adaboost算法不需要预先知道弱学习算法学习正确率的下限即弱分类器的误差,并且最后得到的强分类器的分类精度依赖于所有弱分类器的分类精度,这样可以深入挖掘弱分类器算法的能力。
Adaboost 算法中不同的训练集是通过调整每个样本对应的权重来实现的。开始时,每个样本对应的权重是相同的,即其中 n 为样本个数,在此样本分布下训练出一弱分类器。对于分类错误的样本,加大其对应的权重;而对于分类正确的样本,降低其权重,这样分错的样本就被突出出来,从而得到一个新的样本分布。在新的样本分布下,再次对弱分类器进行训练,得到弱分类器。依次类推,经过T 次循环,得到T 个弱分类器,把这T 个弱分类器按一定的权重叠加(boost )起来,得到最终想要的强分类器。
8 人工神经网络(ANN, artificial neural network )
人工神经网络是由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交互反应。
人工神经网络研究的局限性:
● 研究受到脑科学研究成果的限制;
● 缺少一个完整、成熟的理论体系;
● 研究带有浓厚的策略和经验色彩;
● 与传统技术的接口不成熟。
一般而言, ANN 与经典计算方法相比并非优越, 只有当常规方法解决不了或效果不佳时ANN 方法才能显示出其优越性。尤其对问题的机理不甚了解或不能用数学模型表示的系统,如故障诊断、特征提取和预测等问题,ANN 往往是最有利的工具。另一方面, ANN 对处理大量原始数据而不能用规则或公式描述的问题, 表现出极大的灵活性和自适应性。
8.1 BP 网络
人工神经网络以其具有自学习、自组织、较好的容错性和优良的非线性逼近能力,受到众多领域学者的关注。在实际应用中,80%~90%的人工神经网络模型是采用误差反传算法或其变化形式的网络模型(简称BP 网络),目前主要应用于函数逼近、模式识别、分类和数据压缩或数据挖掘。
(1)BP 网络建模特点:
● 非线性映照能力:神经网络能以任意精度逼近任何非线性连续函数。在建模过程中的许多
问题正是具有高度的非线性。
● 并行分布处理方式:在神经网络中信息是分布储存和并行处理的,这使它具有很强的容错
性和很快的处理速度。
● 自学习和自适应能力:神经网络在训练时,能从输入、输出的数据中提取出规律性的知识,
记忆于网络的权值中,并具有泛化能力,即将这组权值应用于一般情形的能力。神经网络的学习也可以在线进行。
● 数据融合的能力:神经网络可以同时处理定量信息和定性信息,因此它可以利用传统的工
程技术(数值运算)和人工智能技术(符号处理)。
● 多变量系统:神经网络的输入和输出变量的数目是任意的,对单变量系统与多变量系统提
供了一种通用的描述方式,不必考虑各子系统间的解耦问题。
(2)样本数据的收集和整理分组:
采用BP 神经网络方法建模的首要和前提条件是有足够多典型性好和精度高的样本。而且,为监控训练(学习)过程使之不发生“过拟合”和评价建立的网络模型的性能和泛化能力,必须将收集
图12.2 生物神经元功能模型输
入输出神经网络基本模型
到的数据随机分成训练样本、检验样本(10%以上)和测试样本(10%以上)3部分。此外,数据分组时还应尽可能考虑样本模式间的平衡。
由于传统的误差反传BP 算法较为成熟,且应用广泛,因此努力提高该方法的学习速度具有较高的实用价值。BP 算法中有几个常用的参数,包括学习率η,动量因子α,形状因子λ及收敛误差界值E 等。这些参数对训练速度的影响最为关键。
9 Fisher 分类器
X 空间:
W T X-W 0 >0 X ∈ω1
-W T X-W 0 <0 X ∈ω2
映射到Y 空间:
Y = W T X-W 0 >0 X ∈ω1
Y = W T X-W 0 <0 X ∈ω2
把X 空间各点投影到Y 空间的一直线上,维数由2维降为一维。若适当选择W 的方向,可以使两类分开。于是问题便转化为从数学上寻找最好的投影方向,即寻找最好的变换向量W 的问题。
在X 空间上的均值为:2,111==∑=i x N X i N j j i i
在Y 空间上的均值为:2,11111====∑∑==i X W x W N y N Y i T N j j T i N j j i i i i
投影样本类间的分离性用投影样本之差表示:|)(|||2121X X W Y Y T -=-,要求类间的分离性越大越好。
投影样本类内离散度: ()()W S W X W x W Y y i T N j i T j T N j i j i i i =-=-=∑∑==12122
σ,其中,
∑=--=i
N x T i i i X x X x S 1))((。
投影样本总的离散度可用)(2212σσ+来表示,要求投影样本总的离散度越小越好。
W S W W S W W S W w T T T =+=+212212σσ,其中,S S S w 21+=称为类内散布矩阵。
Fisher 准则函数为:()22122
12
||)(σσ+-=Y Y W J , 而W S W X W X W Y Y b T T T =-=-221221)()(,其中,()()2121X X X X S T b --=称为类间散
布矩阵。 所以,W
S W W S W W J w T b T =)(,对)(W J 求极值得()X X S W w 211-=-。这便是n 维X 空间向一维Y 空间的最好投影方向,它实际上是多维空间向一维空间的一种映射。
现在我们已把一个n 维的问题转化为一维的问题。于是只需在一维空间中设计 Fisher 分类器:
ω10∈?>=X W X W Y T
ω20∈?<=X W X W Y T
于是,问题归结为W 0的选择,常用的有以下三种: 1.2
210Y Y W +=; 2.2
121212102122N N X W N X W N N N Y N Y N W T T ++=++=; 3.()()()∑∑∑==-=-+--+=2211111211
22112
1120)(N j j N j j N j j Y y Y y
Y y
Y Y Y W 。 附录 数据挖掘中的十个算法
Top 10 algorithms in data mining
Abstract This paper presents the top 10 data mining algorithms identified by the IEEE International Conference on Data Mining (ICDM) in December 2006: C4.5, k-Means, SVM, Apriori, EM, PageRank, AdaBoost, kNN, Naive Bayes, and CART. These top 10 algorithms are among the most influential data mining algorithms in the research community.With each algorithm, we provide a description of the algorithm, discuss the impact of the algorithm, and reviewcurrent and further research on the algorithm. These 10 algorithms cover classification, X. clustering, statistical learning, association analysis, and link mining, which are all among the most important topics in data mining research and development.
概述 本文介绍有IEEE 2006年12月召开的国际会议确定的十个主要数据挖掘算法:C4.5(决策树),K-means (样本均值),SVM (支持向量机),Apriori (关联规则的一种),EM ,PageRank ,AdaBoost ,KNN ,Naive Bayes (贝叶斯)和CART 。这十个算法几乎在所有流行的数据挖掘研究中都有所包含。对于每一个算法,我们会首先描述算法,然后讨论起优缺点,总结当前应用和将来发展。这十个算法覆盖分类、聚类、统计学习、关联分析和关联挖掘,这些都是目前数据挖掘研究和开发的重要问题。
0 Introduction
0 简介
In an effort to identify some of the most influential algorithms that have been widely used in the data mining community, the IEEE International Conference on Data Mining (ICDM, https://www.360docs.net/doc/4d15301726.html,/~icdm/) identified the top 10 algorithms in data mining for presentation at ICDM ‘06 in Hong Kong.
为了确定最有影响力已广为广泛使用的数据挖掘算法的一些问题,IEEE国际会议(ICDM '06香港)确定的数据挖掘的数据挖掘算法的前10名。
As the first step in the identification process, in September 2006 we invited the ACMKDD Innovation Award and IEEE ICDM Research Contributions Award winners to each nominate up to 10 best-known algorithms in data mining. All except one in this distinguished set of award winners responded to our invitation. We asked each nomination to provide the following information: (a) the algorithm name, (b) a brief justification, and (c) a representative publication reference.We also advised that each nominated algorithm should have been widely cited and used by other researchers in the field, and the nominations from each nominator as a group should have a reasonable representation of the different areas in data mining.
首先2006年9月,我们邀请ACMKDD创新奖和IEEE ICDM研究贡献奖得主分别提名多达10个最知名的数据挖掘算法。此外的所有获奖者我们要求每名候选人提供下列资料:(1)的算法的名称,(b)一个简短的理由,以及(c)一名代表的出版物引用。我们还表示,每个提名的算法应该被广泛引用,并在该领域的其他研究人员使用,以及每个作为一个集团提名人的提名,应该有一个在数据挖掘不同领域合理的代表性。
After the nominations in Step 1, we verified each nomination for its citations on Google Scholar in late October 2006, and removed those nominations that did not have at least 50 citations. All remaining (18) nominations were then organized in 10 topics: association analysis, classification, clustering, statistical learning, bagging and boosting, sequential patterns, integrated mining, rough sets, linkmining, and graph mining. For some of these 18 algorithms such as k-means, the representative publication was not necessarily the original paper that introduced the algorithm, but a recent paper that highlights the importance of the technique. These representative publications are available at the ICDM website (https://www.360docs.net/doc/4d15301726.html,/~icdm/algorithms/CandidateList.shtml).
In the third step of the identification process, we had a wider involvement of the research community. We invited the Program Committee members of KDD-06 (the 2006 ACM SIGKDD International Conference on Knowledge Discovery and Data Mining), ICDM ‘06 (the 2006 IEEE International Conference on Data Mining), and SDM ‘06 (the 2006 SIA M International Conference on Data Mining), as well as the ACMKDD Innovation Award and IEEE ICDM Research Contributions Award winners to each vote for up to 10 well-known algorithms from the 18-algorithm candidate list. The voting results of this step were presented at the ICDM ‘06 panel on Top 10 Algorithms in Data Mining.
At the ICDM ‘06 panel of December 21, 2006, we also took an open vote with all 145 attendees on the top 10 algorithms from the above 18-algorithm candidate list, and the top 10 algorithms from this open vote were the same as the voting results from the above third step. The 3-hour panel was organized as the last session of the ICDM ‘06 conference, in parallel with 7 paper presentation sessions of the Web Intelligence (WI ‘06) and Intelligent Agent Technology (IAT ‘06) conferences at the same location, and attracting 145 participants to this panel clearly showed that the panel was a great success.
1 C4.5 and beyond
1.1 Introduction
Systems that construct classifiers are one of the commonly used tools in data mining. Such systems take as input a collection of cases, each belonging to one of a small number of classes and described by its values for a fixed set of attributes, and output a classifier that can
accurately predict the class to which a new case belongs.
These notes describe C4.5 [64], a descendant of CLS [41] and ID3 [62]. Like CLS and ID3, C4.5 generates classifiers expressed as decision trees, but it can also construct classifiers in more comprehensible ruleset form. We will outline the algorithms employed in C4.5, highlight some changes in its successor See5/C5.0, and conclude with a couple of open
research issues.
1.2 Decision trees
Given a set S of cases, C4.5 first grows an initial tree using the divide-and-conquer algorithm as follows:
? If all the cases in S belong to the same class or S is small, the tree is a leaf labeled with the most
frequent class in S.
? Otherwise, choose a test based on a single attribute with two or more outcomes. Make this test the root of the tree with one branch for each outcome of the test, partition S into corresponding subsets S1, S2, . . . according to the outcome for each case, and apply the same procedure recursively to each subset.
There are usually many tests that could be chosen in this last step. C4.5 uses two heuristic criteria to rank possible tests: information gain, which minimizes the total entropy of the subsets {Si } (but is heavily biased towards tests with numerous outcomes), and the default gain ratio that divides information gain by the information provided by the test outcomes.
Attributes can be either numeric or nominal and this determines the format of the test outcomes. For a numeric attribute A they are {A ≤ h, A > h} where the threshold h is found by sor ting S on the values of A and choosing the split between successive values that maximizes the criterion above. An attribute A with discrete values has by default one outcome for each value, but an option allows the values to be grouped into two or more subsets with one outcome for each subset.
The initial tree is then pruned to avoid overfitting. The pruning algorithm is based on a pessimistic estimate of the error rate associated with a set of N cases, E of which do not belong to the most frequent class. Instead of E/N, C4.5 determines the upper limit of the binomial probability when E events have been observed in N trials, using a user-specified confidence whose default value is 0.25.
Pruning is carried out from the leaves to the root. The estimated error at a leaf with N cases and E errors is N times the pessimistic error rate as above. For a subtree, C4.5 adds the estimated errors of the branches and compares this to the estimated error if the subtree is replaced by a leaf; if the latter is no higher than the former, the subtree is pruned. Similarly, C4.5 checks the estimated error if the subtree is replaced by one of its branches and when this appears beneficial the tree is modified accordingly. The pruning process is completed in one pass through the tree.
C4.5‘s tree-construction algorithm differs in several respects from CART [9], for instance:
? Tests in CART are always binary, but C4.5 allows two or more outcomes.
? CART uses the Gini diversity index to rank tests, whereas C4.5 uses information-based criteria.
? CART prunes trees using a cost-complexity model whose parameters are estimated by cross-validation; C4.5 uses a single-pass algorithm derived from binomial confidence limits.
? This brief discussion has not mentioned what happens when some of a case‘s values are unknown. CART looks for surrogate tests that approximate the outcomes when the tested attribute has an unknown value, but C4.5 apportions the case probabilistically among the outcomes.
1.3 Ruleset classifiers
Complex decision trees can be difficult to understand, for instance because information about one class is usually distributed throughout the tree. C4.5 introduced an alternative formalism consisting of a list of rules of the form ―if A and B and C and ... then class X‖, where rules for each class are grouped together.
A case is classified by finding the first rule whose conditions are satisfied by the case; if no rule is satisfied, the case is assigned to a default class.
C4.5 rulesets are formed from the initial (unpruned) decision tree. Each path from the root of the tree to a leaf becomes a prototype rule whose conditions are the outcomes along the path andwhose class is the label of the leaf. This rule is then simplified by determining the effect of discarding each condition in turn. Dropping a condition may increase the number N of cases covered by the rule, and also the number E of cases that do not belong to the class nominated by the rule, and may lower the pessimistic error rate determined as above. A hill-climbing algorithm is used to drop conditions until the lowest pessimistic error rate is found.
To complete the process, a subset of simplified rules is selected for each class in turn. These class subsets are ordered to minimize the error on the training cases and a default class is chosen. The final ruleset usually has far fewer rules than the number of leaves on the pruned decision tree.
The principal disadvantage of C4.5‘s rulesets is the amount of CPU time and memory that they require. In one experiment, samples ranging from 10,000 to 100,000 cases were drawn from a large dataset. For decision trees, moving from 10 to 100K cases increased CPU time on a PC from 1.4 to 61 s, a factor of 44. The time required for rulesets, however, increased from 32 to 9,715 s, a factor of 300.
1.4 See5/C5.0
C4.5 was superseded in 1997 by a commercial system See5/C5.0 (or C5.0 for short). The changes encompass new capabilities as well as much-improved efficiency, and include:
? A variant of boosting [24], which constructs an ensemble of classifiers that are then voted to give a final classification. Boosting often leads to a dramatic improvement in predictive accuracy.
?New data types (e.g., dates), ―not applicable‖ values, variable misclassification costs, and m echanisms to pre-filter attributes.
? Unordered rulesets—when a case is classified, all applicable rules are found and voted. This improves both the interpretability of rulesets and their predictive accuracy.
? Greatly improved scalability of both decision trees and (particularly) rulesets. Scalability is enhanced by
multi-threading; C5.0 can take advantage of computers with multiple CPUs and/or cores.
More details are available from https://www.360docs.net/doc/4d15301726.html,/see5-comparison.html.
1.5 Research issues
We have frequently heard colleagues express the view that decision trees are a ―solved problem.‖ We do not agree with this proposition and will close with a couple of open research problems.
Stable trees. It is well known that the error rate of a tree on the cases fromwhich itwas constructed (the resubstitution error rate) is much lower than the error rate on unseen cases (the predictive error rate). For example, on a well-known letter recognition dataset with 20,000 cases, the resubstitution error rate for C4.5 is 4%, but the error rate from a leave-one-out (20,000-fold) cross-validation is 11.7%. As this demonstrates, leaving out a single case from 20,000 often affects the tree that is constructed!
Suppose now that we could develop a non-trivial tree-construction algorithm that was hardly ever affected by omitting a single case. For such stable trees, the resubstitution error rate should approximate the leave-one-out cross-validated error rate, suggesting that the tree
is of the ―right‖ size.
Decomposing complex trees.Ensemble classifiers, whether generated by boosting, bagging, weight randomization, or other techniques, usually offer improved predictive accuracy. Now, given a small number of decision trees, it is possible to generate a single (very complex) tree that is exactly equivalent to voting the original trees, but can we go the other way? That is, can a complex tree be broken down to a small collection of simple trees that, when voted together, give the same result as the complex tree? Such decomposition would be of great help in producing comprehensible decision trees.
Research on C4.5 was funded for many years by the Australian Research Council.
C4.5 is freely available for research and teaching, and source can be downloaded from https://www.360docs.net/doc/4d15301726.html,/Personal/c4.5r8.tar.gz.
2 The k-means algorithm
2.1 The algorithm
The k-means algorithm is a simple iterative method to partition a given dataset into a userspecified number of clusters, k. This algorithm has been discovered by several researchers across different disciplines, most notably Lloyd (1957, 1982) [53], Forgey (1965), Friedman and Rubin (1967), and McQueen (1967). A detailed history of k-means alongwith descriptions of several variations are given in [43]. Gray and Neuhoff [34] provide a nice historical background for k-means placed in the larger context of hill-climbing
algorithms. The algorithm operates on a set of d-dimensional vectors, D = {xi | i = 1, . . . , N}, where xi
∈denotes the ith data point. The algorithm is initialized by picking k points in as the initial k cluster representatives or ―centroids‖. Techniques for selecting these initial seeds include sampling at random from the dataset, setting them as the solution of clustering a small subset of the data or perturbing the global mean of the data k times. Then the algorithm iterates between two steps till convergence:
Step 1: Data Assignment. Each data point is assigned to its closest centroid, with ties broken arbitrarily. This results in a partitioning of the data.
Step 2:Relocation of ―means‖. Each cluster representative is relocated to the center (mean) of all data points assigned to it. If the data points come with a probability measure (weights), then the relocation is to the expectations (weighted mean) of the data partitions.
The algorithm convergeswhen the assignments (and hence the cj values) no longer change. The algorithm execution is visually depicted in Fig. 1. Note that each iteration needs N × k comparisons, which determines the time complexity of one iteration. The number of iterations required for convergence varies and may depend on N, but as a first cut, this algorithm can be considered linear in the dataset size.
One issue to resolve is how to quantify ―closest‖ in the assignment step. The default measure of closeness is the Euclidean distance, in which case one can readily show that the non-negative cost function,
will decrease whenever there is a change in the assignment or the relocation steps, and hence convergence is guaranteed in a finite number of iterations. The greedy-descent nature of k-means on a non-convex cost also implies that the convergence is only to a local optimum, and indeed the algorithm is typically quite sensitive to the initial centroid locations. Figure 2-1 illustrates how a poorer result is obtained for the same dataset as in Fig. 1 for a different choice of the three initial centroids. The local minima problem can be countered to some extent by running the algorithm
Fig. 1 Changes in cluster representative locations (indicated by ?+‘ signs) and data assignments (indicated by color) during an execution of the k-means algorithm
Fig. 2 Effect of an inferior initialization on the k-means results
multiple times with different initial centroids, or by doing limited local search about the converged solution.
2.2 Limitations
In addition to being sensitive to initialization, the k-means algorithm suffers from several other problems. First, observe that k-means is a limiting case of fitting data by a mixture of k Gaussians with
identical, isotropic covariance matrices , when the soft assignments of data points to mixture components are hardened to allocate each data point solely to the most likely component. So, it will falter whenever the data is not well described by reasonably separated spherical balls, for example, if there are non-covex shaped clusters in the data. This problem may be alleviated by rescaling the data to ―whiten‖ it before clustering, or by using a different distance measure that ismore appropriate for the dataset. For example, information-theoretic clustering uses theKL-divergence to measure the distance between two data points representing two discrete probability distributions. It has been recently shown that if one measures distance by selecting any member of a very large class of divergences called Bregman divergences during the assignment step and makes no other changes, the essential properties of k-means, including guaranteed convergence, linear separation boundaries and scalability, are retained [3]. This result makes k-means effective for a much larger class of datasets so long as an appropriate divergence is used.
k-means can be paired with another algorithm to describe non-convex clusters. One first clusters the data into a large number of groups using k-means. These groups are then agglomerated into larger clusters using single link hierarchical clustering, which can detect complex shapes. This approach also makes the solution less sensitive to initialization, and since the hierarchical method provides results at multiple resolutions, one does not need to pre-specify k either.
The cost of the optimal solution decreases with increasing k till it hits zero when the umber of clusters equals the number of distinct data-points. This makes it more difficult to (a) directly compare solutions with different numbers of clusters and (b) to find the optimum value of k. If the desired k is not known in advance, one will typically run k-means with different values of k, and then use a suitable criterion to select one of the results. For example, SAS uses the cube-clustering-criterion, while X-means adds a complexity term (which increases with k) to the original cost function (Eq. 1) and then identifies the k which minimizes this adjusted cost. Alternatively, one can progressively increase the number of clusters, in conjunction with a suitable stopping criterion. Bisecting k-means [73] achieves this by first putting all the data into a single cluster, and then recursively splitting the least compact cluster into two using 2-means. The celebrated LBG algorithm [34] used for vector quantization doubles the number of clusters till a suitable code-book size is obtained. Both these approaches thus alleviate the need to know k beforehand.
The algorithm is also sensitive to the presence of outliers, since ―mean‖ is not a robust statistic. A
preprocessing step to remove outliers can be helpful. Post-processing the results, for example to eliminate small clusters, or to merge close clusters into a large cluster, is also desirable. Ball and Hall‘s ISODA TA algorithm from 1967 effectively used both pre- and post-processing on k-means.
2.3 Generalizations and connections
As mentioned earlier, k-means is closely related to fitting a mixture of k isotropicGaussians to the data. Moreover, the generalization of the distance measure to all Bregman divergences is related to fitting the data with a mixture of k components from the exponential family of distributions. Another broad generalization is to view the ―means‖ as probabilistic models instead of points in Rd . Here, in the assignment step, each data point is assigned to the most likely model to have generated it. In the ―relocation‖ step, the model parameters are updated to best fit the assigned datasets. Such model-based k-means allow one to cater to more complex data, e.g. sequences described by Hidden Markov models.
O ne can also ―kernelize‖ k-means [19]. Though boundaries between clusters are still linear in the implicit high-dimensional space, they can become non-linear when projected back to the original space, thus allowing kernel k-means to deal with more complex clusters. Dhillon et al. [19] have shown a close connection between kernel k-means and spectral clustering. The K-medoid algorithm is similar to k-means except that the centroids have to belong to the data set being clustered. Fuzzy c-means is also similar, except that it computes fuzzy membership functions for each clusters rather than a hard one.
Despite its drawbacks, k-means remains the most widely used partitional clustering algorithm in practice. The algorithm is simple, easily understandable and reasonably scalable, and can be easily modified to deal with streaming data. To deal with very large datasets, substantial effort has also gone into further speeding up k-means, most notably by using kd-trees or exploiting the triangular inequality to avoid comparing each data point with all the centroids during the assignment step. Continual improvements and generalizations of the basic algorithm have ensured its continued relevance and gradually increased its effectiveness as well.
3 Support vector machines
In today‘s machine learning applications, support vector machines (SVM) [83] are considered amust try—it offers one of themost robust and accurate methods among all well-known algorithms. It has a sound theoretical foundation, requires only a dozen examples for training, and is insensitive to the number of dimensions. In addition, efficient methods for training SVM are also being developed at a fast pace.
In a two-class learning task, the aim of SVM is to find the best classification function to distinguish between members of the two classes in the training data. The metric for the concept of the ―best‖
工业机器人静力及动力学分析
注:1)2008年春季讲课用;2)带下划线的黑体字为板书内容;3)公式及带波浪线的部分为必讲内容第3章工业机器人静力学及动力学分析 3.1 引言 在第2章中,我们只讨论了工业机器人的位移关系,还未涉及到力、速度、加速度。由理论力学的知识我们知道,动力学研究的是物体的运动和受力之间的关系。要对工业机器人进行合理的设计与性能分析,在使用中实现动态性能良好的实时控制,就需要对工业机器人的动力学进行分析。在本章中,我们将介绍工业机器人在实际作业中遇到的静力学和动力学问题,为以后“工业机器人控制”等章的学习打下一个基础。 在后面的叙述中,我们所说的力或力矩都是“广义的”,包括力和力矩。 工业机器人作业时,在工业机器人与环境之间存在着相互作用力。外界对手部(或末端操作器)的作用力将导致各关节产生相应的作用力。假定工业机器人各关节“锁住”,关节的“锁定用”力与外界环境施加给手部的作用力取得静力学平衡。工业机器人静力学就是分析手部上的作用力与各关节“锁定用”力之间的平衡关系,从而根据外界环境在手部上的作用力求出各关节的“锁定用”力,或者根据已知的关节驱动力求解出手部的输出力。 关节的驱动力与手部施加的力之间的关系是工业机器人操作臂力控制的基础,也是利用达朗贝尔原理解决工业机器人动力学问题的基础。 工业机器人动力学问题有两类:(1)动力学正问题——已知关节的驱动力,求工业机器人系统相应的运动参数,包括关节位移、速度和加速度。(2)动力学逆问题——已知运动轨迹点上的关节位移、速度和加速度,求出相应的关节力矩。 研究工业机器人动力学的目的是多方面的。动力学正问题对工业机器人运动仿真是非常有用的。动力学逆问题对实现工业机器人实时控制是相当有用的。利用动力学模型,实现最优控制,以期达到良好的动态性能和最优指标。 工业机器人动力学模型主要用于工业机器人的设计和离线编程。在设计中需根据连杆质量、运动学和动力学参数,传动机构特征和负载大小进行动态仿真,对其性能进行分析,从而决定工业机器人的结构参数和传动方案,验算设计方案的合理性和可行性。在离线编程时,为了估计工业机器人高速运动引起的动载荷和路径偏差,要进行路径控制仿真和动态模型的仿真。这些都必须以工业机器人动力学模型为基础。 工业机器人是一个非线性的复杂的动力学系统。动力学问题的求解比较困难,而且需要较长的运算时间。因此,简化求解过程,最大限度地减少工业机器人动力学在线计算的时间是一个受到关注的研究课题。 在这一章里,我们将首先讨论与工业机器人速度和静力学有关的雅可比矩阵,然后介绍工业机器人的静力学问题和动力学问题。
第3章 工业机器人静力计算及动力学分析
第3章 工业机器人静力计算及动力学分析 章节题目:第3章 工业机器人静力计算及动力学分析 [教学内容] 3.1 工业机器人速度雅可比与速度分析 3.2 工业机器人力雅可比与静力计算 3.3 工业机器人动力学分析 [教学安排] 第3章安排6学时,其中介绍工业机器人速度雅可比45分钟,工业机器人速度分析45分钟,操作臂中的静力30分钟,机器人力雅可比30分钟,机器人静力计算的两类问题10分钟,拉格朗日方程20分钟,二自由度平面关节机器人动力学方程60分钟,关节空间和操作空间动力学30分钟。 通过多媒体课件结合板书的方式,采用课堂讲授和课堂讨论相结合的方法,首先讨论与机器人速度和静力有关的雅可比矩阵,然后介绍工业机器人的静力学问题和动力学问题。 [知识点及其基本要求] 1、工业机器人速度雅可比(掌握) 2、速度分析(掌握) 3、操作臂中的静力(掌握) 4、机器人力雅可比(掌握) 5、机器人静力计算的两类问题(了解) 6、拉格朗日方程(熟悉) 7、二自由度平面关节机器人动力学方程(理解) 8、关节空间和操作空间动力学(了解) [重点和难点] 重点:1、速度雅可比及速度分析 2、力雅可比 3、拉格朗日方程 4、二自由度平面关节机器人动力学方程 难点:1、关节空间和操作空间动力学 [教学法设计] 引入新课: 至今我们对工业机器人运动学方程还只局限于静态位置问题的讨论,还没有涉及力、速度、加速度等。机器人是一个多刚体系统,像刚体静力学平衡一样,整个机器人系统在外载荷和关节驱动力矩(驱动力)作用下将取得静力平衡;也像刚体在外力作用下发生运动变化一样,整个机器人系统在关节驱动力矩(驱动力)作用下将发生运动变化。 新课讲解: 第一次课 第三章 工业机器人静力计算及动力学分析 3-1 工业机器人速度雅可比与速度分析 一、工业机器人速度雅可比 假设有六个函数,每个函数有六个变量,即: ??? ???? ===),,,,,(),,,,,(),,,,,(654321666543212265432111x x x x x x f y x x x x x x f y x x x x x x f y ,可写成Y=F(X),
分析报告、统计分析和数据挖掘的区别
分析报告、统计分析和数据挖掘的区别 关于数据挖掘的作用,Berry and Linoff的定义尽管有些言过其实,但清晰的描述了数据挖掘的作用。“分析报告给你后见之明 (hindsight);统计分析给你先机 (foresight);数据挖掘给你洞察力(insight)”。 举个例子说。 你看到孙悟空跟二郎神打仗,然后写了个分析报告,说孙悟空在柔韧性上优势明显,二郎神在力气上出类拔萃,所以刚开始不相上下;结果两个人跑到竹林里,在竹子上面打,孙悟空的优势发挥出来,所以孙悟空赢了。这叫分析报告。 孙悟空要跟二郎神打架了,有个赌徒找你预测。你做了个统计,发现两人斗争4567次,其中孙悟空赢3456次。另外,孙悟空斗牛魔王,胜率是89%,二郎神斗牛魔王胜率是71%。你得出趋势是孙悟空赢。因为你假设了这次胜利跟历史的关系,根据经验作了一个假设。这叫统计分析。 你什么都没做,让计算机自己做关联分析,自动找到了出身、教育、经验、单身四个因素。得出结论是孙悟空赢。计算机通过分析发现贫苦出身的孩子一般比皇亲国戚功夫练得刻苦;打架经验丰富的人因为擅长利用环境而机会更多;在都遇得到明师的情况下,贫苦出身的孩子功夫可能会高些;单身的人功夫总比同样环境非单身的高。孙悟空遇到的名师不亚于二郎神,而打架经验绝对丰富,并且单身,所以这次打头,孙悟空赢。这叫数据挖掘。 数据挖掘跟LOAP的区别在于它没有假设,让计算机找出这种背后的关系,而这种关系可能是你所想得到的,也可能是所想不到的。比如数据挖掘找出的结果发现在2亿条打斗记录中,姓孙的跟姓杨的打,总是姓孙的胜利,孙悟空姓孙,所以,悟空胜利。 用在现实中,我们举个例子来说,做OLAP分析,我们找找哪些人总是不及时向电信运营商缴钱,一般会分析收入低的人往往会缴费不及时。通过分析,发现不及时缴钱的穷人占71%。而数据挖掘则不同,它自己去分析原因。原因可能是,家住在五环以外的人,不及时缴钱。这些结论对推进工作有很深的价值,比如在五环外作市场调研,发现需要建立更多的合作渠道以方便缴费。这是数据挖掘的价值。
二自由度机械臂动力学分析培训资料
二自由度机械臂动力 学分析
平面二自由度机械臂动力学分析 姓名:黄辉龙 专业年级:13级机电 单位:汕头大学 摘要:机器臂是一个非线性的复杂动力学系统。动力学问题的求解比较困难,而且需要较长的运算时间,因此,这里主要对平面二自由度机械臂进行动力学研究。拉格朗日方程在多刚体系统动力学的应用方法分析平面二自由度机械臂的正向动力学。经过分析,得出平面二自由度机械臂的动力学方程,为后续更深入研究做铺垫。 关键字:平面二自由度 动力学方程 拉格朗日方程 相关介绍 机器人动力学的研究有牛顿-欧拉(Newton-Euler )法、拉格朗日 (Langrange)法、高斯(Gauss )法等,但一般在构建机器人动力学方程中,多采用牛顿-欧拉法及拉格朗日法。 欧拉方程又称牛顿-欧拉方程,应用欧拉方程建立机器人机构的动力学方程是指研究构件质心的运动使用牛顿方程,研究相对于构件质心的转动使用欧拉方程,欧拉方程表征了力、力矩、惯性张量和加速度之间的关系。 在机器人的动力学研究中,主要应用拉格朗日方程建立机器人的动力学方程,这类方程可直接表示为系统控制输入的函数,若采用齐次坐标,递推的拉格朗日方程也可以建立比较方便且有效的动力学方程。 在求解机器人动力学方程过程中,其问题有两类: 1)给出已知轨迹点上? ??θθθ、及、 ,即机器人关节位置、速度和加速度,求相应的关节力矩矢量τ。这对实现机器人动态控制是相当有用的。 2)已知关节驱动力矩,求机器人系统相应各瞬时的运动。也就是说,给出关节力矩矢量τ,求机器人所产生的运动? ??θθθ、及、 。这对模拟机器人的运动是非常有用的。 平面二自由度机械臂动力学方程分析及推导过程 1、机器人是结构复杂的连杆系统,一般采用齐次变换的方法,用拉格朗日方程建立其系统动力学方程,对其位姿和运动状态进行描述。机器人动力学方程的具体推导过程如下: 1) 选取坐标系,选定完全而且独立的广义关节变量n r ,,2,1,r ???=θ。 2) 选定相应关节上的广义力r F :当r θ是位移变量时,r F 为力;当r θ是角度变量时,r F 为力矩。 3)求出机器人各构件的动能和势能,构造拉格朗日函数。 4) 代入拉格朗日方程求得机器人系统的动力学方程。 2、下面以图1所示说明机器人二自由度机械臂动力学方程的推导过程。
统计学和数据挖掘区别
统计学和数据挖掘区别 数据分析微信公众号datadw——关注你想了解的,分享你需要的。 1.简介 统计学和数据挖掘有着共同的目标:发现数据中的结构。事实上,由于它们的目标相似,一些人(尤其是统计学家)认为数据挖掘是统计学的分支。这是一个不切合实际的看法。因为数据挖掘还应用了其它领域的思想、工具和方法,尤其是计算机学科,例如数据库技术和机器学习,而且它所关注的某些领域和统计学家所关注的有很大不同。 统计学和数据挖掘研究目标的重迭自然导致了迷惑。事实上,有时候还导致了反感。统计学有着正统的理论基础(尤其是经过本世纪的发展),而现在又出现了一个新的学科,有新的主人,而且声称要解决统计学家们以前认为是他们领域的问题。这必然会引起关注。更多的是因为这门新学科有着一个吸引人的名字,势必会引发大家的兴趣和好奇。把“数据挖掘”这个术语所潜在的承诺和“统计学”作比较的话,统计的最初含义是“陈述事实”,以及找出枯燥的大量数据背后的有意义的信息。当然,统计学的现代的含义已经有很大不同的事实。而且,这门新学科同商业有特殊的关联(尽管它还有科学及其它方面的应用)。 本文的目的是逐个考察这两门学科的性质,区分它们的异同,并关注与数据挖掘相关联的一些难题。首先,我们注意到“数据挖掘”对统计学家来说并不陌生。例如,Everitt定义它为:“仅仅是考察大量的数据驱动的模型,从中发现最适合的”。统计学家因而会忽略对数据进行特别的分析,因为他们知道太细致的
研究却难以发现明显的结构。尽管如此,事实上大量的数据可能包含不可预测的但很有价值的结构。而这恰恰引起了注意,也是当前数据挖掘的任务。 2.统计学的性质 试图为统计学下一个太宽泛的定义是没有意义的。尽管可能做到,但会引来很多异议。相反,我要关注统计学不同于数据挖掘的特性。 差异之一同上节中最后一段提到的相关,即统计学是一门比较保守的学科,目前有一种趋势是越来越精确。当然,这本身并不是坏事,只有越精确才能避免错误,发现真理。但是如果过度的话则是有害的。这个保守的观点源于统计学是数学的分支这样一个看法,我是不同意这个观点的。尽管统计学确实以数学为基础(正如物理和工程也以数学为基础,但没有被认为是数学的分支),但它同其它学科还有紧密的联系。 数学背景和追求精确加强了这样一个趋势:在采用一个方法之前先要证明,而不是象计算机科学和机器学习那样注重经验。这就意味着有时候和统计学家关注同一问题的其它领域的研究者提出一个很明显有用的方法,但它却不能被证明(或还不能被证明)。统计杂志倾向于发表经过数学证明的方法而不是一些特殊方法。数据挖掘作为几门学科的综合,已经从机器学习那里继承了实验的态度。这并不意味着数据挖掘工作者不注重精确,而只是说明如果方法不能产生结果的话就会被放弃。
机器人动力学汇总
机器人动力学研究的典型方法和应用 (燕山大学 机械工程学院) 摘 要:本文介绍了动力学分析的基础知识,总结了机器人动力学分析过程中比较常用的动力学分析的方法:牛顿—欧拉法、拉格朗日法、凯恩法、虚功原理法、微分几何原理法、旋量对偶数法、高斯方法等,并且介绍了各个方法的特点。并通过对PTl300型码垛机器人弹簧平衡机构动力学方法研究,详细分析了各个研究方法的优越性和方法的选择。 前 言:机器人动力学的目的是多方面的。机器人动力学主要是研究机器人机构的动力学。机器人机构包括机械结构和驱动装置,它是机器人的本体,也是机器人实现各种功能运动和操作任务的执行机构,同时也是机器人系统中被控制的对象。目前用计算机辅助方法建立和求解机器人机构的动力学模型是研究机器人动力学的主要方法。动力学研究的主要途径是建立和求解机器人的动力学模型。所谓动力学模指的是一组动力学方程(运动微分方程),把这样的模型作为研究力学和模拟运动的有效工具。 报告正文: (1)机器人动力学研究的方法 1)牛顿—欧拉法 应用牛顿—欧拉法来建立机器人机构的动力学方程,是指对质心的运动和转动分别用牛顿方程和欧拉方程。把机器人每个连杆(或称构件)看做一个刚体。如果已知连杆的表征质量分布和质心位置的惯量张量,那么,为了使连杆运动,必须使其加速或减速,这时所需的力和力矩是期望加速度和连杆质量及其分布的函数。牛顿—欧拉方程就表明力、力矩、惯性和加速度之间的相互关系。 若刚体的质量为m ,为使质心得到加速度a 所必须的作用在质心的力为F ,则按牛顿方程有:ma F = 为使刚体得到角速度ω、角加速度εω= 的转动,必须在刚体上作用一力矩M , 则按欧拉方程有:εωI I M += 式中,F 、a 、M 、ω、ε都是三维矢量;I 为刚体相对于原点通过质心并与刚
大数据、数据分析和数据挖掘的区别
大数据、数据分析和数据挖掘的区别 大数据、数据分析、数据挖掘的区别是,大数据是互联网的海量数据挖掘,而数据挖掘更多是针对内部企业行业小众化的数据挖掘,数据分析就是进行做出针对性的分析和诊断,大数据需要分析的是趋势和发展,数据挖掘主要发现的是问题和诊断。具体分析如下: 1、大数据(big data): 指无法在可承受的时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产; 在维克托·迈尔-舍恩伯格及肯尼斯·库克耶编写的《大数据时代》中大数据指不用随机分析法(抽样调查)这样的捷径,而采用所有数据进行分析处理。大数据的5V特点(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(价值)Veracity(真实性) 。 2、数据分析:
是指用适当的统计分析方法对收集来的大量数据进行分析,提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。这一过程也是质量管理体系的支持过程。在实用中,数据分析可帮助人们作出判断,以便采取适当行动。 数据分析的数学基础在20世纪早期就已确立,但直到计算机的出现才使得实际操作成为可能,并使得数据分析得以推广。数据分析是数学与计算机科学相结合的产物。 3、数据挖掘(英语:Data mining): 又译为资料探勘、数据采矿。它是数据库知识发现(英语:Knowledge-Discovery in Databases,简称:KDD)中的一个步骤。数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。 简而言之: 大数据是范围比较广的数据分析和数据挖掘。 按照数据分析的流程来说,数据挖掘工作较数据分析工作靠前些,二者又有重合的地方,数据挖掘侧重数据的清洗和梳理。 数据分析处于数据处理的末端,是最后阶段。 数据分析和数据挖掘的分界、概念比较模糊,模糊的意思是二者很难区分。 大数据概念更为广泛,是把创新的思维、信息技术、统计学等等技术的综合体,每个人限于学术背景、技术背景,概述的都不一样。
统计学和数据挖掘(中文).
统计学和数据挖掘:交叉学科 摘要:统计学和数据挖掘有很多共同点,但与此同时它们也有很多差异。本文讨论了两门学科的性质,重点论述它们的异同。 关键词:统计学知识发现 1.简介 统计学和数据挖掘有着共同的目标:发现数据中的结构。事实上,由于它们的目标相似,一些人(尤其是统计学家认为数据挖掘是统计学的分支。这是一个不切合实际的看法。 因为数据挖掘还应用了其它领域的思想、工具和方法,尤其是计算机学科,例如数据库技术和机器学习,而且它所关注的某些领域和统计学家所关注的有很大不同。 统计学和数据挖掘研究目标的重迭自然导致了迷惑。事实上,有时候还导致了反感。统计学有着正统的理论基础(尤其是经过本世纪的发展,而现在又出现了一个新的学科,有新的主人,而且声称要解决统计学家们以前认为是他们领域的问题。这必然会引起关注。更多的是因为这门新学科有着一个吸引人的名字,势必会引发大家的兴趣和好奇。把“数据挖掘”这个术语所潜在的承诺和“统计学”作比较的话,统计的最初含义是“陈述事实”,以及找出枯燥的大量数据背后的有意义的信息。当然,统计学的现代的含义已经有很大不同的事实。而且,这门新学科同商业有特殊的关联(尽管它还有科学及其它方面的应用。 本文的目的是逐个考察这两门学科的性质,区分它们的异同,并关注与数据挖掘相关联的一些难题。首先,我们注意到“数据挖掘”对统计学家来说并不陌生。例如,Everitt定义它为:“仅仅是考察大量的数据驱动的模型,从中发现最适合的”。统计学家因而会忽略对数据进行特别的分析,因为他们知道太细致的研究却难以发现明显的结构。尽管如此,事实上大量的数据可能包含不可预测的但很有价值的结构。而这恰恰引起了注意,也是当前数据挖掘的任务。
工业机器人剖析
总评成绩:《机器人应用技术》实验报告 专业:机电一体化 班级:机电141班 学号:140212107 姓名:刘宗成 河南工学院 机电工程系
实验一工业机器人机械结构 实验目的:1、认识机器人的基本结构和组成 2、熟悉工业机器人基本工作原理 3、了解工业机器人技术参数 实验原理: 六自由度机械手本体结构图 实验器材:1、FANUC M-6i六自由度机械手二台 2、FANUC M-6iB六自由度机械手一台 3、ABB IRB-2400六自由度机械手一台 4、实验设备使用说明书各一本 实验步骤:1、学习ABB和FANUC六自由度机械手基本构成控制柜与机械本体 2、学习六自由度机械手本体各关节的作用 3、学习六自由度机械手本体中定位关节与姿态关节 4、学习六自由度机械手本体各关节驱动机构与传动机构 5、学习典型工业机器人机械本体质量分布,以及各关节中质量平衡和力矩平衡 6、学习六自由度机械手各关节运动范围及运动速度控制 7、学习工业机器人重复定位精度的定义,并且了解相应机器人的重复定位精度 8、学习工业机器人最大负载 9、学习工业机器人最大运动范围 实验报告:课后每位同学按照要求完成实验报告。 思考题:1、画出六自由度机械手的结构简图 2、分析各关节机械手臂的运动范围 注意事项:1、实验开始之前认真学习工业机器人机械本体结构。 2、实验过程认真阅读实验设备说明书。
实验报告
实验二 机器人运动学实验 实验目的:1、了解四自由机械臂的开链结构 2、掌握机械臂运动关节之间的坐标变换原理 3、学会机器人运动方程的正反解方法 实验原理: 机器人运动学只涉及到物体的运动规律,不考虑产生运动的力和力矩。机器人正运动学所研究的内容是:给定机器人各关节的角度或位移,求解计算机器人末端执行器相对于参考坐标系的位置和姿态问题。 各连杆变换矩阵相乘,可得到机器人末端执行器的位姿方程(正运动学方程)为 : 432140 A A A A T ==????? ???????10 00 z z z z y y y y x x x x p a o n p a o n p a o n 其中:z 向矢量处于手爪入物体的方向上,称之为接近矢量a ,y 向矢量的方向从一个 指尖指向另一个指尖,处于规定手爪方向上,称为方向矢量o ;最后一个矢量叫法线矢量n , 它与矢量o 和矢量a 一起构成一个右手矢量集合,并由矢量的叉乘所规定:a o n ?=。 上式表示了机器人变换矩阵40T ,它描述了末端连杆坐标系{4}相对基坐标系{0}的位姿,是机械手运动分析和综合的基础。 实验器材: 1、RBT-4T03S 机器人一台; 2、RBT-4T03S 机器人控制柜一台; 3、装有运动控制卡和控制软件的计算机一台。 实验步骤: 1、 根据机器人坐标系的建立中得出的A 矩阵,相乘后得到T 矩阵,根据一一对应的关系,写出机器人正解的运算公式,并填入表6-1中; 表6-1机器人的正运动学的参数
机器学习和数据挖掘的联系与区别_光环大数据培训
https://www.360docs.net/doc/4d15301726.html, 机器学习和数据挖掘的联系与区别_光环大数据培训 光环大数据培训机构了解到,从数据分析的角度来看,数据挖掘与机器学习有很多相似之处,但不同之处也十分明显,例如,数据挖掘并没有机器学习探索人的学习机制这一科学发现任务,数据挖掘中的数据分析是针对海量数据进行的,等等。从某种意义上说,机器学习的科学成分更重一些,而数据挖掘的技术成分更重一些。 机器学习(Machine Learning,ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。其专门研究计算机是怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构,使之不断改善自身的性能。 数据挖掘是从海量数据中获取有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。数据挖掘中用到了大量的机器学习界提供的数据分析技术和数据库界提供的数据管理技术。 学习能力是智能行为的一个非常重要的特征,不具有学习能力的系统很难称之为一个真正的智能系统,而机器学习则希望(计算机)系统能够利用经验来改善自身的性能,因此该领域一直是人工智能的核心研究领域之一。在计算机系统中,“经验”通常是以数据的形式存在的,因此,机器学习不仅涉及对人的认知学习过程的探索,还涉及对数据的分析处理。实际上,机器学习已经成为计算机数据分析技术的创新源头之一。由于几乎所有的学科都要面对数据分析任务,因此机
https://www.360docs.net/doc/4d15301726.html, 器学习已经开始影响到计算机科学的众多领域,甚至影响到计算机科学之外的很多学科。机器学习是数据挖掘中的一种重要工具。然而数据挖掘不仅仅要研究、拓展、应用一些机器学习方法,还要通过许多非机器学习技术解决数据仓储、大规模数据、数据噪声等实践问题。机器学习的涉及面也很宽,常用在数据挖掘上的方法通常只是“从数据学习”。然而机器学习不仅仅可以用在数据挖掘上,一些机器学习的子领域甚至与数据挖掘关系不大,如增强学习与自动控制等。所以笔者认为,数据挖掘是从目的而言的,机器学习是从方法而言的,两个领域有相当大的交集,但不能等同。 典型的数据挖掘和机器学习过程 下图是一个典型的推荐类应用,需要找到“符合条件的”潜在人员。要从用户数据中得出这张列表,首先需要挖掘出客户特征,然后选择一个合适的模型来进行预测,最后从用户数据中得出结果。 把上述例子中的用户列表获取过程进行细分,有如下几个部分。 业务理解:理解业务本身,其本质是什么?是分类问题还是回归问题?数据怎么获取?应用哪些模型才能解决? 数据理解:获取数据之后,分析数据里面有什么内容、数据是否准确,为下
统计学和数据挖掘交叉学科
统计学和数据挖掘:交叉学科 摘要:统计学和数据挖掘有很多共同点,但与此同时它们也有很多差异。本文讨论了两门学科的性质,重点论述它们的异同。 关键词:统计学知识发现 1.简介 统计学和数据挖掘有着共同的目标:发现数据中的结构。事实上,由于它们的目标相似,一些人(尤其是统计学家)认为数据挖掘是统计学的分支。这是一个不切合实际的看法。 因为数据挖掘还应用了其它领域的思想、工具和方法,尤其是计算机学科,例如数据库技术和机器学习,而且它所关注的某些领域和统计学家所关注的有很大不同。 统计学和数据挖掘研究目标的重迭自然导致了迷惑。事实上,有时候还导致了反感。统计学有着正统的理论基础(尤其是经过本世纪的发展),而现在又出现了一个新的学科,有新的主人,而且声称要解决统计学家们以前认为是他们领域的问题。这必然会引起关注。更多的是因为这门新学科有着一个吸引人的名字,势必会引发大家的兴趣和好奇。把“数据挖掘”这个术语所潜在的承诺和“统计学”作比较的话,统计的最初含义是“陈述事实”,以及找出枯燥的大量数据背后的有意义的信息。当然,统计学的现代的含义已经有很大不同的事实。而且,这门新学科同商业有特殊的关联(尽管它还有科学及其它方面的应用)。 本文的目的是逐个考察这两门学科的性质,区分它们的异同,并关注与数据挖掘相关联的一些难题。首先,我们注意到“数据挖掘”对统计学家来说并不陌生。例如,Everitt定义它为:“仅仅是考察大量的数据驱动的模型,从中发现最适合的”。统计学家因而会忽略对数据进行特别的分析,因为他们知道太细致的研究却难以发现明显的结构。尽管如此,事实上大量的数据可能包含不可预测的但很有价值的结构。而这恰恰引起了注意,也是当前数据挖掘的任务。 2.统计学的性质 试图为统计学下一个太宽泛的定义是没有意义的。尽管可能做到,但会引来很多异议。相反,我要关注统计学不同于数据挖掘的特性。 差异之一同上节中最后一段提到的相关,即统计学是一门比较保守的学科,目前有一种趋势是越来越精确。当然,这本身并不是坏事,只有越精确才能避免错误,发现真理。但是如果过度的话则是有害的。这个保守的观点源于统计学是数学的分支这样一个看法,我是不同意这个观点的(参见【15】,【9】,【14】,【2】,【3】)尽管统计学确实以数学为基础(正如物理和工程也以数学为基础,但没有被认为是数学的分支),但它同其它学科还有紧密的联系。 数学背景和追求精确加强了这样一个趋势:在采用一个方法之前先要证明,而不是象计算机科学和机器学习那样注重经验。这就意味着有时候和统计学家关注同一问题的其它领域的研究者提出一个很明显有用的方法,但它却不能被证明(或还不能被证明)。统计杂志倾向于发表经过数学证明的方法而不是一些特殊方法。数据挖掘作为几门学科的综合,已经从机器学习那里继承了实验的态度。这并不意味着数据挖掘工作者不注重精确,而只是说明如果方法不能产生结果的话就会被放弃。 正是统计文献显示了(或夸大了)统计的数学精确性。同时还显示了其对推理的侧重。尽管统计学的一些分支也侧重于描述,但是浏览一下统计论文的话就会发现这些文献的核心问题就是在观察了样本的情况下如何去推断总体。当然这也常常是数据挖掘所关注的。下面我们会提到数据挖掘的一个特定属性就是要处理的是一个大数据集。这就意味着,由于可行性的原因,我们常常得到的只是一个样本,但是需要描述样本取自的那个大数据集。然而,
统计学与数据挖掘_中国人民大学统计学系数据挖掘中心
统计学与数据挖掘 中国人民大学统计学系数据挖掘中心* (中国人民大学统计学系,北京100872) 工业界的广泛关注。 统计学是搜集、展示、分析及解释数据的科学。统计学不是方法的集合,而是处理数据的科学。数据挖掘的大部分核心功能的实现都以计量和统计分析方法作为支撑。这些核心功能包括:聚类、估计、预测、关联分组以及分类等。统计学、数据库和人工智能共同构成数据挖掘技术 的三大支柱。许多成熟的统计方法构成了数据挖掘的核心内容。比如:回归分析(多元回归、自 回归、Logistic回归)、判别分析(Bayes判别、非参数判别、Fisher判别)、聚类分析(系统聚类、动态聚类)、探索性数据分析(Exploratory DataAnalysis,简称EDA)、列联分析等统计方法, 一直在数据挖掘领域发挥着巨大的作用。与此同时,从数据挖掘要处理的海量数据和数据的复 杂程度来看,基于总体假定进行推断和检验的传统统计方法,已显露出很大的局限性。统计能否继续作为数据挖掘的有力支撑,数据挖掘将为统计学提供怎样的发展机遇,是我们最关心的问题。 本文中,我们将以统计学最近40年的发展走势作为论述的起点,逐步对统计方法在数据 挖掘算法设计、开发过程中的应用情况,进行全面、系统的考察与分析,进而提出统计学和数据 挖掘协同发展的广阔前景。 二、统计学近40年的走势 20世纪60年代是稳健统计盛行的时代。稳健统计开创性地解决了与理论分布假定有偏 差的数据分析问题。其成果主要包括回归系数的敏感性分析;对异常值(Outliers)、高杠杆点(Leverage values)以及其他一些对少量污染异常敏感的回归诊断;M -估计量(M - estimator)等稳健估计量。稳健统计标志着基于正态假定的理论框架正在打破,打破框架的源动力来自于客观世界里真实的、具有复杂结构的数据。 20世纪70年代早期, John Tukey提出探索性数据分析(EDA),他通过箱线图等简单方 法,指出了统计建模应该结合数据真实分布情况。EDA的主要观点是,对数据的分析,不应该 从理论分布假定出发去建构模型,而是从数据的特征出发去研究和发现数据中有用的信息。这 一观点恰恰是数据挖掘的核心思想。EDA思想的直接体现是,重新提出了描述统计在数据分析中的重要性,这一简单、直观方法在理解数据方面是极为有用的。EDA的这种思想与数据挖 掘过程中的数据理解极为相似。EDA更深刻的意义则在于,它为统计学指明了发展方向——和数据相结合的道路。 继EDA之后,统计学在数据分析的道路上,硕果累累。20世纪70年代后期,广义线性模 型,概括了一个时期以来基于正态理论以外的线性模型研究,该理论通过将响应变量的方差分解成系统和随机两部分,允许建模者通过严格单调的关联函数(Link function)g(μ)=∑xjβj,
机器人机械臂运动学分析(仅供借鉴)
平面二自由度机械臂动力学分析 [摘要] 机器臂是一个非线性的复杂动力学系统。动力学问题的求解比较困难,而且需要较长的运算时间,因此,这里主要对平面二自由度机械臂进行动力学研究。本文采用拉格朗日方程在多刚体系统动力学的应用方法分析平面二自由度机械臂的正向动力学。经过研究得出平面二自由度机械臂的动力学方程,为后续更深入研究做铺垫。 [关键字] 平面二自由度 一、介绍 机器人是一个非线性的复杂动力学系统。动力学问题的求解比较困难,而且需要较长的运算时间,因此,简化解的过程,最大限度地减少工业机器人动力学在线计算的时间是一个受到关注的研究课题。 机器人动力学问题有两类: (1) 给出已知的轨迹点上的,即机器人关节位置、速度和加速度,求相应的关节力矩向量Q r。这对实现机器人动态控制是相当有用的。 (2) 已知关节驱动力矩,求机器人系统相应的各瞬时的运动。也就是说,给出关节力矩向量τ,求机器人所产生的运动。这对模拟机器人的运动是非常有用的。 二、二自由度机器臂动力学方程的推导过程 机器人是结构复杂的连杆系统,一般采用齐次变换的方法,用拉格朗日方程建立其系统动力学方程,对其位姿和运动状态进行描述。机器人动力学方程的具体推导过程如下: (1) 选取坐标系,选定完全而且独立的广义关节变量θr ,r=1, 2,…, n。 (2) 选定相应关节上的广义力F r:当θr是位移变量时,F r为力;当θr是角度变量时, F r为力矩。 (3) 求出机器人各构件的动能和势能,构造拉格朗日函数。 (4) 代入拉格朗日方程求得机器人系统的动力学方程。 下面以图1所示说明机器人二自由度机械臂动力学方程的推导过程。
第六章 机器人动力学
第六章机器人操作臂动力学 动力学研究的是物体的运动和受力之间的关系。操作臂动力学有两个问题需要解决。 ①动力学正问题:根据关节运动力矩或力,计算操作臂的运动(关节位移,速 度和加速度) ②动力学逆问题:已知轨迹运动对应的关节位移,速度和加速度,求出所需要 的关节力矩或力。 机器人操作臂是个复杂的动力学系统,由多个连杆和多个关节组成,具有多个输入和多个输出,存在着错综复杂的耦合关系和严重的非线性。因此,对于机器人动力学的研究,引起了十分广泛的重视。所采用的方法很多,①有拉格朗日方法,②牛顿-欧拉方法,③高斯法,④凯恩方法,⑤旋量对偶数方法等等。在此重点介绍牛顿-欧拉方法,它是基于运动坐标和达朗贝尔原理来建立相应的运动方程。 研究机器人动力学的目的是多方面的,动力学正问题与操作臂仿真有关,逆问题是为实时控制的需要,利用动力学模型,实现最优控制,以期达到良好的动态性能和最优指标。 机器人动力学模型主要用于机器人的设计和离线编程。在设计中需根据连杆质量,运动学和动力学参数,传动机构特征和负载大小进行动态仿真,从而决定机器人的结构参数和传动方案,验算设计方案的合理性和可行性,以及结构优化程度。在离线编程时,为了估计机器人高速运动引起的动载荷和路径偏差,要进行路径控制仿真和动态模型的仿真。这些都必须以机器人动态模型为基础。 为了建立机器人动力学方程,在此首先讨论机器人运动的瞬时状态,对其进行速度分析和加速度分析,研究连杆的静力平衡,然后利用朗贝尔原理,将静力学平衡条件用于动力学。 §6-1连杆的速度和加速度 点的速度表示一般要涉及到两个坐标系: 要指明速度是相对于哪个坐标系的运动所造成的。
第3章 工业机器人静力计算及动力学分析
第3章工业机器人静力计算及动力学分析 章节题目:第3章工业机器人静力计算及动力学分析 [教学内容] 3.1 工业机器人速度雅可比与速度分析 3.2 工业机器人力雅可比与静力计算 3.3 工业机器人动力学分析 [教学安排] 第3章安排6学时,其中介绍工业机器人速度雅可比45分钟,工业机器人速度分析45分钟,操作臂中的静力30分钟,机器人力雅可比30分钟,机器人静力计算的两类问题10分钟,拉格朗日方程20分钟,二自由度平面关节机器人动力学方程60分钟,关节空间和操作空间动力学30分钟。 通过多媒体课件结合板书的方式,采用课堂讲授和课堂讨论相结合的方法,首先讨论与机器人速度和静力有关的雅可比矩阵,然后介绍工业机器人的静力学问题和动力学问题。 [知识点及其基本要求] 1、工业机器人速度雅可比(掌握) 2、速度分析(掌握) 3、操作臂中的静力(掌握) 4、机器人力雅可比(掌握) 5、机器人静力计算的两类问题(了解) 6、拉格朗日方程(熟悉) 7、二自由度平面关节机器人动力学方程(理解) 8、关节空间和操作空间动力学(了解) [重点和难点] 重点:1、速度雅可比及速度分析 2、力雅可比
3、拉格朗日方程 4、二自由度平面关节机器人动力学方程 难点:1、关节空间和操作空间动力学 [教学法设计] 引入新课: 至今我们对工业机器人运动学方程还只局限于静态位置问题的讨论,还没有涉及力、速度、加速度等。机器人是一个多刚体系统,像刚体静力学平衡一样,整个机器人系统在外载荷和关节驱动力矩(驱动力)作用下将取得静力平衡;也像刚体在外力作用下发生运动变化一样,整个机器人系统在关节驱动力矩(驱动力)作用下将发生运动变化。 新课讲解: 第一次课 第三章工业机器人静力计算及动力学分析 3-1 工业机器人速度雅可比与速度分析 一、工业机器人速度雅可比 假设有六个函数,每个函数有六个变量,即:,可写成 Y=F(X,将其微分,得:,也可简写成 。该式中(6×6)矩阵叫做雅可比矩阵。 在工业机器人速度分析和以后的静力分析中都将遇到类似的矩阵,称之为机器人雅可比矩阵,或简称雅可比矩阵。 二自由度平面关节机器人,端点位置x,y与关节θ1、θ2的关系为:
机器人学第六章(机器人运动学及动力学)
第六章 机器人运动学及动力学 6.1 引论 到现在为止我们对操作机的研究集中在仅考虑动力学上。我们研究了静力位置、静力和速度,但我们从未考虑过产生运动所需的力。本章中我们考虑操作机的运动方程式——由于促动器所施加的扭矩或作用在机械手上的外力所产生的操作机的运动之情况。 机构动力学是一个已经写出很多专著的领域。的确,人们可以花费以年计的时间来研究这个领域。显然,我们不可能包括它所应有的完整的内容。但是,某种动力学问题的方程式似乎特别适合于操作机的应用。特别是,那种能利用操作机的串联链性质的方法是我们研究的天然候选者。 有两个与操作机动力学有关的问题我们打算去解决。向前的动力学问题是计算在施加一 组关节扭矩时机构将怎样运动。也就是,已知扭矩矢量τ,计算产生的操作机的运动Θ、Θ 和Θ 。这个对操作机仿真有用,在逆运动学问题中,我们已知轨迹点Θ、Θ 和Θ ,我们欲求出所需要的关节扭矩矢量τ。这种形式的动力学对操作机的控制问题有用。 6.2 刚体的加速度 现在我们把对刚体运动的分析推广到加速度的情况。在任一瞬时,线速度矢量和角速度矢量的导数分别称为线加速度和角加速度。即 B B Q Q B B Q Q 0V ()V ()d V V lim dt t t t t t ?→+?-==? (6-1) 和 A A Q Q A A Q Q 0()()d lim dt t t t t t ?→Ω+?-ΩΩ=Ω=? (6-2) 正如速度的情况一样,当求导的参坐标架被理解为某个宇宙标架{}U 时我们将用下面的记号 U A AORG V V = (6-3) 和 U A A ω=Ω (6-4)
6.2.1 线加速度 我们从描述当原点重合时从坐标架{}A 看到的矢量B Q 的速度 A A B A A Q B Q B B V V B R R Q =+Ω? (6-5) 这个方程的左手边描述A Q 如何随时间而变化。所以,因为原点是重合的,我们可以重写(6-5)为 A A B A A B B Q B B d ()V dt B B R Q R R Q =+Ω? (6-6) 这种形式的方程式当推导对应的加速度方程时特别有用。 通过对(6-5)求导,我们可以推出当{}A 与{}B 的原点重合时从{}A 中看到的B Q 的 加速度表达式 A A B A A A A Q B Q B B B B d d V (V )()dt dt B B R R Q R Q =+Ω?+Ω? (6-7) 现在用(6-6)两次── 一次对第一项,一次对最后一项。(6-7)式的右侧成为: A B A A A A B Q B B Q B B A A A A B B Q B B V () +Ω?+Ω?+Ω?+Ω? B B B B R R V R Q R V R Q (6-8) 把相同两项合起来 A B A A A A B Q B B Q B B A A A B B B V 2 () +Ω?+Ω?+Ω?Ω? B B B R R V R Q R Q (6-9) 最后,为了推广到原点不重合的情况,我们加上一项给出{}B 的原点的线加速度的项,得到下面的最后的一般公式 A B A A A A BORG B Q B B Q B B A A A B B B V 2 () ++Ω?+Ω?+Ω?Ω? A B B B V R R V R Q R Q (6-10) 对于我们将在本章上考虑的情况,我们总是有B Q 为不变,或 B Q Q V 0== B V (6-11) 所以,(6-10)简化为 A A A A A A Q BORG B B B B B V ()=+Ω?Ω?+Ω? A B B V R Q R Q (6-12) 我们将用这一结果来计算操作机杆件的线加速度。 6.2.2 角加速度 考虑{}B 以A B Ω相对于{}A 转动的情况,而{}C 以B C Ω相对于{}B 转动。为了计算 A C Ω我们把矢量在坐标架{}A 中相加
第3章工业机器人静力计算及动力学分析
第 3 章工业机器人静力计算及动力学分析 章节题目:第 3 章工业机器人静力计算及动力学分析 [教学内容 ] 3.1工业机器人速度雅可比与速度分析 3.2工业机器人力雅可比与静力计算 3.3工业机器人动力学分析 [教学安排 ] 第 3 章安排 6 学时,其中介绍工业机器人速度雅可比45 分钟,工业机器人速度分析45分钟,操作臂中的静力30 分钟,机器人力雅可比30 分钟,机器人静力计算的两类问题10分钟,拉格朗日方程20 分钟,二自由度平面关节机器人动力学方程60 分钟,关节空间和操作空间动力学30 分钟。 通过多媒体课件结合板书的方式,采用课堂讲授和课堂讨论相结合的方法,首先讨论与机器人速度和静力有关的雅可比矩阵,然后介绍工业机器人的静力学问题和动力学问题。 [知识点及其基本要求] 1、工业机器人速度雅可比(掌握) 2、速度分析(掌握) 3、操作臂中的静力(掌握) 4、机器人力雅可比(掌握) 5、机器人静力计算的两类问题(了解) 6、拉格朗日方程(熟悉) 7、二自由度平面关节机器人动力学方程(理解) 8、关节空间和操作空间动力学(了解) [重点和难点 ] 重点: 1、速度雅可比及速度分析 2、力雅可比 3、拉格朗日方程 4、二自由度平面关节机器人动力学方程 难点: 1、关节空间和操作空间动力学 [教学法设计 ] 引入新课: 至今我们对工业机器人运动学方程还只局限于静态位置问题的讨论,还没有涉及力、速度、加速度等。机器人是一个多刚体系统,像刚体静力学平衡一样,整个机器人系统在外载 荷和关节驱动力矩(驱动力)作用下将取得静力平衡;也像刚体在外力作用下发生运动变化 一样,整个机器人系统在关节驱动力矩(驱动力)作用下将发生运动变化。 新课讲解: 第一次课 第三章工业机器人静力计算及动力学分析 3-1 工业机器人速度雅可比与速度分析 一、工业机器人速度雅可比 y1 f 1 (x1 , x2 , x3 , x4 , x5 , x6 ) 假设有六个函数,每个函数有六个变量,即:y 2f2 ( x1 , x2 , x3 , x4 , x5 , x6 ),可写成 Y=F(X) , y6f6 (x1 , x2 , x3 , x4 , x5 , x6 )