ARMA模型及SAS求解

第6讲 时间序列分析
教材:应用时间序列分析课件(中国人民大学 王燕),SAS 如何解及下载例程。
时间序列分析(Time series analysis)是一种动态数据处理的统计方法。该方法基于随机过程理论和数理统计学方法,研究随机数据序列所遵从的统计规律,以用于解决实际问题。
时间序列是把反映现象发展水平的统计指标数值,按照时间先后顺序排列起来所形成的一组统计数字序列。时间序列又称动态数列或时间数列。时间序列分析就是利用这组数列,应用数理统计方法加以处理,以预测未来事物的发展。时间序列分析是定量预测方法之一,它的基本原理:一是承认事物发展的延续性。应用过去数据,就能推测事物的发展趋势。二是考虑到事物发展的随机性。任何事物发展都可能受偶然因素影响,为此要利用统计分析中加权平均法对历史数据进行处理。该方法简单易行,便于掌握,但准确性差,一般只适用于短期预测。时间序列预测一般反映三种实际变化规律:趋势变化、周期性变化、随机性变化。
时间序列分析是根据系统观测得到的时间序列数据,通过曲线拟合和参数估计来建立数学模型的理论和方法。时间序列分析常用在国民经济宏观控制、区域综合发展规划、企业经营管理、市场潜量预测、气象预报、水文预报、地震前兆预报、农作物病虫灾害预报、环境污染控制、生态平衡、天文学和海洋学等方面。
时间序列分析主要用途:①系统描述。根据对系统进行观测得到的时间序列数据,用曲线拟合方法对系统进行客观的描述。②系统分析。当观测值取自两个以上变量时,可用一个时间序列中的变化去说明另一个时间序列中的变化,从而深入了解给定时间序列产生的机理。③预测未来。一般用ARMA 模型拟合时间序列,预测该时间序列未来值。④决策和控制。根据时间序列模型可调整输入变量使系统发展过程保持在目标值上,即预测到过程要偏离目标时便可进行必要的控制。
基本步骤:①用观测、调查、统计、抽样等方法取得被观测系统时间序列动态数据。②根据动态数据作相关图,进行相关分析,求自相关函数。相关图能显示出变化的趋势和周期,并能发现跳点和拐点。跳点是指与其他数据不一致的观测值。如果跳点是正确的观测值,在建模时应考虑进去,如果是反常现象,则应把跳点调整到期望值。拐点则是指时间序列从上升趋势突然变为下降趋势的点。如果存在拐点,则在建模时必须用不同的模型去分段拟合该时间序列,例如采用门限回归模型。③辨识合适的随机模型,进行曲线拟合,即用通用随机模型去拟合时间序列的观测数据。对于短的或简单的时间序列,可用趋势模型和季节模型加上误差来进行拟合。对于平稳时间序列,可用通用ARMA 模型(自回归滑动平均模型)及其特殊情况的自回归模型、滑动平均模型或组合ARMA 模型等来进行拟合。当观测值多于50个时一般都采用ARMA 模型。对于非平稳时间序列则要先将观测到的时间序列进行差分运算,化为平稳时间序列,再用适当模型去拟合这个差分序列。
本章重点:1)建立p 阶自回归)(p AR 模型:t p t p t t t x x x x εφφφφ+++++=--- 22110 2)建立q 阶移动平均)(q MA 模型: q t q t t t t x -------+=εθεθεθεμ 2211
3)),(q p ARMA
模型:q t q t t t p t p t t t t x x x x -----------+++++=εθεθεθεφφφφ 221122110 三个模型的拖尾、截尾性
模型
自相关系数k ρ
偏自相关系数kk φ
)(p AR 拖尾
p 阶截尾
)(q MA
q 阶截尾
拖尾
),(q p ARMA
拖尾
拖尾
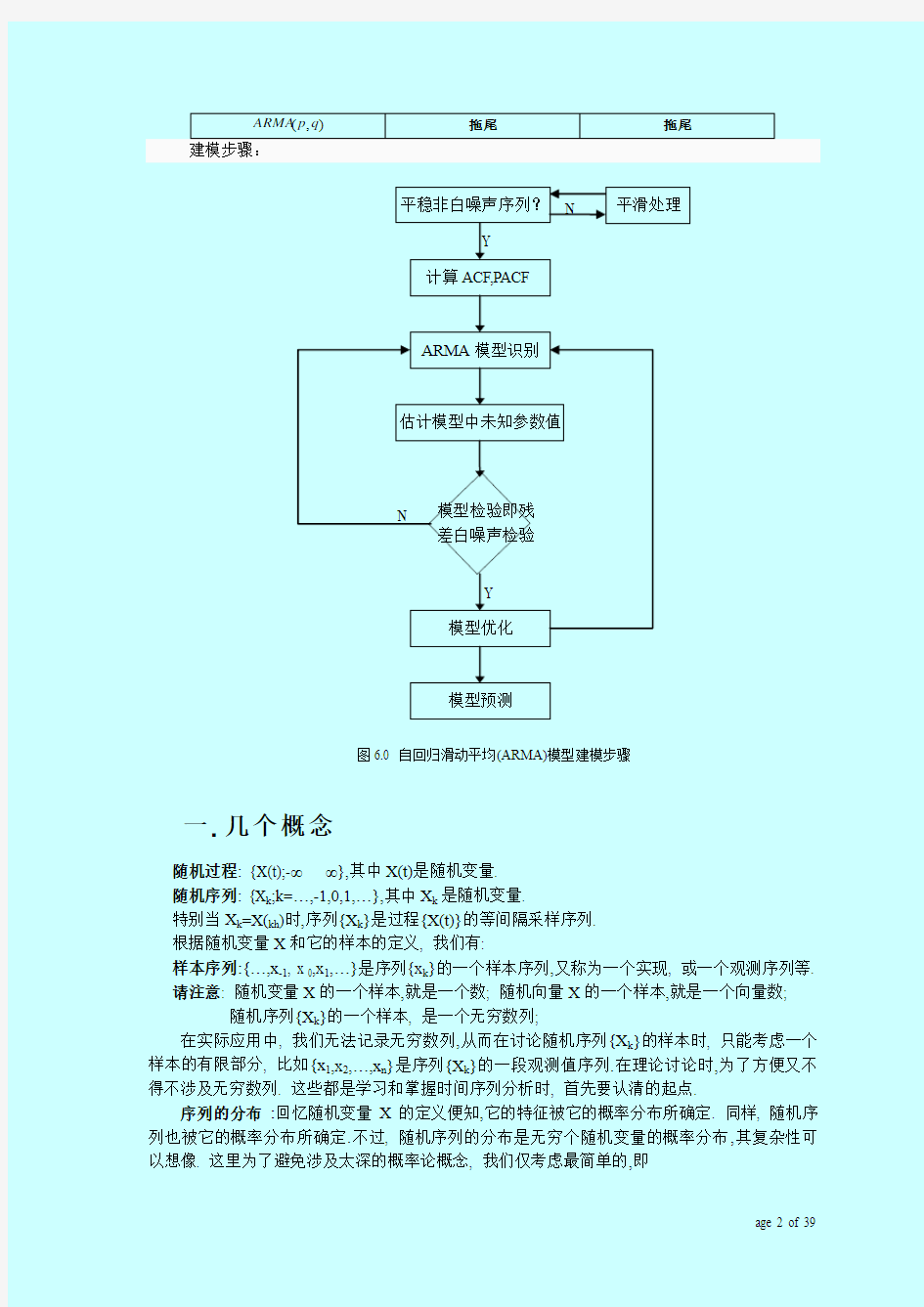
建模步骤:
一. 几个概念
随机过程: {X(t);-∞ 特别当X k =X(kh )时,序列{X k }是过程{X(t)}的等间隔采样序列. 根据随机变量X 和它的样本的定义, 我们有: 样本序列:{…,x -1, x 0,x 1,…}是序列{x k }的一个样本序列,又称为一个实现, 或一个观测序列等. 请注意: 随机变量X 的一个样本,就是一个数; 随机向量X 的一个样本,就是一个向量数; 随机序列{X k }的一个样本, 是一个无穷数列; 在实际应用中, 我们无法记录无穷数列,从而在讨论随机序列{X k }的样本时, 只能考虑一个样本的有限部分, 比如{x 1,x 2,…,x n }是序列{X k }的一段观测值序列.在理论讨论时,为了方便又不得不涉及无穷数列. 这些都是学习和掌握时间序列分析时, 首先要认清的起点. 序列的分布 :回忆随机变量X 的定义便知,它的特征被它的概率分布所确定. 同样, 随机序列也被它的概率分布所确定.不过, 随机序列的分布是无穷个随机变量的概率分布,其复杂性可以想像. 这里为了避免涉及太深的概率论概念, 我们仅考虑最简单的,即 平稳非白噪声序列? 计算ACF,PACF ARMA 模型识别 估计模型中未知参数值 模型优化 模型预测 模型检验即残 差白噪声检验 N Y 图6.0 自回归滑动平均(ARMA)模型建模步骤 Y 平滑处理 N X k ~N(μk ,σ2k ), 它有密度f k (x)=(2πσ2k )-1/2exp{(x-μk )2/2σ2k } 而且(X k+1,X k+2,…,X k+m )有联合正态分布. 于是有: 期望(均值): EX k =?xf k (x)dx=μk , 方差: Var(X k )=E(X k -μk )2=?(x-μk )2f k (x)dx=σ2k . 自协方差: γkj =E[(X k -μk )(X j -μj )]=??(x-μk )(y-μj )f kj (x,y)dxdy = E[(X j -μj )(X k -μk )]= γjk . (注E[(X-EX)(Y-EY)]展开=E(XY)-E(X)E(Y)=cov(X,Y),协方差,不同事件之间的相关性度量) 二. 平稳性检验 1. 严平稳和宽平稳 平稳时间序列有两种定义,根据限制条件的严格程度,分为: ● 严平稳时间序列(strictly stationary )—指序列所有的统计性质都不会随着时间的推移而 发生变化,即(X k+1,X k+2,…,X k+m )的联合分布(实际很难求)与k 无关。 ● 宽平稳时间序列(week stationary )—指序列的统计性质只要保证序列的二阶矩平稳就 能保证序列的主要性质近似稳定。 如果在任取时间t 、s 和k 时,时间序列t X 满足如下三个条件: ∞<2t EX (6.1) μ=t EX (6.2) ))(())((t s k t s k k k s s t t X X E X X E -+-+--=--μμμμ (6.3) 则称为宽平稳时间序列。也称为弱平稳或二阶平稳。对于正态随机序列而言,由于联合概率分布仅由均值向量和协方差阵决定,即只要二阶矩平稳,就等于分布平稳了。 2. 平稳时间序列的统计性质 根据平稳时间序列的定义,可以推断出两个重要的统计性质: ● 均值为常数。即式(6.2)的条件。 ● 自协方差只依赖于时间的平均长度(只与起点有关与跨度无关)。即式(6.3)的条件。 如果定义自协方方差函数(autocovariance function )为: ),())((),(t s X X E s t s s t t γμμγ=--= (6.4) 那么它可由二维函数简化为一维函数)(t s -γ,由此引出延迟k 自协方差函数: )(),()(k k t t k -=+=γγγ (6.5) 容易推断出平稳时间序列一定具有常数方差: ) 0(),()(2 γγμ==-=t t X E Dx t t t (6.6) 如果定义时间序列自相关函数(autocorrelation function ),简记为ACF : s t s s t t DX DX X X E s t ?--= ) )((),(μμρ (6.7) 由延迟k 自协方差函数的概念可以等价得到延迟k 自相关函数的概念: )() 0() ()() 0() ()0()0()())(()(k r k r k r k r k DX DX X X E k k t t k t k t t t -== = =?--= +++ρργγγμμρ或直接定义: (6.8) 容易验证自相关函数具有几个基本性质: ● 1)0(=ρ; ● )()(k k ρρ=-; ● 自相关阵为对称非负定阵; ● 非惟一性。 注意区分: 协方差函数和相关函数——度量两个不同事件彼此之间的相互影响的程度。 自协方差函数和自相关函数——度量同一事件在两个不同时期之间的相互影响的程度。 3. 样本的估计值 在平稳序列场合,序列的均值等于常数意味着原本含有可列多个随机变量的均值序列变成了只含有一个变量的常数序列,所以常数均值μ的估计值为 n x x n t t ∑===1 ?μ (6.9) 同样可以根据平稳序列二阶矩平稳的性质,得到基于样本计算出来的各种估计值。延迟k 自 协方差函数的估计值: k n x x x x k k n t k t t ---= ∑-=+1 ))(()(?γ (6.10) 总体方差的估计值: k n x x n t t --= ∑=1 2 )()0(?γ (6.11) 延迟k 自相关函数的估计值: ∑∑=-=+---= =n t t k n t k t t x x x x x x k k 1 2 1 )() )(() 0(?)(?)(?γγρ (6.12) 4. 平稳性检验的方法 对序列的平稳性检验有两种方法:一种是根据时序图和自相关图显示的特征做出判断的图检验方法;一是构造检验统计量进行假设检验的单位根检验(unit root test )方法。是建模的前提,可借助SAS(见例程)、SPSS 、Eviews 等软件实现。 ● 时序图和自相关图检验 ● 单位根检验(unit root test ) 所谓单位根检验就是通过检验时间序列自回归特征方程的特征根是在单位圆内还是在单位圆外(包括在单元圆上),来检验时间序列的平稳性。 单位根检验统计量中最常用的是ADF 检验统计量,又称增广DF 检验(augmented Dickey-Fuller )。对任一p 阶自回归AR (p )过程 t p t p t t x x x εφφ+++=-- 11 (6.13) 它的特征方程为 011=----p p p φλφλ (6.14) 如果该方程所有的特征根都在单位圆内,即 p i i ,,2,1,1 =<λ则序列t X 平稳。如果至少存在 一个特征根不在单位圆内,不妨设11=λ,则序列t X 非平稳,且自回归系数之和恰好等于1。即 121=+++p φφφ (6.15) 因而,对于AR (p )过程可以通过检验自回归系数之和是否大于等于1来考察该序列的平稳性。设 121-+++=p φφφρ ,那么原假设0H :0≥ρ(序列t X 非平稳),ADF 检验统计量: )?(?ρ ρ τS = (6.16) 式中,)?(ρ S 为参数ρ的样本标准差。1979年,Dickey 和Fuller 使用蒙特卡洛模拟方法算出了τ检验统计量的临界值表。 三. 纯随机性检验 如果序列值彼此之间没有任何相关性,那就意味着该序列是一个没有记忆的数据序列,即过去的行为对未来的发展没有丝毫影响,这种序列我们称之为纯随机序列。从统计分析的角度而言,纯随机序列是没有任何分析价值的序列。因此,为了确保平稳序列还值不值得分析下去,需要对平稳序列进行纯随机性检验。 5. 纯随机序列(白噪声序列) 如果在任取时间t 和s 时,时间序列t X 满足如下三个条件: μ=t EX (6.17) 时当s t s t r ==2),(σ (6.18) 时当s t s t r ≠=0 ),( (6.19) 称此序列为纯随机序列,也称为白噪声(white noise )序列,简记为),(~2 σμWN X t 。之所以 称之为白噪声序列是因为人们最初发现白光具有这种特性。比较平稳时间序列的定义,可看出白噪声序列一定是平稳序列,且是一种最简单的平稳序列。见图6.1所示是随机生成的1000个服从标准正态分布的白噪声序列观察值。 标准正态分布白噪声序列Xt -4 -3-2-1012 340 100 200 300 400 500 600 700 800 900 1000 时间 白噪声 图6.1 标准正态白噪声序列时序图 根据白噪声序列的定义,白噪声序列具有三个重要的性质: ● 常数均值(μ=t EX ); ● 纯随机性(0),(=s t r ); ● 方差齐性(2 ),(σ=s t r ,即序列中每个度量的方差相等)。 6. 纯随机性检验 即白噪声检验(通常对残差序列做)。Barlett 证明,如果一个时间序列是纯随机的,得到一个观察期数为n 的观察序列t X ,那么该序列的延迟非零期的样本自相关系数将近似服从均值为零、方差为序列观察数倒数的正态分布,即 )1 ,0(~)(n N k ρ (6.20) 式中k 为延迟期数,n 为样本观察期数。 根据Barlett 定理,可以构造BP Q 检验统计量和LB Q 检验统计量来检验序列的纯随机性。原假设:延迟期数小于或等于m 期的序列值之间相互独立,即)()2()1(:0m H ρρρ=== ;备选假设:延迟期数小于或等于m 期的序列值之间有相关性,即:1H 至少存在某个0)(≠k ρ。 1) BP Q 检验统计量 由Box 和Pierce 推导出的BP Q 检验统计量为: )(~)(?21 2m k n Q m k BP χρ ∑== (6.21) 式中,n 为序列观察期数,m 为指定延迟期数。 2) LB Q 检验统计量 因为BP Q 检验统计量在小样本场合时不太精确,所以Ljung 和Box 又推导出LB Q 检验统计量 为: )(~)(?)2(2 12m k n k n n Q m k LB χρ∑=? ?? ? ??-+= (6.22) 式中,n 为序列观察期数,m 为指定延迟期数。m 一般取值为6、12。为什么只需要检验前6期和前12期延迟的LB Q 检验统计量就可以直接判断序列是否为白噪声序列呢?这是因为平稳序列通常具有短期相关性,只要序列时期足够长,自相关系数都会收敛于零。所以,如果序列值之 间存在显著的相关关系,通常只存在在延迟时期比较短的序列值之间,而如果短期延迟的序列之间都不存在显著的相关关系,那么长期延迟之间就更不会存在显著的相关关系。 纯随机性检验小结:当Q 统计量的P 值大于给定的显著水平α(譬如=0.05)时,不拒绝原假设,即相关系数为0,认为序列是白噪声无任何信息可取,停止统计分析(建模)。 四. 方法性工具 7. 差分运算 差分运算分为两种:k 步差分和p 阶差分。 1) k 步差分 相距k 期的两个序列值之间的减法运算称为k 步差分运算,记为k ?,表示t x 与k t x -之间的 减法运算,即: k t t k x x --=? (6.23) 2) p 阶差分 相距一期的两个序列值之间的减法运算称为1阶差分运算,记为t x ?,表示t x 与1-t x 之间的 减法运算,即: 1--=?t t t x x x (6.24) 对1阶差分运算后序列t x ?再进行一次1阶差分运算称为2阶差分,记为t x 2 ?,表示t x ?与 1-?t x 之间的减法运算,即: 12-?-?=?t t t x x x (6.25) 依此类推,对1-p 阶差分后序列t p x 1 -? 再进行一次1阶差分运算称为p 阶差分,记为 t p x ?,表示t p x 1-?与11--?t p x 之间的减法运算,即: 111---?-?=?t p t p t p x x x (6.26) 8. 延迟算子 延迟算子类似于一个时间指针,一个延迟算子乘以当前序列值,就相当于把当前序列值的时间向过去拨了一个时间刻度,记B 为延迟算子,有 )! (!!,)1()1(, )(1 i n 0 10221i n i n C B C B c x c x c B B x x B x x B x Bx i n i i n i n t t p t t p t t t t -= -=-?=?====∑=----其中为常数 (6.27) 用延迟算子表示的k 步差分为: t k k t t k x B x x )1(-=-=?- (6.28) 用延迟算子表示的p 阶差分为: ∑=--=-=?p i i t i p i t p t p x C x B x 0 )1()1( (6.29) 五. ARMA 模型 ARMA 模型的全称是自回归移动平均(auto regression moving average )模型,它是目前最常用的拟合平稳时间序列的模型。ARMA 模型又可细分为AR 模型、MA 模型和ARMA 模型三大类。 9. )(p AR 模型 具有如下结构的模型称为p 阶自回归模型,简记为)(p AR : t p t p t t t x x x x εφφφφ+++++=--- 22110 (6.30) 其中包含三个限制条件:模型的最高阶数为p ,即0≠p φ;随机干扰序列t ε为零均值的白噪声 序列,即),0(~2 εσεWN t ;当期的随机干扰与过去的序列值无关,即t s Ex t s <=,0ε。 1) 中心化的)(p AR 模型 当00=φ时,式(6.30)又称为中心化的)(p AR 模型。非中心化的)(p AR 序列都可以通过假设满足平稳性条件,在式(6.30)两边取期望E ,根据平稳时间序列均值为常数的性质,有 μμμ===--p t t t Ex Ex Ex ,,,1 ,且因为t ε为零均值的白噪声,有0=t E ε,所以: P p t p t p t t t x x x E Ex φφφφμμφμφμφφμεφφφφ----= ++++=+++++=--- 210 210221101) ( (6.31) 如果把非中心化的)(p AR 序列减去上式(6.31)中的μ,则转化为中心化)(p AR 序列。特别地,对于中心化)(p AR 序列,有0=t Ex 。 引进延迟算子,设P p B B B B φφφ----=Φ 2 211)(,又称为p 阶自回归系数多项式,则中心化)(p AR 模型可以简记为: t t x B ε=Φ)( (6.32) 2) )(p AR 模型的方差 要得到平稳)(p AR 模型的方差,需要借助于Green 函数的帮助。下面以求)1(AR 模型的方 差为例来说明: 1 21111----+=+=t t t t t t x x x x εφεφ 将第二式代入第一式,有 22111--++=t t t t x x φεφε 当我们继续将2312---+=t t t x x εφ代入上式,一直到1011εφ+=x x ,可得到 ∑-=----+=+++++=1 00 110 111122111t i t i t i t t t t t t x x x φε φφεφεφεφε 如果∞→t ,设Green 函数为 ,1,0,1==j G j j φ,上式可改为 ∑∑∞ =-∞=-==0 1j j t j j j t j t G x εεφ (6.33) 对t x 求方差为 2 12 121412120 21)1() ()(φσφφφφσεεε-= ++++++==∞∞ =-∑ j j j t j t Var G x Var (6.34) 3) )(p AR 模型的协方差 对中心化的平稳模型在等号两边同乘k t x -,再求期望得到 )()()()()(2211k t t k t p t p k t t k t t k t t x E x x E x x E x x E x x E --------++++=εφφφ (6.35) 由)(p AR 模型的限制条件,有0)(=-k t t x E ε,再根据平稳时间序列的统计性质,有自协方差函数只依赖于时间的平均长度而与时间的起止点无关,于是可由(6.35)式得到自协方差函数的递推公式: )()2()1()(21p k k k k p -++-+-=γφγφγφγ (6.36) 例如,对于)1(AR 模型的自协方差函数的递推公式为: 2 12 1 11111) 0()2() 1()(φσφ γφγφφγφγε-==-=-=k k k k k (6.37) 4) )(p AR 模型的自相关函数 由于平稳时间序列有自相关函数)0(/)()(γγρk k =,在自协方差函数的递推公式(6.36)等号 两边同除以方差函数)0(γ,就得到自相关函数的递推公式: )()2()1()(21p k k k k p -++-+-=ρφρφρφρ (6.38) 例如,对于)1(AR 模型的自相关函数的递推公式为: k k k k k 11111)0()2() 1()(φρφρφφρφρ==-=-= (6.39) 根据式(6.38)可以推出,平稳)(p AR 模型的自相关函数有两个显著的性质: ● 拖尾性——指自相关函数)(k ρ始终有非零取值,不会在k 大于某个常数之后就恒等 于零。 ● 负指数衰减——随着时间的推移,自相关函数)(k ρ会迅速衰减,且以负指数k i λ(其中 i λ为自相关函数的差分方程的特征根)的速度在减小。 见图6.2和图6.3所示是两个平稳)1(AR 模型的理论自相关图。 图6.2 ACF 按负指数单调收敛到零 图6.3 ACF 按正负相间地衰减到零 5) )(p AR 模型的偏自相关系数 对于一个平稳)(p AR 模型,求出滞后k 自相关系数)(k ρ时,实际上得到的并不是t x 与k t x -之间单纯的相关关系。因为这个)(k ρ还会受到中间1-k 个随机变量121,,,+---k t t t x x x 的影响,即这1-k 个随机变量既与t x 又与k t x -具有相关关系。为了能单纯测度t x 与k t x -之间的相关关系,引进了时间序列偏自相关函数( partial autocorrelation function ),简记为PACF 。它是在剔除了中间1-k 个随机变量的干扰之后的滞后k 自相关系数,计算公式为: AR(1)模型的自相关函数ACF(k) -1.00 -0.90-0.80-0.70-0.60-0.50-0.40-0.30-0.20-0.100.000.100.200.300.400.500.600.700.800.901.000123456789101112 延迟k 自相关系数 t t t x x ε+-=-18.0AR(1)模型的自相关函数ACF(k) -1.00 -0.90-0.80-0.70-0.60-0.50-0.40-0.30-0.20-0.100.000.100.200.300.400.500.600.700.800.901.000123456789101112 延迟k 自相关系数 t t t x x ε+=-18.0 ] )?[()]?)(?[(),,|,(211k t k t k t k t t t k t t k t t x E x E x E x x E x E x x x x ----+------= ρ (6.40) 式中],|[?11+--=k t t t t x x x E x E ,],|[?11+----=k t t k t k t x x x E x E 。如果我们用过去的k 期序列 值k t k t t t x x x x -+---,,,,121 对t x 作k 阶自回归拟合,即 t k t kk t k t k t x x x x εφφφ++++=--- 2211 (6.41) 那么有),,|,(11+---=k t t k t t kk x x x x ρφ。这说明滞后k 偏自相关系数实际上等于k 阶自回归模型第k 个回归系数的值。根据这个性质很容易计算PACF 的值。在公式(6.41)中等号两边同乘k t x -,求期望并除以)0(γ,得到 n k t k t kk t k t k t ,,,2,1,2211=+++=---ρφρφρφρ (6.42) 取前k 个方程构成的方程组: ?? ???? ?+++=+++=+++=----0 22112 021121 12011ρφρφρφρρφρφρφρρφρφρφρkk k k k k k k kk k k k kk k k (6.43) 该方程组被称为Yule-Walker 方程。根据线性方程组求解的Gramer 法则,有 D D k kk = φ (6.44) 式中: k k k k k k k k D D ρρρρρ ρρρρρρρρ 212 1 11 2121 1 1 111 ,1 111------== 可以证明对于平稳)(p AR 模型,当p k >时,有0=k D ,这样0=kk φ。也就是说平稳)(p AR 模型的偏自相关系数具有p 步截尾性。见图6.4和图6.5所示是两个平稳)1(AR 模型的样本偏自相关图。 图6.4 一个AR(1)模型n=101样本偏自相关函数PACF(k)图 图6.5 一个AR(1)模型n=101样本偏自相关函数PACF(k)图 由于样本的随机性,样本偏自相关系数不会和理论偏自相关系数一样严格截尾,但可以从图6.4和图6.5 中看出,两个平稳)1(AR 模型的样本偏自相关系数1阶显著不为零,1阶之后都近似为零。样本偏自相关图可以直观地验证平稳)(p AR 模型偏自相关系数具有p 步截尾性。 10. )(q MA 模型 具有如下结构的模型称为q 阶移动平均,简记为)(q MA : AR(1)模型的偏自相关函数PACF(k) -1 -0.9-0.8-0.7-0.6-0.5-0.4-0.3-0.2-0.100.10.20.30.40.50.60.70.80.910123456789101112 延迟k 偏自相关系数 t t t x x ε+=-18.0AR(1)模型的偏自相关函数PACF(k) -1 -0.9-0.8-0.7-0.6-0.5-0.4-0.3-0.2-0.100.10.20.30.40.50.60.70.80.910123456789101112 延迟k 偏自相关系数 t t t x x ε+-=-18.0 q t q t t t t x -------+=εθεθεθεμ 2211 (6.45) 其中包含两个限制条件:模型的最高阶数为q ,即0≠q θ;随机干扰序列t ε为零均值的白噪声 序列,即),0(~2 εσεWN t 。 1) 中心化的)(q MA 模型 当0=μ时,式(6.45)又称为中心化的)(q MA 模型。非中心化的)(q MA 序列都可以通过假设满足平稳性条件,在式(6.45)两边取期望E ,根据平稳时间序列均值为常数的性质,有μ=t Ex ,且因为t ε为零均值的白噪声,有0,,0,0,021====---q t t t t E E E E εεεε ,所以: μεθεθεθεμ=----+=---)(2211q t q t t t t E Ex (6.46) 如果把非中心化的)(q MA 序列减去上式(6.46)中的μ,则转化为中心化)(q MA 序列。特别地,对于中心化)(q MA 序列,有0=t Ex 。 引进延迟算子,设q q B B B B θθθ----=Θ 2 211)(,又称为q 阶自移动平均系数多项式,则中心化)(q MA 模型可以简记为: t t B x ε)(Θ= (6.47) 2) )(q MA 模型的方差 平稳)(q MA 模型的方差为: 2 222 2 1 2211)1() ()(ε σθθθεθεθεθεμq q t q t t t t Var x Var ++++=----+=--- (6.48) 3) )(q MA 模型的自协方差 平稳)(q MA 模型的自协方差只与滞后阶数k 相关,且q 阶截尾。当0=k 时, 222221)1()()0(εσθθθγq t x V a r ++++== ;当q k >时,0)(=k γ;当q k ≤≤1时,有 2 111111)()])([() ()(εσθθθεθεθεμεθεθεμγ+-=--------∑+-=---+---+==k k q i i k q k t q k t k t q t q t t k t t E x x E k (6.49) 4) )(q MA 模型的自相关系数 平稳)(q MA 模型的自相关系数为 ???? ??? ?? >≤≤++++-===∑-=+q k k q k k q k q i k i k k , 01,10 ,1)0()(2 2 11 1 θθθθθγγρ (6.50) 5) )(q MA 模型的偏自相关系数 在中心化的平稳)(q MA 模型场合,滞后k 阶偏自相关系数为: ) ,,|() ,,|(1111+---+---= k t t k t k t t k t t kk x x x Var x x x x E φ (6.51) 容易证明平稳)(q MA 模型的偏自相关系数拖尾性。见图6.6和图6.7所示是一个平稳)1(MA 模型的样本自相关图和样本偏自相关图。 图6.6 一个MA(1)模型n=101样本自相关函数截尾图 MA(1)模型的自相关函数ACF(k) -1.000 -0.900-0.800-0.700-0.600-0.500-0.400-0.300-0.200-0.1000.0000.1000.2000.3000.4000.5000.6000.7000.8000.9001.000 0123456789101112 延迟k 自相关系数 1 8.0-+=t t t x εε 图6.7 一个MA(1)模型n=101样本偏自相关函数拖尾图 6) )(q MA 模型的可逆性 容易验证当两个)1(MA 模型具有如下结构时: 1 1 111 :2:1--- =-=t t t t t t x x εθεεθε模型模型 (6.52) 根据公式(6.50)计算,)1/(2 111θθρ+-=,它们的自相关系数正好相等。即不同的模型却拥有完全相同的自相关系数。这种自相关系数的不惟一性将会导致拟合模型和随机时间序列之间不会是一一对应关系。为了保证一个给定的自相关函数能够对应惟一的)(q MA 模型,我们需要给模型增加约束条件。这个约束条件称为)(q MA 的可逆性条件。把上式(6.52)中两个)1(MA 模型表示成两个自相关AR 模型形式: t t t t B x B x εθεθ=-=-1 11 1: 21: 1模型模型 (6.53) 注意表示成自相关AR 模型时运用公式 ++++=--321 1) 1(a a a a ,其中 11/θθB a B a ==或。显然,当11<θ时,模型1收敛,而模型2不收敛;当11>θ时,则模 MA(1)模型的偏自相关函数PACF(k) -1.000 -0.900-0.800-0.700-0.600-0.500-0.400-0.300-0.200-0.1000.0000.1000.2000.3000.4000.5000.6000.7000.8000.9001.0000123456789101112 延迟k 偏自相关系数 1 8.0-+=t t t x εε 型2收敛,而模型1不收敛。若一个)(q MA 模型能够表示成收敛的AR 模型形式,那么该)(q MA 模型称为可逆模型。一个自相关系数惟一对应一个可逆)(q MA 模型。 11. ),(q p ARMA 模型 具有如下结构的模型称为自回归移动平均模型,简记为),(q p ARMA : q t q t t t p t p t t t t x x x x -----------+++++=εθεθεθεφφφφ 221122110 (6.54) 若00=φ,该模型称为中心化),(q p ARMA 模型。模型的限制条件与)(p AR 模型、)(q MA 模型相同。引进延迟算子,中心化),(q p ARMA 模型简记为: t t x B εΘ=Φ)( (6.55) 式中:P p B B B B φφφ----=Φ 2 211)(,称为p 阶自回归系数多项式, q q B B B B θθθ----=Θ 2211)(,称为q 阶自移动平均系数多项式。 显然,当0=q 时,),(q p ARMA 模型就退化成)(p AR 模型;当0=p 时,),(q p ARMA 模型就退化成)(q MA 模型。所以,)(p AR 模型和)(q MA 模型实际上是),(q p ARMA 的特例,它 们统称为ARMA 模型。而),(q p ARMA 模型的统计性质也正是)(p AR 模型和)(q MA 模型统计性质的有机组合。 由于),(q p ARMA 模型可以转化为无穷阶移动平均模型,所以),(q p ARMA 模型的自相关系数不截尾。同理,由于),(q p ARMA 模型也可以转化为无穷阶自回归模型,所以),(q p ARMA 模型的偏自相关系数也不截尾。总结)(p AR 模型、)(q MA 模型和),(q p ARMA 模型的自相关系数和偏自相关系数的规律,见表6.1所示。 表6.1 拖尾性和截尾性 模型 自相关系数k ρ 偏自相关系数kk φ )(p AR 拖尾 p 阶截尾 )(q MA q 阶截尾 拖尾 ),(q p ARMA 拖尾 拖尾 假如某个时间序列观察值可以判定为平稳非白噪声序列,计算出样本自相关系数(ACF )和 样本偏自相关系数(PACF )之后,就要根据它们表现出来的性质,选择阶数适当的ARMA 模型 拟合观察值序列。即根据样本的自相关系数和样本偏自相关系数性质估计自相关阶数p ?和移动平均阶数q ?。因此,这个过程也称为模型定阶过程或模型识别过程。 由于样本的随机性,样本的自相关系数和偏自相关系数不会呈现出理论截尾的完美情况,本 应截尾处仍会呈现出小值震荡的情况。同时,由于平稳时间序列通常都具有短期相关性,随着延迟阶数变大,自相关系数和偏自相关系数都会衰减至零值附近作小值波动。那么,如何判断自相关系数和偏自相关系数是截尾还是拖尾呢?以及如果为截尾那么相应的阶数为多少? 通常分析人员是依据样本的自相关系数和偏自相关系数近似分布来作出尽可能合理的判断。Jankins 和Watts 已经证明样本自相关系数是总体自相关系数的有偏估计: k k n k E ρρ?? ? ??-=1)?( (6.56) 式中k 为延迟阶数,n 为样本容量。根据Bartlett 公式计算样本自相关系数的方差近似等于: j k n n Var j m m j j m m k >+=?∑∑=-=), ?1(1?1)?(1 2 2ρρρ (6.57) 当延迟阶数k 足够大时,0)?(→k E ρ ;当样本容量n 充分大时,n Var k /1)?(→ρ。所以样本自相关系数近似服从正态分布: )1 ,0(~?n N k ρ (6.58) Quenouille 证明,样本偏自相关系数也同样近似服从这个正态分布: )1 ,0(~?n N kk φ (6.59) 设显著水平取%5=α。如果样本自相关系数和样本偏自相关系数在最初的k 阶明显大于2倍标准差,而后几乎95%的系数都落在2倍标准差的范围内,且非零系数衰减为小值波动的过程非常突然,通常视为k 阶截尾;如果有超过5%的样本相关系数大于2倍标准差,或者非零系数衰减为小值波动的过程比较缓慢或连续,通常视为拖尾。 六. 参数估计和检验 对于一个非中心化),(q p ARMA ,有 t p q t B B x εμ) ()(ΦΘ+ = (6.60) 通过样本的自相关系数和偏自相关系数的性质,估计出自相关阶数p ?和移动平均阶数q ?。为模型定阶后,该模型共含有2++q p 个未知参数:2 11,,,,,εσμθθφφq p 。参数μ用样本均值来估计总体均值(矩估计法)。对原序列中心化后,待估参数减少一个。对1++q p 个未知参数的估计方法有三种:矩估计、极大似然估计和最小二乘估计。 12. 参数的矩估计 用时间序列样本数据计算出延迟1阶到q p +阶的样本自相关系数k ρ?,延迟k 阶的总体自相 关系数为),,,(11q k k θ?φφρ ,公式中包含q p +个未知参数变量q p θθφφ ,,,11。如果用计算出的样本自相关系数来估计总体自相系数,那么有q p +个联立方程组: ?? ???????===++q p q p q p k q p k q p ρ θθφφρρθθφφρρ θθφφρ?),,,(?),,,(?),,,(11111111 (6.61) 从中解出q p +个未知参数变量的值作为模型的参数估计值q p θθφφ?,?,?,?11 。这种方法称为参数的矩估计。 白噪声序列的方差2εσ的矩估计,是用时间序列样本数据计算出样本方差2 ?x σ 来估计总体方差2x σ求得。),(q p ARMA 模型的两边同时求方差,并把相应参数变量的估计值代入,可得白噪声 序列的方差估计为: 22212212 ???1??1x q p σθθφφσε++++++= (6.62) 13. 参数的极大似然估计 当总体分布类型已知时,极大似然估计ML (maximum-likelihood )是常用的估计方法。极大似然估计的基本思想,是认为样本来自使该样本出现概率最大的总体。因此,未知参数的极大似然估计,就是使得似然函数(即联合密度函数)达到最大值的参数值。即: {}),,,;,(max ),;?,?,?,?(111111q P n n q P x x p x x L θθφφθθφφ = (6.63) 在时间序列分析中,序列的总体分布通常是未知的。为了便于分析和计算,通常假设序列服从多元正态分布,它的联合密度函数是可导的。当似然函数关于参数可导时,常常可以通过求导方法来获得似然函数极大值对应的参数值。在求极大似然估计时,为了求导方便,常对似然函数取对数,然后对对数似然函数中的未知参数求偏导数,得到似然方程组。理论上,只要求解似然方程组即可得到未知参数的极大似然估计。但是在实际上是使用计算机经过复杂的迭代算法求出未知参数的极大似然估计。 极大似然估计与矩估计的比较:矩估计的优点是不要求知道总体的分布,计算量小,估计思想简单直观。但缺点是只用到了样本自相关系数的信息,序列中的其他信息被忽略了,这导致矩估计方法是一种比较粗糙的估计方法,它的估计精度一般较差。因此,它常被作为极大似然估计和最小二乘估计的迭代计算的初始值。极大似然估计的优点是充分应用了每一个观察值所提供的信息,因而它的估计精度高,同时,还具有估计的一致性、渐近正态性和渐近有效性等优良统计性质,是一种非常优良的参数估计方法。 14. 参数的最小二乘估计 参数的最小二乘估计ULS (unconditional least squares )是使),(q p ARMA 模型的残差平方和 基于ARMA模型的湖南省工业总产值的时间序列分析 摘要:改革开放以来,湖南省的工业经济增长取得了举世瞩目的成就。故本文以1978-2013年湖南省工业总产值的历史数据为基础,对1978-2009年的数据进行了平稳化处理,并进行了模型的识别、参数估计、显著性检验、优化,建立了适合湖南省工业发展的自回归移动平均模型(ARMA);然后对2010-2013年湖南省工业总产值进行了拟合预测,以检验模型的实际拟合效果;最后对2014-2016年的工业总产值进行了统计预测,得出ARMA模型是一种很好的短期时间序列预测方法,并从中找出了湖南省工业发展的内在规律,提出了工业发展的相关政策建议。 关键词:ARMA模型;工业总产值;时间序列;短期预测 一、引言 2014年湖南省政府工作报告在回顾2013年工作时指出“工业实力增强,全部工业增加值突破1万亿元,规模工业主营业务收入超过3万亿元”。改革开放以来,湖南省工业总产值从1978年的142.78亿元上升到2013年的40004.55亿元,工业增加值占地区生产总值的比重也由1978年的35.3%上升到2013年的40.8%。2013年,湖南省规模以上工业增加值增长11.6%,规模以上工业新产品产值增长23.2%,占工业总产值比重为13.1%,比上年提高1个百分点。可见湖南省工业不断得到发展,并取得了较为瞩目的成就。但是工业的发展也呈现出一系列问题,工业的发展速度从1978年的121.6%呈现波动性下降,这进一步说明湖南省工业经济在取得重大发展的过程中也付出了极大的代价,特别是环境方面的代价,这在某种程度上阻碍了湖南省工业经济的进一步发展。此外,随着我国经济增长中心由东部沿海地区向西部地区推移,作为我国主要的能源基地和原材料工业基地的中部六省必定成为我国工业经济的高速增长点,而湖南省两型社会(资源节约型和环境友好型)的构建,使其面临了更多的机遇和挑战。从某种程度上说,湖南省工业发展的好坏,将会影响我国未来经济的发展和环境友好型社会的构建,这就迫切需要我们对湖南省工业经济发展的模式做出重新选择。为了探索出湖南省工业发展的内在规律和短期波动情况,促进湖南省工业经济的发展,从而更好定位我国未来经济的发展和构建环境友好型社会,本文运用ARMA模型对湖南省工业总产值序列进行了平稳化处理、模型识别、参数估计、模型检验以及模型优化,最终建立起符合湖南省工业经济发展的疏系数模型(ARIMA模型),并对2014-2016年的工业总产值进行了统计预测。 ARMA模型是国际上比较流行的单一时间序列预测模型,特别适合处理复杂时间序列的预测,且在短期预测时精度较高,故在各个领域运用得也非常广泛。从宏观层面来看,张煜(2006)将ARMA模型应用于我国外贸进出口总额的时间序列的分析中,证实了ARMA模型是一种较好的短期预测模型]1[。夏蓉(2008)以1952-2004年我国工业总产值的历史数据为基础,建立ARMA模型,探析出ARMA 模型能较好的分析和计算我国工业的发展波动情况,我国工业总产值在保持稳定速度增长的同时也存在一些问题]2[。陈德艳(2011)]3[、苏雷(2012)]4[等分别将ARMA模型应用于我国城乡收入差距、土地利用需求量的预测中。从微观层面 基于ARMA模型的短期风速建模 摘要:建立能够正确反映实际风速特性的风速模型对于风力发电系统动态分析十分必要。自回归滑动平均模型(ARMA)是分析时间序列的重要方法。在分析实际风速统计特性和ARMA模型性质的基础上,建立了可用于动态仿真的短期风速模型。仿真结果表明,所得风速序列能够正确反映实际风速的特性。 关键词:短期风速模型,ARMA,V on Karman功率谱 Short-term Wind Speed simulation based on ARMA Model Abstract: It is necessary to build a wind speed model which accurately reflects the characteristics of actual wind for dynamic analysis of wind power generation system. Auto-regressive and moving average model (ARMA) is an important method of time series analysis; based on the analysis of the statistical characteristics of actual wind speed and the nature of ARMA model, this paper established a short-term wind speed model which can be used for dynamic simulation. Simulation results show that the wind speed model correctly reflects the characteristics of the actual wind speed. Keywords: Short-term Wind Speed Model, ARMA, V on Karman power spectrum 1 引言 随着能源问题日益突出,风力发电等以可再生能源为基础的发电技术越来越受到关注。建立能够正确反映实际风速特性的风速模型是研究风力发电系统控制策略以及并网运行特性的重要基础[1]。由于风速的随机性和波动性,系统中的机械设备和电气设备以及电网均会受到扰动,这种扰动对于系统设备的寿命、运行性能以及电网的稳定性都将产生一定的影响。因而,在研究风电场接入电网的功率波动与电能质量等动态特性时,需要建立与之相适应的风速模型。 目前,用于风电系统仿真的风速模型有两种,一是由基本风速、渐变风速、阵风和随机风四种分量合成风速模型[2-4],其中阵风是风速变化的主要分量;一是由平均风速与湍流风速叠加而成[5-7]。前者无法确定风速变化的具体参数,只能简单描述风速的变化情况,而后者具有特定的参数描述风速变化的特征,是电力系统动态仿真中常用的风速模型。基于对后者模型中湍流风速特性的研究,利 龙源期刊网 https://www.360docs.net/doc/9212964932.html, 基于ARMA模型的股价预测及实证研究 作者:刘伟龙 来源:《智富时代》2017年第02期 【摘要】在现实中很多问题,如利率波动、收益率变化及汇率变化通常都是一个时间序列。然而经济时间序列不同于横截面数据存在重复抽样的情况,它是一个随机事件的唯一记录,这个过程是不可重复的。横截面数据中的随机变量可以非常方便地通过其均值、方差或数据的概率分布加以面熟,但是时间序列中这种描述很不清楚,这就需要用一些特定的计量方法和手段分析其变化规律。ARMA模型在经济预测过程中即考虑了金融市场、股票市场指标在 时间序列上的依存性,又考虑了随机波动你的干扰性,对其指标短期趋势的预测准确率较高,它用有限参数线性模型描述时间的自相关结构,便于进行统计分析与数学处理,因此ARMA 模型是目前常用的用于拟合平稳序列的模型,尤其在金融和股票领域具有重要意义。本文将利用ARMA模型结合民生银行股票的历史数据建模,并运用该模型对招商银行的股票日收盘价进行预测,从而推断其未来趋势。 【关键词】ARMA模型;金融时间序列;平稳序列;收益率;股价预测 一、ARMA模型的理论介绍 ARMA(p,q)模型是由美国统计学家Box GEP和赢过统计学家Jenkins GM在二十世纪七十年代提出的时间序列分析模型,即自回归移动平均模型,一般的ARMA(p,q)模型的 形式可以表示为: yt=c+Φ1yt-1+Φ2yt-2+...+Φpyt-p+εt+θ1εt-1+θ2εt-2+... +θqεt-q 其中:εt是白噪声序列,p和q是非负整数,AR和MA模型都是ARMA模型的特殊情况,p=0时,ARMA模型为MA(q),q=0时,ARMA模型为AR(p)。ARMA模型针对的是平稳序列,对于非平稳的时间序列,不能直接用ARMA模型去描述,只有经过某种处理后,产生一个平稳的新序列,才可应用ARMA模型。对于含有短期趋势的非平稳序列可以进行差分使非平稳序列变成平稳序列。 二、对民生银行的股票日收盘价的实证分析及预测 在wind资讯数据库选取民生银行(600016)的股票日收盘价数据,时间区间为2013/5/22至2016/1/15共计649个样本。下面旨在利用ARMA模型的建模理论结合软件STATA进行ARMA模型的建立和预测分析。 (一)原始数据的平稳化处理 基于ARMA模型的上证指数预测的实证报告 ————————————————————————————————作者:————————————————————————————————日期: 基于ARMA模型的上证指数预测的实证报告 引言 生活中有很多问题都可以看成是时间序列问题,例如银行利率波动、股票收益率变化以及国际汇率变动等问题。所谓的时间序列问题,是指某一统计对象长时间内的数值变化情况。在实际应用中,经常会遇到许多不满足平稳性的时间序列数据,尤其是在经济、金融等领域。因此,能否有效地挖掘非平稳时间序列的有用信息,对于解决一些经济、金融领域的问题显得尤为重要。目前关于预测股票价格的研究文章有很多,这些已有研究大都采用回归分析、组合预测等方法对股票价格未来变动值进行探讨,得出股票价格在未来短期内的变化趋势及预测值,但预测结果并不非常精准,存在较大的误差。模型不仅可用于拟合平稳性时间序列问题,而且对非平稳时间序列问题同样具有良好的拟合效果,尤其是在金融和股票领域应用最为广泛。 本文主要针对 2016-04-18 至 2017-03-15 (共计222个工作日) 期间上证综合指数每日收盘价数据,建立上证综合指数每日收盘价预测模型,采用 模型对上证综合指数每日收盘价进行高精度的拟合预测。研究结果表明,上证综合指数每日收盘价在短期内将保持平稳上涨,不会有大幅涨跌的情况。研究上证综合指数每日收盘价的短期变动情况了解股票市场变化及制定投资决策具有现实意义,能够为投资者和决策者提供可靠的信息服务及决策指导。 1 模型的理论介绍及平稳性检验 1.1模型建模流程 1)时间序列的预处理,用模型预测要求序列必须是平稳的,若所给的序列是非平稳序列,则必须对所给序列做预处理,使其为平稳非白噪声序列。 2)计算出样本自相关系数和偏自相关系数的值。 ARMA模型及分析 本次试验主要是通过等时间间隔,连续读取70个某次化学反应的过程数据,构成一个时间序列。试对该时间序列进行ARMA模型拟合以及模型的优化,最后进行预测。以下本次试验的数据: 表1 连续读取70个化学反应数据 47 64 23 71 38 64 55 41 59 48 71 35 57 40 58 44 80 55 37 74 51 57 50 60 45 57 50 45 25 59 50 71 56 74 50 58 45 54 36 54 48 55 45 57 50 62 44 64 43 52 38 59 55 41 53 49 34 35 54 45 68 38 50 60 39 59 40 57 54 23 资料来源:O’Donovan, Consec. Readings Batch Chemical Proces, https://www.360docs.net/doc/9212964932.html,ler et al. 下面的分析及检验、预测均是基于上述数据进行的,本次试验是在Eviews 6.0上完成的。 一、序列预处理 由于只有对平稳的时间序列才能建立ARMA模型,因此在建立模型之前,有必要对序列进行预处理,主要包括了平稳性检验和纯随机检验。 序列时序图显示此化学反应过程无明显趋势或周期,波动稳定。见图1。 图2 化学反应过程相关图和Q统计量 从图2的序列的相关分析结果:1. 可以看出自相关系数始终在0周围波动,判定该序列为平稳时间序列2.看Q统计量的P值:该统计量的原假设为X的1期,2期……k期的自相关系数均等于0,备择假设为自相关系数中至少有一个不等于0,因此如图知,该P值在滞后2、3、4期是都为0,所以拒接原假设,即序列是非纯随机序列,即非白噪声序列(因为序列值之间彼此之间存在关联,所以说过去的行为对将来的发展有一定的影响,因此为非纯随机序列,即非白噪声序列)。 二、模型识别 由于检验出时间序列是平稳的,且是非白噪声序列,因此可以建立模型,在建立模型之前需要识别模型阶数即确定阶数。阶数确定要借助于时间序列的相关图,即序列的自相关函数和偏自相关函数,并根据他们之间的理论模式进行阶数最后的确定。 下面给出自相关函数和偏自相关函数之间的理论模式: 基于ARMA模型的社会融资规模增长分 析 --——ARMA模型实验 第一部分实验分析目的及方法 一般说来,若时间序列满足平稳随机过程的性质,则可用经典的ARMA模型进行建模和预则.但是,由于金融时间序列随机波动较大,很少满足ARMA模型的适用条件,无法直接采用该模型进行处理。通过对数化及差分处理后,将原本非平稳的序列处理为近似平稳的序列,可以采用ARMA模型进行建模和分析。 第二部分实验数据 2.1数据来源 数据来源于中经网统计数据库.具体数据见附录表5.1 。 2.2所选数据变量 社会融资规模指一定时期内(每月、每季或每年)实体经济从金融体系获得的全部资金总额,为一增量概念,即期末余额减去期初余额的差额,或当期发行或发生额扣除当期兑付或偿还额的差额。社会融资规模作为重要的宏观监测指标,由实体经济需求所决定,反映金融体系对实体经济的资金量支持。 本实验拟选取2005年11月到2014年9月我国以月为单位的社会融资规模的数据来构建ARMA模型,并利用该模型进行分析预测。 第三部分 ARMA模型构建 3。1判断序列的平稳性 首先绘制出M的折线图,结果如下图: 图3.1 社会融资规模M曲线图 从图中可以看出,社会融资规模M序列具有一定的趋势性,由此可以初步判断该序列是非平稳的。此外,m在每年同时期出现相同的变动趋势,表明m还存在季节特征.下面对m的平稳性和季节性·进行进一步检验. 为了减少m的变动趋势以及异方差性,先对m进行对数化处理,记为lm,其时序图如下: 图3。2 lm曲线图 对数化后的趋势性减弱,但仍存在一定的趋势性,下面观察lm的自相关图 针对乳制品月产量数据的时间序列分析 摘要:随着经济的发展,乳制品产业对国民健康水平的影响逐渐加大。该文从乳制品行业月产量的角度出发,采用时间序列数据分析方法,对我国自1990年至2010年以来的乳制品行业月产量进行了建模分析,并在得到模型后对其进行了预测。从分析结果来看,我国的乳制品产量在2004年发生突变,特定的月份也会对其产生影响,并且在不同的时间,影响会发生变化。 关键词:乳制品;月份特征;产量突变;产量预测; 背景: 纵观自1949年发展至今,整个行业可以分为四个发展阶段: 1、缓慢发展阶段(1949~1977):这段时期,我国乳产业受国家经济状况制约发展缓慢。 2、迅速扩张阶段(1978~1992):由于开始实行多种所有制进行奶牛饲养与奶制品加工,原奶与乳品的产量、种类、质量都有明显的提高 3、结构调整阶段(1993~1998):1993年开始,乳品供给增长明显快于消费增长速度,产能出现比较严重的过剩,乳粉出现滞积,部分乳品企业发展艰难。 4、高速增长阶段(1999~至今):1998年起,乳制品产业经过产品结构大力调整,经济效益明显提高,随着消费需求的迅速增长,乳制品产量也连年增长,乳产业已经从一个传统产业摇身一变成为一个朝阳产业。 从市场格局上看,乳制品企业可以分为4类:1、以伊利、蒙牛为代表的全国性企业;2、以光明、三鹿、维维等为代表的区域性企业;3、以北京三元、济南佳宝为代表的本省省会企业;4、以雀巢为代表的外资企业。在行业中,企业之间的竞争非常激烈,特别地,在近十年中市场竞争引起了市场格局的极大改变。 本文将选取1993年1月起到2010年6月的月产量数据进行时间序列分析,尝试建立该时序的时间序列模型及其详细的建立过程,并对模型结果给出必要的经济意义解释。 建立模型过程: 1、建模过程使用eviews软件,将1990年1月到2010年6月总计246个月度数据输入eviews中,Yt即是产量月度序列,现作出散点图如下: 基于ARMA模型的 国内生产总值分析 班级:金融工程3班 学号:2012302350006 姓名:严珂 一、案例分析目的 经济运行过程从较长时间序列看,由于市场机制的作用,呈现一定的规律,这对预测提供了依据。目前,预测经济运行时间序列的理论与方法较多,而ARMA模型在经济预测过程中既考虑了经济现象在时间序列上的依存性,又考虑了随机波动的干扰性,对经济运行短期趋势的预测准确率较高。由于国内生产总值是指一个国家或地区所有常住单位在一定时期内生产活动的最终成果。这个指标把国民经济全部活动的产出成果概括在一个极为简明的统计数字之中,为评价和衡量国家经济状况、经济增长趋势及社会财富的经济表现提供了一个最为综合的尺度,可以说,它是影响经济生活乃至社会生活的最重要的经济指标。不仅能够在总体上度量国民产出和收入规模,也能够在整体上度量经济波动和经济周期状态,因此,对GDP进行精确的拟合和分析对分析一国的宏观经济发展趋势具有重要意义。 我国实行改革开放政策后,逐步走上了市场化的经济道路,在高效率的市场经济机制推动下,我国的GDP的产出规模呈现增长模式,说明我国经济产出能力的不断增强,规模的不断变大。虽然经济的发展有着诸多不确定性,但是这并不影响在既定模式下对GDP产出规模的大概预测。在近十年的经济发展中,我国GDP的规模平稳较快发展,尤其在当前经济形势没有大的危机的情况下,每年的GDP产出规模是一个可以进行较为精确预测的数据。所以,在数据可以预测的情况下,如何以最为精确的方式预测到GDP产出规模是国家管理工作的基础和前提。 本案例拟选取1997年1月到2007年10月的国内生产总值的数据来构建ARMA模型,并利用该模型进行外推预测分析。 二、实验数据 我们以GDP为研究标的,在数据的选取上,我们选择了1994年3月至2013年12 基于ARMA模型的社会融资规模增长分析 ————ARMA模型实验 第一部分实验分析目的及方法 一般说来,若时间序列满足平稳随机过程的性质,则可用经典的ARMA模型进行建模和预则。但是, 由于金融时间序列随机波动较大,很少满足ARMA模型的适用条件,无法直接采用该模型进行处理。通过对数化及差分处理后,将原本非平稳的序列处理为近似平稳的序列,可以采用ARMA模型进行建模和分析。 第二部分实验数据 2.1数据来源 数据来源于中经网统计数据库。具体数据见附录表5.1 。 2.2所选数据变量 社会融资规模指一定时期内(每月、每季或每年)实体经济从金融体系获得的全部资金总额,为一增量概念,即期末余额减去期初余额的差额,或当期发行或发生额扣除当期兑付或偿还额的差额。社会融资规模作为重要的宏观监测指标,由实体经济需求所决定,反映金融体系对实体经济的资金量支持。 本实验拟选取2005年11月到2014年9月我国以月为单位的社会融资规模的数据来构建ARMA模型,并利用该模型进行分析预测。 第三部分 ARMA模型构建 3.1判断序列的平稳性 首先绘制出M的折线图,结果如下图: 图3.1 社会融资规模M曲线图 从图中可以看出,社会融资规模M序列具有一定的趋势性,由此可以初步判断该序列是非平稳的。此外,m在每年同时期出现相同的变动趋势,表明m还存在季节特征。下面对m的平稳性和季节性·进行进一步检验。 为了减少m的变动趋势以及异方差性,先对m进行对数化处理,记为lm,其时序图如下: 图3.2 lm曲线图 对数化后的趋势性减弱,但仍存在一定的趋势性,下面观察lm的自相关图 表3.1 lm的自相关图 上表可以看出,该lm序列的PACF只在滞后一期、二期和三期是显着的,ACF随着滞后结束的增加慢慢衰减至0,由此可以看出该序列表现出一定的平稳性。进一步进行单位根检验,由于存在较弱的趋势性且均值不为零,选择存在趋势项的形式,并根据AIC自动选择之后结束,单位根检验结果如下: 表3.2 单位根输出结果 Null Hypothesis: LM has a unit root Exogenous: Constant, Linear Trend Lag Length: 0 (Automatic - based on SIC, maxlag=12) t-Statistic Prob.* Augmented Dickey-Fuller test statistic -8.674646 0.0000 Test critical values: 1% level -4.046925 5% level -3.452764 10% level -3.151911 *MacKinnon (1996) one-sided p-values. 单位根统计量ADF=-8.674646小于临界值,且P为0.0000,因此该序列不存在单位根,即该序列是平稳序列。 由于趋势性会掩盖季节性,从lm图中可以看出,该序列有一定的季节性,为了分析季节性,对lm进行差分处理,进一步观察季节性: 图3.3 dlm曲线图 观察dlm 的自相关表: 表3.3 dlm的自相关图 Date: 11/02/14 Time: 22:35 Sample: 2005M11 2014M09 Included observations: 106 Autocorrelation Partial Correlation AC PAC Q-Stat Prob ****|. | ****|. | 1 -0.566 -0.566 34.934 0.000 .|* | **|. | 2 0.113 -0.305 36.341 0.000 .|. | *|. | 3 0.032 -0.093 36.455 0.000 *|. | *|. | 4 -0.084 -0.114 37.244 0.000 .|* | .|. | 5 0.105 0.015 38.494 0.000 *|. | *|. | 6 -0.182 -0.182 42.296 0.000 .|* | *|. | 7 0.105 -0.156 43.563 0.000 .|. | *|. | 8 -0.058 -0.171 43.954 0.000 .|. | *|. | 9 -0.019 -0.196 43.996 0.000ARMA模型的应用
基于ARMA模型的短期风速建模
基于ARMA模型的股价预测及实证研究
基于ARMA模型的上证指数预测的实证分析报告
时间序列ARMA模型及分析
时间序列分析——ARMA模型实验
基于时间序列arma模型的分析
ARMA模型案例分析
时间序列分析——ARMA模型实验(1)