应用重定向超速区带离心法纯化HBsAg的研究-1.5

应用重定向超速区带离心法纯化HBs Ag的研究
姚 伟 郑菊梅 孟秀圆
(卫生部兰州生物制品研究所,兰州 730046)
摘 要 采用重定向超速区带离心法进行了从乙肝阳性血清中提纯HBs Ag的研究,获得了一套最佳离心条件,可清除阳性血清中的各种杂蛋白,获得不含乙肝病毒(Dane颗粒)的纯HBs Ag。此方法具有离心时间短、不漏液、故障少及成本低等优点。本试验结果为采用重定向超速区带离心法大规模纯化HBs Ag、基因工程表达产物及其它生物大分子蛋白提供了实验依据。
关键词 重定向超速区带离心 纯化 乙型肝炎表面抗原(HBs Ag)
分类号 R521.6
The Practice Study for The Purif ication of H BsAg by Reorienting Ultra-Zonal Centrif ugation Y ao Wei Zheng J umei Meng Xiuyan.(L anzhou Institute of Biological Products Lanz hou730046) Abstract W e studied the purifica tio n o f HBsAg fro m the po sitiv e serum fo r HBV by reo rienting ultra-zo na l centrifug ation and g ained a suitable co ndition of centrifuga tio n.The ex tra pr otein was eli-minated by the m eth od.We o btained the pur e HBs Ag which ar e no n-Dane pa rtices.T his method has such charac ters of sho rter centrif ug atio n time,less breakdow n,low er co st and w itho ut lea king o f g radi-ent o r sa mple.T he results prov ided th e evidence fo r applying of r eorienting ultra-zonal centrifuga tio n in the la rg e sca le o f purification of HBsAg,the pro ducts o f g ene ex pr ession and o ther bio logical pr otein.
Key words Reorienting ultr a-zo nal centrifug atio n Purificatio n HBs Ag
区带离心法纯化HBs Ag的传统方法是采用一套专门的密封装置,转头在一定转速的动态情况下进、出样〔1〕。此法的缺点是易漏液,常因真空度不好导致离心失败造成样品损失,而且由于转头K系数较大,限制了离心速度,要达到一定的离心力须延长离心时间,因而使生产周期延长。为寻找到一种大规模纯化HBs Ag 等蛋白质分子的最佳方法,我们采用重定向超速区带离心法〔2〕进行了这方面研究。1964年N.
G.Anderson等〔3〕报道了采用重定向离心法在角度转头上分离DN A的实验。1972年Bond 等〔4〕根据颗粒密度(ρ)和沉降系数(S)用等密度区带离心和速率区带离心法,即S-ρ法分离了HBsAg,后来此法被用于大规模纯化HBsAg。但采用区带转头进行重定向超速区带离心大规模纯化HBsAg的实用报告在国内外报道不多。因此,探索重定向超速区带离心法在HB-sAg等生物大分子分离方面应用的可行性具有很高的实用价值。重定向区带离心的方法是:将梯度液和样品依次泵入区带转头内,然后起动离心。离心结束后停机,静态出样,在整个离心过程中梯度液经过水平—垂直—水平的两次重定向。此过程不影响梯度的线性分布,从而达到了分离纯化样品的目的。
1 材料与方法
1.1 设备与原材料
1.1.1 超速离心机:U ltra80。
1.1.2 重定向区带转头:T Z-28。
1.1.3 输液泵:SYB-G-405型。
1.1.4 紫外检测仪:HD-88-5A1型。
1.1.5 溴化钾:分析纯。
1.1.6 蔗糖:分析纯。
1.1.7 HBs Ag阳性血清:由兰州生物制品研究所疫苗三室提供。
36 微生物学免疫学进展1998年第26卷第1期
1.2 试验方法
1.2.1 离心条件的设定
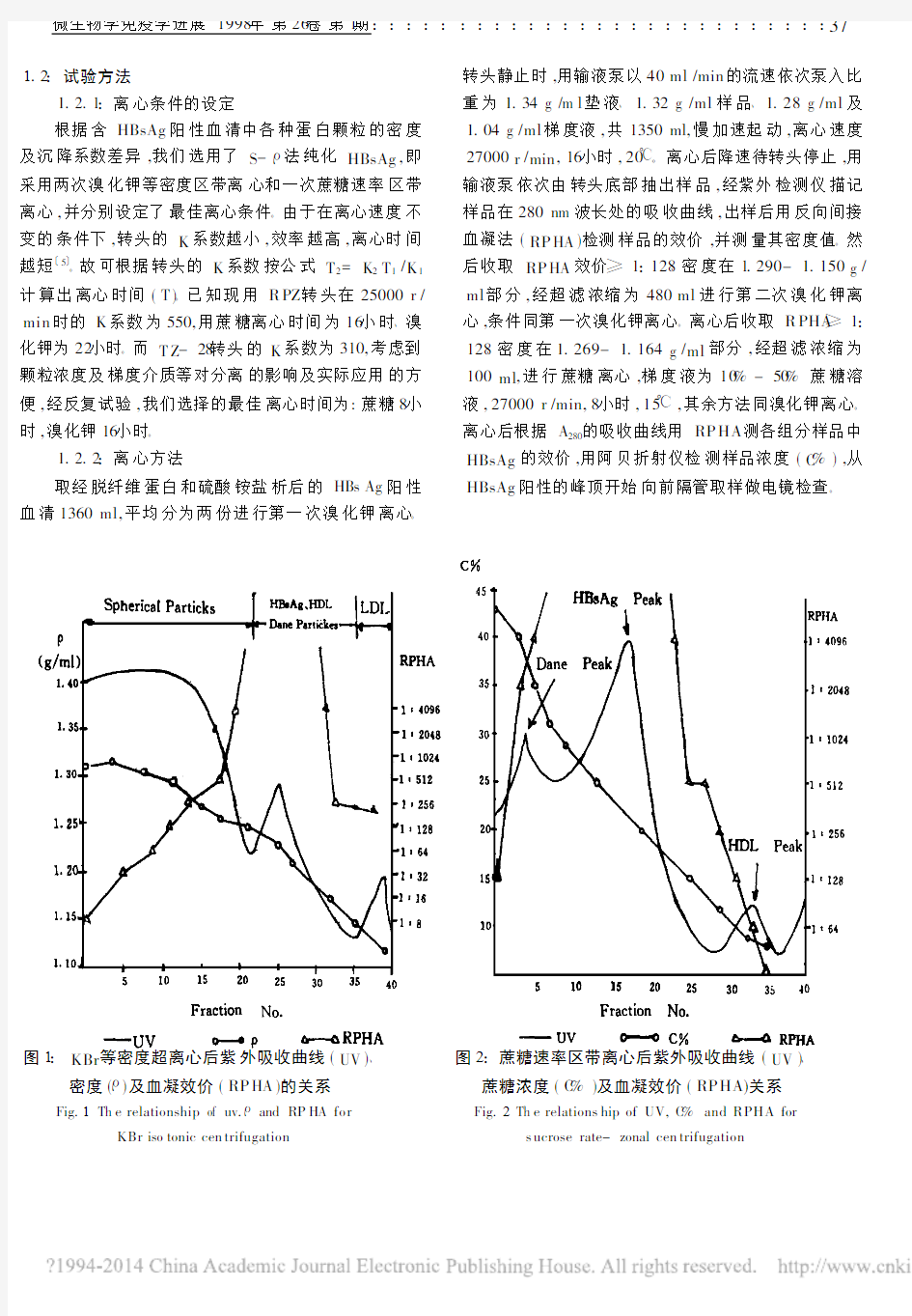
根据含HBsAg 阳性血清中各种蛋白颗粒的密度及沉降系数差异,我们选用了S -ρ法纯化HBsAg ,即采用两次溴化钾等密度区带离心和一次蔗糖速率区带离心,并分别设定了最佳离心条件。由于在离心速度不变的条件下,转头的K 系数越小,效率越高,离心时间越短〔5〕。故可根据转头的K 系数按公式T 2=K 2T 1/K 1计算出离心时间(T )。已知现用R PZ 转头在25000r /min 时的K 系数为550,用蔗糖离心时间为16小时、溴化钾为22小时。而T Z -28转头的K 系数为310,考虑到颗粒浓度及梯度介质等对分离的影响及实际应用的方便,经反复试验,我们选择的最佳离心时间为:蔗糖8小时,溴化钾16小时。
1.2.2 离心方法
取经脱纤维蛋白和硫酸铵盐析后的HBs Ag 阳性血清1360ml,平均分为两份进行第一次溴化钾离心。
转头静止时,用输液泵以40ml /min 的流速依次泵入比重为1.34g /m l 垫液、1.32g /ml 样品、1.28g /ml 及1.04g /ml 梯度液,共1350ml,慢加速起动,离心速度27000r /min ,16小时,20℃。离心后降速待转头停止,用输液泵依次由转头底部抽出样品,经紫外检测仪描记样品在280nm 波长处的吸收曲线,出样后用反向间接血凝法(RP HA )检测样品的效价,并测量其密度值。然
后收取RP HA 效价≥1 128、密度在1.290- 1.150g /ml 部分,经超滤浓缩为480ml 进行第二次溴化钾离心,条件同第一次溴化钾离心。离心后收取R PHA ≥1 128、密度在1.269- 1.164g /ml 部分,经超滤浓缩为100ml ,进行蔗糖离心,梯度液为10%-50%蔗糖溶液,27000r /min,8小时,15℃,其余方法同溴化钾离心。离心后根据A 280的吸收曲线用RP HA 测各组分样品中HBsAg 的效价,用阿贝折射仪检测样品浓度(C %),从HBsAg 阳性的峰顶开始向前隔管取样做电镜检查
。
图1 KBr 等密度超离心后紫外吸收曲线(UV )、
密度(ρ)及血凝效价(RP HA )的关系
Fig.1Th e relationship of uv.ρand RP HA for
KBr iso tonic cen trifugation
图2 蔗糖速率区带离心后紫外吸收曲线(UV )、
蔗糖浓度(C %)及血凝效价(RP HA)关系
Fig.2Th e relations hip of UV,C %and RPHA for
s ucrose rate-zonal cen trifugation
37微生物学免疫学进展1998年第26卷第1期
2 结果
样品经两次溴化钾离心,其紫外吸收图出现三个峰(见图1)。第一峰为球蛋白峰,第二峰为HBsAg与高密度脂蛋白(HDL)及Dane颗粒混合峰,第三峰为低密度脂蛋白(LDL)峰。第一、二峰之间有少量交叉,所收样品密度范围(RPHA≥1128部分)为1.290- 1.150g/m l。蔗糖离心后也出现三个峰(见图2),第一峰为Dane颗粒峰,第二峰为HBsAg峰,第三峰为HDL峰。第二峰电镜检查结果为:15-27管为均匀的22nm球形颗粒即HBsAg,未见Dane 颗粒,电镜检查结果合格〔6〕。
3 讨论
S-ρ法是根据HBsAg与其它血清蛋白的颗粒大小、密度等物理特性〔7、8〕的差异而设定的一种分离方法。根据等密度区带离心的原理,不同密度的颗粒经离心后分别处于与它同密度的区带内。HBs Ag的平均密度为1.2g/ml,LDL 为1.063g/m l,血清杂蛋白为≥1.30g/m l,经等密度区带离心可将其分离。由于阳性血清样品中蛋白浓度较大,经一次溴化钾离心后,HB-s Ag峰与球蛋白峰及LDL峰有少量交叉,所收样品内有少量杂蛋白。经二次溴化钾离心后HBsAg峰呈一独立峰,未与杂蛋白峰交叉,说明已与球蛋白及LDL分离,见图1。根据速率区带离心的原理,直径和沉降系数较大的颗粒沉降的较快。Dane颗粒的直径平均为42nm,S为260-320,HBs Ag的直径平均为22nm,S为33 -45,而HDL的直径平均为10nm,S为3-5,因而经速率区带离心可将其分开。在图2中, HBsAg峰呈一单峰,未与HDL及Dane颗粒峰交叉,说明分离效果较好,经电镜检查证实该峰为不含Dane颗粒的纯HBsAg。根据以上结果我们认为:重定向超速区带离心法用于从乙肝阳性血清中分离HBsAg,用于纯化基因工程表达产物(如CHO细胞表达HBsAg)及在生物领域内分离其它蛋白质等大分子是可行的。采用重定向超速区带离心需注意的是:重定向区带超离心的进样、出样都是在静态进行的,离心过程区带要经过两次重定向,此过程稍不注意可能造成区带之间部分混合,尤其在蔗糖离心时,由于蔗糖粘度大,重定向过程慢,更易造成区带混合。因此,为保证分离精度,离心过程应严格控制进、出样流速,起动时慢加速值应设低一点,从0-500r/min以2-4分钟为宜。另外,梯度液分配要准确,进样中要防止气泡进入,以免打乱梯度。
4 参考文献
1 苏拨贤主编.生物化学制备技术,北京:科学出版社,1986: 169
2 Rick w ood D.Centrifugation Th e Practical approach2nd ed.England:Univ ersity of Es sex,1984:228
3 T.S.W ork&E.W https://www.360docs.net/doc/a510511729.html,bo ratory Tech niques in Bioche-mis try and M olecular Biology.North-Holland,1976:189-196
4 Brakke,M.K,:M eth ods in virology,2:137,1967
5 陶宗晋主编.离心沉降分析技术,北京:科学出版社,1983: 95
6 中国生物制品规程(一部).血源乙型肝炎疫苗制造及检定规程1995:142
7 刘锡光等主编,病毒性肝炎实验诊断,北京:人民卫生出版社,1986:14,245
8 P.Adamowicz et al.Vaccine,Vol.2,Sep1984:211 (收稿 1997-09-23 修回 1998-01-13)
38 微生物学免疫学进展1998年第26卷第1期
集中式网络管理和分布式网络管理的区别及优缺点
集中式网络管理和分布式网络管理的区别及优缺点 集中式网络管理模式是在网络系统中设置专门的网络管理节点。管理软件和管理功能主要集中在网络管理节点上,网络管理节点与被管理节点是主从关系。 优点:便于集中管理 缺点: (1)管理信息集中汇总到管理节点上,信息流拥挤 (2)管理节点发生故障会影响全网的工作 分布式网络管理模式是将地理上分布的网络管理客户机与一组网络管理服务器交互作用,共同完成网络管理的功能。 优点: (1)可以实现分部门管理:即限制每个哭户籍只能访问和管理本部门的部分网络资源,而由一个中心管理站实施全局管理。 (2)中心管理站还能对客户机发送指令,实现更高级的管理 (3)灵活性和可伸缩性 缺点: 不利于集中管理 所以说采取集中式与分布式相结合的管理模式是网络管理的基本方向 snmp安装信息刺探以及安全策略 一、SNMP的概念,功能 SNMP(Simple Network Management Protocol)是被广泛接受并投入使用的工业标准,它的目标是保证管理信息在任意两点中传送,便于网络管理员在网络上的任何节点检索信息,进行修改,寻找故障;完成故障诊断,容量规划和报告生成。它采用轮询机制,提供最基本的功能集。最适合小型、快速、低价格的环境使用。它只要求无证实的传输层协议UDP,受到许多产品的广泛支持。 本文将讨论如何在Win2K安装使支持SNMP功能,SNMP技术对于提升整体安全水准是有益的,但也可能存在风险,本文将同时检验这两个方面。另外,除了介绍一些开发工具外,还将图解通过SNMP收集信息的可能用法,以及如何提高安全性。 二、在Win2K中安装SNMP 提供一个支持SNMP的Win2K设备与增加一个额外的Windows组件同样简单,只需要进入"开始/设置/控制面板/", 选择"添加/删除程序",然后选择"添加/删除Windows组件",随之出现一个对话框,在其中选择"管理和监视工具", 最后点击"下一步",依照提示安装: OK,现在Win2K就可以通过SNMP来访问了. 三、对snmp信息的刺探方法 1、Snmputil get 下面我们在命令行状态下使用Win2K资源工具箱中的程序 来获取安装了SNMP的Win2K机器的网络接口数目,命令参数是get: 前提是对方snmp口令是public 提供基本的、低级的SNMP功能,通过使用不同的参数和变量,可以显示设备情况以及管理设备。
servlet请求转发的三种方式
servlet请求转发的三种方式 servlet中的请求转发主要有三种方式: 1、 forward:是指转发,将当前request和response对象保存,交给指定的url 处理。并没有表示页面的跳转,所以地址栏的地址不会发生改变。 2、 redirect:是指重定向,包含两次浏览器请求,浏览器根据url请求一个新的页面,所有的业务处理都转到下一个页面,地址栏的地址会变发生改变。 3、 include:意为包含,即包含url中的内容,进一步理解为,将url中的内容包含进当前的servlet当中来,并用当前servlet的request和respose来执行url中的内容处理业务.所以不会发生页面的跳转,地址栏地址不会发生改变。 测试如下: 首先编写三个html界面:分别是登录界面:login.html;登录成功界面:success.html;登录失败界面:fail.html. 之后,处理登录逻辑的servlet类如下: Java代码
运行后如果输入正确的用户名密码,则执行include方法,界面显示:include 包含。登录成功!并且地址栏地址未改变,若是输入错误登录名或者密码,界面显示:登录失败!并且地址栏地址改变。其中要注意的是sendRedirect方法中在要跳转的页面url前必须加上当前web程序路径名,这个路径通过request.getContextPath()可以得到。 如果吧其中include方法改为forward方法: Java代码 登录时输入正确信息,则跳转的页面地址不变,显示:登录成功!不包含url中的内容。 总结如下: redirect与include、forward的区别在于是不是同一个Request,redirect会有两次交互。 include与forward的区别在于输出的内容,include包含本身servlet与跳转页面内容的结果,而forward不包含本身servlet的内容。
管道与重定向
管道命令操作符是:”|”,它仅能处理经由前面一个指令传出的正确输出信息,也就是standard output 的信息,对于stdandard error 信息没有直接处理能力。然后,传递给下一个命令,作为标准的输入standard input. 先看下下面图: command1正确输出,作为command2的输入然后comand2的输出作为,comand3的输入,comand3输出就会直接显示在屏幕上面了。 通过管道之后:comand1,comand2的正确输出不显示在屏幕上面 注意: 1、管道命令只处理前一个命令正确输出,不处理错误输出 2、管道命令右边命令,必须能够接收标准输入流命令才行。 实例: [chengmo@centos5 shell]$ cat test.sh | grep -n 'echo' 5: echo "very good!"; 7: echo "good!"; 9: echo "pass!"; 11: echo "no pass!"; #读出test.sh文件内容,通过管道转发给grep 作为输入内容 [chengmo@centos5 shell]$ cat test.sh test1.sh | grep -n 'echo' cat: test1.sh: 没有那个文件或目录 5: echo "very good!"; 7: echo "good!"; 9: echo "pass!"; 11: echo "no pass!"; #cat test1.sh不存在,错误输出打印到屏幕,正确输出通过管道发送给grep [chengmo@centos5 shell]$ cat test.sh test1.sh 2>/dev/null | grep -n 'echo' 5: echo "very good!"; 7: echo "good!"; 9: echo "pass!"; 11: echo "no pass!"; #将test1.sh 没有找到错误输出重定向输出给/dev/null 文件,正确输出通过管道发送给grep [chengmo@centos5 shell]$ cat test.sh | ls catfile httprequest.txt secure test testfdread.sh testpipe.sh testsh.sh testwhile2.sh envcron.txt python sh testcase.sh testfor2.sh testselect.sh test.txt text.txt env.txt release sms testcronenv.sh testfor.sh test.sh testwhile1.sh #读取test.sh内容,通过管道发送给ls命令,由于ls 不支持标准输入,因此数据被丢弃 这里实例就是对上面2点注意的验证。作用接收标准输入的命令才可以用作管道右边。否则传递过程中数据会抛弃。常用来作为接收数据管道命令有:sed,awk,cut,head,top,less,more,wc,join,sort,split 等等,都是些文本处理命令。 管道命令与重定向区别 区别是: 1、左边的命令应该有标准输出| 右边的命令应该接受标准输入 左边的命令应该有标准输出> 右边只能是文件 左边的命令应该需要标准输入< 右边只能是文件
转发与重定向的区别
转发与重定向的区别 我们知道,请求转发和请求包含都是在一个请求内,涉及到多个Servlet 。既然转发和包含都在一个请求内,那么说明多个Servlet 共用同一个request 对象和response 对象。这个时候就存在request 域。 1. request 域 Servlet 的三大域对象:request ,session ,application 。其中request 域是三大域对象中范围最小的域对象,application 对象其实就是ServletContext 对象,在ServletContext 功能详解中我们对它的域功能做了详细的介绍;session 域会在后面学习。 request 域只会在请求转发和请求包含时存在。它的域范围就是整个请求链,如图1-1所示。例如:由AServlet 请求转发到BServlet ,这时在AServlet 中向request 域中存放数据,然后在BServlet 中从request 域中获取数据。如果BServlet 又转发给其他的Servlet ,那么在其他Servlet 中也可以从request 域中获取数据。转发过程中经过的这些Servlet 都在一个请求链中。 客户端AServlet BServlet CServlet 请求AServlet 转发转发 响应 请求链 图1-1 请求转发 2. request 域相关方法介绍 以后只要是域对象,那么它必然会有以下三个方法: ● void setAttribute(String name,Object value) 该方法是向域中保存域属性,例如:setAttribute(“username ”,”zhangsan ”),其中,username 是域属性的名称,zhangsan 是域属性的值。如果多次调用该方法,且属性名称相同,那么后保存的数据会覆盖先保存的数据。 ● Object getAttribute(String name) 该方法是根据属性名称从域中获取域属性的值,如果之前没有调用setAttribute()方法保存数据,那么调用getAttribute()方法返回值是null 。 ● void removeAttribute(String name) 该方法是从域中移出指定名称的域属性,如果该名字的域属性不存在,则该方法什么都不
JAVA试题_4
第8章Servlet技术 一、选择题: (1)下列关于Servlet的功能描述正确的是。 A)Servlet可以创建并返回一个包含基于客户请求性质的动态内容的完整的HTML页面B)Servlet可以创建可嵌入到现有HTML页面中的一部分HTML页面 C)Servlet可以与其它服务器资源(包括数据库和基于Java的应用程序)进行通信 D)Servlet可以用多个客户端处理连接,接收多个客户端的输入,并将结果广播到多个客户端上。 E)Servlet对特殊的处理采用MIME类型过滤数据,例如图像转换或者Word文档转换ABCDE (2)下列关于Servlet技术的特点说法正确的是。 A)可移植性好 B)功能强大 C)安全,简洁,和服务器紧密集成 D)高效耐用 E)Java语言能实现的功能,Servlet基本都能实现 ABDE (3)Servlet的生命周期包括下列哪几个阶段。 A)装载Servlet B)创建一个Servlet实例 C)调用init()方法 D)激活Service()方法,并传递请求和响应对象 E)调用destroy()方法来销毁Servlet BCDE (4)下列对HttpServlet类描述错误的是。 A)HttpServlet类是针对使用Http协议的Web服务器的Servlet类 B)HttpServlet类通过执行Servlet借口,能够提供Http协议的功能 C)HttpServlet的子类实现了doGet()方法去响应HTTP的Get请求 D)HttpServlet的子类实现了doPost()方法去响应HTTP的Post请求 E)HttpServlet类通过init()方法和destory()方法管理Servlet自身的资源 E (5)下列对于web.xml的配置说法错误的是。 A)在web.xml描述中,首先要声明Servlet B)在web.xml描述中,要指定这个Servlet的名字 C)在web.xml描述中,要指定这个Servlet的类 D)在web.xml描述中,要为Servlet做URI映射 E)在web.xml中不可同时指定多个Servlet E
servlet的两种重定向方法的区别及应用
servlet的两种重定向方法的区别及应用 一问题:在servlet/JSP编程学习中,发现有两种方法可以实现服务端输出重定向,一种是通过forward方法(例如JSP中的
Windows进程内标准输出重定向
Windows进程内标准输出重定向及其在程序调试上的应用 一、如何实现 打印调试信息的方法有很多,最常用的是使用标准输出设备(如printf、cout等),也可以用OutPutDebugString输出、用DebugView工具查看,还可以写入日志文件。如果程序运行需要记录日志(log),往往需要打开个文件,或许是写入系统事件、用系统的事件查看器查看。 应用程序打印调试信息、日志的方法往往是确定的,但如果是要编写一个模块或者说组件,那样的输出信息应该写入哪里呢?或者说程序本身对此也没有明确需求的话,那该怎么办呢? 可喜的是一个进程的标准输出是可以重定向的,所以我建议把调试信息直接打到标准输出上,这样代码中可以统一使用cout或者printf,然后根据需要将标准输出重定向。 Linux中重定向标准输出就容易了,因为有强大的dup2函数。而对于Windows的重定向,貌似往往是用于子进程的,在用CreateProcess创建子进程时设置子进程的标准输出句柄。而我们想要的是重定向自己这个进程的标准输出,那个用不上。我在MSDN中也没找到类似dup2的Win32 API函数,只有一个DuplicateHandle函数,这相当于linux中的dup,也用不上。 这里顺便提下,SetStdHandle是不能实现重定向的。这个函数的功能是将某句柄指向标准设备,并不能将标准设备句柄重定向到另外的句柄。 于是我就想到,Windows不是支持一部分POSIX标准的吗。于是我找到了一个CRT的函数,叫_dup2,看起来是不是特眼熟,对了,这就是Windows中dup2的兼容版本。 值得注意的是,_dup2以及与此相关的一系列CRT中的IO函数(如_read,_write)均以下划线开头,其余与linux大致相同,其参数中所谓的文件描述符与Win32中的句柄不一样,文件描述符实际上是句柄数组的索引,也就是说文件描述符不能与句柄混用。比如0,1,2分别是标准输入、标准输出、标准错误的文件描述符,但句柄值不是这样确定的。文件描述符不是Win32的概念,是POSIX中的概念。 _dup2用法与dup2大致相同,不多解释,不了解的可以查阅dup2相关资料。下面讲点应用。 二、如何应用于调试 写一个模块时,我们可以直接用cout/printf来作调试。但是如果这个模块用于图形界面或许是系统服务呢?这时标准输出看不到了,我们可以用OutPutDebugString函数和DebugView 这样的调试工具。这样就带来一种选择,而选择往往是增加软件复杂度的因素。所以我的想法是代码中只用cout/printf,如果需要将其重定向到调试工具中去。 如何实现呢,用匿名管道和线程。 用一个pipe,标准输出重定向到其write端,然后创建一个线程,线程要做的就是从pipe的
web技术应用基础应用 复习
填空题 . Java作为默认的脚本语言1.JSP把2.HTTP的中文含义是超文本传输协议,它 的作用是用于传输超文本标记语言编写的文件。 3.网站一般分为三层,分别是用户界面交互层,应用程序层,数据库层。 4.Servlet的生命周期可以分为4个阶段:载入,初始化,执行,删除(销毁。 5.在JSP文件中使用〈!————〉对HTML文本进行注释,使用〈%————%〉符号对JSP语句进行注释。 6.JSP页面在使用Jag标记来调用一个标签文件之前,必须使用Taglib指令标记引入该Web服务目录下的标记库。 7.在JSP中当执行了查询结果保存在Resultset对象中。 8.在JSP中,连接数据库的方式通常有两种:一种是通过JDBC驱动程序连接;另一种是通过JDBC-ODBC桥连接。 9.HTML是超文本标记语言,作用是WWW页面内容的格式进行说明。在HTML中加入CSS的方法主要有嵌入式样式表,内联式样式表,外联式样式表。 10.Request对象的作用是表示客户端对网页的请求,并使用HTTP协议处理客户端的请求,一个常用的方法是getParameter();其作用为设置作为响应生成内容的类型和字符编码。 11.Reponse对象的作用是处理jsp生成的响应发送给客户端: setContentType(),其作用为设置作为响应生成内部的类型和字符编码。 12.JSP中的五个常见内建对象是out: application: request:reponse:session 13.Servlet中的4个常用方法分别是init():doGet():doPost():destor() 14.在JSP页面中显示用户信息的两种方法是out.println()和〈%= %〉 15.Servlet中实现页面跳转的两种方法是response.sendRedirect()和request.getRequestDispatcher().forward() 16.JSP开发网站的两种模式分为Jsp+javabean和jsp+javabean+servlet 17.一个JSP页面可由5种元素组合而成,分别是普通的HTML.标记,JSP标记,JAVA程序片,JAVA表达式和变量和方法的声明。 application,request,sussion. 和page,request分别scope,个4有JavaBean18. 19.内置对象session的setAttribute()方法可将数据存入session, getAttribute()方法可从session中将数据取出。 20.MVC将应用程序分为3个核心模块,分别是模型,视图和控制器。 21.异常的处理,可在该方法的代码段中包含3类代码:try.catch和finally 22.Servlet的生命周期由三个方法控制,这三个方法分别为:init();service();和destroy(). 23.使用Statement对象的executeQuery()方法执行查询语句,使用executeUpdate()方法执行更新语句,使用execute()方法执行动态的未知操作。 24.JSP中使用reponse的sendRedirect()方法实现页面的跳转。 25.JSP的英文全称是Java Servet Page. 26.将JSP与JavaBean配合使用是通过JSP中的三个动作指令实现 的:jsp:useBean: jsp:getProperty:jsp:setProperty.
太原理工大学_WEB系统与技术试卷
. ;. A. HttpServletRequest、getSession B. HttpServletResponse、newSession C. HtttpSession、newInstance D. HttpSession、getSession 7、给定一个Servlet 的doGet方法中的代码片段,如下: request.setAttribute(“name”,”zhang”); response.sendRedirect(“http://localhost:8080/servlet/MyServlt”); 那么在Servlet 中可以使用()方法把属性name的值取出来。 A. String str=request.getAttribute(“name”); B. String str=(String)request.getAttribute(“name”); C. Object str=request.getAttribute(“name”); D. 无法取出来 8、下边哪个不是JSP的内置对象?() A. session B. request C. cookie D. out 9、关于get和post两种请求,下列说法正确的是?() A. Form表单默认请求是get请求。 B. get请求处理的数据量大小不受到限制。 C. post请求地址栏里是能看到数据的,所以传送用户信息尽量避免使用。 D. post请求可以由doGet方法处理。 10、下面哪一个是正确使用JavaBean的方式?() A.
转发和重定向
1.格式 这是一个链接 这是一个段落
换行
在网页中加一条横线 :这是定义了一个???.css格式文件 =============================================== 1、转发和重定向的区别: 1)地址: 转发的地址必须是同一个应用内部的各个组建。 重定向的地址没有限制。 2)能否共享request 转发可以 重定向不行 3)浏览器地址栏的地址是否变化 转发不变 重定向不会 4)事件是否处理完毕 转发是一件事未做完。 重定向是一件事已经做完。 2、状态管理: 2)怎样进行状态管理: 第一种方式:在客户端管理用户的状态 (cookie) 第二种方式:在服务器端管理用户的状态 (session) 3)cookie: a,什么是cookie? 浏览器在访问服务器时,服务器将一些数据以set—cookie消息头的形式发送给浏览器,浏览器会将这些数据(内存或者硬盘)保存起来,当浏览器再次访问服务器时,会将保存的数据会以cookie的消息头的形式发送给浏览器。通过这种方式可以管理用户的状态。 b,怎样去创建cookie? Cookie cookie=new Cookie(String name, String value);cookie中保存键值对 response.addCookie(cookie);服务器从cookie中读取数据 c,查询cookie //如果没有cookie,则返回null Cookie[] cookies=request.getCookies(); String name=cookie.getName();
Linux输入输出重定向的原理和实现
Linux I/O重定向的原理和实现 在Unix系统中,每个进程都有STDIN、STDOUT和STDERR这3种标准I/O,它们是程序最通用的输入输出方式。几乎所有语言都有相应的标准I/O函数,比如,C语言可以通过scanf从终端输入字符,通过printf向终端输出字符。熟悉Shell的朋友都知道,我们可以方便地对Shell命令进行I/O重定向,比如find -name "*.java" >testfile.txt 把当前目录下的Java文件列表重定向到testfile.txt。多数情况下,我们只需要了解I/O重定向的使用就够了,但是如果要编程实现类似Shell的I/O重定向以及管道功能,那么就需要清楚它的原理和实现。 下面本文就以Linux系统为具体例子,介绍I/O重定向的原理和实现(文中实验环境为Ubuntu 12.04,内核版本3.2.0-59)。 文件描述符表 理解I/O重定向的原理需要从Linux内核为进程所维护的关键数据结构入手。对Linux 进程来讲,每个打开的文件都是通过文件描述符(File Descriptor)来标识的,内核为每个进程维护了一个文件描述符表,这个表以FD为索引,再进一步指向文件的详细信息。在进程创建时,内核为进程默认创建了0、1、2三个特殊的FD,这就是STDIN、STDOUT和STDERR,如下图所示意: 所谓的I/O重定向也就是让已创建的FD指向其他文件。比如,下面是对STDOUT重定向到testfile.txt前后内核文件描述符表变化的示意图 重定向前:
重定向后: 在I/O重定向的过程中,不变的是FD 0/1/2代表STDIN/STDOUT/STDERR,变化的是文件描述符表中FD 0/1/2对应的具体文件,应用程序只关心前者。本质上这和接口的原理是相通的,通过一个间接层把功能的使用者和提供者解耦。 下面我们通过strace命令跟踪一下echo命令的系统调用: dagang@ubuntu12:~$ strace echo hello 2>&1 >/dev/null | grep write write(1, "hello\n", 6) = 6 我们可以看到write(1, "hello\n", 6) 这样一个系统调用,它的第一个参数1就是代表的STDOUT的FD,这说明对于echo程序,它只管(通过标准I/O函数从STDOUT)向FD 1写入,而不关心它们FD 1到底对应的是哪个文件。 Shell正是通过I/O重定向和管道这种特殊的文件把多个程序的STDIN和STDOUT串联在一起组成更复杂功能的,下面是Shell中通过管道的示意图: 下面我们用一个实际的例子来体验一下: dagang@ubuntu12:~$ sleep 30 | sleep 40 & [1] 5584 dagang@ubuntu12:~$ pgrep -l sleep 5583 sleep 5584 sleep dagang@ubuntu12:~$ ll /proc/5583/fd total 0 lrwx------ 1 dagang dagang 64 Feb 27 13:41 0 -> /dev/pts/3 l-wx------ 1 dagang dagang 64 Feb 27 13:41 1 -> pipe:[246469] lrwx------ 1 dagang dagang 64 Feb 27 13:41 2 -> /dev/pts/3 dagang@ubuntu12:~$ ll /proc/5584/fd
java Servlet请求转发和重定向
?请求转发 ?请求转发是指将请求再转发到另一资源(一般为JSP或Servlet)。此过程依然在同一个请求范围内,转发后浏览器地址栏内容不变 ?请求转发使用RequestDispatcher接口中的forward()方法来实现,该方法可以把请求转发到另外一个资源,并让该资源对浏览器的请求进行响应 RequestDispatcher rd = request.getRequestDispatcher(path); rd.forward(request,response); 或 request.getRequestDispatcher(path) .forward(request,response); ?重定向 ?重定向是指页面重新定位到某个新地址,之前的请求失效,进入一个新的请求,且跳转后浏览器地址栏内容将变为新的指定地址 ?重定向是通过HttpServletResponse对象的sendRedirect()来实现,该方法相当于浏览器重新发送一个请求 response.sendRedirect(path); ?请求转发和重定向区别如下: ?forward()只能将请求转发给同一个Web应用中的组件,而sendRedirect()方法不仅可以重定向到当前应用程序中的其他资源,还可以重定向到其他站点的资源。
?sendRedirect()方法重定向的访问过程结束后,浏览器地址栏中显示的URL会发生改变,由初始的URL地址变成重定向的目标URL;而调用forward()方法的请 求转发过程结束后,浏览器地址栏保持初始的URL地址不变。 ?forward()方法的调用者与被调用者之间共享相同的request对象和response对象;而sendRedirect()方法调用者和被调用者使用各自的request对象和response 对象,它们属于两个独立的请求和响应过程。 ?使用请求对象(request)存储数据(在servlet中存,在JSP中取)request. setAttribute(“score”,score); int score=(INTEGER)request. getAttribute(“score”); ?HttpServletRequest接口的方法: public void setAttribute(String name, Object obj) public Object getAttribute(String name) public Enumeration getAttributeNames() public void removeAttribute(String name) ?使用HttpSession对象存储数据 HttpSession session=request.getSession(); session. setAttribute(“score”,score); int score=(Integer) session. getAttribute(“score”); ?HttpSession接口的方法 public void setAttribute(String name, Object obj) public Object getAttribute(String name) public Enumeration getAttributeNames()
服务器重定向方法
以前也没怎么关注301重定向,第一因为没有网站要重定向,第二对于不带www的域名我都是用的转发到带www的域名。不过一场风波之后,很多服务商已经不提供转发服务了,虽说易名现在还可以享用到免费的转发服务,但是却不能不带www的转发到带www的同时进行MX记录解析,这对于需要MX解析的朋友也是一大烦恼。 而且有些域名在国外,转发更是用不了,也只能进行301永久重定向了,不然搜索引擎是把不带www 的站和带www的站分开对待的,只是我们习惯于用带www的域名罢了。 在网络上看了些教程,再根据自己的实践,也终于搞定了IIS服务器上的301永久重定向设置问题。实现方法如下: 1.新建一个站点,对应目录如E:\wwwroot\301web。该目录下只需要1个文件,即index.html或者加个404.htm。绑定要跳转的域名,如图: 2.在IIS中选中刚才我们建立的站点,右键,属性,主目录,选择重定向到,输入网址如: https://www.360docs.net/doc/a510511729.html,,同时注意选中下面的资源的永久重定向选项。如下图:
3.到此,我们已经完成了将https://www.360docs.net/doc/a510511729.html,这个域名301重定向到https://www.360docs.net/doc/a510511729.html,的工作。 注意问题: “上面输入准确的URL(X)”这个选项建议不要选。 不选的结果是: 当输入https://www.360docs.net/doc/a510511729.html,转到了https://www.360docs.net/doc/a510511729.html,, 当输入https://www.360docs.net/doc/a510511729.html,/sanwen/suibi/时,转到了https://www.360docs.net/doc/a510511729.html,/sanwen/suibi/。 选上的结果是: 当你输入https://www.360docs.net/doc/a510511729.html,或者https://www.360docs.net/doc/a510511729.html,/sanwen/suibi/都会转到https://www.360docs.net/doc/a510511729.html,。 好了,如果只是想把不带www的转到带www的或者其他没有用过的域名转到正在使用的域名,这样就可以了。但是如果你要的域名已经做过网站,想要把权重传递给新网站,可以参考下面这个方法: 第一步同上,主要是第二步,如图:
序列超速离心分离血浆脂蛋白
序列超速离心分离血浆脂蛋白 [目的与要求] 了解超速离心分离技术的原理,掌握制备性分离血浆脂蛋白的方法。 [原理] 基本原理见第六章6.1、6.2节。 本实验采用正常人抗凝血浆,以NaBr为密度介质,利用各脂蛋白颗粒密度不同,经过序列超速离心大量制备各血浆脂蛋白,经透析脱盐、PEG20000浓缩后保存备用。 [操作步骤] 1.血浆制备:取献血员全血400mL,EDTANa2抗凝,1000rpm离心15min,分离 血浆。根据血浆体积,加入0.015%的苯甲基氟磺酰(PMSF),防止脂蛋白变性。 2.CM和VLDL分离:血浆中加入适量的NaBr,调节密度至1.019g/ml,分置于离心管(38.5ml/管)中,加盖,用1.019g/ml密度液平衡,放入60Ti转头,在10℃下30,000rpm (100,000×g)离心20小时。CM和VLDL浮于离心管上层,用吸管小心吸取。 3.LDL分离:下层溶液中加入适量的NaBr,调节密度至1.060g/ml,分置于离心管中,加盖,用1.060g/ml密度液平衡,放入60Ti转头,在10℃下40,000rpm(170,000×g)离心24小时。LDL浮于离心管上层,用吸管小心吸取。 4.Lp(a)和HDL分离:下层溶液中加入适量的NaBr,调节密度至1.125g/ml,分 置于离心管中,加盖,用1.125g/ml密度液平衡,放入60Ti转头,在10℃下45,000rpm (225,000×g)离心24小时。Lp(a)、HDL和少量LDL浮于离心管上层,用吸管小心吸取。 5.HDL分离:下层溶液中加入适量的NaBr,调节密度至1.21g/ml,分置于离心管中,加盖,用1.21g/ml密度液平衡,放入60Ti转头,在10℃下50,000rpm(280,000×g)离心24小时。HDL浮于离心管上层,用吸管小心吸取。下层含有总量的50%的游离apoA-Ⅳ,可用于分离apoA-Ⅳ。 6.透析:已分离好的各部分脂蛋白含有大量的NaBr,需要透析脱盐。将各脂蛋白 溶液分别装入透析袋中,对抗0.01mol/L PBS(pH7.4)溶液透析过夜。 7.浓缩:将透析过夜的脂蛋白溶液连同透析袋一起放入盛有40%的PEG20000的 烧杯中,浓缩至适当体积。 [试剂] 1.NaBr 2.密度液:以NaBr与双蒸水配制,以比重计测定密度。配制成1)1.019g/ml; 2) 1.060g/ml;3)1.125g/ml;4)1.21g/ml 四种密度液。 3.苯甲基氟磺酰(PMSF) 4. 0.01mol/L PBS(pH7.4) 5. 40% PEG20000 [材料] 1.比重计: 1.000-1.100g/ml和1.100-1.200g/ml比重计 2.离心管:聚碳酸酯厚壁离心管,Beckman 3.角度转头: 60Ti Beckman 4.超速离心机:Beckman LM-80 5.平衡天平
重定向与转发的区别
重定向与转发的区别: 1.重定向访问服务器两次,转发只访问服务器一次。 2.重定向可以看见目标页面的URL,转发只能看见第一次访问的页面URL,以后的工作都是有服务器来做的。 3.重定向跳转后必须加上return,要不然页面虽然跳转了,但是还会执行跳转后面的语句,转发是执行了跳转页面,下面的代码就不会在执行了。 4.在request级别使用信息共享,使用重定向必然出错 5.还有一个大的区别就是,重定向可以访问自己web应用以外的资源 一、调用方式 我们知道,在servlet中调用转发、重定向的语句如下: request.getRequestDispatcher("new.jsp").forward(request, response);//转发到new.jsp response.sendRedirect("new.jsp");//重定向到new.jsp 在jsp页面中你也会看到通过下面的方式实现转发:
Linux重定向和管道
6.3 Linux重定向和管道 实验目的 通过重定向和管道操作: 1) 熟悉输入/输出(I/O) 重定向; 2) 把标准输出重定向创建一个文件; 3) 防止使用重定向的时候覆盖文件; 4) 把输出追加到一个现有的文件中; 5) 把一个命令的输出导入到另一个命令中。 实验内容与步骤 在本实验中将会用到下列命令: pwd:显示当前的工作路径。 cd:改变目录路径。 ls:显示指定目录的内容。 more:分页显示文件的内容。这是用于显示文本文件的首选方法。 head:截取显示文件的开头部分(默认为开头10行) 。 tail:截取显示文件的结尾部分(默认为最后10行) 。 cal:有关日历的命令。 set:当前shell下定义的一系列变量及其值。 echo:显示变量的值。 ps:显示当前进程的信息。 data:显示或设置系统日期和时间。 grep:查找文件中指定的关键字的行并输出。 步骤1:开机,登录进入GNOME。 在GNOME登录框中填写指导老师分配的用户名和口令并登录。 步骤2:访问命令行。 单击红帽子,在“GNOME帮助”菜单中单击“系统工具”-“终端”命令,打开终端窗口。 1. 使用重定向标准输出符号 步骤3:重定向标准输出,创建一个文件。 右尖括号或称大于符号(>) 把命令的输出发送到一个文件中:使用单个右尖括号,当指定文件名不存在的时候,将创建一个新文件;如果文件名存在,它将被覆盖。(注意:命令、重定向符号和文件名之间的空格是可选的) 。
重定向标准输出命令的格式是: command > file 1) 为核实当前所在目录位置,使用什么命令? ___pwd________________________________________________________ 如果当前位置不在主目录中,使用什么命令可以改变到主目录中? ___cd /__________________________________________________________ 2) 如果希望把文件和目录列表截获,存储为主目录中的一个文件,这样可以追踪主目录中有什么文件。使用什么命令,把长文件列表的输出重定向,创建一个叫做homedir.list的文件。 ____ls >homedir.list________________________________________________ 3) 新文件homedir.list被放在哪里? __根目录_________________________________________________________ 使用ls命令核实新文件存在。 4) 使用什么命令,以一次一屏的方式,来查看刚才创建的文件内容? __ls –l|more homedir.list____________________________________________ 5) 使用head命令截获homedir.list文件的前10行,通过重定向,创建一个叫做dhomedir.list-top-10的新文件。应该使用什么命令? ___head –10 homedir.list >dhomedir.list-tail-10_________________________ 使用more命令查看文件的内容。 6) 使用tail命令,截获homedir.list文件的最后10行,通过重定向,创建一个叫做dhomedir.list-top-10的新文件。使用什么命令? ___tail –10 homedir.list >dhomedir.list-top-10___________________________ 使用more命令查看文件的内容。 7) 截获cal -y命令的输出,把它存到名为calendar的文件中。查看文件的内容。截获了什么? ___cal –y>calendar |more calendar 截获了2008年12个月份的日历 8) 截获cal 2010命令的输出,把它存到名为calendar的文件中。查看文件的内容。其中有什么内容? _ cal -y 2010 > calendar |more calendar 2010年12月份的日历 日历有什么变化? ____不是2008年,变成2010年了_____________________________________ 步骤4:防止使用重定向的时候覆盖文件。 在bash shell中,一个叫做noclobber的选项可以用来设定防止在重定向的过程中覆盖文件。可以在命令行中使用$set -o noclobber命令来完成。o代表选项。 为了重新激活clobber特性,使用$set -o noclobber;撤消则用set +o noclobber。 如果你使用的是csh shell,为了激活/撤消C shell中的clobber特性,使用set noclobber和unset noclobber。 1) 输入命令,打开shell中的noclobber选项。输入什么命令? ___set –o noclobber__________________________________________ _____ 2) 输入命令ls -l > homedir.list,结果是什么? ___bash:homedir.list:cannot overwrite existing file.因为clobber选项防止了重定向过程覆盖文件___________________________________ _ _ 3) 输入命令ls -l > homedir.list2,结果是什么?