密码遗传

8.2染色体遗传学说
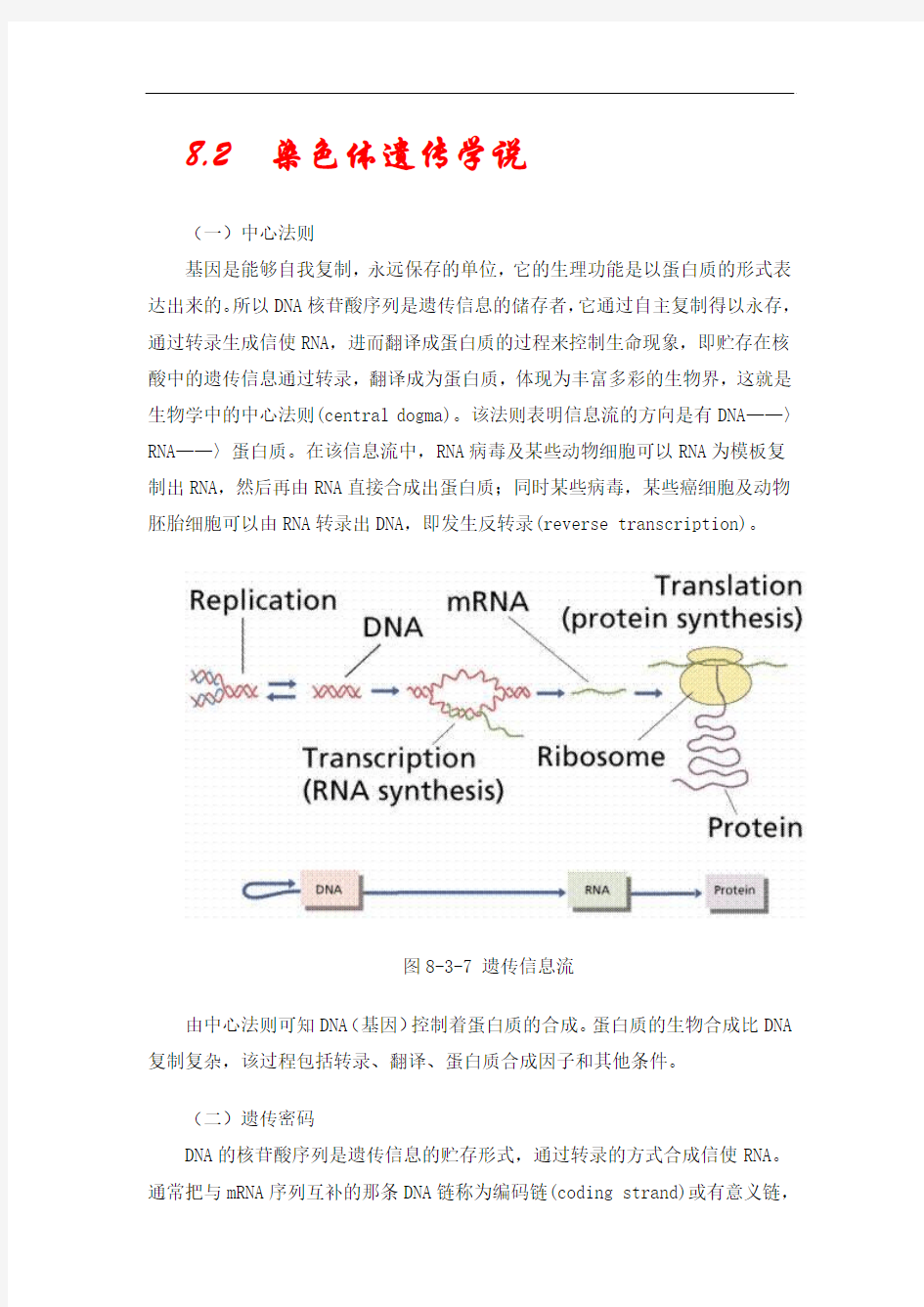
(一)中心法则
基因是能够自我复制,永远保存的单位,它的生理功能是以蛋白质的形式表达出来的。所以DNA核苷酸序列是遗传信息的储存者,它通过自主复制得以永存,通过转录生成信使RNA,进而翻译成蛋白质的过程来控制生命现象,即贮存在核酸中的遗传信息通过转录,翻译成为蛋白质,体现为丰富多彩的生物界,这就是生物学中的中心法则(central dogma)。该法则表明信息流的方向是有DNA——〉RNA——〉蛋白质。在该信息流中,RNA病毒及某些动物细胞可以RNA为模板复制出RNA,然后再由RNA直接合成出蛋白质;同时某些病毒,某些癌细胞及动物胚胎细胞可以由RNA转录出DNA,即发生反转录(reverse transcription)。
图8-3-7 遗传信息流
由中心法则可知DNA(基因)控制着蛋白质的合成。蛋白质的生物合成比DNA 复制复杂,该过程包括转录、翻译、蛋白质合成因子和其他条件。
(二)遗传密码
DNA的核苷酸序列是遗传信息的贮存形式,通过转录的方式合成信使RNA。通常把与mRNA序列互补的那条DNA链称为编码链(coding strand)或有意义链,
另一条不被转录只能通过碱基互补合成新的DNA,称为反义链(anticoding strand)或无意义链。只有mRNA携带的遗传信息才被用于指导蛋白质的生物合成,即决定蛋白质中氨基酸排列顺序。故一般用U、C、A、G四种核苷酸不用T、C、A、G的组合来表示遗传信息。
由上述可知DNA的编码链核苷酸序列决定mRNA中的核苷酸序列,rnRNA的核苷酸序列又决定着蛋白质中的氨基酸序列。实验证明mRNA上每3个核苷酸翻译成蛋白质链上的一个氨基酸,把这3个核苷酸称作遗传密码,也叫三联体密码。
1.遗传密码的提出
1954年物理学家George Gamow研究组成蛋白质的20种氨基酸核rnRNA4个核苷酸之间的关系,即四种不同的核苷酸如何为20种氨基酸编码?如果3种核苷酸为一个氨基酸编码,可组合为:64种氨基酸,满足20种氨基酸的编码还有剩余,于是就把3个核苷酸组合在一起的方式称为三联体密码。
2.遗传密码的破译
遗传密码的破译就是确定每种氨基酸的具体密码。详见通用遗传密码及相应的氨基酸表格。
图8-3-8 遗传密码表
3.遗传密码的性质
(1)密码的简并性:64种密码决定20种氨基酸,必然同一个氨基酸有多个密码。把由一种以上密码编码同一种氨基酸的现象称为简并性(degeneracy),对应于同一氨基酸的密码称为同义密码(synonymous codon)。
(2)密码的普遍性与特殊性:遗传密码不论在体外还是在体内,对绝大多数病毒、原核生物、真菌、植物和动物都是适用的。科学家在比较了大量的核酸和蛋白质序列后发现,密码具有普遍性。据现有生物资料,只有极个别的例外。在蛋白质生物合成过程中,tRNA的反密码子在核糖体蛋白体内是通过碱基的反向(互补)配对的rnRNA的密码相互作用。1966年Crick根据立体化学原理提出了摆动假说,解释了反密码中的某些稀有碱基成分的配对,以及许多氨基酸有2个以上密码问题。据摆动学说,在密码与反密码配对中,前两对碱基严格遵守碱基配对原则,第三对碱基有一定的自由度,可以“摆动”,因而使某些tRNA可以识别1个以上的密码,究竟能识别多少个密码是由反密码的第一个碱基的性质决定的。第一位碱基为A或C者,只能识别1种密码;第一位碱基为G或U者可以识别两种密码;第一位碱基为 I 者可识别三种密码。对于某些个别密码,反密码的第一个碱基可识别4种密码,表明3对碱基中的第三位使无关紧要的,这就是所谓的“三中配二”原则。
(3)密码无逗号及不重叠性:密码与密码之间没有逗号,即密码与密码间没有任何不编码的核苷酸。翻译从起始密码开始然后按连续的码组沿rnRNA多核苷酸链由5’至3’方向进行,直到终止密码处,翻译自然停止。在多核苷酸链上任何两个相邻的密码不共用任何核苷酸。
(4)密码的使用规律:原核生物中大部分以AUG为起始密码,少数使用GUG,,真核生物全部使用AUG为起始密码,终止密码 UAA、UAG、UGA全部被使用,有时连续用两个终止密码,以保证肽链合成的终止。
转录起始转录过程转录终止
(三)mRNA的转录与加工
1、转录(transcription)
活细胞内蛋白质氨基酸排列顺序由DNA所带的遗传信息控制,DNA中遗传信息的表达必须经过中介产物,即转移到信使RNA上,这个过程叫转录。由mRNA 再将这些信息转移到蛋白质合成系统中,合成蛋白质的过程称为翻译(translation)。
图8-3-9 蛋白质合成过程
mRNA合成过程和DNA复制一样,需要多种酶催化,从DNA合成RNA的酶称RNA聚合酶(RNA polymerase)。真核细胞rnRNA转录需要RNA聚合酶 II 。DNA 双链分子转录成RNA的过程是全保留式的,即转录的结果产生一条单链RNA,DNA 仍保留原来的双链结构。转录的第一步是RNA聚合酶 II 和启动子(promotor)结合。启动子是DNA链上的一段特定的核苷酸序列,转录起点即位于其中。然而RNA聚合酶 II 本身不能和启动子结合,只有在另一种称为转录因子的蛋白质与启动子结合后,RNA聚合酶才能识别并结合到启动子上,使DNA分子的双链解开,转录就从此起点开始。解开的DNA双链中只有一条链可以充当转录模板的任务,RNA聚合酶 II 沿着这一条模板链由3’端向5’端移行,一方面使DNA链陆续解开,同时将和模板DNA上的核苷酸互补的核苷酸序列连接起来形成5'—〉3’
的RNA,RNA聚合酶只能在DNA的3'连接新的核苷酸,即mRNA分子按5'—〉3’方向延长,这就说明了为什么DNA两条链中只有一条可作为模板。当RNA聚和酶沿模板链移行到DNA上的终点序列后,RNA聚合酶即停止工作,新合成的RNA陆续脱离模板DNA游离于细胞核中。
图8-3-10 转录过程
2、加工
转录出来的RNA必须经过加工方能变为成熟的mRNA。mRNA的前体是分子较大的hnRNA(heterogeneous nuclear RNA,核内不均一RNA)。真核细胞中的hnRNA5’端要连上一个甲基化的鸟嘌呤,这就是mRNA的5’端帽子。
该帽子由下述功能:①使mRNA免遭核酸酶的破坏;②使mRNA能与核糖体小亚基结合并开始合成蛋白质;③ 被蛋白质合成的起始因子所识别,从而促进蛋白质合成。在mRNA3’端需要加上poly(A)序列的尾巴,其长度因mRNA种类不同而不同,一般为40~200个左右的碱基,有两个功能:①它是mRNA由细胞核进入细胞质所必需的;②提高mRNA在细胞质中的稳定性。HnRNA链上还含有不编码
氨基酸的内含子和编码氨基酸的外显子。mRNA戴上甲基鸟苷“帽子”,加上poly(A)“尾巴”,并且在切除内含子后把所有外显子连接起来才能成为成熟的mRNA。
蛋白质合成
(四)翻译
将mRNA的碱基顺序依次翻译成特定的肽链,这一过程即为翻译。
1.蛋白质合成起始物的形成和氨基酸活化。
mRNA从细胞核进入细胞质后,附在rRNA上并开始形成起始物。起始物包括核糖体的大小亚基,起始tRNA和几十个蛋白合成因子,在mRNA编码区5’端形成核糖体—mRNA—起始tRNA复合物。原核生物和真核生物的起始物略有不同。原核生物的起始tRNA是fMet—tRNA,(fMet, formy lmethionine,甲酰甲硫氨酸)真核生物的起始tRNA是Met—tRNA。原核生物种30S小亚基首先与mRNA模板相结合,再与fMet—tRNA相结合,最后与50S大亚基结合;在真核生物中,40S小亚基首先与Met—tRNA相结合,再与模板mRNA结合,最后与60S大亚基结合生成80S—mRNA—Met—tRNA起始复合物。起始物生成除需要GTP提供能量外,
还需要Mg2+、NH
4+及三个起始因子(IF
1
、IF
2
、IF
3
)在起始tRNA中,无论是fMet
还是Met(甲硫氨酸)均是第一个参与蛋白质合成的氨基酸,它们和所有参与蛋白质合成的氨基酸一样首先必须被活化,所以在起始复合物形成前氨基酸先需活化。氨基酸活化后才能形成AA—tRNA。
图8-3-11 氨基酸活化
在翻译过程中,是由氨酰—tRNA将氨基酸携带到核糖体。
2.肽链的起始
原核生物和真核生物肽链的起始及延伸基本相似。
图8-3-12 肽链合成过程
3.肽链的延伸和终止
30S起始复合物形成之后在形成70S复合物过程中第一个fMet—tRNA fMet,放在大亚基的P位点,70S复合物形成之后,第二个AA—tRNA在延伸因子EF—TU 及GTP的存在下,生成AA—tRNA、EF—TU—GTP复合物,结合到大亚基的A位点上。此时GTP被水解,EF—TU—GTP被释放,通过延伸因子EF—TS和GTP获得再生,形成EF—TU·GTP复合物。落在A位上的第二个氨基酸是通过核糖体沿mRNA5’—〉3’移动即阅读,读出第二个遗传密码,据该密码第二个氨基酸方可上到A位上,即A位上就被带有和该密码子互补的反密码子的tRNA所占据,该AA—tRNA以它的反密码子和mRNA的密码子以氢键连接起来,它所带的氨基酸就是即将生成肽链的第二个氨基酸。至于fMet—tRNA fMet为什么不能首先到第A位上,这是因为EF—TU只能和fMet—tRNA以外的其他AA—tRNA起反应,所以起
始tRNA不能落在A位上,这也是mRNA内部的AUG不会被起始tRNA读出,肽链中也不会出现甲酰甲硫氨酸的原因。
(1)肽链的生成和移位
经上述作用后在该核糖体—mRNA—AA—tRNA复合物中的AA—tRNA占据着A 位,fMet—tRNA fMet占据着P位。在肽转移酶的作用下,P位上的甲酰甲硫氨酸脱离tRNA fMet,而与A位上的tRNA所带的氨基酸的3’方向移动(阅读)一个密码的距离,结果P位上的tRNA fMet脱离P位,成为自由的tRNA,A位上的二肽转移到P位上,A位空出,A位面对mRNA的一个新密码子,于是带有与该密码子互补的反密码子的氨酰—tRNA进入A位。核糖体继续“阅读”,P位上的二肽脱离tRNA而连到A位的tRNA所带的氨基酸上,此时就有了三肽链,核糖体继续“阅读”下去,循环不止。
(2)肽链的终止
肽链延伸过程中,当终止密码子UUA、UAG或UGA出现在核糖体A位时,没有相应的AA—tRNA能与之结合,而释放因子能识别这些密码子并与之结合,激活肽基转移酶,水解P位上的多肽链与tRNA之间的链,新生的肽链和tRNA从核糖体上释放,完成多肽链的合成。
(五)蛋白质的加工
新生的多肽链大多数是没有功能的,必须加工修饰才能转变为有活性的蛋白质。首先要切除N端的fMet或Met,还要形成二硫链,进行磷酸化、糖基化等修饰并切除新生肽链非功能所需片段,然后经过剪接成为有功能的蛋白质,从细胞质中转运到需要该蛋白质的场所。
从DNA到蛋白质的过程叫基因表达(gene expression),对这个过程的调节即为基因表达调控(regulation of gene expression or gene control)。基因调控是现代分子生物学研究的中心课题之一。因为要了解动植物生长发育规律。形态结构特征及生物学功能,就必须搞清楚基因表达调控的时间和空间概念,掌握了基因调控机制,就等于掌握了一把揭示生物学奥秘的钥匙。基因表达调控主要表现在以下几个方面:① 转录水平上的调控;② mRNA加工、成熟水平上的调控;③ 翻译水平上的调控;
基因表达调控的指挥系统有很多种,不同生物使用不同的信号来指挥基因调控。原核生物和真核生物之间存在着相当大差异。原核生物中,营养状况、环境因素对基因表达起着十分重要的作用;而真核生物尤其是高等真核生物中,激素水平、发育阶段等是基因表达调控的主要手段,营养和环境因素的影响则为次要因素。
(一)原核生物的基因表达调控
原核生物的基因表达调控虽然比真核生物简单,然而也存在着复杂的调控系统,如在转录调控种就存在着许多问题:如何在复杂的基因组内确定正确的转录起始点?如何将DNA的核苷酸按着遗传密码的程序转录到新生的RNA链中?如何保证合成一条完整的RNA链?如何确定转录的终止?
上述问题决定于DNA的结构、RNA聚合酶的功能、蛋白因子及其他小分子配基的互相作用,在转录调控中,现已搞清楚了细菌的几个操纵子模型,现以乳糖操纵子和色氨酸操纵子为例予以说明。
乳糖操纵子模型
1.乳糖操纵子
法国巴斯德研究所著名的科学家Jacob和Monod在实验的基础上于1961年建立了乳糖操纵子学说,现在已成为原核生物基因调控的主要学说之一。
图8-3-13 乳糖操纵子
大肠杆菌乳糖操纵子包括4类基因:①结构基因,能通过转录、翻译使细胞产生一定的酶系统和结构蛋白,这是与生物性状的发育和表型直接相关的基因。乳糖操纵子包含3个结构基因:lacZ、lacY、lacA。LacZ合成β—半乳糖苷酶,lacY合成透过酶,lacA合成乙酰基转移酶。②操纵基因O,控制结构基因的转录速度,位于结构基因的附近,本身不能转录成mRNA。③启动基因P,位于操纵基因的附近,它的作用是发出信号,mRNA合成开始,该基因也不能转录成mRNA。
④调节基因i:可调节操纵基因的活动,调节基因能转录出mRNA,并合成一种蛋白,称阻遏蛋白。操纵基因、启动基因和结构基因共同组成一个单位——操纵子(operon)。
调节乳糖催化酶产生的操纵子就称为乳糖操纵子。其调控机制简述如下:抑制作用:调节基因转录出mRNA,合成阻遏蛋白,因缺少乳糖,阻遏蛋白因其构象能够识别操纵基因并结合到操纵基因上,因此RNA聚合酶就不能与启动基因结合,结构基因也被抑制,结果结构基因不能转录出mRNA,不能翻译酶蛋白。
诱导作用:乳糖的存在情况下,乳糖代谢产生别乳糖(alloLactose),别乳糖能和调节基因产生的阻遏蛋白结合,使阻遏蛋白改变构象,不能在和操纵基因结合,失去阻遏作用,结果RNA聚合酶便与启动基因结合,并使结构基因活化,转录出mRNA,翻译出酶蛋白。
负反馈:细胞质中有了β—半乳糖苷酶后,便催化分解乳糖为半乳糖和葡萄糖。乳糖被分解后,又造成了阻遏蛋白与操纵基因结合,使结构基因关闭。
2.色氨酸操纵子
色氨酸操纵子负责调控色氨酸的生物合成,它的激活与否完全根据培养基中有无色氨酸而定。当培养基中有足够的色氨酸时,该操纵子自动关闭;缺乏色氨酸时,操纵子被打开。色氨酸在这里不是起诱导作用而是阻遏,因而被称作辅阻遏分子,意指能帮助阻遏蛋白发生作用。色氨酸操纵子恰和乳糖操纵子相反。
图8-3-14 色氨酸操纵子
(二)真核生物基因表达调控
真核生物基因表达调控与原核生物有很大的差异。原核生物同一群体的每个细胞都和外界环境直接接触,它们主要通过转录调控,以开启或关闭某些基因的表达来适应环境条件(主要是营养水平的变化),故环境因子往往是调控的诱导物。而大多数真核生物,基因表达调控最明显的特征时能在特定时间和特定的细胞中激活特定的基因,从而实现“预定”的,有序的,不可逆的分化和发育过程,并使生物的组织和器官在一定的环境条件范围内保持正常的生理功能。真核生物基因表达调控据其性质可分为两大类:第一类是瞬时调控或叫可逆调控,相当于原核生物对环境条件变化所做出的反应。瞬时调控包括某种代谢底物浓度或激素水平升降时及细胞周期在不同阶段中酶活性和浓度调节。第二类是发育调节或称不可逆调控,这是真核生物基因表达调控的精髓,因为它决定了真核生物细胞分化,生长,和发育的全过程。据基因调控在同一时间中发生的先后次序,又可将其分为转录水平调控,转录后的水平调控,翻译水平调控及蛋白质加工水平的调控,研究基因调控应回答下面三个主要问题:①什么是诱发基因转录的信号?②基因调控主要是在那个环节(模板DNA转录,mRNA的成熟或蛋白质合成)实现的?③不同水平基因调控的分子机制是什么?
回答上述这三个问题是相当困难的,这是因为真核细胞基因组DNA含量比原核细胞多,而且在染色体上除DNA外还含有蛋白质,RNA等,在真核细胞中,转录和翻译两个过程分别是在两个彼此分开的区域:细胞核和细胞质中进行。一条成熟的mRNA链只能翻译出一条多肽链;真核细胞DNA与组蛋白及大量非组蛋白相结合,只有小部分DNA是裸露的;而且高等真核细胞内DNA中很大部分是不转录的;真核生物能够有序的根据生长发育阶段的需要进行DNA片段重排,并能根据需要增加细胞内某些基因的拷贝数等。尽管难度很大,科学家们还是建立起多个调控模型。
1.转录水平的调控
Britten和Davidson于1969年提出的真核生物单拷贝基因转录调控的模型——Britten—Davidson模型。该模型认为在整合基因的5’端连接着一段具有高度专一性的DNA序列,称之为传感基因。在传感基因上有该基因编码的传感蛋白。外来信号分子和传感蛋白结合相互作用形成复合物。该复合物作用于和它相邻的综合基因组,亦称受体基因,而转录产生mRNA,后者翻译成激活蛋白。这些激活蛋白能识别位于结构基因(SG)前面的受体序列并作用于受体序列,从而使结构基因转录翻译。
图8-3-18 Britten—Davidson模型
若许多结构基因的临近位置上同时具有相同的受体基因,那么这些基因就会受某种激活因子的控制而表达,这些基因即属于一个组(set),如果有几个不同的受体基因与一个结构基因相邻接,他们能被不同的因子所激活,那么该结构基因就会在不同的情况下表达,若一个传感基因可以控制几个整合基因,那么一种信号分子即可通过一个相应的传感基因激活几组的基因。故可把一个传感基因所控制的全部基因归属为一套。如果一种整合基因重复出现在不同的套中,那么同一组基因也可以属于不同套。虽然目前验证该模型的正确性困难很多,但真核生物基因组中等重复DNA序列和单拷贝DNA序列的排布形式,说明该模型有其合理型。
2.染色质结构对转录调控的影响
真核细胞中染色质分为两部分,一部分为固缩状态,如间期细胞着丝粒区、端粒、次溢痕,染色体臂的某些节段部分的重复序列和巴氏小体均不能表达,通常把该部分称为异染色质。与异染色质相反的是活化的常染色质。真核基因的活跃转录是在常染色质进行的。转录发生之前,常染色质往往在特定区域被解旋或松弛,形成自由DNA,这种变化可能包括核小体结构的消除或改变,DNA本身局部结构的变化,如双螺旋的局部去超螺旋或松弛、DNA从右旋变为左旋,这些变化可导致结构基因暴露,RNA聚合酶能够发生作用,促进了这些转录因子与启动区DNA的结合,导致基因转录,实验证明,这些活跃的DNA首先释放出两种非组蛋白,(这两种非组蛋白与染色质结合较松弛),非组蛋白是造成活跃表达基因对核算酶高度敏感的因素之一。
目前更多的科学家已经认识到,转录水平调控是大多数功能蛋白编码基因表达调控的主要步骤。关于这一调控机制,现有两种假说。一种假说认为,真核基因与原核基因相同,均拥有直接作用在RNA聚合酶上或聚合酶竞争DNA结合区的转录因子,第二种假说认为,转录调控是通过各种转录因子及反式作用蛋白对特定DNA位点的结合与脱离引起染色质构象的变化来实现的。真核生物DNA严密的染色质结构及其在核小体上的超螺旋结构,决定了真核基因表达与DNA高级结构
变化之间的必然联系。DNA链的松弛和解旋是真核基因起始MRNA合成的先决条件。
3.转录后水平的调控
真核生物基因转录在细胞核内进行,而翻译则在细胞质中进行。在转录过程中真核基因有插入序列,结构基因被分割成不同的片段,因此转录后的基因调控是真核生物基因表达调控的一个重要方面,首要的是RNA的加工、成熟。各种基因转录产物RNA,无论rRNA、tRNA还是mRNA,必须经过转录后的加工才能成为有活性的分子。
4.翻译水平上的调控
蛋白质合成翻译阶段的基因调控有三个方面:① 蛋白质合成起始速率的调控;② MRNA的识别;③ 激素等外界因素的影响。蛋白质合成起始反应中要涉及到核糖体、mRNA蛋白质合成起始因子可溶性蛋白及tRNA,这些结构和谐统一才能完成蛋白质的生物合成。mRNA则起着重要的调控功能。
真核生物mRNA的“扫描模式”与蛋白质合成的起始。真核生物蛋白合成起始时,40S核糖体亚基及有关合成起始因子首先与mRNA模板近5’端处结合,然后向3’方向移行,发现AUG起始密码时,与60S亚基形成80S起始复合物,即真核生物蛋白质合成的“扫描模式”。
mRNA5’末端的帽子与蛋白质合成的关系。真核生物5’末端可以有3种不同帽子:0型、I 型和 II 型。不同生物的mRAN可有不同的帽子,其差异在于帽子的碱基甲基化程度不同。帽子的结构与mRNA的蛋白质合成速率之间关系密切:① 帽子结构是mRNA前体在细胞核内的稳定因素,也是mRNA在细胞质内的稳定因素,没有帽子的转录产物会很快被核酸酶降解;② 帽子可以促进蛋白质生物合成过程中起始复合物的形成,因此提高了翻译强度;③ 没有甲基化(m7G)的帽子(如GPPPN-)以及用化学或酶学方法脱去帽子的mRNA,其翻译活性明显下降。
mRNA的先导序列可能是翻译起始调控中的识别机制。可溶性蛋白因子的修饰对翻译也起着重要的调控作用。
(一)基因重组的类型
基因重组是指一个基因的DNA序列是由两个或两个以上的亲本DNA组合起来的。基因重组是遗传的基本现象,病毒、原核生物和真核生物都存在基因重组现象。减数分裂或体细胞有丝分裂均有可能发生基因重组。基因重组的特点是双DNA链间进行物质交换。真核生物,重组发生在减数分裂期同源染色体的非姊妹染色单体间,细菌可发生在转化或转导过程中,通常称这类重组为同源重组(homologous recombination),即只要两条DNA序列相同或接近,重组可在此序列的任何一点发生。然而在原核生物中,有时基因重组依赖于小范围的同源序列的联会,重组只限于该小范围内,只涉及特定位点的同源区,把这类重组称作位点专一性重组(site-specific recombination),此外还有一种重组方式,完全不依赖于序列间的同源性,使一段DNA序列插入另一段中,在形成重组分子时依赖于DNA复制完成重组,称此类重组为异常重组(illegitimate recombination),也称复制性重组(replicative recombination)。
(二)转座子(transposon, Tn)
1950年麦克林托克(McClintock)在对玉米籽粒颜色遗传进行观察时,认为存在着一种转座因子(transposable elements)控制着籽粒的颜色,这些因子可以在染色体上移动,它控制着某些基因表达。20世纪70年代夏皮罗(Shapiro)用E. coli乳糖操纵子突变株进行杂交分析后,才确认转座子的存在。现在把存在于染色体DNA上可以自主复制和位移的基本单位称为转座子。转座子不同于质粒等一些可移动的因子,当质粒或某些病毒遗传物质成为宿主染色体一部分后,它们是随着染色体复制的,是被动的,转座子不但可以在一条染色体上移动,而且可以从一条染色体跳到另一条染色体上,从一个质粒跳到另一个质粒或染色体上,甚至可以从一个细胞跑到另一个细胞。转座子在移位过程中,导致DNA链的断裂/重接,或是某些基因启动/关闭。这样就会引起:a.插入突变;b.产生新的基因;c.染色体畸变;d.生物进化,遗传效应。转座子普遍存在于原核细胞和真核细胞中,与同源染色体重组相比,细胞中转座子作用的频率却要低得多,不过它在构建突变体方面有重要意义。
1.原核细胞转座子
其原型是E.coli的IS(insertion sequence, 插入序列),一个细菌细胞常带少于10个IS序列。IS两端存在着反向重复序列IR(inverted repeat),IR 长短不一。IS本身没有任何表型效应,只携带和它转座作用有关的基因,称转座酶基因。
2. 真核细胞转座子
真核细胞中转座子以玉米和果蝇研究最多。玉米中至少有4种影响突变和基因重组的转座子;果蝇中有多个在基因组内随机分布而能重复移动的转座子。而在其他高等生物基因组中都存在与玉米或果蝇转座子相似的序列。真和细胞基因组流动性可能比原核细胞更大。
遗传物质本身发生了质的变化,导致生物性状改变,成为突变(mutation)。广义上讲的突变可分为染色体畸变(chromosomal aberration,包括染色体数目或结构改变)和基因(DNA和RNA)的改变,一般称为点突变(point mutation),狭义的突变单指基因突变。
一、染色体的畸变:指染色体数目或结构改变。
(一)染色体的数量畸变
绝大多数真核生物的体细胞内含有2套染色体组,成为二倍体(2n)。
1、非整数畸变:体细胞染色体数目的变异是因配子中个别染色体的增减为基础的变异。主要类型有:
(1)单体性(monosomy):(2n-1), 某同源染色体少一条,绝大多数生物单体型畸变不能成活。人类特纳氏综合症(Turn's syndrome)缺少一个X。
(2)缺体性(nullisomy):(2n-2),缺失一对染色体,这类畸变的生物不能存活,但癌细胞可能存活。
(3)三体性(trisomy):(2n+1),某同源染色体多一条成为三条染色体的现象。Down综合症(21三体)、Edward三体综合症(18三体)和Patau氏综合症(13三体)。
(4)多体性(polysomy):(2n+x),某同源染色体的数目在三条以上的现象。
2、整数倍畸变
体细胞含2n以上整套染色体组的细胞为多倍体(ploidy chromosome),包括3n、4n。多见于植物中,如无籽西瓜(3n),普通小麦为6n。
(二)染色体结构畸变
1、缺失(dificiency): 染色体少了某一片段,通常是致死的,例如猫叫综合症。
2、重复(duplication):染色体上多出了一段,例如猫眼综合症
3、倒位(inversion):染色体内部结构的顺序发生了颠倒,有臂间倒位和臂内倒位两种类型。
4、易位(translocation):染色体断裂,断裂片断接到了非同源染色体上的现象。如慢性粒细胞白血病,是由于22号染色体中的一条染色体长臂断裂,断裂片段易到第9号染色体中的一条长臂上。
二、基因突变
一个基因内部结构发生细微改变,而且这种变化可以遗传下去,成为基因突变(gene mutation)。基因突变是染色体上一个座位内的遗传物质的变化,故又称点突变(point mutation)。基因突变的发生和DNA复制、DNA损伤修复、癌变、衰老等有关,基因突变是生物进化的重要因素之一;基因突变为遗传学研究提供突变型,为育种提供素材。
1、基因突变的特性:(1)随机性;(2)突变的多方向性和复等位基因;(3)稀有性;(4)可逆性
2、基因突变的类型:
(1)碱基置换突变:一对碱基的改变而造成的突变,嘌呤替代嘌呤(A与G 之间的相互替代)、嘧啶替代嘧啶(C与T之间的替代)称为转换(transition),嘌呤变嘧啶或嘧啶变嘌呤则称为颠换(transvertion)。
(2)移码突变
在DNA的碱基序列中一对或少数几对邻接的核苷酸的增加或减少,造成该位置后的一系列编码发生了变化,称为移码突变(frame shift mutation)。
①缺失(deletion):指DNA链上一个或一段核苷酸的消失。
②插入(insertion):指一个或一段核苷酸插入到DNA链中。在为蛋白质编码的序列中如缺失及插入的核苷酸数不是3的整倍数,则发生读框移动(reading frame shift),使其后所译读的氨基酸序列全部混乱,称为移码突变
(frame-shift mutaion)。
③倒位或转位(transposition):指DNA链重组使其中一段核苷酸链方向倒置、或从一处迁移到另一处。
④双链断裂:已如前述,对单倍体细胞一个双链断裂就是致死性事件。
3、突变或诱变对生物可能产生4种后果:①致死性;②丧失某些功能;
③改变基因型(genotype)而不改变表现型(phenotye);④发生了有利于物种生存的结果,使生物进化。
4、诱发基因突变的因素。常见的诱变剂有:①物理诱变,如X射线、紫外线、电离辐射等;②化学诱变,如苯、亚硝酸盐等烷化剂、硷基类似物、修饰剂;
③生物诱变,如病毒。
细胞内的DNA分子因物理、化学等多种因素的作用使碱基组成或排列发生变化,若这些变化都表现为基因突变,机体则难以生存。然而生物在长期进化过程
中,细胞或机体形成了多种DNA损伤的修复系统。DNA损伤修复(repair of DNA damage)是在细胞中多种酶的共同作用下,使DNA受到损伤的结构大部分得以恢复,降低了突变率,保持了DNA分子的相对稳定性。
(一)光复活
光复活(photo-reactivation)又称光修复(photo-repair)。在可见光照(波长310~440nm)照射下,光复活酶(photoreacting enzyme)发生作用。在暗处,光复合酶能识别出因紫外线照射而形成的酶和DNA复合物,但不能解开二聚体,由光提供能量,才使二聚体解开成为单体,然后酶从复合物中释放出来,完成修复过程。
这种修复方式虽然普遍,但主要是低等生物的DNA损伤修复的方式。
小结遗传密码性质及应用
小结遗传密码性质及应用 本文结合一些高考题或冲刺题,浅谈遗传密码子的有关性质,以便师生对遗传密码表引起足够重视以及对遗传密码子有关性质的应用。 1、审察人教版高中《生物》第二册表6-1的遗传密码,可以看出如下特点:(1)简并性:除色氨酸和甲硫氨酸只有1个密码子外,其它18种氨基酸均有1个以上的密码子,其中有2至4个密码子的氨基酸密码子分布在同一方框内,即第一和第二个碱基相同,只有第三个碱基不同;有6个密码子的氨基酸(如亮氨酸、丝氨酸)密码子分别在不同方框内,它们的第一或第一和第二碱基不同。密码子的简并性,特别是第三位的C和U或G和A的简并性常常等同,这说明为什么在不同生物的DNA中的AT/GC比率会有很大的变异,而其蛋白质的氨基酸相对比例却没有很大的变化。换句话说,只改变一个碱基(称为点突变),并不一定编码“错误”氨基酸。 (2)通用性:除某些线粒体、叶绿体和原生生物外(如Barrell等在1979年发现人的线粒体中,通用的密码子AUA却是编码甲硫氨酸,而不是异亮氨酸,UGA 不是作为终止密码子,而是编码色氨酸),所有生物的遗传密码都是相同的。这也是基因工程得以实现的重要理论基础之一。如1993年,中国农业科学院的科学家成功地将苏云金孢杆菌的抗虫基因转入棉植株,培育成了能产生毒蛋白来抵抗棉铃虫的转基因抗虫棉。 (3)起始密码子兼职性:64个密码子中,其中3个并不编码氨基酸的却起着终止肽链合成作用的密码子,称为无义密码子(又称终止密码子);另61个是编码各种氨基酸的密码子,称为有义密码子,在61个有义密码子中,编码氨基酸同时兼职于启动蛋白质形成的两个密码子(AUG和GUG),称为起始密码子。(4)非重叠性:在mRNA模板上的密码子是连续的,在前一个密码子与后一个密码子之间没有间隔,即没有一个间断的信号。因此,在进行翻译时,解读的框架决定于起始的碱基。如果核糖体在mRNA链上移动时,偶然跳越了1个核苷酸,便会生成“不完全”蛋白质,原因是mRNA上密码子中增加或减少一个碱基将引起后续密码子的改变。 (5)方向性:在mRNA模板上密码子读取顺序只能由起始密码子开始,按顺序顺延下去(即5′—3′方向),不能反读。 2、精选习题演练 (1)(2004年江西卷)自然界中,一种生物某一基因及其三种突变基因决定的蛋白质的部分氨基酸序列如下: 正常基因精氨酸苯丙氨酸亮氨酸苏氨酸脯氨酸 突变基因1 精氨酸苯丙氨酸亮氨酸苏氨酸脯氨酸 突变基因2 精氨酸亮氨酸亮氨酸苏氨酸脯氨酸 突变基因3 精氨酸亮氨酸苏氨酸酪氨酸丙氨酸 根据上述氨基酸序列确定这三种突变基因DNA分子的改变是() A、突变基因1和2为一个碱基的替换,突变基因3为一个碱基的增添
生命的密语——遗传密码子的破译 基因组学作业参考
?生命的密语? ——遗传密码子的破译 --------------------------------------------------------------------------------------------------- 姓名:学院:培养单位:学号: 姓名:学院:培养单位:学号: ----------------------------------------------------------------------------------------------------------------- 进入国科大已经一月有半,对于自己所在实验室的科研内容已经有了相对具体的了解,也适应了国科大相对紧张的课程进度。迎面而来的都是具体的专业知识和局限的研究内容,尽管我们都是抱着对生命科学的热情而来,还是在现实的科研环境中略感枯索。 为什么会这样呢?我觉得是由于对生命科学这个学科的了解太少。每个学科都有它自己的历史和文化,对于真正醉心科学魅力的人来说,这种文化渗透在他们的筋骨血脉之中,成为一个科研群体独有的性格传承,让科研人和科研事业两相吸引。就像爱因斯坦说过的,人知道的越多,越觉得自己的无知。从而对未知更渴望和敬畏。对于刚刚踏上科研道路的我们来说,正是“无所知”,造成了“无所求知”。 所以,这一次作业,给了我们一个机会,静下心来了解一段生命科学“咿咿学语”的岁月。我们如今已经熟稔于胸的遗传密码子,这门精密简练的语言,是如何普知于世的。 第一部分:前人栽树,后人乘凉——遗传密码子破译史 一、三联体密码子的提出及其性质——理论研究阶段(1953-1961): 事情要从沃森克里克这对分子生物学创始人开始讲起。 1953 年,克里克和沃森在《Nature》杂志上发表了文章《DNA 结构的遗传学意义》,引起了许多人DNA如何携带遗传信息的诸多猜想,这其中包括物理学家伽莫夫。 基于DNA双螺旋模型的基础,伽莫夫上提出一种设想,并于发表在1954年登上了《Nature》。他把双螺旋结构中由于氢键生成而形成的空穴用氨基酸填
遗传密码子终止密码
终止密码子 .蛋白质翻译过程中终止肽链合成地信使核糖核酸()地三联体碱基序列. 翻译过程中,起蛋白质合成终止信号作用地密码子.分子中终止蛋白质合成地密码子.是终止密码子 发现过程 年在研究色氨酸合成酶蛋白时推测无义密码子地存在.他地推测是从 两个不同地角度:一是为编码地还编码了,,和.即一个分子中可以作为不同多肽地模板,那么有可能在翻译时中途在某个位点(两个肽地连接处〕停止,然后再从下一个新地起点翻译,这样使各个肽可以分开,而不至于产生一条很长地肽链.这就意味着终止密码子地存在.另一个角度是他发现地突变株是不能合成完整地色氨酸合成酶蛋白,但继续对它进行诱变可以得到回复突变.回复突变中有两种,一种是个别发生了变化,而另一种是完全回复,没有任何氨基酸组成地变化,这表明,不可能是任何移码突变地结果,那么这类地突变很可能携带有阻止合成地无义密码子. 年和他地学生对Ⅱ突变地研究时发现野生型地Ⅱ这段有两个顺反子Ⅱ和Ⅱ,共同转录一个多顺反子,但翻译成两个分开地蛋白和.当发生缺失突变时,其中有一个突变型为,证明是缺失所造成,缺失地区域含Ⅱ基因右边地大部分,和Ⅱ左边地小部分.互补实验表明地产物是一条多肽,但无蛋白地活性,但有蛋白地活性.认为,这种缺失可能使失去了蛋白合成“终止”和“”蛋白合成“起始”地密码子,因此翻译时沿着一条阅读下去,产生了一条长地肽链. 年及其同事获得了噬菌体编码头部蛋白基因地琥珀突变(),并进行了精细作图,并分离研究了各种突变型地多肽.突变型地肽链比野生型地要短,因此可以推测琥珀突变可能产生终止密码子,使肽地合成在中途停止下来;由于突变位点越靠近基因地左端,所产生地肽链越短,越靠近右端越接近野生型,据此可以推测翻译地过程是从地’端向’阅读.肽链地合成是从端向端延伸. 由于头部蛋白%是由新合成地蛋白质组成.因此他们将各种突变型及 野生型噬菌体侵染后分钟,把14C标记地氨基酸加到培养基中,过一段时间,从感染地中抽提蛋白,头部蛋白可以通过14C标记来加以鉴别.RTCrp. 实验方法 他们地实验方法不是对各种突变型地产物测序,而是先将野生型地头部蛋白用胰蛋白酶和糜蛋白酶来处理,消化后所产生地极复杂地混合物中,通过电泳能分离、鉴定出个各有特征地头部蛋白蛋白片段,分别是, 7C(), (), (), 2a(), (), ()和()片段.然后再测出各头部蛋白突变型产物含有几个以上地肽段来排序.表示排序地结果和精细作图地序列相一致,不仅表明了基因和蛋白质地共线性关系,同时证明突变型头部蛋白基因内有无义突变地存在,其位置应在各种突变产物地末端. 关键破译 直到年.和由碱性磷酸酶基因中色氨酸位点地氨基酸地置换证明中无 义密码子地碱基组成揭示了琥珀和赭石()突变基因分别是终止密码子和.当时个密码中地个已破译,只留下了、和有待确定.等为了鉴定无义密码子采用了和相似地策略.他们从地碱性磷酸酯酶基因 ( )中地一个无义突变
遗传密码子终止密码
终止密码子 1.蛋白质翻译过程中终止肽链合成的信使核糖核酸(mRNA)的三联体碱基序列。 2.mRNA翻译过程中,起蛋白质合成终止信号作用的密码子。 3.mRNA分子中终止蛋白质合成的密码子。UAG,UAA,UGA是终止密码子 发现过程 1964年Yanofsky在研究E.coli色氨酸合成酶A蛋白时推测无义密码子的存在。他的推测/是从两个不同的角度:一是为trp A编码的mRNA还编码了trpB,trpC,trpD和trpE。即一个mRNA 分子中可以作为不同多肽的模板,那么有可能在翻译时中途在某个位点(两个肽的连接处〕停止,然后再从下一个新的起点翻译,这样使各个肽可以分开,而不至于产生一条很长的肽链。这就意味着终止密码子的存在。另一个角度是他发现E.coli Trp-的突变株是不能合成完整的色氨酸合成酶蛋白,但继续对它进行诱变可以得到回复突变。回复突变中有两种,一种是个别发生了变化,而另一种是完全回复,没有任何氨基酸组成的变化,这表明,E.coliTrp-不可能是任何移码突变的结果,那么这类的突变很可能携带有阻止合成的无义密码子。 1962年Benzer和他的学生S.Champe对T4 r Ⅱ突变的研究时发现野生型的T4rⅡ这段有两个顺反子rⅡA和rⅡB,共同转录一个多顺反子mRNA,但翻译成两个分开的蛋白A和B。当发生缺失突变时,其中有一个突变型为r l589,证明是缺失所造成,缺失的区域含rⅡA基因右边的大部分,和rⅡB 左边的小部分。互补实验表明rl589的产物是一条多肽,但无蛋白A的活性,但有B蛋白的活性。Benzer认为,这种缺失可能使mRNA失去了A蛋白合成“终止”和“B”蛋白合成“起始”的密码子,因此翻译时沿着一条mRNA阅读下去,产生了一条长的肽链。 1964年Brenner及其同事获得了T4噬菌体编码头部蛋白基因的琥珀突变(amber),并进行了精细作图,并分离研究了各种突变型的多肽。突变型的肽链比野生型的要短,因此可以推测琥珀突变可能产生终止密码子,使肽的合成在中途停止下来;由于突变位点越靠近基因的左端,所产生的肽链越短,越靠近右端越接近野生型,据此可以推测翻译的过程是从mRNA 的5’端向3’阅读。肽链的合成是从N端向C端延伸。 由于头部蛋白80%是由新合成的蛋白质组成。因此他们将各种突变型及野生型T4噬菌体侵染E.coli后10分钟,把14C标记的氨基酸加到培养基中,过一段时间,从感染的E.coli 中抽提蛋白,头部蛋白可以通过14C 标记来加以鉴别。 实验方法 他们的实验方法不是对各种突变型的产物测序,而是先将野生型的头部蛋白用胰蛋白酶和糜蛋白酶来处理,消化后所产生的极复杂的混合物中,通过电泳能分离、鉴定出8个各有特征的头部蛋白蛋白片段,分别是Cys, T7C(His), C12b(Tyr), T6(Trp), T2a(Pro), T2(Trp), C2(Tyr)和C5(His)片段。然后再测出各T4头部蛋白突变型产物含有几个以上的肽段来排序。表示排序的结果和精细作图的序列相一致,不仅表明了基因和蛋白质的共
第37章 遗传密码
37章遗传密码 一判断 1、若1个氨基酸有3个遗传密码,则这3个遗传密码的前两个核苷酸通常是相同的。 2、由于遗传密码的通用性,用原核生物表达真核生物基因不存在技术障碍。表达出的蛋白质通常都是有功能的。 3、tRNA 密码子以外的其他区域的碱基改变有可能会改变其氨基酸特性。 4、在一个基因内总是利用同样的密码子编码一个给定的氨基酸。 5、某真核生物的某基因含有4200bp,以此基因编码的肽链应具有1400bp个氨基酸残基。 6、遗传密码在各种生物和细胞器中都绝对通用。 7、摇摆碱基位于密码子的第三位和反密码子的第一位。 8、反密码子GAA只能辩认密码子UUC。 9、密码子和反密码子都是由A、G、C、U4种碱基构成. 10、在同一基因中,总是用同一个密码子编码一种氨基酸。 二单选 1、下列叙述不正确的是() A.共有20个不同的密码子代表遗传密码 B.色氨酸和甲硫氨酸都只有一个密码子 C.每个核苷酸三联体编码一个氨基酸 D.不同的密码子可能编码同一个氨基酸 E.密码子的第三位具有可变性 2、反密码子中哪个碱基对参与了密码子的简并性() A.第一个 B.第二个 C.第三个 D.第一个与第二个 E.第二个与第三个 3、密码子的简并性指的是() A.一些三联体密码可缺少一个嘌呤碱或嘧啶碱 B.各类生物使用同一套密码子 C.大多数氨基酸有一种以上的密码子 D.一些密码子适用于一种以上的氨基酸 E.以上都不是 4、一个mRNA的部分顺序和密码编号如下,用这一mRNA合成的肽链有多少个氨基酸残基……CAG CUC UAU CGG UAG AAU AGC …… A. 141个 B. 142个 C. 143个 D. 144个 E. 145个 5、一个N端为丙氨酸的20肽,其开放阅读框架至少应由多少个核苷酸残基组成 A. 60个 B.63个 C.66个 D.57个 E.69个 6、下列密码子中,终止密码子是() A、UUA B、UGA C、UGU D、UAU 7、下列密码子中,属于起始密码子的是() A、AUG B、AUU C、AUC D、GAG 8、下列有关密码子的叙述,错误的一项是() A、密码子阅读是有特定起始位点的 B、密码子阅读无间断性 C、密码子都具有简并性 D、密码子对生物界具有通用性 9、密码子变偶性叙述中,不恰当的一项是() A、密码子中的第三位碱基专一性较小,所以密码子的专一性完全由前两位决定 B、第三位碱基如果发生了突变如A G、C U,由于密码子的简并性与变 偶性特点,使之仍能翻译出正确的氨基酸来,从而使蛋白质的生物学功能不变
遗传学诞生到遗传密码破译这一时期里具有重大意义的遗传学研究成果及其特点与意义
论述遗传学诞生到遗传密码破译这一时期里具有重大意义的遗传学研 究成果及其特点与意义 1865年2月8日孟德尔根据他8年的植物杂交试验结果,在当地的科学协会上宣读了一篇题为《植物杂交实验》的论文。但这一伟大发现被埋没了35年后才受到人们重视。1900年遗传学诞生了。 遗传学是生物科学领域中发展最快的一门学科,几乎所有生物学科都与遗传学形成交叉学科,可见遗传学的重要性。要想了解遗传学,就得先了解它的历史。遗传学诞生到遗传密码破译这一时期有许多遗传学研究成果,它们对遗传学的发展有着重大的意义。根据研究的特点,现代遗传学的发展大致可分为三个时期。 一、细胞遗传学时期(约1910-1940) 1、确立了遗传的染色体学说 1910年摩尔根创立了连锁定律并证明了基因在染色体上以直线方式排列,并提出了遗传的染色体理论。这一成果还获得了1933年的诺贝尔奖。这是一个伟大的结论,它指出了遗传的染色体学说不再是空洞抽象的概念,为遗传基因找到了物质基础;同时,它指出了某一遗传基因是在某一染色体上,为人们探索生物遗传机理开拓出了一条新路。他阐述的基因的连锁和互换规律,解开了生物变异之迷,弥补了达尔文进化论的不足,为人们杂交育种指明了方向,为预防遗传性疾病提供了理论。 二、微生物遗传及生化遗传学时期(1941-1960) 1、一个基因一个酶假说的提出 G.W.Beadle和E.L.Tatum在1941年发表了链孢霉中生化反应遗传控制的研究;进而使应用各种生化突变型对基因作用的研究有了发展。Beadle在1945年总结了这些结果,提出了一个基因一个酶的假说,认为一个基因仅仅参与一个酶的生成,并决定该酶的特异性和影响表型。随着酶学、蛋白质化学的进展、遗传学方法的进步,进一步弄清楚了基因与酶的关系是建立在基因与多肽链严密对应的关系基础上的,表示这种对应关系的学说就是一个基因一条多肽链假说。这一假说获得了1958年的诺贝尔奖。这一假说为遗传物质的化学本质及基因的功能奠定了初步的理论基础。 2、遗传的物质基础是DNA的提出 1944年 Avery,Macleod 和 McCarty 等从肺炎双球菌的转化试验中发现,转化因子是DNA而不是蛋白质。他们首次提出遗传的物质基础是DNA。1952年 Hershey 和
遗传密码
遗传密码 遗传密码- 概述 遗传密码 遗传密码又称密码子、遗传密码子、三联体密码。指信使RNA(mRNA)分子上从5'端到3'端方向,由起始密码子AUG 开始,每三个核苷酸组成的三联体。它决定肽链上某一个氨基酸或蛋白质合成的起始、终止信号。 遗传密码决定蛋白质中氨基酸顺序的核苷酸顺序,由3个连续的核苷酸组成的密码子所构成。由于脱氧核糖核酸(DNA)双链中一般只有一条单链(称为有义链或编码链)被转录为信使核糖核酸(mRNA),而另一条单链(称为反义链)则不被转录,所以即使对于以双链DNA作为遗传物质的生物来讲,密码也用核糖核酸(RNA)中的核苷酸顺序而不用DNA中的脱氧核苷酸顺序表示。 遗传密码- 简介
人体遗传密码正在被逐步破译图册 在转移核糖核酸 (tRNA)分子中有一组与mRNA中的密码子配对的三联体,称为反密码子 。每种tRNA携带一种特定的氨基酸,在遗传密码的解读中起着关键性的作用。1961年英国分子生物学家F·H·C·克里克 等在大肠杆菌 噬菌体T4中用遗传学方法证明密码子由三个连续的核苷酸所组成。美国 生物化学家M·W·尼伦伯格 等从1961年开始用生物化学 方法进行解码研究。1964年尼伦伯格等人进行人工合成的三核苷酸和氨基酰-tRNA、核糖体三者的结合试验,证明三核苷酸已经具备信使的作用。通过种种实验,遗传密码已于1966年全部阐明。表中所列的64个密码子编码18种氨基酸和两种酰胺。至于胱氨酸、羟脯氨酸、羟赖氨酸等氨基酸则都是在肽链合成后再行加工而成的。64个密码子中还包括3个不编码任何氨基酸的终止密码子,它们是UAA、UAG、UGA。这种由3个连续的核苷酸组成的密码称为三联体密码。
遗传密码特点例析11.19
遗传密码特点例析 遗传密码又称密码子、三联体密码。是指信使RNA(mRNA)分子上从5'端到3'端方向,由起始密码子AUG开始,每三个核苷酸组成的三联体。它决定肽链上某一个氨基酸或蛋白质合成的起始、终止信号。1967年科学家破译了全部密码子并绘制了密码子表。下面结合实例对遗传密码子的特点进行解读,以便对遗传密码表的信息有较全面地把握。 1 三联体密码 例1.细胞内编码20种氨基酸的密码子总数为:() A.4 B.64 C.20 D.61 解析:蛋白质由20种基本氨基酸组成,而mRNA只含有4种核苷酸,由4种核苷酸构成的序列是如何决定多肽链中多至20种氨基酸的序列的呢?显然,在核苷酸和氨基酸之间不能采取简单的一对一的对应关系。2个核苷酸决定一个氨基酸也只能编码16种氨基酸,如果用3个核苷酸决定一个氨基酸,43=64,就足以编码20种氨基酸了,这说明可能需要3个或更多个核苷酸编码一个氨基酸。1961年Francis Crick及其同事的遗传实验进一步肯定3个碱基编码一个氨基酸,此三联体碱基即称为密码子。在64个密码子中,有3个密码子不编码任何氨基酸,从而成为肽链合成的终止信号,称为终止密码子或无义密码子,它们是UAA、UAG、UGA。其余的61个密码子均编码不同的氨基酸,其中AUG和GUG分别是甲硫氨酸和缬氨酸的密码子,同时二者又是肽链合成的起始信号,称为起始密码子。 答案:D 2 不间断性 例2.如果……CGUUUUCUUACGCCU……是某基因产生的 mRNA 中的一个片断 , 如果在序列中某一位置增添了一个碱基 , 则表达时可能发生 ( )。 ①肽链中的氨基酸序列全部改变②肽链提前中断③肽链延长④没有变化⑤不能表达出肽链 A.①②③④⑤ B.①②③④ C.①③⑤ D.②④⑤ 解析: mRNA的三联体密码是连续排列的,相邻密码之间无核苷酸间隔。翻译从起始码AUG开始,3个碱基代表1个氨基酸,从mRNA的5’→3’方向构成1个连续的阅读框,直至终止码。所以,若在某基因编码区的DNA序列或其mRNA中间插入或删除1~2个核苷酸,则其后的三联体组合方式都会改变,不能合成正常的蛋白质,这样的突变亦称移码突变,对微生物常有致死作用。 若增添一个碱基后,导致密码子编组改变,从添加一个碱基的那个密码子开始,一直到末尾都出现误读,相应的氨基酸序列也会从某个氨基酸开始发生全面的改变。这种情况就有可能发生①;若增添一个碱基后,使正常的密码子变成终止密码子,则肽链将提前中断。这
遗传密码的发现
遗传密码的发现——从DNA到蛋白质,冲破思想的牢笼 如果对于同一现象有两种不同的假说,我们应该采取比较简单的那一种。 ——奥卡姆剃刀理论1.沃森和克里克的诺贝尔颁奖典礼-不是DNA,而是RNA 《On the Genetic Code》 …… At the present time, therefore, the genetic code appears to have the following general properties: (1) Most if not all codons consist of three (adjacent) bases. (2) Adjacent codons do not overlap. (3) The message is read in the correct groups of three by starting at some fixed point. (4) The code sequence in the gene is co-linear with the amino acid sequence, the polypeptide chain being synthesized sequentially from the amino end. (5) In general more than one triplet codes each amino acid. (6) It is not certain that some triplets may not code more than one amino acid, i.e. they may be ambiguous. (7) Triplets which code for the same amino acid are probably rather similar. (8) It is not known whether there is any general rule which groups such codons together, or whether the grouping is mainly the result of historical accident. (9) The number of triplets which do not code an amino acid is probably small. (10) Certain codes proposed earlier, such as comma-less codes, two- or three-letter codes, the combination code, and various transposable codes are all unlikely to be correct. (11) The code in different organisms is probably similar. It may be the same in all organisms but this is not yet known. Finally one should add that in spite of the great complexity of protein synthesis and in spite of the considerable technical difficulties in synthesizing polynucleotides with defined sequences it is not unreasonable to hope that all these points will be clarified in the near future, and that the genetic code will be completely established on a sound experimental basis within a few years. ——Francis Crick在1962年诺贝尔生理与医学奖颁奖典礼上的致辞 沃森和克里克在五十年代发现DNA双螺旋结构普遍被认为是现代生物学的开端,可以说是20世纪最伟大的生命科学发现。然而此时,分子生物学只是刚刚起步,虽然关于遗传物质为何物的争论暂告一个段落,然而作为生物学重要大分子的蛋白质怎样合成,如果DNA 就是基因它是如何复制的,它与蛋白质合成有什么关系……种种问题,包围在传统的生物化学的酶学研究、名噪一时的噬菌体研究和大举进入的物理化学研究中的新兴分子生物学怎样既取长补短,又摒弃既有的陈旧的观念和无知的偏见,真正建立分子生物学的大厦、破解生命的密码还是一个令一大批科学家头疼而又迫切需要解决的问题。
遗传密码子教案
遗传密码子的破译教案 一、教学内容:遗传密码子的破译 二、教学目标: 1.知识与技能: 了解遗传密码子的定义,知道遗传密码子的破译过程。 掌握遗传密码子的内容,特性,特殊的密码子及其发现的意义。 2.过程与方法: 分析遗传密码子的发现过程及其特性,总结其规律。 3.情感、态度与价值观: 通过遗传密码子的破译的学习,培养学生的辩证思维能力和实验动手能力。 通过分析遗传密码子的破译意义,初步训练学生分析实际问题的能力。 三、学习者分析: 通过调查问卷的形式对学习者进行遗传密码子的破译的前概念的调查,通过分析调查结果发现大家对遗传密码子的认识很浅,只有1/2的学生知道遗传密码子的作用及其阅读方式,而只有1/5的知道起始密码子和终止密码子的个数和其是否编码氨基酸,基本上没人知道总共有多少个遗传密码子,因而在教学过程中应该注意在这些方面的教学。 四、教材分析: 遗传密码子是一节选学课,课程主要讲遗传密码子的探索发现过程,其探索过程主要通过实验的形式进行发现,对于没怎么进行实验的中学生来说有一定难度,前面课程已经学习了转录翻译过程,已经知道什么是密码子和密码子的作用,有一定的基础。 五、教学重难点: 1.教学重点:三个碱基决定一个氨基酸这一结论的探索过程。 2.教学难点:重叠阅读方式和非重叠阅读方式 六、教学用具与教学方法 1.教学准备:多媒体PPT 2.教学方法: 以讲授法为主,以讨论、探究、实验教学法为辅。 分组学习,问题讨论,激发思维,实施探究,分析归纳,总结梳理。 七、教学设计 教学安排:1课时 时间安排:用5-10分钟时间进行新课的导入,30-35分钟进行新课的展开,最后花5-10分钟进行课程总结。
遗传密码子起源
遗传密码的起源 遗传密码又称密码子、遗传密码子、三联体密码。指信使RNA(mRNA)分子上从5'端到3'端方向,由起始密码子AUG开始,每三个核苷酸组成的三联体。它决定肽链上某一个氨基酸或蛋白质合成的起始、终止信号。 遗传密码是一组规则,将DNA或RNA序列以三个核苷酸为一组的密码子转译为蛋白质的氨基酸序列,以用于蛋白质合成。几乎所有的生物都使用同样的遗传密码,称为标准遗传密码;即使是非细胞结构的病毒,它们也是使用标准遗传密码。但是也有少数生物使用一些稍微不同的遗传密码。 遗传密码的发现是20世纪50年代的一项奇妙想象和严密论证的伟大结晶。mRNA由四种含有不同碱基腺嘌呤[简称A]、尿嘧啶(简称U)、胞嘧啶(简称C)、鸟嘌呤(简称G)的核苷酸组成。最初科学家猜想,一个碱基决定一种氨基酸,那就只能决定四种氨基酸,显然不够决定生物体内的二十种氨基酸。那么二个碱基结合在一起,决定一个氨基酸,就可决定十六种氨基酸,显然还是不够。如果三个碱基组合在一起决定一个氨基酸,则有六十四种组合方式,看来三个碱基的三联体就可以满足二十种氨基酸的表示了,而且还有富余。猜想毕竟是猜想,还要严密论证才行。 自从发现了DNA的结构,科学家便开始致力研究有关制造蛋白质的秘密。伽莫夫指出需要以三个核酸一组才能为20个氨基酸编码。1961年,美国国家卫生院的Matthaei与马歇尔·沃伦·尼伦伯格在无细胞系统 (Cell-free system)环境下,把一条只由尿嘧啶(U)组成的RNA转释成一条只有苯丙氨酸(Phe)的多肽,由此破解了首个密码子(UUU -> Phe)。随后哈尔·葛宾·科拉纳破解了其它密码子,接着罗伯特·W·霍利发现了负责转录过程的tRNA。1968年,科拉纳、霍利和尼伦伯格分享了诺贝尔生理学或医学奖。 一、遗传密码起源的时间 M. Eigen通过rRNA序列比较的统计学评价得出遗传密码出现的时间在36亿年前 二、起源的地点应该与生物大分子起源地方一致 三、起源的学说 凝固事件学说 1968年,Crick在《the Origin of the Genetic Code》提出有一种观点:密码子与氨基酸的关系是在某一时期固定的,以后就不再改变。 理由:现在生物体中只要密码子有微小的改变,将会致死。 立体化学学说 1966年,韦斯(C. R. Woese)提出了立体化学理论,认为:遗传密码的起源和分配与RNA和氨基酸之间的直接化学作用密切相关,最终密码的立体化学本质扩展到氨基酸与相应的密码子之间物理和化学性质的互补性,。理由:。一些研究表明编码氨基酸的三联体密码或反密码子出乎意料地经常出现在对应的氨基酸在RNA上的结合位点 氨基酸与反密码子的直接作用以及疏水-亲水相互作用在遗传密码的起源中可能
遗传密码的破译过程
遗传密码的破译过程 G161001安夏 1953年,美国生物学家沃森(James Watson,1928-)和英国物理学家克里克(Francis Crick,1916-2004)推断出DNA的双螺旋结构之后,分子生物学蓬勃地发展起来。沃森和克里克在《DNA结构的遗传学意义》中提出:“碱基的排列顺序就是携带遗传信息的密码。”也就是说,碱基的中含有特定的遗传信息,这种遗传信息能被翻译成蛋白质上氨基酸特定的顺序。许多科学家的研究,使人们基本了解了遗传信息的流动方向:DNA→mRNA(信使RNA)→蛋白质。也就是说蛋白质由信使RNA指导合成,遗传密码存在于mRNA上。 从1953年提出遗传密码问题到1966年破译全部遗传密码,先后经历了五十年代的数学推理阶段和1961-1965年的实验研究阶段。 1954年,物理学家伽莫夫(George Gamov)根据在DNA中存在四种核苷酸,在蛋白质中存在二十种氨基酸的对应关系,做出如下数学推理:如果每一个核苷酸为一个氨基酸编码,只能决定四种氨基酸;如果每二个核苷酸为一个氨基酸编码,可决定16种氨基酸。上述二种情况编码的氨基酸数小于20种氨基酸,显然是不可能的。那么如果三个核苷酸为一个氨基酸编码的,可编64种氨基酸;若四个核苷酸编码一个氨基酸,可编码256种氨基酸,以此类推。伽莫夫认为只有三个核苷酸为一个氨基酸编码的关系是理想的,因为在有四种核苷酸条件下,64是能满足于20种氨基酸编码的最小数。而四个核苷酸为一个氨基酸编码的关系,虽能保证20种氨基酸编码,但不符合生物体在亿万年进化过程中形成的和遵循的经济原则,因此认为四个以上核苷酸决定一个氨基酸也是不可能的。 1961年,克里克等人在《自然》杂志上发表了一篇题为“蛋白质遗传密码的一般性质”的论文,提出遗传密码具有下列性质:(1)3个碱基编码一个氨基酸,称为“三联体”,又叫“密码子”;(2)遗传密码互不重叠;(3)碱基序列从固定起点开始读取;(4)有些氨基酸可能对应多个三联体。他们通过对基因的移码突变的分析,发现当构建三重突变体时,只有三次都是添加一个碱基的突变或三次都是减少一个碱基的突变,这个基因产物的功能就不会受到较大干扰,也就是说,添加或删除一个碱基分别对应在其氨基酸序列上添加或删除一个氨基酸,由此证明三个核苷酸组成一个密码子。 美国生化学家尼伦伯格(Nirenberg .M)和德国化学家马特伊(Matthaei .J)用仅含有单一碱基的多聚尿苷酸(Poly-U),做试管内合成蛋白质的研究。把多聚尿苷酸放入无细胞蛋白质合成系统,得到由单一一种氨基酸组成的蛋白质。这样合成的蛋白质中,只含有苯丙氨酸(Phe)。于是,人们了解了第一个蛋白质的密码:UUU对应苯丙氨酸。这个实验指出了完全阐明遗传密码的途径。 随后,又有人用U—G交错排列合成了半胱氨酸—缬氨酸—半胱氨酸的蛋白质,从而确定了UGU为半胱氨酸的密码,而GUG为缬氨酸的密码。这样,人们不仅证明了遗传密码是由3个碱基排列组成,而且不断地找出了其他氨基酸的编码。1966年破译全部64个密码子。进一步研究发现,不论生物简单到只一个细胞,还是复杂到与人一样高等,遗传密码是一样的。也就是说,生物共用一套遗传密码。 参考文献:论文《遗传密码是怎样破译的》作者:向义和 《陈阅增普通生物学》
遗传密码特点例析
遗传密码特点例析 吉林省梨树县第一高级中学姜万录 遗传密码又称密码子、三联体密码。是指信使RNA(mRNA)分子上从5'端到3'端方向,由起始密码子AUG开始,每三个核苷酸组成的三联体。它决定肽链上某一个氨基酸或蛋白质合成的起始、终止信号。1967年科学家破译了全部密码子并绘制了密码子表。下面结合实例对遗传密码子的特点进行解读,以便对遗传密码表的信息有较全面地把握。 1 三联体密码 例1.细胞内编码20种氨基酸的密码子总数为:() A.4 B.64 C.20 D.61 解析:蛋白质由20种基本氨基酸组成,而mRNA只含有4种核苷酸,由4种核苷酸构成的序列是如何决定多肽链中多至20种氨基酸的序列的呢?显然,在核苷酸和氨基酸之间不能采取简单的一对一的对应关系。2个核苷酸决定一个氨基酸也只能编码16种氨基酸,如果用3个核苷酸决定一个氨基酸,43=64,就足以编码20种氨基酸了,这说明可能需要3个或更多个核苷酸编码一个氨基酸。1961年Francis Crick及其同事的遗传实验进一步肯定3个碱基编码一个氨基酸,此三联体碱基即称为密码子。在64个密码子中,有3个密码子不编码任何氨基酸,从而成为肽链合成的终止信号,称为终止密码子或无义密码子,它们是UAA、UAG、UGA。其余的61个密码子均编码不同的氨基酸,其中AUG和GUG分别是甲硫氨酸和缬氨酸的密码子,同时二者又是肽链合成的起始信号,称为起始密码子。 答案:D 2 不间断性 例2.如果……CGUUUUCUUACGCCU……是某基因产生的 mRNA 中的一个片断 , 如果在序列中某一位置增添了一个碱基 , 则表达时可能发生 ( )。 ①肽链中的氨基酸序列全部改变②肽链提前中断③肽链延长④没有变化⑤不能表达出肽链 A.①②③④⑤ B.①②③④ C.①③⑤ D.②④⑤ 解析: mRNA的三联体密码是连续排列的,相邻密码之间无核苷酸间隔。翻译从起始码AUG开始,3个碱基代表1个氨基酸,从mRNA的5’→3’方向构成1个连续的阅读框,直至终止码。所以,若在某基因编码区的DNA序列或其mRNA中间插入或删除1~2个核苷酸,则其后的三联体组合方式都会改变,不能合成正常的蛋白质,这样的突变亦称移码突变,对微生物常有致死作用。 若增添一个碱基后,导致密码子编组改变,从添加一个碱基的那个密码子开始,一直到末尾都出现误读,相应的氨基酸序列也会从某个氨基酸开始发生全面的改变。这种情况就有
密码子表
密码子表
表一:密码子表 此表列出了64种密码子以及氨基酸的标准配对。 第二位碱基 U C A G 第一位碱基U UUU (Phe/F)苯丙氨酸 UUC (Phe/F)苯丙氨酸 UUA (Leu/L)亮氨酸 UUG (Leu/L)亮氨酸 UCU (Ser/S)丝 氨酸 UCC (Ser/S)丝 氨酸 UCA (Ser/S)丝 氨酸 UCG (Ser/S)丝 氨酸 UAU (Tyr/Y)酪 氨酸 UAC (Tyr/Y)酪 氨酸 UAA 终止 UAG 终止 UGU (Cys/C)半 胱氨酸 UGC (Cys/C)半 胱氨酸 UGA 终止 UGG (Trp/W)色 氨酸 C CUU (Leu/L)亮氨酸 CUC (Leu/L)亮氨酸 CUA (Leu/L)亮氨酸 CUG (Leu/L)亮氨酸 CCU (Pro/P)脯 氨酸 CCC (Pro/P)脯 氨酸 CCA (Pro/P)脯 氨酸 CCG (Pro/P)脯 氨酸 CAU (His/H)组 氨酸 CAC (His/H)组 氨酸 CAA (Gln/Q)谷 氨酰胺 CAG (Gln/Q)谷 氨酰胺 CGU (Arg/R)精 氨酸 CGC (Arg/R)精 氨酸 CGA (Arg/R)精 氨酸 CGG (Arg/R)精 氨酸 A AUU (Ile/I)异亮氨酸 AUC (Ile/I)异亮氨酸 AUA (Ile/I)异亮氨酸 AUG (Met/M)甲硫氨 酸, 起始1 ACU (Thr/T)苏 氨酸 ACC (Thr/T)苏 氨酸 ACA (Thr/T)苏 氨酸 ACG (Thr/T)苏 氨酸 AAU (Asn/N)天 冬酰胺 AAC (Asn/N)天 冬酰胺 AAA (Lys/K)赖 氨酸 AAG (Lys/K)赖 氨酸 AGU (Ser/S)丝 氨酸 AGC (Ser/S)丝 氨酸 AGA (Arg/R)精 氨酸 AGG (Arg/R)精 氨酸 G GUU (Val/V)缬氨酸 GUC (Val/V)缬氨酸 GUA (Val/V)缬氨酸 GUG (Val/V)缬氨酸 GCU (Ala/A)丙 氨酸 GCC (Ala/A)丙 氨酸 GCA (Ala/A)丙 氨酸 GCG (Ala/A)丙 氨酸 GAU (Asp/D)天 冬氨酸 GAC (Asp/D)天 冬氨酸 GAA (Glu/E)谷 氨酸 GAG (Glu/E)谷 氨酸 GGU (Gly/G)甘 氨酸 GGC (Gly/G)甘 氨酸 GGA (Gly/G)甘 氨酸 GGG (Gly/G)甘 氨酸
3 遗传密码的破译 教学设计 教案
教学准备 1. 教学目标 1.知识与技能 (1)说出遗传密码的阅读方式。 (2)说出遗传密码的破译过程,包括伽莫夫的三联体推断,克里克的实验证据,尼伦伯格和马太的蛋白质的体外合成实验。 2.过程与方法 (1)感受和重温科学家的思维历程。 (2)类比的学习方法。 3.情感态度与价值观 (1)对科学家那种敏锐、大胆、睿智和创新的精神还有那种巧妙的构思表达敬佩。 (2)认同遗传密码的破译对生物学发展的重要意义。 2. 教学重点/难点 ●教学重点 遗传密码的破译过程,引导学生感受这种思维过程并产生与科学家的思维共鸣。 ●教学难点 1.克里克的T4噬菌体实验。 2.尼伦伯格和马太设计的蛋白质体外合成实验。 3. 教学用具 多媒体 4. 标签 生物,教案 教学过程 [情境创设]
在第1节我们学习了有关基因指导蛋白质合成的过程,我们知道了核酸中的碱 基序列就是遗传信息,翻译实际上就是将mRNA中的碱基序列翻译为蛋白质的氨基酸序列,那碱基序列与氨基酸序列是如何对应的呢?就是通过密码子。(呈 现密码子表) 现在大家已经十分清楚了这些遗传密码,而当时是经过许多科学家艰辛的思考 和探索,最后被几个年轻人的富有创新的实验才破译的,这个过程充满了思维 的智慧。那这些遗传密码是怎样被破译的呢?让我们重新重温一下这段科学史,追寻科学家探索的足迹,对我们的思维会有好的启迪作用的。 [师生互动] 1.研究背景 在孟德尔遗传规律于1900年被再次证实之后,许多科学家投入到遗传问题的研究上来,试图揭示基因的本质和作用原理。 1941年比德尔(G.Beadle)和塔特姆(E.Tatum)的工作则强有力地证明了基 因突变引起了酶的改变,而且每一种基因一定控制着一种特定酶的合成,从而 提出了一个基因一种酶的假说。人们逐步地认识到基因和蛋白质的关系。 “中心法则”提出后更为明确地指出了遗传信息传递的方向,总体上来说是从DNA→RNA→蛋白质。那DNA和蛋白质之间究竟是什么关系?或者说DNA是如何 决定蛋白质?这个有趣而深奥的问题在五十年代末就开始引起了一批研究者的 极大兴趣。 1944年,理论物理学家薛定谔发表的《什么是生命》一书中就大胆地预言,染 色体是由一些同分异构的单体分子连续所组成。这种连续体的精确性组成了遗 传密码。他认为同分异构单体可能作为一般民用的莫尔斯电码的两个符号:“·”“—”,通过排列组合来储存遗传信息。 那什么是莫尔斯电码呢?我们来看下面的资料: 莫尔斯电码,是由美国画家和电报发明人莫尔斯于1838年发明的一套有“点”和“划”构成的系统,通过“点”和“划”间隔的不同排列顺序来表达不同的 英文字母、数字和标点符号。1844年在美国国会的财政支持下,莫尔斯开设了 从马里兰州的巴尔地摩到美国首都华盛顿的第一条使用“莫尔斯码”通信的电 报线路,1851年,在欧洲国家有关方面的支持下,莫尔斯码经过简化,以后就 一直成为国际通用标准通信电码。电报的发明、莫尔斯码的使用改变了人类社 会的面貌。随着社会的进步、科学的发展,有更先进的通信方式在等待着我们 使用,但电报“莫尔斯”码通信在业余无线电中占有重要的地位。国际电信联 盟制定的“无线电规则”中明确指出:任何人请求领取使用业余电台设备执照,都应该证明其能够准确地用手发和用耳接收“莫尔斯”电码信号组成的电文。 虽然今天计算机技术给自动或半自动收发电报创造了条件,但每一位真正的爱
遗传密码子表
1.遗传密码子表 第一个核苷酸(5′端) 第二个核苷酸第三个核苷酸(3′端)U C A G U 苯丙氨酸丝氨酸酪氨酸半胱氨酸U 苯丙氨酸丝氨酸酪氨酸半胱氨酸 C 亮氨酸丝氨酸终止码终止码 A 亮氨酸丝氨酸终止码色氨酸G C 亮氨酸脯氨酸组氨酸精氨酸U 亮氨酸脯氨酸组氨酸精氨酸 C 亮氨酸脯氨酸谷氨酰胺精氨酸 A 亮氨酸脯氨酸谷氨酰胺精氨酸G A 异亮氨酸苏氨酸天冬酰胺丝氨酸U 异亮氨酸苏氨酸天冬酰胺丝氨酸 C 异亮氨酸苏氨酸赖氨酸精氨酸 A 蛋氨酸苏氨酸赖氨酸精氨酸G G 缬氨酸丙氨酸天冬氨酸甘氨酸U 缬氨酸丙氨酸天冬氨酸甘氨酸 C 缬氨酸丙氨酸谷氨酸甘氨酸 A 缬氨酸丙氨酸谷氨酸甘氨酸G AUG位于mRNA启动部位时为启动信号。真核生物中此密码子代表蛋氨酸,原核生物中代表甲酰蛋氨酸。 2.氨基酸的特性 氨基酸名称三字母缩写 单字母 缩写质量 侧链电离的 pHa值 结构式 丙氨酸 (alanine) Ala A 89.09
精氨酸 Arg R 174.2 12.48 (arginine) 天冬酰氨 Asn N 132.1 (asparagine) 天冬氨酸 Asp D 133.1 3.86 (aspartic acid) 半胱氨酸 Cys C 121.12 (systeine) 谷氨酰胺 Gln Q 146.15 (glutamine) 谷氨酸 Glu E 147.13 4.25 (glutamic acid) 甘氨酸 Gly G 75.07 (glycine) 组氨酸 His H 155.16 6.0 (histidine)
异亮氨酸 lle I 131.17 (isoleucine) 亮氨酸 Leu L 131.17 (leucine) 赖氨酸 Lys K 146.19 (lycine) 甲硫氨酸 Met M 149.21 (methionine) 苯丙氨酸 Phe P 165.19 (phenylanali ne) 脯氨酸 Pro P 115.13 (proline) 丝氨酸 Ser S 105.06 (serine) 苏氨酸 Thr T 119.12 (threonine) 色氨酸 Trp W 204.22 (tryptophan) 酪氨酸 Tyr Y 181.19 10.07 (tyrosine)