王燕时间序列分析第四章SAS程序
第三章20题
data yx_320;
input x@@;
t=intnx('quarter','1jul1971'd,_n_-1);
format t yyq4;
cards;
63.2 67.9 55.8 49.5 50.2 55.4
49.9 45.3 48.1 61.7 55.2 53.1
49.5 59.9 30.6 30.4 33.8 42.1
35.8 28.4 32.9 44.1 45.5 36.6
39.5 49.8 48.8 29 37.3 34.2
47.6 37.3 39.2 47.6 43.9 49
51.2 60.8 67 48.9 65.4 65.4
67.6 62.5 55.1 49.6 57.3 47.3
45.5 44.5 48 47.9 49.1 48.8
59.4 51.6 51.4 60.9 60.9 56.8
58.6 62.1 64 60.3 64.6 71
79.4 59.9 83.4 75.4 80.2 55.9
58.5 65.2 69.5 59.1 21.5 62.5
170 -47.4 62.2 60 33.1 35.3
43.4 42.7 58.4 34.4
;
proc gplot data=yx_320;
plot x*t=1;
symbol1c=red i=join v=circle;
run;
proc arima data=yx_320;
identify var=x nlag=12;
run;
identify var=x nlag=12minic p=(0:6) q=(0:6); run;
estimate p=1q=3;
run;
estimate p=1q=2noint;
run;
forecast lead=5id=t out=yx_320;
run;
proc gplot data=yx_320;
plot x*t=1 forecast*t=2 l95*t=3 u95*t=3/overlay; symbol1c=balck i=none v=star;
symbol2c=red i=join v=none;
symbol3c=blue i=join v=none l=32;
run;
(1)
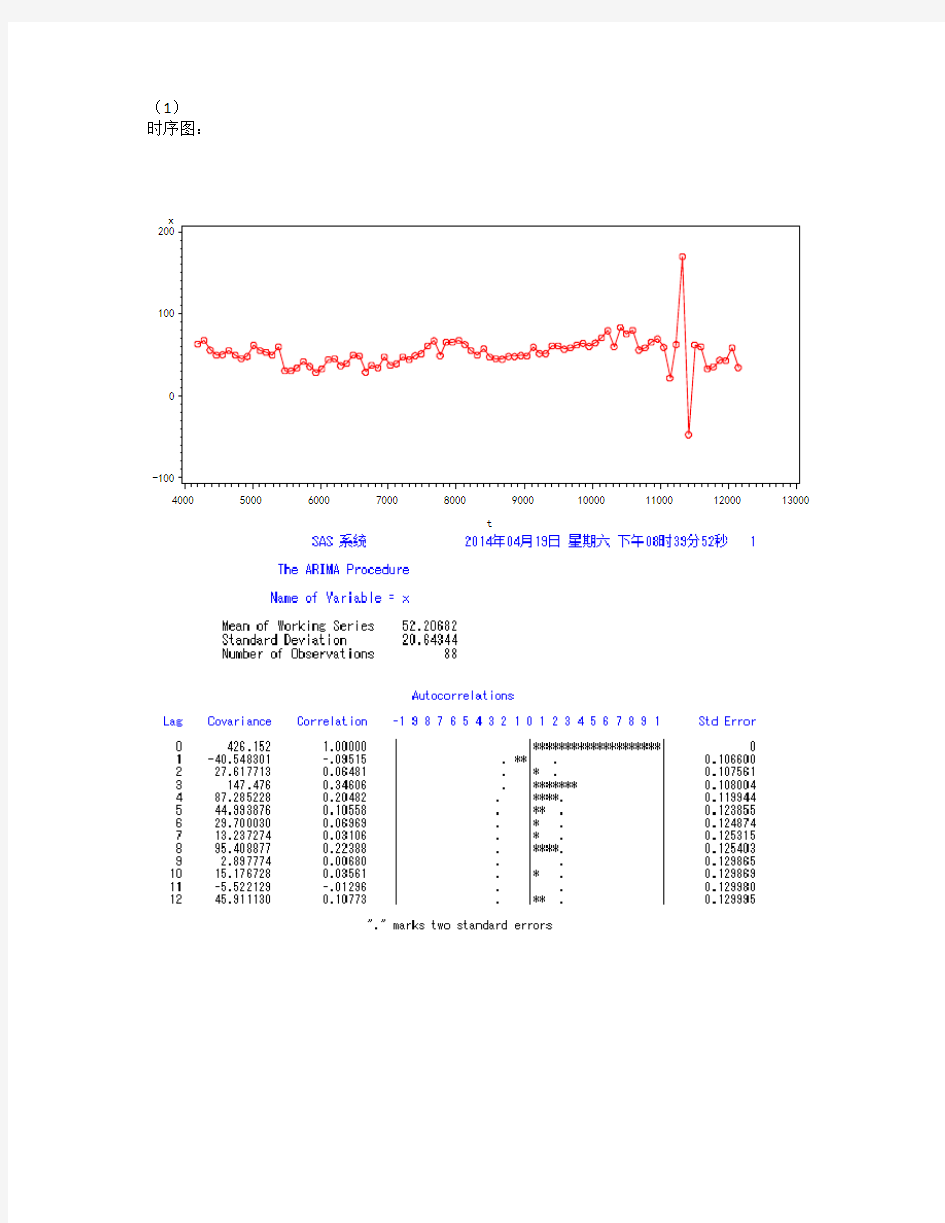
时序图:
通过时序图可以判断,此时间序列平稳。检验结果显示,在各阶延迟下,LB检验统计量的P值都很小,均小于0.05。因而可以认为此时间序列为非纯随机数列。
通过ACF图和PACF图可以判断为ARMA模型。
(2)
由此分析结果可知,相对最优模型为ARMA(1,3)。以此结果作为参考,进行下一步的模型参数估计。
由分析结果可知,θ2,φ1 不显著,故再次估计未知参数的结果。
通过多次估计调整,将模型调整为ARMA(1.2),并去掉常数项,进行估计,得到
如下结果:
可以看出3个参数均显著,P值均远小于0.01。延迟各阶的LB统计量的P值均大于α=0.01,因而认为该拟合模型显著成立。从而可以得到拟合模型的形式;
X t=εt-1.01775εt-1+0.35655εt-2
(3)
第四章5题
data yx_45;
input x@@;
t=1949+_n_-1;
cards;
54167 55196 56300 57482 58796 60266 61465 62828
64653 65994 67207 66207 65859 67295 69172 70499
72538 74542 76368 78534 80671 82992 85229 87177
89211 90859 92420 93717 94974 96259 97542 98705
100072 101654 103008 104357 105851 107507 109300 111026 112704 114333 115823 117171 118517 119850 121121 122389 123626 124761 125786 126743 127627 128453 129227 129988 130756 131448 132129 132802
;
proc gplot data=yx_45;
plot x*t=1;
symbol c=orange i=none v=circle;
run;
proc autoreg data=yx_45;
model x=t;
output out=yx_45 p=xcap;
proc gplot data=yx_45;
plot x*t=2 xcap*t=3/overlay;
由分析结果可知,模型的R2=0.9931很高,结合模型的拟合效果图,可以判断模型拟合较好。
参数估计值对应的P值都很小(均小于0.0001),远小于α=0.05,因而认为显著。可得到拟合的模型:
X t=-2770828+1449t
预测结果:
第四章6题 (将第一个数据视为t=1期)
通过此时间序列的时序图直观判断为二次线性回归模型,即
x t =a+bt+ct
2
。
?2=0.9814很高,结合模型的拟合效果图,可以判断模由分析结果可知,模型的R
型拟合较好。
参数估计值对应的P值都很小(均小于0.0001),远小于α=0.05,因而认为显著。可得到拟合的模型:
X t=1116.85954-23.826t+ 0.52728t2
第四章7题
绘制出此时间序列的时序图,直观判断为非线性模型,通过时序图可以判断,奶牛的产奶量随月份的变化而变化,每12个月呈现为一个周期,并整体呈现上升趋势。我们可以认为产奶量的变化主要受三个因素的影响,一个是长期趋势,一个是季节效应,另一个是随机波动。而且周期的振幅并未随着产奶量的增加而加大,因为认为季节与趋势之间没有相互关系,因而可以尝试加法模型,即x t=T t+S t+I t。用SAS处理后,结果不显著,因而改用乘法模型,即x t=T t S t I t。经SAS处理后,乘法模型显著,处理结果如下:
总平均789.25
季节指数图
通过季节指数图可以看出,5月份的季节指数最大,说明5月份奶牛的产奶量最高,11月份的季节指数最小,说明11月份的奶牛产奶量最小,8月份的奶牛产奶量最接近于年平均奶牛产奶量。
消除季节影响后得到如下序列
用处理后的数据进行模型拟合:
data yx_472;
input x@@; t=intnx('month','1jan1962'd,_n_-1); format t year4.;
cards;
613.0804484 614.7438389 616.4698703 616.3666667 630.186436
624.2351773 613.6613516 608.6395237 610.1313372 614.7786028
612.8913463 609.3098989
624.5301682 620.2228393 628.9919146 632.3395833 643.1889072
641.2516312 632.8382688 626.9291921 626.2439605 625.4333446
626.1909777 626.0606865
653.6749093 677.2044429 662.7051106 662.40625 667.4601867
659.1636879 650.0974943 649.2832314 648.8016332 651.0047249
658.3317536 663.7499585
684.9014177 681.5876432 682.9330282 678.3791667 677.8621636
677.0757447 673.109795 663.5085291 660.617557 661.6594668
667.1981745 664.7968828
704.6782064 695.8330441 708.9403509 709.3854167 703.0002746
714.6910638 704.7517084 708.2166077 710.0296019 710.6712791
714.8551869 720.2838667
742.1500165 730.8986463 733.9844394 736.6333333 725.5378913
731.7075177 735.434776 733.618925 731.5130997 731.9807627
731.4797262 730.7531089
746.3135509 762.6768483 746.5064836 747.9083333 743.7413509
739.7679433 750.7763098 751.9085935 752.9965975 752.2247722
750.3208706 744.3631239
764.0085724 756.1020479 756.1388253 756.3645833 755.0101593
756.7843972 768.0355353 776.2948182 778.7767948 770.3378333
764.7288046 768.442381
780.6627102 774.7306491 777.3299771 774.2166667 768.0126304
769.3228369 785.2947608 795.6005793 794.8894182 795.9092136
788.0031596 786.2400929
;
proc gplot data=yx_472;
plot x*t=1;
symbol1c=black v=star i=join;
run;
proc autoreg data=yx_472;
model x=t;
output out=yx_472 p=xcap;
proc gplot data=yx_472;
plot x*t=2 xcap*t=3/overlay;
symbol2c=blue i=none v=circle;
symbol3c=red i=join v=none;
run;
由分析结果可知,模型的R2=0.9624很高,结合模型的拟合效果图,可以判断模型拟合较好。
参数估计值对应的P值都很小(均小于0.0001),远小于α=0.05,因而认为显著。可得到拟合的模型:
x t S t =-561.8915+0.0592t
时间序列分析方法及应用7
青海民族大学 毕业论文 论文题目:时间序列分析方法及应用—以青海省GDP 增长为例研究 学生姓名:学号: 指导教师:职称: 院系:数学与统计学院 专业班级:统计学 二○一五年月日
时间序列分析方法及应用——以青海省GDP增长为例研究 摘要: 人们的一切活动,其根本目的无不在于认识和改造世界,让自己的生活过得更理想。时间序列是指同一空间、不同时间点上某一现象的相同统计指标的不同数值,按时间先后顺序形成的一组动态序列。时间序列分析则是指通过时间序列的历史数据,揭示现象随时间变化的规律,并基于这种规律,对未来此现象做较为有效的延伸及预测。时间序列分析不仅可以从数量上揭示某一现象的发展变化规律或从动态的角度刻画某一现象与其他现象之间的内在数量关系及其变化规律性,达到认识客观世界的目的。而且运用时间序列模型还可以预测和控制现象的未来行为,由于时间序列数据之间的相关关系(即历史数据对未来的发展有一定的影响),修正或重新设计系统以达到利用和改造客观的目的。从统计学的内容来看,统计所研究和处理的是一批有“实际背景”的数据,尽管数据的背景和类型各不相同,但从数据的形成来看,无非是横截面数据和纵截面数据两类。本论文主要研究纵截面数据,它反映的是现象以及现象之间的关系发展变化规律性。在取得一组观测数据之后,首先要判断它的平稳性,通过平稳性检验,可以把时间序列分为平稳序列和非平稳序列两大类。主要采用的统计方法是时间序列分析,主要运用的数学软件为Eviews软件。大学四年在青海省上学,基于此,对青海省的GDP十分关注。本论文关于对1978年到2014年以来的中国的青海省GDP(总共37个数据)进行时间序列分析,并且对未来的三年中国的青海省GDP进行较为有效的预测。希望对青海省的发展有所贡献。 关键词: 青海省GDP 时间序列白噪声预测
《应用时间序列分析》考试方案
《应用时间序列分析》课程考试大纲 课程性质:专业限选课 总学时: 56 总学分: 3 开课学期:第5学期 适用专业:应用统计学专业 一、课程描述 《应用时间序列分析》作为统计学专业十分重要的专业限选课,在专业培养上有其特殊的地位,因为它是处理大量特殊结构数据的非常有效的一种统计方法,具有非常广泛的应用领域,通过这门课的学习,不仅要把前期的课程内容应用于其中,而且还要为后续的毕业实习、毕业论文打下坚实的理论和技术基础,提升统计学专业学生毕业后的就业能力。 二、考试内容及要求 第一章时间序列分析简介 1.了解时间序列的定义。 2.识记时间序列的基本性质。 3.了解时间序列的基本分析方法。 4.了解时间序列的应用软件介绍。 第二章时间序列的预处理 1.识记时间序列平稳性检验的定义和方法。 2.识记时间序列纯随机性检验的定义和方法。 3.熟练应用Eviews完成基本上机操作。 第三章平稳时间序列分析 1.了解平稳时间序列分析的方法性工具。 2.识记ARMA模型的性质。 3.熟练应用平稳序列完成建模过程。 4.熟练应用平稳序列进行预测。 5.熟练应用Eviews完成平稳序列建模的上机操作。 第四章非平稳序列的确定性分析 1.了解时间序列的分解方法。 2.了解确定性因素分解方法。 3.应用趋势分析的方法。 4.应用季节效应分析的方法。 5.应用综合分析的方法。 6.熟练应用Eviews完成非平稳序列建模的上机操作。 第五章非平稳序列的随机分析 1.识记差分运算方法。 2.应用ARIMA模型的方法。
3.应用残差自回归模型。 4.识记异方差的性质。 5.熟练应用Eviews完成非平稳序列的随机分析建模。 三、考试形式及要求 1.考试方式:考试类型分为小论文、笔试、出勤及课堂表现。 2.考试次数:期末总评成绩由平时考核成绩、阶段考核成绩和结课考核成绩三部分组成。阶段考核方式为小论文,结课考核为开卷考试,平时作业5次,课堂出勤及课堂表现每节课统计。 3.记分方式:采用百分制计分方式。 4.课程总评成绩构成:平时考核占总成绩的25%、阶段考核占总成绩的25%、结课考核占总成绩的50%。 平时考核和阶段考核重点考核单元知识的重点和难点,强调对学生平时课下学习、自学能力、创新意识和学习态度的考核。 结课考核的内容涵盖教学大纲中的全部教学内容,并加强对学生应用软件解决实际问题能力的考核。 四、教材及主要参考书 1.选用教材:王燕编著,《应用时间序列分析(第二版)》,中国人民大学出版社,2011年. 2.参考书:易丹辉主编,《时间序列分析:方法与应用》,中国人民大学出版社,2011年. 3.必读书:马慧慧,《Eviews统计分析与应用》,电子工业出版社,2016年版.
统计基础知识第五章时间序列分析习题及答案
第五章时间序列分析 一、单项选择题 1.构成时间数列的两个基本要素是( C )(2012年1月) A.主词和宾词 B.变量和次数 C.现象所属的时间及其统计指标数值 D.时间和次数 2.某地区历年出生人口数是一个( B )(2011年10月) A.时期数列 B.时点数列 C.分配数列 D.平均数数列 3.某商场销售洗衣机,2008年共销售6000台,年底库存50台,这两个指标是( C ) (2010年10) A.时期指标 B.时点指标 C.前者是时期指标,后者是时点指标 D.前者是时点指标,后者是时期指标 4.累计增长量( A ) (2010年10) A.等于逐期增长量之和 B.等于逐期增长量之积 C.等于逐期增长量之差 D.与逐期增长量没有关系 5.某企业银行存款余额4月初为80万元,5月初为150万元,6月初为210万元,7月初为160万元,则该企业第二季度的平均存款余额为( C )(2009年10) 万元万元万元万元 6.下列指标中属于时点指标的是( A ) (2009年10) A.商品库存量 B.商品销售量 C.平均每人销售额 D.商品销售额 7.时间数列中,各项指标数值可以相加的是( A ) (2009年10) A.时期数列 B.相对数时间数列 C.平均数时间数列 D.时点数列 8.时期数列中各项指标数值( A )(2009年1月) A.可以相加 B.不可以相加 C.绝大部分可以相加 D.绝大部分不可以相加 10.某校学生人数2005年比2004年增长了8%,2006年比2005年增长了15%,2007年比2006年增长了18%,则2004-2007年学生人数共增长了( D )(2008年10月) %+15%+18%%×15%×18% C.(108%+115%+118%)-1 %×115%×118%-1 二、多项选择题 1.将不同时期的发展水平加以平均而得到的平均数称为( ABD )(2012年1月) A.序时平均数 B.动态平均数 C.静态平均数 D.平均发展水平 E.一般平均数2.定基发展速度和环比发展速度的关系是( BD )(2011年10月) A.相邻两个环比发展速度之商等于相应的定基发展速度 B.环比发展速度的连乘积等于定基发展速度
应用时间序列分析第4章答案
河南大学: 姓名:汪宝班级:七班学号:1122314451 班级序号:68 5:我国1949年-2008年年末人口总数(单位:万人)序列如表4-8所示(行数据).选择适当的模型拟合该序列的长期数据,并作5期预测。 解:具体解题过程如下:(本题代码我是做一问写一问的) 1:观察时序图: data wangbao4_5; input x@@; time=1949+_n_-1; cards; 54167 55196 56300 57482 58796 60266 61465 62828 64653 65994 67207 66207 65859 67295 69172 70499 72538 74542 76368 78534 80671 82992 85229 87177 89211 90859 92420 93717 94974 96259 97542 98705 100072 101654 103008 104357 105851 107507 109300 111026 112704 114333 115823 117171 118517 119850 121121 122389 123626 124761 125786 126743 127627 128453 129227 129988 130756 131448 132129 132802 ; proc gplot data=wangbao4_5; plot x*time=1; symbol1c=black v=star i=join; run; 分析:通过时序图,我可以发现我国1949年-2008年年末人口总数(随时间的变化呈现出线性变化.故此时我可以用线性模型拟合序列的发展. X t=a+b t+I t t=1,2,3,…,60 E(I t)=0,var(I t)=σ2 其中,I t为随机波动;X t=a+b就是消除随机波动的影响之后该序列的长期趋势。
第四章教案++时间序列分析
第四章时间序列分析 (一)教学目的 通过本章的学习,掌握时间序列的概念、类型,学会各种动态分析指标的计算方法。 (二)基本要求 要求学会各种水平和速度指标的计算方法,并能对时间序列的长期趋势进行分析和预测。 (三)教学要点 1、时间序列的概念与种类; 2、动态分析指标的计算; 3、长期趋势、季节变动的测定。 (四)教学时数 7——10课时 (五)教学内容 本章共分四节: 第四章时间数列分析 本章前一部分利用时间数列,计算一系列分析指标,用以描述现象的数量表现。后一部分根据影响事物发展变化因素,采用科学的方法,将时间数列受各类因素(长期趋势、季节变动、循环变动和不规则变动)的影响状况分别测定出来,研究现象发展变化的原因及其规律性,为预测未来和决策提供依据。 第一节时间数列分析概述 一、时间数列的概念 时间数列:亦称为动态数列或时间序列(Time Series),就是把反映某一现象的同一指标在不同时间上的取值,按时间的先后顺序排列所形成的一个动态数列。 时间数列的构成要素: 1.现象所属的时间。时间可长可短,可以以日为时间单位,也可以以年为时间单位,甚至更长。 2.统计指标在一定时间条件下的数值。 二、时间数列的分类 时间数列的分类在时间数列分析中具有重要的意义。因为,在很多情况下,时间数列的种类不同,则时间数列的分析方法就不同。因此,为了能够保证对时间数列进行准确分析,则首先必须正确判断时间数列的类型。而要正确判断时间数列的类型,其关键又在于对有关统计指标的分类进行准确理解。 由于时间数列是由统计指标和时间两个要素所构成,因此时间数列的分类实际上和统计指标的分类是一致的。 时间数列分为:总量指标时间数列、相对指标时间数列和平均指标时间数列。 (一)总量指标时间数列 总量指标时间数列:又称为绝对数时间数列,是指由一系列同类的总量指标数值所构成的时间数列。它反映事物在不同时间上的规模、水平等总量特征。总量指标时间数列又分为时期数列和时点数列。 1.时期数列:是指由反映某种社会经济现象在一段时期内发展过程累计量的总量指标所构成的总量指标时间数列。
王燕时间序列分析第四章SAS程序汇编
第三章20题 data yx_320; input x@@; t=intnx('quarter','1jul1971'd,_n_-1); format t yyq4; cards; 63.2 67.9 55.8 49.5 50.2 55.4 49.9 45.3 48.1 61.7 55.2 53.1 49.5 59.9 30.6 30.4 33.8 42.1 35.8 28.4 32.9 44.1 45.5 36.6 39.5 49.8 48.8 29 37.3 34.2 47.6 37.3 39.2 47.6 43.9 49 51.2 60.8 67 48.9 65.4 65.4 67.6 62.5 55.1 49.6 57.3 47.3 45.5 44.5 48 47.9 49.1 48.8 59.4 51.6 51.4 60.9 60.9 56.8 58.6 62.1 64 60.3 64.6 71 79.4 59.9 83.4 75.4 80.2 55.9 58.5 65.2 69.5 59.1 21.5 62.5 170 -47.4 62.2 60 33.1 35.3 43.4 42.7 58.4 34.4 ; proc gplot data=yx_320; plot x*t=1; symbol1c=red i=join v=circle; run; proc arima data=yx_320; identify var=x nlag=12; run; identify var=x nlag=12minic p=(0:6) q=(0:6); run; estimate p=1q=3; run; estimate p=1q=2noint; run; forecast lead=5id=t out=yx_320; run; proc gplot data=yx_320; plot x*t=1 forecast*t=2 l95*t=3 u95*t=3/overlay; symbol1c=balck i=none v=star; symbol2c=red i=join v=none; symbol3c=blue i=join v=none l=32; run;
spss教程第四章时间序列分析
第四章时间序列分析 由于反映社会经济现象的大多数数据是按照时间顺序记录的,所以时间序列分析是研究社会经济现象的指标随时间变化的统计规律性的统计方法。.为了研究事物在不同时间的发展状况,就要分析其随时间的推移的发展趋势,预测事物在未来时间的数量变化。因此学习时间序列分析方法是非常必要的。 本章主要内容: 1. 时间序列的线图,自相关图和偏自关系图; 2. SPSS 软件的时间序列的分析方法季节变动分析。 §4.1 实验准备工作 §4.1.1 根据时间数据定义时间序列 对于一组示定义时间的时间序列数据,可以通过数据窗口的Date菜单操作,得到相应时间的时间序列。定义时间序列的具体操作方法是: 将数据按时间顺序排列,然后单击Date Define Dates打开Define Dates对话框,如图4.1所示。从左框中选择合适的时间表示方法,并且在右边时间框内定义起始点后点击OK,可以在数据库中增加时间数列。 图4.1 产生时间序列对话框 §4.1.2 绘制时间序列线图和自相关图 一、线图 线图用来反映时间序列随时间的推移的变化趋势和变化规律。下面通过例题说明线图的制作。 例题4.1:表4.1中显示的是某地1979至1982年度的汗衫背心的零售量数据。
试根据这些的数据对汗衫背心零售量进行季节分析。(参考文献[2]) 表4.1 某地背心汗衫零售量一览表单位:万件 1979 1980 1981 1982 1 23 30 18 22 2 3 3 37 20 32 3 69 59 92 102 4 91 120 139 155 5 192 311 324 372 6 348 334 343 324 7 254 270 271 290 8 122 122 193 153 9 95 70 62 77 10 34 33 27 17 11 19 23 17 37 12 27 16 13 46 解:根据表4.1的数据,建立数据文件SY-11(零售量),并对数据定义相应的时间值,使数据成为时间序列。为了分析时间序列,需要先绘制线图直观地反映时间序列的变化趋势和变化规律。具体操作如下: 1. 在数据编辑窗口单击Graphs Line,打开Line Charts对话框如图4. 2.。从中选择Simple单线图,从Date in Chart Are 栏中选择Values of individual cases,即输出的线图中横坐标显示变量中按照时间顺序排列的个体序列号,纵坐标显示时间序列的变量数据。 图4.2 Line Charts对话框 2. 单击Define,打开对话框如图4.4所示。选择分析变量进入Line Represents,,在Category Labels 类别标签(横坐标)中选择Case number数据个数(或变量年 度 月 份
《时间序列分析及应用:R语言》读书笔记
《时间序列分析及应用:R语言》读书笔记 姓名:石晓雨学号:1613152019 (一)、时间序列研究目的主要有两个:认识产生观测序列的随机机制,即建立数据生成模型;基于序列的历史数据,也许还要考虑其他相关序列或者因素,对序列未来的可能取值给出预测或者预报。通常我们不能假定观测值独立取自同一总体,时间序列分析的要点是研究具有相关性质的模型。 (二)、下面是书上的几个例子 1、洛杉矶年降水量 问题:用前一年的降水量预测下一年的降水量。 第一幅图是降水量随时间的变化图;第二幅图是当年降水量与去年降水量散点图。 win.graph(width=4.875, height=2.5,pointsize=8) #这里可以独立弹出窗口 data(larain) #TSA包中的数据集,洛杉矶年降水量 plot(larain,ylab='Inches',xlab='Year',type = 'o') #type规定了在每个点处标记一下 win.graph(width = 3,height = 3,pointsize = 8) plot(y = larain,x = zlag(larain),ylab = 'Inches',xlab = 'Previous Year Inches')#zlag 函数(TSA包)用来计算一个向量的延迟,默认为1,首项为NA
从第二幅图看出,前一年的降水量与下一年并没有什么特殊关系。 2、化工过程 win.graph(width = 4.875,height = 2.5,pointsize = 8) data(color) plot(color,ylab = 'Color Property',xlab = 'Batch',type = 'o') win.graph(width = 3,height = 3,pointsize = 8) plot(y = color,x = zlag(color),ylab = 'Color Property',xlab = 'Previous Batch Color Property') len <- length(color) cor(color[2:len],zlag(color)[2:len])#相关系数>0.5549 第一幅图是颜色属性随着批次的变化情况。
时间序列分析——基于R(王燕)第四章
第四章:非平稳序列的确定性分析 题目一: ()()()()()()()12312123121231 ?14111??2144451 . 1616T T T T T T T T T T T T T T T T T T T T T x x x x x x x x x x x x x x x x x x x x x -------------=+++?? =+++=++++++????=+++ 题目二: 因为采用指数平滑法,所以1,t t x x +满足式子()11t t t x x x αα-=+-,下面式子 ()()1 1111t t t t t t x x x x x x αααα-++=+-??? =+-?? 成立,由上式可以推导出()()11111t t t t x x x x αααα++-=+-+-????,代入数据得:2 =5 α. 题目三: ()()()2122192221202019200 1 ?1210101113=11.251 ? 1010111311.2=11.04.5 ???10.40.6.i i i x x x x x x x x αα-==++++=++++===+-=?∑(1)(2) 根据程序计算可得:22?11.79277.x = ()222019181716161?2525x x x x x x =++++(3)可以推导出16,0.425a b ==,则4 25 b a -=-. 题目四: 因为,1,2,3, t x t t ==,根据指数平滑的关系式,我们可以得到以下公式: ()()()()()()() ()()()()()()()() 2 2 1 2 21 11121111 1111311. 2t t t t t t t x t t t x t t αααααααααααααααααααα----=+-------=-+---+--+++2+, + +2+用(1)式减去(2)式得: ()()()()()2 21=11111. t t t t x t αααααααααααα------------- 所以我们可以得到下面的等式: ()()()()()()1 2 2111=11111=. t t t t t x t t αααααααα +---------- -------
应用时间序列分析 -
姓名:葛国峰学号:1122307851 编号:33 习题2.3 2.解: data b; input y@@; time=intnx('month','1jan1975'd,_n_-1); format time data; cards; 330.45 330.97 331.64 332.87 333.61 333.55 331.90 330.05 328.58 328.31 329.41 330.63 331.63 332.46 333.36 334.45 334.82 334.32 333.05 330.87 329.24 328.87 330.18 331.50 332.81 333.23 334.55 335.82 336.44 335.99 334.65 332.41 331.32 330.73 332.05 333.53 334.66 335.07 336.33 337.39 337.65 337.57 336.25 334.39 332.44 332.25 333.59 334.76 335.89 336.44 337.63 338.54 339.06 338.95 337.41 335.71 333.68 333.69 335.05 336.53 337.81 338.16 339.88 340.57 341.19 340.87 339.25 337.19 335.49 336.63 337.74 338.36 ; run; proc gplot; plot y*time; symbol1v=dot i=join c=black w=3; proc arima data=b; identify var=y nlag=24; run; (1)序列图:
第五章 时间序列的模型识别
第五章时间序列的模型识别 前面四章我们讨论了时间序列的平稳性问题、可逆性问题,关于线性平稳时间序列模型,引入了自相关系数和偏自相关系数,由此得到ARMA(p, q)统计特性。从本章开始,我们将运用数据开始进行时间序列的建模工作,其工作流程如下: 图5.1 建立时间序列模型流程图 在ARMA(p,q)的建模过程中,对于阶数(p,q)的确定,是建模中比较重要的步骤,也是比较困难的。需要说明的是,模型的识别和估计过程必然会交叉,所以,我们可以先估计一个比我们希望找到的阶数更高的模型,然后决定哪些方面可能被简化。在这里我们使用估计过程去完成一部分模型识别,但是这样得到的模型识别必然是不精确的,而且在模型识别阶段对于有关问题没有精确的公式可以利用,初步识别可以我们提供有关模型类型的试探性的考虑。 对于线性平稳时间序列模型来说,模型的识别问题就是确定ARMA(p,q)过程的阶数,从而判定模型的具体类别,为我们下一步进行模型的参数估计做准备。所采用的基本方法主要是依据样本的自相关系数(ACF)和偏自相关系数(PACF)初步判定其阶数,如果利用这种方法无法明确判定模型的类别,就需要借助诸如AIC、BIC 等信息准则。我们分别给出几种定阶方法,它们分别是(1)利用时间序列的相关特性,这是识别模型的基本理论依据。如果样本的自相关系数(ACF)在滞后q+1阶时突然截断,即在q处截尾,那么我们可以判定该序列为MA(q)序列。同样的道理,如果样本的偏自相关系数(PACF)在p处截尾,那么我们可以判定该序列为AR(p)序列。如果ACF和PACF 都不截尾,只是按指数衰减为零,则应判定该序列为ARMA(p,q)序列,此时阶次尚需作进一步的判断;(2)利用数理统计方法检验高阶模型新增加的参数是否近似为零,根据模型参数的置信区间是否含零来确定模型阶次,检验模型残差的相关特性等;(3)利用信息准则,确定一个与模型阶数有关
时间序列分析在第三产业中的应用分析
时间序列分析在房地产业中的应用分析 摘要:从改革开放以来中国经济快速增长,特别是第三产业的的快速增长取得了令人瞩目的成绩,同时在第三产业的内部各行业也在相互影响着,其中我们选取了第三产业的经济增长指数的房地产行业作为分析对象。首先看此数据的气势,在应用差分运算的方法对其进行平稳化,再根据相关的理论知识进行模型的建立和分析,以此来了解文莱房地产行业及整个第三产业的经济动态,同时为以后的决策提供相关的数据支持。 关键字:时间序列 差分 ARMA 模型 单位根检验 预测 1.引言 近几年来房地产行业一直过热,其增长态势一浪接一浪,就《新财富》杂志在2003年推出《新财富》400富人榜,据悉,这400个人的财富总和为3031亿元,400人中,共76人是以房地产为主业,占了19%。再加上走综合类中部分涉足房地产行业的,房地产将超过制造业成为产生富豪最多的行业。而早些时候的“《福布斯》2002中国内地富豪榜”中,50%的人涉足或以房地产为主业。这都表明房地产已经成为中国聚集到支柱产业,现在看来该行业已开始出现过热的现象,在2012年中,国家又出台了许多调控政策使得该行业的势头有所减弱,因而对其分析或预测未来的发展态势成为一种必要,我们选取的我1978年到2010的数据作为分析对象,通过用ARMA 模型对样本进行建模对以后房地产行业的增长指数进行预测。 ARMA 模型的全称是自回归移动平均(auto regression moving average )模型,它是目前最常用的拟合平稳序列的模型,它对时间序列的拟合具有很好的效果,本文将会充分利用这种分析方法对所选取的数据进行良好的分析和拟合。 2.ARMA 模型的介绍 ARMA 模型(Auto-Regressive and Moving Average Model )是研究时间序列的重要方法,由自回归模型(简称AR 模型)与滑动平均模型(简称MA 模型)为基础“混合”构成。在市场研究中常用于长期追踪资料的研究,如:Panel 研究中,用于消费行为模式变迁研究;在零售研究中,用于具有季节变动特征的销售量、市场规模的预测等。 ARMA 模型的基本原理:将预测指标随时间推移而形成的数据序列看作是一个随机序列,这组随机变量所具有的依存关系体现着原始数据在时间上的延续性。一方面,影响因素的影响,另一方面,又有自身变动规律,假定影响因素为x1,x2,…,xk ,由回归分析,其中Y 是预测对象的观测值, e 为误差。作为预测对象Yt 受到自身变化的影响,其规律可由下式体现,误差项在不同时期具有依存关系,由下式表示,由此,获得ARMA 模型表达式:公式里的Xt1应该是Xt-1。 模型的基本形式:AR 模型:AR 模型也称为自回归模型。它的预测方式是通过过去的观测值和现在的干扰值的线性组合预测, 自回归模型的数学公式为: 1122t t t p t p t y y y y φφφε---=++++ 式中: p 为自回归模型的阶数i φ(i=1,2, ,p )为模型的待定系数,t ε为误差, t y 为一个平稳时间序列;MA 模型:MA 模型也称为滑动平均模型。它的预测方式是通过过去的干扰值和现在的干扰值的线性组合预测。滑动平均模型的数学公式为: 1122t t t t q t q y εθεθεθε---=---- 式中: q 为模型的阶数; j θ(j=1,2, ,q )为模型的待定系数;t ε为误差; t y 为平稳时间序列;ARMA 模型:自回归模型和滑动平均模型的组合, 便构成了用于描述平稳随机
时间序列分析及其应用
时间序列分析及其应用 摘要:本文介绍了目前时间序列分析的发展状况以及应用情况,对常见的几种趋势拟合及其预测方法进行了简要叙述。 关键词:时间序列趋势建模 1 引言 时间序列分析是一种动态数据处理的统计方法。该方法基于随机过程理论和数理统计学方法,研究随机数据序列所遵从的统计规律,以用于解决实际问题。它包括一般统计分析(如自相关分析,谱分析等),统计模型的建立与推断,以及关于时间序列的最优预测、控制与滤波等内容。经典的统计分析都假定数据序列具有独立性,而时间序列分析则侧重研究数据序列的互相依赖关系。后者实际上是对离散指标的随机过程的统计分析,所以又可看作是随机过程统计的一个组成部分。时间序列是按时间顺序的一组数字序列。时间序列分析就是利用这组数列,应用数理统计方法加以处理,以预测未来 事物的发展。时间序列分析是定量预测方法之一,它的基本原理:一是承认事物发展的延续性。应用过去数据,就能推测事物的发展趋势。二是考虑到事物发展的随机性。任何事物发展都可能受偶然因素影响,为此要利用统计分析中加权平均法对历史数据进行处理。 2 时间序列分析的趋势及建模 时间序列分析的成分有:(1)长期趋势,即时间序列随时间的变化而逐渐增加或减少的长期变化的趋势;(2)季节变动,即时间序列在一年中或固定时间内,呈现出的固定规则的变动;(3)循环变动,即
沿着趋势线如钟摆般地循环变动;(4)不规则变动,即在时间序列中由于随机因素影响所引起的变动。 时间序列建模基本步骤是:用观测、调查、统计、抽样等方法取得被观测系统时间序列动态数据;根据动态数据作相关图,进行相关分析,求自相关函数。相关图能显示出变化的趋势和周期,并能发现跳点和拐点。跳点是指与其他数据不一致的观测值。如果跳点是正确的观测值,在建模时应考虑进去,如果是反常现象,则应把跳点调整到期望值。拐点则是指时间序列从上升趋势突然变为下降趋势的点。如果存在拐点,则在建模时必须用不同的模型去分段拟合该时间序列,例如采用门限回归模型。然后辨识合适的随机模型,进行曲线拟合,即用通用随机模型去拟合时间序列的观测数据。 主要的趋势拟合方法有平滑法、趋势线法和自回归模型。对于很多情况,时间序列具有季节趋势,比如气象学中的气温、降雨量,水文学中雨季和干季的河流水量等等。这就需要分析时间序列时,将季节趋势考虑在内。季节性预测法的基本步骤是(1)对原时间序列求移动平均,以消除季节变动和不规则变动,保留长期趋势;(2)将原序列y除以其对应的趋势方程值(或平滑值),分离出季节变动(含不规则变动),即季节系数=tsci/趋势方程值(tc或平滑值);(3)将月度(或季度)的季节指标加总,以由计算误差导致的值去除理论加总值,得到一个校正系数,并以该校正系数乘以季节性指标从而获得调整后季节性指标;(4)求预测模型,若求下一年度的预测值,延长趋势线即可;若求各月(季)的预测值,需以趋势值乘以各月份(季
应用时间序列分析论文_应用统计18_陈叮_5061214012
应用时间序列分析 大作业 姓名:陈叮 学号: 5061214012 专业班级:应用统计18 院系:信息工程学院数学系 时间:2017/5/22
题目:对苏格兰异性结婚数据的时序分析 摘要: 本文以苏格兰1855年至2015年异性结婚数据为研究对象,首先运用R软件对1855-2010年的结婚数据绘制时序图、自相关图和做差分进行相关分析,得出一阶差分后的数据是趋于平稳的,然后根据主观确定拟合模型为)2( MA,并运用R软件里面的() ARIMA模型即auto函数进行模型的自动选择,得出)2,1,0( .arima MA是最优的,最后运用)2( MA模MA模型最优,故我们所选择的拟合模型)2( )2( 型预测并进行预测残差检验,得出了苏格兰2011-2015年异性结婚数据的预测值(29200.45,28905.94,28905.94,28905.94,28905.94)与实际值(29135,30534,27547,28702,28020)相比,相差不大,这说明模型拟合较好,能反映数据的真实水平,而且残差检验也表明预测残差是平均值为0且方差为常数的正态分 MA模型是可以提供非常合适布(服从零均值、方差不变的正态分布),这进一步说明)2( 预测的模型。 关键词:苏格兰;() arima函数;auto.() arima函数;R软件;预测
二、数据来源 本文的数据是1855-2015年苏格兰的结婚数据(Marriages, Scotland, 1855 to 2015 ),数据可以从网上(https://https://www.360docs.net/doc/be5854031.html,/statistics-and-data/statistics/statistics-by-theme/vital-events/marriages-and-ci vil-partnerships/marriages-time-series-data)下载,数据见附件一。 三、模型的定阶与确定 3.1模型的定阶 3.1.1序列预处理[1] 首先,我们对苏格兰1855年至2010年的时间序列进行时序图和自相关分析,分析结果如图3.1.1.1和图3.1.1.2所示,程序见附录一。 1855-2010年苏格兰结婚数据的时序图 时间 结婚数据 18501900 19502000 2000035000 5000 图3.1.1.1苏格兰1855年至2010年异性结婚数据的时序图 05101520 -0.20.20.61.0 Lag A C F Series dataseries 图3.1.1.2 苏格兰1855年至2010年异性结婚数据的自相关图 图 3.1.1.1显示苏格兰的结婚数值的均值和方差变动很大,随着时间的增加,具有明显的上升趋势,是典型的非平稳序列。 图3.1.1.2显示该序列的自相关系数都超出了两倍标准误差,所以进一步证明了该序列是非平稳的。 综上所述,该序列是非平稳序列。 对于该非平稳时间序列,首先我们对数据进行1阶差分处理,以便消除其具
应用时间序列分析 第5章
佛山科学技术学院 应用时间序列分析实验报告 实验名称第五章非平稳序列的随机分析 一、上机练习 通过第4章我们学习了非平稳序列的确定性因素分解方法,但随着研究方法的深入和研究领域的拓宽,我们发现确定性因素分解方法不能很充分的提取确定性信息以及无法提供明确有效的方法判断各因素之间确切的作用关系。第5章所介绍的随机性分析方法弥补了确定性因素分解方法的不足,为我们提供了更加丰富、更加精确的时序分析工具。 5.8.1 拟合ARIMA模型 【程序】 data example5_1; input x@@; difx=dif(x); t=_n_; cards; 1.05 -0.84 -1.42 0.20 2.81 6.72 5.40 4.38 5.52 4.46 2.89 -0.43 -4.86 -8.54 -11.54 -1 6.22 -19.41 -21.61 -22.51 -23.51 -24.49 -25.54 -24.06 -23.44 -23.41 -24.17 -21.58 -19.00 -14.14 -12.69 -9.48 -10.29 -9.88 -8.33 -4.67 -2.97 -2.91 -1.86 -1.91 -0.80 ; proc gplot; plot x*t difx*t; symbol v=star c=black i=join; proc arima; identify var=x(1); estimate p=1; estimate p=1 noint; forecast lead=5id=t out=out; proc gplot data=out; plot x*t=1 forecast*t=2 l95*t=3 u95*t=3/overlay; symbol1c=black i=none v=star; symbol2c=red i=join v=none; symbol3c=green I=join v=none;
应用时间序列分析第4章答案
大学: :汪宝班级:七班学号:1122314451 班级序号:68 5:我国1949年-2008年年末人口总数(单位:万人)序列如表4-8所示(行数据).选择适当的模型拟合该序列的长期数据,并作5期预测。 解:具体解题过程如下:(本题代码我是做一问写一问的) 1:观察时序图: data wangbao4_5; input x; time=1949+_n_-1; cards; 54167 55196 56300 57482 58796 60266 61465 62828 64653 65994 67207 66207 65859 67295 69172 70499 72538 74542 76368 78534 80671 82992 85229 87177 89211 90859 92420 93717 94974 96259 97542 98705 100072 101654 103008 104357 105851 107507 109300 111026 112704 114333 115823 117171 118517 119850 121121 122389 123626 124761 125786 126743 127627 128453 129227 129988 130756 131448 132129 132802 ; proc gplot data=wangbao4_5; plot x*time=1; symbol1c=black v=star i=join; run; 分析:通过时序图,我可以发现我国1949年-2008年年末人口总数(随时间的变化呈现出线性变化.故此时我可以用线性模型拟合序列的发展. X t=a+b t+I t t=1,2,3,…,60 E(I t)=0,var(I t)=σ2 其中,I t为随机波动;X t=a+b就是消除随机波动的影响之后该序列的长期趋势。
应用时间序列课后答案
第二章习题答案 2.1 (1)非平稳 (2)0.0173 0.700 0.412 0.148 -0.079 -0.258 -0.376 (3)典型的具有单调趋势的时间序列样本自相关图 2.2 (1)非平稳,时序图如下 (2)-(3)样本自相关系数及自相关图如下:典型的同时具有周期和趋势序列的样本自相关图
2.3 (1)自相关系数为:0.2023 0.013 0.042 -0.043 -0.179 -0.251 -0.094 0.0248 -0.068 -0.072 0.014 0.109 0.217 0.316 0.0070 -0.025 0.075 -0.141 -0.204 -0.245 0.066 0.0062 -0.139 -0.034 0.206 -0.010 0.080 0.118 (2)平稳序列 (3)白噪声序列 2.4 ,序列LB=4.83,LB统计量对应的分位点为0.9634,P值为0.0363。显著性水平=0.05 不能视为纯随机序列。 2.5 (1)时序图与样本自相关图如下
(2) 非平稳 (3)非纯随机 2.6 (1)平稳,非纯随机序列(拟合模型参考:ARMA(1,2)) (2)差分序列平稳,非纯随机 第三章习题答案 3.1 解:1()0.7()()t t t E x E x E ε-=?+ 0)()7.01(=-t x E 0)(=t x E t t x ε=-)B 7.01( t t t B B B x εε)7.07.01()7.01(221 +++=-=- 229608.149 .011 )(εεσσ=-= t x Var 49.00212==ρφρ 022=φ 3.2 解:对于AR (2)模型: ?? ?=+=+==+=+=-3.05 .021102112 12112011φρφρφρφρρφφρφρφρ 解得:?? ?==15 /115 /721φφ 3.3 解:根据该AR(2)模型的形式,易得:0)(=t x E 原模型可变为:t t t t x x x ε+-=--2115.08.0
时间序列分析第五章作业
时间序列分析第五章作业 班级:09数学与应用数学 学号: 姓名: 习题5.7 1、 根据数据,做出它的时序图及一阶差分后图形,再用ARIMA 模型模拟该序列的发展,得出 预测。根据输出的结果,我们知道此为白噪声,为非平稳序列,同时可以得出序列t x 模型 应该用随机游走模型(0,1,0)模型来模拟,模型为:,并可以预测到下一天 的收盘价为296.0898。 各代码: data example5_1; input x@@; difx=dif(x); t=_n_; cards ; 304 303 307 299 296 293 301 293 301 295 284 286 286 287 284 282 278 281 278 277 279 278 270 268 272 273 279 279 280 275 271 277 278 279 283 284 282 283 279 280 280 279 278 283 278 270 275 273 273 272 275 273 273 272 273 272 273 271 272 271 273 277 274 274 272 280 282 292 295 295 294 290 291 288 288 290 293 288 289 291 293 293 290 288 287 289 292 288 288 285 282 286 286 287 284 283 286 282 287 286 287 292 292 294 291 288 289 ; proc gplot ; plot x*t difx*t; symbol v =star c =black i =join; proc arima data =example5_1; identify Var =x(1) nlag =8 minic p = (0:5) q = (0:5); estimate p =0 q =0 noint; forecast lead =1 id =t out =results; run ; proc gplot data =results; plot x*t=1 forecast*t=2 l95*t=3 u95*t=3/overlay ; symbol1 c =black i =none v =star; symbol2 c =red i =join v =none; symbol3 c =green i =join v =none l =32; run ; 时序图:
时间序列分析-王燕-习题4答案
6、 方法一:趋势拟合法 income<-scan('习题4.6数据.txt') ts.plot(income) 由时序图可以看出,该序列呈现二次曲线的形状。于是,我们对该序列进行二次曲线拟合: t<-1:length(income) t2<-t^2 z<-lm(income~t+t2) summary(z) lines(z$fitted.values, col=2) 方法二:移动平滑法拟合 选取N=5 income.fil<-filter(income,rep(1/5,5),sides=1) lines(income.fil,col=3)
7、(1) milk<-scan('习题4.7数据.txt') ts.plot(milk) 从该序列的时序图中,我们看到长期递增趋势和以年为固定周期的季节波动同时作用于该序列,因此我们可以采用乘积模型和加法模型。在这里以加法模型为例。 z<-scan('4.7.txt')
ts.plot(z) z<-ts(z,start=c(1962,1),frequency=12) z.s<-decompose(z,type='additive') //运用加法模型进行分解z.1<-z-z.s$seas //提取其中的季节系数,并在z中减去(因为是加法模//型)该季节系数 ts.plot(z.1) lines(z.s$trend,col=3) z.2<-ts(z.1) t<-1:length(z.2) t2<-t^2 t3<-t^3 r1<-lm(z.2~t) r2<-lm(z.2~t+t2) r3<-lm(z.2~t+t2+t3) summary(r1)