1、开始ArtiosCAD

开始ArtiosCAD
进入你的电脑系统后,根据以下步骤开启ArtiosCAD:
1、按开始按钮,然后指向程序。
2、在开始指示集指向ArtiosCAD文件夹,然后按下你刚下载
的ArtiosCAD节录。
3、ArtiosCAD的一切已准备就绪。你能够使用ArtiosCAD创
建或打开单一的设计,把3D的设计折叠,创建一套生产工
具,或设定系统的默认值。
或双击桌面快捷方式
更改视觉角度
观看ArtiosCAD的视觉角度能够改变。但设计的整体建造属
性是不变的,只是呈现的方法有所不同。呈现方法是由三种
基本功能控制的,分别是变焦功能,视图模式和绘图模式。变焦放大或缩小
ArtiosCAD容许你从不同距离查看设计。查看距离是由变焦功能所控制的。变焦放大指的是从近距离仔细查看设
计的一部分。变焦缩小指的是从远距离查看整体设计。你能
够使用变焦放大功能去查看设计其中一部分最细微的公差
缩放迎合
视图指令集(和视图工具条)里的缩放迎合功能让你把设计变焦至最迎合视窗范围的大小,使设计刚好占据整个视
窗画面。当你过分变焦放大或缩小时,这功能最为有用,因
为它让你完整的查看到整体设计。
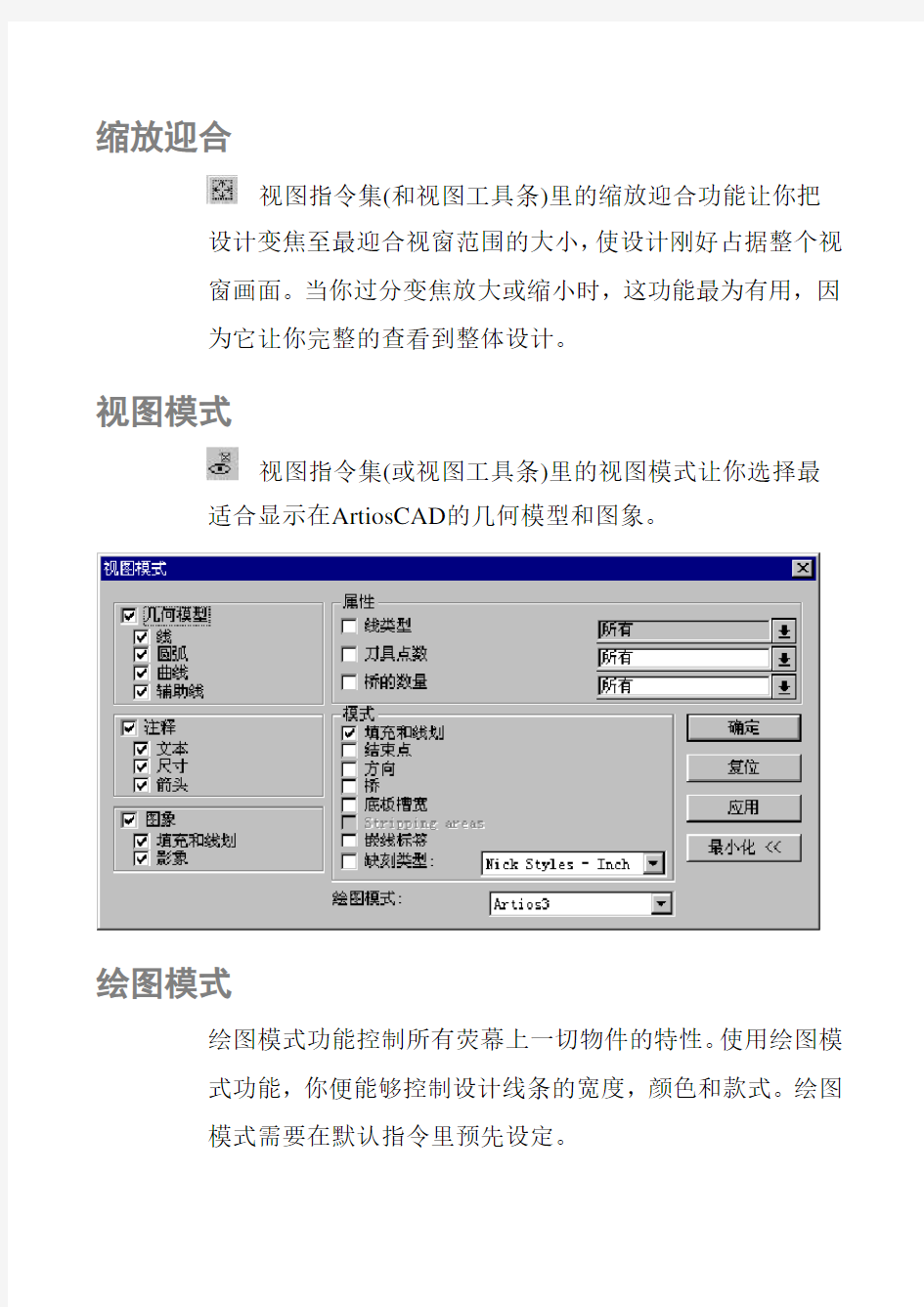
视图模式
视图指令集(或视图工具条)里的视图模式让你选择最适合显示在ArtiosCAD的几何模型和图象。
绘图模式
绘图模式功能控制所有荧幕上一切物件的特性。使用绘图模
式功能,你便能够控制设计线条的宽度,颜色和款式。绘图
模式需要在默认指令里预先设定。
辅助线
辅助线是一些特别用来绘画草稿的线条。它们对于构建几何
模型有很大的帮助,因为几何模型依赖的是不同的点,而辅
助线不会在真正的设计里出现。辅助线不会被输出。
层
ArtiosCAD 使用层的观念创建整体设计。层面被使用在单一
的设计和生产过程里。试想象一张有基本容器图象的纸,然
后,在它的上面加上不同的透明胶片。其中一张胶片上的是
尺寸,另外的胶片分别是艺术设计和增设的几何模型设计如
视窗或选择性的掩盖等。一个设计最多能拥有一百层层面。属性
差不多所有在ArtiosCAD设计里的物件都有特定的属性,如线
型、刀具点数、文本大小和颜色等,都能用选择工具在物件
上以快速双按方式更改。属性对话框会自动出现。关闭对话
框后便能应用改变过的属性。
当前点
目前位置是工作间里的一点,所有创建工具开始创建的位置。
当一个新的空白设计被创建,目前位置会自动移向辅助线的
交叉点。当你从目前位置开始画第一条线,目前位置会自动
移去线条的末端。然后,任何创建物便会从第一条线的末端
开始。接下来,目前位置会把第三件物件放置在第二件物件
的末端开始,如此类推。
目前位置可以使用以下按钮移动:在几何模型工具条里
的移动到点工具(CTRL-W) 或在目前位置指令集里的移动数
值工具(CTRL-Q)。移动到点移动目前位置到已设定点。移动
数值根据设定角度移动目前位置。
捕捉
捕捉容许你在不贴切的范围选择点的位置。只要你按下点位
置的周围,即使有所偏差,ArtiosCAD也会自动帮你选择最贴
切的一点。捕捉公差指的就是选择点周围后,还能够启动自
动选择功能的范围。
设计视窗
ArtiosCAD 里的视窗主要有四部分组成:
1、指令栏,视图栏和工具列表
2、工具条
3、状态栏
4、绘图
1
2
4
3
指令栏,视图栏和工具列
第一个按钮打开对话框。第二个按钮保存现有设计。第三个按
钮重建现有设计。第四个按钮把现有设计转换成生产文档。第
五个按钮把现有设计转换成3D文档。第六个按钮创建出可打印
的文档。第七个按钮则增加、删除和修整层面。
第二组控制功能控制线条的类形和刀具点数。
工具列里的第一个按钮开启或关闭视图工具条。在视图工具条里的功能都是用来改变现有视窗视图模式的。
工具列里的第二个按钮开启或关闭几何模型工具条。几何模型工具条里的按钮是用来建设线条和图形的。
工具列里的第三个按钮开启或关闭尺寸标注工具条。尺寸工具条里的按钮是用来建设和改良线条、角度和弧线的尺寸注释的。
工具列里的第四个按钮开启或关闭修整工具条。修整工具条里的按钮是用来改变现有线条的平直特性。
工具列里的第五个按钮开启或关闭辅助线工具条。辅助线只
在绘图时提供帮助,却不会被生产。辅助线工具条里的按钮是用来控制辅助线的。
工具列里的第六个按钮开启或关闭编辑工具条。编辑工具条里的按钮不是用来改变设计里物件的形态,只能用来移动或复印物件。
工具列里的第七个按钮开启或关闭注释工具条。注释工具条里的按钮是用来增加现有设计的文本、宽度和细节的。
工具列里的第八个按钮开启或关闭修整线条工具条。修整线条工具条里的按钮是用来修整线条的不平直属性的。
工具列里的第九个按钮开启或关闭延伸工具条。这工具条里的功能是创建延伸线条,使延伸线无尽地延伸和把圆弧延伸成圆形。这些延伸线都包含着可以创建新几何模型的延伸点。
工具列里的第十个按钮开启或关闭图象工具条。图象工具条控制从外面带入的张贴影象,如库存颜色、充填、笔画和图象位置等。
工具列里的第十一个按钮开启或关闭报告工具条。报告工具条把现有设计转换成报告形式。
工具列里的第十二个按钮开启或关闭底板工具条。底板工具条里的按钮是用来运作智能底板系统的。
自定义工具条
要制造或改变自定义的工具条,按选项,然后按缺省设置找customized Toolbars 中的artioscad toolbars color 的按钮。
要更换工具条的颜色,按下工具条颜色按钮便会带出工具条颜色的对话框。为工具条选择新的背景颜色,按确定设定,取消按钮除消更换颜色的功能或按下设定系统颜色恢复视窗原有的颜色。
hortonworks测试环境离线安装与配置
目录 目录 0 1.基础环境 (2) 2.准备工作 (3) 2.1配置环境 (4) 2.1.1配置hosts文件 (4) 2.1.2 SSH无密码登入 (4) 2.1.3 NTP 时间同步 (5) 2.1.4 SELinux & iptables 关闭 (6) 2.2Java环境安装 (7) 2.2.1 安装JDK (7) 2.2.2 配置环境变量 (7) 3.Ambari安装配置 (9) 3.1配置本地源 (9) 3.1.1 建立本地资源库 (9) 3.1.2 配置repo文件 (10) 3.1.3 配置Media源 (12) 3.1.4 安装必要工具 (12) 3.1.5 配置Media的http源 (12) 3.1.6 安装ambari-server服务 (17)
3.1.7 安装ambari客户端 (46) 3.2ambari服务器配置与管理 (20) 4.常见问题 (50) 4.1mapreduce (50) 4.2oozie安装 (51)
1.基础环境 本人配置 操作系统:redhat6.4 内核版本: 内存大小: 处理器: Ambari版本:ambari-1.6.0 HDP版本:HDP-2.1-latest-centos6-rpm.tar.gz HDP-UTILS版本:HDP-UTILS-1.1.0.17-centos6.tar.gz JDK版本:jdk-7u45-linux-x64
Ambari安装的环境路径(选择安装所有服务的情况): 2.准备工作 本次配置使用hdp-m2作为主master节点
2.1配置环境 2.1.1配置hosts文件 所有机器都得执行,使用root用户 1)@ hostname hdp-m2(该命令可用于临时修改主机名) 2)@ vi /etc/hosts(该命令可用于配置主机名和IP的对应信息) 10.242.157.115 hdp-m1 10.242.157.117 hdp-m2 10.242.157.122 hdp-s1 3)@ vi /etc/sysconfig/network(该命令可用于修改网络主机名) 2.1.2SSH无密码登入 所有机器都得执行,使用root用户 @ yum install ssh(安装SSH协议) @ yum install rsync(rsync是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件) @ service sshd restart (启动服务) 注:如果系统中没有安装SSH,需要进行以上操作。 @ssh-keygen(该命令生成指定公私秘钥的名字,id_dsa及id_dsa.pub)
CDH-HDP-MAPR-DKH-星环组件比较
一、组件比较:
二、组件简介:
1、Hadoop 简介:集群基础组件,分为存储(HDFS)和计算(Mapreduce)两大部分。apache社区开源。技术来源于2、Hbase 简介:键-值非关系型数据库,apache 3、Zookeeper 4、Spark 简介:内存计算框架,伯克利首先提出,现已开源。 5、Hive 简介:基于HDFS的SQL工具,facebook开发,后开源。 6、Hue 简介:图形化集群工具,cloudera开发,后开源。 7、Impala 简介:基于HDFS的SQL工具,cloudera开发,后开源。 8、Sqoop 简介:用于关系型数据库与NOSQL数据库之间的数据导入导出。Cloudera开发,已开源。 9、Flume 简介:用于数据流的导入, Cloudera开发,已开源。 10、Oozie 简介:工作流系统,用于提交、监控集群作业。Cloudera开发,已开源。 11、Solr 简介:基于Lucene的全文搜索服务器。已开源。 12、Isilon 简介:基于OneFs操作系统的存储产品,美国赛龙公司开发,后属于EMC,一种集群存储方案。 13、K-V store indexer 简介:为HBase到solr的索引中间件,为NGDATA公司开发,已开源。
14、Cloudera Manager 简介:CDH集群安装管理工具。Cloudera开发。 15、kafka 简介:消息队列组件。已经开源。 16、Storm 简介:流数据处理组件。 17、Elasticsearch 简介:基于Lucene的全文搜索服务器。已开源。 18、ESSQL 简介:基于Elasticsearch的SQL工具,大快开发。 19、DK-NLP 简介:自然语言处理组件。大快开发,已开源。 20、DK-SPIDER 简介:分布式爬虫组件。大快开发。 21、DKM 简介:集群安装管理工具。大快开发。 22、DK-DMYSQL 简介:分布式MYSQL组件,大快改写。 23、Apache Falcon 简介:Falcon 是一个面向Hadoop的、新的数据处理和管理平台,设计用于数据移动、数据管道协调、生命周期管理和数据发现。 24、Apache Knox 简介:Apache knox是一个访问hadoop集群的restapi网关,它为所有rest访问提供了一个简单的访问接口点。 25、Apache Phoenix
大数据平台技术框架选型分析
大数据平台框架选型分析 一、需求 城市大数据平台,首先是作为一个数据管理平台,核心需求是数据的存和取,然后因为海量数据、多数据类型的信息需要有丰富的数据接入能力和数据标准化处理能力,有了技术能力就需要纵深挖掘附加价值更好的服务,如信息统计、分析挖掘、全文检索等,考虑到面向的客户对象有的是上层的应用集成商,所以要考虑灵活的数据接口服务来支撑。 二、平台产品业务流程
三、选型思路 必要技术组件服务: ETL >非/关系数据仓储>大数据处理引擎>服务协调>分析BI >平台监管
四、选型要求 1.需要满足我们平台的几大核心功能需求,子功能不设局限性。如不满足全部,需要对未满足的其它核心功能的开放使用服务支持 2.国内外资料及社区尽量丰富,包括组件服务的成熟度流行度较高 3.需要对选型平台自身所包含的核心功能有较为深入的理解,易用其API或基于源码开发
4.商业服务性价比高,并有空间脱离第三方商业技术服务 5.一些非功能性需求的条件标准清晰,如承载的集群节点、处理数据量及安全机制等 五、选型需要考虑 简单性:亲自试用大数据套件。这也就意味着:安装它,将它连接到你的Hadoop安装,集成你的不同接口(文件、数据库、B2B等等),并最终建模、部署、执行一些大数据作业。自己来了解使用大数据套件的容易程度——仅让某个提供商的顾问来为你展示它是如何工作是远远不够的。亲自做一个概念验证。 广泛性:是否该大数据套件支持广泛使用的开源标准——不只是Hadoop和它的生态系统,还有通过SOAP和REST web服务的数据集成等等。它是否开源,并能根据你的特定问题易于改变或扩展?是否存在一个含有文档、论坛、博客和交流会的大社区? 特性:是否支持所有需要的特性?Hadoop的发行版本(如果你已经使用了某一个)?你想要使用的Hadoop生态系统的所有部分?你想要集成的所有接口、技术、产品?请注意过多的特性可能会大大增加复杂性和费用。所以请查证你是否真正需要一个非常重量级的解决方案。是否你真的需要它的所有特性? 陷阱:请注意某些陷阱。某些大数据套件采用数据驱动的付费方式(“数据税”),也就是说,你得为自己处理的每个数据行付费。因为我们是在谈论大数据,所以这会变得非常昂贵。并不是所有的大数据套件都会生成本地Apache Hadoop代码,通常要在每个Hadoop集群的服务器上安装一个私有引擎,而这样就会解除对于软件提供商的独立性。还要考虑你使用大数据套件真正想做的事情。某些解决方案仅支持将Hadoop用于ETL来填充数据至数据仓库,而其他一些解决方案还提供了诸如后处理、转换或Hadoop集群上的大数据分析。ETL仅是Apache Hadoop和其生态系统的一种使用情形。 六、方案分析
Apache atlas使用说明文档
Apache atlas 第一章:Apache atlas简介 为寻求数据治理的开源解决方案,Hortonworks公司联合其他厂商与用户于2015年发起数据治理倡议,包括数据分类、集中策略引擎、数据血缘、安全和生命周期管理等方面。Apache Atlas 项目就是这个倡议的结果,社区伙伴持续的为该项目提供新的功能和特性。该项目用于管理共享元数据、数据分级、审计、安全性以及数据保护等方面,努力与Apache Ranger整合,用于数据权限控制策略。目前最新版本是2.0.0. .1apache atlas 架构介绍 1.1.1核心组件Core Type System: Apache Atlas 允许用户为他们想要管理的元数据对象定义一个模型,该模型被叫做“类型”。类型的实例被称为“实体”,实体用来表示被管理的实际元数据对象类型系统是允许用户定义和管理类型和实体的组件。。 例如:Atlas 本身自带的hive_table类 Name: hive_table TypeCategory: Entity SuperTypes: DataSet Attributes: name: string db: hive_db owner: string createTime: date
lastAccessTime: date comment: string retention: int sd: hive_storagedesc partitionKeys: array
hue安装手册
HUE 安装手册
本文档主要参考cloudera和hortonworks的安装文档,但这两个文档主要是针对自己产品的安装,有些配置是产品特有的配置,特别是cloudera的安装文档,hortonwork的文档不错,本手册主要是参考hortonwork的安装文档而来,并增加了thrift的插件配置和安装。 以上是hue和hadoop组件的整体结构图: 1. 安装步骤: 安装前,最好先阅读下以上提到的两篇安装手册,本手册是安装中软国际的安装包中安装的hue,也可以把yum源地址配置成hortonworks 的安装包,这里的说明的yum安装源是中软国际的安装包。 主节点:master.hadoop jobtracker节点:node4.hadoop 本手册是把hue安装在主节点master.hadoop上 2. 配置hadoop(通过ambari界面更改如下配置文件)
1.hdfs-site.xml
最受关注的13款大数据产品
最受关注的13款大数据产品 大数据是当下IT领域最活跃的话题之一。没有比近日在圣何塞举行的Hadoop Summit 2013更好的地方去了解关于大数据的最新动态了。 有超过60家大数据公司参与其中,既包括像英特尔和https://www.360docs.net/doc/e113683585.html,这样的知名厂商,也有像Sqrrl和Platfora这样成立没有多久的初创公司。以下是这次峰会上展示的13款全新的或者增强的大数据产品。 Continuuity开发公司现在支持批量处理
Continuuity发布了支持批量处理的Continuuity Developer Suite 1.7,将MapReduce集成到平台中为开发者提供更广泛的工作负载能力。 Continuuity帮助Java开发者构建能运行Hadoop和HBase数据库的应用。这些应用支持像运作分析这样的实时应用。但是Continuuity的首席执行官Jon Gray表示,一些应用仍然要求MapReduce的批量处理架构。 Continuuity Developer Suite 1.7还提供了一些用于流式实时分析、定位和个性化以及异常检测的应用模板。 Datameer首次展示大数据分析软件 Datameer发布了面向企业用户的Datameer 3.0数据集成和分析软件。该版本增加了“智能分析”功能,可以从Hadoop中保存的大量复杂数据中自动找出模型和关联性。
Datameer 3.0采用四种机器学习的技术:聚类、决策树、列依赖性和建议。虽然这些通常是数据科学家涉足的领域,但是被集成到了Datameer软件中,这样企业用户就可以将其作为一项自助服务使用。 Datameer 3.0将在未来几个月内提供给用户进行beta测试。 Hortonwork社区预览支持Yarn的HDP 2.0平台 Hortonworks将在社区中预览下一代支持Yarn(下一代Hadoop数据处理框架)的Hortonworks Data Platform。 作为ASF Hadoop项目的一部分,Yarm旨在实现多个用户实例,而不是单一的数据集。HDP 2.0社区预览版本中支持Yarn,将让Hortonworks的合作伙伴和客户能够使用这项新技术,参与到最终规范的制定中,Hortonworks营销副总裁Dave McJannet这样表示。 Kognitio推出第八代分析平台