超文本浏览框与载入网页内容

超文本浏览框与载入网页内容
互联网的时间,千变万化,如何接连在一起呢?这不依赖浏览器之功,易语言中的超文本浏览框,就是一个IE 6内核的浏览器,可以执行javascript,CSS,HTML等代码,并支持浏览网页,下面去实战一下。
拖出一个超文本浏览框,并以几个按钮,设置如图:
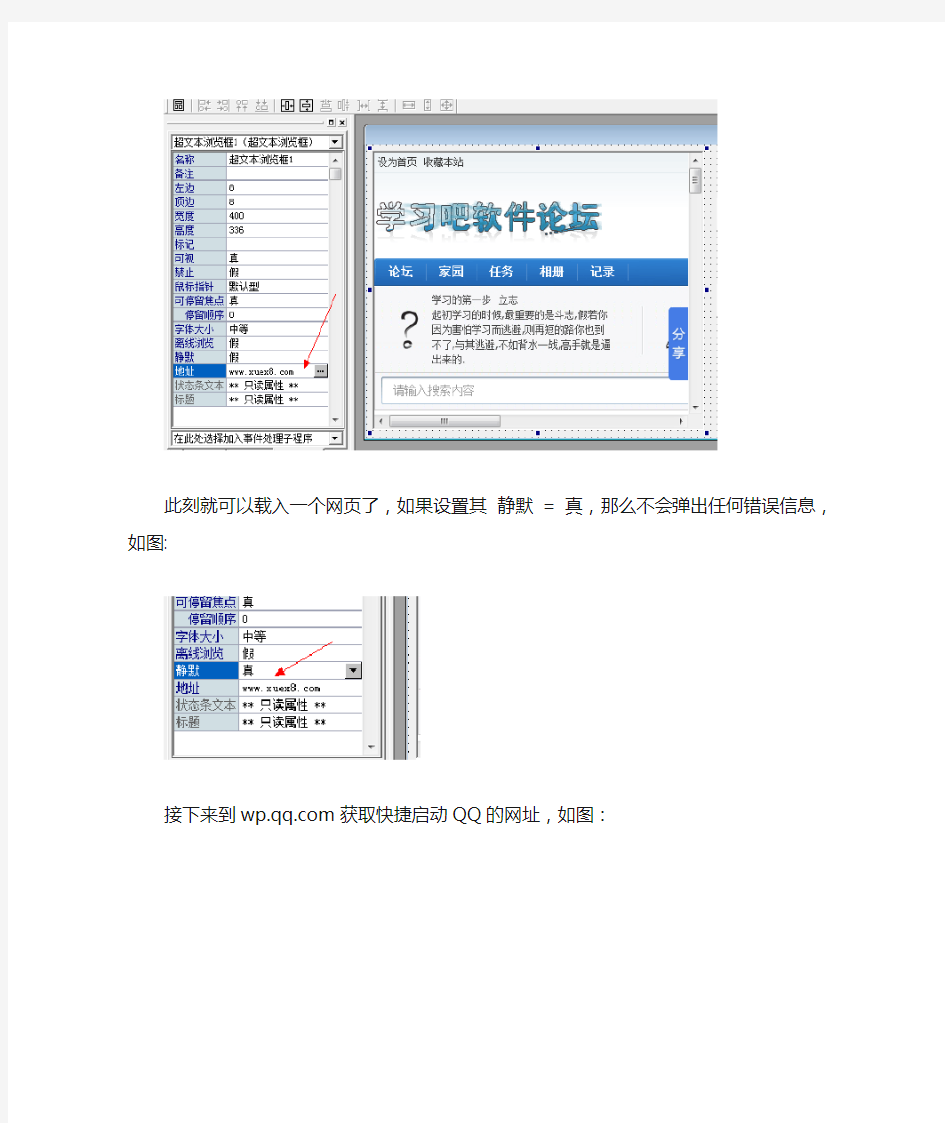
首先看它的属性,修改其地址,如图:
此刻就可以载入一个网页了,如果设置其静默= 真,那么不会弹出任何错误信息,如图:
接下来到https://www.360docs.net/doc/e317655225.html,获取快捷启动QQ的网址,如图:
截取其地址,一般都在href = “网址”上面,然后双击QQ聊天按钮,进入代码编辑,如图:
输入代码:
超文本浏览框1.地址=“https://www.360docs.net/doc/e317655225.html,/msgrd?v=3&uin=853698704”后面的帐号你懂的!
选择一键加群,如图:
这里重复了,就不演示了!
下面来演示如何载入视频,打开一个视频网址:
https://www.360docs.net/doc/e317655225.html,/u53/v_ODg2ODc5Mzg.html
然后复制分享的SWF,如图:
复制其地址,然后到载入视频按钮里,如图:
输入代码:
超文本浏览框1.地址=“https://www.360docs.net/doc/e317655225.html,/v_ODg2ODc5Mzg.swf”运行后就能载入一个视频了,如图:
这就是视频的载入,超文本浏览框是支持SWF的!
网页文字不能复制的几种解决方法 很多朋友遇到一些网页不能复制,感到头疼。现将几种解决办法总结于后,希望给你带来一些方便。 (1)禁用脚本。单击IE浏览器的“工具/Internet选项”菜单,进入“安全”标签页,单击“自定义级别”按钮,在打开的“安全设置”对话框中,将所有“脚本”选项禁用,确定后按F5键刷新网页,你就会发现那些无法选取的文字可以选取了。注意的是在采集到了自己需要的内容后,记得给脚本解禁,否则会影响我们浏览网页。只要禁用活动脚本就可以了,但是,如果你要复制到你的网站,哪知就不适用了,因为同时你的网站的编辑器将不能使用。 (2)打开网页后点“文件”将网页另存为到桌面上以后,单击右键后有“编辑”这样就可以用word编辑了。 (3)把整个网页保存成文本文件方法如下:打开要保存的网页>点文件--另存为-然后在保存类型中选择文本文件(*.txt) >然后保存就好了(4)单击IE窗口中“文件”菜单,选择“使用Microsoft FrontPage编辑”,在FrontPage中复制,还不行就用“文件”“另存为”,然后在FrontPage中打开。
(5)直接按住“Ctrl+A”键将网页中的全部内容选中,接着单击“编辑” 菜单的“复制”命令,然后将这些内容粘贴到Word文档或记事本中,再从Word文档或记事本中选取需要的文字进行复制。 (6)用非IE浏览器就可以了,比如foxfire浏览器或其它都可以. (7)用左键选择,Ctrl+C复制,然后打开记事本,Ctrl+V粘贴。对图片无效图片的按print screen抓屏,在画笔里粘贴。点Print Screen SysR q键.这是全屏接图.然后到程序----附件-----画图工具-----编辑里面去,按个粘贴.这样把你要的东西复制下来。 (8)按住Ctrl键,然后用鼠标选重,然后复制。 (9)将浏览器的安全级别调至最高,重开IE,试试。安全级别最高的时候,一切控件和脚本均不能运行,再厉害的网页限制手段统统全部作废。 (10)首先复制网页地址,然后打开Word,依次单击“文件/打开”,弹出“打开”窗口。在“文件名”中用“Ctrl+V”粘贴入已复制的网页地址,再单击“打开”按钮,这里Word就会自动连接到网站。在打开网页之前,可能会弹出“Word 没有足够的内存,此操作完成后无法撤消。是否继续?”的提示窗口,单击“是”,即弹出新的窗口,询问是否信任文件来源,再单击“是”后,Word会自动链接到对应的服务器并打开网页,这时我们就可以选中其中的文字进行复制粘贴了。
怎么样在将网页上的内容快速保存到印象笔记 印象 如何将网页上的信息快速整理并保存,使用印象笔记是一个好选择。可是,只能复制+粘贴吗?那样既麻烦又可能将广告等不需要的内容复制过来,有没有更好的方法? 其实,使用印象笔记官方推出的一款名为“印象笔记·剪藏”(以下简称“剪藏”)的浏览器插件,可以快速而轻松地将在网页上发现的任何内容保存到印象笔记中。 目前,剪藏插件支持IE、Chrome、Firefox和Safari浏览器。
工具/原料 Windows XP/Vista/7/8 IE9以上版本/Firefox/Chrome最新版 在IE浏览在IE浏览器中使用剪藏 访问印象笔记官方网站(https://www.360docs.net/doc/e317655225.html,/),下载并安装印象笔记电脑客户端软件。 安装完成后,印象笔记会自动在IE中添加相应的印象笔记剪藏工具插件(加载项)。如果你使用IE10浏览器,在安装完成后可能看不到剪藏工具的按钮,那么可以在浏览器工具栏空白处点击鼠标右键,在弹出的菜单中选中“命令栏”。
以后在IE浏览器中看到需要保存的网页时,只需要点击工具栏上的“印象笔记?剪藏”按钮。 你还可以点击鼠标右键,在弹出的菜单中点击“保存到印象笔记4”。
第一次使用时,请输入你注册印象笔记账户的用户名和密码。 印象笔记会自动识别网页中的主体内容区域,你可以根据需要调整并采集到不同的笔记本中。
在Firefox浏览器中使用剪藏 点击Firefox左上角的菜单按钮,选择“附加组件”。 在“获取附加组件”页面中搜索关键字“evernote”。 找到Evernote Web Clipper,点击旁边的“安装”按钮安装,
如何抓取网页数据,以抓取安居客举例 互联网时代,网页上有丰富的数据资源。我们在工作项目、学习过程或者学术研究等情况下,往往需要大量数据的支持。那么,该如何抓取这些所需的网页数据呢? 对于有编程基础的同学而言,可以写个爬虫程序,抓取网页数据。对于没有编程基础的同学而言,可以选择一款合适的爬虫工具,来抓取网页数据。 高度增长的抓取网页数据需求,推动了爬虫工具这一市场的成型与繁荣。目前,市面上有诸多爬虫工具可供选择(八爪鱼、集搜客、火车头、神箭手、造数等)。每个爬虫工具功能、定位、适宜人群不尽相同,大家可按需选择。本文使用的是操作简单、功能强大的八爪鱼采集器。以下是一个使用八爪鱼抓取网页数据的完整示例。示例中采集的是安居客-深圳-新房-全部楼盘的数据。 采集网站:https://https://www.360docs.net/doc/e317655225.html,/loupan/all/p2/ 步骤1:创建采集任务 1)进入主界面,选择“自定义模式”
如何抓取网页数据,以抓取安居客举例图1 2)将要采集的网址复制粘贴到网站输入框中,点击“保存网址”
如何抓取网页数据,以抓取安居客举例图2 步骤2:创建翻页循环 1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。将页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”,以建立一个翻页循环
如何抓取网页数据,以抓取安居客举例图3 步骤3:创建列表循环并提取数据 1)移动鼠标,选中页面里的第一个楼盘信息区块。系统会识别此区块中的子元素,在操作提示框中,选择“选中子元素”
如何抓取网页数据,以抓取安居客举例图4 2)系统会自动识别出页面中的其他同类元素,在操作提示框中,选择“选中全部”,以建立一个列表循环
https://www.360docs.net/doc/e317655225.html, 网页链接提取方法 网页链接的提取是数据采集中非常重要的部分,当我们要采集列表页的数据时,除了列表标题的链接还有页码的链接,数据采集只采集一页是不够,还要从首页遍历到末页直到把所有的列表标题链接采集完,然后再用这些链接采集详情页的信息。若仅仅靠手工打开网页源代码一个一个链接复制粘贴出来,太麻烦了。掌握网页链接提取方法能让我们的工作事半功倍。在进行数据采集的时候,我们可能有提取网页链接的需求。网页链接提取一般有两种情况:提取页面内的链接;提取当前页地址栏的链接。针对这两种情况,八爪鱼采集器均有相关功能实现。下面介绍一个网页链接提取方法。 一、八爪鱼提取页面内的超链接 在网页里点击需要提取的链接,选择“采集以下链接地址”
https://www.360docs.net/doc/e317655225.html, 网页链接提取方法1 二、八爪鱼提取当前地址栏的超链接 从左边栏拖出一个提取数据的步骤出来(如果当前页已经有其他的提取字段,这一步可省略)点击“添加特殊字段”,选择“添加当前页面网址”。可以看到,当前地址栏的超链接被抓取下来
https://www.360docs.net/doc/e317655225.html, 网页链接提取方法2 而批量提取网页链接的需求,一般是指批量提取页面内的超链接。以下是一个使用八爪鱼批量提取页面内超链接的完整示例。 采集网站: https://https://www.360docs.net/doc/e317655225.html,/search?initiative_id=tbindexz_20170918&ie=utf8&spm=a21 bo.50862.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=手表&suggest=history_1&_input_charset=utf-8&wq=&suggest_query=&source=sugg est
网上资料库——网页信息的保存 一、教学内容分析 本课内容是在上一节《答案轻松找——网页的浏览》的基础上,进一步让学生学会使用浏览器保存我们所搜索到的图片、文字等信息,在自主探究与实践的过程中,培养同学们对信息收集、处理的能力,使学生在自主学习、合作探究的过程中获得全面发展。 二、教学对象分析 本课的教学对象是小学四年级的学生。学生基本掌握了IE浏览器的使用,并具有访问网页的经验,他们对于利用浏览器上网搜索信息有浓厚的兴趣。由于是异地教学,学生们仅仅是初步学会使用自己的用户名和密码登陆Moodle网络学习平台。四年级学生的自主学习能力正在逐步形成,教师应积极引导学生开展合作探究,鼓励学生创造性地自主学习,使学生养成自主学习、合作探究的学习习惯。在上一节《答案轻松找——网页的浏览》中,学生们已经学会了IE浏览器的使用,这节课就是在此基础上让学生学习保存网页、图片、文字信息的方法。 三、教学目标 1、知识与技能 (1)进一步掌握浏览网页的操作; (2)学会保存网页、文字、图片的操作。 2、过程和方法 (1)任务驱动; 让学生在完成任务的过程中循序渐进地学会保存网页的信息。 (2)合作探究; 通过多种形式的合作、互助、互学、探究,充分调动学生的学习积极性,及时解决学习中遇到的难题。 (3)交互式教学。 利用Moodle网络学习空间构建“一对一”交互式教学环境,针对每个学生的特点、需要,及时给予学生学习上的辅导和帮助,促进学生的全面发展。 3、情感态度和价值观 (1)激发学生对信息技术的浓厚兴趣; (2)培养学生勇于探索、创新的精神,让学生体会到合作学习的喜悦;(3)培养学生热爱祖国、服务社会的精神。 四、教学重点及难点 1、教学重点: 学会保存网页、文字、图片的操作。 2、教学难点: 学会分类保存信息,学会多种保存信息的方法,在交流合作中提高信息素养和能力。
国内主要信息抓取软件盘点 近年来,随着国内大数据战略越来越清晰,数据抓取和信息采集系列产品迎来了巨大的发展 机遇,采集产品数量也出现迅猛增长。然而与产品种类快速增长相反的是,信息采集技术相 对薄弱、市场竞争激烈、质量良莠不齐。在此,本文列出当前信息采集和数据抓取市场最具 影响力的六大品牌,供各大数据和情报中心建设单位采购时参考: TOP.1 乐思网络信息采集系统 乐思网络信息采系统的主要目标就是解决网络信息采集和网络数据抓取问题。是根据用户自定义的任务配置,批量而精确地抽取因特网目标网页中的半结构化与非结构化数据,转化为结构化的记录,保存在本地数据库中,用于内部使用或外网发布,快速实现外部信息的获取。 主要用于:大数据基础建设,舆情监测,品牌监测,价格监测,门户网站新闻采集,行业资讯采集,竞争情报获取,商业数据整合,市场研究,数据库营销等领域。 TOP.2 火车采集器 火车采集器是一款专业的网络数据采集/信息挖掘处理软件,通过灵活的配置,可以很轻松迅速地从网页上抓取结构化的文本、图片、文件等资源信息,可编辑筛选处理后选择发布到网站后台,各类文件或其他数据库系统中。被广泛应用于数据采集挖掘、垂直搜索、信息汇聚和门户、企业网信息汇聚、商业情报、论坛或博客迁移、智能信息代理、个人信息检索等领域,适用于各类对数据有采集挖掘需求的群体。 TOP.3 熊猫采集软件 熊猫采集软件利用熊猫精准搜索引擎的解析内核,实现对网页内容的仿浏览器解析,在此基础上利用原创的技术实现对网页框架内容与核心内容的分离、抽取,并实现相似页面的有效比对、匹配。因此,用户只需要指定一个参考页面,熊猫采集软件系统就可以据此来匹配类似的页面,来实现用户需要采集资料的批量采集。 TOP.4 狂人采集器 狂人采集器是一套专业的网站内容采集软件,支持各类论坛的帖子和回复采集,网站和博客文章内容抓取,通过相关配置,能轻松的采集80%的网站内容为己所用。根据各建站程序
我为开源做贡献,网页正文提取——Html2Article 2014-1-7 14:38|发布者: 红黑魂|查看: 16722|评论: 4|原作者: StanZhai|来自: 博客园 摘要: 为什么要做正文提取一般做舆情分析,都会涉及到网页正文内容提取。对于分析而言,有价值的信息是正文部分,大多数情况下,为了便于分析,需要将网页中和正文不相干的部分给剔除。可以说正文提取的好坏,直接影响了分 ... 为什么要做正文提取 一般做舆情分析,都会涉及到网页正文内容提取。对于分析而言,有价值的信息是正文部分,大多数情况下,为了便于分析,需要将网页中和正文不相干的部分给剔除。可以说正文提取的好坏,直接影响了分析结果的好坏。 对于特定的网站,我们可以分析其html结构,根据其结构来获取正文信息。先看一下下面这张图: 正文部分,不同的网站,正文所在的位置不同,并且Html的结构也不同,对于 爬虫而言,抓取的页面是各种各样的,不可能针对所有的页面去写抓取规则来提取正文内容,因此需要一种通用的算法将正文提取出来。
现有的网页正文提取算法 ?基于标签用途的正文提取算法(比如title或h1,h2标签一般用作标题,p一 般表示正文段落,根据标签的含义去提取正文) ?基于标签密度判定(这个简单,说白了就是字符统计,正文部分html标签的密度比较低,确定一个阈值,按照标签密度提取正文部分) ?基于数据挖掘思想的网页正文抽取方法(这里会涉及到统计学和概率论的一些知识,在高深点就成了机器学习了,没有深入研究) ?基于视觉网页块分析技术的正文抽取(CV这种高端大气上档次的东西,岂是 我等这么容易就能研究明白的。虽然实现上复杂,但就提取效果而言,这种方法提取的精度还是不错的) 前2中方法还是比较容易实现的,主要是处理简单,先前我把标签密度的提取算法实现了,但实际用起来错误率还是蛮高的;后2种方法在实现上就略复杂了,从算法效率上讲应该也高不了哪去。 我们需要的是一种简单易实现的,既能保证处理速度,提取的准确率也不错的算法。于是结合前两种算法,研究网页html页面结构,有了一种比较好的处理思 路,权且叫做基于文本密度的正文提取算法吧。后来从网上找了一下类似的算法,发现也有使用类似的处理方法来处理正文提取的,不过还是有些不同。接下来跟大家分享一下这个算法的一些处理思想。 网页分析 我任意取了百度,搜狐,网易的一篇新闻类网页,拿来作分析。 先看一篇百度的文章 任正非为什么主动与我合影,https://www.360docs.net/doc/e317655225.html,/article/2011 首先请求这个页面,然后过滤到所有的html标签,只保留文本信息,我们可以 看到正文信息集中在一下位置:
网页内容无法复制怎么解决 平时我们在浏览别人的网站的时候可能会想要去复制别人网站内容,但有的时候还有遇到内容复制不了的状况。碰到网页内容无法复制怎么办呢?下面小编就和大家分享,来欣赏一下吧。 网页内容无法复制解决方法 复制源代码: 1,我们打开需要复制内容的页面。然后点击浏览器左上角的查看-源文件!!(这里用i e8做演示!) 2,点击源文件之后我们就能看到这个页面的源代码了。我们可以往下拖动找到你需要的不能复制的内容。我们也可以使用快捷键C t r l+F来查找! 百度快照复制: 1,这个是使用百度快照的方法。不过这个需要这个页面被百度收录才行。把网址复制到百度搜索里面。然后点击网站标题后面的百度快照! 2,进入百度快照即可复制网页里面不能复制的内容了! 1,用i e打开你的网站、然后点击左上角的文件。然后选择用w p s表格编辑!有的会显示的用e x c e l表格
编辑!!看自己电脑安装的啥! 2,然后在弹出的表格编辑里面就能看到网站所有的文字了。需要复制的文字就可以选择复制啦! 针对脚本屏蔽设置: 1,有的网页中嵌入了j a v a s c r i p t!通过编程手段屏蔽了复制。我们只要点击I E右上角的工具I n t e r n e t选项菜单,进入安全标签页,选择自定义级别! 2,然后将所有脚本全部禁用!!返回到网页刷新一下即可复制网站内容了。在复制完了自己需要的内容后,一定要给脚本解禁,否则会影响到我们浏览网页。 网页字体无法复制怎么办 一、就是保存网页,然后复制 二、在查看-原代码-下看但所要的文字 三、就是换了浏览器,要知道禁用S C R I P T,你换个浏览器就O K 四、用左键选择,C t r l+C复制,然后打开记事本, C t r l+V粘贴。对图片无效图片的按p r i n t s c r e e n抓屏,在画笔里粘贴。点P r i n t S c r e e n S y s R q键.这是全屏接图.然后到程序----附件-----画图工具-----编辑里面去,按个粘贴.
https://www.360docs.net/doc/e317655225.html, 最全的网页图片采集方法 1、图片采集 在八爪鱼中,采集图片有以下几大步 1、先采集网页图片的地址链接url 2、通过八爪鱼提供的专用图片批量下载工具将URL转化为图片 八爪鱼图片批量下载工具:https://https://www.360docs.net/doc/e317655225.html,/s/1c2n60NI 2、常见应用情景 1)非瀑布流网站纯图片采集 采集示例:豆瓣网图片采集教程https://www.360docs.net/doc/e317655225.html,/tutorial/tpcj-7 2)瀑布流网站纯图片采集 这类瀑布流网站的采集需要按下面的步骤对采集规则进行设置: ①点击采集规则打开网页步骤的高级选项; ②勾选页面加载完成后下滚动; ③填写滚动的次数及每次滚动的间隔; ④滚动方式设置为:直接滚动到底部; 完成上面的规则设置后,再对页面中图片的url进行采集
https://www.360docs.net/doc/e317655225.html, 采集示例:百度网图片采集教程https://www.360docs.net/doc/e317655225.html,/tutorial/bdpiccj 3)文章图文采集 需要将文章里的文字和图片都采集下来,一般有两种方法 方法1:判断条件,设置判断条件分别采集文字和图片 采集示例:https://www.360docs.net/doc/e317655225.html,/tutorial/txnewscj 方法2:先整体采集文字,再循环采集图片 采集示例:https://www.360docs.net/doc/e317655225.html,/tutorial/ucnewscj 3、教程目的 采集图片URL这个步骤,以上图片采集教程中都有详细说明,不再赘述。本文将重点讲解图片采集的采集技巧和注意事项。 4、采集图片URL操作步骤 以下演示一个采集图片URL的具体操作步骤,以百度图片url采集为例。不同的网站图片url会遇到不同的情况,请大家灵活处理。
一般的网页我们用:文件——另存为——就可以搞定。 对于受到保护的网页,禁止另存为,禁止复制的,我们也不办法对付。 最简单的办法就是用word中打开中输入要保存的网址,然后保存下来就行了. 反正这个网址可以打开。 使用记事本查看网页的源代码: 方法同(1),打开记事本,在打开文件对话框中填写完整的网页地址,点击“确定”,就可以看到该页面的源代码了。对于那些不允许查看源文件的网页,这种方法很实用。实用技巧:网页保存另类方法看到好的网页,大家都想把它保存下来。通常,我们都是利用IE 本身的保存功能。但在很多时候,我们使用IE 的网页保存功能时,总会出现这样或那样的错误。或是长时间显示“正在保存……”却久无进展;或是表面上好像保存成功了,但当你想脱机浏览时,才发现:得到的是无效或错误网页。那么,这些问题该如何解决呢?下面我们就来看一看。1、长时间无进展在保存网页的时候,有时进度条前进速度非常缓慢。此时,不如先点击“取消”按钮中断保存,稍后再重新进行。但是,如果是由于服务器太忙而影响到了保存进程,那可以先作断线处理。在断线后实施保存,此时是从IE 缓存中提取文件,速度要快得多。不过,一定要保证网页内容已经全部显示完毕再断线,否则网页内容会不完整。2、提示保存成功却无法浏览这种情况往往是由网站的一些保护措施引起的。可以这样解决:按“Ctrl+A”选择网页全部内容,或拖动鼠标,只选择需要的部分,单击鼠标右键选择“复制”,然后打开Word,单击“编辑→粘贴”,即可将网页保存下来。当遇到网页文字无法用鼠标拖动复制的情况时,你可以点击IE 的“工具/Internet选项”菜单,进入“安全”标签,选择“自定义级别”,将所有脚本全部禁用,刷新!然后,你就可以用鼠标拖动进行复制了。3、窗口没有保存菜单有的网页打开后没有IE菜单,无法使用“文件→另存为”保存网页。最典型的例子就是各种广告窗口,如想把这样的网页保存下来,可以按照下面的方法。按下“Ctrl+N”组合键,你会发现:桌面上弹出了一个新窗口,不仅包含了原窗口内容,而且IE菜单一应俱全。现在,你可以利用IE本身的保存功能来保存它了。4、使用同步功能你还可以使用IE 的“同步”功能,把网页添加到收藏夹中,同样可以起到保存网页的目的。方法是:在联网状态下,点击“收藏→添加到收藏夹”命令。当出现“添加到收藏夹”窗口时,勾选“允许脱机使用”项。若点击旁边的“自定义”按钮,还可以作相关设置,比如可以设置保存链接的层数。再点击“确定”按钮,即可进行“同步”操作。这样,你就可以在下网之后脱机浏览“收藏”菜单中相应的网页了 破解部分网站对鼠标右键的限制大家在上网时是否碰到过这样的情况:当你在某个网站看到网页上有精美图片或者精彩文字想保存时,一按鼠标右键就弹出个窗口,上面写着XXX版权所有、禁止使用右键之类的话,要不然就是你一点鼠标右键就出现添加到收藏夹的窗口,碰到这样的情况你是怎么办的呢?让我来教你一些破解方法。第一种情况,出现版权信息类的。破解方法如下:在页面目标上按下鼠标右键,弹出限制窗口,这时不要松开右键,将鼠标指针移到窗口的“确定”按钮上,同时按下左键。现在松开鼠标左键,限制窗口被关闭了,再将鼠标
网页抓取工具如何进行http模拟请求 在使用网页抓取工具采集网页是,进行http模拟请求可以通过浏览器自动获取登录cookie、返回头信息,查看源码等。具体如何操作呢?这里分享给大家网页抓取工具火车采集器V9中的http模拟请求。许多请求工具都是仿照火车采集器中的请求工具所写,因此大家可以此为例学习一下。 http模拟请求可以设置如何发起一个http请求,包括设置请求信息,返回头信息等。并具有自动提交的功能。工具主要包含两大部分:一个MDI父窗体和请求配置窗体。 1.1请求地址:正确填写请求的链接。 1.2请求信息:常规设置和更高级设置两部分。 (1)常规设置: ①来源页:正确填写请求页来源页地址。 ②发送方式:get和post,当选择post时,请在发送数据文本框正确填写发布数据。 ③客户端:选择或粘贴浏览器类型至此处。 ④cookie值:读取本地登录信息和自定义两种选择。 高级设置:包含如图所示系列设置,当不需要以上高级设置时,点击关闭按钮即可。 ①网页压缩:选择压缩方式,可全选,对应请求头信息的Accept-Encoding。 ②网页编码:自动识别和自定义两种选择,若选中自定义,自定义后面会出现编
码选择框,在选择框选择请求的编码。 ③Keep-Alive:决定当前请求是否与internet资源建立持久性链接。 ④自动跳转:决定当前请求是否应跟随重定向响应。 ⑤基于Windows身份验证类型的表单:正确填写用户名,密码,域即可,无身份认证时不必填写。 ⑥更多发送头信息:显示发送的头信息,以列表形式显示更清晰直观的了解到请求的头信息。此处的头信息供用户选填的,若要将某一名称的头信息进行请求,勾选Header名对应的复选框即可,Header名和Header值都是可以进行编辑的。 1.3返回头信息:将详细罗列请求成功之后返回的头信息,如下图。 1.4源码:待请求完毕后,工具会自动跳转到源码选项,在此可查看请求成功之后所返回的页面源码信息。 1.5预览:可在此预览请求成功之后返回的页面。 1.6自动操作选项:可设置自动刷新/提交的时间间隔和运行次数,启用此操作后,工具会自动的按一定的时间间隔和运行次数向服务器自动请求,若想取消此操作,点击后面的停止按钮即可。 配置好上述信息后,点击“开始查看”按钮即可查看请求信息,返回头信息等,为避免填写请求信息,可以点击“粘贴外部监视HTTP请求数据”按钮粘贴请求的头信息,然后点击开始查看按钮即可。这种捷径是在粘贴的头信息格式正确的前提下,否则会弹出错误提示框。 更多有关网页抓取工具或网页采集的教程都可以从火车采集器的系列教程中学习借鉴。
网页无法复制的最简单绝招 很多资料性的网络文章,往往在网页禁止使用“复制”“粘贴”命令。 破解方法很简单:单击IE浏览器的“工具”——“internet选项”——“安全”,将其中的“internet”的安全级别设为最高级别,“确定”后刷新网页即可。安全级别最高的时候,一切控件和脚本均不能运行,再厉害的网页限制手段统统全部作废。 **绝密技巧 复制网页所有内容的捷径制网页所有内容的最简单方法 有时在网上、论坛里,看见有图文教程。重要资料!想保存下来,放在自己的电脑里!用复制,肯定是不行的!以IE收藏嘛.有的又无法收藏.怎么办呢.. 用Word就能解决一切! 第一打开Word 第二文件->打开,在文件名的框内。 把的要保存的网址复制进去。 ========================================================== ========================================================= 第三不用我再说了.Word自己开始连接要收藏的那个网站了!而且当你按住ctrl键并同时点击文章中的连接时,可以如果网页一样打开。 ========================================================== ===========================================================
去除@网页文字@干扰码的两种方法清除文字水印的方法比较多,主要有两种:手动在Word里简易清除、利用浏览器插件来清除。 1.颜色替换巧除“干扰码”在选中网页中的一段预复制内容(含有文字水印)后会发现在每行的前、后端都插入有数字和字母构成的“干扰码”。将它们“Ctrl+V” 粘贴在Word中,但由于不少网页默认“干扰码”字符为白色,所以无法看到这些干扰码(如图1)。 ===================================================== ===================================================== 我们可以将Word更改为“蓝底白字”的显示模式清晰地看到无效字符了,再利用其字体颜色的差异着手一次性清除“干扰码”。点击“编辑→替换”,在“查找内容”栏下点击“高级”,在界面最下端的“格式”中选择“字体”,在“所有字体→字体颜色”下拉列表中选择白色,确认后退回上一界面,而“替换为”栏无需任何设置,留空即可。点击“全部替换”按钮后,就将全部删除那些“干扰码”。干扰码为其他颜色的也可以用类似的方法清除。 2.使用浏览器插件屏蔽网页“干扰码”使用Maxthon浏览器的用户可以安装了《清除烦恼》这个插件(可从Maxthon网站下载)直接屏蔽网页上的“文字水印”,功能菜单如下图所示。启用该 插件后,点击工具栏上的“清除烦恼”向下箭头按钮,在弹出菜单中选择“清除隐藏文字”,而后再 按常规方法执行复制粘贴操作即可。清除烦恼插件菜单而使用Firefox浏览器的用户也可使用CleanHide 屏蔽文字水印。它的最新版本为CleanHide 1.0.3,适用于Firefox: 1.5~2.0.0.*版本。安装完毕后, 重启Firefox。而后点击程序菜单栏“查看→工具栏→定制”,在弹出窗口的列表中将“清除隐藏文字” 按钮拖曳到工具栏上。此后,当遇到含有“文字水印”的页面时点击该按钮即可将其清除。 IE右下角图标有何用IE右下角地球图标的妙用常使用IE的朋友都知道,在IE的窗口的右下方状态栏中,有一个小小的地球图标,在它的右边还有个"internet"字样显示。许多人并没有注意它,其实,它还是很用的,在网吧就非常有用。我们知道在网吧中由于网吧管理软件的限制。是禁止下载文件的, 利用IE右下角的地球图标就可以突破这种限制,实行自由下载。具体方法:双击地球图标,会调出:"internet 安全性属性"的对话框,在该窗口选择"internet自定义级别",弹出"安全设置"窗口,找到"文件下载"和"字体下载",选择"启动",这样一来就可以突破网吧中的禁止下载文件的限制。
网页及图片的保存方法 一、将网页以四种方式保存会有不同效果。 1.网页,全部是将你现打开的网页文字、内容等所有都保存下来。 2.Web档案,单一文件将你打开的网页文字、格式等保存下来,但是没有图片。 3.网页,仅HTML与第一种网页,全部是一种保存方式。 4.文本文件保存是将网页所有文字保存下来。 1 网页,全部(*.htm *.html) 如果存这种格式,IE将当前浏览页面保存到指定位置的文件夹中,同时生成一个与文件同命的文件夹和单 独扩展名为.htm的文件,在该文件夹中当前页面上显示的文件资料。(比如:图片一般为GIF,JPG格式)样式表 扩展名为?.CSS?和脚本语言(JScript Script文件后缀为.js)。使用这种方法可以保存相关的较多网页,并 在脱机浏览时,可以看到看到的效果与原来的网页一样,但有些链接有时候打不开的。而且删除保存的的扩展名为.htm的文件或文件夹中的任何一个,另一个也会被自动删除。 2 Web档案单一文件(mht) 这种格式把当前网页上的所有的内容都保存在一个用。MHT作为扩展名的单一的文件中,而不会出现第一种 方式那样的文件夹,这个文件由于保留了网页的所有内容,所以也比上一种方式的文件要大的多(其实主要是因 为图片占用的空间比较多),不过只有一个文件,所以相对来讲更方便保存。 3 Web页仅(*.htm *.html)方式 与第一种方式相比,这种方式只是生成一个HTML文件而不会创建同名的文件夹,所以它将不保存网页中的图 片等信息(用第一种方式保存在文件夹下的内容),如果你只是希望保存网页中的文字内容或者当前网页的纯粹 的文字,可以保存为这种格式,不过它所占的空间相对于第一种也比较小。 4 文本文件(*.txt) 如果用?文本文件(*.txt)?这种方式保存,IE则会删除当前页面中所有的页面格式,(包括标签,表格等),只把文字内容留下;和web页,仅(*.htm *.html)格式不同的是,它最后得到的是一个纯文本的文件(后 者的文字仍然在页面的原来的位置上)。这种方式保存的文件是最小的,也最便于和其它程序交换数据(交换
https://www.360docs.net/doc/e317655225.html, 网页数据抓取方法详解 互联网时代,网络上有海量的信息,有时我们需要筛选找到我们需要的信息。很多朋友对于如何简单有效获取数据毫无头绪,今天给大家详解网页数据抓取方法,希望对大家有帮助。 八爪鱼是一款通用的网页数据采集器,可实现全网数据(网页、论坛、移动互联网、QQ空间、电话号码、邮箱、图片等信息)的自动采集。同时八爪鱼提供单机采集和云采集两种采集方式,另外针对不同的用户还有自定义采集和简易采集等主要采集模式可供选择。
https://www.360docs.net/doc/e317655225.html, 如果想要自动抓取数据呢,八爪鱼的自动采集就派上用场了。 定时采集是八爪鱼采集器为需要持续更新网站信息的用户提供的精确到分钟的,可以设定采集时间段的功能。在设置好正确的采集规则后,八爪鱼会根据设置的时间在云服务器启动采集任务进行数据的采集。定时采集的功能必须使用云采集的时候,才会进行数据的采集,单机采集是无法进行定时采集的。 定时云采集的设置有两种方法: 方法一:任务字段配置完毕后,点击‘选中全部’→‘采集以下数据’→‘保存并开始采集’,进入到“运行任务”界面,点击‘设置定时云采集’,弹出‘定时云采集’配置页面。
https://www.360docs.net/doc/e317655225.html, 第一、如果需要保存定时设置,在‘已保存的配置’输入框内输入名称,再保存配置,保存成功之后,下次如果其他任务需要同样的定时配置时可以选择这个配置。 第二、定时方式的设置有4种,可以根据自己的需求选择启动方式和启动时间。所有设置完成之后,如果需要启动定时云采集选择下方‘保存并启动’定时采集,然后点击确定即可。如果不需要启动只需点击下方‘保存’定时采集设置即可。
如何复制网页上无法复制的图片 很多资料性的网络文章,往往在网页禁止使用“复制”、“粘贴”命令。其解决方法如下:方法一、最简单的破解方法:单击IE浏览器的“工具”——“internet 选项”——“安全”,将其中的“internet”的安全级别设为最高级别,“确定”后刷新网页即可。 安全级别最高的时候,一切控件和脚本均不能运行,再厉害的网页限制手段统统全部作废。 方法二、破解网页不能复制的方法: 但对有些网页却不管用因为他们并不用脚本限制我们的(好象起点就是这样),他们在网页中加了如下代码: 禁止左键〈body onselectstart='return false'〉 禁止右键〈body oncontextmenu=self.event.returnvalue=false〉 结合起来禁止左右键 〈body oncontextmenu=self.event.returnvalue=false onselectstart='return false'>左右键被禁止了自然无法复制什么的了,在浏览器里查看源文件,搜索oncontextmenu.false之类的代码删除,再刷新就可以了。 现在一般禁止网页复制的代码就是在
里加入以下代码: 以前我是用这样解决的,就是先把网页另存为,保存在本地之后,再对本地的那个页面用记事本编辑,把上面这段代码去掉就可以复制内容了。 方法三、破解网页不能复制的方法:用word破解 某些网页中的文字无论用什么方法都不能选中复制。因为被禁止复制了,如果要得到其中的某段文字,虽然可以用降低安全级别、查看源文件等方法来实施,但我们还可以用常用的Word来更为简单方便的获取。https://www.360docs.net/doc/e317655225.html, 网页内容如何批量提取 网站上有许多优质的内容或者是文章,我们想批量采集下来慢慢研究,但内容太多,分布在不同的网站,这时如何才能高效、快速地把这些有价值的内容收集到一起呢? 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集】,以【新浪博客】为例,教大家如何使用八爪鱼采集软件采集新浪博客文章内容的方法。 采集网站: https://www.360docs.net/doc/e317655225.html,/s/articlelist_1406314195_0_1.html 采集的内容包括:博客文章正文,标题,标签,分类,日期。 步骤1:创建新浪博客文章采集任务 1)进入主界面,选择“自定义采集”
https://www.360docs.net/doc/e317655225.html, 2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/e317655225.html, 步骤2:创建翻页循环
https://www.360docs.net/doc/e317655225.html, 1)打开网页之后,打开右上角的流程按钮,使制作的流程可见状态。点击页面下方的“下一页”,如图,选择“循环点击单个链接”,翻页循环创建完成。(可在左上角流程中手动点击“循环翻页”和“点击翻页”几次,测试是否正常翻页。) 2)由于进入详情页时网页加载很慢,网址一直在转圈状态,无法立即执行下一个步骤,因此在“循环翻页”的高级选项里设置“ajax加载数据”,超时时间设置为5秒,点击“确定”。
https://www.360docs.net/doc/e317655225.html, 步骤3:创建列表循环 1)鼠标点击列表目录中第一个博文,选择操作提示框中的“选中全部”。 2)鼠标点击“循环点击每个链接”,列表循环就创建完成,并进入到第一个循环项的详情页面。
网页文字无法复制怎么办 很多资料性的网络文章,往往在网页禁止使用“复制”“粘贴”命令。 破解方法很简单:单击IE浏览器的“工具”——“internet选项”——“安全”,将其中的“internet”的安全级别设为最高级别,“确定”后刷新网页即可。安全级别最高的时候,一切控件和脚本均不能运行,再厉害的网页限制手段统统全部作废。 绝密技巧 复制网页所有内容的最简单方法 有时在网上、论坛里,看见有图文教程。重要资料!想保存下来,放在自己的电脑里!用复制,肯定是不行的!以IE收藏嘛.有的又无法收藏.怎么办呢..用Word就能解决一切! 第一打开Word 第二文件->打开,在文件名的框内。 把的要保存的网址复制进去。 ========================================================== ========================================================= 第三不用我再说了.Word自己开始连接你要收藏的那个网站了!而且当你按住ctrl键并同时点击文章中的连接时,可以如果网页一样打开。
========================================================== =========================================================== 去除@网页文字@干扰码的两种方法 清除文字水印的方法比较多,主要有两种:手动在Word里简易清除、利用浏览器插件来清除。 1.颜色替换巧除“干扰码” 在选中网页中的一段预复制内容(含有文字水印)后会发现在每行的前、后端都插入有数字和字母构成的“干扰码”。将它们“Ctrl+V” 粘贴在Word中,但由于不少网页默认“干扰码”字符为白色,所以无法看到这些干扰码(如图1)。 =====================================================
将网页上的内容保存到电脑上面的各种方法 1、最常用的方法:“选定”网页内容后,右击,选“另存为”,找到存放地址后,保存即可; 2、如从网页上复制过来的内容成乱码,可在“另存为”中,将格式选为txt格式后保存,然后重新排版;要是网上文件有图片,可以先把文字复制到“文本文档”后,再复制到WORD文档,然后在上面插入图片; 3、如禁用了右键菜单(即右键菜单中“另存为”不可用),可选中某网页内容后,点键盘上的组合键Ctri+C进行复制,再打开一文档,点Ctri+V粘贴即可); 4、若上法不可用,可试试先点击左键,不松手,再点击右键。接着松开左键,最后松开右键。如出现快捷菜单,点“另存为”即可保存; 5、用上面三法还是不能复制时: A、先将该网址保存在收藏夹中后(在打开的这个网页中,点收藏、确定); B、随意打开一个WORD文档(也可以是空白或新建文档),点工具栏中“打开”按钮,在左边的“查找范围”下面点“收藏夹”; C、在收藏夹下面显示的内容中,找到你刚才保存的网址(即打开了要复制内容的网址),选中要复制的内容并右击,点复制; D、再打开要存放下载内容的文档,右击后选“粘贴”、保存即可。 6、在网页中,点/查看/源文件,就可打开一个记事本文件,在其中可找到所需要的文字并右击/选“复制”/保存到文档中即可; 7、有时一些网页对源码进行了加密,其复制方法为: 启动IE浏览器,鼠标点击“工具→Internet选项”菜单,选择“安全”标签,点击“自定义级别”按钮,在出现的窗口中将所有脚本全部禁用,然后按F5刷新页面(这时所有的JavaScript代码都被禁用了,就可对其进行任意的复制、粘贴*操作)。提示:在收集到自己需要的内容后,要给脚本解禁,否则会影响浏览其它网页。 8、用专业软件下载:对加密网页,可到华军软件园下个“网文快爪”来下载; 9、可以在百度上搜索“冰点下载”。然后将冰点下载下载并安装到电脑上。使用冰点下载下载你需要的文档。方法是:将你要下载的文档的下载页面的网址复制到冰点下载上开始任务就可以了。 10、如果是百度文库的内容就好办了。只要在网页上的wenku前面加上wap,然后刷新页面就可以免费下载了。
import java.io.*; import https://www.360docs.net/doc/e317655225.html,.URL; import https://www.360docs.net/doc/e317655225.html,.URLConnection; public class TestURL { public static void main(String[] args) throws IOException { test4(); test3(); test2(); test(); } /** * 获取URL指定的资源。 * * @throws IOException */ public static void test4() throws IOException { URL url = new URL("https://www.360docs.net/doc/e317655225.html,/attachment/200811/200811271227767778082.jpg"); //获得此URL 的内容。 Object obj = url.getContent(); System.out.println(obj.getClass().getName()); } /** * 获取URL指定的资源 * * @throws IOException */ public static void test3() throws IOException { URL url = new URL("https://www.360docs.net/doc/e317655225.html,/down/soft/45.htm"); //返回一个URLConnection 对象,它表示到URL 所引用的远程对象的连接。 URLConnection uc = url.openConnection(); //打开的连接读取的输入流。 InputStream in = uc.getInputStream(); int c; while ((c = in.read()) != -1) System.out.print(c); in.close(); } /** * 读取URL指定的网页内容
网页内容不能选中复制的解决方法大全(转)--很实用哦 2010-01-16 11:50网页内容不能选中复制的解决方法大全(转)以前我也遇到过网页内容不能选定的时候,那时候又确实需要里面的文字,怎么办呢?最后还不是用的一个笨办法,就是选定“查看”菜单下的“源文件”,就会打开一个写字本,里面就有我们需要的文字,但同时也会有很多我们不需要的代码,我们只好一段一段代码的删,时间花得太多,且排版不好,有没有更好的办法呢?? 后来用了很多办法,发现一个办法最简单,也差不多百试百灵,就是选“工具”菜单里的“internet选项……”,就会打开一个对话框,选第二个选项卡“安全”在里面选“自定义级别……”就会打开“安全设置”对话框,在里面找到“脚本”里的“活动脚本”把它设为“禁选”项后,单击“确定”两次,再刷新以前不能选定的页面即可。 网页内容不能选中复制的解决方法大全 破解网页不能复制的方法 现在有很多网页不能复制,现收集一些可取方法: 一屏蔽右键的破解方法 1.出现版权信息类的情况 破解方法:在页面目标上按下鼠标右键,弹出限制窗口,这时不要松开右键,将鼠标指针移到窗口的确定按钮上,同时按下左键现在松开鼠标左键,限制窗口被关闭了,再将鼠标移到目标上松开鼠标右键 2.出现添加到收藏夹的情况 破解方法:在目标上点鼠标右键,出现添加到收藏夹的窗口,这时不要松开右键,也不要移动鼠标,而是使用键盘的Tab键,移动光标到取消按钮上,按下空格键,这时窗口就消失了,松开右键看看,wonderful!右键恢复雄风了!将鼠标移动到你想要的功能上,点击左键吧3.超链接无法用鼠标右键弹出在新窗口中打开菜单的情况 破解方法:这时用上面的两种方法无法破解,看看这一招:在超链接上点鼠标右键,弹出窗口,这时不要松开右键,按键盘上的空格键,窗口消失了,这时松开右键,可爱的右键菜单又出现了,选择其中的在新窗口中打开就可以了 4在浏览器中点击查看菜单上的源文件命令,这样就可以看到html源代码了不过如果网页使用了框架,你就只能看到框架页面的代码,此方法就不灵了,怎么办?你按键盘上的Shift+F10组合键试试, 5看见键盘右Ctrl键左边的那个键了吗?按一下试试,右键菜单直接出现了! 6在屏蔽鼠标右键的页面中点右键,出现限制窗口,此时不要松开右键,用左手按键盘上的ALT+F4组合键,这时窗口就被关闭了,松开鼠标右键,菜单出现了! 二不能复制的网页解决方法 1启动IE浏览器后,用鼠标点击工具中的Internet选项菜单,选择安全选项卡,接下来点击自定义级别按钮,在弹出的窗口中将所有脚本全部选择禁用,确定然后按F5刷新页面,这时我们就能够对网页的内容进行复制粘贴等操作当你收集到自己需要的内容后,再用相同步骤给网页脚本解禁,这样就不会影响到我们浏览其他网页了你或者选文件另存,格式为TXT,然后排版也可以 2左键限制,不让拖动,无法选择内容,怎么办,简单,点右键,点查看源文件,将之前的东东全部DEL,点另存为*HTM,打开,是不是可以拖了 3点??查看----原文件----使用替换法把也替换成空格,再保存为htm格式的文件,注意在