POI文本自动分类

POI文本自动分类
目的
根据现有样本集,建立自动分类模型。对未知数据进行自动分类。
基本概念
文本:一条POI或一篇文章。
特征项T:文本中基本的语言单位词,这里假设每个各不相干。
项的权重W:表示它在文本中的重要程度
向量空间模型:由n个特征项T和其对应的权重W组成的n维欧式空间。由于特征项T之间各不相干,可以假设特征项T为不同坐标轴,二权重W表示在特征项T上的坐标。
相似度:两个文本的内容之间的相关程度,通常用相似度来表示。在向量空间模型中可以借助于向量之间的距离来表示文献间的相似度。
方法
建立样本模型
选取优质的样本集合,尽量保证样本中各分类分布比较均匀。
对每条POI进行分词,计算各个特征项T的权重。
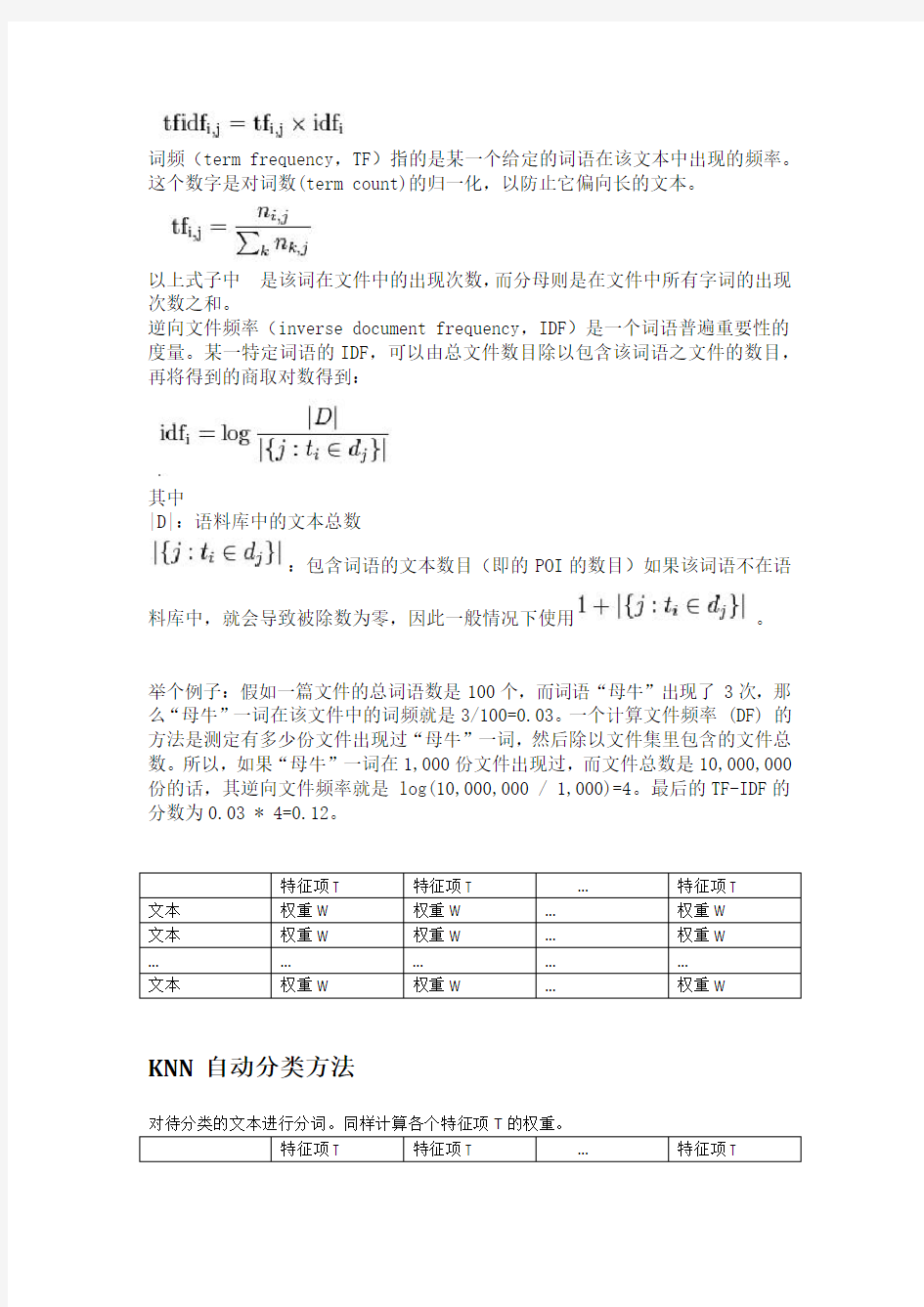
常用的词条权值计算方法为TF-IDF 函数
词频(term frequency,TF)指的是某一个给定的词语在该文本中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文本。
以上式子中是该词在文件中的出现次数,而分母则是在文件中所有字词的出现次数之和。
逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:
其中
|D|:语料库中的文本总数
:包含词语的文本数目(即的POI的数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用。
举个例子:假如一篇文件的总词语数是100个,而词语“母牛”出现了3次,那么“母牛”一词在该文件中的词频就是3/100=0.03。一个计算文件频率 (DF) 的方法是测定有多少份文件出现过“母牛”一词,然后除以文件集里包含的文件总数。所以,如果“母牛”一词在1,000份文件出现过,而文件总数是10,000,000份的话,其逆向文件频率就是 log(10,000,000 / 1,000)=4。最后的TF-IDF的分数为0.03 * 4=0.12。
KNN自动分类方法
1.计算新文本和样本集中各个文本的相似度。
相似度使用两个在向量空间模型中的距离来计算,计算公式为
2.取出与新文本最相似的K个文本。
其中,K 值的确定目前没有很好的方法,一般采用先定一个初始值,然后根据实验测试的结果调整K 值,一般初始值定为几百到几千之间。
3.在新文本的K 个邻居中,依次计算每类的权重,计算公式为
其中,x为新文本的特征向量,Sim(x,di)为相似度计算公式,与上一步骤的计算公式相同,而y(di,Cj)为类别属性函数,即如果di 属于类Cj ,那么函数值为1,否则为0。
4.比较类的权重,将文本分到权重最大的那个类别中。
KNN的不足
当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。
该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
评估方法
选取10W规模的两份POI样品集,其中一个用来建立样本模型,对另一份进行自动分类。对换两份样品集,再进行一次测试。统计自动分类的准确率。
其他评估方法:召回率、F1测试值
使用四维北京的POI,测试结果如下。
第一次测试分类正确69783,准确率69.78%
第二次测试分类正确70252,准确率70.25%
影响分类效果的一些因素
样本数据要竟可能的丰富且各个分类的数据分布是否均匀。但数据量越大,分类的数据会越慢
POI名称分词的准确性,大量POI中的名称无法被准确分词
权值的合理性。通常POI的末尾词更能表达大类信息,但不太适合小类特别多的情况
K值的选取
决策树
POI名称的长短,短POI相对比较难分类
类别越多,分类的难度越大
其他分类方法
贝叶斯算法
向量机
神经网络算法
决策树
参考文档
自动分类模型及算法研究
https://www.360docs.net/doc/f315448260.html,/view/b3d981030740be1e650e9adf.html
向量空间模型
https://www.360docs.net/doc/f315448260.html,/view/46aacd363968011ca30091a5.html
使用KNN算法的文本分类
https://www.360docs.net/doc/f315448260.html,/view/6457280a79563c1ec5da71e8.html
中文文本自动分类算法研究
https://www.360docs.net/doc/f315448260.html,/p-99033347917.html
基于位置和类别结合模式的一种文本自动分类模型
https://www.360docs.net/doc/f315448260.html,/view/ce0041bd960590c69ec3762b.html 基于决策树的分类算法研究和应用
https://www.360docs.net/doc/f315448260.html,/p-371363709394.html
文本分类综述
山西大学研究生学位课程论文(2014 ---- 2015 学年第 2 学期) 学院(中心、所):计算机与信息技术学院 专业名称:计算机应用技术 课程名称:自然语言处理技术 论文题目:文本分类综述 授课教师(职称):王素格(教授) 研究生姓名:刘杰飞 年级:2014级 学号:201422403003 成绩: 评阅日期: 山西大学研究生学院 2015年 6 月2日
文本分类综述 摘要文本分类就是在给定的分类体系下,让计算机根据给定文本的内容,将其判别为事先确定的若干个文本类别中的某一类或某几类的过程。文本分类在冗余过滤、组织管理、智能检索、信息过滤、元数据提取、构建索引、歧义消解、文本过滤等方面有很重要的应用。本文主要介绍文本分类的研究背景,跟踪国内外文本分类技术研究动态。介绍目前文本分类过程中的一些关键技术,以及流形学习在文本分类中降维的一些应用。并且讨论目前文本分类研究面临的一些问题,及对未来发展方向的一些展望。 关键词文本分类;特征选择;分类器;中文信息处理 1.引言 上世纪九十年代以来,因特网以惊人的速度发展起来,到现在我们进入大数据时代互联网容纳了海量的各种类型的数据和信息,包括文本、声音、图像等。这里所指的文本可以是媒体新闻、科技、报告、电子邮件、技术专利、网页、书籍或其中的一部分。文本数据与声音和图像数据相比,占用网络资源少,更容易上传和下载,这使得网络资源中的大部分是以文本(超文本)形式出现的。如何有效地组织和管理这些信息,并快速、准确、全面地从中找到用户所需要的信息是当前信息科学和技术领域面临的一大挑战。基于机器学习的文本分类系统作为处理和组织大量文本数据的关键技术,能够在给定的分类模型下,根据文本的内容自动对文本分门别类,从而更好地帮助人们组织文本、挖掘文本信息,方便用户准确地定位所需的信息和分流信息。 利用文本分类技术可以把数量巨大但缺乏结构的文本数据组织成规范的文本数据,帮助人们提高信息检索的效率。通过对文本信息进行基于内容的分类,自动生成便于用户使用的文本分类系统,从而可以大大降低组织整理文档耗费的人力资源,帮助用户快速找到所需信息。因此文本分类技术得到日益广泛的关注,成为信息处理领域最重要的研究方向之一。 2.文本分类技术的发展历史及现状 2.1文本分类技术发展历史 国外自动分类研究始于1950年代末,早期文本分类主要是基于知识工程,通过手工定义一些规则来对文本进行分类,这种方法费时费力,还需要对某一领域有足够的了解,才能提炼出合适的规则。H.P.Luhn在这一领域进行了开创性的研究,他将词频统计的思想用于文本分类中。这一时期,主要是分类理论的研究,并将文本分类应用用于信息检索。在这一段时期,提出了很多经典文本分类的数学模型。比如1960年Maron在Journal of ASM上发表了有关自动分类的第一篇论文“On relevance Probabilitic indexing and informarion retriral”,这是Maron和Kuhns提出概的率标引(Probabilitic indexing )模型在信息检
藏文字符的分类与功能描述
【专题名称】语言文字学 【专题号】H1 【复印期号】2011年03期 【原文出处】《西藏研究》(拉萨)2010年5期第75~85页 【英文标题】A Classification and Description for Tibetan Characters 【作者简介】江荻(1954- ),博士、研究员,中国社会科学院民族学与人类学研究所,博士生导师,主要从事藏语计算语言学、 汉藏语言学研究(北京100081); 燕海雄(1980- ),博士、助理研究员,中国社会科学院民族学与人类学研究所,主要从事藏语计算语言学、汉藏语言学 研究(北京100081)。 【内容提要】藏文字符除了字母类符号,尚有大量其他文本符号,这些符号的名称、性质与功能历来未作勘定,积疑甚多。藏文文本符号总体上可以分为三大类:藏文(本体)字符、梵源藏文字符、其他文本图形符号。藏文字符专指藏文创制时期以及藏文历 史应用中依据语言变化所创制的符号,通常所说的30个辅音字母和4个元音符号以及相应变体都在此列。除此外,藏文 数字符和标点符号也可归入此类。梵源藏文字符是通过新创藏文字形表示藏语中没有的梵文读音形式和文字形式的字符, 形成了所谓的藏(文)化梵文字符。其他文本图形符号包括藏族自身创造的图形以及来源于梵文文本的图形,其基本特点是 不表达语言声音,仅表示某种文本形式意义,或者以图形方式指示事物的意义。这类符号有吟诵示意符、吟诵会意符、占 星符、装饰符,等等。以上藏文字符大多已收入ISO/IEC国际标准藏文字符基本集,对字符的分类有助于进一步展开藏文 计算机处理研究。 There exist so many scripts and symbols in Tibetan characters, yet their names, graphic forms, origins, functions and applied domains are still not clear and always with some confusions so far. Tibetan characters may be divided into three parts: Tibetan original characters, Tibetan transliterated characters from Sanskrit and other picture symbols. Each of the scripts or symbols is given a name and other features according to its traditional ideas and functions, and with explanations to its classification. Classifing Tibetan characters is important to the research of computer processing of Tibetan characters. 一、引言 藏文文本中除了表达语言声音的字符之外,还存在大量其他类型的符号,这些符号有些具有表达语言功能的作用,有些 则只是文本的装饰性图案。本文将对所有藏文文本符号进行分类研究,确定它们的名称、来源、功能和应用领域。 根据目前从各类文献中收集的藏文符号和图形的分析,藏文文本中的字符与图形可以划分为两大类,即文字符号与非文 字符号。所谓文字符号,是指能够书写语言声音的符号,还包括描写声音连接、停顿和结束的符号;非文字符号可以表示某种事 物或观念意义,但与语言声音无关。文字符号包括藏文字符和梵源藏文字符等;非文字符号包括篇章符、敬重符、历算符,等 等。图1是藏文文本符号的初步分类。 二、藏文本体字符 (一)辅音字符 从来源上看,藏文文字符号包括藏文字符和梵源藏文字符。藏文字符最核心的部分是藏文初创时期的30个辅音字符, 这些符号从古至今一直沿用,都能表达语言的声音,称为基本字符或本体字符。从功能上看,辅音字符大多能独立成字或独立成 词,含有辅音文字的内涵,简单地说即包含了元音a。另一类能够独立使用的符号是数字符号,也能表达语言声音和指称意义。 从结构上看,辅音字符与数字符号具有独立的字形,在文本中出现只要符合构字和语法规则,不受其他符号制约。 图1:藏文文本符号分类
文本分类入门(五)训练Part 2
将样本数据成功转化为向量表示之后,计算机才算开始真正意义上的“学习”过程。 再重复一次,所谓样本,也叫训练数据,是由人工进行分类处理过的文档集合,计算机认为这些数据的分类是绝对正确的,可以信赖的(但某些方法也有针对训练数据可能有错误而应对的措施)。接下来的一步便是由计算机来观察这些训练数据的特点,来猜测一个可能的分类规则(这个分类规则也可以叫做分类器,在机器学习的理论著作中也叫做一个“假设”,因为毕竟是对真实分类规则的一个猜测),一旦这个分类满足一些条件,我们就认为这个分类规则大致正确并且足够好了,便成为训练阶段的最终产品——分类器!再遇到新的,计算机没有见过的文档时,便使用这个分类器来判断新文档的类别。 举一个现实中的例子,人们评价一辆车是否是“好车”的时候,可以看作一个分类问题。我们也可以把一辆车的所有特征提取出来转化为向量形式。在这个问题中词典向量可以为: D=(价格,最高时速,外观得分,性价比,稀有程度) 则一辆保时捷的向量表示就可以写成 vp=(200万,320,9.5,3,9) 而一辆丰田花冠则可以写成 vt=(15万,220,6.0,8,3) 找不同的人来评价哪辆车算好车,很可能会得出不同的结论。务实的人认为性价比才是评判的指标,他会认为丰田花冠是好车而保时捷不是;喜欢奢华的有钱人可能以稀有程度来评判,得出相反的结论;喜欢综合考量的人很可能把各项指标都加权考虑之后才下结论。
可见,对同一个分类问题,用同样的表示形式(同样的文档模型),但因为关注数据不同方面的特性而可能得到不同的结论。这种对文档数据不同方面侧重的不同导致了原理和实现方式都不尽相同的多种方法,每种方法也都对文本分类这个问题本身作了一些有利于自身的假设和简化,这些假设又接下来影响着依据这些方法而得到的分类器最终的表现,可谓环环相连,丝丝入扣,冥冥之中自有天意呀(这都什么词儿……)。 比较常见,家喻户晓,常年被评为国家免检产品(?!)的分类算法有一大堆,什么决策树,Rocchio,朴素贝叶斯,神经网络,支持向量机,线性最小平方拟合,kNN,遗传算法,最大熵,Generalized Instance Set等等等等(这张单子还可以继续列下去)。在这里只挑几个最具代表性的算法侃一侃。Rocchio算法 Rocchio算法应该算是人们思考文本分类问题时最先能想到,也最符合直觉的解决方法。基本的思路是把一个类别里的样本文档各项取个平均值(例如把所有“体育”类文档中词汇“篮球”出现的次数取个平均值,再把“裁判”取个平均值,依次做下去),可以得到一个新的向量,形象的称之为“质心”,质心就成了这个类别最具代表性的向量表示。再有新文档需要判断的时候,比较新文档和质心有多么相像(八股点说,判断他们之间的距离)就可以确定新文档属不属于这个类。稍微改进一点的Rocchio算法不尽考虑属于这个类别的文档(称为正样本),也考虑不属于这个类别的文档数据(称为负样本),计算出来的质心尽量靠近正样本同时尽量远离负样本。Rocchio算法做了两个很致命的假设,使得它的性能出奇的差。一是它认为一个类别的文档仅仅聚集在一个质心的周围,实际情况往往不是如此(这样的数据称为线性不可分的);二是它假设训练数据是绝
基于机器学习的文本分类方法
基于机器学习算法的文本分类方法综述 摘要:文本分类是机器学习领域新的研究热点。基于机器学习算法的文本分类方法比传统的文本分类方法优势明显。本文综述了现有的基于机器学习的文本分类方法,讨论了各种方法的优缺点,并指出了文本分类方法未来可能的发展趋势。 1.引言 随着计算机技术、数据库技术,网络技术的飞速发展,Internet的广泛应用,信息交换越来越方便,各个领域都不断产生海量数据,使得互联网数据及资源呈现海量特征,尤其是海量的文本数据。如何利用海量数据挖掘出有用的信息和知识,方便人们的查阅和应用,已经成为一个日趋重要的问题。因此,基于文本内容的信息检索和数据挖掘逐渐成为备受关注的领域。文本分类(text categorization,TC)技术是信息检索和文本挖掘的重要基础技术,其作用是根据文本的某些特征,在预先给定的类别标记(label)集合下,根据文本内容判定它的类别。传统的文本分类模式是基于知识工程和专家系统的,在灵活性和分类效果上都有很大的缺陷。例如卡内基集团为路透社开发的Construe专家系统就是采用知识工程方法构造的一个著名的文本分类系统,但该系统的开发工作量达到了10个人年,当需要进行信息更新时,维护非常困难。因此,知识工程方法已不适用于日益复杂的海量数据文本分类系统需求[1]。20世纪90年代以来,机器学习的分类算法有了日新月异的发展,很多分类器模型逐步被应用到文本分类之中,比如支持向量机(SVM,Support Vector Machine)[2-4]、最近邻法(Nearest Neighbor)[5]、决策树(Decision tree)[6]、朴素贝叶斯(Naive Bayes)[7]等。逐渐成熟的基于机器学习的文本分类方法,更注重分类器的模型自动挖掘和生成及动态优化能力,在分类效果和灵活性上都比之前基于知识工程和专家系统的文本分类模式有所突破,取得了很好的分类效果。 本文主要综述基于机器学习算法的文本分类方法。首先对文本分类问题进行概述,阐述文本分类的一般流程以及文本表述、特征选择方面的方法,然后具体研究基于及其学习的文本分类的典型方法,最后指出该领域的研究发展趋势。 2.文本自动分类概述 文本自动分类可简单定义为:给定分类体系后,根据文本内容自动确定文本关联的类别。从数学角度来看,文本分类是一个映射过程,该映射可以是一一映射,也可以是一对多映射过程。文本分类的映射规则是,系统根据已知类别中若干样本的数据信息总结出分类的规律性,建立类别判别公式或判别规则。当遇到新文本时,根据总结出的类别判别规则确定文本所属的类别。也就是说自动文本分类通过监督学习自动构建出分类器,从而实现对新的给定文本的自动归类。文本自动分类一般包括文本表达、特征选取、分类器的选择与训练、分类等几个步骤,其中文本表达和特征选取是文本分类的基础技术,而分类器的选择与训练则是文本自动分类技术的重点,基于机器学习的文本分来就是通过将机器学习领域的分类算法用于文本分类中来[8]。图1是文本自动分类的一般流程。
结合中文分词的贝叶斯文本分类
结合中文分词的贝叶斯文本分类 https://www.360docs.net/doc/f315448260.html,/showarticle.aspx?id=247 来源:[] 作者:[] 日期:[2009-7-27] 魏晓宁1,2,朱巧明1,梁惺彦2 (1.苏州大学,江苏苏州215021;2.南通大学,江苏南通226007) 摘要:文本分类是组织大规模文档数据的基础和核心。朴素贝叶斯文本分类方法是种简单且有效的文本分类算法,但是属性间强独立性的假设在现实中并不成立,借鉴概率论中的多项式模型,结合中文分词过程,引入特征词条权重,给出了改进Bayes方法。并由实验验证和应用本方法,文本分类的效率得到了提高。 1. Using Bayesian in Text Classification with Participle-method WEI Xiao-ning1,2,ZHU Qiao-ming1,LIANG Xing-yan2 (1.Suzhou University,Suzhou 215006,China;2.Nantong University,Nantong 226007,China) Abstract:Text classification is the base and core of processing large amount of document data.Native Bayes text classifier is a simple and effective text classification method.Text classification is the key technology in organizing and processing large amount of document data.The practical Bayes algorithm is an useful technique which has an assumption of strong independence of different properties.Based on the polynomial model,a way in feature abstraction considering word-weight and participle-method is introduced. At last the experiments show that efficiency of text classification is improved. 1.0引言 文档分类是组织大规模文档数据的基础和核心,利用计算机进行自动文档分类是自然语言处理和人工智能领域中一项具有重要应用价值的课题。现有的分类方法主要是基于统计理论和机器学习方法的,比较著名的文档分类方法有Bayes、KNN、LLSF、Nnet、Boosting及SVM等。 贝叶斯分类器是基于贝叶斯学习方法的分类器,其原理虽然较简单,但是其在实际应用中很成功。贝叶斯模型中的朴素贝叶斯算法有一个很重要的假设,就是属性间的条件独立[1][2],而现实中属性之间这种独立性很难存在。因此,本文提出了一种改进型的基于朴素贝叶斯网络的分类方法,针对于文本特征,结合信息增益于文本分类过程,实验表明文本分类的准确率在一定程度上有所提高。
文本分类概述
第一章绪论 1.1研究背景 当今的时代,是一个信息技术飞速发展的时代。随着信息技术的飞速发展,科学知识也在短时间内发生了急剧的、爆炸性的增长。 据1998年的资料显示[1],70年代以来,全世界每年出版图书50万种,每一分钟就有一种新书出版。80年代每年全世界发表的科学论文大约500万篇,平均每天发表包含新知识的论文为1.3万-1.4万篇;登记的发明创造专利每年超过30万件,平均每天有800-900件专利问世。近二十年来,每年形成的文献资料的页数,美国约1,750亿页。另据联合国教科文组织所隶属的“世界科学技术情报系统”曾做的统计显示,科学知识每年的增长率,60年代以来已从9.5%增长到10.6%,到80年代每年增长率达12.5%。据说,一位化学家每周阅读40小时,光是浏览世界上一年内发表的有关化学方面的论文和著作就要读48年。而2005年的资料显示[2],进入20世纪后全世界图书品种平均20年增加一倍,册数增加两倍。期刊出版物,平均10年增加一倍。科技文献年均增长率估计为13%,其中某些学科的文献量每10年左右翻一番,尖
端科技文献的增长则更快,约2-3年翻一番。 同时,伴随着Internet的迅猛发展,网站和网页数也在迅速增长,大约每年翻一番。据估计,目前全世界网页数已高达2000亿,而Google宣称其已索引250亿网页。在我国,中国互联网络信息中心从2001年起每年都对中文网页总数作统计调查,统计结果显示,中文网页总数已由2001年4月30日的159,460,056个发展到2005年12月31日的24亿个,增长之快可见一斑[3,4]。 从这些统计数字可以看出,我们被淹没在一个多么浩大的信息海洋里!然而信息的极大丰富并没有提高人们对知识的吸收能力,面对如此浩瀚的信息,人们越来越感觉无法快速找到需要的知识。这就是所谓的“信息是丰富的,知识是贫乏的”。 如何在这样一个巨大的信息海洋中更加有效的发现和使用信息以及如何利用这个信息宝库为人们提供更高质量和智能化的信息服务,一直是当前信息科学和技术领域面临的一大挑战。尽管用户对图像、音频和视频等信息资源的需求也在急剧增加,但文本仍然是最主要的非结构化和半结构化的信息资源。针对目前的出版物和网络信息大部分都以文本形式存在的状况,自动文本分类技术作为处理和组织大量文本数据
贝叶斯分类多实例分析总结
用于运动识别的聚类特征融合方法和装置 提供了一种用于运动识别的聚类特征融合方法和装置,所述方法包括:将从被采集者的加速度信号 中提取的时频域特征集的子集内的时频域特征表示成以聚类中心为基向量的线性方程组;通过求解线性方程组来确定每组聚类中心基向量的系数;使用聚类中心基向量的系数计算聚类中心基向量对子集的方差贡献率;基于方差贡献率计算子集的聚类中心的融合权重;以及基于融合权重来获得融合后的时频域特征集。 加速度信号 →时频域特征 →以聚类中心为基向量的线性方程组 →基向量的系数 →方差贡献率 →融合权重 基于特征组合的步态行为识别方法 本发明公开了一种基于特征组合的步态行为识别方法,包括以下步骤:通过加速度传感器获取用户在行为状态下身体的运动加速度信息;从上述运动加速度信息中计算各轴的峰值、频率、步态周期和四分位差及不同轴之间的互相关系数;采用聚合法选取参数组成特征向量;以样本集和步态加速度信号的特征向量作为训练集,对分类器进行训练,使的分类器具有分类步态行为的能力;将待识别的步态加速度信号的所有特征向量输入到训练后的分类器中,并分别赋予所属类别,统计所有特征向量的所属类别,并将出现次数最多的类别赋予待识别的步态加速度信号。实现简化计算过程,降低特征向量的维数并具有良好的有效性的目的。 传感器 →样本及和步态加速度信号的特征向量作为训练集 →分类器具有分类步态行为的能力 基于贝叶斯网络的核心网故障诊断方法及系统 本发明公开了一种基于贝叶斯网络的核心网故障诊断方法及系统,该方法从核心网的故障受理中心采集包含有告警信息和故障类型的原始数据并生成样本数据,之后存储到后备训练数据集中进行积累,达到设定的阈值后放入训练数据集中;运用贝叶斯网络算法对训练数据集中的样本数据进行计算,构造贝叶斯网络分类器;从核心网的网络管理系统采集含有告警信息的原始数据,经贝叶斯网络分类器计算获得告警信息对应的故障类型。本发明,利用贝叶斯网络分类器构建故障诊断系统,实现了对错综复杂的核心网故障进行智能化的系统诊断功能,提高了诊断的准确性和灵活性,并且该系统构建于网络管理系统之上,易于实施,对核心网综合信息处理具有广泛的适应性。 告警信息和故障类型 →训练集 —>贝叶斯网络分类器
《分类》文本:商品分类
《分类》商品分类 分类依据 商品分类依据是分类的基础。商品的用途、原材料、生产方法、化学成分、使用状态等是这些商品最本质的属性和特征,是商品分类中最常用的分类依据。 用途 一切商品都是为了满足社会上的一定用途而生产的,因此商品的用途是体现商品使用价值的标志,也是探讨商品质量的重要依据,因此被广泛应用于商品的研究、开发和流通。它不仅适合对商品大类的划分,也适用于商品种类、品种的进一步详细划分。 优点:按商品用途分类,便于比较相同用途的各种商品的质量水平和产销情况、性能特点、效用,能促使生产者提高质量、增加品种,并且能方便消费者对比选购,有利于生产、销售和消费的有机衔接。但对贮运部门和有多用途的商品不适用。 原材料 商品的原材料是决定商品质量和性能的重要因素,原材料的种类和质量不同,因而成分、性质、结构不同,使商品具有截然不同的特征。选择以原材料为标志的分类方法是商品的重要分类方法之一。此种分类方法适用那些原材料来源较多、且对商品性能起决定作用的商品。 以原料为标志分类的优点很多,它分类清楚,还能从本质上反映出各类商品的性能、特点,为确定销售、运输、储存条件提供了依据,有利于保证商品流通中的质量。但对那些用多种原材料组成的商品如汽车、电视机、洗衣机、电冰箱等不宜用原材料作为分类标志。 生产方法 很多商品即便采用相同的原材料,由于生产方法不同,也会使商品具有不同的质量特征,从而形成不同的品种。 按生产方法分类,特别适用于原料相同,但可选用多种工艺生产的商品,优点是因为生产方法、工艺不同,突出了商品的个性,有利于销售和工艺的革新。但对于那些虽生产方法有差别但商品性能、特征没实质性区别的商品不宜采用。如平板玻璃可用浮法或垂直引上法。 化学成分 由于商品中所含化学成分和种类和数量对商品质量、性能、用途等有着决定性的或密切的影响,故按化学成分的分类方法便于研究和了解商品的质量、特性、用途、效用和储存条件,是研究商品使用价值的重要分类方法。 有些商品,它们的主要成分虽然相同,但由于含有某种特殊成分,而使商品的质量、性
软件文档的作用和分类
软件文档的作用和分类 软件文档(document)也称文件,通常指的是一些记录的数据和数据媒体,它具有固定不变的形式,可被人和计算机阅读。它和计算机程序共同构成了能完成特定功能的计算机软件(有人把源程序也当作文档的一部分)。我们知道,硬件产品和产品资料在整个生产过程中都是有形可见的,软件生产则有很大不同,文档本身就是软件产品。没有文档的软件,不成其为软件,更谈不到软件产品。软件文档的编制(documentation)在软件开发工作中占有突出的地位和相当的工作量。高效率、高质量地开发、分发、管理和维护文档对于转让、变更、修正、扩充和使用文档,对于充分发挥软件产品的效益有着重要意义。然而,在实际工作中,文档在编制和使用中存在着许多问题,有待于解决。软件开发人员中较普遍地存在着对编制文档不感兴趣的现象。从用户方面看,他们又常常抱怨:文档售价太高、文档不够完整、文档编写得不好、文档已经陈旧或是文档太多,难于使用等等。究竟应该怎样要求它,文档应该写哪些,说明什么问题,起什么作用?这里将给出简要的介绍。 图文档桥梁作用 文档在软件开发人员、软件管理人员、维护人员、用户以及计算机之间的多种桥梁作用可从图中看出。软件开发人员在各个阶段中以文档作为前阶段工作成果的体现和后阶段工作的依据,这个作用是显而易见的。软件开发过程中软件开发人员需制定一些工作计划或工作报告,这些计划和报告都要提供给管理人员,并得到必要的支持。管理人员则可通过这些文档了解软件开发项目安排、进度、资源使用和成果等。软件开发人员需为用户了解软件的使用、操作和维护提供详细的资料,我们称此为用户文档。 以上三种文档构成了软件文档的主要部分。我们把这三种文档所包括的内容列在图6中。其中列举了十三个文档,这里对它们作一些简要说明: ·可行性研究报告:说明该软件开发项目的实现在技术上、经济上和社会因素上的可行性,评述为了合理地达到开发目标可供选择的各种可能实施的方案,说明并论证所选定实施方案的理由。 ·项目开发计划:为软件项目实施方案制定出具体计划,应该包括各部分工作的负责人员、开发的进度、开发经费的预算、所需的硬件及软件资源等。项目开发计划应提供给管理部门,并作为开发阶段评审的参考。 ·软件需求说明书:也称软件规格说明书,其中对所开发软件的功能、性能、用户界面及运行环境等作出详细的说明。它是用户与开发人员双方对软件需求取得共同理解基础上达成的协议,也是实施开发工作的基础。 ·数据要求说明书:该说明书应给出数据逻辑描述和数据采集的各项要求,为生成和维护系统数据文卷作好准备。 ·概要设计说明书:该说明书是概要设计阶段的工作成果,它应说明功能分配、模块划
贝叶斯算法(文本分类算法)java源码
package com.vista; import java.io.IOException; import jeasy.analysis.MMAnalyzer; /** * 中文分词器 */ public class ChineseSpliter { /** * 对给定的文本进行中文分词 * @param text 给定的文本 * @param splitToken 用于分割的标记,如"|" * @return 分词完毕的文本 */ public static String split(String text,String splitToken) { String result = null; MMAnalyzer analyzer = new MMAnalyzer(); try { result = analyzer.segment(text, splitToken); } catch (IOException e) { e.printStackTrace(); } return result; } } 停用词处理 去掉文档中无意思的词语也是必须的一项工作,这里简单的定义了一些常见的停用词,并根据这些常用停用词在分词时进行判断。 package com.vista;
/** * 停用词处理器 * @author phinecos * */ public class StopWordsHandler { private static String stopWordsList[] ={"的", "我们","要","自己","之","将","“","”",",","(",")","后","应","到","某","后","个","是","位","新","一","两","在","中","或","有","更","好",""};//常用停用词public static boolean IsStopWord(String word) { for(int i=0;i 使用kNN Model对文本进行自动分类 Using kNN model for automatic text categorization Soft Comput (2006) 10: 423–430 Gongde Guo · Hui Wang · David Bell Yaxin Bi · Kieran Greer 摘要kNN分类器和Rocchio分类器,在这两个著名的基于相似度学习方法的文本分类上 做了一项研究,在鉴别了每项技术的短处和长处后,提出一个基于kNN模型的新分类器,称为kNN Model ,它结合了kNN和Rocchio的优点。文章描述了这个文本分类的原型,它同时实现了kNN Model、kNN和Rocchio 。在两个常用的文本集(20-newsgroup和Reuters-21578数据集)上对不同的方法执行的实验性评价,实验结果显示所提出的基于kNN Model的方法表现超过了kNN和Rocchio,因此在一些应用上也是对kNN和Rocchio的一个不错替代方法。 关键字kNN Model , kNN , Rocchio , Text categorization , Performance 1 介绍 文本分类的任务是将文本文件指派为许多合适的类别。这种分类处理有很多应用,例如document routing,文档管理,文档传播。在传统的文档分类中,每个进来的文档都要由基于内容的域专家手工分类,完成这个任务需要大量的人力。为了促进文本分类的处理,就需要自动分类方案,其目标是建立可以用于将文本自动分类的模型。 已经有很多方法应用于文本分类,如Na?ve Bayes盖然性分类器(Na?ve Bayes probabilistic classi?ers)[2],决策树分类器(Decis ion tree classi?ers)[3],判断规则(Decision rules)[4],回归方法(Regression methods)[5],神经网络(Neural network)[6],kNN分类器(kNN classi?ers)[5,7],支持向量机(Support vector machine SVM)[8,9],Rocchio分类器(Rocchio classi?ers)[10,11] 。在许多应用中,例如,动态挖掘大型网页仓储(large web repositories),这些方案的计算效率通常被作为关键因素被考虑,Sebastiani在他的文本分类研究中指出这一点[12]。 在这些方法中,kNN和Rocchio被频繁的用到,并且它们都是基于相似度的(similarity-based)。kNN算法使用整个训练实例作为计算相似度的依据。对于一个要被分类的新文档d t离它最近的k个邻居被检索出来,这样形成d t的k个邻居,邻居间对d t的多数投票以决定它属于哪一类。然而,使用kNN,我们需要选择一个合适的k值,成功的分类非常依赖于这个值。此外,kNN是一个懒惰的学习方法(lazy learning method),因为它不需要建立学习模型,并且所有的计算都几乎集中在分类阶段,这也阻止了它应用于效率要求较高的领域,如动态挖掘大型网页仓储。然而kNN在文本分类上的应用从很早[12]就开始了,并且被评价为在路透社新闻专线故事(一个基本数据集)上用于文本分类是最有效的方法。 Rocchio方法在一定程度上可以处理这些问题。在它最简单的方式下,它通过总括实例对每个类别的贡献,使用泛化的实例(generalized instances属于一个类别实例的平均权值形成这个类的一个泛化的实例)作为模型来代替整个训练实例。这种方法高效并且容易实现,因为学习一个分类器基本上可以归结为求平均权值,对一个新实例进行分类仅需要计算新实例和泛化实例之间的内积。它是个基于相似度的算法,因为它使用这些泛化的实例作为计算 2.4Text CIassification One of the most important theories in the book Groundworkfor a General Theory of Translation coauthored by Reiss and V ermeer is Reiss?theory of text types.According to Reiss,text typology helps the translator specify the appropriate hierarchy of equivalence levels needed for a particular translation Skopos.Based on the dominant communicative functions,texts are categorized into informative texts,expressive texts and operative texts. The main function of informative texts is to inform the readers about objects and Phenomena in the real world.The choices of linguistic and stylistic forms are subordinate tO this function.In a translation where both the source text and the target text are informative,the translator should attempt to represent the original text correctly and completely.The translator should be guided by the dominant norms of the target language and culture in terms of stylistic choices.In a more recent description of her typology,geiss points out that the informative texts also include……purely phatic communication,where the actual information value is zero and the message is the communication process itself?(Reiss,qtd.in Nord,2001:38). Expressive texts can produce an aesthetic feeling on the reader and this effect has to be taken into account in translation.In such texts,the informative aspect is complemented or even overruled by the aesthetic aspects.If the target text is aimed to fall into the same category as the source text,the translator of an expressive text should manage to produce an analogous stylistic effect as the original. In operative texts,“both content and form are subordinate to the extralinguistic effect that the text is designed to achieve”(Nord,2001:38).Ifthetarget text is meant to belong to the same category,the translator of an operative text should attempt to bring the same reaction in the target audience regardless of changing the content and/or stylistic features of the original. 2.2Text Functions Related to the text type is the text function.Nord suggests four types of text functions:referential function;expressive function;appellative function and phatic function.The referential function iS similar to the function of the informative text.The referential function is mainly expressed by the denotative value of the lexical items in the text.IIl orderto make the referential function clear,the translator should coordinate the message with the model of the particular world involved which is determined by Cultural perspectives and traditions.As have mentioned above,according to Reiss’S text typology,the expressive function is restricted to the aesthetic aspects of literary or poetic texts.Differently,the expressive function in Nord’S model refers to the sender’S attitude toward the objects and phenomena of the world.One point should be given more attention is that the expressive function is sender-oriented.The sender’S opinions and attitudes are based on the value system of his own culture.hl intercultural interaction,if the source culture and the target culture are different,then problem will arise.For example,“hl India if a man compares the eyes of his wife to those of a cow, he expressed admiration for their beauty.In Germany,though,a woman would not be very pleased if her husband did the same”(Nord,2001:42).Appellative function means the Use of language to make the receiver feel to do something.Here the appellative corresponds with operative in Reiss’S typology.Different from the expressive function, Appellative function is receiver-oriented.“While the source text normally appeals to a source-culture reader’S susceptibility and experience,the appellative function of a translation is 毕业设计(论文)任务书 毕业设计(论文) 题目中文文本分类算法的设计及其实现 电信学院计算机系84班设计所在单位西安交通大学计算机系 西安交通大学本科毕业设计(论文) 毕业设计(论文)任务书 电信学院计算机系84 班学生丰成平 毕业设计(论文)工作自2013 年 2 月21 日起至2013 年 6 月20 日止毕业设计(论文)进行地点:西安交通大学 课题的背景、意义及培养目标 随着文本文件的增多,对其自动进行分门别类尤为重要。文本分类是指采用计算机程序对文本集按照一定的分类体系进行自动分类标记。文本分类器的设计通常包括文本的特征向量表示、文本特征向量的降维、以及文本分类器的设计与测试三个方面。本毕设论文研究文本分类器的设计与实现。通过该毕业设计,可使学生掌握文本分类器设计的基本原理及相关方法,并通过具体文本分类算法的设计与编程实现,提高学生的实际编程能力。 设计(论文)的原始数据与资料 1、文本语料库(分为训练集与测试集语料库)。 2、关于文本分类的各种文献(包括特征表示、特征降维、以及分类器设计)以及资料。 3、中科院文本分词工具(nlpir)。 4、文本分类中需要用到的各种分类方法的资料描述。 课题的主要任务 1.学习文本特征向量的构建方法及常用的降维方法。 2.学习各种分类器的基本原理及其训练与测试方法。 3.设计并编程实现文本分类器。 毕业设计(论文)任务书 4、对试验结果进行分析,得出各种结论。 5、撰写毕业论文。 6、翻译一篇关于文本分类的英文文献。 课题的基本要求(工程设计类题应有技术经济分析要求) 1、程序可演示。 2、对源代码进行注释。 3、给出完整的设计文档及测试文档。 完成任务后提交的书面材料要求(图纸规格、数量,论文字数,外文翻译字数等) 1、提交毕业论文 2、提交设计和实现的系统软件源程序及有关数据 3、提交外文资料翻译的中文和原文资料 主要参考文献: 自然语言处理与信息检索共享平台:https://www.360docs.net/doc/f315448260.html,/?action-viewnews-itemid-103 Svm(支持向量机)算法:https://www.360docs.net/doc/f315448260.html,/zhenandaci/archive/2009/03/06/258288.html 基于神经网络的中文文本分析(赵中原):https://www.360docs.net/doc/f315448260.html,/p-030716713857.html TF-IDF的线性图解:https://www.360docs.net/doc/f315448260.html,/blog-170225-6014.html 东南大学向量降维文献:https://www.360docs.net/doc/f315448260.html,/p-690306037446.html 指导教师相明 接受设计(论文)任务日期2013-02-21~2013-06-20 学生签名:使用kNN Model对文本进行自动分类
文本功能和分类
中文文本分类算法设计及其实现_毕业设计