R语言学习系列32-回归分析

27. 回归分析
回归分析是研究一个或多个变量(因变量)与另一些变量(自变量)之间关系的统计方法。主要思想是用最小二乘法原理拟合因变量与自变量间的最佳回归模型(得到确定的表达式关系)。其作用是对因变量做解释、控制、或预测。
回归与拟合的区别:
拟合侧重于调整曲线的参数,使得与数据相符;而回归重在研究两个变量或多个变量之间的关系。它可以用拟合的手法来研究两个变量的关系,以及出现的误差。
回归分析的步骤:
(1)获取自变量和因变量的观测值;
(2)绘制散点图,并对异常数据做修正;
(3)写出带未知参数的回归方程;
(4)确定回归方程中参数值;
(5)假设检验,判断回归方程的拟合优度;
(6)进行解释、控制、或预测。
(一)一元线性回归
一、原理概述
1. 一元线性回归模型:
Y=β0+β1X+ε
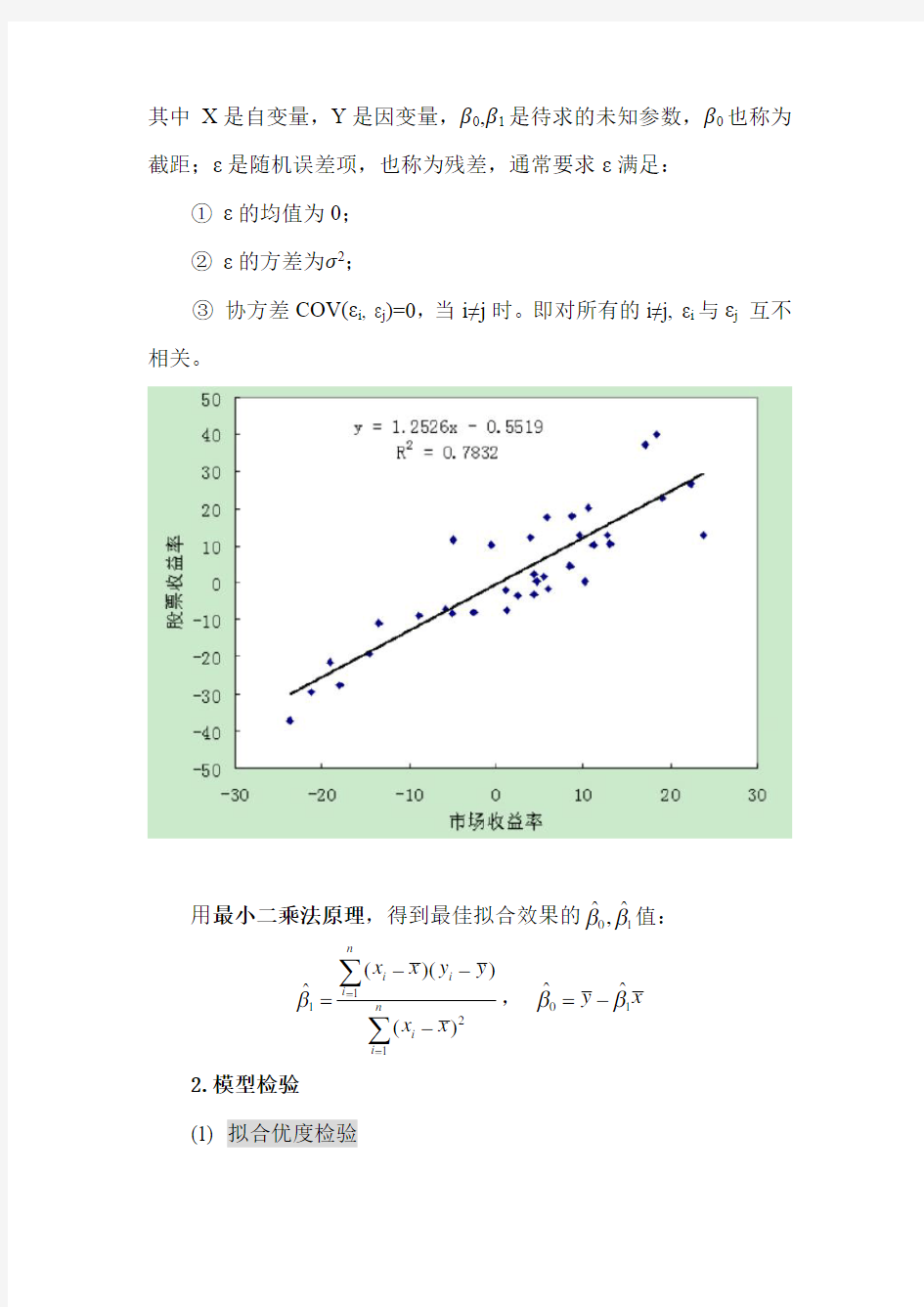
其中 X 是自变量,Y 是因变量,β0,β1是待求的未知参数,β0也称为截距;ε是随机误差项,也称为残差,通常要求ε满足:
① ε的均值为0;
② ε的方差为σ2;
③协方差COV(εi , εj )=0,当i≠j 时。即对所有的i≠j,εi 与εj 互不相关。
用最小二乘法原理,得到最佳拟合效果的01
??,ββ值: 1121()()?()n i i i n
i
i x x y y x x β==--=-∑∑,01
??y x ββ=- 2.模型检验
(1)拟合优度检验
计算R 2,反映了自变量所能解释的方差占总方差的百分比,值越大说明模型拟合效果越好。通常可以认为当R 2大于0.9时,所得到的回归直线拟合得较好,而当R 2小于0.5时,所得到的回归直线很难说明变量之间的依赖关系。
(2)回归方程参数的检验
回归方程反应了因变量Y 随自变量X 变化而变化的规律,若β1=0,则Y 不随X 变化,此时回归方程无意义。所以,要做如下假设检验:
H 0: β1=0, H 1: β1≠0;
① F 检验
若β1=0为真,则回归平方和RSS 与残差平方和ESS/(N-2)都是σ2的无偏估计,因而采用F 统计量:
来检验原假设β1=0是否为真。
②T 检验
对H 0: β1=0的T 检验与F 检验是等价的(t 2=F )。
3. 用回归方程做预测
得到回归方程01???Y X ββ=+后,预测X=x 0处的Y 值0010
???y x ββ=+. 0?y
的预测区间为:
其中t
的自由度为N-2.
α/2
二、R语言实现
使用lm()函数实现,基本格式为:
lm(formula, data, subset, weights, na.action,
method="qr", ...)
其中,formula为要拟合的回归模型的形式,一元线性回归的格式为:y~x,y表示因变量,x表示自变量,若不想包含截距项,使用y~x-1;
data为数据框或列表;
subset选取部分子集;
weights取NULL时表示最小二乘法拟合,若取值为权重向量,则用加权最小二乘法;
na.action设定是否忽略缺失值;
method指定拟合的方法,目前只支持“qr”(QR分解),method=“model.frame”返回模型框架。
三、实例
例1现有埃及卡拉马村庄每月记录儿童身高的数据,做一元线性回归。
datas<-data.frame(age=18:29,height=c(76.1,77,78.1,78.2, 78.8,79.7,79.9,81.1,81.2,81.8,82.8,83.5))
datas
age height
1 18 76.1
2 19 77.0
3 20 78.1
4 21 78.2
5 22 78.8
6 23 79.7
7 24 79.9
8 25 81.1
9 26 81.2
10 27 81.8
11 28 82.8
12 29 83.5
plot(datas)#绘制散点图
res.reg<-lm(height~age,datas)#做一元线性回归
summary(res.reg) #输出模型的汇总结果
Residuals:
Min 1Q Median 3Q Max
-0.27238 -0.24248 -0.02762 0.16014 0.47238
Coefficients:
Estimate Std.Errort value Pr(>|t|) (Intercept) 64.9283 0.5084 127.71 < 2e-16 ***
age0.6350 0.0214 29.66 4.43e-11 ***
---
Signif.codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.256 on 10 degrees of freedom Multiple R-squared: 0.9888, Adjusted R-squared: 0.9876
F-statistic: 880 on 1 and 10 DF, p-value: 4.428e-11
说明:输出了残差信息Residuals;
回归系数估计值、标准误、t统计量值、p值,可得到回归方程:
height=64.9283+0.6350*age
回归系数p值(< 2e-16,4.43e-11)很小,非常显著的≠0;***也表示显著程度非常显著。
拟合优度R2=0.9888>0.5, 表示拟合程度很好。
F统计量=880,p值=4.428e-11远小于0.05,表示整个回归模型显著,适合估计height这一因变量。
coefficients(res.reg)#返回模型的回归系数估计值
(Intercept) age
64.928322 0.634965
confint(res.reg,parm="age",level=0.95) #输出参数age的置信区间,若不指定parm将返回所有参数的置信区间
2.5 % 97.5 %
age 0.5872722 0.6826578
fitted(res.reg)#输出回归模型的预测值
1 2 3 4 5 6 7 8 9 10 11 12
76.35769 76.99266 77.62762 78.26259 78.89755 79.53252 80.16748 80.80245 81.43741 82.07238 82.70734 83.34231
anova(res.reg)#输出模型的方差分析表
Response: height
Df Sum Sq Mean Sq F value Pr(>F)
age 1 57.655 57.655 879.99 4.428e-11 ***
Residuals 10 0.655 0.066
---
Signif.codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 vcov(res.reg)#输出模型的协方差矩阵
(Intercept) age
(Intercept) 0.25848098 -0.010*******
age -0.01076686 0.0004581642
residuals(res.reg)#输出模型的残差
1 2 3 4 5 6 7 8 9 10 11 12
-0.257692308 0.007342657 0.472377622 -0.062587413 -0.097552448 0.167482517 -0.267482517 0.297552448 -0.237412587 -0.272377622 0.09 2657343 0.157692308
AIC(res.reg)#输出模型的AIC值
[1] 5.161407
BIC(res.reg)#输出模型的BIC值
[1] 6.616127
logLik(res.reg)#输出模型的对数似然值
'logLik.' 0.4192965 (df=3)
abline(res.reg)#给散点图加上一条回归线
par(mfrow=c(2,2))
plot(res.reg)#绘制回归诊断图
说明:分别是残差与拟合值图,二者越无关联越好,若有明显的曲线关系,则说明需要对线性回归模型加上高次项;
残差的Q-Q图,看是否服从正态分布;
标准化残差与拟合值图,也叫位置-尺度图,纵坐标是标准化残差的平方根,残差越大,点的位置越高,用来判断模型残差是否等方差,若满足则水平线周围的点应随机分布;
残差与杠杆图,虚线表示Cooks距离(每个数据点对回归线的影响力)等高线,从中可以鉴别出离群点(第3个点较大,表示删除该数据点,回归系数将有实质上的改变,为异常值点)、高杠杆点、强影响点。
datas<-datas[-3,]#删除第3个样本点,重新做一元线性回归
res.reg2<-lm(height~age,datas)
summary(res.reg2)
新的回归方程为:height=64.5540+0.6489*age,拟合优度R2=0.993,拟合效果变得更好。
#用回归模型预测
ages<-data.frame(age=30:34)
pre.res<-predict(res.reg2,ages,interval="prediction",l evel=0.95)#注意predict函数的第1个参数必须是回归模型的自变量数据构成的数据框或列表
pre.res
fitlwrupr
1 84.02034 83.46839 84.57228
2 84.66921 84.09711 85.24132
3 85.31809 84.72365 85.91254
4 85.96697 85.3482
5 86.58569
5 86.61585 85.97114 87.26056
(二)多元线性回归
一、基本原理
1. 多元线性回归模型:
Y=β0+β1X1+…+ βN X N+ε
其中X1,…,X N是自变量,Y是因变量,β0,β1…, βN是待求的未知参数,ε是随机误差项(残差),若记
多元线性回归模型可写为矩阵形式:
Y=Xβ+ε
通常要求:矩阵X的秩为k+1(保证不出现共线性), 且k 用最小二乘法原理,令残差平方和 最小,得到 为β的最佳线性无偏估计量(高斯-马尔可夫定理)。 2. σ2的估计和T检验 选取σ2的估计量: 则 假如t 值的绝对值相当大,就可以在适当选定的置信水平上否定原假设,参数的1-α置信区间可由下式得出: 其中t α/2为与α%显著水平有关的t 分布临界值。 3. R 2和F 检验 若因变量不具有0平均值,则必须对R 2做如下改进: 随着模型中增添新的变量,R 2的值必定会增大,为了去掉这种增大的干扰,还需要对R 2进行修正(校正拟合优度对自由度的依赖关系): 2 2/(1)111(1)/(1)1ESS N k N R R TSS N N k ---=-=----- 做假设检验: H0: β1=…=βN=0; H1: β1…, βN至少有一个≠0; 使用F统计量做检验, 若F值较大,则否定原假设。 4. 回归诊断 (1)残差图分析 ε=-为纵坐标,某一个合适的自变量为横残差图就是以残差?? y y 坐标的散点图。 回归模型中总是假定误差项是独立的正态分布随机变量,且均值为零和方差相等为σ2. 如果模型适合于观察到的数据,那么残差作为误差的无偏估计,应基本反映误差的假设特征。即残差图应该在零点附近对称地密布,越远离零点的地方就疏散(在形象上似有正态趋势),则认为模型与数据拟合得很好。 若残差图呈现如图(a)所示的形式,则认为建立的回归模型正 确,更进一步再诊断“学生化残差”是否具有正态性: 图(b )表明数据有异常点,应处理掉它重新做回归分析(在SAS 的REG 回归过程步中用来度量异常点影响大小的统计量是COOKD 统计量); 图(c )残差随x 的增大而增大,图(d )残差随x 的增大而先增后减,都属于异方差。此时应该考虑在回归之前对数据y 或x 进行变换,实现方差稳定后再拟合回归模型。原则上,当误差方差变化不太快时取变换y ;当误差方差变化较快时取变换log y 或ln y ;当误差方差变化很快时取变换1/y ;还有其他变换,如著名的Box-Cox 幂变换λλ1 -y . 图(e )(f )表示选用回归模型是错误的。 (2)共线性 回归分析中很容易发生模型中两个或两个以上的自变量高度相关,从而引起最小二乘估计可能很不精确(称为共线性问题)。 在实际中最常见的问题是一些重要的自变量很可能由于在假设检验中t 值不显著而被不恰当地剔除了。共线性诊断问题就是要找出哪些变量间存在共线性关系。 (3)误差的独立性 回归分析之前,要检验误差的独立性。若误差项不独立,那么回归模型的许多处理,包括误差项估计、假设检验等都将没有推导依据。 由于残差是误差的合理估计,因此检验统计量通常是建立在残差的基础上。检验误差独立性的最常用方法,是对残差的一阶自相关性进行Durbin-Watson检验。 H0: 误差项是相互独立的; H1: 误差项是相关的 检验统计量: DW接近于0,表示残差中存在正自相关;如果DW接近于4,表示残差中存在负自相关;如果DW接近于2,表示残差独立性。 二、R语言实现 还是用lm()函数实现,不同是需要设置更复杂的formula格式:y~x1+x2——只考虑自变量的主效应(y=k1x1+k2x2),y~.表示全部自变量的主效应; y~x1+x2+x1:x2——考虑主效应和交互效应(y=k1x1+k2x2+k3x1x2); y~x1*x2——考虑全部主效应和交互效应的简写(效果同上); y~(x1+x2+x3)^2——考虑主效应以及至2阶以下的交互效应,相当于x1+x2+x3+x1:x2+x2:x3+x1:x3 y~x1%in%x2——x1含于x2,相当于x2+x2:x1 y~(x1+x2)^2-x1:x2——表示从(x1+x2)^2中去掉x1:x2 y~x1+I((x2+x3)^2)——使用I()函数,相当于用(x2+x3)^2计算出新变量h,然后y~x1+h function——在表达式中使用数学函数,例如log(y)~x1+x2 三、实例 例2现有1990~2009年财政收入的数据revenue.txt: 各变量分别表示: y:财政收入(亿元) x1:第一产业国内生产总值(亿元) x2:第二产业国内生产总值(亿元) x3:第三产业国内生产总值(亿元) x4:人口数(万人) x5:社会消费品零售总额(亿元) x6:受灾面积(万公顷) 做多元线性回归分析。 setwd("E:/办公资料/R语言/R语言学习系列/codes") revenue=read.table("revenue.txt",header=TRUE) lm.reg=lm(y~x1+x2+x3+x4+x5+x6,revenue) summary(lm.reg) Residuals: Min 1Q Median 3Q Max -295.71 -173.52 26.59 90.16 370.01 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 6.046e+04 3.211e+03 18.829 8.12e-11 *** x1 -1.171e-01 8.638e-02 -1.356 0.19828 x2 3.427e-02 3.322e-02 1.032 0.32107 x3 6.182e-01 4.103e-02 15.067 1.31e-09 *** x4 -5.152e-01 2.930e-02 -17.585 1.91e-10 *** x5 -1.104e-01 2.878e-02 -3.837 0.00206 ** x6 -1.864e-02 1.023e-02 -1.823 0.09143. --- Signif.codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 234.8 on 13 degrees of freedom Multiple R-squared: 0.9999, Adjusted R-squared: 0.9999 F-statistic: 2.294e+04 on 6 and 13 DF, p-value: < 2.2e-16 说明:拟合优度R2=0.9999, 效果非常好。但是多元回归时,自变量个数越多,拟合优度必然越好,所以还要看检验效果和回归系数是否显著。结果解释、回归方程、回归预测与前文类似(略)。 结合显著性代码可看出:x1和x2不显著,x6只在0.1显著水平下显著,故应考虑剔除x1和x2. R语言中提供了update()函数,用来在原模型的基础上进行修正,还可以对变量进行运算,其基本格式为: update(object, formula., ..., evaluate=TRUE) 其中,object为前面拟合好的原模型对象; formula指定模型的格式,原模型不变的部分用“.”表示,只写出需要修正的地方即可,例如 update(lm.reg, .~.+x7)表示添加一个新的变量 update(lm.reg, sqrt(.)~.)表示对因变量y开方,再重新拟合回归模型lm.reg2<-update(lm.reg, .~.-x1-x2)#剔除自变量x1,x2 summary(lm.reg2) Residuals: Min 1Q Median 3Q Max -325.62 -147.54 14.07 108.28 427.42 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 6.339e+04 2.346e+03 27.020 3.89e-14 *** x3 6.584e-01 1.548e-02 42.523 < 2e-16 *** x4 -5.438e-01 1.981e-02 -27.445 3.09e-14 *** x5 -1.392e-01 1.918e-02 -7.256 2.80e-06 *** x6 -1.803e-02 9.788e-03 -1.842 0.0854 . --- Signif.codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 233.6 on 15 degrees of freedom Multiple R-squared: 0.9999, Adjusted R-squared: 0.9999 F-statistic: 3.476e+04 on 4 and 15 DF, p-value: < 2.2e-16 (三)逐步回归 多元线性回归模型中,并不是所有的自变量都与因变量有显著关系,有时有些自变量的作用可以忽略。这就需要考虑怎样从所有可能有关的自变量中挑选出对因变量有显著影响的部分自变量。 逐步回归的基本思想是,将变量一个一个地引入或剔出,引入或剔出变量的条件是“偏相关系数”经检验是显著的,同时每引入或剔出一个变量后,对已选入模型的变量要进行逐个检验,将不显著变量剔除或将显著的变量引入,这样保证最后选入的所有自变量都是显著的。 逐步回归每一步只有一个变量引入或从当前的回归模型中剔除,当没有回归因子能够引入或剔出模型时,该过程停止。 R语言中,用step()函数进行逐步回归,以AIC信息准则作为选入和剔除变量的判别条件。AIC是日本统计学家赤池弘次,在熵概念的基础上建立的: AIC=2(p+1)-2ln(L) 其中,p为回归模型的自变量个数,L是似然函数。 注:AIC值越小越被优先选入。 基本格式: step(object, direction=,steps=, k=2, ...) 其中,object是线性模型或广义线性模型的返回结果; direction确定逐步回归的方法,默认“both”综合向前向后法,“backward”向后法(先把全部自变量加入模型,若无统计学意义则剔出模型),“forward”向前法(先将部分自变量加入模型,再逐个添加其它自变量,若有统计学意义则选入模型); steps表示回归的最大步数,默认1000; k默认=2, 输出为AIC值,= log(n)有时输出BIC或SBC值。 另外,有时还需要借助使用drop1(object)和add1(object)函数,其中object为逐步回归的返回结果,判断剔除或选入一个自变量, AIC值的变化情况,以筛选选入模型的自变量。 lm.step<-step(lm.reg) summary(lm.step) Call: lm(formula = y ~ x3 + x4 + x5 + x6, data = revenue) Residuals: Min 1Q Median 3Q Max -325.62 -147.54 14.07 108.28 427.42 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 6.339e+04 2.346e+03 27.020 3.89e-14 *** x3 6.584e-01 1.548e-02 42.523 < 2e-16 *** x4-5.438e-01 1.981e-02 -27.445 3.09e-14 *** x5-1.392e-01 1.918e-02 -7.256 2.80e-06 *** x6-1.803e-02 9.788e-03 -1.842 0.0854 . --- Signif.codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 233.6 on 15 degrees of freedom Multiple R-squared: 0.9999, Adjusted R-squared: 0.9999 F-statistic: 3.476e+04 on 4 and 15 DF, p-value: < 2.2e-16 说明:默认输出每步的结果(略),进行了3步回归,逐步剔除了自变量x1和x2,AIC值逐步减小,最终得到最优的模型。 drop1(lm.step) Single term deletions Model: y ~ x3 + x4 + x5 + x6 Df Sum of Sq RSS AIC x3 1 98701814 99520589 316.40 x4 1 41113643 41932417 299.12 x5 1 2873929 3692704 250.52 x6 1 185123 1003898 224.47 lm.reg3<-lm(y~x3+x4+x5,revenue) summary(lm.reg3) Call: lm(formula = y ~ x3 + x4 + x5, data = revenue) Residuals: Min 1Q Median 3Q Max -336.34 -186.82 1.52 89.46 437.84 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 6.284e+04 2.494e+03 25.191 2.66e-14 *** x3 6.614e-01 1.651e-02 40.066 < 2e-16 *** x4 -5.467e-01 2.118e-02 -25.813 1.81e-14 *** x5 -1.412e-01 2.053e-02 -6.877 3.72e-06 *** --- Signif.codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 250.5 on 16 degrees of freedom Multiple R-squared: 0.9999, Adjusted R-squared: 0.9998 F-statistic: 4.032e+04 on 3 and 16 DF, p-value: < 2.2e-16 说明:使用drop1()函数考察分别剔除每个自变量,AIC值变化的情况,可以看出不剔除x6与剔除x6,AIC值只从222.40变大到224.47,相对其它自变量变化很小。所以,可以考虑剔除掉x6,重新做多元线性回归。 (四)回归诊断 回归分析之后,还需要从残差的随机性、强影响分析、共线性方面进行诊断。 一、残差诊断 (1) 残差 y.res<-lm.reg3$residuals#回归模型的残差 y.fit<-predict(lm.reg3)#回归模型的预测值 plot(y.res~y.fit,main="残差图")#绘制残差图,以预测值作为横坐标 说明:从图形看,残差分布比较均匀,大致满足随机性。 shapiro.test(y.res)#残差的正态性检验 Shapiro-Wilk normality test data: y.res W = 0.94206, p-value = 0.2622 说明:p值=0.2622>0.05, 接受原假设,即残差服从正态分布。 (2) 标准化残差 残差与数据的数量级有关,除以标准误差后得到标准化残差。理想的标准化残差服从N(0,1). rs<-rstandard(lm.reg3)#得到标准化残差 plot(rs~y.fit,main="标准残差图") shapiro.test(rs)#标准化残差的正态性检验 Shapiro-Wilk normality test data: rs W = 0.97766, p-value = 0.9004 (3) 学生化残差 为了回避标准化残差的方差齐性假设,使用学生化残差。 rst<-rstudent(lm.reg3) plot(rs~y.fit,main="学生化残差图") shapiro.test(rst) Shapiro-Wilk normality test data: rst W = 0.97463, p-value = 0.848 (4) 残差自相关性的Durbin-Watson检验 使用car包中的函数: durbinWatsonTest(model,alternative=c("two.side","positive ","negative")) H0:序列不存在自相关性 【例9-3】-【例9-8】 简单回归分析计算举例 利用例9-1的表9-1中已给出我国历年城镇居民人均消费支出和人均可支配收入的数据, (1)估计我国城镇居民的边际消费倾向和基础消费水平。 (2)计算我国城镇居民消费函数的总体方差S2和回归估计标准差S。 (3)对我国城镇居民边际消费倾向进行置信度为95%的区间估计。 (4)计算样本回归方程的决定系数。 (5)以5%的显著水平检验可支配收入是否对消费支出有显著影响;对Ho :β2=0.7,H1:β2<0.7进行检验。 (6)假定已知某居民家庭的年人均可支配收入为8千元,要求利用例9-3中拟合的样本回归方程与有关数据,计算该居民家庭置信度为95%的年人均消费支出的预测区间。 解: (1)教材中的【例9-3】 Yt =β1+β2Xt +u t 将表9-1中合计栏的有关数据代入(9.19)和(9.20)式,可得: 2?β =2129.0091402.57614 97.228129.009 1039.68314) -(-???=0.6724 1 ?β=97.228÷14-0.6724×129.009÷14=0. 7489 样本回归方程为: t Y ?=0.7489+0.6724Xt 上式中:0.6724是边际消费倾向,表示人均可支配收入每增加1千元,人均消费支出会增加0.6724千元;0.7489是基本消费水平,即与收入无关最基本的人均消费为0.7489千元。 (2)教材中的【例9-4】 将例9-1中给出的有关数据和以上得到的回归系数估计值代入(9.23)式,得: ∑2 t e =771.9598-0.7489×97.228-0. 6724×1039.683=0.0808 将以上结果代入(9.21)式,可得: S2=0.0808/(14-2)=0.006732 进而有: S=0.006732=0.082047 (3)教材中的【例9-5】 将前面已求得的有关数据代入(9.34)式,可得: 2 ?βS =0.082047÷14/129.0091402.5762)(-=0.0056 查t分布表可知:显著水平为5%,自由度为12的t分布双侧临界值是2.1788,前 面已求得0.6724?2 =β,将其代入(9.32)式,可得: 0560.01788.20.67240560.01788.26724.02?+≤≤?-β 即:0.68460.66022≤≤β (4)教材中的【例9-6】 r2=1 - SST SSE = 1- 96.7252 0.0808 = 0.9992 上式中的SST是利用表9-1中给出的数据按下式计算的: SST=∑2t Y -(∑Yt )2/n =771.9598-(97.228)2÷14=96.7252 二、多元线性回归模型 在多要素的地理环境系统中,多个(多于两个)要素之间也存在着相互影响、相互关联的情况。因此,多元地理回归模型更带有普遍性的意义。 (一)多元线性回归模型的建立 假设某一因变量y 受k 个自变量k x x x ,...,,21的影响,其n 组观测值为(ka a a a x x x y ,...,,,21),n a ,...,2,1=。那么,多元线性回归模型的结构形式为: a ka k a a a x x x y εββββ+++++=...22110(3、2、11) 式中: k βββ,...,1,0为待定参数; a ε为随机变量。 如果k b b b ,...,,10分别为k ββββ...,,,210的拟合值,则回归方程为 ?=k k x b x b x b b ++++...22110(3、2、12) 式中: 0b 为常数; k b b b ,...,,21称为偏回归系数。 偏回归系数i b (k i ,...,2,1=)的意义就是,当其她自变量j x (i j ≠)都固定时,自变量i x 每变化一个单位而使因变量y 平均改变的数值。 根据最小二乘法原理,i β(k i ,...,2,1,0=)的估计值i b (k i ,...,2,1,0=)应该使 ()[]min (2) 1 2211012 →++++-=??? ??-=∑∑==∧ n a ka k a a a n a a a x b x b x b b y y y Q (3、2、13) 有求极值的必要条件得 ???????==??? ??--=??=??? ??--=??∑∑=∧=∧n a ja a a j n a a a k j x y y b Q y y b Q 110) ,...,2,1(0202(3、2、14) 将方程组(3、2、14)式展开整理后得: 【例9-3】-【例9-8】简单回归分析计算举例 利用例9-1的表9-1中已给出我国历年城镇居民人均消费支出和人均可支配收入的数据,(1)估计我国城镇居民的边际消费倾向和基础消费水平。 (2)计算我国城镇居民消费函数的总体方差S2和回归估计标准差S。 (3)对我国城镇居民边际消费倾向进行置信度为95%的区间估计。(4)计算样本回归方程的决定系数。 (5)以5%的显著水平检验可支配收入是否对消费支出有显著影响;对Ho:β2=0.7,H1:β2<0.7进行检验。 (6)假定已知某居民家庭的年人均可支配收入为8千元,要求利用例9-3中拟合的样本回归方程与有关数据,计算该居民家庭置信度为95%的年人均消费支出的预测区间。 解: (1)教材中的【例9-3】 Yt=β1+β2Xt+u t 将表9-1中合计栏的有关数据代入(9.19)和(9.20)式,可 得: ==0.6724 =97.228÷14-0.6724×129.009÷14=0. 7489 样本回归方程为: =0.7489+0.6724Xt 上式中:0.6724是边际消费倾向,表示人均可支配收入每增加1千元,人均消费支出会增加0.6724千元;0.7489是基本消费水平,即与收入无关最基本的人均消费为0.7489千元。 (2)教材中的【例9-4】 将例9-1中给出的有关数据和以上得到的回归系数估计值代入 (9.23)式,得: =771.9598-0.7489×97.228-0. 6724×1039.683=0.0808 将以上结果代入(9.21)式,可得: S2=0.0808/(14-2)=0.006732 进而有:S==0.082047 (3)教材中的【例9-5】 将前面已求得的有关数据代入(9.34)式,可得: =0.082047÷=0.0056 查t分布表可知:显著水平为5%,自由度为12的t分布双侧临 你应该要掌握的7种回归分析方法 标签:机器学习回归分析 2015-08-24 11:29 4749人阅读评论(0) 收藏举报 分类: 机器学习(5) 目录(?)[+]转载:原文链接:7 Types of Regression Techniques you should know!(译者/刘帝伟审校/刘翔宇、朱正贵责编/周建丁) 什么是回归分析? 回归分析是一种预测性的建模技术,它研究的是因变量(目标)和自变量(预测器)之间的关系。这种技术通常用于预测分析,时间序列模型以及发现变量之间的因果关系。例如,司机的鲁莽驾驶与道路交通事故数量之间的关系,最好的研究方法就是回归。 回归分析是建模和分析数据的重要工具。在这里,我们使用曲线/线来拟合这些数据点,在这种方式下,从曲线或线到数据点的距离差异最小。我会在接下来的部分详细解释这一点。 我们为什么使用回归分析? 如上所述,回归分析估计了两个或多个变量之间的关系。下面,让我们举一个简单的例子来理解它: 比如说,在当前的经济条件下,你要估计一家公司的销售额增长情况。现在,你有公司最新的数据,这些数据显示出销售额增长大约是经济增长的2.5倍。那么使用回归分析,我们就可以根据当前和过去的信息来预测未来公司的销售情况。 使用回归分析的好处良多。具体如下: 1.它表明自变量和因变量之间的显著关系; 2.它表明多个自变量对一个因变量的影响强度。 回归分析也允许我们去比较那些衡量不同尺度的变量之间的相互影响,如价格变动与促销活动数量之间联系。这些有利于帮助市场研究人员,数据分析人员以及数据科学家排除并估计出一组最佳的变量,用来构建预测模型。 我们有多少种回归技术? 有各种各样的回归技术用于预测。这些技术主要有三个度量(自变量的个数,因变量的类型以及回归线的形状)。我们将在下面的部分详细讨论它们。 对于那些有创意的人,如果你觉得有必要使用上面这些参数的一个组合,你甚至可以创造出一个没有被使用过的回归模型。但在你开始之前,先了解如下最常用的回归方法: 1. Linear Regression线性回归 它是最为人熟知的建模技术之一。线性回归通常是人们在学习预测模型时首选的技术之一。在这种技术中,因变量是连续的,自变量可以是连续的也可以是离散的,回归线的性质是线性的。 线性回归使用最佳的拟合直线(也就是回归线)在因变量(Y)和一个或多个自变量(X)之间建立一种关系。 用一个方程式来表示它,即Y=a+b*X + e,其中a表示截距,b表示直线的斜率,e是误差项。这个方程可以根据给定的预测变量(s)来预测目标变量的值。 一元线性回归分析法 一元线性回归分析法是根据过去若干时期的产量和成本资料,利用最小二乘法“偏差平方和最小”的原理确定回归直线方程,从而推算出a(截距)和b(斜率),再通过y =a+bx 这个数学模型来预测计划产量下的产品总成本及单位成本的方法。 方程y =a+bx 中,参数a 与b 的计算如下: y b x a y bx n -==-∑∑ 222 n xy x y xy x y b n x (x)x x x --==--∑∑∑∑∑∑∑∑∑ 上式中,x 与y 分别是i x 与i y 的算术平均值,即 x =n x ∑ y =n y ∑ 为了保证预测模型的可靠性,必须对所建立的模型进行统计检验,以检查自变量与因变量之间线性关系的强弱程度。检验是通过计算方程的相关系数r 进行的。计算公式为: 22xy-x y r= (x x x)(y y y) --∑∑∑∑∑∑ 当r 的绝对值越接近于1时,表明自变量与因变量之间的线性关系越强,所建立的预测模型越可靠;当r =l 时,说明自变量与因变量成正相关,二者之间存在正比例关系;当r =—1时,说明白变量与因变量成负相关,二者之间存在反比例关系。反之,如果r 的绝对值越接近于0,情况刚好相反。 [例]以表1中的数据为例来具体说明一元线性回归分析法的运用。 表1: 根据表1计算出有关数据,如表2所示: 表2: 将表2中的有关数据代入公式计算可得: 1256750x == (件) 2256 1350y ==(元) 1750 9500613507501705006b 2=-??-?=(元/件) 100675011350a =?-=(元/件) 所建立的预测模型为: y =100+X 相关系数为: 9.011638 10500])1350(3059006[])750(955006[1350 750-1705006r 22==-??-???= 计算表明,相关系数r 接近于l ,说明产量与成本有较显著的线性关系,所建立的回归预测方程较为可靠。如果计划期预计产量为200件,则预计产品总成本为: y =100+1×200=300(元) 非线性回归分析 回归分析中,当研究的因果关系只涉及因变量和一个自变量时,叫做一元回归分析;当研究的因果关系涉及因变量和两个或两个以上自变量时,叫做多元回归分析。此外,回归分析中,又依据描述自变量与因变量之间因果关系的函数表达式是线性的还是非线性的,分为线性回归分析和非线性回归分析。通常线性回归分析法是最基本的分析方法,遇到非线性回归问题可以借助数学手段化为线性回归问题处理 两个现象变量之间的相关关系并非线性关系,而呈现某种非线性的曲线关系,如:双曲线、二次曲线、三次曲线、幂函数曲线、指数函数曲线(Gompertz)、S型曲线(Logistic) 对数曲线、指数曲线等,以这些变量之间的曲线相关关系,拟合相应的回归曲线,建立非线性回归方程,进行回归分析称为非线性回归分析 常见非线性规划曲线 1.双曲线1b a y x =+ 2.二次曲线 3.三次曲线 4.幂函数曲线 5.指数函数曲线(Gompertz) 6.倒指数曲线y=a / e b x其中a>0, 7.S型曲线(Logistic) 1 e x y a b-= + 8.对数曲线y=a+b log x,x>0 9.指数曲线y=a e bx其中参数a>0 1.回归: (1)确定回归系数的命令 [beta,r,J]=nlinfit(x,y,’model’,beta0) (2)非线性回归命令:nlintool(x,y,’model’, beta0,alpha) 2.预测和预测误差估计: [Y,DELTA]=nlpredci(’model’, x,beta,r,J) 求nlinfit 或lintool所得的回归函数在x处的预测值Y及预测值的显著性水平为1-alpha的置信区间Y,DELTA. 例2 观测物体降落的距离s与时间t的关系,得到数据如下表,求s 2 解: 1. 对将要拟合的非线性模型y=a/ e b x,建立M文件volum.m如下: 多元线性回归模型公式 HUA system office room 【HUA16H-TTMS2A-HUAS8Q8-HUAH1688】 二、多元线性回归模型 在多要素的地理环境系统中,多个(多于两个)要素之间也存在着相互影响、相互关联的情况。因此,多元地理回归模型更带有普遍性的意义。 (一)多元线性回归模型的建立 假设某一因变量y 受k 个自变量k x x x ,...,,21的影响,其n 组观测值为 (ka a a a x x x y ,...,,,21),n a ,...,2,1=。那么,多元线性回归模型的结构形式为: a ka k a a a x x x y εββββ+++++=...22110() 式中: k βββ,...,1,0为待定参数; a ε为随机变量。 如果k b b b ,...,,10分别为k ββββ...,,,210的拟合值,则回归方程为 ?=k k x b x b x b b ++++...22110() 式中: 0b 为常数; k b b b ,...,,21称为偏回归系数。 偏回归系数i b (k i ,...,2,1=)的意义是,当其他自变量j x (i j ≠)都固定时,自变量i x 每变化一个单位而使因变量y 平均改变的数值。 根据最小二乘法原理,i β(k i ,...,2,1,0=)的估计值i b (k i ,...,2,1,0=)应该使 ()[]min ...212211012→++++-=??? ??-=∑∑==∧n a ka k a a a n a a a x b x b x b b y y y Q () 有求极值的必要条件得 ???????==??? ??--=??=??? ??--=??∑∑=∧=∧n a ja a a j n a a a k j x y y b Q y y b Q 110),...,2,1(0202() 将方程组()式展开整理后得: ?????????????=++++=++++=++++=++++∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑===================n a a ka k n a ka n a ka a n a ka a n a ka n a a a k n a ka a n a a n a a a n a a n a a a k n a ka a n a a a n a a n a a n a a k n a ka n a a n a a y x b x b x x b x x b x y x b x x b x b x x b x y x b x x b x x b x b x y b x b x b x nb 11221211101 121221221121012111121211121011112121110)(...)()()(...)(...)()()()(...)()()()(...)()( () 方程组()式,被称为正规方程组。 如果引入一下向量和矩阵: 则正规方程组()式可以进一步写成矩阵形式 B Ab =(3.2.15’) 二、多元线性回归模型 在多要素的地理环境系统中,多个(多于两个)要素之间也存在着相互影响、相互关联的情况。因此,多元地理回归模型更带有普遍性的意义。 (一)多元线性回归模型的建立 假设某一因变量 y 受 k 个自变量 x 1, x 2 ,..., x k 的影响,其 n 组观测值为( y a , x 1 a , x 2 a ,..., x ka ), a 1,2,..., n 。那么,多元线性回归模型的结构形式为: y a 0 1 x 1a 2 x 2 a ... k x ka a () 式中: 0 , 1 ,..., k 为待定参数; a 为随机变量。 如果 b 0 , b 1 ,..., b k 分别为 0 , 1 , 2 ..., k 的拟合值,则回归方程为 ?= b 0 b 1x 1 b 2 x 2 ... b k x k () 式中: b 0 为常数; b 1, b 2 ,..., b k 称为偏回归系数。 偏回归系数 b i ( i 1,2,..., k )的意义是,当其他自变量 x j ( j i )都固定时,自变量 x i 每变 化一个单位而使因变量 y 平均改变的数值。 根据最小二乘法原理, i ( i 0,1,2,..., k )的估计值 b i ( i 0,1,2,..., k )应该使 n 2 n 2 Q y a y a y a b 0 b 1 x 1a b 2 x 2a ... b k x ka min () a 1 a 1 有求极值的必要条件得 Q n 2 y a y a b 0 a 1 () Q n 2 y a y a x ja 0( j 1,2,..., k) b j a 1 将方程组()式展开整理后得: 一、什么是回归分析 回归分析(Regression Analysis)是研究变量之间作用关系的一种统计分析方法,其基本组成是一个(或一组)自变量与一个(或一组)因变量。回归分析研究的目的是通过收集到的样本数据用一定的统计方法探讨自变量对因变量的影响关系,即原因对结果的影响程度。 回归分析是指对具有高度相关关系的现象,根据其相关的形态,建立一个适当的数学模型(函数式),来近似地反映变量之间关系的统计分析方法。利用这种方法建立的数学模型称为回归方程,它实际上是相关现象之间不确定、不规则的数量关系的一般化。 二、回归分析的种类 1.按涉及自变量的多少,可分为一元回归分析和多元回归分析一元回归分析是对一个因变量和一个自变量建立回归方程。多元回归分析是对一个因变量和两个或两个以上的自变量建立回归方程。 2.按回归方程的表现形式不同,可分为线性回归分析和非线性回归分析 若变量之间是线性相关关系,可通过建立直线方程来反映,这种分析叫线性回归分析。 若变量之间是非线性相关关系,可通过建立非线性回归方程来反映,这种分析叫非线性回归分析。 三、回归分析的主要内容 1.建立相关关系的数学表达式。依据现象之间的相关形态,建立适当的数学模型,通过数学模型来反映现象之间的相关关系,从数量上近似地反映变量之间变动的一般规律。 2.依据回归方程进行回归预测。由于回归方程反映了变量之间的一般性关系,因此当自变量发生变化时,可依据回归方程估计出因变量可能发生相应变化的数值。因变量的回归估计值,虽然不是一个必然的对应值(他可能和系统真值存在比较大的差距),但至少可以从一般性角度或平均意义角度反映因变量可能发生的数量变化。 非线性回归问题, 知识目标:通过典型案例的探究,进一步学习非线性回归模型的回归分析。 能力目标:会将非线性回归模型通过降次和换元的方法转化成线性化回归模型。 情感目标:体会数学知识变化无穷的魅力。 教学要求:通过典型案例的探究,进一步了解回归分析的基本思想、方法及初步应用. 教学重点:通过探究使学生体会有些非线性模型通过变换可以转化为线性回归模型,了解在解决实际问题的 过程中寻找更好的模型的方法. 教学难点:了解常用函数的图象特点,选择不同的模型建模,并通过比较相关指数对不同的模型进行比较. 教学方式:合作探究 教学过程: 一、复习准备: 对于非线性回归问题,并且没有给出经验公式,这时我们可以画出已知数据的散点图,把它与必修模块《数学1》中学过的各种函数(幂函数、指数函数、对数函数等)的图象作比较,挑选一种跟这些散点拟合得最好的函数,然后采用适当的变量代换,把问题转化为线性回归问题,使其得到解决. 二、讲授新课: 1. 探究非线性回归方程的确定: 1. 给出例1:一只红铃虫的产卵数y 和温度x 有关,现收集了7组观测数据列于下表中,试建立y 与x 之间 2. 讨论:观察右图中的散点图,发现样本点并没有分布在某个带状区域内,即两个变量不呈线性相关关系,所以不能直接用线性回归方程来建立两个变量之间的关系. ① 如果散点图中的点分布在一个直线状带形区域,可以选线性回归模型来建模;如果散点图中的点分布在一个曲线状带形区域,就需选择非线性回归模型来建模. ② 根据已有的函数知识,可以发现样本点分布在某一条指数函数曲线y =2C 1e x C 的周围(其中12,c c 是待定的参数),故可用指数函数模型来拟合这两个变量. ③ 在上式两边取对数,得21ln ln y c x c =+ ,再令ln z y =,则21ln z c x c =+, 可以用线性回归方程来拟合. ④ 利用计算器算得 3.843,0.272a b =-=,z 与x 间的线性回归方程为0.272 3.843z x =-$,因此红铃虫的产卵数对温度的非线性回归方程为$0.272 3.843x y e -=. ⑤ 利用回归方程探究非线性回归问题,可按“作散点图→建模→确定方程”这三个步骤进行. 其关键在于如何通过适当的变换,将非线性回归问题转化成线性回归问题. 三、合作探究 例 2.:炼钢厂出钢时所用的盛钢水的钢包,在使用过程中,由于钢液及炉渣对包衬耐火材料的侵蚀,使其容积不断增大,请根据表格中的数据找出使用次数x 与增大的容积y 之间的关系. 方差分析及回归分析 Revised as of 23 November 2020 第九章 回归分析 教学要求 1.一元线性回归及线性相关显着性的检验法,利用线性回归方程进行预测。 2.可线性化的非线性回归问题及简单的多元线性回归。 ?本章重点:理解线性模型,回归模型的概念,掌握线性模型中参数估计的最小二乘法估计法。 ?教学手段:讲练结合 ?课时分配:6课时 § 一元线性回归 回归分析是研究变量之间相关关系的一种统计推断法。 例如,人的血压y 与年龄x 有关,这里x 是一个普通变量,y 是随机变量。Y 与x 之间的相依关系f(x)受随机误差ε的干扰使之不能完全确定,故可设有: ε+=)(x f y () 式中f(x)称作回归函数,ε为随机误差或随机干扰,它是一个分布与x 无关的随机变量,我们常假定它是均值为0的正态变量。为估计未知的回归函数f(x),我们通过n 次独立观测,得x 与y 的n 对实测数据(x i ,y i )i=1,……,n ,对f(x)作估计。 实际中常遇到的是多个自变量的情形。 例如 在考察某化学反应时,发现反应速度y 与催化剂用量x 1,反应温度x 2,所加压力x 3等等多种因素有关。这里x 1,x 2,……都是可控制的普通变量,y 是随机变量,y 与诸x i 间的依存关系受随机干扰和随机误差的影响,使之不能完全确定,故可假设有: ε+=),,,(21k x x x f y 这里ε是不可观察的随机误差,它是分布与x 1,……,x k 无关的随机变量,一般设其均值为0,这里的多元函数f(x 1,……,x k )称为回归函数,为了估计未知的回归函数,同样可作n 次独立观察,基于观测值去估计f(x 1,……,x k )。 以下的讨论中我们总称自变量x 1,x 2,……,x k 为控制变量,y 为响应变量,不难想象,如对回归函数f(x 1,……,x k )的形式不作任何假设,问题过于一般,将难以处理,所以本章将主要讨论y 和控制变量x 1,x 2,……,x k 呈现线性相关关系的情形,即假定 f(x 1,……,x k )=b 0+b 1x 1+……+b k x k 。 并称由它确定的模型 (k=1)及为线性回归模型,对于线性回归模型,估计回归函数f(x 1,……,x k )就转化为估计系数b 0、b i (i=1,……,k) 。 当线性回归模型只有一个控制变量时,称为一元线性回归模型,有多个控制变量时称为多元线性回归模型,本着由浅入深的原则,我们重点讨论一元的,在此基础上简单介绍多元的。 前面我们介绍了通过回归的基本思想是将变量逐一引入回归方程,先建立与y相关最密切的一元线性回归方程,然后再找出第二个变量,建立二元线性回归方程,…。在每一步中都要对引入变量的显著性作检验,仅当其显著时才引入,而每引入一个新变量后,对前面已引进的变量又要逐一检验,一旦发现某变量变得不显著了,就要将它剔除。这些步骤反复进行,直到引入的变量都是显著的而没有引入的变量都是不显著的时,就结束挑选变量的工作,利用所选变量建立多元线性回归方程。为实现上述思想,我们必须在解方程组的同时,求出其系数矩阵的逆矩阵。为节约内存,计算过程中在消去x k时用了如下变换公式——求解求逆紧凑变换。 一、求解求逆紧凑变换 求解求逆紧凑变换记作L k,其基本变换关系式为: (2-3-30) 当对(2-3-27)的增广矩阵 (2-3-31) 依次作L1,L2,…,L m-1变换后,所得矩阵的前m-1列,便是系数矩阵的逆矩阵,最后一列便是(2-3-27)的解,即 求解求逆紧凑变换具有以下性质: (1) 若对作了L k1, L k2,…,L k L变换,则得如下子方程组 (2-3-32) 的解及相应的系数矩阵的逆矩阵,其中k1,k2,…,k l互不相同,若记 L k1L k2…L k l,则 (2-3-33) ,j=1,2,…,l (2) L i L j=L j L i,即求解求逆紧凑变换结果与变换顺序无关。 (3) L k L k= (4) 若,ij=1,2,…,m-1,记 L k1L k2…L k l 则中的元素具有以下性质: 式中上行为对作了变换L i,L j或两个变换均未作过;下行为对作过变换L i和L j之一。 回归分析法的公式: 是不是觉得这个公式很难记啊?我也觉得是这样,要是硬记的话,可能的确很难。因为它太抽象。我推荐一个方法:用推导。这方法是我的老师传授的,现在,我把它与QQ农场融合,贡献出来给大家: 我们把这个公式看成我们的农场,公式中一共有六个项目,每个项目就是我们的空地,我们农场刚刚开的时候,是不是就只有六块空地呀? 第一步:我们先开地,我们暂且把农场称作“y=a+bx”(这个公式很眼熟吧?不就是资金习性预测法嘛) 我们开地了以后,现在就要开始播种了?种子就是各个元素,在这里,也就是我们需要推导的东西,因为只是种子,不知道会长出什么东西来,因此,我们就用星号“*”来表示吧 。 第二步:施肥。这肥料是啥?小鱼下面一步一步告诉大家。这肥料我暂且称它为“N”。它是农家肥。哈哈。就是米田共。 我们将第一步“y=a+bx”中的各项目,各自乘以N。(这一点要好好体会一下这个N的含义)。 1、y乘以N,这里的N是它自身,可以理解为“无数个Y的集合”。则得到“∑y”。 2、a乘以N,这一步就区别第1了,直接写成“na” 3、bx乘以N,和第1是一样的,理解成无数个x的集合,写成“b∑x” 好了,现在我们得到了第一个算式“∑y=na+b∑x”,这就是公式中的①式。 第三步:继续给另外三块地施肥。这次的肥料是高级化肥,我们暂称它为“X”。 我们将①式中的各项目,也就是:“∑y=na+b∑x”同时乘以“X”。 1、∑y乘以X得到“∑Xy”。 2、na乘以X得到“a∑x”,这样理解:有N个X的集合。 3、b∑x乘以X得到“b∑x2” 这不,我们就得出了②式:∑xy=a∑x+b∑x2 然后,我们就把题目资料中所述的历史上产销量和资金占用资料,整理代入这个回归公式,就等着开花,结果吧。不过,注意别让人偷了!! 财务管理还可以这样学 ——致2010年财务管理考生 陈华亭 在中级职称考试的三门课程中,财务管理是一门最容易打击意志薄弱者的自信心,最容易增强意志坚强者的成就感的课程。 “打击弱者的自信心”,是指这门课程有大量的公式,尤其是有个别非常复杂的公式,似乎给人一种“除非数学基础良好、否则难以通过”的错觉,一些考生信心十足的准备参加中级考试,但一看到大量繁琐的公式,顿时“大惊失色”、“信心全无”。 “增强意志坚强者的成就感”,是指这门课程一旦以顽强的意志克服某些难点之后,很容易拿到高分,以至于迸发出一股“豪气”——“财务管理我都过了,还有什么我不能通过的”(注意,这是一种可以长久给你带来收益的无形资产)。 财务管理怎样学?财务管理可以这样学: 1.借助“心理暗示”,建立“阳光心态” 客观地说,学习是一种很艰苦的劳动,在这个过程中,必要的“心理暗示”非常重要,如果你认为你不能成功,可能等待你的就是失败;如果你认为能够成功,可能“鲜花与掌声”就在前方不远处等着你。 一元线性回归分析的应用 ——以微生物生长与温度关系为例 摘要:一元线性回归预测法是分析一个因变量与一个自变量之间的线性关系的预测方法。应用最小二乘法确定直线,进而运用直线进行预测。本文运用一元线性回归分析的方法,构建模型并求出模型参数,对分析结果的显著性进行了假设检验,从而了微生物生长与温度间的关系。 关键词:一元线性回归分析;最小二乘法;假设检验;微生物;温度 回归分析是研究变量之间相关关系的统计学方法,它描述的是变量间不完全确定的关系。回归分析通过建立模型来研究变量间的这种关系,既可以用于分析和解释变量间的关系,又可用于预测和控制,进而广泛应用于自然科学、工程技术、经济管理等领域。本文尝试用一元线性回归分析方法为微生物生长与温度之间的关系建模,并对之后几年的情况进行分析和预测。 1 一元线性回归分析法原理 1.1 问题及其数学模型 一元线性回归分析主要应用于两个变量之间线性关系的研究,回归模型模型为εββ++=x Y 10,其中10,ββ为待定系数。实际问题中,通过观测得到n 组数据(X i ,Y i )(i=1,2,…,n ),它们满足模型i i i x y εββ++=10(i=1,2,…,n )并且通常假定E(εi )=0,V ar (εi )=σ2各εi 相互独立且服从正态分布。回归分析就是根据样本观 察值寻求10,ββ的估计10?,?ββ,对于给定x 值, 取x Y 10???ββ+=,作为x Y E 10)(ββ+=的估计,利用最小二乘法得到10,ββ的估计10? ,?ββ,其中??? ? ??????? ??-???? ??-=-=∑ ∑ ==n i i n i i i x n x xy n y x x y 1221110???βββ。 1.2 相关系数 上述回归方程存在一些计算相关系数。设L XX =∑ ∑==-=-=n i i n i i def xx x n x x x L 1 2 2 1 2 )(,称为关于X 的离 一、什么是回归分析 回归分析 (Regression Analysis) 是研究变量之间作用关系的一种统计分析方法,其基本组成是 一个(或一组)自变量与一个(或一组)因变量。回归分析研究的目的是通过收集到的样本数 据用一定的统计方法探讨自变量对因变量的影响关系,即原因对结果的影响程度。 回归分析是指对具有高度相关关系的现象,根据其相关的形态,建立一个适当的数学模型( 函 数式 ) ,来近似地反映变量之间关系的统计分析方法。利用这种方法建立的数学模型称为 回归方程,它实际上是相关现象之间不确定、不规则的数量关系的一般化。 二、回归分析的种类 1.按涉及自变量的多少,可分为一元回归分析和多元回归分析一元回归分析是对一个因变量 和一个自变量建立回归方程。多元回归分析是对一个因变量和两个或两个以上的自变量建立 回归方程。 2.按回归方程的表现形式不同,可分为线性回归分析和非线性回归分析 若变量之间是线性相关关系,可通过建立直线方程来反映,这种分析叫线性回归分析。 若变量之间是非线性相关关系,可通过建立非线性回归方程来反映,这种分析叫非线性回归分 析。 三、回归分析的主要内容 1.建立相关关系的数学表达式。依据现象之间的相关形态,建立适当的数学模型,通过数学模型来反映现象之间的相关关系,从数量上近似地反映变量之间变动的一般规律。 2.依据回归方程进行回归预测。由于回归方程反映了变量之间的一般性关系,因此当自变量 发生变化时,可依据回归方程估计出因变量可能发生相应变化的数值。因变量的回归估计值,虽 然不是一个必然的对应值 ( 他可能和系统真值存在比较大的差距 ) ,但至少可以从一般性角度或平均意义角度反映因变量可能发生的数量变化。 3.计算估计标准误差。通过估计标准误差这一指标,可以分析回归估计值与实际值之间的差异 程度以及估计值的准确性和代表性,还可利用估计标准误差对因变量估计值进行在一定把握程 度条件下的区间估计。 四、一元线性回归分析 1.一元线性回归分析的特点 1)两个变量不是对等关系,必须明确自变量和因变量。 2) 如果 x 和 y 两个变量无明显因果关系,则存在着两个回归方程:一个是以x 为自变量, y 为因变量建立的回归方程;另一个是以y 为自变量, x 为因变量建立的回归方程。若绘出图 二、多元线性回归模型 在多要素得地理环境系统中,多个(多于两个)要素之间也存在着相互影响、相互关联得情况。因此,多元地理回归模型更带有普遍性得意义。 (一)多元线性回归模型得建立 假设某一因变量y 受k 个自变量得影响,其n 组观测值为(),。那么,多元线性回归模型得结构形式为: (3.2.11) 式中: 为待定参数; 为随机变量。 如果分别为得拟合值,则回归方程为 ?=(3.2.12) 式中: 为常数; 称为偏回归系数。 偏回归系数()得意义就就是,当其她自变量()都固定时,自变量每变化一个单位而使因变量y 平均改变得数值。 根据最小二乘法原理,()得估计值()应该使 ()[]min (2) 1 2211012 →++++-=??? ??-=∑∑==∧ n a ka k a a a n a a a x b x b x b b y y y Q (3.2.13) 有求极值得必要条件得 (3.2.14) 将方程组(3.2.14)式展开整理后得: ??????????? ?? =++++=++++=++++=++++∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑===================n a a ka k n a ka n a ka a n a ka a n a ka n a a a k n a ka a n a a n a a a n a a n a a a k n a ka a n a a a n a a n a a n a a k n a ka n a a n a a y x b x b x x b x x b x y x b x x b x b x x b x y x b x x b x x b x b x y b x b x b x nb 11221211101 1 212212 2112101 21111212111210111 12121110)(...)()()(...)(...)()()()(...)()()()(...)()( (3.2.15) 方程组(3.2.15)式,被称为正规方程组。 如果引入一下向量与矩阵: ??? ??? ? ? ? ????????? ??==kn n n k k k kn k k k n n T x x x x x x x x x x x x x x x x x x x x x x x x X X A ...1..................1...1...1... ...... ... ............1 (1112132313222121211132) 1 2232221 1131211 多元线性回归模型计算分析题 1、某地区通过一个样本容量为722的调查数据得到劳动力受教育年数的一个回归方程为 R2=0.214 式中,为劳动力受教育年数,为劳动力家庭中兄弟姐妹的个数,与分别为母亲与父亲受到教育的年数。问 (1)sibs是否具有预期的影响?为什么?若与保持不变,为了使预测的受教育水平减少一年,需要增加多少? (2)请对的系数给予适当的解释。 (3)如果两个劳动力都没有兄弟姐妹,但其中一个的父母受教育的年数均为12年,另一个的父母受教育的年数均为16年,则两人受教育的年数预期相差多少年 2、考虑以下方程(括号内为标准差): (0.080) (0.072) (0.658) 其中:——年的每位雇员的工资 ——年的物价水平 ——年的失业率 要求:(1)进行变量显著性检验; (2)对本模型的正确性进行讨论,是否应从方程中删除?为什么? 3、以企业研发支出(R&D)占销售额的比重(单位:%)为被解释变量 (Y),以企业销售额(X1)与利润占销售额的比重(X2)为解释变量,一个容量为32的样本企业的估计结果如下: 其中,括号中的数据为参数估计值的标准差。 (1)解释ln(X1)的参数。如果X1增长10%,估计Y会变化多少个百分点? 这在经济上是一个很大的影响吗? (2)检验R&D强度不随销售额的变化而变化的假设。分别在5%和10%的显著性水平上进行这个检验。 (3)利润占销售额的比重X2对R&D强度Y是否在统计上有显著的影响? 4、假设你以校园内食堂每天卖出的盒饭数量作为被解释变量,以盒饭价 格、气温、附近餐厅的盒饭价格、学校当日的学生数量(单位:千 人)作为解释变量,进行回归分析。假设你看到如下的回归结果(括号内为标准差),但你不知道各解释变量分别代表什么。 (2.6) (6.3) (0.61) (5.9) 试判定各解释变量分别代表什么,说明理由。 5、下表给出一二元模型的回归结果。 方差来源平方和(SS)自由度(d.f.) 来自回归(ESS)65965— 来自残差(RSS)_—— 总离差(TSS)6604214 求:(1)样本容量是多少?RSS是多少?ESS和RSS的自由度各是多少? (2)和? (3)检验假设:解释变量总体上对无影响。你用什么假设检验?为什么? (4)根据以上信息,你能确定解释变量各自对的贡献吗? 6、在经典线性回归模型的基本假定下,对含有三个自变量的多元线性 回归模型: 你想检验的虚拟假设是:。 (1)用的方差及其协方差求出。 (2)写出检验H0:的t统计量。 (3)如果定义,写出一个涉及0、、2和3的回归方程,以便能直接得到估计值及其样本标准差。 二、多元线性回归模型 在多要素的地理环境系统中,多个(多于两个)要素之间也存在着相互影响、相互关联的情 况。因此,多元地理回归模型更带有普遍性的意义。 (一)多元线性回归模型的建立 假设某一因变量y 受k 个自变量x 1, x 2,..., x k 的影响,其n 组观测值为( y a , x 1a , x 2a ,..., x ka ), a =1,2,...,n 。那么,多元线性回归模型的结构形式为: y a = + 1x 1a + 2x 2a +...+ k x ka + a (3.2.11) 式中: 0, 1 ,..., k 为待定参数; a 为随机变量。 如果b 0,b 1,...,b k 分别为 , 1 , 2 ..., k 的拟合值,则回归方程为 ?=b +b x +b x +...+b x (3.2.12) 式中: b 0 为常数; b 1,b 2,...,b k 称为偏回归系数。 偏回归系数b i (i =1,2,...,k )的意义是,当其他自变量x j ( j i )都固定时,自变量x i 每 变 化一个单位而使因变量 y 平均改变的数值。 根据最小二乘法原理, i ( i = 0,1,2,..., k )的估计值b i ( i = 0,1,2,..., k )应该使 n 2 n 2 Q = y a -y a = y a - (b 0 + b 1x 1a +b 2x 2a + ... + b k x ka ) → min (3.2.13) a = 1 a =1 有求极值的必要条件得 将方程组(3.2.14)式展开整理后得: Q b 0 = Q b = 3.2.14) y a - y a x ja = 0( j =1,2,..., k ) y a - y a =0 一、什么就是回归分析 回归分析(Regression Analysis)就是研究变量之间作用关系的一种统计分析方法,其基本组成就是一个(或一组)自变量与一个(或一组)因变量。回归分析研究的目的就是通过收集到的样本数据用一定的统计方法探讨自变量对因变量的影响关系,即原因对结果的影响程度。 回归分析就是指对具有高度相关关系的现象,根据其相关的形态,建立一个适当的数学模型(函数式),来近似地反映变量之间关系的统计分析方法。利用这种方法建立的数学模型称为回归方程,它实际上就是相关现象之间不确定、不规则的数量关系的一般化。 二、回归分析的种类 1、按涉及自变量的多少,可分为一元回归分析与多元回归分析一元回归分析就是对一个因变量与一个自变量建立回归方程。多元回归分析就是对一个因变量与两个或两个以上的自变量建立回归方程。 2、按回归方程的表现形式不同,可分为线性回归分析与非线性回归分析 若变量之间就是线性相关关系,可通过建立直线方程来反映,这种分析叫线性回归分析。 若变量之间就是非线性相关关系,可通过建立非线性回归方程来反映,这种分析叫非线性回归分析。 三、回归分析的主要内容 1、建立相关关系的数学表达式。依据现象之间的相关形态,建立适当的数学模型,通过数学模型来反映现象之间的相关关系,从数量上近似地反映变量之间变动的一般规律。 2、依据回归方程进行回归预测。由于回归方程反映了变量之间的一般性关系,因此当自变量发生变化时,可依据回归方程估计出因变量可能发生相应变化的数值。因变量的回归估计值,虽然不就是一个必然的对应值(她可能与系统真值存在比较大的差距),但至少可以从一般性角度或平均意义角度反映因变量可能发生的数量变化。 3、计算估计标准误差。通过估计标准误差这一指标,可以分析回归估计值与实际值之间的差异程度以及估计值的准确性与代表性,还可利用估计标准误差对因变量估计值进行在一定把握程度条件下的区间估计。 四、一元线性回归分析 1、一元线性回归分析的特点 1)两个变量不就是对等关系,必须明确自变量与因变量。 2)如果x与y两个变量无明显因果关系,则存在着两个回归方程:一个就是以x为自变量,y为 1简单回归分析计算例
多元线性回归模型公式
简单回归分析计算例
你应该要掌握的7种回归分析方法
一元线性回归分析法
非线性回归分析(常见曲线及方程)
多元线性回归模型公式定稿版
多元线性回归模型公式().docx
回归分析方法总结全面
非线性回归分析
方差分析及回归分析
逐步回归分析计算法
个人总结zillion回归分析法的公式
一元线性回归分析论文
回归分析方法总结模板全面.doc
多元线性回归模型公式
多元线性回归模型计算分析题
多元线性回归模型公式
回归分析方法总结全面