应用多元统计分析应用报告(DOC)

应用多元统计分析
课程报告
班级专业:_ 市调0901 _
学号: 2009***** __
姓名:__ CYQ _____
成绩:______________
2010年10月7日
我国部分城市主要经济指标统计
——官方与民间数据差异分析
一、引言
经济指标是反映一定社会经济现象数量方面的名称及其数值。本题主要经济指标包括人均GDP 1x (元)、人均工业产值2x (元)、客运总量3x (万人)、货运总量4x (万吨)、5x (亿元)、固定资产投资总额6x (亿元)、在岗职工占总人口的比例7x (%)、在岗职工人均工资额8x (元)、城乡居民年底储蓄余额9x (亿元)。所以我们借助这一指标体系对我国部分城市的主要经济指标进行分析。
二、数据分析 过程
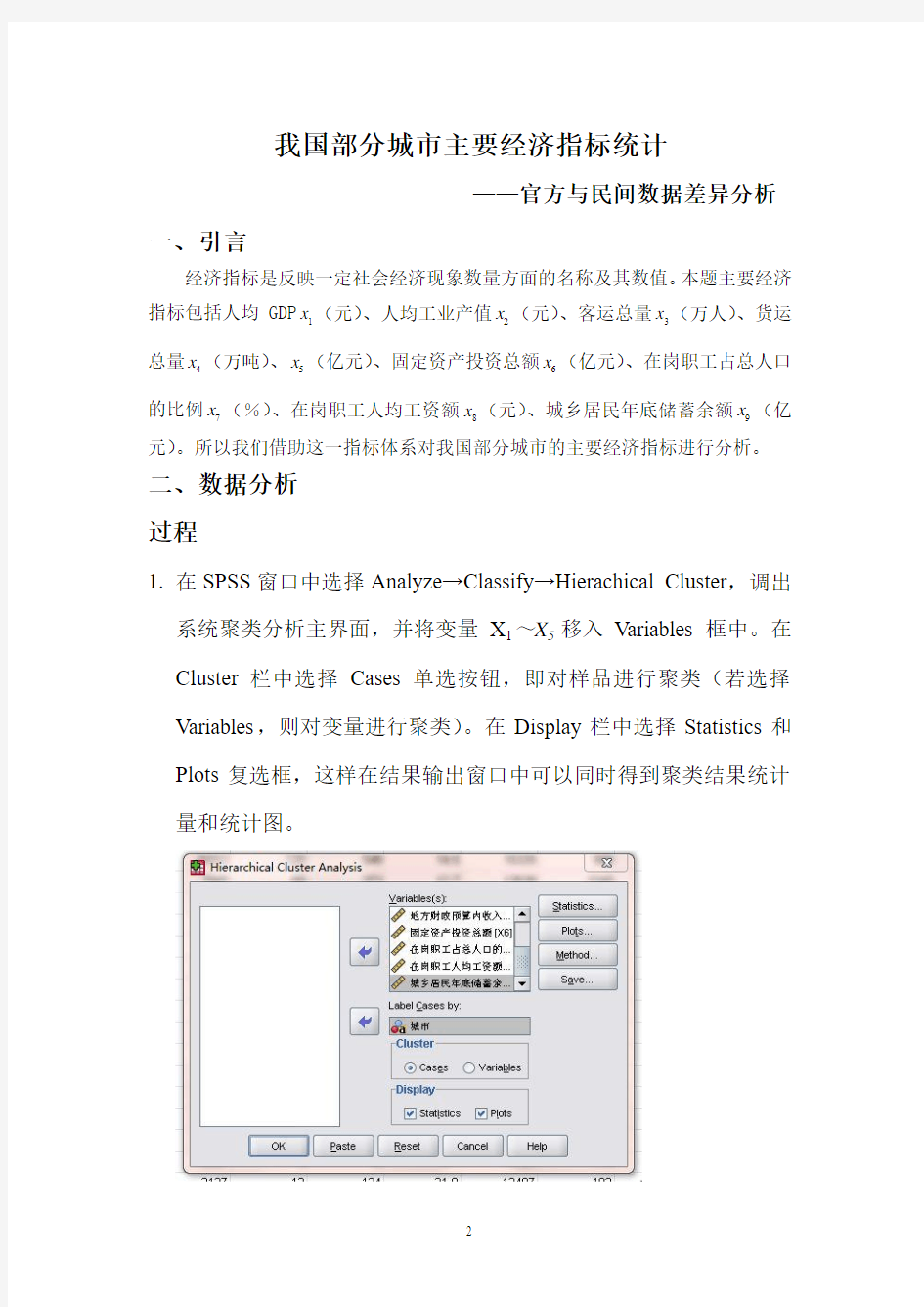
1. 在SPSS 窗口中选择Analyze→Classify→Hierachical Cluster ,调出系统聚类分析主界面,并将变量X 1~X 5移入Variables 框中。在Cluster 栏中选择Cases 单选按钮,即对样品进行聚类(若选择Variables ,则对变量进行聚类)。在Display 栏中选择Statistics 和Plots 复选框,这样在结果输出窗口中可以同时得到聚类结果统计量和统计图。
2. 点击Statistics按钮,设置在结果输出窗口中给出的聚类分析统计
量。这里我们选择系统默认值,点击Continue按钮,返回主界面。
3. 点击Plots按钮,设置结果输出窗口中给出的聚类分析统计图。选
中Dendrogram复选框和Icicle栏中的None单选按钮,即只给出聚类树形图,而不给出冰柱图。单击Continue按钮,返回主界面。
4. 点击Method按钮,设置系统聚类的方法选项。这里我们仍然均沿
用系统默认选项。单击Continue按钮,返回主界面。
5. 点击Save按钮,指定保存在数据文件中的用于表明聚类结果的新
变量。None表示不保存任何新变量;Single solution表示生成一
个分类变量,在其后的矩形框中输入要分成的类数;Range of solutions表示生成多个分类变量。这里我们选择Range of solutions,并在后面的两个矩形框中分别输入2和4,即生成三个新的分类变量,分别表明将样品分为2类、3类和4类时的聚类结果。点击Continue,返回主界面。
6. 点击OK按钮,运行系统聚类过程
从上面的树状图可以直接的观察到,如果用聚类分析将这些地区分为三类,
则24深圳独自为一类,10上海和16厦门为一类,剩下的城市为一类。
三,K值聚类分析
过程
1.在SPSS窗口中选择Analyze→Classify→K-Means Cluster,调出K
均值聚类分析主界面,并将变量—移入Variables框中,将标志变量Region移入Label Case by框中。在Method框中选择Iterate classify,即使用K-means算法不断计算新的类中心,并替换旧的类中心(若选择Classify only,则根据初始类中心进行聚类,在聚类过程中不改变类中心)。如果不手工设置,则系统会自动设置初始类中心,这里我们不作设置。
2.1. 在SPSS窗口中选择Analyze→Classify→K-Means Cluster,调出
K均值聚类分析主界面,并将变量—移入Variables框中,将标志
变量Region移入Label Case by框中。在Method框中选择Iterate classify,即使用K-means算法不断计算新的类中心,并替换旧的类中心(若选择Classify only,则根据初始类中心进行聚类,在聚类过程中不改变类中心)。如果不手工设置,则系统会自动设置初始类中心,这里我们不作设置。
3.点击Save按钮,设置保存在数据文件中的表明聚类结果的新变量。
其中Cluster membership选项用于建立一个代表聚类结果的变量,默认变量名为qcl_1;Distance from cluster center选项建立一个新变量,代表各观测量与其所属类中心的欧氏距离。我们将两个复选框都选中,单击Continue按钮返回。
4.点击Options按钮,指定要计算的统计量。选中Initial cluster centers
和Cluster information for each case复选框。这样,在输出窗口中将给出聚类的初始类中心和每个观测量的分类信息,包括分配到哪一类和该观测量距所属类中心的距离。单击Continue返回。
5. 点击OK按钮,运行K均值聚类分析程序
2.K值聚类分析
(1)给出初始类中心
给出每次迭代结束后类中心的变动。由图看出本次类聚过程共经历了三次迭代
给出各观测量所属的类及所属中心的距离。
用K值聚类分析可以把这些城市被分为3类。第一类包括:深圳。第一类城市人均GDP和人均工业产值较高,属于较发达地区。第二类包括:北京,天津,上海,南京,杭州,宁夏,厦门,青岛,广州,南京,海口。这些地区的人均GDP 和人均工业产值属于三类中居中的位置,属于中等发达地区。剩下的城市被分为第三类,它们的各种数据显示,都表明它们属于欠发达地区。
应用多元统计分析试题及答案
一、填空题: 1、多元统计分析是运用数理统计方法来研究解决多指标问题的理论和方法. 2、回归参数显著性检验是检验解释变量对被解释变量的影响是否著. 3、聚类分析就是分析如何对样品(或变量)进行量化分类的问题。通常聚类分析分为 Q型聚类和 R型聚类。 4、相应分析的主要目的是寻求列联表行因素A 和列因素B 的基本分析特征和它们的最优联立表示。 5、因子分析把每个原始变量分解为两部分因素:一部分为公共因子,另一部分为特殊因子。 6、若 () (,), P x N αμα ∑=1,2,3….n且相互独立,则样本均值向量x服从的分布 为_x~N(μ,Σ/n)_。 二、简答 1、简述典型变量与典型相关系数的概念,并说明典型相关分析的基本思想。 在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数。选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对,如此下去直到两组之间的相关性被提取完毕为止。被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。 2、简述相应分析的基本思想。 相应分析,是指对两个定性变量的多种水平进行分析。设有两组因素A和B,其中因素A包含r个水平,因素B包含c个水平。对这两组因素作随机抽样调查,得到一个rc的二维列联表,记为。要寻求列联表列因素A和行因素B的基本分析特征和最优列联表示。相应分析即是通过列联表的转换,使得因素A
和因素B 具有对等性,从而用相同的因子轴同时描述两个因素各个水平的情况。把两个因素的各个水平的状况同时反映到具有相同坐标轴的因子平面上,从而得到因素A 、B 的联系。 3、简述费希尔判别法的基本思想。 从k 个总体中抽取具有p 个指标的样品观测数据,借助方差分析的思想构造一个线性判别函数 系数: 确定的原则是使得总体之间区别最大,而使每个总体内部的离差最小。将新样品的p 个指标值代入线性判别函数式中求出 值,然后根据判别一定的规则,就可以判别新的样品属于哪个总体。 5、简述多元统计分析中协差阵检验的步骤 第一,提出待检验的假设 和H1; 第二,给出检验的统计量及其服从的分布; 第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域; 第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。 协差阵的检验 检验0=ΣΣ 0p H =ΣI : /2 /21exp 2np n e tr n λ???? =-?? ? ???? S S 00p H =≠ΣΣI : /2 /2**1exp 2np n e tr n λ???? =-?? ? ???? S S
最新多元统计分析思考题
多元统计分析思考题
《多元统计分析思考题》 第一章回归分析 1、回归分析是怎样的一种统计方法,用来解决什么问题? 概念:回归分析(regression analysis)是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法。 解决的问题:自变量对因变量的影响程度、方向、形式 2、线性回归模型中线性关系指的是什么变量之间的关系?自变量与因变量之 间一定是线性关系形式才能做线性回归吗?为什么? 3、实际应用中,如何设定回归方程的形式? 4、多元线性回归理论模型中,每个系数(偏回归系数)的含义是什么? 5、经验回归模型中,参数是如何确定的?有哪些评判参数估计的统计标准? 最小二乘估计两有哪些统计性质?要想获得理想的参数估计值,需要注意一些什么问题? 6、理论回归模型中的随机误差项的实际意义是什么?为什么要在回归模型中 加入随机误差项?建立回归模型时,对随机误差项作了哪些假定?这些假定的实际意义是什么? 7、建立自变量与因变量的回归模型,是否意味着他们之间存在因果关系?为什么? 8、回归分析中,为什么要作假设检验?检验依据的统计原理是什么?检验的 过程是怎样的?
9、回归诊断可以大致确定哪些问题?回归分析有哪些基本假定?如果实际应 用中不满足这些假定,将可能引起怎样的后果?如何检验实际应用问题是否满足这些假定?对于各种不满足假定的情形,分别采用哪些改进方法? 10、回归分析中的R2有何意义?它能用来衡量模型优劣吗? 11、如何确定回归分析中变量之间的交互作用?存在交互作用时,偏回归系 数的意义与不存在交互作用的情形下是否相同?为什么? 12、有哪些确定最优回归模型的准则?如何选择回归变量? 13、在怎样的情况下需要建立标准化的回归模型?标准化回归模型与非标准 化模型有何关系?形式有否不同? 14、利用回归方法解决实际问题的大致步骤是怎样的? 15、你能够利用哪些软件实现进行回归分析?能否解释全部的软件输出结 果? 第二章判别分析 1、判别分析的目的是什么? 根据分类对象个体的某些特征或指标来判断其属于已知的某个类中的哪一类。 2、有哪些常用的判别分析方法?这些方法的基本原理或步骤是怎样的?它 们各有什么特点或优劣之处? 3、判别分析与回归分析有何异同之处? 4、判别分析对变量与样本规模有何要求? 5、如何度量判别效果?有哪些影响判别效果的因素?
多元统计分析报告完整版
多元统计分析报告标准化管理处编码[BBX968T-XBB8968-NNJ668-MM9N]
随着经济的发展,这个差距越来越大。 由于我国人口众多,素质较低,而且就业观念较落后,导致我国劳动力普遍廉价,就业职工工资普遍低下。刚毕业的大学生人数众多,城市发展速度与农村发展速度不平衡,各省市自治区的就业条件和国家政策,就业环境不同,导致职工工资存在行业间的工资水平存在着巨大的差异,从另一个方面反映出了中国贫富差距的不断扩大。对我国就业人员职工工资的研究,对我国的社会保障政策和就业政策,教育政策等具有重要的决策意义。
也为对我国经济社会的研究提供了一个因素。我国就业职工工资水平的行业间的差异已经日益成为我国政府重视的一个问题。 [关键词] 不同行业就业平均工资 一、引言 当前我国处于经济发展快速时期,由于我国人口总数较大,就业人员众多。因此,就业问题成为了我国社会的一个焦点问题。研究好行业间就业问题以及就业职工工资问题,能够有效的把握好社会状况,能够帮助大学生更准确的定位自己,找到自己满意的工作。制定正确的就业政策和社会保障,社会福利政策,来促进大学生的就业问题以及我国国民经济的发展。 本文选取2013年我国各行业城镇单位就业人员平均工资的数据,主要利用以下几种统计方法进行分析:因子分析法、聚类分析法。将全国各省按照不同行业就业人数进行分类和排序,并与人们实际观察到的情况进行比较分析。 因子分析是指研究从变量群中提取共性因子的统计技术。因子分析可在许多变量中找出隐藏的具有代表性的因子。将相同本质的变量归入一个因子,可减少变量的数目,还可检验变量间关系的假设。 聚类分析是一组将研究对象分为的群组的统计分析技术,依据研究对象(样品或指标)的特征,对其进行分类的方法,减少研究对象的数目。 二、数据 下表是我国按行业分城镇单位就业人员平均工资的原始数据,数据来源于《2013中
应用多元统计分析课后答案
应用多元统计分析课后答案 第五章 聚类分析 判别分析和聚类分析有何区别 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 对样品和变量进行聚类分析时, 所构造的统计量分别是什么简要说明为什么这样构造 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1 ()() p q q ij ik jk k d q X X ==-∑ q 取不同值,分为 (1)绝对距离(1q =) 1 (1)p ij ik jk k d X X ==-∑ (2)欧氏距离(2q =) 2 1/21 (2)()p ij ik jk k d X X ==-∑ (3)切比雪夫距离(q =∞) 1()max ij ik jk k p d X X ≤≤∞=- (二)马氏距离 (三)兰氏距离 2 1()()()ij i j i j d M -'=--X X ΣX X 11()p ik jk ij k ik jk X X d L p X X =-=+∑
多元统计分析期末复习试题
第一章: 多元统计分析研究的内容(5点) 1、简化数据结构(主成分分析) 2、分类与判别(聚类分析、判别分析) 3、变量间的相互关系(典型相关分析、多元回归分析) 4、多维数据的统计推断 5、多元统计分析的理论基础 第二三章:
二、多维随机变量的数字特征 1、随机向量的数字特征 随机向量X 均值向量: 随机向量X 与Y 的协方差矩阵: 当X=Y 时Cov (X ,Y )=D (X );当Cov (X ,Y )=0 ,称X ,Y 不相关。 随机向量X 与Y 的相关系数矩阵: 2、均值向量协方差矩阵的性质 (1).设X ,Y 为随机向量,A ,B 为常数矩阵 E (AX )=AE (X ); E (AXB )=AE (X )B; D(AX)=AD(X)A ’; Cov(AX,BY)=ACov(X,Y)B ’; (2).若X ,Y 独立,则Cov(X,Y)=0,反之不成立. (3).X 的协方差阵D(X)是对称非负定矩阵。例2.见黑板 三、多元正态分布的参数估计 2、多元正态分布的性质 (1).若 ,则E(X)= ,D(X)= . )' ,...,,(),,,(2121P p EX EX EX EX μμμ='= )' )((),cov(EY Y EX X E Y X --=q p ij r Y X ?=)(),(ρ) ,(~∑μP N X μ ∑ p X X X ,,,21
特别地,当 为对角阵时, 相互独立。 (2).若 ,A为sxp 阶常数矩阵,d 为s 阶向量, AX+d ~ . 即正态分布的线性函数仍是正态分布. (3).多元正态分布的边缘分布是正态分布,反之不成立. (4).多元正态分布的不相关与独立等价. 例3.见黑板. 三、多元正态分布的参数估计 (1)“ 为来自p 元总体X 的(简单)样本”的理解---独立同截面. (2)多元分布样本的数字特征---常见多元统计量 样本均值向量 = 样本离差阵S= 样本协方差阵V= S ;样本相关阵R (3) ,V分别是 和 的最大似然估计; (4)估计的性质 是 的无偏估计; ,V分别是 和 的有效和一致估计; ; S~ , 与S相互独立; 第五章 聚类分析: 一、什么是聚类分析 :聚类分析是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法。用于对事物类别不清楚,甚至事物总共可能有几类都不能确定的情况下进行事物分类的场合。聚类方法:系统聚类法(直观易懂)、动态聚类法(快)、有序聚类法(保序)...... Q-型聚类分析(样品)R-型聚类分析(变量) 变量按照测量它们的尺度不同,可以分为三类:间隔尺度、有序尺度、名义尺度。 μ ) ,(~∑μP N X ) ,('A A d A N s ∑+μ) () 1(,,n X X X )' ,,,(21p X X X )' )(() () (1 X X X X i i n i --∑=n 1 X μ∑μ X ) 1 , (~∑n N X P μ) ,1(∑-n W p X X
多元统计学SPSS实验报告一
华东理工大学2016–2017学年第二学期 《多元统计学》实验报告 实验名 称实验1数据整理与描述统计分析
教师批阅:实验成绩: 教师签名: 日期: 实验报告正文: 实验数据整理 (一)对“employee”进行数据整理 1.观察量排序 ( based on current salary) 2.变量值排序(based on current salary : rsalary) 3.计算新的变量(incremental salary=current salary - beginning salary)
4.拆分数据文件(based on gender) 结论:There are 215 female employees and 259 male employees. 5.分类汇总 (break variable: gender ; function: mean ) 结论:The average current salary of female is . The average current salary of male is . (二)分别给出三种工作类别的薪水的描述统计量 实验描述统计分析 1)样本均值矩阵 结论:总共分析六组变量,每组含有十个样本。 每股收益(X1)的均值为;净资产收益率(X2)的均值为;总资产报酬率(X3)的均值为;销售净
利率(X4)的均值为;主营业务增长率(X5)的均值为;净利润增长率(X6)的均值为. 2)协方差阵 结论:矩阵共六行六列,显示了每股收益(X1)、净资产收益率(X2)、总资产报酬率(X3)、销售净利率(X4)、主营业务增长率(X5)和净利润增长率(X6)的协方差。 3)相关系数 结论:矩阵共六行六列,显示了每股收益 (X1)、净资产收益率(X2)、总资产报酬 率(X3)、销售净利率(X4)、主营业务增 长率(X5)和净利润增长率(X6)之间的 相关系数。 每格中三行分别显示了相关系数、显著性 检验与样本个数。 4)矩阵散点图
多元统计分析报告 课程设计
多元统计分析课程设计 题目:《因子分析在环境污染方面的应用》 姓名:王厅厅 专业班级:统计学2014级2班 学院:数学与系统科学学院 时间:2016年1月 3 日
目录 1.摘要: (1) 2.引言: (1) 2.1背景 (1) 2.2问题的研究意义 (1) 2.3方法介绍 (2) 3.实证分析 (10) 3.1指标 (10) 3.2原始数据 (10) 3.3数据来源 (13) 3.4分析过程: (13) 4.结论及建议 (25) 5.参考文献 (26)
1.摘要: 中国的环境问题,由于中国政府对环境问题的关注,环境法律日趋完善,执法力度加大,对环境污染治理的投人逐年有较大幅度的增加,中国环境问题已朝着好的方面发展。但是,仍存在着环境问题,主要体现在环境污染问题,其中主要为水污染和大气污染。 关键词:环境污染水污染大气污染因子分析 2.引言: 2.1背景: 我国的环境保护取得了明显的成就,部分地区环境质量有所改善。但是,从整体上看,我国的环境污染仍在加剧,环境质量还在恶化。大气二氧化硫含量居高不下,境质量呈恶化趋势,固体废弃物污染量大面广,噪声扰民严重,环境污染事故时有发生。据中国社会科学院公布的一项报告表明:中国环境污染的规模居世界前列。 2.2问题的研究意义: 为分析比较各地环境污染特点,利用因子分析对环境污染的各个指标进行降维处理并得到影响环境的内在因素,进一步对环境污染原因及治理措施进行分析,让更多的人认识到环境的重要性,准确把
握各地区环境治理方法以及针对不同地区制定不同的政策改善环境问题,这对综合治理环境问题具有重要意义。 2.3方法介绍 因子分析的意义:变量间的信息的高度重叠和高度相关会给统计方法的应用设置许多障碍。为解决此问题,最简单和最直接的解决方案是削减变量个数,但这必然会导致信息丢失和 信息不完全等问题的产生。为此人们希望探索一种更有效地解决方法,它既能大幅减少参与数据建模的变量个数,同时也不会造成信息的大量丢失。因子分析正是这样一种能够有效降低变量维数的分析方法。 因子分析的步骤: ·因子分析的前提条件:要求原有变量之间存在较强的相关关系。 ·因子提取:将原有变量综合成少数几个因子是因子分析的核心内容。 若存在随机向量)(),,(1p q F F F q ≤'= 及),,(1' =p εεε ,使 ??????????+????????????????????=??????????p q pq p q p F F a a a a X X εε 1111111 简记为ε+=AF X ,且 (1)q I F D F E ==)(,0)((标准化); (2) ?? ? ?? ?????==221)(,0)(p D E σσεε (中心化);
matlab与应用多元统计分析
多元统计分析中的应用研究 , 摘要:许多实际问题往往需要对数据进行统计分析,建立合适的统计模型,过去一般采用SAS 、SPSS软件分析,本文给出 Matlab软件在多元统计分析上的应用, 主要介绍Matlab 在聚类分析、判别分析、主成份分析上的应用,文中均给以实例, 结果令人满意。 关键词:Matlab软件;聚类分析;主成份分析 Research for application of Multivariate Statistical Analysis Abstract:Many practice question sometimes need Statistical Analysis to data.,and establish appropriate Statistical model SAS and SPSS software were commonly used in foretime ,this paper give the application of Matlab software in Multivariate Statistical Analysis,mostly introduce the application of Matlab software in priciple component analysis and cluster analysis and differentiate analysis.The example are given in writing and the result are satisfaction. Key words: Matlab software; cluster analysis; priciple component analysis 0 引言 许多实际问题往往需要对数据进行多元统计分析, 建立合适的模型, 在多元统计分析方面, 常用的软件有SAS 、SPSS 、S-PLUS等。我们在这里给出Matlab在多元统计分析上的应用, 在较早的版本中, 统计功能不那么强大, 而在Matlab6.x版本中, 仅在统计工具中的功能函数就达200多个, 功能已足以赶超任何其他专用的统计软件,在应用上Matlab具有其他软件不可比拟的操作简单,接口方便, 扩充能力强等优势, 再加上Matlab的应用范围广泛, 因此可以预见其在统计应用上越来越占有极其重要的地位,下面用实例给出Matlab 在聚类分析、主成份分析上的应用。 1 聚类分析 聚类分析法是一门多元统计分类法,其目的是把分类对象按一定规则分成若干类,所分成的类是根据数据本身的特征确定的。聚类分析法根据变量(或样品或指标)的属性或特征的相似性,用数学方法把他们逐步地划类,最后得到一个能反映样品之间或指标之间亲疏关系的客观分类系统图,称为谱系聚类图。 聚类分析的步骤有:数据变换,计算n个样品的两两间的距离,先分为一类,在剩下的n-1个样品计算距离,按照不同距离最小的原则,增加分类的个数,减少所需要分类的样品的个数,循环进行下去,直到类的总个数为1时止。根
应用多元统计分析应用报告(DOC)
应用多元统计分析 课程报告 班级专业:_ 市调0901 _ 学号: 2009***** __ 姓名:__ CYQ _____ 成绩:______________ 2010年10月7日
我国部分城市主要经济指标统计 ——官方与民间数据差异分析 一、引言 经济指标是反映一定社会经济现象数量方面的名称及其数值。本题主要经济指标包括人均GDP 1x (元)、人均工业产值2x (元)、客运总量3x (万人)、货运总量4x (万吨)、5x (亿元)、固定资产投资总额6x (亿元)、在岗职工占总人口的比例7x (%)、在岗职工人均工资额8x (元)、城乡居民年底储蓄余额9x (亿元)。所以我们借助这一指标体系对我国部分城市的主要经济指标进行分析。 二、数据分析 过程 1. 在SPSS 窗口中选择Analyze→Classify→Hierachical Cluster ,调出系统聚类分析主界面,并将变量X 1~X 5移入Variables 框中。在Cluster 栏中选择Cases 单选按钮,即对样品进行聚类(若选择Variables ,则对变量进行聚类)。在Display 栏中选择Statistics 和Plots 复选框,这样在结果输出窗口中可以同时得到聚类结果统计量和统计图。
2. 点击Statistics按钮,设置在结果输出窗口中给出的聚类分析统计 量。这里我们选择系统默认值,点击Continue按钮,返回主界面。 3. 点击Plots按钮,设置结果输出窗口中给出的聚类分析统计图。选 中Dendrogram复选框和Icicle栏中的None单选按钮,即只给出聚类树形图,而不给出冰柱图。单击Continue按钮,返回主界面。 4. 点击Method按钮,设置系统聚类的方法选项。这里我们仍然均沿 用系统默认选项。单击Continue按钮,返回主界面。 5. 点击Save按钮,指定保存在数据文件中的用于表明聚类结果的新 变量。None表示不保存任何新变量;Single solution表示生成一
(完整版)多元统计分析思考题答案
《多元统计分析》思考题答案 记得老师课堂上说过考试内容不会超出这九道思考题, 如下九道题题目中有错误的或不清楚 的地方,欢迎大家指出、更改、补充。 1、 简述信度分析 答题提示:要答可靠度概念,可靠度度量,克朗巴哈 系数、拆半系数、单项 与总体相 关系数、稀释相关系数等(至少要答四个系数,至少要给出两个指标的公式) 答: 信度( Reliability )即可靠性,它是指采用同样的方法对同一对象重复测量时所得结果 的一致性程度。 信度指标多以相关系数表示, 大致可分为三类: 稳定系数 (跨时间的一致性) 等值系数(跨形式的一致性)和内在一致性系数(跨项目的一致性) 。信度分析的方法主要 有以下四种: 1)、重测信度法 这一方法是用同样的问卷对同一组被调查者间隔一定时间重复施测, 计算两次施测结果 的相关系数。 重测信度属于稳定系数。 重测信度法特别适用于事实式问卷, 如果没有突发事 件导致被调查者的态度、 意见突变, 这种方法也适用于态度、 意见式问卷。 由于重测信度法 需要对同一样本试测两次, 被调查者容易受到各种事件、 活动和他人的影响, 而且间隔时间 长短也有一定限制,因此在实施中有一定困难。 2)、复本信度法 复本信度法是让同一组被调查者一次填答两份问卷复本,计算两个复本的相关系数。复 本信度属于等值系数。复本信度法要求两个复本除表述方式不同外,在内容、格式、难度和 对应题项的提问方向等方面要完全一致,而在实际调查中,很难使调查问卷达到这种要求, 因此采用这种方法者较少。 3)、折半信度法 折半信度法是将调查项目分为两半,计算两半得分的相关系数,进而估计整个量表的信 度。折半信度属于内在一致性系数, 测量的是两半题项得分间的一致性。 这种方法一般不适 用于事实式问卷(如年龄与性别无法相比) ,常用于态度、意见式问卷的信度分析。在问卷 调查中,态度测量最常见的形式是 5 级李克特( Likert )量表。进行折半信度分析时,如果 量表中含有反意题项, 应先将反意题项的得分作逆向处理, 以保证各题项得分方向的一致性, 然后将全部题项按奇偶或前后分为尽可能相等的两半,计算二者的相关系数。 为了校正差异,两半测验的方差相等时,常运用斯皮尔曼 - 布朗公式( Spearman- Brown Formula ):rxx=2rhh/(1+rhh ) ,其中, rhh :两半测验的相关系数; rxx :估计或修正后的信度。 该公式可以估计增长或缩短一个测验对其信度系数的影响。 当两半测验的方差不同时, 应采 用卢伦公式( Rulon Formula )或弗拉纳根公式( Flanagan Formula )进行修正。 4)、α信度系数法 Cronbach α信度系数是目前最常用的信度系数,其公式为: S i 从公式中可以看出,α系数评价的是量表中各题项得分间的一致性,属于内在一致性系数。其中, n n1 i1 S X S i 2 为每一项目的方差; S X 2 为测验总分方差。
多元统计分析对应分析
多元统计分析对应分析
学生实验报告 学院:统计学院 课程名称:多元统计分析 专业班级:统计123班 姓名:叶常青 学号: 0124253
学生实验报告 学生姓名叶常青学号0124253 同组人 实验项目对应分析的上机操作 □必修□选修□演示性实验□验证性实验□操作性实验□综合性实验实验地点实验仪器台号 指导教师李燕辉实验日期及节次 一、实验目的及要求: 目的熟悉和掌握对应分析的原理和上机操作方法 内容及要求本次操作就父母与孩子的受教
育程度的关系进行对应分析,分别对父亲与孩子和母亲与孩子的受教育程度做对应分析,最后再对输出结果进行详细的分析。 二、仪器用具: 仪器名称 规格/型号 数 量 备注 计算机 1 有网络环境 SPSS 软件 1 三、实验方法与步骤: 打开GSS93 subset .sav 数据,对变量Degree 与变量padeg 和madeg 进行对应分析,依次选择 分析→降维 …进入 对应分析 对话框,进行进行如下设置, 便可输出想要的数据的:
四、实验结果与数据处理: 按照上述方法和步骤得出以下输出结果. 对父亲受教育程度与孩子受教育程度的关系进行分析如下: 表1 对应表 Father' s Highest Degree R's Highest Degree Le ss than HS Hi gh school Jun ior college B achel or G radua te 有 效边 际 LT High School 15 6 30 8 29 4 5 2 5 5 63
High School 27 24 8 34 7 9 3 7 4 25 Junior College 1 11 2 8 3 2 5 Bachelo r 6 43 7 4 7 1 8 1 21 Graduat e 3 22 3 2 7 1 6 7 1 有效边际 19 3 63 2 75 2 06 9 9 1 205 表2 摘要 维数奇 异值 惯 量 卡 方 S ig. 惯量 比例 置信 奇异值 解 释 累 积 标 准差 相 关 2 1 . 400 . 160 . 846 . 846 . 025 . 256 2 . 164 . 027 . 142 . 988 . 026
多元统计分析重点归纳.归纳.docx
多元统计分析重点宿舍版 第一讲:多元统计方法及应用;多元统计方法分类(按变量、模型、因变量等) 多元统计分析应用 选择题:①数据或结构性简化运用的方法有:多元回归分析,聚类分析,主成分分析,因子分析 ②分类和组合运用的方法有:判别分析,聚类分析,主成分分析 ③变量之间的相关关系运用的方法有:多元回归,主成分分析,因子分析, ④预测与决策运用的方法有:多元回归,判别分析,聚类分析 ⑤横贯数据:{因果模型(因变量数):多元回归,判别分析相依模型(变量测度):因子分析,聚类分析 多元统计分析方法 选择题:①多元统计方法的分类:1)按测量数据的来源分为:横贯数据(同一时间不同案例的观测数据),纵观数据(同样案例在不同时间的多次观测数据) 2)按变量的测度等级(数据类型)分为:类别(非测量型)变量,数值型(测量型)变量 3)按分析模型的属性分为:因果模型,相依模型 4)按模型中因变量的数量分为:单因变量模型,多因变量模型,多层因果模型 第二讲:计算均值、协差阵、相关阵;相互独立性 第三讲:主成分定义、应用及基本思想,主成分性质,主成分分析步骤 主成分定义:何谓主成分分析 就是将原来的多个指标(变量)线性组合成几个新的相互无关的综合指标(主成分),并使新的综合指标尽可能多地反映原来的指标信息。 主成分分析的应用 :(1)数据的压缩、结构的简化;(2)样品的综合评价,排序 主成分分析概述——思想:①(1)把给定的一组变量X1,X2,…XP ,通过线性变换,转换为一组不相关的变量Y1,Y2,…YP 。(2)在这种变换中,保持变量的总方差(X1,X2,…Xp 的方差之和)不变,同时,使Y1具有最大方差,称为第一主成分;Y2具有次大方差,称为第二主成分。依次类推,原来有P 个变量,就可以转换出P 个主
多元统计分析--判别分析SPSS实验报告
实验课程名称: __多元统计分析--判别分析___
准则判别归类,则可写成: ?? ? ??=>∈<∈) ,(),( ,),(),(,),(),(,21212211G X D G X D G X D G X D G X G X D G X D G X 当待判当当 题目:表11.5的数据包含三种鸢尾的X2=萼片宽度与X4=花瓣的宽度的观测值。对每种鸢尾有n1=n2=n3=50个观测值。 部分数据:
第二部分:实验过程记录(可加页)(包括实验原始数据记录,实验现象记录,实验过程发现的问题等) 散点图:图形→旧对话框→散点图,打开简单散点图子对话框;将想X2选入X轴变量,X4选入Y轴变量,将总体选入设置标记框中,点击确定。 判别分析: 步骤: 1、选择分析→分类→判别,打开判别分析子对话框。 2、选择变量“总体”,单击→,将其加入到分组变量栏中。 3、打开定义范围子对话框,最小值输入1,最大值输入3。 4、将变量“X2萼片宽度”、“X4花瓣的宽度”选入自变量栏中。选择“一起输入自 变量”的方法。 5、打开统计变量子对话框,选择均值、单变量ANOVA、Box’M、未标准化、组内协 方差、分组协方差及总体协方差,单击继续。 6、打开分类子对话框,选择不考虑该个案时的分类,其余为默认值。 7、打开保存,选择所有的变量。
相关系数矩阵a 总体萼片宽度X2 花瓣宽度X4 合计萼片宽度X2 .190 -.122 花瓣宽度X4 -.122 .581 对数行列式 总体秩对数行列式 1 2 -6.496 2 2 -6.141 3 2 -5.189 汇聚的组内 2 -5.583 检验结果 箱的M 52.832 F 近似。8.632 df1 6 df2 538562.769 Sig. .000 Wilks 的Lambda 函数检 验Wilks 的Lambda 卡方df Sig. 1 到 2 .038 477.868 4 .000 2 .809 31.075 1 .000 典型判别式函数系数 函数 1 2 萼片宽度X2 -1.987 2.680 花瓣宽度X4 5.477 .817 (常量) -.494 -9.174 非标准化系数
多元统计报告
中国地质大学研究生课程论文封面 课程名称多元统计分析 教师姓名陈兴荣 研究生姓名王天豪 研究生学号 1201620203 研究生专业安全工程 所在院系工程学院 类别: 硕士
日期: 2016年12月1日 评语 注:1、无评阅人签名成绩无效;
2、必须用钢笔或圆珠笔批阅,用铅笔阅卷无效; 3、如有平时成绩,必须在上面评分表中标出,并计算入总成绩。
回归分析在油气储量密度影响因素分析中的应用 摘要:在石油地质学和石油安全领域中,油气得以保存至今,是受油气的生、储、盖、运、聚五大作用共同控制的。本文运用多元线性回归的方法,研究油气藏储量密度与生油条件参数的关系。 关键词:多元线性回归,储量密度 1、回归分析模型原理 回归分析法是一种处理变量间相关关系的数理统计方法,它不仅可以提供变量间相关关系的数学表达式,而且可以利用概率统计知识对此关系进行分析,以判别其有效性;还可以利用关系式,由一个或多个变量值,预测和控制另一个因变量的取值,进一步可以知道这种预测和控制达到了何种程度,并进行因素分析。回归分析法就是以统计回归概念为基础,采用多种类型的回归方法建立预测方程,包括一元线性回归方程、多元线性回归方程、非线性回归方程等。 多元线性回归时要确定因变量与多个自变量之间的定量关系,它的数学模型为:y=β0+β1x1+…+βm x m+ε。 其中,β0,β1,βm为待定参数;ε为随机变量,是除x以外其他随机因素对y影响的总和。 其中,称E(y)=β0+β1x1+…+βm x m为理论回归方程。 在实际问题的研究中,事先并不能断定随机变量y与变量x1,x2,…,x m之间是否有线性关系,在进行回归参数的估计前,用多元线性回归方程去拟合随机变量y与变量x1,x2,…,x m之间的关系,只是根据一些定性分析所作的一种假设。因此,当求出线性回归方程后,还需对回归方程进行显著性检验,一般采用两种统计方法对回归方程进行检验,一种是回归方程显著性的F检验;另一种是回归系数显著性的t检验。 2、案例分析背景 历史已经证明,石油工业是推动人类文明进步与社会发展的主要动力之一。自1930年世界石油产量不足30亿到目前约500亿桶,从能源给人类社会带来的各种发展变化中,我们会发现石油工业做出的贡献是非常巨大的。随着市场需求增长、新技术出现与地缘政治事件等正一起改变着石油工业的作用与地位,石油已成为世界大国经济、军事、政治斗争的武器。虽然世界能源多样化是大势所趋,但是,石油依然是世界经济发展中的重要能源,在很长一段时间内仍将在世界经济舞台上扮
几种多元统计分析方法及其在生活中的应用[1]
第2章聚类分析及其应用实例 2. 1聚类分析简介 聚类分析是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统 计分析方法,它们讨论的对象是大量的样品,要求能合理地按各自的特性來进行合理的分类,没有任何模式可供参考或依循,即是在没有先验知识的情况下进行的[']。 聚类分析方法有很多,按不同的分类方式,有不同的分类。按聚类方法的不 同可分为以下几种: (1)系统聚类法:对所在的指标进行分类,每一次将最相似的两个数据合并 成一类,合并之后和其他数据的距离会重新计算,这个步骤会不断重复下去直至所有指标合并成一类,并类的过程可用一张谱系聚类图描述. (2)调优法(动态聚类法):所谓调优法,从表面意思就可以看出是在对n 个对象初步分类后,根据分类后的信息损失尽可能小的原则对分类进行择优调整,直到分类合理为止. (3)有序样品聚类法:在很多实际问题中,所谓的样品都是相互独立的个体, 因此可以平等的划分。但是有序样品聚类法的存在就是因为在另外一些实际问题中,样品之间是存在着某种联系而在分类中是不允许打乱顺序的。有序样品聚类法开始时将所有样品归为一类,然后根据某种分类准则将其分为二类等等,一直往下分类下去直至满足分类要求。它的思想正好与系统聚类法的相反。 (4)模糊聚类法:利用模糊聚集理论来处理分类问题,它对经济领域中具有 模糊特征的两态数据或多态数据具有明显的分类效果. (5)图论聚类法:在处理分类问题中独创性的引入了图论中最小支撑树的概
念。 (6)聚类预报法:顾名思义,就是用聚类分析的方法来在各个领域中进行预 报。在多元统计分析中,判别分析、回归分析等方法都可以用来做预报,但是在 一些异常数据面前,这些方法做的预报都不是很准确,方法也不好准确的实施, 而聚类预报则很好的解决了这一点。可以预见,聚类预报法经过更深入的研究后,一定会得到更加广泛的应用。 按聚类对象的不同,聚类分析可分为2型[对样品(CASES)聚类]与型[对 变量(V ARIABLE)聚类],两种聚类在方法和步骤上都基本相同. 2. 2聚类分析方法介绍 数学方法在实际应用中是否受欢迎,最主要的一点就是它能不能适用于大型 6 第2章聚类分析及.11;应用实例 计算的问题。图论聚类法、基于等价关系的聚类方法和谱系聚类法在大型问题中 难以快速有效处理数据而应用甚少。基于目标函数的聚类方法因其设计简单,在 实际生活中被广泛运用,其主要思想是将问题转换为带约束条件的非线性优化, 这样就可以运用完备的线性最优化知识解决问题,而且这种方法也易于在计算机 上实现。而伴随着计算机技术的突飞猛进,基于目标函数的聚类方法必定会成为 研究的热点。 2. 2. 1谱系聚类方法 在待分析样本数较小时,通常采用谱系聚类方法(系统聚类法)。谱系聚类法 是按距离准则来对样本进行分类的,例如我们要将样本集X中的《个样本划分为C
多元统计分析作业一(第四题)
课程名称:多元统计回归分析 实验项目:多元方差分析 实验类型:验证性 学生学号: 学生姓名: 学生班级: 课程教师: 实验日期: 2016-04-18
.995 1832.265(b) 2.000 17.000 .000 .995 3664.530 1.000 距跟踪 Wilks 的 .005 1832.265(b) 2.000 17.000 .000 .995 3664.530 1.000 Lambda Hotelling 215.561 1832.265(b) 2.000 17.000 .000 .995 3664.530 1.000 的跟踪 Roy 的最 215.561 1832.265(b) 2.000 17.000 .000 .995 3664.530 1.000 大根 A Pillai 的 .901 7.378 4.000 36.000 .000 .450 29.511 .991 跟踪 Wilks 的 .101 18.305(b) 4.000 34.000 .000 .683 73.221 1.000 Lambda Hotelling 8.930 35.720 4.000 32.000 .000 .817 142.882 1.000 的跟踪 Roy 的最 8.928 80.356(c) 2.000 18.000 .000 .899 160.712 1.000 大根 B Pillai 的 .205 2.198(b) 2.000 17.000 .142 .205 4.397 .386 跟踪 Wilks 的 .795 2.198(b) 2.000 17.000 .142 .205 4.397 .386 Lambda Hotelling .259 2.198(b) 2.000 17.000 .142 .205 4.397 .386 的跟踪 Roy 的最 .259 2.198(b) 2.000 17.000 .142 .205 4.397 .386 大根
多元统计分析的重点和内容和方法
一、什么是多元统计分析 ?多元统计分析是运用数理统计的方法来研究多变量(多指标)问题的理论和方法,是一元统计学的推广。 ?多元统计分析是研究多个随机变量之间相互依赖关系以及内在统计规律的一门统计学科。 二、多元统计分析的内容和方法 ?1、简化数据结构(降维问题) 将具有错综复杂关系的多个变量综合成数量较少且互不相关的变量,使研究问题得到简化但损失的信息又不太多。 (1)主成分分析 (2)因子分析 (3)对应分析等 ?2、分类与判别(归类问题) 对所考察的变量按相似程度进行分类。 (1)聚类分析:根据分析样本的各研究变量,将性质相似的样本归为一类的方法。 (2)判别分析:判别样本应属何种类型的统计方法。 例5:根据信息基础设施的发展状况,对世界20个国家和地区进行分类。 考察指标有6个: 1、X1:每千居民拥有固定电话数目 2、X2:每千人拥有移动电话数目 3、X3:高峰时期每三分钟国际电话的成本 4、X4:每千人拥有电脑的数目 5、X5:每千人中电脑使用率 6、X6:每千人中开通互联网的人数 ?3、变量间的相互联系 一是:分析一个或几个变量的变化是否依赖另一些变量的变化。(回归分析) 二是:两组变量间的相互关系(典型相关分析) ?4、多元数据的统计推断 点估计 参数估计区间估计 统u检验 计参数t检验 推F检验 断假设相关与回归 检验卡方检验 非参秩和检验 秩相关检验 ?1、假设检验的基本原理
小概率事件原理 ? 小概率思想是指小概率事件(P<0.01或P<0.05等)在一次试验中基本上不会发生。反证法思想是先提 出假设(检验假设H0),再用适当的统计方法确定假设成立的可能性大小,如可能性小,则认为假设不成立;反之,则认为假设成立。 ? 2、假设检验的步骤 (1)提出一个原假设和备择假设 ? 例如:要对妇女的平均身高进行检验,可以先假设妇女身高的均值等于 160 cm (u=160cm )。这种原 假设也称为零假设( null hypothesis ),记为 H 0 。 2.1 均值向量的检验 ? 1、正态总体均值检验的类型 ? 根据样本对其总体均值大小进行检验( One-Sample T Test ) 如妇女身高的检验。 ? 根据来自两个总体的独立样本对其总体均值的检验( Indepent Two-Sample T Test ) 如两个班平均成绩的检验。 ? 配对样本的检验( Pair-Sample T Test ) 如减肥效果的检验。 ? 多个总体均值的检验 ? A 、总体方差已知 用u 检验,检验的拒绝域为 即 ? B 、总体方差未知 用样本方差 代替总体方差 ,这种检验叫t 检验. (2)根据来自两个总体的独立样本对其总体均值的检验 ? 目的是推断两个样本分别代表的总体均数是否相等。其检验过程与上述两种t 检验也没有大的差别,只 是假设的表达和t 值的计算公式不同。 ? 两样本均数比较的t 检验,其假设一般为: 12 { }W z u α- =>112 2 {} W z u z u αα - - =<->或2 s 2σ Ⅲ 0μμ= 0μμ< α--<1u z )1(1--<-n t t α
多元统计分析期末复习试题
第一章: 多元统计分析研究的容(5点) 1、简化数据结构(主成分分析) 2、分类与判别(聚类分析、判别分析) 3、变量间的相互关系(典型相关分析、多元回归分析) 4、多维数据的统计推断 5、多元统计分析的理论基础 第二三章: 二、多维随机变量的数字特征 1、随机向量的数字特征 随机向量X均值向量: 随机向量X与Y的协方差矩阵: 当X=Y时Cov(X,Y)=D(X);当Cov(X,Y)=0 ,称X,Y不相关。 随机向量X与Y的相关系数矩阵: 2、均值向量协方差矩阵的性质 (1).设X,Y为随机向量,A,B 为常数矩阵 E(AX)=AE(X); E(AXB)=AE(X)B; D(AX)=AD(X)A’; )' ,..., , ( ) , , , ( 2 1 2 1P p EX EX EX EXμ μ μ = ' = )' )( ( ) , cov(EY Y EX X E Y X- - = q p ij r Y X ? =) ( ) , (ρ
Cov(AX,BY)=ACov(X,Y)B ’; (2).若X ,Y 独立,则Cov(X,Y)=0,反之不成立. (3).X 的协方差阵D(X)是对称非负定矩阵。例2.见黑板 三、多元正态分布的参数估计 2、多元正态分布的性质 (1).若 ,则E(X)= ,D(X)= . 特别地,当 为对角阵时, 相互独立。 (2).若 ,A为sxp 阶常数矩阵,d 为s 阶向量, AX+d ~ . 即正态分布的线性函数仍是正态分布. (3).多元正态分布的边缘分布是正态分布,反之不成立. (4).多元正态分布的不相关与独立等价. 例3.见黑板. 三、多元正态分布的参数估计 (1)“ 为来自p 元总体X 的(简单)样本”的理解---独立同截面. (2)多元分布样本的数字特征---常见多元统计量 样本均值向量 = 样本离差阵S= 样本协方差阵V= S ;样本相关阵R (3) ,V分别是 和 的最大似然估计; (4)估计的性质 是 的无偏估计; ,V分别是 和 的有效和一致估计; ; S~ , 与S相互独立; 第五章 聚类分析: 一、什么是聚类分析 :聚类分析是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法。用于对事物类别不清楚,甚至事物总共可能有几类都不能确定的情况下进行事物分类的场合。聚类方法:系统聚类法(直观易懂)、动态聚类法(快)、有序聚类法(保序)...... Q-型聚类分析(样品)R-型聚类分析(变量) 变量按照测量它们的尺度不同,可以分为三类:间隔尺度、有序尺度、名义尺度。 二、常用数据的变换方法:中心化变换、标准化变换、极差正规化变换、对数变换(优缺点) 1、中心化变换(平移变换):中心化变换是一种坐标轴平移处理方法,它是先求出每个变量的样本平均值,再从原始数据中减去该变量的均值,就得到中心化变换后的数据。不改变样本间的相互位置,也不改变变量间的相关性。 2、标准化变换:首先对每个变量进行中心化变换,然后用该变量的标准差进行标准化。 经过标准化变换处理后,每个变量即数据矩阵中每列数据的平均值为0,方差为1,且也不再具有量纲,同样也便于不同变量之间的比较。 3、极差正规化变换(规格化变换):规格化变换是从数据矩阵的每一个变量中找出其最大值和最小值,这两者之差称为极差,然后从每个变量的每个原始数据中减去该变量中的最小值,再除以极差。经过规格化变换后,数据矩阵中每列即每个变量的最大数值为1,最小数值为0,其余数据取值均在0-1之间;且变换后的数据都不再具有量纲,便于不同的变量之间的比较。 4、对数变换:对数变换是将各个原始数据取对数,将原始数据的对数值作为变换后的新值。它将具有指数特征的数据结构变换为线性数据结构。 三、样品间相近性的度量 研究样品或变量的亲疏程度的数量指标有两种:距离,它是将每一个样品看作p 维空),(~∑μP N X μ∑μp X X X ,,,21 ),(~∑μP N X ),('A A d A N s ∑+μ)()1(,,n X X X )',,,(21p X X X )')(()()(1X X X X i i n i --∑=n 1X μ ∑μX )1,(~∑n N X P μ),1(∑-n W p X X