(完整版)非结构化存储方案
非结构化数据存储方案
一、存储类型体系:
1.1 存储类型体系结构图
1.2 存储类型体系描述
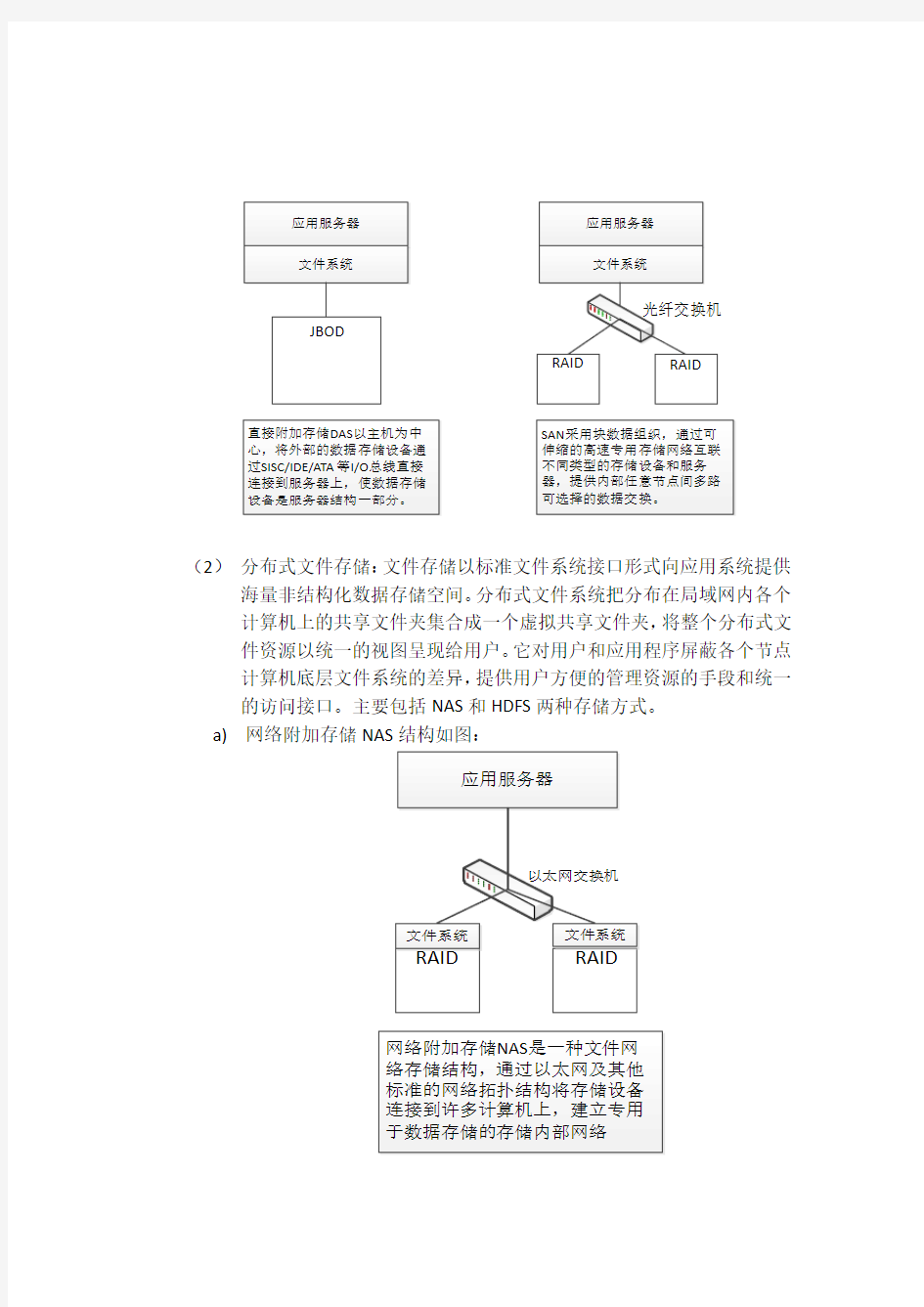
(1)块存储:将存储区域划分为固定大小的小块,是传统裸存设备的存储空间对外暴露方式。块存储系统将大量磁盘设备通过SCSI/SAS或FC
SAN与存储服务器连接,服务器直接通过SCSI/SAS或FC协议控制和
访问数据。主要包括DAS和SAN两种存储方式。对比如下图:
(2) 分布式文件存储:文件存储以标准文件系统接口形式向应用系统提供
海量非结构化数据存储空间。分布式文件系统把分布在局域网内各个计算机上的共享文件夹集合成一个虚拟共享文件夹,将整个分布式文件资源以统一的视图呈现给用户。它对用户和应用程序屏蔽各个节点计算机底层文件系统的差异,提供用户方便的管理资源的手段和统一
的访问接口。主要包括NAS 和HDFS 两种存储方式。 a) 网络附加存储NAS 结构如图:
b)HDFS分布式文件系统存储结构如图:
(3)对象存储:对象存储为海量非结构化数据提供Key-Value这种通过键-值查找数据文件的存储模式,提供了基于对象的访问接口,有效地合并了NAS和SAN的存储结构优势,通过高层次的抽象具有NAS的跨平台共享数据优点,支持直接访问具有SAN的高性能和交换网络结
构的可伸缩性。主要包括swift和ceph两种实现形式。
a)Swift,OpenStack Object Storage(Swift)是OpenStack项目的子项目
之一,被称为对象存储。它构建在比较便宜的标准硬件存储基础设
施之上,无需采用RAID(磁盘冗余阵列),通过在软件层面引入一致性散列技术和数据冗余性,牺牲一定程度的数据一致性来达到高可
用性和可伸缩性,支持多租户模式、容器和对象读写操作,适合解
决非结构化数据存储问题。
b)ceph,Linux下PB级分布式文件系统,可轻松扩展PB容量,提供了
对多种工作负载的高性能和高可靠性。它大致分为四部分:客户端
(数据用户),元数据服务器(缓存和同步分布式元数据),一个对
象存储集群(包括数据和元数据),以及最后的集群监视器(执行监
视功能)。
c)架构关键技术说明:
?Proxy Server:是提供Swift API的服务器进程,负责Swift其余组件间的相互通信。
?Storage Server:提供了磁盘设备上的存储服务。包含架构图上的Object、Container和Account。
2.2 基于ceph的大数据分布式存储
a)Ceph集群部署架构图
视频结构化大数据平台解决方案
视频结构化大数据平台 解 决 方 案 千视通
目录 1. 建设背景 (4) 2. 建设目标 (5) 3. 建设原则 (6) 3.1. 标准化原则 (6) 3.2. 统一设计原则 (6) 3.3. 大数据处理原则 (6) 3.4. 高可靠/高安全性原则 (6) 3.5. 适用性原则 (7) 3.6. 可扩展性原则 (7) 4. 系统总体设计 (7) 4.1. 设计依据 (7) 4.2. 总体架构设计 (10) 4.3. 业务架构设计 (11) 4.4. 网络架构设计 (12) 5. 数据结构化 (13) 5.1. 概述 (13) 5.2. 数据采集 (14) 5.3. 控制调度单元 (15) 5.4. 目标结构化单元 (15) 5.5. 车辆结构化单元 (21) 5.6. 前端要求 (26) 6. 数据存储 (29) 6.1. 概述 (29) 6.2. 功能设计 (29) 6.2.1. 数据存储 (29) 6.2.2. 数据服务 (30) 6.2.3. 系统管理 (31) 6.3. 存储设计 (32) 7. 数据应用 (32) 7.1 以图搜车 (33) 7.2人物大数据 (34) 7.2.1人物综合查询 (34) 7.2.2人物检索 (34) 7.2.3人骑车检索 (36) 7.2.4视频框选嫌疑目标 (37) 7.3以图搜图 (38) 7.3.1智能建库引擎 (38) 7.3.2以图搜图应用 (38) 7.4GIS应用 (39) 7.4.1基本操作 (39) 7.4.2地图查询 (39) 7.4.3轨迹展示 (40)
7.4.4摄像头操作............................................................................ 错误!未定义书签。 7.4.5系统管理 (41) 8. 平台特点 (44) 8.1. 提高海量视频倒查的效能 (44) 8.2. 提供视频关键特征的视频检索 (45) 8.3. 永久保存结构化的视频信息 (45) 8.4. 基于虚拟化服务的云计算架构 (46) 9. 配置清单.................................................................................................... 错误!未定义书签。
结构化数据和非结构化数据
相对于结构化数据(即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据)而言,不方便用数据库二维逻辑表来表现的数据即称为非结构化数据,包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频/视频信息等等。 字段可根据需要扩充,即字段数目不定,可称为半结构化数据,例如Exchange存储的数据。 非结构化数据库 在信息社会,信息可以划分为两大类。一类信息能够用数据或统一的结构加以表示,我们称之为结构化数据,如数字、符号;而另一类信息无法用数字或统一的结构表示,如文本、图像、声音、网页等,我们称之为非结构化数据。结构化数据属于非结构化数据,是非结构化数据的特例 数据清洗从名字上也看的出就是把“脏”的“洗掉”。因为数据仓库中的数据是面向某一主题的数据的集合,这些数据从多个业务系统中抽取而来而且包含历史数据,这样就避免不了有的数据是错误数据、有的数据相互之间有冲突,这些错误的或有冲突的数据显然是我们不想要的,称为“脏数据”。我们要按照一定的规则把“脏数据”“洗掉”,这就是数据清洗.而数据清洗的任务是过滤那些不符合要求的数据,将过滤的结果交给业务主管部门,确认是否过滤掉还是由业务单位修正之后再进行抽取。不符合要求的数据主要是有不完整的数据、错误的数据、重复的数据三大类。 (1)不完整的数据 这一类数据主要是一些应该有的信息缺失,如供应商的名称、分公司的名称、客户的区域信息缺失、业务系统中主表与明细表不能匹配等。对于这一类数据过滤出来,按缺失的内容分别写入不同Excel文件向客户提交,要求在规定的时间内补全。补全后才写入数据仓库。 (2)错误的数据 这一类错误产生的原因是业务系统不够健全,在接收输入后没有进行判断直接写入后台数据库造成的,比如数值数据输成全角数字字符、字符串数据后面有一个回车操作、日期格式不正确、日期越界等。这一类数据也要分类,对于类似于全角字符、数据前后有不可见字符的问题,只能通过写SQL语句的方式找出来,然后要求客户在业务系统修正之后抽取。日期格式不正确的或者是日期越界的这一类错误会导致ETL运行失败,这一类错误需要去业务系统数据库用SQL的方式挑出来,交给业务主管部门要求限期修正,修正之后再抽取。 (3)重复的数据 对于这一类数据——特别是维表中会出现这种情况——将重复数据记录的所有字段导出来,让客户确认并整理。 数据清洗是一个反复的过程,不可能在几天内完成,只有不断的发现问题,解决问题。对于是否过滤,是否修正一般要求客户确认,对于过滤掉的数据,写入Excel文件或者将过滤数据写入数据表,在ETL开发的初期可以每天向业务单位发送过滤数据的邮件,促使他们尽快地修正错误,同时也可以做为将来验证数据的依据。数据清洗需要注意的是不要将有
金融行业非结构化数据存储方案
金融行业非结构化数据存储方案
传统的银行、保险行业的人工柜台、信贷申请、承保和理赔等业务除了在数据库中记录交易信息,往往也会产生大量的非结构化数据:身份证照片、纸质文件扫描件、取证文件扫描件、现场照片等,依据金融行业相关法规要求,这些文件需长期保存,以便于后督审计和避免可能存在的法律风险。 随着互联网金融的迅猛发展,金融行业的竞争日趋白热化,越来越多的金融公司希望金融科技能够帮助企业降低揽客成本和客户服务成本,提升办公效率和风险评估效率。为此,各大金融机构竞相实施金融科技项目,如:智能化柜台,降低营业网点业务开通成本;无纸化柜台,提升柜台工作和服务效率;理赔智能手机客户端,提升用户理赔效率;智能化信贷审核,提升风险评估效率,降低人力投入成本;基础架构云化、容器化,提升基础资源的利用和管理效率等。 这些新型金融科技的背后,显而易见地会产生海量的图片、文档、音频和视频等非结构化数据,其文件个数和数据量都呈现爆发性增长,对原有的存储系统架构带来了更多的新挑战。 海量非结构化数据带来的挑战
对业务部门来说,海量小文件的访问性能至关重要,直接关系到终端用户的体验,而一个股份制银行省分行的柜台系统、信贷系统每年会新增上亿个文件,大量小文件对文件存储是一大挑战,而很多银行已经在考虑如何实现文件大集中。 而随着VTM(远程虚拟银行服务系统)、双录系统的上线,存储容量需求高速增长,如保险公司银保的双录数据半年即可增加数百TB数据,存储是否能够提供高吞吐能力,来保障音视频文件的读写性能是重要的关注点。 大多数金融机构已经采用分布式数据库、大数据技术,来实现历史数据的在线统一存储和查询,而非结构化数据的存储规模可能会达到PB级甚至EB级,在这种情况下如何实现数据的统一存储和管理、历史数据的实时查询、未来的大数据分析,对存储高度智能化的管理能力提出了更高的要求。 当前IaaS层云化是大趋势,私有云实现了计算和存储资源的云化,分布式数据库实现了结构化数据的云化,云化后的资源可按需分配、弹性扩展。而非结构化数据存储的云化却缺乏很好的解决方案,尤其是随着音视频数据的加入,占用的存储空间越来越大,而这些数据的单位价值不高,如何降低单位存储成本也需重点考量。
非结构化存储方案
非结构化数据存储方案 一、存储类型体系: 1.1 存储类型体系结构图 1.2 存储类型体系描述 (1)块存储:将存储区域划分为固定大小的小块,是传统裸存设备的存储空间对外暴露方式。块存储系统将大量磁盘设备通过SCSI/SAS或FC SAN与存储服务器连接,服务器直接通过SCSI/SAS或FC协议控制和 访问数据。主要包括DAS和SAN两种存储方式。对比如下图:
(2) 分布式文件存储:文件存储以标准文件系统接口形式向应用系统提供 海量非结构化数据存储空间。分布式文件系统把分布在局域网内各个计算机上的共享文件夹集合成一个虚拟共享文件夹,将整个分布式文件资源以统一的视图呈现给用户。它对用户和应用程序屏蔽各个节点计算机底层文件系统的差异,提供用户方便的管理资源的手段和统一 的访问接口。主要包括NAS 和HDFS 两种存储方式。 a) 网络附加存储NAS 结构如图:
b)HDFS分布式文件系统存储结构如图: (3)对象存储:对象存储为海量非结构化数据提供Key-Value这种通过键-值查找数据文件的存储模式,提供了基于对象的访问接口,有效地合并了NAS和SAN的存储结构优势,通过高层次的抽象具有NAS的跨平台共享数据优点,支持直接访问具有SAN的高性能和交换网络结 构的可伸缩性。主要包括swift和ceph两种实现形式。 a)Swift,OpenStack Object Storage(Swift)是OpenStack项目的子项目 之一,被称为对象存储。它构建在比较便宜的标准硬件存储基础设 施之上,无需采用RAID(磁盘冗余阵列),通过在软件层面引入一致性散列技术和数据冗余性,牺牲一定程度的数据一致性来达到高可 用性和可伸缩性,支持多租户模式、容器和对象读写操作,适合解 决非结构化数据存储问题。 b)ceph,Linux下PB级分布式文件系统,可轻松扩展PB容量,提供了 对多种工作负载的高性能和高可靠性。它大致分为四部分:客户端 (数据用户),元数据服务器(缓存和同步分布式元数据),一个对 象存储集群(包括数据和元数据),以及最后的集群监视器(执行监 视功能)。
非结构化数据管理系统
非结构化数据管理系统 1 范围 本标准规定了非结构化数据管理系统的功能性要求和质量要求。 本标准适用于非结构化数据管理系统产品的研制、开发和测试。 2 符合性 对于非结构化数据管理系统是否符合本标准的规定如下: a)非结构化数据管理系统若满足本标准基本要求中的所有要求,则称其满足本标准的基本要求; b)非结构化数据管理系统在满足所有基本要求的前提下,若满足某部分扩展要求,则称其满足本 标准的基本要求和该部分扩展要求; c)非结构化数据管理系统若满足本标准基本要求和扩展要求中的所有要求,则称其满足本标准的 所有要求。 3 规范性引用文件 下列文件对于本文件的应用是必不可少的。凡是注日期的引用文件,仅注日期的版本适用于本文件。凡是不注日期的引用文件,其最新版本(包括所有的修改单)适用于本文件。 GB 18030—2005 信息技术中文编码字符集 GB/T AAAAA-AAAA 非结构化数据访问接口规范 4 术语和定义 下列术语和定义适用于本文件。 4.1 非结构化数据unstructured data 没有明确结构约束的数据,如文本、图像、音频、视频等。 4.2 非结构化数据管理系统unstructured data management system 对非结构化数据进行管理、操作的大型基础软件,提供非结构化数据存储、特征抽取、索引、查询等管理功能。 5 缩略语 下列缩略语适用于本文件。 IDF:逆向文件频率 (Inverse Document Frequency) MFCC:梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient)
PB:千万亿字节(Peta Byte) SIFT:尺度不变特征转换(Scale-invariant Feature Transform) TF:词频 (Term Frequency) 6 功能性要求 6.1 总体要求 非结构化数据管理系统的总体要求如下: a)应包括存储与计算设施、存储管理、特征抽取、索引管理、查询处理、访问接口、管理工具七 个基本组成部分; b)宜包括转换加载、分析挖掘、可视展现三个扩展组成部分。 6.2 存储与计算设施 6.2.1 基本要求 存储与计算设施基本要求如下: a)应支持磁盘、磁盘阵列、内存存储、键值存储、关系型存储、分布式文件系统等一种或多种存 储设施; b)应支持单机、并行计算集群、分布式计算集群等一种或多种计算设施。 6.2.2 扩展要求 无。 6.3 存储管理 6.3.1 基本要求 存储管理基本要求如下: a)应提供涵盖原始数据、基本属性、底层特征、语义特征的概念层存储建模功能; b)应提供逻辑层的存储建模功能; c)支持整型、浮点型、布尔型、字符串、日期、日期时间、二进制块等基本数据类型; d)支持向量、矩阵、关联等数据类型; e)应支持根据建好的逻辑层存储模型创建存储实例; f)应支持在创建好的存储实例上插入、修改、删除非结构化数据; g)应支持删除存储实例; h)应支持非结构化数据操作的原子性。 6.3.2 扩展要求 存储管理扩展要求如下: a)应支持全局事务的定义并保证事务的原子性、一致性、隔离性和持久性; b)应支持数据类型的多值结构和层次结构; c)应支持在不同的存储设施上创建存储实例并实现自动映射; d)应支持PB级数据存储。 6.4 特征抽取
Oracle非结构化数据解决方案
Oracle数据库11g管理非结构化数据 (2) 一、引言 (2) 二、在ORACLE 中管理非结构化数据的优势 (3) 三、打破了原来处理非结构化数据的“性能障碍” (4) 3.1 Oracle SecureFiles (4) 3.2 SecureFiles 中的存储优化 (5) 四、专用数据类型和数据结构 (6) 4.1 Oracle XML DB (6) 4.2 Oracle Text (7) 4.3 Oracle Spatial (8) 4.4 RDF、OWL 和语义数据库管理 (9) 4.5 Oracle Multimedia (9) 4.6 Oracle DICOM 医学内容管理 (9) 五结论 (10)
Oracle数据库11g管理非结构化数据 一、引言 公司、企业以及其他机构使用的绝大部分信息都可归类为非结构化数据。 非结构化数据是计算机或人生成的信息,其中的数据并不一定遵循标准的数据结构(如模式定义规范的行和列),若没有人或计算机的翻译,则很难理解这些数据。常见的非结构化数据有文档、多媒体内容、地图和地理信息、人造卫星和医学影像,还有Web 内容,如HTML。 根据数据的创建方式和使用方式的不同,非结构化数据的管理方法大不相同。 1.大量数据分布于桌面办公系统(如文档、电子表格和演示文稿)、专门的工作站和设备 (如地理空间分析系统和医学捕获和分析系统)上。 2.政府、学术界和企业中数TB 的文档存档和数字库。 3.生命科学和制药研究中使用的影像数据银行和库。 4.公共部门、国防、电信、公用事业和能源地理空间数据仓库应用程序。 5.集成的运营系统,包括零售、保险、卫生保健、政府和公共安全系统中的业务或健康记 录、位置和项目数据以及相关音频、视频和图像信息。 6.学术、制药以及智能研究和发现等应用领域中使用的语义 数据(三元组)。 自数据库管理系统引入后,数据库技术就一直用于解决管理大量非结构化数据时所遇到的特有问题。通常通过“基于指针的”方法使用数据库对存储在文件中的文档、影像和媒体内容进行编目和引用。为了在数据库表内存储非结构化数据,二进制大对象(或简称为BLOB)作为容器使用已经数十年了。除了简单的BLOB 外,多年以来,Oracle 数据库一直通过运算符合并智能数据类型和优化数据结构,以分析和操作XML 文档、多媒体内容、文本和地理空间信息。由于有了Oracle 数据库11g,Oracle 再次在非结构化数据管理领域开辟出一片新天地:大幅提升了通过数据库管理系统原生支持的非结构化数据的性能、安全性以及类型。
最新Bigtable 结构化数据的分布式存储系统 上
B i g t a b l e结构化数据的分布式存储系统 上
Bigtable 结构化数据的分布式存储系 统上 转载请注明:作者phylips@bmy 摘要 Bigtable是设计用来管理那些可能达到很大大小(比如可能是存储在数千台服务器上的数PB的数据)的结构化数据的分布式存储系统。Google的很多项目都将数据存储在Bigtable中,比如网页索引,google地球,google金融。这些应用对Bigtable提出了很多不同的要求,无论是数据大小(从单纯的URL到包含图片附件的网页)还是延时需求。尽管存在这些各种不同的需求,Bigtable成功地为google的所有这些产品提供了一个灵活的,高性能的解决方案。在这篇论文中,我们将描述Bigtable所提供的允许客户端动态控制数据分布和格式的简单数据模型,此外还会描述Bigtable的设计和实现。 1.导引 在过去的2年半时间里,我们设计,实现,部署了一个称为Bigtable的用来管理google的数据的分布式存储系统。Bigtable的设计使它可以可靠地扩展到成PB的数据以及数千台机器上。Bigtable成功的实现了这几个目标:广泛的适用性,可扩展性,高性能以及高可用性。目前,Bigtable已经被包括Google分析,google金融,Orkut,个性化搜索,Writely和google地球在内的60多个google产品和项目所使用。这些产品使用Bigtable用于处理各种不同的工作负载类型,从面向吞吐率的批处理任务到时延敏感的面向终端用户的数据服务。这些产品所使用的Bigtable集群也跨越了广泛的配置规模,从几台机器到存储了几百TB数据的上千台服务器。
非结构化数据存储需求及CAS存储架构简介
1 非结构化数据存储需求 1.1 非结构化数据 我们通常把那些不方便用数据库二维逻辑表来表现的数据,称为非结构化数据,也习惯称其为内容信息。随着企业业务的飞速发展和企业信息化建设的步伐,特别是随着网络应用的丰富和发展,各行各业都积累了大量的信息资源,其中大部分都是内容信息。研究部门调查发现,在当前企业存储的大量数据中,传统关系数据库管理系统(RDBMS)处理的结构化数据仅占数据信息总量的20%,而全球80%的信息是非结构化的,包括:纸质文件和报告、电子影像、视频和音频文件、传真件、信件、电子邮件等。 1.2 内容管理系统 内容管理系统就是针对企业非结构化数据的管理而设计的,帮助企业解决在内容信息的管理和使用过程中的一系列问题。 1.2.1 数据存储要求 内容管理系统对数据存储特别是影像数据的存储有如下要求: 海量可扩充的存储设备 由于系统影像数据会随着业务量的增长而迅速增长,所以需要一个具有在线扩容能力,并在扩容时不会影响整个存储系统性能的高效存储。 高读写性能 由于影像文件的存储容量都很大,所以数据存储需要有良好的读写性能。 备份和恢复能力 存储设备要支持在海量情况下高速的在线备份和恢复解决方案。 满足法规遵从 要求采一次写多次读技术(不能修改、删除,只能查看),保证数据的真实性、完整性,满足内部审计要求。 数据完整性与自动修复 希望存储内部提供对于数据进行检测完整性并自动修复的功能,避免出现影像打开后出现色差,黑线,黑块等影响影像质量的问题。
消除重复存储 对于相同的图片如果有多次存储的话只希望在后台保留一份,对于前端应用完全透明,节省了存储空间。 存储的高可用性和性价比 需要存储支持高可用性方案,比如双机热备,在线容灾等,在确保安全性的情况下希望有一个比较好的价格。 方便的部署 部署的设备需要充分利用现有网络和服务器资源,对于业务不中断的部署与升级。 设备管理 随着数据量的增长,设备的不断扩容,设备节点会越来越多,所以希望所购买的存储是一个智能的可自动报警的设备。 2 CAS存储架构 内容寻址存储(Content Addressed Storage,CAS)是由美国EMC公司2002年4月率先提出的针对固定内容存储需求,专为非结构化数据存储而设计的先进网络存储技术(固定内容是指一旦生成就不再发生改变的信息,比如:视频、扫描影像、电子邮件、银行票据等,企业内容管理系统所要管理的资料影像,就属于是固定内容数据)。 CAS具有面向对象存储特征,基于磁记录技术,它按照所存储数据内容的数字指纹寻址,具有良好的可搜索性、安全性、可靠性和扩展性。 2.1 CAS的特点 2.1.1 不需要记住文件路径 CAS和SAN、NAS在技术层面有一个最大的区别。SAN、NAS在存储文件的时候是按照地址存放文件,用户找文件的时候一定要知道它放在哪个磁盘分区的哪个目录里,否则就要搜索。而CAS没有分区、没有目录,用户不需要记住文件路径,只需要把数据交给CAS,CAS给用户一个数字指纹,相当于公民身份证,靠一串数字和字母组合的数字指纹来识别用户存储的数据。当用户需要找这个数据的时候,要提交数字指纹来获取数据,所以它的技术和传统的SAN、NAS是完全不同的。
非结构化数据存储解决方案
1.非结构化数据存储 在上图中,描述了非结构化数据存储架构的基本组成部分,其中: 1. 文件存取统一接口,封装了对数据中心所以非结构化数据的读写操作接口。 2. Hadoop HDFS 负责对大文件的存储,以HDFS:为文件协议标准 3. HBase 通过维护一张文件表完成对小文件的存储,以HBase:为文件协议标识1.1文件存取统一接口 1.1.1 文件存储接口 对文件进行存储前,接口根据文件的大小和HDFS文件分块的配置大小进行比较,当文件超过设定大小时,接口认为该文件是大文件,直接分配到HDFS文件存储接口进行写入;否则当文件小与块大小时,根据系统维护的Hbase小文件存储通用存储表进行存储管理。
1. 对直接存储到HDFS的文件,则文件路径以HDFS为中心存储文件协议头,文件路径则根据该文件的业务属性做完文件的路径,文件名称保留原有名称,例如:HDFS://aaa/bbb.zip 2. 对通过Hbase管理的小文件,则文件路径以HBASE为中心存储文件协议头,文件路径不需要分文件夹,直接以文件的唯一标识标识即可,例如:HBASE://uuid 1.1.2 文件读取接口 文件读取时,通过识别URL,确定文件的存储方式,然后找到对应的存储接口获取文 件。
1.1Had oop HDFS存储接口 完成大文件的存储与读取接口操作。 1.2Hbase存储接口 文件通用存储表结构: 表存在两个列簇,default列簇负责存储基础属性信息,用一个单独的列簇存储图片内容。 HBase是采用面向列的存储模型,按列簇来存储和处理数据,即同一列簇的数据会连续存储。HBase在存储每个列簇时,会以Key-Value的方式来存储每行单元格(Cell)中的数据,形成若干数据块,然后把数据块保存到HFile中,最后把HFile保存到后台的HDFS 上。由于用单元格 (Cell)存储图片小文件的内容,上述存储数据的过程实际上隐含了把图片小文件打包的过程。默认情况下,HBase数据块限制为64KB。由于图片内容作为单元格(Cell)的值保存,其大小受制于数据块的大小。在应用中需根据最大图片大小对HBase数据
Cassandra - 一个分散的非结构化存储系统
Cassandra - 一个分散的非结构化存储系统 https://www.360docs.net/doc/3c645881.html,/?p=372 本文翻译自Facebook员工在LADIS大会上发布的论文.Cassandra – A Decentralized Structured Storage System 这篇论文中,两位作者详细介绍了Cassandra的系统架构,它的设计初衷,设计应用时使用到的相关技术,以及设计/实现/使用过程中得到的经验教训. Cassandra –一个分散的非结构化存储系统 By Avinash Lakshman Facebook ,Prashant Malik Facebook; Translated By Jametong 概要 Cassandra是一个分布式的存储系统,可用来管理分布在大量廉价服务器上的巨量结构化数据,并同时提供没有单点故障的高可用服务.Cassandra的设计目的是运行在由几百个节点(可能分布在多个不同的数据中心)组成的基础设施(infrastructure)上.当节点达到这个规模时,大大小小的组件出现故障就可能经常发生了.Cassandra在管理持久状态时面临这些故障,这种情况也驱动软件系统的可靠性 (reliability)与可伸缩性(scalability)会依赖于Cassandra的服务.虽然大部分情况,Cassandra看上去像一个数据库系统, 也与数据库系统共享大量的设计与实现手段,但是Cassandra并不支持完整的关系数据模型;相反,它提供了一个简单数据模型的客户端,支持对数据布局与数据格式的动态控制.我们设计Cassandra的初衷是,可以运行在廉价硬件上,并能在不牺牲读效率的情况下实现高的写吞吐量. 1. 导论 Facebook维护着世界上最大的社交网络平台,利用分布在世界各地的大量数据中心的成千上万台服务器,为上亿的用户提供服务.Facebook 平台有严格的业务要求,包含性能、可靠性、效率以及高度的可伸缩性以支持平台的持续增长.在一个包含成千上万的组件的基础设施上处理故障是我们的标准运作模式;在任何时候,随时都可能出现相当数量的服务器或网络组件故障.这样,软件系统在构建时就需要将故障当作一种常态而不是异常来处理.为了满足上面描述的这些可靠性与可伸缩性,Facebook开发了Cassandra系统. 为了实现可伸缩性与可靠性,Cassandra组合了多项众所周知的技术.我们设计Cassandra的最初目的是解决收件箱搜索的存储需要.在 Facebook,这意味着这个系统需要能够处理非常大的写吞吐量,每天几十亿的写请求,随着用户数的规模而增长.由于我们是通过在地理上分布的数据中心对用户进行服务的,因此支持跨越多个数据中心的数据复制对于降低搜索延时就非常关键了.当我们在2008年6月发布收件箱搜索项目时,我们有1亿的用户, 现在我们差不多有2.5
数据存储类型分析
数据存储类型分析 胡经国 本文作者的话 云计算具有很强的知识性和专业性。对于业外读者来说,云计算可谓“博大精深”。业外公众要学习云计算,有必要循序渐进地学习有关云计算的一系列基础知识。本文作为《漫话云计算》系列文稿和笔者学习云计算的笔录之一,供云计算业外读者进一步学习和研究参考。希望能够得到大家的指教和喜欢! 下面是正文 一、针对数据存储形式的数据类型分析 结构化数据、非结构化数据和半结构化数据,是针对数据存储形式的一种数据类型分析。 1、结构化数据 结构化数据,是指行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据。 结构化数据,是指以固定字段驻留在一个记录或文件内的数据。它事先被人为组织过,也依赖于一种确保数据如何存储、处理和访问的模型。结构化查询语言(SQL)通常用于管理在数据库中的结构化数据表。 结构化数据,简单来说就是数据库里的数据;具体到典型场景中更容易理解,比如企业ERP、财务系统;医疗HIS数据库;教育一卡通;政府行政审批;其他核心数据库等。这些应用需要哪些存储需求呢?基本包括:高速存储应用需求、数据备份需求、数据共享需求以及数据容灾需求。 链接:ERP ERP (Enterprise Resource Planning,企业资源计划),由美国Gartner Group 公司于1990年提出。企业资源计划是 MRP II(企业制造资源计划)下一代的制造业系统和资源计划软件。除了MRP II 已有的生产资源计划、制造、财务、销售、采购等功能外,还有质量管理,实验室管理,业务流程管理,产品数据管理,存货、分销与运输管理,人力资源管理和定期报告系统。目前,在中国ERP 所代表的含义已经被扩大,用于企业的各类软件,已经统统被纳入ERP 的范畴。它跳出了传统企业边界,从供应链范围去优化企业的资源,是基于网络经济时代的新一代信息系统。它主要用于改善企业业务流程以提高企业核心竞争力。
非结构化存储方案
非结构化存储方案
非结构化数据存储方案 一、存储类型体系: 1.1 存储类型体系结构图 存储类型 块存储 分布式文件存储 直接附加存储DAS 存储区域网络SAN IP SAN FC SAN 网络附加存储NAS HDFS(hadoop分布式 文件系统) 对象存储 OpenStack—Swift ceph 1.2 存储类型体系描述 (1)块存储:将存储区域划分为固定大小的小块,是传统裸存设备的存储空间对外暴露方式。块存储系统将大量磁盘设备通过 SCSI/SAS或FC SAN与存储服务器连接,服务器直接通过SCSI/SAS 或FC协议控制和访问数据。主要包括DAS和SAN两种存储方式。对 比如下图:
应用服务器文件系统 JBOD 直接附加存储DAS 以主机为中心,将外部的数据存储设备通过SISC/IDE/ATA 等I/O 总线直接连接到服务器上,使数据存储设备是服务器结构一部分。 应用服务器文件系统 RAID SAN 采用块数据组织,通过可伸缩的高速专用存储网络互联不同类型的存储设备和服务器,提供内部任意节点间多路可选择的数据交换。 RAID 光纤交换机 (2) 分布式文件存储:文件存储以标准文件系统接口形式向应用系统提供海量非结构化数据存储空间。分布式文件系统把分布在局域网内各个计算机上的共享文件夹集合成一个虚拟共享文件夹,将整个分布式文件资源以统一的视图呈现给用户。它对用户和应用程序屏蔽各个节点计算机底层文件系统的差异,提供用户方便的管理资源的手段和统一的访问接口。主要包括NAS 和HDFS 两种存储方式。 a) 网络附加存储NAS 结构如图: 应用服务器 RAID 网络附加存储NAS 是一种文件网络存储结构,通过以太网及其他标准的网络拓扑结构将存储设备连接到许多计算机上,建立专用于数据存储的存储内部网络 以太网交换机 文件系统文件系统 RAID
(完整版)非结构化数据来袭
非结构化数据来袭 有人说,人类仅仅开发使用了自己大脑容量的10%,要能够利用其他的90%,人类的洞察力和成就将会无比惊人。这种说法的准确性可能有待研究确定,但与之类似,的确属实的情况是企业一直在分析应用的是只占数据总量20%的那些跑在ERP等系统里的结构化数据。如果再能结合利用其余80%的非结构化数据,那效果就可想而知了。 基础技术在不断发展,而电子商务、移动应用、社交网络等日益活跃,这导致大量的像影像资料、办公文档、扫描文件、Web 页面、电子邮件、微博、即时通信以及音视频等非结构化数据迎面而来,企业应接不暇。 结构化vs 非结构化 相对于存储在关系型数据库里,用二维逻辑表来表现的结构化数据而言,那些不方便用数据库二维逻辑表来表现的数据就是所谓的非结构化数据,包括报表、账单、影像、办公文档、扫描文件、Web 页面、电子邮件以及多媒体音频和视频信息等。 据统计,企业中20%的数据是结构化的,80%则是非结
构化或半结构化的。当今世界结构化数据增长率大概是32%,而非结构化数据增长则是63%,至2012年,非结构化数据 占有比例将达到互联网整个数据量的75%以上。而非结构化数据中50%~75%的数据都来源于人与人的互动,都是以人为中心产生的。 我们都很熟悉结构化数据,典型的就是事务数据、定量的数据。企业收集、存储、查询、利用它们来制定商业战略、预判趋势、运行报表、进行分析、优化运营。企业在结构化数据的利用方面已经做得很好,通过它能提供重要的业务洞察力,更有效率和有效益地服务于客户,遵循监管法规,为决策制定者提供所需的即时的、持续的关键信息以优化业务。 但今天,许多企业已经意识到,结构化数据仅仅是企业所拥有数据的一小部分。与业务信息系统中大量用于交易记录、流程控制和统计分析的结构化数据相比,非结构化数据具有某种特定和持续的价值,这种价值在共享、检索、分析等使用过程中得以产生和放大,并最终对企业业务和战略产生影响。 比如在医疗行业,逐渐普及的电子病历的建设中,既存在结构化的电子病历数据,也存在非结构化的电子病历数据,而非结构化的电子病历数据的重要性并不比结构化数据低。因为描述病人病情的自然语言要比患者基本信息等结构化 数据更丰富形象,而临床产生的大量影像文件对医生的诊断
海量非结构化数据存储问题初探
51 档案科技 文/张志刚 姚 玮 ?本栏责任编辑 韩伟 以企业档案系统中的数据信息为研究对象有两类:一类有统一的结构,可以用数字或文字来描述,这类信息具有类似的层次或网络结构,称之为结构化数据;另一类信息则无法用数字或者统一的结构表示,例如扫描图像、传真、照片、计算机生成的报告、字处理文档、电子表格、演示文稿、语音和视频片段等,这些即为非结构化数据。 电力企业非结构化数据存储及管理现状 1.电力企业档案非结构化数据的存储特点 与传统档案的馆藏资源相比,数字档案馆信息资源有其自身的特点。从存储的角度来考虑,数字档案馆馆藏数字资源具有以下特点: (1)存储容量大。数字档案馆的各种数字化信息如流媒体、历史档案等的增长也将一直持续下去。存储信息的度量单位由MB,GB向TB,PB转变,其存储的数据总量达到了海量规模。 (2)媒体形式多。数字档案馆馆藏包括数字化的文书、图纸、实物、照片、电子出版物、互联网内容、政府文件等各种各样的人文与科学数据资源。其存储媒介已不限于印刷体,它包含文本、声音、图像、影视等多种媒体形式,数据类型复杂。 (3)快速增长。近几年来,档案馆数字资源呈几何级数增长,数字档案和 全文数据库是数字档案馆藏资源的重要增长点。如各企业正在进行的历史档案的数字化工作,将会使数字馆藏迅猛增长。 2.电力企业非结构化数据存储管理的现状 目前电力企业对非结构化数据的存储方式有如下几种方式: (1)直接存储在结构化数据库的BLOB字段中。目前电力企业大部分的应用系统中的非结构化数据,如报告、报表、图片等都是以二进制的格式保存在结构化数据库的BLOB字段中。保存在BLOB字段中的好处是调用文件的速度很快,维护和管理简单,与其他应用系统没有任何关联;缺点一是由于非结构化数据文件大,在数据量不断增大的情况下,会使得结构化数据库迅速膨胀,导致数据库性能下降,进而影响整个应用系统的性能;二是由于各个应用系统相对封闭和独立,其他应用无法共享相关文档资料。 (2)以FTP上传的方式保存到文件服务器中。以这种方式保存非结构化数据的应用较少,比较典型的应用有数字档案馆、知识管理和网站。 (3)通过文件系统直接存储在文件服务器中。对于大多数没有应用系统的非结构化数据,如信息管理部门常用的工具软件、开发的应用系统软件、源代码、开发过程文档、技术研究资料等,新闻中心的素材、资料等通常都是将文件直接存储到文件服务器中。 海量非结构化数据存储整合 在数字档案馆建设过程中发现,企业各类业务系统都有数字资源的归档要求。面对各业务系统各自为战的存储系统,许多企业都正在评估和选择实现信息资源整合的最佳途径,而其中绝大多数所瞄准的都是基于文件结构使用SAN或NAS 进行整合的方式。 1.数据整合的驱动因素 进行存储系统整合的根本目的是为了减少存储资源的数量。目前文件服务系统的规模会随着新增企业应用的部署和新的扩展需求而不断增长,最终会形成一个拥有越来越多文件服务器的庞大的文件服务环境。这种复杂的文件服务环境是不利于业务系统数字资源的管理、归档的。下面对非结构化数据存储整合的驱动因素逐一论述。 降低管理成本 系统整合所带来的一个好处就是能够减少企业的IT管理工作。随着需要管理的存储设备的减少,处理这些管理任务所需要用到的人力资源也可以相应地减少。而如果任随这些系统不断增长,随着时间的推移,最终将积累起大量的文件服务器资源,这些资源的维护对IT人员来说将是一个极大的负担。 经济利益 存储系统整合的实现同样会对企业的经济产生极大的正面促进作用。当企业将多个系统整合成一个之后,就能够节省下多余的软件许可费用和磁盘空 海量非结构化 数据存储问题初探
数据存储方案
引言 文献是由Rick Cattell撰写的论文,论文讨论了可扩展的结构化数据的、非结构化的(包括基于键值对的、基于文档的和面向列的)数据存储方案(注:NOSQL 是支撑大数据应用的关键所在。事实上,将NOSQL翻译为“非结构化”不甚准确,因为NOSQL更为常见的解释是:Not Only SQL(不仅仅是结构化),换句话说,NOSQL并不是站在结构化SQL的对立面,而是既可包括结构化数据,也可包括非结构化数据)。 论文信息 Scalable SQL and NoSQL Data Stores Rick Cattell Originally published in 2010, last revised December 2011 摘要 ABSTRACT In this paper, we examine a number of SQL and so- called ―NoSQL‖ data stores designed to scale simple OLTP-style application loads over many servers. Originally motivated by Web 2.0 applications, these systems are designed to scale to thousands or millions of users doing updates as well as reads, in contrast to traditional DBMSs and data warehouses. We contrast the new systems on their data model, consistency mechanisms, storage mechanisms, durability guarantees, availability, query support, and other dimensions. These systems typically sacrifice some of these dimensions, e.g. database-wide transaction consistency, in order to achieve others, e.g. higher availability and scalability. 在这篇文献中,我们验证了许多SQL和所谓的?NoSQL‘数据存储(它设计于支持简单的OLTP风格的应用,能够用于扩展在很多服务器上) 它最先由Web 2.0应用引起,与传统的数据库管理系统和数据仓库对比,这些系统设计为可扩展到数以千计或数以百万计的用户做更新,同时读取。 我们对比了新系统上的数据模型,一致性机制, 存储机制,持久性保证,可用性,支持的查询以及其它属性,这些系统典型的牺牲(为了实现其它属性而去掉)了一些属性。如数据库常有的事务一致性,牺牲了这个是为了其它的属性,如高可用,可扩展。 Note: Bibliographic references for systems are not listed, but URLs for more information can be found in the System References table at the end of this paper. 注:参考书没列出来(翻译省)
非结构化数据存储的技术研究与实现_赵丞
173 企业应用系统中存在大量的非结构化数据,通常企业机构使用基于网络的分布式文件服务器维护非结构化数据,并在企业应用系统中授权访问。 文件服务可以作为多种企业应用系统的基础服务。一方面,我们需要基于网络的分布式文件服务实现大量数据的存储。另一方面,集中的管理、监控和使用文件服务,将在降低企业应用系统开发的难度和工作量的同时,简化企业应用系统的部署、管理和维护工作。 上述结构在保证了文件服务器安全性的同时,存在下列不足:(1)文件传输的处理将极大的占用应用服务器的处理能力及网络带宽,应用服务器很可能因此成为企业应用的瓶颈。(2)按照用户界面中是否执行文件传输操作,最终用户预期的界面平均响应时间也不同,通常用户更难忍受非文件传输时的界面延迟。因此上述结构可能导致的文件传输挤占其他业务的处理能力的情况,将对企业应用系统的用户体验带来较大的影响。 参考互联网应用的文件处理机制,本文提出对分布式文件服务器结构的改进,主要包括:(1)将文件流数据传输的负载从应用服务器分散到多个文件服务器;(2)由于在基于B/S 架构企业应用系统中,企业应用系统的客户端浏览器只能基于http(s)与服务器通信,因此要求文件服务器实现基于http(s)的访问接口,以标准的方式完成与客户端浏览器的通信;(3)为适应企业应用系统中频繁的数据变更和细粒度访问控制需求,确保直接面向最终用户的文件服务器的安全性;(4)通过分布式文件服务器中逻辑存储单元的定义,以及 存储单元与物理存储位置的映射管理,实现不同企业应用系统间的隔离,进而支持建立企业级文件服务,降低企业应用系统开发难度和工作量,简化企业管理和维护文件的工作。 1 基本概念 1.1 分布式文件系统 分布式文件系统是指文件系统时间共享模式的分布式实,通过一个公共文件系统为地理上分布的计算机用户提供数据和存储资源的共享。分布式文件系统的主要特征为网络透明性、位置透明性、可扩展性以及容错。 1.2 电子仓库 电子仓库DV(data vault)是指在PDM 系统中实现产品数据存储与管理的元数据库及其管理系统,它是连接数据库和数据使用界面的一个逻辑单元,它保存所有与产品相关的物理数据和文件的元数据,以及指向物理数据和文件的指针。通过建立在数据库之上的关联指针,建立不同类型的或异构的产品数据之间的联系,实现文档的层次与联系控制。 1.3 HDFS Hadoop 分布式文件系统(Hadoop Distributed File System,HDFS)是一个运行在普通的硬件之上的分布式文件系统。HDFS 具有高容错性,可以部署在低成本的硬件之上,同时HDFS 放松了对POSIX 的需求,使其可以以流的形式访问文件数据,从而提供高吞 非结构化数据存储的技术研究与实现 赵丞 (北京神舟航天软件技术有限公司 北京 100094) 摘要:分布式文件服务器系统是企业应用系统的基础组成部分,通过企业应用系统访问文件服务将给企业应用系统带来极大的网络压力并降低服务质量。本文提出在保证数据安全性的基础上,支持在企业中分布式部署文件服务器群供其他企业应用系统共用,为企业中非结构化数据的管理和维护提供了完整的解决方案,可以有效的降低企业应用系统的研发、部署和维护成本,并提高企业应用系统服务质量。 关键词:分布式 文件存储 文件服务器中图分类号:TP311.13文献标识码:A 文章编号:1007-9416(2013)04-0173-03 图1 分布式文件服务器结构模型图2 文件服务器认证活动图
企业如何管理非结构化数据
企业如何管理非结构化数据? 移动应用要求 企业的信息化往移动端发展已经是一种趋势,移动端的非结构化数据也变的越来越重要,因此,做好移动端和PC端非结构化数据的协同应用是企业面临的难题。 大数据应用要求 大数据时代的到来,让每一个企业都在挖掘大数据的价值,同样,作为大数据的一部分,非结构化数据必将给企业带来巨大的应用价值。物联网应用要求 随着移动及大数据应用,物联网已经在国内逐步推进,非结构化数据是物联网应用基础之一,所以做好非结构化数据管理也是势在必行。 最重要的是,进入高度信息化的大数据时代,企业对信息系统高敏捷协作有了更高度的要求。 网络消耗难题分析:文件同步的传统机制是造成网络消耗最大问题 企业的邮件、OA、ERP、文件服务器等应用所涉及到的文件数据共享都是采用文件全量同步、或者是文件全量上传与下载的文件传输方式,这种传统的文件传输方式最大的问题是没有文件增量同步功能,就是当一个文件做过一小点的改动后,要进行同步时,不是只传改动的那部份数据,而是又将整个文件进行同步。 大数据存储和保护难题:传统SAN式存储的扩展性差并且自身没有实现大数据归档备份保护机制 非结构化数据共享往往是随机会产生大并发量访问存储数据的要求,
需要存储系统高弹性、高可扩展性、高可靠性,并且可以灵活的组成一个跨地区网络的以“本地数据本地访问”原则来解决网络大带宽消耗难题,这都是传统的SAN难以做到的。 非结构化数据不安全根本:本地应用程序编辑预览文件时需要同步或拷贝一整个文件的机制 例如当共享一个pdf文件时,或者是word文件给其他人,他们需要在自身安装有对应的pdf或微软office软件并需要完整将这个文件读入他们计算机系统才能浏览或编辑这个文件,这就意味着这个文件的数据已经可以存储到他们的计算机上了。这是非结构化最难以控制的数据泄漏安全问题根源所在。 LFS企业私有文件云是一个统一、稳定、可靠、安全、高弹性扩展的非结构化数据中心系统 解决非结构化数据管理的最佳思路是:集中存储、统一管理