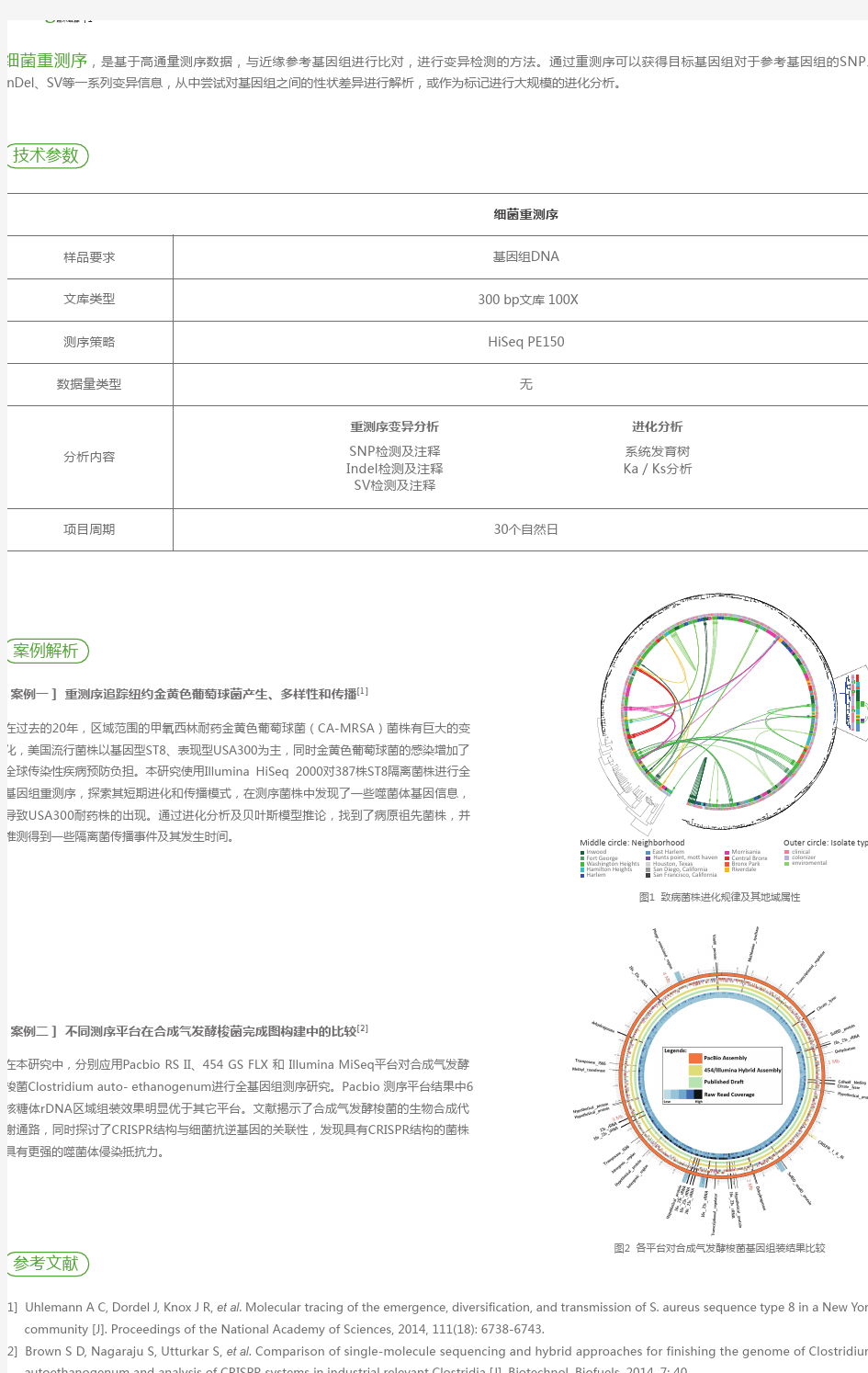
细菌重测序
全基因组关联分析的原理和方法
全基因组关联分析(Genome-wide association study;GWAS)是应用基因组中 数以百万计的单核苷酸多态性(single nucleotide ploymorphism ,SNP)为分子 遗传标记,进行全基因组水平上的对照分析或相关性分析,通过比较发现影响复杂性状的基因变异的一种新策略。 随着基因组学研究以及基因芯片技术的发展,人们已通过GWAS方法发现并鉴定了大量与复杂性状相关联的遗传变异。近年来,这种方法在农业动物重要经济性状主效基因的筛查和鉴定中得到了应用。 全基因组关联方法首先在人类医学领域的研究中得到了极大的重视和应用,尤其是其在复杂疾病研究领域中的应用,使许多重要的复杂疾病的研究取得了突破性进展,因而,全基因组关联分析研究方法的设计原理得到重视。 人类的疾病分为单基因疾病和复杂性疾病。单基因疾病是指由于单个基因的突变导致的疾病,通过家系连锁分析的定位克隆方法,人们已发现了囊性纤维化、亨廷顿病等大量单基因疾病的致病基因,这些单基因的突变改变了相应的编码蛋白氨基酸序列或者产量,从而产生了符合孟德尔遗传方式的疾病表型。复杂性疾病是指由于遗传和环境因素的共同作用引起的疾病。目前已经鉴定出的与人类复杂性疾病相关联的SNP位点有439 个。全基因组关联分析技术的重大革新及其应用,极大地推动了基因组医学的发展。(2005年, Science 杂志首次报道了年龄相关性视网膜黄斑变性GWAS结果,在医学界和遗传学界引起了极大的轰动, 此后一系列GWAS陆续展开。2006 年, 波士顿大学医学院联合哈佛大学等多个研究机构报道了基于佛明翰心脏研究样本关于肥胖的GWAS结果(Herbert 等. 2006);2007 年, Saxena 等多个研究组联合报道了与2 型糖尿病( T2D ) 关联的多个位点, Samani 等则发表了冠心病GWAS结果( Samani 等. 2007); 2008 年, Barrett 等通过GWAS发现了30 个与克罗恩病( Crohns ' disrease) 相关的易感位点; 2009 年, W e is s 等通过GWAS发现了与具有高度遗传性的神经发育疾病——自闭症关联的染色体区域。我国学者则通过对12 000 多名汉族系统性红斑狼疮患者以及健康对照者的GWAS发现了5 个红斑狼疮易感基因, 并确定了4 个新的易感位点( Han 等. 2009) 。截至2009 年10 月, 已经陆续报道了关于人类身高、体重、 血压等主要性状, 以及视网膜黄斑、乳腺癌、前列腺癌、白血病、冠心病、肥胖症、糖尿病、精神分 裂症、风湿性关节炎等几十种威胁人类健康的常见疾病的GWAS结果, 累计发表了近万篇 论文, 确定了一系列疾病发病的致病基因、相关基因、易感区域和SNP变异。) 标记基因的选择: 1)Hap Map是展示人类常见遗传变异的一个图谱, 第1 阶段完成后提供了 4 个人类种族[ Yoruban ,Northern and Western European , and Asian ( Chinese and Japanese) ] 共269 个个体基因组, 超过100 万个SNP( 约1
全基因组重测序数据分析
全基因组重测序数据分析 1. 简介(Introduction) 通过高通量测序识别发现de novo的somatic和germ line 突变,结构变异-SNV,包括重排 突变(deletioin, duplication 以及copy number variation)以及SNP的座位;针对重排突变和SNP的功能性进行综合分析;我们将分析基因功能(包括miRNA),重组率(Recombination)情况,杂合性缺失(LOH)以及进化选择与mutation之间的关系;以及这些关系将怎样使 得在disease(cancer)genome中的mutation产生对应的易感机制和功能。我们将在基因组 学以及比较基因组学,群体遗传学综合层面上深入探索疾病基因组和癌症基因组。 实验设计与样本 (1)Case-Control 对照组设计; (2)家庭成员组设计:父母-子女组(4人、3人组或多人); 初级数据分析 1.数据量产出:总碱基数量、Total Mapping Reads、Uniquely Mapping Reads统计,测序深度分析。 2.一致性序列组装:与参考基因组序列(Reference genome sequence)的比对分析,利用贝叶斯统计模型检测出每个碱基位点的最大可能性基因型,并组装出该个体基因组的一致序列。3.SNP检测及在基因组中的分布:提取全基因组中所有多态性位点,结合质量值、测序深度、重复性等因素作进一步的过滤筛选,最终得到可信度高的SNP数据集。并根据参考基 因组信息对检测到的变异进行注释。 4.InDel检测及在基因组的分布: 在进行mapping的过程中,进行容gap的比对并检测可信的short InDel。在检测过程中,gap的长度为1~5个碱基。对于每个InDel的检测,至少需 要3个Paired-End序列的支持。 5.Structure Variation检测及在基因组中的分布: 能够检测到的结构变异类型主要有:插入、缺失、复制、倒位、易位等。根据测序个体序列与参考基因组序列比对分析结果,检测全基因组水平的结构变异并对检测到的变异进行注释。
细菌的基因预测以及注释
Whole-genome Annotation of an A.baumannii strain A.baumannii ACICU
摘要 随着新一代测序技术的发展,微生物全基因组测序的成本大大减少,DNA序列的生成速度已远远超过其基因的注释速度。功能基因组学的研究已经成为当今研究的主流。然而如此多的数据对现有的基因注释工具提出了巨大的挑战。本研究通过对A.baumanii ACICU染色体序列使用GeneMarks进行基因预测,预测到了3718个基因,然后使用RAST进行基因注释,共注释到了3683个功能基因,将得到的结果与原文献中所注释到的基因进行对比。最后得到结论,基因的预测与注释都需要综合不同软件的结果进行分析,才能得到较为准确的结果。本研究为原核生物全基因组的注释提方法供了参考。 关键字:基因注释全基因组鲍曼不动杆菌GeneMarksRAST
目录 1.引言(Introduction) (2) 1.1.背景介绍 (2) 1.2.全基因组注释软件 (3) 1.3. A.baumannii ACICU相关 (4) 2.材料与方法(Methods and Materials) (5) 2.1.使用GeneMarks进行ORF预测 (5) 2.2.使用RAST进行功能基因注释 (6) 3.结果与讨论(Results and Discussion) (8) 3.1.使用GeneMarks预测ORF的结果以及分析 (8) 3.2.使用RAST进行功能基因注释结果以及分析 (9) 3.3.综合分析 (10) 参考文献 (10) 1.引言(Introduction) 1.1.背景介绍
Ion torrent微生物(细菌)全基因组重测序文库构建实验方案
微生物(细菌)全基因组重测序文库构建实验方案 一、重测序原理 全基因组重测序是对已知基因组序列的物种进行不同个体的基因组测序,并在此基础上对个体或群体进行差异性分析。 二、技术路线 ↓基因组DNA提取 细菌DNA(纯化) ↓超声波打断 DNA片段化 ↓ 文库构建 ↓Ion OneTouch 乳液PCR、ES ↓Ion PGM、Ion Proton 上机测序 ↓ 生物信息学分析 三、实验方案 1.细菌总DNA的提取 液氮速冻、干冰保存的细菌菌液:若本实验室可以提供该细菌生长的条件,则对菌液进行活化,培养至对数期时,对该细菌进行DNA提取;若本实验室不能提供该细菌的生长条件,则应要求客户提供尽可能多的样本,以保证需要的DNA量。 细菌DNA采用试剂盒提取法(如TianGen细菌基因组提取试剂盒)。 取对数生长期的菌液,按照细菌DNA提取试剂盒操作步骤进行操作。提取完成后,对基因组DNA进行纯度和浓度的检测。通过测定OD260/280,范围在1.8-2.0之间则DNA较纯,使用Qubit对提取的DNA进行定量,确定提取的DNA 浓度达到文库构建的量。
2.DNA片段化 采用Covaris System超声波打断仪(Covaris M220),将待测DNA打断 步骤: 1)对待打断的DNA进行定量,将含量控制在100ng或者1μg 2)打开Covaris M220安全盖,将Covaris AFA-grade Water充入水浴容器内,至液面到最高刻度线(约15mL),软件界面显示为绿色 3)将待打断DNA装入Ep LoBind管中,其中DNA为100ng或1μg,加入Low TE 至总体积为50mL 4)将稀释的DNA转移至旋钮盖的Covaris管中(200bp规格),转移过程中不能将气泡带入,完成后旋紧盖子 5)选择Ion_Torrent_200bp_50μL_ScrewCap_microTube,将对应的小管放入卡口,关上安全盖,点击软件界面“RUN” 6)打断结束后,将混合液转移至一支新的1.5mL离心管中 3.末端修复及接头连接 3.1 末端修复 使用Ion Plus Fragment Kit进行,以100ng DNA量为例,各组分使用前瞬时离心2s 步骤: 1)加入核酸酶free水至装有DNA片段的1.5mL离心管中,至总体积为79μL 2)向体系中加入20μL 5×末端修复buffer,1μL末端修复酶,总体积为100μL 3)室温放置20min 3.2 片段纯化 片段纯化使用Agencourt AMpure XP Kit进行 步骤: 1)加入180μL Agencourt AMpure XP Reagent beads于经过末端修复的1.5mL离心管中,充分混匀,室温放置5min
微生物基因组研究进展及意义
微生物基因组研究进展及其意义 近年来,病原微生物的基因组研究取得了飞速的进展。所谓基因组研究是指对微生物的全基因进行核苷酸测序,在了解全基因的结构基础上,研究各个基因单独或数个基因间相互作用的功能。由于过去人们大多从表型分析入手,寻找已知功能的编码基因,实际只了解微生物中极少数的基因,如链球菌的链激酶基因、结核杆菌编码的热休克蛋白基因等。还有大量未知基因未被发现。通过基因组研究,则从根本上揭示了微生物的全部基因,不仅可发现新的基因,还可发现新的基因间相互作用、新的调控因子等。这一研究将使人类从更高层次上掌握病原微生物的致病机制及其规律,从而得以发展新的诊断、预防及治疗微生物感染的制剂、疫苗及药品。此外,新发现的微生物酶及蛋白还可能有在工农业生产上的应用价值。因此,全球除已完成了70余株覆盖重要病毒科的病毒代表株全基因组研究外,据美国基因组研究所(The Institute for Genomic Research, TIGR)报道,目前已完成了19种微生物基因组测序,其中11种与人类及疾病相关(嗜血流感杆菌,生殖道支原体,肺炎支原体,幽门螺杆菌,枯草杆菌,伯氏疏螺旋体,结核杆菌,梅毒螺旋体,沙眼衣原体,普氏立克次体)。另外,还有40余种微生物已被登记正在进行测序,预计在1999~2000年完成〔1〕。 病毒基因组研究进展 病毒因其基因组小,是进行基因组研究最早的生物体。早在1977 年已完成了噬菌体DNA的全基因测序。存在于脊髓灰质炎疫苗中的SV40,是最早完成全基因测序的与疾病相关的病毒;此后,许多病毒均已完成了全基因测序,并根据序列的开放阅读框架(ORF)对编码蛋白进行了推导。已对相当一些病毒蛋白进行了重组表达,还对一些病毒基因编码的调控序列进行了研究。除一般大小的病毒已完成了基因组测序,对大基因组病毒,疱疹病毒科,如水痘病毒基因组为0.125Mb(Mega-basepair,兆碱基对)〔2〕。巨细胞病毒,基因组为0.229Mb〔3〕。我国已对痘苗病毒天坛株(约0.2Mb)进行了全基因测序,发现与国外的痘苗毒株序列有明显的差异〔4〕。我国还对甲、乙、丙、丁、戊、庚型肝炎病毒进行了国内毒株的全基因测序。近来还对国内2株发现的虫媒病毒毒株完成了全基因测序。我国从不同来源的标本中发现了不少乙肝病毒变异株,有的具有特殊的生物学特性〔5〕。对病毒基因中调控因子的分析,发现了与乙肝病毒增强子作用的新细胞核因子〔6〕。 因此,目前对病毒的基因组研究已进入了后基因组阶段,即从全基因水平研究病毒的生物学功能,同时发现新的基因功能。对于医学病毒学当前主要方向是研究病毒基因组中与致病及诱生免疫应答相关的基因,从而揭示和解决迄今尚未解决的问题,以达到控制或消灭一些重要病毒感染的目的。 建议目前可进行后基因组研究的领域为: 1.病毒持续性感染:基因组中与持续性感染相关的基因,基因变异或调控因子研究。已报道的乙肝病毒的前核心基因出现终止密码突变,
基因组测序术语解释
DNA关键词: WG-BSA (全基因组重测序BSA) 对已有参考基因组序列的物种的所有作图群体(F1、F2、RIL、DH 和BC1等),对亲本进行个体重测序,对某个极端性状材料混池测序,检测SNP,获得与性状紧密关联的分子标记和精细定位区域,是目前最高效的基因定位方法。通过选取某个极端性状,利用高效率低成本的混池测序技术,勿需开发分子标记进行遗传图的构建,快速定位与性状相关的候选QTL。 MP-Reseq (多混池全基因组重测序) 针对特有的优良地方品种中的不同品种/品系,通过群体内pooling 建库的方法,进行全基因组重测序,采用生物信息学方法全基因组范围内扫描变异位点,能快速的定位不同混池样品基因组中明显经过人工或自然选择的区域,检测与性状相关的基因区域及其功能基因。 全基因组个体重测序 基于全基因组重测序的变异图谱通过测序手段结合生物信息分析研究同一物种不同个体之间的变异情况,获得大量的变异信息,如SNP、Indel、SV 等。主要可以快速地获得大量的分子标记以及不同个体在基因组水平上的差异。 全基因组关联分析-GWAS 通过重测序对动植物重要种质资源进行全基因组基因型鉴定,与关注的表型数据进行全基因组关联分析,找出与关注表型相关的SNP位点,定位数量性状基因,与数量性状相关的基因紧密连锁的SNP标记,后续可用于分子标记辅助育种,助力育种进程。 全基因组重测序-遗传进化 通过对来自全国各地、具有代表性的XX 份XX 材料进行全基因组重测序,检测SNP、Indel、SV,并利用获得的SNP 与SV 数据进行群体多样性分析,包括连锁不平衡分析、群体进化分析、群体结构分析、群体主成分分析等。 全基因组重测序-遗传图谱 基于全基因组重测序技术对已有参考基因组序列的物种进行个体或群体的全基因组测序,利用高性能计算平台和生物信息学方法,检测单核苷酸多态性位点(SNP),并计算多态性标记间的遗传连锁距离,绘制高密度的遗传图谱。通过与表型性状进行关联分析,利用获得的强关联性标记进行下游基因的精细定位。遗传图可用于分子标记辅助育种,重要性状候选基因克隆,辅助基因组组装,比较基因组学等研究。 细菌基因组de novo 测序 细菌是生物的主要类群之一,是所有生物中数量最多的一类。细菌广泛分布于土壤和水中,或者与其他生物共生,也有部分种类分布在极端环境中,例如温泉,甚至是放射性废弃物中。由于细菌自身的营
重测序-全基因组选择(GS)
首页 科技服务 测序指南 基因课堂 市场活动与进展 文章成果 关于我们 全基因组选择1. Meuwissen T H, Hayes B J, Goddard M E.Prediction of total genetic value using genome-wide dense marker maps[J]. Genetics, 2001, 157(4): 1819 1829. 阅读原文>> 2. Haberland A M, Pimentel E C G, Ytournel F, et al. Interplay between heritability, genetic correlation and economic weighting in a selection index with and without genomic information[J]. Journal of Animal Breeding and Genetics, 2013, 130(6): 456-467. 阅读原文>> 3. Wu X, Lund M S, Sun D, et al. Impact of relationships between test and training animals and among training animals on reliability of genomic prediction[J]. Journal of Animal Breeding and Genetics, 2015, 132(5): 366-375. 阅读原文>> 4. Goddard M E ,Hayes BJ. Genomic selection [J]. Journal of Animal Breeding and Genetics,2007,124:323:330. 阅读原文>> 5. Heffner E L, Sorrells M E, Jannink J L. Genomic selection for crop improvement [J]. Crop Science, 2009, 49(1): 1-12. 阅读原文>> 参考文献 全基因组选择简介 Meuwissen等[1]在2001年首次提出了基因组选择理论(Genomic selection , GS),即利用具有表型和基因型的个体来预测只具有基因型不具有表型值动植物的基因组育种值(GEBV)。 例如,提高奶牛的产奶量一直是奶牛研究者的研究重点,传统育种的方法需要牛生长至成年后,才能进行产奶量的测定,再进行后续的育种进程。如果在犊牛刚出生时就可以通过某种技术预测出其产奶量,就可以大大的减少育种时间,节省大量的育种成本。 全基因组选择(GS)利用覆盖全基因组的高密度分子遗传标记进行标记辅助选择,可以在奶牛的幼年时期就预测出其生产性状和营养性状,快速筛选出具有优良性状的奶牛或者种公牛,加速育种的进程。 全基因组选择技术参数 提供领先的基因组学解决方案 Leading Edge Genomic Services & Solutions 动植物重测序变异检测BSA性状定位遗传图谱群体进化全基因组关联分析Hi-C测序 人类基因组测序全基因组测序外显子测序目标区域测序单细胞基因组测序 动植物基因组测序全基因组survey 全基因组 de novo 测序泛基因组测序组装变异检测 微生物基因组测序16S/18S/ITS等扩增子测序细菌基因组 de novo 测序真菌基因组 de novo 测序微生物重测序宏基因组测序 建库测序建库测序 诺禾致源微信文章精彩阅读 >> 版权所有:北京诺禾致源科技股份有限公司 转录调控测序 真核有参转录组测序医学转录组测序真核无参转录组测序比较转录组与泛转录组测序原核转录组测序宏转录组测序单细胞转录组测序LncRNA测序circRNA测序small RNA测序ChiP-seq RIP-seq 全基因组甲基化测序 GS 重测序新产品发布 群体大小 参考群体的选择十分重要,表型信息及固定效应信息记录需要准确完整。此外,选择出 的参考群体要满足内部亲缘关系比较远,数量达到1000个以上[2]。候选群体最好与参考群体的亲缘关系较近,这样可以保证育种值预测的准确性[3]。 测序策略 测序深度:平均每个样本≥10×;测序平台:Illumina HiSeq PE150测序; 全基因组选择技术优势 全基因组选择与传统的分子标记辅助选择相比,具有很多优势[5]: 能够在得到物种个体DNA的时候即对其进行育种值评估,可以缩短世代间隔,加快遗传进展并且降低经济投入。 全基因组范围内的标记能够解释尽可能多的遗传变异,可以对遗传效应进行较为准确的检测和估计。 能够较准确的评估遗传力较低、难测定的性状或测定费用较高的性状。 通过基因组选择的方式,即使单个标记的效应很微小,导致遗传变异的所有遗传效应也都能够被SNP标记捕获, 所以比传统的基于系谱和表型数据的最佳线性无偏模型得到更高的可靠性。 a b c d
07年完成基因组测序的生物
07年完成基因组测序的生物 生物通报道:在即将过去的2007年,动物、植物、微生物的基因组测序工作进行的如火如荼,多项基因组测序结果被公布,包括第一个个人基因组图谱、马基因组图谱、肺癌基因组图谱和多种致病性细菌的基因组测序结果。 人类基因组测序的进一步深入 世界首份个人DNA图谱出炉 57年前,美国生物学家詹姆斯·沃森与弗朗西斯·克里克共同发现了脱氧核糖核酸(DNA)分子结构的双螺旋模型,并因这项基因研究领域的重大突破获得诺贝尔奖。今天,沃森成为自己研究的受益者--他将成为世界第一份完全破译的“个人版”基因组图谱的拥有者。 第一个个体基因组序列公布 来自美国克莱格凡特研究所(J. Craig Venter Institute,由TIGR所建立),加拿大多伦多大学,加州大学圣地亚哥分校,西班牙巴塞罗那大学(Universitat de Barcelona)的研究人员近期公布了单个个体二倍体基因组序列,为未来的基因组比较打开了一道门,也开创了个体基因组信息的新纪元。 杜克大学公布第一张人类基因组印记基因图谱
来自杜克大学的研究人员创造了第一张人类基因组印记基因(imprinted genes)图谱,并且他们表示其成功的关键在于一个称为机器学习(machine learning)的人工智能形式:modern-day Rosetta stone。这项研究新发现了四倍于之前识别的印记基因,并即将公布在12月3日《Genome Research》封面上。 完成测序的动物 第一张马基因组图谱草图公布 国际马类基因组序列计划(the international Horse Genome Sequencing Project)宣布,科学家们首次完成家马((Equus caballus))的基因图谱草图,得到了270万个DNA碱基对的数据,全部数据已经进入公共数据库,可免费供全世界的生物学家和兽医学家使用。 《自然》封面:首个有袋动物基因组序列公布 一种灰色短尾负鼠(Monodelphis domestica)的基因组测序的完成则为这一推测给出了切实的证据。负鼠是第一个完成基因组测序的有袋动物,测序结果公布在4月10日的《自然》杂志上,而且这种小动物还登上了该期杂志的封面。 家猫基因组测序完成
微生物宏基因组测序
宏基因组学(Metagenomics),又称元基因组学,以特定生境中的整个微生物群落作为研究对象,采用新一代高通量测序技术,获得环境微生物基因信 息总和,研究环境微生物的群落结构、物种分类、系统进化、基因功能及代谢网络等。宏基因组测序摆脱了传统研究中微生物分离培养的技术限制,直接提取 环境样本DNA进行测序,具有通量高、速度快、信息全等特点,在鉴定低丰度的微生物群落、挖掘更多基因资源方面具有很大优势,基于测序技术和生物信息学的快速发展,宏基因组技术优势在微生物研究领域中愈发明显,应用范围愈发广泛。 技术参数 参考文献 [1] B?ckhed F, Roswall J, Peng Y, et al . Dynamics and Stabilization of the Human Gut Microbiome during the First Year of Life [J]. Cell host & microbe, 2015, 17(5): 690-703. [2] Sunagawa S, Coelho L P , Chaffron S, et al . Structure and function of the global ocean microbiome [J]. Science, 2015, 348(6237): 1261359. 案例解析 [案例一] 婴儿肠道微生物宏基因组[1] 肠道微生物对人体至关重要,本文采用宏基因组测序技术对98个瑞典产妇的粪便及婴儿的粪便进行分析,研究出生一年内肠道的微生物,评估分娩方式和喂养方式对肠道菌群建立的影响。与顺产婴儿的肠道微生物相比,剖腹产婴儿肠道微生物与母亲相似性明显降低。营养对肠道微生态的组成和功能有重要影响,促使婴儿肠道微生物向成人肠道微生物群转变的主要驱动力量并不是开始喂食固体食物,而是停止母乳喂养。微生物群落组成和生态网络在不同样本阶段具有明显差异,与微生物功能成熟度相关。 [案例二] 全球海洋微生物群体的结构与功能[2] 微生物是生物地球化学进程的主要推动力,但对它们的功能多样性、微生物种群结构以及生态因素进行总体分析还存在很大的挑战。本研究采集全球海洋68个位点的上层和中层海水的243个样本进行宏基因组分析,得到7.2TB数据。对获得的数据进行分析,发现139个样本中含有的微生物物种数目多于35,000个,而且在上层海水的垂直分层中,温度是影响微生物种群分布的主要因素。分析海洋微生物核心功能,发现其与人体肠道微生物的相似性高达73%。 图1 不同生产方式及不同年龄阶段肠道菌群的差异 图2 Tara Oceans在全球海洋微生物中发现的新基因多样性 多样本标准分析PCA分析Heatmap Cluster Krona物种注释展示差异显著性分析OG-物种归属分析代谢通路分析 样品要求 文库类型测序策略数据量类型 分析内容 项目周期 宏基因组测序 35~75个自然日 HiSeq PE150 5 Gb/10 Gb Raw data 300 bp小片段文库常见环境样本(请使用干冰或冰袋运送) 土壤、淤泥、沉积物≥5 g 粪便≥2 g 组织样本≥1 g 水体送样为过滤后的滤膜(最适滤膜直径3-4cm)拭子样本≥2个 DNA样本(请使用干冰或冰袋运送)DNA:浓度≥50 ng/μl 总量≥2 ng OD260/280:1.8~2.0,无 RNA、蛋白质等 杂质污染 多样本高级分析MRPP分析NMDS分析Anosim分析LEfSe分析 CCA/RDA分析 O c c u r r e n c e f r e q u e n c y (n =15) 1
三代单分子实时测序与细菌全基因组修饰分析
三代单分子实时测序与细菌全基因组修饰分析三代测序,除了具有读长更长之外,还有一个很重要的优势,就是能够同时测得基因组甲基化修饰的信息。这带来了一个新的视角,让我们在获得细菌完成图的同时,还可以了解基因组在表观层面的变化,从更多角度来解析细菌基因组的基因密码。 甲基化修饰是什么? 我们都知道,常见的生命遗传编码是由DNA承载的,DNA 的双链结构,编码核心就是带有ATGC四种不同碱基的脱氧核糖核酸。而实际上在生物体内很多时候DNA的碱基形式不是单纯的ATGC碱基,其中A和C两种碱基经常会存在一些甲基化修饰的现象,如下图所示:
图1 DNA甲基化转移酶的三种常见甲基化修饰方式[1] 为什么要研究甲基化修饰? DNA的甲基化修饰会影响到其与配对碱基之间结合的化学动力学过程,进而使基因的转录及表达受到影响。反应到表观层面,
细胞不同生长周期下,不同位置的甲基化修饰起到了重要的辅助功能[2,3]。 图2 细菌细胞不同周期的甲基化改变[3] 同时DNA的甲基化修饰对于部分细菌的毒力表现也起着相当重要的作用。某些基因的改变,甚至会影响到全基因组的甲基化水平,进而影响到整个菌株的毒力性状表现[4]。
图 3 6个不同菌株的基因差异(A)和不同菌株毒力基因甲基化水平的改变(B)[4] 三代测序如何测得甲基化信息? 三代PacBio平台的测序方法为单分子实时测序(Single Molecule Real Time, SMRT),是基于单分子底物边合成边测序的方法。由于甲基化修饰过的碱基,其同配对碱基结合的化学动力学会有所差异,在底物碱基被甲基化修饰时,检测到的测序信号就会发生改变,如下图所示:
宏基因组测序讲解
宏基因组测序 目的 研究藻类物种的分类,研究与特定环境与相关的代谢通路,以及通过不同样品的比较研究微生物内部,微生物与环境,与宿主的关系。技术简介 宏基因组( Metagenome)(也称微生物环境基因组Microbial Environmental Genome, 或元基因组) 。是由 Handelsman 等 1998 年提出的新名词,其定义为"the genomes of the total microbiota found in nature" , 即生境中全部微小生物遗传物质的总和。它包含了可培养的和未可培养的微生物的基因,目前主要指环境样品中的细菌和真菌的基因组总和。而所谓宏基因组学 (或元基因组学, metagenomics) 就是一种以环境样品中的微生物群体基因组为研究对象,以功能基因筛选和/或测序分析为研究手段,以微生物多样性、种群结构、进化关系、功能活性、相互协作关系及与环境之间的关系为研究目的的新的微生物研究方法。一般包括从环境样品中提取基因组 DNA, 进行高通量测序分析,或克隆DNA到合适的载体,导入宿主菌体,筛选目的转化子等工作。 宏基因组( Metagenome)(也称微生物环境基因组Microbial Environmental Genome, 或元基因组) 。是由 Handelsman 等 1998 年提出的新名词,其定义为"the genomes of the total microbiota found in nature" , 即生境中全部微小生物遗传物质的总和。它包含了可培养的和未可培养的微生物的基因,目前主要指环境样品中的细菌和真菌的基因组总和。而所谓宏基因组学 (或元基因组学, metagenomics) 就是一种以环境样品中的微生物群体基因组为研究对象,以功能基因筛选和/或测序分析为研究手段,以微生物多样性、种群结构、进化关系、功能活性、相互协作关系及与环境之间的关系为研究