最新正态概率图(normal probability plot)
正态概率图(normal probability plot)
方法演变:概率图,分位数-分位数图( Q- Q)
?概述
正态概率图用于检查一组数据是否服从正态分布。是实数与正态分布数据之间函数关系的散点图。如果这组实数服从正态分布,正态概率图将是一条直线。通常,概率图也可以用于确定一组数据是否服从任一已知分布,如二项分布或泊松分布。
?适用场合
·当你采用的工具或方法需要使用服从正态分布的数据时;
·当有50个或更多的数据点,为了获得更好的结果时。
例如:
·确定一个样本图是否适用于该数据;
·当选择作X和R图的样本容量,以确定样本容量是否足够大到样本均值服从正态分布时;·在计算过程能力指数Cp或者Cpk之前;
·在选择一种只对正态分布有效的假设检验之前。
?实施步骤
通常,我们只需简单地把数据输入绘图的软件,就会产生需要的图。下面将详述计算过程,这样就可以知道计算机程序是怎么来编译的了,并且我们也可以自己画简单的图。
1将数据从小到大排列,并从1~n标号。
2计算每个值的分位数。i是序号:
分位数=(i-0.5)/n
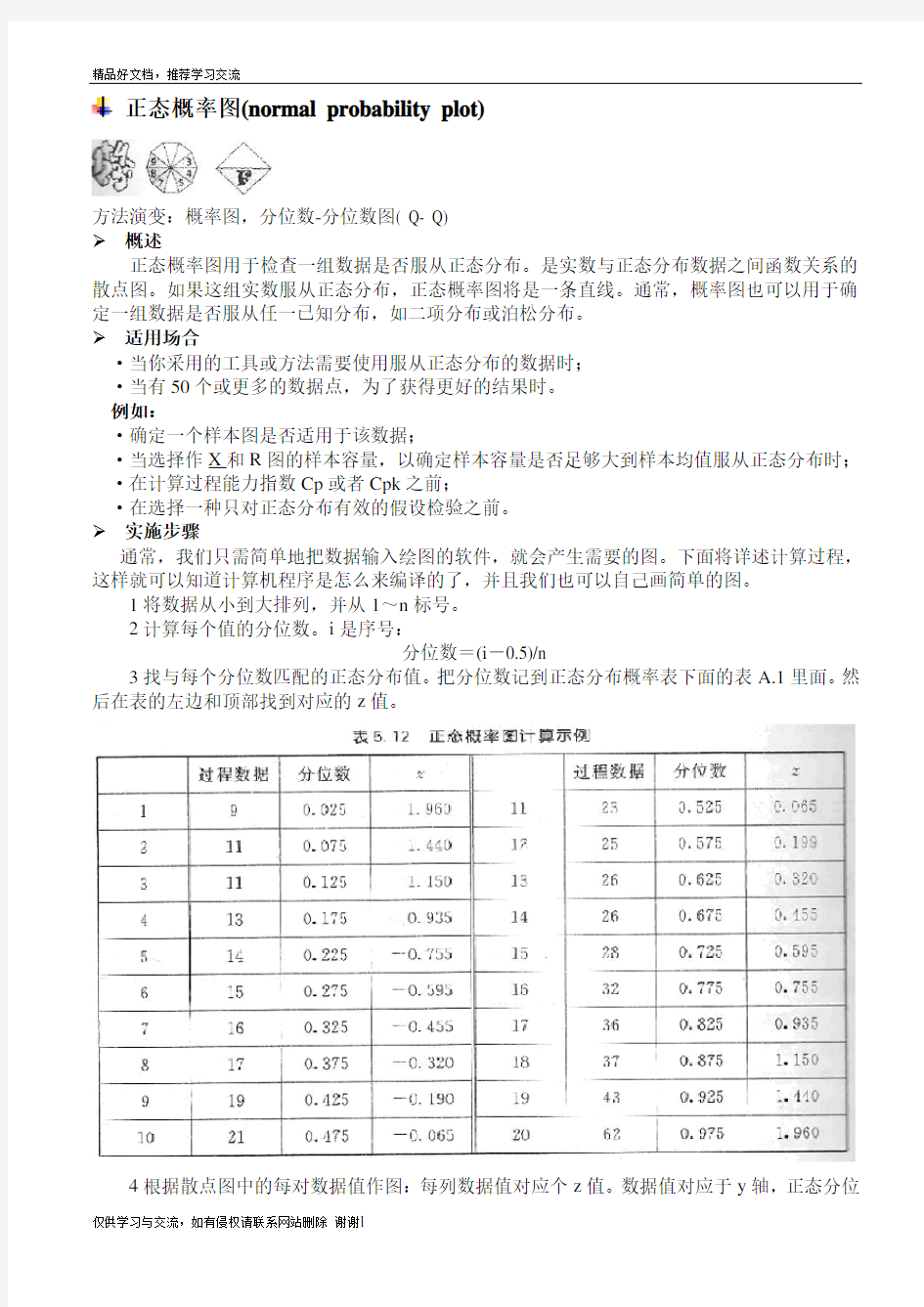
3找与每个分位数匹配的正态分布值。把分位数记到正态分布概率表下面的表A.1里面。然后在表的左边和顶部找到对应的z值。
4根据散点图中的每对数据值作图:每列数据值对应个z值。数据值对应于y轴,正态分位
数z值对应于x轴。将在平面图上得到n个点。
5画一条拟合大多数点的直线。如果数据严格意义上服从正态分布,点将形或一条直线。将点形成的图形与画的直线相比较,判断数据拟合正态分布的好坏。请参阅注意事项中的典型图形。可以计算相关系数来判断这条直线和点拟合的好坏。
?示例
为了便于下面的计算,我们仅采用20个数据。表5. 12中有按次序排好的20个
值,列上标明“过程数据”。
下一步将计算分位数。如第一个值9,计算如下:
分位数=(i-0.5)/n=(1-0.5)/20=0.5/20=0.025
同理,第2个值,计算如下:
分位数=(i-0.5)/n=(2-0.5)/20=1.5/20=0.075
可以按下面的模式去计算:第3个分位数=2.5÷20,第4个分位数=3 5÷20
以此类推直到最后1个分位数=19. 5÷20。
现在可以在正态分布概率表中查找z值。z的前两
个阿拉伯数字在表的最左边一列,最后1个阿拉伯数
字在表的最顶端一行。如第1个分位数=0. 025,它位
于-1.9在行与0.06所在列的交叉处,故z=-1.96。
用相同的方式找到每个分位数。
如果分位数在表的两个值之间,将需要用插值法
进行求解。例如:第4个分位数为0. 175,它位于0.1736
与0.1762之间。0.1736对应的z值为-0.94,0.1762
对应的z值为-0.93,故
这两数的中间值为z=-0.935。
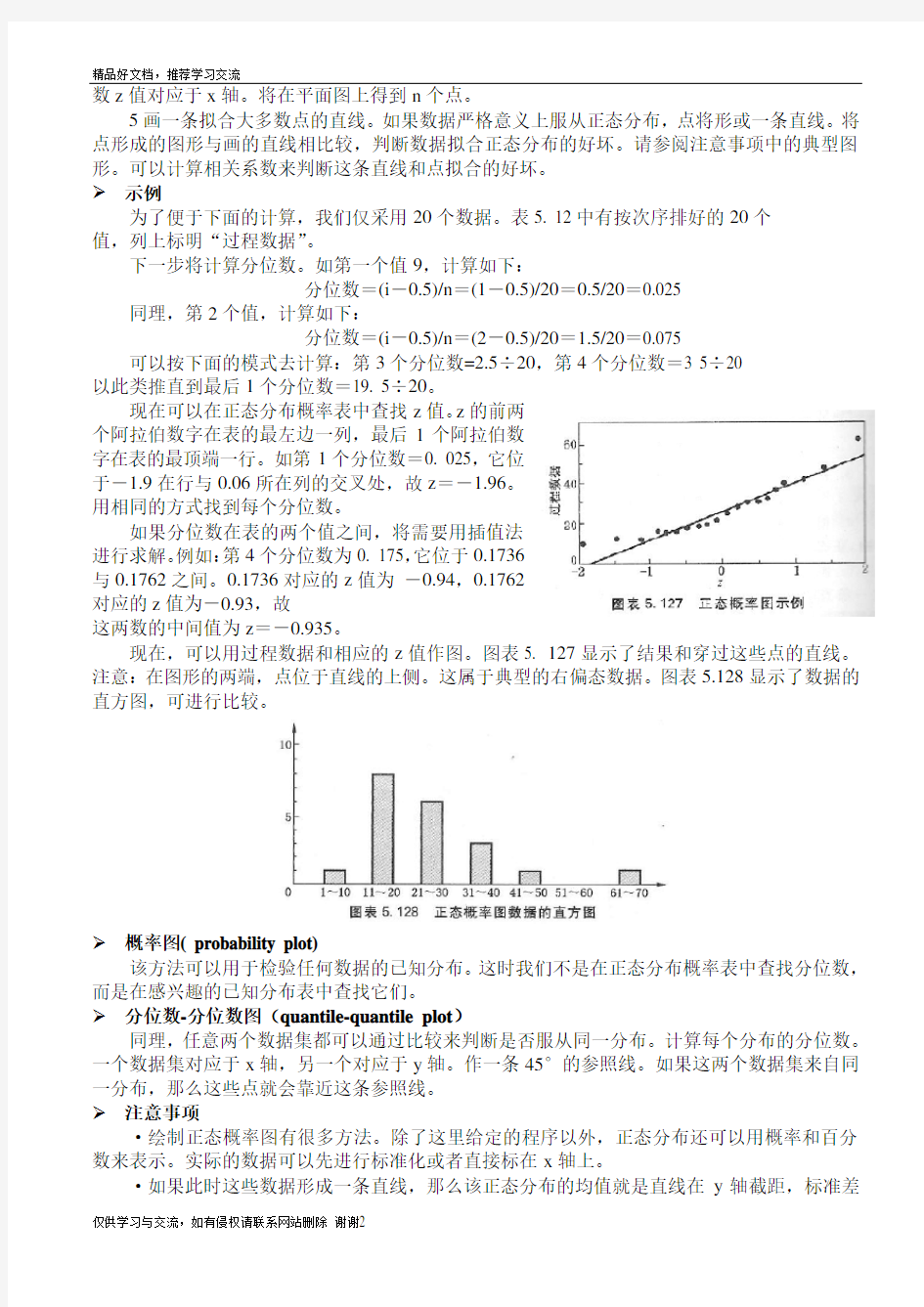
现在,可以用过程数据和相应的z值作图。图表5. 127显示了结果和穿过这些点的直线。注意:在图形的两端,点位于直线的上侧。这属于典型的右偏态数据。图表5.128显示了数据的直方图,可进行比较。
?概率图( probability plot)
该方法可以用于检验任何数据的已知分布。这时我们不是在正态分布概率表中查找分位数,而是在感兴趣的已知分布表中查找它们。
?分位数-分位数图(quantile-quantile plot)
同理,任意两个数据集都可以通过比较来判断是否服从同一分布。计算每个分布的分位数。一个数据集对应于x轴,另一个对应于y轴。作一条45°的参照线。如果这两个数据集来自同一分布,那么这些点就会靠近这条参照线。
?注意事项
·绘制正态概率图有很多方法。除了这里给定的程序以外,正态分布还可以用概率和百分数来表示。实际的数据可以先进行标准化或者直接标在x轴上。
·如果此时这些数据形成一条直线,那么该正态分布的均值就是直线在y轴截距,标准差
就是直线斜率。
·对于正态概率图,图表5.129显示了一些常见的变形图形。
短尾分布:如果尾部比正常的短,则点所形成的图形左边朝直线上方弯曲,右边朝直线下方弯曲——如果倾斜向右看,图形呈S型。表明数据比标准正态分布时候更加集中靠近均值。
长尾分布:如果尾部比正常的长,则点所形成的图形左边朝直线下方弯曲,右边朝直线上方弯曲——如果倾斜向右看,图形呈倒S型。表明数据比标准正态分布时候有更多偏离的数据。一个双峰分布也可能是这个形状。
右偏态分布:右偏态分布左边尾部短,右边尾部长。因此,点所形成的图形与直线相比向上弯曲,或者说呈U型。把正态分布左边截去,也会是这种形状。
左偏态分布:左偏态分布左边尾部长,右边尾部短。因此,点所形成的图形与直线相比向下弯曲。把正态分布右边截去,也会是这种形状。
·如果翻转正态概率图的数轴,那么弯曲的形状也跟着翻转。比如,左偏态分布将是一个U型的曲线。
·记住过程应该在受控状态下对图形作出有效判断。
·尽管作直方图能马上知道数据的分布,但它却不是判断这些数据是否来自同一特定分布的好办法。人眼不能很好地判别曲线,其他的分布也可能形成相似的形状。并且,用服从正态分布的少量数据集作成的直方图可能看起来不是正态的。因此,正态概率图是判断数据分布的较好方法。
·判断数据分布的另一种方法是使用拟合良好性检定,比如Shapiro-Wilk检验,Kolmogorov-Smirnov检验,或者Lilliefors检验。关于这些检验的具体描述,不在本书的讨论范围,这些检验在大多数的统计软件上都能实现。向统计学家咨询如何选择正确的检验并解释其结果。请参阅“假设检验”以理解这些检验和所得到的结论的一般原则。
·最好的方法是使用统计软件得到正态概率图并作拟合性检验。结合使用可以对数据和统计标准有直观的理解,以此判定是否为正态。
END佛经中的经典句子(350句)
1.凡所有相,皆是虚妄。若见诸相非相,即见如来。
2.一切有为法,如梦幻泡影,如露亦如电,应作如是观。
3.知幻即离,不假方便;离幻即觉,亦无渐次。
4.世间无常,国土危脆,四大苦空,五阴无我生灭变异,虚伪无主,心是恶源,形为罪薮。
5.我观是南阎浮提众生,举心动念无不是罪。
6.复次地藏,未来世中,若有善男子、善女人,于佛法中所种善根,或布施供养,或修补塔寺,或装理经典,乃至一毛一尘、一沙一渧。如是善事,但能回向法界,是人功德,百千生中,受上妙乐。如但回向自家眷属,或自身利益,如是之果,即三生受乐,舍一得万报。是故地藏,布施因缘,其事如是。
7.复次地藏,若未来世,有诸国王,至婆罗门等,遇先佛塔庙,或至经像,毁坏破落,乃能发心修补。是国王等,或自营办,或劝他人,乃至百千人等布施结缘。是国王等,百千生中,常为转轮王身。如是他人同布施者,百千生中,常为小国王身。更能于塔庙前,发回向心,如是国王,乃及诸人,尽成佛道。以此果报,无量无边。
8.若人欲了知,三世一切佛。应观法界性,一切唯心造。
9.人在爱欲之中独生独死,独去独来。苦乐自当,无有代者。
10.觉了一切法,犹如梦幻响。
11.佛言:当念身中四大,各自有名,都无我者,我既都无。其如幻耳。
12.阿字十方三世佛,弥字一切诸菩萨。陀字八万诸圣教,三字之中是具足。一句弥陀是佛王、法王、咒王、功德之王。专念「南无阿弥陀佛」一佛,即是总持总念诸佛、诸菩萨、诸经咒、诸行门。所谓「八万四千法门,六字全收。」亦谓「赅罗八教,圆摄五宗。」既得临终往生净土,亦获现世身心安乐。
13.念阿弥陀佛功德,多于念地藏菩萨百千万倍。何以得知?准《观音经》,有一人供养六十二亿恒河沙菩萨,乃至一时,不如礼拜供养观世音菩萨。《十轮经》云:“一百劫念观世音,不如一食顷念地藏菩萨。”《群疑论》曰:“一大劫念地藏菩萨,不如一声念阿弥陀佛。”何以故?佛是法王,菩萨为法臣,如王出时,臣必随从,大能摄小。佛是觉满果圆,超诸地位,所以积念者功德最多,过于地藏百千万倍。菩萨未属佛地,果未**,故功德最少。"
14.心有所住,即为非住。应无所住而生其心。
15.诸行无常,一切皆苦。诸法无我,寂灭为乐。
正态概率图(normal probability plot)
正态概率图(normal probability plot) 方法演变:概率图,分位数-分位数图( Q- Q) 概述 正态概率图用于检查一组数据是否服从正态分布。是实数与正态分布数据之间函数关系的散点图。如果这组实数服从正态分布,正态概率图将是一条直线。通常,概率图也可以用于确定一组数据是否服从任一已知分布,如二项分布或泊松分布。 适用场合 ·当你采用的工具或方法需要使用服从正态分布的数据时; ·当有50个或更多的数据点,为了获得更好的结果时。 例如: ·确定一个样本图是否适用于该数据; ·当选择作X和R图的样本容量,以确定样本容量是否足够大到样本均值服从正态分布时;·在计算过程能力指数Cp或者Cpk之前; ·在选择一种只对正态分布有效的假设检验之前。 实施步骤 通常,我们只需简单地把数据输入绘图的软件,就会产生需要的图。下面将详述计算过程,这样就可以知道计算机程序是怎么来编译的了,并且我们也可以自己画简单的图。 1将数据从小到大排列,并从1~n标号。 2计算每个值的分位数。i是序号: 分位数=(i-0.5)/n 3找与每个分位数匹配的正态分布值。把分位数记到正态分布概率表下面的表A.1里面。然后在表的左边和顶部找到对应的z值。 4根据散点图中的每对数据值作图:每列数据值对应个z值。数据值对应于y轴,正态分位数z值对应于x轴。将在平面图上得到n个点。 5画一条拟合大多数点的直线。如果数据严格意义上服从正态分布,点将形或一条直线。将点形成的图形与画的直线相比较,判断数据拟合正态分布的好坏。请参阅注意事项中的典型图
形。可以计算相关系数来判断这条直线和点拟合的好坏。 示例 为了便于下面的计算,我们仅采用20个数据。表5. 12中有按次序排好的20个 值,列上标明“过程数据”。 下一步将计算分位数。如第一个值9,计算如下: 分位数=(i-0.5)/n=(1-0.5)/20=0.5/20=0.025 同理,第2个值,计算如下: 分位数=(i-0.5)/n=(2-0.5)/20=1.5/20=0.075 可以按下面的模式去计算:第3个分位数=2.5÷20,第4个分位数=3 5÷20 以此类推直到最后1个分位数=19. 5÷20。 现在可以在正态分布概率表中查找z值。z的前两 个阿拉伯数字在表的最左边一列,最后1个阿拉伯数 字在表的最顶端一行。如第1个分位数=0. 025,它位 于-1.9在行与0.06所在列的交叉处,故z=-1.96。 用相同的方式找到每个分位数。 如果分位数在表的两个值之间,将需要用插值法 进行求解。例如:第4个分位数为0. 175,它位于0.1736 与0.1762之间。0.1736对应的z值为-0.94,0.1762 对应的z值为-0.93,故 这两数的中间值为z=-0.935。 现在,可以用过程数据和相应的z值作图。图表5. 127显示了结果和穿过这些点的直线。注意:在图形的两端,点位于直线的上侧。这属于典型的右偏态数据。图表5.128显示了数据的直方图,可进行比较。 概率图( probability plot) 该方法可以用于检验任何数据的已知分布。这时我们不是在正态分布概率表中查找分位数,而是在感兴趣的已知分布表中查找它们。 分位数-分位数图(quantile-quantile plot) 同理,任意两个数据集都可以通过比较来判断是否服从同一分布。计算每个分布的分位数。一个数据集对应于x轴,另一个对应于y轴。作一条45°的参照线。如果这两个数据集来自同一分布,那么这些点就会靠近这条参照线。 注意事项 ·绘制正态概率图有很多方法。除了这里给定的程序以外,正态分布还可以用概率和百分数来表示。实际的数据可以先进行标准化或者直接标在x轴上。 ·如果此时这些数据形成一条直线,那么该正态分布的均值就是直线在y轴截距,标准差就是直线斜率。 ·对于正态概率图,图表5.129显示了一些常见的变形图形。 短尾分布:如果尾部比正常的短,则点所形成的图形左边朝直线上方弯曲,右边朝直线下方弯曲——如果倾斜向右看,图形呈S型。表明数据比标准正态分布时候更加集中靠近均值。 长尾分布:如果尾部比正常的长,则点所形成的图形左边朝直线下方弯曲,右边朝直线上方弯曲——如果倾斜向右看,图形呈倒S型。表明数据比标准正态分布时候有更多偏离的数据。
如何检验数据是否服从正态分布
如何检验数据是否服从正态分布 一、图示法 1、P-P图 以样本的累计频率作为横坐标,以安装正态分布计算的相应累计概率作为纵 坐标,把样本值表现为直角坐标系中的散点。如果资料服从整体分布,则样本点应围绕第一象限的对角线分布。 2、Q-Q图 以样本的分位数作为横坐标,以按照正态分布计算的相应分位点作为纵坐 标,把样本表现为指教坐标系的散点。如果资料服从正态分布,则样本点应该呈一条围绕第一象限对角线的直线。 以上两种方法以Q-Q图为佳,效率较高。 3、直方图 判断方法:是否以钟形分布,同时可以选择输出正态性曲线。 4、箱式图 判断方法:观测离群值和中位数。 5、茎叶图 类似与直方图,但实质不同。 二、计算法 1、偏度系数(Skewness)和峰度系数(Kurtosis) 计算公式: g1表示偏度,g2表示峰度,通过计算g1和g2及其标准误σg1及σg2然后作U检验。两种检验同时得出U
正态分布概率表
参考医学 正态分布概率表 1 — f? 0( u )= t P⑴t F(t)t F(0t卩⑴0.00 0.000 00.230. 181 9 0.46 0.354 5 W9 0. 50 9 8 0.01 0.008 00.24 0. 1H9 70.47 0.361 6 0.70 0,516 1 0+02 0,0160 0. 25 0,197 4 0,48 0.368 80+71 0.522 3 0.03 0*023 9(1. 26 0.205 1 0.49 0.375 9 0.72 0. 52 8 5 044 0.031 9(1.27 0,212 8 0.50O.3R2 9 0.73 "4 6 0R5 0039 90.28 0.220 5 0,51 0.389 9 0.74 0.540 7 0.06 0.047 80.29 0.228 20.52 036 9 0.75 0*546 7 0+07 0 €55 g0,30 0,235 8 0,53 0.403 9 276 0.552 7 0+08 0.063 80 31 0.243 4 0.54 0.410 8 0+77 0.558 7 0+09 (1.(171 7(J. 32 0.251 00.55 0.417 70.78 0.564 6 0. 10 0.0797 fl. 33 0.258 6 0.56 0,424 50.79 0.570 5 0.110,(J87 60.34 0.266 1 0.57 0.431 3 0.B0 0.576 3 0.12 0.09$ 50. 35 0.273 7 0.5S 0.43S 10.S1 O.5S2 1 0+13 OJ03 40. 36 0.281 20.59 0.444 8 0+82 0.587 8 0+14 (1.111 3 0. 37 0.288 6 0.60 0.451 5 M3 0.593 5 0.15 0J19 2 0. 38 0.296 1 0.61 0.458 10.84 0.599 1 0+160.127 10.39 0. 303 50.62 0.464 7 0.85 0.604 7 0.17 0.135 0 040 0330 8 0.63 0.471 3 0.S6 0.610 2 0+18 0.142 S0.41 0.318 20,64 0.477 8 0.87 0.6157 0+19 0.150 7 0 42 0, 325 50.650.484 3 0.88 0.621 1 0,20 0J58 5(J. 43 0. 332 8 0.66 0.490 10.89 0 . 62 6 5 0,21 0J66 3(J.44 0,340 1 0.67 0.497 10.90 0.631 9 0 + 220.174 10.45 0347 3 0.68 0.503 50.91 0.637 2
正态分布、概率
信息系统项目管理师重点知识点:完工概率计算总结 例图: 活动BCD的乐观(m)工期都是9天,最可能(o)工期为12天,最悲观(p)工期都是15天,那么在14天内完成单项活动的概率和完成全部这三项活动的概率是多少 首先计算平均工期(PERT):公式--(乐观时间+4*最可能时间+悲观时间)/ 6 (9+4*12+15)/6=12天; 其次计算标准差:公式--(悲观时间-乐观时间)/ 6 ; (15-9)/6=1天 再计算偏离平均工期:方法--[给出的天数计算(14)-计算出来的平均工期(12)]/标准差(1) (14-12)/1=2 备注:此时得出来的为几,之后就是使用几西格玛 (Sigma)(1σ=68,37%)(2σ=95.46%)(3σ=99.73%)(6σ=99.99966%百万分之三点四) 计算每一项活动在14天内完工的概率是:方法--正态分布概率+西格玛/偏离平均工期数 50%+95.46%/2=97.73% 备注:50%参考正态分布图,95.46参考2西格玛值; 计算全部活动在14天内完工概率是:方法--每一项活动的概率相乘 97.73%*97.73%*97.73%=93.34% 下图为简要正态分布图:
备注:正态分布有50%成功,有50%不成功 如计算将上面的14天,修改为13天; 偏离平均工期就是1天,计算方法:(13-12)/1=1天,则应该使用1西格玛; 计算每一项活动在13天内完工的概率是:方法--正态分布概率+西格玛/偏离平均工期数 50%+68.37%/2=84.19% 备注:50%参考正态分布图,68.37参考1西格玛值; 计算全部活动在13天内完工概率是:方法--每一项活动的概率相乘 84.19%*84.19%*84.19%=59.67% 如果计算为11-15天的概率:最小值的概率+最大值的概率 68.37/2+99.75/2=84.06%
解读Minitab的正态概率图
解读Minitab的正态概率图 已有371 次阅读2009-11-5 20:41 |个人分类:Minitab|关键词:Minitab 在DOE、Regression、统计检定时常需要用到正态分布的假设,检定一组数据是否取自正态分布,进行常态性检定最简单方法就是采用正态概率图。 最近很多贴文询问Minitab正态概率图的坐标系统、意义与手工绘制等议题,因涉及分配概率图的理解与使用,因此撰文剖析,如下图是以一组14个样本数据所画的正态概率图 本图原始数据,经排序后如下 34,35,36,37,38,39,40,40,41,42,43,44,45,46 图上有5个注解,依序说明之 注解1:Probability Plot of x,表示此图是一组数据,放在名为x的栏位上,下方有Normal 表示本项检定的H0是Normal –正态分布,当然H1就是非正态分布 注解2:Mean 40表示数据平均值,StDev 3.742(计算结果3.74166)表示数据标准差,N 14表示数据数,这些计算式依据一般基本统计的公式计算而得 注解3:蓝色直线是画在正态分布机率图纸上,是一条参考线,以判断是否H0成立 详细解说如下 1)鼠标移到Minitab蓝色直线上,就会出现如下图中的黄底的Percent与x数值表
2) Percent与x数值表中,Percent为正态分布累积分配函数(CDF),数值是介于0与1之间,表上数值为%值,习惯上是以F(x)表式之,而x为F(x)的反函数 3)若直接以Percent与x( inv F(x))数值表作散布图不会得到依直线,而是S型曲线 4)在Percent与x( inv F(x))数值表多加一栏z,其值为x( inv F(x))的标准化,z=( inv F(x)) –40)/3.74166 5)以x( inv F(x))为横轴,z为纵轴作散布图+回归线,可得一直线,将每个点以Percent作为数据卷标 6)隐藏纵轴z,改用Percent的数据标签,就是一般的正态概率图纸 ** 此处须要另文说明解读正态概率图-正态概率图纸的秘密** 注解4:红色散布图图点是将样本数据排序后,以median rank估计出该点的CDF值,根据CDF数值求出标准正态分布的反函数z值,再以x vs z绘出散布图(参考注解3) ** 此处须要另文说明解读正态概率图-绘制小样本数据检验常态性** 注解5:Anderson-Darling常态性检定以辅助图型判断 ** 此处须要另文说明解读正态概率图- Anderson-Darling检定** 延伸阅读: 用Excel做简易的正态概率图(Normal probability plot)例
利用Excel软件绘制正态概率纸的方法_图文(精)
数理统计分靳与应用 , 偏差O-,能够直观地分析出工序的过程能力,求出工序的过程能力指数Cr值或Cm值.并且还可咀估计工序的不合格品率。因此,利用正态概率纸分析工序的方法,具有多功能的优点(参阅文献『1]): 利用正态概率纸分析工序,有着直观、简单、快速和易于掌握等诸多优点,在生产现场中使用备受欢迎,但由于它是一种图算法,精度相对较差,然而在现场使用其精度也已足够。如能提高正态概率纸本身的绘制精度,将有助于弥补正态概率纸的这一缺点。 但是采用正态概率纸分析 j 工序,其前提是必须首先有正态j 概率纸,因此,就必须首先解决i 正态概率纸的绘制问题。 过去绘制正态概率纸都是手工放大绘图,然后缩小印制成专用坐标纸再供现场使用,不仅麻烦,而且误差较大,更加影响了使用精度。现在由于电脑的普及,采用电子表格软件Excel绘 态概率纸纵坐标上各代表点的位置问题。 根据文献[2]所提供的手工绘制正态概率纸的步骤,对之加咀改造和发展,形成下列利用Excel绘制正态概率纸的方法和步骤: 1.选纵坐标值中有代表性的点(正态分布函数值“):
0.0l%,0.02%,…,0.09%;0.10%.0.20%,…,0.90%:1.00%,2.00%.….9.00%;1000%.11.00%. ….19.00%;20.00%,22.00%.….28.00%(取偶数);30.00%,32.00%, ?一,38.00%(取偶数);40.00%,42.00%,…,48.00%(取偶数);50.00%,52.00%,…,58.00%(取偶 数):60.00%,62.00%,…,68瑚%(取偶数);70肿%.72.00%,….78.00%f取偶数);80.oo%,81肿%,?一, 89.00%;90.00%,91.00%,….99.00%;99.10%,99.20%, …, 99.90%:99.91%.9992%,….99.99%。 2.查正态分布函数表,查出上 刻度之间的间距)的方法来绘制表格的,故我们需要将原始纵坐标的数据转化成行高数据,以便于纵坐标的绘制;横坐标是等间距的,故一般设为lOO列,间距 即列宽为0.38。 纵坐标数据的转化公式:(1)算出相邻两个Zct之间的差值X。 X=Za..一ZⅡ+l (I)
解读Minitab的正态概率图
解读Minitab的正态概率图 P值是MINITAB通过某种分布(F、T等)转换过来的一个值,正是由于概率中有太多的分布,一般对统计学不是很清楚的人是很难记住这些分布的。通过转换,在MINITAB中,就只需看一个值,即P值,一般取0.05。通过它来做假设检验,而假设检验又有很多类型,不是一下子能讲清楚的。 就LZ问题而言,从图中得出来的P值为0.84,大于0.05,可认为数据为正态分布(虽然样本量少了点)。至于P值到底如何而来,AD值代表何意,就个人见解而言,LZ可以先不到这个深度。 Anderson-Darling 统计量,测量数据服从特定分布的程度。分布与数据拟合越好,此统计量越小。使用Anderson-Darling 统计量可比较若干分布的拟合情况,以查看哪种分布是最佳分布,或者检验数据样本是否来自具有指定分布的总体。例如,可以使用Anderson-Darling 统计量为可靠性数据分析在Weibull 和对数正态分布之间进行选择,或者检验数据是否符合t 检验的正态性假设。其实看一下Minitab帮助什么都有。 AD值代表你的真实的量测数据的累计分布与理论正态的累计正态分布的面积差,AD值越小,说明你的数据越接近正态分布数据。 在DOE、Regression、统计检定时常需要用到正态分布的假设,检定一组数据是否取自正态分布,进行常态性检定最简单方法就是采用正态概率图。 最近很多贴文询问Minitab正态概率图的坐标系统、意义与手工绘制等议题,因涉及分配概率图的理解与使用,因此撰文剖析,如下图是以一组14个样本数据所画的正态概率图 本图原始数据,经排序后如下
34,35,36,37,38,39,40,40,41,42,43,44,45,46 图上有5个注解,依序说明之 注解1:Probability Plot of x,表示此图是一组数据,放在名为x的栏位上,下方有Normal表示本项检定的H0是Normal –正态分布,当然H1就是非正态分布 注解2:Mean 40表示数据平均值,StDev 3.742(计算结果3.74166)表示数据标准差,N 14表示数据数,这些计算式依据一般基本统计的公式计算而得 注解3:蓝色直线是画在正态分布机率图纸上,是一条参考线,以判断是否H0 成立 详细解说如下 1) 鼠标移到Minitab蓝色直线上,就会出现如下图中的黄底的Percent与x数值表 2) Percent与x数值表中,Percent为正态分布累积分配函数(CDF),数值是介于0与1之间,表上数值为%值,习惯上是以F(x)表式之,而x为F(x)的反函数 3) 若直接以Percent与x( inv F(x))数值表作散布图不会得到依直线,而是S型曲线 4) 在Percent与x( inv F(x))数值表多加一栏z,其值为x( inv F(x))的标准化,z=( inv F(x)) – 40)/3.74166 5) 以x( inv F(x))为横轴,z为纵轴作散布图+回归线,可得一直线,将每个点以Percent作为数据卷标 6) 隐藏纵轴z,改用Percent的数据标签,就是一般的正态概率图纸 ** 此处须要另文说明解读正态概率图-正态概率图纸的秘密 ** 注解4:红色散布图图点是将样本数据排序后,以median rank估计出该点的CDF 值,根据CDF数值求出标准正态分布的反函数z值,再以x vs z 绘出散布图(参考注解3) ** 此处须要另文说明解读正态概率图-绘制小样本数据检验常态性** 注解5:Anderson-Darling 常态性检定以辅助图型判断 ** 此处须要另文说明解读正态概率图- Anderson-Darling檢定**
正态分布概率公式(部分)
Generated by Foxit PDF Creator ? Foxit Software https://www.360docs.net/doc/7711122706.html, For evaluation only.
图 62正态分布概率密度函数的曲线 正态曲线可用方程式表示。 n 当 →∞时,可由二项分布概率函数方程推导出正态 分布曲线的方程:
fx= (61 ) () .6
式中: x—所研究的变数; fx —某一定值 x出现的函数值,一般称为概率 () 密度函数 (由于间断性分布已转变成连续性分布,因而我们只能计算变量落在某 一区间的概率, 不能计算变量取某一值, 即某一点时的概率, 所以用 “概率密度” 一词以与概率相区分),相当于曲线 x值的纵轴高度; p—常数,等于 31 .4 19……; e— 常数,等于 2788……; μ 为总体参数,是所研究总体 5 .12 的平均数, 不同的正态总体具有不同的 μ , 但对某一定总体的 μ 是一个常数; δ 也为总体参数, 表示所研究总体的标准差, 不同的正态总体具有不同的 δ , 但对某一定总体的 δ 是一个常数。 上述公式表示随机变数 x的分布叫作正态分布, 记作 N μ ,δ2 ), “具 ( 读作 2 平均数为 μ,方差为 δ 的正态分布”。正态分布概率密度函数的曲线叫正态 曲线,形状见图 62。 (二)正态分布的特性
1、正态分布曲线是以 x μ 为对称轴,向左右两侧作对称分布。因 =
的
数值无论正负, 只要其绝对值相等, 代入公式 61 ) ( .6 所得的 fx 是相等的, () 即在平均数 μ 的左方或右方,只要距离相等,其 fx 就相等,因此其分布是 () 对称的。在正态分布下,算术平均数、中位数、众数三者合一位于 μ 点上。
正态分布概率公式(部分)
图 6-2 正态分布概率密度函数的曲线 正态曲线可用方程式表示。当n→∞时,可由二项分布概率函数方程推导出正态分布曲线的方程: f(x)= (6.16 ) 式中: x —所研究的变数; f(x) —某一定值 x 出现的函数值,一般称为概率密度函数(由于间断性分布已转变成连续性分布,因而我们只能计算变量落在某一区间的概率,不能计算变量取某一值,即某一点时的概率,所以用“概率密度”一词以与概率相区分),相当于曲线 x 值的纵轴高度; p —常数,等于 3.14 159 ……; e —常数,等于 2.71828 ……;μ为总体参数,是所研究总体的平均数,不同的正态总体具有不同的μ,但对某一定总体的μ是一个常数;δ也为总体参数,表示所研究总体的标准差,不同的正态总体具有不同的δ,但对某一定总体的δ是一个常数。 上述公式表示随机变数 x 的分布叫作正态分布,记作 N( μ , δ2 ) ,读作“具平均数为μ,方差为δ 2 的正态分布”。正态分布概率密度函数的曲线叫正态曲线,形状见图 6-2 。 (二)正态分布的特性 1 、正态分布曲线是以 x= μ为对称轴,向左右两侧作对称分布。因的数值无论正负,只要其绝对值相等,代入公式( 6.16 )所得的 f(x) 是相等的,即在平均数μ的左方或右方,只要距离相等,其 f(x) 就相等,因此其分布是对称的。在正态分布下,算术平均数、中位数、众数三者合一位于μ点上。
2 、正态分布曲线有一个高峰。随机变数 x 的取值范围为( - ∞,+ ∞ ),在( - ∞ ,μ)正态曲线随 x 的增大而上升,;当 x= μ时, f(x) 最大;在(μ,+ ∞ )曲线随 x 的增大而下降。 3 、正态曲线在︱x-μ︱=1 δ处有拐点。曲线向左右两侧伸展,当x →± ∞ 时,f(x) →0 ,但 f(x) 值恒不等于零,曲线是以 x 轴为渐进线,所以曲线全距从 -∞到+ ∞。 4 、正态曲线是由μ和δ两个参数来确定的,其中μ确定曲线在 x 轴上的位置 [ 图 6-3] ,δ确定它的变异程度 [ 图 6-4] 。μ和δ不同时,就会有不同的曲线位置和变异程度。所以,正态分布曲线不只是一条曲线,而是一系列曲线。任何一条特定的正态曲线只有在其μ和δ确定以后才能确定。 5 、正态分布曲线是二项分布的极限曲线,二项分布的总概率等于 1 ,正态分布与 x 轴之间的总概率(所研究总体的全部变量出现的概率总和)或总面积也应该是等于 1 。而变量 x 出现在任两个定值 x1到x2(x1≠x2)之间的概率,等于这两个定值之间的面积占总面积的成数或百分比。正态曲线的任何两个定值间的概率或面积,完全由曲线的μ和δ确定。常用的理论面积或概率如下: 区间μ ± 1 δ面积或概率 =0.6826 μ ± 2 δ =0.9545 μ ± 3 δ=0.9973 μ± 1.960δ=0.9500 μ ±2.576 δ =0.9900
正态分布下的累积概率
正态分布 3.1 正态分布 对于连续型随机变量而言,正态分布(normal distribution)是最重要的一种概率分布。 经验表明:对于依赖于众多微小因素;且每一因素均产生微小的或正或负影响的连续型随机变量来说,正态分布是一个相当好的描述模型。 如人的体重,因为遗传、骨骼结构、饮食、锻炼、等都对人的体重有影响,但又没有一种因素起到压到一切的主导作用。与此相类似,人的身高、考试分数等都近似地服从正态分布。 通常用: X~N(u, 2δ) (3 - 1) δ称为正态分布的总表示随机变量X服从正态分布。N表示正态分布,括号的参数u, 2 体均值(或期望)和方差。 3.1.1 正态分布的性质 (1) 正态分布曲线以均值u为中心,对称分布。 (2) 正态分布的概率密度函数呈中间高、两边低,在均值u处达到最高,向两边逐渐降低,即随机变量在远离均值处取值的概率逐渐变小。
(3) 正态曲线下的面积约有68%位于u ± δ两值之间;约有95%的面积位于u±22δ之间;而约有99.7%的面积位于u±3δ之间。 ★ (4) 两个(或多个)正态分布随机变量的线性组合仍服从正态分布。 令X 和Y 相互独立: X ~N(u X ,2x δ) Y ~N(u Y ,2y δ) 现在考虑两个变量的线性组合:W =a X+b Y 则 W ~N(u W , 2w δ) ( 3 - 2 ) 其中, u W =(au X +bu Y ) ( 3 - 3 ) 2w δ = (22x a δ+22y b δ) (3 - 4) 例3.1 令X 表示在下沙高教区一花店每日出售玫瑰花数量, Y 表示在下沙镇一花店每日出售玫瑰花的数量,假定X 和Y 服从正态分布,且相互独立,并有: X ~N( 100,64 ),Y ~N( 150,81 ) 求两天两花商出售玫瑰花数量的期望及方差? W =2X +2Y 根据式( 3 - 3 ) E(w)=E( 2X+ 2Y) = 5 0 0, Var (w) = 4var(X) + 4var(Y) = 5 8 0 因此,W 服从均值为5 0 0,方差为5 8 0的正态分布,即W ~N( 5 0 0,5 8 0 )。 ★★3.1.2 标准正态分布 两个正态分布可能因为期望或方差的不同,或是期望和方差均不同而相区别。如何比较各种不同的正态分布呢?
解读正态概率图-正态概率图纸的秘密
解读正态概率图-正态概率图纸的秘密 本文是对解读Minitab的正态概率图一文中注解3-正态概率图图纸的说明 1上图的H0假设 1)上图单组数据为34,35,36,37,38,39,40,40,41,42,43,44,45,46共N=14个 2)计算得平均值为Xbar=40,标准差为s=3.741657 (图示为3.742) 3)上图的H0假设数据源自正态分布,相对H1就是非正态分布 4)基于正态分布的假设,所以根据样本数可以估计此正态分布的2个参数,平均值μ为40, 标准差σ为3.741657 2正态分布的特性x、z与累积分配函数 1)正态分布z值有人称z score,是正态分布的变量x,转换为标准正态分布时对应值为z, 关系是为z=(x-μ)/σ 2)正态分布下变量x,经转换为标准正态分布对应值z,就可经由正态分布数值表或软件等求得 x的累积分配函数(cdf),cdf一般统计符号写成F(x)= P(X≦x),P就是X≦x累积机率,正态概率图 的纵坐标Percent就是F(x) 3)鼠标移到Minitab蓝色直线上,就会出现如下图中的黄底的Percent与x数值表
4)Percent与x数值表说明 黄底的Percent与x数值表,Percent就是F(x),F(x)是指定的解于0与1之间,表上所示数值系为%,透过标准正态分布,就可求F(x)的反函数z,然后以公式x=zσ+μ得到x值 3正态性检定使用的正态概率图图纸 1)下表为手工计算,结果与minitab的Percent与x数值表相符的 作成蓝色参考值线的数据x、z、F(x)关系表如下表,表中系先指定F(x),就是表中Percent栏, 然后基于正态分布求x=F-1(x),再使用正态分布标准化公式计算z=(x-Xbar)/s
正态分布概率表
正态分布概率表 1 —f? 0( u )= t P⑴t F(t)t F(0t卩⑴0.00 0.000 00.230. 181 9 0.46 0.354 5W9 0. 50 9 8 0.010.008 0(J. 24o. m70.47 0.361 60.70 0,516 1 0+02 0.016 00. 250,197 4 0,48 0.368 80+71 0.522 3 0.03 0.023 9(1. 26 0.205 1 0.49 0.375 9 0.72 0. 52 8 5 044 0.031 9(1.270,212 8 0.5fl O.3R2 90.73"4 6 0+05 0039 90,280. 220 5 0,510.389 9 0.74 0.540 7 0.06 0 047 80.290. 228 20.52036 9 0.75 0*546 7 0+07 0 €55 S0,30 0,235 80,530.403 9 0+76 0.552 7 0+08 0.063 8O 310.243 4 0-540.410 80+77 0.558 7 0+09 (1.(171 7(J. 320.251 00.550.417 70.78 0.564 6 0. 10 0.0797 fl. 33 0.258 6 0.56 0,424 50.79 0.570 5 0.110,087 60.340.266 1 0.57 0.431 30.B0 0.576 3 0.12 0.09$ 50. 350.273 7 0.5S0.43S 10.S1 O.5S2 1 0+13 OJ03 4(J. 360.281 20.59 0.444 80+S2 0.5S7 8 0+14 (1.111 30.37 0.288 6 0.60 0.451 50+83 0.593 5 0.15 0J19 20. 380.296 1 0.61 0.458 10.840.599 1 0+16 0.127 10.39 0. 303 50.62 0.464 70.85 0.604 7 0.17 0.135 00400.330 8 0.63 0.471 30.S6 0.610 2 0+18 0.142 S0.410.318 20,640.477 80.87 0.6157 0+19 0.150 70 420, 325 50.650.484 30.88 0.621 1 0,20 0J58 5(J. 430. 332 80.660.490 10.890.626 5 0,210J66 3(J.440,340 1 0.67 0.497 10.90 0.631 9 0 + 22 0.174 10.450347 3 0,68 0.503 50.91 0.637 2
正态分布推导
A friend of mine and I decided to try to derive the normal pdf and the thinking went along the lines of the central limit theorem which states that the mean of any probability distribution becomes normal as the number of trials increases. The derivation of this is well known. but we asked ourselves how the normal distribution was first achieved. There is another 'normal' derivation which is the binomial approximation and it is through this direction that we wondered how to derive the normal distribution from the binomial as n gets large. So the general approach we will take is to take a binomial distribution, then increase the number of samples n. (提岀一个有趣的问题是在统计分配,这是表明,标准正态分布是有效的-即从负无穷到正无穷的积分等 同于一个,并在这样做表明推导了部分正常的PDF 。 我,我的一个朋友决定尝试推导岀正常的PDF和沿中心极限定理指岀,任何概率分布的均值作为试验增加 的正常思维。 这个推导是众所周知的。但我们问自己如何正态分布首次实现。有另一种“正常”的推导,这是二项 式近似和它是通过这个方向,我们想知道如何从二项式正态分布为n变大。 因此,我们将采取的一般方法是一个二项分布,再增加样本N.的数量) Once we have done this, instead of using the horizontal lines of the distribution histogram (which would be the normal probability mass function of the binomial), we are going to 'draw' a line through each central point. (一旦我们已经做了,而不是使用分布直方图(这将是正常的概率质量函数二项式)水平线,,我们要“画 一条线",通过每一个中心点。)
解读Minitab的正态概率图_一文中注解3-正态概率图图纸的说明
本文是对解读Minitab的正态概率图一文中注解3-正态概率图图纸的说明 1 上图的H0假设 1) 上图单组数据为34,35,36,37,38,39,40,40,41,42,43,44,45,46共N=14个 2) 计算得平均值为Xbar=40,标准差为s=3.741657 (图示为3.742) 3) 上图的H0假设数据源自正态分布,相对H1就是非正态分布 4) 基于正态分布的假设,所以根据样本数可以估计此正态分布的2个参数,平均值μ为40, 标准差σ为3.741657 2 正态分布的特性x 、z与累积分配函数 1) 正态分布z值有人称z score,是正态分布的变量x,转换为标准正态分布时对应值为z, 关系是为z=(x-μ)/σ 2) 正态分布下变量x,经转换为标准正态分布对应值z,就可经由正态分布数值表或软件等求得 x的累积分配函数(cdf),cdf一般统计符号写成F(x)= P(X≦x),P就是X≦x累积机率,正态概率图
的纵坐标Percent就是F(x) 3) 鼠标移到Minitab蓝色直线上,就会出现如下图中的黄底的Percent与x数值表 4) Percent与x数值表说明 黄底的Percent与x数值表,Percent就是F(x),F(x)是指定的解于0与1之间,表上所示数值系为%, 透过标准正态分布,就可求F(x)的反函数z,然后以公式x=zσ+μ得到x值 3 正态性检定使用的正态概率图图纸 1) 下表为手工计算,结果与minitab的Percent与x数值表相符的 作成蓝色参考值线的数据x、z、F(x)关系表如下表,表中系先指定F(x),就是表中Percent栏, 然后基于正态分布求x=F-1(x),再使用正态分布标准化公式计算z=(x-Xbar)/s