C45算法生成决策树的研究

精心整理
C4.5算法生成决策树
1、基础知识
当我们需要对一个随机事件的概率分布进行预测时,我们的预测应当满足全部已知的条件,而对未知的情况不要做任何主观假设。在这种情况下,概率分布最均SEE5、SLIQ 算法的的标准,克服了ID3算法中信息增益选择属性时偏向选择取值多的属性的不足,并能够完成对连续属性离散化的处理,还能够对不完整数据进行处理。根据分割方法的不同,目前决策的算法可以分为两类:基于信息论(InformationTheory )的方法和最小GINI 指标(LowestGINIindex )方法。对应前者的算法有ID3、C4.5,后者的有CART 、SLIQ 和SPRINT 。
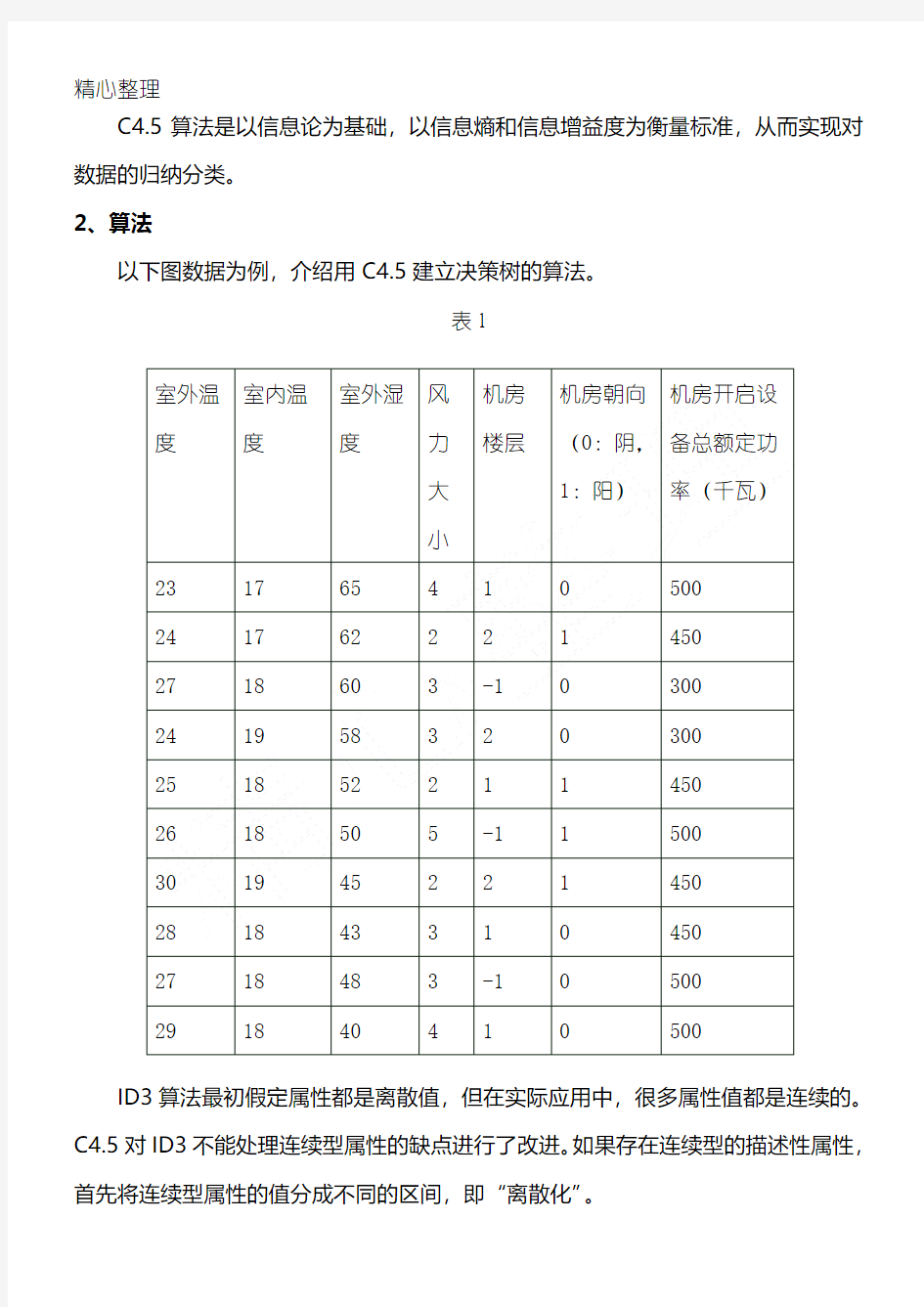
C4.5算法是以信息论为基础,以信息熵和信息增益度为衡量标准,从而实现对数据的归纳分类。
2、算法
以下图数据为例,介绍用C4.5建立决策树的算法。
表1
ID3算法最初假定属性都是离散值,但在实际应用中,很多属性值都是连续的。C4.5对ID3不能处理连续型属性的缺点进行了改进。如果存在连续型的描述性属性,首先将连续型属性的值分成不同的区间,即“离散化”。
对上表中将实际耗电量分为10个区间(0—9)
(300~320,320~340,340~360,360~380,380~400,400~420,420~440,440~460,460~480,480~500)因为最终是要得到实际的耗电量区间,因此“实际耗电量”属于“类别属性”。“室外温度”、“室内温度”、“室外湿度”、“风力大小”、“机房楼层”、“机房朝向”、“机房开启设备总额定功率”属于“非类别属性”。
表2
通过表
知,实
际耗电的个数表3
定义1,一个4个比定义2),n p ,则由该分布传递的信息量称为的熵。
即
定义3,k 则识别T )k C 的例如:表3中,得到实际耗电量区间的信息量为(以下单位为比特,下同):
()2222222/10log (2/10)1/10log (1/10)3/10log (3/10)()1/10log (1/10)2/10log (2/10)1/10log (1/10)Info T I P ?+?+?+??==- ??+?+???
=2.446
定义4:若我们先根据非类别属性X 的值将T 分成集合12,,n T T T ,则确定T 中一个元素类的信息量可通过确定i T 的加权平均值来得到,即Info(i T )的加权平均值为: 例如:属性“室内温度”的值有“17、18、19”,分类见下表:
表4
P (17P (18P (19(17)
Info ()()22222(18)181/6*log (1/6)1/6*log (1/6)Info I P ??
==- ?+??
=2.252
()()()22(19)191/2*log (1/2)1/2*log (1/2)Info I P ==-+=1.000
2/10(17)6/10(18)2/10(19)(,)Info Info In Inf fo o T =?+?+?室内温度=1.751
定义5:将增益Gain (X ,T )定义为:
。所谓增益,就是指在应用了某一测试之后,
其对应的可能性丰富程度下降,不确定性减小,这个减小的幅度就是增益,其实质上对应着分类带来的好处)。
上式的增益值为:()()()
=-室内温度=2.446-1.751=0.695
Gain X T Info T Info T
,,
以上是ID3计算信息增益的方法,C4.5算法对此进行了改进。C4.5算法采用信息增益率作为选择分支属性的标准,克服了ID3算法中信息增益选择属性时偏向选
Tn,
,T)为0
,则
3
个候选的分割阈值点的值为上述排序后的属性值链表中两两前后连续元素的中点,那么我们的任务就是从这个N-1个候选分割阈值点中选出一个,使得前面提到的信息论标准最大。在EXCEL中,对室外温度(第二步)详细介绍了如何分割阈值点并进行计算。
4、树的终止
树的建立实际上是一个递归过程,那么这个递归什么时候到达终止条件退出递归呢?有两种方式,第一种方式是如果某一节点的分支所覆盖的样本都属于同一类的时候,那么递归就可以终止,该分支就会产生一个叶子节点。还有一种方式就是,如果某一分支覆盖的样本的个数如果小于一个阈值,那么也可产生叶子节点,从而终止建立树。我们只考虑二叉分割的情况,因为这样生成的树的准确度更高。
5、树的修剪
树一旦生成后,便进入第二阶段——修剪阶段。决策树为什么要剪枝?原因就是避免决策树“过拟合”样
本。
100%
(
很小时,将所有
对于树的修剪,相对树的生成要简单一些,后续再做讨论。
决策树算法介绍(DOC)
3.1 分类与决策树概述 3.1.1 分类与预测 分类是一种应用非常广泛的数据挖掘技术,应用的例子也很多。例如,根据信用卡支付历史记录,来判断具备哪些特征的用户往往具有良好的信用;根据某种病症的诊断记录,来分析哪些药物组合可以带来良好的治疗效果。这些过程的一个共同特点是:根据数据的某些属性,来估计一个特定属性的值。例如在信用分析案例中,根据用户的“年龄”、“性别”、“收入水平”、“职业”等属性的值,来估计该用户“信用度”属性的值应该取“好”还是“差”,在这个例子中,所研究的属性“信用度”是一个离散属性,它的取值是一个类别值,这种问题在数据挖掘中被称为分类。 还有一种问题,例如根据股市交易的历史数据估计下一个交易日的大盘指数,这里所研究的属性“大盘指数”是一个连续属性,它的取值是一个实数。那么这种问题在数据挖掘中被称为预测。 总之,当估计的属性值是离散值时,这就是分类;当估计的属性值是连续值时,这就是预测。 3.1.2 决策树的基本原理 1.构建决策树 通过一个实际的例子,来了解一些与决策树有关的基本概念。 表3-1是一个数据库表,记载着某银行的客户信用记录,属性包括“姓名”、“年龄”、“职业”、“月薪”、......、“信用等级”,每一行是一个客户样本,每一列是一个属性(字段)。这里把这个表记做数据集D。 银行需要解决的问题是,根据数据集D,建立一个信用等级分析模型,并根据这个模型,产生一系列规则。当银行在未来的某个时刻收到某个客户的贷款申请时,依据这些规则,可以根据该客户的年龄、职业、月薪等属性,来预测其信用等级,以确定是否提供贷款给该用户。这里的信用等级分析模型,就可以是一棵决策树。在这个案例中,研究的重点是“信用等级”这个属性。给定一个信用等级未知的客户,要根据他/她的其他属性来估计“信用等级”的值是“优”、“良”还是“差”,也就是说,要把这客户划分到信用等级为“优”、“良”、“差”这3个类别的某一类别中去。这里把“信用等级”这个属性称为“类标号属性”。数据集D中“信用等级”属性的全部取值就构成了类别集合:Class={“优”,
决策树算法研究及应用概要
决策树算法研究及应用? 王桂芹黄道 华东理工大学实验十五楼206室 摘要:信息论是数据挖掘技术的重要指导理论之一,是决策树算法实现的理论依据。决 策树算法是一种逼近离散值目标函数的方法,其实质是在学习的基础上,得到分类规则。本文简要介绍了信息论的基本原理,重点阐述基于信息论的决策树算法,分析了它们目前 主要的代表理论以及存在的问题,并用具体的事例来验证。 关键词:决策树算法分类应用 Study and Application in Decision Tree Algorithm WANG Guiqin HUANG Dao College of Information Science and Engineering, East China University of Science and Technology Abstract:The information theory is one of the basic theories of Data Mining,and also is the theoretical foundation of the Decision Tree Algorithm.Decision Tree Algorithm is a method to approach the discrete-valued objective function.The essential of the method is to obtain a clas-sification rule on the basis of example-based learning.An example is used to sustain the theory. Keywords:Decision Tree; Algorithm; Classification; Application 1 引言 决策树分类算法起源于概念学习系统CLS(Concept Learning System,然后发展 到ID3
决策树算法分析报告
摘要 随着信息科技的高速发展,人们对于积累的海量数据量的处理工作也日益增重,需发明之母,数据挖掘技术就是为了顺应这种需求而发展起来的一种数据处理技术。 数据挖掘技术又称数据库中的知识发现,是从一个大规模的数据库的数据中有效地、隐含的、以前未知的、有潜在使用价值的信息的过程。决策树算法是数据挖掘中重要的分类方法,基于决策树的各种算法在执行速度、可扩展性、输出结果的可理解性、分类预测的准确性等方面各有千秋,在各个领域广泛应用且已经有了许多成熟的系统,如语音识别、模式识别和专家系统等。本文着重研究和比较了几种典型的决策树算法,并对决策树算法的应用进行举例。 关键词:数据挖掘;决策树;比较
Abstract With the rapid development of Information Technology, people are f acing much more work load in dealing with the accumulated mass data. Data mining technology is also called the knowledge discovery in database, data from a large database of effectively, implicit, previou sly unknown and potentially use value of information process. Algorithm of decision tree in data mining is an important method of classification based on decision tree algorithms, in execution speed, scalability, output result comprehensibility, classification accuracy, each has its own merits., extensive application in various fields and have many mature system, such as speech recognition, pattern recognition and expert system and so on. This paper studies and compares several kinds of typical decision tree algorithm, and the algorithm of decision tree application examples. Keywords: Data mining; decision tree;Compare
基于决策树的分类算法
1 分类的概念及分类器的评判 分类是数据挖掘中的一个重要课题。分类的目的是学会一个分类函数或分类模型(也常常称作分类器),该模型能把数据库中的数据项映射到给定类别中的某一个。分类可用于提取描述重要数据类的模型或预测未来的数据趋势。 分类可描述如下:输入数据,或称训练集(training set)是一条条记录组成的。每一条记录包含若干条属性(attribute),组成一个特征向量。训练集的每条记录还有一个特定的类标签(类标签)与之对应。该类标签是系统的输入,通常是以往的一些经验数据。一个具体样本的形式可为样本向量:(v1,v2,…,…vn:c)。在这里vi表示字段值,c表示类别。 分类的目的是:分析输入数据,通过在训练集中的数据表现出来的特性,为每一个类找到一种准确的描述或者模型。这种描述常常用谓词表示。由此生成的类描述用来对未来的测试数据进行分类。尽管这些未来的测试数据的类标签是未知的,我们仍可以由此预测这些新数据所属的类。注意是预测,而不能肯定。我们也可以由此对数据中的每一个类有更好的理解。也就是说:我们获得了对这个类的知识。 对分类器的好坏有三种评价或比较尺度: 预测准确度:预测准确度是用得最多的一种比较尺度,特别是对于预测型分类任务,目前公认的方法是10番分层交叉验证法。 计算复杂度:计算复杂度依赖于具体的实现细节和硬件环境,在数据挖掘中,由于操作对象是巨量的数据库,因此空间和时间的复杂度问题将是非常重要的一个环节。 模型描述的简洁度:对于描述型的分类任务,模型描述越简洁越受欢迎;例如,采用规则表示的分类器构造法就更有用。 分类技术有很多,如决策树、贝叶斯网络、神经网络、遗传算法、关联规则等。本文重点是详细讨论决策树中相关算法。
决策树算法的原理与应用
决策树算法的原理与应用 发表时间:2019-02-18T17:17:08.530Z 来源:《科技新时代》2018年12期作者:曹逸知[导读] 在以后,分类问题也是伴随我们生活的主要问题之一,决策树算法也会在更多的领域发挥作用。江苏省宜兴中学江苏宜兴 214200 摘要:在机器学习与大数据飞速发展的21世纪,各种不同的算法成为了推动发展的基石.而作为十大经典算法之一的决策树算法是机器学习中十分重要的一种算法。本文对决策树算法的原理,发展历程以及在现实生活中的基本应用进行介绍,并突出说明了决策树算法所涉及的几种核心技术和几种具有代表性的算法模式。 关键词:机器学习算法决策树 1.决策树算法介绍 1.1算法原理简介 决策树模型是一种用于对数据集进行分类的树形结构。决策树类似于数据结构中的树型结构,主要是有节点和连接节点的边两种结构组成。节点又分为内部节点和叶节点。内部节点表示一个特征或属性, 叶节点表示一个类. 决策树(Decision Tree),又称为判定树, 是一种以树结构(包括二叉树和多叉树)形式表达的预测分析模型,决策树算法被评为十大经典机器学习算法之一[1]。 1.2 发展历程 决策树方法产生于上世纪中旬,到了1975年由J Ross Quinlan提出了ID3算法,作为第一种分类算法模型,在很多数据集上有不错的表现。随着ID3算法的不断发展,1993年J Ross Quinlan提出C4.5算法,算法对于缺失值补充、树型结构剪枝等方面作了较大改进,使得算法能够更好的处理分类和回归问题。决策树算法的发展同时也离不开信息论研究的深入,香农提出的信息熵概念,为ID3算法的核心,信息增益奠定了基础。1984年,Breiman提出了分类回归树算法,使用Gini系数代替了信息熵,并且利用数据来对树模型不断进行优化[2]。2.决策树算法的核心 2.1数据增益 香农在信息论方面的研究,提出了以信息熵来表示事情的不确定性。在数据均匀分布的情况下,熵越大代表事物的越不确定。在ID3算法中,使用信息熵作为判断依据,在建树的过程中,选定某个特征对数据集进行分类后,数据集分类前后信息熵的变化就叫作信息增益,如果使用多个特征对数据集分别进行分类时,信息增益可以衡量特征是否有利于算法对数据集进行分类,从而选择最优的分类方式建树。如果一个随机变量X的可以取值为Xi(i=1…n),那么对于变量X来说,它的熵就是
决策树分类算法与应用
机器学习算法day04_决策树分类算法及应用课程大纲 决策树分类算法原理决策树算法概述 决策树算法思想 决策树构造 算法要点 决策树分类算法案例案例需求 Python实现 决策树的持久化保存 课程目标: 1、理解决策树算法的核心思想 2、理解决策树算法的代码实现 3、掌握决策树算法的应用步骤:数据处理、建模、运算和结果判定
1. 决策树分类算法原理 1.1 概述 决策树(decision tree)——是一种被广泛使用的分类算法。 相比贝叶斯算法,决策树的优势在于构造过程不需要任何领域知识或参数设置 在实际应用中,对于探测式的知识发现,决策树更加适用 1.2 算法思想 通俗来说,决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话: 女儿:多大年纪了? 母亲:26。 女儿:长的帅不帅? 母亲:挺帅的。 女儿:收入高不? 母亲:不算很高,中等情况。 女儿:是公务员不? 母亲:是,在税务局上班呢。 女儿:那好,我去见见。 这个女孩的决策过程就是典型的分类树决策。 实质:通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见 假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么这个可以用下图表示女孩的决策逻辑
上图完整表达了这个女孩决定是否见一个约会对象的策略,其中: ◆绿色节点表示判断条件 ◆橙色节点表示决策结果 ◆箭头表示在一个判断条件在不同情况下的决策路径 图中红色箭头表示了上面例子中女孩的决策过程。 这幅图基本可以算是一颗决策树,说它“基本可以算”是因为图中的判定条件没有量化,如收入高中低等等,还不能算是严格意义上的决策树,如果将所有条件量化,则就变成真正的决策树了。 决策树分类算法的关键就是根据“先验数据”构造一棵最佳的决策树,用以预测未知数据的类别 决策树:是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
决策树算法介绍
3.1分类与决策树概述 3.1.1分类与预测 分类是一种应用非常广泛的数据挖掘技术,应用的例子也很多。例如,根据信用卡支付历史记录,来判断具备哪些特征的用户往往具有良好的信用;根据某种病 症的诊断记录,来分析哪些药物组合可以带来良好的治疗效果。这些过程的一个共同特点是:根据数据的某些属性,来估计一个特定属性的值。例如在信用分析案例中,根据用户的“年龄”、“性别”、“收入水平”、“职业”等属性的值,来估计该用户“信用度”属性的值应该取“好”还是“差”,在这个例子中,所研究的属性“信用度”是E—个离散属性,它的取值是一个类别值,这种问题在数 据挖掘中被称为分类。 还有一种问题,例如根据股市交易的历史数据估计下一个交易日的大盘指数,这 里所研究的属性“大盘指数”是一个连续属性,它的取值是一个实数。那么这种 问题在数据挖掘中被称为预测。 总之,当估计的属性值是离散值时,这就是分类;当估计的属性值是连续值时,这就是预测。 3.1.2决策树的基本原理 1. 构建决策树 通过一个实际的例子,来了解一些与决策树有关的基本概念。 表3-1是一个数据库表,记载着某银行的客户信用记录,属性包括“姓名”、“年龄”、“职业”、“月薪”、......、“信用等级”,每一行是一个客户样本,每一列是一个属性(字段)。这里把这个表记做数据集D。 银行需要解决的问题是,根据数据集D,建立一个信用等级分析模型,并根据这个模型,产生一系列规则。当银行在未来的某个时刻收到某个客户的贷款申请时,依据这些规则,可以根据该客户的年龄、职业、月薪等属性,来预测其信用等级,以确定是否提供贷款给该用户。这里的信用等级分析模型,就可以是一棵决策树。在这个案例中,研究的重点是“信用等级”这个属性。给定一个信用等级未知的客户,要根据他/她的其他属性来估计“信用等级”的值是“优”、“良”还是 “差”,也就是说,要把这客户划分到信用等级为“优”、“良”、“差”这3 个类别的某一类别中去。这里把“信用等级”这个属性称为“类标号属性”。数据集D中“信用等级”属性的全部取值就构成了类别集合:Class={ “优”,
C45算法生成决策树的研究
精心整理 C4.5算法生成决策树 1、基础知识 当我们需要对一个随机事件的概率分布进行预测时,我们的预测应当满足全部已知的条件,而对未知的情况不要做任何主观假设。在这种情况下,概率分布最均SEE5、SLIQ 算法的的标准,克服了ID3算法中信息增益选择属性时偏向选择取值多的属性的不足,并能够完成对连续属性离散化的处理,还能够对不完整数据进行处理。根据分割方法的不同,目前决策的算法可以分为两类:基于信息论(InformationTheory )的方法和最小GINI 指标(LowestGINIindex )方法。对应前者的算法有ID3、C4.5,后者的有CART 、SLIQ 和SPRINT 。
C4.5算法是以信息论为基础,以信息熵和信息增益度为衡量标准,从而实现对数据的归纳分类。 2、算法 以下图数据为例,介绍用C4.5建立决策树的算法。 表1 ID3算法最初假定属性都是离散值,但在实际应用中,很多属性值都是连续的。C4.5对ID3不能处理连续型属性的缺点进行了改进。如果存在连续型的描述性属性,首先将连续型属性的值分成不同的区间,即“离散化”。
对上表中将实际耗电量分为10个区间(0—9) (300~320,320~340,340~360,360~380,380~400,400~420,420~440,440~460,460~480,480~500)因为最终是要得到实际的耗电量区间,因此“实际耗电量”属于“类别属性”。“室外温度”、“室内温度”、“室外湿度”、“风力大小”、“机房楼层”、“机房朝向”、“机房开启设备总额定功率”属于“非类别属性”。 表2 通过表 知,实 际耗电的个数表3
决策树原理与应用:C5.0
决策树原理与应用:C5.0 分类预测指通过向现有数据的学习,使模型具备对未来新数据的预测能力。对于分类预测有这样几个重要,一是此模型使用的方法是归纳和提炼,而不是演绎。非数据挖掘类的软件的基本原理往往是演绎,软件能通过一系列的运算,用已知的公式对数据进行运算或统计。分类预测的基本原理是归纳,是学习,是发现新知识和新规律;二是指导性学习。所谓指导性学习,指数据中包含的变量不仅有预测性变量,还有目标变量;三是学习,模型通过归纳而不断学习。 事实上,预测包含目标变量为连续型变量的预测和目标变量为分在变量的分类预测。两者虽然都是预测,但结合决策树算法和我们之前介绍过的时间序列算法知,二者还是有明显的差别的。 Clementine决策树的特点是数据分析能力出色,分析结果易于展示。决策树算法是应用非常广泛的分类预测算法。 1.1决策树算法概述1.11什么是决策树决策树算法属于有指导的学习,即原数据必须包含预测变量和目标变量。决策树之所以如此命名,是因为其分析结果以一棵倒置的树的形式呈现。决策树由上到下依次为根节点、内部节点和叶节点。一个节点对应于数据中的一个字段,即一个字段——即Question——对数据进行一次划分。决策树分为分类决策树
(目标变量为分类型数值)和回归决策树(目标变量为连续型变量)。分类决策树叶节点所含样本中,其输出变量的众数就是分类结果;回归树的叶节点所含样本中,其输出变量的平均值就是预测结果。这一点需要格外注意。 与其它分类预测算法不同的是,决策树基于逻辑比较(即布尔比较)。可以简单描述为:If(条件1)Then(结果1);If (条件2)Then(结果2)。这样,每一个叶节点都对应于一条布尔比较的推理规则,对新数据的预测就正是依靠这些复杂的推理规则。在实际应用中,一个数据产生的推理规则是极为庞大和复杂的,因此对推理规则的精简是需要关注的。 1.12决策树的几何理解将训练样本集(即操作中常说的Training Data)看做一个n维空间上的一个点,则上面我们提到的布尔比较后的推理规则就像是存在于这个n维空间中的“线”。决策树建立的过程形象上看,就是倒置的树生长的过程,其几何意义上是,每个分枝(每条推理规则)完成对n维空间区域划分的过程。决策树正式生成,则n维空间正式划分完毕,则每一个小区域,代表一个叶节点。通常n 维空间不易于理解,故采用倒置的树来表示此结果。需要注意的一点是,在划分过程中,要尽量做到不同类别的结果归于不同的“区域”。 1.13决策树的核心问题:生成与修剪决策树核心问题有二。一是利用Training Data完成决策树的生成过程;二是利用
数据挖掘——决策树分类算法 (1)
决策树分类算法 学号:20120311139 学生所在学院:软件工程学院学生姓名:葛强强 任课教师:汤亮 教师所在学院:软件工程学院2015年11月
12软件1班 决策树分类算法 葛强强 12软件1班 摘要:决策树方法是数据挖掘中一种重要的分类方法,决策树是一个类似流程图的树型结构,其中树的每个内部结点代表对一个属性的测试,其分支代表测试的结果,而树的每个 叶结点代表一个类别。通过决策树模型对一条记录进行分类,就是通过按照模型中属 性测试结果从根到叶找到一条路径,最后叶节点的属性值就是该记录的分类结果。 关键词:数据挖掘,分类,决策树 近年来,随着数据库和数据仓库技术的广泛应用以及计算机技术的快速发展,人们利用信息技术搜集数据的能力大幅度提高,大量数据库被用于商业管理、政府办公、科学研究和工程开发等。面对海量的存储数据,如何从中有效地发现有价值的信息或知识,是一项非常艰巨的任务。数据挖掘就是为了应对这种要求而产生并迅速发展起来的。数据挖掘就是从大型数据库的数据中提取人们感兴趣的知识,这些知识是隐含的、事先未知的潜在有用的信息,提取的知识表示为概念、规则、规律、模式等形式。 分类在数据挖掘中是一项非常重要的任务。 分类的目的是学会一个分类函数或分类模型,把数据库中的数据项映射到给定类别中的某个类别。分类可用于预测,预测的目的是从历史数据记录中自动推导出对给定数据的趋势描述,从而能对未来数据进行预测。分类算法最知名的是决策树方法,决策树是用于分类的一种树结构。 1决策树介绍 决策树(decisiontree)技术是用于分类和预测 的主要技术,决策树学习是一种典型的以实例为基础的归纳学习算法,它着眼于从一组无次序、无规则的事例中推理出决策树表示形式的分类规则。它采用自顶向下的递归方式,在决策树的内部节点进行属性的比较,并根据不同属性判断从该节点向下的分支,在决策树的叶节点得到结论。所以从根到叶节点就对应着一条合取规则,整棵树就对应着一组析取表达式规则。 把决策树当成一个布尔函数。函数的输入为物体或情况的一切属性(property),输出为”是”或“否”的决策值。在决策树中,每个树枝节点对应着一个有关某项属性的测试,每个树叶节点对应着一个布尔函数值,树中的每个分支,代表测试属性其中一个可能的值。 最为典型的决策树学习系统是ID3,它起源于概念学习系统CLS,最后又演化为能处理连续属性的C4.5(C5.0)等。它是一种指导的学习方法,该方法先根据训练子集形成决策树。如果该树不能对所有给出的训练子集正确分类,那么选择一些其它的训练子集加入到原来的子集中,重复该过程一直到时形成正确的决策集。当经过一批训练实例集的训练产生一棵决策树,决策树可以根据属性的取值对一个未知实例集进行分类。使用决策树对实例进行分类的时候,由树根开始对该对象的属性逐渐测试其值,并且顺着分支向下走,直至到达某个叶结点,此叶结点代表的类即为该对象所处的类。 决策树是应用非常广泛的分类方法,目前有多种决策树方法,如ID3,C4.5,PUBLIC,
决策树分类算法的时间和性能测试(DOC)
决策树分类算法的时间和性能测试 姓名:ls 学号:
目录 一、项目要求 (3) 二、基本思想 (3) 三、样本处理 (4) 四、实验及其分析 (9) 1.总时间 (9) 2.分类准确性. (12) 五、结论及不足 (13) 附录 (14)
一、项目要求 (1)设计并实现决策树分类算法(可参考网上很多版本的决策树算法及代码, 但算法的基本思想应为以上所给内容)。 (2)使用UCI 的基准测试数据集,测试所实现的决策树分类算法。评价指标 包括:总时间、分类准确性等。 (3) 使用UCI Iris Data Set 进行测试。 二、基本思想 决策树是一个类似于流程图的树结构,其中每个内部节点表示在一个属性变量上的测试,每个分支代表一个测试输出,而每个叶子节点代表类或分布,树的最顶层节点是根节点。 当需要预测一个未知样本的分类值时,基于决策树,沿着该树模型向下追溯,在树的每个节点将该样本的变量值和该节点变量的阈值进行比较,然后选取合适的分支,从而完成分类。决策树能够很容易地转换成分类规则,成为业务规则归纳系统的基础。 决策树算法是非常常用的分类算法,是逼近离散目标函数的方法,学习得到的函数以决策树的形式表示。其基本思路是不断选取产生信息增益最大的属性来划分样例集和,构造决策树。信息增益定义为结点与其子结点的信息熵之差。信息熵是香农提出的,用于描述信息不纯度(不稳定性),其计算公式是 Pi为子集合中不同性(而二元分类即正样例和负样例)的样例的比例。这样信息收益可以定义为样本按照某属性划分时造成熵减少的期望,可以区分训练样本中正负样本的能力,其计算公式是
决策树算法的原理与应用
决策树算法的原理与应用 摘要:在机器学习与大数据飞速发展的21世纪,各种不同的算法成为了推动发 展的基石.而作为十大经典算法之一的决策树算法是机器学习中十分重要的一种算法。本文对决策树算法的原理,发展历程以及在现实生活中的基本应用进行介绍,并突出说明了决策树算法所涉及的几种核心技术和几种具有代表性的算法模式。 关键词:机器学习算法决策树 1.决策树算法介绍 1.1算法原理简介 决策树模型是一种用于对数据集进行分类的树形结构。决策树类似于数据结 构中的树型结构,主要是有节点和连接节点的边两种结构组成。节点又分为内部 节点和叶节点。内部节点表示一个特征或属性, 叶节点表示一个类. 决策树(Decision Tree),又称为判定树, 是一种以树结构(包括二叉树和多叉树)形式表达的 预测分析模型,决策树算法被评为十大经典机器学习算法之一[1]。 1.2 发展历程 决策树方法产生于上世纪中旬,到了1975年由J Ross Quinlan提出了ID3算法,作为第一种分类算法模型,在很多数据集上有不错的表现。随着ID3算法的 不断发展,1993年J Ross Quinlan提出C4.5算法,算法对于缺失值补充、树型结 构剪枝等方面作了较大改进,使得算法能够更好的处理分类和回归问题。决策树 算法的发展同时也离不开信息论研究的深入,香农提出的信息熵概念,为ID3算 法的核心,信息增益奠定了基础。1984年,Breiman提出了分类回归树算法,使 用Gini系数代替了信息熵,并且利用数据来对树模型不断进行优化[2]。 2.决策树算法的核心 2.1数据增益 香农在信息论方面的研究,提出了以信息熵来表示事情的不确定性。在数据 均匀分布的情况下,熵越大代表事物的越不确定。在ID3算法中,使用信息熵作 为判断依据,在建树的过程中,选定某个特征对数据集进行分类后,数据集分类 前后信息熵的变化就叫作信息增益,如果使用多个特征对数据集分别进行分类时,信息增益可以衡量特征是否有利于算法对数据集进行分类,从而选择最优的分类 方式建树。 如果一个随机变量X的可以取值为Xi(i=1…n),那么对于变量X来说,它 的熵就是 在得到基尼指数增益之后,选择基尼指数增益最大的特征来作为当前步骤的 分类依据,在之后的分类中重复迭代使用这一方法来实现模型的构造。 3. 决策树算法的优缺点 3.1决策树算法的优点[3] (1)计算速度快,算法简单,分类依据清晰 (2)在处理数据时,有很高的准确度,同时分类结果清晰,步骤明朗。 (3)可以处理连续和种类字段 (4)适合高维数据 3.2决策树算法的缺点 (1)决策树算法可以帮助使用者创建复杂的树,但是在训练的过程中,如
数据挖掘——决策树分类算法 (2)
贝叶斯分类算法 学号:20120311108 学生所在学院:软件工程学院学生姓名:朱建梁 任课教师:汤亮 教师所在学院:软件工程学院 2015年11月
12软件1班 贝叶斯分类算法 朱建梁 12软件1班 摘要:贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。本文作为分类算法的第一篇,将首先介绍分类问题,对分类问题进行一个正 式的定义。然后,介绍贝叶斯分类算法的基础——贝叶斯定理。最后,通过实例讨论 贝叶斯分类中最简单的一种:朴素贝叶斯分类。 关键词:朴素贝叶斯;文本分类 1 贝叶斯分类的基础——贝叶斯定理 每次提到贝叶斯定理,我心中的崇敬之情都油然而生,倒不是因为这个定理多高深,而是因为它特别有用。这个定理解决了现实生活里经常遇到的问题:已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)。这里先解释什么是条件概率: P(A|B)表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。其基本求解公式为:P(A|B)=P(AB)/P(B)。 贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易直接得出P(A|B),P(B|A)则很难直接得出,但我们更关心P(B|A),贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。 下面不加证明地直接给出贝叶斯定理:P(B|A)=P(A|B)P(B)/P(A) 2 朴素贝叶斯分类的原理与流程 朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素,朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。通俗来说,就好比这么个道理,你在街上看到一个黑人,我问你你猜这哥们哪里来的,你十有八九猜非洲。为什么呢?因为黑人中非洲人的比率最高,当然人家也可能是美洲人或亚洲人,但在没有其它可用信息下,我们会选择条件概率最大的类别,这就是朴素贝叶斯的思想基础。 朴素贝叶斯分类的正式定义如下: 1、X={a1,a2,....am}设为一个待分类项,而每个a为x的一个特征属性。 2、有类别集合c={y1,y2,...,yn} 3、计算p(y1|x),p(y2|x),...,p(yn|x)。 4、如果p(yk|x)=max{p(y1|x),p(y2|x),...,p(yn|x)}, 那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做: 1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集。 2、统计得到在各类别下各个特征属性的条件概率估计。即p(a1|y1),p(a2|y1),...,p(am|y1);p(a1|y2),p(a2|y2),...,p(am|y2);p(a1|yn),p(a2 |yn),...,p(am|yn);。
企业CRM系统中决策树算法的应用
企业CRM系统中决策树算法的应用 河北金融学院郭佳许明 保定市科技局《基于数据挖掘的客户关系管理系统应用研究》09ZG009 摘要:客户资源决定企业的核心竞争力,更多的关心自己的销售群体,并与之建立良好的、长期的客户关系,提升客户价值,对全面提升企业竞争能力和盈利能力具有重要作用。本文以某企业销售业绩为对象,利用决策树分类算法,得到支持决策,从而挖掘出理想客户。 关键字:客户关系管理;数据挖掘;分类算法 决策树分类是一种从无规则、无序的训练样本集合中推理出决策树表示形式的分类规则的方法。该方法采用自顶向下的比较方式,在决策树的内部结点进行属性值的比较,然后根据不同的属性值判断从该结点向下的分支,在决策树的叶结点得到结论。 本文主要研究决策树分类算法中ID3算法在企业CRM系统中的应用情况。 1.ID3算法原理 ID3算法是一种自顶向下的决策树生成算法,是一种根据熵减理论选择最优的描述属性的方法。该算法从树的根节点处的训练样本开始,选择一个属性来区分样本。对属性的每一个值产生一个分支。分支属性的样本子集被移到新生成的子节点上。这个算法递归地应用于每个子节点,直到一个节点上的所有样本都分区到某个类中。 2.用于分类的训练数据源组 数据挖掘的成功在很大程度上取决于数据的数量和质量。我们应从大量的企业客户数据中找到与分析问题有关的,具有代表性的样本数据子集。然后,进行数据预处理、分析,按问题要求对数据进行组合或增删生成新的变量,从而对问题状态进行有效描述。 在本文研究的企业数据中,是将客户的年龄概化为“小于等于30”、“30到50之间”和“大于50”三个年龄段,分别代表青年、中年和老年客户,将产品价格分为高、中、低三档等,详见表1,将企业CRM系统数据库中销售及客户信息汇总为4个属性2个类别。4个属性是客户年龄段、文化程度、销售地区、产品档次,类别是销售业绩,分为好和差两类。
决策树算法总结
决策树研发二部
目录 1. 算法介绍 (1) 1.1.分支节点选取 (1) 1.2.构建树 (3) 1.3.剪枝 (10) 2. sk-learn中的使用 (12) 3. sk-learn中源码分析 (13)
1.算法介绍 决策树算法是机器学习中的经典算法之一,既可以作为分类算法,也可以作为回归算法。决策树算法又被发展出很多不同的版本,按照时间上分,目前主要包括,ID3、C4.5和CART版本算法。其中ID3版本的决策树算法是最早出现的,可以用来做分类算法。C4.5是针对ID3的不足出现的优化版本,也用来做分类。CART也是针对ID3优化出现的,既可以做分类,可以做回归。 决策树算法的本质其实很类似我们的if-elseif-else语句,通过条件作为分支依据,最终的数学模型就是一颗树。不过在决策树算法中我们需要重点考虑选取分支条件的理由,以及谁先判断谁后判断,包括最后对过拟合的处理,也就是剪枝。这是我们之前写if语句时不会考虑的问题。 决策树算法主要分为以下3个步骤: 1.分支节点选取 2.构建树 3.剪枝 1.1.分支节点选取 分支节点选取,也就是寻找分支节点的最优解。既然要寻找最优,那么必须要有一个衡量标准,也就是需要量化这个优劣性。常用的衡量指标有熵和基尼系数。 熵:熵用来表示信息的混乱程度,值越大表示越混乱,包含的信息量也就越多。比如,A班有10个男生1个女生,B班有5个男生5个女生,那么B班的熵值就比A班大,也就是B班信息越混乱。 基尼系数:同上,也可以作为信息混乱程度的衡量指标。
有了量化指标后,就可以衡量使用某个分支条件前后,信息混乱程度的收敛效果了。使用分支前的混乱程度,减去分支后的混乱程度,结果越大,表示效果越好。 #计算熵值 def entropy(dataSet): tNum = len(dataSet) print(tNum) #用来保存标签对应的个数的,比如,男:6,女:5 labels = {} for node in dataSet: curL = node[-1] #获取标签 if curL not in labels.keys(): labels[curL] = 0 #如果没有记录过该种标签,就记录并初始化为0 labels[curL] += 1 #将标签记录个数加1 #此时labels中保存了所有标签和对应的个数 res = 0 #计算公式为-p*logp,p为标签出现概率 for node in labels: p = float(labels[node]) / tNum res -= p * log(p, 2) return res #计算基尼系数 def gini(dataSet): tNum = len(dataSet) print(tNum) # 用来保存标签对应的个数的,比如,男:6,女:5 labels = {} for node in dataSet: curL = node[-1] # 获取标签 if curL not in labels.keys(): labels[curL] = 0 # 如果没有记录过该种标签,就记录并初始化为0 labels[curL] += 1 # 将标签记录个数加1 # 此时labels中保存了所有标签和对应的个数 res = 1 # 计算公式为-p*logp,p为标签出现概率
决策树分类-8页文档资料
基于专家知识的决策树分类 概述 基于知识的决策树分类是基于遥感影像数据及其他空间数据,通过专家经验总结、简单的数学统计和归纳方法等,获得分类规则并进行遥感分类。分类规则易于理解,分类过程也符合人的认知过程,最大的特点是利用的多源数据。 如图1所示,影像+DEM就能区分缓坡和陡坡的植被信息,如果添加其他数据,如区域图、道路图土地利用图等,就能进一步划分出那些是自然生长的植被,那些是公园植被。 图1.JPG 图1 专家知识决策树分类器说明图 专家知识决策树分类的步骤大体上可分为四步:知识(规则)定义、规则输入、决策树运行和分类后处理。 1.知识(规则)定义 规则的定义是讲知识用数学语言表达的过程,可以通过一些算法获取,也可以通过经验总结获得。 2.规则输入
将分类规则录入分类器中,不同的平台有着不同规则录入界面。 3.决策树运行 运行分类器或者是算法程序。 4.分类后处理 这步骤与监督/非监督分类的分类后处理类似。 知识(规则)定义 分类规则获取的途径比较灵活,如从经验中获得,坡度小于20度,就认为是缓坡,等等。也可以从样本中利用算法来获取,这里要讲述的就是C4.5算法。 利用C4.5算法获取规则可分为以下几个步骤: (1)多元文件的的构建:遥感数据经过几何校正、辐射校正处理后,进行波段运算,得到一些植被指数,连同影像一起输入空间数据库;其他空间数据经过矢量化、格式转换、地理配准,组成一个或多个多波段文件。 (2)提取样本,构建样本库:在遥感图像处理软件或者GIS软件支持下,选取合适的图层,采用计算机自动选点、人工解译影像选点等方法采集样本。 (3)分类规则挖掘与评价:在样本库的基础上采用适当的数据挖掘方法挖掘分类规则,后基于评价样本集对分类规则进行评价,并对分类规则做出适当的调整和筛选。这里就是C4.5算法。 4.5算法的基本思路基于信息熵来“修枝剪叶”,基本思路如下: 从树的根节点处的所有训练样本D0开始,离散化连续条件属性。计算增益比率,取GainRatio(C0)的最大值作为划分点V0,将样本分为两个部分D11和D12。对属性C0的每一个值产生一个分支,分支属性值的相应样本子集被移到新生成的子节点上,如果得到的样本都属于同一个类,那么直接得到叶子结点。相应地将此方法应用于每个子节点上,直到节点的所有样本都分区到某个类中。到达决策树的叶节点的每条路径表示一条分类规则,利用叶列表及指向父结点的指针就可以生成规则表。
分类论文决策树相关算法论文:决策树相关算法研究
分类论文决策树相关算法论文:决策树相关算法研究 摘要:id3算法和c4.5算法是经典的决策树算法,通过对id3算法和c4.5算法的数据结构、算法描述和分裂属性选取等方面进行比较,为其他研究者提供参考。 关键词:分类;id3;c4.5 an association explore based on decision tree algorithm wang hui, hou chuan-yu (school of information engineering, suzhou university, suzhou 234000, china) abstract: id3 algorithm and c4.5algorithm is classic decision tree algorithm in data mining. the article has some comparisons about c4.5 algorithm and id3 algorithm ,for example, data structure of decision tree, the process of algorithm of c4.5 and id3, and the choice of division attribute and so on, in order to provide this for others. key words: categories; id3; c4.5 随着计算机的普及和网络的高速发展,人们获得信息的途径越来越多,同时获取信息的量呈几何级数的方式增长。如何从海量信息获得有用知识用于决策,成为大家关注的问
决策树分类算法
决策树分类算法 决策树是一种用来表示人们为了做出某个决策而进行的一系列判断过程的树形图。决策树方法的基本思想是:利用训练集数据自动地构造决策树,然后根据这个决策树对任意实例进行判定。 1.决策树的组成 决策树的基本组成部分有:决策节点、分支和叶,树中每个内部节点表示一个属性上的测试,每个叶节点代表一个类。图1就是一棵典型的决策树。 图1 决策树 决策树的每个节点的子节点的个数与决策树所使用的算法有关。例如,CART算法得到的决策树每个节点有两个分支,这种树称为二叉树。允许节点含有多于两个子节点的树称为多叉树。 下面介绍一个具体的构造决策树的过程,该方法
是以信息论原理为基础,利用信息论中信息增益寻找数据库中具有最大信息量的字段,建立决策树的一个节点,然后再根据字段的不同取值建立树的分支,在每个分支中重复建立树的下层节点和分支。 ID3算法的特点就是在对当前例子集中对象进行分类时,利用求最大熵的方法,找出例子集中信息量(熵)最大的对象属性,用该属性实现对节点的划分,从而构成一棵判定树。 首先,假设训练集C 中含有P 类对象的数量为p ,N 类对象的数量为n ,则利用判定树分类训练集中的对象后,任何对象属于类P 的概率为p/(p+n),属于类N 的概率为n/(p+n)。 当用判定树进行分类时,作为消息源“P ”或“N ”有关的判定树,产生这些消息所需的期望信息为: n p n log n p n n p p log n p p )n ,p (I 22++-++- = 如果判定树根的属性A 具有m 个值{A 1, A 2, …, A m },它将训练集C 划分成{C 1, C 2, …, C m },其中A i 包括C 中属性A 的值为A i 的那些对象。设C i 包括p i 个类P 对象和n i 个类N 对象,子树C i 所需的期望信息是I(p i , n i )。以属性A 作为树根所要求的期望信息可以通过加权平均得到
决策树算法总结
决策树决策树研发二部
目录 1. 算法介绍 (1) 1.1. 分支节点选取 (1) 1.2. 构建树 (3) 1.3. 剪枝 (10) 2. sk-learn 中的使用 (12) 3. sk-learn中源码分析 (13)
1. 算法介绍 决策树算法是机器学习中的经典算法之一,既可以作为分类算法,也可以作 为回归算法。决策树算法又被发展出很多不同的版本,按照时间上分,目前主要包括,ID3、C4.5和CART版本算法。其中ID3版本的决策树算法是最早出现的,可以用来做分类算法。C4.5是针对ID3的不足出现的优化版本,也用来做分类。CART也是针对 ID3优化出现的,既可以做分类,可以做回归。 决策树算法的本质其实很类似我们的if-elseif-else语句,通过条件作为分支依据,最终的数学模型就是一颗树。不过在决策树算法中我们需要重点考虑选取分支条件的理由,以及谁先判断谁后判断,包括最后对过拟合的处理,也就是剪枝。这是我们之前写if语句时不会考虑的问题。 决策树算法主要分为以下3个步骤: 1. 分支节点选取 2. 构建树 3. 剪枝 1.1. 分支节点选取 分支节点选取,也就是寻找分支节点的最优解。既然要寻找最优,那么必须要有一个衡量标准,也就是需要量化这个优劣性。常用的衡量指标有熵和基尼系数。 熵:熵用来表示信息的混乱程度,值越大表示越混乱,包含的信息量也就越多。比如,A班有10个男生1个女生,B班有5个男生5个女生,那么B班的熵值就比A班大,也就是B班信息越混乱。 Entropy = -V p ” 基尼系数:同上,也可以作为信息混乱程度的衡量指标。 Gini = 1 - p: l-L