东北大学编译原理实验1

编译原理程序设计实验报告
——实验题目班级:计算机1507班姓名:罗艺博学号:20154377
一、实验目标:
词法分析扫描器的设计实现。在程序源文件中输入类C语言程序源文件,设计词法分析扫描器,并以TOKEN类别码序列的形式输出扫描结果。
二、实验内容:
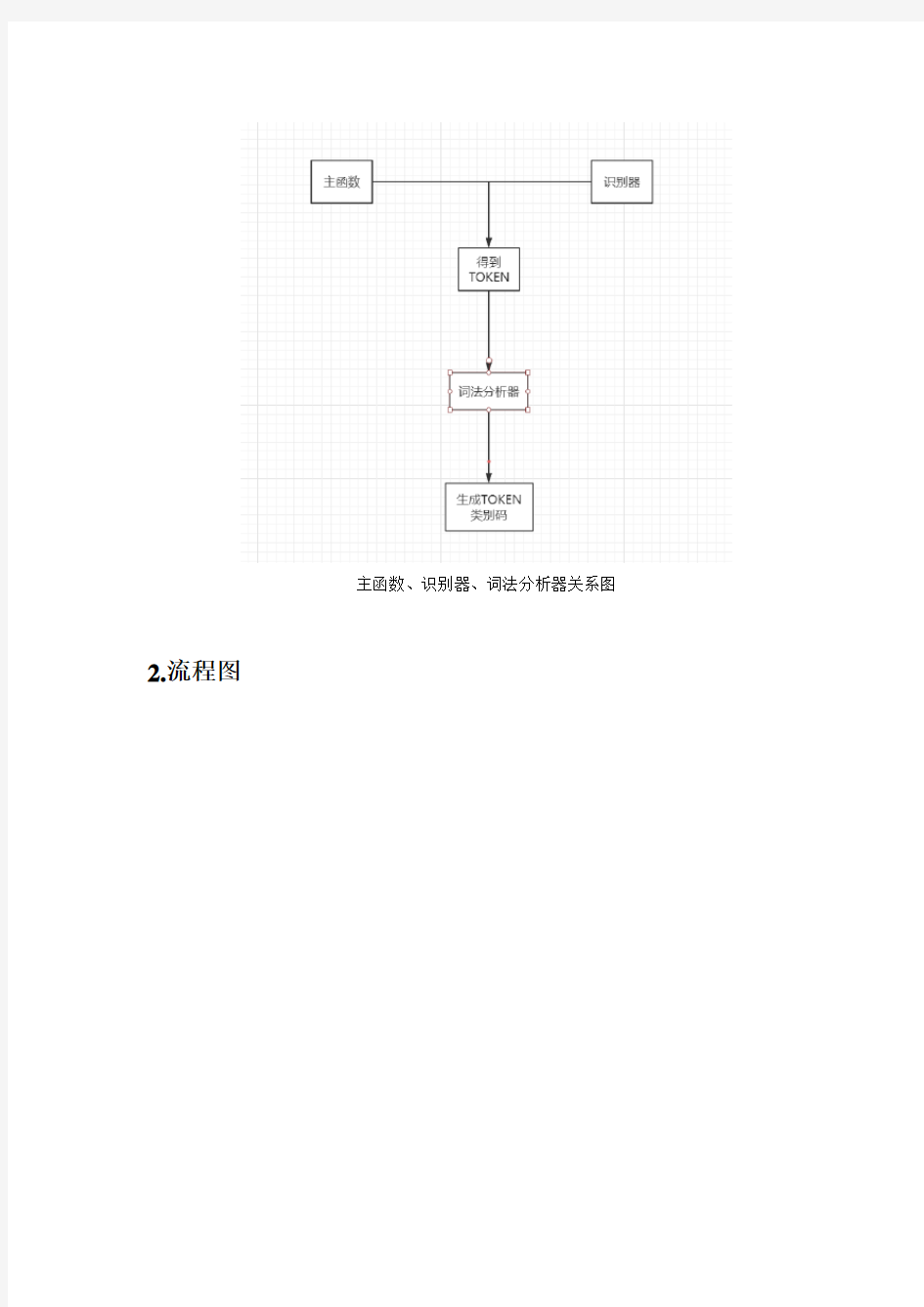
1.概要设计:
将程序大致分为:主函数、识别器(有限自动机state_change)、词法分析器(state_to_code)三大部分。
其中,主函数所完成的功能为:打开、读取、关闭文件(即C语言源程序),重置token串等。
识别器的功能为:识别字符,完成token串的生成,判断词法错误等。
词法分析器的功能为:生成token类别码,判断token 是否出错等。
2.流程图
词法分析扫描器流程图
3.关键函数
a. 识别器(有限自动机state_change)
int state_change(state,ch) //识别器,有限自动机
{
if((ch == ' ') || (ch == '\t') || (ch == '\n'))
//略去空格、TAB、换行
return 0;
else if((IsAlpha(ch) == 1) || (ch == '_')) //判断是否为字母或'_',从而判断是关键字、标识符、CT字符还是ST字符串
{
if(state == 1)
return 2;
else if(state == 2)
return 2;
else if(state == 7)
return 8;
else if(state == 8)
return 8;
else if(state == 10)
return 11;
else if(state == 11)
return 11;
else if(state == 6) //考虑与PT相连的情况
{
state_to_code(state_before,token);
i = 0;
memset(token,0,10);
return 2;
}
else
return -1;
}
else if(IsNum(ch) == 1) //判断是否为数字,从而进一步判断是为IT,CT,KT
{
if(state == 1)
return 3;
else if(state == 2)
return 2;
else if(state == 3)
return 3;
else if(state == 4)
return 4;
else if(state == 5)
return 5;
else if(state == 6) //考虑与PT相连的情况
{
state_to_code(state_before,token);
i = 0;
memset(token,0,10);
return 3;
}
else
return -1;
}
else if(ch == '.') //判断是否为CT中的小数点{
if(state == 3)
return 4;
else
return -1;
}
else if(ch == '\'') //判断是否为CT字符{
if(state == 1)
return 7;
else if(state == 6) //考虑与PT相连的情况{
state_to_code(state_before,token);
i = 0;
memset(token,0,10);
return 7;
}
else if(state == 8)
return 9;
else
return -1;
}
else if(ch == '\"') //判断是否为ST {
if(state == 1)
return 10;
else if(state == 6) //考虑与PT相连的情况{
state_to_code(state_before,token);
i = 0;
memset(token,0,10);
return 10;
}
else if(state == 11)
return 12;
else
return -1;
}
else //判断是否为PT {
if(state == 1)
return 6;
else if(state == 2) //考虑与IT,KT相连的情况{
state_to_code(state_before,token);
i = 0;
memset(token,0,10);
return 6;
}
else if(state == 3) //考虑与CT相连的情况{
state_to_code(state_before,token);
i = 0;
memset(token,0,10);
return 6;
}
else if(state == 9) //考虑与CT字符相连的情况{
state_to_code(state_before,token);
i = 0;
memset(token,0,10);
return 6;
}
else if(state == 12) //考虑与ST相连的情况
{
state_to_code(state_before,token);
i = 0;
memset(token,0,10);
return 6;
}
else if(state == 6)
{
if(((i == 1)&&(ch == '='))&&((token[0] == '>')||(token[0] == '<')||(token[0] == '=')))
{
return 6;
}
else
return 0;
}
else
return -1;
}
}
b. 词法分析器(state_to_code)
int state_to_code(state_before,token) //词法分析器{
int n; //循环
code1 = 0;
code2 = 0;
switch(state_before)
{
case 2:
//KT <1 X>
for(n=0; n<6; n++) {
if(strcmp(token, KT[n]) == 0)
{
code1 = 1;
code2 = n;
printf("<%d %d>\n",code1,code2); //why改变不了全局的code1,code2
break;
}
}
if(code1 == 0) //IT <2 0> {
printf("<2 0>\n");
}
break;
case 3:
//CT <3 0>
printf("<3 0>\n");
break;
case 5: //CT(小数) <3 0> printf("<3 0>\n");
break;
case 6: //PT <6 X> for(n=0; n<18; n++)
{
if(strcmp(token, PT[n]) == 0)
{
code1 = 6;
code2 = n;
printf("<%d %d>\n",code1,code2); //why改变不了全局的code1,code2
break;
}
}
break;
case 9:
//CT字符<4 0>
printf("<4 0>\n");
break;
case 12: //ST <5 0> printf("<5 0>\n");
break;
default : //不被任何词识别printf("Sorry it's going wrong!");
}
return 0;
}
c.判断函数
int IsAlpha(char c) //判断是否为字母{
if(((c>='a')&&(c<='z')) || ((c>='A')&&(c<='Z')))
return 1;
else
return 0;
}
int IsNum(char c) //判断是否为数字{
if(c>='0'&&c<='9')
return 1;
else
return 0;
}
int IsKey(char *word) //判断是否为关键字{
int m,n;
for(n=0; n<6; n++)
{
if((m = strcmp(word, KT[n])) == 0)
{
if(n == 0)
return 2;
return 1;
}
}
return 0;
}
int IsDelimiter(char *token) //判断是否为界符{
int m,n;
for(n=0; n<18; n++)
{
if((m = strcmp(token, PT[n])) == 0)
{
if(n == 0)
return 2;
return 1;
}
}
return 0;
}
源程序代码:(加入注释)
#include
#include
#include
FILE *fp;
char input[200]; //存放输入字符串
char token[10]; //存放构成单词符号的符号串char word[10]; //存放识别出的单词流
char ch;
//存放当前读入字符
int p;
//input下标int i=0; //token下标
int state;
//存放状态标记
int code1; //token类别码,1->KT,2->IT,3->CT,4->CTT,5->ST,6->PT
int code2;
int state_before; //存放之前状态
int num;
//存放整形值
char *KT[6] = {"int", "main", "void", "if", "else", "char"}; //1
char *PT[18] = {">=", "<=", "==", "=", ">", "<", "+", "-", "*", "/", "{", "}", ",", ";", "(", ")", "[", "]"}; //18 //char *IT[20] = {NULL}; //2
//char *CT[20] = {NULL}; //3
//char *CTT[20] = {"\0"}; //4
//char *ST[20] = {NULL}; //5
int state_change(state, ch);
int state_to_code(state_before, token);
int IsAlpha(char c);
int IsNum(char c);
int IsKey(char *word);
int IsDelimiter(char *token);
int main()
{
state = 1; //state=1设为初始态,0设为结束态
if((fp = fopen("E:\\Cwork\\Analysis\\test.txt", "r")) == NULL)
{
printf("Cannot open file.\n");
exit(1);
}
while((ch = fgetc(fp)) != '#')
{
state_before = state;
state = state_change(state,ch);
if(state == -1) {
printf(" Err! Stupid man!\n");
}
else if (state != 0)
{
token[i++] = ch;
}
else
{
if(state_before != 1) {
state_to_code(state_before,token);
}
memset(token,0,10);
i = 0;
state = 1;
}
}
fclose(fp);
return 0;
}
int state_change(state,ch) //识别器,有限自动机
{
if((ch == ' ') || (ch == '\t') || (ch == '\n'))
//略去空格、TAB、换行
return 0;
else if((IsAlpha(ch) == 1) || (ch == '_')) //判断是否为字母或'_',从而判断是关键字、标识符、CT字符还是ST字符串
{
if(state == 1)
return 2;
else if(state == 2)
return 2;
else if(state == 7)
else if(state == 8)
return 8;
else if(state == 10)
return 11;
else if(state == 11)
return 11;
else if(state == 6) //考虑与PT相连的情况{
state_to_code(state_before,token);
i = 0;
memset(token,0,10);
return 2;
}
else
return -1;
}
else if(IsNum(ch) == 1) //判断是否为数字,从而进一步判断是为IT,CT,KT {
if(state == 1)
return 3;
else if(state == 2)
else if(state == 3)
return 3;
else if(state == 4)
return 4;
else if(state == 5)
return 5;
else if(state == 6) //考虑与PT相连的情况{
state_to_code(state_before,token);
i = 0;
memset(token,0,10);
return 3;
}
else
return -1;
}
else if(ch == '.') //判断是否为CT中的小数点{
if(state == 3)
return 4;
else
东南大学编译原理试题
东南大学一九九三年攻读硕士学位研究生入学考试试题 试题编号:553 试题名称:编译原理 一:(15分)判断下列命题的真假,并简述理由: 1.文法G的一个句子对应于多个推导,则G是二义的. 2.LL(1)分析必须对原有文法提取左因子和消除左递归. 3.算符优先分析法采用"移近-归约"技术,其归约过程是规范的. 4.文法S→aA;A→Ab;A→b是LR(0)文法(S为文法的开始符号). 5.一个BASIC解释程序和编译程序的不同在于,解释程序由语法制导翻译成目标代码并立即执行之,而编译程序需产生中间代码及优化. 二:(15分)设计一个最小状态有穷自动机,识别由下列子串组成的任意字符串. GO,GOTO,TOO,ON 例如:GOTOONGOTOOGOON是合法字符串. 三:(15分)构造一个LL(1)文法G,识别语言L: L={ω|ω为{0,1}上不包括两个相邻的1的非空串} 并证明你的结论. 四:(20分)设有一台单累加器计算机,并汇编语言含有通常的汇编指令LOAD,STORE,ADD和MUL. 1.写一个递归下降分析程序,将如下文法所定义的赋值语句翻译成汇编语言: A→i:=E E→E+E|E*E|(E)|i 2.利用加,乘法满足交换率这一性质,改进你的分析程序,以期产生比较高效的目标代码. 五:(15分)C为大家熟知的程序语言. 1.C的参数传递采用传值的方式,而且允许函数定义和调用时的参数个数不一致(如printf).请指出其函数调用语句: f(arg1,arg2,...,argn) 翻译成的中间代码序列,并简述其含义. 2.C语言中的变量具有不同的作用范围,试述C应采用的存储分配策略. 六:(20分)设有一个子程序的四元式序列为: (1) I:=1 (2) if I>20 GOTO (16) (3) T1:=2*J (4) T2:=20*I (5) T3:=T1+T2 (6) T4:=addr(A)-22 (7) T5:=2*I (8) T6:=T5*20 (9) T7:=2*J (10) T8:=T6+T7 (11) T9:=addr(A)-22 (12) T10:=T9[T8] (13) T4[T3]:=T10+J
编译原理实验指导
编译原理实验指导 实验安排: 上机实践按小组完成实验任务。每小组三人,分别完成TEST语言的词法分析、语法分析、语义分析和中间代码生成三个题目,语法分析部分可任意选择一种语法分析方法。先各自调试运行,然后每小组将程序连接在一起调试,构成一个相对完整的编译器。 实验报告: 上机结束后提交实验报告,报告内容: 1.小组成员; 2.个人完成的任务; 3.分析及设计的过程; 4.程序的连接; 5.设计中遇到的问题及解决方案; 6.总结。
实验一词法分析 一、实验目的 通过设计编制调试TEST语言的词法分析程序,加深对词法分析原理的理解。并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。 编制一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本字、标识符、常数、运算符、分隔符五大类。并依次输出各个单词的内部编码及单词符号自身值。 二、实验预习提示 1.词法分析器的功能和输出格式 词法分析器的功能是输入源程序,输出单词符号。词法分析器的单词符号常常表示 成以下的二元式(单词种别码,单词符号的属性值)。 2.TEST语言的词法规则
东南大学电路实验实验报告
电路实验 实验报告 第二次实验 实验名称:弱电实验 院系:信息科学与工程学院专业:信息工程姓名:学号:
实验时间:年月日 实验一:PocketLab的使用、电子元器件特性测试和基尔霍夫定理 一、仿真实验 1.电容伏安特性 实验电路: 图1-1 电容伏安特性实验电路 波形图:
图1-2 电容电压电流波形图 思考题: 请根据测试波形,读取电容上电压,电流摆幅,验证电容的伏安特性表达式。 解:()()mV wt wt U C cos 164cos 164-=+=π, ()mV wt wt U R sin 10002cos 1000=??? ? ? -=π,us T 500=; ()mA wt R U I I R R C sin 213.0== =∴,ππ40002==T w ; 而()mA wt dt du C C sin 206.0= dt du C I C C ≈?且误差较小,即可验证电容的伏安特性表达式。 2.电感伏安特性 实验电路: 图1-3 电感伏安特性实验电路 波形图:
图1-4 电感电压电流波形图 思考题: 1.比较图1-2和1-4,理解电感、电容上电压电流之间的相位关系。对于电感而言,电压相位 超前 (超前or 滞后)电流相位;对于电容而言,电压相位 滞后 (超前or 滞后)电流相位。 2.请根据测试波形,读取电感上电压、电流摆幅,验证电感的伏安特性表达式。 解:()mV wt U L cos 8.2=, ()mV wt wt U R sin 10002cos 1000=??? ? ? -=π,us T 500=; ()mA wt R U I I R R L sin 213.0===∴,ππ 40002==T w ; 而()mV wt dt di L L cos 7.2= dt di L U L L ≈?且误差较小,即可验证电感的伏安特性表达式。 二、硬件实验 1.恒压源特性验证 表1-1 不同电阻负载时电压源输出电压 电阻()Ωk 0.1 1 10 100 1000 电源电压(V ) 4.92 4.98 4.99 4.99 4.99 2.电容的伏安特性测量
软件工程专业介绍范文
软件工程专业介绍范文 软件工程学的定义 软件工程一直以来都缺乏一个统一的定义,很多学者、组织机构都分别给出了自己的定义: Boehm:运用现代科学技术知识来设计并构造计算机程序及为开发、运行和维护这些程序所必需的相关文件资料。IEEE:软件工程是开发、运行、维护和修复软件的系统方法。FritzBauer:建立并使用完善的工程化原则,以较经济的手段获得能在实际机器上有效运行的可靠软件的一系列方法。 编辑本段软件工程学的内容 软件工程学的主要内容是软件开发技术和软件工程管理。软件开发技术包含软件工程方法学、软件工具和软件开发环境;软件工程管理学包含软件工程经济学和软件管理学。 专业简介 是计算机领域发展最快的学科分支之一,国家非常重视软件行业的发展,对软件人才的培养给予了非常优惠的政策。本专业培养掌握计算机软件基本理论知识,熟悉软件开发和管理技术、能够在计算机软件领域中从事软件设计、开发和管理的高级人才。
主修课程 该专业除了学习公共基础课外,还将系统学习离散数学、数据结构、算法分析、面向对象程序设计、现代操作系统、数据库原理与实现技术、编译原理、软件工程、软件项目管理、计算机安全等课程,根据学生的兴趣还可以选修一些其它选修课。 毕业去向 除考取国内外名牌大学研究生外,主要毕业去向是计算机软件专业公司﹑信息咨询公司﹑以及金融等其它独资、合资企业。 培养目标 本专业培养适应社会发展需求,德、智、体、美全面发展,具有扎实的计算机应用理论和知识基础,掌握软件工程领域的前沿技术和软件开发方法,具有较强的实践能力和创新精神,具备较强的软件项目的系统分析、设计、开发和测试能力,能够按照工程化的原则和方法从事软件项目开发和管理的应用型人才。 就业方向
东南大学编译原理词法分析器实验报告
词法分析设计 1. 实验目的 通过本实验的编程实践,了解词法分析的任务,掌握词法分析程序设计的原理和构造方法,对编译的基本概念、原理和方法有完整的和清楚的理解,并能正确地、熟练地运用。 2. 实验内容 用C++语言实现对C++语言子集的源程序进行词法分析。通过输入源程序从左到右对字符串进行扫描和分解,依次输出各个单词的内部编码及单词符号自身值;若遇到错误则显示“Error”,然后跳过错误部分继续显示;同时进行标识符登记符号表的管理。 3. 实验原理 本次实验采用NFA->DFA->DFA0的过程: 对待分析的简单的词法(关键词/id/num/运算符/空白符等)先分别建立自己的FA,然后将他们用产生式连接起来并设置一个唯一的开始符,终结符不合并。 待分析的简单的词法 (1)关键字: "asm","auto","bool","break","case","catch","char","class","
const","const_cast"等 (2)界符(查表) ";",",","(",")","[","]","{","}" (3)运算符 "*","/","%","+","-","<<","=",">>","&","^","|","++","--"," +=","-=","*=","/=","%=","&=","^=","|=" relop: (4)其他单词是标识符(ID)和整型常数(SUM),通过正规式定义。 id/keywords: digit: (5)空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
编译原理实验报告实验一编写词法分析程序
编译原理实验报告实验名称:实验一编写词法分析程序 实验类型:验证型实验 指导教师:何中胜 专业班级:13软件四 姓名:丁越 学号: 电子邮箱: 实验地点:秋白楼B720 实验成绩: 日期:2016年3 月18 日
一、实验目的 通过设计、调试词法分析程序,实现从源程序中分出各种单词的方法;熟悉词法分析 程序所用的工具自动机,进一步理解自动机理论。掌握文法转换成自动机的技术及有穷自动机实现的方法。确定词法分析器的输出形式及标识符与关键字的区分方法。加深对课堂教学的理解;提高词法分析方法的实践能力。通过本实验,应达到以下目标: 1、掌握从源程序文件中读取有效字符的方法和产生源程序的内部表示文件的方法。 2、掌握词法分析的实现方法。 3、上机调试编出的词法分析程序。 二、实验过程 以编写PASCAL子集的词法分析程序为例 1.理论部分 (1)主程序设计考虑 主程序的说明部分为各种表格和变量安排空间。 数组 k为关键字表,每个数组元素存放一个关键字。采用定长的方式,较短的关键字 后面补空格。 P数组存放分界符。为了简单起见,分界符、算术运算符和关系运算符都放在 p表中 (编程时,还应建立算术运算符表和关系运算符表,并且各有类号),合并成一类。 id和ci数组分别存放标识符和常数。 instring数组为输入源程序的单词缓存。 outtoken记录为输出内部表示缓存。 还有一些为造表填表设置的变量。 主程序开始后,先以人工方式输入关键字,造 k表;再输入分界符等造p表。 主程序的工作部分设计成便于调试的循环结构。每个循环处理一个单词;接收键盘上 送来的一个单词;调用词法分析过程;输出每个单词的内部码。 ⑵词法分析过程考虑 将词法分析程序设计成独立一遍扫描源程序的结构。其流程图见图1-1。 图1-1 该过程取名为 lexical,它根据输入单词的第一个字符(有时还需读第二个字符),判断单词类,产生类号:以字符 k表示关键字;i表示标识符;c表示常数;p表示分界符;s表示运算符(编程时类号分别为 1,2,3,4,5)。 对于标识符和常数,需分别与标识符表和常数表中已登记的元素相比较,如表中已有 该元素,则记录其在表中的位置,如未出现过,将标识符按顺序填入数组id中,将常数 变为二进制形式存入数组中 ci中,并记录其在表中的位置。 lexical过程中嵌有两个小过程:一个名为getchar,其功能为从instring中按顺序取出一个字符,并将其指针pint加1;另一个名为error,当出现错误时,调用这个过程, 输出错误编号。 2.实践部分
编译原理实验指导书2010
《编译原理》课程实验指导书 课程编号: 课程名称:编译原理/Compiler Principles 实验总学时数: 8 适用专业:计算机科学与技术、软件工程 承担实验室:计算机学院计算机科学系中心实验室、计算机技术系中心实验室 一、实验教学的目的与要求 上机实习是对学生的一种全面综合训练,是与课堂听讲、自学和练习相辅相成的必不可少的一个教学环节。通常,实习题中的问题比平时的练习题要复杂,也更接近实际。编译原理这门课程安排的2次上机实验都属于一种设计类型的实验,每个实验的训练重点在于基本的编译技术和方法,而不强调面面俱到;实验的目的是旨在使学生进一步巩固课堂上所学的理论知识,深化理解和灵活掌握教学内容;培养学生编制算法的能力和编程解决实际问题的动手能力。 要求学生在上机前应认真做好各种准备工作,熟悉机器的操作系统和语言的集成环境,独立完成算法设计和程序代码的编写;上机时应随带有关的编译原理教材或参考书;要学会程序调试与纠错。 每次实验后要交实验报告,实验报告的内容应包括: (1)实验题目、班级、学号、姓名、完成日期; (2)简要的需求分析与概要设计; (3)详细的算法描述; (4)源程序清单; (5)给出软件的测试方法和测试结果; (6)实验的评价、收获与体会。 开发工具: (1)DOS环境下使用Turbo C; (2)Windows环境下使用Visual C++ 。 考核: 实验成绩占编译原理课程结业成绩的10%。 三、单项实验的内容和要求: 要求每个实验保证每个学生一台微机。 实验一(4学时):单词的词法分析程序设计。 (一)目的与要求 1.目的 通过设计、编制、调试一个具体的词法分析程序,加深对词法分析原理的理解,并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。
东北大学学生必读手册
zt:东北大学学生必读手册(2007-03-08 22:50:37)转载分类:他山石 号外:发现一篇东大宝典《东北大学学生必读手册》!读来正是大块人心,佩服写这个宝典的东大校友了,这比东大官方版的学生必读手册通俗易懂、总结全面,建议以此替换掉官方版的必读手册.......下面是全文摘录,是东大的都来通读一遍啊.... 东北大学学生必读手册 学习篇 1. 注意,馆里面有偷东西的(真为东大丢人),他们喜欢在中午11:30-13:00,晚上4:30-5:30出没(这个时间段大家都去吃饭了,馆里人少),目的在于窃取那些出去吃饭人的书包。所以当自习室人少或者较长时间离开时,书包等个人物品随身带走。 2. 上自习要早点去,不然很容易找不到座位的,一般采矿馆、机电馆、教学馆、逸夫楼的人比较多哦,冶金馆的人少(传说闹鬼)。 3. 不要拿个书、坐垫一类的占座,很烦人的,尤其是占着座还不去的,纯占着茅楼不拉屎,还容易丢失。 4. 尽量去上每一节课,毕竟花那么多学费是用来买这些课程的,而且学点东西没有什么不好,最起码的关系到你期末是不是可以及格的问题。 5. 考试前一个月一定要上自习,不然有挂科的危险。 6. 英语和计算机作为工具还是要好好学习的,争取拿个证什么的,一方面有目标可以学习东西,另一方面为将来工作做准备。 7. 考试前一个星期,你基本上会面临着没有地方上自习的情况,所以,一定要早早的去,一般情况下7点30之前还是能找到空座的。 8. 一定要多去图书馆,会有意外的收获。 9. 不要浪费电子资源,我校图书馆提供的电子文献,还是非常不错的。 10. 考试挂科了可以补,不要因为挂几科就想不开,寻短见,怨天尤人,人生的路还长着呢,努力学习把挂的课补过去才是正确的做法。 11. 图书馆夏天凉快,而且累了还可以上网。 12. 考试前突击2星期大多可以过,除数学,物理,运筹学,编译原理等理论性强的科目。 13. 考试之前一定要搞到以前该科目的试卷,弄懂上面的题目就可以顺利通过考试了,一不小心还可能考个优秀什么的。图书馆一楼的复印室有卖。 吃饭篇 1. 各位如果厌烦了平时的饭菜,我建议到西门的菜市场弄一下新鲜蔬菜(尤其是小葱沾酱)吃,美味啊! 2. 餐饮中心基本上是不刷盘子的,盘子刷的较干净的是一食堂。但是注意有时一食堂的餐盘由于刚刚消毒过,很烫手,当心啊。 3. 西门超市的食堂,油烟很重,会弄一身味道的。尤其是冬天。 4. 去食堂打饭一定要排队,否则遭受鄙视,切记。 5. 饭卡应该设置最大消费额度,比如15元,这样可以避免丢失饭卡时被人家把钱花光。免费办理在二食堂那个管饭卡挂失的地方。实在不行,还可以给饭卡加密码,就是用起来比较麻烦,但是那样就不怕丢失被人乱划了。
《编译原理》实验指导书-2015
武汉科技大学计算机科学与技术学院 编译原理实验指导书
实验一词法分析器设计 【实验目的】 1.熟悉词法分析的基本原理,词法分析的过程以及词法分析中要注意的问题。 2.复习高级语言,进一步加强用高级语言来解决实际问题的能力。 3.通过完成词法分析程序,了解词法分析的过程。 【实验内容】 用C语言编写一个PL/0词法分析器,为语法语义分析提供单词,使之能把输入的字符串形式的源程序分割成一个个单词符号传递给语法语义分析,并把分析结果(基本字,运算符,标识符,常数以及界符)输出。 【实验要求】 1.要求绘出词法分析过程的流程图。 2.根据词法分析的目的以及内容,确定完成分析过程所需模块。 3.写出每个模块的源代码,并给出注释。 4.整理程序清单及所得结果。 【说明】 运行成功以后,检查程序,并将运行结果截图打印粘贴到实验报告上。 辅助库函数scanerLib设计以及使用说明: 下面内容给出了一个辅助库函数的接口说明以及具体实现。 接口设计 //字符类 class Token { TokenType type; String str; Int line; } //词法分析结果输出操作类 class TokenWriter { ArrayList tokens; //用来记录所识别出来的token TokenWriter(); //构造函数指定输入文件名,创建文件输出流 V oid Add(Token); //将词法分析器中分析得到的Token添加到tokens中 WriteXML(); //将tokens写出到目标文件.xml中 } //词法分析操作词法分析生成文件接口<暂时不需要对该类的操作;下一步做语法分析的时候使用> class TokenReader
《编译原理》实验指导书
《编译原理》实验指导书 实验目的和内容 编译原理实验的目的是使学生将编译理论运用到实际当中,实现一个简单语言集的词法、语法和语义分析程序,验证实际编译系统的实现方法,并加深对编译技术的认识。 实验内容共需实现编译器的词法、语法和语义分析程序三个组成部分。要求学生必须完成每个实验的基本题目要求,有余力的同学可尝试实验的扩展要求部分。 实验报告 要求每人针对所完成的实验内容上交一份实验报告,其中主要包括三方面内容:1、实验设计:实验采用的实现方法和依据(如描述语言的文法及其机内表示,词分析 的单词分类码表、状态转换图或状态矩阵等,语法分析中用到的分析表或优先矩阵等,语法制导翻译中文法的拆分和语义动作的设计编写等);具体的设计结果(应包括整体设计思想和实现算法,程序结构的描述,各部分主要功能的说明,法以及所用数据结构的介绍等)。 2、程序代码:实验实现的源程序清单,要求符合一般的程序书写风格,有详细的注释。 3、实验结果分析:自行编写若干源程序作为测试用例,对所生成的编译程序进行测试 (编译程序的输入与输出以文件的形式给出);运行结果分析(至少包括一个正确和一个错误单词或语句的运行结果);以及改进设想等。 注意事项 1、电子版实验报告和源程序在最后一次机时后的一周内上交。(每个同学上交一个压 缩文件,其命名格式为“学号_姓名.rar”,内含实验报告和一个命名为“源程序” 的文件夹。注意提交的源程序应是经过调试、测试成功的较为通用的程序,并应有相应的注释、运行环境和使用方法简介。) 2、不接受不完整的实验报告和没有说明注释的源程序,或者说明与程序、运行结果不 符合的作业。 特别鼓励:扩展题目 1、为亲身经历一个小型编译器的开发全过程,触摸一下与实际编译器开发相关的工作, 大家可以自由组成3人左右的小组,推举组长,模拟一个团队分工协作开发大型软件的实战环境,融入软件工程的思想规范和一般理论方法,初步体验从系统分析设计、编码测试到交付维护的一个完整编译器软件的开发过程。要求组长为每个小组成员分配主要负责的任务,完成相应的分析设计员、程序员和测试员等角色的工作,并以小组为单位提交一份实验报告和源程序,在报告封面上写明每个同学主要完成和负责的部分。 2、以组为单位完成的实验内容至少必须整合词法、语法和语义三个部分的实验,对于 选定的适当规模的文法(如C语言的一个大小适宜的子集),进行系统的总体设计、功能分析、编码测试等工作。完成一个从对源程序的词法分析开始,到中间代码生成的完整的编译器前端的开发,使所涉及到的编译系统的各个组成模块有机地衔接在一起,提交一份完整的实验报告和源程序,并将以下几个方面描述清楚:
东南大学计算方法与实习上机实验一
东南大学计算方法与实习实验报告 学院:电子科学与工程学院 学号:06A12528 姓名:陈毓锋 指导老师:李元庆
实习题1 4、设S N=Σ (1)编制按从大到小的顺序计算S N的程序; (2)编制按从小到大的顺序计算S N的程序; (3)按两种顺序分别计算S1000,S10000,S30000,并指出有效位数。 解析:从大到小时,将S N分解成S N-1=S N-,在计算时根据想要得到的值取合适的最大的值作为首项;同理从小到大时,将S N=S N-1+ ,则取S2=1/3。则所得式子即为该算法的通项公式。 (1)从大到小算法的C++程序如下: /*从大到小的算法*/ #include
编译原理实验指导书
编译原理 实 验 指 导 书 作者:莫礼平 2011年3月
实验一简单词法分析程序设计 一、实验目的 了解词法分析程序的基本构造原理,掌握词法分析程序的手工构造方法。 二、实验内容 1、了解编译程序的词法分析过程。 2、根据PASCAL语言的说明语句形式,用手工方法构造一个对说明语句进行词法分析的程序。该程序能对从键盘输入或从文件读入的形如: “const count=10,sum=81.5,char1=’f’,string1=”hj”, max=169;” 的常量说明串进行处理,分析常量说明串中各常量名、常量类型及常量值,并统计各种类型常量个数。 三、实验要求 1、输入的常量说明串,要求最后以分号作结束标志; 2、根据输入串或读入的文本文件中第一个单词是否为“const”判断输入串或文本文件是否为常量说明内容; 3、识别输入串或打开的文本文件中的常量名。常量名必须是标识符,定义为字母开头,后跟若干个字母,数字或下划线; 4、根据各常量名紧跟等号“=”后面的内容判断常量的类型。其中:字符型常量定 义为放在单引号内的一个字符;字符串常量定义为放在双引号内所有内容;整型常量定 义为带或不带+、- 号,不以0开头的若干数字的组合;实型常量定义为带或不带+、- 号, 不以0开头的若干数字加上小数点再后跟若干数字的组合; 5、统计并输出串或文件中包含的各种类型的常量个数; 6、以二元组(类型,值)的形式输出各常量的类型和值; 7、根据常量说明串置于高级语言源程序中时可能出现的错误情况,模仿高级语言编 译器对不同错误情况做出相应处理。 四、运行结果 1、输入如下正确的常量说明串: const count=10,sum=81.5,char1=‘f’,max=169,str1=“h*54 2..4S!AAsj”, char2=‘@’,str2=“aa!+h”; 输出: count(integer,10) sum(float,81.5) char1(char, ‘f’) max(integer,169) str1(string,“h*54 2..4S!AAsj”) char2(char, ‘@’) str2(string,“aa!+h”) int_num=2; char_num=2; string_num=2; float_num=1. 2、输入类似如下的保留字const错误的常量说明串: Aconstt count=10,sum=81.5,char1=‘f’; 输出类似下面的错误提示信息:
电气工程及其自动化考研总况
电气工程及其自动化考 研总况 IMB standardization office【IMB 5AB- IMBK 08- IMB 2C】
电气工程及其自动化考研总况 一、全国电气工程及其自动化专业学校排名 1.清华大学 2.西安交通大学 3.华中科技大学 4.浙江大学 5.重庆大学 6.天津大学 7.哈尔滨工业大学 8.上海交通大学 9.华北电力大学10.东南大学11.西南交通大学12.沈阳工业大学13.中国矿业大学14.华南理工大学15.南京航空航天大学16.北京交通大学17.武汉大学18.哈尔滨理工大学19.四川大学20.河海大学21.哈尔滨工程大学22.郑州大学23.广西大学24.陕西科技大学 二,电气工程与自动化专业 (1)业务培养目标: 业务培养目标:本专业培养在工业与电气工程有关的运动控制、工业过程控制、电气工程、电力电子技术、检测与自动化仪表、电子与计算机技术等领域从事工程设计、系统分析、系统运行、研制开发、经济管理等方面的高级工程技术人才。 业务培养要求:本专业学生主要学习电工技术、电子技术、自动控制理论、信息处理、计算机技术与应用等较宽广领域的工程技术基础和一定的专业知识。学生受到电工电子、信息控制及计算机技术方面的基本训练,具有工业过程控制与分析,解决强弱电并举的宽口径专业的技术问题的能力。
(2)主干课程: 主干学科:电气工程、控制科学与工程、计算机科学与技术 主要课程:电路原理、电子技术基础、计算机原理及应用、计算机软件基础、控制理论、电机与拖动、电力电子技术、信号分析与处理、电力拖动控制系统、工业过程控制与自动化仪表等。高年级可根据社会需要设置柔性的专业方向模块课及选修课。 主要实践性教学环节:包括电路与电子基础实验、电子工艺实习、金工实习、专业综合实验、计算机上机实践、课程设计、生产实习、毕业设计。 主要实验:运动控制实验、自动控制实验、计算机控制实验、检测仪表实验、电力电子实验等 (3)修业年限: 四年 (4)授予学位: 工学学士 (5)相近专业: 微电子学自动化电子信息工程通信工程计算机科学与技术电子科学与技术生物医学工程电气工程与自动化信息工程信息科学技术软件工程
编译原理实验-词法分析器的设计说明
集美大学计算机工程学院实验报告 课程名称:编译原理班级: 指导教师:: 实验项目编号:实验一学号: 实验项目名称:词法分析器的设计实验成绩: 一、实验目的 通过设计编制调试一个具体的词法分析程序,加深对词法分析原理的理解。并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。 二、实验容 编写一个词法分析器,从输入的源程序(编写的语言为C语言的一个子集)中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。并依次输出各个单词的部编码及单词符号自身值。(遇到错误时可显示“Error”,然后跳过错误部分继续显示) 三、实验要求 1、词法分析器的功能和输出格式 词法分析器的功能是输入源程序,输出单词符号。词法分析器的单词符 2 别单词的类型,将标识符和常量分别插入到相应的符号表中,增加错误处理等。 3、编程语言不限。
四、实验设计方案 1、数据字典 本实验用到的数据字典如下表所示:
3、实验程序 #include
编译原理实验指导书-语法分析
编译原理实验指导书 实验2 语法分析 实验目的 1.巩固对语法分析的基本功能和原理的认识。 2.通过对语法分析表的自动生成加深语法分析表的认识。 3.理解并处理语法分析中的异常和错误。 实验要求 一、对学生要求: 1.掌握语法分析程序的总体框架,并将其实现。 2.掌握语法分析表的构造方法 3.掌握语法分析的异常和错误处理。 二、对实验指导教师要求: 1.明确语法分析的基本功能和原理。 2.语法分析程序的总体结构及其关键之处。 3.语法分析表的生成程序。 4.语法分析的异常和错误处理。 5.编写并运行该题目程序代码,具有该题目的参考答案。 6.深刻理解题目内涵,能够清晰描述问题,掌握该题目涉及的知识点,指导学生实验时需要注意的问题。 实验内容 采用至少一种语法分析技术(LL(1)、SLR(1)、LR(1)或LALR(1))分析类高级语言中的基本语句(至少包括函数定义、变量说明、赋值、循环、分支等语句)。 对如下工作进行展开描述 (1)给出如下语言成分的文法描述 ?函数定义(或过程定义) ?变量说明 ?赋值
?表达式 ?循环 ?分支 (2) 语法分析程序的总体结构及物理实现(程序框图) (3) 核心数据结构和功能函数的设计 (4) 错误处理 错误的位置及类型等 实验评分标准 一、课堂表现(10分) 1.出勤情况(按时,迟到,早退,缺席) 2.是否遵守课堂纪律 二、实验结果(50分) 1.当堂按时完成(10分) 2.独立完成(10分),(和同学协商完成,在老师帮助下完成)3.结果正确无误(15分)其中分析表的输出占5分 4.功能齐全,界面美观,具有较好演示效果(10分) 5.在源程序中有必要的注释和说明,程序文档齐全(5分)三、实验报告(40分) 1.语言的文法描述(10分) 2.语法分析程序的模块结构图(10分) 3.核心数据结构的设计(10分) 4.错误处理(5分) 5.实验过程中遇到的问题的总结及实验的体会(5分)
东北大学编译原理实验3
编译原理程序设计实验报告 ——四元式生成班级:计算机1507班姓名:罗艺博学号:20154377 一、实验目标: 利用上次实验所编写的语法分析器,完成算术表达式四元式翻译器的设计。 二、实验内容: 1.概要设计: 2.流程图
主程序Z 子程序E
子程序T 子程序F 3.关键函数
//主程序 int ParserPlus() { is = 0; //初始化 flag = 0; qt = qToken.front(); //Next(w) qreal = qTreal.front(); SubE(); if(qt==50&&flag==0) { cout << "语法正确!" << endl; cout << endl; cout << "生成的四元式如下:" << endl; } else if(flag != 0) return 1; else { flag = 1; cout << "语法错误(err 1)!" << endl; return flag; }
//cout<<"myQT.size="< 实验八:抽样定理实验(PAM ) 一. 实验目的: 1. 掌握抽样定理的概念 2. 掌握模拟信号抽样与还原的原理和实现方法。 3. 了解模拟信号抽样过程的频谱 二. 实验内容: 1. 采用不同频率的方波对同一模拟信号抽样并还原,观测并比较抽样信号及还原信号的波形和频谱。 2. 采用同一频率但不同占空比的方波对同一模拟信号抽样并还原,观测并比较抽样信号及还原信号的波形和频谱 三. 实验步骤: 1. 将信号源模块、模拟信号数字化模块小心地固定在主机箱中,确保电源接触良好。 2. 插上电源线,打开主机箱右侧的交流开关,在分别按下两个模块中的电源开关,对应的发光二极管灯亮,两个模块均开始工作。 3. 信号源模块调节“2K 调幅”旋转电位器,是“2K 正弦基波”输出幅度为3V 左右。 4. 实验连线 5. 不同频率方波抽样 6. 同频率但不同占空比方波抽样 7. 模拟语音信号抽样与还原 四. 实验现象及结果分析: 1. 固定占空比为50%的、不同频率的方波抽样的输出时域波形和频谱: (1) 抽样方波频率为4KHz 的“PAM 输出点”时域波形: 抽样方波频率为4KHz 时的频谱: 50K …… …… PAM 输出波形 输入波形 分析: 理想抽样时,此处的抽样方波为抽样脉冲,则理想抽样下的抽样信号的频谱应该是无穷多个原信号频谱的叠加,周期为抽样频率;但是由于实际中难以实现理想抽样,即抽样方波存在占空比(其频谱是一个Sa()函数),对抽样频谱存在影响,所以实际中的抽样信号频谱随着频率的增大幅度上整体呈现减小的趋势,如上面实验频谱所示。仔细观察上图可发现,某些高频分量大于低频分量,这是由于采样频率为4KHz ,正好等于奈奎斯特采样频率,频谱会在某些地方产生混叠。 (2) 抽样方波频率为8KHz 时的“PAM 输出点”时域波形: 2KHz 6K 10K 14K 输入波形 PAM 输出波形 S o ut he a s t Uni v e r si ty E xa mi na ti o n P a per (i n-t e r m) Course Name Principles of Compiling Examination Term Score Related Major Computer & Software Examination Form Close test Test Duration120 Mins There are 5 problems in this paper. Y ou can write the answers in English or Chinese on the attached paper sheets. 1.Please construct context-free grammars with ε-free productions for the following languages (20%). (1){i|i∈N(Natural number), and i is a palindrome, and (i mod 5)=0} (2){ω| ω∈(a,b,c,d)* and the numbers of a’s ,b’s and c’s occurred in ω are even, and ωstarts with a or c , ends with d } 2.Please construct a DFA with minimum states for the following regular expression. (20%) (((a|b)*a)*(a|b))*(a|b) 3.Please eliminate the left recursions (if there are)and extract maximum common left factors (if there are) from the following context free grammar, and then decide the resulted grammar is whether a LL(1) grammar by constructing the related LL(1) parsing table.(20%) Please obey the rules of examination. If you violate the rules, your answer sheets will be invalid 共 2 页第 1 页 编译原理实验指导 书 《编译原理》实验指导书 太原科技大学计算机学院 -3-1 序 《编译原理》是国内外各高等院校计算机科学技术类专业,特别是计算机软件专业的一门重要专业课程。该课程系统地向学生介绍编译程序的结构、工作流程及编译程序各组成部分的设计原理和实现技术。由于该课程理论性和实践性都比较强,内容较为抽象复杂,涉及到大量的软件设计和算法,因此,一直是一门比较难学的课程。为了使学生更好地理解和掌握编译原理和技术的基本概念、基本原理和实现方法,实践环节非常重要,只有经过上机进行程序设计,才能使学生对比较抽象的教学内容产生具体的感性认识,增强学生综合分析问题、解决问题的能力,并对提高学生软件设计水平大有益处。 为了配合《编译原理》课程的教学,考虑到本课程的内容和特点,本指导书设置了七个综合性实验,分别侧重于词法分析、NFA的确定化、非递归预测分析、算符优先分析器的构造、LR分析、语义分析和中间代码的生成、基于DAG的基本块优化,以支持编译程序的各个阶段,基本涵盖了《编译原理》课程的主要内容。 本指导书可作为《编译原理》课程的实验或课程设计内容,在课程教学的同时,安排学生进行相关的实验。实验平台可选择在MS-DOS或Windows操作系统环境,使用C/C++的任何版本作为开发工具。学生在做完试验后,应认真撰写实验报告,内容应 包括实验名称、实验目的、实验要求、实验内容、测试或运行结果等。 目录 实验一词法分析 ........................................................... 错误!未定义书签。实验二 NFA的确定化.................................................... 错误!未定义书签。实验三非递归预测分析 ............................................... 错误!未定义书签。实验四算符优先分析器的构造................................... 错误!未定义书签。实验五 LR分析 .............................................................. 错误!未定义书签。实验六语义分析和中间代码生成................................ 错误!未定义书签。实验七基于DAG的基本块优化................................... 错误!未定义书签。 程序员书单 Document serial number【KK89K-LLS98YT-SS8CB-SSUT-SST108】 很多程序员响应,他们在推荐时也写下自己的评语。以前就有国内网友介绍这个程序员书单,不过都是推荐数 Top 10的书。其实除了前10本之外,推荐数前30左右的书籍都算经典,整理编译这个问答贴,同时摘译部分推荐人的评语。下面就按照各本书的推荐数排列。 1.《代码大全》史蒂夫·迈克康奈尔 推荐数:1684 “优秀的编程实践的百科全书,《代码大全》注重个人技术,其中所有东西加起来,就是我们本能所说的“编写整洁的代码”。这本书有50页在谈论代码布局。” —— Joel Spolsky 对于新手来说,这本书中的观念有点高阶了。到你准备阅读此书时,你应该已经知道并实践过书中99%的观念。– esac 2. 《程序员修炼之道》 推荐数:1504 对于那些已经学习过编程机制的程序员来说,这是一本卓越的书。或许他们还是在校生,但对要自己做什么,还感觉不是很安全。就像草图和架构之间的差别。虽然你在学校课堂上学到的是画图,你也可以画的很漂亮,但如果你觉得你不太知道从哪儿下手,如果某人要你独自画一个P2P的音乐交换网络图,那这本书就适合你了。—— Joel 3. 《计算机程序的构造和解释》 推荐数:916 就个人而言,这本书目前为止对我影响醉倒的一本编程书。 《代码大全》、《重构》和《设计模式》这些经典书会教给你高效的工作习惯和交易细节。其他像《人件集》、《计算机编程心理学》和《人月神话》这些书会深入软件开发的心理层面。其他书籍则处理算法。这些书都有自己所属的位置。 然而《计算机程序的构造和解释》与这些不同。这是一本会启发你的书,它会燃起你编写出色程序的热情;它还将教会你认识并欣赏美;它会让你有种敬畏,让你难以抑制地渴望学习更多的东西。其他书或许会让你成为一位更出色的程序员,但此书将一定会让你成为一名程序员。 同时,你将会学到其他东西,函数式编程(第三章)、惰性计算、元编程、虚拟机、解释器和编译器。 一些人认为此书不适合新手。个人认为,虽然我并不完全认同要有一些编程经验才能读此书,但我还是一定推荐给初学者。毕竟这本书是写给着名的,是麻省理工学院的入门编程课程。此书或许需要多做努力(尤其你在做练习的时候,你也应当如此),但这个价是对得起这本书的。 你还不确信么那就读读第一版的前言或序言。网上有免费的电子版。 - Antti Syk?ri 4. 《C程序设计语言》 推荐数:774东南大学系统实验报告
东南大学编译原理试卷
编译原理实验指导书
程序员书单