数据流聚类算法研究

第27卷第2期通化师范学院学报Vol.27No.2 2006年3月JOURNAL OF TON GHUA TEACHERS’COLL EGE Mar.2006
数据流聚类算法研究①
赵法信1,刘俊岭2
(1.通化师范学院网络中心,吉林通化134002;2.沈阳建筑大学计算中心辽宁沈阳110004)
摘 要:数据流是一类新的数据对象,流挖掘是数据库领域的研究热点,有很大的应用前景.本文
首先综述了传统聚类算法的分类及其各自特点,并对它们进行了分析评价.然后结合流聚类分析的要
求,对目前最新的几个数据流聚类研究成果进行了分析,并对数据流聚类进一步的研究方向进行了讨
论.
关键词:数据挖掘;聚类分析;数据流;数据流聚类
中图分类号:TP311.13 文献标识码:A 文章编号:1008-7974(2006)02-0029-04
近年来,越来越多的应用产生数据流,它不同于传统的存储在磁盘上的静态的数据,而是一类新的数据对象,它是连续的、有序的、快速变化的、海量的数据[1].典型的数据流包括网络与道路交通监测系统的监测信息数据、电信部门的通话记录数据、由传感器传回的各种监测数据、股票交易所的股票价格信息数据以及环境温度的监测数据等.数据流分析是数据流研究的一个重要方向,目前的研究主要包括数据流聚类、分类、频繁模式以及数据流OLAP等[3][4][5].数据流本身的特点决定了数据流聚类与传统数据聚类的不同,本文根据数据流本身的特点分析了数据流对聚类的要求以及数据流聚类方面的最新研究成果,并对数据流聚类下一步的研究方向进行了讨论.
1 传统聚类分析
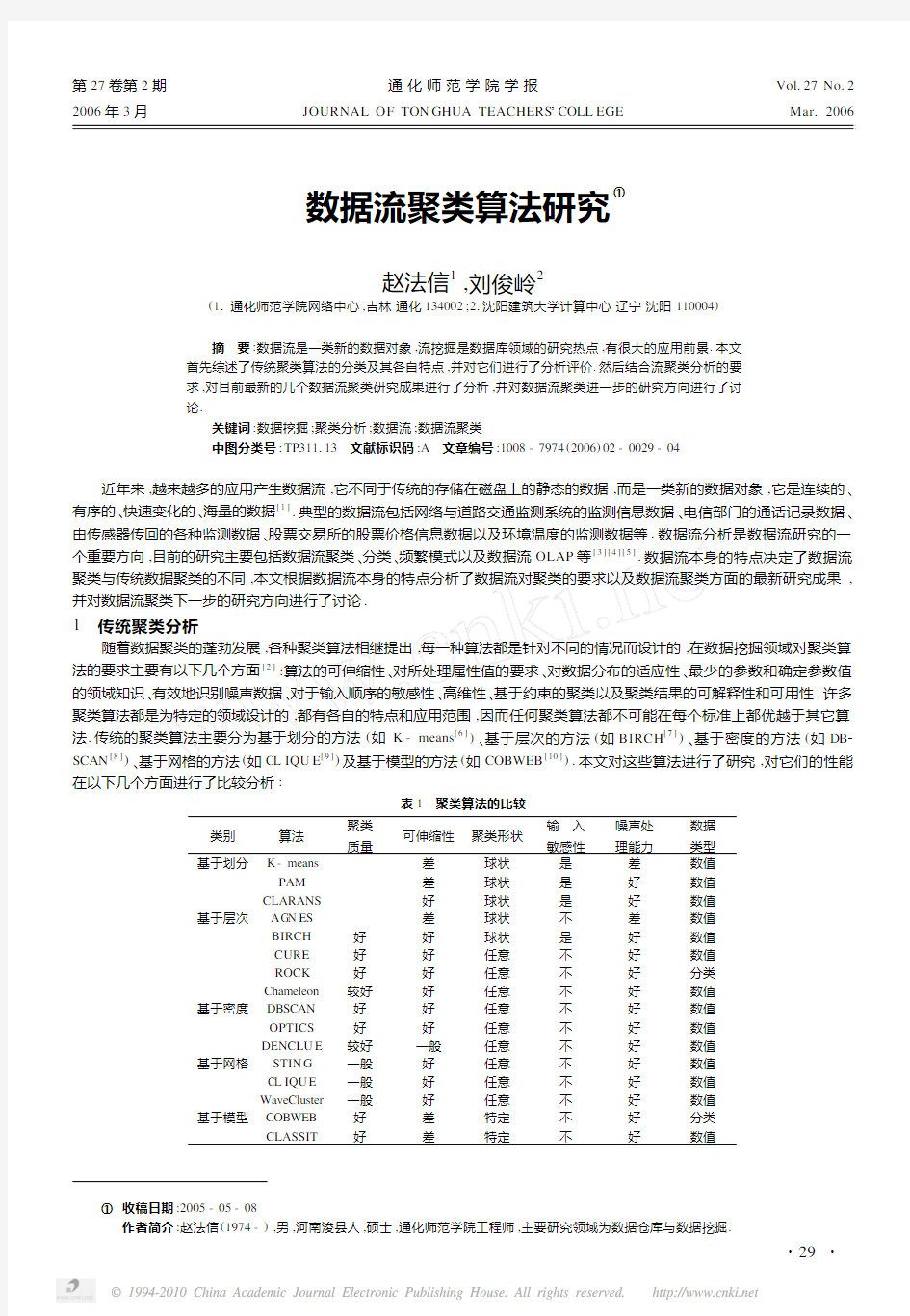
随着数据聚类的蓬勃发展,各种聚类算法相继提出,每一种算法都是针对不同的情况而设计的,在数据挖掘领域对聚类算法的要求主要有以下几个方面[2]:算法的可伸缩性、对所处理属性值的要求、对数据分布的适应性、最少的参数和确定参数值的领域知识、有效地识别噪声数据、对于输入顺序的敏感性、高维性、基于约束的聚类以及聚类结果的可解释性和可用性.许多聚类算法都是为特定的领域设计的,都有各自的特点和应用范围,因而任何聚类算法都不可能在每个标准上都优越于其它算法.传统的聚类算法主要分为基于划分的方法(如K-means[6])、基于层次的方法(如BIRCH[7])、基于密度的方法(如DB2 SCAN[8])、基于网格的方法(如CL IQU E[9])及基于模型的方法(如COBWEB[10]).本文对这些算法进行了研究,对它们的性能在以下几个方面进行了比较分析:
表1 聚类算法的比较
类别算法聚类
质量
可伸缩性聚类形状
输 入
敏感性
噪声处
理能力
数据
类型
基于划分K-means差球状是差数值
PAM差球状是好数值
CLARANS好球状是好数值基于层次A GN ES差球状不差数值
BIRCH好好球状是好数值
CURE好好任意不好数值
ROCK好好任意不好分类
Chameleon较好好任意不好数值基于密度DBSCAN好好任意不好数值
OPTICS好好任意不好数值
DENCLU E较好一般任意不好数值基于网格STIN G一般好任意不好数值
CL IQU E一般好任意不好数值
WaveCluster一般好任意不好数值基于模型COBWEB好差特定不好分类
CLASSIT好差特定不好数值
①收稿日期:2005-05-08
作者简介:赵法信(1974-),男,河南浚县人,硕士,通化师范学院工程师,主要研究领域为数据仓库与数据挖掘.
2 数据流聚类分析算法
数据流是数据点x1,x2,……,x n的一个有序的序列,它只能被按顺序访问,而且仅能被扫描一次或有限的几次[10].数据流是快速变化的,因而,流聚类算法要能够跟上流的速度并抓住流的特征;数据流是连续的,所以对数据流聚类要能随时间而不断地进行;数据流是海量而有序的,不可能保证存贮整个数据集,只能分析一定范围内的数据,因而要有效地利用有限的空间与时间.本文首先介绍了数据流聚类分析的特点,然后介绍了现有的流聚类算法,并对这些算法进行了分析与评价.
2.1 数据流聚类分析特点
数据流本身所具有的特征使得传统的聚类算法不可能(甚至不能)直接应用于数据流聚类.因而,与传统的聚类算法相比,数据流聚类算法还应当具有以下特点[1]:
①一遍扫描:在满足聚类要求的情况下,要尽可能少的扫描数据集,最好是一遍扫描;②有限的内存及存贮空间:由于数据流具有无限连续性,不可能存贮如此海量的数据,因而要对数据流进行概化或有选择的舍弃;③实时性:每一个记录的处理时间要尽可能的少,要能够跟上流的速度.
2.2 数据流聚类算法
目前,学术界对数据流的研究刚刚起步,数据流的聚类算法也处于初始阶段.现有的算法主要有数据流聚类理论与实践[11][12],通过数据流窗口维护方差和中值[13],聚类演变数据流的一个框架[14],用K平均聚类二进制数据流[15].这些都是基于划分的流聚类算法,下面将对这些算法进行介绍.
(1)数据流聚类理论与实践.
分而治之(divide-and-conquer)的策略可以解决流聚类的空间代价问题(小空间聚类),该算法的运行时间是O(n1+ε),使用O(nε)(0<ε<1)的内存并扫描一遍数据集.该聚类算法特点是一次扫描数据,并在限定的空间、时间内聚类.
分而治之算法思想如图1所示:首先将数据集S分为大小相等的n个不相交的片段x1,x2,...x n,然后将每个片段聚为k 个类,最后将各个片段的聚类结果(nk个带权重的中值点)聚成k个带权重的中值点,即k个类.
图1 分而治之思想示意图
分而治之思想在流聚类中的应用的基本算法:
①输入第一批m个点,将其聚为2k个中值点,每个点的权重是赋于它的点的个数;②重复上述过程直到已输入m2/(2k)个原始点,此时可以得到m个中值点;③将这m个第一层中值点聚类成2k个第二层中值点并处理;④通常,维护最多m个i层中值点,点数一达到m,就产生2k个i+1层的中值点;⑤当所有的数据都到达(或需要仅对截止到目前的所有点进行聚类)时,将所有中值点聚类为最后k个中值点.
(2)通过数据流窗口维护方差和k-Medians.利用滑动窗口解决数据流中的数据过时问题,并在滑动窗口中维护方差和k -Medians.该算法是一个在线维护聚类的算法,更能真实反映数据流的特征.
滑动窗口模型:设N为窗口的大小,那么始终只有来自于数据流的最后N个元素才被认为和查询相关.最近的N个元素被称为活动的数据元素,其余的元素被称为废弃元素(expired elements),且不能再用于回答查询或参与数据集统计.一旦一个数据元素已经被处理过就不再将其保存在内存里,在以后的时间里它就不能被重新获取用于进一步的计算.应注意的是,在要求存贮整个活动数据集的算法中不能使用此模型.
图2 数据流滑动窗口示意图
如图2所示,在这个模型中,滑动窗口大小为N,并将窗口N分为m个桶,B m3称之为后缀桶,它包含了在桶B m之后到达的所有元素的信息.后缀桶中的信息是在需要时临时计算的,无需在线维护.该算法通过在线维护不等式f(B i,i-1)>
2f(B i-13)(i>2,f(B i)为基于桶的代价函数)来限制所生成的桶的数量,当相邻的两个桶不满足不等式时将桶合并,这样就保证了在线维护的桶的数量不会超过O(log N/τ)(τ=1/L,L为每个桶中所维护的数据的层数).同时,该算法通过在线维护不等式f(B i)≤2f(B i3)来保证聚类结果的精确度,从而使该算法的代价与最佳K-median的代价之比不会超过2O(1/τ).该算法基于滑动窗口模型的流聚类相关处理过程如下:
流聚类过程中桶的生成及维护方法.①对于数据流中的每一个数据点,将其放到桶B1中,当桶B1中的点数超过K时,创建一新桶B1,并对所有的桶重新编号;②如果桶B m的时间戳超过N,就删除该桶;③对所有桶按从近到老的顺序进行扫描,搜寻满足桶编号i>2且f(B i,i-1)≤2f(B i-13)的所有i值,并从中找出最小的i值,并将桶B i和B i-1合并.
桶中数据的维护方法.桶中共存贮L层数据,每层m个点(m L=N),每层满m个点时,向下一层聚成K个中值点,该思想借鉴了上文中分而治之的策略.
桶合并方法.桶中相应层的数据按自顶向下的顺序进行合并,若该层中的数据点数超过m,就向下一层聚类,聚类结果和下一层中的数据合为一起.
聚类方法.对B m及B m用K-median方法分别聚成K个类.
精确聚类方法.通过减去B m中非活动对象,对B m和B m3一起进行聚类.
(3)聚类演变数据流的一个框架.以上两个算法只是考虑当前的时间窗内的聚类描述,并没有考虑历史信息的因素.这样,当数据流速相当大时,聚类质量较差.为解决这个问题,该框架将聚类过程分为两个组件,一个是在线微聚类组件,用于阶段性存贮详细的摘要统计信息,由于该组件仅处理摘要统计信息,因而能够处理流速较大的数据流;另一个是离线宏聚类组件,利用该组件,分析者可以根据需要输入不同的参数(如时间段或类的个数)来对在线微聚类存贮的摘要统计信息进行聚类,以便能够从不同角度对数据流的聚类结果进行分析,从而提高了聚类结果的可理解性.同时,在线微聚类所存贮的详细的摘要统计信息,也为离线宏聚类高质量的聚类结果提供了保障.
在线微聚类过程中,微聚类按金字塔时间框架所产生的时间序列及时以快照的形式存贮.这个框架一方面考虑了存贮需求,另一方面兼顾了离线宏聚类在不同时间段恢复摘要统计信息的能力.金字塔时间框架定义如下:
①每一层最多存贮αL+1个快照.②第i层快照的时间间隔为αi且该快照所对应的时间要能被αi整除;③第i层仅保留不能被αi+1整除的快照;④在T时间段内最多维护(αL+1)logα(T)个快照.其中,金字塔最大层次数=logα(T),T表示从数据流开始至今所逝去的时间.α为大于等于1的整数,它决定了金字塔时间框架的时间粒度.L为大于1的整数,它的大小决定了金字塔时间框架所产生的快照的精度.
如图3所示,当前时间为T=55,α=2,L=2;则最大层数为5,每层最多5个快照.最终得到的金字塔时间序列为16, 24,32,36,40,44,46,48,50,51,52,53,54,55.
图3 金字塔时间框架存贮的快照序列(α=2,L=2)
在线微聚类过程.
①初始化:将初始的n个点用标准k-means算法聚为q个类,每个类中仅存贮统计信息(q>>k);②对每一个新到达的点,有如下处理:将其放置到原有类中;产生一个新类,同时删除一个旧类或合并两个旧类以维持总类数不变;在进行上一步的同时,若当前时间能被2i整除,则存贮当前时间所对应的微聚类的快照并按时间戳索引,同时删除过时的快照离线宏聚类过程.①用户输入时间范围T及聚类数K;②从磁盘上取出该时间范围所对应的微聚类,用k-means变种算法将其进一步聚为K个类.
(4)用K平均聚类二进制数据流.Carlos Ordonez提出了一种基于K-means的针对二进制数据流的聚类算法Incremental K-means,它根据二进制数据能够表示分类数据,能够被高效地存贮、索引和获取的特点,对传统的K-means进行了改进,并将之运用到二进制数据流聚类上,取得了很好的执行效果.
算法中数据集D的定义为:D={t1,t2,……t n},t i为一个二进制向量,定义为T i={l|D li=1,l∈{1,2,……d},i∈{1,2,……n}}.因此矩阵D是一个d×n的稀疏二进制矩阵.也就是说,T i是t i中非零坐标的集合,这样输入数据集D就成为一整数数据流,其中整数指相应值为1的维数,每个事物之间用事物标志符间隔.
该算法根据以上二进制数据流的特点对传统K-means的改进主要体现在以下几个方面:
①在数值聚类过程中,每个类的摘要需要用三个矩阵表示:用M表示每个类中数据点和的矩阵;用Q表示每个类中数据点平方和的矩阵;用N表示每个类中数据点数的矩阵.而在二进制向量聚类过程中,仅用矩阵N,M即可计算出C(d×k的平
均值矩阵,其中d 为维数,k 为类数)、R (d ×k 的距离的平方矩阵)、W (k ×1簇的权值矩阵),而无需再存贮矩阵Q.
②因为D 为稀疏矩阵,当d 很大时,直接用距离公式计算二进制向量之间距离的开销是非常大的.为提高计算效率,算法首先利用公式△j =δ(0-
,C j )预计算出空事务和所有质心C j 的距离,这样原距离公式δ(t i ,C j )=(t i -C j )t (t i -C j )就可以化简为δ(t i ,C j )=△j +∑
d
i =1,(t i )l ≠0
((t i )l -C lj )2-C 2
lj .此后,实验表明这种方法丝毫不影响计算结果的精确度且能够显著提高
计算效率.
③在聚类结果概要表仅存贮出现频率较高的数据点和孤立点.这样用户就不用去理解表示聚类结果的整个d ×k 浮点数矩阵,而将精力集中于那些更令人感兴趣的矩阵条目.而且此概要表易于维护,其开销可以忽略不记.
上述改进大大提高了聚类的速度,并节省了聚类所需要的空间.另外基于均值的初始化和增量学习等方法的采用,进一步缩短了聚类的时间并提高了聚类的质量,从而使该算法能够更好地应用于流速较高的二进制数据流.
2.3 数据流聚类算法分析
综上几种算法的结果如表2所示,这几种算法对数据的访问次数均为一遍.其中时间复杂度中n 为数据流点的数量,k 为聚类的个数.文献[11][12]只是解决了小空间聚类问题,没有针对废弃元素的解决办法.文献[13]考虑了利用时间窗来解决废弃元素问题,但没有考虑利用历史数据.文献[14]综合小空间聚类、时间窗及历史数据的使用思想,进一步提高了聚类质量.基于二进制数据流的聚类算法具有最好的时间复杂度和空间复杂度,但只适用于能用二进制数据表示的分类数据.
表2 数据流聚类算法比较
文献
采用聚类
算法
核心思想
扫描次数时 间复杂度
空间复杂度
数据流聚类和实践
K -median 分而治之的小空间聚类
一遍 O (nk )O (n ′
)(0<ε<1)通过数据流窗口维护方差和K -Medians K -median 滑动窗口(大小为N ),解决了过时数据的废弃问题一遍 O (k )
O (
k T 4
N 2T log 2
N )聚类演变数据流的一个框架K -means 在线微聚类与离线宏聚类相
结合
金字塔时间框架
一遍用K 平均聚类二进制数据流
K -means
根据二进制数据流的特点对K -means 进行改进
一遍
O (kn )
O (dk )
3 结论
在数据挖掘领域,聚类是一个非常活跃的方向.传统的聚类算法有很多种,每一种都有其各自的特点及应用领域.数据流是一类新的数据对象,很多应用(如网络流量监测、交通工程及传感器网络等)都产生数据流.以前往往将这些数据以静态数据的形式来处理,而实际上这种处理方式不能真实反映数据流的特点且严重影响了数据流处理结果的时效性,因而很有必要研究那些新产生的数据流的分析方法.聚类分析是对传统数据进行分析的一个重要方法,对数据流分析也不例外,目前对数据流分析的研究也是从聚类开始的.本文介绍的这几种方法是最新的流聚类研究成果,它们针对数据流的特征提出了一系列相应的处理技术(如一遍扫描数据集,小空间聚类,滑动窗口模型以及在线与离线相结合等),这些技术为以后进一步的流聚类分析研究奠定了很好的基础.
参考文献:
[1]M.G arofalakis ,J.G ehrke ,and R.Rastogi.Querying and mining data streams :Y ou only get one look[C].SIGMOD 2002[2]Jiawei Han ,Micheline K amber.Data Mining Concepts and Techniques[M ].Morgan K aufmann Publishers.Inc.2001.
[3]Y.Chen ,G.Dong ,J.Han ,J.Pei ,B.W.Wu ,and J.Wang.Online analytical processing stream data :Is it feasible ?[C].DM K D 2002.[4]C.G iannella ,J.Han ,J.Pei ,X.Y an and P.S.Yu.Mining Frequent Patterns in Data Streams at Multiple Time Granularities[C].H.K ar 2gupta ,A.Joshi ,K.Sivakumar ,and Y.Y esha (eds.),Next G eneration Data Mining.2003.
[5]Qiang Ding ,Qin Ding ,William Perrizo.Decision Tree Classification of Spatial Data StreamsUsing Peano Count Trees[C].ACM 2002.[6]HARTIG AN ,J.1975.Clustering Algorithms[M ].John Wiley &Sons ,New Y ork ,N Y.
[7]ZHAN G ,T.,RAMA KRISHNAN ,R.and L IVN Y ,M.1996.BIRCH :an efficient data clustering method for very large databases[C].In Proceedings of the ACM SIGMOD Conference ,103-114,Montreal ,Canada.
[8]ESTER ,M.,KRIEGEL ,H -P.,SANDER ,J.and XU ,X.1996.A density -based algorithm for discovering clusters in large spatial databases with noise[C].In Proceedings of the 2nd ACM SIGK DD ,226-231,Portland ,Oregon.
[9]A GRAWAL ,R.,GEHR KE ,J.,GUNOPULOS ,D.,and RA GHAVAN ,P.1998.Automatic subspace clustering of high dimensional data for data mining applications[C].In Proceedings of the ACM SIGMOD Conference ,94-105,Seattle ,WA.
[10]FISHER ,D.1987.Knowledge acquisition via incremental conceptual clustering[J ].Machine Learning ,2,139-172.[11]S.Guha ,N.Mishra ,R.Motwani ,L.O ’Callaghan.Clustering Data Streams[C].IEEE FOCS Conference ,2000.[12]Sudipto Guha ,Adam Meyerson ,Nina Mishra ,Rajeev Motwani.Clustering Data Streams :Theory and Practice[C].IEEE 2003.
[13]Brian Babcock ,Mayur Datar ,Rajeev Motwani ,LiadanO ’Callaghan.Maintaining Variance and k -Medians over Data Stream Windows[C].PODS 2003,J une
[14]Charu C.Aggarwal ,Jiawei Han ,Jianyoung Wang ,Philip S.Yu.A Framework for Clustering Evolving Data Streams[C].VLDB 2003[15]Carlos Ordonez.Clustering Binary Data Streams with K -means[C].SIGMOD.2003.
MATLAB实现FCM 聚类算法
本文在阐述聚类分析方法的基础上重点研究FCM 聚类算法。FCM 算法是一种基于划分的聚类算法,它的思想是使得被划分到同一簇的对象之间相似度最大,而不同簇之间的相似度最小。最后基于MATLAB实现了对图像信息的聚类。 第 1 章概述 聚类分析是数据挖掘的一项重要功能,而聚类算法是目前研究的核心,聚类分析就是使用聚类算法来发现有意义的聚类,即“物以类聚” 。虽然聚类也可起到分类的作用,但和大多数分类或预测不同。大多数分类方法都是演绎的,即人们事先确定某种事物分类的准则或各类别的标准,分类的过程就是比较分类的要素与各类别标准,然后将各要素划归于各类别中。确定事物的分类准则或各类别的标准或多或少带有主观色彩。 为获得基于划分聚类分析的全局最优结果,则需要穷举所有可能的对象划分,为此大多数应用采用的常用启发方法包括:k-均值算法,算法中的每一个聚类均用相应聚类中对象的均值来表示;k-medoid 算法,算法中的每一个聚类均用相应聚类中离聚类中心最近的对象来表示。这些启发聚类方法在分析中小规模数据集以发现圆形或球状聚类时工作得很好,但当分析处理大规模数据集或复杂数据类型时效果较差,需要对其进行扩展。 而模糊C均值(Fuzzy C-means, FCM)聚类方法,属于基于目标函数的模糊聚类算法的范畴。模糊C均值聚类方法是基于目标函数的模糊聚类算法理论中最为完善、应用最为广泛的一种算法。模糊c均值算法最早从硬聚类目标函数的优化中导出的。为了借助目标函数法求解聚类问题,人们利用均方逼近理论构造了带约束的非线性规划函数,以此来求解聚类问题,从此类内平方误差和WGSS(Within-Groups Sum of Squared Error)成为聚类目标函数的普遍形式。随着模糊划分概念的提出,Dunn [10] 首先将其推广到加权WGSS 函数,后来由Bezdek 扩展到加权WGSS 的无限族,形成了FCM 聚类算法的通用聚类准则。从此这类模糊聚类蓬勃发展起来,目前已经形成庞大的体系。 第 2 章聚类分析方法 2-1 聚类分析 聚类分析就是根据对象的相似性将其分群,聚类是一种无监督学习方法,它不需要先验的分类知识就能发现数据下的隐藏结构。它的目标是要对一个给定的数据集进行划分,这种划分应满足以下两个特性:①类内相似性:属于同一类的数据应尽可能相似。②类间相异性:属于不同类的数据应尽可能相异。图2.1是一个简单聚类分析的例子。
数据挖掘中的聚类分析方法
计算机工程应用技术本栏目责任编辑:贾薇薇 数据挖掘中的聚类分析方法 黄利文 (泉州师范学院理工学院,福建泉州362000) 摘要:聚类分析是多元统计分析的重要方法之一,该方法在许多领域都有广泛的应用。本文首先对聚类的分类做简要的介绍,然后给出了常用的聚类分析方法的基本思想和优缺点,并对常用的聚类方法作比较分析,以便人们根据实际的问题选择合适的聚类方法。 关键词:聚类分析;数据挖掘 中图分类号:TP311文献标识码:A文章编号:1009-3044(2008)12-20564-02 ClusterAnlaysisMethodsofDataMining HUANGLi-wen (SchoolofScience,QuanzhouNormalUniversity,Quanzhou362000,China) Abstract:Clusteranalysisisoneoftheimportantmethodsofmultivariatestatisticalanalysis,andthismethodhasawiderangeofapplica-tionsinmanyfields.Inthispaper,theclassificationoftheclusterisintroducedbriefly,andthengivessomecommonmethodsofclusteranalysisandtheadvantagesanddisadvantagesofthesemethods,andtheseclusteringmethodwerecomparedandanslyzedsothatpeoplecanchosesuitableclusteringmethodsaccordingtotheactualissues. Keywords:ClusterAnalysis;DataMining 1引言 聚类分析是数据挖掘中的重要方法之一,它把一个没有类别标记的样本集按某种准则划分成若干个子类,使相似的样品尽可能归为一类,而不相似的样品尽量划分到不同的类中。目前,该方法已经被广泛地应用于生物、气候学、经济学和遥感等许多领域,其目的在于区别不同事物并认识事物间的相似性。因此,聚类分析的研究具有重要的意义。 本文主要介绍常用的一些聚类方法,并从聚类的可伸缩性、类的形状识别、抗“噪声”能力、处理高维能力和算法效率五个方面对其进行比较分析,以便人们根据实际的问题选择合适的聚类方法。 2聚类的分类 聚类分析给人们提供了丰富多彩的分类方法,这些方法大致可归纳为以下几种[1,2,3,4]:划分方法、层次方法、基于密度的聚类方法、基于网格的聚类方法和基于模型的聚类方法。 2.1划分法(partitiongingmethods) 给定一个含有n个对象(或元组)的数据库,采用一个划分方法构建数据的k个划分,每个划分表示一个聚簇,且k≤n。在聚类的过程中,需预先给定划分的数目k,并初始化k个划分,然后采用迭代的方法进行改进划分,使得在同一类中的对象之间尽可能地相似,而不同类的中的对象之间尽可能地相异。这种聚类方法适用于中小数据集,对大规模的数据集进行聚类时需要作进一步的改进。 2.2层次法(hietarchicalmethods) 层次法对给定数据对象集合按层次进行分解,分解的结果形成一颗以数据子集为节点的聚类树,它表明类与类之间的相互关系。根据层次分解是自低向上还是自顶向下,可分为凝聚聚类法和分解聚类法:凝聚聚类法的主要思想是将每个对象作为一个单独的一个类,然后相继地合并相近的对象和类,直到所有的类合并为一个,或者符合预先给定的终止条件;分裂聚类法的主要思想是将所有的对象置于一个簇中,在迭代的每一步中,一个簇被分裂为更小的簇,直到最终每个对象在单独的一个簇中,或者符合预先给定的终止条件。在层次聚类法中,当数据对象集很大,且划分的类别数较少时,其速度较快,但是,该方法常常有这样的缺点:一个步骤(合并或分裂)完成,它就不能被取消,也就是说,开始错分的对象,以后无法再改变,从而使错分的对象不断增加,影响聚类的精度,此外,其抗“噪声”的能力也较弱,但是若把层次聚类和其他的聚类技术集成,形成多阶段聚类,聚类的效果有很大的提高。2.3基于密度的方法(density-basedmethods) 该方法的主要思想是只要临近区域的密度(对象或数据点的数目)超过某个阈值,就继续聚类。也就是说,对于给定的每个数据点,在一个给定范围的区域中必须至少包含某个数目的点。这样的方法就可以用来滤处"噪声"孤立点数据,发现任意形状的簇。2.4基于网格的方法(grid-basedmethods) 这种方法是把对象空间量化为有限数目的单元,形成一个网格结构。所有的聚类操作都在这个网格结构上进行。用这种方法进行聚类处理速度很快,其处理时间独立于数据对象的数目,只与量化空间中每一维的单元数目有关。 2.5基于模型的方法(model-basedmethod) 基于模型的方法为每个簇假定一个模型,寻找数据对给定模型的最佳拟合。该方法经常基于这样的假设:数据是根据潜在的概 收稿日期:2008-02-17 作者简介:黄利文(1979-),男,助教。
聚类分析算法解析.doc
聚类分析算法解析 一、不相似矩阵计算 1.加载数据 data(iris) str(iris) 分类分析是无指导的分类,所以删除数据中的原分类变量。 iris$Species<-NULL 2. 不相似矩阵计算 不相似矩阵计算,也就是距离矩阵计算,在R中采用dist()函数,或者cluster包中的daisy()函数。dist()函数的基本形式是 dist(x, method = "euclidean", diag = FALSE, upper = FALSE, p = 2) 其中x是数据框(数据集),而方法可以指定为欧式距离"euclidean", 最大距离"maximum", 绝对值距离"manhattan", "canberra", 二进制距离非对称"binary" 和明氏距离"minkowski"。默认是计算欧式距离,所有的属性必须是相同的类型。比如都是连续类型,或者都是二值类型。 dd<-dist(iris) str(dd) 距离矩阵可以使用as.matrix()函数转化了矩阵的形式,方便显示。Iris数据共150例样本间距离矩阵为150行列的方阵。下面显示了1~5号样本间的欧式距离。 dd<-as.matrix(dd)
二、用hclust()进行谱系聚类法(层次聚类) 1.聚类函数 R中自带的聚类函数是hclust(),为谱系聚类法。基本的函数指令是 结果对象 <- hclust(距离对象, method=方法) hclust()可以使用的类间距离计算方法包含离差法"ward",最短距离法"single",最大距离法"complete",平均距离法"average","mcquitty",中位数法 "median" 和重心法"centroid"。下面采用平均距离法聚类。 hc <- hclust(dist(iris), method="ave") 2.聚类函数的结果 聚类结果对象包含很多聚类分析的结果,可以使用数据分量的方法列出相应的计算结果。 str(hc) 下面列出了聚类结果对象hc包含的merge和height结果值的前6个。其行编号表示聚类过程的步骤,X1,X2表示在该步合并的两类,该编号为负代表原始的样本序号,编号为正代表新合成的类;变量height表示合并时两类类间距离。比如第1步,合并的是样本102和143,其样本间距离是0.0,合并后的类则使用该步的步数编号代表,即样本-102和-143合并为1类。再如第6行表示样本11和49合并,该两个样本的类间距离是0.1,合并后的类称为6类。 head (hc$merge,hc$height)
PAM聚类算法的分析与实现
毕业论文(设计)论文(设计)题目:PAM聚类算法的分析与实现 系别: 专业: 学号: 姓名: 指导教师: 时间:
毕业论文(设计)开题报告 系别:计算机与信息科学系专业:网络工程 学号姓名高华荣 论文(设计)题目PAM聚类算法的分析与实现 命题来源□√教师命题□学生自主命题□教师课题 选题意义(不少于300字): 随着计算机技术、网络技术的迅猛发展与广泛应用,人们面临着日益增多的业务数据,这些数据中往往隐含了大量的不易被人们察觉的宝贵信息,为了得到这些信息,人们想尽了一切办法。数据挖掘技术就是在这种状况下应运而生了。而聚类知识发现是数据挖掘中的一项重要的内容。 在日常生活、生产和科研工作中,经常要对被研究的对象经行分类。而聚类分析就是研究和处理给定对象的分类常用的数学方法。聚类就是将数据对象分组成多个簇,同一个簇中的对象之间具有较高的相似性,而不同簇中的对象具有较大的差异性。 在目前的许多聚类算法中,PAM算法的优势在于:PAM算法比较健壮,对“噪声”和孤立点数据不敏感;由它发现的族与测试数据的输入顺序无关;能够处理不同类型的数据点。 研究综述(前人的研究现状及进展情况,不少于600字): PAM(Partitioning Around Medoid,围绕中心点的划分)算法是是划分算法中一种很重要的算法,有时也称为k-中心点算法,是指用中心点来代表一个簇。PAM算法最早由Kaufman和Rousseevw提出,Medoid的意思就是位于中心位置的对象。PAM算法的目的是对n个数据对象给出k个划分。PAM算法的基本思想:PAM算法的目的是对成员集合D中的N个数据对象给出k个划分,形成k个簇,在每个簇中随机选取1个成员设置为中心点,然后在每一步中,对输入数据集中目前还不是中心点的成员根据其与中心点的相异度或者距离进行逐个比较,看是否可能成为中心点。用簇中的非中心点到簇的中心点的所有距离之和来度量聚类效果,其中成员总是被分配到离自身最近的簇中,以此来提高聚类的质量。 由于PAM算法对小数据集非常有效,但对大的数据集合没有良好的可伸缩性,就出现了结合PAM的CLARA(Cluster LARger Application)算法。CLARA是基于k-中心点类型的算法,能处理更大的数据集合。CLARA先抽取数据集合的多个样本,然后用PAM方法在抽取的样本中寻找最佳的k个中心点,返回最好的聚类结果作为输出。后来又出现了CLARNS(Cluster Larger Application based upon RANdomized
数据流聚类算法D-Stream
Density-Based Clustering for Real-Time Stream Data 基于密度的实时数据流聚类(D-Stream) 翻译by muyefei E-mail: muyefei@https://www.360docs.net/doc/c615194733.html, 注释:版权归作者所有,文档仅用于交流学习,可以用大纲视图查看文档结构 摘要:现有的聚类算法比如CluStream是基于k-means算法的。这些算法不能够发现任意形状的簇以及不能处理离群点。而且,它需要预先知道k值和用户指定的时间窗口。为了解决上述问题,本文提出了D-Stream算法,它是基于密度的算法。这个算法用一个在线部分将数据映射到一个网格,在离线部分计算网格的密度然后基于密度形成簇。算法采用了密度衰减技术来捕获数据流的动态变化。为了探索衰减因子、数据密度以及簇结构之间的关系,我们的算法能够有效的并且有效率地实时调整簇。而且,我们用理论证明了移除那些属于离群点的稀疏网格是合理的,从而提高了系统的时间和空间效率。该技术能聚类高速的数据流而不损失聚类质量。实验结果表明我们的算法在聚类质量和效率是有独特的优势,并且能够发现任意形状的簇,以及能准确地识别实时数据流的演化行为。 关键词 流数据挖掘基于密度的聚类D-Stream 分散的网格 1 介绍 实时聚类高维数据流是困难的但很重要。因为它在各个领域应用到。比如... 聚类是一项关键的数据挖掘任务。挖掘数据流有几项关键的挑战: (1)单遍扫描 (2)将数据流视为数据一个很长的向量在很多应用中捉襟见肘,用户更加关注簇的演化行为。 近来,出现了许多数据流聚类方法。比如STREAM、CluStream以及扩展(在多数据流,分布式数据流,并行数据流上的扩展)等。 CluStream以及扩展的算法有以下一些缺陷: 1、只能发现球形簇,不能发现任意形状的簇。 2、不能够识别噪声和离群点。 3、基于k-means的算法需要多次扫描数据(其实CluStream利用两阶段方法和微簇解决了该问题)。 基于密度的聚类算法介绍。基于密度的方法可以发现任意形状的簇,可以处理噪声,对原始数据集只需一次扫描。而且,它不需要像k-means算法那样预先设定k值。 文本提出了D-Stream,一种基于密度的数据流聚类框架。它不是简单用基于密度的算法替代k-means的数据流算法。它有两项主要的技术挑战: 首先,我们不大愿意将数据流视为静态数据很长的一个序列,因为我们对数据流演化的时间特征更加感兴趣。为了捕获簇的动态变化,我们提出了一个新颖的方案,它可以将衰减
1基于网格的数据流聚类算法
3)国家自然科学基金(60172012)。刘青宝 博士生,副教授,主要研究方向为数据仓库技术和数据挖掘;戴超凡 博士,副教授,主要研究方向为数据仓库技术和数据挖掘;邓 苏 博士,教授,主要研究方向指挥自动化、信息综合处理与辅助决策;张维明 博士生导师,教授,主要研究方向为军事信息系统、信息综合处理与辅助决策。 计算机科学2007Vol 134№13 基于网格的数据流聚类算法3) 刘青宝 戴超凡 邓 苏 张维明 (国防科学技术大学信息系统与管理学院 长沙410073) 摘 要 本文提出的基于网格的数据流聚类算法,克服了算法CluStream 对非球形的聚类效果不好等缺陷,不仅能在 噪声干扰下发现任意形状的类,而且有效地解决了聚类算法参数敏感和聚类结果无法区分密度差异等问题。关键词 聚类,数据流,聚类参数,相对密度 G rid 2based Data Stream Clustering Algorithm L IU Qing 2Bao DA I Chao 2Fan DEN G Su ZHAN G Wei 2Ming (College of Information System and Management ,National University of Defense Technology ,Changsha 410073) Abstract With strong ability for discovering arbitrary shape clusters and handling noise ,grid 2based data stream cluste 2ring algorithm efficiently resolves these problem of being very sensitive to the user 2defined parameters and difficult to distinguish the density distinction of clusters.K eyw ords Clustering ,Data stream ,Clustering parameter ,Relative density 随着计算机和传感器技术的发展和应用,数据流挖掘技术在国内外得到广泛研究。它在网络监控、证券交易分析、电信记录分析等方面有着巨大的应用前景。特别在军事应用中,为了获得及时的战场态势信息,大量使用了各种传感器,对这些传感器数据流的分析处理已显得极为重要。针对数据流数据持续到达,且速度快、规模大等特点,数据流挖掘技术的研究重点是设计高效的单遍数据集扫描算法[12]。数据流聚类问题一直是吸引许多研究者关注的热点问题,已提出多种一次性扫描的方法和算法,如文[1~4]等等,但它们的聚类结果通常是球形的,不能支持对任意形状类的聚类[5]。 本文提出的基于网格的数据流聚类算法,在有限内存条件下,以单遍扫描方式,不仅能在噪声干扰下发现任意形状的类,而且有效地解决了基于绝对密度聚类算法所存在的高密度聚类结果被包含在相连的低密度聚类结果中的问题。 本文第1节简要介绍数据流聚类相关研究,并引出基于网格的数据流聚类算法的思路及其与相关研究的异同;第2节给出基于网格的数据流聚类算法所使用到的基本概念;第3节给出一个完整的基于网格的数据流聚类算法,详细解析算法的执行过程;第4节进行算法性能分析对比;最后总结本文的主要工作和贡献,并指出需要进一步研究和改进的工作。 1 相关研究 在有限内存约束下,一般方法很难对数据流进行任意形状的聚类。第一个增量式聚类挖掘方法是文[6]提出的In 2crementalDBSCAN 算法,它是一个用于数据仓库环境(相对稳定的数据流)的有效聚类算法,可以在有噪声的数据集中发现任意形状的类。但是,它为了形成任意形状的类,必须用类中的所有点来表示,要求获得整个数据流的全局信息,这在内存有限情况下是难以做到的。而且,它采用全局一致的绝对 密度作参数,使得聚类结果对参数值非常敏感,设置的细微不同即可能导致差别很大的聚类结果。 Aggarwal 在2003年提出的一个解决数据流聚类问题的框架CluStream [1]。它使用了两个过程来处理数据流聚类问题:首先,使用一个在线的micro 2cluster 过程对数据流进行初级聚类,并按一定的时间跨度将micro 2cluster 的结果按一种称为pyramid time f rame 的结构储存下来。同时,使用另一个离线的macro 2cluster 过程,根据用户的具体要求对micro 2cluster 聚类的结果进行再分析。但它采用距离作为度量参数,聚类结果通常是球形的,不能支持对任意形状类的聚类。而且,它维护的是micro 2cluster 的聚类特征向量(CF 2x ;CF 1x ;CF 2t ;CF 1t ;n ),这在噪声情况下,会产生干扰误差。 2006年,Feng Cao 等人在文[5]中提出了针对动态进化数据流的DenStream 算法。它相对CluStream 有很大的改进,继承了IncrementalDBSCAN 基于密度的优点,能够支持对有噪声的动态进化(非稳定)的数据流进行任意形状的聚类。但由于采用全局一致的绝对密度作参数,使得聚类结果对参数值非常敏感。同时,与CluStream 算法相比,它只能提供对当前数据流的一种描述,不能反映用户指定时间窗内的流数据的变化情况。 朱蔚恒等在文[13]中提出的基于密度与空间的ACluS 2tream 聚类算法,通过引入有严格空间的意义聚类块,在对数据流进行初步聚类的同时,尽量保留数据的空间特性,有效克服了CluStream 算法不能支持对任意形状聚类的缺陷。但它在处理不属于已有聚类块的新数据点时,使用一种类似“抛硬币”的方法来猜测是否为该点创建一个新的聚类块,误差较大。而且它以绝对密度做参考,所以在聚类结果中无法区分密度等级不同的簇[7]。 本文提出的基于网格的数据流聚类算法GClustream
各种聚类算法及改进算法的研究
论文关键词:数据挖掘;聚类算法;聚类分析论文摘要:该文详细阐述了数据挖掘领域的常用聚类算法及改进算法,并比较分析了其优缺点,提出了数据挖掘对聚类的典型要求,指出各自的特点,以便于人们更快、更容易地选择一种聚类算法解决特定问题和对聚类算法作进一步的研究。并给出了相应的算法评价标准、改进建议和聚类分析研究的热点、难点。上述工作将为聚类分析和数据挖掘等研究提供有益的参考。 1 引言随着经济社会和科学技术的高速发展,各行各业积累的数据量急剧增长,如何从海量的数据中提取有用的信息成为当务之急。聚类是将数据划分成群组的过程,即把数据对象分成多个类或簇,在同一个簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大。它对未知数据的划分和分析起着非常有效的作用。通过聚类,能够识别密集和稀疏的区域,发现全局的分布模式,以及数据属性之间的相互关系等。为了找到效率高、通用性强的聚类方法人们从不同角度提出了许多种聚类算法,一般可分为基于层次的,基于划分的,基于密度的,基于网格的和基于模型的五大类。 2 数据挖掘对聚类算法的要求(1)可兼容性:要求聚类算法能够适应并处理属性不同类型的数据。(2)可伸缩性:要求聚类算法对大型数据集和小数据集都适用。(3)对用户专业知识要求最小化。(4)对数据类别簇的包容性:即聚类算法不仅能在用基本几何形式表达的数据上运行得很好,还要在以其他更高维度形式表现的数据上同样也能实现。(5)能有效识别并处理数据库的大量数据中普遍包含的异常值,空缺值或错误的不符合现实的数据。(6)聚类结果既要满足特定约束条件,又要具有良好聚类特性,且不丢失数据的真实信息。(7)可读性和可视性:能利用各种属性如颜色等以直观形式向用户显示数据挖掘的结果。(8)处理噪声数据的能力。(9)算法能否与输入顺序无关。 3 各种聚类算法介绍随着人们对数据挖掘的深入研究和了解,各种聚类算法的改进算法也相继提出,很多新算法在前人提出的算法中做了某些方面的提高和改进,且很多算法是有针对性地为特定的领域而设计。某些算法可能对某类数据在可行性、效率、精度或简单性上具有一定的优越性,但对其它类型的数据或在其他领域应用中则不一定还有优势。所以,我们必须清楚地了解各种算法的优缺点和应用范围,根据实际问题选择合适的算法。 3.1 基于层次的聚类算法基于层次的聚类算法对给定数据对象进行层次上的分解,可分为凝聚算法和分裂算法。 (1)自底向上的凝聚聚类方法。这种策略是以数据对象作为原子类,然后将这些原子类进行聚合。逐步聚合成越来越大的类,直到满足终止条件。凝聚算法的过程为:在初始时,每一个成员都组成一个单独的簇,在以后的迭代过程中,再把那些相互邻近的簇合并成一个簇,直到所有的成员组成一个簇为止。其时间和空间复杂性均为O(n2)。通过凝聚式的方法将两簇合并后,无法再将其分离到之前的状态。在凝聚聚类时,选择合适的类的个数和画出原始数据的图像很重要。 [!--empirenews.page--] (2)自顶向下分裂聚类方法。与凝聚法相反,该法先将所有对象置于一个簇中,然后逐渐细分为越来越小的簇,直到每个对象自成一簇,或者达到了某个终结条件。其主要思想是将那些成员之间不是非常紧密的簇进行分裂。跟凝聚式方法的方向相反,从一个簇出发,一步一步细化。它的优点在于研究者可以把注意力集中在数据的结构上面。一般情况下不使用分裂型方法,因为在较高的层很难进行正确的拆分。 3.2 基于密度的聚类算法很多算法都使用距离来描述数据之间的相似性,但对于非凸数据集,只用距离来描述是不够的。此时可用密度来取代距离描述相似性,即基于密度的聚类算法。它不是基于各种各样的距离,所以能克服基于距离的算法只能发现“类圆形”的聚类的缺点。其指导思想是:只要一个区域中的点的密度(对象或数据点的数目)大过某个阈值,就把它加到与之相近的聚类中去。该法从数据对象的分布密度出发,把密度足够大的区域连接起来,从而可发现任意形状的簇,并可用来过滤“噪声”数据。常见算法有DBSCAN,DENCLUE 等。[1][2][3]下一页 3.3 基于划分的聚类算法给定一个N个对象的元组或数据库,根据给定要创建的划分的数目k,将数据划分为k个组,每个组表示一个簇类(<=N)时满足如下两点:(1)每个组至少包含一个对象;(2)每个对
数据挖掘考试题精编版
数据挖掘考试题 公司内部编号:(GOOD-TMMT-MMUT-UUPTY-UUYY-DTTI-
数据挖掘考试题 一.选择题 1. 当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数据相分离( ) A.分类 B.聚类 C.关联分析 D.主成分分析 2. ( )将两个簇的邻近度定义为不同簇的所有点对邻近度的平均值,它是一种凝聚层次聚类技术。 A.MIN(单链) B.MAX(全链) C.组平均 D.Ward方法 3.数据挖掘的经典案例“啤酒与尿布试验”最主要是应用了( )数据挖掘方法。 A 分类 B 预测 C关联规则分析 D聚类 4.关于K均值和DBSCAN的比较,以下说法不正确的是( ) A.K均值丢弃被它识别为噪声的对象,而DBSCAN一般聚类所有对象。 B.K均值使用簇的基于原型的概念,DBSCAN使用基于密度的概念。 C.K均值很难处理非球形的簇和不同大小的簇,DBSCAN可以处理不同大小和不同形状的簇 D.K均值可以发现不是明显分离的簇,即便簇有重叠也可以发现,但是DBSCAN 会合并有重叠的簇 5.下列关于Ward’s Method说法错误的是:( ) A.对噪声点和离群点敏感度比较小 B.擅长处理球状的簇
C.对于Ward方法,两个簇的邻近度定义为两个簇合并时导致的平方误差 D.当两个点之间的邻近度取它们之间距离的平方时,Ward方法与组平均非常相似 6.下列关于层次聚类存在的问题说法正确的是:( ) A.具有全局优化目标函数 B.Group Average擅长处理球状的簇 C.可以处理不同大小簇的能力 D.Max对噪声点和离群点很敏感 7.下列关于凝聚层次聚类的说法中,说法错误的事:( ) A.一旦两个簇合并,该操作就不能撤销 B.算法的终止条件是仅剩下一个簇 C.空间复杂度为()2m O D.具有全局优化目标函数 8.规则{牛奶,尿布}→{啤酒}的支持度和置信度分别为:( ) 9.下列( )是属于分裂层次聚类的方法。 A.Min B.Max C.Group Average D.MST 10.对下图数据进行凝聚聚类操作,簇间相似度使用MAX计算,第二步是哪两个簇合并:( ) A.在{3}和{l,2}合并 B.{3}和{4,5}合并 C.{2,3}和{4,5}合并
机器学习聚类算法实现
《人工智能与机器学习》 实验报告 年级__ xxxx班____________ 专业___________xxxxx____ _____ 学号____________6315070301XX___________ 姓名_____________gllh________________ 日期___________2018-5-12 __
实验五聚类算法实现 一、实验目的 1、了解常用聚类算法及其优缺点 2、掌握k-means聚类算法对数据进行聚类分析的基本原理和划分方法 3、利用k-means聚类算法对已知数据集进行聚类分析 实验类型:验证性 计划课间:4学时 二、实验内容 1、利用python的sklearn库函数对给定的数据集进行聚类分析 2、分析k-means算法的实现流程 3、根据算法描述编程实现,调试运行 4、对所给数据集进行验证,得到分析结果 三、实验步骤 1、k-means算法原理 2、k-means算法流程 3、k-means算法实现 4、对已知数据集进行分析 四、实验结果分析 1.利用python的sklearn库函数对给定的数据集进行聚类分析: 其中数据集选取iris鸢尾花数据集 import numpy as np from sklearn.datasets import load_iris iris = load_iris() def dist(x,y):
return sum(x*y)/(sum(x**2)*sum(y**2))**0.5 def K_means(data=iris.data,k=3,ping=0,maxiter=100): n, m = data.shape centers = data[:k,:] while ping < maxiter: dis = np.zeros([n,k+1]) for i in range(n): for j in range(k): dis[i,j] = dist(data[i,:],centers[j,:]) dis[i,k] = dis[i,:k].argmax() centers_new = np.zeros([k,m]) for i in range(k): index = dis[:,k]==i centers_new[i,:] = np.mean(data[index,:],axis=0) if np.all(centers==centers_new): break centers = centers_new ping += 1 return dis if __name__ == '__main__': res = K_means() print(res) (1)、首先求出样本之间的余弦相似度: sum(x*y)/(sum(x**2)*sum(y**2))**0.5 (2)、设置k类别数为3,最大迭代次数为100 K_means(data=iris.data,k=3,ping=0,maxiter=100):
基于k—means聚类算法的试卷成绩分析研究
基于k—means聚类算法的试卷成绩分析研 究 第39卷第4期 2009年7月 河南大学(自然科学版) JournalofHenanUniversity(NaturalScience) V o1.39NO.4 Ju1.2009 基于k—means聚类算法的试卷成绩分析研究 谭庆' (洛阳师范学院信息技术学院,河南洛阳471022) 摘要:研究_rk-means聚类算法,并将此算法应用于高校学生试卷成绩分析中.首先对数据进行了预处理,然后 使用k-means算法,对学生试卷成绩进行分类评价.用所获得的结果指导学生的学习和今后的教学工作. 关键词:数据挖掘;聚类;k-means算法;试卷成绩 中圈分类号:TP311文献标志码:A文章编号:1003—4978(2009)04—0412—04 AnalysisandResearchofGradesofExaminationPaper BasedonK—meansClusteringAlgorithm TANQing (Acaderny.l,InformationTechnologY,LuoyangNormalUniversity,LuoyangHenan47102 2,China) Abstract:Thispaperresearcheslhekmeansclusteringalgorithmandappliesittotheanalysiso fthegradedataof examinationpaperofhighereducationschoolSstudents.Firstly,itpreprocessesthedatabefor eminingThen,it usesthek—
K 均值聚类算法(原理加程序代码)
K-均值聚类算法 1.初始化:选择c 个代表点,...,,321c p p p p 2.建立c 个空间聚类表:C K K K ...,21 3.按照最小距离法则逐个对样本X 进行分类: ),(),,(min arg J i i K x add p x j ?= 4.计算J 及用各聚类列表计算聚类均值,并用来作为各聚类新的代表点(更新代表点) 5.若J 不变或代表点未发生变化,则停止。否则转2. 6.),(1∑∑=∈=c i K x i i p x J δ 具体代码如下: clear all clc x=[0 1 0 1 2 1 2 3 6 7 8 6 7 8 9 7 8 9 8 9;0 0 1 1 1 2 2 2 6 6 6 7 7 7 7 8 8 8 9 9]; figure(1) plot(x(1,:),x(2,:),'r*') %%第一步选取聚类中心,即令K=2 Z1=[x(1,1);x(2,1)]; Z2=[x(1,2);x(2,2)]; R1=[]; R2=[]; t=1; K=1;%记录迭代的次数 dif1=inf; dif2=inf; %%第二步计算各点与聚类中心的距离 while (dif1>eps&dif2>eps) for i=1:20 dist1=sqrt((x(1,i)-Z1(1)).^2+(x(2,i)-Z1(2)).^2); dist2=sqrt((x(1,i)-Z2(1)).^2+(x(2,i)-Z2(2)).^2); temp=[x(1,i),x(2,i)]'; if dist1 第24卷第5期 2007年5月 计算机应用研究 Application Resea心h of Computers V01.24.No.5 Mav 2007 基于聚类分析的K—means算法研究及应用爿: 张建萍1,刘希玉2 (1.山东师范大学信息科学与工程学院,山东济南250014;2.山东师范大学管理学院,山东济南250014 摘要:通过对聚类分析及其算法的论述,从多个方面对这些算法性能进行比较,同时以儿童生长发育时期的数据为例通过聚类分析的软件和改进的K.means算法来进一步阐述聚类分析在数据挖掘中的实践应用。 关键词:数据挖掘;聚类分析;数据库;聚类算法 中图分类号:TP311文献标志码:A 文章编号:1001—3695(200705—0166-03 Application in Cluster’s Analysis Is Analyzed in Children DeVelopment Period ZHANG Jian—pin91,UU Xi—yu。 (1.coz比伊矿,咖mo砌n 5c掂Me&E蟛袱^增,|s胁础增Ⅳo丌mf‰洫瑙毋,五n 帆5^a蒯D昭250014,吼i胁;2.cozz学矿讹加舻删眦, s^0n幽凡g舳丌Mf‰i孵璐匆,^加n乩。砌。昭250014,傩iM Abstract: nis paper passed cluster’s analysis and its algorithm corTectly,compared these algorithm perfbrnlances f}om a lot of respects,and explained that cluster analysis excavates the practice application of in datum further to come through software and impmved K—means aIgorithm,cIuster of analysis at the same time practise appIication. Key words:data mining; cluster analysis; database; cluster algorithm 随着计算机硬件和软件技术的飞速发展,尤其是数据库技 术的普及,人们面临着日益扩张的数据海洋,原来的数据分析工具已无法有效地为决策者提供决策支持所需要的相关知识, 从而形成一种独特的现象“丰富的数据,贫乏的知识”。数据挖掘…又称为数据库中知识发现(Knowledge Discovery from Database,KDD,它是一个从大量数据中抽取挖掘出未知的、有价值的模式或规律等知识的复杂过程。目的是在大量的数据中发现人们感兴趣的知识。 常用的数据挖掘技术包括关联分析、异类分析、分类与预测、聚类分析以及演化分析等。由于数据库中收集了大量的数据,聚类分析已经成为数据挖掘领域的重要技术之一。 1问题的提出 随着社会的发展和人们生活水平的提高,优育观念嵋一。逐渐渗透到每个家庭,小儿的生长发育越来越引起家长们的重视。中国每隔几年都要进行全国儿童营养调查,然而用手工计算的方法在大量的数据中分析出其中的特点和规律,显然是不现实的,也是不可行的。为了有效地解决这个问题,数据挖掘技术——聚类分析发挥了巨大的作用。 在数据挖掘领域,聚类算法经常遇到一些问题如聚类初始点的选择H J、模糊因子的确定‘5o等,大部分均已得到解决。现在的研究工作主要集中在为大型的数据库有效聚类分析寻找适当的方法、聚类算法对复杂分布数据和类别性数据聚类的有效性以及高维数据聚类技术等方面。本文通过对聚类分析算法的分析并重点 朴素贝叶斯: 有以下几个地方需要注意: 1. 如果给出的特征向量长度可能不同,这是需要归一化为通长度的向量(这里以文本分类为例),比如说是句子单词的话,则长度为整个词汇量的长度,对应位置是该单词出现的次数。 2. 计算公式如下: 其中一项条件概率可以通过朴素贝叶斯条件独立展开。要注意一点就是的计算方法,而由朴素贝叶斯的前提假设可知, = ,因此一般有两种,一种是在类别为ci的那些样本集中,找到wj出现次数的总和,然后除以该样本的总和;第二种方法是类别为ci的那些样本集中,找到wj出现次数的总和,然后除以该样本中所有特征出现次数的总和。 3. 如果中的某一项为0,则其联合概率的乘积也可能为0,即2中公式的分子为0,为了避免这种现象出现,一般情况下会将这一项初始化为1,当然为了保证概率相等,分母应对应初始化为2(这里因为是2类,所以加2,如果是k类就需要加k,术语上叫做laplace 光滑, 分母加k的原因是使之满足全概率公式)。 朴素贝叶斯的优点: 对小规模的数据表现很好,适合多分类任务,适合增量式训练。 缺点: 对输入数据的表达形式很敏感。 决策树: 决策树中很重要的一点就是选择一个属性进行分枝,因此要注意一下信息增益的计算公式,并深入理解它。 信息熵的计算公式如下: 其中的n代表有n个分类类别(比如假设是2类问题,那么n=2)。分别计算这2类样本在总样本中出现的概率p1和p2,这样就可以计算出未选中属性分枝前的信息熵。 现在选中一个属性xi用来进行分枝,此时分枝规则是:如果xi=vx的话,将样本分到树的一个分支;如果不相等则进入另一个分支。很显然,分支中的样本很有可能包括2个类别,分别计算这2个分支的熵H1和H2,计算出分枝后的总信息熵H’=p1*H1+p2*H2.,则此时的信息增益ΔH=H-H’。以信息增益为原则,把所有的属性都测试一边,选择一个使增益最大的属性作为本次分枝属性。 决策树的优点: 计算量简单,可解释性强,比较适合处理有缺失属性值的样本,能够处理不相关的特征; 缺点: 容易过拟合(后续出现了随机森林,减小了过拟合现象); Logistic回归: Logistic是用来分类的,是一种线性分类器,需要注意的地方有: 1. logistic函数表达式为: 其导数形式为: 2. logsitc回归方法主要是用最大似然估计来学习的,所以单个样本的后验概率为: 到整个样本的后验概率: 内容摘要本文在分析和实现经典k-means算法的基础上,针对初始类中心选择问题,结合已有的工作,基于对象距离和密度对算法进行了改进。在算法实现部分使用vc6.0作为开发环境、sql sever2005作为后台数据库对算法进行了验证,实验表明,改进后的算法可以提高算法稳定性,并减少迭代次数。 关键字 k-means;随机聚类;优化聚类;记录的密度 1 引言 1.1聚类相关知识介绍 聚类分析是直接比较各事物之间性质,将性质相近的归为一类,将性质不同的归为一类,在医学实践中也经常需要做一些分类工作。如根据病人一系列症状、体征和生化检查的结果,将其划分成某几种方法适合用于甲类病的检查,另几种方法适合用于乙类病的检查,等等。聚类分析被广泛研究了许多年。基于聚类分析的工具已经被加入到许多统计分析软件或系统中,入s-plus,spss,以及sas。 大体上,聚类算法可以划分为如下几类: 1) 划分方法。 2) 层次方法。 3) 基于密度的算法。 4) 基于网格的方法。 5) 基于模型的方法。 1.2 研究聚类算法的意义 在很多情况下,研究的目标之间很难找到直接的联系,很难用理论的途径去解决。在各目标之间找不到明显的关联,所能得到的只是些模糊的认识,由长期的经验所形成的感知和由测量所积累的数据。因此,若能用计算机技术对以往的经验、观察、数据进行总结,寻找个目标间的各种联系或目标的优化区域、优化方向,则是对实际问题的解决具有指导意义和应用价值的。在无监督情况下,我们可以尝试多种方式描述问题,其中之一是将问题陈述为对数分组或聚类的处理。尽管得到的聚类算法没有明显的理论性,但它确实是模式识别研究中非常有用的一类技术。聚类是一个将数据集划分为若干聚类的过程,是同一聚类具有较高相似性,不同聚类不具相似性,相似或不相似根据数据的属性值来度量,通常使用基于距离的方法。通过聚类,可以发现数据密集和稀疏的区域,从而发现数据整体的分布模式,以及数据属性间有意义的关联。 2 k-means算法简介 2.1 k-means算法描述 k-means 算法接受输入量k,然后将n个数据对象划分为k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高,而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”来进行计算的。k-means 算法的工作过程说明如下:首先从n个数据对象任意选择 k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用均方差作为标准测度函数。 k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。 2.2 k-means算法实现步骤 在原始的k-means算法中,由于数据对象的分类被不断地调整,因此平均误差准则函数在每次迭代过程中的值必定在不断减小。当没有数据对象被调整时,e(e指每个对象到该类中心的距离平方之和)的值不再变化,说明算法运行结果已经达到最优,同时算法运行结束。基于聚类分析的Kmeans算法研究及应用概要
数据挖掘主要算法
K-MEANS聚类算法的实现及应用