山东大学生物信息学期末作业

山东大学生命科学学院2011~2012学年第一学期期末考试试卷(研究实践性)
考试科目: 《生物信息学》
适用类别: 本科
院系:生命科学学院
专业:生物技术
年级:09级
姓名:余振洋
学号:200900140156
第 1 页共28 页
第 2 页 共 28 页
考试说明和要求
1.试卷的格式包括七部分:目录、引言、实践资源(使用的软件和数据库)、
实践方法、实践结果和讨论、参考文献、心得与致谢。(要求使用此论文模板创建规范统一的答卷,详见模板使用说明,请从此模板的第3页开始答卷;参考文献要求使用专业软件中《微生物学报》样式统一进行参考文献格式化;请于16周课程结束后,一周内提交电子版和纸质版答卷;团队讨论或受他人帮助的请在致谢中说明体现)
2.考试内容:请从以下三题中任选一题进行期末考试实践(实践部分请提供说
明问题的截图),鼓励同学们拓展思考与发挥。
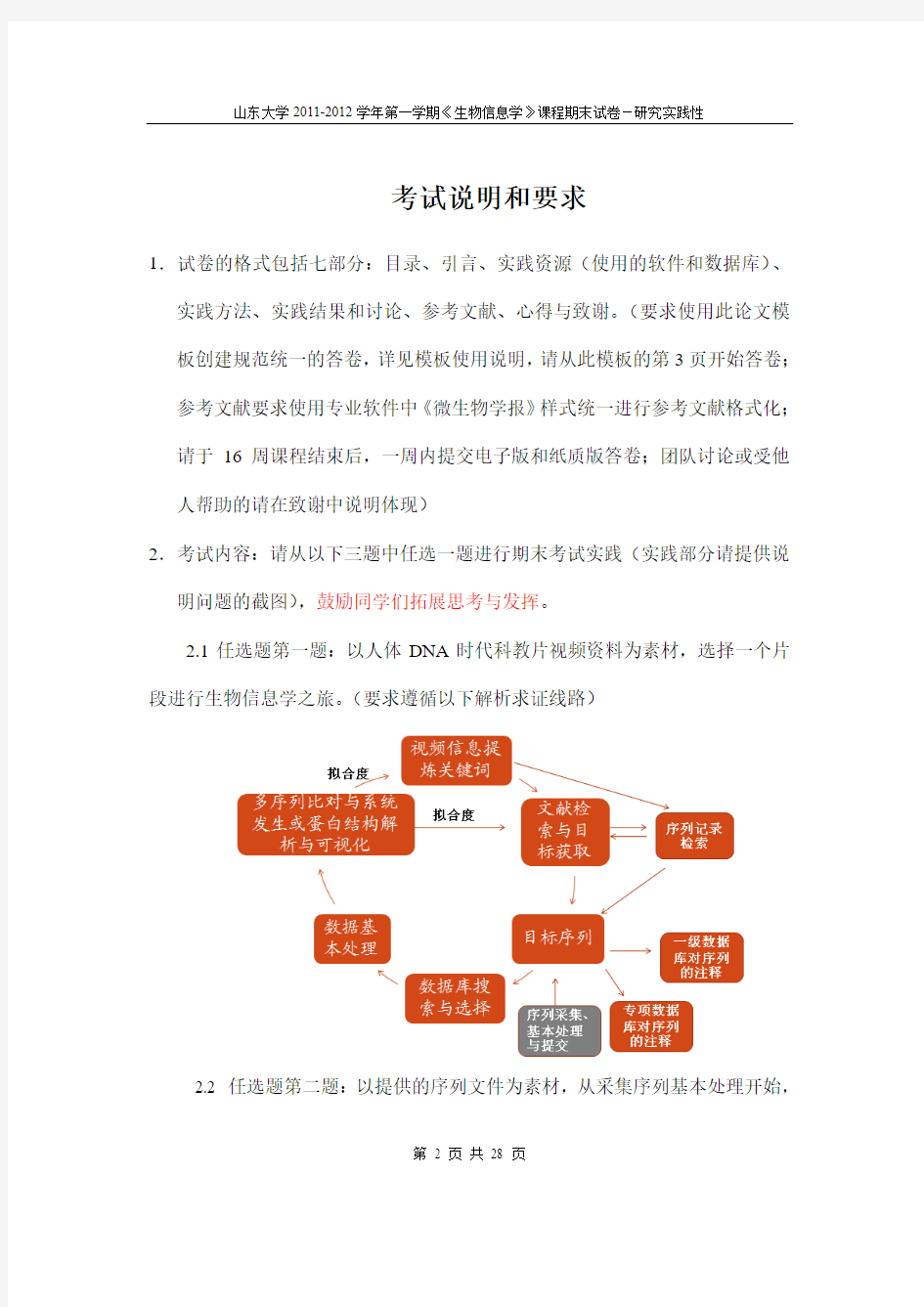
2.1任选题第一题:以人体DNA 时代科教片视频资料为素材,选择一个片段进行生物信息学之旅。(要求遵循以下解析求证线路)
2.2 任选题第二题:以提供的序列文件为素材,从采集序列基本处理开始,
利用软件包和各种数据库注释、解析数据(包括数据的注释分析、功能结构分析和进化分析)
2.3任选题第三题:自己选定文献来源或其它来源的生物问题素材,利用一套或一个生物信息学软件或数据库,进行一次生物数据的信息学之旅。(要求实践过程中涉及课堂讲授以外的生物信息学软件或数据库资源)
第 3 页共28 页
目录
1.引言 (5)
1.1 镰状血球贫血症简介 (5)
1.2 镰状血球贫血症病因及病理 (5)
2.实践资源 (6)
2.1 数据库 (6)
2.2 实践软件 (6)
3.实践方法 (6)
3.1 问题来源 (6)
3.1.1 视频《DNA时代06——打开潘多拉的盒子》画面资料剪辑 (7)
3.1.2 视频资料分析 (7)
3.1.3 镰状血球贫血症分子生物学机制探究 (8)
3.2 NCBI数据库分析 (8)
3.2.1 主题词的确定 (8)
3.2.2 镰状血球细胞相关基因的查找与序列分析 (10)
3.2.2.1 镰状血球细胞相关基因的查找 (10)
3.2.2.2 镰状血球细胞相关基因的序列分析 (11)
3.2.3 核酸序列对比 (14)
3.2.4 用BioEdit分析 (16)
3.2.5 氨基酸序列查找 (17)
3.2.6 氨基酸序列对比信息 (20)
3.2.7 用Swiss Model数据库进行hemoglobin s的三维结构预测 (23)
4.实践结果和讨论 (27)
5.参考文献 (27)
6.心得与致谢 (28)
第 4 页共28 页
镰状血球贫血症分子生物学特征的信息学分析
1.引言
1.1 镰状血球贫血症简介
镰刀状血球贫血症(视频中说法,大陆说法为镰刀形细胞贫血症(sickle-cell anemia)),是一种潜在的人类致死遗传病。患病者的血液红细胞表现为镰刀状,其携带氧的功能只有正常红细胞的一半。现在医生可以用regular blood transfusion避开伤害患者的大脑来阻止这类疾病的发病,但是,迄今为止还没有能真正治愈的药物。
1949年,美国著名化学家鲍林便在《科学》杂志上发表了题为《镰刀型细胞贫血症——一种分子病》的研究报告,报告中指出,有证据表明红细胞镰变的过程可能是与红细胞内血红蛋白的状态和性质密切相关的。据悉,非洲有的地区高达40%的人携带该病基因.
1.2 镰状血球贫血症病因及病理
镰状血球贫血症是血红蛋白分子遗传缺陷造成的一种疾病,病人的大部分红细胞呈镰刀状,许多红血球还会因此而破裂造成严重贫血,甚至引起病人死亡。其特点是病人的血红蛋白β—亚基N端的第六个氨基酸残基是缬氨酸(val),而不是下正常的谷氨酸残基(Glu)。血红蛋白是个四聚体蛋白,也是个别构蛋白,
第 5 页共28 页
因此镰刀型细胞贫血病是一种由基因突变产生的血红蛋白质分子结构改变的一种分子病。
2.实践资源
2.1 数据库
NCBI 的MeSH、Gene、Protein和Nucleotide 数据库,Swiss Model蛋白分析库
2.2 实践软件
BioEdit: BioEdit是一个序列列编辑器与分析工具软件。功能包括:序列编辑、外挂分析程序、RNA分析、寻找特征序列、支持超过20000个序列的多序列文件、基本序列处理功能、质粒图绘制等等。
RasMol:观看生物分子3D微观立体结构的软件,可以旋转,可以以多种模式观看,并可以存成普通图形文件。
3.实践方法
3.1 问题来源
第 6 页共28 页
第 7 页 共 28 页
3.1.1 视频《DNA 时代06——打开潘多拉的盒子》画面资料剪辑
3.1.2 视频资料分析
镰状血球疾病是由第11
对染色体基因突变引起的疾病,它的发生是因为在
正常情况下呈圆盘状柔软的红血球僵化而变成镰刀状,因此无法顺利输送氧气,造成患者呼吸困难,肝脏和肾脏的负荷加重,免疫系统也出现缺陷,可能会致人于死。该病往往出现在非洲后裔身上,因为非洲某些地方的生活环境中多为沼泽地带,加上蚊子丛生和人口密集等因素,为疟疾的传染提供了最理想的环境。居民被带有疟疾原虫的疟蚊叮咬后便会感染疾病,原虫进入人体,破坏血球、肝脏、脾脏等细胞。医学界认为,镰状血球病患者由于红血球的含氧量过低,疟疾原虫无法增生。因此,带有镰状红血球基因的人抵抗疟疾感染及感染疟疾重症后的存活率较普通人要高,也是由此,非洲热带和中、东部地区有镰状血球基因的人非常多。患者要同时遗传父母亲的这一基因才会发病,在美国,即使只遗传一个镰状血球基因的人也会受到歧视,由此看来,基因已经超越了人类社会的期望。
3.1.3 镰状血球贫血症分子生物学机制探究
镰状血球贫血症是一种家族型隐性遗传疾病,为了更好地了解此病,我们应该从核酸、蛋白质水平上来进一步探究镰状血球病的分子发病机理。
3.2 NCBI数据库分析
3.2.1 主题词的确定
根据生物学大辞典的翻译,确定镰刀形细胞贫血症——sickle-cell anemia为
第8 页共28 页
第 9 页 共 28 页
初选关键词,然后利用NCBI MeSH 主题词确定标准主题词为——Anemia, Sickle Cell ,并且确定其相关蛋白为hemoglobin S (血红蛋白S ),即HbS 。如图一。
图一 主题词的确定
3.2.2 镰状血球细胞相关基因的查找与序列分析
3.2.2.1 镰状血球细胞相关基因的查找
将MeSH库换为Gene库,输入Sickle Cell Anemia,得到其相关基因为HBB。点击“HBB”进入详细页面介绍,根据Summary可以得知:α(HBA)和β(HBB)基因的结构决定了成人体内两种类型的多肽链,正常人血红蛋白四聚物由两条α链和两条β链组成,而突变β血球蛋白能导致镰状血球贫血。因此可以确定是突变的HBB基因导致了人类的镰状血球贫血症。见图二。
第10 页共28 页
图二镰状血球细胞相关基因的确定
3.2.2.2 镰状血球细胞相关基因的序列分析
1)HBB基因序列分析
从此前得到的页面中可以查找到HBB基因在物理图谱中的位置,从图三中可以看到,HBB基因位于第11条染色体上,与视频资料中得到的信息一致。基
因序列为5246696——5248301,总长1605bp。
第11 页共28 页
第 12 页 共 28 页
图三 HBB 基因序列物理图谱分析
点击“FASTA ”,得到HBB 基因的FASTA 序列,见图四。
图四 HBB 基因的FASTA 序列
2)HBB 突变基因(HbS 基因)序列分析
回到“Mucleotide ”库,输入“hemoglobin S ”,搜索结果出来第一条便是HBB 突变基因(HbS )的标题,点击进入后,可以得到突变基因的基因序列号和片段大小,见图五。
图五HbS基因序列号和片段大小
点击左上方的“FASTA”,得到突变基因的FASTA序列,见图六。
第13 页共28 页
图六HbS基因FASTA序列
3.2.3 核酸序列对比
进入Blast,选择“Human”,在“blastn”下的“Enter Query Sequence”框内输入从上一步找到的突变基因序列号:AY027800,得出对比结果。见图七。
第14 页共28 页
图七核酸序列对比
由比对结果可知,镰状血球贫血症基因和人类第11对染色体基因匹配度极高,完美验证了视频中“位于第11对染色体”的说法。
点击页面上方的“Human genome view”,出现突变基因在染色体上的具体位置图。从图中可看到突变基因在11号染色体的短臂上,且靠近端点。见图八。
图八突变基因在染色体中的位置
第15 页共28 页
3.2.4 用BioEdit分析
将正常和突变基因的FASTA序列互不干扰顺序地放在新建的TXT文档中,用BioEdit打开,见图九。
图九BioEdit界面
点击窗口上方的“Accessory application”菜单,再点击“clustelW multiple alignment”,弹出一个窗口,直接选择“Run clustalW”,又弹出一个窗口,选择ok,得到比对结果。可以看到,突变基因有大量的缺失。见图十。
第16 页共28 页
缺失序列
同源序列
图十BioEdit比对结果
3.2.5 氨基酸序列查找
在“Nucleotide”库中输入“hemoglobin s”,点击第三条目录,进入页面后可得到hemoglobin s的氨基酸序列号和蛋白质ID。见图十一。
第17 页共28 页
第18 页共28 页
图十一hemoglobin s氨基酸序列的查找
在Protein库,输入上一步搜索到的蛋白质ID:AAK15811.1,得到了同样的但更为详细的氨基酸序列。见图十二。
图十二蛋白库中氨基酸序列
第19 页共28 页
3.2.6 氨基酸序列对比信息
在得到hemoglobin s的氨基酸序列号和蛋白质ID的页面右侧点击“Run BLAST”,运行,BLAST得到102个BLAST结果。见图十二。
图十二氨基酸序列对比信息
第20 页共28 页
生物信息学考研报考院校
学科门类:07 理学 一级学科:0710 生物学 以下表格数据来自:中国研究生信息网北京: (10001)北京大学 071020 生物学(生物信息学)071021 生物学(生物技术) (90106)中国人民解放军军事医学科学院071020 生物信息学
(10019)中国农业大学 071021 生物信息学 (80167)中国科学院北京基因组研究所071021 生物信息学 071022 基因组学 (80112)中国科学院生物物理研究所 071021 生物信息学 (80156)中国科学院北京遗传与发育生物研究所071021 生物信息学 (90106)中国人民解放军军事医学科学院071020 生物信息学 071021 生物安全
上海: (10246)复旦大学071020 生物信息学071021 人类生物学
(10248)上海交通大学
吉林: (10200)东北师范大学 071020 基因组学 071021 生物医学 071023 化学生物学 (80100)中国科学院上海生命科学研究院 071020 生物技术与医药 071021 生物信息学 071023 计算生物学 071024 生物情报学 具体考试的要求很详细具体由于表格很大就不一一列举 了:https://www.360docs.net/doc/c61943121.html,/zsml/querySchAction.do?dwdm=80100&mldm=07&yjxkdm=0710&zymc=&pageno=8 江苏: (10319)南京师范大学 071020 生物技术 071021 生物物理化学 浙江: (10335)浙江大学 071020 生物信息学
生物信息学作业
生物信息学试题 1、构建分子系统树得主要方法有哪些?并简要说明构建分子进化树 得一般步骤。(20分) 答:(1)构建进化树得方法包括两种:一类就是序列类似性比较,主要就是基于氨基酸相对突变率矩阵(常用PAM250)计算不同序列差异性积分作为它们得差异性量度(序列进化树);另一类在难以通过序列比较构建序列进化树得情况下,通过蛋白质结构比较包括刚体结构叠合与多结构特征比较等方法建立结构进化树 (2)序列比对——选取所需序列——软件绘制 具体如下: a测序获取序列或者在NCBI上搜索所需得目得序列 b在NCBI上做blast:比对相似度较高得基因,并以fast格式下载,整合在*txt文档中。 c比对序列,比对序列转化成*meg格式 d打开保存得*meg格式文件,构建系统进化树 2、氨基酸序列打分矩阵PAM与BLOSUM中序号有什么意义?它们各自 得规律就是什么?(10分) (1)PAM矩阵:基于进化得点突变模型,如果两种氨基酸替换频繁,说明自然界接受这种替换,那么这对氨基酸替换得分就高。一个PAM就就是一个进化得变异单位, 即1%得氨基酸改变。 BLOSUM矩阵:首先寻找氨基酸模式,即有意义得一段氨基酸片断,分别比较相同得氨基酸模式之间氨基酸得保守性(某种氨基酸对另一种氨基酸得取代数据),然后,以所有60%保守性得氨基酸模式之间得比较数据为根据,产生BLOSUM60;以所有80%保守性得氨基酸模式之间得比较数据为根据,产生BLOSUM80。
(2)PAM用于家族内成员相比,然后把所有家族中对某种氨基酸得比较结果加与在一起,产生“取代”数据(PAM-1 );PAM-1自乘n次,得PAM-n。 PAM-n中,n 越小,表示氨基酸变异得可能性越小;相似得序列之间比较应该选用n值小得矩阵,不太相似得序列之间比较应该选用n值大得矩阵。PAM-250用于约 20%相同序列之间得比较。 BLOSUM-n中,n越小,表示氨基酸相似得可能性越小;相似得序列之间比较应该选用 n 值大得矩阵,不太相似得序列之间比较应该选用n值小得矩阵。BLOSUM-62用来比较62%相似度得序列,BLOSUM-80用来比较80%左右得序列。 3、蛋白质三维结构预测得主要方法有哪些?试选择其中得一种方 法,说明蛋白质三维结构预测得一般步骤。(10分) (1) a同源建模(序列相似性低于30%得蛋白质难以得到理想得结构模型 b折叠识别(已知结模板得序列一致率小于25%) c从头预测得方法(无已知结构蛋白质模板)。 (2) 4、您所熟悉得生物信息学软件有哪些?请选择其中得至少一种软 件,结合自己得研究课题,谈谈您所选择软件得基本原理,使用
基因组学与生物信息学教案
《基因组学与生物信息学》教案 授课专业:生物学大类各专业 课程名称:基因组学与生物信息学 主讲教师:夏庆友程道军赵萍徐汉福
课程说明 一、课程名称:基因组学与生物信息学 二、总课时数:36学时(理论27学时实验9学时) 三、先修课程:遗传学、分子生物学、基因工程 四、使用教材: 杨金水. 基因组学. 北京:高等教育出版社,2002. 张成岗. 贺福初, 生物信息学方法与实践. 北京:科学出版社,2002. 五、教学参考书: T.A.布朗著,袁建刚译著,基因组(2rd版),北京:科学出版社,2006. 沈桂芳,丁仁瑞,走向后基因组时代的分子生物学,杭州:浙江教育出版社,2005. 罗静初译,生物信息学概论,北京:北京大学出版社,2002. 六、考核方式:考查 七、教案编写说明: 教案又称课时授课计划,是任课教师的教学实施方案。任课教师应遵循专业教学计划制订的培养目标,以教学大纲为依据,在熟悉教材、了解学生的基础上,结合教学实践经验,提前编写设计好每门课程每个章、节或主题的全部教学活动。教案可以按每堂课(指同一主题连续1~2节课)设计编写。教案编写说明如下: 1、编号:按施教的顺序标明序号。 2、教学课型表示所授课程的类型,请在相应课型栏内选择打“√”。 3、题目:标明章、节或主题。 4、教学内容:是授课的核心。将授课的内容按逻辑层次,有序设计编排,必要时标以“*”、“#”“?” 符号分别表示重点、难点或疑点。 5、教学方式既教学方法,如讲授、讨论、示教、指导等。教学手段指教科书、板书、多媒体、模型、 标本、挂图、音像等教学工具。 6、讨论、思考题和作业:提出若干问题以供讨论,或作为课后复习时思考,亦可要求学生作为作业 来完成,以供考核之用。 7、参考书目:列出参考书籍、有关资料。 8、日期的填写系指本堂课授课的时间。
山东大学细胞生物学期末考试题基地班必看
细胞生物学名词解释1、双亲性分子(amphipathic molecule):是指由磷脂的磷脂酰碱基构成亲水极性头部和脂肪酸链构成疏水非极性尾部的分子,是膜脂的主体。 2、内在膜蛋白(intrinsic membrane protein):它贯穿膜脂双层,以非极性氨基酸与脂双层分子的非极性疏水区,相互作用而结合在质膜上,内在膜蛋白不溶于水,占膜蛋白总量的70%-80%,如膜上的受体蛋白与通道蛋白。 3、外在膜蛋白(extrinsic membrane protein):外在膜蛋白约占膜蛋白的20%~30%,分布在膜的内外表面,主要在内表面,为水溶性蛋白,靠离子键或其它弱键与能够暂时与膜或内在膜蛋白结合的蛋白质,易分离。 4、脂锚定蛋白(lipid anchored protein):质膜外侧的蛋白质通过糖链连接到磷脂酰肌醇上,形成“蛋白质—糖—磷脂”复合物,或质膜胞质侧的蛋白质通过脂肪酸链共价结合在脂双层上,这种蛋白即称为脂锚定蛋白(GPI)。包括:细胞粘附分子、免疫球蛋白超家族、Src、Ras蛋白。 5、被动运输(passive transport):通过简单扩散或协助扩散方式实现物质由高浓度向低浓度方向的跨膜转运,顺物质浓度梯度,不需消耗能量。 6、简单扩散(simple diffusion):质膜转运小分子物质时,不需膜蛋白的帮助,可以顺物质浓度梯度从高浓度一侧到低浓度方向进行,它不需消耗能量,属于被动扩散。以简单扩散方式运输的物质为:脂溶性小分子、非极性的小分子。 7、载体蛋白介导的易化扩散(Facilitated diffusion):物质穿越膜时在膜上载体蛋白的介导下,不消耗细胞的代谢能量,将溶质顺着浓度梯度或电化学势梯度进行转运,这种运输方式称易化扩散。部分载体蛋白; 非脂溶性物质。属于被动运输的范畴。 8、主动运输(active transport):指由载体蛋白介导的物质逆浓度梯度(或化学梯度)的由低浓度一侧向高浓度一侧消耗能量的跨膜运输方式。主要包括离子泵:直接水解ATP供能;协同运输:间接消耗ATP。 9、协同运输(coupled transport):一种物质的运输依赖第二种物质的同时运输。这种运输需要先建立离子梯度,在动物细胞主要是靠Na+泵、在植物细胞则是由H+泵完成的。
分子生物学考试复习资料 山东大学
1.复制和转录的异同:共同点:反应都是核苷酸的聚合过程,模版是DNA,酶依赖DNA的聚合酶,化学键3,5磷酸二酯键,方向5-3延伸,配对是碱基配对规律。不同点:底物不同分别是dNTP和NTP ;酶不同分别是DNA聚合酶和RNA 聚合酶;模版不同,分别是整个染色体双链DNA和部分基因模板链转录;产物不同,分别是子代双链DNA和mtrRNA ;引物分别是需要和不需要;碱基配对分别是A=T,GC和A=UT=AGC 2.转录的过程:模板DNA原料:NTP(ATP,GTP,CTP,UTP)酶:RNA聚合酶(RNA-pol)其它蛋白质因子:如ρ因子,转录因子(TF)等. A转录起始过程,RNA聚合酶全酶结合,DNA双链解开,在RNA聚合酶作用下发生第一次聚合反应,形成转录起始复合物b转录延长,伽马o亚基脱落,核心酶变构,与,模版结合松弛,沿着DNA模板前移在核心酶作用下,NTP不断聚合,RNA链不断延长,合成方向沿5-3进行c终止转录RNA聚合酶在DNA模板上停止前进,转录产物RNA链在转录复合物上脱落下来。 3.基因克隆的步骤:目的基因的获取;目的基因与载体的拼接,将重组体导入受体细胞,重组体筛选和鉴定,扩增和表达a获取,从基因组文库中制备,从CDNA 文库中制备,PCR扩增目的基因,人工合成目的基因b目的基因片段与适当的载体经限制性内切酶剪切后,再在DNA连接酶的催化下即可相互连接形成人工重组体,粘性末端连接,平端连接,同聚物加尾连接,人工头连接c氯化钙法,电穿孔法,脂质体转染法,显微注射法d遗传学法,分子杂交法,免疫化学筛选法,PCR筛选法e重组体的扩增与表达。 4.寡核苷酸定点诱变技术所依据的原理是:首先制备单链核酸,即按体外DNA重组技术,将待诱变的目的基因插入到M13噬菌体上,制备此种含有目的基因的M13单链DNA,即正链DNA。再使用化学合成的含有突变碱基的寡核苷酸短片段作引物,启动M13单链DNA分子进行复制,随后这段寡核苷酸引物便成为新合成的DNA子链的一个组成部分。因此所产生的新链便具有已发生突变的碱基序列,将其转入细胞后,经过不断复制,即可获得突变的DNA分子,再经表达即可获得改造后蛋白质.为了使目的基因的特定位点发生突变,所设计的寡核苷酸引物的序列除了所需的突变碱基外,其余的则与目的基因编码链的特定区段完全互补。B 诱变过程1)合成含有目的基因的正链DNA;2)合成含有特殊突变碱基的引物;3)
生物信息学作业1实验2
上海师范大学实验报告 实验二 一、实验原理 答:利用Blast全球联网数据库,对输入的序列进行生物信息学分析,给出与输入序列相关性最大的对应的基因信息,比较两者的同源性。 二、操作步骤 答:(1)先打开网址https://www.360docs.net/doc/c61943121.html,/ (2)点击右边的Blast链接,打开Blast数据库,进入Blast界面 (3)在Basic Blast中选择nucleotide blast (4)在对话框中输入核苷酸序列,在choose search set下的Database选项中选择Others (nr etc.) (5)把网页拉到最下方,点击Blast按钮 (6)在Descriptions 栏下找到Max ident 百分率最高的序列名称 (7)再往下拉,找到Alignments项下第一个序列,可以找到输入序列相关信息 (8)点击Accession,即能找到更多输入序列的相关信息。 1. tttcactcca tagttactcc ccaggtga 1.1它属于哪类生物? 答:属于Hepatitis C virus (丙型肝炎病毒) 1.2它属于哪类基因? 答:属于non-structural protein 5B gene 1.3它在该基因的什么位置? 答:它在该基因的第749-776这个位置。 1.4它与你搜索到的序列的同源性(Identities)是多少? 答:同源性100% 2.(1)ccacccactg aaactgcaca gacaaatttg tacataagag 1.1它属于哪类生物? 答:属于Influenza A virus (A/chicken/Iran261/01(H9N2)) hemagglutinin (HA) gene (A型流感病毒,A型伊朗型261鸡流感病毒,H9N2病毒,血细胞凝集素抗原基因为依据) 1.2它属于哪类基因? 答:属于ssRNA negative-strand viruses Orthomyxoviridae (单链RNA,负义链病毒,正粘病毒科) 1.3它在该基因的什么位置? 答:它在该基因的第1-40这个位置 1.4它与你搜索到的序列的同源性(Identities)是多少?
生物信息学课程论文 作业题目 分配表
生物技术12-1 生物技术12-1 学号姓名性 别 签名学号姓名性别签名学号姓名性 别 签名 12114350101陈丽娜女大肠杆菌连接 酶 12114350104黄少敏女人的胰蛋白 酶 12114350105黄晓静女T4噬菌体 DNA聚合酶12114350106纪秀玲女人的肌红蛋白12114350107列泳婵女蛋白酶K序 列 12114350108石彩虹女小鼠P53基 因12114350110周海琪女拟南芥端粒酶 序列 12114350111曹杰濠男淀粉酶12114350113陈永成男G-谷氨酰转 肽酶12114350115方壮杰男乳酸脱氢酶12114350116冯健锋男肝癌铁蛋白12114350118黄静云男牛血清白蛋 白12114350119李树森男18S rDNA 12114350120李涛男ATP合成酶12114350121林秀尧男谷氨酸脱羧 酶12114350123刘国标男CDK4 12114350124罗皓炽男胃蛋白酶12114350125阮永刚男鲨烯合酶基 因12114350126石晓洲男肌动蛋白12114350129王佐正男肥胖基因相 关蛋白 12114350130吴文祯男柑橘果胶酯 酶12114350131吴永鹏男凝血酶原12114350132徐国相男维生素C合 成基因 12114350133叶业林男葡萄糖脱氢 酶
12114350134张维彬男大肠杆菌Β-半 乳糖苷酶 12114350135张伟龙男抗干旱基因12114350136郑晓坤男人血红蛋白 12114350142郑桂捷男磷酸酶的蛋白 质12114350138黄忠海男牛凝乳酶原 基因 12114350139徐少东男岩藻糖苷酶 12114350141王晓敏女木瓜蛋白酶 本班总人数:31 生物技术12-2 生物技术12-2 学号姓名性别签名学号姓名性别签名学号姓名性别签名12114350201黄雪梅女人的胰岛素12114350202李晨晨女热震惊蛋白/ 热击蛋白 1211435020 3 廖垭娣女乙肝病毒 CABYR- binding prot ein 12114350204冉梦梦女腺苷酸环化酶12114350205魏丹璇女DNA ase I 1211435020 6 吴彩凤女纤维素酶 12114350207武亦婷女18 rDNA 12114350208叶国玲女谷胱甘肽1211435020 9 叶锦玉女线粒体基因
山东大学分子生物学相关资料
Section A - Cells and macromolecules 1.The glycosylation of secreted proteins takes place in the . . . A mitochondria. B peroxisomes. C endoplasmic reticulum. D nucleus. 2.Which of the following is an example of a nucleoprotein? A keratin. B chromatin. C histone. D proteoglycan. 3.Which of the following is not a polysaccharide? A chitin. B amylopectin. C glycosaminoglycan. D glycerol. 4. Transmembrane proteins A join two lipid bilayers together. B have intra- and extracellular domains. C are contained completely within the membrane. D are easily removed from the membrane. Section B - Protein structure 1. Which of the following is an imino acid? A proline. B hydroxy lysine. C tryptophan. D histidine. 2.Protein family members in different species that carry out the same biochemical role are described as . . . A paralogs. B structural analogs. C heterologs. D orthologs. 3. Which of the following is not a protein secondary structure? A α-helix. B triple helix. C double helix. D ?-pleated sheet. 4.In isoelectric focusing, proteins are separated . A in a pH gradient. B in a salt gradient. C in a density gradient. D in a temperature gradient. 5.Edman degradation sequences peptides . . .
生物技术专业本科教学质量国家标准-山东大学生命科学学院
生物技术专业本科教学质量国家标准 1. 概述 生物技术是以现代生命科学理论为基础,应用生命科学研究成果,结合化学、物理学、数学和信息学等学科的科学原理,采用先进的科学技术手段,按照应用要求预先设计改造和利用生物体(微生物、动植物)的技术。生物技术是一门综合的、交叉性的学科,侧重于应用基础研究和应用技术开发,其主要任务是为新兴生物技术产业提供人才、技术、产品和服务。 生物技术是全球发展最快的高新技术之一,也是21世纪的主导技术之一。生物技术的发展经历了传统生物技术和现代生物技术两个阶段,前者以微生物发酵技术为核心,后者以重组DNA和PCR技术为基本手段。按其应用领域现代生物技术被依次划分为:医药生物技术、农业生物技术、工业生物技术、海洋生物技术等。进入新世纪以来,随着组学、系统生物学、合成生物学、干细胞、脑科学、生物信息学等生命科学前沿的发展,生物技术已经成为世界各国争相优先发展的高新技术领域,在解决人类面临的人口、健康、环境、粮食、资源、能源等诸多难题方面将发挥更加重要的作用。生物技术是我国中长期科技发展规划的优先发展前沿技术,生物技术产业作为正在崛起的主导性产业,已成为我国产业结构调整的战略重点和新的经济增长点,将成为我国赶超世界发达国家生产力水平,实现后发优势和跨越式发展的重要领域,将为国家经济转型和生态文明型社会的发展做出
重大贡献。 在生命科学与技术体系中,生物技术是一门承上启下的学科/专业,上接生物科学、下连生物工程,是将基础理论成果转化为具有应用价值的技术和产品的枢纽和桥梁。生物技术专业的特点是交叉性、前沿性、实践性和新颖性。交叉性不仅体现在生物学科内部的交叉,而且需要与其它自然科学(化学、物理学、数学)和新兴学科(计算机科学、信息学)的交融;前沿性则表现为生物技术产业是战略性新兴产业,生物技术产品是生命科学前沿研究的最新成果;实践性反映出生物技术专业属于实验性学科的基本特征,实验技能和实践创新能力是该专业对学生的基本要求;新颖性就是生物技术能够创造出一些前所未有的、满足人们生活需要的新产品、新服务、新体验。 2.适用专业范围 2.1 专业类代码 0710生物科学类 2.2 本标准适用的专业 071002生物技术专业 3.培养目标 3.1 生物技术专业培养目标 生物技术专业是以理为主、以工为辅的理工复合型办学专业。 生物技术专业的培养目标是:通过各种教育教学活动培养学生德智体美全面发展,具有健全人格;具有成为高素质人才所具备的人文
生物信息学课程作业
生物信息学作业 1. Align the leghemoglobin protein from soy bean and myoglobin from human with global and local alignment software (ex. needle and water) respectively and interpret the results. ANSWER: (1)Use Needle to Align the two sequence: Aligned_sequences: 2 # 1: CAA38024.1 # 2: NP_001157488.1 # Matrix: EBLOSUM62 # Gap_penalty: 10.0 # Extend_penalty: 0.5 # Length: 203 # Identity: 43/203 (21.2%) # Similarity: 58/203 (28.6%) # Gaps: 90/203 (44.3%) # Score: 30.0 (2)Use Water to Align the two sequence: Aligned_sequences: 2 # 1: CAA38024.1 # 2: NP_001157488.1 # Matrix: EBLOSUM62 # Gap_penalty: 14 # Extend_penalty: 4 # Length: 32 # Identity: 11/32 (34.4%) # Similarity: 15/32 (46.9%) # Gaps: 0/32 ( 0.0%) # Score: 35 两种软件虽然使用同一罚分标准但得分不同。因为Needle程序实现标准pairwise全局比对,而Water则是局部比对。全局比对因为是比对全长序列,所以空位罚分多,得分较局部比对低。
部分山大真题(细胞生物学)
山东大学2001年硕士研究生细胞生物学入学考试试题 一.名词解释(任选10个,每个2分,共20分) 1.原位杂交 2.差别基因表达 3.胞质体 4.分子伴娘 5.重组小结 6.同向协同运输 7.端粒 8.光合磷酸化 9.核定位信号 10.自噬溶酶体 11.细胞 12.细胞识别 三.简答题(每小题5分,共30分) 1.原核细胞和真核细胞有哪些主要区别? 2.请说出线粒体内膜重组实验的过程及其说明的问题 3.真核细胞核小体是如何形成的? 4.细胞周期可分为哪几个时期?各时期有何主要特点? 5.何为原癌基因?其激活途径有哪几条? 6.何为细胞凋亡?有何特征? 四.综述题(任选3题,每题10分,共30分) 1.试述细胞外基质的组成成分及各自的分子结构特点,并说明细胞外基质的主要功能 2.请说明内膜系统的组成并阐明其结构与功能分别如何相互联系 3.试述微管的形态结构和主要功能并列举出其构成的两种细胞器的结构特点4.说明用放射自显影技术检测细胞是否进行DNA合成的原理,并设计一实验证明rRNA(核糖体DNA)在细胞内的合成场所 山东大学2002年硕士研究生细胞生物学入学考试试题 一.名词解释(任选10个,每个2分,共20分) 1.抑癌基因 2.内膜系统 3.非细胞体系 4.配体门通道 5.微粒体 6.核小体 7.联会复合体 8.细胞周期蛋白 9.G蛋白 10.信号斑 11.多线染色体 12.胚胎干细胞 二.填空
1。叶绿体的光合作用可分为____和____ 两个阶段,前者在发生,产物为. 后者在发生,产物为。 2。组成衣被小泡底被的主要成分为____ 和____ 。 3。细胞分化的两个主要特点是____和_______。 4。原核细胞的呼吸酶定位在____上,而真核细胞的则位于____ 上。 5。真核细胞分裂中期染色体是由两条____所组成,二者在____相互结合。 6。细胞外基质的组成成分有____________________。 7。精子的顶体是一种特化的____,而肌纤维肌质网是一种特化的____ 。 三.简答题(每小题6分,共30分) 1。细胞学说是谁创立的及主要内容有哪些?, 2。线粒体氧化磷酸化的机制如何? 3。何为常染色体质和异染色质?二者有哪些区别? 4。微管的形态结构特点和功能如何? 5。请举例说明从增殖的角度,细胞可以分为哪几类? 四。综述题(任选3个,每题10分,共30分) 1。锚定连接包括哪几种连接方式?其结构特点及功能如何?试比较其异同点。2。试述真核细胞内蛋白质的合成和分选途径。 3。减数分裂前期I依次由哪几个时期组成,各个时期有何变化及意义? 4。试述哺乳动物克隆技术的原理,方法及意义。 山东大学2000年硕士研究生细胞生物学入学考试试题 一.名词解释(任选10题,每小题2分,共20分) 1.细胞 2.冰冻断裂 3.细胞株 4.细胞外被 5.核孔复合体 6.导肽 7.常染色质 8.着丝点 9.接触抵制 10.细胞决定 11.原癌基因 12.胚胎诱导 二.填空 1.化学法细胞拆合就是有处理细胞,结合离心技术,将细胞拆为核体和胞质体。2.与桥粒相连的中间纤维的成分依不同细胞类型而不同,上皮细胞中是___,心肌细胞中为___。 3.构成细胞外基质的化学成分可分为4类:___,___,___,___。 4.糖酵解,脂肪酸氧化,氧化磷酸化,三羧酸循环进行的部位分别是___,___,___,___。 5.肌质网是特化的___,而精子的顶体是特化的___。 6.细胞周期中,两个关键的时相转换点是___和___转换。 7.C-分带法主要显示___。
微生物学[第十三章微生物物种的多样性]山东大学期末考试知识点复习
第十三章微生物物种的多样性 一、要点提示 1.生物的多样性系指遗传多样性、物种多样性和生态系统多样性。由于微生物具有与高等动植物迥然不同的特点,使微生物在营养类型、呼吸类型、代谢类型3方面也呈现出丰富的多样性。 2.长期以来人们对细菌的认识仅从形态结构、生理生化、免疫学特性、生态分布进行区分。由于分子生物学方法的建立和发展,特别是16S rRNA寡核苷酸的序列分析,改变或修正了对细菌人为地传统分类的概念,进入了细菌系统发育和自然进化的研究阶段。按照Woese的观点,真细菌占据自然界生物三大域中的一个域,即:细菌域。在确认了16S rRNA中标志性的寡核苷酸保守序列后,真细菌被划分为12个独特的类群。每个类群可以看成是独立的门,它包括了《伯杰系统细菌学手册》中所描述的23个门的细菌。腐生型的细菌在自然界中碳、氮、硫、磷4种元素的循环和能量流动中起着不可替代的作用;一些种是动、植物和人的致病菌,与动、植物的生长和人体健康密切相关;一些具有特殊形态,如具附属物或鞘的细菌,产子实体的黏细菌等,它们的存在丰富了微生物物种的多样性。 3.古生菌是极端环境微生物,它们在形态结构、营养代谢、生理特性、遗传物质及生态分布等方面与真细菌具有十分明显的差异。16S rRNA寡核苷酸序列分析表明它们是生物总系统发育中一个重要的域,包括:产甲烷古生菌、极端嗜热S0代谢菌、极端嗜盐古生菌、无细胞壁的热原体和还原硫酸盐古生菌5个类群。古生菌的发现为人们利用古生菌中的嗜热酶(例如:Taq、Pfu DNA聚合酶)、产甲烷辅酶及其他参与碳、氮物质代谢的酶类,进行分子生物学研究和进行酶法水解、酶法转化制取有用产品提供了丰富的微生物资源。另外,对古生菌嗜热、嗜酸、厌氧、耐高盐、产甲烷、还原硫酸盐及光介导ATP合成的研究,为探索地球上早期原始生命的起源,提供了有力的佐证。 4.生物的共同祖先沿着真细菌、古生菌、真核生物3条路线进化。目前认
控制科学与工程的二级学科以及排名
控制科学与工程 是一门研究控制的理论、方法、技术及其工程应用的学科。它是20世纪最重要的科学理论和成就之一,它的各阶段的理论发展及技术进步都与生产和社会实践需求密切相关。11世纪我国北宋时代发明的水运仪象台就体现了闭环控制的思想。到18世纪,近代工业采用了蒸汽机调速器。但直到20世纪20年代逐步建立了以频域法为主的经典控制理论并在工业中获得成功应用,才开始形成一门新兴的学科——控制科学与工程。此后,经典控制理论继续发展并在工业中获得了广泛的应用。在空间技术发展的推动下,50年代又出现了以状态空间法为主的现代控制理论,并相继发展了若干相对独立的学科分支,使本学科的理论和研究方法更加丰富。60年代以来,随着计算机技术的发展,许多新方法和技术进入工程化、产品化阶段,显著加快了工业技术更新的步伐。在控制科学发展的过程中,模式识别和人工智能与控制相结合的研究变得更加活跃;由于对大系统的研究和控制学科向社会、经济系统的渗透,形成了系统工程学科。特别是近20年来,非线性及具有不确定性的复杂系统向“控制科学与工程”提出了新的挑战,进一步促进了本学科的迅速发展。目前,本学科的应用已经遍及工业、农业。交通、环境、军事、生物、医学、经济、金融、人口和社会各个领域,从日常生活到社会经济无不体现本学科的作用。 控制科学以控制论、信息论、系统论为基础,研究各领域内独立于具体对象的共性问题,即为了实现某些目标,应该如何描述与分析对象与环境信息,采取何种控制与决策行为。它对于各具体应用领域具有一般方法论的意义,而与各领域具体问题的结合,又形成了控制工程丰富多样的内容。本学科的这一特点,使它对相关学科的发展起到了有力的推动作用,并在学科交叉与渗透中表现出突出的活力。例如:它与信息科学和计算机科学的结合开拓了知识工程和智能机器人领域。与社会学、经济学的结合使研究的对象进入到社会系统和经济系统的范畴中。与生物学、医学的结合更有力地推动了生物控制论的发展。同时,相邻学科如计算机、通信、微电子学和认知科学的发展也促进了控制科学与工程的新发展,使本学科所涉及的研究领域不断扩大。 相关学科关系 本学科在本科阶段叫自动化,研究生阶段叫控制科学与工程,本学科下设的六个二级学科:“控制理论与控制工程”、“检测技术与自动装置”、“系统工程”、“模式识别与智能系统”、“导航、制导与控制”和“企业信息化系统与工程”。各二级学科的主要研究范畴及相互联系如下。
《生物信息学》上机作业
《生物信息学》上机作业 题目:对人血红蛋白(HBA1)编码基因序列的生物信息分析
目录 引言 .............................................................................................................................................. - 1 -1 正文......................................................................................................................................... - 2 - 1.1 NCBI上对相关核苷酸序列的查找............................................................................ - 2 - 1.2 BLAST运行及其结果.................................................................................................. - 2 - 1.3 BLASTX运行及其结果................................................................................................ - 6 - 2 其他软件的运行及其结果..................................................................................................... - 8 - 2.1 Clustal W运行及其结果 ............................................................................................. - 9 - 2.2 MEGA4.0运行及其结果............................................................................................. - 10 -结论 ............................................................................................................................................ - 10 -
千万亿次高性能计算中心建设可行性研究结果汇报2010070
国家超级计算山东中心建设可行性报告 一、建设超级计算机系统的必要性 超级计算机系统是科技实力和综合国力的重要标志。超级计算是采用计算、通信和数据处理能力强大的计算机进行数据处理、信息服务、在线事物处理和科学工程计算。计算模拟在新材料设计、新型纳米结构与分子器件设计、全球气候变化研究、工业工程设计、航空航天器的制造等方面发挥了重要作用。计算机辅助药物设计改变了药物筛选的模式,使得新药研发周期缩短了0.9 年,直接研发费用降低了1.3 亿美元。事实证明,超级计算机为科学研究和发现提供了强有力的实验与分析工具,已成为支撑科学研究和高新技术发展的基础性交叉学科,为越来越多的科学研究和重大工程中的关键问题提供了新的研究途径,对增强国家安全、提升科研水平、提高企业竞争力产生了广泛而深远的影响。超级计算机的能力与水平是一个国家综合国力的重要标志。 为适应现代科学与工程研究的发展要求,世界许多国家都非常重视国家超级计算基础设施的建设,制定了国家层面的战略计划,推动以超级计算为核心的科研信息化基础设施建设和应用。在2008年全球超级计算机500强中,美国257台,英国53台,德国46台,法国34台,日本22台,中国16台(含台湾3台)。在中国大陆上榜的13台计算机中,
排名最靠前的是曙光5000A超级计算机,峰值运算能力为每秒230万亿次、Linpack值180万亿次,位居世界超级计算机前10(江南计算技术研究所未参加)。对超级计算的持续大力支持,使美国在超级计算机系统研制、运行维护、计算应用及服务等方面一直保持国际领先地位,极大推动了高性能计算在科学与工程应用,特别是在国防、能源、新材料、气象与环境、宇航和太空科学等方面的发展。Top500排名第1的IBM最新军用超级计算机“Roadrunner”每秒计算能力超过了1千万亿次,主要用于解决机密军事问题,以确保美国核武器储备的持续发展。此外,欧洲和日本也有类似的研究发展。纵观国际发达国家高科技领域发展趋势,千万亿次高性能计算已成为当今科技竞争的热点。 建设千万亿次超级计算中心是国家科技创新战略的重大举措。近年来,我国对高性能计算进行了重要部署。2002年,国家863计划启动了“高性能计算机及其核心软件”重大专项,支持了以中科院网络中心超级计算中心、上海超级计算中心为主节点,共8个计算节点的网格试验床“中国国家网格”(China National Grid,CNGrid),开发网格软件,支持建设了气象、资源环境、生物信息、新药研发、仿真应用、城市交通信息、地质调查等11个应用网格,通过资源共享、协同工作和服务机制,支持科学研究、资源环境、先进制造和信息服务等应用。国家自然科学基金委员会制定的“以网络为基础的科学活动环境研究”重大研究计划,在气
生物信息学作业
CDK2基因和蛋白质序列的生物信息学分析 姓名: 学号: 专业: 1前言 细胞周期蛋白依赖激酶2(cyclin-dependent kinase 2,CDK2),又名细胞分裂激酶2(cell division kinase 2)或p33蛋白激酶(p33 protein kinase),其基因定位于人类基因组的12号染色体上的q13染色带上。CDK2基因全长6013bp,这部分中有7个外显子和6个内含子,7个外显子的长度依次为353bp、78bp、121bp、171bp、102bp、204bp、1264bp(可依次记为外显子1-7)。在翻译过程中,该基因转录成的mRNA的外显子1的前137bp和外显子7的后1159bp不进行翻译,属于调控序列。mRNA上只有中间的部分编码蛋白质。 CDK2基因可以转录为两种mRNA。其中,变体1长度为2325bp,编码298个氨基酸;变体2长度为2223bp,编码264个氨基酸。这两种蛋白质为CDK2的同型蛋白,功能相同,具有调控细胞分裂的功能,主要在G1期到S期和S期到G2期这两个阶段起作用。CDK2广泛分布在生物体的各种细胞的胞质溶胶和细胞核质中,但只在进行分裂的细胞中行使功能,这是因为CDK2只有与不同的细胞周期蛋白(cyclin)结合后才具有活性。CDK2可以与细胞周期蛋白A、B1、B3、E等结合后,参与细胞周期调控。由于CDK2在细胞内的数量变化有可能导致细胞周期异常而产生癌症,故CDK2基因可以被看作癌基因,其活性和表达量可以作为衡量癌症的指标。CDK2与周期蛋白E的复合体不仅能直接参与中心体复制的起始调控,还能与类Rb蛋白p107或转录因子E2F结合,促进细胞从G1期向S期转化或调控DNA复制有关的基因转录。而CDK2与周期蛋白A的复合体可以增强DNA复制因子RF-A的活性。 在CDK2分子中,被称为T环的氨基酸环阻断了活性部位,妨碍激酶履行它的酶功能,而且活性部位的氨基酸形成一种难于为蛋白质结合的形状。CDK2与周期蛋白结合时,周期蛋白将T环转出2nm以上,又将CDK2中的PSTAIRE螺旋部分转了, 并把活性部位氨基酸变成能与底物蛋白结合的正确构象。CDK2的活性不仅与周期蛋白有关,还与其上的Thr-15、Tyr-15、Thr-160三个位点是否磷酸化有关。一般情况下,与周期蛋白结合的CDK2的上述三个位点被Wee/Mik1和CAK激酶磷酸化,但此时复合体还没有活性,只有当Cdc25c将Thr-15、Tyr-15两个位点去磷酸化后,复合体才有活性。细胞中存在多种因子对CDK2进行修饰调节,此外还存在对其活性起负性调控的蛋白质,即CDK激酶抑制物,例如p21CIP/WAF1、p27KIP2等。 前面提到,CDK2基因转录的产物有两种。这两种mRNA的不同之处在于变体1由全部7个外显子组成,而变体2缺失外显子5,由剩余的6个外显子组成。这样翻译成的两种同型蛋白的长度就相差34个氨基酸。 2 材料和方法: 2.1序列数据来源 采用蛋白质名称对NCBI非冗余蛋白质数据库进行检索,CDK2蛋白的记录有1013个。而采用基因名称对NCBI非冗余核酸数据库进行检索,CDK2蛋白的记录有680个。 采用人(Homo sapiens)的CDK2蛋白序列进行BLAST搜索。 2.2序列分析方法
(完整版)山东大学细胞生物学期末考试题,基地班必看
细胞生物学名词解释 1、双亲性分子(amphipathic molecule):是指由磷脂的磷脂酰碱基构成亲水极性头部和脂肪酸链构成疏水非极性尾部的分子,是膜脂的主体。 2、内在膜蛋白(intrinsic membrane protein):它贯穿膜脂双层,以非极性氨基酸与脂双层分子的非极性疏水区,相互作用而结合在质膜上,内在膜蛋白不溶于水,占膜蛋白总量的70%-80%,如膜上的受体蛋白与通道蛋白。 3、外在膜蛋白(extrinsic membrane protein):外在膜蛋白约占膜蛋白的20%~30%,分布在膜的内外表面,主要在内表面,为水溶性蛋白,靠离子键或其它弱键与能够暂时与膜或内在膜蛋白结合的蛋白质,易分离。 4、脂锚定蛋白(lipid anchored protein):质膜外侧的蛋白质通过糖链连接到磷脂酰肌醇上,形成“蛋白质—糖—磷脂”复合物,或质膜胞质侧的蛋白质通过脂肪酸链共价结合在脂双层上,这种蛋白即称为脂锚定蛋白(GPI)。包括:细胞粘附分子、免疫球蛋白超家族、Src、Ras蛋白。 5、被动运输(passive transport):通过简单扩散或协助扩散方式实现物质由高浓度向低浓度方向的跨膜转运,顺物质浓度梯度,不需消耗能量。 6、简单扩散(simple diffusion):质膜转运小分子物质时,不需膜蛋白的帮助,可以顺物质浓度梯度从高浓度一侧到低浓度方向进行,它不需消耗能量,属于被动扩散。以简单扩散方式运输的物质为:脂溶性小分子、非极性的小分子。 7、载体蛋白介导的易化扩散(Facilitated diffusion):物质穿越膜时在膜上载体蛋白的介导下,不消耗细胞的代谢能量,将溶质顺着浓度梯度或电化学势梯度进行转运,这种运输方式称易化扩散。部分载体蛋白; 非脂溶性物质。属于被动运输的范畴。 8、主动运输(active transport):指由载体蛋白介导的物质逆浓度梯度(或化学梯度)的由低浓度一侧向高浓度一侧消耗能量的跨膜运输方式。主要包括离子泵:直接水解ATP供能;协同运输:间接消耗ATP。 9、协同运输(coupled transport):一种物质的运输依赖第二种物质的同时运输。这种运输需要先建立离子梯度,在动物细胞主要是靠Na+泵、在植物细胞则是由H+泵完成的。
山东大学细胞生物学期末考试题5.doc
任安然2011级生科1班学号201100140034 细胞周期各时象的主要事件及调控机制 细胞周期(cell cycle)是指细胞从前一次分裂结束起到下一次分裂结束为止的活动过程,分为间期与分裂期两个阶段。 (一)间期 间期又分为三期、即DNA合成前期(G1期)、DNA合成期(S期)与DNA合成后期(G2期)。 1. G1期: 主要进行细胞体积的增大,并为DNA合成作准备。不分裂细胞则停留在G1 期, 也称为G0期。G1期,代谢旺盛,开始合成细胞生长需要的各种蛋白质,糖类,脂类、RNA等生化物质,细胞体积增大,为DNA合成做好准备,因此G1期也叫DNA合成预备期或复制前期。G1期染色体去凝集。 合成一定量RNA及专一性蛋白质,也称为触发蛋白,又称不稳定蛋白(U蛋白),触发蛋白积累到一定程度,即可通过G1期限制点,进入S期。G1期还合成了微管蛋白和抑素,组蛋白、非组蛋白及一些蛋白激酶发生磷酸化。抑素与细胞停留在G1期有关,具有组织特异性,是一种水溶性物质。 在G1期早期,cdc6水平升高,与ORC(多蛋白起始识别复合物)结合,促进Mcm结合到ORC上,形成pre-Rc(前复制复合物)。在G1晚期,G1-cdk使S期抑制物磷酸化,以便后来激活S-cdk,G1-cdk还使cdh1失活。 G1期限制点又称:监控点、检验点(checkpoint),酵母细胞中称start、启动点,哺乳类称R点、限制点,是细胞周期调控的第一大关卡。调控过程为cyclin E表达,在生长因子的诱导下,现有周期蛋白D的表达,并与Cdk2、Cdk4、Cdk5的结合,是个CDK磷酸化而激活。此后周期蛋白E表达,并与Cdk2结合使Cdk2的苏氨酸及酪氨酸残基磷酸化而活化,使细胞通过G1/S限制点进入S期,此时周期蛋白D及E降解。 2. S 期: 主要事件是DNA复制(半保留复制)和组蛋白合成(细胞质合成运往细胞核),也合成非组蛋白。诱导DNA合成的物质是SPF。细胞中微管的解聚可以导致DNA合成和细胞分裂。是细胞周期的关键时刻,DNA经过复制而含量增加一倍,使体细胞成为4倍体,每条染色质丝都转变为由着丝点相连接的两条染色质丝。与此同时,还合成组蛋白,进行中心粒复制。S期一般需几个小时。S期周期蛋白A合成,并与Cdk2结合而活化,进而促使转录因子E2F活化而促进与DNA合成有关的基因表达,以促进DNA的合成。S期有促DNA 复制的因子,只能促没有复制过的G1期细胞DNA复制,已复制过的G2期细胞其DNA不能再复制。 S期调控过程首先是cyclin D和E的降解,然后SCF(泛素蛋白质连接酶)降解G1期磷酸化了的S-周期蛋白——Cdk抑制物。cyclin A 合成,与Cdk2结合而活化,进而通过磷酸化RB使转录因子E2F游离于RB活化而促进与DNA合成有关的基因表,以促进DNA 的合成。S-cdk还可将cdc6磷酸化,使其脱离ORC,使SCF参与的泛素化途径降解,pre-RC 去组装;将某些Mcm磷酸化,使其被输出细胞核,不再与ORC结合。 这两步保证了DNA仅复制一次。CDK2/ cyclinA控制DNA 复制起始、且仅复制一次。