Chapter9 受限因变量模型

第1章 受限因变量模型
这一章讨论响应变量仅仅被部分观测到的情况。引入被部分观测到的潜在随机变量y *,y *的实际观测变量为y i 。引入二元指示变量D i ,如果a i < y *
****,,,i i i
i i i i i i i i a y a y y a y b b y b ?
= ≤≤?? >?
如果如果如果。 (1)
如果只有当D i = 1时实际观测变量y i 才有观测数据,即:当D i = 1时,潜在变量与实际观测变量相等,而当D i = 0时,y i 没有观测值,这时称数据被截断(truncated ),即小于a i 的数据和大于a i 的数据被截断了。因此截断数据与归并数据的区别在于,对于观测区间外的数据,归并数据将将其都归并为一点,而截断数据没有观测值。
将潜在随机变量y *的基本模型设定为:
*i i i y v μσ=+。 (2)
其中μi 为位置参数,σ为刻度参数;v i 为独立于x i 的连续随机扰动项,均值为0,方差为1,其分布函数、密度函数分别为F 、f 。在这些假定条件下,y i *
的均值为μi ,方差为σ2
,分布函数为*()i i
y F μσ
-,
概率密度函数为*(
)/i i
y f μσσ
-(证明请参见附录1)。a i < y i * < b i 等价于i i
i i
i i i a b c v d μμσ
σ
--=
<<
=,
那么y i *被观测到的概率为:
*Pr()Pr(1)()()i i i i i i a y b D F d F c <<===- (3)
下面对截断数据模型和归并数据模型分别进行介绍
1.1 截断数据模型
如果样本数据是从总体的一部分抽取得到,我们把这类数据称为截断数据。比如,研究高收入阶层(月收入x ≥ 10000)的消费与收入的关系,所采集的数据只是位于收入总体分布的一个区间里。假设所有居民的收入服从正态分布,那么高收入阶层的收入只是在x ≥ 10000的区间里观测得到的。下面介绍截断数据的分布特征和模型估计。
1.1.1 截断数据的分布特征
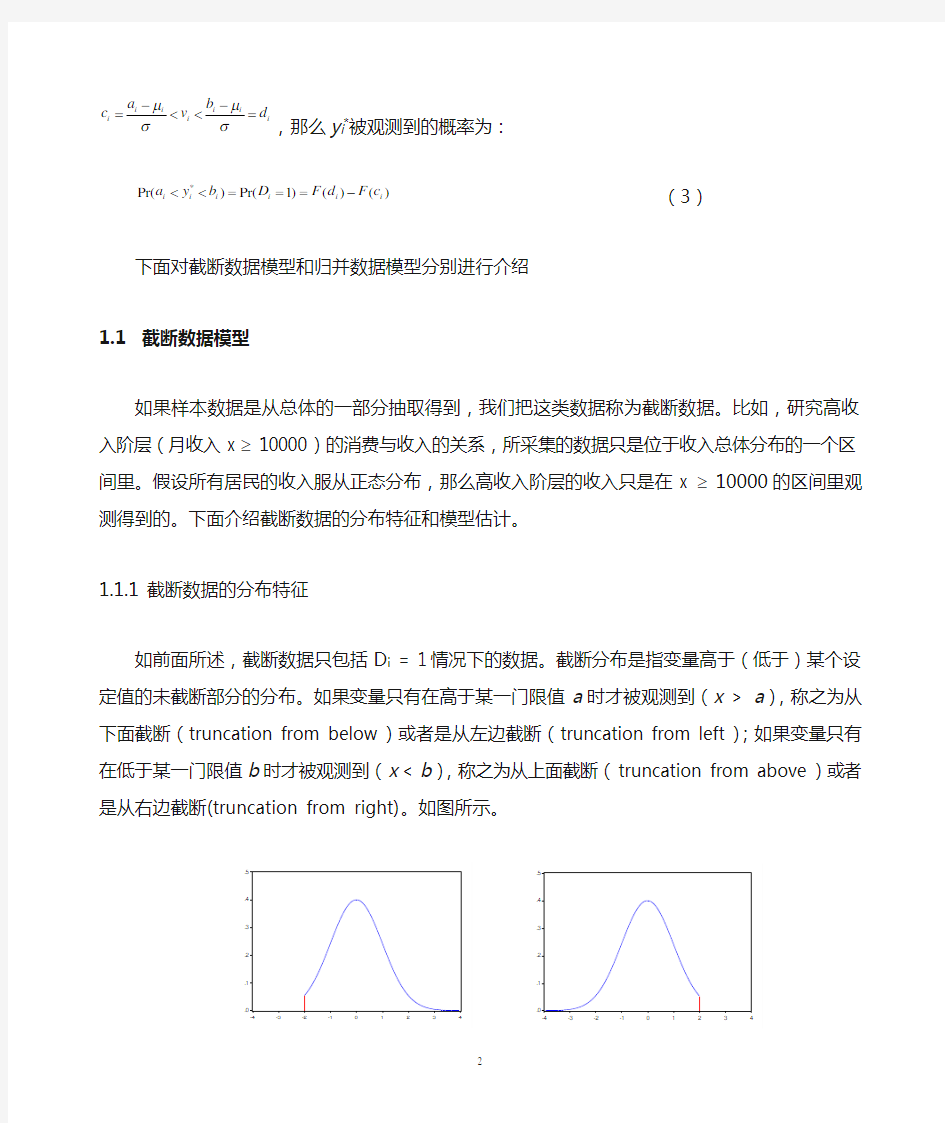
如前面所述,截断数据只包括D i = 1情况下的数据。截断分布是指变量高于(低于)某个设定值的未截断部分的分布。如果变量只有在高于某一门限值a 时才被观测到(x > a ),称之为从下面截断(truncation from below )或者是从左边截断(truncation from left );如果变量只有在低于某一门限值b 时才被观测到(x < b ),称之为从上面截断(truncation from above )或者是从右边截断(truncation from right)。如图所示。
图一 截断分布图(上面截断(左图)、下面截断(右图))
下面分析截断数据的分布函数、密度函数、均值和方差。
1. 截断变量的分布函数和密度函数
给定模型(1)及相应的观测概率(2),那么第i 个观测变量y i 的条件分布函数为(证明请参见附录2):
()()()()***0,()/(),1,i i
i i i y i i i i i i i i y a F y F c F y a y b F d F c y b
μσ?
--?= ≤≤?-?
? >?
如果如果如果 (4)
(注:此处及后面的,,,i i i i a b c d 的定义均与前面相同)
密度函数为:
()
()()
*()/1,()0,i i i i i i i y i f y a y b F d F c f y μσσ?- ≤≤?
-=?? ?
如果其他 (5) 从截断数据的密度函数(4)式我们可以推出从下面截断或从上面截断的各种不同分布的变量的密度函数。读者可以参阅下面介绍的几个例子。 例1 截断均匀分布的密度函数和分布函数
如果x *在区间[a ,b ]上服从均匀分布(uniform distribution ),那么
1
(),()()x a
f x F x a x b b a
b a
-=
=
<<--, (6) 如果在x *= c 处截断,即实际观测值x = x *,如果x *≥ c ;x = c ,如果x *< c 。
这是左截断的例子,即右截断点=b 。根据(5)式,在x = c 处截断的随机变量x 的截断分布的密
度函数为:
**()()1/()1
()(1)()()1()/()i f x f x b a f x P D F b F c c a b a b c
-====
=----- (7) 分布函数为:
()()()/()()/()()Pr(1)1()/()i F x F c x a b a c a b a x c
F x D c a b a b c
-------=
===---- (8)
例2 截断正态分布的密度函数
模型设定为:
*i i i y v μσ=+,
y i = y i *,如果*i i i a y b << (9) y i = a i ,如果*i i y a ≤ y i = b i ,如果*i i y b ≥
其中v i ~N (0, 1)。即 y i * ~N (μi , σ2),其中μi 、σ分布表示y i 的均值和标准差。以φ、Φ分别表示标准正态分布密度函数和分布函数。那么:
Pr()Pr(
)
()()
()()
i i
i i
i i
i i i i i i i
i i a y b a y b b a d c μμμσσσ
μμσσ
---<<=<
<
-- =Φ-Φ = Φ-Φ (10)
其中,,i i
i i
i i b a d c μμσ
σ
--=
=
。
根据截断正态分布的密度函数公式:
()
()()
*()/1,()0,i i i i i i i y i f y a y b F d F c f y μσσ?- ≤≤?
-=?? ?
如果其他 可直接得到*i i i a y b ≤≤时y i 的密度函数:
1
(
)
()()()
()1()
()11()
i i
y i i i i i i i i i i i y f y d c y if a d y if b c μφσ
σ
μφσσμφσσ-=Φ-Φ-?? →-∝?Φ? =
?-?? →+∝
?-Φ?
(11) 根据截断正态分布的分布函数公式:
()()()()***0,()/(),1,i i i i i y i i i i i i i i y a F y F c F y a y b F d F c y b
μσ?
--?= ≤≤?-?
? >?
如果如果如果
可直接得到*i i i a y b ≤≤时y i 的分布函数:
(
)()
()()
()()()()()
()()
()()1()i i
i i
i i y i i i i i i i
i
i i i i i i y y a c F y d c d c y if a d y c if b c μμσ
σ
μσμσ--Φ-ΦΦ-Φ=
=
Φ-ΦΦ-Φ-?Φ? →-∝?Φ? =
?-?Φ-Φ? →+∝?-Φ?
(12)
图二 截断正态分布变量的累积分布函数图
(设潜变量y *~N (0, 1),图中虚线表示标准正态分布函数,实线表示截断正态分布函数,截断点为-1、1)
2. 截断变量的均值和方差
截断随机变量的均值和方差称之为截断均值(truncated mean )和截断方差(truncated variance ),由下面的(5)、(6)式可以推出各种不同截断分布的均值和方差。给定模型(9),
y i 的均值为:
[]i i i E y μσ?=+ (13)
其中,()
[]()()
i
i d i i i i i c i i f v E v |c v d v
dv F d F c ?=<<=-?
y i 的方差为:
2[|1][|]i i i i i i Var y D Var v c v d σ==<< (14)
其中,2
2()
[]()()
i
i d i i i i i c i i f v Var v |c v d v dv F d F c ?<<=--?。
(证明请参见附录3)。
例3:均匀分布的截断均值和截断方差
给定模型(6),截断变量x 的均值和方差分别为:
2222211
()(|)()2
()[(|)](|)11
[()]21
[()()]
2
b b
c
c
b c
b
c E x xf x x c dx x
dx b c b c Var x x E x x c f x x c dx x b c dx
b c b c c a b c =>==+-=->> =-+- =---+???? (15)
例4:正态分布的截断均值和截断方差
给定模型(9),那么y i 的均值和方差分别为:
[]i i i E y μσ?=+ (16)
其中,()()
[|]()()
i i i i i i i i i d c E v c v d d c φφ?-=<<=-
Φ-Φ
y i 的方差为:
2[|1][|]i i i i i i Var y D Var v c v d σ==<< (17)
其中,2
()()()()[]1[]()()()()
i i i i i i i i i i i i i i d d c c d c Var v |c v d d c d c φφφφ--<<=-
-Φ-ΦΦ-Φ。
其中,φ、Φ分别表示正态分布的密度函数和分布函数。
(1) 如果c i -∝,即数据只是在右边截断,这时φ( c i ) = 0、Φ( c i ) = 0,因此:
()
[]()()
i i i i i i i d E v |v d d d φ?λ=<=-
=Φ<0 (17a )
2[]1()-()i i i i i i Var v |v d d d d λλ<=+ (17b )
(2) 如果d i +∝,即数据只是在左边截断,这时φ( d i ) = 0、Φ( d i ) = 1,因此:
()
[]()1()
i i i i i i i c E v |v c c c φ?λ=>=
=-Φ>0 (18a )
2[]1()-()i i i i i i Var v |v c c c c λλ>=+ (18b )
(17a )式中()
()=-
()
i i i d d d φλΦ称之为Inverse Mills Ratio ,将(18a )式中()
()=
1()
i i i c c c φλ-Φ称之为风险
函数(Hazard Function )。 结论1
(|)()(|)E y y b E y E y y a <<<>。即,如果变量为从上面截断,则截断变量的均值小于初始
变量的均值;如果变量为从下面截断,则截断变量的均值大于初始变量的均值。 结论2 截断变量的方差低于初始变量的方差。
图三 截断分布的均值(左图)、方差(右图)(假定潜在变量y *
~N (2, 2))
1.1.2 截断回归模型估计
下面以左截断模型为例说明截断回归模型的估计。
设回归模型为:i i i y v σ=+x β (19)
其中,v i ~N (0, 1)。那么,2~(,)i i y N σx β。根据例4,我们可以得到截断随机变量y i 的均值和方差。
()
[|][|]()1()
i i i i i i i i i i E y y a E y v φαασ
σλαα>=>=+=+-Φx βx β (20)
其中,-i i a ασ
=
x β
,()()/[1()]i i i λαφαα=-Φ
2[|]1()()1()i i i i i i Var y y a αλαλαδα>=+-=- (21)
其中,()()[()]i i i i δαλαλαα=-
由(20)式可以看出,截断均值为β和x i 的非线性函数。同一般的非线性模型一样,变量x k 对y 的边际影响不等于其系数:
()2[|]()()()[1()]
E y y a d d λαα
σ
ασλααλασδα?>?=+??-??
= +- ???
=-βx x
βββ (22)
因为0()1i δα<<,所以变量x k 对y 的边际影响要小于其系数。y i 的方差也存在类似的缩减(attenuation ):
22(|)[1()]i i i Var y y a σδασ>=-< (23)
注:
对于y i < b 的情况,可以得到相同的结论。
下面分析截断模型中参数的最小二乘估计和极大似然估计。 1. OLS 估计
根据[|]()i i i i E y y a σλα>=+x β,截断模型可以写为:
[|]i i i i i i i
y E y y a v u σσλ=>+ =++x β (24)
其中,u i = σv i 为y i 减去其条件期望,E(u i )=0。
如果以最小二乘法估计(19)式,就忽略了非线性项λi ,因此OLS 估计量是有偏的。
另外,y i |y i >a 的方差与u i 的方差相同,由2(|)[1()]i i i Var y y a σδα>=-可知,y i 存在异方差,为:
2222[][][|](1)(1())
i i i i i i i i i Var y Var u Var v v σασλλασδα==> =-+ = - (25)
它是x i 的函数。
2. ML 估计
对于模型(19),由截断随机变量的概率密度函数可得y i 的密度函数为,
(
)
1
()1()
i i y i i y f y φσ
σα-=
-Φx β
, (26)
可以得到y i 的对数似然函数:
222-11
[log(2)log ]()log[1()]22i i i i a LogL y πσσσ
=-+----Φx βx β (27)
对于N 个观测值(y 1, …, y N ),其联合对数似然函数为:
22
2
1
1
-1
[log(2)log ]()log[1(
)]22N N
i i i i i i a N LogL y πσσσ
===-+-
---Φ∑∑x β
x β (28)
通过最优化方法可以解得上式的参数β和σ的值。
1.2 归并数据模型
计量经济学当中经常能碰到数据的归并问题,简单地说,归并数据即是被解释变量在某个区间的观测值都转化为同一个值。比如,研究电影院的座位需求情况,电影院总的座位是20000个。如果实际的需求量少于20000,那么观测到的需求量就等于实际需求量;但如果实际需求量大于(等于)20000,那么实际可观测到的需求数量只能为20000。这时我们说需求量数据被归并,即所有大于20000的数据都被归并为20000。
格林(Greene ,2000)列举了经验文献中归并数据的应用。其中包括:
1, 家庭耐用品消费支出[Tobin(1958)] 2, 婚外情次数[Fair(1977,1978)]
3, 劳动力市场中妇女工作的小时数[Quester and Greene(1982)] 4, 罪犯重新入狱的次数[White(1980)]等。
下面分别介绍归并数据的分布特征和模型估计。
1.2.1 归并数据的分布特征
如前所述,归并数据与截断数据的区别在于,归并变量包含D i = 1和D i = 0两种情况下的数据。
****
,,,i i i i i i i i i i i
a y a y y a y
b b y b ? ≤?
= <
或者写作:*max[,min(,)]i i i i y a y b =。即当*i i y a ≤时,所有值被归并为a i ;当*i i y b ≥时,所有值被归并为b i 。
归并数据按照归并点a i , b i 是随机的还是确定的分为固定归并(fixed censoring )和随机归并(random censoring )两种。如果a i , b i 是确定性的,我们称之为固定归并;如果a i , b i 是随机的,我们称之为随机归并。本章只介绍固定归并的情况。
归并数据按照归并点与观测区间的关系还可以分为左边归并和右边归并。如果:
*
**
,,i i i
i i
i i a y a y y y a ? ≤?=? >??如果如果 称潜在变量y *被从下面归并(censored below )或者从左边归并(censored from left );
如果:
**
*
,,i i i
i i
i i b y b y y y b ? ≥?=?
图 归并变量示意图
1.归并变量的分布函数和密度函数
给定基本模型(1)的假定,y i 的分布函数为:
10()((-)/) i y i i i i i i
i i i y a F y F y a y b y b μσ<≤≤ ? ?
= ??
>
?如果如果如果 (30)
归并变量的分布函数为一种混合分布(连续型和离散型综合在一起)。在y i = a i 和y i = b i 两点的概率分别为*()()((-)/) i i i i i i P y a P y a F a μσ==≤=和*()()1((-)/)i i i i i i P y b P y b F b μσ==≥=-,因此对于同一个潜在变量,其归并变量和截断变量的分布函数不相同,在观测区间内,归并分布同潜在变量的分布重叠在一起。
图四 归并正态分布变量的分布函数图
密度函数(概率分布)为:
()*
*
()Pr()()(-)/(),()Pr()1()i i y i
i i i i i y i
i i y i
i i i y i i i a P y a y a F f y f y a b b P y b y b F μσ
μσσμσ<<-?==≤= ??
?
= ??
-?==≥=-??
如果 (31) 例5:正态分布归并变量的密度函数。
假定潜在变量(latent variable )y i *服从均值为μi 、方差为σ2的正态分布,*i i i y v μσ=+,v i ~N (0, 1)。y i 为实际观测变量:y i =a ,如果y i *≤ a ;y i =b ,如果y i * ≥ b ;y i = y i *,如果a i < y i * < b i 。的概率密度函数为:
当y i * ≤ a i 时,y i =a i 。其概率为,
*Pr()Pr()(
)i i
i i i i a y a y a μσ
-==≤=Φ
当a i < y i * < b i 时,y i 与y i *的概率密度函数相同,
*()()(
)/i i
i i y f y f y f μσσ
-==
当y i * ≥b i 时,y i =b i 。其概率为,
*Pr()Pr()1(
)i i
i i i i b y b y b μσ
-==≥=-Φ
(1)当仅从左边归并时,即:y i =a i ,如果y i * ≤ a i ;y i = y i *,如果y i * > a i 。 当y i * ≤ a i 时,y i =a i 。其概率为,
*Pr()Pr()(
)i i
i i i i a y a y a μσ
-==<=Φ
当y i * > a i 时,y i 与y i *的概率密度函数相同,
*()()(
)/i i
i i y f y f y f μσσ
-==
因此,可以将y i 的密度函数综合写成:
2
-1()12-()[(
)]
]i i i
i y D D i i
i a f y μ
μσ
--=Φ,当y i * > a i 时,D i = 1;否则,D i = 0。
(2)当仅从右边归并时,即:y i =b i ,如果y i * ≥ b i ;y i = y i *,如果y i * < b i 。 当y i * ≥b i 时,y i =b i 。其概率为,
*Pr()Pr()1(
)i i
i i i i b y b y b μσ
-==>=-Φ
当y i * < b i 时,y i 与y i *的概率密度函数相同,
*()()(
)/i i
i i y f y f y f μσσ
-==
因此,可以将y i 的密度函数综合写成:
2
-1()12-()[1(
)]
]i i i
i y D D i i
i b f y μσ
μσ
--=-Φ,当y i * > a i 时,D i = 1;否则,D i = 0。
2.归并变量的均值和方差
归并随机变量的均值和方差,我们称之为归并均值(censored mean )和归并方差(censored variance ) 归并均值为:
**[][|1]Pr(1)Pr()Pr()i i i i i i i i i i E y E y D D a y a b y b ===+≤+≥ (32)
其中,
**[|1]Pr(1)[()()]()Pr()()Pr()1()
i
i
d i i i i i i c i i i i i i E y D D F d F c vf v dv
y a F c y b F d μσ===-+≤=≥=-? (33)
归并方差为:
2[][|1]()[|1][]i i i i i i i Var y Var y D E D E y D Var D ==+= (34)
其中,D i 服从0-1分布,()()()i i i E D F d F c =-,[][](1[])i i i Var D E D E D =-。 (证明请参见附录4)。
设潜在变量y *~N (0, 1),下图显示了标准正态分布和归并正态分布的分布函数间的差异,虚线表示正态分布函数,实线表示归并正态变量分布函数,归并点为-1、1,在区间[-1,1]上实线和虚线重合。
例6:正态分布归并变量的均值和方差
如果*2~[,]i i y N μσ。y i =a ,如果y i *≥ a ;y i =b ,如果y i * ≥ b ;y i = y i *,如果a i < y i * < b i 。那么 y i 的均值为:
[][()()][()()]()[1()]i i i i i i i i i i E y d c d c a c b d μσφφ=Φ-Φ+-+Φ+-Φ (35)
(证明请参见附录5)。
(1)如果a i -∝(仅从上面归并),那么
[]()()[1()]i i i i i i E y d d b d μσφ=Φ-+-Φ
= ()()[1()]()i i i i i i d d b d d φμσ??
Φ-+-Φ ?Φ?
?
= ()()()[1()]i i i i i d d b d μσλΦ++-Φ (37)
()()2
2[](1()()1()i i i i i Var y d d d d σδλ??=Φ-+--Φ??
, (38)
其中,()()/()i i i d d d λφ=-Φ,2()=()()i i i i d d d d δλλ-
(2)如果b i +∝(仅从下面归并),那么
[][1()]()()i i i i i i E y c c a c μσφ=-Φ++Φ
=()[1()]()1()i i i i i i c c a c c φμσ??
-Φ++Φ ?-Φ?
?
=()[1()]()()i i i i i c c a c μσλ-Φ++Φ (39)
()22[]1()[(1)()()]i i i i i i Var y c c c σδλ=-Φ-+-Φ (40)
其中,()()/[1()]i i i c c c λφ=-Φ,2i i i i c δλλ=- (证明请参见格林(Greene(2000)P907)。
由(37)式和(39)式可以推出:
结论3 对于从上面归并的变量来讲,当归并点为b i = 0时,
()[][1(
)()i
i i i E y d μμσλσ
=-Φ+, (41) 其中(/)(/)
()(/)1(/)
i i i i i d φμσφμσλμσμσ-=-
=-
Φ--Φ 对于从下面归并的变量来讲,当归并点为a i = 0时,
()[](
)()i
i i i E y c μμσλσ
=Φ+ , (42) 其中()()
//()1(/)(/)
i i i i i c φμσφμσλμσμσ-==
-Φ-Φ
例7:以电影院的座位需求为例,我们来看一下如何利用归并数据模型通过实际观测到的变量来推断潜在变量的均值、方差。设电影院总共有20000个座位,平均售出的座位数为18000,有25%的时间全部售出。那么潜在的座位需求量和方差各是多少呢?
图二 座位需求图
解:设潜在座位需求量为μ,座位需求模型可以设定为:
****
,2000020000,20000
i i
i i i i y v y y y y μσ=+?
20000()(
)Pr(*18000)=0.75d y μ
σ
-Φ=Φ=Φ=<=
200000.675d μ
σ
-== (43)
因此,()()/()(0.675)/0.750.424d d d λφφ=-Φ=-=-; 又由平均观测到的需求量为18000,根据归并变量的均值公式可得:
()()()()[1()]=0.75(0.424)200000.2518000
E y d d b d μσλμσ=Φ++-Φ -+?= (44)
综合(43)(44)可以解出潜在变量y *的均值和方差分别为μ=2426、σ2=18362。即,对电影院座位的平均需求量是2426个。
1.2.2 归并模型的极大似然估计
设归并回归模型中,潜在变量y *和实际观测变量y 有:
*'i i i y u =+βx i i y a =,如果*i i y a ≤ i i y b =,如果*i i y b ≥
*i i y y =,其它
设f (u )、F (u )为u 的密度函数和分布函数。假定u 是均值为0,方差为σ2的连续随机变量,u 与x 不相关。
由归并模型的概率密度函数可知其对数似然函数为:
222
()1[log(2)log ]2--log[(
)]log[1(
)]
i i i i i
i i
i i a y b i i i i y a y b y LogL a b πσσσ
σ
≤≤==-=-+- + Φ+ -Φ∑∑∑x βx β
x β
虽然它是离散分布和连续分布的总和,但Amemiya (1973b )证明,按照普通的最优化方式使得对数似然函数极大化,得到的估计量仍然具有极大似然估计量的合意的性质。
归并回归模型的边际影响为:
()*[|]
Pr[]()()k i i i k i i k
E y a y b
F d F c ββ?=?<<=-?x x (证明请参见Greene(2000)P909)。
例:考察囚犯在释放后被再次被捕入狱的时间,共1445名调查者,其中只有552名被再次被捕入狱。(file :recid.raw )。
例:妇女就业时间的案例(在0点截断)。(file :mroz.raw )
1.3 Tobit 模型
1.3.1 Tobit 模型的设定与估计
Tobin 在1958年第一次提出归并模型,因此归并模型又称为Tobit 模型。设潜在变量y *的回归模型为:
****0,0,0
i i i
i i i i i y v y y y y y σ=+= ≤= >x β如果如果, 潜在变量y *的期望值为:
*[]i i E y =x β
其中,(/)
(/)
i i i φσλσ=
Φx βx β
因此,解释变量对被解释变量y *的边际影响为常数:
*[|]
k k
E y x x β?=? 实际观测变量y 的期望值为:
()(|1)(1)i i i i E y E y D P D ===
而(1)(/)i i P D σ==Φx β,(|1)(/)i i i i E y D σλσ==+x βx β,将其代入上式可得:
[](
)()(
)(
)i i i i i i i E y σλσφσ
σ
σ
=Φ+=Φ+x β
x β
x β
x βx β
解释变量对实际观测变量的边际影响是非线性的。
由()(|1)(1)i i i i E y E y D P D ===可得:
(1)
(|1)()(|1)(1)i i i i i i k k k
P D E y D E y E y D P D x x x ?=?=?==+=??? 其中,
(1)(1)(/)(/)i k
i k P D P D x βσφσσ
?===Φ?
=?x βx β
(|1)(/)(|1)(/)(/)(/)()
i i i i i i i i k k i k E y D E y D x x σλσλσσβσ
σ==+?=???
=+???x βx βx βx βx β
= (/)
(/)
i k k
i λσββσ?+?x βx β
= []()1(/)/(/)k i i i βλσσλσ-+x βx βx β
因此,
()
(/)k k
E y x βσ?=Φ?x β Tobit 模型的似然函数为:
22
2
00
()1[log(2)log ]log[1()]2i i i i i y y y LogL πσσσ>=-=-+- + -Φ∑∑x βx β 利用最优化方法可以求出参数估计量。
例:考察不同变量对妇女工作时间的影响。(file :mroz.raw )。共753个观测值,其中325个为0。用Tobit 模型进行估计。
Tobit 模型的一个重要局限是,*(|0,)i i E y y >x 与*(0)i P y >直接相关。x k 对*(0)i P y >的边际影响
(0|)k P y x ?>?x 与βk 呈正比,x k 对*
(|0,)i i E y y >x 的边际影响*(|0,)i i k
E y y x ?>?x 与βk 也呈正比,即x k 对
*(0)i P y >的影响和对*(|0,)i i E y y >x 的影响在方向上是相同的。在一些情况下,这一暗含的假定可
能不合适。
1.3.2 模型的设定分析
衡量Tobit 模型是否合适的一种方法是将Tobit 模型的估计结果与Probit 模型的估计结果相比较。由Tobit 模型的设定,*(0)(0)(/)1(/)i i i i P y P y P v σσ==≤=≤-=-Φx βx β,(0)(/)i i P y σ>=Φx β。因此,如果将y 降级为二元选择变量w (如果y =0,w =0;如果y ≠0,w =1),那么上述Tobit 模型就转化为Probit 模型。如果Probit 模型估计的结果与Tobit 模型的估计结果近似相同,说明Tobit 模型设定合适;否则,Tobit 模型的设定不合适。需要注意的是,在Probit 模型中,(1|)(|)()P y E y ===Φx x x γ;
而在Tobit 模型中,(1)(/)P w σ==Φx β。因此,应该将Probit 模型中的参数估计量?γ
与Tobit 模型中的参数估计量??/σβ
进行比较。如果?γ与??/σβ符号不同,或者二者差异很大,都表明Tobit 模型设定不合适。
事实上,Tobit 模型是截断模型和Probit 模型的结合。 对于Tobit 模型:
~(0,1)
0i i i i i i i i v v N y y y y y σ***
*
=+, ? , >0?=?, ≤0
??x β (A)
设共有N 个观测值,其中y i =0有N 0个观测值,y i =1有N 1个观测值,N = N 0+ N 1。 其似然函数为
()11
01(|)(0)1(/)i i i i i N N Tobit
i i i N N y f y y y LnL P y y φσσσ*
**?-??>0= , >0 ????=??==-Φ, ≤0
?∑∑∑∑x βx β
对于截断模型(截断点为0):
,~(0,1),i i i i i i i v v N y y y y σ**
*
=+ = >0
x β
其似然函数为:
1
111(|)1(/)()1(/),i i i i Trucn i N
N i i i i i N
N f y y y LnL P y y y φσσσφσσσ***>0-??
==Φ, ?>0??
-??
=- Φ >0 ???
∑∑∑∑x βx βx βx β
对于Probit 模型
(1)()(0)1()i i i i P D P D ==Φ
??
==-Φ?
x γx γ 其似然函数为:
()10
Pr ()1()i i N obit
i
i N y LnL y **
?Φ
, >0?= ?-Φ ≤ , 0??∑∑x γx γ 因此,截断模型与Probit 模型的似然函数之和为:
()()1
11010
Pr 1(/)()1()11()i i Trunc obit i i i N
N N N i i i N N y LnL y φσσσφσσ+-??=- Φ +Φ+-Φ ???
-??
= +-Φ ???∑∑∑∑∑∑x βx βx γx γx βx γ
与Tobit 模型的似然函数()1
011(/)i i Tobit i N
N y LnL φσσσ-??
=+-Φ ???
∑∑x βx β相比较,可以发现,Tobit 模型是Truncated 模型和Probit 模型之和的约束形式,约束条件为:/σ=γβ。因此,检验Tobit 设定是否合适可以利用似然比检验方法。具体步骤为: Step1:分别估计截断模型、Probit 模型和Tobit 模型;
Step2:计算似然比统计量:LR =2(LL Trunc + LL Probit – LL Tobit ),自由度为Tobit 模型中未知参数的个数。
例:考察不同变量对妇女工作时间的影响。(file :mroz.raw )。分析Tobit 模型的估计是否恰当。
如果检验结果表明Tobit 模型设定不恰当,那么可以利用Hurdle (或称之为Two-Part )方法。(略)
注:
1. 在EViews 中,截断回归模型和归并回归模型中,对于随机扰动项可以设定为三种不同的形式:标准正态、Logistic 分布和极值分布。对于模型
'i i i y v σ=+βx
v i 服从标准正态分布:E(v i )=0, Var(v i )=σ2。 v i 服从Logistic 分布:E(v i )=0, Var(v i )=π2/3。 v i 服从标准正态分布:E(v i )≈0.5772,Var(v i )=σ2/6。
2. 对于归并模型,归并点可以已知,也可以未知;但对于截断模型,截断点必须是已知的。
附录:截断分布的矩
1.随机变量的截断分布特征
2.标准正态分布变量的截断分布特征
二次函数在实际生活中的应用及建模应用
二次函数的建模 知识归纳:求最值的问题的方法归纳起来有以下几点: 1.运用配方法求最值; 2.构造一元二次方程,在方程有解的条件下,利用判别式求最值; 3.建立函数模型求最值; 4.利用基本不等式或不等分析法求最值. 一、利用二次函数解决几何面积最大问题 1、如图1,用长为18米的篱笆(虚线部分)和两面墙围成矩形苗圃。 (1)设矩形的一边长为x (米),面积为y (平方米),求y 关于x 的函数关系式; (2)当x 为何值时,所围成的苗圃面积最大?最大面积是多少? 解:(1)设矩形的长为x (米),则宽为(18- x )(米), 根据题意,得: x x x x y 18)18(2+-=-=; 又∵180,0180<x<x >x >∴? ??- (自变量x 的取值范围是关键,在几何类题型中,经常采用的办法是: 利用含有自变量的加减代数式的边长来确定自变量的取值范围,例如上式 中,18-x ,就是含有自变量的加减代数式,考虑到18-x 是边长,所以边长应该>0,但边长最长不能超过18,于是有0<18-x <18,0<x <18) (2)∵x x x x y 18)18(2 +-=-=中,a= -1<0,∴y 有最大值, 即当9) 1(2182=-?-=-=a b x 时, 81)1(41804422max =-?-=-=a b ac y 故当x=9米时,苗圃的面积最大,最大面积为81平方米。 点评:在回答问题实际时,一定注意不要遗漏了单位。 2、如图2,用长为50米的篱笆围成一个养鸡场,养鸡场的一面靠墙。问如何围,才能使养鸡场的面积最大? 解:设养鸡场的长为x (米),面积为y (平方米),则宽为(250x -)(米), 根据题意,得:x x x x y 252 1)250(2+-=-=; 又∵500,02 500<x<>x x >∴?????- ∵x x x x y 252 1)250(2+-=-=中,a=21-<0,∴y 有最大值,
Chapter9-受限因变量模型
第1章 受限因变量模型 这一章讨论响应变量仅仅被部分观测到的情况。引入被部分观测到的潜在随机变量y *,y *的实际观测变量为y i 。引入二元指示变量D i ,如果a i < y *? 如果如果如果。 (1) 如果只有当D i = 1时实际观测变量y i 才有观测数据,即:当D i = 1时,潜在变量与实际观测变量相等,而当D i = 0时,y i 没有观测值,这时称数据被截断(truncated ),即小于a i 的数据和大于a i 的数据被截断了。因此截断数据与归并数据的区别在于,对于观测区间外的数据,归并数据将将其都归并为一点,而截断数据没有观测值。 将潜在随机变量y *的基本模型设定为: *i i i y v μσ=+。 (2) 其中μi 为位置参数,σ为刻度参数;v i 为独立于x i 的连续随机扰动项,均值为0,方差为1,其分布函数、密度函数分别为F 、f 。在这些假定条件下,y i *的均值为μi ,方差为σ2,分布函数为*()i i y F μσ -, 概率密度函数为*( )/i i y f μσσ-(证明请参见附录1) 。a i < y i * < b i 等价于i i i i i i i a b c v d μμσ σ --=<< =, 那么y i *被观测到的概率为: *Pr()Pr(1)()()i i i i i i a y b D F d F c <<===- (3) 下面对截断数据模型和归并数据模型分别进行介绍 1.1 截断数据模型 如果样本数据是从总体的一部分抽取得到,我们把这类数据称为截断数据。比如,研究高收入阶层(月收入x ≥ 10000)的消费与收入的关系,所采集的数据只是位于收入总体分布的一个区间里。假设所有居民的收入服从正态分布,那么高收入阶层的收入只是在x ≥ 10000的区间里观测得到的。下面介绍截断数据的分布特征和模型估计。
面板数据的F检验固定效应检验
面板数据的F检验固定 效应检验 标准化工作室编码[XX968T-XX89628-XJ668-XT689N]
面板数据模型(P A N E L D A T A)F检验,固定效应检验1.面板数据定义。 时间序列数据或截面数据都是一维数据。例如时间序列数据是变量按时间得到的数据;截面数据是变量在截面空间上的数据。面板数据(panel data)也称时间序列截面数据(time series and cross section data)或混合数据(pool data)。面板数据是同时在时间和截面空间上取得的二维数据。面板数据示意图见图1。面板数据从横截面(cross section)上看,是由若干个体(entity, unit, individual)在某一时刻构成的截面观测值,从纵剖面(longitudinal section)上看是一个时间序列。 面板数据用双下标变量表示。例如 y , i= 1, 2, …, N; t= 1, 2, …, T i t N表示面板数据中含有N个个体。T表示时间序列的最大长度。若固定t不变,y , ( i i . = 1, 2, …, N)是横截面上的N个随机变量;若固定i不变,y. t, (t= 1, 2, …, T)是纵剖面上的一个时间序列(个体)。 图1 N=7,T=50的面板数据示意图 例如1990-2000年30个省份的农业总产值数据。固定在某一年份上,它是由30个农业总产总值数字组成的截面数据;固定在某一省份上,它是由11年农业总产值数据组成的一个时间序列。面板数据由30个个体组成。共有330个观测值。 对于面板数据y i t, i = 1, 2, …, N; t= 1, 2, …, T来说,如果从横截面上看,每个变量都有观测值,从纵剖面上看,每一期都有观测值,则称此面板数据为平衡面板数据(balanced panel data)。若在面板数据中丢失若干个观测值,则称此面板数据为非平衡面板数据(unbalanced panel data)。 注意:EViwes 、、既允许用平衡面板数据也允许用非平衡面板数据估计模型。
第八章 离散因变量模型
第八章离散因变量模型 离散(分类)因变量模型(Models with Discrete /Categorical Dependent Variables)分为二元选择模型(Binary Choice Models)和多类别选择(反应)模型(Multicategory Choice /Polytomous Response Models)。在多类别选择模型中,根据因变量的反应类别(response category)是否排序,又分为无序选择模型(Multinominal Choice Models)和有序选择模型(Ordered Choice Models)(也称有序因变量模型Ordered Dependent Variable Models、有序类别模型Ordered Category Models等) 一、二元选择模型 设因变量 1、线性概率模型(LPM模型) 如果采用线性模型, 给定,设某事件发生的概率为P i,则有 所以 称之为线性概率模型。 不足之处: 1、不能满足对自变量的任意取值都有。 2、 3、 所以线性概率模型不是标准线性模型。 给定,为使, 可对建立某个分布函数,使的取值在(0,1)。 2、Logit模型(Dichotomous/ Binary Logit Model) Logit模型是离散(分类)因变量模型的常用形式,它采用的是逻
辑概率分布函数(Cumulative Logistic Probability Function)(e为自然对数的底),逻辑曲线如图4-1所示。其中,二元Logit模型是掌握多类别Logit模型的基础。
图4-1 逻辑曲线(Logit Curve) 以二元选择问题为例,设因变量有0和1两个选择,由自变量来决定选择的结果。为了使二元选择问题的研究成为可能,首先建立随机效用模型: 令表示个体i选择=1的效用, 表示个体i选择=0的效用, 显然当时,选择结果为1,反之为0。将两个效用相减,即得随机效用模型: , 记为(4-1) 当时,,则个体i选择=1的概率为: 若的概率分布为Logistic分布,则有 即(4-2) 式(4-2)即为最常用的二元选择模型——Logit模型。 二元Logit选择模型的参数估计通常使用最大似然估计法,令似然函数,再求似然函数L的对数值最大时的参数估计量。 对(4-2)式进行适当的变换,得 即(4-3) 式(4-3)与式(4-2)是等价的,而且更易于解释,式中为个体i做出选择1的机会比(odds),式中的因变量是机会比(odds)的自然对数,参数的含义为自变量每增加一个单位机会比(odds)的自然对数
计量经济学经典eviews 离散和受限因变量模型
离散和受限因变量模型 前面所描述的回归方法要求能在连续和无限制的规模上观察到因变量。然而,也经常出现违背上述条件的情形,即产生非连续或受限因变量。我们将会识别三种类型的变量: 1.定性(在离散或排序的规模上); 2.审查或截断; 3.整数估值(计数数据)。 在这章里我们讨论这几种定性和受限因变量模型的估计方法。EViews 提供了二元或排序(普罗比特probit 、逻辑logit 、威布尔gompit ),审查或截断(托比特tobit 等),和计数数据模型的估计程序。 §17.1 二元因变量模型 二元因变量模型(Binary Dependent V ariable Models )估计方法主要发展与20世纪80年代初期。普遍应用于经济布局、企业定点、交通问题、就业问题、购买决策领域的研究。例如,公共交通工具和私人交通工具的选择问题。选择利用公共交通工具还是私人交通工具,取决于两类因素:一类是诸如速度、耗费时间、成本等两种交通工具所具有的属性;一类是决策个体所具有的属性,诸如职业、年龄、收入水平、健康状况等。从大量的统计中,可以发现选择结果与影响因素之间具有一定的因果关系。研究这一关系对制定交通工具发展规划无疑是十分重要的。 在本节介绍的模型中,因变量y 只具有两个值:1或者0。y 可能是代表某一事件出现的虚拟变量,或者是两种选择中的一种。例如,y 可能是每个人(被雇佣或不被雇佣)雇用状况的模型,每一人在年龄、教育程度、种族、婚姻状况和其它可观测的特征方面存在差异,我们将其设为x 。目标是将个体特征和被雇用的概率之间的关系量化。 假定一个二元因变量y ,具有0和1两个值。y 对x 简单的线性回归是不合适的。而且从简单的线性回归中得到y 的的拟合值也不局限于0和1之间。替代地,我们采用一种设定用于处理二元因变量的特殊需要。假定我们用以下模型刻画观察值为1的概率为: Pr )(1),1(ββi i i x F x y '--== 这里F 是一个连续、严格单调递增的函数,它采用实际值并返回一个介于0和1之间的数。F 函数的选择决定了二元模型的类型。可以得到 Pr )(),0(ββi i i x F x y '-== 给出了这样的设定以后,我们能用极大似然估计方法估计模型的参数。极大似然函数为 ∑=--+'--==n i i i i i x F y x F y L 0))(log )1())(1log(()(log )(ββββ 极大似然函数的一阶条件是非线性的,所以得到参数估计需要一种迭代的解决方法。缺省地,EViews 使用二阶导数用于参数估计的协方差矩阵的迭代和计算。 有两种对这种设定的重要的可选择的解释。首先,二元变量经常作为一种潜在的变量规定被生成。假定有一个未被观察到的潜在变量*i y ,它与x 是线性相关的: i i i u x y +'=β* 这里i u 是随机扰动。然后被观察的因变量由*i y 是否超过临界值来决定
随机解释变量问题
第四章 随机解释变量问题 1. 随机解释变量的来源有哪些? 答:随机解释变量的来源有:经济变量的不可控,使得解释变量观测值具有随机性;由于随机干扰项中包括了模型略去的解释变量,而略去的解释变量与模型中的解释变量往往是相关的;模型中含有被解释变量的滞后项,而被解释变量本身就是随机的。 2.随机解释变量有几种情形? 分情形说明随机解释变量对最小二乘估计的影响与后果? 答:随机解释变量有三种情形,不同情形下最小二乘估计的影响和后果也不同。(1)解释变量是随机的,但与随机干扰项不相关;这时采用OLS 估计得到的参数估计量仍为无偏估计量;(2)解释变量与随机干扰项同期无关、不同期相关;这时OLS 估计得到的参数估计量是有偏但一致的估计量;(3)解释变量与随机干扰项同期相关;这时OLS 估计得到的参数估计量是有偏且非一致的估计量。 3. 选择作为工具变量的变量必须满足那些条件? 答:选择作为工具变量的变量需满足以下三个条件:(1)与所替代的随机解释变量高度相关;(2)与随机干扰项不相关;(3)与模型中其他解释变量不相关,以避免出现多重共线性。 4.对模型 Y t =β0+β1X 1t +β2 X 2t +β3 Y t-1+μt 假设Y t-1与μt 相关。为了消除该相关性,采用工具变量法:先求Y t 关于X 1t 与 X 2t 回归,得到Y t ?,再做如下回归: Y t =β0+β1X 1t +β2 X 2t +β3Y t ?1 -+μt 试问:这一方法能否消除原模型中Y t-1与μt 的相关性? 为什么? 解答:能消除。在基本假设下,X 1t ,X 2t 与μt 应是不相关的,由此知,由X 1t 与X 2t 估计出的Y t ?应与μt 不相关。 5.对于一元回归模型 Y t =β0+β1X t *+μt 假设解释变量X t *的实测值X t 与之有偏误:X t = X t *+e t , 其中e t 是具有零均值、无序列相关,且与X t *及μt 不相关的随机变量。试问: (1) 能否将X t = X t *+e t 代入原模型,使之变换成Y t =β0+β1X t +νt 后进行估计? 其中,νt 为变换后模型的随机干扰项。 (2) 进一步假设μt 与e t 之间,以及它们与X t *之间无异期相关,那么E(X t-1νt )=0成立 吗?X t 与X t-1相关吗? (3) 由(2)的结论,你能寻找什么样的工具变量对变换后的模型进行估计? 解答:(1)不能。因为变换后的模型为 Y t =β0+β1X t +(μt -β 1e t ) 显然,由于 e t 与X t 同期相关,则说明变换后的模型中的随机干扰项νt =μt -β1e t 与X t 同 期相关。 (2) E(X t-1νt )=E[(X t-1* +e t-1)( μt -β1e t )]
引力模型的应用领域
引力模型的应用领域 引力模型是应用广泛的空间相互作用模型,它以牛顿万有引力公式为基础,这也是引力模型名字的由来。目前这个模型理论相当成熟,应用领域也很广泛。比如:空间布局、旅游、贸易、城市分析、交通、市场营销、企业区位、考古、高校招生和生物迁徙等领域。下面我将从引力模型应用的不同领域来谈谈自己对引力模型的理解。 一、引力模型在国际贸易领域的应用 引力模型最早应用于国际贸易研究,并且应用的相当广泛。最早将引力模型应用到贸易领域的是Jan Tinbergen(1962)。以下是我看过的有关该领域的一些期刊论文。 1、戴明辉、沈文星写的“中国木质林产品贸易流量与潜力研究:引力模型方法”,来源于资源科学2010(11)。本文在传统引力模型的基础上,通过引入具有林产品特色的要素禀赋、森林认证变量,对传统引力模型进行修正。运用1999年到2008年这10年间中国对28个木质林产品贸易伙伴国的面板数据进行实证分析,并进行中国主要木质林产品贸易潜力测算。结果表明中国木质林产品贸易流量和双方的经济规模成正相关,与距离因子成负相关,要素禀赋和双边贸易流量成正相关,而森林认证在双边贸易中起着积极的作用。 2、刘岩写的“贸易流量引力模型的理论研究综述”,来源于国际商务——对外经济贸易大学学报2010(3)。本文主要是进行引力模型的理论研究,笔者主要通过梳理近30 年来引力模型的理论发展脉络,全面展示了该理论从局部均衡到一般均衡的扩展;由无贸易理论基础到与贸易国自身禀赋的融合;并提出今后相关理论和实证研究可能进行扩展的方向。比如:人均收入水平是否可以用于解释双边发展中国家的贸易流量。 3、谢国娥、李亮写的“基于引力模型的中澳双边农产品贸易影响因素研究”,来源于华东理工大学学报社会科学版2010(4)。本文主要以1992~2008 年中澳双边农产品贸易的面板数据为基础,运用引力模型分析影响中澳双边农产品贸易的各种因素。其结果表明:中澳双边农产品贸易流量与两国对农产品的需求成正相关;与澳大利亚进口关税率成负相关;与两国的RCA的相关系数、SARS的相
2019-2020年九年级数学下册 21 建立二次函数模型教案 湘教版
2019-2020年九年级数学下册 21 建立二次函数模型教案湘教版教学目标: 1、从实际情景中让学生经历探索分析和建立两个变量之间的二次函数关系的过程,进一步体验如何用数学的方法去描述变量之间的数量关系。 2、理解二次函数的概念,掌握二次函数的形式。 3、会建立简单的二次函数的模型,并能根据实际问题确定自变量的取值范围。 4、会用待定系数法求二次函数的解析式。 教学重点:二次函数的概念和解析式 教学难点:本节“合作学习”涉及的实际问题有的较为复杂,要求学生有较强的概括能力。 教学设计: 一、创设情境,导入新课 问题1、现有一根12m长的绳子,用它围成一个矩形,如何围法,才使举行的面积最大?小明同学认为当围成的矩形是正方形时,它的面积最大,他说的有道理吗? 问题2、很多同学都喜欢打篮球,你知道吗:投篮时,篮球运动的路线是什么曲线?怎样计算篮球达到最高点时的高度? 这些问题都可以通过学习俄二次函数的数学模型来解决,今天我们学习“二次函数”(板书课题) 二、合作学习,探索新知 请用适当的函数解析式表示下列问题中情景中的两个变量y与x之间的关系: (1)面积y (cm2)与圆的半径 x ( Cm ) (2)王先生存人银行2万元,先存一个一年定期,一年后银行将本息自动转存为又一个一年定期,设一年定期的年存款利率为文 x 两年后王先生共得本息y元; (3)拟建中的一个温室的平面图如图,如果温室外围是一个矩形,周长为12Om , 室内通道的尺寸如图,设一条边长为 x (cm), 种植面积为 y (m2)
(一) 教师组织合作学习活动: 1、 先个体探求,尝试写出y 与x 之间的函数解析式。 2、 上述三个问题先易后难,在个体探求的基础上,小组进行合作交流,共同探讨。 (1)y =πx 2 (2)y = xx(1+x)2 = xx0x 2+40000x+xx0 (3) y = (60-x-4)(x-2)=-x 2 +58x-112 (二)上述三个函数解析式具有哪些共同特征? 让学生充分发表意见,提出各自看法。 教师归纳总结:上述三个函数解析式经化简后都具y=ax 2+bx+c (a,b,c 是常数, a ≠0)的形式. 板书:我们把形如y=ax 2+bx+c(其中a,b,C 是常数,a ≠0)的函数叫做二次函数(quadratic funcion) 称a 为二次项系数, b 为一次项系数,c 为常数项, 请讲出上述三个函数解析式中的二次项系数、一次项系数和常数项 (二) 做一做 1、 下列函数中,哪些是二次函数? (1) (2) (3) (4) (5))1)(1()1(2 -+--=x x x y 2、分别说出下列二次函数的二次项系数、一次项系数和常数项: (1) (2) (3) 3、若函数为二次函数,则m 的值为 。 三、例题示范,了解规律 例1、已知二次函数 当x=1时,函数值是4;当x=2时,函数值是-5。求这个二次函数的解析式。
第7章 随机解释变量
第7章 随机解释变量 单方程线性计量经济学模型假定解释变量是确定性变量,并且与随机误差项不相关,违背这一基本假设的问题被称为随机解释变量问题。本章介绍了随机解释变量问题的概念、产生的原因和后果、检验方法以及解决方法。 随机解释变量问题的概念 对于计量经济模型 n 21i i k i k i 22i 110 ,,, ββββ=+++++=u X X X Y i (7.1.1) 其中一个基本假设是解释变量k 21,,X X X 是确定性变量,即解释变量与随机扰动项不相关。但是在现实经济生活中,这个假定不一定成立,这一方面是因为用于建模的经济变量的观测值一般会存在观测误差,另一方面是经济变量之间联系的普遍性使得解释变量可能在一定程度上依赖于应变量,即解释变量X 影响应变量Y ,而应变量Y 也会反过来影响解释变量X 。 模型中如果存在一个或多个随机变量作为解释变量,就称为模型出现了随机解释变量问题。其中k x 可能与随机误差项u 不相关,就是说,解释变量121,,-k x x x 都是外生的,但k x 有可能在方程(4.4.1)中是内生的,则称原模型存在随机解释变量问题。内生性可能源自于省略误差、测量误差,联立性等①。为讨论方便,我们假设中2X 为随机解释变量。 在模型()中,根据解释变量2X 与随机误差项的关系,可以分为三种类型: 1)随机解释变量与随机干扰项独立 )()(),(),(222===u E x E u x E u X Cov (7.1.2) 2)随机解释变量与随机干扰项同期无关但异期相关 n 21i 0),(),(i 2i 2 ,,, ===u x E u X Cov i i ① 具体详见《Econometric analysis of cross section and panal data 》(Jeffrey Wooldrige,2007 )。
地理引力模型应用及参数取舍问题
地理引力模型应用及参数取舍问题 陈英鹏 201132020128 一概念 引力模型是由地理学家,社会学家以及经济学家为了了解和预测人类在地理空间上的经济、社会及政治性相互影响与相互作用方式,利用经典力学中牛顿万有引力公式建立的一种理论假说。最早将引力模型用于研究国际贸易的是丁伯根(荷兰经济学家,创建了丁伯根原则,首届诺贝尔经济学奖得主,他为了说明在由多个国家组成的世界里,贸易流量的不对称现象即大国的贸易量占其GNP的比重小于小国,而建立了贸易引力模型)和Pōōnen,他们分别独立使用引力模型研究分析了双边贸易流量,并得出了相同的结果:两国双边贸易规模与他们的经济总量成正比,与两国之间的距离成反比。Linnemannn于1966年,在引力模型里加入了人口变量,认为两国之间的贸易规模还与人口有关,人口多少与贸易规模成正相关关系。Berstrand(1989)则更进一步,用人均收入替代了人口数量指标。引力模型应用广泛,它是国际贸易流量的主要实证研究工具。在后续的引力模型扩展中,研究者主要是依据研究自己的重点,按照影响双边贸易流量的主要因素设置不同的解释变量。 为了更好地理解引力模型,首先写出牛顿万有引力公式:
在方程中,F ij为物体i与j之间的引力,m i,m j是物体i与j各自的质量,d ij为物体i与j之间的距离,k为常数,它可依据具体情况来确定。该公式表明,引力的大小与物体i与j各自的质量成正比,与距离的平方成反比。在这里,我介绍丁伯根建立的贸易引力模型: (1) 在方程中,X ij是 i城市向j 城市的总出口;Y i与Y j分别为i城市与j 城市的生产总值,D ij为i城市与j 城市之间的距离,K,e 为常数,a、b为参数。该公式表明,i城市向j城市出口总量的大小或者i城市与j城市之间的贸易量的大小与i城市与j 城市的城市居民收入的总量成正比,与两城市之间的距离成反比。 二引力模型的变量取舍及引力模型的改进在扩展后的引力模型中,常常添加的变量有两类:一类是添加虚拟变量,如共同语言、共同边界、共同殖民历史、共同宗教等,早期对引力模型的扩展以这一类为主;另一类是添加制度质量指标变量,如是否同属一个优惠贸易协定或者区域经济一体化组织、政府治理质量、合约实施保障等。两经济体双边农产品贸易流量主要受经济规模、国家人口数量、两国首府之间的直线距离以及各种贸易制度安排等因素的影响。其中经济规模和优惠贸易安排是最重要的影响因素。 在引力模型公式(1)中,通常取引力衰减的基数为两城市之间的距离,但随着城市快速轨道交通的建成,居民出行时间大大缩短,客观上拓展了城市的边界,两点之间空间距离已经不是影响两点相互作用
第十八章-离散选择模型和受限因变量模型
第18章离散选择模型和受限因变量模型 18.1概述 在经典计量经济学模型中,被解释变量通常被假定为连续变量,但在现实的经济决策中经常面临许多选择问题。在这样的决策问题中,或者选择问题中,人们必须对可供选择的方案作出选择。通常被解释变量是连续的变量,但此时的因变量只取有限多个离散的值。例如:人们对交通工具的选择,是选择坐轻轨、地铁还是公共汽车;某大型企业是否合并另一企业;对某一方案的建议持强烈反对、反对、中立、支持和强烈支持5种态度,可以分别用0,1,2,3和4表示。以这样的选择结果作为被解释变量建立的计量经济学模型,称为离散被解释变量数据计量经济学模型(models with discrete dependent variables),或称为离散选择模型(DCM,discrete choice model)。如果被解释变量只能有两种选择,称为二元选择模型(binary choice model);如果被解释变量有多种选择,称为多元选择模型(multiple choice model)。20世纪70和80年代,离散选择模型普遍应用于经济布局、企业定点、交通问题、就业问题、购买决策等经济决策领域的研究。 在实际中,还会经常遇到因变量受到某种限制的情况,这种情况下,取得样本数据来自总体的一个子集,可能不能完全反映总体。例如,小时工资、住房价格和名义利率都必须大于零。这时需要建立的经济计量模型称为受限因变量模型(limited dependent variable model)。这两类模型经常用于调查数据的分析中。 本章将讨论三类模型及其估计方法和软件操作。一是定性(观测值为离散的或者表示排序);二是截取或者截断问题;三是观测值为整数值的计数模型。 18.2二元因变量模型 在这个模型中,被解释变量只取两个值,可以是代表某件事发生与否的虚拟变量,也可以是两个决策中选一个,称为二元因变量模型。例如:对样本个体是否就业的研究,个体的
第五章离散选择模型
第五章离散选择模型 在初级计量经济学里,我们已经学习了解释变量是虚拟变量的情况,除此之外,在实际问题中,存在需要人们对决策与选择行为的分析与研究,这就是被解释变量为虚拟变量的情况。我们把被解释变量是虚拟变量的线性回归模型称为离散选择模型,本章主要介绍这一类模型的估计与应用。 本章主要介绍以下内容: 1、为什么会有离散选择模型。 2、二元离散选择模型的表示。 3、线性概率模型估计的缺陷。 4、Logit模型和Probit模型的建立与应用。 第一节模型的基础与对应的现象 一、问题的提出 在研究社会经济现象时,常常遇见一些特殊的被解释变量,其表现是选择与决策问题,是定性的,没有观测数据所对应;或者其观测到的是受某种限制的数据。 1、被解释变量是定性的选择与决策问题,可以用离散数据表示,即取值是不连续的。例如,某一事件发生与否,分别用1和0表示;对某一建议持反对、中立和赞成5种观点,分别用0、1、2表示。由离散数据建立的模型称为离散选择模型。 2、被解释变量取值是连续的,但取值的范围受到限制,或者将连续数据转化为类型数据。例如,消费者购买某种商品,当消费者愿意支付的货币数量超过该商品的最低价值时,则表示为购买价格;当消费者愿意支付的货币数量低于该商品的最低价值时,则购买价格为0。这种类型的数据成为审查数据。再例如,在研究居民储蓄时,调查数据只有存款一万元以上的帐户,这时就不能以此代表所有居民储蓄的情况,这种数据称为截断数据。这两种数据所建立的模型称为受限被解释变量模型。有的时候,人们甚至更愿意将连续数据转化为上述类型数据来度量,例如,高考分数线的设置,
就把高出分数线和低于分数线划分为了两类。 下面是几个离散数据的例子。 例5.1 研究家庭是否购买住房。由于,购买住房行为要受到许多因素的影响,不仅有家庭收入、房屋价格,还有房屋的所在环境、人们的购买心理等,所以人们购买住房的心理价位很难观测到,但我们可以观察到是否购买了住房,即 我们希望研究买房的可能性,即概率(1) P Y=的大小。 例5.2 分析公司员工的跳槽行为。员工是否愿意跳槽到另一家公司,取决于薪资、发展潜力等诸多因素的权衡。员工跳槽的成本与收益是多少,我们无法知道,但我们可以观察到员工是否跳槽,即 例5.3 对某项建议进行投票。建议对投票者的利益影响是无法知道的,但可以观察到投票者的行为只有三种,即 研究投票者投什么票的可能性,即(),1,2,3 ==。 P Y j j 从上述被解释变量所取的离散数据看,如果变量只有两个选择,则建立的模型为二元离散选择模型,又称二元型响应模型;如果变量有多于二个的选择,则为多元选择模型。本章主要介绍二元离散选择模型。 离散选择模型起源于Fechner于1860年进行的动物条件二元反射研究。1962年,Warner首次将它应用于经济研究领域,用于研究公共交通工具和私人交通工具的选择问题。70-80年代,离散选择模型被普遍应用于经济布局、企业选点、交通问题、就业问题、购买行为等经济决策领域的研究。模型的估计方法主要发展于20世纪80年代初期。(参见李子奈,高等计量经济学,清华大学出版社,2000年,第155页-第156页) 二、线性概率模型 对于二元选择问题,可以建立如下计量经济模型。
第14章-受限被解释变量
? 陈强,《高级计量经济学及Stata 应用》课件,第二版,2014 年,高等教育出版社。 第 14 章受限被解释变量 被解释变量的取值范围有时受限制,称为“受限被解释变量”(Limited Dependent Variable)。 14.1 断尾回归 对线性模型y i =x i 'β +ε i ,假设只有满足y i ≥c 的数据才能观测到。 例:y i 为所有企业的销售收入,而统计局只收集规模以上企业 数据,比如y i ≥100,000。被解释变量在100,000 处存在“左边断尾”。
2 ? 断尾随机变量的概率分布 随机变量 y 断尾后,其概率密度随之变化。 记 y 的概率密度为 f ( y ) ,在 c 处左边断尾后的条件密度函数为 ? f ( y ) 若 y > c f ( y | y > c ) = ? ?? P( y 0, > c ) , 若 y ≤ c 由于概率密度曲线下面积为 1,故断尾变量的密度函数乘以因子 1 。 P( y > c )
图14.1 断尾的效果 3
断尾分布的期望也发生变化。以左边断尾为例。对于最简单情形,y ~ N (0, 1),可证明(参见附录) E( y |y >c) = φ(c) 1 -Φ(c) 对于任意实数c,定义“反米尔斯比率”(Inverse Mill’s Ratio,简记IMR)为 则E( y | y >c) =λ(c)。λ(c) ≡ φ(c) 1 -Φ(c) 4
图14.2 反米尔斯比率 5
6 对 于 正 态 分 布 y ~ N (μ, σ 2 ) , 定 义 y - μ z ≡ σ ~ N (0, 1) , 则 y = μ + σ z 。故 E( y | y > c ) = E(μ + σ z | μ + σ z > c ) = E ??μ + σ z z > (c - μ) ?? = μ + σ E ?? z z > (c - μ) σ ?? = μ + σ ? λ [(c - μ) σ ] 对于模型y = x 'β + ε ,ε | x ~ N (0, σ 2 ),则y | x ~ N ( x 'β , σ 2 ),故 i i i i i i i i E( y i | y i > c ) = x i 'β + σ ? λ [(c - x i 'β ) σ ] 如 果 用 OLS 估 计 y i = x i 'β + εi , 则 遗 漏 了 非 线 性 项 σ ? λ [(c - x i 'β ) σ ],与x i 相关,导致 OLS 不一致。
面板数据的常见处理
面板数据的常见处理 (2012-03-02 11:16:14) 标签: 在写论文时经常碰见一些即是时间序列又是截面的数据,比如分析1999-2010的公司盈余管 如上图所示的数据即为面板数据。显然面板数据是三维的,而时间序列数据和截面数据都是二维的,把面板数据当成时间序列数据或者截面数据来处理都是不合适的。 处理面板数据的软件较多,一般使用、Stata等。个人推荐使用Stata,因为Stata比较适合处理面板数据,且个性化强。以下以为例来讲解怎么样处理面板数据。 由于面板数据的存储结构与我们通常使用的存储结构不太一样,所在统计分析前,最好在excel中整理一下数据,形成如下图所示的数据
变量定义及输入数据 启动,Stata界面有4个组成部分,Review(在左上角)、Variables(左下角)、输出窗口(在右上角)、Command(右下角)。首先定义变量,可以输入命令,也可以通过点击Data----Create new Variable or change variable。 特别注意,这里要定义的变量除了因素1、因素2、……因素6、盈余管理影响程度等,还要定义年份和公司名称两个变量,这两个变量的数据类型(Type)最好设置为int(整型),公司名称不要使用中文名称或者字母等,用数字代替。定义好变量之后可以输入数据了。数据可以直接导入(File-Import),也可以手工录入或者复制粘贴(Data-Data Edit(Browse)),手工录入数据和在excel中的操作一样。 以上面说的为例,定义变量year、company、factor1、factor2、factor3、factor4、factor5、factor6、DA。 变量company 和year分别为截面变量和时间变量。显然,通过这两个变量我们可以非常清楚地确定panel data 的数据存储格式。因此,在使用STATA 估计模型之前,我们必须告诉它截面变量和时间变量分别是什么,所用的命令为tsset,命令为: tsset company year 输出窗口将输出相应结果。 由于面板数据本身兼具截面数据和时间序列二者的特性,所以对时间序列进行操作的运算同样可以应用到面板数据身上。这一点在处理某些数据时显得非常方便。如,对于上述数据,我们想产生一个新的变量Lag _factor1 ,也就是factor1 的一阶滞后,那么我们可以采用如下命令: gen Lag_factor1= 统计描述: 在正式进行模型的估计之前,我们必须对样本的基本分布特性有一个总体的了解。对于面板数据而言,我们至少要知道我们的数据中有多少个截面(个体) ,每个截面上有多少个观察期间,整个数据结构是平行的还是非平行的。进一步地,我们还要知道主要变量的样本均值、标准差、最大值、最小值等情况。这些都可以通过以下三个命令来完成:xtdes命令用于初步了解数据的大体分布状况,我们可以知道数据中含有多少个截面,最大和最小的时间跨度是多少。在某些要求使用平行面板数据的情况下,我们可以采用该命令来诊断处理后的数据是否为平行数据。Xtsum用来查询对组内、组间、整体计算各个变量的基本统计量(如均值、方差等)。为了方便,以下的举例都只用factor1,factor2两个自变量。 xtdes DA factor1 facto2
二次函数的建模运用
二次函数的应用 1.有一座抛物线形拱桥,正常水位桥下面宽度为20米,拱顶距离水平面4米,如图建立直角坐标系,若正确水位时,桥下水深6米,为保证 过往船只顺利航行,桥下水面宽度不得小于18米,则当水深超过多少米时,就会影响过往船只的顺利 航行( ) A .2.76米 B .6.76米 C .6米 D .7米 考点:二次函数的应用. 专题:应用题;压轴题. 分析:根据已知,假设解析式为y=ax 2,把(10,-4)代入求出解析式.假设在水面宽度18米时,能顺利通过,即可把x=9代入解析式,求出此时水面距拱顶的高度,然后和正常水位相比较即可解答. 解答:解:设该抛物线的解析式为y=ax 2,在正常水位下x=10,代入解析式 可得-4=a×102 ∴ 故此抛物线的解析式为: 因为桥下水面宽度不得小于18米,所以令x=9 时可得: 此时水深6+4-3.24=6.76米 即桥下水深6.76米时正好通过,所以超过6.76米时则不能通过. 故选B . 点评:本题考查点的坐标的求法及二次函数的实际应用,借助二次函数解决实际问题.难度中上,首先要知道水面宽度与水位上升高度的关系才能求解. 2.林书豪身高1.91m ,在某次投篮中,球的运动路线是抛物线y=?51 -x 2+3.5的一部分(如 图),若命中篮圈中心,则他与篮底的距离约为( ) A .3.2m B .4m C .4.5m D . 考点:二次函数的应用. 专题:数形结合. 分析:把y=3.05代入所给二次函数解析式,求得相应的x 的值, 加上2.5即为所求的数值. 2 251 -y x =25 1 -a =米 24.381251-y -=?=
第4章(3)受限数据模型
§4.6受限被解释变量数据模型 ——选择性样本 Model with Limited Dependent Variable ——Selective Samples Model 一、经济生活中的受限被解释变量问题 二、“截断”问题的计量经济学模型 三、“归并”问题的计量经济学模型
The Bank of Sweden Prize in Economic Sciences in Memory of Alfred Nobel 2000 "for his development of theory and methods for analyzing selective samples” James J Heckman USA
?“Shadow Prices, Market Wages and Labour Supply”,Econometrica42 (4), 1974, P679-694发现并提出“选择性样本”问题。 ?“Sample Selection Bias as a Specification Error”,Econometrica47(1), 1979, P153-161 证明了偏误的存在并提出了Heckman两步修正法。
一、经济生活中的受限被解释变量问题
2、“归并”(censoring)问题 ?将被解释变量的处于某一范围的样本观测值都用一个相同的值代替。 ?经常出现在“检查”、“调查”活动中,因此也称为“检查”(censoring) 问题。 ?需求函数模型中用实际消费量作为需求量的观测值,如果存在供给限制,就出现“归并”问题。?被解释变量观测值存在最高和最低的限制。例如考试成绩,最高100,最低0,出现“归并”问题。
离散选择模型完整版
离散选择模型 HEN system office room 【HEN16H-HENS2AHENS8Q8-HENH1688】
第五章离散选择模型 在初级计量经济学里,我们已经学习了解释变量是虚拟变量的情况,除此之外,在实际问题中,存在需要人们对决策与选择行为的分析与研究,这就是被解释变量为虚拟变量的情况。我们把被解释变量是虚拟变量的线性回归模型称为离散选择模型,本章主要介绍这一类模型的估计与应用。 本章主要介绍以下内容: 1、为什么会有离散选择模型。 2、二元离散选择模型的表示。 3、线性概率模型估计的缺陷。 4、Logit模型和Probit模型的建立与应用。 第一节模型的基础与对应的现象 一、问题的提出 在研究社会经济现象时,常常遇见一些特殊的被解释变量,其表现是选择与决策问题,是定性的,没有观测数据所对应;或者其观测到的是受某种限制的数据。 1、被解释变量是定性的选择与决策问题,可以用离散数据表示,即取值是不连续的。例如,某一事件发生与否,分别用1和0表示;对某一建议持反对、中立和赞成5种观点,分别用0、1、2表示。由离散数据建立的模型称为离散选择模型。 2、被解释变量取值是连续的,但取值的范围受到限制,或者将连续数据转化为类型数据。例如,消费者购买某种商品,当消费者愿意支付的货币数量超过该商品的最低价值时,则表示为购买价格;当消费者愿意支付的货币数量低于该商品的最低价值时,则购买价格为0。这种类型的数据成为审查数据。再例如,在研究居民储蓄时,调查数据只有存款一万元以上的帐户,这时就不能以此代表所有居民储蓄的情况,这种数据称为截断数据。这两种数据所建立的模型称为受限被解释变量模型。有的时候,人们甚至更愿意将连续数据转化为上述类型数据来度量,例如,高考分数线的设置,就把高出分数线和低于分数线划分为了两类。 下面是几个离散数据的例子。 例研究家庭是否购买住房。由于,购买住房行为要受到许多因素的影响,不仅有家庭收入、房屋价格,还有房屋的所在环境、人们的购买心理等,所以人们购买住
第五讲-虚拟变量模型
第七讲 经典单方程计量经济学模型:专门问题 虚拟变量模型 学习目标: 1. 了解什么是虚拟变量以及什么是虚拟变量模型; 2. 理解虚拟变量的设置原则; 3. 掌握虚拟变量模型的两种基本引入方式(加法方式和乘法方式); 4. 能够自行设计虚拟变量模型,并能够解释其中蕴含的经济意义; 教学基本内容 一、 虚拟变量 许多经济变量是可以定量度量,例如:商品需求量、价格、收入、产量等;但有一些影响经济变量的因素是无法定量度量。例如:职业、性别对收入的影响,战争、自然灾害对GDP 的影响,季节对某些产品(如冷饮)销售的影响等。 定性变量:把职业、性别这样无法定量度量的变量称为定性变量。 定量变量:把价格、收入、销售额这样可以可以定量度量的变量称为定量变量。 为了能够在模型中能够反映这些因素的影响,提高模型的精度,拓展回归模型的功能,需要将它们“量化”。 这种“量化”通常是通过引入“虚拟变量”来完成的。根据这些因素的属性类型,构造只取“0”或“1”的人工变量,通常称为虚拟变量(dummy variables ) ,记为D 。 虚拟变量只作为解释变量。 例如:反映性别的虚拟变量? ??=女男;0;1D 反映文化程度的虚拟变量???=非本科学历 本科学历;0;1D 一般地,基础类型和肯定类型取值为1;比较类型和否定类型取值为0。 二、 虚拟变量的设置原则 设置原则: 每一定性变量(qualitative variable)所需的虚拟变量个数要比该定性变量的状态类别数(categories)少1。即如果有m 种状态,只在模型中引入m-1个虚拟变量。 例如,冷饮的销售量会受到季节变化的影响。季节定性变量有春、夏、秋、冬4种状态,只需要设置3个虚拟变量: