db2top监控最慢sql语句

1、登陆数据库的主机,输入db2top –d pcsw_db(库名),
进入db2top界面
2、运行场景前需要重置数据库快照:在上一个页面按R,
跟具提示输入y,回车,如图
3、按D进入sql监控页面,按z进行排序,会提示按哪一
列进行排序(第一列输0),比如按照执行时间Exectime
排序,那就输入3,回车
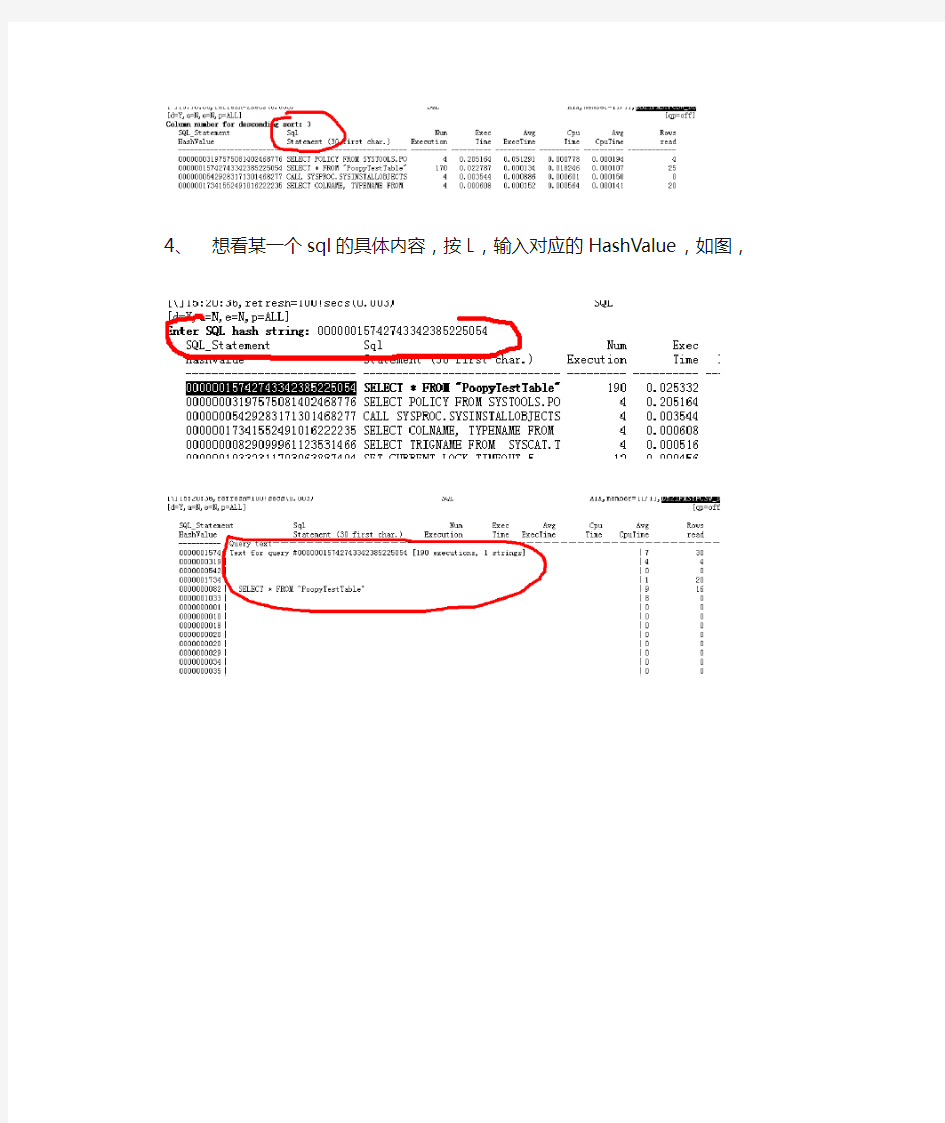
4、想看某一个sql的具体内容,按L,输入对应的HashValue,
如图,
常用SQL语句大全
常用SQL语句大全 一、基础 1、说明:创建数据库 CREATE DATABASE database-name 2、说明:删除数据库 DROP database dbname 3、说明:备份sql server --- 创建备份数据的device USE master EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1.dat' --- 开始备份 BACKUP DATABASE pubs TO testBack 4、说明:创建新表 create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..) 根据已有的表创建新表: A:create table tab_new like tab_old (使用旧表创建新表) B:create table tab_new as select col1,col2…from tab_old definition only 5、说明:删除新表 DROP table tabname 6、说明:增加一个列 Alter table tabname add column col type 注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。 7、说明:添加主键:Alter table tabname add primary key(col) 说明:删除主键:Alter table tabname DROP primary key(col) 8、说明:创建索引:create [unique] index idxname on tabname(col….) 删除索引:DROP index idxname 注:索引是不可更改的,想更改必须删除重新建。 9、说明:创建视图:create view viewname as select statement 删除视图:DROP view viewname 10、说明:几个简单的基本的sql语句 选择:select * from table1 where 范围 插入:insert into table1(field1,field2) values(value1,value2) 删除:delete from table1 where 范围 更新:update table1 set field1=value1 where 范围 查找:select * from table1 where field1 like ’%value1%’---like的语法很精妙,查资料! 排序:select * from table1 order by field1,field2 [desc] 总数:select count as totalcount from table1 求和:select sum(field1) as sumvalue from table1 平均:select avg(field1) as avgvalue from table1 最大:select max(field1) as maxvalue from table1 最小:select min(field1) as minvalue from table1 11、说明:几个高级查询运算词
在程序开发中怎样写SQL语句可以提高数据库的性能
1、首先要搞明白什么叫执行计划? 执行计划是数据库根据SQL语句和相关表的统计信息作出的一个查询方案,这个方案是由查询优化器自动分析产生的,比如一条SQL语句如果用来从一个10万条记录的表中查1条记录,那查询优化器会选 择“索引查找”方式,如果该表进行了归档,当前只剩下5000条记录了,那查询优化器就会改变方案,采用“全表扫描”方式。 可见,执行计划并不是固定的,它是“个性化的”。产生一个正确 的“执行计划”有两点很重要: (1) SQL语句是否清晰地告诉查询优化器它想干什么? (2) 查询优化器得到的数据库统计信息是否是最新的、正确的? 2、统一SQL语句的写法 对于以下两句SQL语句,程序员认为是相同的,数据库查询优化器认为是不同的。 select * from dual Select * From dual 其实就是大小写不同,查询分析器就认为是两句不同的SQL语句,必须进行两次解析。生成2个执行计划。所以作为程序员,应该保证相同的查询语句在任何地方都一致,多一个空格都不行! 3、不要把SQL语句写得太复杂 我经常看到,从数据库中捕捉到的一条SQL语句打印出来有2张A4纸这么长。一般来说这么复杂的语句通常都是有问题的。我拿着这2页长的SQL语句去请教原作者,结果他说时间太长,他一时也看不懂了。可想而知,连原作者都有可能看糊涂的SQL语句,数据库也一样会看糊涂。 一般,将一个Select语句的结果作为子集,然后从该子集中再进行查询,这种一层嵌套语句还是比较常见的,但是根据经验,超过3层嵌套,查询优化器就很容易给出错误的执行计划。因为它被绕晕了。像这种类似人工智能的东西,终究比人的分辨力要差些,如果人都看晕了,我可以保证数据库也会晕的。 另外,执行计划是可以被重用的,越简单的SQL语句被重用的可能性越高。而复杂的SQL语句只要有一个字符发生变化就必须重新解析,
实验5 数据库监视与性能优化
实验项目名称:数据库监视与性能优化实验学时: 4 同组学生姓名:实验地点: 实验日期:实验成绩: 批改教师:批改时间: 一、实验目的和要求 1、利用索引优化查询性能、优化SQL语句。 2、了解通过对SQL profiler跟踪系统运行数据。 二、实验仪器和设备 设备:奔腾Ⅳ或奔腾Ⅳ以上计算机; 环境:WINDOWS 7 或WINDOWS XP、Microsoft SQL Server 2008。 三、实验过程 1、完成以下的实验。 1)使用对象资源管理器创建、管理索引 ①为员工表创建一个索引名为“emp_id”的唯一性非聚集索引,索引关键字是“员工号”,填充因子80 % 。 ②重命名索引,将索引“emp_id”重命名为“员工表_员工号”。 ③删除索引“员工表_员工号”。 2)使用T-SQL语句创建、管理索引 ①为员工表创建一个索引名为“emp_id”的唯一性非聚集索引,索引关键字是“员工号”,填充因子80 % 。 ②重命名索引,将索引“emp_id”重命名为“员工表_员工号”。 ③为员工参与项目表创建一个索引名为“员工_项目_index”的非聚集复合索引,索引关键字为“员工号”,升序,项目编号,降序,填充因子50%。 ④删除索引“员工表_员工号”和“员工_项目_index”。 3)索引前后的执行计划 ①删除员工表中员工号上的主键。按员工姓名和项目名称查询对应的职责,然后观察执行计划信息,计算总的I/O和CPU开销。(员工表和员工参与项目表中的员工号都没有索引)②为员工参与项目表创建一个索引名为“员工参与项目_员工号”的非聚集索引,索引关键字为“员工号”,升序;按员工姓名和项目名称查询对应的职责,然后观察执行计划信息,计算总的I/O和CPU开销。(员工表中员工号没索引,员工参与项目表中的员工号有非聚集
sql语句(mysql优化)绝对经典
sql语句(mysql优化)绝对经典 误区1:count(1)和count(primary_key) 优于count(*) 很多人为了统计记录条数,就使用count(1) 和count(primary_key) 而不是count(*) ,他们认为这样性能更好,其实这是一个误区。对于有些场景,这样做可能性能会更差,应为数据库对count(*) 计数操作做了一些特别的优化。 误区2:count(column) 和count(*) 是一样的 这个误区甚至在很多的资深工程师或者是DBA 中都普遍存在,很多人都会认为这是理所当然的。实际上,count(column) 和count(*) 是一个完全不一样的操作,所代表的意义也完全不一样。count(column) 是表示结果集中有多少个column字段不为空的记录,count(*) 是表示整个结果集有多少条记录 误区3:select a,b from … 比select a,b,c from …可以让数据库访问更少的数据量 这个误区主要存在于大量的开发人员中,主要原因是对数据库的存储原理不是太了解。实际上,大多数关系型数据库都是按照行(row)的方式存储,而数据存取操作都是以一个固定大小的IO单元(被称作block 或者page)为单位,一般为4KB,8KB… 大多数时候,每个IO单元中存储了多行,每行都是存储了该行的所有字段(lob等特殊类型字段除外)。 所以,我们是取一个字段还是多个字段,实际上数据库在表中需要访问的数据量其实是一样的。当然,也有例外情况,那就是我们的这个查询在索引中就可以完成,也就是说当只取a,b两个字段的时候,不需要回表,而c这个字段不在使用的索引中,需要回表取得其数据。在这样的情况下,二者的IO量会有较大差异。(覆盖索引) 误区4:order by 一定需要排序操作 我们知道索引数据实际上是有序的,如果我们的需要的数据和某个索引的顺序一致,而且我们的查询又通过这个索引来执行,那么数据库一般会省略排序操作,而直接将数据返回,因为数据库知道数据已经满足我们的排序需求了。实际上,利用索引来优化有排序需求的SQL,是一个非常重要的优化手段。延伸阅读:MySQL ORDER BY 的实现分析,MySQL 中GROUP BY 基本实现原理以及MySQL DISTINCT 的基本实现原理。(order by null)
SQL查询语句大全集锦(超经典)
SQL查询语句大全集锦 MYSQL查询语句大全集锦 一、简单查询 简单的Transact-SQL查询只包括选择列表、FROM子句和WHERE子句。它们分别说明所查询列、查询的 表或视图、以及搜索条件等。 例如,下面的语句查询testtable表中姓名为“张三”的nickname字段和email字段。 复制内容到剪贴板 代码:SELECT `nickname`,`email`FROM `testtable`WHERE `name`='张三' (一) 选择列表 选择列表(select_list)指出所查询列,它可以是一组列名列表、星号、表达式、变量(包括局部变量和全局变量)等构成。 1、选择所有列 例如,下面语句显示testtable表中所有列的数据: 复制内容到剪贴板 代码:SELECT * FROM testtable 2、选择部分列并指定它们的显示次序 查询结果集合中数据的排列顺序与选择列表中所指定的列名排列顺序相同。 例如: 复制内容到剪贴板 代码:SELECT nickname,email FROM testtable 3、更改列标题 在选择列表中,可重新指定列标题。定义格式为: 列标题=列名 列名列标题 如果指定的列标题不是标准的标识符格式时,应使用引号定界符,例如,下列语句使用汉字显示列 标题:
复制内容到剪贴板 代码:SELECT 昵称=nickname,电子邮件=email FROM testtable 4、删除重复行 SELECT语句中使用ALL或DISTINCT选项来显示表中符合条件的所有行或删除其中重复的数据行,默认 为ALL。使用DISTINCT选项时,对于所有重复的数据行在SELECT返回的结果集合中只保留一行。 5、限制返回的行数 使用TOP n [PERCENT]选项限制返回的数据行数,TOP n说明返回n行,而TOP n PERCENT时,说明n是 表示一百分数,指定返回的行数等于总行数的百分之几。 例如: 复制内容到剪贴板 代码:SELECT TOP 2 * FROM `testtable` 复制内容到剪贴板 代码:SELECT TOP 20 PERCENT * FROM `testtable` (二) FROM子句 FROM子句指定SELECT语句查询及与查询相关的表或视图。在FROM子句中最多可指定256个表或视图, 它们之间用逗号分隔。 在FROM子句同时指定多个表或视图时,如果选择列表中存在同名列,这时应使用对象名限定这些列 所属的表或视图。例如在usertable和citytable表中同时存在cityid列,在查询两个表中的cityid时应使用下面语句格式加以限定: 复制内容到剪贴板 代码:SELECT `username`,citytable.cityid FROM `usertable`,`citytable` WHERE usertable.cityid=citytable.cityid在FROM子句中可用以下两种格式为表或视图指定别名: 复制内容到剪贴板 代码:表名 as 别名 表名别名例如上面语句可用表的别名格式表示为: 复制内容到剪贴板
SQL监控及性能优化
SQL 性能监控及SQL 语句优化 性能监控 作为SQL的数据库服务器,我们可以将其比作一个人,而SQL则是他的心脏,管理员就是他的大脑。要监控心脏是否健康首先要看他这个人是否健康。这两者是相辅相成的,少了一方都是不健康的。 数据库服务器的性能监视器 性能监视器 性能工具的介绍 性能监视器是一种简单而功能强大的可视化工具,用于实时收集系统状态并从日志文件中查看性能数据。 使用性能监视器可以: 获得对诊断系统问题和规划系统资源增长有用的性能数据、了解工作负载及其对系统资源的影响、观察工作负载和资源使用情况的变化和趋势,以便计划未来的升级、通过监视结果来测试配置变化、诊断问题并确定需要优化的组件或进程。 现在,可以开始选择这些对象和要监视的计数器了。 https://www.360docs.net/doc/0017079354.html, 应用程序性能计数器有关https://www.360docs.net/doc/0017079354.html, 应用程序性能计数器的大部分信息最近已被合并到一个题为“改善 .NET 应用程序的性能和伸缩性”的综合文档中。下表描述了一些可用于监视和优化 https://www.360docs.net/doc/0017079354.html, 应用程序(包括 Reporting Services)性能的重要计数器。
除了上表中介绍的这些核心监视要素之外,在您试图诊断 https://www.360docs.net/doc/0017079354.html, 应用程序具有的特定性能问题时,下表中的性能计数器也可对您有所帮助。
Reporting Services 性能计数器 Reporting Services 包括一组它自己的性能计数器,用于收集有关报告处理和资源消耗方面的信息。可通过 Windows 性能监视器工具中出现的两个对象来监视实例和组件的状态和活动:MSRS 2005 Web Service 和 MSRS 2005 Windows Service 对象。 MSRS 2005 Web Service 性能对象包括一组用来跟踪 Report Server 处理过程的计数器,这些处理过程通常通过在线交互式报告浏览操作而引发。这些计数器在https://www.360docs.net/doc/0017079354.html, 停止该 Web 服务后被重设。下表列出了可用于监视 Report Server 性能的计数器,并描述了它们的目的。 性能对象:RS Web Service
经典SQL语句大全
一、基础 1、说明:创建数据库 CREATE DATABASE database-name 2、说明:删除数据库 drop database dbname 3、说明:备份sql server --- 创建备份数据的 device USE master EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1. dat' --- 开始备份 BACKUP DATABASE pubs TO testBack 4、说明:创建新表 create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..) 根据已有的表创建新表: A:create table tab_new like tab_old (使用旧表创建新表) B:create table tab_new as select col1,col2… from tab_old definition only 5、说明:删除新表 drop table tabname 6、说明:增加一个列 Alter table tabname add column col type 注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。 7、说明:添加主键:Alter table tabname add primary key(col) 说明:删除主键: Alter table tabname drop primary key(col) 8、说明:创建索引:create [unique] index idxname on tabname(col….) 删除索引:drop index idxname 注:索引是不可更改的,想更改必须删除重新建。 9、说明:创建视图:create view viewname as select statement 删除视图:drop view viewname 10、说明:几个简单的基本的sql语句 选择:select * from table1 where 范围 插入:insert into table1(field1,field2) values(value1,value2) 删除:delete from table1 where 范围 更新:update table1 set field1=value1 where 范围 查找:select * from table1 where field1 like ’%value1%’ ---like的语法很精妙,查资料! 排序:select * from table1 order by field1,field2 [desc] 总数:select count as totalcount from table1
2020年(Oracle管理)如何优化SQL语句以提高Oracle执行效率
(Oracle管理)如何优化SQL语句以提高Oracle执 行效率
(1)选择最有效率的表名顺序(只在基于规则的优化器中有效): Oracle的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表drivingtable)将被最先处理,在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表。如果有3个以上的表连接查询,那就需要选择交叉表(intersectiontable)作为基础表,交叉表是指那个被其他表所引用的表。 (2)WHERE子句中的连接顺序: Oracle采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前,那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾。(3)SELECT子句中避免使用‘*’: Oracle在解析的过程中,会将‘*’依次转换成所有的列名,这个工作是通过查询数据字典完成的,这意味着将耗费更多的时间。 (4)减少访问数据库的次数: Oracle在内部执行了许多工作:解析SQL语句,估算索引的利用率,绑定变量,读数据块等。(5)在SQL*Plus,SQL*Forms和Pro*C中重新设置ARRAYSIZE参数,可以增加每次数据库访问的检索数据量,建议值为200。 (6)使用DECODE函数来减少处理时间: 使用DECODE函数可以避免重复扫描相同记录或重复连接相同的表。 (7)整合简单,无关联的数据库访问: 如果你有几个简单的数据库查询语句,你可以把它们整合到一个查询中(即使它们之间没有关系)。 (8)删除重复记录: 最高效的删除重复记录方法(因为使用了ROWID)例子:DELETEFROMEMPEWHEREE.ROWID>(SELECTMIN(X.ROWID)
第3章 自动数据库性能监视器
第3章自动数据库性能监视器 自动数据库性能监视器(ADDM)自动检查和报告数据库的性能问题。结果作为ADDM调查报告显示在Oracle企业管理器的数据库主页中,审查ADDM调查结果让你可以快速找出性能问题。 每个ADDM调查结果都提供了一串有关减少性能问题影响的建议,审查ADDM调查结果并执行建议是你每天正常维护数据库应该要做的事情,即使数据库处于未最佳的性能状态,你也应该继续使用ADDM监视数据库性能。 3.1 自动数据库诊断监视器概述 ADDM是构建在Oracle数据库内部的自我诊断软件,ADDM检查并分析自动工作量仓库(AWR)捕获到的数据,确定Oracle数据库可能存在的性能问题,然后它定位性能问题的根本原因,为纠正这些性能问题提供建议,并量化预计的性能收益,ADDM也可以识别不需要行动的区域。 3.1.1 ADDM分析 每次AWR快照(默认每小时一次)后就会执行ADDM分析,分析报告保存在数据库中,你可以通过Oracle企业管理器来查看这些报告,在使用本指南描述的另一个性能调整方法之前,先审查一下ADDM分析报告。 ADDM分析是从上到下执行的,首先确定症状,然后完善分析报告,指出导致性能问题的根本原因,ADDM使用DB time统计信息确定性能问题,DB time是数据库除了用户请求花去的递增式时间,包括等待时间和所有非空闲会话的CPU时间。 数据库性能调整的目标是减少给定工作量的DB time,通过减少DB time,数据库使用相同数量的资源可以支持更多用户请求,ADDM报告使用了大量DB time的系统资源,将其显示在问题区域,并按消耗的DB time数量进行倒序排序,关于DB time统计信息的更多信息请参考"时间模型统计"小节的内容。 3.1.2 ADDM建议 除了诊断性能问题外,ADDM还会给出建议解决方案,并且有时会建议多个可选的解决方案让你选择,ADDM建议包括: 硬件改造 添加CPU或修改I/O子系统配置 数据库配置 修改初始化参数配置 方案修改 对表或索引进行哈希分区,或使用自动段空间管理(ASSM) 修改应用程序 为序列使用缓存选项或使用绑定变量 使用其它顾问 在高负载SQL语句上运行SQL调整顾问或在热点对象上运行分段顾问。 ADDM应用在生产系统上受益良多,即使在开发和测试系统上,ADDM也可以提前提供潜在的性能问题警报。 性能调整是一个反复的过程,修复一个问题可能会导致瓶颈转移到系统的其它部分,即使使用ADDM分析报告,也要经过多次反复的调整才能使性能达到理想的水平。 3.1.3 Oracle真正应用集群中的ADDM 在Oracle真正引用集群(Oracle RAC)环境中,你可以使用ADDM分析整个数据库集群的性能,Oracle RAC中的ADDM会认为DB time是所有数据库实例数据库时间的总和,它只会报告集群级别的重要分析结果,例如,考虑局部各个集群节点的I/O水平就没什么意义,但所有节点的I/O水平的总和对于判定集群问题就显得很重要了。 3.2 配置自动数据库诊断监视器 3.2.1 设置初始化参数启用ADDM 默认情况下自动数据库诊断监视功能是被启用的,由初始化参数CONTROL_MANAGEMENT_PACK_ACCESS和STATISTICS_LEVEL控制。 CONTROL_MANAGEMENT_PACK_ACCESS初始化参数应该被设置为DIAGNOSTIC+TUNING(默认)或DIAGNOSTIC以确保启用自动数据库诊断监视器,如果将CONTROL_MANAGEMENT_PACK_ACCESS设置为NONE,就会禁用掉许多Oracle数据库特性,包括ADDM,强烈建议不要这么做。
SQL2019系统性能优化解决方案共12页文档
SQL Server 系统性能调优解决方案 前言 近几年,医药流通市场经历了激烈的震荡,导致行业逐步成熟和企业的快速变革,差异化经营成为众多医药流通的竞争选择。时空产品在中国医药流通企业的发展过程中得到了广泛且深入应用,大量的客户化开发和定制支撑了企业管理中横向和纵向的变化,很好的适应了企业在发展过程中不断变化的需求。 对于数据库管理系统的使用,很多用户都面临着一个很棘手的问题:系统效率下降。产生效率下降的因素是多方面: 1.硬件问题 2.软件问题 3.实施问题 正因为产生效率下降的因素很多,所以如何去查找原因成为我们首要关注的问题,时空公司也处在积极探索过程中。时空公司在解决一些客户问题的过程中积累了一些方法和思路,归纳总结后呈现给体系内的技术人员,本方案就系统效率调整所必需的基础知识、方法、技巧等几个方面进行阐述,从而让技术人员能够快速定位问题,解决问题,为合作伙伴提供优质,快捷的服务。 索引简介 索引是根据数据库表中一个或多个列的值进行排序的结构。索引提供指针以指向存储在表中指定列的数据值,然后根据指定的排序次序排列这些指针。数据库使用索引的方式与使用书的目录很相似,通过搜索索引找到特定的值,然后跟随指针到达包含该值的行。 索引键:用于创建索引的列。 索引类型 ?聚集索引: 聚集索引基于数据行的键值在表内排序和存储这些数据行。由于数据行按基于聚集索引键的排序次序存储,因此聚集索引对查找行很有效。每个表只能有一个聚集索引,因为数据行本身只能按一个顺序存储。数据行本身构成聚集索引的最低级别(叶子节点)。只有当表包含聚集索引时,表内的数据行才按排序次序存储。如果表没有聚集索引,则其数据行按堆集方式存储。 聚集索引对于那些经常要搜索范围值的列特别有效。使用聚集索引找到包含第一个值的行后,便可以确保包含后续索引值的行在物理相邻。例如:如果应用程序执行的一个查询经常检索某一日期范围内的记录,则使用聚集索引可以迅速找到包含开始日期的行,然后检索表中所有相邻的行,直到到达结束日期。这样有助于提高此类查询的性能。同样,如果对从表中检索的数据进行排序时经常要用到某一列,则可以将该表在该列上聚集(物理排序),避免每次查询该列时都进行排序,从而节省成本。 ?非聚集索引 非聚集索引具有完全独立于数据行的结构。非聚集索引的最低行包含非聚集索引的键值,并且每个键值项都有指针指向包含该键值的数据行。数据行不按基于非聚集键的次序存储。如
数据库经典SQL语句大全
数据库经典SQL语句大全 篇一:经典SQL语句大全 下列语句部分是Mssql语句,不可以在access中使用。 SQL分类: DDL—数据定义语言(CREATE,ALTER,DROP,DECLARE) DML—数据操纵语言(SELECT,DELETE,UPDATE,INSERT) DCL—数据控制语言(GRANT,REVOKE,COMMIT,ROLLBACK) 首先,简要介绍基础语句: 1、说明:创建数据库 CREATE DATABASE database-name 2、说明:删除数据库 drop database dbname 3、说明:备份sql server --- 创建备份数据的 device USE master EXEC sp_addumpdevice 'disk','testBack', 'c:mssql7backupMyNwind_1.dat' --- 开始备份 BACKUP DATABASE pubs TO testBack 4、说明:创建新表
create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..) 根据已有的表创建新表: A:create table tab_new like tab_old (使用旧表创建新表) B:create table tab_new as select col1,col2? from tab_old definition only 5、说明: 删除新表: tabname 6、说明: 增加一个列:Alter table tabname add column col type 注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。 7、说明: 添加主键:Alter table tabname add primary key(col) 说明: 删除主键:Alter table tabname drop primary key(col) 8、说明: 创建索引:create [unique] index idxname on tabname(col?.) 删除索引:drop index idxname 注:索引是不可更改的,想更改必须删除重新建。
如何优化sql语句
如何优化sql语句.txt心态决定状态,心胸决定格局,眼界决定境界。当你的眼泪忍不住要流出来的时候,睁大眼睛,千万别眨眼,你会看到世界由清晰到模糊的全过程。2010-01-18 honglove (高级程序员) 1、查询时不返回不需要的行、列 业务代码要根据实际情况尽量减少对表的访问行数,最小化结果集,在查询时,不要过多地使用通配符如:select * from table1语句,要用到几列就选择几列,如:select col1,col2 from table1;在可能的情况下尽量限制结果集行数如:select top 100 col1,col2,col3 from talbe2,因为某些情况下用户是不需要那么多的数据的。 2、合理使用EXISTS, NOT EXISTS字句 如下所示: SELECT SUM(T1.C1) FROM T1 WHERE ((SELECT COUNT(*) FROM T2 WHERE T2.C2=T1.C2)>0) SELECT SUM(T1.C1) FROM T1 WHERE EXISTS(SELECT * FROM T2 WHERE T2.C2=T1.C2) 两种产生相同的结果,但是后者的效率显然要高过于前者。银行后者不会产生大量锁定的表扫描或是索引扫描。 经常需要些一个T_SQLL语句比较一个父结果集和子结果集,从而找到是否存在在父结果集中有而在子结果集中乜嘢的记录,如: SELECT _a.hdr_key FROM hdr_tb1 a -----------tb1 a 表示tb1用别名a代替 WHERE NOT EXISTS (SELECT * FROM dt1_tb1 b WHERE a.hdr_key = b.hdr_key) SELECT _a.hdr_key FROM hdr_tb1 a -----------tb1 a 表示tb1用别名a代替 LEFT JION dt1_tb1 b ON a.hdr_key = b.hdr_key WHERE b.hdr_key IS NULL SELECT hdr_key FROM hdr_tb1
Oracle SQL性能优化方法研究
Oracle SQL性能优化方法探讨 Oracle性能优化方法(SQL篇) (1) 1综述 (2) 2表分区的应用 (2) 3访问Table的方式 (3) 4共享SQL语句 (3) 5选择最有效率的表名顺序 (5) 6WHERE子句中的连接顺序. (6) 7SELECT子句中幸免使用’*’ (6) 8减少访问数据库的次数 (6) 9使用DECODE函数来减少处理时刻 (7) 10整合简单,无关联的数据库访问 (8) 11删除重复记录 (8) 12用TRUNCATE替代DELETE (9) 13尽量多使用COMMIT (9) 14计算记录条数 (9) 15用Where子句替换HAVING子句 (9) 16减少对表的查询 (10) 17通过内部函数提高SQL效率 (11)
18使用表的不名(Alias) (12) 19用EXISTS替代IN (12) 20用NOT EXISTS替代NOT IN (13) 21识不低效执行的SQL语句 (13) 22使用TKPROF 工具来查询SQL性能状态 (14) 23用EXPLAIN PLAN 分析SQL语句 (14) 24实时批量的处理 (16)
1综述 ORACLE数据库的性能调整是个重要,却又有难度的话题,如何有效地进行调整,需要通过反反复复的过程。在数据库建立时,就能依照顾用的需要合理设计分配表空间以及存储参数、内存使用初始化参数,对以后的数据库性能有专门大的益处,建立好后,又需要在应用中不断进行应用程序的优化和调整,这需要在大量的实践工作中不断地积存经验,从而更好地进行数据库的调优。 数据库性能调优的方法 ●调整内存 ●调整I/O ●调整资源的争用问题 ●调整操作系统参数 ●调整数据库的设计 ●调整应用程序 本文针对应用程序的调整,来讲明对数据库性能如何进行优化。 2表分区的应用 关于海量数据的表,能够考虑建立分区以提高操作效率。建
数据库基本----sql语句大全
学会数据库是很实用D~~记录一些常用的sql语句...有入门有提高有见都没见过的...好全...收藏下... 其实一般用的就是查询,插入,删除等语句而已....但学学存储过程是好事...以后数据方面的东西就不用在程序里搞喽..而且程序与数据库只要一个来回通讯就可以搞定所有数据的操作.... 一、基础 1、说明:创建数据库 Create DATABASE database-name 2、说明:删除数据库 drop database dbname 3、说明:备份sql server --- 创建备份数据的device USE master EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1.dat' --- 开始备份 BACKUP DATABASE pubs TO testBack 4、说明:创建新表 create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..) 根据已有的表创建新表: A:create table tab_new like tab_old (使用旧表创建新表) B:create table tab_new as select col1,col2… from tab_old definition only 5、说明:删除新表 drop table tabname 6、说明:增加一个列 Alter table tabname add column col type 注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。 7、说明:添加主键:Alter table tabname add primary key(col) 说明:删除主键:Alter table tabname drop primary key(col) 8、说明:创建索引:create [unique] index idxname on tabname(col….) 删除索引:drop index idxname 注:索引是不可更改的,想更改必须删除重新建。 9、说明:创建视图:create view viewname as select statement 删除视图:drop view viewname 10、说明:几个简单的基本的sql语句 选择:select * from table1 where X围 插入:insert into table1(field1,field2) values(value1,value2) 删除:delete from table1 where X围 更新:update table1 set field1=value1 where X围 查找:select * from table1 where field1 like ’%value1%’ ---like的语法很精妙,查资料! 排序:select * from table1 order by field1,field2 [desc] 总数:select count as totalcount from table1 求和:select sum(field1) as sumvalue from table1 平均:select avg(field1) as avgvalue from table1 最大:select max(field1) as maxvalue from table1
基础:如何编写优化的sql语句
一.SQL的优化器执行分析 在ORACLE RDBMS SERVER软件的内部,对于SQL语句的执行有一个优化器(OPTIMIZER)对SQL语句的执行进行优化。在我们使用后面介绍的工具对SQL的执行路径进行查看的时候,系统显示出来的是由优化器给出的执行路径的解释方案,如果对优化器的解释方案不了解的话,就无法针对出现的问题进行SQL语句的调整。现把ORACLE8提供的优化器的执行解释方案公布如下。 这部分内容的详细解释可以参照oracle的文档。这里给出的是快速参考。实际上,这些操作的含义往往名字上就可以表现出来,不用查手册。 1.如何看SQL解释方案 Execution Plan ---------------------------------------------------------- 1SELECT STATEMENT Optimizer=CHOOSE (Cost=94 Card=1) 2SORT (AGGREGATE) 3COUNT (STOPKEY) 4INDEX (FULL SCAN) OF 'PK_TBI_TM' (UNIQUE) (Cost=94 Car d=27164) (图1) 图1为ORACLE对语句“select count(*) from tbi_tm where rownum<10”给出的一个执行的解释方案,那我们该如何看这个方案呢?我们在看这个执行方案的时候要遵循一个原则“由里到外,由高到低”,同时“由里到外”不能违反“由高到低”的原则。因此上述的语句的执行步骤顺序为:4、3、2;假设存在一个步骤5的话,而且它的层次同3一致,那么,上述语句的执行步骤顺序就会改为:4、3、5、2。在图1中还给出了执行了何种操作(例如:INDEX(FULL SCAN),COUNT (STOPKEY)等,具体的说明在下面进行解释),同时在最后还给出了执
数据库语言大全
经典SQL语句大全 —、基础 1说明:创建数据库 CREATE DATABASE database-n ame 2、说明:删除数据库 drop database dbn ame 3、说明:备份sql server ---创建备份数据的device USE master EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwi nd_1.dat' ---开始备份 BACKUP DATABASE pubs TO testBack 4、说明:创建新表 create table tab name(col1 type1 [not nu II] [primary key],col2 type2 [not nul l] ,..) 根据已有的表创建新表: A: create table tab_new like tab_old ( 使用旧表创建新表) B: create table tab_new as select col1,col2 …from tab_old definition only 5、说明:删除新表 drop table tab name 6、说明:增加一个列 Alter table tab name add colu mn col type 注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varc har类型的长度。 7、说明:添加主键:Alter table tab name add primary key(col) 说明:删除主键 : Alter table tab name drop primary key(col) 8、说明:创建索弓丨:create [unique] index idxname on tabname(col ….) 删除索弓丨:drop index idxname 注:索引是不可更改的,想更改必须删除重新建。 9、说明:创建视图:create view view name as select stateme nt 删除视图:drop view view name 10、说明:几个简单的基本的sql语句 选择:select * from tablei where 范围 插入:in sert into table1(field1,field2) values(value1,value2) 删除:delete from table1 where 范围 更新:update table1 set field1=value1 where 范围 查找:select * from table1 where field1 like ' %value1% ---like 的语法很精妙,查资料! 排序:select * from table1 order by field1,field2 [desc] 总数:select count as totalcount from table1
使用SpotLight监控数据库性能
使用SpotLight监控数据库性能 8.1.4 使用SpotLight监控数据库性能(1) SpotLight On Oracle是由Quest公司出品的一款针对Oracle进行监控的软件。SpotLight监控Oracle的基本原理与LoadRunner监控类似,通过获取Oracle的数据字典和动态性能视图,然后把性能数据按直观的方式展现出来,如图8.11所示。 (点击查看大图)图8.11 SpotLight On Oracle监控数据库下面简要介绍使用SpotLight对Oracle进行监控的过程。 1.建立Oracle连接 第一步要建立Connection,如图8.12所示,这样才能够使用SpotLight连接到要监测的数据库。
新建连接,然后输入Oracle连接用户账号,确定之后即可进入监控主页面。 2.查看系统主界面进行Oracle监控 系统主界面反映了系统的整体运行情况,如果系统哪方面出现问题,会报相应的警告,最严重为红色警告。然后根据警告可转到相应的子窗口,查看相应的情况。下面介绍各子窗口。 1)Sessions面板 Response:系统的响应时间。 Total Users:总的用户Session数量。 Active Users:当前正在执行的用户Session数量。 2)Host面板 Host面板主要显示CPU利用率和内存使用情况。 3)Server Processes面板 Server Processes面板主要显示服务器进程的信息。主要关注以下几点。 PGA Target/Used:PGA目标总数及当前使用数。 Dedicated:专用服务器进程的个数。 Shared:共享服务器进程的个数。 Job Queue:作业进程的个数。 4)SGA面板 SGA面板主要显示SGA中各组件的内存使用情况,主要关注以下几点。