正则表达式语言 - 快速参考

正则表达式语言?-?快速参考
正则表达式是正则表达式引擎尝试匹配输入文本的一种模式。?模式由一个或多个字符文本、运算符或构造组成。
字符转义
正则表达式中的反斜杠字符?(\)?指示其后跟的字符是特殊字符(如下表所示),或应按原义解释该字符。?有关更多信息,请参见正则表达式中的字符转义。
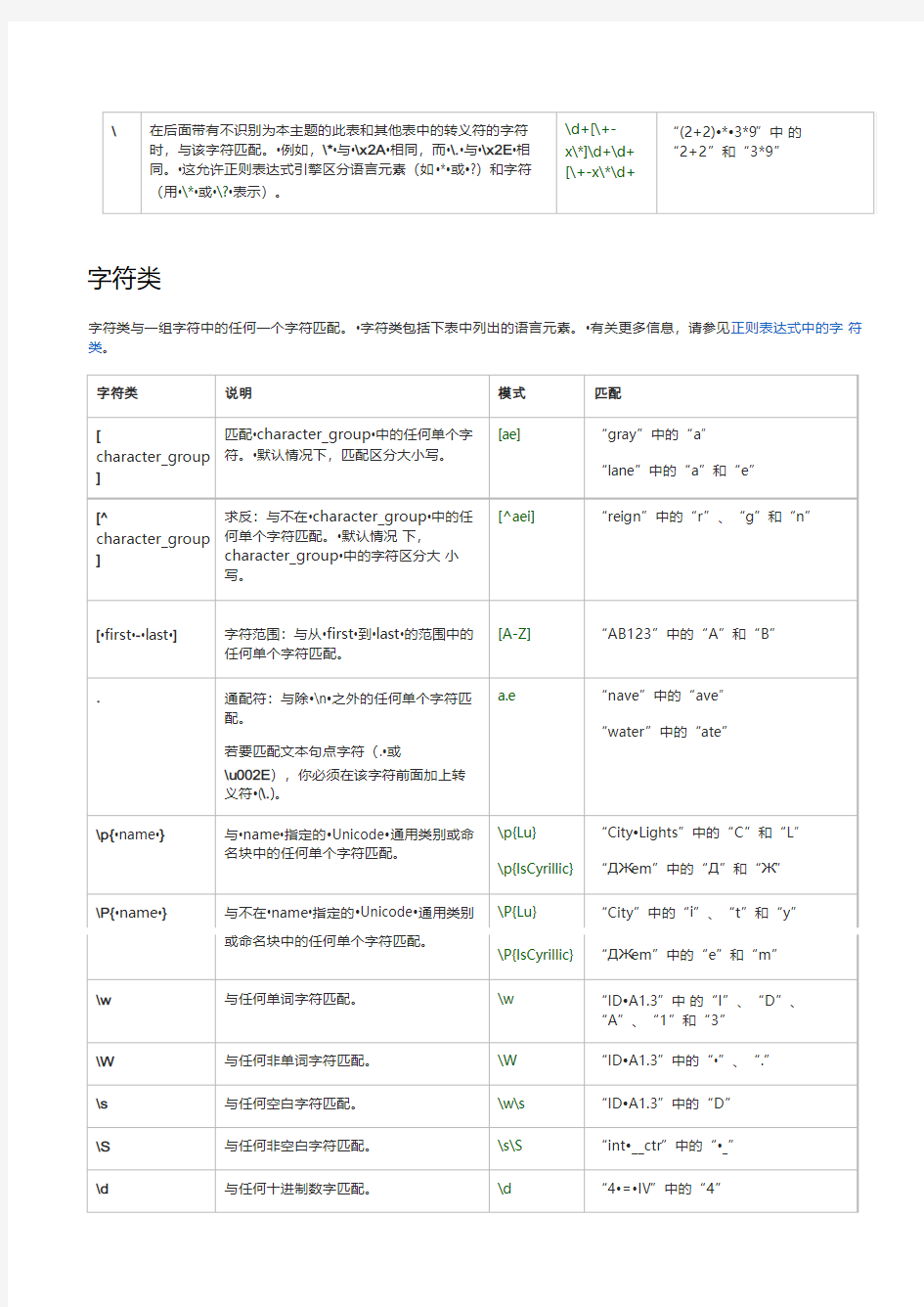
字符类
字符类与一组字符中的任何一个字符匹配。?字符类包括下表中列出的语言元素。?有关更多信息,请参见正则表达式中的字符类。
定位点
定位点或原子零宽度断言会使匹配成功或失败,具体取决于字符串中的当前位置,但它们不会使引擎在字符串中前进或使用字符。?下表中列出的元字符是定位点。?有关更多信息,请参见正则表达式中的定位点。
分组构造描述了正则表达式的子表达式,通常用于捕获输入字符串的子字符串。?分组构造包括下表中列出的语言元素。?有关更多信息,请参见正则表达式中的分组构造。
限定符
限定符指定在输入字符串中必须存在上一个元素(可以是字符、组或字符类)的多少个实例才能出现匹配项。?限定符包括下表中列出的语言元素。?有关更多信息,请参见正则表达式中的限定符。
反向引用构造
反向引用允许在同一正则表达式中随后标识以前匹配的子表达式。?下表列出了?.NET?Framework?的正则表达式支持的反向引用构造。?有关更多信息,请参见正则表达式中的反向引用构造。
替换构造用于修改正则表达式以启用?either/or?匹配。?这些构造包括下表中列出的语言元素。?有关更多信息,请参见正则表达式中的备用构造。
替换
替换是替换模式中支持的正则表达式语言元素。?有关更多信息,请参见正则表达式中的替代。?下表中列出的元字符是原子零宽度断言。
正则表达式选项
可以指定控制正则表达式引擎如何解释正则表达式模式的选项。?其中的许多选项可以指定为内联(在正则表达式模式中)或指定为一个或多个?RegexOptions?常量。?本快速参考仅列出内联选项。?有关内联和?RegexOptions?选项的更多信息,请参见文章正则表达式选项。
可通过两种方式指定内联选项:
通过使用杂项构造(?imn s x-imn s x),可以用选项或选项组前的减号?(-)?关闭这些选项。?例如,(?i-mn)?启用不区分大小写
的匹配?(i),关闭多行模式?(m)?并关闭未命名的组捕获?(n)。?该选项自定义选项的点开始应用于此正则表达式,
且持续有效直到模式结束或者到另一构造反转此选项的点。
通过使用分组构造(?imn s x-imn s x:subexpression)(只定义指定组的选项)。
.NET?Framework?正则表达式引擎支持以下内联选项。
其他构造
其他构造可修改某个正则表达式模式或提供有关该模式的信息。?下表列出了?.NET?Framework?支持的其他构造。?有关更多信息,请参见正则表达式中的其他构造。
正则表达式语言 - 快速参考
正则表达式语言?-?快速参考 正则表达式是正则表达式引擎尝试匹配输入文本的一种模式。?模式由一个或多个字符文本、运算符或构造组成。 字符转义 正则表达式中的反斜杠字符?(\)?指示其后跟的字符是特殊字符(如下表所示),或应按原义解释该字符。?有关更多信息,请参见正则表达式中的字符转义。
字符类 字符类与一组字符中的任何一个字符匹配。?字符类包括下表中列出的语言元素。?有关更多信息,请参见正则表达式中的字符类。
定位点 定位点或原子零宽度断言会使匹配成功或失败,具体取决于字符串中的当前位置,但它们不会使引擎在字符串中前进或使用字符。?下表中列出的元字符是定位点。?有关更多信息,请参见正则表达式中的定位点。 分组构造描述了正则表达式的子表达式,通常用于捕获输入字符串的子字符串。?分组构造包括下表中列出的语言元素。?有关更多信息,请参见正则表达式中的分组构造。
限定符 限定符指定在输入字符串中必须存在上一个元素(可以是字符、组或字符类)的多少个实例才能出现匹配项。?限定符包括下表中列出的语言元素。?有关更多信息,请参见正则表达式中的限定符。
反向引用构造 反向引用允许在同一正则表达式中随后标识以前匹配的子表达式。?下表列出了?.NET?Framework?的正则表达式支持的反向引用构造。?有关更多信息,请参见正则表达式中的反向引用构造。 替换构造用于修改正则表达式以启用?either/or?匹配。?这些构造包括下表中列出的语言元素。?有关更多信息,请参见正则表达式中的备用构造。
替换 替换是替换模式中支持的正则表达式语言元素。?有关更多信息,请参见正则表达式中的替代。?下表中列出的元字符是原子零宽度断言。 正则表达式选项 可以指定控制正则表达式引擎如何解释正则表达式模式的选项。?其中的许多选项可以指定为内联(在正则表达式模式中)或指定为一个或多个?RegexOptions?常量。?本快速参考仅列出内联选项。?有关内联和?RegexOptions?选项的更多信息,请参见文章正则表达式选项。 可通过两种方式指定内联选项: 通过使用杂项构造(?imn s x-imn s x),可以用选项或选项组前的减号?(-)?关闭这些选项。?例如,(?i-mn)?启用不区分大小写
正则表达式常用发发总结
//判断输入内容是否为空 function IsNull(){ var str = document.getElementById('str').value.trim(); if(str.length==0){ alert('对不起,文本框不能为空或者为空格!'); //请将“文本框”改成你需要验证的属性名称! } } //判断日期类型是否为YYYY-MM-DD格式的类型 function IsDate(){ var str = document.getElementById('str').value.trim(); if(str.length!=0){ var reg = /^(\d{1,4})(-|\/)(\d{1,2})\2(\d{1,2})$/; var r = str.match(reg); if(r==null) alert('对不起,您输入的日期格式不正确!'); //请将“日期”改成你需要验证的属性名称! } } //判断日期类型是否为YYYY-MM-DD hh:mm:ss格式的类型 function IsDateTime(){ var str = document.getElementById('str').value.trim();
if(str.length!=0){ var reg = /^(\d{1,4})(-|\/)(\d{1,2})\2(\d{1,2}) (\d{1,2}): (\d{1,2}):(\d{1,2})$/; var r = str.match(reg); if(r==null) alert('对不起,您输入的日期格式不正确!'); //请将“日期”改成你需要验证的属性名称! } } //判断日期类型是否为hh:mm:ss格式的类型 function IsTime() { var str = document.getElementById('str').value.trim(); if(str.length!=0){ reg=/^((20|21|22|23|[0-1]\d)\:[0-5][0-9])(\:[0-5][0-9])?$/ if(!reg.test(str)){ alert("对不起,您输入的日期格式不正确!"); //请将“日期”改成你需要验证的属性名称! } } } //判断输入的字符是否为英文字母
正则表达式教程
正则表达式 学习要点: 1.什么是正则表达式 2.创建正则表达式 3.获取控制 4.常用的正则 假设用户需要在HTML 表单中填写姓名、地址、出生日期等。那么在将表单提交到服 务器进一步处理前,JavaScript 程序会检查表单以确认用户确实输入了信息并且这些信息是 符合要求的。 一.什么是正则表达式 正则表达式(regular expression)是一个描述字符模式的对象。ECMAScript 的RegExp 类 表示正则表达式,而String 和RegExp 都定义了使用正则表达式进行强大的模式匹配和文本 检索与替换的函数。 正则表达式主要用来验证客户端的输入数据。用户填写完表单单击按钮之后,表单就会 被发送到服务器,在服务器端通常会用PHP、https://www.360docs.net/doc/0418080325.html, 等服务器脚本对其进行进一步处理。 因为客户端验证,可以节约大量的服务器端的系统资源,并且提供更
好的用户体验。 二.创建正则表达式 创建正则表达式和创建字符串类似,创建正则表达式提供了两种方法,一种是采用new 运算符,另一个是采用字面量方式。 1.两种创建方式 var box = new RegExp('box'); //第一个参数字符串 var box = new RegExp('box', 'ig'); //第二个参数可选模式修饰符 模式修饰符的可选参数 参数含义 i 忽略大小写 g 全局匹配 m 多行匹配 var box = /box/; //直接用两个反斜杠 var box = /box/ig; //在第二个斜杠后面加上模式修饰符 2.测试正则表达式 RegExp 对象包含两个方法:test()和exec(),功能基本相似,用于测试字符串匹配。test() 方法在字符串中查找是否存在指定的正则表达式并返回布尔值,如果存在则返回true,不存 在则返回false。exec()方法也用于在字符串中查找指定正则表达式,如果exec()方法执行成
find与grep命令简介及正则表达式
find与grep命令简介及正则表达式写给大家看的Shell脚本编程入门教程索引 两个更为有用的命令和正则表达式 在我们开始学习新的Shell编程知识之前,我们先来看一下两个更为有用的两个命令,这两个命令虽然并不是Shell的一部分,但是在进行Shell编程时却会经常用到.随后我们会来看一下正则表达式. find命令 我们先来看的是find命令.这个命令对于我们用来查找文件时是相当有用的,但是对于Linux新手来说却有一些难于使用,在一定程序是由于他所带的选项,测试,动作类型参数,而且一个参数的执行结果会影响接下来的参数. 在我们深入这些选项和参数之前,我们先来看一个非常简单的例子.假如在我们的机子上有一个文件wish.我们来进行这个操作时要以root身份来运行,这样就可以保证我们可以搜索整个机子: #find/-name wish-print /usr/bin/wish # 正如我们可以想到的,他会打印出搜索到的结果.很简单,是不是? 然而,他却需要一定的时间来运行,因为他也会同时搜索网络上的Window机器上的磁盘.Linux机器会挂载大块的Window机器的文件系统.他也会同时那些位置,虽然我们知道我们要查找的文件位于Linux机器上. 这也正是第一个选项的用武之地.如果我们指定了-mount选项,我们就可以告诉find命令不要搜索挂载的目录.
#find/-mount-name wish-print /usr/bin/wish # 这样我们仍然可以搜索这个文件,但是这一次并没有搜索挂载的文件系统. find命令的完整语法如下: find[path][options][tests][actions] path是一个很简单的部分:我们可以使用绝对路径,例如/bin,或者是使用相对路径,例如..如果我们需要我们还可以指定多个路径,例如find/var/home 主要的一些选项如下: -depth在查看目录本身以前要先搜索目录中的内容 -follow跟随符号链接 -maxdepths N在搜索一个目录时至多搜索N层 -mount(或-xdev)不要搜索其他的文件系统 下面的是一些test的选项.我们可以为find命令指定大量的测试,并且每一个测试会返回真或是假.当find命令工作时,他会考查顺序查找到的文件,并且会在这个文件上按顺序进行他们所定义的测试.如果一个测试返回假,find命令会停止他当前正在考查的文件并继续进行下面的动作.我们在下表中列出的只是一些我们最常用到的测试,我们可以通过查看手册页得到我们可以利用find 命令使用的可能的扩展列表项. -atime NN天以前访问的文件 -mtime NN天以前修改的文件
常用正则表达式
1. 平时做网站经常要用正则表达式,下面是一些讲解和例子,仅供大家参考和修改使用: 2. "^\d+$"//非负整数(正整数+ 0) 3. "^[0-9]*[1-9][0-9]*$"//正整数 4. "^((-\d+)|(0+))$"//非正整数(负整数+ 0) 5. "^-[0-9]*[1-9][0-9]*$"//负整数 6. "^-?\d+$"//整数 7. "^\d+(\.\d+)?$"//非负浮点数(正浮点数+ 0) 8. "^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$"//正浮点数 9. "^((-\d+(\.\d+)?)|(0+(\.0+)?))$"//非正浮点数(负浮点数+ 0) 10. "^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$"//负浮点数 11. "^(-?\d+)(\.\d+)?$"//浮点数 12. "^[A-Za-z]+$"//由26个英文字母组成的字符串 13. "^[A-Z]+$"//由26个英文字母的大写组成的字符串 14. "^[a-z]+$"//由26个英文字母的小写组成的字符串 15. "^[A-Za-z0-9]+$"//由数字和26个英文字母组成的字符串 16. "^\w+$"//由数字、26个英文字母或者下划线组成的字符串 17. "^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$"//email地址 18. "^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$"//url 19. /^(d{2}|d{4})-((0([1-9]{1}))|(1[1|2]))-(([0-2]([1-9]{1}))|(3[0|1]))$/ // 年-月-日 20. /^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})$/ // 月/日/年 21. "^([w-.]+)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(([w-]+.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(]?)$" //Emil 22. /^((\+?[0-9]{2,4}\-[0-9]{3,4}\-)|([0-9]{3,4}\-))?([0-9]{7,8})(\-[0-9]+)?$/ //电话号码 23. "^(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}| 1dd|2[0-4]d|25[0-5])$" //IP地址 24. 25. 匹配中文字符的正则表达式:[\u4e00-\u9fa5] 26. 匹配双字节字符(包括汉字在内):[^\x00-\xff] 27. 匹配空行的正则表达式:\n[\s| ]*\r 28. 匹配HTML标记的正则表达式:/<(.*)>.*<\/\1>|<(.*) \/>/ 29. 匹配首尾空格的正则表达式:(^\s*)|(\s*$) 30. 匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)* 31. 匹配网址URL的正则表达式:^[a-zA-z]+://(\\w+(-\\w+)*)(\\.(\\w+(-\\w+)*))*(\\?\\S*)?$ 32. 匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$ 33. 匹配国内电话号码:(\d{3}-|\d{4}-)?(\d{8}|\d{7})? 34. 匹配腾讯QQ号:^[1-9]*[1-9][0-9]*$ 35. 36. 37. 元字符及其在正则表达式上下文中的行为:
c正则表达式
C语言中巧用正则表达式 如果用户熟悉Linux下的sed、awk、grep或vi,那么对正则表达式这一概念肯定不会陌生。由于它可以极大地简化处理字符串时的复杂度,因此现在已经在许多Linux实用工具中得到了应用。千万不要以为正则表达式只是Perl、Python、Bash等脚本语言的专利,作为C语言程序员,用户同样可以在自己的程序中运用正则表达式。 标准的C和C++都不支持正则表达式,但有一些函数库可以辅助C/C++程序员完成这一功能,其中最著名的当数Philip Hazel的Perl-Compatible Regular Expression库,许多Linux发行版本都带有这个函数库。 编译正则表达式 为了提高效率,在将一个字符串与正则表达式进行比较之前,首先要用regcomp()函数对它进行编译,将其转化为regex_t结构: 参数regex是一个字符串,它代表将要被编译的正则表达式;参数preg指向一个声明为regex_t 的数据结构,用来保存编译结果;参数cflags决定了正则表达式该如何被处理的细节。 cflags 有如下4个值或者是它们或运算(|)后的值: REG_EXTENDED 以功能更加强大的扩展规则表达式的方式进行匹配。 REG_ICASE 匹配字母时忽略大小写。 REG_NOSUB 不用存储匹配后的结果。 REG_NEWLINE 识别换行符,这样'$'就可以从行尾开始匹配,'^'就可以从行的开头开始匹配。 如果函数regcomp()执行成功,并且编译结果被正确填充到preg中后,函数将返回0,任何其它的返回结果都代表有某种错误产生。 匹配正则表达式 一旦用regcomp()函数成功地编译了正则表达式,接下来就可以调用regexec()函数完成模式匹配:
正则表达式语法完整版
正则表达式基础知识 一个正则表达式就是由普通字符(例如字符a 到z)以及特殊字符(称为元字符)组成的文字模式。该模式描述在查找文字主体时待匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。如:
下面看几个例子: "^The":表示所有以"The"开始的字符串("There","The cat"等); "of despair$":表示所以以"of despair"结尾的字符串; "^abc$":表示开始和结尾都是"abc"的字符串——呵呵,只有"abc"自己了;"notice":表示任何包含"notice"的字符串。 '*','+'和'?'这三个符号,表示一个或一序列字符重复出现的次数。它们分别表示“没有或更多”,“一次或更多”还有“没有或一次”。下面是几个例子: "ab*":表示一个字符串有一个a后面跟着零个或若干个b。("a", "ab", "abbb",……);"ab+":表示一个字符串有一个a后面跟着至少一个b或者更多; "ab?":表示一个字符串有一个a后面跟着零个或者一个b; "a?b+$":表示在字符串的末尾有零个或一个a跟着一个或几个b。 也可以使用范围,用大括号括起,用以表示重复次数的范围。 "ab{2}":表示一个字符串有一个a跟着2个b("abb"); "ab{2,}":表示一个字符串有一个a跟着至少2个b; "ab{3,5}":表示一个字符串有一个a跟着3到5个b。
请注意,你必须指定范围的下限(如:"{0,2}"而不是"{,2}")。 还有,你可能注意到了,'*','+'和'?'相当于"{0,}","{1,}"和"{0,1}"。 还有一个'|',表示“或”操作: "hi|hello":表示一个字符串里有"hi"或者"hello"; "(b|cd)ef":表示"bef"或"cdef"; "(a|b)*c":表示一串"a""b"混合的字符串后面跟一个"c"; '.'可以替代任何字符: "a.[0-9]":表示一个字符串有一个"a"后面跟着一个任意字符和一个数字; "^.{3}$":表示有任意三个字符的字符串(长度为3个字符); 方括号表示某些字符允许在一个字符串中的某一特定位置出现: "[ab]":表示一个字符串有一个"a"或"b"(相当于"a|b"); "[a-d]":表示一个字符串包含小写的'a'到'd'中的一个(相当于"a|b|c|d"或者"[abcd]");"^[a-zA-Z]":表示一个以字母开头的字符串; "[0-9]%":表示一个百分号前有一位的数字; "[0-9]+":表示一个以上的数字; ",[a-zA-Z0-9]$":表示一个字符串以一个逗号后面跟着一个字母或数字结束。 你也可以在方括号里用'^'表示不希望出现的字符,'^'应在方括号里的第一位。(如:"%[^a-zA-Z]%"表 示两个百分号中不应该出现字母)。 为了逐字表达,必须在"^.$()|*+?{\"这些字符前加上转移字符'\'。 请注意在方括号中,不需要转义字符。
正则表达式
要想真正的用好正则表达式,正确的理解元字符是最重要的事情。下表列出了所有的元字符和对它们的一个简短的描述。 字符描述 \ 将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。例如,“\n”匹配字符“n”。“\\n”匹配一个换行符。序列“\\”匹配“\”而“\(”则匹配“(”。 ^ 匹配输入字符串的开始位置。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。 $ 匹配输入字符串的结束位置。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。 * 匹配前面的子表达式零次或多次。例如,zo*能匹配“z”以及“zoo”。*等价于{0,}。 + 匹配前面的子表达式一次或多次。例如,“z o+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 ? 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“does”或“does”中的“d o”。?等价于{0,1}。 {n} n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 {n,} n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“fo o o ood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 {n,m} m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 ? 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o?”将匹配单个“o”,而“o+”将匹配所有“o”。 点匹配除“\n”之外的任何单个字符。要匹配包括“\n”在内的任何字符,请使用像“[\s\S]”的模式。
正则表达式
正则表达式定义 正则表达式(regular expression)描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串、将匹配的子串做替换或者从某个串中取出符合某个条件的子串等。 列目录时,dir *.txt或ls *.txt中的*.txt就不是一个正则表达式,因为这里*与正则式的*的含义是不同的。 正则表达式是由普通字符(例如字符a 到z)以及特殊字符(称为元字符)组成的文字模式。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。 普通字符 由所有那些未显式指定为元字符的打印和非打印字符组成。这包括所有的大写和小写字母字符,所有数字,所有标点符号以及一些符号。 非打印字符 字符含义 \cx 匹配由x指明的控制字符。例如,\cM 匹配一个Control-M 或回车符。x 的值必须为A-Z 或a-z 之一。否则,将c 视为一个原义的'c' 字符。 \f 匹配一个换页符。等价于\x0c 和\cL。 \n 匹配一个换行符。等价于\x0a 和\cJ。 \r 匹配一个回车符。等价于\x0d 和\cM。 \s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。 \S 匹配任何非空白字符。等价于[^ \f\n\r\t\v]。 \t 匹配一个制表符。等价于\x09 和\cI。 \v 匹配一个垂直制表符。等价于\x0b 和\cK。 特殊字符 所谓特殊字符,就是一些有特殊含义的字符,如上面说的"*.txt"中的*,简单的说就是表示任何字符串的意思。 如果要查找文件名中有*的文件,则需要对*进行转义,即在其前加一个\。ls \*.txt。正则表达式有以下特殊字符。 $ 匹配输入字符串的结尾位置。如果设置了RegExp 对象的Multiline 属性,则$ 也匹配'\n' 或'\r'。要匹配$ 字符本身,请使用\$。 ( ) 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用\( 和\)。 * 匹配前面的子表达式零次或多次。要匹配* 字符,请使用\*。 = + 匹配前面的子表达式一次或多次。要匹配+ 字符,请使用\+。 . 匹配除换行符\n之外的任何单字符。要匹配 .,请使用\。 [ 标记一个中括号表达式的开始。要匹配[,请使用\[。 ? 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配? 字符,请使用\?。 \ 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如,'n' 匹配字符'n'。'\n' 匹配换行符。序列'\\' 匹配"\",而'\(' 则匹配"("。 ^ 匹配输入字符串的开始位置,除非在方括号表达式中使用,此时它表示不接受该字符集合。要匹配^ 字符本身,请使用\^。 { 标记限定符表达式的开始。要匹配{,请使用\{。| 指明两项之间的一个选择。要匹配|,请使用\|。
awk正则表达式介绍
awk命令详解 简单使用: awk :对于文件中一行行的独处来执行操作。 awk -F :'{print $1,$4}' :使用‘:’来分割这一行,把这一行的第一第四个域打印出来。 详细介绍: AWK命令介绍 awk语言的最基本功能是在文件或字符串中基于指定规则浏览和抽取信息,awk抽取信息 后,才能进行其他文本操作,完整的awk脚本通常用来格式化文本文件中的信息 1.调用awk: 第一种命令行方式,如: awk [-Field-separator] 'commands' input-file(s) 这里commands是真正的awk命令,[-F域分隔符]是可选的,awk默认使用空格分隔, 因此如果要浏览域间有空格的文本,不必指定这个选项,但如果浏览如passwd文件,此文件 各域使用冒号作为分隔符,则必须使用-F选项: awk -F : 'commands' input-file 第二种,将所有awk命令插入一个文件,并使awk程序可执行,然后用awk命令解释器作为脚 本的首行,以便通过键入脚本名称来调用它 第三种,将所有awk命令插入一个单独文件,然后调用,如: awk -f awk-script-file input-file -f选项指明在文件awk-script-file的awk脚本,input-file是使用awk进行浏览 的文件名 2.awk脚本: awk脚本由各种操作和模式组成,根据分隔符(-F选项),默认为空格,读取的内容依次放置到 对应的域中,一行一行记录读取,直到文件尾 2.1.模式和动作
任何awk语句都是由模式和动作组成,在一个awk脚本中可能有许多语句。模式部分决定动作语句何时触发及触发事件。动作即对数据进行的操作,如果省去模式部分,动作将时刻保持执行状态 模式可以是任何条件语句或复合语句或正则表达式,模式包含两个特殊字段BEGIN和END,使用BEGIN语句设置计数和打印头,BEGIN语句使用在任何文本浏览动作之前,之后文本浏览动作依据输入文件开始执行;END语句用来在awk完成文本浏览动作后打印输出文本总数和结尾状态标志,有动作必须使用{}括起来 实际动作在大括号{}内指明,常用来做打印动作,但是还有更长的代码如if和循环looping 语句及循环退出等,如果不指明采取什么动作,awk默认打印出所有浏览出的记录 2.2.域和记录: awk执行时,其浏览标记为$1,$2...$n,这种方法称为域标记。使用$1,$3表示参照第1和第3域,注意这里使用逗号分隔域,使用$0表示使用所有域。例如: awk '{print $0}' temp.txt > sav.txt 表示打印所有域并把结果重定向到sav.txt中 awk '{print $0}' temp.txt|tee sav.txt 和上例相似,不同的是将在屏幕上显示出来 awk '{print $1,$4}' temp.txt 只打印出第1和第4域 awk 'BEGIN {print "NAME GRADE\n----"} {print $1"\t"$4}' temp.txt 表示打信息头,即输入的内容的第一行前加上"NAME GRADE\n-------------",同时内容以tab分开 awk 'BEGIN {print "being"} {print $1} END {print "end"}' temp 同时打印信息头和信息尾 2.3.条件操作符: <、<=、==、!=、>=、~匹配正则表达式、!~不匹配正则表达式
正则表达式经典教程
正则表达式是常见常忘,所以还是记下来比较保险,于是就有了这篇笔记。 希望对大家会有所帮助。J 1.什么是正则表达式 简单的说,正则表达式是一种可以用于文字模式匹配和替换的强有力的工具。是由一系列普通字符和特殊字符组成的能明确描述文本字符串的文字匹配模式。 正则表达式并非一门专用语言,但也可以看作是一种语言,它可以让用户通过使用一系列普通字符和特殊字符构建能明确描述文本字符串的匹配模式。除了简单描述这些模式之外,正则表达式解释引擎通常可用于遍历匹配,并使用模式作为分隔符来将字符串解析为子字符串,或以智能方式替换文本或重新设置文本格式。正则表达式为解决与文本处理有关的许多常见任务提供了有效而简捷的方式。 正则表达式具有两种标准: ·基本的正则表达式(BRE – Basic Regular Expressions) ·扩展的正则表达式(ERE – Extended Regular Expressions)。 ERE包括BRE功能和另外其它的概念。 正则表达式目前有两种解释引擎: ·基于字符驱动(text-directed engine) ·基于正则表达式驱动(regex-directed engine) Jeffery Friedl把它们称作DFA和NFA解释引擎。 约定: 为了描述起来方便,在本文中做一些约定: 1. 本文所举例的所有表达时都是基于NFA解释引擎的。 2. 正则表达式,也就是匹配模式,会简写为Regex。 3. Regex的匹配目标,也就是目标字符串,会简写为String。 4. 匹配结果用会用黄色底色标识。 5. 用1\+1=2 括起来的表示这是一个regex。 6. 举例会用以下格式: Regex Target String Description test This is a test 会匹配test,testcase等 2.正则表达式的起源正则表达式的?祖先?可以一直上溯至对人类神经系统如何工作的早期研究。Warren McCulloch 和 Walter Pitts 这两位神经生理学家研究出一种数学方式来描述这些神经网络。 1956 年, 一位叫 Stephen Kleene 的美国数学家在 McCulloch 和 Pitts 早期工作的基础上,发表了一篇标题为?神经网事件的表示法?的论文,引入了正则表达式的概念。正则表达式就是用来描述他称为?正则集的代数?的表达式,因此采用?正则表达式?这个术语。
正则表达式教程
正则表达式教程 早期起源 正则表达式的“祖先”可以一直上溯至对人类神经系统如何工作的早期研究。Warren McCulloc h 和Walter Pitts 这两位神经生理学家研究出一种数学方式来描述这些神经网络。 1956 年, 一位叫Stephen Kleene 的数学家在McCulloch 和Pitts 早期工作的基础上,发表了一篇标题为“神经网事件的表示法”的论文,引入了正则表达式的概念。正则表达式就是用来描述他称为“正则集的代数”的表达式,因此采用“正则表达式”这个术语。 随后,发现可以将这一工作应用于使用Ken Thompson 的计算搜索算法的一些早期研究,K en Thompson 是Unix 的主要发明人。正则表达式的第一个实用应用程序就是Unix 中的qed 编辑器。 如他们所说,剩下的就是众所周知的历史了。从那时起直至现在正则表达式都是基于文本的编辑器和搜索工具中的一个重要部分。 正则表达式 如果原来没有使用过正则表达式,那么可能对这个术语和概念会不太熟悉。不过,它们并不是您想象的那么新奇。 请回想一下在硬盘上是如何查找文件的。您肯定会使用? 和* 字符来帮助查找您正寻找的文件。? 字符匹配文件名中的单个字符,而* 则匹配一个或多个字符。一个如'data?.dat' 的模式可以找到下述文件: data1.dat data2.dat datax.dat dataN.dat 如果使用* 字符代替? 字符,则将扩大找到的文件数量。'data*.dat' 可以匹配下述所有文件名: data.dat data1.dat data2.dat data12.dat datax.dat dataXYZ.dat 尽管这种搜索文件的方法肯定很有用,但也十分有限。? 和* 通配符的有限能
正则表达式
多少年来,许多的编程语言和工具都包含对正则表达式的支持,.NET基础类库中包含有一个名字空间和一系列可以充分发挥规则表达式威力的类,而且它们也都与未来的Perl 5中的规则表达式兼容。 此外,regexp类还能够完成一些其他的功能,例如从右至左的结合模式和表达式的编辑等。 在这篇文章中,我将简要地介绍System.Text.RegularExpression中的类和方法、一些字符串匹配和替换的例子以及组结构的详细情况,最后,还会介绍一些你可能会用到的常见的表达式。 应该掌握的基础知识 规则表达式的知识可能是不少编程人员“常学常忘”的知识之一。在这篇文章中,我们将假定你已经掌握了规则表达式的用法,尤其是Perl 5中表达式的用法。.NET的regexp类是Perl 5中表达式的一个超集,因此,从理论上说它将作为一个很好的起点。我们还假设你具有了C#的语法和.NET架构的基本知识。 如果你没有规则表达式方面的知识,我建议你从Perl 5的语法着手开始学习。在规则表达式方面的权威书籍是由杰弗里?弗雷德尔编写的《掌握表达式》一书,对于希望深刻理解表达式的读者,我们强烈建议阅读这本书。 RegularExpression组合体 regexp规则类包含在System.Text.RegularExpressions.dll文件中,在对应用软件进行编译时你必须引用这个文件,例如: csc r:System.Text.RegularExpressions.dll foo.cs 命令将创建foo.exe文件,它就引用了System.Text.RegularExpressions文件。 名字空间简介 在名字空间中仅仅包含着6个类和一个定义,它们是: Capture: 包含一次匹配的结果; CaptureCollection: Capture的序列; Group: 一次组记录的结果,由Capture继承而来; Match: 一次表达式的匹配结果,由Group继承而来; MatchCollection: Match的一个序列; MatchEvaluator: 执行替换操作时使用的代理; Regex: 编译后的表达式的实例。 Regex类中还包含一些静态的方法: Escape: 对字符串中的regex中的转义符进行转义; IsMatch: 如果表达式在字符串中匹配,该方法返回一个布尔值; Match: 返回Match的实例; Matches: 返回一系列的Match的方法; Replace: 用替换字符串替换匹配的表达式; Split: 返回一系列由表达式决定的字符串; Unescape:不对字符串中的转义字符转义。
正则表达式.DOC
正则表达式 第一部分: ----------------- 正则表达式(REs)通常被错误地认为是只有少数人理解的一种神秘语言。在表面上它们确实看起来杂乱无章,如果你不知道它的语法,那么它的代码在你眼里只是一堆文字垃圾而已。实际上,正则表达式是非常简单并且可以被理解。读完这篇文章后,你将会通晓正则表达式的通用语法。 支持多种平台 正则表达式最早是由数学家Stephen Kleene于1956年提出,他是在对自然语言的递增研究成果的基础上提出来的。具有完整语法的正则表达式使用在字符的格式匹配方面上,后来被应用到熔融信息技术领域。自从那时起,正则表达式经过几个时期的发展,现在的标准已经被ISO(国际标准组织)批准和被Open Group 组织认定。 正则表达式并非一门专用语言,但它可用于在一个文件或字符里查找和替代文本的一种标准。它具有两种标准:基本的正则表达式(BRE),扩展的正则表达式(ERE)。ERE包括BRE功能和另外其它的概念。 许多程序中都使用了正则表达式,包括xsh,egrep,sed,vi以及在UNIX平台下的程序。它们可以被很多语言采纳,如HTML和XML,这些采纳通常只是整个标准的一个子集。 比你想象的还要普通 随着正则表达式移植到交叉平台的程序语言的发展,这的功能也日益完整,使用也逐渐广泛。网络上的搜索引擎使用它,e-mail程序也使用它,即使你不是一个UNIX程序员,你也可以使用规则语言来简化你的程序而缩短你的开发时间。 正则表达式101 很多正则表达式的语法看起来很相似,这是因为你以前你没有研究过它们。通配符是RE的一个结构类型,即重复操作。让我们先看一看ERE标准的最通用的基本语法类型。为了能够提供具有特定用途的范例,我将使用几个不同的程序。
《易语言“正则表达式”详细教程》
《易语言“正则表达式”教程》 本文改编自多个文档,因此如有雷同,不是巧合。 “正则表达式”的应用范围越来越广,有了这个强大的工具,我们可以做很多事情,如搜索一句话中某个特定的数据,屏蔽掉一些非法贴子的发言,网页中匹配特定数据,代码编辑框中字符的高亮等等,这都可以用正则表达式来完成。 本书分为四个部分。 第一部分介绍了易语言的正则表达式支持库,在这里,大家可以了解第一个正则表达式的易语言程序写法,以及一个通用的小工具的制作。 第二部分介绍了正则表达式的基本语法,大家可以用上述的小工具进行试验。 第三部分介绍了用易语言写的正则表达式工具的使用方法。这些工具是由易语言用户提供的,有的工具还带有易语言源码。他们是:monkeycz、零点飞越、寻梦。 第四部分介绍了正则表达式的高级技巧。 目录 《易语言“正则表达式”教程》 (1) 目录 (1) 第一章易语言正则表达式入门 (3) 一.与DOS下的通配符类似 (3) 二.初步了解正则表达式的规定 (3) 三.一个速查列表 (4) 四.正则表达式支持库的命令 (5) 4.1第1个正则表达式程序 (5) 4.2第2个正则表达式例程 (7) 4.3第3个例程 (8) 4.4一个小型的正则工具 (9) 第二章揭开正则表达式的神秘面纱 (11) 引言 (12) 一.正则表达式规则 (12) 1.1普通字符 (12) 1.2简单的转义字符 (13) 1.3能够与“多种字符”匹配的表达式 (14) 1.4自定义能够匹配“多种字符”的表达式 (16) 1.5修饰匹配次数的特殊符号 (17) 1.6其他一些代表抽象意义的特殊符号 (20) 二.正则表达式中的一些高级规则 (21) 2.1匹配次数中的贪婪与非贪婪 (21)
TCL+正则表达式参考
正则表达式参考 ——蒋小超 2007-07-23一、介绍 追根溯源,正则表达式是在1956年的时候,人类最早研究神经网络的产物,但随着时间的流逝,几乎所有编程语言都加入了对它的支持,hoho~其实这个东西也是程序员开发中比较有名的一个难点。但是不要以为它只能用于程序开发,在Unix/Linux系统管理中它也有极为广泛的应用。 不要认为正则表达式很可怕,用直白的话来说,正则表达式就是利用26个英文字符与一些特殊符号的配合来进行文字内容比对的方法,绝大部分情况下,26个英文字符都代表它们本身,但在特殊符号的辅助下,这些英文字符也会有其他的含义,正则表达式比较困难的地方,也就在这种字符的2义性上面,这篇文档中对于这种具有字符2义性的地方,都会有专门的标注和说明。 如果用过Dos/Windows/Linux中的通配符,就可以理解正则表达式的作用了,通配符用*号匹配任意多的任意字符,用?号匹配任意的一个字符,正则表达式有更加复杂的一套匹配系统,可以用来匹配几乎所有希望匹配的文字内容。
二、文档约定 本文档中的所有实例,都是在以下环境中调试和运行的: 操作系统: CentOS4.1(Linux 2.6.9-11) 编程语言: TCL8.4文本编辑器: VIM6.3.46文档格式约定:实例的解释性文字,使用华文楷体小四号蓝色字体显示 实例的解释性文字 系统或程序输出,使用浅蓝色底纹表示 特别需要注意和标注的地方,将以笑脸符号专门表示看我可爱吗? 系统或者程序输出
三、基本正则表达式 正则表达式中,26个英文字符代表它们本身,但是下面表格中的特殊字符则赋予了更多不同的含义,一定要记住它们,因为它们是一切正则表达式的基础 别看基本正则表达式就是这么9个符号,但是想完全理解和用好它们,还是很困难的,为了加深理解,我来详细的说明一下,这也是我自己学习时的理解和心得,请仔细的阅读。 要想完全明白这些符号的作用,必须多方位理解,我大概是根据符号所属的类型以及它们所起的作用这2个方向来理解它们的。
很完整的一篇正则表达式总结
1、正则表达式-完结篇---工具类开发--- ? 1 2 3 4 5 6 7 8 9 1 0 1 1 1 2 1 3 1 4 1 '/.+/', 'email'=> '/^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$/', 'url'=> '/^http(s?):\/\/(?:[A-za-z0-9-]+\.)+[A-za-z]{2,4}(?:[\/ \?#][\/=\?%\-&~`@[\]\':+!\.#\w]*)?$/', 'currency'=> '/^\d+(\.\d+)?$/', 'number'=> '/^\d+$/', 'zip'=> '/^\d{6}$/', 'integer'=> '/^[-\+]?\d+$/', 'double'=> '/^[-\+]?\d+(\.\d+)?$/',
5 1 6 1 7 1 8 1 9 2 0 2 1 2 2 2 3 2 4 2 5 2 6 2'english'=> '/^[A-Za-z]+$/', 'qq'=> '/^\d{5,11}$/', 'mobile'=> '/^1(3|4|5|7|8)\d{9}$/', ); //定义其他属性 private$returnMatchResult=false; //返回类型判断 private$fixMode=null; //修正模式 private$matches=array(); //存放匹配结果 private$isMatch=false; //构造函数,实例化后传入默认的两个参数 public function __construct($returnMatchResult=false,$fixMode=null){ $this->returnMatchResult=$returnMatchResult; $this->fixMode=$fixMode; } //判断返回结果类型,为匹配结果matches还是匹配成功与否isMatch,并调用返回方法 private function regex($pattern,$subject){ if(array_key_exists(strtolower($pattern), $this->validate)) $pattern=$this->validate[$pattern].$this->fixMode; //判断后再连接上修正模式作为匹配的正则表达式 $this->returnMatchResult ?
正则表达式入门
/b 代表着单词的开头或结尾,也就是单词的分界处.如果要精确地查找hi这个单词的话,我们应该使用/bhi/b. .是另一个元字符,匹配除了换行符以外的任意字符,*同样是元字符,它指定*前边的内容可以重复任意次以使整个表达式得到匹配。 .*连在一起就意味着任意数量的不包含换行的字符。 /d是一个新的元字符,匹配任意的数字,0/d/d‐/d/d/d/d/d/d/d/d也就是中国的电话号码.为了避免那么多烦人的重复,我们也可以这样写这个表达式:0/d{2}‐/d{8}。 /s匹配任意的空白符,包括空格,制表符(Tab),换行符,中文全角空格等。/w匹配字母或数字或下划线或汉字。 /b/w{6}/b 匹配刚好6个字母/数字的单词。 字符转义:使用/来取消这些字符的特殊意义。因此,你应该使用/.和/*。当然,要查找/本身,你也得用//。 代码 说明 . 匹配除换行符以外的任意字符 /w 匹配字母或数字或下划线或汉字 /s 匹配任意的空白符 /d 匹配数字 /b 匹配单词的开始或结束 ^ 匹配字符串的开始 $ 匹配字符串的结束 重复: 常用的限定符 代码/语法 说明 * 重复零次或更多次 + 重复一次或更多次 ? 重复零次或一次 {n} 重复n次 {n,} 重复n次或更多次 {n,m} 重复n到m次 要想查找数字,字母或数字,你只需要在中括号里列出它们就行了,像[aeiou]就匹配任何一个元音字母,[.?!]匹配标点符号(.或?或!)
常用的反义代码 代码/语法 说明 /W 匹配任意不是字母,数字,下划线,汉字的字符 /S 匹配任意不是空白符的字符 /D 匹配任意非数字的字符 /B 匹配不是单词开头或结束的位置 [^x] 匹配除了x以外的任意字符 [^aeiou] 匹配除了aeiou这几个字母以外的任意字符 替换: 正则表达式里的替换指的是有几种规则,如果满足其中任意一种规则都应该当成匹配,具体方法是用|把不同的规则分隔开。 0/d{2}‐/d{8}|0/d{3}‐/d{7}这个表达式能匹配两种以连字号分隔的电话号码:一种是三位区号,8位本地号(如010‐12345678),一种是4位区号,7位本地号(0376‐2233445)。 /(0/d{2}/)[‐ ]?/d{8}|0/d{2}[‐ ]?/d{8}这个表达式匹配3位区号的电话号码,其中区号可以用小括号括起来,也可以不用,区号与本地号间可以用连字号或空格间隔,也可以没有间隔。你可以试试用替换|把这个表达式扩展成也支持4位区号的。 /d{5}‐/d{4}|/d{5}这个表达式用于匹配美国的邮政编码。美国邮编的规则是5位数字,或者用连字号间隔的9位数字。之所以要给出这个例子是因为它能说明一个问题:使用替换时,顺序是很重要的。如果你把它改成/d{5}|/d{5}‐/d{4}的话,那么就只会匹配5位的邮编(以及9位邮编的前5位)。原因是匹配替换时,将会从左到右地测试每个分枝条件,如果满足了某个分枝的话,就不会去管其它的替换条件了。 分组: 如果想要重复一个字符串又该怎么办?你可以用小括号来指定子表达式(也叫做分组),然后你就可以指定这个子表达式的重复次数了。 (/d{1,3}/.){3}/d{1,3}是一个简单的IP地址匹配表达式。要理解这个表达式,请按下列顺序分析它:/d{1,3}匹配1到3位的数字,(/d{1,3}/.}{3}匹配三位数字加上一个英文句号(这个整体也就是这个分组)重复3次,最后再加上一个一到三位的数字(/d{1,3})。不幸的是,它也将匹配256.300.888.999这种不可能存在的IP地址(IP地址中每个数字都不能大于255)。如果能使用算术比较的话,或许能简单地解决这个问题,但是正则表达式中并不提供关于数学的任何功能,所以只能使用冗长的分组,选择,字符类来描述一个正确的IP地址:((2[0‐4]/d|25[0‐5]|[01]?/d/d?)/.){3}(2[0‐4]/d|25[0‐5]|[01]?/d/d?)。 后向引用: 后向引用用于重复搜索前面某个分组匹配的文本。例如,/1代表分组1匹配的文本。难以理解?请看示例: /b(/w+)/b/s+/1/b可以用来匹配重复的单词,像go go, kitty kitty。首先是一个单词,也就是单词开始处和结束处之间的多于一个的字母或数字(/b(/w+)/b),然后是1个或几个空白符(/s+,最后是前面匹配的那个单词(/1)。