Visual C++利用多线程模拟并行计算

Visual C++利用多线程模拟并行计算
随着信息时代的到来,需要处理的信息量越来越庞大,需要解决的问题越来越复杂,使得计算量剧增。通过提高单个处理器的计算速度和采用传统的"顺序(串行)"计算技术已难以胜任。因此,需要有功能更强大的计算机系统和计算机技术来支撑。并行计算机及并行计算技术应运而生。
但由于缺乏实验环境和机器设备,我们普通人很难研究并行算法,即使有了想法也同样面临着无法验证的尴尬。不过,好在像面向对象语言c++,java等都提供了多线程,使我们可以模拟多台处理机。下面,我就一个简单的例子,向大家介绍一下在vc下如何利用多线程模拟多处理机并行求取最大值问题。
题目如下:令n=2的m次方,A是一个2n维的数组,待求最大值的数存放在A(n),A(n+1),……A(2n-1)中,所求得的最大值置于A(1),于是算法描述如下:
输入:n=2的m次方个数存在数组A(n;2n-1)中;
输出:最大数置于A(1)中。
显然,算法的时间t(n)=O(lgn),总比较次数为O(n),而最大的处理器数
p(n)=n/2。(也即最大的线程数。)
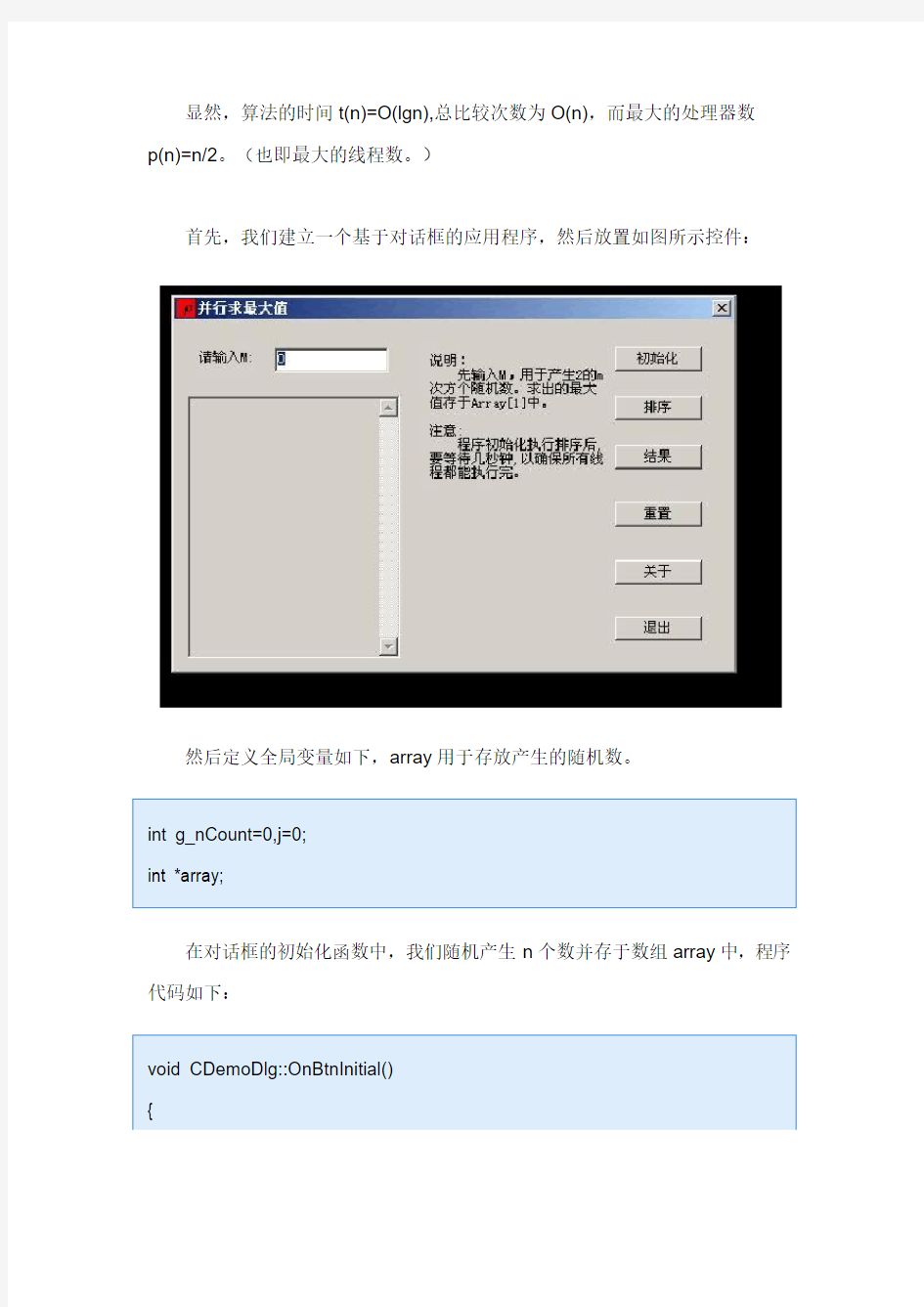
首先,我们建立一个基于对话框的应用程序,然后放置如图所示控件:
然后定义全局变量如下,array用于存放产生的随机数。
在对话框的初始化函数中,我们随机产生n个数并存于数组array中,程序代码如下:
重置功能的实现代码,主要是将数组清空:
运行结果如图:
从运行的结果图上我们可以清楚的看到线程的计算排序过程。
此程序只是一个利用多线程进行并行计算的简单例子,希望对各位进行并行算法的研究有所帮助。
大数据与并行计算
西安科技大学 计算机科学与技术学院 实习报告 课程:大数据和并行计算 班级:网络工程 姓名: 学号:
前言 大数据技术(big data),或称巨量资料,指的是所涉及的资料量规模巨大到无法通过目前主流软件工具,在合理时间内达到撷取、管理、处理、并整理成为帮助企业经营决策更积极目的的资讯。在维克托·迈尔-舍恩伯格及肯尼斯·库克耶编写的《大数据时代》中大数据指不用随机分析法(抽样调查)这样的捷径,而采用所有数据进行分析处理。大数据的4V特点:Volume(大量)、Velocity(高速)、Variety(多样)、Value(价值)。 特点具体有: 大数据分析相比于传统的数据仓库应用,具有数据量大、查询分析复杂等特点。《计算机学报》刊登的“架构大数据:挑战、现状与展望”一文列举了大数据分析平台需要具备的几个重要特性,对当前的主流实现平台——并行数据库、MapReduce及基于两者的混合架构进行了分析归纳,指出了各自的优势及不足,同时也对各个方向的研究现状及作者在大数据分析方面的努力进行了介绍,对未来研究做了展望。 大数据的4个“V”,或者说特点有四个层面:第一,数据体量巨大。从TB级别,跃升到PB级别;第二,数据类型繁多。前文提到的网络日志、视频、图片、地理位置信息等等。第三,处理速度快,1秒定律,可从各种类型的数据中快速获得高价值的信息,这一点也是和传统的数据挖掘技术有着本质的不同。第四,只要合理利用数据并对其进行正确、准确的分析,将会带来很高的价值回报。业界将其归纳为4个“V”——Volume(数据体量大)、Variety(数据类型繁多)、Velocity(处理速度快)、Value(价值密度低)。 从某种程度上说,大数据是数据分析的前沿技术。简言之,从各种各样类型的数据中,快速获得有价值信息的能力,就是大数据技术。明白这一点至关重要,也正是这一点促使该技术具备走向众多企业的潜力。 1.大数据概念及分析 毫无疑问,世界上所有关注开发技术的人都意识到“大数据”对企业商务所蕴含的潜在价值,其目的都在于解决在企业发展过程中各种业务数据增长所带来的痛苦。 现实是,许多问题阻碍了大数据技术的发展和实际应用。 因为一种成功的技术,需要一些衡量的标准。现在我们可以通过几个基本要素来衡量一下大数据技术,这就是——流处理、并行性、摘要索引和可视化。 大数据技术涵盖哪些内容? 1.1流处理 伴随着业务发展的步调,以及业务流程的复杂化,我们的注意力越来越集中在“数据流”而非“数据集”上面。 决策者感兴趣的是紧扣其组织机构的命脉,并获取实时的结果。他们需要的是能够处理随时发生的数据流的架构,当前的数据库技术并不适合数据流处理。 1.2并行化 大数据的定义有许多种,以下这种相对有用。“小数据”的情形类似于桌面环境,磁盘存储能力在1GB到10GB之间,“中数据”的数据量在100GB到1TB之间,“大数据”分布式的存储在多台机器上,包含1TB到多个PB的数据。 如果你在分布式数据环境中工作,并且想在很短的时间内处理数据,这就需要分布式处理。 1.3摘要索引 摘要索引是一个对数据创建预计算摘要,以加速查询运行的过程。摘要索引的问题是,你必须为要执行的查询做好计划,因此它有所限制。 数据增长飞速,对摘要索引的要求远不会停止,不论是长期考虑还是短期,供应商必须对摘要索引的制定有一个确定的策略。 1.4数据可视化 可视化工具有两大类。
并行计算综述
并行计算综述 姓名:尹航学号:S131020012 专业:计算机科学与技术摘要:本文对并行计算的基本概念和基本理论进行了分析和研究。主要内容有:并行计算提出的背景,目前国内外的研究现状,并行计算概念和并行计算机类型,并行计算的性能评价,并行计算模型,并行编程环境与并行编程语言。 关键词:并行计算;性能评价;并行计算模型;并行编程 1. 前言 网络并行计算是近几年国际上并行计算新出现的一个重要研究方向,也是热门课题。网络并行计算就是利用互联网上的计算机资源实现其它问题的计算,这种并行计算环境的显著优点是投资少、见效快、灵活性强等。由于科学计算的要求,越来越多的用户希望能具有并行计算的环境,但除了少数计算机大户(石油、天气预报等)外,很多用户由于工业资金的不足而不能使用并行计算机。一旦实现并行计算,就可以通过网络实现超级计算。这样,就不必要购买昂贵的并行计算机。 目前,国内一般的应用单位都具有局域网或广域网的结点,基本上具备网络计算的硬件环境。其次,网络并行计算的系统软件PVM是当前国际上公认的一种消息传递标准软件系统。有了该软件系统,可以在不具备并行机的情况下进行并行计算。该软件是美国国家基金资助的开放软件,没有版权问题。可以从国际互联网上获得其源代码及其相应的辅助工具程序。这无疑给人们对计算大问题带来了良好的机遇。这种计算环境特别适合我国国情。 近几年国内一些高校和科研院所投入了一些力量来进行并行计算软件的应用理论和方法的研究,并取得了可喜的成绩。到目前为止,网络并行计算已经在勘探地球物理、机械制造、计算数学、石油资源、数字模拟等许多应用领域开展研究。这将在计算机的应用的各应用领域科学开创一个崭新的环境。 2. 并行计算简介[1] 2.1并行计算与科学计算 并行计算(Parallel Computing),简单地讲,就是在并行计算机上所作的计算,它和常说的高性能计算(High Performance Computing)、超级计算(Super Computing)是同义词,因为任何高性能计算和超级计算都离不开并行技术。
并行计算1
并行计算 实 验 报 告 学院名称计算机科学与技术学院专业计算机科学与技术 学生姓名 学号 年班级 2016年5 月20 日
一、实验内容 本次试验的主要内容为采用多线程的方法计算pi的值,熟悉linux下pthread 形式的多线程编程,对实验结果进行统计并分析以及加速比曲线分析,从而对并行计算有初步了解。 二、实验原理 本次实验利用中值积分定理计算pi的值 图1 中值定理计算pi 其中公式可以变换如下: 图2 积分计算pi公式的变形 当N足够大时,可以足够逼近pi,多线程的计算方法主要通过将for循环的计算过程分到几个线程中去,每次计算都要更新sum的值,为避免一个线程更新sum 值后,另一个线程仍读到旧的值,所以每个线程计算自己的部分,最后相加。三、程序流程图 程序主体部分流程图如下:
多线程执行函数流程图如下: 四、实验结果及分析
令线程数分别为1、2、5、10、20、30、40、50和100,并且对于每次实验重复十次求平均值。结果如下: 图5 时间随线程的变化 实验加速比曲线的计算公式类似于 结果如下: 图5 加速比曲线 实验结果与预期类似,当线程总数较少时,线程数的增多会对程序计算速度带来明显的提升,当线程总数增大到足够大时,由于物理节点的核心数是有限的,因此会给cpu带来较多的调度,线程的切换和最后结果的汇总带来的时间开销较大,所以线程数较大时,增加线程数不会带来明显的速度提升,甚至可能下降。 五、实验总结
本次试验的主要内容是多线程计算pi的实现,通过这次实验,我对并行计算有了进一步的理解。上学期的操作系统课程中,已经做过相似的题目,因此程序主体部分相似。不同的地方在于,首先本程序按照老师要求应在命令行提供参数,而非将数值写定在程序里,其次是程序不是在自己的电脑上运行,而是通过ssh和批处理脚本等登录到远程服务器提交任务执行。 在运行方面,因为对批处理任务不够熟悉,出现了提交任务无结果的情况,原因在于windows系统要采用换行的方式来表明结束。在实验过程中也遇到了其他问题,大多还是来自于经验的缺乏。 在分析实验结果方面,因为自己是第一次分析多线程程序的加速比,因此比较生疏,参考网上资料和ppt后分析得出结果。 从自己遇到的问题来看,自己对批处理的理解和认识还比较有限,经过本次实验,我对并行计算的理解有了进一步的提高,也意识到了自己存在的一些问题。 六、程序代码及部署 程序源代码见cpp文件 部署说明: 使用gcc编译即可,编译时加上-pthread参数,运行时任务提交到服务器上。 编译命令如下: gcc -pthread PI_3013216011.cpp -o pi pbs脚本(runPI.pbs)如下: #!/bin/bash #PBS -N pi #PBS -l nodes=1:ppn=8 #PBS -q AM016_queue #PBS -j oe cd $PBS_O_WORKDIR for ((i=1;i<=10;i++)) do ./pi num_threads N >> runPI.log
权威.NET多线程详解(源码示例)
目录 本文档网上收集,如果出现版权问题,请及时的联系我,我将删除之! 1基础篇 ?怎样创建一个线程 ?受托管的线程与Windows线程 ?前台线程与后台线程 ?名为BeginXXX和EndXXX的方法是做什么用的 ?异步和多线程有什么关联 WinForm多线程编程篇 ?我的多线程WinForm程序老是抛出InvalidOperationException ,怎么解决? ?Invoke,BeginInvoke干什么用的,内部是怎么实现的 ?每个线程都有消息队列吗? ?为什么Winform不允许跨线程修改UI线程控件的值 ?有没有什么办法可以简化WinForm多线程的开发 线程池 ?线程池的作用是什么? ?所有进程使用一个共享的线程池,还是每个进程使用独立的线程池? ?为什么不要手动线程池设置最大值? ?.Net线程池有什么不足? 同步 ?CLR怎样实现lock(obj)锁定? ?WaitHandle是什么,他和他的派生类怎么使用 ?什么是用双锁实现Singleton,为什么要这样做,为什么有人说双锁检验是不安全的?互斥对象(Mutex)、事件(Event)对象与lock语句的比较 什么时候需要锁定 ?只有共享资源才需要锁定 ?把锁定交给数据库 ?了解你的程序是怎么运行的
?业务逻辑对事务和线程安全的要求 ?计算一下冲突的可能性 ?请多使用lock,少用Mutex Web和IIS ?应用程序池,WebApplication,和线程池之间有什么关系 ?Web页面怎么调用异步WebService 基础篇 怎样创建一个线程 一)使用Thread类 ThreadStart threadStart=new ThreadStart(Calculate);//通过ThreadStart委托告诉子线程讲执行什么方法,这里执行一个计算圆周长的方法 Thread thread=new Thread(threadStart); thread.Start(); //启动新线程 public void Calculate(){ double Diameter=0.5; Console.Write("The perimeter Of Circle with a Diameter of {0} is {1}"Diameter,Diameter*Math.PI); } 二)使用Delegate.BeginInvoke delegate double CalculateMethod(double Diameter); //申明一个委托,表明需要在子线程上执行的方法的函数签名 static CalculateMethod calcMethod = new CalculateMethod(Calculate);//把委托和具体的方法关联起来 static void Main(string[] args) {
并行计算-练习题
2014年《并行计算系统》复习题 (15分)给出五种并行计算机体系结构的名称,并分别画出其典型结构。 ①并行向量处理机(PVP) ②对称多机系统(SMP) ③大规模并行处理机(MPP) ④分布式共享存储器多机系统(DSM) ⑤工作站机群(COW) (10分)给出五种典型的访存模型,并分别简要描述其特点。 ①均匀访存模型(UMA): 物理存储器被所有处理机均匀共享 所有处理机访存时间相同 适于通用的或分时的应用程序类型 ②非均匀访存模型(NUMA): 是所有处理机的本地存储器的集合 访问本地LM的访存时间较短 访问远程LM的访存时间较长 ③Cache一致性非均匀访存模型(CC-NUMA): DSM结构 ④全局Cache访存模型(COMA): 是NUMA的一种特例,是采用各处理机的Cache组成的全局地址空间 远程Cache的访问是由Cache目录支持的 ⑤非远程访存模型(NORMA): 在分布式存储器多机系统中,如果所有存储器都是专用的,而且只能被本地存储机访问,则这种访问模型称为NORAM 绝大多数的NUMA支持NORAM 在DSM中,NORAM的特性被隐匿的 3. (15分)对于如下的静态互连网络,给出其网络直径、节点的度数、对剖宽度,说明该网络是否是一个对称网络。 网络直径:8 节点的度数:2 对剖宽度:2 该网络是一个对称网络 4. (15分)设一个计算任务,在一个处理机上执行需10个小时完成,其中可并行化的部分为9个小时,不可并行化的部分为1个小时。问: (1)该程序的串行比例因子是多少,并行比例因子是多少? 串行比例因子:1/10
并行比例因子:9/10 如果有10个处理机并行执行该程序,可达到的加速比是多少? 10/(9/10 + 1) = 5.263 (3)如果有20个处理机并行执行该程序,可达到的加速比是多少? 10/(9/20 + 1)= 6.897 (15分)什么是并行计算系统的可扩放性?可放性包括哪些方面?可扩放性研究的目的是什么? 一个计算机系统(硬件、软件、算法、程序等)被称为可扩放的,是指其性能随处理机数目的增加而按比例提高。例如,工作负载能力和加速比都可随处理机的数目的增加而增加。可扩放性包括: 1.机器规模的可扩放性 系统性能是如何随着处理机数目的增加而改善的 2.问题规模的可扩放性 系统的性能是如何随着数据规模和负载规模的增加而改善 3.技术的可扩放性 系统的性能上如何随着技术的改变而改善 可扩放性研究的目的: 确定解决某类问题时何种并行算法与何种并行体系结构的组合,可以有效的利用大量的处理器; 对于运用于某种并行机上的某种算法,根据在小规模处理机的运行性能预测移植到大规模处理机上的运行性能; 对固定问题规模,确定最优处理机数和可获得的最大的加速比 (15分)给出五个基本的并行计算模型,并说明其各自的优缺点。 ①PRAM:SIMD-SM 优点: 适于表示和分析并行计算的复杂性; 隐匿了并行计算机的大部底层细节(如通信、同步),从而易于使用。 缺点: 不适于MIMD计算机,存在存储器竞争和通信延迟问题。 ②APRAM:MIMD-SM 优点: 保存了PRAM的简单性; 可编程性和可调试性(correctness)好; 易于进行程序复杂性分析。 缺点: 不适于具有分布式存储器的MIMD计算机。 ③BSP:MIMD-DM 优点: 把计算和通信分割开来; 使用hashing自动进行存储器和通信管理; 提供了一个编程环境。 缺点: 显式的同步机制限制并行计算机数据的增加; 在一个Superstep中最多只能传递h各报文。
并行计算第一次实验报告
并行计算上机实验报告题目:多线程计算Pi值 学生姓名 学院名称计算机学院 专业计算机科学与技术时间
一. 实验目的 1、掌握集群任务提交方式; 2、掌握多线程编程。 二.实验内容 1、通过下图中的近似公式,使用多线程编程实现pi的计算; 2、通过控制变量N的数值以及线程的数量,观察程序的执行效率。 三.实现方法 1. 下载配置SSH客户端 2. 用多线程编写pi代码 3. 通过文件传输界面,将文件上传到集群上 4.将命令行目录切换至data,对.c文件进行编译 5.编写PBS脚本,提交作业 6.实验代码如下: #include
#include
多线程编程实例---pthread_join函数详解1
多线程编程实例---pthread_join函数详解1 单处理器上的linux多线程,是通过分时操作完成的; 此时互斥锁的作用,只有在时间足够的情况下才能体现出来,即有时线程内需要延时; 否则只有第一个线程不断解锁和获锁,别的线程在第一个线程执行完前无法获得互斥锁。三pthread_join pthread_exit 函数pthread_join用来等待一个线程的结束。函数原型为: extern int pthread_join __P ((pthread_t __th, void **__thread_return)); 第一个参数为被等待的线程标识符,第二个参数为一个用户定义的指针,它可以用来存储被等待线程的返回值。这个函数是一个线程阻塞的函数,调用它的函数将一直等待到被等待的线程结束为止,当函数返回时,被等待线程的资源被收回。一个线程的结束有两种途径,一种是象我们上面的例子一样,函数结束了,调用它的线程也就结束了;另一种方式是通过函数pthread_exit来实现。它的函数原型为: extern void pthread_exit __P ((void *__retval)) __attribute__ ((__noreturn__)); 唯一的参数是函数的返回代码,只要pthread_join中的第二个参数thread_return不是NULL,这个值将被传递给thread_return。最后要说明的是,一个线程不能被多个线程等待,否则第一个接收到信号的线程成功返回,其余调用pthread_join的线程则返回错误代码ESRCH。 在这一节里,我们编写了一个最简单的线程,并掌握了最常用的三个函数pthread_create,pthread_join和pthread_exit。下面,我们来了解线程的一些常用属性以及如何设置这些属性。 /////////////////////////////////////////////////////////////////////////// 源程序: /*thread_example.c : c multiple thread programming in linux */ #include
并行计算环境搭建
并行计算环境搭建 一.搭建并调试并行计算环境MPI的详细过程。 1.首先,我们选择在Windows XP平台下安装MPICH。第一步确保Windows平台下安装上了.net框架。 2.在并行环境的每台机子上创建相同的用户名和密码,并使该平台下的各台主机在相同的工作组中。 3.登陆到新创建的帐号下,安装MPICH软件,在选择安装路径时,每台机子的安装路径要确保一致。安装过程中,需要输入一致的passphrase,也即本机的用户名。 4.安装好软件后,要对并行环境进行配置(分为两步): 第一步:注册。在每台机器上运行wmpiregister,按照提示输入帐号和密码,即 本机的登录用户名和密码。 第二步:配置主机。在并行环境下,我们只有一台主机,其他机子作为端结点。 运行主机上的wmpiconfig,在界面左侧栏目中选择TNP工作组,点击“select”按 钮,此时主机会在网络中搜索配置好并行环境的其他机子。配置好并行环境的其他 机子会出现绿色状态,点击“apply”按钮,最后点击“OK”按钮。 5.在并行环境下运行的必须是.exe文件,所以我们必须要对并行程序进行编译并生成.exe文件。为此我们选择Visual C++6.0编译器对我们的C语言程序进行编译, 在编译过程中,主要要配置编译器环境: (1)在编译器环境下选择“工程”,在“link”选项卡的“object/library modules” 中输入mpi.lib,然后点击“OK”按钮。 (2)选择“选项”,点击“路径”选项卡,在“show directories for”下选择“Include files”,在“Directories”中输入MPICH软件中“Include”文件夹的路径; 在“show directories for”下选择“Library files”,在“Directories”中输入 MPICH软件中Library文件夹的路径,点击“OK”。 (3)对并行程序进行编译、链接,并生成.exe文件。 6.将生成的.exe文件拷贝到并行环境下的各台机子上,并确保每台机子的存放路径要相同。 7.在主机上运行“wmpiexec”,在Application中选择生成的.exe文件;输入要执行此程序的进程数,选中“more options”选项卡,在“host”栏中输入主机和各个端结 点的计算机名,点击“execute”执行程序。 二.搭建并调试并行计算环境MPI的详细过程。 1.以管理员身份登录每台计算机,在所有连接的计算机上建立一个同样的工作组,命名为Mshome,并在该工作组下建立相同的帐户,名为GM,密码为GM。 2.安装文件Microsoft NET Framwork1.1,将.NET框架安装到每台计算机上,再安装MPI到每台主机。在安装MPI的过程中,必须输入相同的passphrase,在此输 入之前已建好的帐户名GM。 3.安装好MPI后,再对每台计算机进行注册和配置,其中注册必须每台计算机都要进行,配置只在主控计算机进行: (1)注册:将先前在每台计算机上申请的帐号和密码注册到MPI中去,这样
22进程、线程与并行计算(windows 编程技术)
第22章 进程、线程与并行计算 进程是正在运行的程序,线程是轻量级的进程。多任务的并发执行会用到多线程(multithreading ),而CPU 的多核(mult-core )化又将原来只在巨型机和计算机集群中才使用的并行计算带入普通PC 应用的多核程序设计中。 本章先介绍进程与线程的概念和编程,再给出并行计算的基本概念和内容。下一章讨论基于多核CPU 的并行计算的若干具体编程接口和方法。 22.1 进程与线程 进程(process )是执行中的程序,线程(thread )是一种轻量级的进程。 22.1.1 进程与多任务 现代的操作系统都是多任务(multitask )的,即可同时运行多个程序。进程(process )是位于内存中正被CPU 运行的可执行程序实例,参见图22-1。 图22-1 程序与进程 目前的主流计算机采用的都是冯·诺依曼(John von Neumann )体系结构——存储程序计算模型。程序(program )是在内存中顺序存储并以线性模式在CPU 中串行执行的指令序列。对于传统的单核CPU 计算机,多任务操作系统的实现是通过CPU 分时(time-sharing )和程序并发(concurrency )完成的。即在一个时间段内,操作系统将CPU 分配给不同的程序,虽然每一时刻只有一个程序在CPU 中运行,但是由于CPU 的速度非常快,在很短的时间段中可在多个进程间进行多次切换,所以用户的感觉就像多个程序在同时执行,我们称之为多任务的并发。 22.1.2 进程与线程 程序一般包括代码段、数据段和堆栈,对具有GUI (Graphical User Interfaces ,图形用户界面)的程序还包含资源段。进程(process )是应用程序的执行实例,即正在被执行的程进程(内存中) 可执行文件(盘上) 运行
大规模并行计算
计算机学院 课程设计 课程名称高性能计算设计 题目名称大规模并行计算 专业__ 软件工程 _ __ _ 年级班别 2012级 学号 学生姓名 指导教师 联系方式 2015年12月18日
结构化数据访问注释对于大规模并 行计算 马可aldinucci1索尼亚营,2,基尔帕特里克3,和马西莫torquati2p.kilpatrick@https://www.360docs.net/doc/122608104.html, 1计算机科学系,大学都灵,意大利 aldinuc@di.unito.it 2比萨大学计算机科学系,意大利 {营,torquati}@di.unipi。它 3女王大学计算机科学系,贝尔法斯特 p.kilpatrick@https://www.360docs.net/doc/122608104.html, 摘要。我们描述了一种方法,旨在解决的问题控制联合开发(流)和一个数据并行骨架吨并行编程环境,基于注释重构。注解驱动一个并行计算的高效实现。重构是用来改造相关联的骨架树到一个更高效,功能上相当于骨架树。在大多数情况下成本模型是用来驱动的重构过程。我们展示了如何示例用例应用程序/内核可以被优化,讨论初步的实验评估结果归属理论。 克-词:算法的骨架,并行设计模式,重构,数据并行性,成本模型。 1我新台币 结构化并行程序设计方法已抽象出概念控制和数据并行通过骨骼上的[ 10 ],这是众所周知的PA T控制[ 8 ]燕鸥。控制并行的设想,设计和实施作为一个图的节点(骨架),每个节点代表一个函数。一股流独立的任务流经图:当每个节点的输入是有效的,它可以计算产生的输出被发送到它的连接节点。在另一方面,数据并行的kelet的描述一个计算模式定义如何在并行数据中访问数据,并将其应用于数据的功能分区以获得最终结果。传统上,控制之间的正交性并行和数据并行解决了采用双层模型控制流驱动的方法进行数据的并行能力增强,可能与并行数据结构暴露出集体行动[ 13 ]反之亦然。然而,控制并行和数据并行的方法。 这项工作已经由欧盟框架7批 ist-2011-288570”释义:自适应异构多核系统的并行模式” 我caragiannis 冯湛华。(E DS。):E尿PAR 2012个车间,LNCS 7640,pp. 381–390,2013。他是cspringe r-ve rlag用IDE L B E RG 2013382米aldinucci等人。 往往缺乏有效的应用程序,在这两个问题的能力被利用,因为本质上不同的手段,通过并行表示,有时,优化。一种高效的任务分配控制驱动的环境,可我nvalidated由糟糕的数据访问策略,反之亦然[ 14 ]。 在本文中,我们勾勒出一个新的方法来面对的控制与基于数据并行二分法的思想,即:数据与控制并行关注需要独立表达因为他们描述正交方面的并行性,和II)的数据访问和控制的并行模式的需要becoordin ED为了有效地支持并行应用的实现。虽然利用并行模式是不是一个新的方法[ 11 ]和协调工作在过去的语言方面作出了努力[ 17,12 ]或框架,本文提出的想法是,这样的协调可以通过对控制定义的图形表示关于数据访问的骨架。此外,我们将展示如何这样的注释可以用来驱动优化的实施图的执行。 2他骨骼框架 考虑骨骼系统包括控制(即流)和数据并行骨架,造型更一般的并行开发模式。我们的骨架是由下面的语法定义的 这些骷髅代表著名的并行开发模式[ 4 ]:序列把现有的序列码,管/农场流并行骨架处理流项
联想网御的多核并行计算网络安全平台
龙源期刊网 https://www.360docs.net/doc/122608104.html, 联想网御的多核并行计算网络安全平台 作者:李江力王智民 来源:《中国计算机报》2008年第44期 随着网络带宽的不断发展,网络如何安全、高效地运行逐渐成为人们关注的焦点。上期文章《多核技术开创万兆时代》指出,经过多年不断的努力探索,在历经了高主频CPU、FPGA、ASIC、NP后,我们迎来了多核时代。是不是有了多核,就能够满足当前人们对网络安全处理能力的需求呢?答案也许并非那么简单。 本文将从多核处理器带来的机遇与挑战、多核编程的困境、联想网御的解决方案三个方面来详细阐述多核并行计算相关的技术问题。 多核处理器带来机遇与挑战 通常我们所说的多核处理器是指CMP(ChipMulti-processors)的芯片结构。CMP是由美国斯坦福大学提出的,其思想是将大规模并行处理器中的SMP(Symmetric Multi-processors,对称多处理器)集成到同一芯片内,各个处理器并行执行,在同一个时刻同时有多条指令在执行。 多核处理器的出现使得人们从以前的单纯靠提高CPU主频的“死胡同”走了出来,同时又使得软件开发人员能够采用高级语言进行编程,看似是一个比较完美的技术方案,但同时我们也应该看到多核处理器也给业界带来了一系列的挑战。 同构与异构 CMP的构成分成同构和异构两类,同构是指内部核的结构是相同的,而异构是指内部的核结构是不同的。核内是同构还是异构,对不同的应用,带来的性能影响是不同的。 核间通信 多核处理器各个核之间通信是必然的事情,高效的核间通信机制将是多核处理器性能的重要保障。目前主流的芯片内部高效通信机制有两种,一种是基于总线共享的Cache结构,一种是基于片上的互连结构。采用第一种还是第二种,也是设计多核处理器的时候必须考虑的问题。 并行编程
C++多线程编程入门及范例详解
多线程编程之一——问题提出 一、问题的提出 编写一个耗时的单线程程序: 新建一个基于对话框的应用程序SingleThread,在主对话框IDD_SINGLETHREAD_DIALOG 添加一个按钮,ID为IDC_SLEEP_SIX_SECOND,标题为“延时6秒”,添加按钮的响应函数,代码如下: 1.void CSingleThreadDlg::OnSleepSixSecond() 2.{ 3.Sleep(6000);//延时6秒 4.} 编译并运行应用程序,单击“延时6秒”按钮,你就会发现在这6秒期间程序就象“死机”一样,不在响应其它消息。为了更好地处理这种耗时的操作,我们有必要学习——多线程编程。 二、多线程概述 进程和线程都是操作系统的概念。进程是应用程序的执行实例,每个进程是由私有的虚拟地址空间、代码、数据和其它各种系统资源组成,进程在运行过程中创建的资源随着进程的终止而被销毁,所使用的系统资源在进程终止时被释放或关闭。 线程是进程内部的一个执行单元。系统创建好进程后,实际上就启动执行了该进程的主执行线程,主执行线程以函数地址形式,比如说main或WinMain函数,将程序的启动点提供给Windows 系统。主执行线程终止了,进程也就随之终止。 每一个进程至少有一个主执行线程,它无需由用户去主动创建,是由系统自动创建的。用户根据需要在应用程序中创建其它线程,多个线程并发地运行于同一个进程中。一个进程中的所有线程都在该进程的虚拟地址空间中,共同使用这些虚拟地址空间、全局变量和系统资源,所以线程间的通讯非常方便,多线程技术的应用也较为广泛。 多线程可以实现并行处理,避免了某项任务长时间占用CPU时间。要说明的一点是,目前大多数的计算机都是单处理器(CPU)的,为了运行所有这些线程,操作系统为每个独立线程安排一些CPU时间,操作系统以轮换方式向线程提供时间片,这就给人一种假象,好象这些线程都在同时运行。由此可见,如果两个非常活跃的线程为了抢夺对CPU的控制权,在线程切换时会消耗很多的CPU资源,反而会降低系统的性能。这一点在多线程编程时应该注意。 Win32SDK函数支持进行多线程的程序设计,并提供了操作系统原理中的各种同步、互斥和临界区等操作。Visual C++6.0中,使用MFC类库也实现了多线程的程序设计,使得多线程编程更加方便。 三、Win32API对多线程编程的支持 Win32提供了一系列的API函数来完成线程的创建、挂起、恢复、终结以及通信等工作。下面将选取其中的一些重要函数进行说明。
并行计算大纲
附件二: 成都信息工程学院 硕士研究生课程教学大纲 课程名称(中):并行计算 课程名称(英):Parallel Computing 课程编号: 开课单位:软件工程系 预修课程:C语言,Linux操作系统 适用专业:计算机,电子类,大气类1年级研究生 课程性质:学位课 学时:32学时 学分:2学分 考核方式:考试 一、教学目的与要求(说明本课程同专业培养目标、研究方向、培养要求的关 系,及与前后相关课程的联系) 通过本课程的学习,使学生可以对并行程序设计有一个具体的基本的概念,对MPI有比较全面的了解,掌握MPI的基本功能,并且可以编写基本的MPI程序,可以用MPI来解决实际的比较基本的并行计算问题。具体如下: 从内容上,使学生了解并行计算的基本发展过程及现在的发展水平,掌握并行系统的组织结构,并行机群系统的构建方法。掌握MPI并行编程知识,了解并行技术的遗传算法迭代算法中的应用,了解并行监控系统的构成。 从能力方面,要求学生掌握并行机群系统的实际配置方法,能用MPI编制一般难度的并行算法程序并在机群系统上实现。 从教学方法上,采用启发、引导的教学方法,结合多媒体教学方式,提高学生学习兴趣。 二、课程内容简介 本课程以并行计算为主题,对并行计算技术的发展,应用以及并行计算机模型进行概述,与此同时系统介绍了MPI并行编程环境的使用与搭建,旨在帮助学生完成简单的并行程序设计,掌握并行计算平台的搭建,为深入学习并行计算技术打下坚实的基础。
三、主要章节和学时分(含相应章节内容的教学方式,如理论教学、实验教学、 上机、自学、综述文献等) 主要章节章节主要内容简述教学方式学时备注 第1章并行计算的发展及应用1.并行计算技术的发展过 程 2.并行系统在现代技术中 的应用 理论教学2学时 第2章并行计算机系统与结构1、典型并行计算机系统简 介 2、当代并行计算机体系结 构 理论教学2学时 第3章 PC机群系统的搭建1、机群系统概述 2、机群系统的搭建方法 3、机群系统的性能测试方 法 理论教学4学时 第4章机群系统的MPI编程1、MPI语言概述 2、MPI的六个基本函数 3、MPI的消息 4、点对点通讯 5、群集通讯 6、MPI的扩展 理论教学8学时 第5章实践环节上机完成并行机群系统的 配置。 实现简单并行计算程序的 编写。上机16学 时 (此页可附页) 四、采用教材(正式出版教材要求注明教材名称、作者姓名、出版社、出版时间;自编教材要求注明是否成册、编写者姓名、编写者职称、字数等) 《并行计算应用及实战》机械工业出版社王鹏主编 2008
浅谈多核CPU、多线程与并行计算
0.前言 最近发觉自己博客转帖的太多,于是决定自己写一个原创的。笔者用过MPI 和C#线程池,参加过比赛,有所感受,将近一年来,对多线程编程兴趣一直不减,一直有所关注,决定写篇文章,算是对知识的总结吧。有说的不对的地方,欢迎各位大哥们指正:) 1.CPU发展趋势 核心数目依旧会越来越多,依据摩尔定律,由于单个核心性能提升有着严重的瓶颈问题,普通的桌面PC有望在2017年末2018年初达到24核心(或者16核32线程),我们如何来面对这突如其来的核心数目的增加?编程也要与时俱进。笔者斗胆预测,CPU各个核心之间的片内总线将会采用4路组相连:),因为全相连太过复杂,单总线又不够给力。而且应该是非对称多核处理器,可能其中会混杂几个DSP处理器或流处理器。 2.多线程与并行计算的区别 (1)多线程的作用不只是用作并行计算,他还有很多很有益的作用。 还在单核时代,多线程就有很广泛的应用,这时候多线程大多用于降低阻塞(意思是类似于 while(1) { if(flag==1) break;
sleep(1); } 这样的代码)带来的CPU资源闲置,注意这里没有浪费CPU资源,去掉sleep(1)就是纯浪费了。 阻塞在什么时候发生呢?一般是等待IO操作(磁盘,数据库,网络等等)。此时如果单线程,CPU会干转不干实事(与本程序无关的事情都算不干实事,因为执行其他程序对我来说没意义),效率低下(针对这个程序而言),例如一个IO操作要耗时10毫秒,CPU就会被阻塞接近10毫秒,这是何等的浪费啊!要知道CPU是数着纳秒过日子的。 所以这种耗时的IO操作就用一个线程Thread去代为执行,创建这个线程的函数(代码)部分不会被IO操作阻塞,继续干这个程序中其他的事情,而不是干等待(或者去执行其他程序)。 同样在这个单核时代,多线程的这个消除阻塞的作用还可以叫做“并发”,这和并行是有着本质的不同的。并发是“伪并行”,看似并行,而实际上还是一个CPU在执行一切事物,只是切换的太快,我们没法察觉罢了。例如基于UI 的程序(俗话说就是图形界面),如果你点一个按钮触发的事件需要执行10秒钟,那么这个程序就会假死,因为程序在忙着执行,没空搭理用户的其他操作;而如果你把这个按钮触发的函数赋给一个线程,然后启动线程去执行,那么程序就不会假死,继续响应用户的其他操作。但是,随之而来的就是线程的互斥和同步、死锁等问题,详细见有关文献。 现在是多核时代了,这种线程的互斥和同步问题是更加严峻的,单核时代大都算并发,多核时代真的就大为不同,为什么呢?具体细节请参考有关文献。我
Delphi中多线程分析详解
Delphi中多线程分析详解 时间:2011-9-3 15:35:57 点击:1530 核心提示:0. 前言多线程是多任务操作系统下一个重要的组成部分,它能够提高应用程序的效率,然而,我们想利用好多线程,必须要了解很多的东西,比如操作系统的原理,堆栈概念和使用方法。然而,使用不当,将会造成无尽的痛... 0. 前言 多线程是多任务操作系统下一个重要的组成部分,它能够提高应用程序的效率,然而,我们想利用好多线程,必须要了解很多的东西,比如操作系统的原理,堆栈概念和使用方法。然而,使用不当,将会造成无尽的痛苦。曾经刚刚接触的时候,我也为之恐惧,迷惑了好久。在无数次的失败和查找资料解决问题之后,稍有感触,故写下此文,总结一下自己,同时,也给后学者一点启示,希望让他们少走弯路。 1. 基础知识。 线程是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。一个线程可以创建和撤消另一个线程,同一进程中的多个线程之间可以并发执行。由于线程之间的相互制约,致使线程在运行中呈现出间断性。线程也有就绪、阻塞和运行三种基本状态。 线程的生死。在windows中,我们可以通过调用 API CreateThread/CreateRemoteThread创建一个线程(其实,在Windows内部,CreateThread最终是调用了CreateRemoteThread创建线程)。当线程函数执行退出时,可以说这个线程已经完成了它的使命。调用ExitThread可以结束一个线程,同时调用CloseHandle来释放Windows分配给它的句柄资源。GetExitCodeThread可以用来检测线程是否已经退出。 HANDLE CreateThread( LPSECURITY_ATTRIBUTES lpThreadAttributes, // SD,线程的属性 DWORD dwStackSize, // initial stack size,线程堆栈的大小LPTHREAD_START_ROUTINE lpStartAddress, // thread function,线程函数LPVOID lpParameter, // thread argument,参数 DWORD dwCreationFlags, // creation option,创建时的标志 LPDWORD lpThreadId // thread identifier,线程的ID ); 线程的控制。线程的有三种状态:就绪,阻塞,运行。当我们在CreateThread的时候,第5个参数为CREATE_SUSPENDED标志时,线程创建后就处于挂起,即阻塞状态,否
基于Abaqus软件的并行计算异构集群平台的搭建
第31卷第5期 2011年10月地震工程与工程振动JOURNAL OF EARTHQUAKE ENGINEERING AND ENGINEERING VIBRATION Vol.31No.5Oct.2011收稿日期:2011-05-27;修订日期:2011-07-25 基金项目:国家公益性行业(地震)科研专项(200808022);江苏省自然科学基金项目(BK2008368) 作者简介:毛昆明(1985-),男,博士研究生,主要从事轨道交通引起的环境振动方面研究.E- mail :kun -ming@yeah.net 通讯作者:陈国兴(1963-),男,教授,博士,主要从事土动力学与岩土地震工程研究.E- mail :gxchen@njut.edu.cn 文章编号:1000-1301(2011)05-0184-06 基于Abaqus 软件的并行计算异构集群平台的搭建 毛昆明,陈国兴 (南京工业大学岩土工程研究所,江苏南京210009) 摘要:在异构集群上充分利用新、旧硬件资源调度计算任务是实现集群高性能并行计算的难点。 通过测试已搭建集群服务器的CPU 和内存对Abaqus 软件计算速度的影响,发现CPU 的主频对 Abaqus /Explicit 模块计算速度的影响大,CPU 的缓存对Abaqus /Standard 模块速度影响大;当内存满 足计算任务的最小需求时, 增加内存对计算速度无任何影响;当内存不足时,计算速度会大幅减慢。据此测试结果,新增4台服务器作为计算节点和一台Infiniband QDR 交换机作为交换节点,搭建了新 的异构集群, 性能测试结果表明:相对于千兆以太网络交换机,Infiniband QDR 交换机的并行计算效率更好,且集群的计算节点越多越显著;Abaqus /Standard 模块并行计算效率的提高幅度要比Abaqus / Explicit 模块的稍高一些。针对异构集群硬件构架相差较大的2批新、旧硬件,设置了2个管理节点、 2个网络节点、2个存储节点,充分利用了新、旧硬件资源,高效地实现了在一个异构集群平台上提交 与下载任务。 关键词:异构集群;Abaqus 软件;并行计算;Infiniband QDR 交换机 中图分类号:P315.69文献标志码:A Construction of parallel computing heterogeneous cluster platform based on Abaqus software MAO Kunming ,CHEN Guoxing (Institute of Geotechnical Engineering ,Nanjing University of Technology ,Nanjing 210009,China ) Abstract :Taking full advantage of new and old hardware resources on the heterogeneous cluster to schedule compu-ting jobs is a difficult point in the realization of high performance parallel computing.The influence of servers ’CPU and memory on computing speed of Abaqus software on the cluster which has been constructed is tested.The conclusions are drawn :CPU clock speed has a great effect on the computing speed of Abaqus /Explicit module and CPU internal cache has a great effect on computing speed of Abaqus /Standard module.When memory satisfies the minimum requirement of a computing job ,increasing memory has no effect on the computing speed.When memory is insufficient ,computing speed will slow down sharply.According to the testing results ,four servers as the compu- ting nodes and an Infiniband QDR switch as the network node are added , and then the heterogeneous cluster is con-structed.Parallel computing speed of the Infiniband QDR switch is tested ,and the result shows that the parallel effect of the Infiniband QDR switch is superior to the gigabit ethernet switch.The more the number of computing nodes is ,the better the parallel effect is.Abaqus /Standard module ’ s elevated range of parallel computing efficien-cy is slightly better than Abaqus /Explicit module ’s.Specific to two groups of new and old equipment whose archi-