ceph分布式存储介绍

Ceph分布式存储
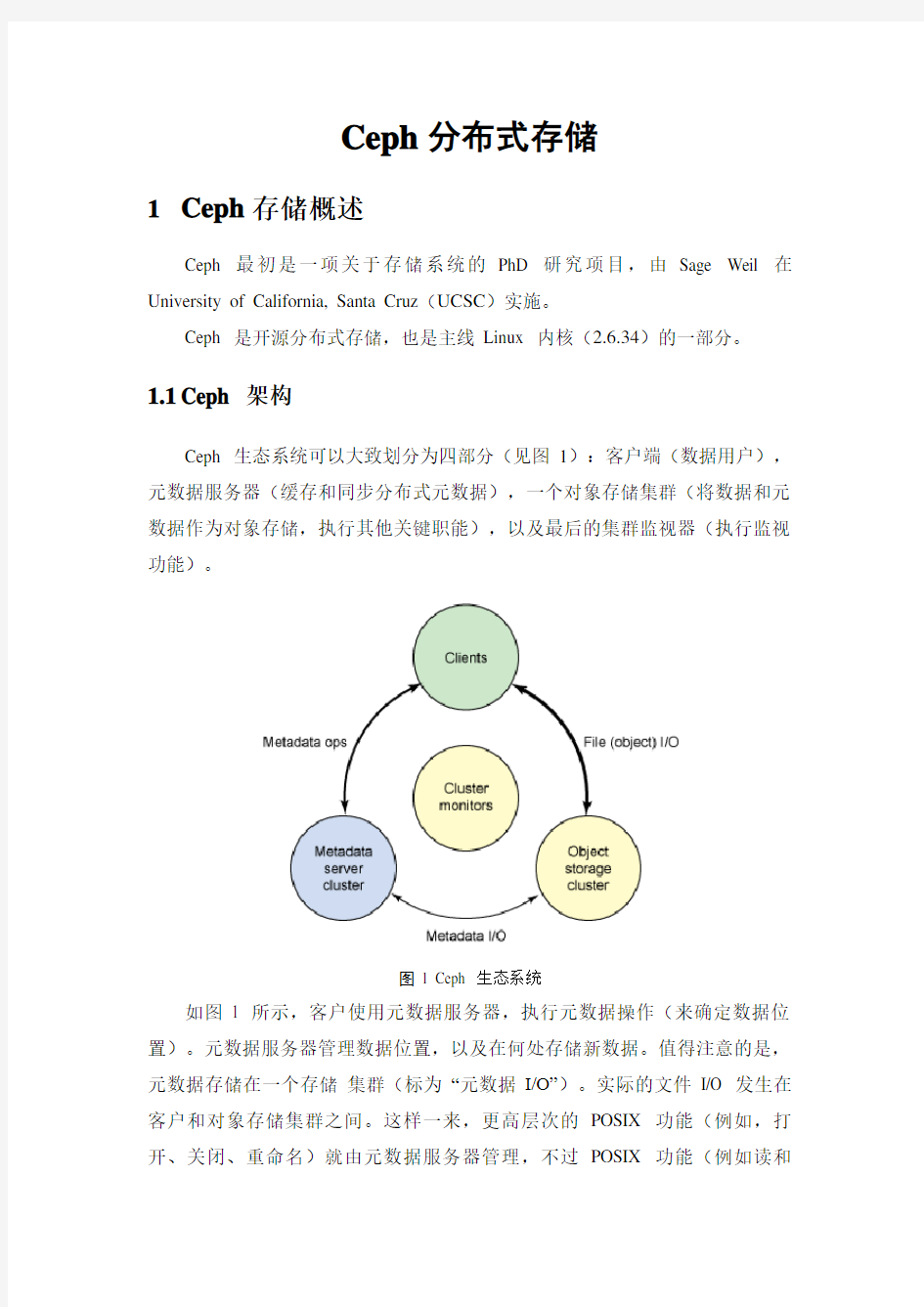
1Ceph存储概述
Ceph 最初是一项关于存储系统的PhD 研究项目,由Sage Weil 在University of California, Santa Cruz(UCSC)实施。
Ceph 是开源分布式存储,也是主线Linux 内核(2.6.34)的一部分。1.1Ceph 架构
Ceph 生态系统可以大致划分为四部分(见图1):客户端(数据用户),元数据服务器(缓存和同步分布式元数据),一个对象存储集群(将数据和元数据作为对象存储,执行其他关键职能),以及最后的集群监视器(执行监视功能)。
图1 Ceph 生态系统
如图1 所示,客户使用元数据服务器,执行元数据操作(来确定数据位置)。元数据服务器管理数据位置,以及在何处存储新数据。值得注意的是,元数据存储在一个存储集群(标为―元数据I/O‖)。实际的文件I/O 发生在客户和对象存储集群之间。这样一来,更高层次的POSIX 功能(例如,打开、关闭、重命名)就由元数据服务器管理,不过POSIX 功能(例如读和
写)则直接由对象存储集群管理。
另一个架构视图由图2 提供。一系列服务器通过一个客户界面访问Ceph 生态系统,这就明白了元数据服务器和对象级存储器之间的关系。分布式存储系统可以在一些层中查看,包括一个存储设备的格式(Extent and B-tree-based Object File System [EBOFS] 或者一个备选),还有一个设计用于管理数据复制,故障检测,恢复,以及随后的数据迁移的覆盖管理层,叫做Reliable Autonomic Distributed Object Storage(RADOS)。最后,监视器用于识别组件故障,包括随后的通知。
图2 ceph架构视图
1.2Ceph 组件
了解了Ceph 的概念架构之后,您可以挖掘到另一个层次,了解在Ceph 中实现的主要组件。Ceph 和传统的文件系统之间的重要差异之一就是,它将智能都用在了生态环境而不是文件系统本身。
图3 显示了一个简单的Ceph 生态系统。Ceph Client 是Ceph 文件系统的用户。Ceph Metadata Daemon 提供了元数据服务器,而Ceph Object Storage Daemon 提供了实际存储(对数据和元数据两者)。最后,Ceph Monitor 提供了集群管理。要注意的是,Ceph 客户,对象存储端点,元数据服务器(根据文件系统的容量)可以有许多,而且至少有一对冗余的监视器。那么,这个文件系统是如何分布的呢?
图3简单的Ceph 生态系统
1.3Ceph 客户端
因为Linux 显示文件系统的一个公共界面(通过虚拟文件系统交换机[VFS]),Ceph 的用户透视图就是透明的。管理员的透视图肯定是不同的,考虑到很多服务器会包含存储系统这一潜在因素(要查看更多创建Ceph 集群的信息,见参考资料部分)。从用户的角度看,他们访问大容量的存储系统,却不知道下面聚合成一个大容量的存储池的元数据服务器,监视器,还有独立的对象存储设备。用户只是简单地看到一个安装点,在这点上可以执行标准文件I/O。
Ceph 文件系统—或者至少是客户端接口—在Linux 内核中实现。值得注意的是,在大多数文件系统中,所有的控制和智能在内核的文件系统源本身中执行。但是,在Ceph 中,文件系统的智能分布在节点上,这简化了客户端接口,并为Ceph 提供了大规模(甚至动态)扩展能力。
Ceph 使用一个有趣的备选,而不是依赖分配列表(将磁盘上的块映射到指定文件的元数据)。Linux 透视图中的一个文件会分配到一个来自元数据服
务器的inode number(INO),对于文件这是一个唯一的标识符。然后文件被推入一些对象中(根据文件的大小)。使用INO 和object number(ONO),每个对象都分配到一个对象ID(OID)。在OID 上使用一个简单的哈希,每个对象都被分配到一个放置组。放置组(标识为PGID)是一个对象的概念容器。最后,放置组到对象存储设备的映射是一个伪随机映射,使用一个叫做Controlled Replication Under Scalable Hashing(CRUSH)的算法。这样一来,放置组(以及副本)到存储设备的映射就不用依赖任何元数据,而是依赖一个伪随机的映射函数。这种操作是理想的,因为它把存储的开销最小化,简化了分配和数据查询。
分配的最后组件是集群映射。集群映射是设备的有效表示,显示了存储集群。有了PGID 和集群映射,您就可以定位任何对象。
1.4Ceph 元数据服务器
元数据服务器(cmds)的工作就是管理文件系统的名称空间。虽然元数据和数据两者都存储在对象存储集群,但两者分别管理,支持可扩展性。事实上,元数据在一个元数据服务器集群上被进一步拆分,元数据服务器能够自适应地复制和分配名称空间,避免出现热点。如图4 所示,元数据服务器管理名称空间部分,可以(为冗余和性能)进行重叠。元数据服务器到名称空间的映射在Ceph 中使用动态子树逻辑分区执行,它允许Ceph 对变化的工作负载进行调整(在元数据服务器之间迁移名称空间)同时保留性能的位置。
图4 元数据服务器的Ceph 名称空间的分区
但是因为每个元数据服务器只是简单地管理客户端人口的名称空间,它的主要应用就是一个智能元数据缓存(因为实际的元数据最终存储在对象存储集群中)。进行写操作的元数据被缓存在一个短期的日志中,它最终还是被推入物理存储器中。这个动作允许元数据服务器将最近的元数据回馈给客户(这在元数据操作中很常见)。这个日志对故障恢复也很有用:如果元数据服务器发生故障,它的日志就会被重放,保证元数据安全存储在磁盘上。
元数据服务器管理inode 空间,将文件名转变为元数据。元数据服务器将文件名转变为索引节点,文件大小,和Ceph 客户端用于文件I/O 的分段数据(布局)。
1.5Ceph 监视器
Ceph 包含实施集群映射管理的监视器,但是故障管理的一些要素是在对象存储本身中执行的。当对象存储设备发生故障或者新设备添加时,监视器就检测和维护一个有效的集群映射。这个功能按一种分布的方式执行,这种方式中映射升级可以和当前的流量通信。Ceph 使用Paxos,它是一系列分布式共识算法。
1.6Ceph 对象存储
和传统的对象存储类似,Ceph 存储节点不仅包括存储,还包括智能。传
统的驱动是只响应来自启动者的命令的简单目标。但是对象存储设备是智能设备,它能作为目标和启动者,支持与其他对象存储设备的通信和合作。
从存储角度来看,Ceph 对象存储设备执行从对象到块的映射(在客户端的文件系统层中常常执行的任务)。这个动作允许本地实体以最佳方式决定怎样存储一个对象。Ceph 的早期版本在一个名为EBOFS 的本地存储器上实现一个自定义低级文件系统。这个系统实现一个到底层存储的非标准接口,这个底层存储已针对对象语义和其他特性(例如对磁盘提交的异步通知)调优。今天,B-tree 文件系统(BTRFS)可以被用于存储节点,它已经实现了部分必要功能(例如嵌入式完整性)。
因为Ceph 客户实现CRUSH,而且对磁盘上的文件映射块一无所知,下面的存储设备就能安全地管理对象到块的映射。这允许存储节点复制数据(当发现一个设备出现故障时)。分配故障恢复也允许存储系统扩展,因为故障检测和恢复跨生态系统分配。Ceph 称其为RADOS。
2Ceph快速配置
资源:
两台机器:一台server,一台client,安装ubuntu12.10
其中,server安装时,另外分出两个区,作为osd0、osd1的存储,没有的话,系统安装好后,使用loop设备虚拟出两个也可以。
步骤:
1、安装操作系统
2、添加key到APT中,更新sources.list,安装ceph
#sudo wget -q -O- 'https://https://www.360docs.net/doc/12813292.html,/git/?p=ceph.git;a=blob_plain;f=keys/release.asc' | sudo apt-key add -
#sudo echo deb https://www.360docs.net/doc/12813292.html,/debian/ $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph.list
# sudo apt-get update && sudo apt-get install ceph
3、查看版本
# ceph-v //将显示ceph的版本和key信息
如果没有显示,请执行如下命令
# sudo apt-get update && apt-get upgrade
4、在/etc/ceph/下创建ceph.conf配置文件,并将配置文件拷贝到Client 。[global]
# For version 0.55 and beyond, you must explicitly enable
# or disable authentication with "auth" entries in [global].
auth cluster required = none
auth service required = none
auth client required = none
[osd]
osd journal size = 1000
#The following assumes ext4 filesystem.
filestore xattr use omap = true
# For Bobtail (v 0.56) and subsequent versions, you may
# add settings for mkcephfs so that it will create and mount
# the file system on a particular OSD for you. Remove the comment `#`
# character for the following settings and replace the values
# in braces with appropriate values, or leave the following settings
# commented out to accept the default values. You must specify the
# --mkfs option with mkcephfs in order for the deployment script to
# utilize the following settings, and you must define the 'devs'
# option for each osd instance; see below.
osd mkfs type = xfs
osd mkfs options xfs = -f # default for xfs is "-f"
osd mount options xfs = rw,noatime # default mount option is "rw,noatime"
# For example, for ext4, the mount option might look like this:
#osd mkfs options ext4 = user_xattr,rw,noatime
# Execute $ hostname to retrieve the name of your host,
# and replace {hostname} with the name of your host.
# For the monitor, replace {ip-address} with the IP
# address of your host.
[mon.a]
host = ubuntu
mon addr = 192.168.60.125:678
[osd.0]
host = ubuntu
# For Bobtail (v 0.56) and subsequent versions, you may
# add settings for mkcephfs so that it will create and mount
# the file system on a particular OSD for you. Remove the comment `#`
# character for the following setting for each OSD and specify
# a path to the device if you use mkcephfs with the --mkfs option.
devs = /dev/loop0
[osd.1]
host = ubuntu
devs = /dev/loop1
[mds.a]
host = ubuntu
说明:
1)配置文件请将认证设置成none
auth cluster required = none
auth service required = none
auth client required = none
2)指定osd0、osd1的位置
如果没有/sda,可使用loop设备虚拟,方法如下:
# losetup –a //查看loop设备的使用情况
# dd if=/dev/zero of=osd1 bs=1M count=1000 //格式化
# losetup /dev/loop0 osd0 //建立对应关系
#mkfs –t xfs /dev/loop0 //格式化
按照相同的方法设置loop1为osd1
5、创建目录
sudo mkdir -p /var/lib/ceph/osd/ceph-0
sudo mkdir -p /var/lib/ceph/osd/ceph-1
sudo mkdir -p /var/lib/ceph/mon/ceph-a
sudo mkdir -p /var/lib/ceph/mds/ceph-a
6、执行初始化
cd /etc/ceph
sudo mkcephfs -a -c /etc/ceph/ceph.conf -k ceph.keyring
7、启动
# sudo service ceph -a start
8、执行健康检查
sudo ceph health
如果返回的是HEALTH_OK,代表成功!
出现:HEALTH_WARN 576 pgs stuck inactive; 576 pgs stuck unclean; no osds之类的,请执行:
#ceph pg dump_stuck stale
#ceph pg dump_stuck inactive
#ceph pg dump_stuck unclean
再次健康检查是,应该是OK
注意:重新执行如下命令#sudo mkcephfs -a -c /etc/ceph/ceph.conf -k ceph.keyring 前,请先清空创建的四个目录:/var/lib/ceph/osd/ceph-0、/var/lib/ceph/osd/ceph-
1、/var/lib/ceph/mon/ceph-a、/var/lib/ceph/mds/ceph-a
# rm –frv /var/lib/ceph/osd/ceph-0/*
# rm –frv /var/lib/ceph/osd/ceph-1/*
# rm –frv /var/lib/ceph/mon/ceph-a/*
# rm –frv /var/lib/ceph/mds/ceph-a/*
3CephFS的使用
在客户端上操作:
sudo mkdir /mnt/mycephfs
sudo mount -t ceph {ip-address-of-monitor}:6789:/ /mnt/mycephfs
或者
sudo mkdir /home/{username}/cephfs
sudo ceph-fuse -m {ip-address-of-monitor}:6789 /home/{username}/cephfs
# sudo mount -l
……
192.168.60.125:6789:/ on /mnt/mycephfs type ceph (0)
# cd /mnt/mycephfs
可进行文件操作
4源码包编译流程:
1、安装好系统后,选择系统设置-软件源,将APT的源修改为https://www.360docs.net/doc/12813292.html,/ubuntu
#sudo apt-get update
2、添加ceph的源到/etc/apt/sources.list中
deb https://www.360docs.net/doc/12813292.html,/debian quantal main
deb-src https://www.360docs.net/doc/12813292.html,/debian quantal main
3、新建目录,存放ceph源码包
# mkdir ceph
# ce ceph
4、下载最新的ceph源码包
# apt-get source ceph
包含四个文件目录
ceph_0.56.3-1quantal_amd64.deb
ceph_0.56.3.orig.tar.gz
ceph_0.56.3-1quantal.diff.gz
ceph_0.56.3-1quantal.dsc
ceph-0.56.3
5、进入到ceph-0.56.3,开始编译工作
# cd ceph-0.56.3
6、查看README文件,按步骤编译,如下:
# apt-get install automake autoconf automake gcc g++ libboost-dev libedit-dev libssl-dev libtool libfcgi libfcgi-dev libfuse-dev linux-kernel-headers libcrypto++-dev libaio-dev libgoogle-perftools-dev libkeyutils-dev uuid-dev libatomic-ops-dev libboost-program-options-dev libboost-thread-dev
# sudo apt-get dpkg-dev
# dpkg-checkbuilddeps # make sure we have all dependencies
apt-get install 安装缺少的依赖包
# dpkg-buildpackage 编译,需要一段时间
7、编译完成后,在ceph-0.56.3生成二进制文件和执行文件,并在上层目录(ceph)打成.deb包
8、修改后可使用make编译
# make
9、修改代码,make只编译修改的部分,并指明编译文件和修改文件
5源码编译测试情况
1、替换编译后的mds到/usr/bin下,启动成功,健康检查如下:
root@ubuntu:/usr/bin# ceph health
HEALTH_WARN 576 pgs stale //是不是一段时间没动?
root@ubuntu:/usr/bin# ceph pg dump_stuck stale
ok
pg_stat o bjects mip degr unf bytes log disklogstate state_stamp v reported up acting last_scrub scrub_stamp last_deep_scrub
deep_scrub_stamp
root@ubuntu:/usr/bin# ceph health
HEALTH_OK
Client可正常创建、拷贝文件
2、替换osd后,OK
root@ubuntu:/usr/bin# scp xiao@192.168.60.115:/home/xiao/ceph/ceph-0.56.3/src/ceph-osd .
xiao@192.168.60.115's password:
ceph-osd
100% 93MB 10.4MB/s 00:09
root@ubuntu:/usr/bin# service ceph -a start
=== mon.a ===
Starting Ceph mon.a on ubuntu...
starting mon.a rank 0 at 192.168.60.125:6789/0 mon_data /var/lib/ceph/mon/ceph-a fsid d188f2d1-d8f3-4f6d-94c6-0a271ff64dab
=== mds.a ===
Starting Ceph mds.a on ubuntu...
starting mds.a at :/0
=== osd.0 ===
Starting Ceph osd.0 on ubuntu...
starting osd.0 at :/0 osd_data /var/lib/ceph/osd/ceph-0 /var/lib/ceph/osd/ceph-0/journal === osd.1 ===
Starting Ceph osd.1 on ubuntu...
starting osd.1 at :/0 osd_data /var/lib/ceph/osd/ceph-1 /var/lib/ceph/osd/ceph-1/journal root@ubuntu:/usr/bin# service ceph status
=== mon.a ===
mon.a: running {"version":"0.56.3"}
=== mds.a ===
mds.a: running {"version":"0.56.3"}
=== osd.0 ===
osd.0: running {"version":"0.56.3"}
=== osd.1 ===
osd.1: running {"version":"0.56.3"}
root@ubuntu:/usr/bin# ceph health
HEALTH_OK
Client可正常创建、拷贝文件
3、替换mon,OK
root@ubuntu:/usr/bin# cp ceph-mon ceph-mon.bak
root@ubuntu:/usr/bin# scp xiao@192.168.60.115:/home/xiao/ceph/ceph-0.56.3/src/ceph-mon .
xiao@192.168.60.115's password:
ceph-mon
100% 46MB 11.4MB/s 00:04
root@ubuntu:/usr/bin# service ceph -a start
=== mon.a ===
Starting Ceph mon.a on ubuntu...
starting mon.a rank 0 at 192.168.60.125:6789/0 mon_data /var/lib/ceph/mon/ceph-a fsid d188f2d1-d8f3-4f6d-94c6-0a271ff64dab
=== mds.a ===
Starting Ceph mds.a on ubuntu...
starting mds.a at :/0
=== osd.0 ===
Starting Ceph osd.0 on ubuntu...
starting osd.0 at :/0 osd_data /var/lib/ceph/osd/ceph-0 /var/lib/ceph/osd/ceph-0/journal === osd.1 ===
Starting Ceph osd.1 on ubuntu...
starting osd.1 at :/0 osd_data /var/lib/ceph/osd/ceph-1 /var/lib/ceph/osd/ceph-1/journal root@ubuntu:/usr/bin# service ceph status
=== mon.a ===
mon.a: running {"version":"0.56.3"}
=== mds.a ===
mds.a: running {"version":"0.56.3"}
=== osd.0 ===
osd.0: running {"version":"0.56.3"}
=== osd.1 ===
osd.1: running {"version":"0.56.3"}
root@ubuntu:/usr/bin# ceph health
HEALTH_OK
Client可正常创建、拷贝文件
6mds源码分析
暂时未完成……
附录问题记录
ceph health命令
ceph按照官方文档部署成功,健康检查为health_OK,一段时间没有使用,也没有关机,下次使用时,各节点均能够重启启动成功,但健康检查提示:HEALTH_ERR 576 pgs stuck inactive; 576 pgs stuck unclean; no osds
客户端挂在cephfs文件系统无法成功。
网上查找后,提示注释掉配置文件的#devs = /dev/loop1
#devs = /dev/loop0
清空目录,执行如下命令:
# mkcephfs -a -c /etc/ceph/ceph.conf /etc/ceph/ceph.keyring
# service ceph start
#ceph health
HEALTH_WARN 576 pgs stuck inactive; 576 pgs stuck unclean; no osds
错误变成了警告……
#ceph pg dump_stuck stale
#ceph pg dump_stuck inactive
#ceph pg dump_stuck unclean
#ceph health
HEALTH_OK
解决方法:
http://irclogs.ceph.widodh.nl/index.php?date=2013-02-13
ceph分布式存储介绍
Ceph分布式存储 1Ceph存储概述 Ceph 最初是一项关于存储系统的PhD 研究项目,由Sage Weil 在University of California, Santa Cruz(UCSC)实施。 Ceph 是开源分布式存储,也是主线Linux 内核(2.6.34)的一部分。1.1Ceph 架构 Ceph 生态系统可以大致划分为四部分(见图1):客户端(数据用户),元数据服务器(缓存和同步分布式元数据),一个对象存储集群(将数据和元数据作为对象存储,执行其他关键职能),以及最后的集群监视器(执行监视功能)。 图1 Ceph 生态系统 如图1 所示,客户使用元数据服务器,执行元数据操作(来确定数据位置)。元数据服务器管理数据位置,以及在何处存储新数据。值得注意的是,元数据存储在一个存储集群(标为―元数据I/O‖)。实际的文件I/O 发生在客户和对象存储集群之间。这样一来,更高层次的POSIX 功能(例如,打开、关闭、重命名)就由元数据服务器管理,不过POSIX 功能(例如读和
写)则直接由对象存储集群管理。 另一个架构视图由图2 提供。一系列服务器通过一个客户界面访问Ceph 生态系统,这就明白了元数据服务器和对象级存储器之间的关系。分布式存储系统可以在一些层中查看,包括一个存储设备的格式(Extent and B-tree-based Object File System [EBOFS] 或者一个备选),还有一个设计用于管理数据复制,故障检测,恢复,以及随后的数据迁移的覆盖管理层,叫做Reliable Autonomic Distributed Object Storage(RADOS)。最后,监视器用于识别组件故障,包括随后的通知。 图2 ceph架构视图 1.2Ceph 组件 了解了Ceph 的概念架构之后,您可以挖掘到另一个层次,了解在Ceph 中实现的主要组件。Ceph 和传统的文件系统之间的重要差异之一就是,它将智能都用在了生态环境而不是文件系统本身。 图3 显示了一个简单的Ceph 生态系统。Ceph Client 是Ceph 文件系统的用户。Ceph Metadata Daemon 提供了元数据服务器,而Ceph Object Storage Daemon 提供了实际存储(对数据和元数据两者)。最后,Ceph Monitor 提供了集群管理。要注意的是,Ceph 客户,对象存储端点,元数据服务器(根据文件系统的容量)可以有许多,而且至少有一对冗余的监视器。那么,这个文件系统是如何分布的呢?
分布式存储技术及应用介绍
根据did you know(https://www.360docs.net/doc/12813292.html,/)的数据,目前互联网上可访问的信息数量接近1秭= 1百万亿亿 (1024)。毫无疑问,各个大型网站也都存储着海量的数据,这些海量的数据如何有效存储,是每个大型网站的架构师必须要解决的问题。分布式存储技术就是为了解决这个问题而发展起来的技术,下面让将会详细介绍这个技术及应用。 分布式存储概念 与目前常见的集中式存储技术不同,分布式存储技术并不是将数据存储在某个或多个特定的节点上,而是通过网络使用企业中的每台机器上的磁盘空间,并将这些分散的存储资源构成一个虚拟的存储设备,数据分散的存储在企业的各个角落。 具体技术及应用: 海量的数据按照结构化程度来分,可以大致分为结构化数据,非结构化数据,半结构化数据。本文接下来将会分别介绍这三种数据如何分布式存储。 结构化数据的存储及应用 所谓结构化数据是一种用户定义的数据类型,它包含了一系列的属性,每一个属性都有一个数据类型,存储在关系数据库里,可以用二维表结构来表达实现的数据。 大多数系统都有大量的结构化数据,一般存储在Oracle或MySQL的等的关系型数据库中,当系统规模大到单一节点的数据库无法支撑时,一般有两种方法:垂直扩展与水平扩展。 ? 垂直扩展:垂直扩展比较好理解,简单来说就是按照功能切分数据库,将不同功能的数据,存储在不同的数据库中,这样一个大数据库就被切分成多个小数据库,从而达到了数据库的扩展。一个架构设计良好的应用系统,其总体功能一般肯定是由很多个松耦合的功能模块所组成的,而每一个功能模块所需要的数据对应到数据库中就是一张或多张表。各个功能模块之间交互越少,越统一,系统的耦合度越低,这样的系统就越容易实现垂直切分。 ? 水平扩展:简单来说,可以将数据的水平切分理解为按照数据行来切分,就是将表中的某些行切分到一个数据库中,而另外的某些行又切分到其他的数据库中。为了能够比较容易地判断各行数据切分到了哪个数据库中,切分总是需要按照某种特定的规则来进行的,如按照某个数字字段的范围,某个时间类型字段的范围,或者某个字段的hash值。 垂直扩展与水平扩展各有优缺点,一般一个大型系统会将水平与垂直扩展结合使用。 实际应用:图1是为核高基项目设计的结构化数据分布式存储的架构图。
ceph源码分析之读写操作流程(2)
ceph源码分析之读写操作流程(2) 上一篇介绍了ceph存储在上两层的消息逻辑,这一篇主要介绍一下读写操作在底两层的流程。下图是上一篇消息流程的一个总结。上在ceph中,读写操作由于分布式存储的原因,故走了不同流程。 对于读操作而言: 1.客户端直接计算出存储数据所属于的主osd,直接给主osd 上发送消息。 2.主osd收到消息后,可以调用Filestore直接读取处在底层文件系统中的主pg里面的内容然后返回给客户端。具体调用函数在ReplicatedPG::do_osd_ops中实现。读操作代码流程如图:如我们之前说的,当确定读操作为主osd的消息时(CEPH_MSG_OSD_OP类型),会调用到ReplicatePG::do_osd_op函数,该函数对类型做进一步判断,当发现为读类型(CEPH_OSD_OP_READ)时,会调用FileStore中的函数对磁盘上数据进行读。 [cpp] view plain copy int ReplicatedPG::do_osd_ops(OpContext *ctx, vector<OSDOp>& ops) { …… switch (op.op) { …… case CEPH_OSD_OP_READ: ++ctx->num_read; { // read into a buffer bufferlist
bl; int r = osd->store->read(coll, soid, op.extent.offset, op.extent.length, bl); // 调用FileStore::read从底层文件系统读 取……} case CEPH_OSD_OP_WRITE: ++ctx->num_write; { ……//写操作只是做准备工作,并不实际的 写} ……} } FileStore::read 函数是底层具体的实现,会通过调用系统函数 如::open,::pread,::close等函数来完成具体的操作。[cpp] view plain copy int FileStore::read( coll_t cid, const ghobject_t& oid, uint64_t offset, size_t len, bufferlist& bl, bool allow_eio) { …… int r = lfn_open(cid, oid, false, &fd); …… got = safe_pread(**fd, bptr.c_str(), len, offset); //FileStore::safe_pread中调用了::pread …… lfn_close(fd); ……} 而对于写操作而言,由于要保证数据写入的同步性就会复杂很多: 1.首先客户端会将数据发送给主osd, 2.主osd同样要先进行写操作预处理,完成后它要发送写消息给其他的从osd,让他们对副本pg进行更改, 3.从osd通过FileJournal完成写操作到Journal中后发送消息
分布式存储技术及应用
分布式存储技术及应用 根据did you know(https://www.360docs.net/doc/12813292.html,/)的数据,目前互联网上可访问的信息数量接近1秭= 1百万亿亿 (1024)。毫无疑问,各个大型网站也都存储着海量的数据,这些海量的数据如何有效存储,是每个大型网站的架构师必须要解决的问题。分布式存储技术就是为了解决这个问题而发展起来的技术,下面让将会详细介绍这个技术及应用。 分布式存储概念 与目前常见的集中式存储技术不同,分布式存储技术并不是将数据存储在某个或多个特定的节点上,而是通过网络使用企业中的每台机器上的磁盘空间,并将这些分散的存储资源构成一个虚拟的存储设备,数据分散的存储在企业的各个角落。 具体技术及应用: 海量的数据按照结构化程度来分,可以大致分为结构化数据,非结构化数据,半结构化数据。本文接下来将会分别介绍这三种数据如何分布式存储。 结构化数据的存储及应用 所谓结构化数据是一种用户定义的数据类型,它包含了一系列的属性,每一个属性都有一个数据类型,存储在关系数据库里,可以用二维表结构来表达实现的数据。 大多数系统都有大量的结构化数据,一般存储在Oracle或MySQL的等的关系型数据库中,当系统规模大到单一节点的数据库无法支撑时,一般有两种方法:垂直扩展与水平扩展。 ?垂直扩展:垂直扩展比较好理解,简单来说就是按照功能切分数据库,将不同功能的数据,存储在不同的数据库中,这样一个大数据库就被切分成多个小数据库, 从而达到了数据库的扩展。一个架构设计良好的应用系统,其总体功能一般肯定 是由很多个松耦合的功能模块所组成的,而每一个功能模块所需要的数据对应到 数据库中就是一张或多张表。各个功能模块之间交互越少,越统一,系统的耦合 度越低,这样的系统就越容易实现垂直切分。 ?水平扩展:简单来说,可以将数据的水平切分理解为按照数据行来切分,就是将表中的某些行切分到一个数据库中,而另外的某些行又切分到其他的数据库中。为 了能够比较容易地判断各行数据切分到了哪个数据库中,切分总是需要按照某种 特定的规则来进行的,如按照某个数字字段的范围,某个时间类型字段的范围, 或者某个字段的hash值。 垂直扩展与水平扩展各有优缺点,一般一个大型系统会将水平与垂直扩展结合使用。 实际应用:图1是为核高基项目设计的结构化数据分布式存储的架构图。
7种分布式文件系统介绍
FastDFS (7) Fastdfs简介 (7) Fastdfs系统结构图 (7) FastDFS和mogileFS的对比 (8) MogileFS (10) Mogilefs简介 (10) Mogilefs组成部分 (10) 0)数据库(MySQL)部分 (10) 1)存储节点 (11) 2)trackers(跟踪器) (11) 3)工具 (11) 4)Client (11) Mogilefs的特点 (12) 1. 应用层——没有特殊的组件要求 (12) 2. 无单点失败 (12) 3. 自动的文件复制 (12) 4. “比RAID好多了” (12) 5. 传输中立,无特殊协议 (13) 6.简单的命名空间 (13) 7.不用共享任何东西 (13) 8.不需要RAID (13)
9.不会碰到文件系统本身的不可知情况 (13) HDFS (14) HDFS简介 (14) 特点和目标 (14) 1. 硬件故障 (14) 2. 流式的数据访问 (14) 3. 简单一致性模型 (15) 4. 通信协议 (15) 基本概念 (15) 1. 数据块(block) (15) 2. 元数据节点(Namenode)和数据节点(datanode) . 16 2.1这些结点的用途 (16) 2.2元数据节点文件夹结构 (17) 2.3文件系统命名空间映像文件及修改日志 (18) 2.4从元数据节点的目录结构 (21) 2.5数据节点的目录结构 (21) 文件读写 (22) 1.读取文件 (22) 1.1 读取文件示意图 (22) 1.2 文件读取的过程 (23) 2.写入文件 (24) 2.1 写入文件示意图 (24)
CEPH分布式存储部署要点
CEPH分布式存储部署 PS:本文的所有操作均在mon节点的主机进行,如有变动另有注释 作者:网络技术部徐志权 日期:2014年2月10日 VERSION 1.0 更新历史: 2014.2.10:首次完成ceph部署文档,块设备及对象存储的配置随后添加。
一、部署前网络规划 1.1 环境部署 主机名公网IP(eth0)私网IP(eth1)操作系统运行服务node1 192.168.100.101 172.16.100.101 CentOS6.5 mon、mds node2 192.168.100.102 172.16.100.102 CentOS6.5 osd node3 192.168.100.103 172.16.100.103 CentOS6.5 osd ◆操作系统使用CentOS6.5,因为系统已经包含xfs的支持可以直接使用不需要再次 编译。 ◆由于CentOS6.5系统的内核为2.6.32,因此要关闭硬盘的写入缓存,若高于此版本 不需要关闭。 #hdparm -W 0 /dev/sdb 0 ◆本次部署一共有一个监控节点、一个元数据节点、两个数据节点,每个数据节点拥 有两个硬盘作为数据盘。 1.2 网络拓扑
1.3 配置服务器、安装ceph ●添加ceph的rpm库key #rpm --import 'https://https://www.360docs.net/doc/12813292.html,/git/?p=ceph.git;a=blob_plain;f=keys/release.asc' #rpm --import 'https://https://www.360docs.net/doc/12813292.html,/git/?p=ceph.git;a=blob_plain;f=keys/autobuild.asc' ●添加ceph-extras库 #vi /etc/yum.repos.d/ceph-extras [ceph-extras] name=Ceph Extras Packages baseurl=https://www.360docs.net/doc/12813292.html,/packages/ceph-extras/rpm/centos6/$basearch enabled=1 priority=2 gpgcheck=1 type=rpm-md gpgkey=https://https://www.360docs.net/doc/12813292.html,/git/?p=ceph.git;a=blob_plain;f=keys/release.asc [ceph-extras-noarch] name=Ceph Extras noarch baseurl=https://www.360docs.net/doc/12813292.html,/packages/ceph-extras/rpm/centos6/noarch enabled=1 priority=2 gpgcheck=1 type=rpm-md gpgkey=https://https://www.360docs.net/doc/12813292.html,/git/?p=ceph.git;a=blob_plain;f=keys/release.asc [ceph-extras-source] name=Ceph Extras Sources baseurl=https://www.360docs.net/doc/12813292.html,/packages/ceph-extras/rpm/centos6/SRPMS enabled=1 priority=2 gpgcheck=1 type=rpm-md gpgkey=https://https://www.360docs.net/doc/12813292.html,/git/?p=ceph.git;a=blob_plain;f=keys/release.asc ●添加ceph库 #rpm -Uvh https://www.360docs.net/doc/12813292.html,/rpms/el6/noarch/ceph-release-1-0.el6.noarch.rpm ●添加epel库 #rpm -Uvh https://www.360docs.net/doc/12813292.html,/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm ●安装ceph #yum update -y && yum install ceph -y
(完整版)Ceph分布式存储
Ceph分布式存储系统 Ceph是根据加州大学Santa Cruz分校的Sage Weil的博士论文所设计开发的新一代自由软件分布式文件系统,其设计目标是良好的可扩展性(PB级别以上)、高性能及高可靠性。Ceph其命名和UCSC(Ceph 的诞生地)的吉祥物有关,这个吉祥物是“Sammy”,一个香蕉色的蛞蝓,就是头足类中无壳的软体动物。这些有多触角的头足类动物,是对一个分布式文件系统高度并行的形象比喻。 其设计遵循了三个原则:数据与元数据的分离,动态的分布式的元数据管理,可靠统一的分布式对象存储机制。本文将从Ceph的架构出发,综合性的介绍Ceph分布式文件系统特点及其实现方式。 一、Ceph基本架构 Ceph是一个高可用、易于管理、开源的分布式存储系统,可以在一套系统中同时提供对象存储、块存储以及文件存储服务。其主要由Ceph存储系统的核心RADOS以及块存取接口、对象存取接口和文件系统接口组成,如图所示 Ceph的底层是RADOS,它的意思是“A reliable,autonomous, distributed object storage”。 RADOS作为Ceph分布式文件系统的一个子项目,是为了满足Ceph的需求
而设计的,但是,其也可以单独作为一种分布式数据存储系统,给其他的有类似需求的分布式文件系统提供数据存储服务。Ceph文件系统, Ceph对象存储和Ceph块设备从RADOS的存储集群中读去和写入数据。 Ceph作为一个分布式存储系统,其对外提供的接口,决定了其通用性以及扩展性。如上图架构图中所示的那样,Ceph对外提供了丰富多样的服务接口,包括多种编程语言接口LIBRADOS(备注,上图来自Ceph中文社区,社区人员在翻译的过程中将字母L遗失掉了)、对象存储接口(RADOSGW)、块存储接口(RBD)以及文件系统接口(Ceph FS)。其中LIBRADOS编程接口是其他各种客户端接口的基础,其他接口都是基于LIBRADOS 来进行扩展实现的。 1.1. RADOS Ceph中RADOS(Reliable Autonomic Distributed Object Store)存储集群是所有其他客户端接口使用和部署的基础。RADOS由两个组件组成: ?OSD: Object StorageDevice,提供存储资源。 ?Monitor:维护整个Ceph集群的全局状态。 典型的RADOS部署架构由少量的Monitor监控器以及大量的OSD存储设备组成,它能够在动态变化的基于异质结构的存储设备集群之上提供一种稳定的、可扩展的、高性能的单一逻辑对象存储接口。 RADOS系统的架构如图所示: 我们看到,RADOS不是某种组件,而是由OSD(Object Storage Device)集群和Monitor集群组成。通常,一个RADOS系统中,OSD集群是由大量的智能化的OSD节点组成;Monitor集群是由少量的Monitor节点组成。OSD集群负责存储所有对象的数据。Monitors集群负责管理Ceph集群中所有成员、关系、属性以及数据分发等信息。
分布式存储系统技术说明
技术层次图 各技术简介 1.1mybatis简介 MyBatis 是支持普通SQL查询,存储过程和高级映射的优秀持久层框架。MyBatis 消除
了几乎所有的JDBC代码和参数的手工设置以及结果集的检索。MyBatis 使用简单的XML 或注解用于配置和原始映射,将接口和Java 的POJOs(Plain Old Java Objects,普通的Java对象)映射成数据库中的记录。 每个MyBatis应用程序主要都是使用SqlSessionFactory实例的,一个SqlSessionFactory实例可以通过SqlSessionFactoryBuilder获得。SqlSessionFactoryBuilder可以从一个xml配置文件或者一个预定义的配置类的实例获得。 用xml文件构建SqlSessionFactory实例是非常简单的事情。推荐在这个配置中使用类路径资源(classpath resource),但你可以使用任何Reader实例,包括用文件路径或file://开头的url创建的实例。MyBatis有一个实用类----Resources,它有很多方法,可以方便地从类路径及其它位置加载资源。 1.2webservice简介 Web service是一个平台独立的,低耦合的,自包含的、基于可编程的web的应用程序,可使用开放的XML(标准通用标记语言下的一个子集)标准来描述、发布、发现、协调和配置这些应用程序,用于开发分布式的互操作的应用程序。 1.3jquery简介
jQuery UI 是以jQuery 为基础的开源JavaScript 网页用户界面代码库。包含底层用户交互、动画、特效和可更换主题的可视控件。我们可以直接用它来构建具有很好交互性的web应用程序。所有插件测试能兼容 jQuery UI包含了许多维持状态的小部件(Widget),因此,它与典型的jQuery 插件使用模式略有不同。所有的jQuery UI 小部件(Widget)使用相同的模式,所以,只要您学会使用其中一个,您就知道如何使用其他的小部件(Widget)。 1.4springmvc简介 Spring MVC属于SpringFrameWork的后续产品,已经融合在Spring Web Flow里面。Spring 框架提供了构建Web 应用程序的全功能MVC 模块。使用Spring 可插入的MVC 架构,可以选择是使用内置的Spring Web 框架还可以是Struts 这样的Web 框架。通过策略接口,Spring 框架是高度可配置的,而且包含多种视图技术,例如JavaServer Pages(JSP)技术、Velocity、Tiles、iText 和POI。Spring MVC 框架并不知道使用的视图,所以不会强迫您只使用JSP 技术。Spring MVC 分离了控制器、模型对象、分派器以及处理程序对象的角色,这种分离让它们更容易进行定制。 1.5spring简介 Spring是一个开源框架,Spring是于2003 年兴起的一个轻量
ceph学习资料
Ceph分布式存储 1. ceph概念 Ceph作为分布式存储,它有如下特点: ?高扩展性:普通的x86服务器组成的ceph集群,最多支持1000台以上的服务器扩展,并且可以在线扩展。 ?高可靠性:数据容错性高,没有因为单点故障造成的数据丢失;多副本技术,数据安全性更加可靠;自动修复,数据丢失或者部分磁盘故障对全局没影响,不会影响上层的应用,对用户全透明。 ?高性能:数据是均匀分布到每个磁盘上的,读写数据都是有多个osd并发完成的,集群性能理论上来说随着集群节点数和osd的增长而线性增长。 2. ceph架构 2.1 组件
Ceph的底层是RADOS,它的意思是“A reliable, autonomous, distributed object storage”(一个可靠的自治的分布式存储,字面意思哈)。 RADOS系统逻辑架构图: RADOS主要由两个部分组成。一种是大量的、负责完成数据存储和维护功能的OSD(Object Storage Device),另一种则是若干个负责完成系统状态检测和维护的monitor。osd和monitor之间相互传输节点状态信息。 而ceph集群主要包括mon、mds、osd组件 其中,mon负责维护整个集群的状态以及包括crushmap、pgmap、osdmap等一系列map 信息记录与变更。 Osd负责提供数据存储,数据的恢复均衡。 Mds(元数据服务器)主要是使用文件系统存储的时候需要,它主要负责文件数据的inode 信息,并让客户端通过该inode信息快速找到数据实际所在地。 2.2 数据映射流程 在Ceph中,文件都是以object(对象)的方式存放在众多osd上。 一个file(数据)的写入顺序: 首先mon根据map信息将file(数据)切分成多个的object;再通过hash算法决定这些个object对象分别会存放在那些pg(放置组)里面;接下来在通过crushmap再决定将pg放在底层的那些osd上,pg与osd的关系属于一对多的关系。一个osd可以包括多
概述分布式存储应用技术
概述分布式存储应用技术 发表时间:2018-10-22T16:57:01.773Z 来源:《防护工程》2018年第16期作者:蒋仕亮吴文涛[导读] 本文通过对存储数据的分类,分析了结构化数据、非结构化数据和半结构化数据存储技术,并介绍了相关的应用场景 中国移动广西公司 530022 摘要:本文通过对存储数据的分类,分析了结构化数据、非结构化数据和半结构化数据存储技术,并介绍了相关的应用场景。帮助用户构建适合自己需求的分布式存储系统。关键词:分布式;存储;结构化数据一、分布式存储技术概述 从本质上而言,分布式存储技术是一种相对于集中式存储技术而存在的概念,不同于集中式存储技术,分布式存储技术将数据存储在了虚拟的网络空间中,而非特点的节点之上。具体来说,分布式存储技术充分利用了网络的优势,把网络上相对比较零散的存储空间虚拟为一个整体,进而将这一空间作为数据存储的主体。而在实际中,数据已经分别存储于各个存储空间当中,而非传统意义上某些特定的节点。在分布式存储技术的发展过程中,衍生出了分布式存储管理系统,该系统能够将有效整合零散的网络存储空间,并且通过多台服务器实现载荷的分散存储,进而为系统的安全性、可靠性与实用性提供有效保证。对于分布式存储技术而言,“分散存储”与“集中管理”是其最为主要的特点,同时也是其得以广泛应用的主要优势所在。 二、分布式存储技术 2.1结构化数据的分布式存储技术很多系统都有大量的结构化数据,一般存储在Oracle、SQLServer等关系型数据库中。当单一节点的数据库无法支撑其应用系统时,业界一般采用垂直扩展与水平扩展方法来解决。垂直扩展:垂直扩展简单来说就是将不同功能的数据,存储在不同的数据库中。将一个整体数据库进行切分,从而达到了数据库的扩展。一个架构设计良好的应用系统,其系统的耦合度越低,各个功能模块之间交互越少越统一,将数据库的垂直切分就越容易实现。水平扩展:水平扩展简单来说,是将数据按照数据行来切分,是将表中不同行的数据切分到不同的数据库中。按照某种特定的规则将数据切分至不同的数据库,可以方便判断数据被划分到了哪个数据库中,其规则可以是某个字段的范围,某个字段的hash值,某个时间型字段的范围等等。 图1水平与垂直切分扩展的数据访问框架 2.2非结构化数据的分布式存储应用非结构化数据的分布式存储中最有名的当属GFS(Google File System)。GFS将整个系统分为三类角色:主服务器(Master)、客户端(Client)、数据块服务器(Chunk Server)。主服务器(Master):主要存储与数据文件相关的元数据,而非数据块(Chunk)。元数据包括:命名空间(Name Space),即包含整个文件系统的目录结构,数据块副本位置信息,能将映射到数据块的位置(通常是一个64位标签)及其组成文件的表格,正在读写特定的数据块的进程信息等。为保持元数据保持最新状态,Master节点会通过周期性地接收从每个Chunk节点来的更新("Heart-beat")。主服务器是GFS的管理节点。 客户端(Client):是一组专用接口,是GFS提供给应用程序的访问接口,以库文件的形式提供。应用程序通过直接调用这些库函数,并与该库链接在一起,它不遵守POSIX规范。数据块服务器(Chunk Server):负责具体的存储工作。GFS将文件按照固定大小进行分块,Chunk(数据块)是它存储的基本单位,其默认值为64MB,每个Chunk有一个唯一的64位标签。每一个Chunk以Block再进行划分,其默认值为64KB。GFS容错方式为副本模式,每一个Chunk有多个存储副本,其默认值为3。GFS可以根据它的规模需求,来定义数据块服务器的个数。 图2 Google-file-system架构图
分布式存储基础、Ceph、cinder及华为软件定义的存储方案
块存储与分布式存储 块存储,简单来说就是提供了块设备存储的接口。通过向内核注册块设备信息,在Linux 中通过lsblk可以得到当前主机上块设备信息列表。 本文包括了单机块存储介绍、分布式存储技术Ceph介绍,云中的块存储Cinder,以及华为软件定义的存储解决方案。 单机块存储 一个硬盘是一个块设备,内核检测到硬盘然后在/dev/下会看到/dev/sda/。因为需要利用一个硬盘来得到不同的分区来做不同的事,通过fdisk工具得到/dev/sda1, /dev/sda2等,这种方式通过直接写入分区表来规定和切分硬盘,是最死板的分区方式。 分布式块存储 在面对极具弹性的存储需求和性能要求下,单机或者独立的SAN越来越不能满足企业的需要。如同数据库系统一样,块存储在scale up的瓶颈下也面临着scale out的需要。 分布式块存储系统具有以下特性: 分布式块存储可以为任何物理机或者虚拟机提供持久化的块存储设备; 分布式块存储系统管理块设备的创建、删除和attach/detach; 分布式块存储支持强大的快照功能,快照可以用来恢复或者创建新的块设备; 分布式存储系统能够提供不同IO性能要求的块设备。 现下主流的分布式块存储有Ceph、AMS ESB、阿里云磁盘与sheepdog等。 1Ceph 1.1Ceph概述 Ceph目前是OpenStack支持的开源块存储实现系统(即Cinder项目backend driver之一) 。Ceph是一种统一的、分布式的存储系统。“统一的”意味着Ceph可以一套存储系统同时提供对象存储、块存储和文件系统存储三种功能,以便在满足不同应用需求的前提下简化部署
RedHat Ceph分布式存储指南-块设备模块
Red Hat Customer Content Services Red Hat Ceph Storage 1.3Ceph Block Device Red Hat Ceph Storage Block Device
Red Hat Ceph Storage 1.3 Ceph Block Device Red Hat Ceph Storage Block Device
Legal Notice Copyright ? 2015 Red Hat, Inc. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at https://www.360docs.net/doc/12813292.html,/licenses/by-sa/3.0/ . In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, JBoss, MetaMatrix, Fedora, the Infinity Logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ? is the registered trademark of Linus Torvalds in the United States and other countries. Java ? is a registered trademark of Oracle and/or its affiliates. XFS ? is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ? is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ? is an official trademark of Joyent. Red Hat Software Collections is not formally related to or endorsed by the official Joyent Node.js open source or commercial project. The OpenStack ? Word Mark and OpenStack Logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation's permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community. All other trademarks are the property of their respective owners. Abstract This document describes how to manage create, configure and use Red Hat Ceph Storage block devices.
Ceph分布式存储平台部署手册
Ceph分布式存储平台 部署手册
目录 1.CEPH的架构介绍 (5) 2.CEPH在OPENSTACK中应用的云存储的整体规划 (6) 3.CEPH集群安装在UBUNTU 12.04 (7) 3.1.配置ceph源7 3.2.依需求修改ceph.conf配置文件7 3.3.设置主机的hosts 9 3.4.设置集群节点之间无密钥访问9 3.5.创建目录10 3.6.创建分区与挂载10 3.7.执行初始化11 3.8.启动ceph 11 3.9.ceph健康检查11 4.CEPH集群安装在CENTOS6.4 (12) 4.1.安装更新源12 4.2.使用rpm安装ceph0.67.4 12 4.3.依需求修改ceph.conf配置文件13 4.4.设置主机的hosts 21 4.5.设置集群节点之间无密钥访问21 4.6.创建目录22 4.7.执行初始化22 4.8.启动ceph 22 4.9.ceph健康检查23
5.OPENSTACK GLANCE 使用CEPH集群的配置 (24) 5.1.创建卷池和图像池24 5.2.增加两个池的复制水平24 5.3.为池创建 Ceph 客户端和密钥环24 5.4.在计算节点应用密钥环24 5.4.1.创建libvirt密钥24 5.4.2.计算节点ceph安装25 5.5.更新你的 glance-api 配置文件25 6.OPENSTACK VOLUMES使用CEPH集群的配置 (27) 6.1.计算节点ceph安装27 6.2.创建临时的 secret.xml 文件27 6.3.设定 libvirt 使用上面的密钥28 6.4.更新 cinder 配置28 6.4.1.cinder.conf文件更改28 6.4.2.更改 cinder 启动脚本配置文件29 6.4.3.更改/etc/nova/nova.conf配置29 6.4.4.重启 cinder 服务29 6.5.验证cinder-volume 29 6.6.验证rdb创建volume 30 7.挂载CEPHFS (31) 7.1.配置/etc/fstab 31 7.2.挂载vm实例目录31 8.FQA (32)
从GoogleSpanner漫谈分布式存储与数据库技术
从Google Spanner漫谈分布式存储与数据库技术 文/曹伟 Spanner 的设计反映了 Google 多年来在分布式存储系统领域上经验的积累和沉淀,它采用了 Megastore 的数据模型,Chubby 的数据复制和一致性算法,而在数据的可扩展性上使用了 BigTable 中的技术。新颖之处在于,它使用高精度和可观测误差的本地时钟来判断分布式系统中事件的先后顺序。Spanner 代表了分布式数据库领域的新趋势——NewSQL。 Spanner 是 Google 最近公开的新一代分布式数据库,它既具有 NoSQL 系统的可扩展性,也具有关系数据库的功能。例如,它支持类似 SQL 的查询语言、支持表连接、支持事务(包括分布式事务)。Spanner 可以将一份数据复制到全球范围的多个数据中心,并保证数据的一致性。一套 Spanner 集群可以扩展到上百个数据中心、百万台服务器和上T条数据库记录的规模。目前,Google 广告业务的后台(F1)已从 MySQL 分库分表方案迁移到了Spanner 上。 数据模型 传统的 RDBMS(例如 MySQL)采用关系模型,有丰富的功能,支持 SQL 查询语句。而NoSQL 数据库多是在 key-value 存储之上增加有限的功能,如列索引、范围查询等,但具有良好的可扩展性。Spanner 继承了 Megastore 的设计,数据模型介于 RDBMS 和 NoSQL 之间,提供树形、层次化的数据库 schema,一方面支持类 SQL 的查询语言,提供表连接等关系数据库的特性,功能上类似于 RDBMS;另一方面整个数据库中的所有记录都存储在同一个key-value 大表中,实现上类似于 BigTable,具有 NoSQL 系统的可扩展性。 在 Spanner 中,应用可以在一个数据库里创建多个表,同时需要指定这些表之间的层次关系。例如,图 1 中创建的两个表——用户表(Users)和相册表(Albums),并且指定用户表是相册表的父节点。父节点和子节点间存在着一对多的关系,用户表中的一条记录(一
分布式存储技术
分布式存储技术 分布式存储概念 与目前常见的集中式存储技术不同,分布式存储技术并不是将数据存储在某个或多个特定的节点上,而是通过网络使用企业中的每台 机器上的磁盘空间,并将这些分散的存储资源构成一个虚拟的存储设备,数据分散的存储在企业的各个角落。结构化数据的存储及应 用所谓结构化数据是一种用户定义的数据类型,它包含了一系列的属性,每一个属性都有一个数据类型,存储在关系数据库里,可以用 二维表结构来表达实现的数据。大多数系统都有大量的结构化数据,一般存储在 Oracle 或 MySQL 的等的关系型数据库中,当系统规 模大到单一节点的数据库无法支撑时,一般有两种方法:垂直扩展与水平扩展。 垂直扩展:垂直扩展比较好理解,简单来说就是按照功能切分数据库,将不同功能的数据,存储在不同的数据库中,这样一个大数据 库就被切分成多个小数据库,从而达到了数据库的扩展。一个架构设计良好的应用系统,其总体功能一般肯定是由很多个松耦合的功 能模块所组成的,而每一个功能模块所需要的数据对应到数据库中就是一张或多张表。各个功能模块之间交互越少,越统一,系统的 耦合度越低,这样的系统就越容易实现垂直切分。 水平扩展:简单来说,可以将数据的水平切分理解为按照数据行来切分,就是将表中的某些行切分到一个数据库中,而另外的某些行 又切分到其他的数据库中。为了能够比较容易地判断各行数据切分到了哪个数据库中,切分总是需要按照某种特定的规则来进行的, 如按照某个数字字段的范围,某个时间类型字段的范围,或者某个字段的 hash 值。 垂直扩展与水平扩展各有优缺点,一般一个大型系统会将水平与垂直扩展结合使用。 非结构化数据的存储及应用 相对于结构化数据而言,不方便用数据库二维逻辑表来表现的数据即称为非结构化数据,包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频/视频信息等等。分布式文件系统是实现非结构化数据存储的主要技术,说到分布式文件系统就不得不 提GFS(全称为"Google File System"),GFS 的系统架构图如下图所示。 GFS 将整个系统分为三类角色:Client(客户端)、Master(主服务器)、Chunk Server(数据块服务器)。 Client(客户端):是 GFS提供给应用程序的访问接口,它是一组专用接口,不遵守 POSIX 规范,以库文件的形式提供。应用程序直 接调用这些库函数,并与该库链接在一起。 Master(主服务器):是 GFS的管理节点,主要存储与数据文件相关的元数据,而不是 Chunk(数据块)。元数据包括:命名空间(Name Space),也就是整个文件系统的目录结构,一个能将 64 位标签映射到数据块的位置及其组成文件的表格,Chunk 副本位置信息和哪个进程正在读写特定的数据块等。还有Master 节点会周期性地接收从每个Chunk节点来的更新("Heart- beat")来让元数据保 持最新状态。 Chunk Server(数据块服务器):负责具体的存储工作,用来存储 Chunk。GFS将文件按照固定大小进行分块,默认是 64MB,每一块 称为一个 Chunk(数据块),每一个 Chunk以 Block 为单位进行划分,大小为 64KB,每个Chunk有一个唯一的64位标签。GFS采用 副本的方式实现容错,每一个Chunk有多个存储副本(默认为三个)。Chunk Server 的个数可有有多个,它的数目直接决定了 GFS 的 规模。
SKY 分布式存储解决方案
XSKY统一存储解决方案 2017.5
研发核心?团队A :来自一线互联网,国内Ceph 社区贡献第一;?团队B :来自IT 领导厂商的存储产品研发。 关于XSKY | 星辰天合 ?总部位于北京,在上海、深圳等地有办事处和研发中心 ?启明创投、北极光创投和红点投资,A 轮前融资额¥7200万, B 轮融资额¥1亿2000万元; ?员工140+人,研发+服务~100+人; ?公司愿景:提供企业就绪的分布式软件定义存储产品,帮助客 户实现数据中心架构革新; ?产品:X-EBS 分布式块存储,X-EOS 分布式对象存储,X-EDP 统一数据平台。XSKY 公司和团队简介 Future Ready SDS 关于公司 ?Ceph 分布式存储技术中国领先者,2016年Ceph 社区中 国贡献率第一 ? 拥有近40个产品专利和软著? 中国开源云联盟理事会员?IDC 重点关注的软件定义存储创业公司
XSKY在ceph 社区的贡献度 3
XSKY如何为Ceph社区贡献源代码 XSKY开源贡献主要集中在NVMe, DPDK/SPDK/RDMA整合,BlueStore,网络 优化,OSD,MON性能优化等等方面。 XSKY为Ceph网络层AsyncMessanger的主 要贡献和维护者。 XSKY2016年10月将Ceph的 InfiniBand/RDMA互联共享给upstream。
产品以Ceph为引擎,构建企业级分布式存储产品 ?企业级接口,FC和iSCSI,多路径 ?高性能,低延时、百亿级文件对象 ?持续服务,高水平SLA和业务QoS保证 ?易运维,全图形化操作,0命令行运维 ?内置数据保护功能,一站式解决数据安全问题 ?完善的社区生态,高速增长的数据服务能力 ?成熟的数据分布算法(CRUSH) ?统一存储API,主流云平台接口 ?软件定义,硬件持续革新 5