统计学t分布表格模板
精心整理
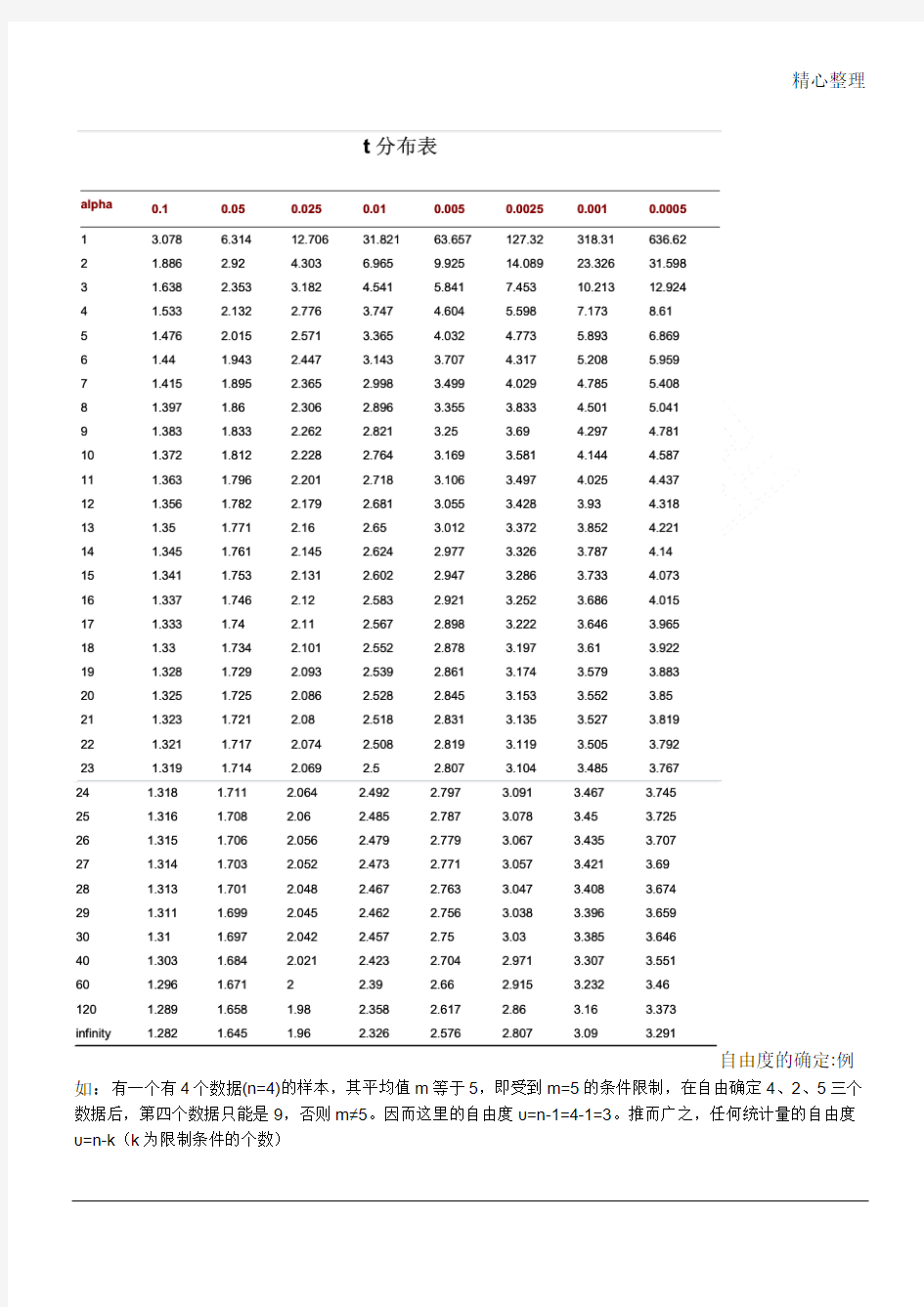
自由度的确定:例如:有一个有4个数据(n=4)的样本,其平均值m等于5,即受到m=5的条件限制,在自由确定4、2、5三个数据后,第四个数据只能是9,否则m≠5。因而这里的自由度υ=n-1=4-1=3。推而广之,任何统计量的自由度υ=n-k(k为限制条件的个数)
统计学名词解释汇总情况
1什么是统计学?统计方法可分为哪两大类?统计学是收集、处理、分析、解释数据并从数据中得出结论的科学。方法有描述统计和推断统计两类 2统计数据可分为哪几种类型?不同类型数据各有什么特点?按采取计量尺度,分类、顺序、数值型数据;按统计数据收集方法,观测、实验数据;按被描述对象与时间关系,截面、时间序列数据 统计数据;按所采用的计量尺度不同分; (定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。它也是有类别的,但这些类别是有序的。 (定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。 统计数据;按统计数据都收集方法分; 观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。 实验数据:在实验中控制实验对象而收集到的数据。 统计数据;按被描述的现象与实践的关系分; 截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。 3举例说明总体、样本、参数、统计量、变量这几个概念:对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。 4什么是有限总体和无限总体?举例说明 有限总体指总体的范围能够明确确定,而且元素的数目是有限可数的,如若干个企业构成的总体,一批待检查的灯泡。无限总体指总体包括的元素是无限不可数的,如科学实验中每个试验数据可看做是一个总体的一个元素,而试验可无限进行下去,因此由试验数据构成的总体是无限总体 5变量可分为哪几类? 变量可以分为分类变量,顺序变量,数值型变量。 变量也可以分为随机变量和非随机变量。经验变量和理论变量。
统计学三大分布与正态分布的关系
统计学三大分布与正态分布的关系[1] 张柏林 41060045 理实1002班 摘要:本文首先将介绍2χ分布,t 分布,F 分布和正态分布的定义及基本性质, 然后用理论说明2χ分布,t 分布,F 分布与正态分布的关系,并且利用数学软件MATLAB 来验证之. 1. 三大分布函数[2] 1.12χ分布 2()n χ分布是一种连续型随机变量的概率分布。这个分布是由别奈梅 (Benayme)、赫尔默特(Helmert)、皮尔逊分别于1858年、1876年、1900年所发现,它是由正态分布派生出来的,主要用于列联表检验。 定义:若随机变量12n ,,X X …X 相互独立,且都来自正态总体01N (,) ,则称统计量2222 12n =+X X χ++…X 为 服从自由度为n 的2χ分布,记为22~()n χχ. 2χ分布的概率密度函数为 122210(;),2()200n x n x e x n f x n x --?≥??=Γ???? ,2χ分布的密度函数图形是一个只取非负值 的偏态分布,如下图.
卡方分布具有如下基本性质: 性质1:22(()),(())2E n n D n n χχ==; 性质2:若221122(),()X n X n χχ==,12,X X 相互独立,则21212~()X X n n χ++; 性质3:2 n χ→∞→时,( n )正态分布; 性质4:设)(~2 2n αχχ,对给定的实数 ),10(<<αα称满足条件: αχχαχα==>? +∞ ) (222 )()}({n dx x f n P 的点)(2 n α χ为)(2n χ分布的水平α的上侧分位数. 简称为上侧α分位数. 对不同的α与n , 分位数的值已经编制成表供查用. 2()n χ分布的上α分位数 1.2t 分布 t 分布也称为学生分布,是由英国统计学家戈赛特在1908年“student”的笔名首次发表的,这个分布在数理统计中也占有重要的位置. 定义:设2 ~0~X N χ(,1),Y (n ),,X Y 相互独立,,则称统计量 T = 服从自由度为n 的t 分布,记为~()T t n . t 分布的密度函数为
常用医学统计学方法汇总
选择合适的统计学方法 1连续性资料 1.1 两组独立样本比较 1.1.1 资料符合正态分布,且两组方差齐性,直接采用t检验。 1.1.2 资料不符合正态分布,(1)可进行数据转换,如对数转换等,使之服从正态分布,然后对转换后的数据采用t检验;(2)采用非参数检验,如Wilcoxon检验。 1.1.3 资料方差不齐,(1)采用Satterthwate 的t’检验;(2)采用非参数检验,如Wilcoxon检验。 1.2 两组配对样本的比较 1.2.1 两组差值服从正态分布,采用配对t检验。 1.2.2 两组差值不服从正态分布,采用wilcoxon的符号配对秩和检验。 1.3 多组完全随机样本比较 1.3.1资料符合正态分布,且各组方差齐性,直接采用完全随机的方差分析。如果检验结果为有统计学意义,则进一步作两两比较,两两比较的方法有LSD检验,Bonferroni法,tukey 法,Scheffe法,SNK法等。 1.3.2资料不符合正态分布,或各组方差不齐,则采用非参数检验的Kruscal-Wallis法。如果检验结果为有统计学意义,则进一步作两两比较,一般采用Bonferroni法校正P值,然后用成组的Wilcoxon检验。 1.4 多组随机区组样本比较 1.4.1资料符合正态分布,且各组方差齐性,直接采用随机区组的方差分析。如果检验结果为有统计学意义,则进一步作两两比较,两两比较的方法有LSD检验,Bonferroni法,tukey 法,Scheffe法,SNK法等。 1.4.2资料不符合正态分布,或各组方差不齐,则采用非参数检验的Fridman检验法。如果检验结果为有统计学意义,则进一步作两两比较,一般采用Bonferroni法校正P值,然后用符号配对的Wilcoxon检验。 ****需要注意的问题: (1)一般来说,如果是大样本,比如各组例数大于50,可以不作正态性检验,直接采用t 检验或方差分析。因为统计学上有中心极限定理,假定大样本是服从正态分布的。 (2)当进行多组比较时,最容易犯的错误是仅比较其中的两组,而不顾其他组,这样作容易增大犯假阳性错误的概率。正确的做法应该是,先作总的各组间的比较,如果总的来说差别有统计学意义,然后才能作其中任意两组的比较,这些两两比较有特定的统计方法,如上面提到的LSD检验,Bonferroni法,tukey法,Scheffe法,SNK法等。**绝不能对其中的两
(完整版)t分布的概念及表和查表方法.doc
t分布介绍 在概率论和统计学中,学生 t - 分布(t -distribution ),可简称为 t 分布,用于根据小样本来估计呈正态分布且方差未知的总体的均值。如果总体方差已知(例如在样本数量足够多时),则应该用正态分布来估计总体均值。 t 分布曲线形态与 n(确切地说与自由度 df )大小有关。与标准正态分布曲线相比,自由度df 越小, t 分布曲线愈平坦,曲线中间愈低,曲线双侧尾部翘得愈高;自由度 df 愈大, t 分布曲线愈接近正态分布曲线,当自由度 df= ∞时, t 分布曲线为标准正态分布曲线。 中文名t 分布应用在对呈正态分布的总体 外文名t -distribution 别称学生 t 分布 学科概率论和统计学相关术语t 检验 目录 1历史 2定义 3扩展 4特征 5置信区间 6计算 历史 在概率论和统计学中,学生 t -分布( Student's t-distribution )经常应用在对呈正态分布的总体的均值进行估计。它是对两个样本均值差异进行显著性测试的学生t 测定的基础。 t 检定改进了Z 检定(en:Z-test ),不论样本数量大或小皆可应用。在样本数量大(超过 120 等)时,可以应用Z 检定,但 Z 检定用在小的样本会产生很大的误差,因此样本很小的情况下得改用学生t 检定。在数据有三组以上时,因为误差无法压低,此时可以用变异数分析代替学生t 检定。 当母群体的标准差是未知的但却又需要估计时,我们可以运用学生t-分布。 学生 t-分布可简称为t 分布。其推导由威廉·戈塞于 1908 年首先发表,当时他还在都柏林的健力士酿酒厂工作。因为不能以他本人的名义发表,所以论文使用了学生(Student )这一笔名。之后t 检验以及相关理论经由罗纳德·费雪的工作发扬光大,而正是他将此分布称为学生分布。 定义
spss教程常用的数据描述统计:频数分布表等统计学
第二节常用的数据描述统计 本节拟讲述如何通过SPSS菜单或命令获得常用的统计量、频数分布表等。 1.数据 这部分所用数据为第一章例1中学生成绩的数据,这里我们加入描述学生性别的变量“sex”和班级的变量“class”,前几个数据显示如下(图2-2),将数据保存到名为“2-6-1.sav”的文件中。 图2-2:数据输入格式示例 1.Frequencies语句 (1)操作 打开数据文件“2-6-1.sav”,单击主菜单Analyze /Descriptive Statistics / F requencies…,出现频数分布表对话框如图2-3所示。 图2-3:Frequencies定义窗口 把score变量从左边变量表列中选到右边,并请注意选中下方的Display frequency table复选框(要求
显示频数分布表)。如果您只要求得到一个频数分布表,那么就可以点OK按钮了。如果您想同时获得一些统计量,及统计图表,还需要进一步设置。 ①Statistics选项 单击Statistics按钮,打开对话框,请按图2-4自行设置。有关说明如下: (ⅰ)在定义百分位值(percentile value)的矩形框中,选择想要输出的各种分位数,SPSS提供的选项有: ●Quartiles四分位数,即显示25%、50%、75%的百分位数。 ●Cut points equal 把数据平均分为几份。如本例中要求平均分为3份。 Percentile显示用户指定的百分位数,可重复多次操作。本例中要求15%、50%、85%的百分位数。(ⅱ) 在定义输出集中趋势(Central Tendency)的矩形框中,选择想要输出的集中统计量,常用的选项有: ●Mean 算术平均数 ●Median 中数 ●Mode 众数 ●Sum 算术和 (ⅲ)在定义输出离散统计量(Dispersion)的矩形框中,选择想要输出的离散统计量,常用的选项有: ●Std. Deviation 标准差 ●Variance 方差 ●Range 全距 ●Minimum 最小值 ●Maximum 最大值 ●S.E. mean 平均数的标准误 (ⅳ)描述数据分布(Distribution)的统计量 ●Skewness 偏度,非对称分布指数。 ●Kurtosis 峰度,CASE围绕中心点的扩展程度。 另外,频数过程(Frequence)除了能够提供上面常用的统计量外,还可以对分组数据计算百分位数和中数(Values are group midpoints),即对于已经分组的数据,并且数据中的原始数据表示的是组中数的数据计算百分位数的值和中位数。
三大抽样分布
三大抽样分布 众所周知,在概率论中有二项分布、正态分布、泊松分布着三大分布,而统计学中也有三大抽样分布,分别是x2 分布、t布和F分布。这三大抽样分布的发现正好是现代统计学的形成时期,对于以参数统计推断为主要内容的现代统计学理论的形成有着重要意义。X2分布的发现来源于Kad Pears0n创立X2拟合优度理论的过程,而t分布的发现来源于Gosset小样本理论的创立过程,F分布则是来源于Fisher创立方差分析理论的过程。 三大抽样分布的研究意义 c.R.Rao曾经说过“在终极的分析中,一切知识都是历史,在抽象的意义下,一切科学都是数学,在理性的基础上,所有的判断都是统计学。”这句话一语道破统计学的重要性。三大抽样分布在统计学理论中占据着重要地位,由此可见,研究三大抽样分布对于科学研究有着重要意义。在实际工作中,统计工作者对于三大抽样分布的研究必不可少,通过研究三大抽样分布的产生、发展和完善,能够充分了解三大抽样分布理论的重要性。具体到统计学三大分布,对于三大分布理论的研究,能够在充分吸收前人研究成果的基础上不断进行理论创新,从而推动科学技术的进步。纵观所有的科技进步,无一不是在充分研究前人成果的基础上发展而来的研究统计学三大抽样分布,对于我国社会经济发展有着重要的推动作用。三大抽样分布产生于19世纪末20世纪初,在统计学的发展过程中,每一次新的分析统计数据概率模型的发现,统计学理论都会发生一次重大飞跃。为此,要想研究三大抽样分布,就应该对其发展过程进行研究。统计量是样本的函数,是随机变量,有其概率分布,统计量的分布称为抽样分布。 X2分布 x2的早期发展 由于受到中心极限定理和正态误差理论的影响,正态分布一直在统计学中占据重要地位。在很多数学家和哲学家心目中,正态分布是唯一可用的分析和解释统计数据的方法。但是随着时代的发展,一些学者开始对正态性提出了质疑,随后,在多位科学家的试验验证下,正态分布与实际数据拟合不好的情况日渐凸显出来,科学家纷纷开始研究比正态分布范围更广的分布类型,波那个人产生了偏态分布,其中,x2就是最早的偏态分布最早引入偏态分布的是JamesClerk Maxwel,他在研究气体分子运动的过程中引入了X2分布。1891年,X2分布首次被作为统计量的分布导出。Pizzetti在求线性 模型最小二乘估计残差平方和的分布时,通过富氏分析法得出了X2的分布。随着时代的发展,正态分布理论的局限更加明显,更加推动了偏态分布的发展。KarlPearson是对偏态分布贡献最大的人,成为了一代统计学巨人。按照他的观点,统计学应该把在模型基础上对观测数据进行有效预测作为基本任务,所以他开创了一族曲线对观测数据进行拟合,使得分布拟台数据的应用范围进一步扩大。 X2模型
统计学附录F分布,t分布临界值表全.docx
统计学附录F—分布临界值表 ——α( 0.005 ―0.10 ) α=0.005 Fα k112345681224∞k2 116211200002161522500230562343723925244262494025465 2198.5199.0199.2199.2199.3199.3199.4199.4199.5199.5 355.5549.8047.4746.1945.3944.8444.1343.3942.6241.83 431.3326.2824.2623.1522.4621.9721.3520.7020.0319.32 522.7818.3116.5315.5614.9414.5113.9613.3812.7812.14 618.6314.4512.9212.0311.4611.0710.5710.039.478.88 716.2412.4010.8810.059.529.168.688.187.657.08 814.6911.049.608.818.307.957.507.01 6.50 5.95 913.6110.118.727.967.477.13 6.69 6.23 5.73 5.19 1012.839.438.087.34 6.87 6.54 6.12 5.66 5.17 4.64 1112.238.917.60 6.88 6.42 6.10 5.68 5.24 4.76 4.23 1211.758.517.23 6.52 6.07 5.76 5.35 4.91 4.43 3.90 1311.378.19 6.93 6.23 5.79 5.48 5.08 4.64 4.17 3.65 1411.067.92 6.68 6.00 5.56 5.26 4.86 4.43 3.96 3.44 1510.807.70 6.48 5.80 5.37 5.07 4.67 4.25 3.79 3.26 1610.587.51 6.30 5.64 5.21 4.91 4.52 4.10 3.64 3.11 1710.387.35 6.16 5.50 5.07 4.78 4.39 3.97 3.51 2.98 1810.227.21 6.03 5.37 4.96 4.66 4.28 3.86 3.40 2.87 1910.077.09 5.92 5.27 4.85 4.56 4.18 3.76 3.31 2.78 209.94 6.99 5.82 5.17 4.76 4.47 4.09 3.68 3.22 2.69
(完整word版)统计学三大分布与正态分布的关系
统计学三大分布与正态分布的关系 [1] 张柏林 41060045 理实1002班 摘要:本文首先将介绍 2分布,t 分布,F 分布和正态分布的定义及基本性质, 然后 用理论说明2分布,t 分布,F 分布与正态分布的关系,并且利用数学软件 MATLAB 来验证之. 1.三大分布函数[2] 1.1 2分布 2(n )分布是一种连续型随机变量的概率分布。这个分布是由别奈梅 (Benayme )赫尔默特(Helmert )、皮尔逊分别于1858年、1876年、1900年所发 现,它是由正态分布派生出来的,主要用于列联表检验。 定义:若随机变量X 1,X 2,…X n 相互独立,且都来自正态总体 N (0,,),则称 统计量 2 =x ; X ;…+X ;为服从自由度为n 的2分布,记为 2 2 ~ (n ). 2 分布的概率密度函数为 1 x e 2 x 0 J x 0 其中伽玛函数(X ) e t t x 1dt,x 0, 2 分布的密度函数图形是一个只取非负值 的偏态分布,如下图? x 2 n 2° f(x; n)
2(n2) ,X!,X2相互独立,则X! X2~ 2g n2); 性质3: n 时,2(n) 正态分布; 性质4:设2~ 2(n),对给定的实数 (0 1),称满足条件: P{ 2 2(n)} 2(、f(x)dx (n) 的点2(n)为2(n)分布的水平的上侧分位数. 简称为上侧分位数.对不同的与n,分位 数的值已经编制成表供查 分布,是由英国统计学家戈赛特在1908年“student的'笔名 布在数理统计中也占有重要的位置. 1), Y?2(n), X,Y相互独立,,则称统计量T —X VY/ n 分布,记为T~t( n). 为 性质1: E( 2(n)) n,D( 2(n)) 2n ; 性质2:若X! 2(nJ,X2
统计学数据
2009年城镇私营单位就业人员年平均工资主要情况 一、2009年城镇私营单位就业人员年平均工资主要数据 2009年城镇私营单位就业人员年平均工资统计数据汇总工作已经完成,现予以公布。 2009年全国城镇私营单位就业人员年平均工资为18199元,与2008年的17071元相比,增加了1128元,名义增长6.6%,比去年增长幅度回落了7个百分点。私营单位就业人员年平均工资和增长速度均低于城镇非私营单位在岗职工。 表1:2009年分区域的城镇私营单位就业人员年平均工资 表2:2009年分行业的私营单位就业人员年平均工资
二、城镇私营单位就业人员年平均工资的地区和行业差异 (一)城镇私营单位年平均工资的地区差异(见表1) 分四大区域看,城镇私营单位年平均工资由高到低依次是东部、东北、西部和中部,分别是19840元、16414元、16234元和15402元。四大区域年平均工资的增长率从高到低依次为:中部11.3%、西部10.1%、东北9.9%、东部4.5%。 (二)城镇私营单位年平均工资的行业差异(见表2) 分行业门类看,与2008年相比,各行业年平均工资都有不同幅度的增长,绝大部分行业工资增长都在1000元以上。年平均工资最高的三个行业分别是金融业30453元,是全国平均水平的1.7倍;信息传输、计算机服务和软件业28166元,是全国平均水平的1.5倍;科学研究、技术服务和地质勘查业26187元,是全国平均水平的1.4倍。年平均工资最低的三个行业分别是公共管理和社会组织(主要单位是一些小的区域性行业协会,就业人员多以兼职为主)8191元,只有全国平均水平的45%;农、林、牧、渔业14585元,只有全国平均水平的80%;住宿和餐饮业15623元,只有全国平均水平的86%。最高行业与最低行业年平均工资之比为3.7:1。 附注: 关于城镇私营单位就业人员年平均工资统计方法的说明
统计学常用分布及其分位数
§1、4 常用得分布及其分位数 1、 卡平方分布 卡平方分布、t 分布及F 分布都就是由正态分布所导出得分布,它们与正态分布一起,就是试验统计中常用得分布。 当X 1、X 2、… 、Xn 相互独立且都服从N(0,1)时,Z=∑i i X 2 得分布称为自由度等于n 得2χ分布,记作Z ~2χ(n),它得分布 密度 p(z )=??? ????>??? ??Γ--,,00,2212122其他z e x n z n n 式中得??? ??Γ2n =u d e u u n ?∞+--012,称为Gamma 函数,且()1Γ=1, ?? ? ??Γ21=π。2χ分布就是非对称分布,具有可加性,即当Y 与Z 相互独立,且Y ~2χ(n ),Z ~2χ(m ),则Y+Z ~2χ(n+m )。 证明: 先令X 1、X 2、…、X n 、X n+1、X n+2、…、 X n+m 相互独立且都服从N(0,1),再根据2χ分布得定义以及上述随机变量得相互独立性,令 Y=X 21+X 22+…+X 2n ,Z=X 21+n +X 22+n +…+X 2m n +, Y+Z= X 21+X 22+…+X 2n + X 21+n +X 22+n +…+X 2m n +, 即可得到Y+Z ~2χ(n +m )。 2、 t 分布 若X 与Y 相互独立,且 X ~N(0,1),Y ~2χ(n ),则Z =n Y X 得分布称为自由度等于n 得t 分布,记作Z ~ t (n ),它得分布密度 P(z)=)()(221n n n ΓΓ+2121+-???? ??+n n z 。 请注意:t 分布得分布密度也就是偶函数,且当n>30时,t
统计学三大分布及正态分布的关系
统计学三大分布与正态分布的关系 [1] 张柏林 41060045 理实1002班 摘要:本文首先将介绍2χ分布,t 分布,F 分布和正态分布的定义及基本性质, 然后用理论说明2χ分布,t 分布,F 分布与正态分布的关系,并且利用数学软件MATLAB 来验证之. 1.三大分布函数[2] 1.12χ分布 2()n χ分布是一种连续型随机变量的概率分布。这个分布是由别奈梅(Benayme)、赫尔默特(Helmert)、皮尔逊分别于1858年、1876年、1900年所发现,它是由正态分布派生出来的,主要用于列联表检验。 定义:若随机变量12n ,,X X …X 相互独立,且都来自正态总体01N (,) ,则称统计量222 212n =+X X χ++…X 为服从自由度为n 的2χ分布, 记为22~()n χχ. 2χ分布的概率密度函数为 122210(;),2()200n x n x e x n f x n x --?≥??=Γ???? ,2χ分布的密度函数图形是一个只取非负值的偏态分布,如下图.
卡方分布具有如下基本性质: 性质1:22(()),(())2E n n D n n χχ==; 性质2:若221122(),()X n X n χχ==,12,X X 相互独立,则21212~()X X n n χ++; 性质3:2 n χ→∞→时,( n )正态分布; 性质4:设)(~2 2n α χχ,对给定的实数),10(<<αα称满足条 件:αχχα χα ==>?+∞ ) (2 22)()}({n dx x f n P 的点)(2 n α χ为)(2n χ分布的水平α的上侧分位数. 简称为上侧α分位数. 对不同的α与n , 分位数的值已经编制成表供查 用. 2()n χ分布的上α分位数 1.2t 分布 t 分布也称为学生分布,是由英国统计学家戈赛特在1908年“student ”的笔名 首次发表的,这个分布在数理统计中也占有重要的位置. 定义:设2 ~0~X N χ(,1),Y (n ),,X Y 相互独立,,则称统计量/T Y n = 服从自由度为n 的t 分布,记为~()T t n .
t分布的概念及表和查表方法
t分布介绍 在概率论和统计学中,学生t-分布(t-distribution),可简称为t分布,用于根据小样本来估计呈正态分布且方差未知的总体的均值。如果总体方差已知(例如在样本数量足够多时),则应该用正态分布来估计总体均值。 t分布曲线形态与n(确切地说与自由度df)大小有关。与标准正态分布曲线相比,自由度df越小,t分布曲线愈平坦,曲线中间愈低,曲线双侧尾部翘得愈高;自由度df愈大,t分布曲线愈接近正态分布曲线,当自由度df=∞时,t分布曲线为标准正态分布曲线。 目录 1历史 2定义 3扩展 4特征 5置信区间 6计算 历史 在概率论和统计学中,学生t-分布(Student's t-distribution)经常应用在对呈正态分布的总体的均值进行估计。它是对两个样本均值差异进行显著性测试的学生t测定的基础
。t检定改进了Z检定(en:Z-test),不论样本数量大或小皆可应用。在样本数量大(超过120等)时,可以应用Z检定,但Z检定用在小的样本会产生很大的误差,因此样本很小的情况下得改用学生t 检定。在数据有三组以上时,因为误差无法压低,此时可以用变异数分析代替学生t检定。 当母群体的标准差是未知的但却又需要估计时,我们可以运用学生t-分布。 学生t-分布可简称为t分布。其推导由威廉·戈塞于1908年首先发表,当时他还在都柏林的健力士酿酒厂工作。因为不能以他本人的名义发表,所以论文使用了学生(Student)这一笔名。之后t检验以及相关理论经由罗纳德·费雪的工作发扬光大,而正是他将此分布称为学生分布。 定义 由于在实际工作中,往往σ是未知的,常用s作为σ的估计值,为了与u变换区别,称为t变换,统计量t 值的分布称为t分布。 假设X服从标准正态分布N(0,1),Y服从分布,那么的分布称为自由度为n 的t分布,记为。 分布密度函数, 其中,Gam(x)为伽马函数。
统计学常用分布
二项分布(,)B n p n 为试验次数,p 为每次成功概率 {}x x n x n p X x C p q -== 其中1p q += (),()E X np Var X npq == ()()tX t n E e q pe =+其中t -¥<<¥ 解释:n 重贝努里实验中正好成功x 次的概率 几何分布()Geo p p 为成功概率 ()x P X x pq == 2(),()E X q p Var X q p == ()(1),ln tX t E e p qe t q =-<- 解释:n 重贝努里实验中首次成功正好在第x+1次 负二项分布(,),1NB k p k >,k 为成功次数,01p <<,p 为成功概率 1{}x k x k x P X x C p q +-== 2(),()E X kq p Var X kq p == ()(),ln 1tX k t p E e t q qe =<-- 解释:贝努里实验系列中第k 次成功正好出现在第x +k 次实验上地概率 泊松分布()P l {},0! x P X x e x l l l -==> (),()E X Var X l l == (1)()t tX e E e e l -=,t -¥<<¥ 解释:贝努里概型中的实验次数很大,但每次成功的概率很小,平均成功次数接近于常数
均匀分布(,)U a b 1 (),X f x a x b b a =<<-;(),X x a F x a x b b a -=<<- 2 ()(),()212a b b a E X Var X +-== 11 ()(1)()r r r b a E X r b a ++-=+- 正态分布2(,)N m s 2 1) 2()x X f x m s -- = 2(),()E X Var X m s == 22 1 2()t t tX E e e m s += 对数正态分布2log (,)N m s 2 1 ln () 2()x X f x m s --=2 221 22(),()(1)E X e Var X e e m m s s ++==- 22 1 2()t t t E X e m s += 解释:如果X~2log (,)N m s ,则logX ~2(,)N m s 指数分布()Exp l ()x X f x e l l -=,()1x X F x e l -=- 21 1 (),()E X Var X l l == (1) ()r r r E X l G += 1()(1,X t M t t l l -=-<
统计学t分布表word精品
统计学t分布表 t分布表 alpha0.10.050.4250.010.0050.00250.0010.0005 1 3.0766314 1 2 70631.821 6 3 657127.32 31B.31 63662 2 1 S86 Z92 4.3036M69.92514 0S9 2 3 32631 3 1.630 2 353 31B2 4 541 5 841 7.453 110.21312 924 4 1.533 2.132 2776 3.747 4.604 5.5967.173 8 61 5 1 4762015 2 571 3 365 4 032 4.773 5 893 6369 6 1.44 1.943 2 44 7 3.1433707 4 317 5 20 8 5.959 7 1 415 1.8S5 2 165 2998 3499 4.029 4.785 540fi 8 1.397 1.86 Z3O6 2.896 3.355 3.833 4.501 5 041 9 1.363 1 833 2 262 2821 3 25 3.69 4.297 4 7B1 10 1.372 1.812 2.2282764 3.169 3 581 4 144 4 567 11 1.363 1.7S6 2 201 2.71fi 3.106 3.407 4D25 4437 12 1.356 1.762 2179 2.681 3.G55 3.42B 3.93 4 31B 13 1 35 1771216265 3012 3.372 3 852 4 221 14 1 345 1,761 2.1452624 2.97733263787 4 14 15 1.341 1.753 2 1312602 2.947 3.2B6 3.733 4073 16 1.337 1.746 212 2.5832921 3.252 3.686 4015 17 1 333 174 2 112567 2 898 3.222 3 646 3 965 18 1 33 1 73421012552 2 570 3.1973613922 19 1.320 1.729 2093 2.533 2861 3.174 3.579 3 883 20 1.325 1.725 2096 2.528 2.845 3.153 3.552 3 85 21 1 323 1.721 2 082518 2 831 3.13& 3 5273BW 22 1 321 1.717207425062819 3.119 3 5053792 23 1.319 1.714 2 069 2.5 2.807 3.104 3.485 3767 24 1.31B 1.711 2 064 2.492 2 797 3.091 3.467 3 745 25 1.3W 1700 2.06248S 2.7A7 3078 3 453725 26 1 315 1.70620S6247& 2 779 3.067 3 435 3.707 27 1.314 1.703 2 052 2.473 2771 3.057 3.421 369 28 1.313 1.701 2 048 2.467 2 763 3.047 3.4OB 3674 29 1 311 価g 2.0452462 2.756 3 038 3 39€3659 30 1 31 1.697 2 0422457 2 75 3.03 3.335 3 &46 40 1.303 1.604 2021 2.423 2.704 2.971 3.307 3551 60 1.296 1.671 2 2 39 2.66 2.915 3.232 345 12C 1269 1,皈 1 9B 2 358 2.617 2 86 3 16 3.373 infinity 1 2B2 1.645 1 96 2 326 2 576 2.fiO7 3 093291 自由度的确定:例如:有一个有4个数据(n=4)的样本,其平均值m等于5,即受到m=5 的条件限制,在自由确定4、2、5三个数据后,第四个数据只能是9,否则m^5。因而这 里的自由度u =-1=4-1=3。推而广之,任何统计量的自由度u =n(k为限制条件的个数)
统计学三大分布与正态分布的差异
申请大学学士学位论文 大学 学士学位论文 统计学三大分布与正态分布的差异年级专业: 学生: 指导教师:
统计学三大分布与正态分布的差异 中文摘要 统计学是应用数学的一个分支,主要通过利用概率论建立数学模型,收集所观察系统的数据,进行量化的分析、总结,并进而进行推断和预测,为相关决策者提供依据和参考。它被广泛的应用在各门学科之上,从物理和社会科学到人文科学,甚至被用来工商业及政府的情报决策之上。而对数据的分析过程中就需要利用到数据的分布来研究分类。 在实际遇到的许多随机现象都服从或近似服从正态分布。而由正态分布构造的三大分布在实际中有广泛的应用,因为这三大分布不仅有明确的背景,而且其抽样分布的密度函数有明显表达式,研究三大分布与正态分布有助于研究实际事例,比如经济安全与金融保险领域、人口统计等。 本文讨论了三大分布与正态分布,并将它们之间的密度函数进行比较说明. 第二章介绍了正态分布的定义、性质,三大分布的定义、性质。 第三章介绍了正态分布与三大分布的密度函数,并将它们之间的密度函数进行比较关键词:正态分布;三大分布;密度函数 The Difference between the Three Statistical Distributions and the Normal Distribution Abstract Statistics is a branch of applied mathematics, the mathematical models are mainly established by the probability and statistics theory based on the collecting
统计学名词解释
名词解释 1.统计学:是应用概率论和数理统计的基本原理和方法,研究数据的收集、整 理、分析、表达和解释的一门科学。 2.医学统计学:是应用统计学的基本原理和方法,研究医学及其有关领域数据 信息的搜集整理、分析、表达和解释的一门科学。 3.抽样:是从研那个研究总体抽取少量有代表性的个体,称为抽样。 4.统计推断:是根据已知的样本信息来推断未知的总体,是统计分析的目的, 包括参数估计和假设检验。 5.总体:是根据研究目的确定的同质研究对象的全体。 6.概率:是随机事件发生可能性大小的数值度量。 7.同质:是指所研究的观察对象具有某些相同的性质或特征。 8.变异:是同质个体的某项指标之间的差异,即个体差异。 9.正态分布:频数分布的高峰在中间,两端基本对称,逐步减少,这种分布称 为近似正态分布,如果两端完全对称则称为正态分布。 10.医学参考值范围:又称正常值范围,医学上常将包括绝大多数正常人的某指 标值的波动范围称为该指标的正常值范围。 11.动态数列(dynamic series):是按照一定的时间顺序,将一系列描述某事 物的统计指标依次排列起来,观察和比较该事物在时间上的变化和发展趋势,这些统计指标可以为绝对数、相对数或平均数。 12.人口金字塔:将人口的性别与年龄资料结合起来以图形的方式表达人口的性 别与年龄结构,以年龄为纵轴,人口百分比为横轴,左侧为男,右侧为女,两个对应的直方图,其形似金字塔。 13.负担系数(dependency ratio):又称抚养比或抚养系数,是指人口中非劳 动年龄人数与劳动年龄人数之比。 14.标准化死亡比(SMR):实际死亡人数与期望死亡人数之比称为标准化死亡比。
贾俊平《统计学》(第5版)课后习题-第6章 统计量及其抽样分布【圣才出品】
第6章 统计量及其抽样分布一、思考题 1.什么是统计量?为什么要引进统计量?统计量中为什么不含任何未知参数? 答:(1)设12n X X X ,, …,是从总体X 中抽取的容量为n 的一个样本,如果由此 样本构造一个函数12()n T X X X ,,…,,不依赖于任何未知参数,则称函数12()n T X X X ,,…,是一个统计量。 (2)在实际应用中,当从某总体中抽取一个样本后,并不能直接应用它去对总体的有关性质和特征进行推断,这是因为样本虽然是从总体中获取的代表,含有总体性质的信息,但仍较分散。为了使统计推断成为可能,首先必须把分散在样本中关心的信息集中起来,针对不同的研究目的,构造不同的样本函数。 (3)统计量是样本的一个函数。由样本构造具体的统计量,实际上是对样本所含的总体信息按某种要求进行加工处理,把分散在样本中的信息集中到统计量的取值上,不同的统计推断问题要求构造不同的统计量,所以统计量不包含未知参数。 2.判断下列样本函数哪些是统计量?哪些不是统计量? 1121021210310410()/10 min() T X X X T X X X T X T X μ μσ =+++==-=-…,,…,()/答:统计量中不能含有未知参数,故1T 、2T 是统计量,3T 、4T 不是统计量。
3.什么是次序统计量? 答:设12n X X X ,, …,是从总体X 中抽取的一个样本,()i X 称为第i 个次序统计量,它是样本 12()n X X X ,,…,满足如下条件的函数:每当样本得到一组观测值12X X ,,…,n X 时,其由小到大的排序 (1)(2)()()i n X X X X ≤≤≤≤≤……中,第i 个值()i X 就作为次序统计量()i X 的观测值,而(1)(2)()n X X X ,,…,称为次序统计量,其中(1)X 和()n X 分别为最小和最大次序统计量。 4.什么是充分统计量? 答:在统计学中,假如一个统计量能把含在样本中有关总体的信息一点都不损失地提取出来,那对保证后边的统计推断质量具有重要意义。统计量加工过程中一点信息都不损失的统计量通常称为充分统计量。 5.什么是自由度? 答:统计学上的自由度是指当以样本的统计量来估计总体的参数时,样本中独立或能自由变化的变量的个数。 6.简述2 χ分布、t 分布、F 分布及正态分布之间的关系。答:(1)随机变量X 1,X 2,… X n 相互独立,且都服从标准正态分布,则它们的平方和21 n i i X =∑服从自由度为n 的2 χ分布。(2)随机变量X 服从标准正态分布,Y 服从自由度为n 的2 χ分布,且X 与Y 独立,
统计学常用分布及分位数
§1.4 常用的分布及其分位数 1. 卡平方分布 卡平方分布、t 分布及F 分布都是由正态分布所导出的分 布,它们与正态分布一起,是试验统计中常用的分布。 当X 1、X 2、… 、Xn 相互独立且都服从N(0,1)时,Z=∑i i X 2 的分布称为自由度等于n 的2χ分布,记作Z ~2χ(n),它的分布密度 p(z )=??? ????>??? ??Γ--,,00,2212122其他z e x n z n n 式中的??? ??Γ2n =u d e u u n ?∞+--012,称为Gamma 函数,且()1Γ=1, ?? ? ??Γ21=π。2χ分布是非对称分布,具有可加性,即当Y 与Z 相互独立,且Y ~2χ(n ),Z ~2χ(m ),则Y+Z ~2χ(n+m )。 证明: 先令X 1、X 2、…、X n 、X n+1、X n+2、…、 X n+m 相互独立且都服从N(0,1),再根据2χ分布的定义以及上述随机变量的相互独立性,令 Y=X 21+X 22+…+X 2n ,Z=X 21+n +X 22+n +…+X 2m n +, Y+Z= X 21+X 22+…+X 2n + X 21+n +X 22+n +…+X 2m n +, 即可得到Y+Z ~2χ(n +m )。 2. t 分布 若X 与Y 相互独立,且 X ~N(0,1),Y ~2χ(n ),则Z =n Y X 的分布称为自由度等于n 的t 分布,记作Z ~ t (n ),它的分布密度 P(z)=)()(221n n n ΓΓ+2121+-???? ??+n n z 。
请注意:t 分布的分布密度也是偶函数,且当n>30时,t 分布与标准正态分布N(0,1)的密度曲线几乎重叠为一。这时, t 分布的分布函数值查N(0,1)的分布函数值表便可以得到。 3. F 分布 若X 与Y 相互独立,且X ~2χ(n ),Y ~2χ(m ), 则Z=m Y n X 的分布称为第一自由度等于n 、第二自由度等于m 的F 分布,记作Z ~F (n , m ),它的分布密度 p(z)=???? ?????>++-??? ??Γ??? ??Γ??? ??+Γ?。其他,00,2)(1222222z m n z n m n z m n m n m m n n 请注意:F 分布也是非对称分布,它的分布密度与自由度的次序有关,当Z ~F (n , m )时,Z 1~F (m ,n )。 4. t 分布与F 分布的关系 若X ~t(n ),则Y=X 2~F(1,n )。 证:X ~t(n ),X 的分布密度p(x )=??? ??Γ?? ? ??+Γ221n n n π2121+-???? ??+n n x 。 Y=X 2的分布函数F Y (y ) =P{Y 2012-2013第一学期《统计学原理》课程期末测试 关于第三产业旅游业的调研报告 -------基于数据的分析 班级: ------- 姓名: ====== 学号: -------- 总分: 完成时间:2112 年 12 月10 日 评分标准:(总分100分)(四号字,宋体) 一、数据方面(最高分15分) 1.数据量的多少(0-5分) 2.数据的真实性(0-5分) 3.数据选取的合理性(0-5分) 二、分析方法的选择(最高分15分) 1.方法的合理性(0-5分) 2.方法选取的难度(0-5分) 3.方法的多样性(0-5分) 三、分析过程(最高分55分) 1.分析思路的条理性(0-15分) 2.分析过程中的图表利用(0-10分) 3.计算过程的正确情况(0-15分) 4.分析过程中的解释和说明(0-15分) 四、结论的解释(最高分15分) 1.只有简单的解释(0-8分) 2..能做到定性和定量结合的分析解释(8-15分)特别说明:如发现有抄袭,成绩按0分处理。 一:调研目的 中国经济实力不断争强,进入21世纪的中国面临的机遇又是挑战,第一、第二产业不足以支撑起整个中国经济的命脉,势必会加大对第三产业的重视,第三产业的发展,也是我们国家的一项重要的工作,我今天就从第三产业中的旅游业作为一个考察对象,针对当前的社会情况,中国国民近几年掀起一股旅游高潮来进行此项调研,分析中国旅游业发展的情况。 二:调研方式 本次作业调研方式,采用数据收集,主要从人均GDP的各项数据、CPI指数和旅游业的各项数据结合分析。针对获得的数据进行数据整理,利用统计学相关知识进行相关计算。 三:调研数据分析 (一)表1 1999-2009年全国国内旅游收入、CPI、人均GDP及国内旅游人数 年份国内旅游收入 (亿元) CPI(%)人均GDP(元) 国内旅游人数 (百万) 19992831.9298.67159719统计学的数据分析