图的邻接表存储方式.

图的邻接表存储方式——数组实现初探
焦作市外国语中学岳卫华在图论中,图的存储结构最常用的就是就是邻接表和邻接矩阵。一旦顶点的个数超过5000,邻接矩阵就会“爆掉”空间,那么就只能用邻接表来存储。比如noip09的第三题,如果想过掉全部数据,就必须用邻接表来存储。
但是,在平时的教学中,发现用动态的链表来实现邻接表实现时,跟踪调试很困难,一些学生于是就觉得邻接表的存储方式很困难。经过查找资料,发现,其实完全可以用静态的数组来实现邻接表。本文就是对这种方式进行探讨。
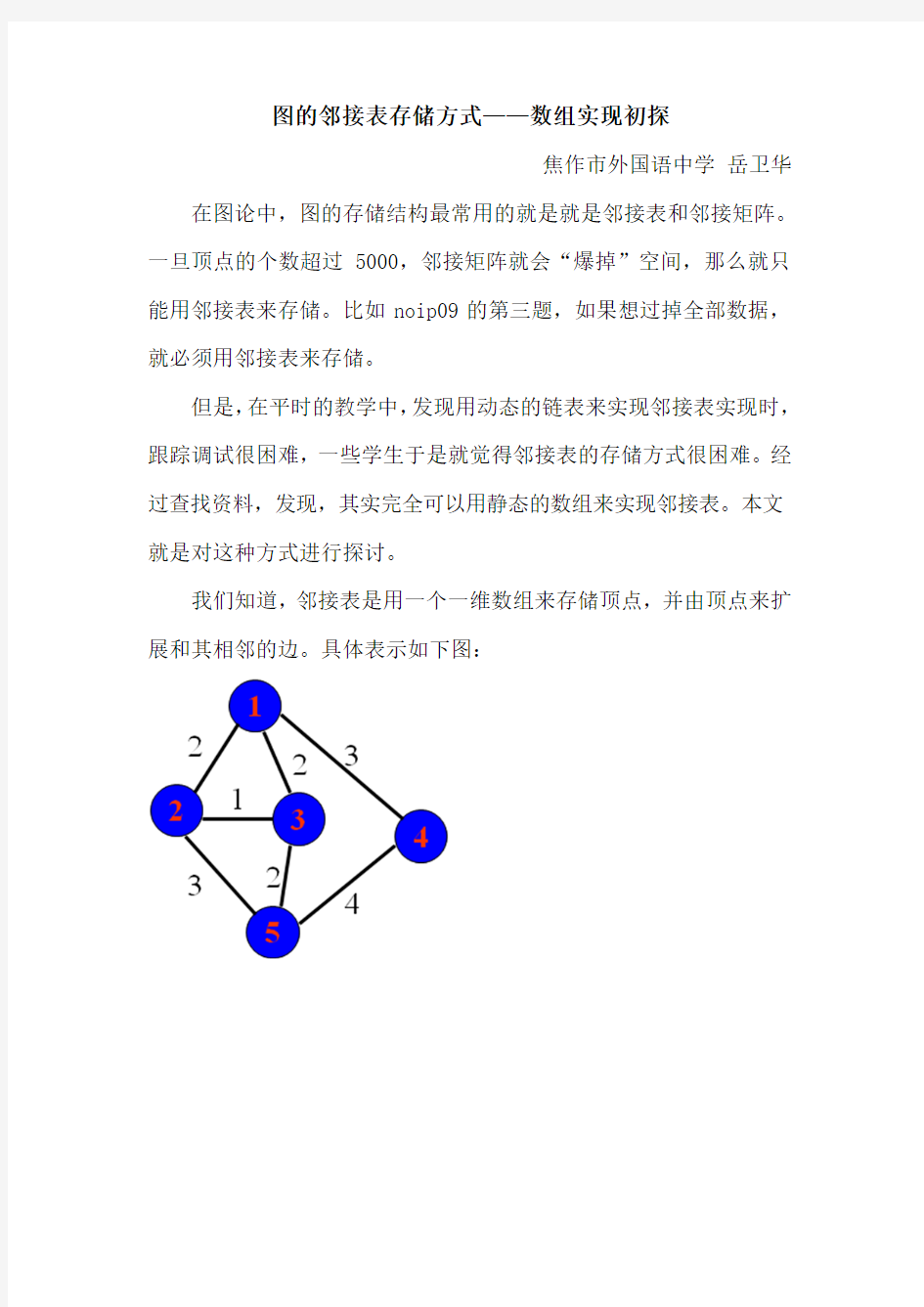
我们知道,邻接表是用一个一维数组来存储顶点,并由顶点来扩展和其相邻的边。具体表示如下图:
其相应的类型定义如下:
type
point=^node;
node=record
v:integer; //另一个顶点
next:point; //下一条边
end;
var
a:array[1..maxv]of point;
而用数组实现邻接表,则需要定义两个数组:一个是顶点数组,一个
是边集数组。
顶点编号结点相临边的总数s第一条邻接边next
此边的另一邻接点边权值下一个邻接边
对于上图来说,具体的邻接表就是:
由上图我们可以知道,和编号为1的顶点相邻的有3条边,第一条边在边集数组里的编号是5,而和编号为5同一个顶点的下条边的编号为3,再往下的边的编号是1,那么和顶点1相邻的3条边的编号分别就是5,3,1。同理和顶点3相邻的3条边的编号分别是11,8,4。如果理解数组表示邻接表的原理,那么实现就很容易了。
类型定义如下:
见图的代码和动态邻接表类似:
下面提供一道例题
邀请卡分发deliver.pas/c/cpp 【题目描述】
AMS公司决定在元旦之夜举办一个盛大展览会,将广泛邀请各方人士参加。现在公司决定在该城市中的每个汽车站派一名员工向过往的行人分发邀请卡。
但是,该城市的交通系统非常特别,每条公共汽车线路都是单向的,且只包含两个车站,即起点站与终点站,汽车从起点到终点站后空车返回。
假设AMS公司位于1号车站,每天早上,这些员工从公司出发,分别到达各自的岗位进行邀请卡的分发,晚上再回到公司。
请你帮AMS公司编一个程序,计算出每天要为这些分发邀请卡的员工付的交通费最少为多少?
【输入文件】
输入文件的第一行包含两个整数P和Q (1<=P<=10000,0<=Q<=20000)。P为车站总数(包含AMS公司),Q为公共汽车线路数目。接下来有Q行,每行表示一条线路,包含三个数:起点,终点和车费。所有线路上的车费是正整数,且总和不超过1000000000。并假设任何两个车站之间都可到达。
【输出文件】
输出文件仅有一行为公司花在分发邀请卡员工交通上的最少费用。
【样例输入】
Case1:
2 2
1 2 13
2 1 33
Case2:
4 6
1 2 10
2 1 60
1 3 20
3 4 10
2 4 5
4 1 50
【样例输出】
Case1:
46
Case2:
210
【分析】此题是一道基本最短路径问题,但是如果想通过全部数据,10000个点,20000条边,必须用邻接表来实现。
下面给出此题目用dijkstra和 spfa两种算法的实现。
program delive_dijstrkalr;
const
inf='deliver.in';
ouf='deliver.out';
maxm=20000;
maxn=10000;
type
node=record
s,next:longint; //s为与第i个点相临的边有多少个,next为第一条边的编号为多少?
end;
edge=record
y,v,next:longint; // y为这条边的另一个顶点,v为权值,next为和第i个节点相临的另一条边,next为0 则表示结束。 end;
var
i,j,k,m,n,x1,y1,w1,ans:longint;
a,a1:array[1..maxn] of node;
e,e1:array[1..maxm] of edge;
d,d1:array[1..maxn] of longint;
procedure dij;
var
i,j,k,min,jj,kk:longint;
f:array[1..maxn] of boolean;
begin
fillchar(d,sizeof(d),$7f);
fillchar(f,sizeof(f),false);
j:=a[1].next;
for i:=1 to a[1].s do
begin
k:=e[j].y;
d[k]:=e[j].v;
j:=e[j].next;
end;
//用邻接表来找和第1个点相临的点,并给 d数组赋初值。。。。
f[1]:=true; d[1]:=0;
for i:=2 to n do
begin
min:=maxlongint; k:=0;
for j:=1 to n do
if (not f[j]) and (d[j] begin min:=d[j]; k:=j; end; if k=0 then exit; f[k]:=true; jj:=a[k].next; for j:=1 to a[k].s do begin kk:=e[jj].y; if (not f[kk]) and ( d[k]+e[jj].v jj:=e[jj].next; end; //邻接表的使用,要好好注意。。。 end; end; begin assign(input,inf);reset(input); assign(output,ouf);rewrite(output); fillchar(a,sizeof(a),0); fillchar(e,sizeof(e),0); fillchar(a1,sizeof(a1),0); fillchar(e1,sizeof(e1),0); readln(n,m); for i:=1 to m do begin readln(x1,y1,w1); e[i].y:=y1; e[i].v:=w1; e[i].next:=a[x1].next; a[x1].next:=i; inc(a[x1].s); e1[i].y:=x1; e1[i].v:=w1; e1[i].next:=a1[y1].next; a1[y1].next:=i; inc(a1[y1].s); end; dij; d1:=d; a:=a1; e:=e1; dij; ans:=0; for i:=2 to n do ans:=ans+d[i]+d1[i]; writeln(ans); close(input);close(output); end. program deliver; const inf='deliver.in'; ouf='deliver.out'; maxm=20000; maxn=10000; type node=record s,next:longint; //s为与第i个点相临的边有多少个,next为第一条边的编号为多少? end; edge=record y,v,next:longint; // y为这条边的另一个顶点,v为权值,next为和第i个节点相临的另一条边,next为0 则表示结束。 end; var i,j,k,m,n,x1,y1,w1,ans:longint; a,a1:array[1..maxn] of node; e,e1:array[1..maxm] of edge; d,d1:array[1..maxn] of longint; q:array[1..100000] of longint; procedure spfa; //spfa 是基于边的松弛操作的最短路径求法。基本原理就是 var i,j,k,now,min,t,w:longint; f:array[1..maxn] of boolean; begin fillchar(d,sizeof(d),$7f); fillchar(f,sizeof(f),false); fillchar(q,sizeof(q),0); d[1]:=0; t:=1;f[1]:=true; w:=1; q[t]:=1; repeat k:=q[t]; j:=a[k].next; for i:=1 to a[k].s do begin now:=e[j].y; if d[now]>d[k]+e[j].v then begin d[now]:=d[k]+e[j].v; if not f[now] then begin inc(w); q[w]:=now; f[now]:=true; end; end; j:=e[j].next; end; f[k]:=false; inc(t); until t>w; end; begin assign(input,inf);reset(input); assign(output,ouf);rewrite(output); fillchar(a,sizeof(a),0); fillchar(e,sizeof(e),0); fillchar(a1,sizeof(a1),0); fillchar(e1,sizeof(e1),0); readln(n,m); for i:=1 to m do begin readln(x1,y1,w1); e[i].y:=y1; e[i].v:=w1; e[i].next:=a[x1].next; a[x1].next:=i; inc(a[x1].s); e1[i].y:=x1; e1[i].v:=w1; e1[i].next:=a1[y1].next; a1[y1].next:=i; inc(a1[y1].s); end; spfa; d1:=d; a:=a1; e:=e1; spfa; ans:=0; for i:=2 to n do ans:=ans+d[i]+d1[i]; writeln(ans); close(input);close(output); end. //算法功能:采用邻接表存储结构建立无向图 #include 2007 C C C 语言的特点,简单的C 程序介绍,C 程序的上机步骤。1 、算法的概念2、简单的算法举例3、算法的特性4、算法的表示(自然语言、流程图、N-S 图表示) 1 、 C 的数据类型、常量与变星、整型数据、实型数据、字符型数据、字符串常量。2、 C 的运算符运算意义、优先级、结合方向。3、算术运算符和算术表达式,各类数值型数据间的混合运算。4、赋值运算符和赋值表达式。5、逗号运算符和逗号表达式。 1 、程序的三种基本结构。2、数据输入输出的概念及在C 语言中的实现。字符数据的输入输出,格式输入与输出。 1 、关系运算符及其优先级,关系运算和关系表达式。2、逻辑运算符及其优先级,逻辑运算符和逻辑表达式。3、if语句。if语句的三种形式,if语句的嵌套,条件运算符。4、switch 语句. 1 、while 语句。2、do/while 语句。3、for 语句。4、循环的嵌套。5、break 语句和continue 语句。1 、一维数组的定义和引用。2、二维数组的定义和引用。3、字符数组。4、字符串与字符数组。5、字符数组的输入输出。6、字符串处理函数1 、函数的定义。2、函数参数和函数的值,形式参数和实际参数。3、函数的返回值。4、函数调用的方式,函数的声明和函数原型。5、函数的嵌套调用。 6、函数的递归调用。 7、数组作为函数参数。 8、局部变量、全局变量的作用域。 9、变量的存储类别,自动变星,静态变量。1 、带参数的宏定义。2、“文件包含”处理。1 、地址和指针的概念。2、变量的指针和指向变量的指针变量。3、指针变量的定义 和引用。4、指针变量作为函数参数。5、数组的指针和指向数组的指针变量。6、指向数组元素的指针。7、通过指针引用数组元素。8、数组名作函数参数。9、二维数组与指针。 1 0、指向字符串的指针变星。字符串的指针表示形式,字符串指针作为函数参数。11 、字符指针变量和字符数组的异同。1 2、返回指针值的函数。1 3、指针数组。1 、定义结构体类型变星的方法。2、结构体变量的引用。3、结构体变量的初始化。4、结构体数组5、指向结构体类型数据的指针。6、共用体的概念,共用体变量的定义和引用,共用体类型数据的特点。typedef 1 、数据结构的逻辑结构、存储结构及数据运算的含义及其相互关系。2、数据结构的两大类逻辑结构和常用的存储表示方法。3、算法描述和算法分析的方法,对于一般算法能分析出时间复杂度。 1 、线性表的逻辑结构特征。2、线性表上定义的基本运算。3、顺序表的特点,即顺序表如何反映线性表中元素之间的逻辑关系。4、顺序表上的插入、删除操作及其平均时间性能分析。5、链表如何表示线性表中元素之间的逻辑关系。6、链表中头指针和头结点的使用。7、单链表上实现的建表、查找、插入和删除等基本算法,并分析其时间复杂度。8、顺序表和链表的主要优缺点。9、针对线性表上所需的主要操作,选择时空性能优越的存储结构。 1 、栈的逻辑结构特点.栈与线性表的异同。2、顺序栈和链栈实现的进栈、退栈等基本算法。3、栈的空和栈满的概念及其判定条件。4、队列的逻辑结构特点,队列与线性表的异同。5、顺序队列(主要是循 邻接表存储表示 Status Build_AdjList(ALGraph &G)//输入有向图的顶点数,边数,顶点信息和边的信息建立邻接表 { InitALGraph(G); scanf("%d",&v); if(v<0) return ERROR; G.vexnum=v; scanf("%d",&a); if(a<0) return ERROR; G.arcnum=a; for(m=0;m 一、图的邻接矩阵存储 1.存储表示 #define vexnum 10 typedef struct{ vextype vexs[vexnum]; int arcs[vexnum][vexnum]; }mgraph; 2.建立无向图的邻接矩阵算法 void creat(mgraph *g, int e){ for(i=0;i for(i=0;i 浙江大学城市学院实验报告 课程名称数据结构基础 实验项目名称实验十三图的基本操作—邻接表存储结构 学生姓名专业班级学号 实验成绩指导老师(签名)日期2015-1-15 一.实验目的和要求 1、掌握图的存储结构:邻接表。 2、学会对图的存储结构进行基本操作。 二.实验内容 1、图的邻接表的定义及实现:建立头文件AdjLink.h,在该文件中定义图的邻接表存储结构,并编写图的初始化、建立图、输出图、输出图的每个顶点的度等基本操作实现函数。同时在主函数文件test5_2.cpp中调用这些函数进行验证。 2、选做:编写图的深度优先遍历函数与广度优先遍历函数,要求把这两个函数添加到头文件AdjLink.h中,并在主函数文件test5_2.cpp中添加相应语句进行测试。 3、填写实验报告,实验报告文件取名为report13.doc。 4、上传实验报告文件report13.doc及源程序文件test5_2.cpp、AdjLink.h到Ftp服务器上自己的文件夹下。 三. 函数的功能说明及算法思路 (包括每个函数的功能说明,及一些重要函数的算法实现思路) 邻接表表示法的C语言描述: typedef struct Node { int adjvex; // 邻接点的位置 WeightType weight; //权值域,根据需要设立 struct Node *next; // 指向下一条边(弧) } edgenode; // 边结点 typedef edgenode *adjlist[ MaxVertexNum ];//定义图的邻接表结构类型(没包含顶点信息) typedef struct{ vexlist vexs; //顶点数据元素 数据结构实验---图的储存与遍历 学号: 姓名: 实验日期: 2016.1.7 实验名称: 图的存贮与遍历 一、实验目的 掌握图这种复杂的非线性结构的邻接矩阵和邻接表的存储表示,以及在此两种常用存储方式下深度优先遍历(DFS)和广度优先遍历(BFS)操作的实现。 二、实验内容与实验步骤 题目1:对以邻接矩阵为存储结构的图进行DFS 和BFS 遍历 问题描述:以邻接矩阵为图的存储结构,实现图的DFS 和BFS 遍历。 基本要求:建立一个图的邻接矩阵表示,输出顶点的一种DFS 和BFS 序列。 测试数据:如图所示 题目2:对以邻接表为存储结构的图进行DFS 和BFS 遍历 问题描述:以邻接表为图的存储结构,实现图的DFS 和BFS 遍历。 基本要求:建立一个图的邻接表存贮,输出顶点的一种DFS 和BFS 序列。 测试数据:如图所示 V0 V1 V2 V3 V4 三、附录: 在此贴上调试好的程序。 #include #define M 100 typedef struct node { char vex[M][2]; int edge[M ][ M ]; int n,e; }Graph; int visited[M]; Graph *Create_Graph() { Graph *GA; int i,j,k,w; GA=(Graph*)malloc(sizeof(Graph)); printf ("请输入矩阵的顶点数和边数(用逗号隔开):\n"); scanf("%d,%d",&GA->n,&GA->e); printf ("请输入矩阵顶点信息:\n"); for(i = 0;i 《图的邻接表存储结构实验报告》1.需解决的的问题 利用邻接表存储结果,设计一种图。 2.数据结构的定义 typedef struct node {//边表结点 int adj;//边表结点数据域 struct node *next; }node; typedef struct vnode {//顶点表结点 char name[20]; node *fnext; }vnode,AList[M]; typedef struct{ AList List;//邻接表 int v,e;//顶点树和边数 }*Graph; 3.程序的结构图 4.函数的功能 1)建立无向邻接表 Graph Create1( )//建立无向邻接表{ Graph G; int i,j,k; node *s; G=malloc(M*sizeof(vnode)); printf("输入图的顶点数和边数:"); scanf("%d%d",&G->v,&G->e);//读入顶点数和边数for(i=0;i 图的邻接表存储方式——数组实现初探 焦作市外国语中学岳卫华在图论中,图的存储结构最常用的就是就是邻接表和邻接矩阵。一旦顶点的个数超过5000,邻接矩阵就会“爆掉”空间,那么就只能用邻接表来存储。比如noip09的第三题,如果想过掉全部数据,就必须用邻接表来存储。 但是,在平时的教学中,发现用动态的链表来实现邻接表实现时,跟踪调试很困难,一些学生于是就觉得邻接表的存储方式很困难。经过查找资料,发现,其实完全可以用静态的数组来实现邻接表。本文就是对这种方式进行探讨。 我们知道,邻接表是用一个一维数组来存储顶点,并由顶点来扩展和其相邻的边。具体表示如下图: 其相应的类型定义如下: type point=^node; node=record v:integer; //另一个顶点 next:point; //下一条边 end; var a:array[1..maxv]of point; 而用数组实现邻接表,则需要定义两个数组:一个是顶点数组,一个 是边集数组。 顶点编号结点相临边的总数s第一条邻接边next 此边的另一邻接点边权值下一个邻接边 对于上图来说,具体的邻接表就是: 由上图我们可以知道,和编号为1的顶点相邻的有3条边,第一条边在边集数组里的编号是5,而和编号为5同一个顶点的下条边的编号为3,再往下的边的编号是1,那么和顶点1相邻的3条边的编号分别就是5,3,1。同理和顶点3相邻的3条边的编号分别是11,8,4。如果理解数组表示邻接表的原理,那么实现就很容易了。 类型定义如下: 见图的代码和动态邻接表类似: 下面提供一道例题 邀请卡分发deliver.pas/c/cpp 【题目描述】 实现图的邻接矩阵和邻接表存储 1.需求分析 对于下图所示的有向图G,编写一个程序完成如下功能: 1.建立G的邻接矩阵并输出之 2.由G的邻接矩阵产生邻接表并输出之 3.再由2的邻接表产生对应的邻接矩阵并输出之 2.系统设计 1.图的抽象数据类型定义: ADT Graph{ 数据对象V:V是具有相同特性的数据元素的集合,称为顶点集 数据关系R: R={VR} VR={ 一旦Visit()失败,则操作失败 BFSTraverse(G,Visit()) 初始条件:图G存在,Visit是顶点的应用函数 操作结果:对图进行广度优先遍历,在遍历过程中对每个顶点调用函数Visit一次且仅一次。一旦Visit()失败,则操作失败 }ADT Graph 2.主程序的流程: 调用CreateMG函数创建邻接矩阵M; 调用PrintMatrix函数输出邻接矩阵M 调用CreateMGtoDN函数,由邻接矩阵M创建邻接表G 调用PrintDN函数输出邻接表G 调用CreateDNtoMG函数,由邻接表M创建邻接矩阵N 调用PrintMatrix函数输出邻接矩阵N 3.函数关系调用图: 3.调试分析 (1)在MGraph的定义中有枚举类型 typedef enum{DG,DN,UDG,UDN}GraphKind;//{有向图,有向网,无向图,无向网} 赋值语句G.kind(int)=M.kind(GraphKind);是正确的,而反过来M.kind=G.kind则是错误的,要加上那个强制转换M.kind=GraphKind(G.kind);枚举类型enum{DG,DN,UDG,UDN} 会自动赋值DG=0;DN=1,UDG=2,UDN=3;可以自动从GraphKind类型转换到int型,但不会自动从int型转换到GraphKind类型 一、实验目的 掌握图这种复杂的非线性结构的邻接矩阵和邻接表的存储表示,以及在此两种常用存储方式下深度优先遍历(DFS)和广度优先遍历(BFS)操作的实现。 二、实验内容与实验步骤 题目1:对以邻接矩阵为存储结构的图进行DFS 和BFS 遍历 问题描述:以邻接矩阵为图的存储结构,实现图的DFS 和BFS 遍历。 基本要求:建立一个图的邻接矩阵表示,输出顶点的一种DFS 和BFS 序列。 测试数据:如图所示 题目2:对以邻接表为存储结构的图进行DFS 和BFS 遍历 问题描述:以邻接表为图的存储结构,实现图的DFS 和BFS 遍历。 基本要求:建立一个图的邻接表存贮,输出顶点的一种DFS 和BFS 序列。 测试数据:如图所示 三、附录: 在此贴上调试好的程序。 #include #define M 100 typedef struct node { char vex[M][2]; int edge[M ][ M ]; int n,e; }Graph; int visited[M]; Graph *Create_Graph() { Graph *GA; int i,j,k,w; GA=(Graph*)malloc(sizeof(Graph)); printf ("请输入矩阵的顶点数和边数(用逗号隔开):\n"); scanf("%d,%d",&GA->n,&GA->e); printf ("请输入矩阵顶点信息:\n"); for(i = 0;i ===实习报告一“邻接表表示的带权有向图(网)”演示程序=== (一)、程序的功能和特点 1. 程序功能:建立有向图的带权邻接表,能够对建立的邻接表进行添加顶点,添加边和删除顶点,删除边的操作,并能显示输出邻接表。 2. 程序特点:采用java面向对象语言,对边,顶点和邻接表用类进行封装。采用链式存储结构。 (二八程序的算法设计 算法一:“插入一个顶点”算法: 1. 【逻辑结构与存储结构设计】 逻辑结构:线性结构。存储结构:顺序存储与链式存储结合。 邻接表(Adjacency List)是图的一种顺序存储与链式存储结合的存储方法。。邻接表表示法类似于树的孩子链表表示法。就是对于图G中的每个顶点vi,将所有邻接于vi的顶点vj链成一个单链表,这个单链表就称为顶点vi的邻接表,再将所有点的邻接表表头放到数组中,就构成了图的邻接表。如下图就是一个临界表的存储图。 vertex firstedge adjvex n ext 序号vertex firstedge 图的邻接表表示在邻接表表示中有两种结点 结构,如图所示。 邻接矩阵表示的结点结构 顶点域边指针 流程示意图:顶点数据组成的数组 顶点数组表的顺序存储: V0 V1— V2— O 2.【基本操作设计】 文字说明: (1) .首先判断顶点表是否满。 (2) .若满则插入失败,放回false 。 (3) .顶点表若不满,创建新顶点,将新顶点加入顶点表 (4) .插入顶点成功,返回true 。 添加顶点前状态 添加顶点v2后 网图的边表结构 //插入一个顶点 public boolea n In sertVertex ( char vertex ){ if (NumVertices ==MaxVertices ) return false ; // 顶点表满 Vertex t= n ewVertex(); t. data =vertex; t. adj =null ; NodeTable[ NumVertices ]=t; NumVertices++; //注明:企图以下赋值不合Java 语法 〃NodeTable[NumVertices].data=vertex; 〃NodeTable[NumVertices].adj=null; return true ; } 算法二:“插入一条边”算法: 1. 【逻辑结构与存储结构设计】 逻辑结构:线性结构。 存储结构:链式存储结构 网图的边表结构如图所示。 邻接点域 4.【高级语言代码】 实验四图的存储、遍历与应用姓名:班级: 学号:日期:一、实验目的: 二、实验内容: 三、基本思想,原理和算法描述: 四、源程序: (1)邻接矩阵的存储: #include #include 实验六图的邻接表存储及遍历 一、实验学时 2学时 二、背景知识 1.图的邻接表存储结构 在图的邻接表中,图中每个顶点都建立一个单链表,第i个单链表中的结点数为顶点i的出度。(逆邻接表中,第i个单链表中的结点数为顶点i的入度) 邻接表的数据结构描述为: struct node { int vertex; struct node *nextnode; }; typedef struct node *graph; struct node head[vertexnum]; 2.图的遍历 深度优先遍历(DFS)法: 算法步骤: 1)初始化: (1)置所有顶点“未访问”标志; (2)打印起始顶点; (3)置起始顶点“已访问”标志; (4)起始顶点进栈。 2)当栈非空时重复做: (1)取栈顶点; (2)如栈顶顶点存在未被访问过的邻接顶点,则选择第一个顶点做: ①打印该顶点; ②置顶点为“已访问”标志; ③该顶点进栈; 否则,当前栈顶顶点退栈。 3)结束。 广度优先遍历(BFS)法: 算法步骤: 1) 初始化: (1)置所有顶点“未访问”标志; (2)打印起始顶点; (3)置起始顶点“已访问”标志; (4)起始顶点入队。 2)当队列非空时重复做: (1)取队首顶点; (2)对与队首顶点邻接的所有未被访问的顶点依次做: ①打印该顶点; ②置顶点为“已访问”标志; ③该顶点入队; 否则,当前队首顶点出队。 3) 结束。 三、目的要求 1.掌握图的基本存储方法; 2.掌握有关图的操作算法并用高级语言实现; 3.熟练掌握图的两种搜索路径的遍历方法。 四、实验内容 1.编写程序实现下图的邻接表表示及其基础上的深度和广度优先遍历。 五、程序实例 图的邻接表表示法的C语言描述: #include 数据结构图的存储结构及基本操作 1.实验目的 通过上机实验进一步掌握图的存储结构及基本操作的实现。 2.实验内容与要求 要求: ⑴能根据输入的顶点、边/弧的信息建立图; ⑵实现图中顶点、边/弧的插入、删除; ⑶实现对该图的深度优先遍历; ⑷实现对该图的广度优先遍历。 备注:单号基于邻接矩阵,双号基于邻接表存储结构实现上述操作。 3.数据结构设计 逻辑结构:图状结构 存储结构:顺序存储结构、链式存储结构 4.算法设计 #include }ArcNode; typedef struct VNode { char data[2]; //顶点就设置和书上V1等等一样吧 ArcNode *firstarc; }VNode,AdjList[MAX _VERTEX_NUM]; typedef struct { AdjList vertices; int vexnum,arcnum; }ALGraph; typedef struct { int data[MAX_VERTEX_ NUM+10]; int front; int rear; }queue; int visited[MAX_VERTE X_NUM]; queue q; int main() { ALGraph G; int CreateUDG(ALGraph &G); int DeleteUDG(ALGraph &G); int InsertUDG(ALGraph &G); void BFSTraverse(ALGrap h G, int (*Visit)(ALGraph 分别以邻接矩阵和邻接表作为图的存储结构,给出连通图的深度优先 遍历的递归算法 算法思想: (1)访问出发点vi,并将其标记为已访问过。 (2)遍历vi的的每一个邻接点vj,若vi未曾访问过,则以vi为新的出发点继续进行深度优先遍历。 算法实现: Boolean visited[max]; // 访问标志数 void DFS(Graph G, int v) { // 算法7.5从第v个顶点出发递归地深度优先遍历图G int w; visited[v] = TRUE; printf("%d ",v); // 访问第v个顶点for (w=FirstAdjVex(G, v); w>=0; w=NextAdjVex(G, v, w)) if (!visited[w]) // 对v的尚未访问的邻接顶点w递归调用DFS DFS(G, w); } /*****************************************************/ /*以邻接矩阵作为存储结构*/ DFS1(MGraph G,int i) {int j; visited[i]=1; printf("%c",G.vexs[i]); for(j=1;j<=G.vexnum;j++) if(!visited[j]&&G.arcs[i][j]==1) DFS1(G,j); } /*以邻接表作为存储结构*/ DFS2(ALGraph G,int i) {int j; ArcPtr p; visited[i]=1; printf("%c",G.vertices[i].data); for(p=G.vertices[i].firstarc;p!=NULL;p=p->nextarc) {j=p->adjvex; if(!visited[j]) DFS2(j); } } 1.实验目的 通过上机实验进一步掌握图的存储结构及基本操作的实现。 2.实验内容与要求 要求: ⑴能根据输入的顶点、边/弧的信息建立图; ⑵实现图中顶点、边/弧的插入、删除; ⑶实现对该图的深度优先遍历; ⑷实现对该图的广度优先遍历。 备注:单号基于邻接矩阵,双号基于邻接表存储结构实现上述操作。 3.数据结构设计 逻辑结构:图状结构 存储结构:顺序存储结构、链式存储结构 4.算法设计 #include int vexnum,arcnum; }ALGraph; typedef struct { int data[MAX_VERTEX_NUM+10]; int front; int rear; }queue; int visited[MAX_VERTEX_NUM]; queue q; int main() { ALGraph G; int CreateUDG(ALGraph &G); int DeleteUDG(ALGraph &G); int InsertUDG(ALGraph &G); void BFSTraverse(ALGraph G, int (*Visit)(ALGraph G,ArcNode v)); int PrintElement(ALGraph G,ArcNode v); void menu(); void depthfirstsearch(ALGraph *g,int vi); void travel(ALGraph *g); void breadfirstsearch(ALGraph *g); int i; G.arcnum = G.vexnum = 0; while(1) { menu(); do { printf ( "请输入要进行的操作\n" ); scanf ("%d",&i); if (i<1||i>6) printf("错误数字,请重新输入\n"); }while (i<1||i>6); switch (i) { case 1: CreateUDG(G); ata && i < ; i++) ; if(i >= return -1; return i; } ata); irstarc = NULL; getchar(); } char v1, v2; for(int k = 0; k < ; k++) { printf("输入第 %d 条边依附的顶点v1: ", k+1); scanf("%c", &v1); getchar(); printf("输入第 %d 条边依附的顶点v2: ", k+1); scanf("%c", &v2); getchar(); int i = LocateVex(G, v1); int j = LocateVex(G, v2); irstarc; [i].firstarc =s; t->adjvex = i; irstarc; [j].firstarc =t; } return OK; } Status PrintAdjList(ALGraph &G) { ArcNode *p; printf("%4s%6s%12s\n", "编号", "顶点", "相邻边编号"); for(int i = 0; i < ; i++) { printf("%4d%6c", i, [i].data); for(p = [i].firstarc; p; p = p->nextarc) printf("%4d", p->adjvex); printf("\n"); } return OK; } int main() { ALGraph G; CreateUDN(G); rintAdjList(G); return 0; } 福建江夏学院 《数据结构与关系数据库(本科)》实验报告姓名班级学号实验日期 课程名称数据结构与关系数据库(本科)指导教师成绩 实验名称:深度优先遍历以邻接表存储的图 一、实验目的 1、掌握以邻接表存储的图的深度优先遍历算法; 二、实验环境 1、硬件环境:微机 2、软件环境:Windows XP,VC6.0 三、实验内容、步骤及结果 1、实验内容: 基于图的深度优先遍历编写一个算法,判别以邻接表方式存储的有向图中是否存在由顶点vi到顶点vj的路径(i≠j)。 2、代码: #include 邻接表存储结构建立无向图
数据结构的逻辑结构、存储结构及数据运算的含义及其相互关系
邻接表存储表示
图的两种存储结构及基本算法
实验十三 图的基本操作—邻接表存储结构
数据结构实验---图的储存与遍历
图的邻接表存储结构实验报告
图的邻接表存储方式.
实现图的邻接矩阵和邻接表存储
数据结构实验 - 图的储存与遍历
邻接表表示的带权有向图(网)
数据结构 图的存储、遍历与应用 源代码
实现图的邻接矩阵和邻接表存储
实验六 图的邻接表存储及遍历
数据结构图的存储结构及
分别以邻接矩阵和邻接表作为图的存储结构
数据结构图的存储结构及基本操作
邻接表存储结构建立无向图
2-深度优先遍历以邻接表存储的图-实验报告