医学统计学(李晓松主编第2版高等教育出版社)附录思考与练习95%问题详解

一、SPSS 基本功能
SPSS
基本功能数据管理
统计分析
图表分析:条图、直方图、饼图、线图、散点图等
输出管理:对输出结果复制、编辑等
描述性分析
均数比较
一般线性模型
相关与回归分析
非参数检验
生存分析
Frequencies
Descriptives
Explore
Crosstabs 统计资料的类型
资料类型定量资料:用定量的方法获得的数值资料
计数资料:按性质或类别分组后清点各组
个数
等级资料:半定量资料
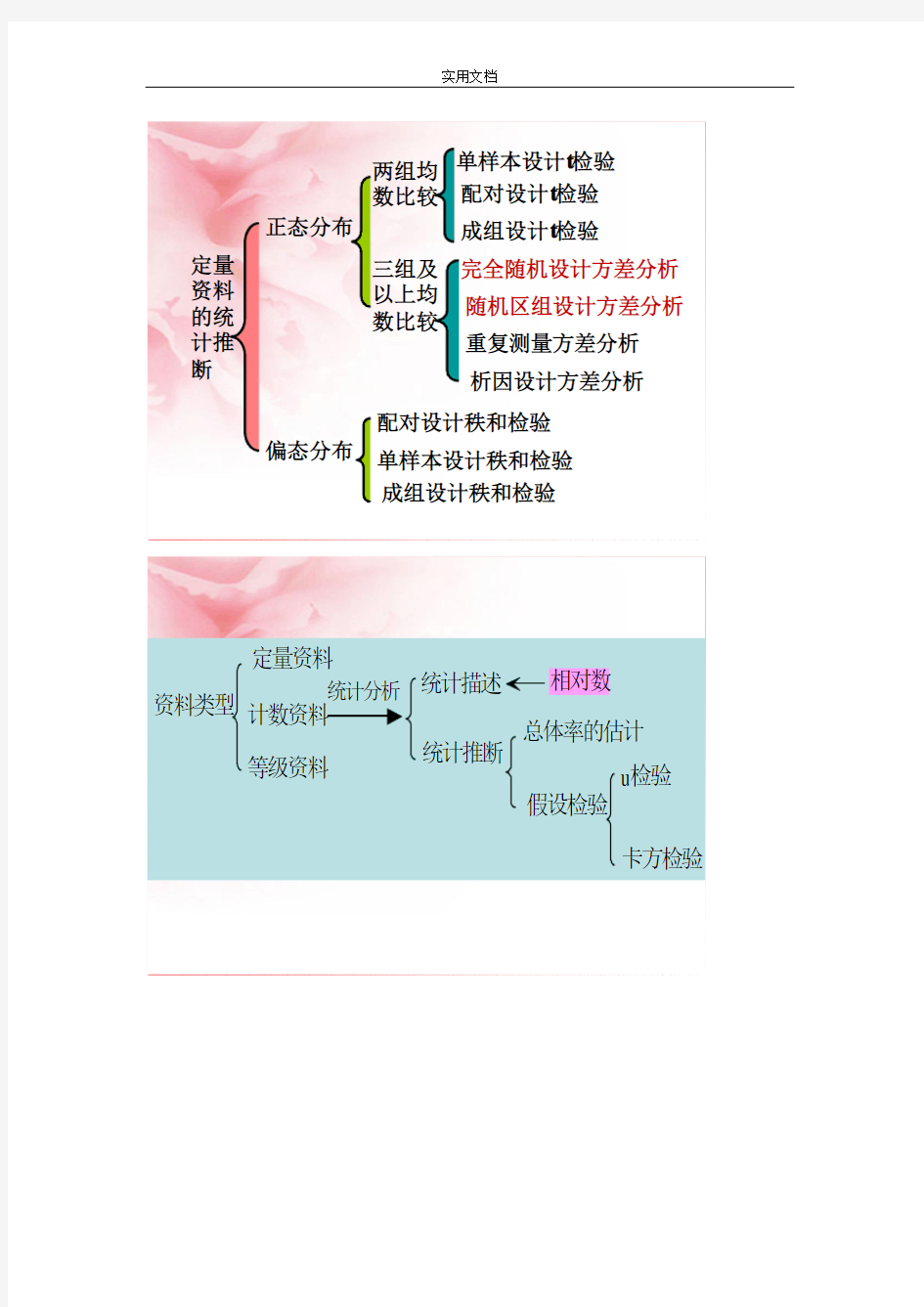
定量资料的统计推断正态分布
两组均
数比较
单样本设计t检验
配对设计t检验
成组设计t检验
三组及
以上均
数比较
完全随机设计方差分析
随机区组设计方差分析
重复测量方差分析
析因设计方差分析
偏态分布
配对设计秩和检验
单样本设计秩和检验
成组设计秩和检验
资料类型定量资料
计数资料
等级资料
统计分析统计描述
统计推断
相对数
总体率的估计
假设检验
u检验
卡方检验
4
假设检验
参数检验
非参数检验
正态分布等级资料偏态分布资料分布类型未知
方差不齐,且不易变换达到齐性
数据一端或两端不确定的资料
1.参数检验:已知总体分布类型,对未知的总体参数做推断的假设检验方法。故参数检验依赖于特定的分布类型,比较的是总体参数
2.非参数检验:不依赖于总体分布类型、不针对总体参数的检验方法。故非参数检验对总体的分布类型不做任何要求,不受总体参数的影响,比较的是分布或分布位置。适用范围广,可适用于任何类型资料 参数检验
? 优点:资料信息利用充分;检验效能较高 ? 缺点:对资料的要求高;适用范围有限 ? 优点:适用范围广,可适用于任何类型的资料 ? 缺点:检验效能低,易犯Ⅱ型错误 凡适合参数检验的资料,应首选参数检验
对于符合参数检验条件者,采用非参数检验,其
检验效能低,易犯Ⅱ型错误
第一章绪论
1.举例说明总体和样本的概念。
研究人员通常需要了解和研究某一类个体,这个类就是总体。总体是根据研究目的所确定的所有同质观察单位某种观察值(即变量值)的集合,通常有无限总体和有限总体之分,前者指总体中的个体是无限的,如研究药物疗效,某病患者就是无限总体,后者指总体中的个体是有限的,它是指特定时间、空间中有限个研究个体。但是,研究整个总体一般并不实际,通常能研究的只是它的一部分,这个部分就是样本。例如在一项关于2007年西藏自治区正常成年男子的红细胞平均水平的调查研究中,该地2007年全部正常成年男子的红细胞数就构成一个总体,从此总体中随即抽取2000人,分别测的其红细胞数,组成样本,其样本含量为2000人。
2.简述误差的概念。
误差泛指实测值与真实值之差,一般分为随机误差和非随机误差。随机误差是使重复观测获得的实际观测值往往无方向性地围绕着某一个数值左右波动的误差;非随机误差中最常见的为系统误差,系统误差也叫偏倚,是使实际观测值系统的偏离真实值的误差。
3.举例说明参数和统计量的概念。
某项研究通常想知道关于总体的某些数值特征,这些数值特征称为参数,如整个城市的高血压患病率。根据样本算得的某些数值特征称为统计量,如根据几百人的抽样调查数据所算得的样本人群高血压患病。统计量是研究人员能够知道的,而参数是他们想知道的。一般情况下,这些参数是难以测定的,仅能够根据样本估计。显然,只有当样本代表了总体时,根据样本统计量估计的总体参数才是合理的。
4.简述小概率事件原理。
当某事件发生的概率小于或等于0.05时,统计学上习惯称该事件为小概率事件,其含义是该事件发生的可能性很小,进而认为它在一次抽样中不可能发生,这就是所谓的小概率事件原理,它是进行统计推断的重要基础。
第二章调查研究设计
1.调查研究主要特点是什么?
调查研究的主要特点是:①研究的对象及其相关因素(包括研究因素和非研究因素)是客观存在的,不能人为给予干预措施②不能用随机化分组来平衡混杂因素对调查结果的影响。
2.简述调查设计的基本内容。
①明确调查目的和指标②确定调查对象和观察单位③确定调查方法④确定调查方式⑤确定调查项目和调查表⑥制定资料整理分析计划⑦制定调查的组织计划。
3.试比较常用的四种概率抽样方法的优缺点。
(1)单纯随机抽样优点是:均数(或率)及标准误的计算简便。缺点是:当总体观察单位数较多时,要对观察单位一一编号,比较麻烦,实际工作中有时难以办到。
(2)系统抽样优点是:①易于理解,简便易行②容易得到一个按比例分配的样本,由于样本相应的顺序号在总体中是均匀散布的,其抽样误差小于单纯随机抽样。缺点是:①当总体的观察单位按顺序有周期趋势或单调递增(或递减)趋势,系统抽样将产生明显的偏性。但对于适合采用系统抽样的情形,一旦确定了抽样间隔,就必须严格遵守,不能随意更改,否则可能造成另外的系统误差②实际工作中一般按单纯随机抽样方法估计抽样误差,因此这样计算得到的抽样误差一般偏大。
(3)分层抽样优点是:①减少抽样误差:分层后增加了层内的同质性,因而观测值的
变异度减小,各层的抽样误差减小,在样本含量先锋等的情况下其标准误一般小于单纯随机抽样、系统抽样和整群抽样的标准误②便于对不同的层采用不同的抽样方法,有利于调查组织工作的实施③还可对不同层进行独立分析。缺点是:当需要确定的分层数较多时,操作比较麻烦,实际工作中实施难度较大。
(4)整群抽样优点是:便于组织,节省经费,容易控制调查质量;缺点是:当样本含量一定时,其抽样误差一般大于单纯随机抽样的误差,。
4.常用的非概率抽样方法有哪些?
有偶遇抽样、立意抽样、定额抽样、雪球抽样等。
5.简述调查问题的顺序安排。
调查问题顺序安排总原则:①符合逻辑②一般问题在前,特殊问题在后③易答题在前,难答题在后④如果采用封闭式和开放式相结合的问题,一般先设置封闭式问题⑤敏感问题一般放在最后。此外,在考虑问题顺序时,还应注意问题是否适合全部调查对象,并采用跳答的形式安排问题和给出指导语。
二、最佳选择题
1. 实验性研究与观察性研究的根本区别在于
A. 抽样方法不同
B. 研究对象不同
C. 是否设立对照组
D. 假设检验方法不同
E. 是否人为施加干预措施
2. 以下抽样方法中不属于概率抽样的是
A. 单纯随机抽样
B. 系统抽样
C. 整群抽样
D. 分层抽样
E. 雪球抽样
3. 条件相同时,下列抽样方法中抽样误差最大的是
A. 单纯随机抽样
B. 系统抽样
C. 分层抽样
D. 整群抽样
E. 无法直接比较
4. 下列关于调查设计的叙述,正确的是
A. 明确调查目的是调查研究最核心的问题
B. 采用抽样调查还是普查是由该地区的经济水平决定的
C. 调查设计出现缺陷时,可以通过相应的统计分析方法弥补
D. 一旦制定了调查研究计划,在实际操作过程中,就不可改变
E. 调查的质量控制主要在调查问卷设计阶段
5. 为了解乌鲁木齐市儿童的肥胖状况,分别从汉族、维吾尔族、哈族、回族等民族中随机抽取部分儿童进行调查,这种抽样方法属于
A. 单纯随机抽样
B. 分层抽样
C. 系统抽样
D. 整群抽样
E. 多阶段抽样
6. 某县有30万人口,其中农村人口占80%,现欲对农村妇女的计划生育措施情况进行调查,调查对象应为
A. 该县所有的已婚夫妻
B. 该县所有的农村妇女
C. 该县所有的育龄期妇女
D. 该县所有的已婚妇女
E. 该县所有已婚育龄期农村妇女
7. 欲了解某地区狂犬病死亡人数上升的原因,较适宜的抽样方式为
A. 单纯随机抽样
B. 整群抽样
C. 分层抽样
D. 典型调查
E. 普查
8. 普查是一种全面调查的方法,与抽样调查相比,叙述正确的是
A.确定普查观察单位非常简单
B.普查适于发病频率较低疾病的调查
C.普查不易获得反映平均水平的统计指标
D.因涉及面广普查可产生较大的抽样误差
E.普查更易统一调查技术,提高调查质量
9. 以下五个问题中,最符合调查问卷设计要求的是
A.你一个月工资多少?
B.你一个月吃多少克盐?
C.你是否有婚外恋:①有②无
D.你和你的妈妈认为女孩几岁结婚比较好?
E.如果只生一个孩子,你希望孩子的性别是:①女②男③男女均可
1.E
2.
E
3.
D
4.
A 第三章实验研究设计
【思考与练习】
一、思考题
1. 实验设计根据对象的不同可分为哪几类?
2. 实验研究中,随机化的目的是什么?
3. 什么是配对设计?它有何优缺点?
4. 什么是交叉设计?它有何优缺点?
5. 临床试验中使用安慰剂的目的是什么?
二、案例辨析题
“三联药物治疗士兵消化性溃疡”一文中,对2000~2006年在某卫生所采用三联药物治疗的38例消化性溃疡患者进行分析。内镜检测结果显示,痊愈13人,显效14人,进步7人,无效4人,有效率达89.5%。据此认为该三联疗法的疗效较好,且由于其价格适中,可在部队卫生所中推广。该结论是否正确?如果不正确,请说明理由。
三、最佳选择题
1. 实验设计的三个基本要素是
A. 处理因素、实验效应、实验场所
B. 处理因素、实验效应、受试对象
C. 受试对象、研究人员、处理因素
D. 受试对象、干扰因素、处理因素
E. 处理因素、实验效应、研究人员
2. 实验设计的三个基本原则是
A. 随机化、对照、重复
B. 随机化、对照、盲法
C. 随机化、重复、盲法
D. 均衡、对照、重复
E. 盲法、对照、重复
3. 实验组与对照组主要不同之处在于
A. 处理因素
B. 观察指标
C. 抽样误差
D. 观察时间
E. 纳入、排除受试对象的标准
4. 为了解某疗法对急性肝功能衰竭的疗效,用12头健康雌性良种幼猪建立急性肝功能衰竭模型,再将其随机分为两组,仅实验组给予该疗法治疗,对照组不给予任何治疗。7天后观察两组幼猪的存活情况。该研究采用的是
A. 空白对照
B. 安慰剂对照
C. 实验对照
D. 标准对照
E. 自身对照
5. 观察指标应具有
A. 灵敏性、特异性、准确度、精密度、客观性
B. 灵敏性、变异性、准确度、精密度、客观性
C. 灵敏性、特异性、变异性、均衡性、稳定性
D. 特异性、准确度、稳定性、均衡性、客观性
E. 灵敏性、变异性、准确度、精密度、均衡性
6. 比较两种疗法对乳腺癌的疗效,若两组患者的乳腺癌分期构成不同可造成
A. 选择性偏倚
B. 测量性偏倚
C. 混杂性偏倚
D. 信息偏倚
E. 失访性偏倚
7. 将两个或多个处理因素的各水平进行组合,对各种可能的组合都进行实验,该实验设计方案是
A. 随机区组设计
B. 完全随机设计
C. 析因设计
D. 配对设计
E. 交叉设计
8. 在某临床试验中,将180例患者随机分为两组,实验组给予试验药+对照药的模拟剂,对照给予对照药+试验药的模拟剂,整个过程中受试对象和研究者均不知道受试对象的分组。本试验中采用的控制偏倚的方法有
A. 单盲、多中心
B. 随机化、多中心
C. 随机化、单盲
D. 随机化、双盲双模拟
E. 双盲双模拟、多中心
9. 临床试验的统计分析应主要包括
A. 可比性分析、疗效评价、安全性评价
B. 可比性分析、优效性分析、劣效性分析
C. 可比性分析、安全性评价、可行性分析
D. 优效性分析、等效性分析、安全性评价
E. 疗效评价、安全性评价、可行性分析
10. 药品上市后应用阶段进行的临床试验属于
A. I期临床试验
B. II期临床试验
C. III期临床试验
D. IV临床试验
E. 现场试验
四、综合分析题
1. 欲将16只豚鼠随机分为两组,某研究员闭上眼睛从笼中抓了8只豚鼠作为实验组,剩下8只作为对照组。该分组方法是否正确?若不正确,请说明理由。
2. 某研究人员欲将12只小鼠按月龄、体重相近的原则配成对,然后将每一对中的小鼠随机分配到实验组和对照组,应如何分组?
3. 某研究欲了解褪黑素(MEL)和通心络超微粉(TXL)对糖尿病模型大鼠血管紧张素的影响,并欲分析两药联合应用是否更为有效。
(1) 你认为该研究最好采用何种实验设计方案?并说明理由。
(2) 请帮该研究者实现32只大鼠的随机分组。
【习题解析】
一、思考题
1. 根据受试对象不同,实验可以分为动物实验、临床试验和现场试验三类。动物实验的受试对象为动物,也可以是器官、细胞或血清等生物材料;临床试验的受试对象通常为患者,持续时间可以较长,目的在于评价药物或治疗方法的疗效;现场试验的受试对象通常是未患某种疾病的人群,持续时间一般较长,目的是通过干扰某些危险因素或施加某些保护性措施,了解其在人群中产生的预防效果。
2. 实验研究中,随机化的目的在于使非处理因素在实验组和对照组中的影响相当,提高对比
组间的可比性,使实验结论的外推具有科学性和可靠性。随机化是对资料进行统计推断的前提。
3. 配对设计是将受试对象按一定条件配成对子,再将每对中的两个受试对象随机分配到不同处理组。用以配对的因素应为可能影响实验结果的主要混杂因素。在动物实验中,常将窝别、性别、体重等作为配对因素;在临床试验中,常将病情、性别、年龄等作为配对因素。
配对设计和完全随机设计相比,其优点在于可增强处理组间的均衡性、实验效率较高;其缺点在于配对条件不易严格控制,当配对失败或配对欠佳时,反而会降低效率。在临床试验中,配对的过程还可能延长实验时间。
4. 交叉设计是一种特殊的自身对照设计。其中2 2交叉设计首先是将同质个体随机分为两组,每组先接受一种处理措施,待第一阶段结束后,两组交换处理措施进行第二阶段的实验,这样每个个体都接受了两种处理。当然阶段数和处理数都可以扩展,成为多种处理多重交叉实验。交叉设计一般不适于具有自愈倾向或病程较短的疾病研究。
交叉设计的优点有:①节约样本含量;②能够控制个体差异和时间对处理因素的影响;③在临床试验中同等地考虑了每个患者的利益。其缺点有:①处理时间不能太长;②当受试对象的状态发生根本变化时,后一阶段的处理将无法进行;③受试对象一旦在某一阶段退出试验,就会造成数据缺失。
5. 临床试验中使用安慰剂,目的在于消除由于受试对象和试验观察者的心理因素引起的偏倚,还可控制疾病自然进程的影响,显示试验药物的效应。
二、案例辨析题
该结论不正确。
研究某治疗方案对某病患者的治疗效果需进行临床试验,应遵循实验设计的三个基本原则,即对照、随机化和重复。只有设立了对照才能较好地控制非处理因素对实验结果的影响,不设立对照往往会误将非处理因素造成的偏倚当成处理效应,从而得出错误的结论。此研究仅纳入38例消化性溃疡患者,并未设立相应的对照组。而且这38例患者接受治疗的时间为2000年至2006年,时间跨度太大,可能对研究结果造成影响的因素很多,在没有对照的情况下,不能控制非处理因素对试验结果的影响,其研究结论不具有说服力。
三、最佳选择题
1.B
2.A 3A. 4.A 5.A 6.C 7.C 8.D 9.A 10.D
四、综合分析题
1. 解:该分组方法不正确。
随机不等于随便,随机的含义是指每只动物都有相同机会进入实验组或对照组,而该分组方法由于豚鼠活跃程度不相同,进入各组的机会就不同,较活跃的豚鼠进入实验组的机会增大,因此破坏了随机化原则。
2. 解:先将6对小鼠按体重从小到大的顺序编号。再从随机数字表中任一行,如第18行最左端开始横向连续取12个两位数字。事先规定,每一对中,随机数较小者序号为1,对应于A 组,随机数较大者序号为2,对应于B组。分配结果见表3-1。
表3-1 配对设计的12只小鼠随机分组的结果
动物编号1.
1
1.
2
2.
1
2.
2
3.
1
3.
2
4.
1
4.
2
5.
1
5.
2
6.
1
6.
2
随机数12 96 88 17 31 65 19 69 02 83 60 75 序号 1 2 2 1 1 2 1 2 1 2 1 2 组别 A B B A A B A B A B A B
SPSS操作
数据录入:
打开SPSS Data Editor窗口,点击Variable View标签,定义要输入的变量number和pair,再点击Data View标签,录入数据(见图3-1,图3-2)。
Variable View窗口内定义要输入的变量number和pair
图3-1
分析:
Transform→Random Number
Generators …
Active Generator Initialization
Set Starting Point
Fixed Value
Value: 键入20071222 设定随机种子为20071222 OK
Transform→Compute…
Target Valuable: 键入random
Numeric Expression: RV.Uniform(0,1) 产生范围在0~1之间的伪随机数
Transform→Rank Cases…
Variables(s): random
By: pair 对每个对子中的两个伪随机数进行排序
注:当样本量较大时,最好编程实现,以免除数据录入的不便。以下为SPSS的Syntax窗口中用编程来完成本题。
File→New→Syntax,打开Syntax窗口,键入如下程序:
input program. 开始数据录入程序段
numeric k b n number pair
(F8.0)/random(F8.6).
string treat(A1).
compute k=2. 处理组为2
compute b=6. 对子数为6
compute n=b*k.
loop number=1 to n.
compute pair=rnd((number-1)/k+0.5).
end case.
compute k=lag(k).
end loop.
end file.
end input program. 结束数据录入程序段
set seed 20071222. 设定随机种子为20071222
compute random=uniform(1). 产生范围在0~1之间的伪随机
数
rank variables=random by pair. 对伪随机数排序
formats rrandom(F3.0).
根据伪随机数的序号进行分组compute
treat=substr("ABCDEFGHIJKLMN
",rrandom,1).
list number pair treat. 结果中显示受试对象编号及被
分到的处理组
在Syntax窗口中选择Run→All 提交运行。
注:程序中的b(即对子数)可根据实际情况赋予不同的值。随机区组设计受试对象的分配也可以用此程序来实现,仅需将k值设为处理组数,b值设为相应的区组数。
结果及解释
Data View窗口
图3-3 SPSS编程实现受试对象随机分配结果
Output窗口
List
number pair treat
1 1 A
2 1 B
3 2 A
4 2 B
5 3 B
6 3 A
7 4 A
8 4 B
9 5 B
10 5 A
11 6 B
12 6 A
编程实现随机分配的结果见data view窗口(图3-3)或output 窗口。可以看出12只小鼠被随机分配到A组和B组。在用此程序进行随机分组前,规定A组表示实验组,B组表示对照组。则1,3,6,7,10,12号小鼠被分到实验组,2,4,5,8,9,11号小鼠被分到对照组。
3. 解:
(1) 该研究最好采用2×2析因设计的实验方案,如表3-2所示。因为析因设计不仅可以检验两因素各水平之间的差异有无统计学意义,而且可以检验两因素间的交互作用。因此既可分
析MEL和TXL对糖尿病模型大鼠血管紧张素的影响,又可分析两药合用时的交互效应。
表3-2 MEL和TXL对32只大鼠血管紧张素影响的析因设计
MEL
TXL
(用)b1(不用)b2
(用)a1a1b1a1b2
(不用)a2a2b1a2b2
(2) 先将32只大鼠按体重从小到大的顺序编号。再从随机数字表中任一行,如第2列最上端开始纵向连续取32个两位数字。对随机数字排序,事先规定,序号为1~8的豚鼠分为A 组,序号为9~16的大鼠分为B组,序号为17~24的大鼠分为C组,序号为25~32的大鼠分为D组,分配结果见表3-3。
表3-3 32只大鼠随机分组的结果
编号 1 2 3 4 5 6 7 8 9 10 11 12 13 14
5 6
随机数1
7
36 77 43 28 22 76 68 39 71 35 50 96 93
8
7
5
6
序号 1 8 25 11 5 4 22 19 9 20 7 14 30 28 2
7
1
5
分组 A A D B A A C C B C A B D D D B
编号1
7
18 19 20 21 22 23 24 25 26 27 28 29 30
3
1
3
2
随机数7
2
96 94 64 44 76 17 17 76 29 80 40 56 65
4
3
9
6
序号2
1
31 29 17 13 23 2 3 24 6 26 10 16 18
1
2
3
2
分组 C D D C B C A A C A D B B C B D
SPSS操作
数据录入:
打开SPSS Data Editor窗口,点击Variable View标签,定义要输入的变量number,见图3-4。再点击Data View标签,录入变量number的值,即从1~32。
图3-4 Variable View窗口内定义要输入的变量number
分析:
Transform→Random Number Generators…
Active Generator Initialization
Set Starting Point
Fixed Value
Value: 键入20071222 设定随机种子为20071212
OK
Transform→Compute…
Target Valuable: 键入random
Numeric Expression: RV.Uniform(0,1) 产生范围在0~1之间的伪随机数OK
Transform→Rank Cases…
Variables(s): random 对伪随机数排序
OK
Transform→Recode→Into Different Variables…
Input Variable Output Variable: Rrandom 原变量名为伪随机数的序号
Rrandom
Output Variable
Name: 键入treat 新变量名为treat
点击Change
点击Old And New Values…
Old Value
Range: 键入1 through 8
Output variables are strings
New Value
Value: 键入A Rrandom值为1~8时,treat值为
A
Old New: 点击Add
Old Value
Range: 键入9 through 16
New Value
Value: 键入B Rrandom值为9~16时,treat值为
B
Old New: 点击Add
Old Value
Range: 键入17 through 24
New Value
Value: 键入C Rrandom值为17~24时,treat值
为C
Old New: 点击Add
医学统计学(李晓松主编 第2版 高等教育出版社)附录 第3章思考与练习答案
第三章实验研究设计 【思考与练习】 一、思考题 1. 实验设计根据对象的不同可分为哪几类? 2. 实验研究中,随机化的目的是什么? 3. 什么是配对设计?它有何优缺点? 4. 什么是交叉设计?它有何优缺点? 5. 临床试验中使用安慰剂的目的是什么? 二、案例辨析题 “三联药物治疗士兵消化性溃疡”一文中,对2000~2006年在某卫生所采用三联药物治疗的38例消化性溃疡患者进行分析。内镜检测结果显示,痊愈13人,显效14人,进步7人,无效4人,有效率达89.5%。据此认为该三联疗法的疗效较好,且由于其价格适中,可在部队卫生所中推广。该结论是否正确?如果不正确,请说明理由。 三、最佳选择题 1. 实验设计的三个基本要素是 A. 处理因素、实验效应、实验场所 B. 处理因素、实验效应、受试对象 C. 受试对象、研究人员、处理因素 D. 受试对象、干扰因素、处理因素 E. 处理因素、实验效应、研究人员 2. 实验设计的三个基本原则是 A. 随机化、对照、重复 B. 随机化、对照、盲法 C. 随机化、重复、盲法 D. 均衡、对照、重复 E. 盲法、对照、重复
3. 实验组与对照组主要不同之处在于 A. 处理因素 B. 观察指标 C. 抽样误差 D. 观察时间 E. 纳入、排除受试对象的标准 4. 为了解某疗法对急性肝功能衰竭的疗效,用12头健康雌性良种幼猪建立急性肝功能衰竭模型,再将其随机分为两组,仅实验组给予该疗法治疗,对照组不给予任何治疗。7天后观察两组幼猪的存活情况。该研究采用的是 A. 空白对照 B. 安慰剂对照 C. 实验对照 D. 标准对照 E. 自身对照 5. 观察指标应具有 A. 灵敏性、特异性、准确度、精密度、客观性 B. 灵敏性、变异性、准确度、精密度、客观性 C. 灵敏性、特异性、变异性、均衡性、稳定性 D. 特异性、准确度、稳定性、均衡性、客观性 E. 灵敏性、变异性、准确度、精密度、均衡性 6. 比较两种疗法对乳腺癌的疗效,若两组患者的乳腺癌分期构成不同可造成 A. 选择性偏倚 B. 测量性偏倚 C. 混杂性偏倚 D. 信息偏倚 E. 失访性偏倚 7. 将两个或多个处理因素的各水平进行组合,对各种可能的组合都进行实验,该实验设计方案是 A. 随机区组设计 B. 完全随机设计
李晓松医学统计学作业题
实践一、数值变量的整理与描述 题1 在某市做调查获得102名7岁男童坐高资料如下图所示: (1)计算平均数与标准差; (2)计算中位数与四分位数间距。 实践二正态分布理论与应用 题1抽样调查某市45-55岁健康男性居民的血脂水平,184名45-55岁健康 男性居血清总胆固醇(TC)的X=4. 84 mmol/L, S=0.96 mmol/L.(健康人的血 清总胆固醇服从正态分布)。 (1)估计该市45 ~55岁健康男性居民的血清总胆固醇的95%参考值范围; (2)估计该市45 ~55岁健康男性居民中,血清总胆固醇住3.25-5.25 mmol/L范 围内的比例; (3)估计该市45 ~55岁健康男性居民中,血清总胆固醇低于3.80 mrnoUL所占 的比例。 实践三率的标准化在医学研究中的应用 题1:对某地不同年龄、性别人群的HBsAg阳性率进行检测,结果如下表所示,试着对该地男、女HBsAg阳性率进行率的标准化。 提示:标准组的选择可以用合并人群,也可以任选其中一组作为标准组 表某地不同年龄、性别人群的HBsAg阳性率(%) 年龄组男性女性 检查数阳性数阳性率检查数阳性数阳性率 0~ 521 12 2.30 560 13 2.32 20~ 516 14 2.71 957 26 2.72 40~ 710 43 6.06 836 54 6.46 60~ 838 63 7.52 570 49 8.60 合计2585 132 5.11 2923 142 4.86
实验四 总体均数估计在医学研究中的运用 题1 从某疾病患者中随机抽取25例,其红细胞沉降率(mm/h )的均数为9.15,标准差为2.13。假定该类患者的红细胞沉降率服从正态分布,试估计该总体均数的95%的置信区间。 ()()某实验随机测定了100名正常人血浆内皮素ET 含量ng/L , 得均数X =81.0标准差S =18.2, (1)计算抽样误差指标 ( 2)估计正常人血浆内皮素的95%总体均数可题 2 信区间。 实验五 假设检验与t 检验 题1 经研究显示,汉族成年男子的环指长度的总体均数为10.1cm.某医生记录 了某地区12名汉族正常成年男子的环指长度(cm )分别为:10.05 10.33 10.49 10.00 9.89 10.15 9.52 10.33 10.16 10.37 10.11 10.27 问:该地区正常成年男子的环指长度是否大于一般成年男子? 题2 将18名某疾病患者随机分成两组,分别用A/B 两种药物治疗,观察前后的血红蛋白含量如下表: 表 疾病患者经A 、B 两种药物治疗前后的血红蛋白的变化结果(g/L ) A 药 物 患者编号 1 2 3 4 5 6 7 8 9 治疗前 36 44 53 56 62 58 45 43 26 治疗后 47 62 68 87 73 58 69 49 50 B 药 物 患者编号 10 11 12 13 14 15 16 17 18 治疗前 56 49 67 58 73 40 48 36 29 治疗后 81 86 70 62 84 76 58 49 60 问 (1)A 药物是否有效? (2)B 药物是否有效? (3)A 、B 药物之间疗效有无差别?
医学统计学名解
医学统计学复习题 一、名词解释 1、几何均数 2、四分位数间距 3、方差 4、变异 5、概率 6、总体 7、参数 8、统计量 9、算术均数 10、中位数 11、百分位数 12、频数分布表 13、随机误差 14、样本 15、随机抽样 16、标准差 17、变异系数 18、标准正态分布 19、医学参考值范围 20、可信区间 21、统计推断 22、参数估计 23、标准误及 24、检验水准 25、检验效能 26、率 27、直线相关 28、直线回归 29、实验研究 30、回归系数 二、单项选择 1.观察单位为研究中的( )。 A.样本 B.全部对象 C.影响因素 D.个体 E.观察指标 2. 在进行成组设计的t 检验之前,要注意两个前题条件,一是各样本是否来自正态总体,二是( )。 A.核对数据 B.总体方差是否相等 C.求 D.作变量变换 E.处理缺失值 3. 描述某地某年流行性乙脑患者的年龄分布,宜选择的统计图是( )。 A.直方图 B.线图 C.直条图 D.圆图 E.箱式图 4.参数是指( ) 。 s 、s x x 和
A.参与个体数 B.总体中研究对象的总和 C.样本的统计指标 D.样本的总和 E.总体的统计指标 5.关于随机抽样,下列哪一项说法是正确的()。 A.抽样时应使得总体中的每一个个体都有同等的机会被抽取 B.研究者在抽样时应精心挑选个体,以使样本更能代表总体 C.随机抽样即随机抽取个体 D.为确保样本具有更好的代表性,样本量应越大越好 E.选择符合研究者意愿的样本 6.实验设计的基本原则是()。 A.随机化、盲法、设置对照 B.重复、随机化、配对 C.随机化、盲法、配对 D.随机化、重复、设置对照 E.重复、随机化、盲法 7.表示总体均数的符号是( ) 。 A.σ B.μ C.X D. S E. M 8.下列指标中,不属于集中趋势指标的是()。 A.均数 B.中位数 C.百分位数 D.几何均数 E.众数 9. ( )分布的资料,均数等于中位数。 A.对称分布 B.正偏态分布 C.负偏态分布 D.对数正态分布 E.正态分布 10.一组某病患者的潜伏期(天)分别是:2、5、4、6、9、7、10和18,其平均水平的 指标该选()。 A.中位数 B.算术均数 C.几何均数 D.平均数 E.百分位数末端有确定数据 11.实验研究中设立实验组和对照组的原则是()。 A. 实验因素和非实验因素在两组中均不同 B.实验因素和非实验因素在两组中均相同 C.实验因素在两组中齐同,非实验因素在两组中不同 D.实验因素在两组中不同,非实验因素在两组中齐同 E. 以上都不是 12.一些以老年人为主的慢性病患者,年龄分布的集中位置偏向于年龄大的一侧,称为()。 A.正偏态分布 B.负偏态分布 C.对数正态分布 D.正态分布 E.对称分布 13.编制频数分布时,组距通常是()。 A.极差的1/20 B.极差的1/10 C.极差的1/5 D.极差的1/4 E.极差的1/2 14.以下适宜描述计量资料离散趋势的指标有()。 A.均数、标准差、方差 B.极差、标准差、中位数 C.均数、中位数、变异系数 D.标准差、四分位数间距、变异系数 E.几何均数、标准差、变异系数 15.下列指标中,适和描述偏态分布的离散趋势的指标是( ) 。 A.平均偏差 B.四分位数间距 C.标准差 D. 方差 E. 变异系数 16.下列关于标准差的说法中错误的是()。 A.标准差一定大于0 B.标准差和观察指标有相同的度量衡单位 C.同一资料的标准差一定小于均数 D.标准差常用于描述正态分布资料的变异程度 E.方差和标准差属于描述变异程度的同类指标 17. 变异系数的值( ) 。 A.一定大于1 B.一定小于1 C.可以大于1,可以小于1 D.一定比标准差小 E.一定比均数小 18.观察指标分别为身高和体重的两组数据。欲比较其变异程度的大小,宜选用()。 A.平均偏差 B.四分位间距 C.标准差 D.方差 E.变异系数 19.正态分布有两个参数()。 A. 和 S B. μ和σ C. 和σ D. μ和 S E. μ和 CV x x
卫生统计学Ⅰ本科教学大纲-华西第四医院
科研能力培养模块-2本科实验教学大纲 供卫生事业管理、卫生检验用 四川大学华西公共卫生学院 流行病与卫生统计系编 一、课程基本信息 课程名称:科研能力培养模块-2 课程号:504071040 课程属性:专业课/类级平台课 先修课程:高等数学,医学基础课程 学分:4 总学时:64 理论学时:44 实验学时:20 实验指导书名称:医学统计学实习指导 出版单位:高等教育出版社 出版日期:2008年12月 主编:李晓松 实验讲义名称:SPSS 10.0实验指导 编写单位:华西医学中心卫生统计教研室 编写日期:2000年8月 主编:王柏松潘晓平 二、实验的地位、作用和目的 实验课是卫生统计学教学不可缺少的一部分。通过联系讲授的理论知识,结合医学实例,针对不同内容采用选择题,填空题,计算分析题,讨论题,思考题等多种形式,进行统计分析基本技能的训练。让学生独立完成习题,以利于活跃思想,培养及开发学生智能。提倡自学与讨论。可安排部分内容让学生自学,教师提供思考问题,学生独立回答。讨论课应结合医学科研和论文中存在的主要统
计问题进行,力求充分发挥学生的主观能动性,让每位学生都有参与的机会,培养学生发现问题,分析问题和解决问题的能力。鼓励学生提出阅读专业期刊中遇到的统计问题来进行讨论。 在实验中应加强学生计算机应用知识和技能的培养,让其了解SPSS统计软件包的用途,应结合实验题进行上机训练。上机实验应结合指导教师安排的课题进行,使学生将所学的理论知识与实际相结合,对整个统计工作的全过程有所了解,培养对数据处理严肃认真的科学作风,保证统计资料的准确性,反对伪造和篡改统计数字。 三、实验方式及基本要求 将各班同学进行适当分组,一般每组学生约40人,每个小组安排一名助教作为实验老师教授和指导上机的实践内容。实验的基本要求包括习题的解答、上机操作和理论课有关问题的讨论。上机实验主要是了解SPSS软件包的操作和统计分析的过程,使得学生能够选择恰当的统计方法,并通过软件分析的结果正确地做出结论。 四、实验报告 卫生统计学实验课,主要是通过计算机软件操作来了解该软件的运用,巩固所学的理论课程,完成习题,因此实验的内容主要在课堂上通过学生对统计软件的操作,课后完成相应的作业并以此作为实验报告。 五、考核与考试 实验课的考核一般在课堂上由带习老师提问或让学生独立运用软件分析资料来实现。在期末的考卷中通过具体的计算机软件的分析结果来考核学生对实验内容的掌握情况。 六、基本设备与器材配置(名称及数量) 卫生统计教研室实验室现有42台计算机供学生使用,并配有多媒体教学设备。
医学统计学课后思考题答案(李晓松版)
第一章绪论 1.举例说明总体和样本的概念。 研究人员通常需要了解和研究某一类个体,这个类就是总体。总体是根据研究目的所确定的所有同质观察单位某种观察值(即变量值)的集合,通常有无限总体和有限总体之分,前者指总体中的个体是无限的,如研究药物疗效,某病患者就是无限总体,后者指总体中的个体是有限的,它是指特定时间、空间中有限个研究个体。但是,研究整个总体一般并不实际,通常能研究的只是它的一部分,这个部分就是样本。例如在一项关于2007年西藏自治区正常成年男子的红细胞平均水平的调查研究中,该地2007年全部正常成年男子的红细胞数就构成一个总体,从此总体中随即抽取2000人,分别测的其红细胞数,组成样本,其样本含量为2000人。 2.简述误差的概念。 误差泛指实测值与真实值之差,一般分为随机误差和非随机误差。随机误差是使重复观测获得的实际观测值往往无方向性地围绕着某一个数值左右波动的误差;非随机误差中最常见的为系统误差,系统误差也叫偏倚,是使实际观测值系统的偏离真实值的误差。 3.举例说明参数和统计量的概念。 某项研究通常想知道关于总体的某些数值特征,这些数值特征称为参数,如整个城市的高血压患病率。根据样本算得的某些数值特征称为统计量,如根据几百人的抽样调查数据所算得的样本人群高血压患病。统计量是研究人员能够知道的,而参数是他们想知道的。一般情况下,这些参数是难以测定的,仅能够根据样本估计。显然,只有当样本代表了总体时,根据样本统计量估计的总体参数才是合理的。 4.简述小概率事件原理。 当某事件发生的概率小于或等于0.05时,统计学上习惯称该事件为小概率事件,其含义是该事件发生的可能性很小,进而认为它在一次抽样中不可能发生,这就是所谓的小概率事件原理,它是进行统计推断的重要基础。第二章调查研究设计 1.调查研究主要特点是什么? 调查研究的主要特点是:①研究的对象及其相关因素(包括研究因素和非研究因素)是客观存在的,不能人为给予干预措施②不能用随机化分组来平衡混杂因素对调查结果的影响。 2.简述调查设计的基本内容。 ①明确调查目的和指标②确定调查对象和观察单位③确定调查方法④确定调查方式⑤确定调查项目和调查表⑥制定资料整理分析计划⑦制定调查的组织计划。 3.试比较常用的四种概率抽样方法的优缺点。 (1)单纯随机抽样优点是:均数(或率)及标准误的计算简便。缺点是:当总体观察单位数较多时,要对观察单位一一编号,比较麻烦,实际工作中有时难以办到。 (2)系统抽样优点是:①易于理解,简便易行②容易得到一个按比例分配的样本,由于样本相应的顺序号在总体中是均匀散布的,其抽样误差小于单纯随机抽样。缺点是:①当总体的观察单位按顺序有周期趋势或单调递增(或递减)趋势,系统抽样将产生明显的偏性。但对于适合采用系统抽样的情形,一旦确定了抽样间隔,就必须严格遵守,不能随意更改,否则可能造成另外的系统误差②实际工作中一般按单纯随机抽样方法估计抽样误差,因此这样计算得到的抽样误差一般偏大。 (3)分层抽样优点是:①减少抽样误差:分层后增加了层内的同质性,因而观测值的变异度减小,各层的抽样误差减小,在样本含量先锋等的情况下其标准误一般小于单纯随机抽样、系统抽样和整群抽样的标准误②便于对不同的层采用不同的抽样方法,有利于调查组织工作的实施③还可对不同层进行独立分析。缺点是:当需要确定的分层数较多时,操作比较麻烦,实际工作中实施难度较大。 (4)整群抽样优点是:便于组织,节省经费,容易控制调查质量;缺点是:当样本含量一定时,其抽样误差一般大于单纯随机
李晓松医学统计学作业题
李晓松医学统计学作业题-标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII
实践一、数值变量的整理与描述 题1 在某市做调查获得102名7岁男童坐高资料如下图所示: (1)计算平均数与标准差; (2)计算中位数与四分位数间距。 实践二正态分布理论与应用 题1抽样调查某市 45-55岁健康男性居民的血脂水平,184名45-55岁健康 男性居血清总胆固醇(TC)的X =4. 84 mmol/L, S=0.96 mmol/L.(健康人的血 清总胆固醇服从正态分布)。 (1)估计该市45 ~55岁健康男性居民的血清总胆固醇的95%参考值范围; (2)估计该市45 ~55岁健康男性居民中,血清总胆固醇住3.25-5.25 mmol/L范 围内的比例; (3)估计该市45 ~55岁健康男性居民中,血清总胆固醇低于3.80 mrnoUL所占 的比例。 实践三率的标准化在医学研究中的应用 题1:对某地不同年龄、性别人群的HBsAg阳性率进行检测,结果如下表所示,试着对该地男、女HBsAg阳性率进行率的标准化。
提示:标准组的选择可以用合并人群,也可以任选其中一组作为标准组 表 某地不同年龄、性别人群的HBsAg 阳性率(%) 年龄组 男性 女性 检查数 阳性数 阳性率 检查数 阳性数 阳性率 0~ 521 12 2.30 560 13 2.32 20~ 516 14 2.71 957 26 2.72 40~ 710 43 6.06 836 54 6.46 60~ 838 63 7.52 570 49 8.60 合计 2585 132 5.11 2923 142 4.86 实验四 总体均数估计在医学研究中的运用 题1 从某疾病患者中随机抽取25例,其红细胞沉降率(mm/h )的均数为9.15,标准差为2.13。假定该类患者的红细胞沉降率服从正态分布,试估计该总体均数的95%的置信区间。 ()()某实验随机测定了100名正常人血浆内皮素ET 含量ng /L , 得均数X =81.0标准差S =18.2, (1)计算抽样误差指标 ( 2)估计正常人血浆内皮素的95%总体均数可题 2 信区间。 实验五 假设检验与t 检验 题1 经研究显示,汉族成年男子的环指长度的总体均数为10.1cm.某医生记录 了某地区12名汉族正常成年男子的环指长度(cm )分别为:10.05 10.33 10.49 10.00 9.89 10.15 9.52 10.33 10.16 10.37 10.11 10.27 问:该地区正常成年男子的环指长度是否大于一般成年男子?
李晓松医学统计学作业题【内容充实】
题1 在某市做调查获得102名7岁男童坐高资料如下图所示: (1)计算平均数与标准差; (2)计算中位数与四分位数间距。 实践二正态分布理论与应用 题1抽样调查某市45-55岁健康男性居民的血脂水平,184名45-55岁健康 男性居血清总胆固醇(TC)的X=4. 84 mmol/L, S=0.96 mmol/L.(健康人的血 清总胆固醇服从正态分布)。 (1)估计该市45 ~55岁健康男性居民的血清总胆固醇的95%参考值范围; (2)估计该市45 ~55岁健康男性居民中,血清总胆固醇住3.25-5.25 mmol/L范 围内的比例; (3)估计该市45 ~55岁健康男性居民中,血清总胆固醇低于3.80 mrnoUL所占 的比例。 实践三率的标准化在医学研究中的应用 题1:对某地不同年龄、性别人群的HBsAg阳性率进行检测,结果如下表所示,试着对该地男、女HBsAg阳性率进行率的标准化。 提示:标准组的选择可以用合并人群,也可以任选其中一组作为标准组 表某地不同年龄、性别人群的HBsAg阳性率(%) 年龄组男性女性 检查数阳性数阳性率检查数阳性数阳性率 0~ 521 12 2.30 560 13 2.32 20~ 516 14 2.71 957 26 2.72 40~ 710 43 6.06 836 54 6.46 60~ 838 63 7.52 570 49 8.60
实验四 总体均数估计在医学研究中的运用 题1 从某疾病患者中随机抽取25例,其红细胞沉降率(mm/h )的均数为9.15,标准差为2.13。假定该类患者的红细胞沉降率服从正态分布,试估计该总体均数的95%的置信区间。 ()()某实验随机测定了100名正常人血浆内皮素ET 含量ng /L , 得均数X =81.0标准差S =18.2, (1)计算抽样误差指标 ( 2)估计正常人血浆内皮素的95%总体均数可题 2 信区间。 实验五 假设检验与t 检验 题1 经研究显示,汉族成年男子的环指长度的总体均数为10.1cm.某医生记录 了某地区12名汉族正常成年男子的环指长度(cm )分别为:10.05 10.33 10.49 10.00 9.89 10.15 9.52 10.33 10.16 10.37 10.11 10.27 问:该地区正常成年男子的环指长度是否大于一般成年男子? 题2 将18名某疾病患者随机分成两组,分别用A/B 两种药物治疗,观察前后的血红蛋白含量如下表: 表 疾病患者经A 、B 两种药物治疗前后的血红蛋白的变化结果(g/L ) A 药 物 患者编号 1 2 3 4 5 6 7 8 9 治疗前 36 44 53 56 62 58 45 43 26 治疗后 47 62 68 87 73 58 69 49 50 B 药 物 患者编号 10 11 12 13 14 15 16 17 18 治疗前 56 49 67 58 73 40 48 36 29 治疗后 81 86 70 62 84 76 58 49 60 问 (1)A 药物是否有效? (2)B 药物是否有效? (3)A 、B 药物之间疗效有无差别?
医学统计学(李晓松主编第2版高等教育出版社)附录思考与练习95%问题详解
一、SPSS 基本功能 SPSS 基本功能数据管理 统计分析 图表分析:条图、直方图、饼图、线图、散点图等 输出管理:对输出结果复制、编辑等 描述性分析 均数比较 一般线性模型 相关与回归分析 非参数检验 生存分析 Frequencies Descriptives Explore Crosstabs 统计资料的类型 资料类型定量资料:用定量的方法获得的数值资料 计数资料:按性质或类别分组后清点各组 个数 等级资料:半定量资料
定量资料的统计推断正态分布 两组均 数比较 单样本设计t检验 配对设计t检验 成组设计t检验 三组及 以上均 数比较 完全随机设计方差分析 随机区组设计方差分析 重复测量方差分析 析因设计方差分析 偏态分布 配对设计秩和检验 单样本设计秩和检验 成组设计秩和检验 资料类型定量资料 计数资料 等级资料 统计分析统计描述 统计推断 相对数 总体率的估计 假设检验 u检验 卡方检验
4 假设检验 参数检验 非参数检验 正态分布等级资料偏态分布资料分布类型未知 方差不齐,且不易变换达到齐性 数据一端或两端不确定的资料 1.参数检验:已知总体分布类型,对未知的总体参数做推断的假设检验方法。故参数检验依赖于特定的分布类型,比较的是总体参数 2.非参数检验:不依赖于总体分布类型、不针对总体参数的检验方法。故非参数检验对总体的分布类型不做任何要求,不受总体参数的影响,比较的是分布或分布位置。适用范围广,可适用于任何类型资料 参数检验 ? 优点:资料信息利用充分;检验效能较高 ? 缺点:对资料的要求高;适用范围有限 ? 优点:适用范围广,可适用于任何类型的资料 ? 缺点:检验效能低,易犯Ⅱ型错误 凡适合参数检验的资料,应首选参数检验 对于符合参数检验条件者,采用非参数检验,其
李晓松医学统计学作业题教学内容
李晓松医学统计学作 业题
实践一、数值变量的整理与描述 题1 在某市做调查获得102名7岁男童坐高资料如下图所示: (1)计算平均数与标准差; (2)计算中位数与四分位数间距。 实践二正态分布理论与应用 题1抽样调查某市 45-55岁健康男性居民的血脂水平,184名45-55岁健康 男性居血清总胆固醇(TC)的X =4. 84 mmol/L, S=0.96 mmol/L.(健康人的血 清总胆固醇服从正态分布)。 (1)估计该市45 ~55岁健康男性居民的血清总胆固醇的95%参考值范围; (2)估计该市45 ~55岁健康男性居民中,血清总胆固醇住3.25-5.25 mmol/L范 围内的比例; (3)估计该市45 ~55岁健康男性居民中,血清总胆固醇低于3.80 mrnoUL所占 的比例。 实践三率的标准化在医学研究中的应用
题1:对某地不同年龄、性别人群的HBsAg 阳性率进行检测,结果如下表所示,试着对该地男、女HBsAg 阳性率进行率的标准化。 提示:标准组的选择可以用合并人群,也可以任选其中一组作为标准组 表 某地不同年龄、性别人群的HBsAg 阳性率(%) 年龄组 男性 女性 检查数 阳性数 阳性率 检查数 阳性数 阳性率 0~ 521 12 2.30 560 13 2.32 20~ 516 14 2.71 957 26 2.72 40~ 710 43 6.06 836 54 6.46 60~ 838 63 7.52 570 49 8.60 合计 2585 132 5.11 2923 142 4.86 实验四 总体均数估计在医学研究中的运用 题1 从某疾病患者中随机抽取25例,其红细胞沉降率(mm/h )的均数为9.15,标准差为2.13。假定该类患者的红细胞沉降率服从正态分布,试估计该总体均数的95%的置信区间。 ()()某实验随机测定了100名正常人血浆内皮素ET 含量ng /L , 得均数X =81.0标准差S =18.2, (1)计算抽样误差指标 ( 2)估计正常人血浆内皮素的95%总体均数可题 2 信区间。 实验五 假设检验与t 检验 题1 经研究显示,汉族成年男子的环指长度的总体均数为10.1cm.某医生记录 了某地区12名汉族正常成年男子的环指长度(cm )分别为:10.05 10.33 10.49 10.00 9.89 10.15 9.52 10.33 10.16 10.37 10.11 10.27
李晓松医学统计学作业题
实践一、数值变量的整理与描述 题1在某市做调查获得102名7岁男童坐高资料如下图所示: (1) 计算平均数与标准差; (2) 计算中位数与四分位数间距。 实践二正态分布理论与应用 题1抽样调查某市45-55岁健康男性居民的血脂水平,184名45-55岁健康男性居血清总胆固醇仃C的X =4. 84 mmol/L, S=0.96 mmol/L.(健康人的血清总胆固醇服从正态分布)。 (1) 估计该市45 ~55岁健康男性居民的血清总胆固醇的95%参考值范围; (2) 估计该市45 ~55岁健康男性居民中,血清总胆固醇住3.25-5.25 mmol/L范围内 的比例; (3) 估计该市45 ~55岁健康男性居民中,血清总胆固醇低于 3.80 mrnoUL所占 的比例。 实践三率的标准化在医学研究中的应用 题1:对某地不同年龄、性别人群的HBsAB日性率进行检测,结果如下表所示,试着对该地男、女HBsAB日性率进行率的标准化。 提示:标准组的选择可以用合并人群,也可以任选其中一组作为标准组
题1从某疾病患者中随机抽取25例,其红细胞沉降率(mm/h)的均数为9.15, 标准差为2.13。假定该类患者的红细胞沉降率服从正态分布,试估计该总体均数的95%的置信区间。 题2某实验随机测定了100名正常人血浆内皮素ET含量ng/ L , 得均数X = 81.0标准差S =18.2, (1)计算抽样误差指标 (2)估计正常人血浆内皮素的95%总体均数可信区间 题1经研究显示,汉族成年男子的环指长度的总体均数为10.1cm某医生记录了某地区12名汉族正常成年男子的环指长度(cm)分别为:10.05 10.33 10.49 10.00 9.89 10.15 9.52 10.33 10.16 10.37 10.11 10.27 问:该地区正常成年男子的环指长度是否大于一般成年男子? 题2将18名某疾病患者随机分成两组,分别用A/B两种药物治疗, 观察前后的血红蛋白含量如下表: 问()药物是否有效? (2)B药物是否有效? (3)A、B药物之间疗效有无差别?
卫生综合复习经验谈之医学统计学
卫生综合复习经验谈之医学统计学(一) 卫生综合五大科目中流行病学是最难复习的,而医学统计学是最基础的,只有学好医学统计,才能更深入的理解流行病学。这些话有些夸张,但医学统计学的基础地位却是毋庸置疑的。 医学统计学是一门工具学科,它是数理统计学在医学领域的具体应用。复习医学统计学的关键在于领会每一种统计学方法的原理,训练统计学思维;无论公式、定理背诵的多么熟练,spss软件操作的多么流畅,如果统计原理弄不清楚,那么还是相当于没学会统计学。去年旁听的一次研究生答辩会上,某同学选取某医院某科室2011年2月至2011年9月就诊的所有患者作为研究对象,按照医保类型、家庭经济状况等进行分组,采用t检验以及方差分析等方法,比较各组之间的差异,分析软件使用的是spss13.0,各组间默认正态、等方差。 大家觉得这个分析思路有没有问题?是不是很完备?方法应用的也符合统计学规范?表面上看来的确如此,实际情况呢?这个分析思路从根本上来讲就是立不住的。有一句话,叫做“无抽样,无检验”。上面的课题设计中,研究对象是某时间段内所有患者,这属于普查的一种,既然是普查就不存在抽样的问题,不抽样就没有假设检验的什么事了。
假设检验是用来干什么的?为什么要用假设检验?其目的是为了用 样本去推断总体,看一看样本的特性是否适用于总体。如果一个研究的研究对象本身就选用了总体,那么还用假设检验做什么?类似的例子,说透了可能大家都明白,但是在实际操作中却有很多人犯这种错误,根源还是没有透彻的理解统计学的原理和思路。 医学统计学说白了,包括两大部分,一是统计描述,二是统计推断;统计描述包括定量资料的描述和定性资料的描述;统计推断包括区间估计和假设检验,统计推断也涵盖定性和定量两种,但以定量资料为主。统计描述中的核心概念,均数、方差、变异系数、四分位数、率、构成比;统计推断中的核心知识点,t检验、单因素方差分析、卡方检验、二项分布和泊松分布、相关、回归。把握住这些核心知识点,其实医学统计学的复习已经完成了大半了 (二) 医学统计学复习中首先接触到的概念是总体和样本,这两个概念希望大家能够认真领会,虽然不会考察名词解释,但却是统计的基础所在。所要研究的对象的全体称为总体,包括有限总体和无限总体;无论是对于有限总体和无限总体,在实际研究中,我们或者受到资金、时间、技术等的限制,不能将所有的研究对象逐一研究,这就需要从总体中按照一定的方法抽取一部分对象进行研究,这一部分能够代表总体的研究对象就是样本。统计学中绝大多数的研究都属于抽样研究。这是我对于总体和样本的理解,希望和大家共同探讨。
医学统计学第二版答案
医学统计学第二版答案 【篇一:医学统计学(第六版)课后答案】 ) 第一章绪论 一、单项选择题 1. d 2. e 3. d 4. b 5. a 6. d 7. a 8. c 9. e 10. d 二、简答题 1 更容易理解,统计推断则可以使用概率的方式给出结论,两者的重要作用在于能够透过偶然现象来探测具有变异性的医学规律,使研究结论具有科学性。 2 能够提高研究效率,并使结果更加准确和可靠,数据整理主要是对数据进行归类,检查数据质量,以及是否符合特定的统计分析方法要求等。统计描述用来描述及总结数据的重要特征,统计推断指由样本数据的特征推断总体特征的方法,包括参数估计和假设检验。3 计算参数估计的可信区间、假设检验的p 值得出相互比较是否有差别的结论。 4 述样本特征的指标,由样本数据计算得到,参数是描述总体分布特征的 5 差是生物体的自然变异和各种不可预知因素产生的误差,抽样误差是由于抽样而引起的样本统计量与总体参数间的差异。 6 第二章定量数据的统计描述 一、单项选择题 1. a 2. b 3. e 4. b 5. a 6. e 7. e 8. d 9. b 10. e 二、计算与分析 2 第三章正态分布与医学参考值范围 一、单项选择题 1. a 2. b 3. b 4. c 5. d 6. d 7. c 8. e 9. b 10. a 二、计算与分析
1 2 [参考答案] 题中所给资料属于正偏态分布资料,所以宜用百分位数法计算其参考值范围。又因血铅含量仅过大为异常,故应计算只 有上限的单侧范围,即95p 。 第四章定性数据的统计描述 一、单项选择题 1. a 2. c 3. d 4. d 5. e 6. e 7. e 8. a 9. d 10. e 二、计算与分析 1[参考答案] 不正确,因为此百分比是构成比,不 是率,要知道男女谁更易患病,需得到1290名职工中的男女比例, 然后分别计算男女患病率。 2[参考答案] 不正确,此为构成比替代 率来下结论,正确的计算是用各年龄段的死亡人数除各年龄段的调 查人数得到死亡率。 3[参考答案] 不正确,此为构成比替代率来下 结论,正确的计算是用各型肝炎的新病例数除以同时期内可能会发 生该病的人群人口数得到发病率。 第五章统计表与统计图 一、单项选择题 1. e 2. d 3. b 4. e 5. d 6. e 7. e 8. e 9. e 10. d 1.[参考答案] 本表的缺点有:12、横表目与纵标目分类不明确,标 目设计不 3、线条过多,比例数小数位不统一。 2..[参考答案] 本题应用直方图表示839例正常人发汞值分布情况, 由于最后一组的组距与其它组不等,需要变成等组距。为保持原始 数据的组距一致为0.2,把最后一组频数转换为36/(0.6/0.2)=12 3.[参考答案] 将表中数据绘制成普通线图可以看出:60岁之前,男 女食管癌年龄别发病率随年龄增长的变化趋势差异较小,60岁之后,男性随年龄变化食管癌发病率比女性增长较快,差异明显扩大。 将表中数据绘制成半对数线图可以看出, 不同性别食管癌年龄别发病率随年龄变化的快慢速 度相当,且女性的趋势和转折点更清楚。应用半对数线图能够更恰 当地表示指标的变化趋势 第六章参数估计与假设检验 一、单项选择题 1. e 2. d 3. e 4. c 5. b 6. e 7. c 8. d 9. d 10. d 1. [参考答案] 样本含量为450,属于大样本,可采用正态近似的方 法计算可信区间。 2. [参考答案] 1n=1022n=1041p=94.4%2p=91.26%