数据挖掘实验教案

实验三:Naive Bayes算法实现分类分析
实验四:决策树算法分析分类与回归
解释一下“Confusion Matrix”的含义。
这个矩阵是说,原本“pep”是“YES”的实例,有74个被正确的预测为“YES”,有64个错误的预测成了“NO”;原本“pep”是“NO”的实例,有30个被错误的预测为“YES”,有132个正确的预测成了“NO”。74+64+30+132 = 300是实例总数,而(74+132)/300 = 0.68667正好是正确分类的实例所占比例。这个矩阵对角线上的数字越大,说明预测得越好。
3、训练集应用:
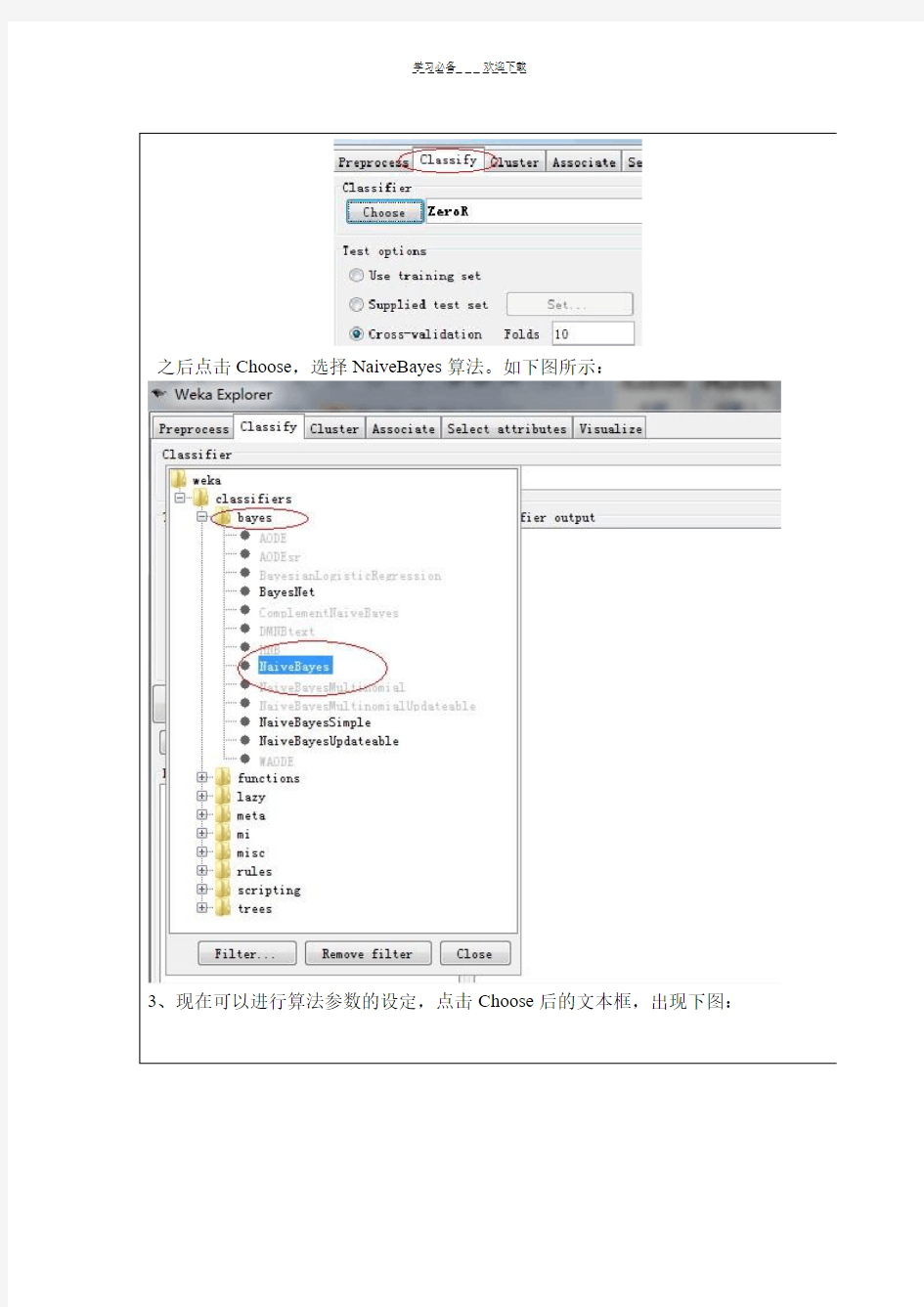
在test option中选择supplied test set
数据挖掘试题与答案
一、解答题(满分30分,每小题5分) 1. 怎样理解数据挖掘和知识发现的关系?请详细阐述之 首先从数据源中抽取感兴趣的数据,并把它组织成适合挖掘的数据组织形式;然后,调用相应的算法生成所需的知识;最后对生成的知识模式进行评估,并把有价值的知识集成到企业的智能系统中。 知识发现是一个指出数据中有效、崭新、潜在的、有价值的、一个不可忽视的流程,其最终目标是掌握数据的模式。流程步骤:先理解要应用的领域、熟悉相关知识,接着建立目标数据集,并专注所选择的数据子集;再作数据预处理,剔除错误或不一致的数据;然后进行数据简化与转换工作;再通过数据挖掘的技术程序成为模式、做回归分析或找出分类模型;最后经过解释和评价成为有用的信息。 2. 时间序列数据挖掘的方法有哪些,请详细阐述之 时间序列数据挖掘的方法有: 1)、确定性时间序列预测方法:对于平稳变化特征的时间序列来说,假设未来行为与现在的行为有关,利用属性现在的值预测将来的值是可行的。例如,要预测下周某种商品的销售额,可以用最近一段时间的实际销售量来建立预测模型。 2)、随机时间序列预测方法:通过建立随机模型,对随机时间序列进行分析,可以预测未来值。若时间序列是平稳的,可以用自回归(Auto Regressive,简称AR)模型、移动回归模型(Moving Average,简称MA)或自回归移动平均(Auto Regressive Moving Average,简称ARMA)模型进行分析预测。 3)、其他方法:可用于时间序列预测的方法很多,其中比较成功的是神经网络。由于大量的时间序列是非平稳的,因此特征参数和数据分布随着时间的推移而变化。假如通过对某段历史数据的训练,通过数学统计模型估计神经网络的各层权重参数初值,就可能建立神经网络预测模型,用于时间序列的预测。
数据挖掘实验报告
《数据挖掘》Weka实验报告 姓名_学号_ 指导教师 开课学期2015 至2016 学年 2 学期完成日期2015年6月12日
1.实验目的 基于https://www.360docs.net/doc/4512799163.html,/ml/datasets/Breast+Cancer+WiscOnsin+%28Ori- ginal%29的数据,使用数据挖掘中的分类算法,运用Weka平台的基本功能对数据集进行分类,对算法结果进行性能比较,画出性能比较图,另外针对不同数量的训练集进行对比实验,并画出性能比较图训练并测试。 2.实验环境 实验采用Weka平台,数据使用来自https://www.360docs.net/doc/4512799163.html,/ml/Datasets/Br- east+Cancer+WiscOnsin+%28Original%29,主要使用其中的Breast Cancer Wisc- onsin (Original) Data Set数据。Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 3.实验步骤 3.1数据预处理 本实验是针对威斯康辛州(原始)的乳腺癌数据集进行分类,该表含有Sample code number(样本代码),Clump Thickness(丛厚度),Uniformity of Cell Size (均匀的细胞大小),Uniformity of Cell Shape (均匀的细胞形状),Marginal Adhesion(边际粘连),Single Epithelial Cell Size(单一的上皮细胞大小),Bare Nuclei(裸核),Bland Chromatin(平淡的染色质),Normal Nucleoli(正常的核仁),Mitoses(有丝分裂),Class(分类),其中第二项到第十项取值均为1-10,分类中2代表良性,4代表恶性。通过实验,希望能找出患乳腺癌客户各指标的分布情况。 该数据的数据属性如下: 1. Sample code number(numeric),样本代码; 2. Clump Thickness(numeric),丛厚度;
数据挖掘实验三报告
实验三:基于Weka 进行关联规则挖掘 实验步骤 1.利用Weka对数据集contact-lenses.arff进行Apriori关联规则挖掘。要求: 描述数据集;解释Apriori 算法及流程;解释Weka 中有关Apriori 的参数;解释输出结果 Apriori 算法: 1、发现频繁项集,过程为 (1)扫描 (2)计数 (3)比较 (4)产生频繁项集 (5)连接、剪枝,产生候选项集 (6)重复步骤(1)~(5)直到不能发现更大的频集 2、产生关联规则 (1)对于每个频繁项集L,产生L的所有非空子集; (2)对于L的每个非空子集S,如果 P(L)/P(S)≧min_conf(最小置信度阈值) 则输出规则“S=>L-S” Weka 中有关Apriori 的参数:
1. car 如果设为真,则会挖掘类关联规则而不是全局关联规则。 2. classindex 类属性索引。如果设置为-1,最后的属性被当做类属性。 3.delta 以此数值为迭代递减单位。不断减小支持度直至达到最小支持度或产生了满足数量要求的规则。 4. lowerBoundMinSupport 最小支持度下界。 5. metricType 度量类型。设置对规则进行排序的度量依据。可以是:置信度(类关联规则只能用置信度挖掘),提升度(lift),杠杆率(leverage),确信度(conviction)。 在Weka中设置了几个类似置信度(confidence)的度量来衡量规则的关联程度,它们分别是: a)Lift :P(A,B)/(P(A)P(B)) Lift=1时表示A和B独立。这个数越大(>1),越表明A和B存在于一个购物篮中不是偶然现象,有较强的关联度. b)Leverage :P(A,B)-P(A)P(B) Leverage=0时A和B独立,Leverage越大A和B的关系越密切
《数据挖掘》试题与标准答案
一、解答题(满分30分,每小题5分) 1. 怎样理解数据挖掘和知识发现的关系?请详细阐述之 首先从数据源中抽取感兴趣的数据,并把它组织成适合挖掘的数据组织形式;然后,调用相应的算法生成所需的知识;最后对生成的知识模式进行评估,并把有价值的知识集成到企业的智能系统中。 知识发现是一个指出数据中有效、崭新、潜在的、有价值的、一个不可忽视的流程,其最终目标是掌握数据的模式。流程步骤:先理解要应用的领域、熟悉相关知识,接着建立目标数据集,并专注所选择的数据子集;再作数据预处理,剔除错误或不一致的数据;然后进行数据简化与转换工作;再通过数据挖掘的技术程序成为模式、做回归分析或找出分类模型;最后经过解释和评价成为有用的信息。 2.时间序列数据挖掘的方法有哪些,请详细阐述之 时间序列数据挖掘的方法有: 1)、确定性时间序列预测方法:对于平稳变化特征的时间序列来说,假设未来行为与现在的行为有关,利用属性现在的值预测将来的值是可行的。例如,要预测下周某种商品的销售额,可以用最近一段时间的实际销售量来建立预测模型。 2)、随机时间序列预测方法:通过建立随机模型,对随机时间序列进行分析,可以预测未来值。若时间序列是平稳的,可以用自回归(Auto Regressive,简称AR)模型、移动回归模型(Moving Average,简称MA)或自回归移动平均(Auto Regressive Moving Average,简称ARMA)模型进行分析预测。 3)、其他方法:可用于时间序列预测的方法很多,其中比较成功的是神经网络。由于大量的时间序列是非平稳的,因此特征参数和数据分布随着时间的推移而变化。假如通过对某段历史数据的训练,通过数学统计模型估计神经网络的各层权重参数初值,就可能建立神经网络预测模型,用于时间序列的预测。
数据挖掘实验报告(一)
数据挖掘实验报告(一) 数据预处理 姓名:李圣杰 班级:计算机1304 学号:1311610602
一、实验目的 1.学习均值平滑,中值平滑,边界值平滑的基本原理 2.掌握链表的使用方法 3.掌握文件读取的方法 二、实验设备 PC一台,dev-c++5.11 三、实验内容 数据平滑 假定用于分析的数据包含属性age。数据元组中age的值如下(按递增序):13, 15, 16, 16, 19, 20, 20, 21, 22, 22, 25, 25, 25, 25, 30, 33, 33, 35, 35, 35, 35, 36, 40, 45, 46, 52, 70。使用你所熟悉的程序设计语言进行编程,实现如下功能(要求程序具有通用性): (a) 使用按箱平均值平滑法对以上数据进行平滑,箱的深度为3。 (b) 使用按箱中值平滑法对以上数据进行平滑,箱的深度为3。 (c) 使用按箱边界值平滑法对以上数据进行平滑,箱的深度为3。 四、实验原理 使用c语言,对数据文件进行读取,存入带头节点的指针链表中,同时计数,均值求三个数的平均值,中值求中间的一个数的值,边界值将中间的数转换为离边界较近的边界值 五、实验步骤 代码 #include
数据挖掘实验报告资料
大数据理论与技术读书报告 -----K最近邻分类算法 指导老师: 陈莉 学生姓名: 李阳帆 学号: 201531467 专业: 计算机技术 日期 :2016年8月31日
摘要 数据挖掘是机器学习领域内广泛研究的知识领域,是将人工智能技术和数据库技术紧密结合,让计算机帮助人们从庞大的数据中智能地、自动地提取出有价值的知识模式,以满足人们不同应用的需要。K 近邻算法(KNN)是基于统计的分类方法,是大数据理论与分析的分类算法中比较常用的一种方法。该算法具有直观、无需先验统计知识、无师学习等特点,目前已经成为数据挖掘技术的理论和应用研究方法之一。本文主要研究了K 近邻分类算法,首先简要地介绍了数据挖掘中的各种分类算法,详细地阐述了K 近邻算法的基本原理和应用领域,最后在matlab环境里仿真实现,并对实验结果进行分析,提出了改进的方法。 关键词:K 近邻,聚类算法,权重,复杂度,准确度
1.引言 (1) 2.研究目的与意义 (1) 3.算法思想 (2) 4.算法实现 (2) 4.1 参数设置 (2) 4.2数据集 (2) 4.3实验步骤 (3) 4.4实验结果与分析 (3) 5.总结与反思 (4) 附件1 (6)
1.引言 随着数据库技术的飞速发展,人工智能领域的一个分支—— 机器学习的研究自 20 世纪 50 年代开始以来也取得了很大进展。用数据库管理系统来存储数据,用机器学习的方法来分析数据,挖掘大量数据背后的知识,这两者的结合促成了数据库中的知识发现(Knowledge Discovery in Databases,简记 KDD)的产生,也称作数据挖掘(Data Ming,简记 DM)。 数据挖掘是信息技术自然演化的结果。信息技术的发展大致可以描述为如下的过程:初期的是简单的数据收集和数据库的构造;后来发展到对数据的管理,包括:数据存储、检索以及数据库事务处理;再后来发展到对数据的分析和理解, 这时候出现了数据仓库技术和数据挖掘技术。数据挖掘是涉及数据库和人工智能等学科的一门当前相当活跃的研究领域。 数据挖掘是机器学习领域内广泛研究的知识领域,是将人工智能技术和数据库技术紧密结合,让计算机帮助人们从庞大的数据中智能地、自动地抽取出有价值的知识模式,以满足人们不同应用的需要[1]。目前,数据挖掘已经成为一个具有迫切实现需要的很有前途的热点研究课题。 2.研究目的与意义 近邻方法是在一组历史数据记录中寻找一个或者若干个与当前记录最相似的历史纪录的已知特征值来预测当前记录的未知或遗失特征值[14]。近邻方法是数据挖掘分类算法中比较常用的一种方法。K 近邻算法(简称 KNN)是基于统计的分类方法[15]。KNN 分类算法根据待识样本在特征空间中 K 个最近邻样本中的多数样本的类别来进行分类,因此具有直观、无需先验统计知识、无师学习等特点,从而成为非参数分类的一种重要方法。 大多数分类方法是基于向量空间模型的。当前在分类方法中,对任意两个向量: x= ) ,..., , ( 2 1x x x n和) ,..., , (' ' 2 ' 1 'x x x x n 存在 3 种最通用的距离度量:欧氏距离、余弦距 离[16]和内积[17]。有两种常用的分类策略:一种是计算待分类向量到所有训练集中的向量间的距离:如 K 近邻选择K个距离最小的向量然后进行综合,以决定其类别。另一种是用训练集中的向量构成类别向量,仅计算待分类向量到所有类别向量的距离,选择一个距离最小的类别向量决定类别的归属。很明显,距离计算在分类中起关键作用。由于以上 3 种距离度量不涉及向量的特征之间的关系,这使得距离的计算不精确,从而影响分类的效果。
数据挖掘-题库带答案
数据挖掘-题库带答案 1、最早提出“大数据”时代到来的是全球知名咨询公司麦肯锡() 答案:正确 2、决策将日益基于数据和分析而作出,而并非基于经验和直觉() 答案:错误 解析:决策将日益基于数据和分析而作出,而并非基于经验和直觉 3、2011年被许多国外媒体和专家称为“大数据元年”() 答案:错误 解析:2013年被许多国外媒体和专家称为“大数据元年” 4、我国网民数量居世界之首,每天产生的数据量也位于世界前列() 答案:正确 5、商务智能的联机分析处理工具依赖于数据库和数据挖掘。() 答案:错误 解析:商务智能的联机分析处理工具依赖于数据仓库和多维数据挖掘。 6、数据整合、处理、校验在目前已经统称为 EL() 答案:错误 解析:数据整合、处理、校验在目前已经统称为 ETL 7、大数据时代的主要特征() A、数据量大 B、类型繁多 C、价值密度低 D、速度快时效高 答案: ABCD 8、下列哪项不是大数据时代的热门技术() A、数据整合 B、数据预处理 C、数据可视化 D、 SQL
答案: D 9、()是一种统计或数据挖掘解决方案,包含可在结构化和非结构化数据中使用以确定未来结果的算法和技术。 A、预测 B、分析 C、预测分析 D、分析预测 答案: C 10、大数据发展的前提? 答案: 解析:硬件成本的降低,网络带宽的提升,云计算的兴起,网络技术的发展,智能终端的普及,电子商务、社交网络、电子地图等的全面应用,物联网的兴起 11、调研、分析大数据发展的现状与应用领域。? 答案: 解析:略 12、大数据时代的主要特征? 答案: 解析:数据量大(Volume) 第一个特征是数据量大。大数据的起始计量单位至少是P(1000个T)、E(100万个T)或Z(10亿个T)。 类型繁多(Variety) 第二个特征是数据类型繁多。包括网络日志、音频、视频、图片、地理位置信息等等,多类型的数据对数据的处理能力提出了更高的要求。 价值密度低(Value) 第三个特征是数据价值密度相对较低。如随着物联网的广泛应用,信息感知无处不在,信息海量,但价值密度较低,如何通过强大的机器算法更迅速地完成数据的价值“提纯”,是大数据时代亟待解决的难题。 速度快、时效高(Velocity) 第四个特征是处理速度快,时效性要求高。这是大数据区分于传统数据挖掘最显著的特征。 13、列举大数据时代的主要技术? 答案: 解析:预测分析: 预测分析是一种统计或数据挖掘解决方案,包含可在结构化和非结构化数据中使用以确定未来结果的算法和技术。可为预测、优化、预报和模拟等许多其他用途而部署。随着现在硬件和软件解决方案的成熟,许多公司利用大数据技术来收集海量数据、训练模型、优化模型,并发布预测模型来提高业务
数据挖掘试验指导书
《商务数据分析》实验指导书(适用于国际经济与贸易专业) 江西财经大学国际经贸学院 编写人:戴爱明
目录 前言 (1) 实验一、SPSS Clementine 软件功能演练 (5) 实验二、SPSS Clementine 数据可视化 (9) 实验三、决策树C5.0 建模 (17) 实验四、关联规则挖掘 (30) 实验五、聚类分析(异常值检测) (38)
前言 一、课程简介 商务数据分析充分利用数据挖掘技术从大量商务数据中获取有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。数据挖掘的广义观点:数据挖掘就是从存放在数据库,数据仓库或其他信息库中的大量的数据中“挖掘”有趣知识的过程。数据挖掘,又称为数据库中知识发现(Knowledge Discovery in Database, KDD),因此,数据挖掘和数据仓库的协同工作,一方面,可以迎合和简化数据挖掘过程中的重要步骤,提高数据挖掘的效率和能力,确保数据挖掘中数据来源的广泛性和完整性。另一方面,数据挖掘技术已经成为数据仓库应用中极为重要和相对独立的方面和工具。 数据挖掘有机结合了来自多学科技术,其中包括:数据库、数理统计、机器学习、高性能计算、模式识别、神经网络、数据可视化、信息检索、图像与信号处理、空间数据分析等,这里我们强调商务数据分析所处理的是大规模数据,且其算法应是高效的和可扩展的。通过数据分析,可从数据库中挖掘出有意义的知识、规律,或更高层次的信息,并可以从多个角度对其进行浏览察看。所挖掘出的知识可以帮助进行商务决策支持。当前商务数据分析应用主要集中在电信、零售、农业、网络日志、银行等方面。
数据挖掘实验报告三
实验三 一、实验原理 K-Means算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。 在数据挖掘中,K-Means算法是一种cluster analysis的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。 算法原理: (1) 随机选取k个中心点; (2) 在第j次迭代中,对于每个样本点,选取最近的中心点,归为该类; (3) 更新中心点为每类的均值; (4) j<-j+1 ,重复(2)(3)迭代更新,直至误差小到某个值或者到达一定的迭代步 数,误差不变. 空间复杂度o(N) 时间复杂度o(I*K*N) 其中N为样本点个数,K为中心点个数,I为迭代次数 二、实验目的: 1、利用R实现数据标准化。 2、利用R实现K-Meams聚类过程。 3、了解K-Means聚类算法在客户价值分析实例中的应用。 三、实验内容 依据航空公司客户价值分析的LRFMC模型提取客户信息的LRFMC指标。对其进行标准差标准化并保存后,采用k-means算法完成客户的聚类,分析每类的客户特征,从而获得每类客户的价值。编写R程序,完成客户的k-means聚类,获得聚类中心与类标号,并统计每个类别的客户数
四、实验步骤 1、依据航空公司客户价值分析的LRFMC模型提取客户信息的LRFMC指标。
2、确定要探索分析的变量 3、利用R实现数据标准化。 4、采用k-means算法完成客户的聚类,分析每类的客户特征,从而获得每类客户的价值。
五、实验结果 客户的k-means聚类,获得聚类中心与类标号,并统计每个类别的客户数 六、思考与分析 使用不同的预处理对数据进行变化,在使用k-means算法进行聚类,对比聚类的结果。 kmenas算法首先选择K个初始质心,其中K是用户指定的参数,即所期望的簇的个数。 这样做的前提是我们已经知道数据集中包含多少个簇. 1.与层次聚类结合 经常会产生较好的聚类结果的一个有趣策略是,首先采用层次凝聚算法决定结果
数据挖掘报告
哈尔滨工业大学 数据挖掘理论与算法实验报告(2016年度秋季学期) 课程编码S1300019C 授课教师邹兆年 学生姓名汪瑞 学号 16S003011 学院计算机学院
一、实验内容 决策树算法是一种有监督学习的分类算法;kmeans是一种无监督的聚类算法。 本次实验实现了以上两种算法。在决策树算法中采用了不同的样本划分方式、不同的分支属性的选择标准。在kmeans算法中,比较了不同初始质心产生的差异。 本实验主要使用python语言实现,使用了sklearn包作为实验工具。 二、实验设计 1.决策树算法 1.1读取数据集 本次实验主要使用的数据集是汽车价值数据。有6个属性,命名和属性值分别如下: buying: vhigh, high, med, low. maint: vhigh, high, med, low. doors: 2, 3, 4, 5more. persons: 2, 4, more. lug_boot: small, med, big. safety: low, med, high. 分类属性是汽车价值,共4类,如下: class values:unacc, acc, good, vgood 该数据集不存在空缺值。
由于sklearn.tree只能使用数值数据,因此需要对数据进行预处理,将所有标签类属性值转换为整形。 1.2数据集划分 数据集预处理完毕后,对该数据进行数据集划分。数据集划分方法有hold-out法、k-fold交叉验证法以及有放回抽样法(boottrap)。 Hold—out法在pthon中的实现是使用如下语句: 其中,cv是sklearn中cross_validation包,train_test_split 方法的参数分别是数据集、数据集大小、测试集所占比、随机生成方法的可
数据挖掘分类实验详细报告概论
《数据挖掘分类实验报告》 信息安全科学与工程学院 1120362066 尹雪蓉数据挖掘分类过程 (1)数据分析介绍 本次实验为典型的分类实验,为了便于说明问题,弄清数据挖掘具体流程,我们小组选择了最经典的决策树算法进行具体挖掘实验。 (2)数据准备与预处理 在进行数据挖掘之前,我们首先要对需要挖掘的样本数据进行预处理,预处理包括以下步骤: 1、数据准备,格式统一。将样本转化为等维的数据特征(特征提取),让所有的样 本具有相同数量的特征,同时兼顾特征的全面性和独立性 2、选择与类别相关的特征(特征选择) 3、建立数据训练集和测试集 4、对数据集进行数据清理 在本次实验中,我们选择了ILPD (Indian Liver Patient Dataset) 这个数据集,该数据集已经具有等维的数据特征,主要包括Age、Gender、TB、DB、Alkphos、Sgpt、Sgot、TP、ALB、A/G、classical,一共11个维度的数据特征,其中与分类类别相关的特征为classical,它的类别有1,2两个值。 详见下表: 本实验的主要思路是将该数据集分成训练集和测试集,对训练集进行训练生成模型,然后再根据模型对测试集进行预测。 数据集处理实验详细过程:
●CSV数据源处理 由于下载的原始数据集文件Indian Liver Patient Dataset (ILPD).csv(见下图)中间并不包含属性项,这不利于之后分类的实验操作,所以要对该文件进行处理,使用Notepad文件,手动将属性行添加到文件首行即可。 ●平台数据集格式转换 在后面数据挖掘的实验过程中,我们需要借助开源数据挖掘平台工具软件weka,该平台使用的数据集格式为arff,因此为了便于实验,在这里我们要对csv文件进行格式转换,转换工具为weka自带工具。转换过程为: 1、打开weka平台,点击”Simple CLI“,进入weka命令行界面,如下图所示: 2、输入命令将csv文件导成arff文件,如下图所示: 3、得到arff文件如下图所示: 内容如下:
(完整版)数据挖掘概念课后习题答案
第 1 章 1.6 定义下列数据挖掘功能:特征化、区分、关联和相关分析、预测聚类和演变分析。 使用你熟悉的现实生活的数据库,给出每种数据挖掘功能的例子。 ?特征化是一个目标类数据的一般特性或特性的汇总。例如,学生的特征可被提出,形成所 有大学的计算机科学专业一年级学生的轮廓,这些特征包括作为一种高的年级平均成绩 (GPA:Grade point a ve r s ge) 的信息,还有所修的课程的最大数量。 ?区分是将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比 较。例如,具有高GPA 的学生的一般特性可被用来与具有低GPA 的一般特性比较。最 终的描述可能是学生的一个一般可比较的轮廓,就像具有高GPA 的学生的75%是四年级 计算机科学专业的学生,而具有低GPA 的学生的65%不是。 ?关联是指发现关联规则,这些规则表示一起频繁发生在给定数据集的特征值的条件。 例如,一个数据挖掘系统可能发现的关联规则为: m a j or(X,“c omput i ng s c i e nc e”) ?owns(X, “pe r s ona l c omput e r”) [s uppor t=12%,c on f i d e nc e=98%] 其中,X 是一个表示学生的变量。这个规则指出正在学习的学生,12%(支持度)主修计算机科学并且拥有一台 。 个人计算机。这个组一个学生拥有一台个人电脑的概率是98%(置信度,或确定度) ?分类与预测不同,因为前者的作用是构造一系列能描述和区分数据类型或概念的模型(或,而后者是建立一个模型去预测缺失的或无效的、并且通常是数字的数据值。它们的 功能) 相似性是他们都是预测的工具:分类被用作预测目标数据的类的标签,而预测典型的应用是 预测缺失的数字型数据的值。 ?聚类分析的数据对象不考虑已知的类标号。对象根据最大花蕾内部的相似性、最小化类之间的相似性的原则进行聚类或分组。形成的每一簇可以被看作一个对象类。聚类也便于分类法组织形式,将观测组织成类分层结构,把类似的事件组织在一起。 ?数据延边分析描述和模型化随时间变化的对象的规律或趋势,尽管这可能包括时间相关数 据的特征化、区分、关联和相关分析、分类、或预测,这种分析的明确特征包括时间序列数据分 析、序列或周期模式匹配、和基于相似性的数据分析 1.9 列举并描述说明数据挖掘任务的五种原语。 五种原语是: ?任务相关数据:这种原语指明给定挖掘所处理的数据。它包括指明数据库、数据库表、或 数据仓库,其中包括包含关系数据、选择关系数据的条件、用于探索的关系数据的属性或 维、关于修复的数据排序和分组。 ?挖掘的数据类型:这种原语指明了所要执行的特定数据挖掘功能,如特征化、区分、关 联、分类、聚类、或演化分析。同样,用户的要求可能更特殊,并可能提供所发现的模式必 须匹配的模版。这些模版或超模式(也被称为超规则)能被用来指导发现过程。 ?背景知识:这种原语允许用户指定已有的关于挖掘领域的知识。这样的知识能被用来指导 知识发现过程,并且评估发现的模式。关于数据中关系的概念分层和用户信念是背景知识的 形式。 ?模式兴趣度度量:这种原语允许用户指定功能,用于从知识中分割不感兴趣的模式,并且 被用来指导挖掘过程,也可评估发现的模式。这样就允许用户限制在挖掘过程返回的不感兴 趣的模式的数量,因为一种数据挖掘系统可能产生大量的模式。兴趣度测量能被指定为简易 性、确定性、适用性、和新颖性的特征。 ?发现模式的可视化:这种原语述及发现的模式应该被显示出来。为了使数据挖掘能有效地
数据挖掘实验三
实验三设计并构造AdventureWorks数据仓库实例 【实验要求】 在SQL Server 平台上,利用AdventureWorks数据库作为商业智能解决方案的数据源,设计并构造数据仓库,建立OLAP和数据挖掘模型,并以输出报表的形式满足决策支持的查询需求。 【实验内容】 步骤1:需求分析:以决策者的视角分析和设计数据仓库的需求; 步骤2:根据所设计的需求,确定本数据仓库的主题和主题与边界; 步骤3:设计并构造逻辑模型; 步骤4:进行数据转换和抽取,建立数据仓库:创建数据源,,建立OLAP和挖掘模型,使用多维数据集进行分析,建立数据挖掘结构和数据挖掘模型,创建报表。 【实验平台】 Win7操作系统,SQL Server 2005 【实验过程】 一、创建Analysis Services 项目 1.打开Business Intelligence Development Studio。 2.在“文件”菜单上,指向“新建”,然后选择“项目”。 3.确保已选中“模板”窗格中的“Analysis Services 项目”。 4.在“名称”框中,将新项目命名为AdventureWorks。 5. 单击“确定”。 二、创建数据库和数据源 1.运行AdventureWorks sql server 2005示例数据库.msi,然后用SQL Server Management Studio 附加数据库AdventureWorks_Data.mdf 。 (1)运行AdventureWorks sql server 2005示例数据库.msi
(2)用SQL Server Management Studio附加数据库AdventureWorks_Data.mdf
数据挖掘概念与技术(第三版)部分习题答案
1.4 数据仓库和数据库有何不同?有哪些相似之处? 答:区别:数据仓库是面向主题的,集成的,不易更改且随时间变化的数据集合,用来支持管理人员的决策,数据库由一组内部相关的数据和一组管理和存取数据的软件程序组成,是面向操作型的数据库,是组成数据仓库的源数据。它用表组织数据,采用ER 数据模型。 相似:它们都为数据挖掘提供了源数据,都是数据的组合。 1.3 定义下列数据挖掘功能:特征化、区分、关联和相关分析、预测聚类和演变分析。使用你熟悉的现实生活的数据库,给出每种数据挖掘功能的例子。 答:特征化是一个目标类数据的一般特性或特性的汇总。例如,学生的特征可被提出,形成所有大学的计算机科学专业一年级学生的轮廓,这些特征包括作为一种高的年级平均成绩(GPA :Grade point aversge) 的信息, 还有所修的课程的最大数量。 区分是将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比较。例如, 具有高GPA 的学生的一般特性可被用来与具有低GPA 的一般特性比较。最终的描述可能是学生的一个一般可比较的轮廓,就像具有高GPA 的学生的75% 是四年级计算机科学专业的学生,而具有低GPA 的学生的65% 不是。 关联是指发现关联规则,这些规则表示一起频繁发生在给定数据集的特征值的条件。例如,一个数据挖掘系统可能发现的关联规则为:major(X, “ computing science ” ) ? owns(X, “ personal computer ” ) [support=12%, confidence=98%] 其中,X 是一个表示学生的变量。这个规则指出正在学习的 学生,12% (支持度)主修计算机科学并且拥有一台个人计算机。这个组一个学生拥有一台个人电脑的概率是98% (置信度,或确定度)。 分类与预测不同,因为前者的作用是构造一系列能描述和区分数据类型或概念的模型(或功能),而后者是建立一个模型去预测缺失的或无效的、并且通常是数字的数据值。它们的相似性是他们都是预测的工具: 分类被用作预测目标数据的类的标签,而预测典型的应用是预测缺失的数字型数据的值。 聚类分析的数据对象不考虑已知的类标号。对象根据最大花蕾内部的相似性、最小化类之间的相似性的原则进行聚类或分组。形成的每一簇可以被看作一个对象类。聚类也便于分类法组织形式,将观测组织成类分 层结构,把类似的事件组织在一起。 数据演变分析描述和模型化随时间变化的对象的规律或趋势,尽管这可能包括时间相关数据的特征化、区分、关联和相关分析、分类、或预测,这种分析的明确特征包括时间序列数据分析、序列或周期模式匹配、和基于相似性的数据分析 2.3 假设给定的数据集的值已经分组为区间。区间和对应的频率如下。 年龄频率 1~5200 5~15450 15~20300 20~501500 50~80700 80~11044 计算数据的近似中位数值。 解答:先判定中位数区间:N=200+450+300+1500+700+44=3194 ;N/2=1597
数据挖掘实验报告1
实验一 ID3算法实现 一、实验目的 通过编程实现决策树算法,信息增益的计算、数据子集划分、决策树的构建过程。加深对相关算法的理解过程。 实验类型:验证 计划课间:4学时 二、实验内容 1、分析决策树算法的实现流程; 2、分析信息增益的计算、数据子集划分、决策树的构建过程; 3、根据算法描述编程实现算法,调试运行; 4、对所给数据集进行验算,得到分析结果。 三、实验方法 算法描述: 以代表训练样本的单个结点开始建树; 若样本都在同一个类,则该结点成为树叶,并用该类标记; 否则,算法使用信息增益作为启发信息,选择能够最好地将样本分类的属性; 对测试属性的每个已知值,创建一个分支,并据此划分样本; 算法使用同样的过程,递归形成每个划分上的样本决策树 递归划分步骤,当下列条件之一成立时停止: 给定结点的所有样本属于同一类; 没有剩余属性可以进一步划分样本,在此情况下,采用多数表决进行 四、实验步骤 1、算法实现过程中需要使用的数据结构描述: Struct {int Attrib_Col; // 当前节点对应属性 int Value; // 对应边值 Tree_Node* Left_Node; // 子树 Tree_Node* Right_Node // 同层其他节点 Boolean IsLeaf; // 是否叶子节点 int ClassNo; // 对应分类标号 }Tree_Node; 2、整体算法流程
主程序: InputData(); T=Build_ID3(Data,Record_No, Num_Attrib); OutputRule(T); 释放内存; 3、相关子函数: 3.1、 InputData() { 输入属性集大小Num_Attrib; 输入样本数Num_Record; 分配内存Data[Num_Record][Num_Attrib]; 输入样本数据Data[Num_Record][Num_Attrib]; 获取类别数C(从最后一列中得到); } 3.2、Build_ID3(Data,Record_No, Num_Attrib) { Int Class_Distribute[C]; If (Record_No==0) { return Null } N=new tree_node(); 计算Data中各类的分布情况存入Class_Distribute Temp_Num_Attrib=0; For (i=0;i 数据分析与挖掘实验报告 《数据挖掘》实验报告 目录 1.关联规则的基本概念和方法 (1) 1.1数据挖掘 (1) 1.1.1数据挖掘的概念 (1) 1.1.2数据挖掘的方法与技术 (2) 1.2关联规则 (5) 1.2.1关联规则的概念 (5) 1.2.2关联规则的实现——Apriori算法 (7) 2.用Matlab实现关联规则 (12) 2.1Matlab概述 (12) 2.2基于Matlab的Apriori算法 (13) 3.用java实现关联规则 (19) 3.1java界面描述 (19) 3.2java关键代码描述 (23) 4、实验总结 (29) 4.1实验的不足和改进 (29) 4.2实验心得 (30) 1.关联规则的基本概念和方法 1.1数据挖掘 1.1.1数据挖掘的概念 计算机技术和通信技术的迅猛发展将人类社会带入到了信息时代。在最近十几年里,数据库中存储的数据急剧增大。数据挖掘就是信息技术自然进化的结果。数据挖掘可以从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的,人们事先不知道的但又是潜在有用的信息和知识的过程。 许多人将数据挖掘视为另一个流行词汇数据中的知识发现(KDD)的同义词,而另一些人只是把数据挖掘视为知识发现过程的一个基本步骤。知识发现过程如下: ·数据清理(消除噪声和删除不一致的数据)·数据集成(多种数据源可以组合在一起)·数据转换(从数据库中提取和分析任务相关的数据) ·数据变换(从汇总或聚集操作,把数据变换和统一成适合挖掘的形式) ·数据挖掘(基本步骤,使用智能方法提取数 据模式) ·模式评估(根据某种兴趣度度量,识别代表知识的真正有趣的模式) ·知识表示(使用可视化和知识表示技术,向用户提供挖掘的知识)。 1.1.2数据挖掘的方法与技术 数据挖掘吸纳了诸如数据库和数据仓库技术、统计学、机器学习、高性能计算、模式识别、神经网络、数据可视化、信息检索、图像和信号处理以及空间数据分析技术的集成等许多应用领域的大量技术。数据挖掘主要包括以下方法。神经网络方法:神经网络由于本身良好的鲁棒性、自组织自适应性、并行处理、分布存储和高度容错等特性非常适合解决数据挖掘的问题,因此近年来越来越受到人们的关注。典型的神经网络模型主要分3大类:以感知机、bp反向传播模型、函数型网络为代表的,用于分类、预测和模式识别的前馈式神经网络模型;以hopfield 的离散模型和连续模型为代表的,分别用于联想记忆和优化计算的反馈式神经网络模型;以art 模型、koholon模型为代表的,用于聚类的自组 12/13 年第2学期《数据挖掘与知识发现》期末考试试卷及答案 一、什么是数据挖掘?什么是数据仓库?并简述数据挖掘的步骤。(20分) 数据挖掘是从大量数据中提取或发现(挖掘)知识的过程。 数据仓库是面向主题的、集成的、稳定的、不同时间的数据集合,用于支持经营管理中的决策制定过程。 步骤: 1)数据清理(消除噪声或不一致数据) 2) 数据集成(多种数据源可以组合在一起) 3 ) 数据选择(从数据库中检索与分析任务相关的数据) 4 ) 数据变换(数据变换或统一成适合挖掘的形式,如通过汇总或聚集操作) 5) 数据挖掘(基本步骤,使用智能方法提取数据模式) 6) 模式评估(根据某种兴趣度度量,识别表示知识的真正有趣的模式;) 7) 知识表示(使用可视化和知识表示技术,向用户提供挖掘的知识) 二、元数据的定义是什么?元数据包括哪些内容?(20分) 元数据是关于数据的数据。在数据仓库中, 元数据是定义仓库对象的数据。 元数据包括: 数据仓库结构的描述,包括仓库模式、视图、维、分层结构、导出数据的定义, 以及数据集市的位置和内容。 操作元数据,包括数据血统(移植数据的历史和它所使用的变换序列)、数据流通(主动的、档案的或净化的)、管理信息(仓库使用统计量、错误报告和审计跟踪)。 汇总算法,包括度量和维定义算法, 数据所处粒度、划分、主题领域、聚集、汇总、预定义的查询和报告。 由操作环境到数据仓库的映射,包括源数据库和它们的内容,网间连接程序描述, 数据划分, 数据提取、清理、转换规则和缺省值, 数据刷新和净化规则, 安全 (用户授权和存取控制)。 关于系统性能的数据,刷新、更新定时和调度的规则与更新周期,改善数据存取和检索性能的索引和配置。 商务元数据,包括商务术语和定义, 数据拥有者信息和收费策略。 三、在 O L A P 中,如何使用概念分层? 请解释多维数据模型中的OLAP上卷 下钻切片切块和转轴操作。(20分) 在多维数据模型中,数据组织成多维,每维包含由概念分层定义的多个抽象层。这种组织为用户从不同角度观察数据提供了灵活性。有一些 O L A P 数据立方体操作用来物化这些不同视图,允许交互查询和分析手头数据。因此, O L A P 为交互数据分析提供了友好的环境。 上卷:上卷操作通过一个维的概念分层向上攀升或者通过维归约,在数据立方体上进行聚集。 下钻:下钻是上卷的逆操作,它由不太详细的数据到更详细的数据。下钻可以通过沿维的概念分层向下或引入新的维来实现。 切片:在给定的数据立方体的一个维上进行选择,导致一个子方。 切块:通过对两个或多个维执行选择,定义子方。 通信与信息工程学院 课程设计说明书 课程名称: 数据仓库与数据挖掘课程设计题目: 超市商品销售分析及数据挖掘专业/班级: 电子商务(理) 组长: 学号: 组员/学号: 开始时间: 2011 年12 月29 日完成时间: 2012 年01 月 3 日 目录 1.绪论 (1) 1.1项目背景 (1) 1.2提出问题 (1) 2.数据仓库与数据集市的概念介绍 (1) 2.1数据仓库介绍 (1) 2.2数据集市介绍 (2) 3.数据仓库 (3) 3.1数据仓库的设计 (3) 3.1.1数据仓库的概念模型设计 (4) 3.1.2数据仓库的逻辑模型设计 (5) 3.2 数据仓库的建立 (5) 3.2.1数据仓库数据集成 (5) 3.2.2建立维表 (8) 4.OLAP操作 (10) 5.数据预处理 (12) 5.1描述性数据汇总 (12) 5.2数据清理与变换 (13) 6.数据挖掘操作 (13) 6.1关联规则挖掘 (13) 6.2 分类和预测 (17) 6.3决策树的建立 (18) 6.4聚类分析 (22) 7.总结 (25) 8.任务分配 (26) 数据挖掘实验报告 1.绪论 1.1项目背景 在商业领域中使用计算机科学与技术是当今商业的发展方向,而数据挖掘是商业领域与计算机领域的乔梁。在超市的经营中,应用数据挖掘技术分析顾客的购买习惯和不同商品之间的关联,并借由陈列的手法,和合适的促销手段将商品有魅力的展现在顾客的眼前, 可以起到方便购买、节约空间、美化购物环境、激发顾客的购买欲等各种重要作用。 1.2提出问题 那么超市应该对哪些销售信息进行挖掘?怎样挖掘?具体说,超市如何运用OLAP操作和关联规则了解顾客购买习惯和商品之间的关联,正确的摆放商品位置以及如何运用促销手段对商品进行销售呢?如何判断一个顾客的销售水平并进行推荐呢?本次实验为解决这一问题提出了解决方案。 2.数据仓库与数据集市的概念介绍 2.1数据仓库介绍 数据仓库,英文名称为Data Warehouse,可简写为DW或DWH,是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的,它并不是所谓的“大型数据库”。........ 2.2数据集市介绍 数据集市,也叫数据市场,是一个从操作的数据和其他的为某个特殊的专业人员团体服务的数据源中收集数据的仓库。....... 3.数据仓库 3.1数据仓库的设计 3.1.1数据库的概念模型 3.1.2数据仓库的模型 数据仓库的模型主要包括数据仓库的星型模型图,我们创建了四个数据分析与挖掘实验报告
数据挖掘试卷及答案
数据挖掘实验报告 超市商品销售分析及数据挖掘