拉丁方实验设计

上机操作4 拉丁方实验设计与SPSS 分析
习题:
采用拉丁方对草莓品种进行比较试验,分析不同品种间是否存在显著性差异?
草莓品种试验产量(kg/株)
一、假设: H 0:草莓不同品种对其产量无显著性影响
1
二、定义变量,输入数据 (1)定义变量:打开SPSS 数据编辑器,在“变量视图”模式下,在名称列下输入 “横行”、“直行”、“品种”、“产量”等字符,将“品种”的类型设置为字符串,其它的均设置为数字,小数保留为零位;
(2)输入数据:在“数据视图”模式下,在各名称列输入相应的数据,如图所示:
三、数据处理过程
分析→常规线性模型→单变量→将“产量”移入因变量,将“横行”、“直行”、“品种”移入固定因子→模型:指定模型选“定制”;建立项选择“主效应”,将“横行”、“直行”、“品种”移入模型内;平方和选择“类型Ⅲ”;选中在模型中包含截距→继续→选项:显示均值中移入“品种”;显著性水平为0.05→继续→两两比较:两两比较检验中移入“品种”,假定方差齐性勾选“Duncan ”→继续→确定
四、输出结果并分析
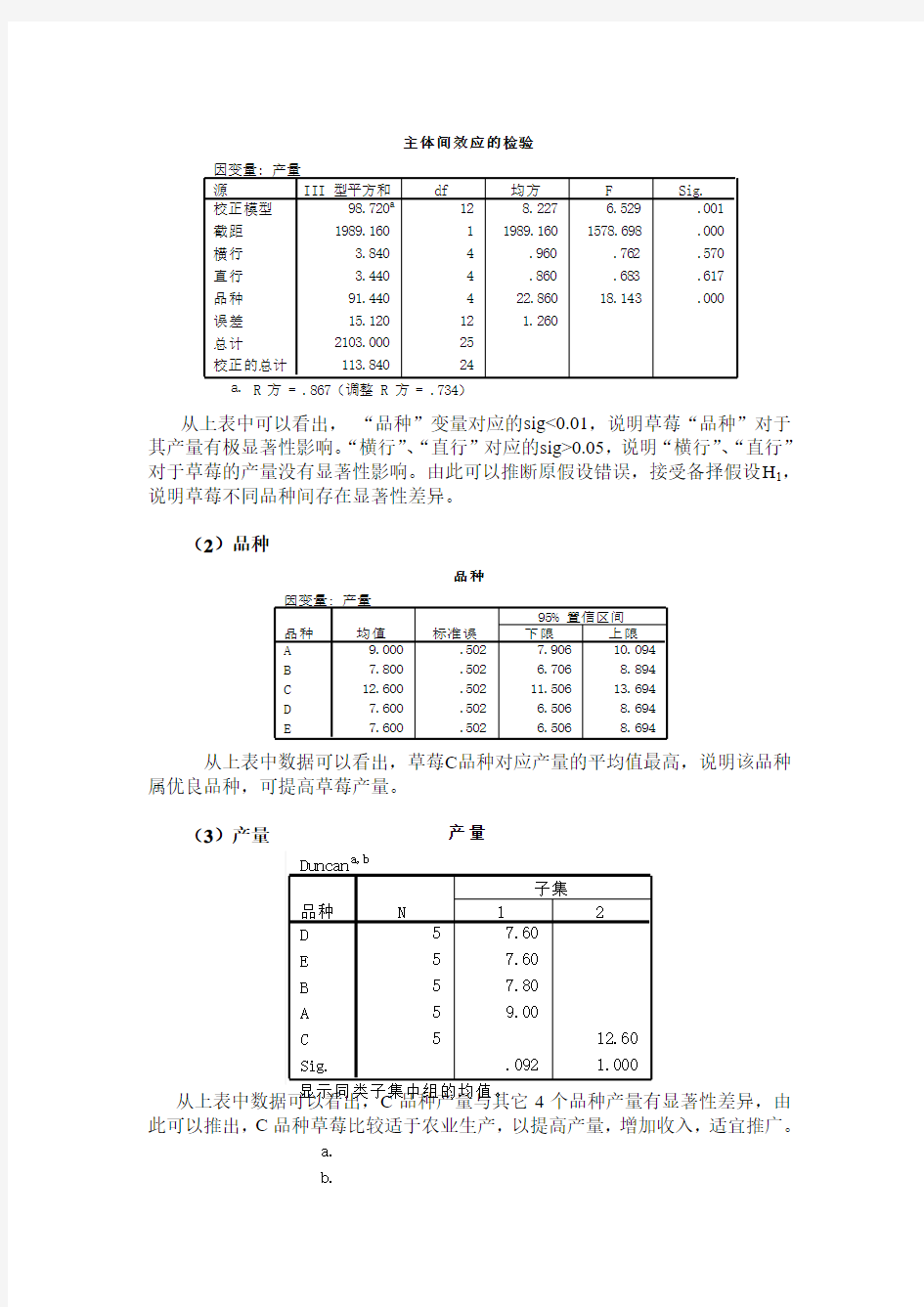
(1)主体间效应的检验
其产量有极显著性影响。“横行”、“直行”对应的sig>0.05,说明“横行”、“直行”对于草莓的产量没有显著性影响。由此可以推断原假设错误,接受备择假设H1,说明草莓不同品种间存在显著性差异。
(2)品种
从上表中数据可以看出,草莓C品种对应产量的平均值最高,说明该品种属优良品种,可提高草莓产量。
(3)产量
此可以推出,C适宜推广。
如何理解拉丁方实验设计
如何理解“拉丁方实验设计”(邓涛) 近来,不少学生问到拉丁方设计如何理解的问题,而且提出不同教材的表述也不一样.为了不去一一解答,我这里再结合《应用实验心理学》上的表述作一说明. 我的基本看法是:拉丁方实验设计与区组实验设计一样,都是为了平衡额外变量,以防止这些额外变量成为混淆因子,破坏实验研究的内部效度.如果简化点来解释,一般来说,区组实验设计多用于对一个额外变量的平衡,如被试因素、时间顺序因素、空间位置因素等;拉丁方实验设计则可以看成是区组设计的扩展,即扩展到可以平衡两个额外变量(当然,如果设计巧妙,也可以达到对多于两个额外变量的平衡,但那也是在二维平衡模式上变化出来的).为了说明,拉丁方设计及其与区组设计的联系,我们先说一说区组设计. 区组实验设计是在考察自变量影响效应的实验中,考虑到一个额外变量的影响,将这个额外变量作为区组变量,对其在各种实验处理条件下产生的影响进行平衡,同时将该区组变量引起的变异从残差中分离出来. 比如,限于实验室条件,研究者开展某一实验研究时每天只能为4名被试进行测试,实验处理也有四个水平:A1、A2、A3、A4.如果认为不在每周中的同一天进行测试,可能会引起测试结果的变化,这种影响又是比较重要的.于是可以将测试时间作为区组变量,即把同一天接受测试的被试看作是一个区组.这样就可以形成一个区组实验设计,如表2-8所示. 表2-8 四种实验处理的随机区组实验设计 现在我们进一步设想: 假如,在每天的实验中,一次只能测试一人,每天参加实验的四名被试只能分别在下午2~3点、3~4点、4~5点和5~6点的四个时段接受测试,而测试时段不同也可能会造成结果变化.这样一来,每一种实验处理条件安排的时段就也要取得平衡才行,你不能每天都在2点钟安排所有被试接受A1处理条件,或3点钟接受A1处理条件.于是,研究中采用测试天和测试时段两方面因素的平衡方法安排实验,构成了一个单因素的拉丁方实验设计,设计模式如图2-9所示.在这一设计中,测试是在星期几、测试是在每一天的哪一时段,这两个额外变量就都取得了很好的平衡. 从这一例子可以看出,拉丁方(latin square)是一个含P行P列,把P个实验处 理分配给P×P方格的管理方案,它便于在 复杂研究程序中有条理地管理各个工作单 元,并平衡两种额外变量的影响.在工农业 生产实验和心理与教育研究中,拉丁方都得到普遍应用.在这种实验设计中,首先根据自变量处理的水平数确定两个额外变量的水平数,然后利用两个额外变量的各个水平结合在一起构造一个拉丁方格,最后再将自变量的不同处理平衡地安排在这个方格中,就构成了一个研究方案,其结果要保证自变量的每一个水平在拉丁方格的每一行和每一列都出现且只出现一次.很明显,在这种设计中,自变量的水平数或水平结合数、额外变量的水平数必须相等.
单因素实验设计报告
单因素实验设计报告 :因素实验报告设计单因素实验设计举例正交实验单因素实验设计方案篇一:实验报告单因素方差分析 5.1、实验步骤: 1(建立数据文件。 定义2个变量:PWK和DCGJSL,分别表示排污口和大肠杆菌数量。 2. 选择菜单“分析?比较均值?单因素”,弹出“单因素方差分析”对话框。在对话 框左侧的变量列表中,选择变量“DCGJSL”进入“因变量”列表框,选择变量“PWK”进入“因子”列表框。 3(单击“确定”按钮,得到输出结果。 结果解读: 由以上结果可以看到,观测变量大肠杆菌数量的总离差平方和为460.438;如果仅考虑“排污口”单个因素的影响,则大肠杆菌数量总变差中,排污口可解释的变差为308.188,抽样误差引起的变差为152.250,它们的方差(平均变差)分别为102.729和12.6 88,相除所得的F统计量的观测值为8.097,对应的概率P值为0.003。在显著性水平α为0.05的情况下。由于概率P值小于显著性水平α,则应拒绝零假设,认为不同的排污口对大肠杆菌数量产生了显著影响,它对大肠杆菌数量的影响效应不全为0。 因此,可判断各个排污口的大肠杆菌数量是有差别的。 5.2、实验步骤: 1(建立数据文件。 定义2个变量:Branch和Turnover,分别表示分店和日营业额。将Branch的值定义为1=第一分店,2=第二分店,3=第三分店,4=第四分店,5=第五分店。
2. 选择菜单“分析?比较均值?单因素”,弹出“单因素方差分析”对话框。在对话 框左侧的变量列表中,选择变量“Turnover”进入“因变量”列表框,选择变量“Branch”进入“因子”列表框。 3(单击“确定”按钮,得到输出结果。 结果解读: 由以上结果可以看到,观测变量日营业额的总离差平方和为1187668.733;如果仅考虑“分店”单个因素的影响,则日营业额总变差中,分店可解释的变差为366120.900,抽样误差引起的变差为821547.833,它们的方差(平均变差)分别为91530.225和14937.233,相除所得的F统计量的观测值为6.128,对应的概率P 值近似为0。在显著性水平α为0.05的情况下,由于概率P值小于显著性水平α,则应拒绝零假设,认为不同的分店对日营业额产生了显著影响,它对日营业额的影响效应不全为0。 因此,在α,0.05的显著性水平下,“这五个分店的日营业额相同”这一假设不成立。 5.3、实验步骤: 1(建立数据文件。 定义3个变量:weight和method,分别表示幼苗干重(mg)和处理方式。将method的值定义为1=HCI,2=丙酸,3=丁酸,4=对照。 2. 选择菜单“分析?比较均值?单因素”,弹出“单因素方差分析”对话框。在对话 框左侧的变量列表中,选择变量“,method”进入“因变量”列表框,选择变量“weight”进入“因子”列表框。在“两两比较”选项中选择LSD、Bonferroni和Scheffe方法。 3(单击“确定”按钮,得到输出结果。
常见的实验设计与计算举例
常见的实验设计与举例 一、单因素实验设计 单因素完全随机设计、单因素随机区组设计、单因素拉丁方实验设计和单因素重复测量实验设计是四种基本的实验设计,复杂的实验设计大多都是在这四种形式上的组合。研究者根据不同的研究假设、实验目的与条件使用不同的实验设计,但无论哪种实验设计都有一个共同的目标,即控制无关变异,使误差变异最小。 1.完全随机设计研究中有一个自变量,自变量有两个或多个水平,采用随机化方法,通过随机分配被试给各个实验处理,以期实现各个处理的被试之间在统计上无差异,这种设计每个(组)被试只接受一个水平的处理。完全随机实验的方差分析中,所有不能由处理效应解释的变异全部被归为误差变异,因此,处理效应不够敏感。 例:研究阅读理解随着文章中的生字密度的增加而下降。自变量为生字密度,共有四个水平:5:1、10:1、15:1、20:1,因变量是被试的阅读理解测验分数。实验实施时,研究者将32名被试随机分为四个组,每组被试阅读一种生字密度的文章,并回答阅读理解测验中有关文章内容的问题。 完全随机实验设计实施简单,接受每个处理水平的被试数量可以不等,但需要被试的数量较大,且被试个体差异带来的无关变异混杂在组内变异中,从而使实验较为不敏感。完全随机实验数据的统计分析,如果是单因素两组设计,采用独立样本t检验;如果是单因素完全随机多组设计则采用一元方差分析(One -Way ANOV A)。 2.随机区组设计研究中有一个自变量,自变量有两个或多个水平,研究中还有一个无关变量,也有两个或多个水平,并且自变量的水平与无关变量的水平之间没有交互作用。当无关变量是被试变量时,一般首先将被试在这个无关变量上进行匹配,然后将他们随机分配给不同的实验处理。 例:仍以文章的生字密度对阅读理解影响的研究为例,但由于考虑到学生的智力可能对阅读理解测验分数产生影响,但它又不是该实验感兴趣的因素,于是研究者采用单因素随机区组设计,在实验实施前,研究者首先给32个学生做了智力测验,并按智力测验分数将学生分为8个区组,然后随机分配每个区组内的4个同质被试分别阅读一种生字密度的文章。
单因素实验设计
单因素试验设计是指只有一个因素(或仅考查一个因素)对试验指标构成影响的试验。单因素试验设计要求对试验水平进行布局和优化,是一种水平试验设计。 单因素试验设计方法可分为两类:同时试验设计和序贯试验设计。同时试验设计就是一次给出全部试验水平,一次完成全部试验并得到最佳试验结果,如穷举试验设计。序贯试验设计要求分批进行试验,后批试验需根据前批试验结果进一步优化后序贯进行,直到获取最佳试验结果,如平分试验设计、黄金分割试验设计。 一、试验范围与试验精度 (一)试验范围 试验范围指试验水平的范围。试验设计时需预先确定试验范围,一般采用两种方法:○ 1经验估计。可凭经验估计试验范围,并在试验过程中作调整。○2预先试验。要求在较大范围 内进行探索,通过试验逐步缩小范围。 (二)试验间隔与试验精度 试验间隔是指试验水平的间距,试验精度是指试验结果逼近最佳水平的程度。显然,试验间隔与试验精度是一对矛盾,试验间隔越大,试验精度越低。在保证试验精度的条件下,试验水平变化而引起的试验结果变动必须显著地超过试验误差。 (三)试验顺序 在确定试验顺序时,往往习惯于按照试验水平高低依次做试验。这样,随着试验的进行,有些因素会发生缓慢变化甚至影响试验结果。因此,正确的做法是采用随机化方法来确定试验顺序。在试验工作量较少或者试验准确度要求较低时,也可以采用按水平高低或者选取中间试验点的方法来进行试验排序。 需强调指出,以上不仅对单因素试验设计,而且对所有试验设计方法都适用。 二、单因素试验设计 (一)平分试验设计 平分试验设计就是平分试验范围,把其中间点作为新试验点,然后不断缩小试 验范围直到找到最佳条件。当试验结果呈单向变化时,也就是说最佳试验点只可能在试验中间点的一侧,可采用平分试验设计。该方法简便易行,但要注意单向性特征。 (二)穷举试验设计与均分试验设计 穷举试验设计是将所有可能的试验点在一批试验中全部进行试验。均分试验设 计是根据试验精度要求,均分整个试验范围以获得所有试验点。显然,均分试验设计不仅充分体现了穷举试验设计的思想,而且也明确了具体试验设计方法。 如试验起始点为a ,终点为b ,试验点的间隔区间为L ,则均分试验设计的试 验点数n 为 1L a b n +-= (1-1) 该试验设计的特点是对所试验的范围进行“普查”,试验点数量较多,宜用于 对目标函数性质没有掌握或很少掌握的情况。 (三)黄金分割试验设计 黄金分割试验设计就是在预定试验范围内采用0.618黄金分割原理安排新试验 点,直到找到最佳试验结果为止,因而又称0.618试验设计。黄金分割就是在特定范围内寻求黄金分割点(k )及对称点(1-k )。在0~1的试验范围内,黄金分割点(k )为0.618,其对称点(1-k )为0.382。 黄金分割点试验设计涉及两个层面,一是已知试验范围内的黄金分割点的寻 求,二是新试验范围的确定与进一步寻优。如图1-1所示,首先在试验范围(a ,b )内,按照0.618黄金分割原理安排两个试验点x 1、x 2;然后根据试验结果确定进一
拉丁方设计
拉丁方设计 ----------------------------------------------------------------- “拉丁方”的名字最初是由R、A、Fisher给出的。拉丁方设计(latin square design)是从横行和直列两个方向进行双重局部控制,使得横行和直列两向皆成单位组,是比随机单位组设计多一个单位组的设计。在拉丁方设计中,每一行或每一列都成为一个完全单位组,而每一处理在每一行或每一列都只出现一次,也就是说,在拉丁方设计中,试验处理数=横行单位组数=直列单位组数=试验处理的重复数。在对拉丁方设计试验结果进行统计分析时,由于能将横行、直列二个单位组间的变异从试验误差中分离出来,因而拉丁方设计的试验误差比随机单位组设计小,试验精确性比随机单位组设计高。 拉丁方设计又叫平衡对抗设计(baIanced design)、轮换设计。这三个名称是从其模式、作用和方法三个不同的角度来说明这种设计的意义。 所谓平衡对抗设计,是指在实验中,由于前一个实验处理往往会影响后一个实验处理的效果,而该实验设计的作用就在于提供对实验处理顺序的控制,使实验条件均衡,抵消由于实验处理的先后顺序的影响而产生的顺序误差,因而也可称之为抵消法设计。 所谓轮换设计,是指在实验中,由于学习的首因效应,先实验的内容,被试容易记住;又因为学习的近因效应,对于刚刚学过的内容,被试回忆的效果一般也较好。因此、在实验方法上,有必要使不同实验条件出现的先后顺序轮换,使情境条件以及先后顺序对各个实验组的机会均等,打破顺序界限。 所谓拉丁方设计,是指平衡对抗设计的结构模式,犹如拉丁字母构成的方阵。例如四组被试接受A、B、C、D四种处理,其实验模式为: 上述模式表可以看出,每种处理即表中的字母在每一行和每一列都出现了一次而且仅出现了一次。像这样的一个方阵列就称为一个拉丁方。要构成一个拉丁方,必须使行数等于列数,并且两者都要等于实验处理的种数。 在只有两个实验处理的情况下,通常采用的平衡对抗设计是以ABBA的顺序来安排实验处理的顺序。或者把单组被试分为两半.一半按照ABBA的顺序实施处理,另一半按照BAAB 的顺序实施处理。 一、拉丁方简介 (一)拉丁方——以n个拉丁字母A,B,C……,为元素,作一个n阶方阵,若这n 个拉丁方字母在这n阶方阵的每一行、每一列都出现、且只出现一次,则称该n阶方阵为n×n 阶拉丁方。 例如:2×2阶、3×3阶拉丁方。
单因素实验设计
单因素实验设计 单因素实验设计是指在实验中只有一个研究因素,即研究者只分析一个因素对效应指标的作用,但单因素实验设计并不是意味着该实验中只有一个因素与效应指标有关联。单因素实验设计的主要目标之一就是如何控制混杂因素对研究结果的影响。常用的控制混杂因素的方法有完全随机设计、随机区组设计和拉丁方设计等。 一、完全随机设计 1.概念与特点 又称单因素设计或成组设计,是医学科研中最常用的一种研究设计方法,它是将同质的受试对象随机地分配到各处理组进行实验观察,或从不同总体中随机抽样进行对比研究。该设计适用面广,不受组数的限制,且各组的样本含量可以相等,也可以不相等,但在总体样本量不变的情况下,各组样本量相同时的设计效率最高。 例如:为了研究煤矿粉尘作业环境对尘肺的影响,将18只大鼠随机分到甲、乙、丙3组,每组6只,分别在地面办公楼、煤炭仓库和矿井下染尘,12周后测量大鼠全肺湿重(g),通过评价不同环境下大鼠全肺平均湿重推断煤矿粉尘对作用尘肺的影响,具体的随机分组可以如下实施: 第一步:将18只大鼠编号:1,2,3, (18) 第二步:可任意设置种子数,但应作为实验档案记录保存(本例设置spss11.0软件的种子数为200); 第三步:用计算机软件一次产生18个随机数,每个随意数对应一只老鼠(本例用spss11.0软件采用均匀分布最大值为18时产成的18个随机数); 第四步:最小的6个随机数对应编号的大鼠为甲组,排序后的第7个至第12个随机数随因编号为乙组,最大的6个随机数对应编号的大鼠为丙组(结果见表1)。 表1 分配结果 编号 1 2 3 4 5 6 7 8 9 3.75 8.75 16.29 11.12 5.49 3.98 13.64 16.71 1.69 随机 数 组别甲乙丙乙乙甲丙丙甲 编号10 11 12 13 14 15 16 17 18 13.62 16.36 2.12 4.74 11.54 3.98 0.13 17.35 16.38 随机 数 组别丙丙甲乙乙甲甲丙丙 2.随机数的产生方法 (1)随机数字表:如附表13(马斌荣,医学统计学,第4版),这是一个由0~9十个数字组成60行25列的数字表。说这些数字是随机的,是因为十个数字出现的频率近似相同,且出现的次序也没有规律。欲获得随机数,则事先根据研究性质确定随机数的位数,然后任意指定行和列,按事先确定的方向和方法读取随机数。如:将符合实验要求的20只动物随
拉丁方试验设计
拉丁方试验设计 拉丁方试验设计在统计上控制两个不相互作用的外部变量并且操纵自变量。每个外部变量或分区变量被划分为一个相等数目的区组或级别,自变量也同样被分为相同数目的级别。它是从横行和直列两个方向进行双重局部控制,使得横行和直列两向皆成单位组,是比随机单位组设计多一个单位组的设计。在拉丁方设计中,每一行或每一列都成为一个完全单位组,而每一处理在每一行或每一列都只出现一次,也就是说,在拉丁方设计中,试验处理数=横行单位组数=直列单位组数=试验处理的重复数。 拉丁方——以n个拉丁字母A,B,C……,为元素,作一个n 阶方阵,若这n个拉丁方字母在这n阶方阵的每一行、每一列都出现、且只出现一次,则称该n阶方阵为n×n阶拉丁方。第一行与第一列的拉丁字母按自然顺序排列的拉丁方,叫标准型拉丁方。 拉丁方设计一般用于5~8个处理的试验,设计的基本要求:必须是三个因素的试验,且三个因素的水平数相等;三因素间是相互独立的,均无交互作用;各行、列、字母所得实验数据的方差齐(F 检验)。 试验设计的步骤:根据主要处理因素的水平数,确定基本型拉丁方,并从专业角度使另外两个次要因素的水平数与之相同;先将基本型拉丁方随机化,然后按随机化后的拉丁方阵安排实验。可通过对拉丁方的任两列交换位置或任两行交换位置实现随机化;规定
行、列、字母所代表的因素与水平,通常用字母表示主要处理因素。 数据处理的相关理论:拉丁方设计实验结果的分析,是将两个单位组因素与试验因素一起,按三因素试验单独观测值的方差分析法进行。将横行单位组因素记为A ,直列单位组因素记为B ,处理因素记为C ,横行单位组数、直列单位组数与处理数记为r ,对拉丁方试验结果进行方差分析的数学模型为: ),,2,1()()(r k j i x k ij k j i k ij ===++++=εγβαμ 式中:μ为总平均数;i α为第i 横行单位组效应;j β为第j 直列单位组效应,)(k γ为第k 处理效应。单位组效应i α、j β通常是随机的,处理效应)(k γ通常是固定的,且有01=∑=r k k γ;)(k ij ε为随机误差,相互独立, 且都服从),(20σN 。 平方和与自由度划分式为: e C B A T SS SS SS SS SS +++= e C B A T v v v v v +++= 矫正数:22/..r x C = 总平方和:C x SS k ij T -=∑2 )( 横行平方和:C r x SS i A -=∑/2. 直列平方和:C r x SS j B -=∑/2. 处理平方和:C r x SS k C -=∑/2)( 误差平方和:C B A T e SS SS SS SS SS ---= 总自由度:12-=r v T 横行自由度:1-=r v A
拉丁方设计的方差分析
拉丁方设计的方差分析 ——双向随机区组设计 【10.3】研究5种不同的饲料配方对奶牛产奶量的影响(检测日产奶量)。 试验单元的初始条件:不同牛只的日产奶量有较大差异,同一牛只在其一个泌乳期的不同泌乳阶段的日产奶量也有很大差异。 A=配方5,B=配方1,C=配方3,D=配方4,E=配方2 一、按照SPSS编制数据文件: 按照下列格式在Excel中编制数据,并存为“拉丁方设计的方差分析-例题10-3” 泌乳阶段牛只饲料编码日产奶量 Ⅰ 1 E 30 Ⅰ 2 D 42 Ⅰ 3 B 35 Ⅰ 4 A 28 Ⅰ 5 C 40 Ⅱ 1 A 32 Ⅱ 2 C 39 Ⅱ 3 E 36 Ⅱ 4 D 40 Ⅱ 5 B 38 Ⅲ 1 B 39 Ⅲ 2 E 28 Ⅲ 3 D 40 Ⅲ 4 C 39 Ⅲ 5 A 35 Ⅳ 1 C 39 Ⅳ 2 B 37 Ⅳ 3 A 26 Ⅳ 4 E 28
Ⅳ 5 D 43 Ⅳ 1 D 38 Ⅳ 2 A 27 Ⅳ 3 C 40 Ⅳ 4 B 37 Ⅳ 5 E 32 二、用SPSS打开“拉丁方设计的方差分析-例题10-3.xls”,并按照下列步骤完成方差分析。 1. 选择单变量多因素方差分析的菜单命令
2. 选定因变量和自变量 3. 打开“模型”对话框,按照图示进行设置。因为拉丁方设计不能进行交互作用分析,故选择“主效应”分析,并选定欲分析的变量。 4. 点击“继续”按钮,回到“单变量”对话框。选择打开“两两对比”对话框
原题关心的是饲料配方对日产奶量的影响,故只需对“饲料编码”进行多重比较。 5. 点击“继续”按钮,回到“单变量”对话框。选择打开“选项”对话框
拉丁方试验设计
拉丁方试验设计的具体实例 拉丁方试验设计 拉丁方试验设计在统计上控制两个不相互作用的外部变量并且操纵自变量。每个外部变量或分区变量被划分为一个相等数目的区组或级别,自变量也同样被分为相同数目的级别。它是从横行和直列两个方向进行双重局部控制,使得横行和直列两向皆成单位组,是比随机单位组设计多一个单位组的设计。在拉丁方设计中,每一行或每一列都成为一个完全单位组,而每一处理在每一行或每一列都只出现一次,也就是说,在拉丁方设计中,试验处理数=横行单位组数=直列单位组数=试验处理的重复数。 拉丁方——以n个拉丁字母A,B,C……,为元素,作一个n 阶方阵,若这n个拉丁方字母在这n阶方阵的每一行、每一列都出现、且只出现一次,则称该n阶方阵为n×n阶拉丁方。第一行与第一列的拉丁字母按自然顺序排列的拉丁方,叫标准型拉丁方。 拉丁方设计一般用于5~8个处理的试验,设计的基本要求:①必须是三个因素的试验,且三个因素的水平数相等;②三因素间是相互独立的,均无交互作用;③各行、列、字母所得实验数据的方差齐(F 检验)。 试验设计的步骤:①根据主要处理因素的水平数,确定基本型拉丁方,并从专业角度使另外两个次要因素的水平数与之相同;②先将基本型拉丁方随机化,然后按随机化后的拉丁方阵安排实验。可通过对拉丁方的任两列交换位置或任两行交换位置实现随机化;③规定
行、列、字母所代表的因素与水平,通常用字母表示主要处理因素。 数据处理的相关理论:拉丁方设计实验结果的分析,是将两个单位组因素与试验因素一起,按三因素试验单独观测值的方差分析法进行。将横行单位组因素记为A ,直列单位组因素记为B ,处理因素记为C ,横行单位组数、直列单位组数与处理数记为r ,对拉丁方试验结果进行方差分析的数学模型为: ),,2,1()()(r k j i x k ij k j i k ij ===++++=εγβαμ 式中:μ为总平均数;i α为第i 横行单位组效应;j β为第j 直列单位组效应,)(k γ为第k 处理效应。单位组效应i α、j β通常是随机的,处理效应)(k γ通常是固定的,且有01=∑=r k k γ;)(k ij ε为随机误差,相互独立, 且都服从),(20σN 。 平方和与自由度划分式为: e C B A T SS SS SS SS SS +++= e C B A T v v v v v +++= 矫正数:22/..r x C = 总平方和:C x SS k ij T -=∑2 )( 横行平方和:C r x SS i A -=∑/2. 直列平方和:C r x SS j B -=∑/2. 处理平方和:C r x SS k C -=∑/2)( 误差平方和:C B A T e SS SS SS SS SS ---= 总自由度:12-=r v T 横行自由度:1-=r v A
拉丁方试验和统计方法
拉丁方试验和统计方法
第十三章拉丁方试验和统计方法 知识目标: ●掌握拉丁方试验设计方法; ●掌握拉丁方试验结果统计分析方法。 技能目标: ●学会拉丁方试验设计; ●学会拉丁方试验结果统计分析。 第一节拉丁方试验设计 一、拉丁方设计 将k个不同符号排成k列,使得每一个符号在每一行、每一列都只出现一次的方阵,叫做k×k 拉丁方。应用拉丁方设计(latin square design)就是将处理从纵横二个方向排列为区组(或重复),使每个处理在每一列和每一行中出现的次数相等(通常一次),即在行和列两个方向都进
行局部控制。所以它是比随机区组多一个方向局部控制的随机排列的设计,因而具有较高的精确性。 二、拉丁方设计步骤 拉丁方设计的特点是处理数、重复数、行数、列数都相等。如图13-1为5×5拉丁方,它的每一行和每一列都是一个区组或一次重复,而每一个处理在每一行或每一列都只出现一次,因此,它的处理数、重复数、行数、列数都等于5。 C D A E B E C D B A B A E C D A B C D E D E B A C
拉丁方试验设计的步骤如下: (1)选择标准方标准方是指代表处理的字母,在第一行和第一列均为顺序排列的拉丁方。如图13-2。 A B C D E B A E C D C D A E B D E B A C E C D B A 在进行拉丁方设计时,首先要根据试验处理数k从标准方表中选定一个k×k的标准方。例如处理数为5,那么需要选定一个5×5的标准方,
如图13-2。随后我们要对选定的标准方的行、列和处理进行随机化排列。本例处理数为5,因此根据随机数字表任选一页中的一行,除去0、6以上数字和重复数字,满5个为一组,要得到这样的3组5位数。假设得到的3随机数字为14325,53124,41235。 (2)列随机用第一组5个数字14325调整列顺序,即把第4列调至第2列,第2列调至第4列,其余列不动。如图13-3。 (3)行随机用第二组5个数字53124调整行顺序,即把第5行调至第1行,第3行调至第2行,第1行调至第3行,第2行调至第4行,第4行调至第5行。如图13-3。 (4)处理随机将处理的编号按第三组5 (2)列随机 (按14325排列) 1 4 3 (3)行随 机 (按53124 排列) (4)处理 随机 (按4=A, 1=B,2= C,3=D,5图13-3 拉丁方试验设计步骤图
拉丁方设计
拉丁方的应用注意事项 一:当实验的动物数量较少的时候 二:当需要排除单位组因素所产生的系统误差对实验造成的影响的时候。(在后面有详细的例子会对该问题就行阐述)。 三;主要是为了消除单位组内的实验单位之间的差异 而对于拉丁方的定义是什么呢? 如果有n个字母排列起来,将他们分成一个矩阵,这n个字母在n排和n列当中只能出现一次,我们称之为n阶方程为n×n阶拉丁方。 第一行第一列都是按照顺序来排列的拉丁方叫做基本拉丁方或标准拉丁方。 拉丁方实验的优点
①精确度高:他比随即组多设置了一个单位组因素,因此横列和竖列两个单位组的变异则从实验误差当中分离了出来,误差小,而且精确度较高,在动物较少的情况下可以选择。 ②实验结果的分析非常的方便 ③尤其是适合做大型动物或者成本比较高,数量较少的一些动物实验,因此反刍动物的实验用的比较多。 拉丁方实验设计可用于处理三因素的实验,行因素和列因素考虑在内,而不考虑其他的外来因素时所使用的方法。 拉丁方实验的缺点 ①因为在处理的过程当中,横列、竖列、实验处理数等都必须要相等,因此在处理数这一环节收到了比较大的影响,处理数多了工作量大,处理数少了影响检验的灵敏性。因此此实验设计就缺乏灵活性,实验空间缺乏延展性,而且重复过多。 ②注意是否有交互影响,例如做钙与磷对泌乳的影响时,他们都会对奶牛的泌乳量产生影响,但是还可能会产生交互影响,发挥1+1>2的效果。还有就是例如前一阶段做的奶牛的泌乳实验,用的某种微量元素或者添加剂,在做下一阶段实验时还要考虑到是否有残留效应。 为了研究夏季蛋鸭圈舍当中不同的温度对蛋鸭的生产性能的影响,我们将温度分为了A、B、C、D、E,5个,这5种温度分别在5个圈舍内起作用,对应的圈舍为1、2、3、4、5,由于鸭群和温度对于它的
单因素实验优秀论文模板
毕业论文(设计) 题目竹叶中多糖的提取方法研究指导老师汪洪 专业班级食品营养与检测112 姓名戴晓鹏 学号 20117100203 2014年5月28日
摘要:本研究以竹叶为研究对象,通过单因素试验和正交试验观察了温度、时间、固液比、提取次数对多糖提取率的影响,比较了水提、超声波提取和微波提取三种提取方法对竹叶多糖得率的影响。结果表明,水提最佳浸提参数:温度80℃,时间90min,固液比1:25,浸提次数3次。超声波提取最佳浸提参数为:温度70℃,时间20min,固液比1:20,浸提次数3次。微波提取最佳浸提参数为:微波功率500W,固液比1:15,时间2min,浸提次数3次。最佳提取工艺方法是超声波提取,条件是温度70℃,时间20min,固液比1:20,浸提3次。 关键词:水提;超声波;微波;沉淀;提取次数
目录 引言 (1) 1材料与仪器 (2) 1.1实验材料 (2) 1.2实验试剂 (2) 1.3实验仪器 (2) 2 实验方法 (3) 2.1竹叶多糖提取工艺流程 (3) 2.2样品中多糖含量的测定 (3) 2.3浸提条件对多糖提取效果的影响 (4) 2.3.1单因素试验 (4) 2.3.2浸提工艺正交试验 (4) 2.3.3不同浸提方法的比较研究 (5) 2.4分析方法 (5) 3 结果与分析 (5) 3.1 单因素试验结果 (5) 3.1.1温度对多糖得率的影响 (5) 3.1.2时间对多糖得率的影响 (6) 3.1.3固液比对多糖得率的影响 (6) 3.1.4提取次数对多糖得率的影响 (7) 3.1.5乙醇浓度对多糖得率的影响 (8) 3.2正交试验 (9) 3.2.1水提工艺正交试验效果 (9) 3.2.2超声波提取工艺正交试验结果 (10) 3.2.3微波提取工艺正交试验效果 (11) 3.3竹叶多糖不同提取方法的比较效果 (12) 结论 (12) 参考文献 (13)
实验六 拉丁方试验设计
实验六拉丁方实验设计 实验目的 了解拉丁方实验设计的基本方法及数据的分析方法。 实验工具 Spss中的Analyze →General linear Model →Univariate。 知识准备 一、拉丁方设计的概念 将k个不同符号排成k列,使得每一个符号在每一行、每一列都只出现一次的方阵,叫做k×k拉丁方。利用拉丁方阵进行实验设计的方法叫做拉丁方设计。最初设计实验方案时,拉丁方阵用拉丁字母组成的方阵来表示。后来,尽管方阵中的元素改用了字母、阿拉伯数字或其它的符号,人们仍称这种实验方案为拉丁方实验。 拉丁方设计的特点是处理数、重复数、行数、列数都相等。如图6.47为4×4拉丁方,它的每一行和每一列都是一个区组或一次重复,而每一个处理在每一行或每一列都只出现一次,因此,它的处理数、重复数、行数、列数都等于4。 拉丁方设计的特点: 重复数=处理数=列数=横行数;每个处理在横行的区组内或列的区组内都能出现一次,从两个方向都可看成重复,排列呈方形;两个方向的排列都是随机的,从两个方向进行局部控制,试验精确度较高。 缺点:处理数=重复数,若处理过多,重复随之增多,使实验工作量过大。一般不宜超过8个处理。若处理数过少,方差分析时的自由度过小,影响分析结果的精确性。由于重复数与处理数必须相等,缺乏灵活性。 二、拉丁方设计步骤 (1)根据因素的水平数选择标准方。标准方是指代表处理的字母,在第一行和第一列均为顺序排列的拉丁方。如图6.48。
在进行拉丁方设计时,首先要根据实验处理数k 从标准方表中选定一个k×k 的标准方。例如处理数为5时,则需要选一个5×5的标准方,如图6.48所示。随后我们要对选定的标准方的行、列和处理进行随机化排列。本例处理数是5,因此根据随机数字表任选一页中的一行,除去0、6以上数字和重复数字,满5个为一组,要得到这样的3组5位数。假设得到的3组随机数字为14325,53124,41235。 (2)列随机。根据第一组5个数字14325调整列的顺序,即把第4列调至第2列,第2列调至第4列,其余列不动。如图6.49所示。 (3)行随机。根据第二组5个数字53124调整行的顺序,即把第5行调至第1行,第3行调至第2行,第1行调至第3行,第2行调至第4行,第4行调至第5行。如图6.49。 (4)处理随机。将处理的编号按第三组5个数字41235的顺序进行随机排列。即4号=A ,1号=B ,2号=C ,3号=D ,5号=E 。因此经过随机重排的拉丁方中A 处理用4,B 处理用1,C 处理用2,D 处理用3,E 处理用5。如图6.49。 三、拉丁方实验结果的统计分析 拉丁方差实验结果可以用两种表格表示:一是纵横区组两向表,二是各处理的单向分组表。
拉丁方试验设计及统计分析
前言 拉丁方试验设计及分析 1前言 “拉丁方”的名字最初是由R、A、Fisher给出的。拉丁方设计(latin square design)是从横行和直列两个方向进行双重局部控制,使得横行和直列两向皆成单位组,是比随机单位组设计多一个单位组的设计。在拉丁方设计中,每一行或每一列都成为一个完全单位组,而每一处理在每一行或每一列都只出现一次,也就是说,在拉丁方设计中,试验处理数=横行单位组数=直列单位组数=试验处理的重复数。在对拉丁方设计试验结果进行统计分析时,由于能将横行、直列二个单位组间的变异从试验误差中分离出来,因而拉丁方设计的试验误差比随机单位就在于提供对实验处理顺序的控制,使实验条件均衡,抵消由于实验处理的先后顺序的影响而产生的顺序误差,因而也可称之为抵消法设计。组设计小,试验精确性比随机单位组设计高。 拉丁方设计又叫平衡对抗设计(baIanced design)、轮换设计。这三个名称是从其模式、作用和方法三个不同的角度来说明这种设计的意义。所谓平衡对抗设计,是指在实验中,由于前一个实验处理往往会影响后一个实验处理的效果,而该实验设计的作用。所谓轮换设计,是指在实验中,由于学习的首因效应,先实验的内容,被试容易记住;又因为学习的近因效应,对于刚刚学过的内容,被试回忆的效果一般也较好。因此、在实验方法上,有必要使不同实验条件出现的先后顺序轮换,使情境条件以及先后顺序对各个实验组的机会均等,打破顺序界限。所谓拉丁方设计,是指平衡对抗设计的结构模式,犹如拉丁字母构成的方阵。例如四组被试接受A、B、C、D四种处理,其实验模式为: 上述模式表可以看出,每种处理即表中的字母在每一行和每一列都出现了一次而且仅出现了一次。像这样的一个方阵列就称为一个拉丁方。要构成一个拉丁方,必须使行数等于列数,并且两者都要等于实验处理的种数。
试验设计与分析
试验方案:根据试验目的和要求所拟进行比较的一组试验处理的总称。 试验因素:在试验中所研究的影响试验指标的某一项目称为因素 单因素试验:探索某一个因素对试验指标作用的试验 多因素试验:探索多个因素对试验指标作用的试验 (试验)处理:事先设计好的实施在试验单元上的具体项目,即试验中具体比较的项目称为实验处理 处理组合:不同因素不同水平的组合。 试验指标:用于衡量试验效果的指示性状。 因素水平:实验因素所处的某种特定状态或数量等级称为因素水平 显著水平:用来判断是否属于小概率事件的概率值称为显著水平,及拒绝零假设的概率,通常取0.05或0.01 参数:用来描述总体的特征值称为参数 随机化:试验处理的分配和各个试验进行的次序都是随机确定的,这个原理称为随机化 试验单元:在试验中能够施以不同处理的最小的材料单元 接受域:一个假设总体的概率分布中,可能接受假设时所能取的一切可能值所在的范围,即接 受H0的区间 试验效应:试验因素对试验指标所起的增加或减少的作用。简单效应:在同一因素内两种水平间 试验指标的相差。 平均效应:一个因素内各简单效应的平均数。也称主要效应,简称主效。 交互作用效应:两个因素简单效应间的平均差异。简称互作。 对照:试验方案中包括有对照水平或处理,简称对照。(试验当中所设计的比较标准的处理) 唯一差异原则:指在试验中进行比较的各个处理,其间的差别仅在于不同的试验因素或不同的水平,其余所 有的条件都应完全一致。 (试验)误差:测量值与真实值之间的差异称为试验误差。 随机误差:由随机或偶然因素造成的试验结果与处理真值之间的差异称为偶然性误差或随机误差。 系统误差:由固定原因一起的试验结果与处理真值之间的差异称为系统误差。 错失误差:实验中由于试验人员粗心大意所发生的差错称为错失误差 精确度:试验中同一性状的重复观察值彼此接近的程度。(即试验误差的大小) 准确度:试验中某一性状的观察值与其理论值真值的接近程度。 固定模型:仅考察参试处理均值差异或主效应差异的单因素等重复试验的模型 试验控制:为了提高试验的准确度和精确度,必须使所有试验单元或区组内的试验单元的试验条件一致, 叫试验控制 局部控制:将整个试验空间分为若干个各自相对均与的局部,每一个局部叫一个区组,所有局部构成区组因素,在每一个区组内随机排列一套试验的所有处理,它等价于一个重复 边际效应:小区两边或两端的植株,因占较大空间而表现的差异。 生长竞争:相邻小区种植不同品种或施用不同肥料时,由于株高、分蘖力或生长期的不同,通常有一行或更 多行受到影响。 总体:具有共同性质的个体所组成的集团。 样本:从总体中随机抽取一些个体进行观察得到的总体变量称为样本 小概率事件不可能性原理:概率很小的事件,在一次试验中几乎不可能发生或可认为不可能发生。 接受区域:指一个假设总体的概率分布中,可能接受假设时所能取的一切可能值所在的范围,即接受H0 的区间 一尾测验:备择假设只有一种可能性,假设检验只有一个否定区域,这类测验叫一尾测验。 两尾测验:指概率分布下,显著水平按左边和右边两尾的概率的和进行检验假设检验有两个否定区 第一类错误:指不同总体的参数间本来没有差异,而测验结果认为有差异,这种错误称为第一类错误(否定 本来正确的无效假设) 第二类错误:指参数间本来有差异,而测验结果认为参数间无差异,这种错误称为第二类错误。(接受了本 来错误的无效假设) 置信度:保证区间能覆盖参数的概率。 置信区间:在一定概率保证下,能够覆盖参数的一个估计范围。 1.Fisher试验设计的三个基本原理:设置突变,随机化,局部控制 2.数据资料变异度的表示方法:变异系数,极差,方差,标准差 3.统计假设检验的一般步骤为:提出统计假设,确定显著水平的统计区间,计算μ值或t值,统计推断 4.在直线回归分析中,检验回归关系是否显著的方法有:相关系数,回归方程,直线回归方程进行方差分 析 5.常用的随机排列试验设计有:完全随机,随机区组试验,拉丁方试验,裂区和条区试验 6.实验因素对试验指标所起的增加或减少作用称为试验效应 7.进行田间试验时设置重复的主要作用是降低误差 8.样本容量>30时,认为是大样本 9.番茄种子发芽试验的概率分布为二项分布
如何理解拉丁方实验设计
如何理解拉丁方实验设计 如何理解“拉丁方实验设计”(邓涛) 近来,不少学生问到拉丁方设计如何理解的问题,而且提出不同教材的表述也不一样。为了不去一一解答,我这里再结合《应用实验心理学》上的表述作一说明。 我的基本看法是:拉丁方实验设计与区组实验设计一样,都是为了平衡额外变量,以防止这些额外变量成为混淆因子,破坏实验研究的内部效度。如果简化点来解释,一般来说,区组实验设计多用于对一个额外变量的平衡,如被试因素、时间顺序因素、空间位置因素等;拉丁方实验设计则可以看成是区组设计的扩展,即扩展到可以平衡两个额外变量(当然,如果设计巧妙,也可以达到对多于两个额外变量的平衡,但那也是在二维平衡模式上变化出来的)。为了说明,拉丁方设计及其与区组设计的联系,我们先说一说区组设计。 区组实验设计是在考察自变量影响效应的实验中,考虑到一个额外变量的影响,将这个额外变量作为区组变量,对其在各种实验处理条件下产生的影响进行平衡,同时将该区组变量引起的变异从残差中分离出来。 比如,限于实验室条件,研究者开展某一实验研究时每天只能为4名被试进行测试,实验处理也有四个水平:A、A、A、A。如果认为不在每周中的同一天进行测试,可能1234 会引起测试结果的变化,这种影响又是比较重要的。于是可以将测试时间作为区组变量,即把同一天接受测试的被试看作是一个区组。这样就可以形成一个区组实验设计,如表2-8所示。 表2-8 四种实验处理的随机区组实验设计 区组 A A A A 1234
1 1 1 1 星期一 1 1 1 1 星期二 星期三 1 1 1 1 星期四 1 1 1 1 现在我们进一步设想: 假如,在每天的实验中,一次只能测试一人,每天参加实验的四名被试只能分别在下午2,3点、3,4点、4,5点和5,6点的四个时段接受测试,而测试时段不同也可能会造成结果变化。这样一来,每一种实验处理条件安排的时段就也要取得平衡才行,你不能每天都在2点钟安排所有被试接受A处理条件,或3点钟接受A处理条件。于是,研究11中采用测试天和测试时段两方面因素的平衡方法安排实验,构成了一个单因素的拉丁方实验设计,设计模式如图2-9所示。在这一设计中,测试是在星期几、测试是在每一天的哪一时段,这两个额外变量就都取得了很好的平衡。 表2-9 四种实验处理的拉丁方实验设计 日期 2,3点 3,4点 4,5点 5,6点从这一例子可以看出,拉丁方(latin 星期一 A A A A 1234square)是一个含P行P列,把P个实验处星期二 A A A A 2341理分配给P×P方格的管理方案,它便于在星期三 A A A A 3412复杂研究程序中有条理地管理各个工作单星期四 A A A A 4123元,并平衡两种额外变量的影响。在工农业 生产试验和心理与教育研究中,拉丁方都得到普遍应用。在这种实验设计中,首先根据自变量处理的水平数确定两个额外变量的水平数,然后利用两个额外变量的各个水平结合在一起构造一个拉丁方格,最后再将自变量的不同处理平衡地安排在这个方格中,就构成了一个研究方案,其结果要保证自变量的每一个水平在拉丁