RSF 分布式服务框架设计
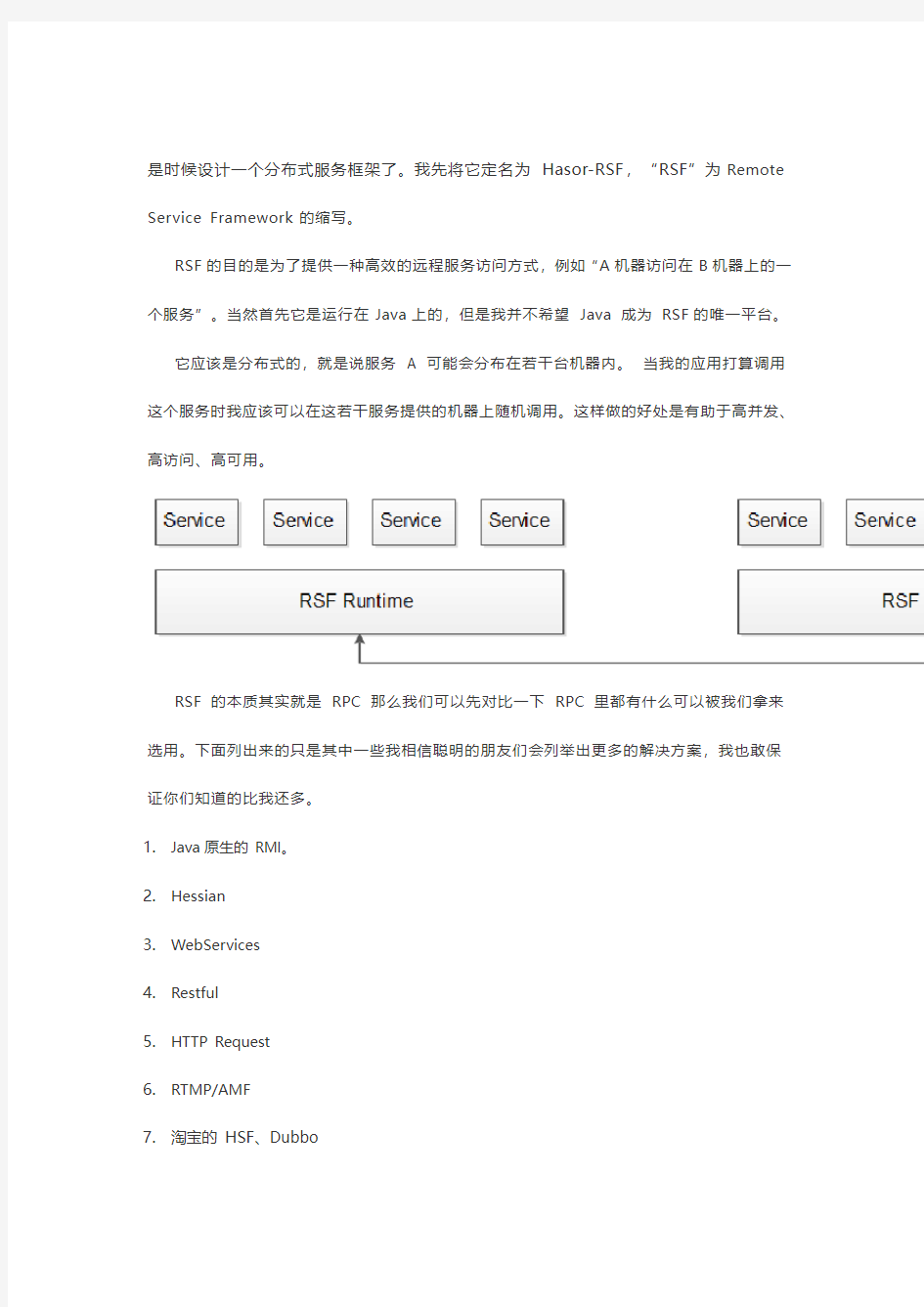

是时候设计一个分布式服务框架了。我先将它定名为Hasor-RSF,“RSF”为Remote Service Framework 的缩写。
RSF的目的是为了提供一种高效的远程服务访问方式,例如“A机器访问在B机器上的一个服务”。当然首先它是运行在Java上的,但是我并不希望Java 成为RSF的唯一平台。
它应该是分布式的,就是说服务 A 可能会分布在若干台机器内。当我的应用打算调用这个服务时我应该可以在这若干服务提供的机器上随机调用。这样做的好处是有助于高并发、高访问、高可用。
RSF 的本质其实就是RPC 那么我们可以先对比一下RPC 里都有什么可以被我们拿来选用。下面列出来的只是其中一些我相信聪明的朋友们会列举出更多的解决方案,我也敢保证你们知道的比我还多。
1.Java原生的 RMI。
2.Hessian
3.WebServices
4.Restful
5.HTTP Request
6.RTMP/AMF
7.淘宝的HSF、Dubbo
RMI,这个Java 原生的东东似乎从一开始就没有被人们所看好,究其原因是速度太慢。但是它的好处是Java原生,使用RMI 不需要引入其它任何第三方软件包。不过挑剔的同学们似乎不太看好这个优点。
Hessian,原则上说Hessian我并不认为它是一个远程服务框架范畴的东西。我更觉
得 Hessian 是一种数据交互格式。就像是JSON,XML-RPC,AMF,Kryo 一类的东西。Hessian 的优点是大量的兼容平台例如:“IOS、Java、.net、C++、Python、Flash、Ruby、PHP”,其次它的第二个有点是二进制格式。在大对象序列化上会占有很大的优势。
WebServices,一个老牌技术解决方案。在我印象中WebServices 是跟随着SOA 这个东西一起出名的,他有一个最大的好处是防火墙穿透。毕竟人家是靠80 端口吃饭的,牛叉的很。不过话说回来WebServices的最大要害就是,Xml传输格式。把一个对象序列化成为一个Xml数据是一件很容易的事,但是反序列化成本似乎是很高。再加上SOAP 协议本身是建立在XML 形式上,这就使得Web Service 奇慢无比了。当然因素还有很多我就不多说了。
Restful,其实restful 我更觉得它是一种API 表述规范。但在社区论坛中讨论看来,restful 的应用似乎也延伸到远程服务的领域。所以有必要说明一下。restful 最初是出现在web 上,究其本质是还是HTTP。例如对于:“http://xxxxx/xxxx”这个资源的访问可以利用HTTP 的“GET、PUT、DELETE”等方法对资源操作加以描述说明。我个人觉得这东西用在RPC 上并不合适。
HTTP,这是我用过最多的一种远程交互方式。远离很见dna,服务发布者将服务发布成为一个http资源。调用者请求这个http资源。数据传输格式完全程序双方自行协商。这种方法简单除暴行之有效。不过缺点是我们要自己补充通信协议,例如请求参数和响应数据格式。常规的交互格式有JSON、XML。
RTMP/AMF,这个组合的确是一套很完善的远程调用解决方案。RTMP协议中专门为Invoke 开辟了一条通道,在配合AMF 格式极大的方便了Flash 下远程服务访问。不过这些都是Flash下的东西,即使是拥有Red5 这样的神器让我们在java 下可以使用rtmp 但是究其目的还是为了和flash 通信。一般flash 调用业务系统的方式还都停留在http 请求或者通过red5 服务器代为转发。
HSF,这个东西是淘宝内部用的很广泛的远程服务框架。它是使用NIO、Mina 并且工作在长连接模式下。话说这个东西的确是个好东西,淘宝也将其开源了!只可惜,开源了hsf 但是相关配套依赖没有开源。在加上hsf 依赖繁杂。这个东西也就只能让局外人膜拜一下,在淘系之外的同学们是无福享受了。
Dubbo,也是淘系的另外一个服务框架,它比较HSF 来说要轻巧很多。依赖会少一些,这个东东目前也是开源状态。由于我对 dubbo 一点都不了解,在这里保持沉默不做评价。
最后补充一下,真正原生就支持分布式服务调用的也就只有“HSF、Dubbo”至于京东内部是否有更好的解决方案我并不知道。哦还有一点,如果您想脱离Spring 的话HSF、Dubbo 会让你失望的。这就是说您的技术构架如果是非Spring 阵营的会比较悲催。
so,上面提到了很多可用的技术方案,想必最后符合要求也就只有其中HSF 和Dubbo 了。为什么其它的方案都不入选呢?原因就是它们虽然可以完成RPC 但是并不支持分布式。当然您可以通过架设集群来提高它们的可靠性,这些都是您需要额外付出的。
------------------------------
下面这个是RSF 的架构图,包括服务生产着和消费者在内RSF 被分为 6 层(网络层、协议层、请求响应层、调度层、接口层、消费者生产者)。
关键5层:
Netty,其中位于最下层的网通信部分RSF 采用Netty 实现。Netty 是一款非常优秀的网络通信框架,使用Netty 可以帮助RSF 减少大量底层网络上的代码开发。这也就意味着RSF 将采用 Selector 方式实现异步IO。
Protocol,协议层。该层主要的目的是负责解释翻译RSF 数据包,并将RSF 数据包转意成为Request 和Response 对象。协议层可以是一个协议栈,这就意味您可以通过RTMP 、或者其它自定义网络协议传输RSF 数据包。
Request/Response层,请求响应层。这个在这个层中,RSF 脱离了底层网络方面的特性将每次调用请求对象化为一个Request 对象,并且将调用结果封装成为一个Response 对象。这种编程模式和Web 很像。
调度层,这一层最为复杂。它负责管理本地RSF 服务的注册,远程传输对象序列化方式的管理,并且还要负责实现其它更加复杂的功能。
接口层,这一层是最终RSF 暴露给业务系统的接口,将会由两个类提供。一个代表服务生产着,另一个是服务消费者。
序列化格式:
RSF 规定在网络中传输的数据格式可以是任意的。这就意味着您可以使用AMF 作为RSF 数据传输格式发布(同时如果协议层支持RTMP 那您可以在Flash 中无需通过red5 这样的中间代理直接访问RSF 服务)。同样的,如果您使用 Hessian 作为数据传输格式,在其它平台。例如.net、php。也会很方便的调用RSF 服务(需要解析RSF 数据包)。如果协议采用HTTP,RSF序列化格式采用JSON ,那么运行在浏览器中的javascript 也可以绕过web 服务器,直接访问RSF 服务。
服务配置Config:
说是服务配置,其实就是路由的功能。先假设我们有4台服务器,其中有两台是位于北京机房,另外两台分别位于青岛和内蒙古。这四台机器上都运行着RSF,跑着相同的业务系统,这种架构通常前端会有一个CDN 之类的东西负责让用户就近访问网站。
如果没有服务路由的情况下,用户A在北京即使访问了最近的北京服务器,但是由于调用的RDS 服务是青岛的,那么也会降低访问速度。因此服务配置所负责的路由特性可以很方便的高速服务调用程序,优先选用北京机房的RSF 服务。只有当北京机房的服务撑不住的情况下才会动用其它地域的RSF 服务。
流量管控:高级一点的特性是可以通过服务路由来控制服务流量。假如目前要做一个全国范围的活动,我们充分的为每个地方准备了若干机器。但是在活动现场很可能某一个地区的服务使用量达到了临界点,服务路由应该可以通过配置的方式让附近地区的机器提供一定的流量来减缓这个地区的访问压力。
分布式服务架构方案
高并发分布式服务架构方案 下图是一个非常全面的架构蓝图,针对不同的应用系统需要的模块各有不同。此架构方案主要包括以下几个方面的设计:数据存储和读取,基础服务,应用层(APP/业务/Proxy),日志监控等,下面对这些主要的问题提供具体的各项针对性技术方案。 数据的存储和读取 分布式系统应该根据应用对数据不同的一致性、可用性等要求和数据的不同特性,采用不同的数据存储和读取方案,主要有以下几种可选方案: 1)内存型数据库。内存型的数据库,以高并发高性能为目标,在事务性方面没那么严格, 适合进行海量数据的存储和读取。例如开源nosql数据库mongodb、redis等。 2)关系型数据库。关系型数据库在满足并发性能的同时,也需要满足事务性,可通过 读写分离,分库分表来应对高并发大数据量的情况。例如Oracle,Mysql等。 3)分布式数据库。对于数据的高并发的访问,传统的关系型数据库提供读写分离的方案, 但是带来的确实数据的一致性问题提供的数据切分的方案;对于越来越多的海量数据,传统的数据库采用的是分库分表,实现起来比较复杂,后期要不断的进行迁移维护;对
于高可用和伸缩方面,传统数据采用的是主备、主从、多主的方案,但是本身扩展性比较差,增加节点和宕机需要进行数据的迁移。对于以上提出的这些问题,分布式数据库HBase有一套完善的解决方案,适用于高并发海量数据存取的要求。 基础服务 基础服务主要是指数据层之上的数据路由,Cache,搜索等服务。 1)路由Router。对于数据库切分方案中的分库分表问题,需要解决在请求对应的数据时 定位需要访问的位置,可根据一致性Hash,维护路由表至内存数据库等方案解决。 2)Cache。对于高并发的系统来讲,使用Cache可以减轻对后端系统的压力,所有Cache 可承担大部分热数据的读操作。当前用的比较多的是redis和memcache,redis比memcache有丰富的数据操作的API,redis对数据进行了持久化,而memcache没有这个功能,因此memcache更加适合在关系型数据库之上的数据的缓存。 3)搜索。搜索可以支持应用系统的按照关键词的检索,搜索提示,搜索排序等功能。开源 开源的企业级搜索引擎主要有lucene, sphinx,选择搜索引擎主要考虑以下三个方面: a)搜索引擎是否支持分布式的索引和搜索,来应对海量的数据,支持读写分离,提高 可用性 b)索引的实时性 c)搜索引擎的性能 Solr是基于Lucene开发的高性能的全文搜索服务器,满足以上三个方面的考虑,而且目前在企业中应用非常广泛。 应用层 应用层主要包括面向用户的应用,网站、APP等,还包括相关的业务处理的运算等。 1)负载均衡-反向代理。一个大型的平台包括很多个业务域,不同的业务域有不同的集群, 可以用DNS做域名解析的分发或轮询,DNS方式实现简单。但是因存在cache而缺乏灵活性;一般基于商用的硬件F5、NetScaler或者开源的软负载lvs在做分发,当然会采用做冗余(比如lvs+keepalived)的考虑,采取主备方式。Nginx是基于事件驱动的、异步非阻塞的架构、支持多进程的高并发的负载均衡器/反向代理软件,可用作反向代理的工具。
主流分布式系统架构分析
主流分布式系统架构分析 主流分布式---系统架构分析
目录 一、前言 (3) 二、SOA架构解析 (3) 三、微服务( Microservices )架构解析 (7) 四、SOA和微服务架构的差别 (9) 五、服务网格( Service Mesh )架构解析 (9) 六、分布式架构的基本理论 ......................................................................................... 1 1 七、分布式架构下的高可用设计 (15) 八、总结 .......................................................................................................... 1 9
、八、 、 》 本文我们来聊一聊目前主流的分布式架构和分布式架构中常见理论以及如何才能设计出高可用的分布式架构好了。分布式架构中,SOA和微服务架构是最常见两种分布式架构,而且目前服务网格的 概念也越来越火了。那我们本文就先从这些常见架构开始。 、SOA架构解析 SOA全称是:Service Oriented Architecture ,中文释义为"面向服务的架构",它是一种设计理念,其中包含多个服务,服务之间通过相互依赖最终提供一系列完整的功能。各个服务通常以独立 的形式部署运行,服务之间通过网络进行调用。架构图如下:
Appl 跟SOA 相提并论的还有一个 ESB (企业服务总线),简单来说ESB 就是一根管道,用来连接各个服 务节点。 ESB 的存在是为了集成基于不同协议的不同服务, ESB 做了消息的转化、解释以及路由的工 作,以此来让不 同的服务互联互通;随着我们业务的越来越复杂, 会发现服务越来越多,SOA 架构下, 它们的调用关系会变成如下形式: App 2 App 6 App 3 App 4
分布式系统架构设计
本文作者Kate Matsudaira是一位美丽的女工程副总裁,曾在Sun Microsystems、微软、亚马逊这些一流的IT公司任职。她有着非常丰富的工作经验和团队管理经验,当过程序员、项目经理、产品经理以及人事经理。专注于构建和操作大型Web应用程序/网站,目前她的主要研究方向是SaaS(软件即服务)应用程序和云计算(如大家所说的大数据)。 本文是作者在AOSA一书介绍如何构建可扩展的分布式系统里的内容,在此翻译并分享给大家。 开源软件已经成为许多大型网站的基本组成部分,随着这些网站的逐步壮大,他们的网站架构和一些指导原则也开放在开发者们的面前,给予大家切实有用的指导和帮助。 这篇文章主要侧重于Web系统,并且也适用于其他分布式系统。 Web分布式系统设计的原则 构建并运营一个可伸缩的Web站点或应用程序到底是指什么?在最初,仅是通过互联网连接用户和访问远程资源。 和大多数事情一样,当构建一个Web服务时,需要提前抽出时间进行规划。了解大型网站创建背后的注意事项以及学会权衡,会给你带来更加明智的决策。下面是设计大型Web系统时,需要注意的一些核心原则: ?可用性 ?性能 ?可靠性 ?可扩展 ?易管理 ?成本 上面的这些原则给设计分布式Web架构提供了一定的基础和理论指导。然而,它们也可能彼此相左,例如实现这个目标的代价是牺牲成本。一个简单的例子:选择地址容量,仅通过添加更多的服务器(可伸缩性),这个可能以易管理(你不得不操作额外的服务器)和成本作为代价(服务器价格)。 无论你想设计哪种类型的Web应用程序,这些原则都是非常重要的,甚至这些原则之间也会互相羁绊,做好它们之间的权衡也非常重要。 基础
分布式服务框架Dubbo及相关组件集成
1.D ubbo介绍 1.1.简介 Dubbo是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,是阿里巴巴SOA服务化治理方案的核心框架,每天为2,000+个服务提供3,000,000,000+次访问量支持,并被广泛应用于阿里巴巴集团的各成员站点。 Dubbo最大的特点是按照分层的方式来架构,使用这种方式可以使各个层之间解耦合(或者最大限度地松耦合)。从服务模型的角度来看,Dubbo采用的是一种非常简单的模型,要么是提供方提供服务,要么是消费方消费服务,所以基于这一点可以抽象出服务提供方(Provider)和服务消费方(Consumer)两个角色。 上图中,蓝色方块表示与业务有交互,绿色方块表示只对Dubbo内部交互。上述图所描述的调用流程如下: 1)服务提供方发布服务到服务注册中心; 2)服务消费方从服务注册中心订阅服务; 3)服务消费方调用已经注册的可用服务; 1.2.核心功能 远程通讯: 提供对多种基于长连接的NIO框架抽象封装,包括多种线程模型,序列化,以及“请求-响应”模式的信息交换方式。 集群容错: 提供基于接口方法的透明远程过程调用,包括多协议支持,以及软负载均衡,失败容错,地址路由,动态配置等集群支持。 自动发现: 基于注册中心目录服务,使服务消费方能动态的查找服务提供方,使地址透明,使服务提供方可以平滑增加或减少机器。 1.3.Dubbo能做什么? 透明化的远程方法调用:就像调用本地方法一样调用远程方法,只需简单配置,没有任何API 侵入。 软负载均衡及容错机制:可在内网替代F5等硬件负载均衡器,降低成本,减少单点。 服务自动注册与发现:不再需要写死服务提供方地址,注册中心基于接口名查询服务提供者的IP地址,并且能够平滑添加或删除服务提供者。
RSF 分布式服务框架设计
是时候设计一个分布式服务框架了。我先将它定名为Hasor-RSF,“RSF”为Remote Service Framework 的缩写。 RSF的目的是为了提供一种高效的远程服务访问方式,例如“A机器访问在B机器上的一个服务”。当然首先它是运行在Java上的,但是我并不希望Java 成为RSF的唯一平台。 它应该是分布式的,就是说服务 A 可能会分布在若干台机器内。当我的应用打算调用这个服务时我应该可以在这若干服务提供的机器上随机调用。这样做的好处是有助于高并发、高访问、高可用。 RSF 的本质其实就是RPC 那么我们可以先对比一下RPC 里都有什么可以被我们拿来选用。下面列出来的只是其中一些我相信聪明的朋友们会列举出更多的解决方案,我也敢保证你们知道的比我还多。 1.Java原生的 RMI。 2.Hessian 3.WebServices 4.Restful 5.HTTP Request 6.RTMP/AMF 7.淘宝的HSF、Dubbo
RMI,这个Java 原生的东东似乎从一开始就没有被人们所看好,究其原因是速度太慢。但是它的好处是Java原生,使用RMI 不需要引入其它任何第三方软件包。不过挑剔的同学们似乎不太看好这个优点。 Hessian,原则上说Hessian我并不认为它是一个远程服务框架范畴的东西。我更觉 得 Hessian 是一种数据交互格式。就像是JSON,XML-RPC,AMF,Kryo 一类的东西。Hessian 的优点是大量的兼容平台例如:“IOS、Java、.net、C++、Python、Flash、Ruby、PHP”,其次它的第二个有点是二进制格式。在大对象序列化上会占有很大的优势。 WebServices,一个老牌技术解决方案。在我印象中WebServices 是跟随着SOA 这个东西一起出名的,他有一个最大的好处是防火墙穿透。毕竟人家是靠80 端口吃饭的,牛叉的很。不过话说回来WebServices的最大要害就是,Xml传输格式。把一个对象序列化成为一个Xml数据是一件很容易的事,但是反序列化成本似乎是很高。再加上SOAP 协议本身是建立在XML 形式上,这就使得Web Service 奇慢无比了。当然因素还有很多我就不多说了。 Restful,其实restful 我更觉得它是一种API 表述规范。但在社区论坛中讨论看来,restful 的应用似乎也延伸到远程服务的领域。所以有必要说明一下。restful 最初是出现在web 上,究其本质是还是HTTP。例如对于:“http://xxxxx/xxxx”这个资源的访问可以利用HTTP 的“GET、PUT、DELETE”等方法对资源操作加以描述说明。我个人觉得这东西用在RPC 上并不合适。 HTTP,这是我用过最多的一种远程交互方式。远离很见dna,服务发布者将服务发布成为一个http资源。调用者请求这个http资源。数据传输格式完全程序双方自行协商。这种方法简单除暴行之有效。不过缺点是我们要自己补充通信协议,例如请求参数和响应数据格式。常规的交互格式有JSON、XML。
关于分布式服务框架Dubbo的调研报告
关于分布式服务框架Dubbo的调研报告 在接触过的项目中由于功能比较少,数据访问量并不是很大,在项目设计架构的时候总是优先考虑如何使代码简化,抽象相似方法。因此会引入诸如面向接口编程,面向切面编程,以及设计模式的考量。此时,ORM(Object/Relation Mapping)的数据访问框架,这种对象关系映射解决了面向对象与关系数据库存在的互不匹配的问题,也成了中小型项目基本的服务框架。其中,我了解的比较多的是显示层的struts2,数据持久层的Hibernate,以及业务逻辑层的Spring,三者通力配合可以大大简化应用服务的代码编程数量,可以让程序员在编写代码的时候优先考量功能需求,而不必为冗余的操作代码而浪费时间,其中我深有体会的有像将服务放入Spring,自动完成事物操作。还有关于CDUR的操作,数据存储与取得,只要进行简单的Hibernate配置就可以直接实现关系对象的转化。 当然以上ORM框架的核心以及它所完成的任务决定了一个项目分层架构是一种垂直纵向的关系,比如说我们经典的MVC模式,我们需要实体层,数据持久层,业务逻辑层,以及显示层。持久层,业务逻辑层,显示层在设计的时候需要从上往下传递数据对象,因而考量设计的重点在于高内聚,低耦合。层与层之间要相互依赖,又要相互独立。这样的设计在进行功能量适中,访问服务数量不多的情况能够应对自如,但是当访问服务数量激增,系统功能变得复杂的时候这种基于ORM的服务架构就会显得笨重,并且不利于测试。 当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变得市场需求。那么,提高业务复用及整合的分布式服务框架RPC(Remote Procedure Call Protocol)就成了关键。 这种抽取核心功能的方式非常类似于MVC模型下模板方法模式,即抽取公共方法为抽象基类,而在此处就将相似服务功能抽取出来形成注册服务中心来统一调配资源。 Duboo就是这种分布式服务框架,它主要针对的是一种SOA方案,我们知道面向对象模型是紧耦合的,而SOA指得就是一种面向服务体系,实际上就是我们都认知的面向接口编程,这也是分布式核心思想,尽量用接口定义公共服务
分布式架构知识体系
1.问题 1、何为分布式何为微服务? 2、为什么需要分布式? 3、分布式核心理论基础,节点、网络、时间、顺序,一致性? 4、分布式是系统有哪些设计模式? 5、分布式有哪些类型? 6、如何实现分布式? 2.关键词 节点,时间,一致性,CAP,ACID,BASE,P2P,机器伸缩,网络变更,负载均衡,限流,鉴权,服务发现,服务编排,降级,熔断,幂等,分库分表,分片分区,自动运维,容错处理,全栈监控,故障恢复,性能调优 3.全文概要 随着移动互联网的发展智能终端的普及,计算机系统早就从单机独立工作过渡到多机器协作工作。计算机以集群的方式存在,按照分布式理论的指导构建出庞大复杂的应用服务,也已经深入人心。本文力求从分布式基础理论,架构设计模式,工程应用,部署运维,业界方案这几大方面,介绍基于MSA(微服务架构)的分布式的知识体系大纲。从而对SOA 到MSA进化有个立体的认识,从概念上和工具应用上更近一步了解微服务分布式的本质,身临其境的感受如何搭建全套微服务架构的过程。
4.基础理论 4.1SOA到MSA的进化 SOA面向服务架构 由于业务发展到一定层度后,需要对服务进行解耦,进而把一个单一的大系统按逻辑拆分成不同的子系统,通过服务接口来通讯,面向服务的设计模式,最终需要总线集成服务,而且大部分时候还共享数据库,出现单点故障的时候会导致总线层面的故障,更进一步可能会把数据库拖垮,所以才有了更加独立的设计方案的出现。 MSA微服务架构
微服务是真正意义上的独立服务,从服务入口到数据持久层,逻辑上都是独立隔离的,无需服务总线来接入,但同时增加了整个分布式系统的搭建和管理难度,需要对服务进行编排和管理,所以伴随着微服务的兴起,微服务生态的整套技术栈也需要无缝接入,才能支撑起微服务的治理理念。 4.2节点与网络 节点 传统的节点也就是一台单体的物理机,所有的服务都揉进去包括服务和数据库;随着虚拟化的发展,单台物理机往往可以分成多台虚拟机,实现资源利用的最大化,节点的概念也变成单台虚拟机上面服务;近几年
分布式服务框架 Zookeeper -- 管理分布式环境中的数据
安装和配置详解 本文介绍的Zookeeper 是以3.2.2 这个稳定版本为基础,最新的版本可以通过官 网https://www.360docs.net/doc/5c3959199.html,/zookeeper/来获取,Zookeeper 的安装非常简单,下面将从单机模式和集群模式两个方面介绍Zookeeper 的安装和配置。 单机模式 单机安装非常简单,只要获取到Zookeeper 的压缩包并解压到某个目录如: /home/zookeeper-3.2.2 下,Zookeeper 的启动脚本在bin 目录下,Linux 下的启动脚本是zkServer.sh,在3.2.2 这个版本Zookeeper 没有提供windows 下的启动脚本,所以要想在windows 下启动Zookeeper 要自己手工写一个,如清单1 所示: 清单1. Windows 下Zookeeper 启动脚本 在你执行启动脚本之前,还有几个基本的配置项需要配置一下,Zookeeper 的配置文件在conf 目录下,这个目录下有zoo_sample.cfg 和log4j.properties,你需要做的就是将zoo_sample.cfg 改名为zoo.cfg,因为Zookeeper 在启动时会找这个文件作为默认配置文件。下面详细介绍一下,这个配置文件中各个配置项的意义。 tickTime:这个时间是作为Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime 时间就会发送一个心跳。
?dataDir:顾名思义就是Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。 ?clientPort:这个端口就是客户端连接Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。 当这些配置项配置好后,你现在就可以启动Zookeeper 了,启动后要检查Zookeeper 是否已经在服务,可以通过netstat – ano 命令查看是否有你配置的clientPort 端口号在监听服务。 集群模式 Zookeeper 不仅可以单机提供服务,同时也支持多机组成集群来提供服务。实际上Zookeeper 还支持另外一种伪集群的方式,也就是可以在一台物理机上运行多个Zookeeper 实例,下面将介绍集群模式的安装和配置。 Zookeeper 的集群模式的安装和配置也不是很复杂,所要做的就是增加几个配置项。集群模式除了上面的三个配置项还要增加下面几个配置项: ?initLimit:这个配置项是用来配置Zookeeper 接受客户端(这里所说的客户端不是用户连接Zookeeper 服务器的客户端,而是Zookeeper 服务器集群中连接到 Leader 的Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过10 个心跳的时间(也就是tickTime)长度后Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒 ?syncLimit:这个配置项标识Leader 与Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个tickTime 的时间长度,总的时间长度就是2*2000=4 秒?server.A=B:C:D:其中A 是一个数字,表示这个是第几号服务器;B 是这个服务器的ip 地址;C 表示的是这个服务器与集群中的Leader 服务器交换信息的端口;D 表示的是万一集群中的Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于B 都是一样,所以不同的Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。 除了修改zoo.cfg 配置文件,集群模式下还要配置一个文件myid,这个文件在dataDir 目录下,这个文件里面就有一个数据就是A 的值,Zookeeper 启动时会读取这个文件,拿到里面的数据与zoo.cfg 里面的配置信息比较从而判断到底是那个server。 数据模型 Zookeeper 会维护一个具有层次关系的数据结构,它非常类似于一个标准的文件系统,如图1 所示:
分布式服务框架 Zookeeper -- 管理分布式环境中的数据
分布式服务框架Zookeeper -- 管理分布式环境中的数据 简介:Zookeeper 分布式服务框架是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。本文将从使用者角度详细介绍Zookeeper 的安装和配置文件中各个配置项的意义,以及分析Zookeeper 的典型的应用场景(配置文件的管理、集群管理、同步锁、Leader 选举、队列管理等),用Java 实现它们并给出示例代码。 安装和配置详解 本文介绍的Zookeeper 是以3.2.2 这个稳定版本为基础,最新的版本可以通过官 网https://www.360docs.net/doc/5c3959199.html,/zookeeper/来获取,Zookeeper 的安装非常简单,下面将从单机模式和集群模式两个方面介绍Zookeeper 的安装和配置。 单机模式 单机安装非常简单,只要获取到Zookeeper 的压缩包并解压到某个目录如: /home/zookeeper-3.2.2 下,Zookeeper 的启动脚本在bin 目录下,Linux 下的启动脚本是zkServer.sh,在3.2.2 这个版本Zookeeper 没有提供windows 下的启动脚本,所以要想在windows 下启动Zookeeper 要自己手工写一个,如清单1 所示: 清单1. Windows 下Zookeeper 启动脚本 在你执行启动脚本之前,还有几个基本的配置项需要配置一下,Zookeeper 的配置文件在conf 目录下,这个目录下有zoo_sample.cfg 和log4j.properties,你需要做的就是将 zoo_sample.cfg 改名为zoo.cfg,因为Zookeeper 在启动时会找这个文件作为默认配置文件。下面详细介绍一下,这个配置文件中各个配置项的意义。
分布式软件体系结构
分布式软件体系结构 编写目标: ●面向计算机专业高年级本科生与研究生的教程。 ●可供从事基于Internet/Intranet的分布式软件开发人员参考使用。 要求读者: ●已掌握面向对象程序设计方法与一门面向对象程序设计语言(Java最佳)。 ●具备软件工程的基本知识。 总体构思: ●强调理论与实践相结合:理论上以CORBA 2.4为模型,实践中以VisiBroker for Java 4.0为工具。 ●强调深度与广度相结合:重点介绍CORBA的同时,兼顾DCOM与EJB两种模型, 最后总结对比这三种典型体系结构的特点。 主要内容: ●分布式计算的基本概念:从C/S过渡到分布式体系结构、OMA体系结构、CORBA 基本概念。 ●分布式应用程序的开发:分布式应用程序框架、用IDL编写对象接口、编写服务 程序与客户程序、部署应用程序。 ●分布式计算更深入的课题:探讨分布式应用程序的可靠性、伸缩性、安全性、性能 等课题可能提出的问题以及解决途径。 ●不同体系结构的比较:总结CORBA、DCOM、EJB、XML等特点。 ●配合教学需要的内容:在前言部分提供教学进度供参考,每一章后均配有课后练习 思考题和上机实习题。
引言 分布式计算是当前软件开发技术的一个重要发展方向。C.A.R.Hoare指出:“分布式计算是一个具有重大理论与实践意义的迷人课题,其迷人之处在于理论与实践的同步发展,一方面实践推动了理论,另一方面理论又指导着实践。”本书为读者介绍分布式计算领域的基本概念、开发过程、规范标准等内容。 分布式计算有两种典型的应用途径。第一种应用途径是将分布式软件系统看作直接反映了现实世界中的分布性,例如当今许多业务处理流程通常呈现一种分布式运作方式,负责加工或制造的工厂可能位于珠江三角洲一带,而负责销售与市场营销的部门则可能分别位于北京、上海和广州,这时负责业务流程的软件系统也可作相应的分布式处理。第二种应用途径主要用于改进某些应用程序的运行性能,使它们比单进程的集中式实现更具有效率,此时软件系统的分布性并不是现实世界中分布性的映射,而是为充分利用额外的计算资源而人为引入的。 在计算机硬件技术与网络通信技术的支持下,应用需求驱使计算机软件的规模与复杂度不断增长。面对这种情况,对整个软件系统的体系结构进行分析与设计就远远重要于对算法与数据结构的选择。软件体系结构关心的正是整个软件系统的结构,它决定了一个软件系统由什么样的组件组成,以及这些组件之间的交互关系如何。典型的软件体系结构风格有设计图形用户界面常用的事件驱动风格、操作系统常用的层次化设计、设计编译程序常用的管道与过滤器风格、许多应用程序都会使用的面向对象风格等。 分布式软件系统通常基于客户机/服务器风格,其中客户程序提出信息或服务的请示,而服务程序提供这些信息或服务。客户机/服务器计算模型的发展大约经历了三个里程碑:局域网文件服务器、数据库服务器以及分布式对象。由于当前面向对象技术几乎已渗透到软件开发的每一个角落,先进的分布式软件开发方法当然离不开与面向对象技术的结合,因而分布式软件体系结构通常是客户机/服务器风格与面向对象风格的有效组合,典型的例子有OMG的公共对象请求代理体系结构(CORBA)、Microsoft的分布式组件对象模型(DCOM)、Sun Microsystems的企业JavaBeans(EJB)等。 在这些模型中,CORBA以其规范的严格性、供应商的无关性和其他许多先进的分布式计算特性成为我们教学的首选。在理论教学方面,我们可参考OMG发布的一系列规范和关于CORBA的丰富读物;在课程实验方面,我们既可下载使用IONA Orbix、Inprise VisiBroker 等商品化CORBA产品的30或60天试用版,也可使用OmniORB、TAO等免费CORBA产品。相对于其他分布式计算模型而言,CORBA在理论更为严格与完善,即使读者采用的开发平台未必是CORBA兼容的,CORBA中提出的许多问题也应加以考虑,并可借鉴CORBA 提出的问题解决方案。 本书从软件体系结构的角度介绍分布式软件系统分析与设计的基本概念,描述了分布式软件的开发与布署过程,并探讨分布式软件的可靠性、性能、可伸缩性等高级概念。本书的主要内容分为四个部分。 第一部分“基本概念”介绍分布式计算中的基本概念与基本原理,从客户机/服务器计算模型过渡到真正的分布式计算模型,并掌握OMA与CORBA的基本概念。为避免为传统集中式软件的开发人员一次性引入太多分布式对象计算的新概念,我们需要一个过渡性介绍以实现循序渐进的教学目标,Java RMI以其简单性与实用性自然进入我们的视野。
HSF分布式开发框架
HSF 初体验
目录 一句话形容HSF 0 HSF安装 0 Ali-Tomcat安装 0 Pandora安装 0 环境配置 0 提供HSF服务 0 创建Web项目 0 添加maven依赖 (1) 编写需要发布的服务 (2) 配置Spring (3) 消费HSF服务 (4) 添加spring配置 (4) 编写测试代码 (5) 打包测试 (5) 实践 (6)
一句话形容HSF HSF就好比人体的血管,它是阿里内部各个系统通信的基础软件。 HSF安装 先了解下HSF应用的运行环境。如图: 首先,应用运行在潘多拉(Pandora)容器中,容器又通过Ali-Tomcat启动。Ali-Tomcat安装 下载并解压Ali-Tomcat即可。 Pandora安装 下载并解压Pandora到Ali-Tomcat的deploy目录即可。 到此,HSF的运行环境就安装完毕。 环境配置 //TODO configserver 绑定
提供HSF服务 创建Web项目 首先用idea(或者eclipse,这里以idea为例)创建一个maven web项目。 File -> New Project -> Maven -> Create from archetype -> maven-archetype-webapp -> 连续Next 项目目录结构如图:
添加maven依赖 在项目pom.xml中添加如下依赖:
主流分布式系统架构分析
主流分布式---系统架构分析
目录 一、前言 (3) 二、SOA架构解析 (3) 三、微服务(Microservices)架构解析 (7) 四、SOA 和微服务架构的差别 (9) 五、服务网格(Service Mesh)架构解析 (9) 六、分布式架构的基本理论 (11) 七、分布式架构下的高可用设计 (15) 八、总结 (19)
一、前言 本文我们来聊一聊目前主流的分布式架构和分布式架构中常见理论以及如何才能设计出高可用的分布式架构好了。分布式架构中,SOA和微服务架构是最常见两种分布式架构,而且目前服务网格的概念也越来越火了。那我们本文就先从这些常见架构开始。 二、SOA架构解析 SOA 全称是: Service Oriented Architecture,中文释义为“面向服务的架构”,它是一种设计理念,其中包含多个服务,服务之间通过相互依赖最终提供一系列完整的功能。各个服务通常以独立的形式部署运行,服务之间通过网络进行调用。架构图如下:
跟SOA 相提并论的还有一个ESB(企业服务总线),简单来说ESB 就是一根管道,用来连接各个服务节点。ESB的存在是为了集成基于不同协议的不同服务,ESB 做了消息的转化、解释以及路由的工作,以此来让不同的服务互联互通; 随着我们业务的越来越复杂,会发现服务越来越多,SOA架构下,它们的调用关系会变成如下形式:
很显然,这样不是我们所想要的,那这时候如果我们引入ESB的概念,项目调用就又会很清晰,如下:
SOA所要解决的核心问题 ?系统间的集成: 我们站在系统的角度来看,首先要解决各个系统间的通信问题,目的是将原先系统间散乱、无规划的网状结构,梳理成规整、可治理的星形结构,这步的实现往往需要引入一些概念和规范,比如ESB、以及技术规范、服务管理规范; 这一步解决的核心问题是【有序】。 ?系统的服务化: 我们站在功能的角度,需要把业务逻辑抽象成可复用、可组装的服务,从而通过服务的编排实现业务的快速再生,目的是要把原先固有的业务功能抽象设计为通用的业务服务、实现业务逻辑的快速复用;这步要解决的核心问题是【复用】。 ?业务的服务化: 我们站在企业的角度,要把企业职能抽象成可复用、可组装的服务,就要把原先职能化的企业架构转变为服务化的企业架构,以便进一步提升企业的对外服务的能力。“前面两步都是从
分布式架构知识体系必读
分布式架构知识体系必读
1.问题 ?1、何为分布式何为微服务? ?2、为什么需要分布式? ?3、分布式核心理论基础,节点、网络、时间、顺序,一致性? ?4、分布式是系统有哪些设计模式? ?5、分布式有哪些类型? ?6、如何实现分布式? 2.关键词 节点,时间,一致性,CAP,ACID,BASE,P2P,机器伸缩,网络变更,负载均衡,限流,鉴权,服务发现,服务编排,降级,熔断,幂等,分库分表,分片分区,自动运维,容错处理,全栈监控,故障恢复,性能调优 3.全文概要 随着移动互联网的发展智能终端的普及,计算机系统早就从单机独立工作过渡到多机器协作工作。计算机以集群的方式存在,按照分布式理论的指导构建出庞大复杂的应用服务,也已经深入人心。本文力求从分布式基础理论,架构设计模式,工程应用,部署运维,业界方案这几大方面,介绍基于MSA(微服务架构)的分布式的知识体系大纲。从而对SOA到MSA 进化有个立体的认识,从概念上和工具应用上更近一步了解微服务分布式的本质,身临其境的感受如何搭建全套微服务架构的过程。 4.基础理论 4.1SOA到MSA的进化 SOA面向服务架构 由于业务发展到一定层度后,需要对服务进行解耦,进而把一个单一的大系统按逻辑拆分成不同的子系统,通过服务接口来通讯,面向服务的设计模式,最终需要总线集成服务,而且大部分时候还共享数据库,出现单点故障的时候会导致总线层面的故障,更进一步可能会把数据库拖垮,所以才有了更加独立的设计方案的出现。
MSA微服务架构 微服务是真正意义上的独立服务,从服务入口到数据持久层,逻辑上都是独立隔离的,无需服务总线来接入,但同时增加了整个分布式系统的搭建和管理难度,需要对服务进行编排和管理,所以伴随着微服务的兴起,微服务生态的整套技术栈也需要无缝接入,才能支撑起微服务的治理理念。
基于Spring-DM实现分布式服务框架(DSF)
基于Spring-DM实现分布式服务框架(DSF)(一) 发布时间:2008年01月29日作者:BlueDavy 阅读次数:448次类别:OSGi、SCA永久链接Trackback 经过上篇分析分布式服务框架的blog后,正式对之前的基于OSGi实现分布式服务框架的系列改名(顺便把分布式服务框架改为使用DSF缩写),因为已经决定基于Spring-DM来实现,为什么呢,而且为什么一定要是Spring-DM,而不直接说Spring呢? 今天是Spring-DM 1.0 release的大好日子,,不容易呀,做了这么久,具体怎么样还没来得及细看,不过之前有用过1.0 m2,已经觉得很不错了,相信1.0 release更不 会失望。 在我眼里看来,Spring是个很大的东西,其实DSF需要的基础的东西并不多,但又希望保持微核性和扩展性,插件化、具备良好扩展支持的框架无疑是最佳的选择,OSGi无疑是个好的选择,但基于OSGi要自己去实现的东西实在是太多了,Spring-DM则是能满足 我以上两点需求的最佳选择,既有了插件化的框架,又有了很多可用而且是很强大的东西,尤其是Spring在本地调用和远程调用的透明化提供了优秀的设计支持和指导,例如Spring提供的 HessianServiceExporter、JNDIObjectFactoryBean等等,而且Spring 和OSGi结合后,就可以根据需求来选择自己所需的Spring的那些增强功能了,不用每 次都抱着整个巨大的Spring,当然,目前Spring还没完全剥离好,等Spring-DM 1.1后会好很多。 在之前的分析分布式服务框架的blog中,已经说到其实实现DSF简明扼要的说就是:高效的存储、查找策略+高效的通讯策略+满足需求的服务模型+强大的集成能力,其实这里