属性数据分析第五章课后答案

属性数据分析第五章课后作业
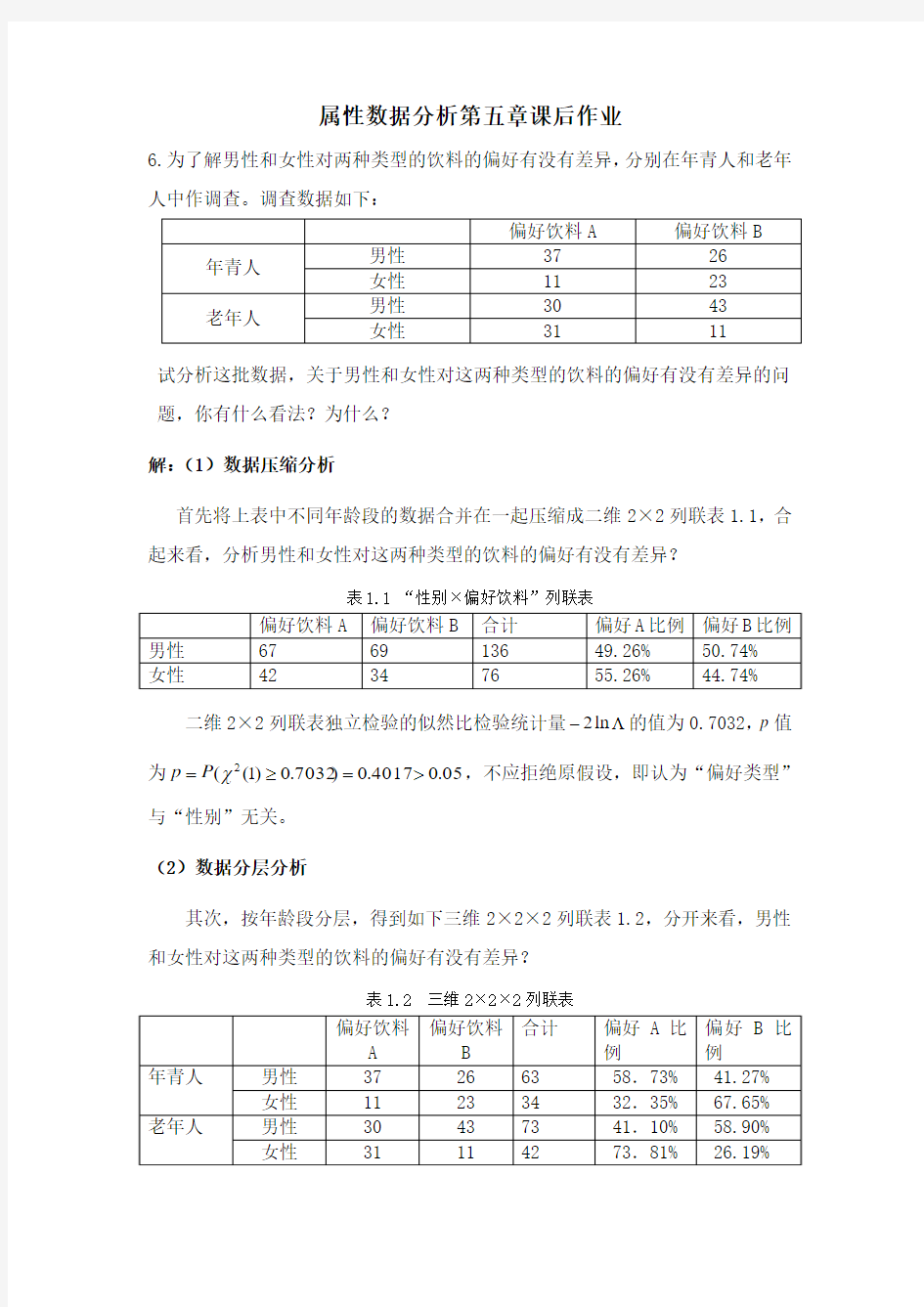
6.为了解男性和女性对两种类型的饮料的偏好有没有差异,分别在年青人和老年人中作调查。调查数据如下:
试分析这批数据,关于男性和女性对这两种类型的饮料的偏好有没有差异的问题,你有什么看法?为什么?
解:(1)数据压缩分析
首先将上表中不同年龄段的数据合并在一起压缩成二维2×2列联表1.1,合起来看,分析男性和女性对这两种类型的饮料的偏好有没有差异?
表1.1 “性别×偏好饮料”列联表
二维2×2列联表独立检验的似然比检验统计量Λ
2的值为0.7032,p值
-ln
为05
≥
=
=χ
p,不应拒绝原假设,即认为“偏好类型”
(2>
P
4017
.0
)1(
)
.0
7032
.0
与“性别”无关。
(2)数据分层分析
其次,按年龄段分层,得到如下三维2×2×2列联表1.2,分开来看,男性和女性对这两种类型的饮料的偏好有没有差异?
表1.2 三维2×2×2列联表
在上述数据中,分别对两个年龄段(即年青人和老年人)进行饮料偏好的调查,在“年青人”年龄段,男性中偏好饮料A 占58.73%,偏好饮料B 占41.27%;女性中偏好饮料A 占58.73%,偏好饮料B 占41.27%,我们可以得出在这个年龄段,男性和女性对这两种类型的饮料的偏好有一定的差异。同理,在“老年人”年龄段,也有一定的差异。 (3)条件独立性检验
为验证上述得出的结果是否可靠,我们可以做以下的条件独立性检验。 即由题意,可令C 表示年龄段,1C 表示年青人,2C 表示老年人;D 表示性别,1D 表示男性,2D 表示女性;E 表示偏好饮料的类型,1E 表示偏好饮料A ,2E 表示偏好饮料B 。欲检验的原假设为:C 给定后D 和E 条件独立。
按年龄段分层后得到的两个四格表,以及它们的似然比检验统计量Λ-ln 2的值如下:
2C 层
822.11ln 2=Λ-248.6ln 2=Λ-
条件独立性检验问题的似然比检验统计
量是这两个
似然比检验统计量的和,其值为 07.18822.11248.6ln 2=+=Λ- 由于2===t c r ,所以条件独立性检验的似然比检验统计量的渐近2χ分布的自由度为2)1)(1(=--t c r ,也就是上面这2个四格表的渐近2χ分布的自由度的和。由于p 值50.00011916)07.18)2((2=≥χP 很小,所以认为条件独立性不成立,即在年龄段给定的条件下,男性和女性对两种类型的饮料的偏好是有差异的。 (4)产生偏差的原因
a 、在(1)中,将不同年龄段的数据压缩在一起合起来后分析发现男性和女性在
对两种类型的饮料的偏好上是没有差异的。但将数据以不同的年龄段分层后并分别分析发现男性和女性在对两种类型的饮料的偏好上是有一定差异的。合起来看和分开来看的结果不同。
b、由此看来,年龄段在此次调查中属于混杂因素。由于不同年龄段的人对饮料的选择也会有差异,例如现在的年青人偏好喝一些像可口可乐,美年达等这样的碳酸饮料,而老年人则偏好喝一些红茶,绿茶等这样的非碳酸饮料,在调查中,“老年人”年龄段共有115人,所占比例大,从而使整个结果就倾向于老年人的观点,即使得混杂因素“年龄段”起到一定的干扰作用,从而导致整个调查结果产生了偏差。
8.某工厂有三个车间。车间主任分别为王、张和李。过去的一年里,该工厂产品的质量情况总结如下:
王主任将内销和外销产品合并在一起,然后计算各个车间的不合格率。计算结果如下:
王主任说,我负责的车间生产情况最好,其次是李主任负责的车间,最差的是张主任负责的车间。这样的比较是不是有偏比较?为什么?
解:不是,有偏比较是指将数据压缩后合起来看与分层后分开来看得出的结果不一致时所产生的偏差,而此题只是将数据压缩起来后相互间比较,因此这样
的比较不是有偏比较。
具体分析如下:
由题知,分析车间主任与产品的质量情况之间的关系,则本题是以产品类别为层,以车间主任为行,产品的质量情况为列进行相关分析。
(1)数据压缩分析
首先将上表中不同产品类别的数据合并在一起压缩成二维3×2列联表2.1,合起来看,分析车间主任与产品的质量情况两者之间的关系?
表2.1 “车间主任×产品质量”列联表
可计算出该表独立性检验的似然比检验统计量Λ
2的值为48.612,p值为
-ln
≥
=χ
p。应该拒绝原假设,即认为车间主任与产品的质量情P
(2≈
612
)
.
48
)2(
况两者是有一定相关性的。
(2)数据分层分析
其次,按产品类别分层,得到如下三维2×3×2列联表2.2,分开来看,分析车间主任与产品的质量情况两者之间的关系?
表1.2 三维2×2×2列联表
在上述数据中,分别对两个产品类别(即内销和外销)进行分析,在“内
销”类别中,王姓主任车间的产品不合格率最高,即车间生产情况最差,张姓主任车间的不合格率最低,即车间生产情况最好;在“外销”类别中,王姓主任车间的产品不合格率最高,即车间生产情况最差,张姓和李姓主任车间生产情况差不多。 (3)条件独立性检验
为验证上述得出的结果是否可靠,我们可以做以下的条件独立性检验。 即由题意,可令A 表示产品类别,1A 表示内销,2A 表示外销;B 表示车间主任,
1B 表示王姓主任,2B 表示张姓主任,3B 表示李姓主任;C 表示产品的质量情况,1C 表示合格产品数,2C 表示不合格产品数。欲检验的原假设为:A 给定后B 和C 条件独立。
按产品类别分层后得到的两张表格,以及它们的似然比检验统计量Λ-ln 2的值如下:
1A 层
289.15ln 2=Λ-
2A 层
684
.51ln 2=Λ-条件独立性检验问题的似然比检验统计量是这两个似然比检验统计量的和,其值为
973.66684.51289.15ln 2=+=Λ-
由于3,2===r t c ,所以条件独立性检验的似然比检验统计量的渐近2χ分布的自由度为3)1)(1(=--t c r ,也就是上面这2个表格的渐近2χ分布的自由度的和。
由于p 值0)973.66)3((2≈≥χP 很小,所以认为条件独立性不成立,即在产品类别给定的条件下,车间主任与产品的质量情况两者是有一定相关性的。 (4)结论
在(1)中,将不同产品类别的数据压缩在一起合起来后分析发现车间主任与产品的质量情况两者是有一定相关性的;在(2)中,将数据以不同的产品类别分层后分析发现车间主任与产品的质量情况两者也是有一定相关性的。即合起来看和分开来看的结果相同。据我们所知,有偏比较是指将数据压缩后合起来看与分层后分开来看得出的结果不一致时所产生的偏差,而此题合起来看和分开来看的结果都是相同的。因此此题若是分析车间主任与产品的质量情况两者之间的相关关系的话,则该题是无偏的,即不均有有偏性,无法进行有偏比较。
11属性数据分析
技能训练十一属性数据分析 一、训练目的与要求 1.掌握属性数据分析方法。 2.掌握属性数据分析图表与原图形的组合。 二、训练准备 1.训练数据:本训练数据保存于文件夹Exercise-11中。 2.预备知识:属性分析的方法。 三、训练步骤与内容 1.数据准备 将训练数据复制,粘贴至各自文件夹内。 启动MAPGIS主程序。在主菜单界面中,点击参数按钮,在弹出的对话框中,设置工作目录最终指向Exercise-14(盘符依据各人具体情况设置)。 2.属性分析 执行如下命令:空间分析?空间分析?文件?装载区文件,加载要进行属性分析的数据文件。 Step1: 加载数据文件中所提供 的REGION.WP区文件 执行如下命令:属性分析?单属性分类统计?立体饼图,选择属性分析类型。
Step2: 属性 Step3: 选择分类属性字段为小麦,保留属性字段为乡名、水稻、玉米Step4: 设置分类方式为分段方式 Step5: 确定,退出设置 分类值域按图中所示输 入
分类统计结果图 3.保存文件 执行如下命令:文件?保存当前文件,换名保存属性分析所生成的图形文件,系统生成的表格文件(*.WB)不需要保存。 Step: 将缺省文件名改为“属性分析”,点 击保存按钮。按此方法依次将线、区 文件名均改为“属性分析” 4.文件组合 执行如下命令:图形处理?输入编辑?打开已有工程文件,打开所提供的Exercise-14.MPJ,在工程文件管理窗口,点击鼠标右键,选择“添加项目”选项,将前面生成的属性分析.WT、属性分析.WL、属性分析.WP添加进此工程文件。 关闭REGION.WP、POINT.WT、RIVER.WL和LINE.WL四个文件。 执行如下命令:其它?整块移动,调整属性分析.WT、属性分析.WL、属性分析.WP三个图形文件的位置,使与主图位置相适应。若此三个图形与主图相比过大的话,执行如下命令:其它?整图变换?键盘输入参数,来进行调整(注意应确定REGION.WP、POINT.WT、RIVER.WL 和LINE.WL四个文件处于关闭状态)。
《数据分析》练习题
《数据分析》练习题 1.一个地区某月前两周从星期一到星期五各天的最低气温依次是(单位:℃):x 1, x 2, x 3, x 4, x 5和x 1+1, x 2+2, x 3+3, x 4+4, x 5+5,若第一周这五天的平均最低气温为7℃,则第二周这五天的平均最低气温为 。 2.有10个数据的平均数为12,另有20个数据的平均数为15,那么所有这30个数据的平均数是( ) A .12 B. 15 C. 1 3.5 D. 14 3.一组数据8,8,x ,6的众数与平均数相同,那么这组数据的中位数是 ( ) A. 6 B. 8 C.7 D. 10 4.某校在一次考试中,甲乙两班学生的数学成绩统计如下: 请根据表格提供的信息回答下列问题: (1)甲班众数为 分,乙班众数为 分,从众数看成绩较好的是 班; (2)甲班的中位数是 分,乙班的中位数是 分; (3)若成绩在80分以上为优秀,则成绩较好的是 班;、 (4)甲班的平均成绩是 分,乙班的平均成绩是 分,从平均分看成绩较好的是 班. 5.在方差的计算公式 ()()()222 21210120202010 s x x x ??= -+-+???+-??中, 数字10和20分别表示的意义可以是( ) A .数据的个数和方差 B .平均数和数据的个数 C .数据的个数和平均数 D .数据组的方差和平均数 6..如果将所给定的数据组中的每个数都减去一个非零常数,那么该数组的 ( ) A.平均数改变,方差不变 B.平均数改变,方差改变 C.平均输不变,方差改变 D.平均数不变,方差不变 7..已知7,4,3,,321x x x 的平均数是6,则_____________321=++x x x . 8..已知一组数据-3,-2,1,3,6,x 的中位数为1,则其方差为 . 9..已知一组数据x 1,x 2,x 3,x 4,x 5的平均数是2,方差是 3 1 ,那么另一组数据3x 1-2,3x 2-2,3x 3-2, 3x 4-2,3x 5-2的平均数是和方差分别是 . 10..关于一组数据的平均数、中位数、众数,下列说法中正确的是( ) A.平均数一定是这组数中的某个数 B. 中位数一定是这组数中的某个数 C.众数一定是这组数中的某个数 D.以上说法都不对 分数 50 60 70 80 90 100 人数 甲 1 6 12 11 15 5 乙 3 5 15 3 13 11
《统计分析及SPSS的应用(第五版)》课后练习答案解析(第4章)
《统计分析与SPSS的应用(第五版)》(薛薇) 课后练习答案 第4章SPSS基本统计分析 1、利用第2章第7题数据采用SPSS频数分析,分析被调查者的常住地、职业和年龄分布特征,并绘制条形图。 分析——描述统计——频率,选择“常住地”,“职业”和“年龄”到变量中,然后,图表——条形图——图表值(频率)——继续,勾选显示频率表格,点击确定。 Statistics 户口所在 地职业 , 年龄 N Valid282282282 Missing00~ 户口所在地 Frequency Percent Valid Percent Cumulative Percent Valid 中心城市] 200 边远郊区82 Total282 职业 ( Frequency Percent Valid Percent Cumulative Percent Valid 国家机关24 商业服务业54 文教卫生18】公交建筑业15 经营性公司】 18 学校15
一般农户 35 种粮棉专业 户 4(种果菜专业 户 10 工商运专业户 ~ 34 退役人员17 金融机构35 现役军人3: Total282 、 年龄 Frequency Percent Valid Percent Cumulative Percent Valid 20岁以下4/ 20~35岁146 35~50岁: 91 50岁以上41 Total282
《 分析:本次调查的有效样本为282份。常住地的分布状况是:在中心城市的人最多,有200人,而在边远郊区只有82人;职业的分布状况是:在商业服务业的人最多,其次是一般农户和金融机构;年龄方面:在35-50岁的人最多。由于变量中无缺失数据,因此频数分布表中的百分比相同。 2、利用第2章第7题数据,从数据的集中趋势、离散程度以及分布形状等角度,分析被调查者本次存款金额的基本特征,并与标准正态分布曲线进行对比。进一步,对不同常住地储户存款金额的基本特征进行对比分析。 分析——描述统计——描述,选择存款金额到变量中。点击选项,勾选均值、标准差、方差、最小值、最大值、范围、偏度、峰度、按变量列表,点击继续——确定。 分析:由表中可以看出,有效样本为282份,存(取)款金额的均值是,标准差为,峰度系数为,偏度系数为。与标准正态分布曲线进行对比,由峰度系数可以看出,此表的存款金额的数据分布比标准正态分布更陡峭;由偏度系数可以看出,此表的存款金额的数据为右偏分布,表明此表的存款金额均值对平均水平的测度偏大。
LFA457数据分析向导资料
LFA447数据分析向导 1.新建/打开数据库 打开分析软件Proteus LFA Analysis。弹出如下界面: 如果要把导入数据保存在原有的数据库中,选择数据库所在的文件夹,双击打开该数据库。 如果要为导入数据新建一个数据库,选择存盘路径,在“文件名”中输入数据库文件名,点击“打开”,软件会自动创建一个新的数据库文件。 随后出现数据库管理窗口:
注:LFA Proteus的数据以Access数据库文件(*.mdb)的形式进行管理。LFA447(Nanoflash)的原始数据文件(*.dat)需要导入到数据库文件中,一个数据库文件可存放多个测量数据。从数据分类管理的角度出发,一般建议为每一批样品单独创建一个数据库。 2.导入LFA447数据文件/设定材料属性 点击“LFA数据库”窗口的“数据库”菜单下的“导入LFA447文件”,弹出“选择导入文件”对话 框:
选择所要导入的数据文件,点击“打开”,弹出“导入–材料选择”对话框: 如果在数据库中原已有该材料的信息,只需在材料列表中“选择已有材料”即可;如果是新建的数据库或原数据库中没有该材料的信息,则“定义新材料”,点击“下一步”,弹出“材料定义”对话框: LFA Proteus中每一个测试数据都有相应的材料属性定义,包含样品的名称、密度、比热表、热膨胀系数表、热扩散系数表等信息,其中比热、热膨胀与热扩散系数三个表格可通过点击“对应表”按钮进行设定。对于单层样品: 如果仅仅是热扩散系数测试,三个表都不需链接,直接点击“完成”。 如果除热扩散测试外还同时使用比较法计算比热,则此时先可点击“完成”,待比热计算完成后使用“导出比热表”的方法重新对材料属性中所链接的比热表进行设定。(详见LFA比热与导热系数计算方法) 如果已有比热的文献值(或使用其它仪器得到的测量值),需要链接到材料属性中,以便结合热扩散测试结果进一步计算导热系数,则在“比热表”的选项卡中点击“对应表…”,弹出如下窗
数据分析(梅长林)习题
第五章习题 1.习题 解:假定两总体服从正态分布,且协方差矩阵21∑=∑,误判损失相同又先验概 即:0.4285711=P 0.5714292=P 又计算可得: (1)(2)25.31622.025,2.416 1.187x x ????==--???????? 并且:-2.38145ln =S 计算广义平方距离函数: 2()1 ()()()()ln 2ln j T j j j j j d p -=--+-x x x S x x S 并计算后验概率: 2 2 2 ??0.5()0.5()1 ?(|)e e j k d d j k P G --==∑x x x 1,2j = 回代判别结果如下:
由此可见误判的回代估计: 0.07141/14* ==r P 若按照交叉确认法,定义广义平方距离如下: 2()1() ()()()()()()()ln 2ln j j j T j j x x x x j d p -=--+-x x x S x x S 逐个剔除, 交叉判别,后验概率按下式计算: 2 2 2 ??0.5()0.5()1 ?(|)e e j k d d j k P G --==∑x x x 1,2j = 通过SAS 计算得到表所示结果。发现同样也是属于G1的4号被误判为G2,因此误判率的交 叉确认估计为* ?1/140.0714c p ==
*121p p p ΦΦ?? =+- ?? ? 其中(1) (2)1(1)(2)?()()T λ -=--x x S x x =, 2 1(1|2)ln (2|1)c p d c p =,又因为(1|2)(2|1)c c c ==,所以288.0ln 1 2==P P d , 最后可得后验概率p 为: 习题 解:(1)在21∑≠∑并且先验概率相同的的假设前提下,建立矩离判别的线性判别函数。利用SAS 的proc discrim 过程首先计算得到总体的协方差矩阵,如表:
数据属性
数据属性 数据具有数值属性、物理属性。在数据处理上数据又具有集合性、隶属性、稳定性、方便性、重复性、共同性、指向性以及运算规则及运算约束。我们先看一个命题,求一个苹果和一个梨的和?由于它们的物理属性不同,我们不能求出它们的和。再看命题现在有一个苹果和一个梨,问是否满足3个人,每人一个苹果或梨,由于物理属性转移到“人”概念下的“个”,所以必须先进行加法运算,其结果是分析命题的依据。数据是复杂的,它可以是任何介质上所记录的信息,比如我们可以对文字信息进行拷贝、连接、检索、删除,都是数据概念下的操作。 详细解释 进行各种统计、计算、科学研究或技术设计等所依据的数值。 柯岩《奇异的书简·船长》:“ 贝汉廷分析着各个不同的数据,寻找着规律,终于抓住了矛盾的牛鼻子。”数据(data)是载荷或记录信息的按一定规则排列组合的物理符号。可以是数字、文字、图像,也可以是计算机代码。对信息的接收始于对数据的接收,对信息的获取只能通过对数据背景的解读。数据背景是接收者针对特定数据的信息准备,即当接收者了解物理符号序列的规律,并知道每个符号和符号组合的指向性目标或含义时,便可以获得一组数据所载荷的信息。亦即数据转化为信息,可以用公式“数据+背景=信息”表示。 编辑本段计算机科学中的解释 数据:在计算机系统中,各种字母、数字符号的组合、语音、图形、图像等统称为数据,数据经过加工后就成为信息。 在计算机科学中,数据是指所有能输入到计算机并被计算机程序处理的符号的介质的总称,是用于输入电子计算机进行处理,具有一定意义的数字、字母、符号和模拟量等的通称。是组成地理信息系统的最基本要素,种类很多。 按性质分为 ①定位的,如各种坐标数据;②定性的,如表示事物属性的数据(居民地、河流、道路等);③定量的,反映事物数量特征的数据,如长度、面积、体积等几何量或重量、速度等物理量;④定时的,反映事物时间特性的数据,如年、月、日、时、分、秒等。 按表现形式分为
数据分析课后答案spss教学提纲
数据分析课后答案 s p s s
习题1.3 統計資料 全国居民 N 有效 22 遺漏 0 平均數 1117.00 中位數 727.50 標準偏差 1015.717 變異數 1031680.286 偏斜度 1.025 偏斜度標準誤 .491 峰度 -.457 峰度標準誤 .953 百分位數 25 304.25 50 727.50 75 1893.50 (1).由表可知,全国居民的均值、方差、标准差、偏度、峰度分别为1117.00、1031680.286、1015.717、1.025、-0.457。 变异系数有公式计算得90.9325。 (2)中位数为727.50,上四分位数304.35,下四分位数为1893.50。 四分位极差由公式 得到1579.15 三均值由公式 得到913.1857。 (3)直方图 (%) *100cv _x s =1 31Q Q R -=3 141 2141Q M Q M ++=∧
(4)茎叶图 全国居民 Stem-and-Leaf Plot Frequency Stem & Leaf 9.00 0 . 122223344 5.00 0 . 56788 2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689 1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s)
(5) 由箱图可以看出并不异常点。 統計資料 农村居民 N 有效22 遺漏0 平均數747.86 中位數530.50 標準偏差632.198 變異數399673.838 偏斜度 1.013 偏斜度標準誤.491 峰度-.451 峰度標準誤.953 百分位數25 239.75 50 530.50 75 1197.00
第2章 数据分析(梅长林)习题题答案
第2章 习 题 一、习题 (1)回归模型 15,2,1,22110 =+++=i x x y i i i i εβββ 调用proc reg : ] 由此输出得到的回归方程为: 2100920.049600.045261.3X X y ++=∧ 由最后一列可以看出,使用化妆品的人数X1和月收入X2对化妆品的销售数量有着显著影响。46521.30=∧ β可以理解为该化妆品作为一种必需品每个月的销售量。当购买该化妆品的人数固定时,月收入没增加一个一个单位,改化妆品的销售数量将增加个单位。同理,当购买该化妆品的人均月收入固定时,购买该化妆品的人数每增加一千人,该化妆品的销售数量将增加个单位。 p n SSE -= ∧2 σ 是2σ的无偏估计,所以2σ的估计值是. (2)调用 由此可到线性回归关系显著性检验: 0至少有一个为0:2,1:1210ββββH H ?==
的统计量/(1)/()SSR p MSR F SSE n p MSE -= =-的观测值47.56790=F ,检验的p 值 0001.0)(000<>==F F p p H 另外9989.053902 53845 2=== SST SSR R ,2R 描述了由自由变量的线性关系函数值所能反映的Y 的总变化量的比例。2R 越大,表明线性关系越明显。这些结果均表明Y 与X1,X2之间的回归关系高度显著。 (3)若置信水平05.0=α,由17881.2)12(975.0=t ,利用参数估计值得 到21,0,βββ的置信区间分别为: 对,0β2942.54516.343065.21781.245216.3±=?±,即)7458.8,8426.1(-) 对1β:01318.049600.000605.01781.249600.0±=?±,即)50198.0,48282.0( ) 2β:0021 .000920.00009681.01781.200920.0±=?±,即)00113.0,0071.0(- (4)首先检验X1对Y 是否有显著性影: 假设其约简模型为:15,2, 1,220 =++=i x y i i i εββ 由观测数据并利用proc reg 过程拟合此模型求得: 88137.484)(=R SSE 13215=-=R f 88357.56)(=F SSE 12315=-=R f 由[()()]() ()/R F F SSE R SSE F f f F SSE F f --= 求得检验统计量的值为: 3 .9012/88357.5688357 .5688137.4840=-= F 05.0))13,1(()(0000<>==>==F F P F F p p H 由此拒绝原假设,所以x2对Y 有显著影响。 ~ 同理检验X2对Y 是否有显著性影: 假设其约简模型为:15,2, 1,110 =++=i x y i i i εββ 由观测数据并利用proc reg 过程拟合此模型求得: 31872)(=R SSE 13215=-=R f 88357.56)(=F SSE 12315=-=R f 由[()()]() ()/R F F SSE R SSE F f f F SSE F f --= 求得检验统计量的值为: 12/88357.5688357.56318720-= F 05.0))13,1(()(0000<>==>==F F P F F p p H 由此拒绝原假设,所以x2对Y 有显著影响。
实验十四 属性数据分析
实验十四属性数据分析 一、实验目的 1.掌握属性数据分析方法。 2.掌握属性数据分析图表与原图形的组合。 二、实验准备 1.实验数据:本实验数据保存于文件夹Exercise-14中。 2.预备知识:属性分析的方法。 三、实验步骤与内容 1.数据准备 将实验数据复制,粘贴至各自文件夹内。 启动MAPGIS主程序。在主菜单界面中,点击参数按钮,在弹出的对话框中,设置工作目录最终指向Exercise-14(盘符依据各人具体情况设置)。 2.属性分析 执行如下命令:空间分析?空间分析?文件?装载区文件,加载要进行属性分析的数据文件。 Step1: 加载数据文件中所提供 的REGION.WP区文件执行如下命令:属性分析?单属性分类统计?立体饼图,选择属性分析类型。
Step2: 属性 Step4: 设置分类方 式为分段方 式 Step3: 选择分类属 性字段为小 麦,保留属 性字段为乡 名、水稻、 玉米 Step5: 确定,退出 设置 分类值域按图中所示输 入
分类统计结果图 3.保存文件 执行如下命令:文件?保存当前文件,换名保存属性分析所生成的图形文件,系统生成的表格文件(*.WB)不需要保存。 Step: 将缺省文件名改为“属性分析”,点 击保存按钮。按此方法依次将线、区 文件名均改为“属性分析” 4.文件组合 执行如下命令:图形处理?输入编辑?打开已有工程文件,打开所提供的Exercise-14.MPJ,在工程文件管理窗口,点击鼠标右键,选择“添加项目”选项,将前面生成的属性分析.WT、属性分析.WL、属性分析.WP添加进此工程文件。 关闭REGION.WP、POINT.WT、RIVER.WL和LINE.WL四个文件。 执行如下命令:其它?整块移动,调整属性分析.WT、属性分析.WL、属性分析.WP三个图形文件的位置,使与主图位置相适应。若此三个图形与主图相比过大的话,执行如下命令:其它?整图变换?键盘输入参数,来进行调整(注意应确定REGION.WP、POINT.WT、RIVER.WL和LINE.WL四个文件处于关闭状态)。 完成后,保存此工程文件。
GIS中的数据分析
二、GIS中的数据分析 第1节空间数据分析 地理信息系统(GIS)与—般的计算机辅助制图(CAM/CAD)系统的主要区别在于GIS具有空间数据的分析、变换能力。除一些基本的变换功能如数据更新、比例尺变换,投影变换外.主要的空间分析和变换功能为地理数据的拓扑和空间状况运算,属性综合运算,几何要素与属性的联合运算等。为了完成这些运算,GIS一般都以用户和系统交互的形式提供以上分析处理能力。应指出,栅格数据结构与矢量数据结构的空间分析方法有所不同。一般来说,栅格结构组织数据的空间分析方法要简单一些。 下图以分级结构形式概括的各种空间分析类型和方法:
图: GIS空间分析方法 一、综合属性数据分析 GIS中属性数据一般采用关系型数据库管理,因此,关系数据库中各种分析功能都可以对属性性数据进行分析。 (一)数学计算 属性数据中的数字型数据可以进行“加”、“减”、“乘”、“除”、“乘方”等数学运算,以产生新的属性值,如人口数/图斑面积(km)=人口密度。 (二)逻辑运算 逻辑运算的基本原理是布尔代数,这种逻辑分析几乎可以在所有
的空间分析中得到应用。它按属性数据的组合条件来检索其他属性项目或图形数据,以及进行空间聚类. (三)单变量分级分析 属性的单变量分级分析是把单个属性作为变量,依据布尔逻辑方法分成若干个类别。这种分析方法,可进行属性数据的合并式转换,把复杂的属性类别合并成简单的类别,以实现空间聚合 (四)多变量统计分析 多变量统计分析主要用于数据分类。在GIS中存储的数据具有原始的性质,以便用户可以根据不同的使用目的,进行任意提取和分析,特别是对于观测和取样数据.随着采用的分类和内插方法的不同,得到的结果有很大的差异, 因此,在大多数情况下, 首先是将大量未经分类的属性数据输入信息系统的数据库,然后要求用户建立具体的分类算法,以获得所需要的信息。 1.变量筛选分析 随着现代数据收集系统的不断改进,在一个取样点上常可以收集到几十种原始变量。在这些变量中有许多是相互关联的,可以通过寻找一组相互独立的变量,使多变量数据得到简化,这就是变量筛选分析。常用的变量筛选方法有主成分分析法、主因子分析法和关键变量分析法等。 主成分分析是以取样点作为坐标轴,以属性变量作为矢量矩阵,研究属性变量之间的亲疏关系。 主因子分析是以属性变量作为坐标轴,以取样点作为矢量矩阵,
属性数据与空间数据
属性数据与空间数据 1. 属性数据 地理要素具有描述性属性,与空间数据相对应的描述性数据。 2. 空间数据 空间数据是用来描述来自于现实的目标,将数据统一化,借以表明空间实体的形状大小以及位置和分布特征。定位是指在已知的坐标系里空间目标都具有唯一的空间位置;定性是指有关空间目标的自然属性,它伴随着目标的地理位置;时间是指空间目标是随时间的变化而变化;空间关系通常一般用拓扑关系表示。空间数据是一种用点、线、面以及实体等基本空间数据结构来表示人们赖以生存的自然世界的数据。空间数据是数字地球的基础信息,数字地球功能的绝大部分将以空间数据为基础。现在空间数据已广泛应用于社会各行业、各部门,如城市规划、交通、银行、航空航天等。随着科学和社会的发展,人们已经越来越认识到空间数据对于社会经济的发展、人们生活水平提高的重要性,这也加快了人们获取和应用空间数据的步伐。 空间数据是数据的一种特殊类型。它是指凡是带有空间坐标的数据,如建筑设计图、机械设计图和各种地图表示成计算机能够接受的数字形式。 3. 空间数据结构 空间数据结构是空间数据在计算机内的组织和编码形式。它是一种适合于计算机存贮、管理和处理空间数据的逻辑结构,是地理实体的空间排列和相互关系的抽象描述。它是对数据的一种理解和解释。空间数据结构又是指空间数据的编排方式和组织关系。空间数据编码是指空间数据结构的具体实现,是将图形数据、影像数据、统计数据等资料按一定的数据结构转换为适合计算机存储和处理的形式。不同数据源采用不同的数据结构处理,内容相差极大,计算机处理数据的效率很大程度取决于数据结构。 4. 特点 目标构成数据库的逻辑过程 随着信息技术的飞速发展和企业界新需求的不断提出,以面向事务处理为主的空间数据库系统已不能满足需要,信息系统开始从管理转向决策处理,空间数据仓库就是为满足这种新的需求而提出的空间信息集成方案,它有四个特点: ①主题与面向主题:与传统空间数据库面向应用进行数据组织的特点相对应,空间数据仓库中的数据是面向主题进行数据组织的。它在较高层次上将企业信息系统中的数据进行综合、归类,并加以抽象地分析利用。 ②集成的数据:空间数据仓库的数据是从原有的空间数据库数据中抽取来的。因此在数据进入空间数据仓库之前,必然要经过统一与综合,这一步是空间数据仓库建设中最关键最复杂的一步,所要完成的工作包括消除源数据中的不一致性和进行数据综合计算。 ③数据是持久的:空间数据仓库中的数据主要供决策分析之用,所涉及的数据操作主要是数据查询,一般情况下并不进行修改操作。空间数据仓库的数据反映的是一段相当长的时间内的数据内容,是不同时间的空间数据库快照的集合和基于这些快照进行统计、综合和重组导出的数据,而不是联机处理的数据。空间数据库中进行联机处理的数据经过集成输入到空间数据仓库中,一旦空间数据仓库存放的数据已经超过空间数据仓库的数据存储期限,这些数据将从空间数据仓库中删去。 ④数据是随时间不断变化的:空间数据仓库的数据是随时间的变化不断变化的,它会不断增加新的数据内容,不断删去旧的数据内容,不断对数据按时间段进行综合。空间数据仓库用于支撑空间决策支持系统,它由四大部分组成:数据源、空间数据库系统、空间
定性数据分析第二章课后答案资料
定性数据分析第二章 课后答案
第二章课后作业 【第1题】 解:由题可知消费者对糖果颜色的偏好情况(即糖果颜色的概率分布),调查 者取500块糖果作为研究对象,则以消费者对糖果颜色的偏好作为依据,500块糖果的颜色分布如下表1.1所示: 表1.1 理论上糖果的各颜色数 由题知r=6,n=500,我们假设这些数据与消费者对糖果颜色的偏好分布是相符,所以我们进行以下假设: 原假设::0H 类i A 所占的比例为)6,...,1(0==i p p i i 其中i A 为对应的糖果颜色,)6,...,1(0=i p i 已知,16 10=∑=i i p 则2χ检验的计算过程如下表所示: 在这里6=r 。检验的p 值等于自由度为5的2χ变量大于等于18.0567的概率。在Excel 中输入“)5,0567.18(chidist =”,得出对应的p 值为
05.00028762.0<<=p ,故拒绝原假设,即这些数据与消费者对糖果颜色的偏好 分布不相符。 【第2题】 解:由题可知 ,r=3,n=200,假设顾客对这三种肉食的喜好程度相同,即顾 客选择这三种肉食的概率是相同的。所以我们可以进行以下假设: 原假设 )3,2,1(3 1 :0==i p H i 则2χ检验的计算过程如下表所示: 在这里3=r 。检验的p 值等于自由度为2的2χ变量大于等于15.72921的概率。在Excel 中输入“)2,72921.15(chidist =”,得出对应的p 值为 05.00003841.0<<=p ,故拒绝原假设,即认为顾客对这三种肉食的喜好程度是 不相同的。 【第3题】 解:由题可知 ,r=10,n=800,假设学生对这些课程的选择没有倾向性,即选 各门课的人数的比例相同,则十门课程每门课程被选择的概率都相等。所以我们可以进行以下假设: 原假设)10,...,2,1(1.0:0==i p H i 则2χ检验的计算过程如下表所示:
《统计分析与SPSS的应用(第五版)》课后练习标准答案(第8章)
《统计分析与SPSS的应用(第五版)》课后练习答案(第8章)
————————————————————————————————作者:————————————————————————————————日期:
《统计分析与SPSS的应用(第五版)》(薛薇) 课后练习答案 第8章SPSS的相关分析 1、对15家商业企业进行客户满意度调查,同时聘请相关专家对这15家企业的综合竞争力进行评分,结果如下表。 编号客户满意度得分综合竞争力得分编号客户满意度得分综合竞争力得分 1 90 70 9 10 60 2 100 80 10 20 30 3 150 150 11 80 100 4 130 140 12 70 110 5 120 90 13 30 10 6 110 120 14 50 40 7 40 20 15 60 50 8 140 130 请问,这些数据能否说明企业的客户满意度与其综合竞争力存在较强的正相关,为什么? 能。步骤:(1)图形→旧对话框→散点/点状→简单分布→进行相应设置→确定;(2)再双击图形→元素→总计拟合线→拟合线→线性→确定
(3)分析→相关→双变量→进行相关项设置→确定 相关性 客户满意度得分综合竞争力得分客户满意度得分Pearson 相关性 1 .864** 显著性(双尾).000 N 16 15 综合竞争力得分Pearson 相关性.864** 1 显著性(双尾).000 N 15 15 **. 在置信度(双测)为 0.01 时,相关性是显著的。 两者的简单相关系数为0.864,说明存在正的强相关性。
2、为研究香烟消耗量与肺癌死亡率的关系,收集下表数据。(说明:1930年左右几乎极少的妇女吸烟;采用1950年的肺癌死亡率是考虑到吸烟的效果需要一段时间才可显现)。 国家1930年人均香烟消耗量1950年每百万男子中死于肺癌的人数 澳大利亚480 180 加拿大500 150 丹麦380 170 芬兰1100 350 英国1100 460 荷兰490 240 冰岛230 60 挪威250 90 瑞典300 110 瑞士510 250 美国1300 200 绘制上述数据的散点图,并计算相关系数,说明香烟消耗量与肺癌死亡率之间是否存在显著的相关关系。 香烟消耗量与肺癌死亡率的散点图(操作方法与第1题相同) 相关性 人均香烟消耗死于肺癌人数 人均香烟消耗Pearson 相关性 1 .737** 显著性(双尾).010 N 11 11 死于肺癌人数Pearson 相关性.737** 1
(完整版)Excel数据分析课后测试答案
Excel数据分析 单选题 ?1、数据透视表被形象地形容为企业经营管理中的什么部分?(10 分) ?A 血液 ?B 骨架 ?C 皮肤 ?D 肌肉 正确答案:A ?2、需要选择整张报表进行透视表计算时,可以怎样操作?(10 分) ?A Ctrl+a快选整张表格 ?B 鼠标在最左行,变为黑色箭头时可以全选行 ?C 鼠标移动至报表内部可自动选择整张报表 正确答案:C ?3、在数据透视表中,需要对某一字段进行对比分析时,应将该数据放在哪类标签中更便利? (10 分)
?A 报表筛选 ?B 列标签 ?C 行标签 ?D 西格玛数值(∑) 正确答案:B ?4、需要为单元格中的信息添加单位时,在设置单元格选项卡中,选择哪个功能项操作?(10 分) ?A 常规 ?B 文本 ?C 特殊 ?D 自定义 正确答案:D ?5、需要为数据进行比重分析时,选择值字段设置中的哪个选项?(10 分) ?A
值汇总方式 ?B 值显示方式 正确答案:B ?6、如何对汇总表中的单个数据进行核查操作?(10 分) ?A 在原明细表中生成新的汇总数据 ?B 双击该单元格查看对应汇总数据 ?C 以上方法都可以 正确答案:C ?7、汇总表中的标题字段可以自定义吗?(10 分) ?A 可以 ?B 不可以 正确答案:A 多选题 ?1、创建数据透视表的方式?(10 分) A 创建一个新工作表,点击“数据透视表”,选择一个表或区域
B 创建一个新工作表,点击“数据透视表”,选择外部数据源 C 点选明细表中有效单元格,再点击“数据透视表”选项 D 点选明细表中任意单元格,再点击“数据透视表”选项 正确答案:B C 判断题 ?1、数据透视表是Excel中一种交互式的工作表,可以根据用户的需要按照不同关键字段来提取组织和分析数据。(10 分) ?A 正确 ?B 错误 正确答案:正确 ?2、汇总表中的数据如果需要修正时,不可以直接更改,必须返回原明细表修改对应的原始数据。(10分) ?A 正确 ?B 错误 正确答案:正确
《统计分析与SPSS的应用(第五版)》课后练习答案.doc (1)
《统计分析与SPSS的应用(第五版)》课后练习答案 第一章练习题答案 1、SPSS的中文全名是:社会科学统计软件包(后改名为:统计产品与服务解决方案) 英文全名是:Statistical Package for the Social Science.(Statistical Product and Service Solutions) 2、SPSS的两个主要窗口是数据编辑器窗口和结果查看器窗口。 ●数据编辑器窗口的主要功能是定义SPSS数据的结构、录入编辑和管理待分析的数据; ●结果查看器窗口的主要功能是现实管理SPSS统计分析结果、报表及图形。 3、SPSS的数据集: ●SPSS运行时可同时打开多个数据编辑器窗口。每个数据编辑器窗口分别显示不同 的数据集合(简称数据集)。 ●活动数据集:其中只有一个数据集为当前数据集。SPSS只对某时刻的当前数据集 中的数据进行分析。 4、SPSS的三种基本运行方式: ●完全窗口菜单方式、程序运行方式、混合运行方式。 ●完全窗口菜单方式:是指在使用SPSS的过程中,所有的分析操作都通过菜单、按 钮、输入对话框等方式来完成,是一种最常见和最普遍的使用方式,最大优点是简 洁和直观。 ●程序运行方式:是指在使用SPSS的过程中,统计分析人员根据自己的需要,手工 编写SPSS命令程序,然后将编写好的程序一次性提交给计算机执行。该方式适用 于大规模的统计分析工作。 ●混合运行方式:是前两者的综合。 5、.sav是数据编辑器窗口中的SPSS数据文件的扩展名 .spv是结果查看器窗口中的SPSS分析结果文件的扩展名 .sps是语法窗口中的SPSS程序 6、SPSS的数据加工和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。 7、概率抽样(probability sampling):也称随机抽样,是指按一定的概率以随机原则抽取样本,抽取样本时每个单位都有一定的机会被抽中,每个单位被抽中的概率是已知的,或是可以计算出来的。概率抽样包括简单随机抽样、系统抽样(等距抽样)、分层抽样(类型抽样)、整群抽样、多阶段抽样等。 ●简单随机抽样(simple random sampling):从包括总体N个单位的抽样框中随机地 抽取n个单位作为样本,每个单位抽入样本的概率是相等的。是最基本的抽样方法,是其它抽样方法的基础。优点:简单、直观,在抽样框完整时,可直接从中抽取样 本,用样本统计量对总体参数进行估计比较方便。局限性:当N很大时,不易构造 抽样框,抽出的单位很分散,给实施调查增加了困难。 ●分层抽样(stratified sampling):将抽样单位按某种特征或某种规则划分为不同 的层,然后从不同的层中独立、随机地抽取样本。优点:保证样本的结构与总体的 结构比较相近,从而提高估计的精度,组织实施调查方便(当层是以行业或行政区 划分时),既可以对总体参数进行估计,也可以对各层的参数进行估计。 ●整群抽样(cluster sampling):将总体中若干个单位合并为组(群),抽样时直接抽 取群,然后对选中群中的所有单位全部实施调查。优点:抽样时只需群的抽样框, 可简化工作量;调查的地点相对集中,节省调查费用,方便调查的实施。缺点:估
数据挖掘中客户的特征化及其划分(一)
数据挖掘中客户的特征化及其划分(一) 摘要]良好客户关系已成为电子商务时代制胜的关键。在激烈的市场竞争中,客户关系管理逐渐成为企业关注的焦点。深入研究客户和潜在客户是在市场中保持竞争力的关键。本文通过对客户行为的特征化分析,以数据挖掘为分析工具,对客户关系管理进行了讨论,给出了相应的划分方法,使用这些划分方法,对客户进行分析是有意义的。 关键词]客户关系管理数据挖掘聚类分析 一、引言 在激烈的市场竞争中,客户关系管理(CustomerRelationshipManagement)逐渐成为各企业关注的焦点。一个成熟的CRM系统要能够有效地获取客户的各种信息,识别客户与企业间的关系及所有交互操作,寻找其中的规律,为客户提供个性化的服务,为企业决策提供支持。 在企业与客户的交互操作中,“二八原则”是值得借鉴的,即20%的客户对企业做出80%的利润贡献。但究竟谁是那20%的客户?又如何确定特定消费群体的消费习惯与消费倾向,进而推断出相应消费群体或个体下一步的消费行为?这都是企业需要认真研究的问题。 二、客户的特征化及其划分 企业认识客户和潜在客户是在市场保持竞争力的关键。特征分析是了解客户和潜在客户的极好方法,包括对感兴趣对象范围进行一般特征的度量。一旦知道带来最大利润客户的特征和行为,就可以直接将其应用到寻找潜在客户之中。有效寻找客户,认识哪些人群像自己的客户。因此,在争取客户的活动中,对感兴趣对象进行特征化及其划分是很有意义的。 对客户的特征化,顾名思义就是用数据来描述或给出客户(潜在客户)特征的活动。特征化可以在数据库(或数据库的不同部分)上进行。这些不同部分也称为划分,通常他们互不包含。 划分分析(SegmentationAnalysis)通常用于根据利润和市场潜力划分客户。如:零售商按客户在所有零售商店的总体购买行为,将客户划分为若干描述他们各自购买行为的区域,这样零售商可以评估哪些客户有最大利润。划分是把数据库分成互不相交部分或分区的活动。一般有两种方法:市场驱动法和数据驱动法。市场驱动法需要决定那些对业务有重要影响的特征,即需要预先选择一些特征变量(属性),以最终定义得到划分。数据驱动法是利用数据挖掘中的聚类技术或要素分析技术寻找同质群体。 三、数据挖掘的概念 数据挖掘(DataMining)是从大型数据库或数据仓库中提取人们感兴趣的知识,这些知识是隐含的、事先未知的潜在有用信息。通过数据挖掘提取的知识表示为概念、规则、规律、模式等,它对企业的趋势预测和行为决策提供支持。 1.分类分析 分类是指将数据映射到预先定义好的群组或类。分类要求基于数据属性值来定义类别,通过数据特征来描述类别。根据它与预先定义好的类别相似度,划分到某一类中去。分类的主要应用是导出数据的分类模型,然后使用模型预测。 2.聚类分析 聚类是对抽象样本集合分组的过程。与分类不同之处在于聚类操作要划分的类是事先未知。按照同一类中对象之间较高相似度原则进行划分,目的是使同一类别个体之间距离尽可能小,不同类别中个体间距离尽可能大。类的形成是由数据驱动的。 3.关联规则 关联规则是从大量的数据中挖掘出有价值的描述数据项之间相互关联的知识。关联规则中有两个重要概念:支持度(Support)和信任度(Confidence)。它们是两个度量有关规则的方法,描述了被挖掘出规则的有用性和确定性。关联规则挖掘,希望发现事务数据库中数据项之间的关联,这些规则往往能反映客户的购买行为模式。
课后习题模块一电商数据分析概述
(课后习题)模块一电商数据分析概述 16. 简答题(分值:5分) 电子商务数据分析指标分类请将以下运营类指标按照不同细分类别进行归类,填入表1-2中 参考答案:客户指标:活跃客户数、客户留存率、客户回购率; 推广指标:跳失率、转化率、展现量、点击量、访客数、访客量; 销售指标:销售量、投资回报率、滞销率、动销率、件单价、客单价、订单退货率、销售利润率; 供应链指标:订单响应时长、库存周转率、平均配送成本。 17. 简答题(分值:10分) 电子商务数据分析指标的理解与计算在电子商务运营过程中,当买家在访问过程中产生疑问,会通过通讯工具(如阿里旺旺)与客服交流。如果客服解决了买家的相关问题,有一部分买家就会选择购买商品。在此过程中,客服的响应速度、咨询转化率会影响整个电商平台的销售额。 (1)咨询转化率除了影响电商平台的销售额外,还在哪些方面对电商平台有影响? 参考答案:(1)咨询转化率主要还会影响店铺DSR评分和品牌口碑。 18. 简答题(分值:10分)
(2)请根据表1-3的数据,完成该网店各时期的旺旺咨询转化率的计算。(注:旺旺咨询转化率是指通过阿里旺旺咨询客服成交的人数与咨询总人数的比值。旺旺咨询率=(旺旺咨询人数÷访客数)×100% 旺旺咨询转化率=(旺旺咨询成交人数÷旺旺咨询总人数)×100% ); (3)结合以上数据,总结一下访问深度和咨询率、咨询转化率之间的关系? 参考答案:(2)要计算旺旺咨询转化率,需要先计算旺旺咨询人数,由旺旺咨询率计算公式可知,旺旺咨询人数=旺旺咨询率×访客数,结果依次是221,161,103,169,计算出旺旺咨询人数后,完成旺旺咨询转化率的计算。 旺旺咨询转化率从上至下依次为: 15.84%、13.04%、12.62%、13.03%。 (3)访问深度越深,通常咨询率越高,咨询率越高,通常咨询转化率越高。 (课后习题)模块二基础数据采集 16. 简答题(分值:25分) 下图为某天猫店铺的推广数据,其中包含展现量、花费、点击量、点击率、成交额、投入产出比等数据,试从分析推广效果的角度制作数据采集表。
第四章 数据分析(梅长林)习题答案
第四章 习题 一、习题4.4 解:(1)通过SAS 的proc princomp 过程对相关系数矩阵R 做主成分分析,得到个主成分的贡献率以及累计贡献率如表1所 表 1 从表中可以得到特征值向量为: ]0.2429 0.4515 0.5396 0.8091 2.8567[=*λ 第一主成分贡献率为:57.13 % 第二主成分贡献率为:16.18 % 第三主成分贡献率为: 10.79% 第四主成分贡献率为:9.03 % 第五主成分贡献率为:6.86 % 进一步得到各主成分分析结果如表2所示: 表 2
(2)由(1)中得到的结果可知前两个主成分的累积贡献率为73.32%,得到第一主成分、第二主成分为: 54212.044215.034702.024571.014636.01x x x x x Y ++++=* 55820.045257.032604.025093.012404.02x x x x x Y ++---=* 由于1*Y 是五个标准化指标的加权和,由此第一主成分更能代表三种化工股票和两种石油股票周反弹率的综合作用效果,1*Y 越大表示各股票的综合周反弹率越大。* 2Y 中关于三种化工股票的周反弹率系数为 负,而关于两种石油的系数为正,它放映了两种石油周反弹率和三种化工股票周反弹率的对比,* 2Y 的绝对值越大, 表明两种石油周反弹率和三种化工股票周反弹率的差距越大。 二、习题4.5 解:(1)利用SAS 的proc corr 过程求得相关系数矩阵如表3: 表 3 (2)从相关系数矩阵出发,通过proc princomp 过程对其进行主成分分析,表4给出了各主成分的贡献率以及累积贡献率: