正则表达式元字符和元符号
正则表达式中的元字符和元符号
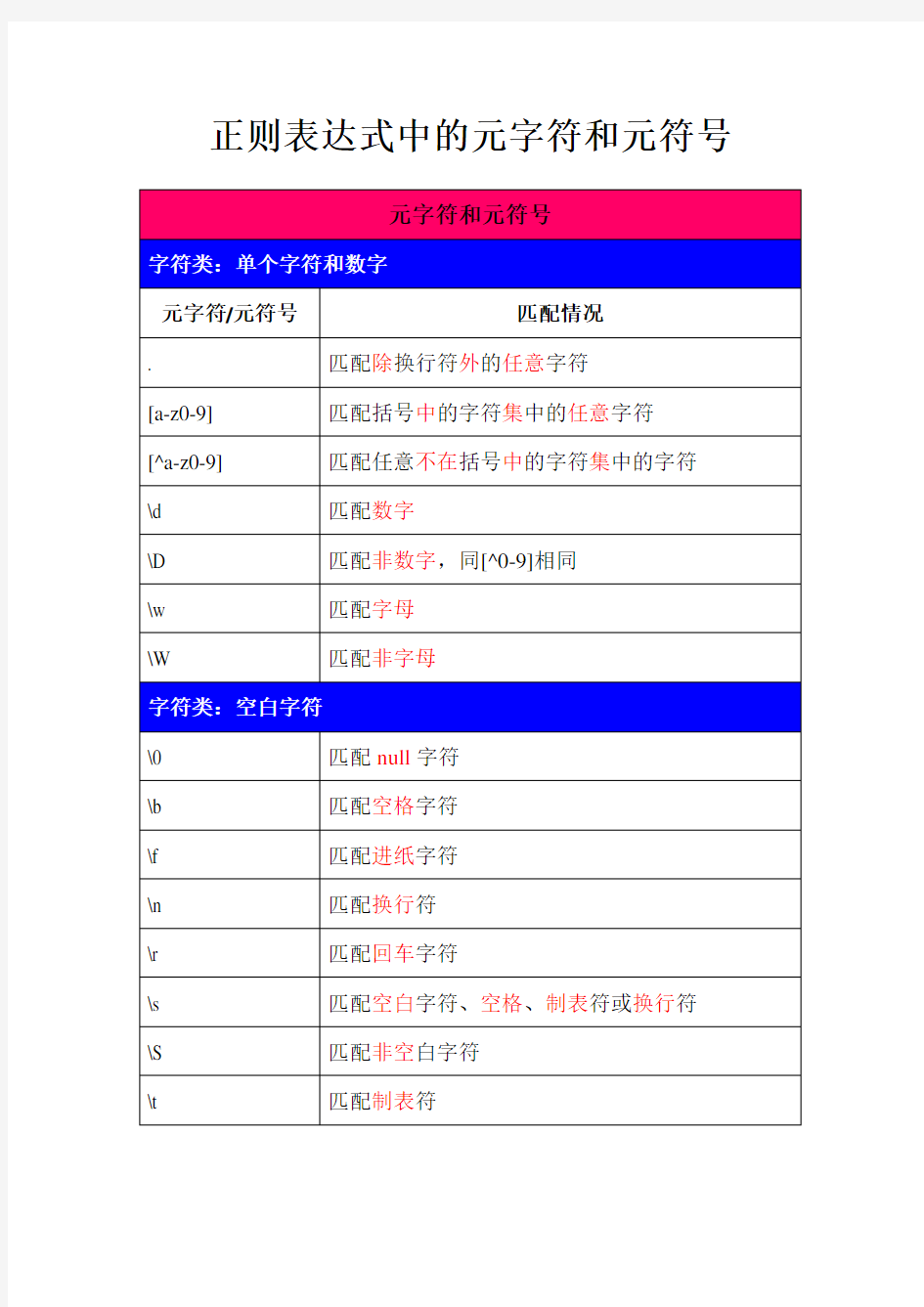
元字符和元符号
字符类:单个字符和数字
元字符/元符号匹配情况
. 匹配除换行符外的任意字符
[a-z0-9] 匹配括号中的字符集中的任意字符
[^a-z0-9] 匹配任意不在括号中的字符集中的字符
\d 匹配数字
\D 匹配非数字,同[^0-9]相同
\w 匹配字母
\W 匹配非字母
字符类:空白字符
\0 匹配null字符
\b 匹配空格字符
\f 匹配进纸字符
\n 匹配换行符
\r 匹配回车字符
\s 匹配空白字符、空格、制表符或换行符
\S 匹配非空白字符
\t 匹配制表符
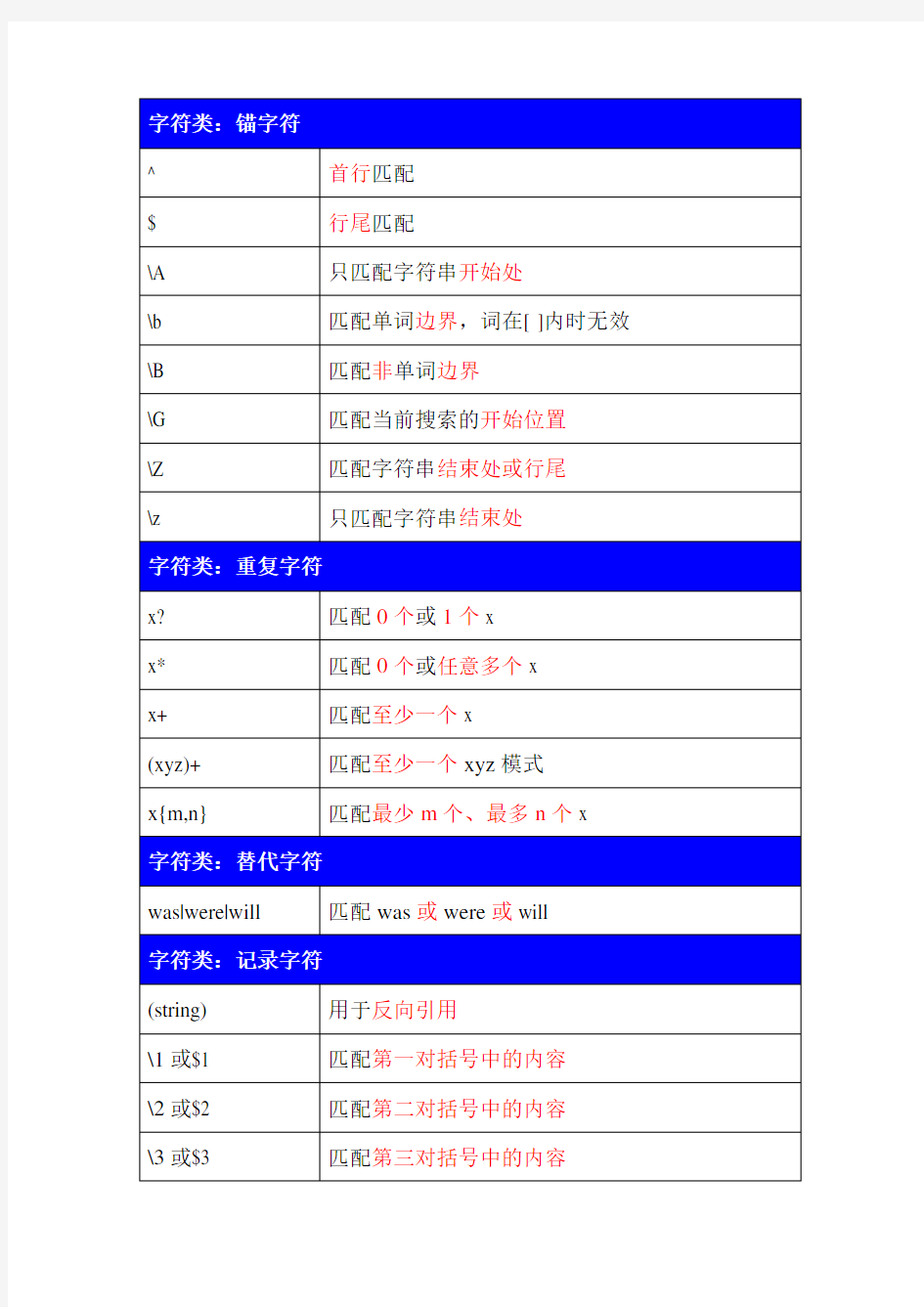
字符类:锚字符
^ 首行匹配
$ 行尾匹配
\A 只匹配字符串开始处
\b 匹配单词边界,词在[ ]内时无效\B 匹配非单词边界
\G 匹配当前搜索的开始位置
\Z 匹配字符串结束处或行尾
\z 只匹配字符串结束处
字符类:重复字符
x? 匹配0个或1个x
x* 匹配0个或任意多个x
x+ 匹配至少一个x
(xyz)+ 匹配至少一个xyz模式
x{m,n} 匹配最少m个、最多n个x
字符类:替代字符
was|were|will 匹配was或were或will
字符类:记录字符
(string) 用于反向引用
\1或$1 匹配第一对括号中的内容
\2或$2 匹配第二对括号中的内容
\3或$3 匹配第三对括号中的内容
JavaScript1.5中新加入的字符
(?:x) 匹配x但不记录匹配结果。这被称为非捕获括号。x(?=y) 当x后接y时匹配x。
x(?!y) 当x后不是y时匹配x。
单字符和一位元字符
元字符匹配情况
匹配除换行以外的任意字符
[a-z0-9_] 匹配字符集中的任意字符
[^a-z0-9_] 匹配不在字符集中的任意字符
元符号
元符号匹配内容对应字符
\d 数字[0-9]
\D 非数字[^0-9]
\s 非白字符(制表符、空格、换行符、回车、
换页符、垂直制表符)
\S 非空白字符
\w 单词字符[A-Za-z0-9_]
\W 非单词字符[^A-Za-z0-9_]
j s正则表达式
正则 正则:一个规则,它是用来处理字符串的,验证字符串是否符合某个规则(正则匹配),或者是把字符串中符合规则的内容取出来(正则捕获) 一个正则是由元字符组成的。 创建正则有两种方式(有一些区别) var reg1=/\d/;//字面量方式,代表包含0-9之间的任意一个数字即可var reg2=new RegExp("\\d");//实例创建方式 区别在于: 1.实例创建方式需要多转译一次,把具有特殊意思,并且带\的都要多转译一次。 2.字面量方式无法识别变量,而实例创建方式可以,也就是说实例创建可以进行我们的字符串拼接(把一个变量代表的值放到正则中作为规则)。 var reg1=/\d/; var reg2=new RegExp("\\d"); varreg=/zhufeng/; console.log(reg.test("welcome zhufeng student"));//true console.log(reg.test("welcome zhufeng student"));//false var c="w100"; varreg=/^"+c+"$/;//以"开头,出现一到多次,然后是c出现一到多次,最后以"结尾,而不是我们认为的字符串拼接 varreg=new RegExp("^"+c+"$");//此时只能包含w100的 正则中还包含修饰符:i(ignoreCase忽略大小写), m(multiline 匹配换行), g(global 全局匹配) varreg=/^[a-z]$/i; varreg=new RegExp("^[a-z]$","i"); console.log(reg.test("Z")); 具有特殊意义的元字符 \d :0-9之间任意一个数字 \ :转译字符 ^ :以某一个元字符开始 $ :以某一个元字符结束 \n :一个换行符 . :匹配除了\n以为的任何字符 x|y :x或者y [xyz] :x y z 三个中一个 [^xyz] :除三个中的任一个 [a-z] :a--z之间任意一个 [^a-z] :除了a--z之间任意一个
csharp正则表达式
学习笔记:正则表达式 2011-8-29 一.正则表达式 正则表达式(Regex)是用来进行文本处理的技术,是语言无关的,在几乎所有语言中都有实现。 一个正则表达式就是由普通的字符及特殊字符(称为元字符符)组成的文字模式。该模式秒杀在查找文章主体时待匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。 正则表达式的常用元字符(全为英文状态,注意可以代表的字符种类和个数): 元字符含义 .(点) 可以匹配除”\n”外的任意一个字符 [](中括号) 可以匹配中括号内的任意一个字符 例如,"[abc]" 匹配"plain"中的"a" |(或符号) 可以匹配或符号两边的任意一个字符,优先级比较低 匹配x 或y。例如"z|food" 可匹配"z" 或"food"。 正则表达式的常用限定符(全为英文状态): 元字符含义 *(星号) 其限定的表达式出现次数等于或大于0次 例如,"zo*"可以匹配"z"、"zoo" +(加号) 其限定的表达式至少出现1次 例如,"zo+"可以匹配"zoo",但不匹配"z" ?(问号) 其限定的表达式出现1次或0次 例如,"a?ve?"可以匹配"never"中的"ve" {n} 其限定的表达式出现次数确定n次(n≥0) {n,} 其限定的表达式至少出现n次 {n,m} 其限定的表达式出现的次数为≥n次,≤m次(m>n) 还有几个重要的符号: 符号含义 ^ (Shift+6)匹配输入的开始位置 非的意思。例如[^a-z],匹配非a-z的一个字符。 $ (Shift+4)匹配输入的结尾 \将下一个字符标记为特殊字符或字面值 例如:想匹配”.”时或其他特殊字符时,需写为的”\.” ()(小括号) 1.改变优先级 2.分组,提取信息 需要熟记一些简写: \d = [0-9]
编写正则表达式的常用符号
正则表达式中常用符号 符号含义举例或说明 .任何字符或非字符 2.4匹配204, 214, 2t4, 2 4, 2.4, 2-4 *重复0次或更多BA*匹配B,BA,BAA,BAAA等 .* 某个字符重复0次或更多R.* 表示R后面有0个过多个字符,不同类副词 的赋码包括RR,RG,PGQ,RGQV等, 所以R.*表示, 不分类笼统地指所有副词, 类似的所有名词 N.*,所有形容词J.* +重复1次或多次A+匹配A,AA,AAA等 ?有或者无BA?匹配B和BA .*?任何字符串 |或者(|号在回车键上面)(analyze|analyse) 检索analyse 或者 analyze [ ] 方括号中的任意字符或单词[abc]匹配a、b或c [abc]+匹配 [ ]* n个单词。 () 组合,使得括号中的部分可以当作 一个符号处理 act(ing)可以匹配act和acting (cat|dog),把dog 和cat 两个词一块检索出来, ([pos="R.*"][pos="J.*"]) 前面一个词的词性为副词, 后面一个词的词性为形容词,把副词和形容词作 为一个整体检索 {} { }表示选择范围,{0,3}表示0~3个 范围内[pos="J.*"]{0,2} 表示其前的形容词有0个,1个或者2个 [ ] {0,}中,[ ]表示任意单词,{0,2}表示这个单词有0个,1个,或者无穷个,后面一个数字不写表示无穷个。 & 和,并且
段首标记, “however|However”表示句首为However或 however 开头的句子 !不等于[word!=","] "which"表示which 前没有逗号 [pos!="JJ.*|N.*|I.*"] 词性不是形容词、名词、介词 的词 N.*名词、V.* 动词、J.*形容词、R.* 副词、AT.* 冠词、I.* 介词、P.*代词 VB.*表示be动词、VH*有动词、VV.*实意动词及其各种变形、VM*情态动词
find与grep命令简介及正则表达式
find与grep命令简介及正则表达式写给大家看的Shell脚本编程入门教程索引 两个更为有用的命令和正则表达式 在我们开始学习新的Shell编程知识之前,我们先来看一下两个更为有用的两个命令,这两个命令虽然并不是Shell的一部分,但是在进行Shell编程时却会经常用到.随后我们会来看一下正则表达式. find命令 我们先来看的是find命令.这个命令对于我们用来查找文件时是相当有用的,但是对于Linux新手来说却有一些难于使用,在一定程序是由于他所带的选项,测试,动作类型参数,而且一个参数的执行结果会影响接下来的参数. 在我们深入这些选项和参数之前,我们先来看一个非常简单的例子.假如在我们的机子上有一个文件wish.我们来进行这个操作时要以root身份来运行,这样就可以保证我们可以搜索整个机子: #find/-name wish-print /usr/bin/wish # 正如我们可以想到的,他会打印出搜索到的结果.很简单,是不是? 然而,他却需要一定的时间来运行,因为他也会同时搜索网络上的Window机器上的磁盘.Linux机器会挂载大块的Window机器的文件系统.他也会同时那些位置,虽然我们知道我们要查找的文件位于Linux机器上. 这也正是第一个选项的用武之地.如果我们指定了-mount选项,我们就可以告诉find命令不要搜索挂载的目录.
#find/-mount-name wish-print /usr/bin/wish # 这样我们仍然可以搜索这个文件,但是这一次并没有搜索挂载的文件系统. find命令的完整语法如下: find[path][options][tests][actions] path是一个很简单的部分:我们可以使用绝对路径,例如/bin,或者是使用相对路径,例如..如果我们需要我们还可以指定多个路径,例如find/var/home 主要的一些选项如下: -depth在查看目录本身以前要先搜索目录中的内容 -follow跟随符号链接 -maxdepths N在搜索一个目录时至多搜索N层 -mount(或-xdev)不要搜索其他的文件系统 下面的是一些test的选项.我们可以为find命令指定大量的测试,并且每一个测试会返回真或是假.当find命令工作时,他会考查顺序查找到的文件,并且会在这个文件上按顺序进行他们所定义的测试.如果一个测试返回假,find命令会停止他当前正在考查的文件并继续进行下面的动作.我们在下表中列出的只是一些我们最常用到的测试,我们可以通过查看手册页得到我们可以利用find 命令使用的可能的扩展列表项. -atime NN天以前访问的文件 -mtime NN天以前修改的文件
正则表达式
正则表达式 一、什么是这则表达式 正则表达式(regular expressions)是一种描述字符串集的方法,它是以字符串集中各字符串的共有特征为依据的。正则表达式可以用于搜索、编辑或者是操作文本和数据。它超出了java程序设计语言的标准语法,因此有必要去学习特定的语法来构建正则表达式。一般使用的java.util.regex API所支持的正则表达式语法。 二、测试用具 import java.io.BufferedReader; import java.io.InputStreamReader; import java.util.Scanner; import java.util.regex.Matcher; import java.util.regex.Pattern; public class Regex{ public static void main(String[]args)throws Exception{ BufferedReader br=new BufferedReader(new InputStreamReader(System.in)); if(br==null){ System.out.println("没有输入任何数据"); System.exit(1); } while(true){ System.out.print("输入表达式:"); Pattern pattern=https://www.360docs.net/doc/7e11149313.html,pile(br.readLine()); System.out.print("输入字符串:"); Matcher matcher=pattern.matcher(br.readLine()); boolean found=false; while(matcher.find()){ System.out.println("找到子字符串"+matcher.group()+" 开始于索引"+matcher.start()+"结束于索引"+matcher.end()+"\n") found=true; } if(!found){ System.out.println("没有找到子字符串\n"); } } } }
JS正则表达式大全
JS正则表达式大全 JS正则表达式大全【1】 正则表达式中的特殊字符【留着以后查用】字符含意 \ 做为转意,即通常在"\"后面的字符不按原来意义解释,如/b/匹配字符"b",当b前面加了反斜杆后/\b/,转意为匹配一个单词的边界。 -或- 对正则表达式功能字符的还原,如"*"匹配它前面元字符0次或多次,/a*/将匹配a,aa,aaa,加了"\"后,/a\*/将只匹配"a*"。 ^ 匹配一个输入或一行的开头,/^a/匹配"an A",而不匹配"An a" $ 匹配一个输入或一行的结尾,/a$/匹配"An a",而不匹配"an A" * 匹配前面元字符0次或多次,/ba*/将匹配b,ba,baa,baaa + 匹配前面元字符1次或多次,/ba*/将匹配ba,baa,baaa ? 匹配前面元字符0次或1次,/ba*/将匹配b,ba (x) 匹配x保存x在名为$1...$9的变量中 x|y 匹配x或y {n} 精确匹配n次 {n,} 匹配n次以上 {n,m} 匹配n-m次 [xyz] 字符集(character set),匹配这个集合中的任一一个字符(或元字符) [^xyz] 不匹配这个集合中的任何一个字符 [\b] 匹配一个退格符 \b 匹配一个单词的边界 \B 匹配一个单词的非边界 \cX 这儿,X是一个控制符,/\cM/匹配Ctrl-M \d 匹配一个字数字符,/\d/ = /[0-9]/ \D 匹配一个非字数字符,/\D/ = /[^0-9]/ \n 匹配一个换行符 \r 匹配一个回车符 \s 匹配一个空白字符,包括\n,\r,\f,\t,\v等 \S 匹配一个非空白字符,等于/[^\n\f\r\t\v]/ \t 匹配一个制表符 \v 匹配一个重直制表符 \w 匹配一个可以组成单词的字符(alphanumeric,这是我的意译,含数字),包括下划线,如[\w]匹配
awk正则表达式介绍
awk命令详解 简单使用: awk :对于文件中一行行的独处来执行操作。 awk -F :'{print $1,$4}' :使用‘:’来分割这一行,把这一行的第一第四个域打印出来。 详细介绍: AWK命令介绍 awk语言的最基本功能是在文件或字符串中基于指定规则浏览和抽取信息,awk抽取信息 后,才能进行其他文本操作,完整的awk脚本通常用来格式化文本文件中的信息 1.调用awk: 第一种命令行方式,如: awk [-Field-separator] 'commands' input-file(s) 这里commands是真正的awk命令,[-F域分隔符]是可选的,awk默认使用空格分隔, 因此如果要浏览域间有空格的文本,不必指定这个选项,但如果浏览如passwd文件,此文件 各域使用冒号作为分隔符,则必须使用-F选项: awk -F : 'commands' input-file 第二种,将所有awk命令插入一个文件,并使awk程序可执行,然后用awk命令解释器作为脚 本的首行,以便通过键入脚本名称来调用它 第三种,将所有awk命令插入一个单独文件,然后调用,如: awk -f awk-script-file input-file -f选项指明在文件awk-script-file的awk脚本,input-file是使用awk进行浏览 的文件名 2.awk脚本: awk脚本由各种操作和模式组成,根据分隔符(-F选项),默认为空格,读取的内容依次放置到 对应的域中,一行一行记录读取,直到文件尾 2.1.模式和动作
任何awk语句都是由模式和动作组成,在一个awk脚本中可能有许多语句。模式部分决定动作语句何时触发及触发事件。动作即对数据进行的操作,如果省去模式部分,动作将时刻保持执行状态 模式可以是任何条件语句或复合语句或正则表达式,模式包含两个特殊字段BEGIN和END,使用BEGIN语句设置计数和打印头,BEGIN语句使用在任何文本浏览动作之前,之后文本浏览动作依据输入文件开始执行;END语句用来在awk完成文本浏览动作后打印输出文本总数和结尾状态标志,有动作必须使用{}括起来 实际动作在大括号{}内指明,常用来做打印动作,但是还有更长的代码如if和循环looping 语句及循环退出等,如果不指明采取什么动作,awk默认打印出所有浏览出的记录 2.2.域和记录: awk执行时,其浏览标记为$1,$2...$n,这种方法称为域标记。使用$1,$3表示参照第1和第3域,注意这里使用逗号分隔域,使用$0表示使用所有域。例如: awk '{print $0}' temp.txt > sav.txt 表示打印所有域并把结果重定向到sav.txt中 awk '{print $0}' temp.txt|tee sav.txt 和上例相似,不同的是将在屏幕上显示出来 awk '{print $1,$4}' temp.txt 只打印出第1和第4域 awk 'BEGIN {print "NAME GRADE\n----"} {print $1"\t"$4}' temp.txt 表示打信息头,即输入的内容的第一行前加上"NAME GRADE\n-------------",同时内容以tab分开 awk 'BEGIN {print "being"} {print $1} END {print "end"}' temp 同时打印信息头和信息尾 2.3.条件操作符: <、<=、==、!=、>=、~匹配正则表达式、!~不匹配正则表达式
正则表达式
要想真正的用好正则表达式,正确的理解元字符是最重要的事情。下表列出了所有的元字符和对它们的一个简短的描述。 字符描述 \ 将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。例如,“\n”匹配字符“n”。“\\n”匹配一个换行符。序列“\\”匹配“\”而“\(”则匹配“(”。 ^ 匹配输入字符串的开始位置。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。 $ 匹配输入字符串的结束位置。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。 * 匹配前面的子表达式零次或多次。例如,zo*能匹配“z”以及“zoo”。*等价于{0,}。 + 匹配前面的子表达式一次或多次。例如,“z o+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 ? 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“does”或“does”中的“d o”。?等价于{0,1}。 {n} n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 {n,} n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“fo o o ood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 {n,m} m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 ? 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o?”将匹配单个“o”,而“o+”将匹配所有“o”。 点匹配除“\n”之外的任何单个字符。要匹配包括“\n”在内的任何字符,请使用像“[\s\S]”的模式。
js正则表达式使用
js正则表达式使用 一,概述 1,正则表达式,可以说是任何一种编程语言都提供的机制,它主要是提供了对字符串的处理能力。 2,正则表达式在页面处理中的使用场景: 1)表单验证。验证某些域符合某种规则,例如邮件输入框必须输入的是邮件、联系电话输入框输入的必须是数字等等 2)处理DOM模型。例如通过表达式定位DOM中的一个对象或一系列对象,一个例子就是定位id属性中含有某个特殊字符的div对象。 3)纯编程逻辑。直接用于编程的逻辑之中。 3,说明:本部分所举的正则表达式的代码片断,都是经过测试的,但有一点需要注意,对于换行的字符串的定义,我们在表述时使用的是类似如下的形式: var str=“It?s is a beautiful city”; 这种形式直接写在JS代码中是错误的,那如何获取具有换行的字符串呢?简单的办法:在textarea中输入文本并换行,然后将该值赋给JS变量即可。例如: var str=document.forms[0].mytextarea.value; 二,语法与使用 1,定义正则表达式 1)定义正则表达式有两种形式,一种是普通方式,一种是构造函数方式。 2)普通方式:var reg=/表达式/附加参数 表达式:一个字符串,代表了某种规则,其中可以使用某些特殊字符,来代表特殊的规则,后面会详细说明。 附加参数:用来扩展表达式的含义,目前主要有三个参数: g:代表可以进行全局匹配。 i:代表不区分大小写匹配。 m:代表可以进行多行匹配。 上面三个参数,可以任意组合,代表复合含义,当然也可以不加参数。 例子: var reg=/a*b/; var reg=/abc+f/g; 3)构造函数方式:var reg=new RegExp(“表达式”,”附加参数”); 其中“表达式”与“附加参数”的含义与上面那种定义方式中的含义相同。 例子: var reg=new RegExp(“a*b”); var reg=new RegExp(“abc+f”,”g”); 4)普通方式与构造函数方式的区别 普通方式中的表达式必须是一个常量字符串,而构造函数中的表达式可以是常量字符串,也可以是一个js变量,例如根据用户的输入来作为表达式参数等等: var reg=new RegExp(document.forms[0].exprfiled.value,”g”);
正则表达式
多少年来,许多的编程语言和工具都包含对正则表达式的支持,.NET基础类库中包含有一个名字空间和一系列可以充分发挥规则表达式威力的类,而且它们也都与未来的Perl 5中的规则表达式兼容。 此外,regexp类还能够完成一些其他的功能,例如从右至左的结合模式和表达式的编辑等。 在这篇文章中,我将简要地介绍System.Text.RegularExpression中的类和方法、一些字符串匹配和替换的例子以及组结构的详细情况,最后,还会介绍一些你可能会用到的常见的表达式。 应该掌握的基础知识 规则表达式的知识可能是不少编程人员“常学常忘”的知识之一。在这篇文章中,我们将假定你已经掌握了规则表达式的用法,尤其是Perl 5中表达式的用法。.NET的regexp类是Perl 5中表达式的一个超集,因此,从理论上说它将作为一个很好的起点。我们还假设你具有了C#的语法和.NET架构的基本知识。 如果你没有规则表达式方面的知识,我建议你从Perl 5的语法着手开始学习。在规则表达式方面的权威书籍是由杰弗里?弗雷德尔编写的《掌握表达式》一书,对于希望深刻理解表达式的读者,我们强烈建议阅读这本书。 RegularExpression组合体 regexp规则类包含在System.Text.RegularExpressions.dll文件中,在对应用软件进行编译时你必须引用这个文件,例如: csc r:System.Text.RegularExpressions.dll foo.cs 命令将创建foo.exe文件,它就引用了System.Text.RegularExpressions文件。 名字空间简介 在名字空间中仅仅包含着6个类和一个定义,它们是: Capture: 包含一次匹配的结果; CaptureCollection: Capture的序列; Group: 一次组记录的结果,由Capture继承而来; Match: 一次表达式的匹配结果,由Group继承而来; MatchCollection: Match的一个序列; MatchEvaluator: 执行替换操作时使用的代理; Regex: 编译后的表达式的实例。 Regex类中还包含一些静态的方法: Escape: 对字符串中的regex中的转义符进行转义; IsMatch: 如果表达式在字符串中匹配,该方法返回一个布尔值; Match: 返回Match的实例; Matches: 返回一系列的Match的方法; Replace: 用替换字符串替换匹配的表达式; Split: 返回一系列由表达式决定的字符串; Unescape:不对字符串中的转义字符转义。
常用正则表达式
1. 平时做网站经常要用正则表达式,下面是一些讲解和例子,仅供大家参考和修改使用: 2. "^\d+$"//非负整数(正整数+ 0) 3. "^[0-9]*[1-9][0-9]*$"//正整数 4. "^((-\d+)|(0+))$"//非正整数(负整数+ 0) 5. "^-[0-9]*[1-9][0-9]*$"//负整数 6. "^-?\d+$"//整数 7. "^\d+(\.\d+)?$"//非负浮点数(正浮点数+ 0) 8. "^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$"//正浮点数 9. "^((-\d+(\.\d+)?)|(0+(\.0+)?))$"//非正浮点数(负浮点数+ 0) 10. "^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$"//负浮点数 11. "^(-?\d+)(\.\d+)?$"//浮点数 12. "^[A-Za-z]+$"//由26个英文字母组成的字符串 13. "^[A-Z]+$"//由26个英文字母的大写组成的字符串 14. "^[a-z]+$"//由26个英文字母的小写组成的字符串 15. "^[A-Za-z0-9]+$"//由数字和26个英文字母组成的字符串 16. "^\w+$"//由数字、26个英文字母或者下划线组成的字符串 17. "^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$"//email地址 18. "^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$"//url 19. /^(d{2}|d{4})-((0([1-9]{1}))|(1[1|2]))-(([0-2]([1-9]{1}))|(3[0|1]))$/ // 年-月-日 20. /^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})$/ // 月/日/年 21. "^([w-.]+)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(([w-]+.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(]?)$" //Emil 22. /^((\+?[0-9]{2,4}\-[0-9]{3,4}\-)|([0-9]{3,4}\-))?([0-9]{7,8})(\-[0-9]+)?$/ //电话号码 23. "^(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}| 1dd|2[0-4]d|25[0-5])$" //IP地址 24. 25. 匹配中文字符的正则表达式:[\u4e00-\u9fa5] 26. 匹配双字节字符(包括汉字在内):[^\x00-\xff] 27. 匹配空行的正则表达式:\n[\s| ]*\r 28. 匹配HTML标记的正则表达式:/<(.*)>.*<\/\1>|<(.*) \/>/ 29. 匹配首尾空格的正则表达式:(^\s*)|(\s*$) 30. 匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)* 31. 匹配网址URL的正则表达式:^[a-zA-z]+://(\\w+(-\\w+)*)(\\.(\\w+(-\\w+)*))*(\\?\\S*)?$ 32. 匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$ 33. 匹配国内电话号码:(\d{3}-|\d{4}-)?(\d{8}|\d{7})? 34. 匹配腾讯QQ号:^[1-9]*[1-9][0-9]*$ 35. 36. 37. 元字符及其在正则表达式上下文中的行为:
js 验证各种格式类型的正则表达式
JavaScript code: