网页数据获取方法

https://www.360docs.net/doc/8a1437873.html,
网页数据获取方法
大数据时代,面对大量的网页数据,您不知道如何处理?或者是为编写爬虫代码而发愁?不管您是属于哪一类,不管您是有基础或是零基础,只要您看完这篇教程,可以学会网页数据获取方法。本文就给大家推荐一款可以自动抓取数据的工具——八爪鱼。
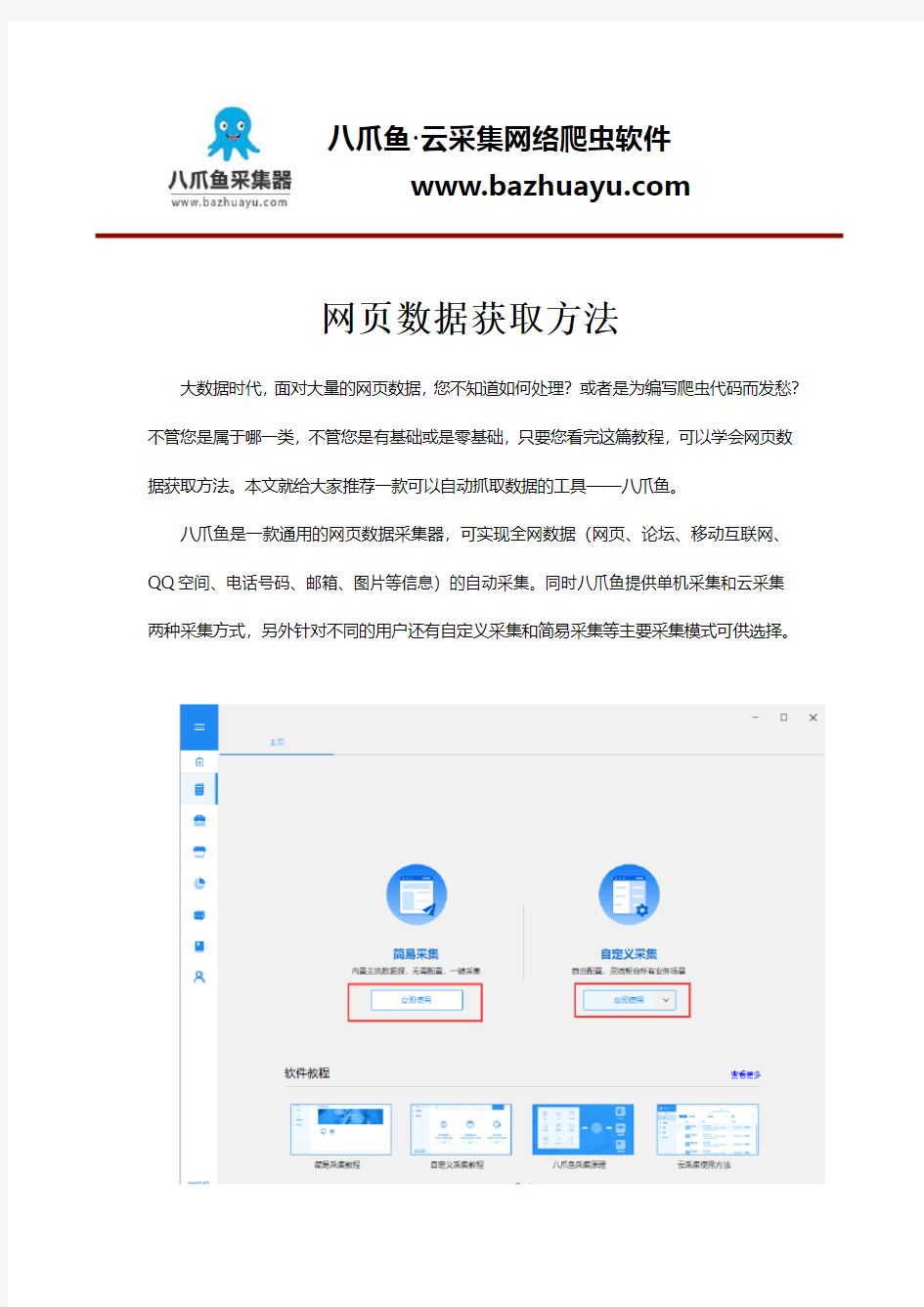
八爪鱼是一款通用的网页数据采集器,可实现全网数据(网页、论坛、移动互联网、QQ空间、电话号码、邮箱、图片等信息)的自动采集。同时八爪鱼提供单机采集和云采集两种采集方式,另外针对不同的用户还有自定义采集和简易采集等主要采集模式可供选择。
https://www.360docs.net/doc/8a1437873.html,
如果想要自动抓取数据呢,八爪鱼的自动采集就派上用场了。
定时采集是八爪鱼采集器为需要持续更新网站信息的用户提供的精确到分钟的,可以设定采集时间段的功能。在设置好正确的采集规则后,八爪鱼会根据设置的时间在云服务器启动采集任务进行数据的采集。定时采集的功能必须使用云采集的时候,才会进行数据的采集,单机采集是无法进行定时采集的。
定时云采集的设置有两种方法:
方法一:任务字段配置完毕后,点击‘选中全部’→‘采集以下数据’→‘保存并开始采集’,进入到“运行任务”界面,点击‘设置定时云采集’,弹出‘定时云采集’配置页面。
https://www.360docs.net/doc/8a1437873.html,
第一、如果需要保存定时设置,在‘已保存的配置’输入框内输入名称,再保存配置,保存成功之后,下次如果其他任务需要同样的定时配置时可以选择这个配置。
第二、定时方式的设置有4种,可以根据自己的需求选择启动方式和启动时间。所有设置完成之后,如果需要启动定时云采集选择下方‘保存并启动’定时采集,然后点击确定即可。如果不需要启动只需点击下方‘保存’定时采集设置即可。
https://www.360docs.net/doc/8a1437873.html,
方法二:在任务列表页面,每个任务名称右方都有‘更多操作’选项,点击之后,在下拉选项中选择云采集设置定时,同样可以进行上述操作。
相关采集教程:
循环翻页爬取网页数据
https://www.360docs.net/doc/8a1437873.html,/tutorial/gnd/xunhuan
ajax网页数据抓取
h ttp://https://www.360docs.net/doc/8a1437873.html,/tutorial/gnd/ajaxlabel
https://www.360docs.net/doc/8a1437873.html,
网页数据导出
https://www.360docs.net/doc/8a1437873.html,/tutorial/gnd/dataexport
网页数据提取方法,以添加特殊字段、上移下移、导入导出举例
https://www.360docs.net/doc/8a1437873.html,/tutorial/tjtszd_7
网页数据采集如何模拟手机端,以百姓网手机端采集为例
https://www.360docs.net/doc/8a1437873.html,/tutorial/mnsj_7
网页数据采集相对XPATH使用教程
https://www.360docs.net/doc/8a1437873.html,/tutorial/xdxpath-7
新浪微博网页数据采集,通过微博关键词搜索为例
https://www.360docs.net/doc/8a1437873.html,/tutorial/wbgjcss-7
腾讯网网页数据常见的几种采集方法,以简易模式
举例https://www.360docs.net/doc/8a1437873.html,/tutorial/txw
八爪鱼——90万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
https://www.360docs.net/doc/8a1437873.html,
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。
3、云采集,关机也可以。配置好采集任务后可关机,任务可在云端执行。庞大云采集集群24*7不间断运行,不用担心IP被封,网络中断。
4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的基本采集需求。同时设置了一些增值服务(如私有云),满足高端付费企业用户的需要。
网页链接提取方法
https://www.360docs.net/doc/8a1437873.html, 网页链接提取方法 网页链接的提取是数据采集中非常重要的部分,当我们要采集列表页的数据时,除了列表标题的链接还有页码的链接,数据采集只采集一页是不够,还要从首页遍历到末页直到把所有的列表标题链接采集完,然后再用这些链接采集详情页的信息。若仅仅靠手工打开网页源代码一个一个链接复制粘贴出来,太麻烦了。掌握网页链接提取方法能让我们的工作事半功倍。在进行数据采集的时候,我们可能有提取网页链接的需求。网页链接提取一般有两种情况:提取页面内的链接;提取当前页地址栏的链接。针对这两种情况,八爪鱼采集器均有相关功能实现。下面介绍一个网页链接提取方法。 一、八爪鱼提取页面内的超链接 在网页里点击需要提取的链接,选择“采集以下链接地址”
https://www.360docs.net/doc/8a1437873.html, 网页链接提取方法1 二、八爪鱼提取当前地址栏的超链接 从左边栏拖出一个提取数据的步骤出来(如果当前页已经有其他的提取字段,这一步可省略)点击“添加特殊字段”,选择“添加当前页面网址”。可以看到,当前地址栏的超链接被抓取下来
https://www.360docs.net/doc/8a1437873.html, 网页链接提取方法2 而批量提取网页链接的需求,一般是指批量提取页面内的超链接。以下是一个使用八爪鱼批量提取页面内超链接的完整示例。 采集网站: https://https://www.360docs.net/doc/8a1437873.html,/search?initiative_id=tbindexz_20170918&ie=utf8&spm=a21 bo.50862.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=手表&suggest=history_1&_input_charset=utf-8&wq=&suggest_query=&source=sugg est
网页数据抓取分析
1、抓取网页数据通过指定的URL,获得页面信息,进而对页面用DOM进行 NODE分析, 处理得到原始HTML数据,这样做的优势在于,处理某段数据的灵活性高,难点在节算法 需要优化,在页面HTML信息大时,算法不好,会影响处理效率。 2、htmlparser框架,对html页面处理的数据结构,HtmlParser采用了经典的Composite 模式,通过RemarkNode、TextNode、TagNode、AbstractNode和Tag来描述HTML页面 各元素。Htmlparser基本上能够满足垂直搜索引擎页面处理分析的需求,映射HTML标签,可方便获取标签内的HTML CODE。 Htmlparser官方介绍: htmlparser是一个纯的java写的html解析的库,它不依赖于其它的java库文件,主要用于改造或提取html。它能超高速解析html,而且不会出错。现在htmlparser最新版本为2.0。毫不夸张地说,htmlparser就是目前最好的html解析和分析 的工具。 3、nekohtml框架,nekohtml在容错性、性能等方面的口碑上比htmlparser好(包括htmlunit也用的是nekohtml),nokehtml类似XML解析原理,把html标签确析为dom, 对它们对应于DOM树中相应的元素进行处理。 NekoHTML官方介绍:NekoHTML是一个Java语言的HTML扫描器和标签补全器(tag balancer) ,使得程序能解析HTML文档并用标准的XML接口来访问其中的信息。这个解析 器能够扫描HTML文件并“修正”许多作者(人或机器)在编写HTML文档过程中常犯的错误。 NekoHTML能增补缺失的父元素、自动用结束标签关闭相应的元素,以及不匹配的内嵌元 素标签。NekoHTML的开发使用了Xerces Native Interface (XNI),后者是Xerces2的实现基础。由https://www.360docs.net/doc/8a1437873.html,/整理
网站爬虫如何爬取数据
https://www.360docs.net/doc/8a1437873.html, 网站爬虫如何爬取数据 大数据时代,用数据做出理性分析显然更为有力。做数据分析前,能够找到合适的的数据源是一件非常重要的事情,获取数据的方式有很多种,最简便的方法就是使用爬虫工具抓取。今天我们用八爪鱼采集器来演示如何去爬取网站数据,以今日头条网站为例。 采集网站: https://https://www.360docs.net/doc/8a1437873.html,/ch/news_hot/ 步骤1:创建采集任务 1)进入主界面选择,选择“自定义模式” 网站爬虫如何爬取数据图1
https://www.360docs.net/doc/8a1437873.html, 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 网站爬虫如何爬取数据图2 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容
https://www.360docs.net/doc/8a1437873.html, 网站爬虫如何爬取数据图3 步骤2:设置ajax页面加载时间 ●设置打开网页步骤的ajax滚动加载时间 ●找到翻页按钮,设置翻页循环 ●设置翻页步骤ajax下拉加载时间 1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定
https://www.360docs.net/doc/8a1437873.html, 网站爬虫如何爬取数据图4 注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量
https://www.360docs.net/doc/8a1437873.html, 网站爬虫如何爬取数据图5 步骤3:采集新闻内容 创建数据提取列表 1)如图,移动鼠标选中评论列表的方框,右键点击,方框底色会变成绿色 然后点击“选中子元素”
URL 筛选小工具 提取网页中的链接地址
这个VBS是用来将一个本地网页中的URL筛选出来并保存在新的网页文件中。当然,只要改变里面的正则表达式,就可以作其他用途了。 使用方法:将下面的代码保存为jb51.vbs 然后拖动你保存在本地的htm页面,拖放在这个vbs即可 代码如下: '备注:URL筛选小工具 '防止出现错误 On Error Resume Next 'vbs代码开始---------------------------------------------- Dim p,s,re If Wscript.Arguments.Count=0 Then Msgbox "请把网页拖到本程序的图标上!",,"提示" Wscript.Quit End If For i= 0 to Wscript.Arguments.Count - 1 p=Wscript.Arguments(i) With CreateObject("Adodb.Stream") .Type=2 .Charset="GB2312"s) s="" For Each Match In Matches s=s & "<a href=""" & Match.Value & """>" & Match.Value & "<p>" Next re.Pattern= "&\w+;?|\W{5,}" s=re.Replace(s,"") .Position=0 .setEOS .WriteText s .SaveToFile p & "'s URLs.html",2 .Close End With Next Msgbox "网址列表已经生成!",,"成功" 'vbs代码结束----------------------------------------------
python抓取网页数据的常见方法
https://www.360docs.net/doc/8a1437873.html, python抓取网页数据的常见方法 很多时候爬虫去抓取数据,其实更多是模拟的人操作,只不过面向网页,我们看到的是html在CSS样式辅助下呈现的样子,但爬虫面对的是带着各类标签的html。下面介绍python抓取网页数据的常见方法。 一、Urllib抓取网页数据 Urllib是python内置的HTTP请求库 包括以下模块:urllib.request 请求模块、urllib.error 异常处理模块、urllib.parse url解析模块、urllib.robotparser robots.txt解析模块urlopen 关于urllib.request.urlopen参数的介绍: urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None) url参数的使用 先写一个简单的例子:
https://www.360docs.net/doc/8a1437873.html, import urllib.request response = urllib.request.urlopen(' print(response.read().decode('utf-8')) urlopen一般常用的有三个参数,它的参数如下: urllib.requeset.urlopen(url,data,timeout) response.read()可以获取到网页的内容,如果没有read(),将返回如下内容 data参数的使用 上述的例子是通过请求百度的get请求获得百度,下面使用urllib的post请求 这里通过https://www.360docs.net/doc/8a1437873.html,/post网站演示(该网站可以作为练习使用urllib的一个站点使用,可以 模拟各种请求操作)。 import urllib.parse import urllib.request data = bytes(urllib.parse.urlencode({'word': 'hello'}), encoding='utf8')
如何抓取网页数据
https://www.360docs.net/doc/8a1437873.html, 如何抓取网页数据 很多用户不懂爬虫代码,但是却对网页数据有迫切的需求。那么怎么抓取网页数据呢? 本文便教大家如何通过八爪鱼采集器来采集数据,八爪鱼是一款通用的网页数据采集器,可以在很短的时间内,轻松从各种不同的网站或者网页获取大量的规范化数据,帮助任何需要从网页获取信息的客户实现数据自动化采集,编辑,规范化,摆脱对人工搜索及收集数据的依赖,从而降低获取信息的成本,提高效率。 本文示例以京东评论网站为例 京东评价采集采集数据字段:会员ID,会员级别,评价星级,评价内容,评价时间,点赞数,评论数,追评时间,追评内容,页面网址,页面标题,采集时间。 需要采集京东内容的,在网页简易模式界面里点击京东进去之后可以看到所有关于京东的规则信息,我们直接使用就可以的。
https://www.360docs.net/doc/8a1437873.html, 京东评价采集步骤1 采集京东商品评论(下图所示)即打开京东主页输入关键词进行搜索,采集搜索到的内容。 1、找到京东商品评论规则然后点击立即使用
https://www.360docs.net/doc/8a1437873.html, 京东评价采集步骤2 2、简易模式中京东商品评论的任务界面介绍 查看详情:点开可以看到示例网址 任务名:自定义任务名,默认为京东商品评论 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组 商品评论URL列表:提供要采集的网页网址,即商品评论页的链接。每个商品的链接必须以#comment结束,这个链接可以在商品列表点评论数打开后进行复制。或者自己打开商品链接后手动添加,如果没有这个后缀可能会报错。多个商品评论输入多个商品网址即可。 将鼠标移动到?号图标可以查看详细的注释信息。 示例数据:这个规则采集的所有字段信息。
教你如何提取网页中的视频、音乐歌曲、
教你如何提取网页中的视频、音乐歌曲、flash、图片等多媒体文件(很实用) 打开网页后,发现里面有好看的视频、好听的音乐、好看的图片、很炫的flash,是不是想把它们弄到自己电脑上或手机、mp4上?但很多时候视频无法下载,音乐只能试听,或者好听的背景音乐根本就不知道什么名字,更别说怎么下了;至于图片直接右键另存为即可,不过如果网页突然关掉了,但又想把看过的图片弄下来,而忘了图片网页地址或者不想再通过历史记录打开,这时又该怎么办? 其实这些问题都能很好的解决,并且很简单,只要用一个软件 来替你从电脑的缓存中搜索一下就OK了,因为网页中显示的内容基本 上全部都在缓存中,如果自己手动搜索,那将是很累人滴,又不好找,东西太多,又没分类。 无意中发现一个小软件很强(对此感兴趣,本人玩过无数小软件),我一直在用,也是用它帮了很多网友的忙,为了让更多的网友解决问题,于是拿来和亲们分享一下。不废话了,下面进入主题: 这款免费小软件就是YuanBox(元宝箱)v1.6,百度一搜就能下载。 下面是我自己整理的使用步骤,供亲们参考(其实不用看就行,软件简单,不用学就会),我只是用的时间长了,很熟练罢了: 软件下好后,解压,打开里面的YuanBox.exe即可,不用安装;打开此软件前,先打开你要提取东西的网页(之后再关掉也行),这是为了保证电脑缓存中有你要的东西。 运行软件,初始界面如下图:
之后直接是flv格式视频搜索结果的界面,原因就是此软件的全称是 元宝箱FLV视频下载专家,不想要视频的话,点击最上面的设置或者最下面的高级设置,即可进行搜索范围设定
下面是搜索条件设定界面 以swf格式flash为例,进行搜索,选择类型中的第二项 点击确定,开始搜索,结果如下:
网页数据抓取方法详解
https://www.360docs.net/doc/8a1437873.html, 网页数据抓取方法详解 互联网时代,网络上有海量的信息,有时我们需要筛选找到我们需要的信息。很多朋友对于如何简单有效获取数据毫无头绪,今天给大家详解网页数据抓取方法,希望对大家有帮助。 八爪鱼是一款通用的网页数据采集器,可实现全网数据(网页、论坛、移动互联网、QQ空间、电话号码、邮箱、图片等信息)的自动采集。同时八爪鱼提供单机采集和云采集两种采集方式,另外针对不同的用户还有自定义采集和简易采集等主要采集模式可供选择。
https://www.360docs.net/doc/8a1437873.html, 如果想要自动抓取数据呢,八爪鱼的自动采集就派上用场了。 定时采集是八爪鱼采集器为需要持续更新网站信息的用户提供的精确到分钟的,可以设定采集时间段的功能。在设置好正确的采集规则后,八爪鱼会根据设置的时间在云服务器启动采集任务进行数据的采集。定时采集的功能必须使用云采集的时候,才会进行数据的采集,单机采集是无法进行定时采集的。 定时云采集的设置有两种方法: 方法一:任务字段配置完毕后,点击‘选中全部’→‘采集以下数据’→‘保存并开始采集’,进入到“运行任务”界面,点击‘设置定时云采集’,弹出‘定时云采集’配置页面。
https://www.360docs.net/doc/8a1437873.html, 第一、如果需要保存定时设置,在‘已保存的配置’输入框内输入名称,再保存配置,保存成功之后,下次如果其他任务需要同样的定时配置时可以选择这个配置。 第二、定时方式的设置有4种,可以根据自己的需求选择启动方式和启动时间。所有设置完成之后,如果需要启动定时云采集选择下方‘保存并启动’定时采集,然后点击确定即可。如果不需要启动只需点击下方‘保存’定时采集设置即可。
我用ajax获取后台数据并展示在前端页面的方法【源码】
我用ajax获取后台数据并展示在前端页面的方法【源码】 WEB前端开发与传统的网页制作最大的一个区别就是:以前的网页制作只是涉及到一些图片制作、切图、然后实现静态页面的布局;而WEB前端开发既然涉及到开发,就会和后台打交道,后台或数据库里边的信息要根据用户的需求显示在前端特定的位置上,供用户查看。所以现在的前端开发不仅仅是会点div、css或者是简单的javascript特效就可以了。 今天为大家说一下如何运用Ajax调用后台数据显示在前端页面。 源码中有详细的注释说明,只要懂得Ajax的基本工作原理和javascript和运行机制,就能看得懂。 下面是我在本地环境中测试的案例源代码: HTML部分:
如何利用爬虫爬取马蜂窝千万+数据
https://www.360docs.net/doc/8a1437873.html, 如何利用爬虫爬取马蜂窝千万+数据 最近有人爬了马蜂窝的1800万数据就刷爆了网络,惊动了互联网界和投资界,背后的数据团队也因此爆红。 你一定会想像这个团队像是电影里演的非常牛掰黑客一样的人物吧? 你以为爬数据一定要懂爬虫写代码、懂Python才能爬取网络数据是吧? 小八告诉你,过去可能是,但现在真的不!是!
https://www.360docs.net/doc/8a1437873.html, 爬这样千万级数据的工作,我们绝大部分人即使不懂写代码,都可以实现。 如何实现? 就是利用「数据爬虫工具」。 目前的爬虫工具已经趋向于简易、智能、可视化了,即使不懂代码和爬虫的小白用户都可以用。 比如在全球坐拥百万用户粉丝的八爪鱼数据采集器。 简单来说,用八爪鱼 爬取马蜂窝数据只要4个步骤。这里我们以爬取【马蜂窝景点点评数据】举例。
https://www.360docs.net/doc/8a1437873.html, ★ 第一步 打开马蜂窝,选择某城市的景点页面,(本文以采集成都景点点评为例) 第二步 用八爪鱼爬取马蜂窝的成都的top30景点页面超链接url地址
https://www.360docs.net/doc/8a1437873.html, 八爪鱼采集成都top30 景点网址url
https://www.360docs.net/doc/8a1437873.html, 第三步 用八爪鱼简易模板「蚂蜂窝国内景点点评爬虫」 第四步 导出数据到EXCEL。
https://www.360docs.net/doc/8a1437873.html, 小八只花了15分钟的时间就采集到成都TOP热门30景点的842条点评数据。如果同时运行多个客户端并使用使用云采集,将会更快。 (由于只是示例,每个景点小八只采集了842条评,如果有需要可以采集更多,这个可自己设置) 爬取结果
网页信息抓取软件使用方法
https://www.360docs.net/doc/8a1437873.html, 网页信息抓取软件使用方法 在日常工作生活中,有时候经常需要复制网页上的文字内容,比如淘宝、天猫、京东等电商类网站的商品数据;微信公众号、今日头条、新浪博客等新闻文章数据。收集这些数据,一般都需要借助网页信息抓取软件。市面上抓取的小工具有很多,但真正好用,功能强大,操作又简单的,却屈指可数。下面就为大家介绍一款免费的网页信息抓取软件,并详细介绍其使用方法。 本文介绍使用八爪鱼采集器采集新浪博客文章的方法。 采集网站: https://www.360docs.net/doc/8a1437873.html,/s/articlelist_1406314195_0_1.html 采集的内容包括:博客文章正文,标题,标签,分类,日期。 步骤1:创建新浪博客文章采集任务 1)进入主界面,选择“自定义采集”
https://www.360docs.net/doc/8a1437873.html, 2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/8a1437873.html, 步骤2:创建翻页循环 1)打开网页之后,打开右上角的流程按钮,使制作的流程可见状态。点击页面下方的“下一页”,如图,选择“循环点击单个链接”,翻页循环创建完成。(可在左上角流程中手动点击“循环翻页”和“点击翻页”几次,测试是否正常翻页。)
https://www.360docs.net/doc/8a1437873.html, 2)由于进入详情页时网页加载很慢,网址一直在转圈状态,无法立即执行下一个步骤,因此在“循环翻页”的高级选项里设置“ajax 加载数据”,超时时间设置为5秒,点击“确定”。
https://www.360docs.net/doc/8a1437873.html, 步骤3:创建列表循环 1)鼠标点击列表目录中第一个博文,选择操作提示框中的“选中全部”。
网站数据爬取方法
https://www.360docs.net/doc/8a1437873.html, 网站数据爬取方法 网站数据主要是指网页上的文字,图像,声音,视频这几类,在告诉的信息化时代,如何去爬取这些网站数据显得至关重要。对于程序员或开发人员来说,拥有编程能力使得他们能轻松构建一个网页数据抓取程序,但是对于大多数没有任何编程知识的用户来说,一些好用的网络爬虫软件则显得非常的重要了。以下是一些使用八爪鱼采集器抓取网页数据的几种解决方案: 1、从动态网页中提取内容。 网页可以是静态的也可以是动态的。通常情况下,您想要提取的网页内容会随着访问网站的时间而改变。通常,这个网站是一个动态网站,它使用AJAX技术或其他技术来使网页内容能够及时更新。AJAX即延时加载、异步更新的一种脚本技术,通过在后台与服务器进行少量数据交换,可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
https://www.360docs.net/doc/8a1437873.html, 表现特征为点击网页中某个选项时,大部分网站的网址不会改变;网页不是完全加载,只是局部进行了数据加载,有所变化。这个时候你可以在八爪鱼的元素“高级选项”的“Ajax加载”中可以设置,就能抓取Ajax加载的网页数据了。 八爪鱼中的AJAX加载设置
https://www.360docs.net/doc/8a1437873.html, 2.从网页中抓取隐藏的内容。 你有没有想过从网站上获取特定的数据,但是当你触发链接或鼠标悬停在某处时,内容会出现?例如,下图中的网站需要鼠标移动到选择彩票上才能显示出分类,这对这种可以设置“鼠标移动到该链接上”的功能,就能抓取网页中隐藏的内容了。 鼠标移动到该链接上的内容采集方法
https://www.360docs.net/doc/8a1437873.html, 在滚动到网页底部之后,有些网站只会出现一部分你要提取的数据。例如今日头条首页,您需要不停地滚动到网页的底部以此加载更多文章内容,无限滚动的网站通常会使用AJAX或JavaScript来从网站请求额外的内容。在这种情况下,您可以设置AJAX超时设置并选择滚动方法和滚动时间以从网页中提取内容。
php获取网页内容方法
1.file_get_contents获取网页内容 2.curl获取网页内容 3.fopen->fread->fclose获取网页内容
从网站资源中轻松提取资料
从网站资源中轻松提取资料 1、从图片中提取文字 现在许多网站都有电子书下载,常见的格式有exe、chm、pdf等。为了保护作者的权益,这些电子书可以看,但是其中的内容却不能进行复制,因为它简直就像一幅图片一样。如果我们需要使用这些资料中的文本内容的话,是不是就一定要重新输入一遍呢?当然不用这么麻烦。下面就为大家介绍如何将这些内容从资料中提取出来。 第一种方法:用SnagIt工具进行文字提取。 首先使用SnagIt的文字捕捉功能将文字提取出来。SnagIt当前版本为7.1.1,大小为9756 KB,下载链接:https://www.360docs.net/doc/8a1437873.html,:8080/down/snagit.exe。启动SnagIt ,选择菜单“输入/区域”,选择菜单“工具/文字捕获”。 然后我们打开要捕捉的文件窗口,按下捕捉快捷键,选定捕捉区域即可捕捉到文字。 接着用相应工具重排文字。此时我们发现提取的文字可能会有很多空格或段落错乱等现象,而且字号、字体等不合自己的心意。这时我们可以用熟悉的Wps和Word软件进行重新编排。我们以Wps Office 2003为例看看如何对付提取后文章的编排。 用Wps Officd 2003打开提取文章;然后选择“工具”菜单下的“文字”\“段落重排”。
这时你会看到提取文章重新进行排版;接下来选择“工具”菜单下的“文字”\“删除段首空格”命令,使得文章的每段参差不齐的行首空格被删除;再选择“工具”菜单下的“文字”\“增加段首空格”,文章变为正常的书写格式;提取文章一般都留有空段,为删除这些空段,继续选择“工具”菜单下的“文字”\“删除空段”命令,这时文章完全变为我们所要的形式;用你熟悉的界面任意编辑(格式化)文章吧。 第二种方法:用屏幕截图然后让OCR软件识别。 打开带有文字的图片或电子书籍,翻页到你希望提取的页面,点击键盘上的捕获键(Print Screen)进行屏幕捕获;打开Windows自带的画图工具,将刚才捕获的屏幕截图,粘贴进去,保存为一个.bmp文件;接着打开刚才保存的文件,在编辑器中进行修正,根据你所要提取的文字进行裁剪,尽量去除不要的部分;最后启动OCR软件,在OCR中打开刚才保存的修改文件,进行文字识别,然后可随心所欲进行编辑。
如何抓取网页数据
网页源码中规则数据的获取过程: 第一步:获取网页源码。 第二步:使用正则表达式匹配抽取所需要的数据。 第三步:将结果进行保存。 这里只介绍第一步。 https://www.360docs.net/doc/8a1437873.html,.HttpWebRequest; https://www.360docs.net/doc/8a1437873.html,.HttpWebResponse; System.IO.Stream; System.IO.StreamReader; System.IO.FileStream; 通过C#程序来获取访问页面的内容(网页源代码)并实现将内容保存到本机的文件中。 方法一是通过https://www.360docs.net/doc/8a1437873.html,的两个关键的类 https://www.360docs.net/doc/8a1437873.html,.HttpWebRequest; https://www.360docs.net/doc/8a1437873.html,.HttpWebResponse; 来实现的。 具体代码如下 方案0:网上的代码,看明白这个就可以用方案一和方案二了 HttpWebRequest httpReq; HttpWebResponse httpResp; string strBuff = ""; char[] cbuffer = new char[256]; int byteRead = 0; string filename = @"c:\log.txt"; ///定义写入流操作 public void WriteStream() { Uri httpURL = new Uri(txtURL.Text); ///HttpWebRequest类继承于WebRequest,并没有自己的构造函数,需通过WebRequest 的Creat方法建立,并进行强制的类型转换 httpReq = (HttpWebRequest)WebRequest.Create(httpURL); ///通过HttpWebRequest的GetResponse()方法建立HttpWebResponse,强制类型转换 httpResp = (HttpWebResponse) httpReq.GetResponse(); ///GetResponseStream()方法获取HTTP响应的数据流,并尝试取得URL中所指定的网页内容///若成功取得网页的内容,则以System.IO.Stream形式返回,若失败则产生 ProtoclViolationException错误。在此正确的做法应将以下的代码放到一个try块中处理。这里简单处理 Stream respStream = httpResp.GetResponseStream(); ///返回的内容是Stream形式的,所以可以利用StreamReader类获取GetResponseStream的内容,并以StreamReader类的Read方法依次读取网页源程序代码每一行的内容,直至行尾(读取的编码格式:UTF8) StreamReader respStreamReader = new StreamReader(respStream,Encoding.UTF8); byteRead = respStreamReader.Read(cbuffer,0,256);
股票交易数据抓取采集的方法
https://www.360docs.net/doc/8a1437873.html, 股票交易数据抓取采集的方法 本文介绍使用八爪鱼采集器简易模式采集抓取股票交易数据的方法。 股票交易数据采集详细字段说明:股票代码,股票名称,股票最新价,股票最新价,股票换手率,股票市盈率,股票主力成本,机构参与度,数据日期,数据采集日期。 需要采集东方财富网里详细内容的,在网页简易模式界面里点击东方财富网,进去之后可以看到关于东方财富网的三个规则信息,我们依次直接使用就可以的。 采集东方财富网 -千评千股-数据中心内容(下图所示)即打开东方财富网主页点击第二个(千评千股-数据中心)采集搜索到的内容。
https://www.360docs.net/doc/8a1437873.html, 1、找到东方财富网-千评千股-数据中心规则然后点击立即使用 2、下图显示的即为简易模式里面千评千股-数据中心的规则 ①查看详情:点开可以看到示例网址 ②任务名:自定义任务名,默认为千评千股-数据中心 ③任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组 ④翻页次数:设置要采集几页 ⑤示例数据:这个规则采集的所有字段信息
https://www.360docs.net/doc/8a1437873.html, 3、规则制作示例 任务名:自定义任务名,也可以不设置按照默认的就行 任务组:自定义任务组,也可以不设置按照默认的就行 翻页次数: 2 设置好之后点击保存,保存之后会出现开始采集的按钮 保存之后会出现开始采集的按钮
https://www.360docs.net/doc/8a1437873.html, 4、选择开始采集之后系统将会弹出运行任务的界面 可以选择启动本地采集(本地执行采集流程)或者启动云采集(由云服务器执行采集流程),这里以启动本地采集为例,我们选择启动本地采集按钮
动态网页数据爬取
动态网站的抓取静态网站困难一些,主要涉及ajax和html,传统的web应用,我们提交一个表单给服务器接受请求返回一个页面给浏览器,这样每次用户的交互都需要向服务器发送请求。同时对整个网页进行刷新,这样会浪费网络宽带影响用户体验。 怎么解决? Ajax--异步JavaScript和xml。是JavaScript异步加载技术、xml及dom还有xhtml和css等技术的组合。他不必刷新整个页面只需要页面的局部进行更新。Ajax只取回一些必要数据,使用soap、xml或者支持json的web service接口。这样提高服务器的响应减少了数据交互提高了访问速度。 Dhtml动态html,他只是html、css、和客户的的一宗集合,一个页面有html、css、JavaScript 制作事事变换页面的元素效果的网页设计。 如何分辨? 最简单的就是看有没有“查看更多”字样,也可以使用response访问网页返回的response 内容和浏览器的内容不一致时就是使用了动态技术。这样我们也无法提取有效数据 如何提取? 1直接在JavaScript中采集的数据分析 2使用采集器中加载好的数据 为什么使用Phantomjs? Ajax请求太多并加密,手动分析每个ajax请求无疑愚公移山,phantomjs直接提取浏览器渲染好的结果不进行ajax请求分析,其实phantomjs就是基于webkit 的服务端JavaScript api。支持web而无需浏览器支持运行快,支持各种web标准:dom、css、json、canvas、svg。常用于页面自动化、网络监测、网页截屏、无界面测试。 安装? 下载https://www.360docs.net/doc/8a1437873.html,/download.html解压设置环境变量phantomjs -v测试安装 下载:{l55l59〇6〇9〇} 使用 页面加载:分析创建网页对象的呈现 代码:使用webpage模块创建一个page对象,通过page对象打开url网址,如果状态为success 通过render方法将页面保存。 代码评估:利用evaluate执行沙盒它执行网页外的JavaScript代码,evaluate返回一个对象然后返回值仅限对象不包含函数 屏幕捕获: 网络监控: 页面自动化: 常用模块和方法? Phantom,webpage,system,fs 图形化? Selenium将Python和phantomjs紧密结合实现爬虫开发。Selenium是自动化测试工具,支持各种浏览器,就是浏览器驱动可以对浏览器进行控制。并且支持多种开发语言phantomjs 负责解析JavaScript,selenium负责驱动浏览器和Python对接。 安装 pip install selenium===3.0.1 或者https://https://www.360docs.net/doc/8a1437873.html,/pypi/selenium#downloads 下载源码解压python setup.py install selenium3然后下载https://https://www.360docs.net/doc/8a1437873.html,/SeleniumHQ/selenium/
js 爬虫如何实现网页数据抓取
https://www.360docs.net/doc/8a1437873.html, js 爬虫如何实现网页数据抓取 互联网Web 就是一个巨大无比的数据库,但是这个数据库没有一个像SQL 语言可以直接获取里面的数据,因为更多时候Web 是供肉眼阅读和操作的。如果要让机器在Web 取得数据,那往往就是我们所说的“爬虫”了。有很多语言可以写爬虫,本文就和大家聊聊如何用js实现网页数据的抓取。 Js抓取网页数据主要思路和原理 在根节点document中监听所有需要抓取的事件 在元素事件传递中,捕获阶段获取事件信息,进行埋点 通过getBoundingClientRect() 方法可获取元素的大小和位置 通过stopPropagation() 方法禁止事件继续传递,控制触发元素事件 在冒泡阶段获取数据,保存数据 通过settimeout异步执行数据统计获取,避免影响页面原有内容 Js抓取流程图如下
https://www.360docs.net/doc/8a1437873.html, 第一步:分析要爬的网站:包括是否需要登陆、点击下一页的网址变化、下拉刷新的网址变化等等 第二步:根据第一步的分析,想好爬这个网站的思路 第三步:爬好所需的内容保存 爬虫过程中用到的一些包:
https://www.360docs.net/doc/8a1437873.html, (1)const request = require('superagent'); // 处理get post put delete head 请求轻量接http请求库,模仿浏览器登陆 (2)const cheerio = require('cheerio'); // 加载html (3)const fs = require('fs'); // 加载文件系统模块将数据存到一个文件中的时候会用到 fs.writeFile('saveFiles/zybl.txt', content, (error1) => { // 将文件存起来文件路径要存的内容错误 if (error1) throw error1; // console.log(' text save '); }); this.files = fs.mkdir('saveFiles/simuwang/xlsx/第' + this.page + '页/', (e rror) => { if (error) throw error; }); //创建新的文件夹 //向新的文件夹里面创建新的文件 const writeStream = fs.createWriteStream('saveFiles/simuwang/xlsx/'
最全的八爪鱼循环提取网页数据方法
https://www.360docs.net/doc/8a1437873.html, 最全的八爪鱼循环提取网页数据方法在八爪鱼中,创建循环列表有两种方式,适用于列表信息采集、列表及详情页采集,是由八爪鱼自动创建的。当手动创建的循环不能满足需求的时候,则需要我们手动创建或者修改循环,以满足更多的数据采集需求。 循环的高级选项中,有5大循环方式:URL循环、文本循环、单个元素循环、固定元素列表循环和不固定元素列表循环。 一、URL循环 适用情况:在多个同类型的网页中,网页结构和要采集的字段相同。 示例网址: https://https://www.360docs.net/doc/8a1437873.html,/subject/26387939/ https://https://www.360docs.net/doc/8a1437873.html,/subject/6311303/ https://https://www.360docs.net/doc/8a1437873.html,/subject/1578714/ https://https://www.360docs.net/doc/8a1437873.html,/subject/26718838/ https://https://www.360docs.net/doc/8a1437873.html,/subject/25937854/ https://https://www.360docs.net/doc/8a1437873.html,/subject/26743573/
https://www.360docs.net/doc/8a1437873.html, 操作演示: 具体请看此教程:https://www.360docs.net/doc/8a1437873.html,/tutorialdetail-1/urlxh_7.html 二、文本循环 适用情况:在搜索框中循环输入关键词,采集关键词搜索结果的信息。 实现方式:通过文本循环方式,实现循环输入关键词,采集关键词搜索结果。示例网址:https://https://www.360docs.net/doc/8a1437873.html,/ 操作演示:
https://www.360docs.net/doc/8a1437873.html, 具体请看此教程:https://www.360docs.net/doc/8a1437873.html,/tutorialdetail-1/wbxh_7.html 注意事项:有的网页,点击搜索按钮后,页面会发生变化,只能采集到第一个关键词的数据,则打开网页步骤需放在文本循环内。 例:https://https://www.360docs.net/doc/8a1437873.html,/ 如图,如果将打开网页步骤,放在循环外,则只能提取到第一个关键词的搜索结果文本,不能提取到第二个关键词的搜索结果文本,文本循环流程不能正常执行。
活用excel超简单网页列表数据手动抓取法
思路:将直接复制下来的列表信息,通过对各种符号的批量替换,最终使其能在excel文档里,自动排列为A、B、C等不同列,最终通过excel公式,批量生成sql查询语句,直接执行查询,数据入库; 例: https://www.360docs.net/doc/8a1437873.html,/search.aspx?ctl00$ContentPlaceHolder1$cboPrevio=%E5% 8C%97%E4%BA%AC 1.直接把列表信息复制进新建的txt文档,格式非自动换行,如下图:
2.再把txt里的数据复制进新建的word文档,如图: (注:此处先复制进txt再复制进word的原因是,从网上拿下来的数据直接放入word会包含自身的列表结构甚至是图片,那些都是不需要的东西) 3. ctrl+H打开搜索替换,通过观察,我们在搜索中输入“回车+空格”,即“^p ”,替换中输入“空格”,即“”,如图:
4.全部替换,如图: 5.搜索替换,搜索中输入两个空格“”,替换中输入一个空格“”,疯狂的全部替换,一直到再也搜不到双空格,最终把所有有间隔的地方,变成了一个空格,如图所示:
6.将数据全选复制到新建excel文件的A列,选中A列,数据,分列,如图: 7.选分隔符号,下一步,空格,完成分列,(有连续识别符作为单个处理的选项,可以节省步骤5,但是我为了保险,还是没省略),如图:
8.手动修改例如第三行的,奇葩的、不合群的数据: 9.在此特殊例中,由于每四个电话号码出现一个空格,导致了分列,可用一个简单公式:在E1中输入“=C1&D1”,回车,然后在E1单元格的右下角下拉公式至最后一行,合并如图:
教你怎样获取网页中视频的链接地址
教你怎样获取网页中视频的链接地址(转载+原创) 大家有这样的体会吧:进论坛或一些网站,看到好的mtv、视频短剧或Flash很想发出来和大家分享,可我是菜鸟,找不出这些视频资源的链接地址,怎么办?不急!看完本文你也就老家贼变大虾啦!呵呵!相信自己:你也一样棒! 其实这个问题是很容易解决的,因为对于互联网来说一切地址都是公开的,只要你运用了正确的方法,加上一些常用的工具,所有的资源链接地址都可以获得的。我们最常见的在web页面中内嵌视频的播放器是real、windows media player和flash三种系列的播放器和相对应的播放格式。对于不同的播放期需要采用不同的方法,下面一一进行介绍。 一、windows media player流媒体网址攻略篇 对于windows media player来说是非常简单的,你利用Media Player 的右键菜单,只需要用鼠标右键点击媒体播放器,在菜单中选择“属性”,即可在新出现的窗口中找到媒体文件的网络地址。嘿嘿!大家要注意wmv中的v代表video【视频】wma里面的a代表audio【音频】。请注意!知道了这一点还不够,你可能还会碰到如下问题: (1)右键失效 解决方法:a、建议换个浏览器,maxthon傲游浏览器有右键锁定破解的功能,点鼠标的那个图示就行了,这可能是最方便的一种方法。b、ie工具栏上面有查看一项,在里面有查看源文件这个命令。c、有很多破解右键锁定的方法,基本都是点击弹出的窗口然后不要松手点击右键。第一种情况,出现版权信息类的,破解方法:在页面目标上按下鼠标右键,弹出限制窗口,这时不要松开右键,将鼠标指针移到窗口的“确定”按钮上,同时按下左键。松开鼠标左键,限制窗口就被关闭了,再将鼠标移到目标上松开鼠标右键,这样弹出了鼠标右键菜单,限制被取消了。第二种情况,出现“添加到收藏夹”的。破解方法:在目标上点鼠标右键,出现添加到收藏夹的窗口,不要松开右键,也不要移动鼠标,而是使用键盘的TAB键,移动到取消按钮上,按下空格键,这时窗口就消失了,松开右键看看,右键又恢复了。第三种情况,超链接无法用鼠标右键弹出“在新窗口中打开”菜单的。用这一招:在超链接上点击鼠标右键,弹出窗口,不要松开右键,按键盘上的空格键,窗口消失了,这时在松开右键,右键菜单便会出现,选择其中的“在新窗口中打开”就OK了。 (2)弹出的窗口的大小不能改变,右键点击的是背景图片,没有查看源文件,只有图片另存为这些 解决方法:a、用maxthon或者腾迅tt浏览器,可以把探出的窗口最大化,这样就可以在扩大的地方点右键找到源文件了。b、在存放源文件的临时文件加里面找,这个确实有点麻烦。