海量地形数据的Web发布与交互浏览

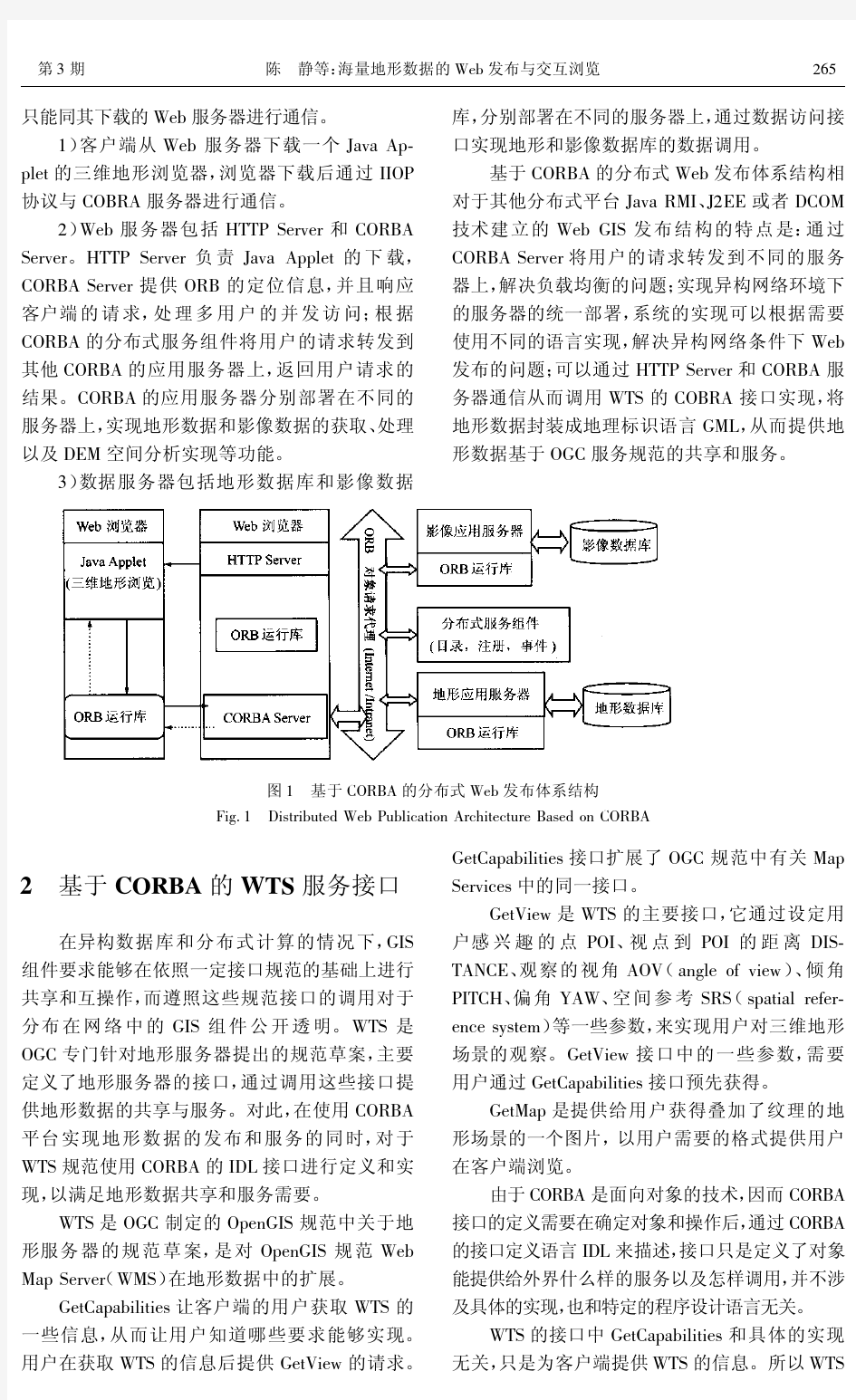
石坎原始地形测量数据
原始地形测量数据 1,,491121.443,3569607.295,909.352 2,,491109.328,3569591.811,907.622 3,,491104.751,3569667.016,909.795 4,,491135.387,3569652.337,907.141 5,,491092.920,3569604.681,901.074 6,,491094.541,3569607.308,901.129 7,,491098.673,3569615.807,902.096 8,,491105.964,3569625.825,903.501 9,,491121.682,3569640.331,905.906 10,,491117.707,3569632.317,905.027 11,,491099.369,3569581.272,906.257 12,,491078.793,3569566.005,903.679 13,,491027.859,3569534.073,898.757 14,,491059.216,3569555.480,901.652 15,,491073.317,3569563.173,903.074 16,,491084.212,3569575.801,903.074 17,,491113.579,3569654.990,908.565 18,,491101.046,3569639.005,906.471 19,,491083.175,3569610.400,903.484 20,,491061.480,3569586.329,901.024 21,,491048.029,3569569.465,899.764
海量数据存储论文
海量数据存储 (----计算机学科前沿讲座论文 昆明理工大学信息院 计算机应用技术 2010/11 随着信息社会的发展,越来越多的信息被数据化,尤其是伴随着Internet的发展,数据呈爆炸式增长。从存储服务的发展趋势来看,一方面,是对数据的存储量的需求越来越大,另一方面,是对数据的有效管理提出了更高的要求。首先是存储容量的急剧膨胀,从而对于存储服务器提出了更大的需求;其次是数据持续时间的增加。最后,对数据存储的管理提出了更高的要求。数据的多样化、地理上的分散性、对重要数据的保护等等都对数据管理提出了更高的要求。随着数字图书馆、电子商务、多媒体传输等用的不断发展,数据从GB、TB到PB量级海量急速增长。存储产品已不再是附属于服务器的辅助设备,而成为互联网中最主要的花费所在。海量存储技术已成为继计算机浪潮和互联网浪潮之后的第三次浪潮,磁盘阵列与网络存储成为先锋。 一、海量数据存储简介 海量存储的含义在于,其在数据存储中的容量增长是没有止境的。因此,用户需要不断地扩张存储空间。但是,存储容量的增长往往同存储性能并不成正比。这也就造成了数据存储上的误区和障碍。 海量存储技术的概念已经不仅仅是单台的存储设备。而多个存储设备的连接使得数据管理成为一大难题。因此,统一平台的数据管理产品近年来受到了广大用户的欢迎。这一类型产品能够整合不同平台的存储设备在一个单一的控制界面上,结合虚拟化软件对存储资源进行管理。这样的产品无疑简化了用户的管理。 数据容量的增长是无限的,如果只是一味的添加存储设备,那么无疑会大幅增加存储成本。因此,海量存储对于数据的精简也提出了要求。同时,不同应用对于存储
(完整版)Android大数据的存储和大数据的访问
南昌航空大学实验报告 二0一4 年11 月14 日 课程名称:Android 实验名称:Android数据存储和数据访问 班级:姓名:同组人: 指导教师评定:签名: 一:实验目的 掌握SharedPreferences的使用方法; 掌握各种文件存储的区别与适用情况; 了解SQLite数据库的特点和体系结构; 掌握SQLite数据库的建立和操作方法; 理解ContentProvider的用途和原理; 掌握ContentProvider的创建与使用方法 二:实验工具 Eclipse(MyEclipse)+ ADT + Android2.2 SDK; 三:实验题目 1.应用程序一般允许用户自己定义配置信息,如界面背景颜色、字体大小和字体颜色等,尝试使用SharedPreferences保存用户的自定义配置信息,并在程序启动时自动加载这些自定义的配置信息。 2.尝试把第1题的用户自己定义配置信息,以INI文件的形式保存在内部存储器上。 3.使用代码建库的方式,创建名为test.db的数据库,并建立staff数据表,表内的属性值如下表所示:
4.建立一个ContentProvider,用来共享第3题所建立的数据库; 四:实验代码 InternalFileDemo public class InternalFileDemo extends Activity { private final String FILE_NAME = "fileDemo.txt"; private TextView labelView; private TextView displayView; private CheckBox appendBox ; private EditText entryText; @Override public void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(https://www.360docs.net/doc/8f8717348.html,yout.main); labelView = (TextView)findViewById(https://www.360docs.net/doc/8f8717348.html,bel); displayView = (TextView)findViewById(R.id.display); appendBox = (CheckBox)findViewById(R.id.append); entryText = (EditText)findViewById(R.id.entry); Button writeButton = (Button)findViewById(R.id.write); Button readButton = (Button)findViewById(R.id.read); writeButton.setOnClickListener(writeButtonListener); readButton.setOnClickListener(readButtonListener); entryText.selectAll(); entryText.findFocus(); } OnClickListener writeButtonListener = new OnClickListener() {
数字地形测量学实习报告
淮海工学院实习报告书 题目:数字地形测量实习 学院:测绘工程学院 专业:测绘工程 班级:测绘 112 姓名:许艳超 学号: 2011122712 2013年 7月10日
成绩 目录 1 概述·3 1.1实习名称··3 1.2实习时间··3 1.3实地地点··3 1.4指导教师··3 1.5实习目的及要求··3 1.6仪器及工具··3 2测区概况·3 3平面控制测量·3 3.1平面坐标系统··3 3.2导线等级及精度指标··4 3.3导线控制网的布设··5 3.4导线施测方法··5 3.5数据处理、平差计算··5 4 高程控制测量·7 4.1高程系统的选择·7
4.2精度等级及技术指标··7 4.3水准网的布设··7 4.4高程施测方法··8 4.5数据处理、平差计算··8 5 碎部点测量··9 5.1 碎测量的步骤··9 5.2 测量时应该注意的问题··9 6 成图方法··9 6.1测量数据传输··9 6.2 南方CASS软件绘制地形图··9 7 分幅与编号··10 7.1 大比例尺地形图的分幅··10 7.2 大比例尺地形图的编号··10 7.3 1:500地形图的分幅及编号··10 8 实习体会··10 附图、附表··11 1 概述 1.1实习名称:数字地形测量实习 1.2实习时间:2013.6.17-2013.7.14 1.3实地地点:淮海工学院校区第四测区
1.4指导教师:赵宝锋 1.5实习目的及要求 数字地形测量学实习是《数字地形测量学》课程教学的重要组成部分,是巩固和深化课程所学知识的必要的环节,通过实习培养学生理论联系实际、分析问题和解决问题的能力以及实际动手操作能力,使学生具有严格认真的科学态度、实事求是的工作作风、吃苦耐劳的劳动态度以及团结协作的集体观念。同时,也使学生在业务组织能力和实际工作能力方面得到锻炼,为今后从事测绘工作打下良好基础。本次数字地形测量的实习,是对我们数字化测图学习情况的一次实践检验,同时也是一次让我们在实践中体会理解所学知识,并在实际应用中融会贯通的难得机会。 实习要求: (1) 掌握水准仪、全站仪的使用; (2) 掌握导线测量的外业施测过程与方法、内业数据处理过程与方法; (3) 掌握水准测量的外业施测及内业数据处理的过程、方法; (4) 掌握三角高程导线测量的外业施测及内业数据处理的过程、方法; (5) 掌握全站仪数字化测图的外业测量方法及内业软件的使用; (6) 熟悉大比例尺测图的工作内容及作业过程; (7) 掌握地物、地貌的合理表示与取舍原则。 1.6仪器及工具: (1)水准仪每组一套,包括:水准尺一对、水准仪一台、水准仪脚架一个; (2)全站仪一套,包括:主机、脚架一个、棱镜两个、对中杆两个、充电器; (3)铁钉、斧子 (4)导线测量、等外等水准测量、测量手薄、计算表自备 2 测区概况 淮海工学院第四测区位于江苏省连云港市,地处苏北平原,平均海拔高程约3.7米。测区内均为人造河流、湖泊、草地等,另外有体育馆和体育场等。测区属季风特点的海洋性气候,四季分明,寒暑适宜,光照充足,雨量适中。气候温和湿润,常年平均气温14度左右,年平均降水量约910-980毫米之间,降雨期集中在7-9三个月。 测区内地势较为平坦,道路通畅,交通便利,视野开阔这都有利于我们测量的进行。实习中,我们使用中纬全站仪和精密水准仪进行测量作业,同时我们会避开正午的高温天气,利用早出、午休、晚归的作业方法,摆脱酷热天气的影响,使我们的测量实习可以顺利的进行。 3 平面控制测量
大数据存储方式概述
大数据存储方式概述 随着信息社会的发展,越来越多的信息被数据化,尤其是伴随着Internet的发展,数据呈爆炸式增长。从存储服务的发展趋势来看,一方面,是对数据的存储量的需求越来越大,另一方面,是对数据的有效管理提出了更高的要求。首先是存储容量的急剧膨胀,从而对于存储服务器提出了更大的需求;其次是数据持续时间的增加。最后,对数据存储的管理提出了更高的要求。数据的多样化、地理上的分散性、对重要数据的保护等等都对数据管理提出了更高的要求。随着数字图书馆、电子商务、多媒体传输等用的不断发展,数据从GB、TB 到PB量级海量急速增长。存储产品已不再是附属于服务器的辅助设备,而成为互联网中最主要的花费所在。海量存储技术已成为继计算机浪潮和互联网浪潮之后的第三次浪潮,磁盘阵列与网络存储成为先锋。 一、海量数据存储简介 海量存储的含义在于,其在数据存储中的容量增长是没有止境的。因此,用户需要不断地扩张存储空间。但是,存储容量的增长往往同存储性能并不成正比。这也就造成了数据存储上的误区和障碍。海量存储技术的概念已经不仅仅是单台的存储设备。而多个存储设备的连接使得数据管理成为一大难题。因此,统一平台的数据管理产品近年来受到了广大用户的欢迎。这一类型产品能够整合不同平台的存储设备在一个单一的控制界面上,结合虚拟化软件对存储资源进行管理。这样的产品无疑简化了用户的管理。 数据容量的增长是无限的,如果只是一味的添加存储设备,那么无疑会大幅增加存储成本。因此,海量存储对于数据的精简也提出了要求。同时,不同应用对于存储容量的需求也有所不同,而应用所要求的存储空间往往并不能得到充分利用,这也造成了浪费。 针对以上的问题,重复数据删除和自动精简配置两项技术在近年来受到了广泛的关注和追捧。重复数据删除通过文件块级的比对,将重复的数据块删除而只留下单一实例。这一做法使得冗余的存储空间得到释放,从客观上增加了存储容量。 二、企业在处理海量数据存储中存在的问题 目前企业存储面临几个问题,一是存储数据的成本在不断地增加,如何削减开支节约成本以保证高可用性;二是数据存储容量爆炸性增长且难以预估;三是越来越复杂的环境使得存储的数据无法管理。企业信息架构如何适应现状去提供一个较为理想的解决方案,目前业界有几个发展方向。 1.存储虚拟化 对于存储面临的难题,业界采用的解决手段之一就是存储虚拟化。虚拟存储的概念实际上在早期的计算机虚拟存储器中就已经很好地得以体现,常说的网络存储虚拟化只不过是在更大规模范围内体现存储虚拟化的思想。该技术通过聚合多个存储设备的空间,灵活部署存储空间的分配,从而实现现有存储空间高利用率,避免了不必要的设备开支。 存储虚拟化的好处显而易见,可实现存储系统的整合,提高存储空间的利用率,简化系统的管理,保护原有投资等。越来越多的厂商正积极投身于存储虚拟化领域,比如数据复制、自动精简配置等技术也用到了虚拟化技术。虚拟化并不是一个单独的产品,而是存储系统的一项基本功能。它对于整合异构存储环境、降低系统整体拥有成本是十分有效的。在存储系统的各个层面和不同应用领域都广泛使用虚拟化这个概念。考虑整个存储层次大体分为应用、文件和块设备三个层次,相应的虚拟化技术也大致可以按这三个层次分类。 目前大部分设备提供商和服务提供商都在自己的产品中包含存储虚拟化技术,使得用户能够方便地使用。 2.容量扩展 目前而言,在发展趋势上,存储管理的重点已经从对存储资源的管理转变到对数据资源
基于一种海量数据处理分析系统设计文档
中科基于一种海量数据处理分析 系统的设计文档 一、海量数据处理的背景分析 在当前这个信息量飞速增长的时代,业的成功已经越来越多地与其海量数据处理能力相关联。高效、迅速地从海量数据中挖掘出潜在价值并转化为决策依据的能力,将成为企业的核心竞争力。数据的重要性毋庸置疑,但随着数据的产生速度越来越快,数据量越来越大,数据处理技术的挑战自然也越来越大。如何从海量数据中挖掘出价值所在,分析出深层含义,进而转化为可操作的信息,已经成为各互联网企业不得不研究的课题。数据量的增长,以及分析需求的越来越复杂,将会对互联网公司的数据处理能力提出越来越高的要求、越来越大的挑战。但每一个场景都有其特点与功能,充分分析其数据特性,将合适的软件用在合适的场景下,才能更好地解决实际问题。 二、海量数据处理分析的特点 (一)、数据量大,情况多变 现在的数据量比以前任何时期更多,生成的速度更快,以前如果说有10条数据,繁琐的操作时每条去逐一检查,人为处理,如果有上百条数据,也可以考虑,如果数据上到千万级别,甚至过亿,那不是手工能解决的了,必须通过工具或者程序进行处理,尤其海量的数据中,情况多变,手工操作是完不成任务的。例如,数据中某处格式出了问题,尤其在程序处理时,前面还能正常处理,突然到了某个地方问题出现了,程序将会终止。海量数据处理系统的诞生是输入层每个神经元的输入是同一个向量的一个分量,产生的输出作
为隐藏层的输入,输出层每一个神经元都会产生一个标量结果,所以整个输出层所有神经元的输出构成一个向量,向量的维数等于输出层神经元的数目在人工神经网络模型中,各个神经元通过获取输入和反馈,相对独立地进行训练和参数计算。其拓扑结构的重要特点便是每一层内部的神经元之间相互独立,各个层次间的神经元相互依赖。 由于各个层次内部神经元相互独立,使得各个层次内部的神经元的训练可以并行化。但由于不同层之间的神经元具有相互依赖关系,因此各个层次之间仍然是串行处理的。可以将划分出的每一层内部的不同神经元通过map操作分布到不同的计算机上。各个神经元在不同的计算终端上进行训练,在统一的调度和精度控制下进行多个层次的神经元的训练,这样神经网络算法的训练就可以实现并行化。训练结束后,同样可以通过每层内节点的并行化处理快速地得到输出结果。在神经网络算法中,每层内的节点都可以进行并行化处理,并行化程度非常高。 (二)、软硬件要求高,系统资源占用率高 各种应用对存储系统提出了更多的需求,数据访问需要更高的带宽,不仅要保证数据的高可用性,还要保证服务的高可用性;可扩展性:应用在不断变化,系统规模也在不断变化,这就要求系统提供很好的扩展性,并在容量、性能、管理等方面都能适应应用的变化;对海量的数据进行处理,除了好的方法,最重要的就是合理使用工具,合理分配系统资源。一般情况,如果处理的数据过TB级,小型机是要考虑的,普通的机子如果有好的方法可以考虑,不过也必须加大CPU和内存,对电脑的内存、显卡、硬盘及网络都要求相对较高!其中对网络要求高的原因是因为其引入目前最前沿的“云端计算”好多东西都要从网络上调用;对硬盘要求是最高的,用SATA6.0的固态硬盘,对整机性能限制比较大的就是高速系统总线对低速硬盘传输,32位的系统,最大只能认到3.5G内存,就是说,不论你装几根内存条,装多大容量的内存条,你装8G的,它也只能用到3.5G,64位的系统就可以突破了这个限制。如果你的电脑配置不是特别高的话,XP是比较好的选择。32位的XP是最低要求。基于23G互操作测试生成23G互操作测试报告测试起始点时间、测试终止点时间、 3G网络驻留时间(秒)、2G网络驻留时间(秒)、3G覆盖总采样点、3G覆盖总采样点不同区间数量统计、3G覆盖总采样点不同门限范围内数量统计、2G覆盖总采样点、2G覆盖总采样点不同区间数量统计、2G覆盖总采样点不同门限范围内数量统计、3G到2G重选成功次数、2G到3G重选成功次数、3G到2G切换尝试次数、3G到2G切换成功次数、切换掉话次数和其它掉话次数。
海量三维地形数据的实时可视化研究
海量三维地形数据的实时可视化研究 相对于光学影像对空间三维地形的描述,点云数据具有无可替代的优势,本项目基于海量三维地形点云数据,提出大容量缓存加无级缩放算法以及对图像显示方法的优化方案,研究从数据存储、读取到显示,快速、有效地组建三维空间,实时高效地展示用户需求的三维图像;研究在用户改变视点时快速重新建模三维空间图像及实时显示当前视域三维图像的理论和方法;研究从数据库服务器中快速提取用户需求方位坐标数据的理论和方法。具体包括,利用金字塔影像技术对点云数据进行多尺度、多比例尺分割存储,通过隐面消除技术,利用OpenGL引擎加速将点云展示在客户端成为3D模型,根据用户视点向用户提供一个可交互的空间三维影像显示系统。 标签:海量空间三维点云数据;三维建模;可视化显示 1 引言 随着科技和社会发展,三维空间数据的实时可视化研究显得越来越重要。随着对地形数据分辨率等指标要求的提高,地形数据的数据量不断加大。目前,较成熟的空间三维可视化显示均是基于光学影像。然而,这种基于光学影像的三维可视化模型,数据量极大,处理速度必然受到限制。海量数据的实时显示对算法等要求高,至今仍是一个难点。本项目针对海量三维地形(点云)数据,提出了对数据存储和显示的优化方案。 1.1 研究背景 迄今为止,三维地形的可视化技术分为两种,一种是面绘制技术,另一种是体绘制技术。现在已经可以绘制出具有高度真实性和可测量性的三维地形模型,实现三维地形表面的逼真还原。 基于面繪制的三维地形建模技术基本上可以归纳为三类:分形地景仿真、曲面拟合地形仿真和基于真实地形数据的多边形模拟。前两种方法均有各种限制,而基于真实地形数据的建模由于能通过剖分方法生成连续的多边形网格,有利于计算机绘制,同时生成的地形也具有高度的真实感,所以它便成为人们描述三维地形的主要手段。 然而对于多边形模拟,当地形数据量大时,多边形数量会急剧增加,模型就会变得复杂,即使是最高端的图形工作站也不能满足实时绘制的要求。通过提高硬件水平,以实现建立大规模三维地形显示所期望的硬件性能,是解决大规模三维地形实时显示重要且必然的途径,算法优化及数据处理方式变更显得更加灵活便捷。 1.2 研究现状
常用大数据量、海量数据处理方法 (算法)总结
大数据量的问题是很多面试笔试中经常出现的问题,比如baidu goog le 腾讯这样的一些涉及到海量数据的公司经常会问到。 下面的方法是我对海量数据的处理方法进行了一个一般性的总结,当然这些方法可能并不能完全覆盖所有的问题,但是这样的一些方法也基本可以处理绝大多数遇到的问题。下面的一些问题基本直接来源于公司的面试笔试题目,方法不一定最优,如果你有更好的处理方法,欢迎与我讨论。 1.Bloom filter 适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集 基本原理及要点: 对于原理来说很简单,位数组+k个独立hash函数。将hash函数对应的值的位数组置1,查找时如果发现所有hash函数对应位都是1说明存在,很明显这个过程并不保证查找的结果是100%正确的。同时也不支持删除一个已经插入的关键字,因为该关键字对应的位会牵动到其他的关键字。所以一个简单的改进就是counting Bloom filter,用一个counter数组代替位数组,就可以支持删除了。 还有一个比较重要的问题,如何根据输入元素个数n,确定位数组m 的大小及hash函数个数。当hash函数个数k=(ln2)*(m/n)时错误率最小。在错误率不大于E的情况下,m至少要等于n*lg(1/E)才能表示任
意n个元素的集合。但m还应该更大些,因为还要保证bit数组里至少一半为0,则m应该>=nlg(1/E)*lge 大概就是nlg(1/E)1.44倍(lg 表示以2为底的对数)。 举个例子我们假设错误率为0.01,则此时m应大概是n的13倍。这样k大概是8个。 注意这里m与n的单位不同,m是bit为单位,而n则是以元素个数为单位(准确的说是不同元素的个数)。通常单个元素的长度都是有很多bit的。所以使用bloom filter内存上通常都是节省的。 扩展: Bloom filter将集合中的元素映射到位数组中,用k(k为哈希函数个数)个映射位是否全1表示元素在不在这个集合中。Counting bloom filter(CBF)将位数组中的每一位扩展为一个counter,从而支持了元素的删除操作。Spectral Bloom Filter(SBF)将其与集合元素的出现次数关联。SBF采用counter中的最小值来近似表示元素的出现频率。 问题实例:给你A,B两个文件,各存放50亿条URL,每条URL占用6 4字节,内存限制是4G,让你找出A,B文件共同的URL。如果是三个乃至n个文件呢? 根据这个问题我们来计算下内存的占用,4G=2^32大概是40亿*8大概是340亿,n=50亿,如果按出错率0.01算需要的大概是650亿个
海量数据挖掘的关键技术及应用现状
网络化时代信息膨胀成为必然,如何准确、高效地从丰富而膨胀的数据中筛选出对经营决策有用的信息已经成为企业和机构迫切需要解决的问题,针对于此,海量数据挖掘技术应运而生,并显示出强大的解决能力。Gartner的报告指出,数据挖掘会成为未来10年内重要的技术之一。 一、海量数据挖掘关键技术随时代而变化 所谓海量数据挖掘,是指应用一定的算法,从海量的数据中发现有用的信息和知识。海量数据挖掘关键技术主要包括海量数据存储、云计算、并行数据挖掘技术、面向数据挖掘的隐私保护技术和数据挖掘集成技术。 1.海量数据存储 海量存储系统的关键技术包括并行存储体系架构、高性能对象存储技术、并行I/O访问技术、海量存储系统高可用技术、嵌入式64位存储操作系统、数据保护与安全体系、绿色存储等。 海量数据存储系统为云计算、物联网等新一代高新技术产业提供核心的存储基础设施;为我国的一系列重大工程如平安工程等起到了核心支撑和保障作用;海量存储系统已经使用到石油、气象、金融、电信等国家重要行业与部门。发展具有自主知识产权、达到国际先进水平的海量数据存储系统不仅能够填补国内在高端数据存储系统领域的空白,而且可以满足国内许多重大行业快速增长的海量数据存储需要,并创造巨大的经济效益。 2.云计算 目前云计算的相关应用主要有云物联、云安全、云存储。云存储是在云计算(cloud computing)概念上延伸和发展出来的新概念,是指通过集群应用、网格技术或分布式文件系统等功能,将网络中大量各种不同类型的存储设备通过应用软件集合起来协同工作,共同对外提供数据存储和业务访问功能的一个系统。
当云计算系统运算和处理的核心是大量数据的存储和管理时,云计算系统中就需要配置大量的存储设备,那么云计算系统就转变成为一个云存储系统,所以云存储是一个以数据存储和管理为核心的云计算系统。 3.并行数据挖掘技术 高效率的数据挖掘是人们所期望的,但当数据挖掘的对象是一个庞大的数据集或是许多广泛分布的数据源时,效率就成为数据挖掘的瓶颈。随着并行处理技术的快速发展,用并行处理的方法来提高数据挖掘效率的需求越来越大。 并行数据挖掘涉及到了一系列体系结构和算法方面的技术,如硬件平台的选择(共享内存的或者分布式的)、并行的策略(任务并行、数据并行或者任务并行与数据并行结合)、负载平衡的策略(静态负载平衡或者动态负载平衡)、数据划分的方式(横向的或者纵向的)等。处理并行数据挖掘的策略主要涉及三种算法:并行关联规则挖掘算法、并行聚类算法和并行分类算法。 4.面向数据挖掘的隐私保护技术 数据挖掘在产生财富的同时也随之出现了隐私泄露的问题。如何在防止隐私泄露的前提下进行数据挖掘,是信息化时代各行业现实迫切的需求。 基于隐私保护的数据挖掘是指采用数据扰乱、数据重构、密码学等技术手段,能够在保证足够精度和准确度的前提下,使数据挖掘者在不触及实际隐私数据的同时,仍能进行有效的挖掘工作。 受数据挖掘技术多样性的影响,隐私保护的数据挖掘方法呈现多样性。基于隐私保护的数据挖掘技术可从4个层面进行分类:从数据的分布情况,可以分为原始数据集中式和分布式两大类隐私保护技术;从原始数据的隐藏情况,可以分为对原始数据进行扰动、替换和匿名隐藏等隐私保护技术;从数据挖掘技术层面,可以分为针对分类挖掘、聚类挖掘、关联规则挖掘等隐私保护技术;从隐藏内容层面,可以分为原始数据隐藏、模式隐藏。
第6章 数据存储与访问
电子教案 第6章数据存储与访问 教学目标: 课程重点: 学习目标: 1.掌握SharePreferences的使用方法 2.掌握各种文件存储的使用及步骤 3.掌握SQLite方式的存储实现 4.掌握CotentProvider方式的存储实现 课程难点: 1.SharePreferences的使用方法 2.各种文件存储的使用及步骤 3.SQLite方式的存储实现 4.CotentProvider方式的存储实现 教学方法:理论讲解、案例实训 教学过程: 6.1简单存储 在Android中提供了一种简单的数据存储方式SharedPreferences,这是一种轻量级的数据保存方式,用来存储一些简单的配置信息,以键值对的方式存储在一个XML配置文件中。 使用SharedPreferences方式来存取数据,通常用到位于android.content包中的SharedPreferences接口和SharedPreferences的内部接口SharedPreferences.Editor。 使用Context. getSharedPreferences (String name, int mode)方法得到SharedPreferences接口对象。该方法的第一个参数是配置文件名称,即保存数据的文件,第二个参数是访问操作模式。 获取SharedPreferences对象的方法如下所示: SharedPreferences sharedpreferences=getSharedPreferences(Preferences_Name, MODE); SharedPreferences常用方法如下: edit()返回SharedPreferences的内部接口SharedPreferences.Editor contains(String Key) 判断是否包含该键值 getAll() 返回所有配置信息Map getBoolean(String key, boolean defValue) 获得一个boolean值 getFloat(String key, float defValue) 获得一个float值 getInt{String key, int defValue) 获得一个int值 getSting{String key, int defValue) 获得一个String值 SharedPreferences.Editor常用方法如下: Clear( ) 清除所有值 commit( ) 保存数据 remove(String key) 删除该键对应的值 getAll() 返回所有配置信息Map putBoolean(String key, boolean defValue) 保存一个boolean值
一种高效的机载设备地形数据加载方法
一种高效的机载设备地形数据加载方法 吕亚方,缪炜涛,滕飞,冯伟 (西安航空计算技术研究所,陕西西安710068) 摘要:文章设计了一种实时、快速的地形数据加载方法,用以提高地形数据的处理效率。在进行三维地形建模时,需要根据飞机的实时位置加载地形数据,并随着飞机实时位置的改变,实时更新地形数据,以实现视景合成界面能够实时、连续显示。 关键词:地形数据;三维地形建模;合成视景系统;DEM;AC20-167 中图分类号:P627文献标识码:A文章编号:1673-1131(2019)02-0170-02 0引言 随着民用航空业的发展及科学技术的进步,综合化、直观化的显示控制系统将成为未来民用飞机座舱发展的必然趋势。由于市场的需求,合成视景系统[1]在近年来获得了迅猛的发展。随着技术的逐步成熟,集成了合成视景系统的机载座舱综合显示控制系统必将大大提高飞行员对飞机周围飞行环境的情景意识,从而进一步提高飞行的安全性。 1基本原理 三维地形合成显示是合成视景系统的核心,它是以地形数据库为基础,在选定的参考坐标系下以飞行员的视角建立的三维地形模型,并能提供任何时间、地方(取决于机载地形数据库)和气象条件下的实时三维地形。三维地形显示是对飞机前方真实地形的描述,可以有效地增加飞行员对飞机前方地形的感知能力。同时,三维地形建模也是合成视景系统实现其他功能的基础。 构建三维地形需要相应位置的地形数据,这就需要将地形数据加载到内存中,随着飞机位置的改变,不断更新地形数据。由于地形数据的数据量很大,不能将其全部读入到内存中,特别是对于机载嵌入式设备,其软硬件资源非常有限,应当在不影响三维地形合成显示的范围和质量的前提下,应尽可能地降低地形数据处理对设备资源的占用。传统的加载处理地形数据的方法是在内存空间中定义一整块空间,存储地形数据,当更新地形数据时,保持地形数据物理存储位置的相对位置不变,对整块数据存储空间的数据大量进行移动,消耗大量系统资源,地形数据的处理效率比较差,会严重影响三维地形的构建和显示,出现画面卡顿的现象,实时性大大降低[2]。 由于地形数据的数据量庞大,因此,需要提供一种实时、快速的地形数据加载方法,以提高地形数据的处理效率。 三维地形合成显示使用的是数字高程模型(Digital Elev-ation Model,DEM),DEM是由规则间隔的经纬网点阵列或者正方形网格点构成的,将DEM的覆盖区域划分成排列规则的正方形网格,每一个网格点的高度值使用一个16位二进制数进行存储。DEM的分辨率分为1″、3″、30″等等,在赤道上分别对应30.9米、92.7米和927.2米[3]。 根据机载设备的软硬件资源和飞机对显示区域以及显示缓冲区大小的要求,确定提取的地形数据的区域大小。由于不同纬度时,相同经度差对应的地理距离是不同的,随着纬度的增高,相同经度差对应的地理距离越来越小。综合考虑以上两方面的因素,可以确定提取的地形数据对应的经纬度范围。 由于DEM数据是按照规则的正方形网格进行存储的,为了方便加载和管理地形数据,对提取的地形数据进行分块,并对每一块数据进行编号,以确定各数据块的相对位置关系。在内存空间创建与之对应数据存储空间,当需要更新地形数据时,以整行整列数据块的方式进行更新。 在处理地形数据时,是以数据块为单位进行处理的。为了确定地形数据的分块方式,不仅要需要考虑数据块的数量、每次更新的数据量和每行(列)数据块的更新周期,还需考虑设备读取数据的速度、每块数据所代表的地理距离的大小以及飞机对地形数据的精度要求[4-6]。 综合考虑以上因素,将地形数据划分为N×M个数据块,那么每个数据块的大小可根据地形数据的经度差LON、纬度差LAT和地形数据的精度PRE确定,设每块数据有L×K个地形数据点。 LON=(K-1)×M×PRE LAT=(L-1)×N×PRE 如果求得的L和K不为整数,在满足飞机对提取的地形数据的要求下,可对经度差LON和纬度差LAT进行适当的调整,使L和K为整数。 参考文献: [1]基于UT1553BCRTM协议芯片的GJB289A通信接口:电 子技术,2014. [2]基于HKS1553BCRT芯片的1553B总线通信软件设计: 计算机技术与发展2012. [3]基于SOC芯片的1553B远程终端的设计与实现:中国市 场,2015.[4]GJB5186.2-2004数字式时分制指令/响应型多路传输数 据总线测试方法,第2部分:总线控制器测试方法 [5]国防科学技术工业委员会.1553B-1997数字式时分制 指令/响应型多路传输数据总线[S].1997. [6]NHI-15XXX Terminal User's Manual Version2006. [7]Texas Instruments.TMS320F2810,TMS320F2811,TMS320 F2812,TMS320C2810,TMS320C2811,TMS320C2812,Digital Signal Processors DataManual[R].April 2001. 170
地形测量作业指导书
地形测量作业指导书(一)地形测量工艺流程图
(二)地形测量方法及要求 一、说明 本指导书只适用于工程施工中局部范围内的大比例尺地形图测量。地形测量控制网点是在施工控制网基础上加密得到的,坐标系统和高程系统应与施工坐标系、高程系统相一致。远离工区时,也可以采用北京坐标系或独立坐标系统。比例尺为1:200、1:500、1:1000和1:2000,按正方形或矩形法分幅。图式符号执行国家最新版本的《1:500 1:1000 1:2000地形图图式》。地形测量由于外业数据采集和内业成图所使用的仪器和软件不同而采用不同的方法,不论采用何种方法,成图都必须满足规范要求和用户要求。 本指导书中用字母M表示地形图比例尺分母。 二、图根控制点(包括测站点)的测量 1.一般规定 1.1图根点是直接供测图使用的平面和高程控制点,可在各等级控制点上采用经纬仪交会法、测距导线法、全站仪坐标法、三角高程、水准测量、GPS等方法测量。 1.2图根点或测站点的精度以相对于邻近控制点的中误差来衡量,其点位中误差不应超过图上±0.1㎜;其高程中误差不应超过测图基本等高距的1/10。 1.3为了节约,图根点可以采用临时地面标志。 1.4图根点的密度因测图使用的仪器不同要求也不同,只要能够保证碎部点的平面高程精度即可。 1.5测站点可以在测图过程中根据需要随时测放。 2.图根点测量(略)
三、地形测量测绘内容及取舍 地形图应表示测量控制点、居民地和垣栅、工矿建筑物及其他设施、交通及附属设施、管线及附属设施、水系及附属设施、境界、地貌和土质、植被等各项地物、地貌要素,以及地理名称注记等。并着重显示与测图用途有关的各项要素。 地物、地貌的各项要素的表示方法和取舍原则,除应按现行国家标准地形图图式执行外,还应符合如下有关规定。 1.测量控制点测绘 1.1测量控制点是测绘地形图和工程测量施工放样的主要依据,在图上应精确表示。 1.2各等级平面控制点、导线点、图根点、水准点,应以展点或测点位置为符号的几何中心位置,按图式规定符号表示。 2.居民地和垣栅的测绘 2.1居民地的各类建筑物、构筑物及主要附属设施应准确测绘实地外围轮廓和如实反映建筑结构特征。 2.2房屋的轮廓应以墙基外角为准,并按建筑材料和性质分类,注记层数。1:500与1:1000比例尺测图,房屋应逐个表示,临时性房屋可舍去;1:2000比例尺测图可适当综合取舍,图上宽度小于0.5mm的小巷可不表示。 2.3建筑物和围墙轮廓凸凹在图上小于0.4mm,简单房屋小于0.6mm时,可用直线连接。 2.4 1:500比例尺测图,房屋内部天井宜区分表示;1:1000比例尺测图,图上6mm2以下的天井可不表示。 2.5测绘垣栅应类别清楚,取舍得当。城墙按城基轮廓依比例尺表示,城楼、城门、豁口均应实测;围墙、栅栏、栏杆等可根据其永久性、规整性、
海量数据的存储需求及概念
海量数据的存储需求及概念 海量数据的存储需求其实就是时下流行的云存储概念,使用NVR的集群技术作为基础搭建的海量数据存储系统,可称为音视频云存储系统,在此基 础上的各种新型的智能高效查询服务可以称为云查询。 云存储是以NVR为硬件基础,使用软件分布式技术搭建的一个虚拟存储服务,此方式的具体工作NVR硬件对用户透明,用户提出存储需求,云存储服务系统满足需求。此系统具有高性价比、高容错性、服务能力几乎可以无限伸缩。在云存储系统里面的单机NVR,对其可靠性要求很低,因此我们可以使用 大量廉价的NVR硬件(不带RAID功能)来搭建系统。由此大量减少了硬件成本。由于数据IO吞吐处理被分散到了很多单机上,对单机的处理器、硬盘IO的能 力要求也可变得很低,进一步降低硬件成本。另外,由于云管理系统做了大量 的智能管理工作,将使得安装维护变得更容易。 云查询就是音视频云存储系统里的云计算,由于数据是分散存储在各个 单机节点上,故大量的查询可以是并行的,使得可以实现一些以前很难做到的 密集型计算的查询应用,如视频内容检索,历史视频智能分析等。 云软件开发模式使用强大的分布式中间件平台,其开发难度可大大降低。例如,由某公司开发的分布式平台就是一款云开发的利器,它高效、易学易用、能力强大、跨平台和编程语言,内置了很多分布式开发的基本特性。 未来几年中国的家庭宽带将升级到光纤入户,企业数据网络将升级到万 兆网,在网络化高度发达的大背景下,IT行业正在改变传统的IT资源拥有模式。安防行业在完全融入IT的背景下,行业发展和IT行业的发展趋势是一致的, IT行业的主流趋势是资源正在向可运营、可服务的方向发展。视频监控在智能
海量空间数据存储技术研究.
海量空间数据存储技术研究作者:作者单位:唐立文,宇文静波唐立文(装备指挥技术学院试验指挥系北京 101416,宇文静波(装备指挥技术学院装备指挥系北京 101416 相似文献(10条 1.期刊论文戴海滨.秦勇.于剑.刘峰.周慧娟铁路地理信息系统中海量空间数据组织及分布式解决方案 -中国铁道科学2004,25(5 铁路地理信息系统采用分布式空间数据库系统和技术实现海量空间数据的组织、管理和共享.提出中心、分中心、子中心三层空间数据库分布存储模式,实现空间数据的全局一致和本地存放.铁路基础图库主要包括不同比例尺下的矢量和栅格数据.空间数据库的访问和同步采用复制和持久缓存.复制形成主从数据库结构,从数据库逻辑上是主数据库全部或部分的镜象.持久缓存是在本地形成对远程空间数据的部分缓存,本地所有的请求都通过持久缓存来访问. 2.学位论文骆炎民基于XML的WebGIS及其数据共享的研究 2003 随着计算机技术、网络通信技术、地球空间技术的发展,传统的GIS向着信息共享的WebGIS发展,WebGIS正成为大众化的信息工具,越来越多的 Web站点提供空间数据服务。但我们不得不面对这样的一个现实:数以万计的Web站点之间无法很好地沟通和协作,很难通过浏览器访问、处理这些分布于Web的海量空间数据;而且由于行业政策和数据安全的原因,这些空间资源
大多是存于特定的GIS系统和桌面应用中,各自独立、相对封闭,从而形成空间信息孤岛,难以满足Internet上空间信息决策所需的共享的需要。此外,从地理空间信息处理系统到地理空间信息基础设施和数字地球,地理空间信息共享是它们必须解决的核心问题之一。因此,对地理空间信息共享理论基础及其解决方案的研究迫在眉睫;表达、传输和显示不同格式空间数据,实现空间信息共享是数字地球建设的关键技术之一,GIS技术正在向更适合于Web的方向发展。本文着重于探索新的网络技术及其在地理信息领域中的应用。 3.学位论文马维峰面向Virtual Globe的异构多源空间信息系统体系结构与关键技术 2008 GIS软件技术经过30多年的发展,取得了巨大发展,但是随着GIS应用和集成程度的深入、Internet和高性能个人计算设备的普及,GIS软件技术也面临着诸多新的问题和挑战,主要表现为:GIS封闭式的体系结构与IT主流信息系统体系结构脱节,GIS与其他IT应用功能集成、数据集成困难;基于地图 (二维数据的数据组织和表现方式不适应空间信息应用发展的需求;表现方式单一,三维表现能力不足。现有GIS基础平台软件的设计思想、体系结构和数据组织已经不适应GIS应用发展的要求,尤其不能适应“数字地球”、“数字城市”、“数字区域”建设中对海量多源异构数据组织和管理、数据集成、互操作、应用集成、可视化和三维可视化的需求。 Virtual Globe 是目前“数字地球”最主要的软件实现技术,Vtrtual Globe通过三维可视化引擎,在用户桌面显示一个数字地球的可视化平台,用户可以通过鼠标、键盘操作在三维空间尺度对整个地球进行漫游、缩放等操作。随着Google Earth的普及,Virtual Globe已成为空间数据发布、可视化、表达、集成的一个重要途径和手段。 Virtual Globe技术在空间数据表达、海量空间数据组织、应用集成等方面对GIS软件技术具有重要的参考价值:从空间数据表达和可视化角度,基于Virtual Globe的空间信息可视化方式是GIS软件二维电子地图表达方式的最好替代者,其空间表达方式可以作为基于地图表达方式的数字化天然替代,对于GIS基础平台研究具有重要借鉴意义;从空间数据组织角度,Virtual Globe技术打破了以图层为基础的空间数据组织方式,为解决全球尺度海量数据的分布式存取提供了新的思路;从应用集成和空间数据互操作角度,基于VirtualGlobe的组件化GIS平台可以提供更好的与其他IT系统与应用的集成方式。论文在现有理论和技术基础上,借鉴和引入
数据分级存储及访问方式设计方案研究随记
数据分级存储及访问方式设计方案 研究随记 认知问题的过程:what(什么)?→why(为什么)?→how(怎么做)?每一个需要研究的主题,我大都会按照这样的顺序重点在这三个问题上展开讨论和研究。 1. 数据分级存储的设计方案 1.1 什么是分级存储 分级存储是指根据数据不同的重要性、可用性、访问频次、存储成本等指标,分别存放在相应的存储设备上。其工作原理是基于数据访问的局部性,通过将不经常访问的数据自动移到存储层次中较低的层次,大大减少非重要性数据在一级磁盘所占用的空间,释放出较高成本的存储空间给更频繁访问的数据,从而加快整个系统的存储性能,获得更好的总体性价比。在分级存储系统中,一般分为在线存储、近线存储和离线存储三级存储方式。 1.2 为什么要分级存储 应用系统在线处理大量的数据,随着数据量的不断加大,如果都采用传统的在线存储方式,就需要大容量本地一级硬盘。这样一来一方面投资会相当较大,而且管理起来也相对较复杂;另一方面由于
磁盘中存储的大部分数据访问率并不高,但仍然占据硬盘空间,会导致存取速度下降。在这种情况下,数据分级存储的方式,可以在性能和价格间作出最好的平衡。 1.3 怎么实现分级存储架构 1.3.1 标准的三级数据分级存储架构 在线存储又称工作级的存储,是指将数据存放在高速的磁盘存储设备上(如FC 磁盘、SCSI 或光纤接口的磁盘阵列),其最大特征是存储设备和所存储的数据时刻保持“在线”状态,可随时读取和修改,以满足前端应用服务器或数据库对数据访问的速度要求。在线存储适合存储那些需要经常和快速访问的程序和文件,其存取速度快,性能好,存储价格相对昂贵。例如:用于应用的数据库和短近期(通常6个月-12个月)的数据的存储,需要满足大容量、高性能、高可靠性等特征。 近线存储是指将那些并不是经常用到或者访问量并不大的数据存放在性能较低、单位存储价格较便宜的存储设备上(通常是采用数据迁移技术自动将在线存储中不常用的数据迁移到近线存储设备上)。近线存储外延比较广泛,定位于用户在线存储和离线存储之间的应用,包括一些存取速度和价格介于高速磁盘与磁带之间的低端磁盘设备,如SATA 磁盘阵列、IDE磁盘阵列、DVD-RAM 光盘塔和光盘库、磁带库、NAS等。近线存储对性能总体要求相对不高,但要求能确保数据共享、可靠、传输稳定、适应一般的数据访问负荷。