MAPGIS新建数据库方法

MAPGIS数据库建设流程
MAPGIS建库需要以下几个图层,JHTB(接合图表)、CODE(数据字典)、DLTB(地类图斑)、XZDW(线状地物)、XZQ(行政区)、JBNTBHPK(基本农田保护片块)、JBNTBHTB (基本农田保护图斑)
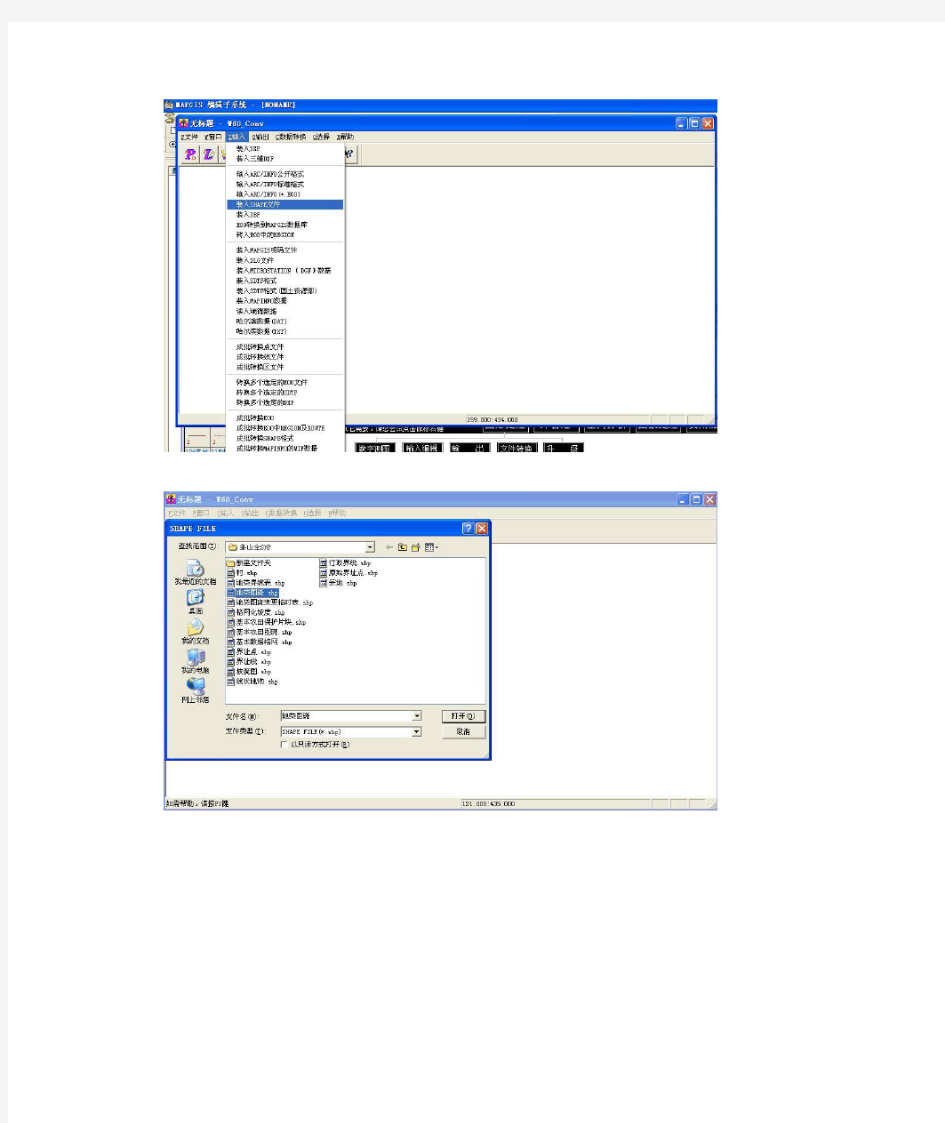
1、将SHAPE格式数据转换为MAPGIS格式数据,在MAPGIS主菜单下点击图形处理下的“文件转换”
运行完后点关闭,提示是否保存对话框
选择保存路径和文件名称
2、将苍穹下的属性结构按照《土地利用数据库标准》转换为MAPGIS的属性结构(各层都
要进行修改)。
其实就是按照标准将苍穹下的英文字段名改为MAPGIS 下的中文字段名 3、建立数据库
打开MAPGIS 建库系统,工程管理下新建工程
按以上设置进行设置,将接合图表和数据字典层导入后,点击确定。
点击坐标系统设置,按下图进行设置,然后点击确定。
将XZQ、PDT、DLTB、XZDW、JBNTBHPK、JBNTBHTB层按下图设置导入工程。
点击是,即将一个图层导入工程,所有图层都按此方法导入,导入完成后再次统改地图参数,只设置投影带类型(3度带)和投影带序号即可(35)。
4、工程下运行右边工具赋属性(都是双击工具)
①数据结构升级
②编号工具菜单下生成地类图斑编号(初次建库时使用此工具,若已有图斑编号就不再使用此工具)
③数据加工的数据处理工具下运行按图斑边界剪断线状地物,目的是将线状地物打断,并给线状地物赋长度,若已有长度,可不在运行此工具。
④线状地物属性赋值
⑤地类界线属性赋值
⑦线状地物属性修改
⑧要素代码赋值
⑨根据代码赋名称
5、计算面积
面积计算前要将XZQ层的控制面积和计算面积字段清空,将地类图斑层的所有面积字段清空,将线状地物层的线状地物面积字段清空,将基本农田保护片块和图斑层的面积字段也全部清空,方法如下图所示:
先在左侧双击要清空属性的图层,使其变为红色,然后在“区编辑”菜单下运行“根据参数赋属性”,将控制面积和计算面积字段前面选中,后面的内容全部删除,点击确定即可,所有图层要清空的字段都按此方法,若要清空的是线状地物,则在“线编辑”菜单下的“参
数编辑”下运行根据参数赋属性。
右边工具栏里双击“椭球面积计算”,按下图进行设置(将行政区层添加,中央经线输入105)
再按下图进行设置并计算
以上面积计算完后,在右边点击“控制面积设置”工具,在空白处输入县级控制面积进行平差(因为此数据库为一个村,故不进行平差)
设置完后,点击“控制面积处理”,即可进行平差。
平差完后点击“土地利用面积重算”工具。
6、数据汇总
在“成果输出”菜单下点击“数据汇总”,选择汇总到本地,然后点击确定。
7、打印表格
在“成果输出”菜单下点击“打印表格”菜单
将右下角的分页选项取消,点击“打印”即可输出所选中的所有表格。
8、导出VCT文件
点击“工具”菜单下VCT数据交换下的国家级农村VCT导出。
备注:因为在MAPGIS里权属层是自动生成的,所以我不知道怎样把你的数据导进去。
数据库及基本表的建立
一、实验目的 1、掌握SQL SERVER的查询分析器和企业管理器的使用; 2、掌握创建数据库和表的操作; 二、实验内容和要求 1、练习使用SQL语句、企业管理器(Enterprise Manager)创建数据库; 2、练习使用SQL语句、企业管理器(Enterprise Manager)创建数据库表; 三、实验主要仪器设备和材料 1.计算机及操作系统:PC机,Windows 2000/xp; 2.数据库管理系统:SQL sever 2005; 四、实验方法、步骤及结果测试 题目1、创建数据库“学生情况”: 实现代码及截图: SQL语句 create database学生情况 题目2、将数据库“学生情况”改名为“student” SQL语句 alter database学生情况modify name=student 题目3、创建基本表 SQL语句 S表: use Student create table S (Sno char(10) primary key, Sname char(10) not null, Ssex char(2) check(Ssex='男'or Ssex='女'), Ssp char(20), Sdept char(20), Sbirth datetime, Sfrom varchar(30), Schg char(10), Spa char(8) default('团员'), Snation char(8) default('汉族'), ); C表: use Student
create table C (Cno char(10) primary key, Cname char(10) unique, Tname char(8), Cdept char(20), CCredit real check(CCredit>=0and CCredit<=20), ); SC表: use Student create table Sc (Sno char(10), Cno char(10), Grade real check(Grade>=0and Grade<=100), Remark varchar(50), primary key(Sno,Cno), foreign key(Sno) references S(Sno), foreign key(Cno) references C(Cno), ); 题目4、用sql语句将C表中的ccredit改为整型 use Student /*首先手动删除约束才可以修改*/ alter table C alter column CCredit int; /*重新建立约束*/ alter table C add check(CCredit>=0and CCredit<=20); 题目5、用sql语句在“学生”表中添加一格“备注”字段remark,变长字符型,并保存结果 alter table S add remark varchar(50); 题目6. 用sql语句将“学生”表中“专业”字段数据类型改为varchar,长度为30并保存结果 alter table S alter column Ssp varchar(30); 题目7. 用sql语句删除“学生成绩”表中的“备注”字段并保存结果 alter table Sc drop column Remark; 题目8. 通过sql语句向s表中添加信息。 INSERT INTO S(Sno,Sname,Ssex,Ssp,Sdept,Sbirth,Sfrom,Schg,Spa,Snation,remark) VALUES ('001','李春刚','男','计算机应用','CS','1985-5-10','河源','','团员','汉',''); INSERT INTO S(Sno,Sname,Ssex,Ssp,Sdept,Sbirth,Sfrom,Schg,Spa,Snation,remark) VALUES ('002','东学婷','女','计算机应用','CS','1986-10-24','包头','转系','团员','蒙 ','');
数据库规范
数据库相关规范 1.使用utf8mb4字符集 2.所有表、字段必须写清中文注释 3.金额字段禁止使用小数存储(单位:分) 4.禁止使用字段属性隐式转换(如:“WHERE ms_no = 1234”ms_no为字符串类型) 5.尽量不使用负向查询(NOT、!=、<>、!<、!>、NOT IN、NOT LIKE等) 6.禁止使用外键,如有完整性约束,需要应用程序控制 7.禁止使用程序配置文件内的账号访问线上数据库 8.禁止非DBA对线上数据库进行写操作 9.开发、测试、线上环境分离 10.所以提交的SQL语句必须经过测试 11.禁止存储大文件或大照片 12.库名、表名、字段名:小写,下划线分割,不超过32个字符,必须见名知意,禁止拼 音英文混用 13.表必须有主键 14.必须把字段定义为NOT NULL并设置默认值 15.必须使用varchar(20)来存储手机号 16.单表索引控制在5个以内,单索引字段数不许超过5个 a)索引的使用。? b)(1) 尽量避免对索引列进行计算。如计算较多,请提请管理员建立函数索引。? c)(2) 尽量注意比较值与索引列数据类型的一致性。? d)(3) 对于复合索引,SQL语句必须使用主索引列? e)(4) 索引中,尽量避免使用NULL。? f)(5) 对于索引的比较,尽量避免使用NOT=(!=)? g)(6) 查询列和排序列与索引列次序保持一致 (7) 禁止在更新频繁、区分度不高(如:性别)的字段上建立索引 (8) 建立组合索引,必须把区分度高的字段放在前面 17.禁止使用SELECT * ,只获取必要的字段 18.禁止使用INSERT INTO t_xxx VALUES(xxx),必须指定插入的列名 19.禁止在WHERE条件的属性上使用函数或表达式 20.禁止%开头的模糊查询 21.禁止使用OR条件 22.应用程序必须捕获SQL异常,并作出相应处理 23.逻辑删除代替物理删除 24.选择最有效的表名、查询条件顺序(从右到左) 25.减少访问数据库的次数 26.SQL中的关键字均使用大写字母,数据表最好起别名 27.查询条件中“>=”代替“>” 28.等号两边使用空格,逗号后使用空格 29.多表操作必须使用别名 30.整条语句必须写明注释,关键逻辑单独书写注释,说明算法、功能 a)注释风格:注释单独成行、放在语句前面。? b)(1) 应对不易理解的分支条件表达式加注释;? c)(2) 对重要的计算应说明其功能;?
MySql 数据库用java程序创建表以及存储过程
MySql 数据库用java程序创建表以及存储过程 1.同一般的数据库操作基本一样。 2.Statement.executeUpdate(String sql); 这个方法可以用来执行DDL语句,以及执行更新操作。 3.需要注意 CallableStatement 接口的用法。 用于执行 SQL 存储过程的接口。JDBC API 提供了一个存储过程 SQL 转义语法,该语法允许对所有 RDBMS 使用标准方式调用存储过程。此转义语法有一个包含结果参数的形式和一个不包含结果参数的形式。如果使用结果参数,则必须将其注册为 OUT 型参数。其他参数可用于输入、输出或同时用于二者。参数是根据编号按顺序引用的,第一个参数的编号是 1。 {?= call
实验一数据库及基本表的建立
实验一数据库及基本表的建立 一、实验目的 1、掌握SQL SERVER的查询分析器和企业管理器的使用; 2、掌握创建数据库和表的操作; 二、实验内容和要求 1、练习使用SQL语句、企业管理器(Enterprise Manager)创建数据库; 2、练习使用SQL语句、企业管理器(Enterprise Manager)创建数据库表; 三、实验主要仪器设备和材料 1.计算机及操作系统:PC机,Windows 2000/xp; 2.数据库管理系统:SQL sever 2005; 四、实验方法、步骤及结果测试 题目1、创建数据库“学生情况”: 实现代码及截图: SQL语句 Create database 学生情况 查询分析器执行情况 :SQL语句及执行结果截图显示 找到主数据文件和日志文件,观察大小,并给出截图。
题目2、将数据库“学生情况”改名为“student” SQL语句 EXEC sp_renamedb学生情况, student 查询分析器执行情况: SQL语句及执行结果截图显示 题目3、创建基本表 S表 含义字段名字段类型字段 宽度 说明学号Sno Char10主键,不允许为空姓名Sname char10不允许为空 性别Ssex char2取值为男或女
C表 Sc表: 创建各表的实现代码及截图:
查询分析器执行情况: SQL语句及执行结果截图显示
题目4*、用sql语句将C表中的ccredit改为整型,同样约束为0-20之间 题目5、用sql语句在S表中添加一格“备注”字段remark,变长字符型,长度30,并保存结果
win7下mapgis点属性不能编辑破解
Win7下的MapGIS 6.7 兼容问题 最近装了 Windows 7,突然发现 MapGIS 6.7 有异常。主要是编辑功能里面,如点属性结构编辑等,其他一切都正常。就是想修改点线面的属性结构时,那个对话框会卡死。如下图。 不过,Win 7 还是可以兼容 MapGIS 6.7 的。网上流行的解决办法: 1.是关掉进程管理器中taskhost.exe或终止taskeng进程,但是有些时候但这样还是不行。 2.装一个虚拟机(在win7里面的一个软件),其功能就是相当于你装了xp,这样之后你在虚拟机中,启动mapgis,让后再其中编辑,修改等操作,这个也不是完全可以的。 3.后来研究发现,只要对 mdiedit6x.exe 作如下设置,就可以正常运行了(当然taskhost.exe 还是要关掉)。 mdiedit6x.exe位于安装目录里面,(例如:我的是 G:\mapgis67\program)
设置完以后,重新打开输入编辑——点属性结构编辑,如下图,可以正常编辑属性结构了。
你是不是觉得每次都这样操作也太麻烦了呀,有没有更加简单的办法呢? 答案是肯定的,你往下看吧。 那就要借助批处理来自动结束这个进程。 批处理内容,线内红色部分,复制到记事本,另存为bat文件,就做成批处理了。每次需要编辑点属性的时候就运行一次批处理。 说明:结束该进程导致输入法切换出问题的请使用下面快捷键切换 CTRL+空格切换中英文,左ALT+SHIFT切换输入法 输入法设置界面 把这个批处理放到启动目录中
启动目录路径C:\Users\你的用户名\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup 也可以直接拖入开始→所有程序→启动
数据库基础试题6(2)(20200521130409)
1.关系数据库中,实现表与表之间的联系是通过(D). A.实体完整性规则 B.用户自定义的完整性规则 C.值域 D.参照完整性规则 2. Visual FoxPro中索引类型包括(A). A.主索引、候选索引、唯一索引、普通索引 B.主索引、候选索引、普通索引、视图索引 C.主索引、次索引、候选索、普通索引 D.主索引、次索引、唯一索引、普通索引 3. 删除数据表文件的命令是(B). TABLE TABLE 4. 假设某字段所要存储的数值介于0~100,且不具备小数,则此字段 采用哪种数据类型最合适(C). A.双精度类型 B.浮动数类型 C.整型类型 D.数值类型
5. 每一个表只能拥有一个(B)索引. A.普通 B.主 C.唯一 D.候选 6.顺序执行下列命令后,屏幕所显示的记录号顺序是(B). USE STUDENT GO 6 LIST NEXT 4 ~10 ~9 ~7 ~4 7. 在数据库设计器中,建立两个表之间的一对多联系是通过以下索引实现的(D). A.一方表的普通索引,"多方"表的候选索引或普通索引 B.一方表的主索引,"多方"表的普通索引或候选索引 C.一方表的普通索引,"多方"表的主索引或候选索引 D."一方"表的主索引或候选索引,"多方"表的普通索引 8. 当前工作区是指(C). A.最后执行REPLACE命令所在的工作区 B.建立数据表时所在的工作区 C.最后执行SELECT命令所选择的工作区 D.最后执行USE命令所在的工作区
9. 已知当前表中有60条记录,当前记录为第6号记录.如果执行命令 SKIP 3后,则当前为第(D)号记录. 10. 执行SELECT 0 选择工作区的结果是(A). A.选择了空闲的最小号工作区 B.选择了0号工作区 C.显示出错信息 D.选择了一个空闲的工作区 11. 唯一索引中的"唯一性"是指(B)的唯一. A.字段值 B.索引项 C.视图项 D.字符值 12. 在Visual Foxpro中,求余运算和(C)函数作用相同. () () () ()
数据库及数据库表的创建与管理
《数据库技术》上机实验 实验三数据库及数据库表的创建与管理 一、实验目的 熟悉和掌握数据库的创建和连接方法; 熟悉和掌握数据表的建立、修改和删除; 加深对表的实体完整性、参照完整性和用户自定义完整性的理解。 二、实验软件平台 Windows XP/7/8/10操作系统; 安装了SQL SERVER 三、实验内容 背景材料:在以下实验中,使用学生-课程数据库(school),它描述了学生的基本信息、课程的基本信息及学生选修课程的基本信息。(要求使用命令的方式创建) 1.创建学生-课程数据库create database school Sno:char(9) Sname: varchar(6) Ssex:char(2) Sage:tinyint Sdept:char(2) Sno为主键,姓名不能为空,性别只能取男或女,年龄大于等于0。 Cno为主键,课程名不能为空,先行课可以为空,学分大于等于0 Sno:char(9) Cno:varchar(3) grade: float 主键是课程号和学号思考?成绩可以为空么?为什么? 5.将以上创建表S、C、SC的SQL命令以.SQL文件的形式保存在磁盘上。[文件操作的方 式直接保存即可,这部分不用写在“四实验结果”中] 温馨提示:到这部分内容做完为止,可以用数据库的备份功能将所建好的数据库及数据库表完全备份下来,下周的实验课程会利用这个表结构。或者直接保存题5的SQL语句也可以,下次课直接执行这些sql文件,也可以达到保存的目的。 6.在表S上增加“出生日期”属性列。 7.删除表S的“年龄”属性列。 8.删除表SC,利用磁盘上保存的.SQL文件重新创建表SC。 9.修改C表,将学分的约束改为0到5之间 10.修改S表的性别的类型,设置为char(1),并将约束改为0和1
mapgis属性输出至excel或dbf其他数据库
MAPGIS 属性输出到execl(转载加心得) 注意:只需在文件->导出这里操作即可,别去点属性那里再去输出属性,那里行不通。 方法一: 大家用mapgis 输出属性时经常会碰到这样的问题:不能输出到execl或者有时可以输出有时却不能输出dbf 。 出现这种情况大都是因为输出设置问题(数据源的配置及输出路径的设置),或者是盗版狗的问题,呵呵,如果是盗版狗的问题,我解决不了,否则,请你继续往下看: 下面说说详细步骤: 1、先建立一个EXECL空文件,并保存(如存文件名为:1.xls),如果想导出DBF格式,此步不必做。注意:文件路径不能为桌面,文件路径也不能太深。 2、打开“属性库管理模块”,选择“文件—>导出...”,在弹出的“导出内部数据”窗口中,打开你需要导出的MAPGIS文件。 3、在弹出的窗口“导出内部数据” 窗口中的下方“数据源”那一行有一“+”号,点击它。如果是导出DBF格式,跳过此步。 4、在弹出窗口“ODBC数据源管理器"中选择你要输出的数据格式(Execl Files),点“配置”,如果是导出DBF格式,跳过此步。 5、在弹出窗口“ODBC Microsoft Execel 安装”,点击“选择工作簿(s)”,选择你要将数据输出到的Execel文件(找到第1步建立的1.xls文件),点“确定”,此时窗口返回到“ODBC Microsoft Execel 安装” 窗口,再点“确定”,窗口返回到“ODBC数据源管理器” 窗口,再点“确定”,窗口返回到“导出内部数据”对话框。如果是导出DBF格式,跳过此步。 6、在“导出内部数据” 窗口中,数据源选择“EXECEL FILES”,在表格名称那里填入表格名称,如输入2,这时“导出”按钮激活,点击它就可以将属性数据导出到第1步选择的Execel 文件(1.xls)中了。如果是导出DBF格式, 在窗口中点“表格名称”,此时会弹出“换名存文件” 窗口,选择文件路径(注意:文件路径不能为桌面,文件路径也不能太深),输入DBF 文件名,然后点“保存”,再回到“导出内部数据” 窗口,点“导出”就OK了。
数据库原理-基本表的创建1
计算机工程学院实验报告 2017-2018学年第1学期 课程名称:数据库原理专业:计算机科学与技术班级:2班 学号: 姓名: 指导教师:
实验内容与完成情况 建立学生成绩管理数据库中的四张表: 一、实验代码: CREATE TABLE Course( courseNo char(3) NOT NULL, courseName varchar(30) not null, creaditHour n umeric(1) default 0 not null, courseHour t inyint default 0 not null, priorCourse c har(3) Null, CONSTRAINT CoursePK PRIMARY KEY(courseNO), FOREIGN KEY (priorcourse) references course(courseNo) ) 运行截图: 二、实验代码: CREATE TABLE Class( classno char(6) not null, classname varchar(30) not null, institute v archar(30) not null, grade smallint default 0 not null,
classnum tinyint null, constraint classpk primary key(classno) ) 运行截图: 三、实验代码: create table student( studentno char(7) not null, studentname varchar(20) not null, sex char(2) null, birthday datetime null, native varchar(20) null, nation varchar(30) default '汉族' null, classno char(6) null, constraint studentpk primary key(studentno), constraint studentfk foreign key (classno) references class(classno) ) 运行截图: 四、实验代码: create table score( studentno char(7) not null,
人力资源需求预测的常用方法
人力资源需求预测的常用方法 1.管理人员判断法 管理人员判断法,即企业各级管理人员根据自己的经验和直接,自下而上确定未来所需人员。这是一种粗浅的人力需求预测方法,主要适用于短期预测。 2.经验预测法 经验预测法也称比率分析,即根据以往的经验对人力资源需求进行预测。 由于不同人的经验会有差别,不同新员工的能力也有差别,特别是管理人员、销售人员,在能力、业绩上的差别更大。所以,若采用这种方法预测人员需求,要注意经验的积累和预测的准确度。 3.德尔菲法 德尔菲法(Delphi Method)是使专家们对影响组织某一领域发展(如组织将来对劳动力的需求)达成一致意见的结构化方法。该方法的目标是通过综合专家们各自的意见来预测某一领域的发展趋势。具体来说,由人力资源部作为中间人,将第一轮预测中专家们各自单独提出的意见集中起来并加以归纳后反馈给他们,然后重复这一循环,使专家们有机会修改他们的预测并说明修改的原因。一般情况下重复3~5次之后,专家们的意见即趋于一致。 这里所说的专家,可以是来自一线的管理人员,也可以是高层经理;可以是企业内部的,也可以是外请的。专家的选择基于他们对影响企业的内部因素的了解程度。 4.趋势分析法 这种定量分析方法的基本思路是:确定组织中哪一种因素与劳动力数量和结构的关系最密切,然后找出这一因素随聘用人数而变化的趋势,由此推断出未来人力资源的需求。 选择与劳动力数量有关的组织因素是需求预测的关键一步。这个
因素至少应满足两个条件: 第一,组织因素应与组织的基本特性直接相关 第二,所选因素的变化必须与所需人员数量变化成比例。 有了与聘用人数相关的组织因素和劳动生产率,我们就能够估计出劳动力的需求数量了。 在运用趋势分析法做预测时,可以完全根据经验估计,也可以利用计算机进行回归分析。 所谓回归分析法,就是利用历史数据找出某一个或几个组织因素与人力资源需求量的关系,并将这一关系用一个数学模型表示出来,借助这个数学模型,就可推测未来人力资源的需求。但此过程比较复杂,需要借助计算机来进行。
SQL索引详解(优化数据库)
SQL索引一步到位 SQL索引在数据库优化中占有一个非常大的比例,一个好的索引的设计,可以让你的效率提高几十甚至几百倍,在这里将带你一步步揭开他的神秘面纱。 1.1 什么是索引? SQL索引有两种,聚集索引和非聚集索引,索引主要目的是提高了SQL Server系统的性能,加快数据的查询速度与减少系统的响应时间 下面举两个简单的例子: 图书馆的例子:一个图书馆那么多书,怎么管理呢?建立一个字母开头的目录,例如:a开头的书,在第一排,b开头的在第二排,这样在找什么书就好说了,这个就是一个聚集索引,可是很多人借书找某某作者的,不知道书名怎么办?图书管理员在写一个目录,某某作者的书分别在第几排,第几排,这就是一个非聚集索引 字典的例子:字典前面的目录,可以按照拼音和部首去查询,我们想查询一个字,只需要根据拼音或者部首去查询,就可以快速的定位到这个汉字了,这个就是索引的好处,拼音查询法就是聚集索引,部首查询就是一个非聚集索引. 看了上面的例子,下面的一句话大家就很容易理解了:聚集索引存储记录是物理上连续存在,而非聚集索引是逻辑上的连续,物理存储并不连续。就像字段,聚集索引是连续的,a后面肯定是b,非聚集索引就不连续了,就像图书馆的某个作者的书,有可能在第1个货架上和第10个货架上。还有一个小知识点就是:聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个。 1.2 索引的存储机制 首先,无索引的表,查询时,是按照顺序存续的方法扫描每个记录来查找符合条件的记录,这样效率十分低下,举个例子,如果我们将字典的汉字随即打乱,没有前面的按照拼 音或者部首查询,那么我们想找一个字,按照顺序的方式去一页页的找,这样效率有多底,大家可以想象。 聚集索引和非聚集索引的根本区别是表记录的排列顺序和与索引的排列顺序是否一致,其实理解起来非常简单,还是举字典的例子:如果按照拼音查询,那么都是从a-z的,是 具有连续性的,a后面就是b,b后面就是c,聚集索引就是这样的,他是和表的物理排列顺序是一样的,例如有id为聚集索引,那么1后面肯定是2,2后面肯定是3,所以说这样的搜索顺序的就是聚集索引。非聚集索引就和按照部首查询是一样是,可能按照偏房查询的时候,根据偏旁‘弓’字旁,索引出两个汉字,张和弘,但是这两个其实一个在100页,一个在1000页,(这里只是举个例子),他们的索引顺序和数据库表的排列顺序是不一样的,这个样的就是非聚集索引。 原理明白了,那他们是怎么存储的呢?在这里简单的说一下,聚集索引就是在数据库 被开辟一个物理空间存放他的排列的值,例如1-100,所以当插入数据时,他会重新排列 整个整个物理空间,而非聚集索引其实可以看作是一个含有聚集索引的表,他只仅包含原表中非聚集索引的列和指向实际物理表的指针。他只记录一个指针,其实就有点和堆栈差不多的感觉了
数据库建立索引的原则
数据库建立索引的原则 使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构,例如employee 表的姓(lname)列。如果要按姓查找特定职员,与必须搜索表中的所有行相比,索引会帮助您更快地获得该信息。 索引是一个单独的、物理的数据库结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。 索引提供指向存储在表的指定列中的数据值的指针,然后根据您指定的排序顺序对这些指针排序。数据库使用索引的方式与您使用书籍中的索引的方式很相似:它搜索索引以找到特定值,然后顺指针找到包含该值的行。 在数据库关系图中,您可以在选定表的“索引/键”属性页中创建、编辑或删除每个索引类型。当保存索引所附加到的表,或保存该表所在的关系图时,索引将保存在数据库中。 建立索引的优点 1.大大加快数据的检索速度; 2.创建唯一性索引,保证数据库表中每一行数据的唯一性; 3.加速表和表之间的连接; 4.在使用分组和排序子句进行数据检索时,可以显著减少查询中分组和排序的时间。 索引的缺点 1.索引需要占物理空间。 2.当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度。 根据数据库的功能,可以在数据库设计器中创建三种索引:唯一索引、主键索引和聚集索引。有关数据库所支持的索引功能的详细信息,请参见数据库文档。 提示尽管唯一索引有助于定位信息,但为获得最佳性能结果,建议改用主键或唯一约束。有关这些约束的更多信息,请参见主键约束和唯一约束。 唯一索引
唯一索引是不允许其中任何两行具有相同索引值的索引。 当现有数据中存在重复的键值时,大多数数据库不允许将新创建的唯一索引与表一起保存。数据库还可能防止添加将在表中创建重复键值的新数据。例如,如果在employee 表中职员的姓(lname) 上创建了唯一索引,则任何两个员工都不能同姓。 有关唯一索引的更多信息,请参见创建唯一索引。 主键索引 数据库表经常有一列或列组合,其值唯一标识表中的每一行。该列称为表的主键。 在数据库关系图中为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型。该索引要求主键中的每个值都唯一。当在查询中使用主键索引时,它还允许对数据的快速访问。有关主键的更多信息,请参见定义主键。 聚集索引 在聚集索引中,表中行的物理顺序与键值的逻辑(索引)顺序相同。一个表只能包含一个聚集索引。 如果某索引不是聚集索引,则表中行的物理顺序与键值的逻辑顺序不匹配。与非聚集索引相比,聚集索引通常提供更快的数据访问速度。 一、索引 1. 概念:索引是揭示文献内容出处,提供文献查考线索的工具书。 2. 类型:种类很多,从不同的角度可以划分出不同的类型。按文种分,可以分为中文索引的外文索引;按收录范围分,可以分为综合性索引和专题性索引;按收录文献的时间分,可以分为近期索引和回溯性索引;按索引款目的标目分,可以分为题名索引、著者索引、语词索引、主题索引、分类索引等。 3. 功能:揭示文献的内容和指引读者查找信息 4. 作用:索引揭示了一书、一刊的基本情况,如篇目、文句。可以深入、完整、详细、系统地为读者提所需文献的具体线索。 铁律一:天下没有免费的午餐,使用索引是需要付出代价的。 索引的优点有目共睹,但是,却很少有人关心过采用索引所需要付出的成本。若数据库管理员能够对索引所需要付出的代价有一个充分的认识,也就不会那么随意到处建立索引了。
常见的预测方法
常见的预测方法 一、外推法 这是利用过去的资料来预测未来状态的方法。它是基于这样的认识:承认事物发展的延续性,同时考虑到事物发展中随机因素的影响和干扰。其最大优点是简单易行,只要有有关过去情况的可靠资料就可对未来做出预测。其缺点是撇开了从因果关系上去分析过去与未来之间的联系,因而长期预测的可靠性不高。外推法在短期和近期预测中用的较多。其中常用的一种方法是时间序列法。 时间序列法是按时间将过去统计得到的数据排列起来,看它的发展趋势。时间序列最重要的特征是它的数据具有不规则性。为了尽可能减少偶然因素的影响,一般采用移动算术平均法和指数滑动平均法。 1.移动算术平均法。移动算术平均法是假设未来的状况与较近时期有关,而与更早的时期关系不大。一般情况下,如果考虑到过去几个月的数据,则取前几个月的平均值。 2.指数滑动平均法。指数滑动平均法只利用过去较近的一部分时间序列。当时间序列已表现出某种规律性趋势时,预测就必须考虑这些趋势的意义,因此要采用指数滑动平均法。指数滑动平均法是对整个时间序列进行加权平均,其中的指数为0~1之间的小数,一般取0.7~0.8左右。 二、因果法 因果法是研究变量之间因果关系的一种定量方法。变量之间的因果关系通常有两类:一类是确定性关系,也称函数关系;另一类是不确定性关系,也称相关关系。因果法就是要找到变量之间的因果关系,据此预测未来。 1.回归分析法。没有因果关系的预测只是形式上的一种预测,而找出因果关系的预测才是本质的预测。回归分析法就是从事物变化的因果关系出发来进行的一种预测方法,不仅剔除了不相关的因素,并且对相关的紧密程度加以综合考虑,因而其预测的可靠性较高。 回归分析的做法是:首先进行定性分析,确定有哪些可能的相关因素,然后收集这些因素的统计资料,应用最小二乘法求出各因素(各变量)之间的相关系数和回归方程。根据这个方程就可预测未来。在技术预测中,多元回归分析很有价值。
mapgis属性编辑参数
图斑属性结构: 行政辖区属性结构
争议区属性结构 接合图表属性结构
分式编排:/分子/分母/ 如:/123/456/表示:123 456 2.13、修改文本 修改文本:用鼠标左键来捕获注释或版面,修改其文本内容。 子串统改文本:系统弹出统改文本的对话框,用户可输入“搜索文本内容”和“替换文本内容”,系统即将包含有“搜索文本内容”的字串替换成“替换文本内容”,它的替换条件是只要字符串包含有“搜索文本内容”即可替换。 全串统改文本:系统弹出统改文本的对话框,用户可输入“搜索文本内容”和“替换文本内容”,系统即将符合“搜索文本内容”的字串替换成“替换文本内容”,它的替换条件是只有字符串与“搜索文本内容”完全相同时才进行替换。 ⑶、比例尺分母 比例尺输入只需输入比例尺分母即可,值得注意的是本程序在进行投影转换时,输入的长度单位若为米,而MAPGIS系统中绘出图形的长度单位是毫米,因此转换时,需将米转换成毫米,这样在输入比例尺分母时,需在原有比例的基础上,除以1000,即生成1:10
00000图时,输入的比例尺分母应为1000,而非1000000。对于毫米单位,则直接输入相应的比例尺倒数即可,即1000000。若求高斯大地坐标,则设置单位为米,比例尺分母为1即可。 ⑶、比例尺分母 比例尺输入只需输入比例尺分母即可,值得注意的是本程序在进行投影转换时,输入的长度单位若为米,而MAPGIS系统中绘出图形的长度单位是毫米,因此转换时,需将米转换成毫米,这样在输入比例尺分母时,需在原有比例的基础上,除以1000,即生成1:1000000图时,输入的比例尺分母应为1000,而非1000000。对于毫米单位,则直接输入相应的比例尺倒数即可,即1000000。若求高斯大地坐标,则设置单位为米,比例尺分母为1即可。 4.7.5、条件合并 在用户选择条件合并的功能后,首先要求用户选择要合并的区文件,然后才弹出条件合并的对话框如下图: 合并条件:根据属性提取要合并的区实体。 合并方式: (1)、只合并符合条件的实体:指区的合并只在合并条件选择出来的区实体中进行;(2)、合并所有符合条件的选择的实体相邻的某一个区,如果两个区符合合并的条件,不管相邻的区是否在选择的实体中,都把他们合并起来。 相等字段条件:系统根据选择的字段的值决定两个区是否能合并。 注: 1 、对于要求全部合并的实体,用户可以选择可以包含全部实体的条件,如:ID >= 0,在进行辖区处理后,系统有可能没有对辖区进行合并,用户可在此进行条件和并。 2 、合并之前,用户需要确保区的拓扑关系正确 3 、如果用户不选择合并相等条件,则只合并按照合并条件选择的实体。 4.7.6、同类拼接 添加文件:选择要进行拼接的文件,用户可以按住CTRL或SHIFT键的同时用鼠标来
MySQL优化原则
MySQL优化原则 转载2014年05月20日10:27:13 1113 数据库已成为互联网应用必不可少的底层依赖,其中MySQL作为开源数据库得到了更加广泛的应用。最近一直专注于项目工程的开发,对开发过程中使用到的一些关于数据库的优化原则进行了总结,希望能够帮助更多的应用开发人员更好的使用MySQL数据库。 MySQL的优化主要包括三个方面,首先是SQL语句的优化,其次是表结构的优化,这里主要指索引的优化,最后是服务器配置的优化。第四点代码结构的优化!!! 1.SQL语句的优化 1)查询语句应该尽量避免全表扫描,首先应该考虑在Where子句以及OrderBy子句上建立索引,但是每一条SQL语句最多只会走一条索引,而建立过多的索引会带 来插入和更新时的开销,同时对于区分度不大的字段,应该尽量避免建立索引,可 以在查询语句前使用explain关键字,查看SQL语句的执行计划,判断该查询语 句是否使用了索引; 2)应尽量使用EXIST和NOT EXIST代替 IN和NOT IN,因为后者很有可能导致全表扫描放弃使用索引; 3)应尽量避免在Where子句中对字段进行NULL判断,因为NULL判断会导致全表扫描; 4)应尽量避免在Where子句中使用or作为连接条件,因为同样会导致全表扫描; 5)应尽量避免在Where子句中使用!=或者<>操作符,同样会导致全表扫描; 6)使用like “%abc%”或者like “%abc”同样也会导致全表扫描,而like “abc%”会使用索引。 7)在使用Union操作符时,应该考虑是否可以使用Union ALL来代替,因为Union 操作符在进行结果合并时,会对产生的结果进行排序运算,删除重复记录,对于没
MAPGIS实验三、属性编辑及属性连接
实验四、属性编辑、属性连接及空间分析实验目的:通过上机操作使同学们掌握属性编辑的具体步骤和属性连接的具体步骤。 实验步骤: 一、属性编辑 打开属性库管理窗口,点击:装区文件,装入“呼市包头.wp”
对“呼市包头.wp”添加属性,具体数据详看“呼市包头.xls”,将该excel 文件中的数据一一添加上。 二、属性连接 打开属性库管理窗口,打开区文件:内蒙旗县.wp,检查属性。 打开“内蒙旗县.xls”,将该文件另存为“内蒙旗县.dbf”,利用属性连接功能,将内蒙旗县.wp和内蒙旗县.dbf连接。在连接中,注意关键字 段的选择。结果如图所示。
三、空间分析 输入检索条件,即输入运算结果为逻辑值的表达式,在表达式中可以包含窗口中所列的字段名称、常数和输入模板所列的操作符。操作符说明如下:+、-、×、/ :分别表示加、减、乘、除运算。 >、>=、<、<=、==、!=:分别表示大于、大于等于、小于、小于等于、等于、不等。 &&、||、^、~:分别表示逻辑与、逻辑或、逻辑异或、逻辑非。 如给定条件: (面积>=100)&&(面积<=1000) 即要求从所选文件中检索出满足条件(面积大于等于100而且面积小 于等于1000)的所有图元。
4> 系统根据条件进行检索,若成功,则显示属性,并闪烁图元。 条件检索是根据用户给定的条件进行检索,因而具有较强的灵活性,只要图元的属性数据能够区分开来,该功能就可以将它检索出来。 根据给定的区文件“土地类型”进行检索 表1 土地利用类型及其代码 土地代码土地类型土地代码土地类型土地代码土地类型1111 平田131 有林地253 农村宅基地1112 梯田132 灌木林地271 水库水面112 望天田133 蔬林地272 水工建筑用地1141 平旱地134 未成林造森地283 宗教用地1142 坡地136 苗圃311 荒草地115 菜地154 坑塘水面315 裸土地121 果园156 农田水利用地316 裸岩石砾地121K 可调整果园222 采矿地317 其他未利用土地123 茶园 运用空间分析的条件检索功能对“土地类型”或“土地代码”检索。 注意:检索语句中的双引号是拼音模式下的。表达式不是唯一的,但一般尽可能选比较简单的表示式。 寻找是平田的土地类型 寻找既是菜地又是果园的土地类型 寻找面积<1000而且>10000的土地类型 寻找既不是其它未利用土地又不是裸岩石砾地,而且面积>3000而且<5000的土地类型。
索引的建立和运用
一、问题的提出 在应用系统开发初期,由于开发数据库数据比较少,对于查询SQL语句,复杂视图的编写等体会不出SQL语句各种写法的性能优劣, 但是如果将应用系统提交实际应用后,随着数据库中数据的增加,系统的响应速度就成为目前系统需要解决的最主要的问题之一。 系统优化中一个很重要的方面就是SQL语句的优化。对于海量数据,劣质SQL语句和优质SQL语句之间的速度差别可以达到上百倍,可见 对于一个系统不是简单地能实现其功能就可,而是要写出高质量的SQL 语句,提高系统的可用性。 在多数情况下,Oracle使用索引来更快地遍历表,优化器主要根据定义的索引来提高性能。但是,如果在SQL语句的where子句中 写的SQL代码不合理,就会造成优化器删去索引而使用全表扫描,一般就这种SQL语句就是所谓的劣质SQL语句。在编写SQL语句时我们 应清楚优化器根据何种原则来删除索引,这有助于写出高性能的SQL语句。 二、SQL语句编写注意问题 下面就某些SQL语句的where子句编写中需要注意的问题作详细介绍。 在这些where子句中,即使某些列存在索引,但是由于编写了劣质的SQL,系统在运行该SQL语句时也不能使用该索引,而同样使用 全表扫描,这就造成了响应速度的极大降低。 1. IS NULL 与IS NOT NULL 不能用null作索引,任何包含null值的列都将不会被包含在索引中。即使索引有多列这样的情况下,只要这些列中有一列含有null, 该列就会从索引中排除。也就是说如果某列存在空值,即使对该列建索引也不会提高性能。 任何在where子句中使用is null或is not null的语句优化器是不允许使用索引的。 2. 联接列 对于有联接的列,即使最后的联接值为一个静态值,优化器是不会使用索引的。 我们一起来看一个例子,假定有一个职工表(employee),对于一个职工的姓和名分成两列存放(FIRST_NAME和LAST_NAME), 现在要查询一个叫比尔.克林顿(Bill Cliton)的职工。 下面是一个采用联接查询的SQL语句, select * from employee where first_name||''||last_name ='Beill Cliton'; 上面这条语句完全可以查询出是否有Bill Cliton这个员工,但是这里需要注意,系统优化器对基于last_name创建的索引没有 使用。 当采用下面这种SQL语句的编写,Oracle系统就可以采用基于last_name创建的索引。 Select * from employee where first_name ='Beill' and last_name ='Cliton'; 遇到下面这种情况又如何处理呢?如果一个变量(name)中存放着Bill Cliton这个员工的姓名,对于这种情况我们又如何避免 全程遍历,使用索引呢?
mapgis属性库管理
属性库管理 一.编辑属性结构 编辑步骤如下: a)首先,装入或选定要修改的属性结构文件, 如右图: b)根据文件类型执行相应编辑功能,编辑界 面如下图: c)键入字段名,回车。出现下图。选择字段类 型。 二.浏览属性结构 只能查看文件属性结构,不能修改属性结构。 三.修改多媒体数据局目录 该功能用来上设置媒体属性数据所在的目录。选中后,系统首先弹出窗口,选择带有多媒体属性字段数据,选择文件,弹出设置窗口。 四.属性数据
属性数据,提供增加、修改、删除属性数据功能。 1.编辑浏览属性 具体步骤: a)装入或选定要修改属性的文件。 b)根据文件类型,执行相应编辑功能,编辑属性界面如图 c)在相应的字段里修改,完成后,结束编辑。 2.编辑和浏览单个属性 具体步骤: a)先激活编辑单个属性选单。 b)选定要编辑的具体实体,系统弹出界面如图。 c)修改具体的值,按YES.浏览单个属性只能查看具体实体属性,操 作与编辑单个属性类似。 浏览单个属性只能查看具体实体属性,不能修改属性,操作与编辑单个属性类似。 3.输出属性 输出属性功能将已装入的MAPGIS图形文件中的属性信息写到外部属性数据表或MAPGIS表文件中,这里所指的外部数据库是DBASE.FOXBASE,FOXPRO,ACESS,EXCEL,SQL SERVER,ORACLE等数据库软件的表文件,MAPGIS的表文件是指*.WB文件。
4.输入表格 将指定的外部数据库表转换成MAPGIS文件。用此功能,系统会弹出如右对话框: 5.连接属性 将外部数据库中的数据与MAPGIS中实体相关联,并将满足条件部分数据写进MAPGIS图形数据属性中。通过此功能,将外部数据库的属性数据输入到MAPGIS图形文件的属性数据中。连接属性界面。如下图: