Speex语音编码算法实现与优化

186 2009年第10期,第42卷 通 信 技 术 Vol.42,No.10,2009 总第214期 Communications Technology No.214,Totally
·信源处理·
Speex 语音编码算法实现与优化
穆 捷, 李 敬, 唐 昆
(清华大学 电子工程系,北京 100084)
【摘 要】介绍了Speex 编码原理,对其特有的编码方式进行了深入的分析,针对其编码特点提出了3种降低运算复杂度的优化方法,并在DSP 芯片上进行了实现。通过使用ITU P.862规范中的评分方法进行分析,所述方法能在保证语音质量基本不下降的前提下,显著的降低运算复杂度。
【关键词】Speex ;感觉加重;逆滤波;简单相关
【中图分类号】TN91 【文献标识码】A 【文章编号】1002-0802(2009)10-0186-03
Realization and Optimization of Speex
MU Jie , LI Jing , TANG Kun
(Department of Electronic Engineering, Tsinghua University, Beijing 10084, China )
【Abstract 】This paper first tells of the principle of Speex. Then, based on the analysis, three ways for simplifying computation are described. Through analysis by using PESQ in ITU P.862, the three proposed ways could help reduce the complexity of computation while the speech quality is guaranteed.
【Key words 】Speex; perceptual weighting; reverse filter; simple correlation
0 引言
互联网的发展推动着VOIP(V oice Over IP)技术应用的不断扩大,而现有的语音编码算法如G .729,虽然在语音质量上已经取得了很好的效果,但是由于应用环境不同,这些算法并不能很好的适应因特网网络环境多变的特点。Speex 是在VOIP 的应用背景下提出的一种基于CELP(Code Excited Linear Prediction)算法的免费、开源的语音编码器,其编码方式非常灵活,可以依据不同的应用环境采用统一的码流格式和编码算法,实现多码率,多采样率的灵活的语音编码,以适应网络语音通信的需求。
然而,传统的CELP 算法虽然在低码率的条件下依然能够保证良好的语音效果,但是其较高的运算量使得一些基于该算法的编码器难以在一些低功耗的芯片上实现。本文首先简要介绍了Speex 编解码算法,然后针对CELP 算法运算量大的缺点提出了调整感觉加权滤波器、利用简单互相关简化自适应码本搜索和固定码本逆滤波3种降低运算复杂度的优化方法,最后给出了试验结果,经试验验证,本文提出的优
化方法在较好保证语音质量的同时能够有效地降低运算量。
1 Speex 语音编解码算法简介
Speex 基于CELP(Code Excited Linear Prediction)算法,可同时进行窄带和宽带编码,并且具有多种速率。 自适应码本搜索利用互相关算法进行三阶基因预测,得到相应子帧的残差信号。然后将经过自适应码本搜索后的子帧残差信号分为长度不等的从5到20个样点的子矢量,依速率的不同采用各自对应的独立码本进行固定码本搜索。解码就是编码的逆过程,由于解码过程中并没有涉及码本搜索,因此,整个编解码的运算量主要集中在编码上,其中自适应码本和固定码本搜索占据了绝大部分,而宽带模式由于编码方式基本与窄带相同,因此我们的优化测试都基于窄带模式。
2 算法优化
CELP 结构的编码器虽然可以在低码率下仍然保持较高的语音质量,但其主要缺点就是运算量较大。对于Speex 编解码算法,当其工作在高模式下时,由于码本的增加和搜索精度的提高,使得算法复杂度加大,同时也就造成了在一些低功耗的DSP 芯片上较难实现实时的语音通信。为了解决这一问题,我们在CELP 模型运算量集中的码本搜索和基音周
收稿日期:2008-10-23。 作者简介:穆 捷(1979-),男,硕士研究生,从事语音压缩编码方
向研究;李 敬,男,讲师,从事多媒体通信方向研究;唐 昆,男,教授,从事多媒体通信方向研究。
万方数据
187
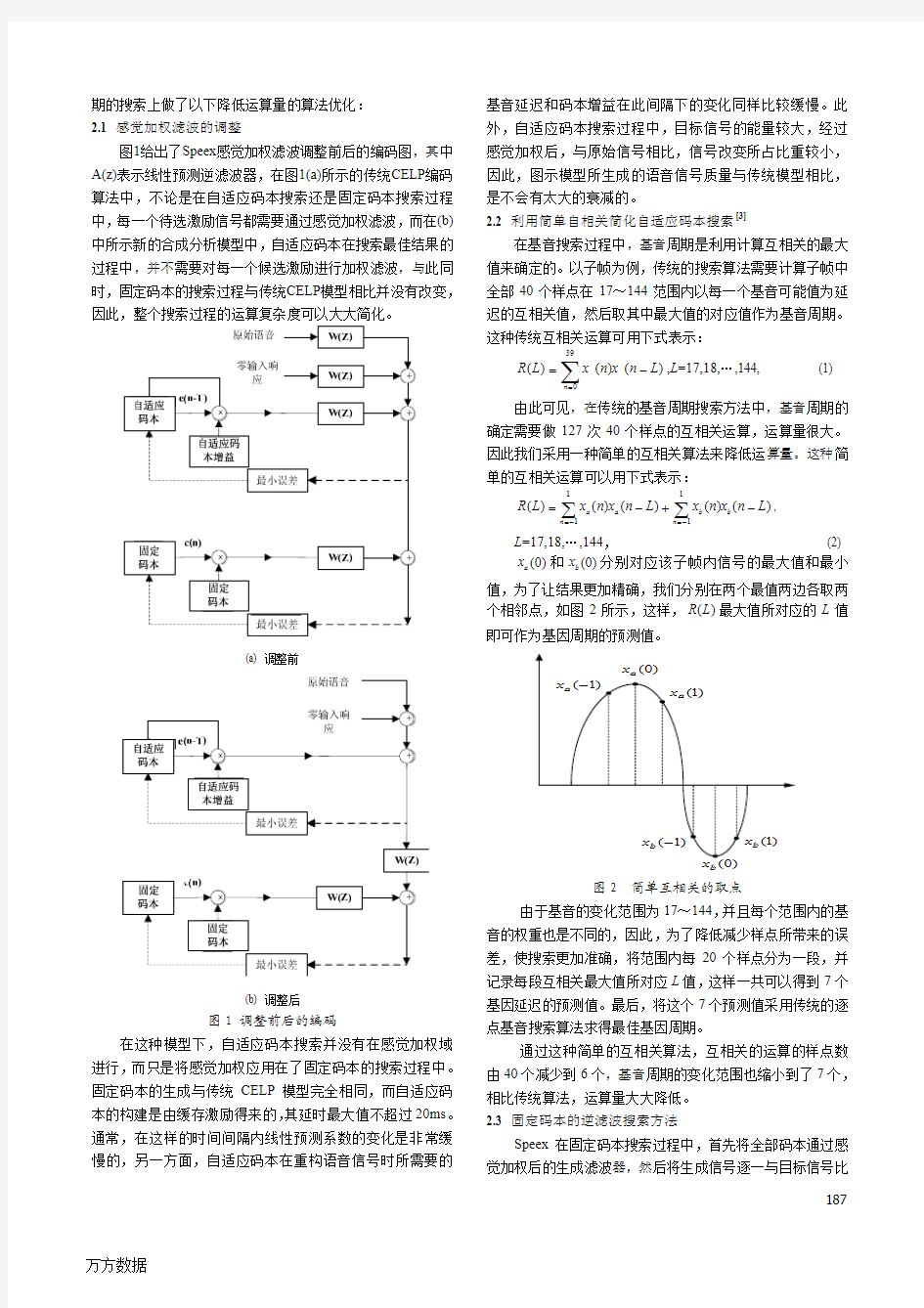
期的搜索上做了以下降低运算量的算法优化: 2.1 感觉加权滤波的调整
图1给出了Speex 感觉加权滤波调整前后的编码图,其中A(z)表示线性预测逆滤波器,在图1(a)所示的传统CELP 编码算法中,不论是在自适应码本搜索还是固定码本搜索过程中,每一个待选激励信号都需要通过感觉加权滤波,而在(b)中所示新的合成分析模型中,自适应码本在搜索最佳结果的过程中,并不需要对每一个候选激励进行加权滤波,与此同时,固定码本的搜索过程与传统CELP 模型相比并没有改变,因此
(a) 调整前
(b) 调整后
图1 调整前后的编码
在这种模型下,自适应码本搜索并没有在感觉加权域进行,而只是将感觉加权应用在了固定码本的搜索过程中。固定码本的生成与传统CELP 模型完全相同,而自适应码本的构建是由缓存激励得来的,其延时最大值不超过20ms 。通常,在这样的时间间隔内线性预测系数的变化是非常缓慢的,另一方面,自适应码本在重构语音信号时所需要的
基音延迟和码本增益在此间隔下的变化同样比较缓慢。此外,自适应码本搜索过程中,目标信号的能量较大,经过感觉加权后,与原始信号相比,信号改变所占比重较小,因此,图示模型所生成的语音信号质量与传统模型相比,是不会有太大的衰减的。
2.2 利用简单自相关简化自适应码本搜索[3]
在基音搜索过程中,基音周期是利用计算互相关的最大值来确定的。以子帧为例,传统的搜索算法需要计算子帧中全部40个样点在17~144范围内以每一个基音可能值为延迟的互相关值,然后取其中最大值的对应值作为基音周期。这种传统互相关运算可用下式表示:
)()()(39
L n x n x L R n -=
?=,L =17,18,…,144, (1)
由此可见,在传统的基音周期搜索方法中,基音周期的确定需要做127次40个样点的互相关运算,运算量很大。因此我们采用一种简单的互相关算法来降低运算量。这种简单的互相关运算可以用下式表示:
1
1
11
()()()()()a a b
b
n n R L x n x n L x n x n L =-=-=
-
+
-??,
L =17,18,…,144, (2) (0)a x 和(0)b x 分别对应该子帧内信号的最大值和最小值,为了让结果更加精确,我们分别在两个最值两边各取两个相邻点,如图2所示,这样,()R L 最大值所对应的L 值
即可作为基因周期的预测值。
b
图2 简单互相关的取点
由于基音的变化范围为17~144,并且每个范围内的基音的权重也是不同的,因此,为了降低减少样点所带来的误差,使搜索更加准确,将范围内每20个样点分为一段,并
记录每段互相关最大值所对应L 值,这样一共可以得到7个基因延迟的预测值。最后,将这个7个预测值采用传统的逐点基音搜索算法求得最佳基因周期。
通过这种简单的互相关算法,互相关的运算的样点数由40个减少到6个,基音周期的变化范围也缩小到了7个,相比传统算法,运算量大大降低。 2.3 固定码本的逆滤波搜索方法
Speex 在固定码本搜索过程中,首先将全部码本通过感觉加权后的生成滤波器,然后将生成信号逐一与目标信号比
万方数据
188 较找出最小值,其对应索引值即作为固定码本的最佳索引。这样,当固定码本较大时,逐一通过滤波器的运算量会很大,因此,尝试做以下改变:首先,将目标信号通过生成滤波器的逆滤波器,得到激励信号,然后将此激励信号与原始码本进行比较找出误差最小值,将对应索引作为最佳索引。为了让搜索更加准确,还可以进一步记录3个误差最小值,将3个最小值对应的码本通过感觉加权后的生成滤波器,再从中找出最佳码本。这样,避免了码本中每一个矢量逐一通过合成滤波器,减少了运算量。
3 试验及结论
测试中,我们采用ITU 的P.862规范进行语音质量的评估。首先,用ITU 提供的or109等6个测试序列对Speex 原
始算法在24.6 kb/s 速率下进行MOS 评分,然后用同样的方法对本文提出的3种优化算法也进行测试,最后给出平均MOS 分。对于运算复杂度的评估我们将原始算法和优化后的算法分别在ADSP -2100芯片上予以实现,通过计算DSP 芯片执行算法的指令数(MIPS )来评估优化效果,各部分调整后综合效果对比如表1所示。
通过试验验证我们可以看到,本文提出的去加重和自适应码本简单相关两种优化方法使运算复杂度的下降6.14MIPS ,同时,其RAW-MOS 分分别只下降了0.071和0.001,基本对语音质量没有影响,其中简单相关的优化方法甚至对3个测试序列的MOS 分还略有提高。而固定码本的逆滤波由于DSP 硬件指令并行的原因,其复杂度只下降了0.1,但仍具有一定借鉴意义。
表1 Speex 优化前后语音质量和运算复杂度对比
测试序列
原始算法
去加重
固定码本逆滤波
3个最小值
固定码本逆滤波
1个最小值 自适应码本简单相关
Or109.wav 3.849 3.755 3.8 3.564 3.84 Or114.wav 3.71 3.612 3.645 3.212 3.699 Or129.wav 4.166 4.119 4.01 3.82 4.144 Or134.wav 4.145 4.076 4.108 3.892 4.15 Or145.wav 3.746 3.638 3.66 3.238 3.794 Or152.wav 3.78 3.716 3.646 3.337 3.776 平均分 3.899 -0.07(3.819) -0.099(3.875) -0.356(3.618) -0.001(3.898)
DSP 复杂度
43.7MIPS
-2.5MIPS
-0.1MIPS
-0.8MIPS
3.64MIPS
4 结语
本文介绍了Speex 语音编解码算法的特点,并针对其运算量较大的码本搜索和基音搜索部分提出了优化方法,试验结果证明该方法在较好保证语音质量的同时能够有效地降低运算量。文中给出的优化方法在相似CELP 结构的语音编解码算法中同样适用。
参考文献
[1] Valin M J. Speex: A Free Codec For Free Speech[EB/OL], (2007)
https://www.360docs.net/doc/a63915841.html,/docs/manual/speex-manual.pdf
[2] de Silva L M ,Alcaim A. A Modified CELP Model with
Computationally Efficient Adaptive Codebook Search[J]. IEEE Signal Processing Letters ,1995,2(3):44-45.
[3] Myung Jin Bae ,Hwe Yoong Whang ,Hah Young Yoo. On a Fast Pitch
Searching by Using A Simple Correlation Technique in the CELP Vocoder[C]// Proceedings of the 38th Midwest Symposium on Circuits and Systems, Rio De Janeiro, Brazil, 1995:1256-1259..
作者须知(1)
为了提高本刊的编辑出版质量,请作者用word 、photoshop 、VISIO 等软件作图,以便我部好对你所提供的图进行编辑修改。
作者绘图时注意: 1)采用两种尺寸的图,即长不大于8厘米和长不大于15厘米(因为《通信技术》采用的是双栏排版,故请作者尽量采用长为8厘米的图); 2)图的大小比例要合适,图要画得紧凑些,线条粗细要得当,连线请画短些,这样画出的图会紧凑些; 3)图内字请用6号宋字居中排; 4)请不要用截来的图和扫描的图, 那样印刷出的图会很不清楚,需要时请作者画出仿真图; 5)图中的字母是变量的请用斜体,是矩阵和矢量的字母还要用黑斜体,非变量或英文单词请用正体,数字和标点符号在任何情况下均为正体; 6)图的线条着色请用黑色,用其他颜色画线条印刷效果不好(印出的线条不清晰); 7)
图中箭头如无特殊要求请按我部所给的箭头形式
画箭头 ;8)图中的纵、横坐标表示的量和单位要标识出,图片的量和单位一般以“量的斜体/单位符号的正体”表示。如:/s t ;sn /A; /dB; I R LL
应先有图在正文中的说明,再附上图。 图1 矢量滤波器预处理的多小波的分解和重构
万方数据
音频的编解码
音频编码解码基本概念介绍 对数字音频信息的压缩主要是依据音频信息自身的相关性以及人耳对音频信息的听觉冗余度。音频信息在编码技术中通常分成两类来处理,分别是语音和音乐,各自采用的技术有差异。 语音编码技术又分为三类:波形编码、参数编码以及混合编码。 波形编码:波形编码是在时域上进行处理,力图使重建的语音波形保持原始语音信号的形状,它将语音信号作为一般的波形信号来处理,具有适应能力强、话音质量好等优点,缺点是压缩比偏低。该类编码的技术主要有非线性量化技术、时域自适应差分编码和量化技术。非线性量化技术利用语音信号小幅度出现的概率大而大幅度出现的概率小的特点,通过为小信号分配小的量化阶,为大信号分配大的量阶来减少总量化误差。我们最常用的G.711标准用的就是这个技术。自适应差分编码是利用过去的语音来预测当前的语音,只对它们的差进行编码,从而大大减少了编码数据的动态范围,节省了码率。自适应量化技术是根据量化数据的动态范围来动态调整量阶,使得量阶与量化数据相匹配。G.726标准中应用了这两项技术,G.722标准把语音分成高低两个子带,然后在每个子带中分别应用这两项技术。 参数编码:广泛应用于军事领域。利用语音信息产生的数学模型,提取语音信号的特征参量,并按照模型参数重构音频信号。它只能收敛到模型约束的最好质量上,力图使重建语音信号具有尽可能高的可懂性,而重建信号的波形与原始语音信号的波形相比可能会有相当大的差别。这种编码技术的优点是压缩比高,但重建音频信号的质量较差,自然度低,适用于窄带信道的语音通讯,如军事通讯、航空通讯等。美国的军方标准LPC-10,就是从语音信号中提取出来反射系数、增益、基音周期、清/浊音标志等参数进行编码的。MPEG-4标准中的HVXC声码器用的也是参数编码技术,当它在无声信号片段时,激励信号与在CELP时相似,都是通过一个码本索引和通过幅度信息描述;在发声信号片段时则应用了谐波综合,它是将基音和谐音的正弦振荡按照传输的基频进行综合。 混合编码:将上述两种编码方法结合起来,采用混合编码的方法,可以在较低的数码率上得到较高的音质。它的特点是它工作在非常低的比特率(4~16 kbps)。混合编码器采用合成分析技术。
语音编码技术及其在通信系统中的应用
多媒体技术基础期末论文 题目:语音压缩编码及其在通信系统中的应用 专业:通信工程 姓名:张娴 学号: 1 2 3 0 7 1 3 0 4 4 9
2016年5月24日 在现代通信中,随着科学技术的迅速发展,图像、数据等非话音信息在通信信息总量中所占的比例大大提高,而且这种提高的趋势仍然会继续下去。比如说,以前的手机基本上只可以打电话,发短信,不能接收文件,不能观看视频,但是现在的3G手机甚至4G手机,可以看视频,接发文件,还有很多的应用软件。语音信号所占的传输比例的确是大大减小。但是,到目前为止,在大多数通信系统中,传输最多的信息仍然是语音信号。比如说我们经常打电话,用语音发微信,听音乐,看视频等等。在可以预见的未来通信中,尽管语音信号在通信信息总量中所占的比例会有所下降,但仍然会是传输最多的信息。 语音信号是模拟信号,不能直接在数字通信系统中传输,必须先进行模/数转换再进行数/模转换,这种转换就称为语音编译码(简称语音编码),其作用是将语音模拟信号转换为数字信号,到了接收端,再将收到的语音数字信号还原为语音模拟信号。可见,语音编码技术在数字通信中具有十分重要的作用,随着计算机技术与超大规模集成电路技术的飞速发展和广泛应用,信号的数字处理、数字传输和数字存储日益显示出巨大的优越性。数字化技术的应用范围迅速扩大到各个科学技术领域,渗透到工农业生产和社会生活的各个方面。因此,尽量减少信号占有带宽、持续时间和存储容积,以节省信号在传输、处理和存储中的开销,具有巨大的经济价值。所以,语音编码技术,尤其是语音压缩编码技术(编码速率在16kbit/s以下),近年来受到人们的广泛关注和重视,有着极为迫切的客观需求。正是在这种强大的客观需求推动下,近二十几年来,随着计算
语音增强算法的研究与实现
语音增强算法的研究与实现 目录 目 录 ..................................................................... ............................................................ I 河西学院本科生毕业论文(设计)诚信声 明 ................................... 错误~未定义书签。I 河西学院本科生毕业论文(设计)任务 书 ...................................... 错误~未定义书签。II 河西学院本科毕业论文(设计)开题报 告 ..................................... 错误~未定义书签。IV 摘 要 ..................................................................... .................................................................. I Abstract ........................................................... ....................................................................... I 1 引 言 ..................................................................... .. (1) 2 语音增强算法概 述 ..................................................................... (1)
语音识别方法及发展趋势分析
语音识别改进方法及难点分析 ——《模式识别》结课小论文 学院:化工与环境学院 学号:2120151177 姓名:杜妮
摘要:随着计算机技术的不断发展,人工智能程度也越来越高,作为人工智能的一部分——模式识别也在模型和算法上愈发成熟。本文根据近105年文献,分析最新声音识别的方法和应用。 关键字:模式识别声音识别方法应用 随着人工智能的迅速发展,语音识别的技术越来越成为国内外研究机构的焦点。人们致力于能使机器能够听懂人类的话语指令,并希望通过语音实现对机器的控制。语音识别的研究发展将在不远的将来极大地方便人们的生活。 语音识别大致的流程包括:特征提取、声学模型训练、语音模型训练以及识别搜索算法。作为一项人机交互的关键技术,语音识别在过去的几十年里取得了飞速的发展,人们在研究和探索过程中针对语音识别的各部流程进行了各种各样的尝试和改造,以期发现更好的方法来完成语音识别流程中的各步骤,以此来促进在不同环境下语音识别的效率和准确率。本文通过查阅近10年国内外文献,分析目前语音识别流程中的技术进展和趋势,并在文章最后给出几项语音识别在日常生活中的应用案例,从而分析语音识别之后的市场走势和实际利用价值。 一、语音识别的改进方法 (一)特征提取模块改进 特征提取就是从语音信号中提取出语音的特征序列。提取的语音特征应该能完全、准确地表达语音信号,特征提取的目的是提取语音信号中能代表语音特征的信息,减少语音识别时所要处理的数据量。语音信号的特征分析是语音信号处理的前提和基础,只有分析出可以代表语音信号本质特征的参数,才能对这些参数进行高效的语音通信,语音合成,和语音识别等处理,并且语音合成的好坏,语音识别率的高低,也都取决于语音特征提取的准确性和鲁棒性。目前,针对特定应用的中小词汇量、特定人的语音识别技术发展已较为成熟,已经能够满足通常应用的要求,并逐步投入了实用。而非特定人、大词汇量、连续语音识别仍是
基于麦克风阵列的语音增强算法概述
- 29 - 基于麦克风阵列的语音增强算法概述 丁 猛 (海军医学研究所,上海 200433) 【摘 要】麦克风阵列语音增强技术是将阵列信号处理与语音信号处理相结合,利用语音信号的空间相位信息对语音信号进行增强的一种技术。文章介绍了各种基于麦克风阵列的语音增强基本算法,概述了各算法的基本原理,并总结了各算法的特点及其所适用的声学环境特性。 【关键词】麦克风阵列;阵列信号处理;语音增强 【中图分类号】TN911.7 【文献标识码】A 【文章编号】1008-1151(2011)03-0029-02 (一)引言 在日常生活和工作中,语音通信是人与人之间互相传递信息沟通不可缺少的方式。近年来,虽然数据通信得到了迅速发展,但是语音通信仍然是现阶段的主流,并在通信行业中占主导地位。在语音通信中,语音信号不可避免地会受到来自周围环境和传输媒介的外部噪声、通信设备的内部噪声及其他讲话者的干扰。这些干扰共同作用,最终使听者获得的语音不是纯净的原始语音,而是被噪声污染过的带噪声语音,严重影响了双方之间的交流。 应用阵列信号处理技术的麦克风阵列能够充分利用语音信号的空时信息,具有灵活的波束控制、较高的空间分辨率、高的信号增益与较强的抗干扰能力等特点,逐渐成为强噪声环境中语音增强的研究热点。美国、德国、法国、意大利、日本、香港等国家和地区许多科学家都在开展这方面的研究工作,并且已经应用到一些实际的麦克风阵列系统中,这些应用包括视频会议、语音识别、车载声控系统、大型场所的记录会议和助听装置等。 文章将介绍各种麦克风阵列语音增强算法的基本原理,并总结各个算法的特点及存在的局限性。 (二)常见麦克风阵列语音增强方法 1.基于固定波束形成的麦克风阵列语音增强 固定波束形成技术是最简单最成熟的一种波束形成技术。1985年美国学者Flanagan 提出采用延时-相加(Delay-and-Sum)波束形成方法进行麦克风阵列语音增强,该方法通过对各路麦克风接收到的信号添加合适的延时补偿,使得各路输出信号在某一方向上保持同步,并在该方向的入射信号获得最大增益。此方法易于实现,但要想获取较高的噪声抑制能力则需要增加麦克风数目,然而对非相干噪声没有抑制能力,环境适应性差,因此实际中很少单独使用。后来出现的微分麦克风阵列(Differential Microphone Arrays)、超方向麦克风阵列(Superairective Microphone Arrays )和固定频率波束形成(Frequency-Invariant Beamformers) 技术也属于固定波束形成。 2.基于自适应波束形成器的麦克风阵列语音增强 自适应波束形成是现在广泛使用的一类麦克风阵列语音增强方法。最早出现的自适应波束形成算法是1972年由Frost 提出的线性约束最小方差(Linearly Constrained Minimum Variance,LCMV)自适应波束形成器。其基本思想是在某方向有用信号的增益一定的前提下,使阵列输出信号的功率最小。在线性约束最小方差自适应波束形成器的基础上,1982年Griffiths 和Jim 提出了广义旁瓣消除器(Generalized Sidelobe Canceller, GSC),成为了许多算法的基本框架(图1)。 图1 广义旁瓣消除器的基本结构 广义旁瓣消除器是麦克风阵列语音增强应用最广泛的技术,即带噪声的语音信号同时通过自适应通道和非自适应通道,自适应通道中的阻塞矩阵将有用信号滤除后产生仅包含多通道噪声参考信号,自适应滤波器根据这个参考信号得到噪声估计,最后由这个被估计的噪声抵消非自适应通道中的噪声分量,从而得到有用的纯净语音信号。 如果噪声源的数目比麦克风数目少,自适应波束法能得到很好的性能。但是随着干扰数目的增加和混响的增强,自适应滤波器的降噪性能会逐渐降低。 3.基于后置滤波的麦克风阵列语音增强 1988年Zelinski 将维纳滤波器应用在麦克风阵列延时—相加波束形成的输出端,进一步提高了语音信号的降噪效果,提出了基于后置滤波的麦克风阵列语音增强方法(图2)。基于后置滤波的方法在对非相干噪声抑制方面,不仅具有良好的效果,还能够在一定程度上适应时变的声学环境。它的基本原理是:假设各麦克风接收到的目标信号相同,接收到的噪声信号独立同分布,信号和噪声不相关,根据噪声特性, 【收稿日期】2010-12-30 【作者简介】丁猛(1983-),男,海军医学研究所研究实习员。
基本语音增强方法
基本语音增强方法概述 摘要:语音增强是当今语音处理的一个非常重要的领域,本文主要介绍当今比较普遍的几种基于人耳掩蔽阈值的语音增强方法:谱减法,维纳滤波法,子空间方法等,并对它们的优缺点作简要论述。 关键词:语音增强、人耳掩蔽、谱减法、维纳滤波、子空间 现今时代的主流步伐将我们带向自动化方向,语音识别在这一背景下显得尤为重要。目前已经开发出好几款语音识别软件,但是如何较为精确地实现人耳的掩蔽效应下的语音增强,仍是大家着重解决的问题。它的首要目标就是在接收端尽可能从带噪语音信号中提取纯净的语音信号,改善其质量。目前已经出现了谱减法等一系列较为普遍的方法。本文将对这几种方法进行简要介绍。 一、语音的特性 语音信号是一种非平稳、时变的随机过程,其产生过程与发声器官的运动紧密相关。而发声器官的状态变化速度比声音振动的速度要缓慢得多,因此语音信号可以认为是短时平稳的。在一段短时间内其特性基本保持不变即相对稳定,从而可以应用平稳随机过程的分析方法来处理语音信号,并可以在语音增强中利用短时频谱的平稳特性。 人耳在嘈杂的环境中,仍然能够清晰地听到自己想听的内容,一个较弱的声音(被掩蔽音)的听觉感受被另一个较强的声音(掩蔽音)影响的现象称为人耳的“掩蔽效应”。被掩蔽音单独存在时的听阈分贝值,或者说在安静环境中能被人耳听到的纯音的最小值称为绝对闻阈。在进行机器语音识别的时候,由于干扰信号和目标信号的强度差别不大,导致机器无法识别。这时语音增强就显得特别重要了。 二、时域方法 此类方法主要依赖于语音生成模型(例如AR模型)的使用,需要提取模型参数(如基音周期、LPC系数等),经常使用迭代方法。这种方法的最大缺点就是如果实际噪声或语音与模型有较大的差别,或者由于某些原因使得提取语音参数较困难,则这方法较容易失败。这类方法常用到一些滤波器,如梳状滤波器、维纳滤波器、卡尔曼滤波器等。 (1)经典的维纳滤波法是根据Winer-Hopf 积分方程求出纯语音和混合音
语音识别字符分割算法_原创.
5.设计方法 5.1概述 5.2硬件系统的设计 语音信号预处理 (1)预加重 预加重的目的是提升高频部分,使信号的频谱变得平坦,保持在低频到高频的整个频带中,能用同样的信噪比求频谱,以便于频谱分析或声道参数分析。在计算机里用具有6dB/频程升高频特性的预加重数字滤波器来实现,一般是一阶的FIR数字滤波器: 为预加重系数,值接近于l,在0.9和1之间,典型值为0.94。 预加重的DSPBuilder实现: 为了便于实现,将上式中的一阶FIR预加重滤波器用差分方程表示为: 其中,为原始语音信号序列,N为语音长度,上面的公式显示其在时域 上的特性。又因为0.94接近于15/16,所以将上面的式子变为 除以16可以用右移4位来实现,这样就将除法运算化简为移位运算,降低了计算复杂度。在后面的模块设计中,也乘以或者除以一些这样的数,这些数为2的幂次,都可以用移位来实现。 预加重的硬件实现框图如下: 预加重实现框图 DSP Builder中的图形建模为:
预加重滤波器的DSPBuilder结构图 (2)分帧 语音信号是一种典型的非平稳信号,其特性随时间变化,其在很短的时间内是平稳的,大概为1小20ms,其频谱特性和物理特征可近似的看做不变,这样就可以采用平稳过程的分析处理方法来处理。 分帧的DSP Builder实现: 语音信号在10到20ms之间短时平稳(这样可以保证每帧内包含1一7个基音周期),也就是说选取的帧长必须介于10到20ms之间,此外,在MFCC特征提取时要进行FFT变换,FFT点数一般为2的幂次,所以本文中选择一帧长度为16ms,帧移为1/2帧长,这样一帧就包含了16KHz*16ms=256个点,既满足短时平稳,又满足FFT变换的要求。 由于采集的语音是静态的,语音长度已知,很容易计算出语音的帧数,但是在硬件上或实时系统中,语音长度是无法估计的,而且还要考虑存储空间的大小和处理速度,采用软件实现时的静态分帧方法是行不通的,可以利用硬件本身的特点进行实时的动态分帧。 为了使帧与帧之间平滑过渡,保持连续语音流的自相关性和过渡性,采用交叠分帧的算法。帧移取1/2帧长,即128个数据点当作一个数据块。FIFO1大小为一帧语音长度,分成两个数据块,预加重后的数据写入这个FIFO。为了实现帧移交叠,在FIFO1读数据时,同时再用FIFO2保存起来,当FIFO的一块数据读完以后,紧接着从FIF22读出这一块的副本。写入的一块数据,相当于被重复读出2次,所以FIFO1的读时钟频率设计为写时钟频率的2倍,而FIFOZ的读写时钟频率和FIFO1的读时钟频率相同。分帧以后的数据在图中按时间标号为1、2、2、3.··…,1、2为第一帧,2、3为第二帧,以此类推。
CDMA语音编码和信道编码
CDMA的语音编码与信道编码 摘要:随着3G移动通信技术的逐步实现以及移动通信与互联网的融合,全球正迅速步入移动信息时代。CDMA已被广泛接纳为第三代移动通信的核心技术之一,它具有优越的性能。本文主要介绍CDMA中常用的语音编码技术与信道技术。 关键词:语音编码信道编码受激励线性编码码激励线性预测编码矢量和激励线性预测编码编码器解码器卷积码 1 CDMA中的语音编码技术 语音编码为信源编码,是将模拟信号转变为数字信号,然后在信道中传输。在数字移动通信中,语音编码技术具有相当关键的作用,高质量低速率的话音编码技术与高效率数字调制技术相结合,可以为数字移动网提供高于模拟移动网的系统容量。目前,国际上语音编码技术的研究方向有两个:降低话音编码速率和提高话音质量。 1.1 语音编码技术的分类 语音编码技术有三种类型:波形编码、参量编码和混合编码。 ●波形编码:是在时域上对模拟话音的电压波形按一定的速率抽样,再将 幅度量化,对每个量化点用代码表示。解码是相反过程,将接收的数字 序列经解码和滤波后恢复成模拟信号。波形编码能提供很好的话音质 量,但编码信号的速率较高,一般应用在信号带宽要求不高的通信中。 脉冲编码调制(PCM)和增量调制(ΔM)常见的波形编码,其编码速率 在16~64kbps。 ●参量编码:又称声源编码,是以发音模型作基础,从模拟话音提取各个 特征参量并进行量化编码,可实现低速率语音编码,达到2~4.8kbps。 但话音质量只能达到中等。 ●混合编码:是将波形编码和参量编码结合起来,既有波形编码的高质量 优点又有参量编码的低速率优点。其压缩比达到4~16kbps。泛欧GSM 系统的规则脉冲激励-长期预测编码(RPE-LTP)就是混合编码方案。1.2 CDMA的语音编码
语音识别综述
山西大学研究生学位课程论文(2014 ---- 2015 学年第 2 学期) 学院(中心、所):计算机与信息技术学院 专业名称:计算机应用技术 课程名称:自然语言处理技术 论文题目:语音识别综述 授课教师(职称): 研究生姓名: 年级: 学号: 成绩: 评阅日期: 山西大学研究生学院 2015年 6 月2日
语音识别综述 摘要随着大数据、云时代的到来,我们正朝着智能化和自动化的信息社会迈进,作为人机交互的关键技术,语音识别在五十多年来不仅在学术领域有了很大的发展,在实际生活中也得到了越来越多的应用。本文主要介绍了语音识别技术的发展历程,国内外研究现状,具体阐述语音识别的概念,基本原理、方法,以及目前使用的关键技术HMM、神经网络等,具体实际应用,以及当前面临的困境与未来的研究趋势。 关键词语音识别;隐马尔科夫模型;神经网络;中文信息处理 1.引言 语言是人类相互交流最常用、有效的和方便的通信方式,自从计算机诞生以来,让计算机能听懂人类的语言一直是我们的梦想,随着大数据、云时代的到来,信息社会正朝着智能化和自动化推进,我们越来越迫切希望能够摆脱键盘等硬件的束缚,取而代之的是更加易用的、自然的、人性化的语音输入。语音识别是以语音为研究对象,通过对语音信号处理和模式识别让机器自动识别和理解人类口述的语言。 2.语音识别技术的发展历史及现状 2.1语音识别发展历史 语音识别的研究工作起源与上世纪50年代,当时AT&T Bell实验室实现了第一个可识别十个英文数字的语音识别系统——Audry系统。1959年,J.W.Rorgie和C.D.Forgie采用数字计算机识别英文元音及孤立字,开始了计算机语音识别的研究工作。 60年代,计算机应用推动了语音识别的发展。这时期的重要成果是提出了动态规划(DP)和线性预测分析技术(LP),其中后者较好的解决了语音信号产生模型的问题,对后来语音识别的发展产生了深远的影响。 70年代,LP技术得到了进一步的发展,动态时间归正技术(DTW)基本成熟,特别是矢量量化(VQ)和隐马尔科夫(HMM)理论的提出,并且实现了基于线性预测倒谱和DTW技术的特定人孤立语音识别系统。 80年代,实验室语音识别研究产生了巨大的突破,一方面各种连接词语音识别算法被开发,比如多级动态规划语音识别算法;另一方面语音识别算法从模板匹配技术转向基于统计模型技术,研究从微观转向宏观,从统计的角度来建立最佳的语音识别系统。隐马尔科夫模型(HMM)就是其典型代表,能够很好的描述语音信号的时变性和平稳性,使大词汇量连
基于DTW算法的语音识别原理与实现
广州大学机械与电气工程学院 数字语音信号处理 基于DTW算法的语音识别原理与实现 院系: 机电学院电子与通信工程 姓名: 张翔 学号: 2111307030 指导老师: 王杰 完成日期: 2014-06-11
基于DTW算法的语音识别原理与实现 [摘要]以一个能识别数字0~9的语音识别系统的实现过程为例,阐述了基于DTW算法的特定人孤立词语音识别的基本原理和关键技术。其中包括对语音端点检测方法、特征参数计算方法和DTW算法实现的详细讨论,最后给出了在Matlab下的编程方法和实验结果,结果显示该算法可以很好的显示特定人所报出的电话号码。 [关键字]语音识别;端点检测;MFCC系数;DTW算法 Principle and Realization of Speech Recognition Based on DTW Algorithm Abstract With an example of the realization of a 0~9 identifiable speech recognition system, the paper described the basic principles and key technologies of isolated word speech recognition based on DTW algorithm, including method of endpoint detection, calculation of characteristic parameters, and implementation of DTW algorithm. Programming method under Matlab and experimental results are given at the end of the paper.,and the results show that the algorithm can well display the phone number of the person reported. Keyword speech recognition; endpoint detection; MFCC parameter; DTW algorithm 一、引言 自计算机诞生以来,通过语音与计算机交互一直是人类的梦想,随着计算机软硬件和信息技术的飞速发展,人们对语音识别功能的需求也更加明显和迫切。语音识别技术就是让机器通过识别和理解过程把人类的语音信号转变为相应的文本或命令的技术,属于多维模式识别和智能计算机接口的范畴。传统的键盘、鼠标等输入设备的存在大大妨碍了系统的小型化,而成熟的语音识别技术可以辅助甚至取代这些设备。在PDA、智能手机、智能家电、工业现场、智能机器人等方面语音识别技术都有着广阔的前景。 语音识别技术起源于20世纪50年代,以贝尔实验室的Audry系统为标志。先后取得了线性预测分析(LP)、动态时间归整(DTW)、矢量量化(VQ)、隐马尔可夫模型(HMM)等一系列关键技术的突破和以IBM的ViaVoice、Microsoft的V oiceExpress为代表的一批显著成果。国内的语音识别起步较晚,1987年开始执行国家863计划后语音识别技术才得到广泛关注。具有代表性的研究单位为清华大学电子工程系与中科院自动化研究所模式识别国家重点实验室,中科院声学所等。其中中科院自动化所研制的非特定人连续语音听写系统和汉语语音人机对话系统,其准确率和系统响应率均可达90%以上。 常见的语音识别方法有动态时间归整技术(DTW)、矢量量化技术(VQ)、隐马尔可夫模型(HMM)、基于段长分布的非齐次隐马尔可夫模型(DDBHMM)和人工神经元网络(ANN)。
浅谈移动通信系统中的语音编码技术
浅谈移动通信系统中的语音编码技术 赵彦辉 (050000 河北坐地管线工程股份有限公司 河北 石家庄) 【摘 要】为提高移动通信系统的抗干扰能力和抗衰弱能力,移动通信采取了多种有效的技术措施,而语音编码技术就是其中非常重要的一种。本文对移动通信中的语音编码技术做出如下论述。 【关键词】语音编码 移动通信 技术 随着科学技术的迅速发展,移动通信技术已成为人们日常生活中的重要组成部分。为了提高数字移动通信中频带的使用率,我们通常使用的是调控解调技术和无线线路控制,在此基础上我们也可以使用语音编码技术,科学有效的去除数字移动通信系统中存在的语音冗余,达到维护优质编码的目的。 一、语音编码技术的种类 (一)参数编码 参数编码就是人们口中常说的声码器。其主要工作原理是通过将频率域内的信源信号或其他正交变化域内信源信号中的特征参量进行提取。然后通过对其进行系统的处理和转换,将其变成易于传输的数字代码,进而完成传输工作。相同的道理,参数解码则是将系统所接受到了数字序列经过系统的处理和转换,将其转变成为与之相对应的特征参量,并依靠所转变出的特征参量对语音信号进行重建。这种算法的最大优点就是其并不依赖于所输入语音的原始波形,而是能够根据其使用者(人类)的听觉特性来进行适当的调整,进而保证所解码的语音在任何时候能够具有一定的清晰度,便于使用者的理解和使用。目前所普遍使用的线性预测编码(LPC)就是参量编码当中最为常见的一种。 (二)波形编码 波形编码在语音编码方法中是最常见的一种,是指通过模拟语音波形的采样,然后量化采样的幅度,对其进行二进制编码。解码器作数模变化之后,低通滤波器会由现在的模式改变为原始模拟语音波形,以上为线性编码调制,也被称之为脉冲编码调制。可以通过自动适应预测、样值差分和非线性量化等方法实现数据的压缩。波形编码的最终目的是尽量使原始波形与解码器所恢复的模拟信号相一致,也就是将失真降到最小。波形编码可以称之为是最简单的方法,数码率相对较高,比较容易达到,当数码频率小于16k b i t音质很差,数码频率小于32k b i t音质会逐渐降低,数码频率为32kbit—64 kbit其音质最优。所以,在普通信号宽带通信中波形编码被有效利用,目前的移动通信中频率资源是非常紧张的,显然波形编码并适合。波形编码技术包括自适应差分编码、脉冲编码调制、增量调制等。 (三)混合编码 混合编码是语音编码方法当中相对困难的一种方法,其主要工作原理就是将参数编码与波形编码两者相结合,去糟取精择两者之优而用。在此基础之上,混合编码相对于参数编码和波形编码而言其音质更好一些,当然其复杂程度与技术含量也更高一些,正因如此笔者才会将混合编码定位于编码程序当中相对困难的依据。目前,规划脉冲、码本脉冲以及多脉冲激励线性预测编码等技术都是混合编码工作当中的主流技术。 二、语音编码技术在移动通信系统中的应用与发展 (一)窄带CDMA系统中的激励和矢量LPC编码 目前,美国的语音编码技术是较为先进的,其所使用的矢量预测和线性预测是构成其数字窝蜂系统的主要编码方式。在该编码系统当中,所使用的矢量预测和线性预测的数字信息速率为4.8k b i t/s,这在很大程度上提高了语音通话的质量。其通过脉冲编码调制技术将语音信号转化为数字信号,然后将数字信号输入到编码器,在编码器当中采用线性预测分析法来实现对语音信号的分析,得到预测参数,进而得到具有逆特性的滤波器。接着以滤波器为标准将声源信号当中的声道特性去除,并得出残差波形。通过残差波形与码本当中的各矢量模块进行加权组合,从而得出残差矢量。 (二)移动通信系统中的RPE-LTP 移动通信的第一代系统所使用的是F D M A模拟蜂窝系统,然而由于该系统的系统容量小、频带利用率低、业务种类有限等多种弊端,使其极大程度上的限制了移动通信系统的发展水平。为此第二代移动通信系统很快的就取代了第一代通信系统。相对于第一代移动通信系统而言,第二代移动通信系统的实际应用水平得到了显著的提高,其将所使用的系统更换为数字窝蜂系统,混合编码技术也成为了该系统当中的语音编码方式。另外根据所使用的激励源不同,第二代移动通信系统还将其编码方案进行了优化和处理。第二代移动通信系统所使用的语音编码方案是以相位间隔相等、幅度优化的规则脉冲信号作为激励源的,这使得所使用的混合波形信号最大程度的接近原始信号。此种方法在结合长期的预测的基础上,有效的降低了编码的速率和信号的多余度,同时此种方法具有语音质量高、计算量适中、易于硬件化和计算简单的优点。 (三)G系统中的VMR-WB编解码器 WCDMA和GSM系统中使用的多速率编码器为窄带的AMR,由于其受到带宽的限制,在语音处理中方面还是存在一些问题的。当宽带AMR音频带宽达到7KHz,采样频率达到16KHz时,其语音的音乐和自然度,尤其是在免提电话中,窄带语音编解码器会得到很大的改变。最初的GSM无线网络定义的宽带编码器为AMR—WB,现已被扩展为有线系统。AMR—WB的计量强度较大,因此,应充分的使用DSP处理能力。 三、结束语 综上所述,随着研发工作的不断深入,在语音编码技术中也在引进高阶统计分析技术、多精度时频分析技术和非线性预测等新分析技术。预计以上这些技术更能贴近于人耳的特性,最真实的分析与合成出最真实的语音,使编译码工作最大化接近于人们的听觉器官处理方式,实现低速率语音编研究工作的新突破。 参考文献: [1]郑国宏,陈亮,张翼鹏. 宽带语音编码技术专题讲座 (四)第8讲 移动通信中的宽带语音编码[J].军事通信技术,2012,01:100-104. [2]冯晓荣.分布式电话调度系统语音编解码方案的研究及DSP实现[D].重庆大学,2012. 57
语音增强算法的分类
语音增强算法的分类 现实环境中的噪声多种多样,特性各异,很难找到一种通用的语音增强算法适用于各种噪声的消除;同时语音增强算法与语音信号数字处理理论、人的听觉系统和语音学等学科紧密相关,这也促使人们必须根据不同的噪声源来选择不同的对策。以上原因使语音增强技术研究呈现百花齐放的局面。几十年来,许许多多的学者在这方面进行了不懈的努力,总结出了许多有效的方法。 根据信号输入的通道数,可将这些方法分为单通道的语音增强算法与多通道的语音增强算法。单通道的语音系统在现实生活中较常见,手机、耳麦等都属于单通道语音系统。这种情况下,语音与噪声同时存在于一个通道中,语音信号与噪声信号必须从同一个带噪语音中获得。这种系统一般要求信号中的噪声比较平稳,以便在无声段对噪声进行估计,再依据估计得到的噪声参数对有声段进行处理,得到增强语音。而多通道的语音系统中语音增强的一种算法是,利用各个通道的语音信号之间存在的某些相关性,对带噪语音信号进行处理,得到增强的语音。比如,在自适应噪声抵消法中采用了两个话筒作为输入,其中一个采集带噪的语音信号,另外一个采集噪声,从噪声通道所采集的噪声直接当作带噪语音中的噪声,并将它从带噪语音中减去即可。另一种多通道的语音增强算法是采用阵列信号,这种方法采用多个以一定方式排列的采集设备接收信号。由于不同的独立信号源与各个采集设备之间的距离不同,最后在各个接收设备中的合成信号也不同,再根据这些信号将各个独立信号分离出来。 按照所依据原理的不同,我们可以将语音增强分为以下几类: (1)参数方法 此类方法主要依赖于语音生成模型(例如AR模型)的使用,需要提取模型参数(如基音周期、LPC系数等),经常使用迭代方法。这种方法的最大缺点就是如果实际噪声或语音与模型有较大的差别,或者由于某些原因使得提取语音参数较困难,则这方法较容易失败。这类方法常用到一些滤波器,如梳状滤波器、维纳滤波器、卡尔曼滤波器等。 (2)非参数方法 非参数方法不需要从带噪语音信号中估计语音模型参数,这就使得此类方法相对于参数方法而言应用较广。但由于没有利用可能的语言统计信息,故结果一般不是最优的。同时,我们知道,语音信号是非平稳的随机过程,但语音信号特性的缓慢变化使得在较短的时间(比如10~30ms)内,可以视其为平稳的,如果能从带噪语音的短时谱中估计出“纯净”语音的短时谱,即可达到语音增强的目的。由于人耳对语音的感知主要是通过语音信号中各频谱分量的幅度来获得的,而对各分量的相位并不敏感,因此,这类方法的重点是将估计的对象放在语音信号的短时谱幅度上。非参数方法主要包括谱减法、自适应滤波法等。 (3)统计方法 统计方法比较充分地利用了语音和噪声的统计特性,如语音信号可视不同情况和需要采用高斯模型、拉普拉斯模型以及伽玛模型等。此类方法一般是在建立了模型库后,经历一个训练过程来获得初始统计参数,并且在后续的工作过程中要根据实际的数据实时的更新这些统计参数,以使模型能更好的符合实际情况,它与语音系统的联系非常密切。这类方法里面主要包括最小均方误差估计(MMSE,Minimum Mean Square Error)、对数谱估计的最小均方误差(MMSE-LSA,Minimum Mean-Square Error Log-SpectralAmplitude)、听觉掩蔽效应(Masking Effect)等。 (4)多通道方法 多通道方法利用了更多的信息,包括空间信息,可以更好地滤除噪声、分离语音,但对硬件设备要求高,算法一般较复杂。噪声抵消法、延迟一相加波束形成器(delay-sum beamformer)、
《语音识别入门教程》
语音识别入门(V1.0) 丁鹏、梁家恩、苏牧、孟猛、李鹏、王士进、王晓瑞、张世磊 中科院自动化所高创中心,北京,100080 【摘要】本文主要以剑桥工程学院(CUED)的语音识别系统为例,并结合我们实验室自身的研究与开发经验,讲述当前主流的大词汇量连续语音识别系统(LVCSR)的框架和相关技术,对实验室的同学进行一个普及和入门引导。 【关键词】语音识别,HTK,LVCSR,SRI 1. 引言 语音识别技术发展到今天,取得了巨大的进步,但也存在很多的问题。本文主要以CUED 的语言识别系统为例,说明LVCSR系统技术的最新进展和研究方向,对实验室的同学进行一个普及和入门引导。 1.1 国际语音识别技术研究机构 (1)Cambridge University Engineering Department (CUED) (2)IBM (3)BBN (4)LIMSI (5)SRI (6)RWTH Aachen (7)AT&T (8)ATR (9)Carnegie Mellon University (CMU) (10)Johns Hopkins University (CLSP) 1.2 国际语音识别技术期刊 (1)Speech Communication (2)Computer Speech and Language (CSL) (3)IEEE Transactions on Speech and Audio Processing 1.3 国际语音识别技术会议 (1)ICASSP(International Conference on Acoustic, Speech and Signal Processing)每年一届,10月截稿,次年5月开会。 (2)ICSLP(International Conference on Spoken Language Processing) 偶数年举办,4月截稿,9月开会。
Speex语音编码算法实现与优化
186 2009年第10期,第42卷 通 信 技 术 Vol.42,No.10,2009 总第214期 Communications Technology No.214,Totally ·信源处理· Speex 语音编码算法实现与优化 穆 捷, 李 敬, 唐 昆 (清华大学 电子工程系,北京 100084) 【摘 要】介绍了Speex 编码原理,对其特有的编码方式进行了深入的分析,针对其编码特点提出了3种降低运算复杂度的优化方法,并在DSP 芯片上进行了实现。通过使用ITU P.862规范中的评分方法进行分析,所述方法能在保证语音质量基本不下降的前提下,显著的降低运算复杂度。 【关键词】Speex ;感觉加重;逆滤波;简单相关 【中图分类号】TN91 【文献标识码】A 【文章编号】1002-0802(2009)10-0186-03 Realization and Optimization of Speex MU Jie , LI Jing , TANG Kun (Department of Electronic Engineering, Tsinghua University, Beijing 10084, China ) 【Abstract 】This paper first tells of the principle of Speex. Then, based on the analysis, three ways for simplifying computation are described. Through analysis by using PESQ in ITU P.862, the three proposed ways could help reduce the complexity of computation while the speech quality is guaranteed. 【Key words 】Speex; perceptual weighting; reverse filter; simple correlation 0 引言 互联网的发展推动着VOIP(V oice Over IP)技术应用的不断扩大,而现有的语音编码算法如G .729,虽然在语音质量上已经取得了很好的效果,但是由于应用环境不同,这些算法并不能很好的适应因特网网络环境多变的特点。Speex 是在VOIP 的应用背景下提出的一种基于CELP(Code Excited Linear Prediction)算法的免费、开源的语音编码器,其编码方式非常灵活,可以依据不同的应用环境采用统一的码流格式和编码算法,实现多码率,多采样率的灵活的语音编码,以适应网络语音通信的需求。 然而,传统的CELP 算法虽然在低码率的条件下依然能够保证良好的语音效果,但是其较高的运算量使得一些基于该算法的编码器难以在一些低功耗的芯片上实现。本文首先简要介绍了Speex 编解码算法,然后针对CELP 算法运算量大的缺点提出了调整感觉加权滤波器、利用简单互相关简化自适应码本搜索和固定码本逆滤波3种降低运算复杂度的优化方法,最后给出了试验结果,经试验验证,本文提出的优 化方法在较好保证语音质量的同时能够有效地降低运算量。 1 Speex 语音编解码算法简介 Speex 基于CELP(Code Excited Linear Prediction)算法,可同时进行窄带和宽带编码,并且具有多种速率。 自适应码本搜索利用互相关算法进行三阶基因预测,得到相应子帧的残差信号。然后将经过自适应码本搜索后的子帧残差信号分为长度不等的从5到20个样点的子矢量,依速率的不同采用各自对应的独立码本进行固定码本搜索。解码就是编码的逆过程,由于解码过程中并没有涉及码本搜索,因此,整个编解码的运算量主要集中在编码上,其中自适应码本和固定码本搜索占据了绝大部分,而宽带模式由于编码方式基本与窄带相同,因此我们的优化测试都基于窄带模式。 2 算法优化 CELP 结构的编码器虽然可以在低码率下仍然保持较高的语音质量,但其主要缺点就是运算量较大。对于Speex 编解码算法,当其工作在高模式下时,由于码本的增加和搜索精度的提高,使得算法复杂度加大,同时也就造成了在一些低功耗的DSP 芯片上较难实现实时的语音通信。为了解决这一问题,我们在CELP 模型运算量集中的码本搜索和基音周 收稿日期:2008-10-23。 作者简介:穆 捷(1979-),男,硕士研究生,从事语音压缩编码方 向研究;李 敬,男,讲师,从事多媒体通信方向研究;唐 昆,男,教授,从事多媒体通信方向研究。 万方数据
语音识别的matlab实现
语音识别的MATLAB实现 声控小车结题报告 小组成员:关世勇吴庆林 一、项目要求: 声控小车是科大华为科技制作竞赛命题组的项目,其要求是编写一个语言识别程序并适当改装一个小型机动车,使之在一个预先不知道具体形状的跑道上完全由声控来完成行驶比赛。跑道上可以有坡面,坑,障碍等多种不利条件,小车既要具有较快的速度,也要同时具有较强的灵活性,能够克服上述条件。 二、项目分析: 由于小车只要求完成跑道上的声控行驶,所以我们可以使用简单的单音命令来操作,如“前”、“后”、“左”、“右”等。 由于路面有各种不利条件,而且规则要求小车尽可能不越过边线,这就决定了我们的小车不能以较高的速度进行长时间的快速行驶。所以我们必须控制小车的速度和行进距离。 由于外界存在噪声干扰,所以我们必须对噪声进行处理以减小其影响。 鉴于上诉各种要求,我们决定对购买的遥控小车进行简单改造,使用PC机已有的硬件条件编写软件来完成语音的输入,采集,处理和识别,以实现对小车的控制。 三、解决思路与模块: 整个程序大致可划分为三个模块,其结构框图如下图所示: 整个程序我们在Visual C++ 环境下编写。 四、各模块的实现: 1 声音的采集: 将声音信号送入计算机,我们利用了声卡录音的低层操作技术,即对winmm.lib进行API调用。具体编程时这一部分被写在一个类中(Soundin类)。 在构造函数中设定包括最大采样率(11025),数据缓存(作为程序一次性读入的数据,2048),声卡本身所带的一些影响采样数据等的各种参数; 调用API函数waveInGetNumDevs(返回UNIT,参数为空)检察并打开声音输入设备,即声卡;并进而使用waveInGetDevCaps得到声卡的容量(在waveInCaps中存有该数据,对其进行地址引用,从DWORD dwFormats得到最大采样率、声道数和采样位); 创建一个叫WaveInThreadEvent的事件对象,并赋予一个Handle,叫m_WaveInEvent,开始利用线程指针m_WaveInThread调用自定义的线程WaveInThreadProc; 对结构WAVEFORMATEX中WaveInOpen开始提供录音设备。注意设备句柄的得到是通过对HWAVEIN 型数据m_WaveIn的引用。 由于通过这种方式进行录音的文件格式是.wav,所以要先设置录音长度,以及对头文件进行一些设置:包括buffer的地址为InputBuffer的初始地址,大小为录音长度的两倍,类型。使用waveInPrepareHeader 为录音设备准备buffer。然后使用waveInAddBuffer函数为录音设备送出一个输入buffer。最后使用waveInStart(m_WaveIn)打开设备。 程序中WaveInThreadProc需要提出另外说明,因为通过这个线程我们可以实现采样和数据提取。该线程首先定义一个指向CsoundIn类的指针pParam,并将其宏定义为PT_S。而线程参数即为空指针pParam。使用WaitForSingleObject将录音过程设置为一旦开始就不中止(除非中止线程)。在此线程中做如下两个工作:将数据送入buffer,并将数据传入某个参数(其调用一个函数,将buffer中的数据送入该函数的参