数据仓库多维数据模型的设计说明

1、数据仓库基本概念
1.1、主题(Subject)
主题就是指我们所要分析的具体方面。例如:某年某月某地区某机型某款App的安装情况。主题有两个元素:一是各个分析角度(维度),如时间位置;二是要分析的具体量度,该量度一般通过数值体现,如App安装量。
1.2、维(Dimension)
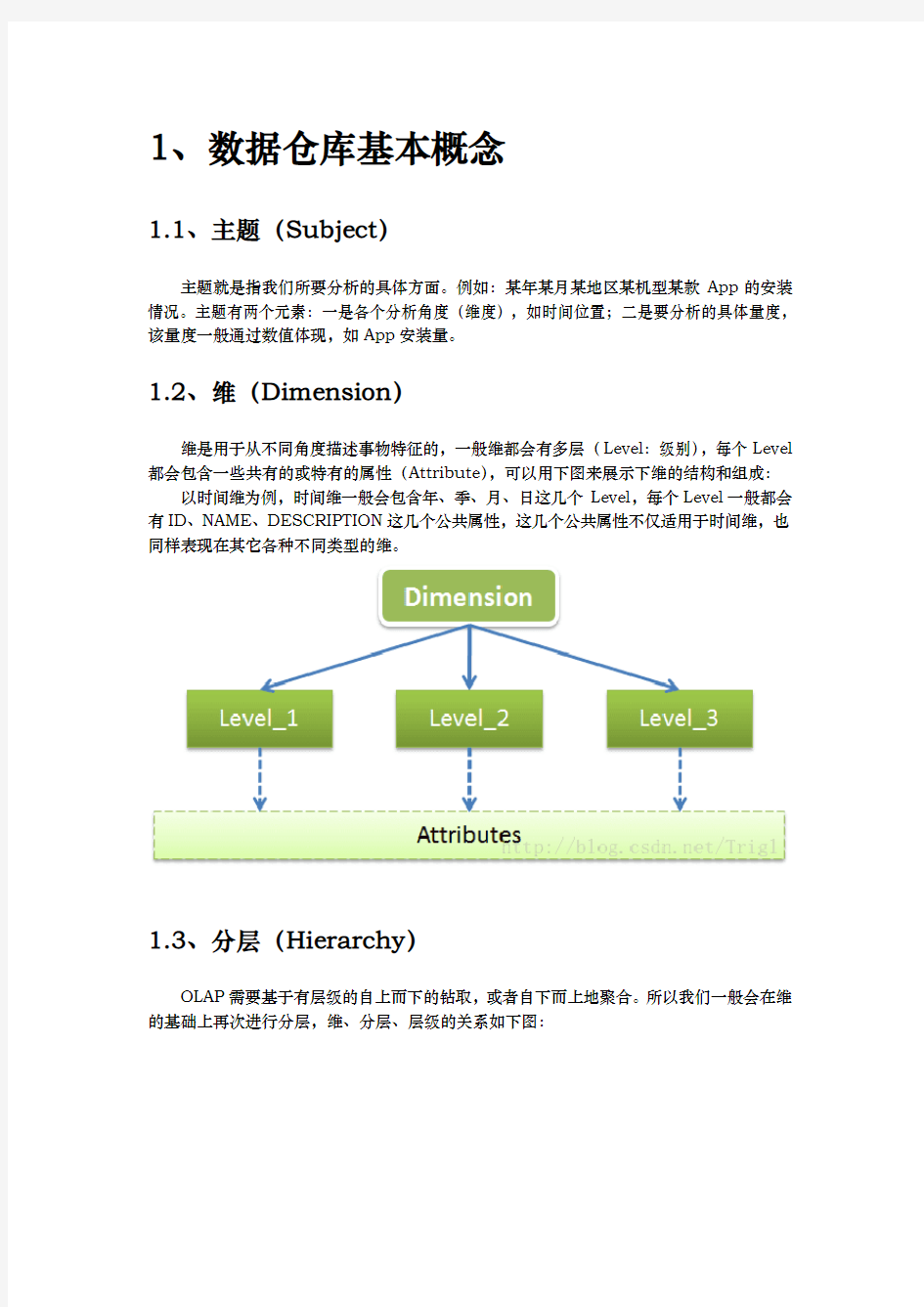
维是用于从不同角度描述事物特征的,一般维都会有多层(Level:级别),每个Level 都会包含一些共有的或特有的属性(Attribute),可以用下图来展示下维的结构和组成:以时间维为例,时间维一般会包含年、季、月、日这几个Level,每个Level一般都会有ID、NAME、DESCRIPTION这几个公共属性,这几个公共属性不仅适用于时间维,也同样表现在其它各种不同类型的维。
1.3、分层(Hierarchy)
OLAP需要基于有层级的自上而下的钻取,或者自下而上地聚合。所以我们一般会在维的基础上再次进行分层,维、分层、层级的关系如下图:
每一级之间可能是附属关系(如市属于省、省属于国家),也可能是顺序关系(如天周年),如下图所示:
1.4、量度
量度就是我们要分析的具体的技术指标,诸如年销售额之类。它们一般为数值型数据。我们或者将该数据汇总,或者将该数据取次数、独立次数或取最大最小值等,这样的数据称为量度。
1.5、粒度
数据的细分层度,例如按天分按小时分。
1.6、事实表和维表
事实表是用来记录分析的内容的全量信息的,包含了每个事件的具体要素,以及具体发
生的事情。事实表中存储数字型ID以及度量信息。
维表则是对事实表中事件的要素的描述信息,就是你观察该事务的角度,是从哪个角度去观察这个内容的。
事实表和维表通过ID相关联,如图所示:
1.7、星形/雪花形/事实星座
这三者就是数据仓库多维数据模型建模的模式
上图所示就是一个标准的星形模型。
雪花形就是在维度下面又细分出维度,这样切分是为了使表结构更加规范化。雪花模式可以减少冗余,但是减少的那点空间和事实表的容量相比实在是微不足道,而且多个表联结操作会降低性能,所以一般不用雪花模式设计数据仓库。
事实星座模式就是星形模式的集合,包含星形模式,也就包含多个事实表。
1.8、企业级数据仓库/数据集市
企业级数据仓库:突出大而全,不论是细致数据和聚合数据它全都有,设计时使用事实星座模式
数据集市:可以看做是企业级数据仓库的一个子集,它是针对某一方面的数据设计的数据仓库,例如为公司的支付业务设计一个单独的数据集市。由于数据集市没有进行企业级的设计和规划,所以长期来看,它本身的集成将会极其复杂。其数据来源有两种,一种是直接从原生数据源得到,另一种是从企业数据仓库得到。设计时使用星形模型
2、数据仓库设计步骤
2.1、确定主题
主题与业务密切相关,所以设计数仓之前应当充分了解业务有哪些方面的需求,据此确定主题。
2.2、确定量度
在确定了主题以后,我们将考虑要分析的技术指标,诸如年销售额之类。量度是要统计的指标,必须事先选择恰当,基于不同的量度将直接产生不同的决策结果。
2.3、确定数据粒度
考虑到量度的聚合程度不同,我们将采用“最小粒度原则”,即将量度的粒度设置到最小。例如如果知道某些数据细分到天就好了,那么设置其粒度到天;但是如果不确定的话,就将粒度设置为最小,即毫秒级别的。
2.4、确定维度
设计各个维度的主键、层次、层级,尽量减少冗余。
2.5、创建事实表
事实表中将存在维度代理键和各量度,而不应该存在描述性信息,即符合“瘦高原则”,即要求事实表数据条数尽量多(粒度最小),而描述性信息尽量少。
3、数据仓库-全量表
全量表:保存用户所有的数据(包括新增与历史数据)
增量表:只保留当前新增的数据
快照表:按日分区,记录截止数据日期的全量数据
切片表:切片表根据基础表,往往只反映某一个维度的相应数据。其表结构与基础表结构相同,但数据往往只有某一维度,或者某一个事实条件的数据
3.1、更新插入算法
更新插入(主表)算法适用于保留最新状态表的处理。
案例:银行账户余额表,全表表大约8000万,非结息日每日变动100万,结息日变动2000万。
非结息日:它是指根据主键(或指定字段)进行数据对比,如果增量表存在记录,则更新原全量表,否则插入数据。
ETL更新的优化?Merge?
结息日:新建空表,它是指根据主键(或指定字段)进行数据对比,首先插入原全量表与增量表无法匹配的非变更数据,再次插入可以匹配的增量表数据,最后补齐增量表与全量表无法匹配的增量数据。
3.2、直接追加算法
直接追加算法是指增量数据直接追加到目标表中,此算法适合流水、交易、事件、话单等增量且不修改的数据。
由于历史信息表数据量过于庞大,往往在数据库设计中将引入分区表的逻辑来处理,具体实现逻辑自查。
3.3、全量历史表算法
拉链表。
4、数据仓库-拉链表
拉链表:数据仓库设计中表存储数据的方式而定义的,顾名思义,所谓拉链,就是记录历史。记录一个事物从开始,一直到当前状态的所有变化的信息。
我们先看一个示例,这就是一张拉链表,存储的是用户的最基本信息以及每条记录的生命周期。我们可以使用这张表拿到最新的当天的最新数据以及之前的历史数据。
在数据仓库的数据模型设计过程中,经常会遇到下面这种表的设计:
1、有一些表的数据量很大,比如一张用户表,大约10亿条记录,50个字段,这种表,即使使用ORC压缩,单张表的存储也会超过100G(在HDFS使用双备份或者三备份的话就更大一些)。
2、表中的部分字段会被update更新操作,如用户联系方式,产品的描述信息,订单的状态等等。
3、需要查看某一个时间点或者时间段的历史快照信息,比如,查看某一个订单在历史某一个时间点的状态。
4、表中的记录变化的比例和频率不是很大,比如,总共有10亿的用户,每天新增和发生变化的有200万左右,变化的比例占的很小。
那么对于这种表我该如何设计呢?下面有几种方案可选:
方案一:每天只留最新的一份(比如我们每天用Sqoop抽取最新的一份全量数据到Hive 中)。
方案二:每天保留一份全量的切片数据。
方案三:使用拉链表。
4.1、为什么使用拉链表
现在我们对前面提到的三种进行逐个的分析。
方案一
这种方案就不用多说了,实现起来很简单,每天drop掉前一天的数据,重新抽一份最新的。
优点很明显,节省空间,一些普通的使用也很方便,不用在选择表的时候加一个时间分区什么的。
缺点同样明显,没有历史数据,先翻翻旧账只能通过其它方式,比如从流水表里面抽。
方案二
每天一份全量的切片是一种比较稳妥的方案,而且历史数据也在。
缺点就是存储空间占用量太大了,如果对这边表每天都保留一份全量,那么每次全量中会保存很多不变的信息,对存储是极大的浪费。
当然我们也可以做一些取舍,比如只保留近一个月的数据?但是,需求是无耻的,数据的生命周期不是我们能完全左右的。
拉链表在使用上基本兼顾了我们的需求。
首先它在空间上做了一个取舍,虽说不像方案一那样占用量那么小,但是它每日的增量可能只有方案二的千分之一甚至是万分之一。
其实它能满足方案二所能满足的需求,既能获取最新的数据,也能添加筛选条件也获取历史的数据。
所以我们还是很有必要来使用拉链表的。
4.2、拉链表的实现
下面我们来举个栗子详细看一下拉链表。
我们先看一下在Mysql关系型数据库里的user表中信息变化。
在2017-01-01这一天表中的数据是:
在2017-01-02这一天表中的数据是,用户002和004资料进行了修改,005是新增用户:
在2017-01-03这一天表中的数据是,用户004和005资料进行了修改,006是新增用户:
如果在数据仓库中设计成历史拉链表保存该表,则会有下面这样一张表,这是最新一天(即2017-01-03)的数据:
说明
t_start_date表示该条记录的生命周期开始时间,t_end_date表示该条记录的生命周期结束时间。
t_end_date = ‘9999-12-31’表示该条记录目前处于有效状态。
如果查询当前所有有效的记录,则select * from user where t_end_date = ‘9999-12-31’。
如果查询2017-01-02的历史快照,则select from user where t_start_date <= ‘2017-01-02’ and t_end_date >= ‘2017-01-02’。(*此处要好好理解,是拉链表比较重要的一块。**)
4.3、拉链表在Hive中的实现
在现在的大数据场景下,大部分的公司都会选择以Hdfs和Hive为主的数据仓库架构。目前的Hdfs版本来讲,其文件系统中的文件是不能做改变的,也就是说Hive的表智能进行删除和添加操作,而不能进行update。基于这个前提,我们来实现拉链表。
还是以上面的用户表为例,我们要实现用户的拉链表。在实现它之前,我们需要先确定一下我们有哪些数据源可以用。
我们需要一张ODS层的用户全量表。至少需要用它来初始化。
每日的用户更新表。
而且我们要确定拉链表的时间粒度,比如说拉链表每天只取一个状态,也就是说如果一天有3个状态变更,我们只取最后一个状态,这种天粒度的表其实已经能解决大部分的问题了。
ods层的user表
现在我们来看一下我们ods层的用户资料切片表的结构:
CREATE EXTERNAL TABLE https://www.360docs.net/doc/cf528896.html,er (
user_num STRING COMMENT '用户编号',
mobile STRING COMMENT '手机号码',
reg_date STRING COMMENT '注册日期'
COMMENT '用户资料表'
PARTITIONED BY (dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINAT ED BY '\n'
STORED AS ORC
LOCATION '/ods/user';
)
ods层的user_update表
然后我们还需要一张用户每日更新表,前面已经分析过该如果得到这张表,现在我们假设它已经存在。
CREATE EXTERNAL TABLE https://www.360docs.net/doc/cf528896.html,er_update (
user_num STRING COMMENT '用户编号',
mobile STRING COMMENT '手机号码',
reg_date STRING COMMENT '注册日期'
COMMENT '每日用户资料更新表'
PARTITIONED BY (dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINAT ED BY '\n'
STORED AS ORC
LOCATION '/ods/user_update';
)
拉链表
现在我们创建一张拉链表:
CREATE EXTERNAL TABLE https://www.360docs.net/doc/cf528896.html,er_his (
user_num STRING COMMENT '用户编号',
mobile STRING COMMENT '手机号码',
reg_date STRING COMMENT '用户编号',
t_start_date ,
t_end_date
COMMENT '用户资料拉链表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINAT ED BY '\n'
STORED AS ORC
LOCATION '/dws/user_his';
)
实现sql语句
然后初始化的sql就不写了,其实就相当于是拿一天的ods层用户表过来就行,我们写一下每日的更新语句。
现在我们假设我们已经已经初始化了2017-01-01的日期,然后需要更新2017-01-02那一天的数据,我们有了下面的Sql。
然后把两个日期设置为变量就可以了。
INSERT OVERWRITE TABLE https://www.360docs.net/doc/cf528896.html,er_his
SELECT * FROM
(
SELECT https://www.360docs.net/doc/cf528896.html,er_num,
A.mobile,
A.reg_date,
A.t_start_time,
CASE
WHEN A.t_end_time = '9999-12-31' AND https://www.360docs.net/doc/cf528896.html,er_num IS NOT NUL L THEN '2017-01-01'
ELSE A.t_end_time
END AS t_end_time
FROM https://www.360docs.net/doc/cf528896.html,er_his A
LEFT JOIN https://www.360docs.net/doc/cf528896.html,er_update B
ON https://www.360docs.net/doc/cf528896.html,er_num = https://www.360docs.net/doc/cf528896.html,er_num
UNION
SELECT https://www.360docs.net/doc/cf528896.html,er_num,
C.mobile,
C.reg_date,
'2017-01-02' AS t_start_time,
'9999-12-31' AS t_end_time
FROM https://www.360docs.net/doc/cf528896.html,er_update AS C
) AS T
好了,我们分析了拉链表的原理、设计思路、并且在Hive环境下实现了一份拉链表,下面对拉链表做一些小的补充。
拉链表和流水表
流水表存放的是一个用户的变更记录,比如在一张流水表中,一天的数据中,会存放一个用户的每条修改记录,但是在拉链表中只有一条记录。
这是拉链表设计时需要注意的一个粒度问题。我们当然也可以设置的粒度更小一些,一般按天就足够。
查询性能
拉链表当然也会遇到查询性能的问题,比如说我们存放了5年的拉链数据,那么这张表势必会比较大,当查询的时候性能就比较低了,个人认为两个思路来解决:在一些查询引擎中,我们对start_date和end_date做索引,这样能提高不少性能。
保留部分历史数据,比如说我们一张表里面存放全量的拉链表数据,然后再对外暴露一张只提供近3个月数据的拉链表。
使用拉链表的时候可以不加t_end_date,即失效日期,但是加上之后,能优化很多查询。
可以加上当前行状态标识,能快速定位到当前状态。
在拉链表的设计中可以加一些内容,因为我们每天保存一个状态,如果我们在这个状态里面加一个字段,比如如当天修改次数,那么拉链表的作用就会更大。
5、对私数据仓库实战
数据仓库主题,客户资产等级。何为客户资产等级,根据客户的纯资产的月均总额、贷款余额的总额、信用卡近一年消费额的总额,分别按照规则制定,计算出分别的等级,取三者的最高等级,用于定义客户在我行的资产等级。分别为:私行、财富、理财、普通。
源事实表:存款账户表、基金账户、理财账户、客户信息表、汇率表、信用卡交易表、贷款余额表。
数据仓库模型的设计
2.5数据仓库模型的设计 数据仓库模型的设计大体上可以分为以下三个层面的设计151: .概念模型设计; .逻辑模型设计; .物理模型设计; 下面就从这三个层面分别介绍数据仓库模型的设计。 2.5.1概念模型设计 进行概念模型设计所要完成的工作是: <1>界定系统边界 <2>确定主要的主题域及其内容 概念模型设计的成果是,在原有的数据库的基础上建立了一个较为稳固的概念模型。因为数据仓库是对原有数据库系统中的数据进行集成和重组而形成的数据集合,所以数据仓库的概念模型设计,首先要对原有数据库系统加以分析理解,看在原有的数据库系统中“有什么”、“怎样组织的”和“如何分布的”等,然后再来考虑应当如何建立数据仓库系统的概念模型。一方面,通过原有的数据库的设计文档以及在数据字典中的数据库关系模式,可以对企业现有的数据库中的内容有一个完整而清晰的认识;另一方面,数据仓库的概念模型是面向企业全局建立的,它为集成来自各个面向应用的数据库的数据提供了统一的概念视图。 概念模型的设计是在较高的抽象层次上的设计,因此建立概念模型时不用考虑具体技术条件的限制。 1.界定系统的边界 数据仓库是面向决策分析的数据库,我们无法在数据仓库设计的最初就得到详细而明确的需求,但是一些基本的方向性的需求还是摆在了设计人员的面前: . 要做的决策类型有哪些? . 决策者感兴趣的是什么问题? . 这些问题需要什么样的信息? . 要得到这些信息需要包含原有数据库系统的哪些部分的数据? 这样,我们可以划定一个当前的大致的系统边界,集中精力进行最需要的部分的开发。因而,从某种意义上讲,界定系统边界的工作也可以看作是数据仓库系统设计的需求分析,因为它将决策者的数据分析的需求用系统边界的定义形式反映出来。 2,确定主要的主题域 在这一步中,要确定系统所包含的主题域,然后对每个主题域的内
图销售分析”的多维数据集模型的设计共8页word资料
数据仓库与数据挖掘 实验报告 姓名:岩羊先生 班级:数技2011 学号:XXXXXX 实验日期:2013年11月14日 目录 实验.............................................. 错误!未定义书签。 【实验目的】............................... 错误!未定义书签。 1、熟悉SQLservermanager studio和VisualStudio2008软件功能 和操作特点; ................................ 错误!未定义书签。 2、了解SQLservermanager studio和VisualStudio2008软件的各 选项面板和操作方法; ........................ 错误!未定义书签。 3、熟练掌握SQLserver manager studio和VisualStudio2008工 作流程。................................... 错误!未定义书签。 【实验内容】............................... 错误!未定义书签。 1.打开SQLserver manager studio软件,逐一操作各选项,熟悉
软件功能; (4) 2.根据给出的数据库模型“出版社销售图书Pubs”优化结构,新建立数据库并导出; (4) 3.打开VisualStudio2008,导入已有数据库、或新建数据文件,设计一个“图书销售分析”的多维数据集模型。并使用各种输出节点,熟悉数据输入输出。 (4) 【实验环境】............................... 错误!未定义书签。【实验步骤】............................... 错误!未定义书签。 1.打开 SQL Server manager studio; (5) 2.附加备份的数据库文件pubs_DW_Data.MDF和pubs_DW_Log.LDF 并且做出优化; (5) 3.修改数据库属性; (5) 4.建立数据仓库所需的数据库bb(导出); (5) 5. 创建新的分析服务项目; (5) 6. 新建数据源(本地服务器输入“.”) (5) 7.建立多维数据集 (6) 8.处理多维数据集,得出模型: (6) 9.模型实例: (6) 【实验中的困难及解决办法】................. 错误!未定义书签。问题1:SQLserver中数据库的到导出. (6)
数据仓库物理模型设计
数据仓库物理模型设计 数据仓库的物理模型就是数据仓库逻辑模型在物理系统中的实现模式。其中包括了逻辑模型中各种实体表的具体化,例如表的数据结构类型、索引策略、数据存放位置和数据存储分配等。在进行物理模型的设计实现时,所考虑的因素有:I/O存取时间、空间利用率及维护的代价。 为确定数据仓库的物理模型,设计人员必须做这样几方面工作:首先要全面了解所选用的数据库管理系统,特别是存储结构和存取方法;其次了解数据环境、数据的使用频率、使用方式、数据规模及响应时间要求等,这些都是对时间和空间效率进行平衡和优化的重要依据;最后还需要了解外部存储设备的特征。只有这样才能在数据的存储需求与外部存储设备条件两者之间获得平衡。 1 设计存储结构 在物理设计时,常常要按数据的重要性、使用频率及对反应时间的要求进行分类,并将不同类型的数据分别存储在不同的存储设备中。重要性高、经常存取并对反应时间要求高的数据存放在高速存储设备上;存取频率低或对存取响应时间要求低的数据则可以存放在低速存储设备上。另外,在设计时还要考虑数据在特定存储介质上的布局。在设计数据的布局时要注意遵循以下原则。 l 不要把经常需要连接的几张表放在同一存储设备上,这样可以利用存储设备的并行操作功能加快数据查询的速度。 l 如果几台服务器之间的连接会造成严重的网络业务量的问题,则要考虑服务器复制表格,因为不同服务器之间的数据连接会给网络带来沉重的数据传输负担。 l 考虑把整个企业共享的细节数据放在主机或其他集中式服务器上,提高这些共享数据的使用速度。 l 不要把表格和它们的索引放在同一设备上。一般可以将索引存放在高速存储设备上,而表格则存放在一般存储设备上,以加快数据的查询速度。 在对服务器进行处理时往往要进行大量的等待磁盘数据的工作,此时,可以在系统中使用RAID(Redundant Array of Inexpensive Disk,廉价冗余磁盘阵列)。 2 设计索引策略 数据仓库的数据量很大,因而需要对数据的存取路径进行仔细地设计和选择。由于数据仓库的数据一般很少更新,所以可以设计索引结构来提高数据存取效率。在数据仓库中,设计人员可以考虑对各个数据存储建立专用的索引和复杂的索引,以获取较高的存取效率,虽然建立它们需要付出一定的代价,但建立后一般不需要过多的维护。 数据仓库中的表通常要比联机事务处理系统(OLTP)中的表建立更多的索引,表中应用的最大索引数应与表格的规模成正比。数据仓库是个只读的环境,建立索引可以取得灵活性,对性能极为有利。但是表若有很多索引,那么数据加载时间就会延长,因此索引的建立需要进行综合的考虑。在建立索引时,可以按照索引使用的频率由高到低逐步添加,直到某一索引加入后,使数据加载或重组表的时间过长时,就结束索引的添加。 最初,一般都是按主关键字和大多数外部关键字建立索引,通常不要添加很多的其他索引。在表建立大量的索引后,对表进行分析等具体使用时,可能需要许多索引,这会导致表的维护时间也随之增加。如果从主关键字和外部关键字着手建立索引,并按照需要添加其他索引,就会避免首先建立大量的索引带来的后果。如果表格过大,而且需要另外增加索引,那么可以将表进行分割处理。如果一个表中所有用到的列都在索引文件中,就不必访问事实表,只要访问索引就可以达到访问数据的目的,以此来减少I/O操作。如果表太大,并且经常要对它进行长时间的扫描,那么就要考虑添加一张概括表以减少数据的扫描任务。 3 设计存储策略
数据仓库的多维数据模型定义 作用 实例
数据仓库的多维数据模型定义作用实例 2010年08月19日06:53 来源:网站数据分析作者:佚名编辑:李伟评论:0条 本文Tag:信息化频道商业智能数据仓库参考文献BI行业信息化【IT168 信息化】 可能很多人理解的数据仓库就是基于多维数据模型构建,用于OLAP的数据平台,通过上一篇文章——数据仓库的基本架构,我们已经看到数据仓库的应用可能远不止这些。但不得不承认多维数据模型是数据仓库的一大特点,也是数据仓库应用和实现的一个重要的方面,通过在数据的组织和存储上的优化,使其更适用于分析型的数据查询和获取。 多维数据模型的定义和作用 多维数据模型是为了满足用户从多角度多层次进行数据查询和分析的需要而建立起来的基于事实和维的数据库模型,其基本的应用是为了实现OLAP (Online Analytical Processing)。 当然,通过多维数据模型的数据展示、查询和获取就是其作用的展现,但其真的作用的实现在于,通过数据仓库可以根据不同的数据需求建立起各类多维模型,并组成数据集市开放给不同的用户群体使用,也就是根据需求定制的各类数据商品摆放在数据集市中供不同的数据消费者进行采购。 多维数据模型实例 在看实例前,这里需要先了解两个概念:事实表和维表。事实表是用来记录具体事件的,包含了每个事件的具体要素,以及具体发生的事情;维表则是对事实表中事件的要素的描述信息。比如一个事件会包含时间、地点、人物、事件,事实表记录了整个事件的信息,但对时间、地点和人物等要素只记录了一些关键标记,比如事件的主角叫“Michael”,那么Michael到底“长什么样”,就需要到相应的维表里面去查询“Michael”的具体描述信息了。基于事实表和维表就可以构建出多种多维模型,包括星形模型、雪花模型和星座模型。这里不再展开了,解释概念真的很麻烦,而且基于我的理解的描述不一定所有人都能明白,还是直接上实例吧:
实验1_建立多维数据集
实验1 建立多维数据集 实验目的 通过使用SQL Server建立多维数据集,使学生理解和掌握建立多维数据集的一般过程和方法。 实验内容 1、建立FoodMart多维数据集 实验条件 1.操作系统:Windows XP SP2 2.SQL Server 2000 实验要求: 1、按照实验步骤中练习建立FOODMART多维数据集。 实验步骤 第一步, 建立系统数据源连接 1.单击“开始”按钮,指向“设置”,单击“控制面板”,然后双击“管理工具”,再双击“数据源(ODBC)”。 1.在“系统DSN”选项卡上单击“添加”按钮。 2.选择“Microsoft Access 驱动程序(*.mdb)”,然后单击“完成”按钮。 3.在“数据源名”框中,输入“教程”,然后在“数据库”下,单击“选择”。 4.在“选择数据库”对话框中,浏览到“C:\Program Files\Microsoft Analysis Services\Samples”,然后单击“FoodMart 2000.mdb”。单击“确定”按钮。 5.在“ODBC Microsoft Access 安装”对话框中单击“确定”按钮。 6.在“ODBC 数据源管理器”对话框中单击“确定”按钮。 第二步, 启动Analysis Manager
单击“开始”按钮,依次指向“程序”、“Microsoft SQL Server”和“Analysis Services”,然后单击“Analysis Manager”。 第三步,建立数据库和数据源 1.在Analysis Manager 树视图中展开“Analysis Servers”。 2.单击服务器名称,即可建立与Analysis Servers 的连接。 3.右击服务器名称,然后单击“新建数据库”命令。 4.在“数据库”对话框中的“数据库名称”框中,输入“教程”,然后单击“确定”按钮。 5.在Analysis Manager 树窗格中展开服务器,然后展开刚才创建的“教程”数据库。 6.在Analysis Manager 树窗格中,右击“教程”数据库下的“数据源”文件夹,然后单击“新数据源” 命令。 7.在“数据链接属性”对话框中,单击“提供者”选项卡,然后单击“Microsoft OLE DB Provider for ODBC Drivers”。
数据仓库与数据挖掘实验二(多维数据组织与分析)
一、实验内容和目的 目的: 1.理解维(表)、成员、层次(粒度)等基本概念及其之间的关系; 2.理解多维数据集创建的基本原理与流程; 3.理解并掌握OLAP分析的基本过程与方法; 内容: 1.运用Analysis Server工具进行维度、度量值以及多维数据集的创建(模拟案例)。 2.使用维度浏览器进行多维数据的查询、编辑操作。 3.对多维数据集进行切片、切块、旋转、钻取操作。 二、所用仪器、材料(设备名称、型号、规格等) 操作系统平台:Windows 7 数据库平台:SQL Server 2008 SP2 三、实验原理 在数据仓库系统中,联机分析处理(OLAP)是重要的数据分析工具。OLAP的基本思想是企业的决策者应能灵活地、从多方面和多角度以多维的形式来观察企业的状态和了解企业的变化。 OLAP是在OLTP的基础上发展起来的,OLTP是以数据库为基础的,面对的是操作人员和低层管理人员,对基本数据的查询和增、删、改等进行处理。而OLAP是以数据仓库为基础的数据分析处理。它具有在线性(online)和多维分析(multi-dimension analysis)的特点。OLAP超越了一般查询和报表的功能,是建立在一般事务操作之上的另外一种逻辑步骤,因此,它的决策支持能力更强。 建立OLAP的基础是多维数据模型,多维数据模型的存储可以有多种不同的形式。MOLAP和ROLAP是OLAP的两种主要形式,其中MOLAP(multi-dimension OLAP)是基
于多维数据库的OLAP,简称为多维OLAP;ROLAP(relation OLAP)是基于关系数据库的OLAP,简称关系OLAP。 OLAP的目的是为决策管理人员通过一种灵活的多维数据分析手段,提供辅助决策信息。基本的多维数据分析操作包括切片、切块、旋转、钻取等。随着OLAP的深入发展,OLAP也逐渐具有了计算和智能的能力,这些能力称为广义OLAP操作。 四、实验方法、步骤 要求:利用实验室和指导教师提供的实验软件,认真完成规定的实验内容,真实地记录实验中遇到的各种问题和解决的方法与过程,并根据实验案例绘出多维数据组织模型及其OLAP操作过程。实验完成后,应根据实验情况写出实验报告。 五、实验过程原始记录(数据、图表、计算等) 本实验以实验一建立的数据仓库为基础,使用Microsoft的SQL Server Business Intelligence Development Studio工具,建立OLAP相关模型,并实现OLAP的一些简单基本功能。 首先打开SQL Server Business Intelligence Development Studio工具,新建一个Analysis Service项目,命名为:DW
SQL Server 2005 多维数据集创建过程
SQL Server 2005 多维数据集创建过程 一.创建新的Analysis Services项目 1.单击“开始”,指向“所有程序”,再指向Microsoft SQL Server 2005,再单击SQL Server Business Intelligence Development Studio,打开Microsoft Visual Studio 2005开发环境。 2.在Visual Studio的“文件”菜单上,指向“新建”,再单击“项目”。 3.在“新建项目”对话框中,从“项目类型”窗格中选择“商业智能项目”,再在“模板”窗格中选择“Analysis Services项目”。 4.将项目名称更改为Analysis Services Tutorial1,这也将更改解决方案名称,然后单击“确定”。 至此,在同样名为Analysis Services Tutorial1的新解决方案中基于Analysis Services项目模板成功创建了Analysis Services Tutorial1项目。 二.定义新的数据源 1.在Microsoft Visual Studio 2005开发环境中,打开解决方案资源管理器,右键单击“数据源”,然后单击“新建数据源”,将打开数据源向导。
2.在“欢迎使用数据源向导”页上,单击“下一步”。 3.在“选择如何定义连接”页上,单击“新建”。 4.在“提供程序”的下拉列表框中,选中“本机OLE DB\Microsoft OLE DB Provider for SQL Server”,然后单击“确定”。 5.在“服务器名称”文本框中,键入localhost。 6.确保已选中“使用Windows身份验证”。在“选择或输入数据库名称”列表中,选择AdventureWorksDW,然后单击“确定”。 7.在“新建数据源向导”页上,然后单击“下一步”。 8.选择“使用服务帐户”,然后单击“下一步”。 9.在“完成向导”页上,单击“完成”以创建名为Adventure Works DW的新数据源。 10.打开解决方案资源管理器,可以看到“数据源”文件夹中的新数据源。 三.定义一个新的数据源视图 1.在解决方案资源管理器中,右键单击“数据源视图”,再单击“新建数据源视图”。 2.在“欢迎使用数据源视图向导”页中,单击“下一步”。
BI_数据仓库基础
1 BI Business Intelligence,即商业智能,商务智能综合企业所有沉淀下来的信息,用科学的分析方法,为企业领导提供科学决策信息的过程。 BOSS业务运营支撑系 BPM企业绩效管理 BPR业务流程重整 CRM客户关系管理 CUBE立方体 DM(Datamart)数据集市数据仓库的子集,它含有较少的主题域且历史时间更短数据量更少,一般只能为某个局部范围内的管理人员服务,因此也称之为部门级数据仓库。 DM(DataMine)数据挖掘 DSS决策支持系统 EDM企业数据模型 3 ERP Enterprise Resourse Planning企业资源规划。它是一个以管理会计为核心的信息系统,识别和规划企业资源,从而获取客户订单,完成加工和交付,最后得到客户付款。换言之,ERP将企业内部所有资源整合在一起,对八个采购、生产、成本、库存、分销、运输、财务、人力资源进行规划,从而达到最佳资源组合,取得最佳效益。 4 ETL 数据抽取(Extract)、转换(Transform)、清洗(Cleansing)、装载(Load)的过程。构建数据仓库的重要一环,用户从数据源抽取出所需的数据,经过数据清洗,最终 按照预先定义好的数据仓库模型,将数据加载到数据仓库中去。 KDD数据库中知识发现 5 KPI 企业关键业绩指标(KPI:KeyProcessIndication)是通过对组织内部流程的输入端、输出端的关键参数进行设臵、取样、计算、分析,衡量流程绩效的一种目标式量化管理指标,是把企业的战略目标分解为可操作的工作目标的工具,是企业绩效管理的基础。 LDM逻辑数据模型 6 MDD 多维数据库(Multi Dimesional Database,MDD)可以简单地理解为:将数据存放在一个n维数组中,而不是像关系数据库那样以记录的形式存放。因此它存在大量稀疏矩阵,人们可以通过多维视图来观察数据。多维数据库增加了一个时间维,与关系数据库相比,它的优势在于可以提高数据处理速度,加快反应时间,提高查询效率。 Metadata(元数据),它是“关于数据的数据,其内容主要包括数据仓库的数据字典、数据的定义、数据的抽取规则、数据的转换规则、数据加载频率等信息。 MOLAP自行建立了多维数据库,来存放联机分析系统数据 7 ODS(四个特点) (Oprational Data Store)操作型数据存储,是建立在数据准备区和数据仓库之间的一个部件。用来满足企业集成的、综合的操作型处理需要,操作数据存储是个可选的部件。对于一些准实时的业务数据库当中的数据的暂时存储,支持一些同时关连到历史数据与实时数据分
数据仓库建模
背景介绍 熟悉社保行业的读者可以知道,目前我们国家的社保主要分为养老,失业,工伤,生育,医疗保险和劳动力市场这6 大块主要业务领域。在这6 大业务领域中,目前的状况养老和事业的系统已经基本完善,已经有一部分数据开始联网检测。而,对于工伤,生育,医疗和劳动力市场这一块业务,有些地方发展的比较成熟,而有些地方还不够成熟。 1.业务建模阶段 基于以上的背景介绍,我们在业务建模阶段,就很容易来划分相应的业务。因此,在业务建模阶段,我们基本上确定我们本次数据仓库建设的目标,建设的方法,以及长远规划等。如下图: 图8. 业务建模阶段 在这里,我们将整个业务很清楚地划分成了几个大的业务主线,例如:养老,失业,工伤,生育,医疗,劳动力等着几个大的部分,然后我们可以根据这些大的模块,在每个业务主线内,考虑具体的业务主线内需要分析的业务主题。 因此,业务建模阶段其实是一次和业务人员梳理业务的过程,在这个过程中,不仅能帮助我们技术人员更好的理解业务,另一方面,也能够发现业务流程中的一些不合理的环节,加以改善和改进。 同时,业务建模阶段的另一个重要工作就是确定我们数据建模的范围,例如:在某些数据准备不够充分的业务模块内,我们可以考虑先不建设相应的数据模型。等到条件充分成熟的情况下,我们可以再来考虑数据建模的问题。 2.领域概念建模阶段领域概念建模阶段是数据仓库数据建模的一个重要阶段,由于我们在业务建模阶段已经完全理清相应的业务范围和流程,因此,我们在这个领域概念建模阶段的最主要的工作就是进行概念的抽象,整个领域概念建模的工作层次如下图所示:
图9. 领域概念建模阶段 从上图我们可以清楚地看到,领域概念建模就是运用了实体建模法,从纷繁的业务表象背后通过实体建模法,抽象出实体,事件,说明等抽象的实体,从而找出业务表象后抽象实体间的相互的关联性,保证了我们数据仓库数据按照数据模型所能达到的一致性和关联性。 从图上看,我们可以把整个抽象过程分为四个层次,分别为: ?抽象方法层,整个数据模型的核心方法,领域概念建模的实体的划分通过这种抽象方法来实现。 ?领域概念层,这是我们整个数据模型的核心部分,因为不同程度的抽象方法,决定了我们领域概念的不同。例如:在这里,我们可以使用“参与方”这个概念,同时,你也可以把他分成三个概念:“个人”,“公司”,和“经办机构”这三个概念。而我们在构建自己的模型的时候,可以参考业务的状况以及我们自己模型的需要,选择抽象程度高的概念或者是抽象程度低的概念。相对来说,抽象程度高的概念,理解起来较为复杂,需要专业的建模专家才能理解,而抽象程度低的概念,较适合于一般业务人员的理解,使用起来比较方便。笔者在这里建议读者可以选用抽象概念较低的实体,以方便业务人员和技术人员之间的交流和沟通。 ?具体业务层,主要是解决具体的业务问题,从这张图我们可以看出,具体的业务层,其实只是领域概念模型中实体之间的一些不同组合而已。因此,完整的数据仓库的数据模型应该能够相应灵活多变的前端业务的需求,而其本身的模型架构具有很强的灵活性。这也是数据仓库模型所具备的功能之一。 ?业务主线层,这个层次主要划分大的业务领域,一般在业务建模阶段即已经完成这方面的划分。 我们一般通过这种大的业务主线来划分整个业务模型大的框架。 通过领域概念建模,数据仓库的模型已经被抽象成一个个的实体,模型的框架已经搭建完毕,下面的工作就是给这些框架注入有效的肌体。
数据仓库多维数据模型的设计
1、数据仓库基本概念 1.1、主题(Subject) 主题就是指我们所要分析的具体方面。例如:某年某月某地区某机型某款App的安装情况。主题有两个元素:一是各个分析角度(维度),如时间位置;二是要分析的具体量度,该量度一般通过数值体现,如App安装量。 1.2、维(Dimension) 维是用于从不同角度描述事物特征的,一般维都会有多层(Level:级别),每个Level 都会包含一些共有的或特有的属性(Attribute),可以用下图来展示下维的结构和组成:以时间维为例,时间维一般会包含年、季、月、日这几个Level,每个Level一般都会有ID、NAME、DESCRIPTION这几个公共属性,这几个公共属性不仅适用于时间维,也同样表现在其它各种不同类型的维。 1.3、分层(Hierarchy) OLAP需要基于有层级的自上而下的钻取,或者自下而上地聚合。所以我们一般会在维的基础上再次进行分层,维、分层、层级的关系如下图:
每一级之间可能是附属关系(如市属于省、省属于国家),也可能是顺序关系(如天周年),如下图所示: 1.4、量度 量度就是我们要分析的具体的技术指标,诸如年销售额之类。它们一般为数值型数据。我们或者将该数据汇总,或者将该数据取次数、独立次数或取最大最小值等,这样的数据称为量度。 1.5、粒度 数据的细分层度,例如按天分按小时分。 1.6、事实表和维表 事实表是用来记录分析的内容的全量信息的,包含了每个事件的具体要素,以及具体发
生的事情。事实表中存储数字型ID以及度量信息。 维表则是对事实表中事件的要素的描述信息,就是你观察该事务的角度,是从哪个角度去观察这个内容的。 事实表和维表通过ID相关联,如图所示: 1.7、星形/雪花形/事实星座 这三者就是数据仓库多维数据模型建模的模式 上图所示就是一个标准的星形模型。 雪花形就是在维度下面又细分出维度,这样切分是为了使表结构更加规范化。雪花模式可以减少冗余,但是减少的那点空间和事实表的容量相比实在是微不足道,而且多个表联结操作会降低性能,所以一般不用雪花模式设计数据仓库。 事实星座模式就是星形模式的集合,包含星形模式,也就包含多个事实表。
数据仓库设计文档模板
数据仓库设计与实现 学号 128302106 姓名江晨婷 成绩 教师张丹平 二O一五年四月
数据仓库建设方案设计与实现 摘要:本文以博士学位调查为基础,创建方案,设计与实现数据仓库,通过对当前各种主流数据仓库软件在性能、价格等方面的对比,充分考虑统计业务、单位数量等实际情况,本系统决定采用SQL Server 2005数据仓库软件来构建综合信息分析系统的数据仓库。 关键词:数据仓库;联机分析;数据挖掘;博士学位 一、概述 数据仓库的设计一般从操作型数据开始,通常需要经过以下几个处理过程;数据仓库设计——数据抽取——数据管理。 1.数据仓库设计 根据决策主题设计数据仓库结构,一般采用星型和雪花模型设计其数据模型,在设计过程中应保证数据仓库的规范化和体系各元素的必要联系。 2.数据抽取 根据元数据库中的主题表定义、数据源定义、数据抽取规则定义对异地异构数据源进行清理、转换、对数据进行重新组织和加工,装载到数据仓库的目标库中。 3.数据管理 数据管理分为目标数据维护和元数据维护两方面。目标数据维护是根据元数据为所定义的更新频率、更新数据项等更新计划任务来刷新数据仓库,以反映数据源的变化,且对时间相关性进行处理。元数据是数据仓库的组成部分,元数据的质量决定整个数据仓库的质量。当数据源的运行环境、结构及目标数据的维护计划发生变化时,需要修改元数据。 二、博士学位授予信息年度数据统计分析 1.按主管部门统计 从主管部门的角度,分析在一个时间段(年)内,各主管部门所授予的博士学位信息统计。可回答如“2008,由某部门主管的,博士学位授予一共有多少,其平均学习年限是多少,脱产学习的有多少人?”等问题。具有表格和图形两种方式来展示分析结果。典型报表格式如表1所示
数据仓库的数据模型
业务驱动 任何需求均来源于业务,业务决定了需求,需求分析的正确与否是关系到项目成败的关键所在,从任何角度都可以说项目是由业务驱动的所以数据仓库项目也是由业务所驱动的. 但是数据仓库不同于日常的信息系统开发,除了遵循其他系统开发的需求,分析,设计,测试等通常的软件声明周期之外;他还涉及到企业信息数据的集成,大容量数据的阶段处理和分层存储,数据仓库的模式选择等等,因此数据仓库的物理模型异常重要,这也是关系到数据仓库项目成败的关键. 数据仓库的结构总的来说是采用了三级数据模型的方式: 概念模型: 也就是业务模型,由企业决策者,商务领域知识专家和IT专家共同企业级地跨领域业务系统需求分析的结果. 逻辑模型:用来构建数据仓库的数据库逻辑模型。根据分析系统的实际需求决策构建数据库逻辑关系模型,定义数据库物体结构及其关系。他关联着数据仓库的逻辑模型和物理模型这两头. 物理模型:构建数据仓库的物理分布模型,主要包含数据仓库的软硬件配置,资源情况以及数据仓库模式。 如上图所示,在数据仓库项目中,物理模型设计和业务模型设计象两个轮子一样有力的支撑着数据仓库的实施,两者并行不悖,缺一不可.实际上,我有意的扩大了物理模型和业务模型的内涵和外延.在这里物理模型不仅仅是数据的存储,而且也包含了数据仓库项目实施的方法论,资源,以及软硬件选型等等;而业务模型不仅仅是主题模型的确立,也包含了企业的发展战略,行业模本等等. 一个优秀的项目必定会兼顾业务需求和行业的标准两个方面,业务需求即包括用户提出的实际需求,也要客观分析它隐含的更深层次的需求,但是往往用户的需求是不明确的,需要加以提炼甚至在商务知识专家引导下加以引导升华,和用户一起进行需求分析工作;不能满足用户的需求,项目也就失去原本的意义了. 物理模型就像大厦的基础架构,就是通用的业界标准,无论是一座摩天大厦也好,还是茅草房也好,在架构师的眼里,他只是一所建筑,地基->层层建筑->封顶,这样的工序一样也不能少,关系到住户的安全,房屋的建筑质量也必须得以保证,唯一的区别是建筑的材料,地基是采用钢筋水泥还是石头,墙壁采用木质还是钢筋水泥或是砖头;当然材料和建筑细节还是会有区别的,视用户给出的成本而定;还有不可忽视的一点是,数据仓库的数据从几百GB到几十TB不等,即使支撑这些数据的RDBMS无论有多么强大,仍不可避免的要考虑到数据库的物理设计. 接下来,将详细阐述数据仓库概念模型(业务模型),逻辑模型,物理模型的意义. 概念模型设计 进行概念模型设计所要完成的工作是: 界定系统边界 确定主要的主题域及其内容
多维数据组织与分析
多维数据组织与分析 Prepared on 22 November 2020
昆明理工大学信息工程与自动化学院学生实验报告 ( 2016 — 2017 学年第二学期) 一、上机目的 目的: 1.理解维(表)、成员、层次(粒度)等基本概念及其之间的关系; 2.理解多维数据集创建的基本原理与流程; 3.理解并掌握OLAP分析的基本过程与方法; 4. 学会使用基本的MDX语句 二、上机内容 1.基于上次实验建立的地铁数据仓库,构建地铁公司收入的多维数据 集。 2.使用维度浏览器进行多维数据的查询、编辑操作。 3.对多维数据集进行切片、切块、旋转、钻取操作。 4.使用MDX语句对多维数据集进行切片。 注意:可参照Analysis Services的教程,构建多维数据集。要求时间和站点维度采用层次结构。 利用实验室和指导教师提供的实验软件,认真完成规定的实验内
容,真实地记录实验中遇到的各种问题和解决的方法与过程,并根据实验案例绘出多维数据组织模型及其OLAP操作过程。实验完成后,应根据实验情况写出实验报告。 三、实验原理及基本技术路线图(方框原理图或程序流程图) 请描述联机分析处理的相关基本概念(MOLAP、ROLAP、切片、切块、旋转、钻取等)。 1.M OLAP:表示基于多维数据组织的OLAP实现。使用多维数组存储数 据。 特点:将细节数据和聚合后的数据均保存在cube中,所以以空间换效率,查询时效率高,但生成cube时需要大量的时间和空间。 2.R OLAP:表示基于关系数据库的OLAP实现。将多维数据库的多维结构 划分为事实表,和维表。 特点:将细节数据保留在关系型数据库的事实表中,聚合后的数据也保存在关系型的数据库中。这种方式查询效率最低,不推荐使用。 3.切片:在给定数据立方体的一个维上进行选择操作就是切片,切片的 结果是得到一个二维平面数据。 4.切块:在给定数据立方体的两个或多个维上进行选择操作就是切块, 切块的结果得到一个子立方体。 5.旋转:维度变换的方向,即在表格中重新安排维的放置(例如行列互 换)。 6.钻取:改变维的层次,变换分析的粒度。它包括向下钻取和向上钻 取。 四、实验方法、步骤(或:程序代码或操作过程) 1.多维数据集
20120405-032 医院数据仓库数据模型设计
医院数据仓库数据模型设计 汪涛① ①安徽省中医院,230009,安徽省合肥市梅山路117号 摘要目的:数据模型设计是数据仓库建设的核心,本文提出一种医院数据仓库数据模型的设计方法。方法:以某一三甲医院的HIS数据为背景,采用数据驱动的手段,结合医院的需求,提出了医院数据仓库的三层数据模型,概念模型、逻辑模型、物理模型,并完整地给出了每个模型的具体的设计和主要内容。结果:设计并实现了医院数据仓库的的数据模型,并结合医院具体的数据给出了相应的实例。结论:此医院数据仓库的三层数据模型易于理解和实现,为医院数据仓库设计最终完成提供了基础。 关键词数据模型概念模型逻辑模型数据仓库 1 引言 随着医疗市场的竞争越来越激烈,为了提高医院的竞争力,各家医院对信息化建设投入不断加大[1]。医院信息系统的使用提高基本业务处理的效率,提升了管理的手段。但随着时间的推移,现有系统积累了海量数据,如何对其中的各类业务数据加以整合和利用,从中挖掘出隐藏在背后的有价值、可以利用的潜在信息,对以后医院科学的业务分析和管理决策十分重要的意义。数据仓库的出现正好可以解决以上问题,如“军字一号”医院信息系统上建立数据仓库,整合和分析历史数据[2],为医院决策提供数据。而数据仓库系统如何对海量数据进行有效组织和管理,并使之支持千变万化的管理业务分析与决策,主要依赖于数据仓库系统逻辑数据模型(Logical Data Model,简称LDM )的设计[3]。一个好的逻辑数据模型能够最大的保证灵活性和可扩展性,以满足数据源的变化和应用需求的拓展。因此建设好LDM 是医院数据仓库的关键,本就此进行探讨。 2 数据仓库数据模型的概述 数据仓库是一个面向主题的、集成的、非易失的且随时间变化的数据集合,用来支持管理人员的决策,其与操作型数据库系统(OLTP)的建模方法是有不同的[4]。操作性数据库系统是为具体的业务活动,是在传统开发生命周期(SDLC)下进行的,但不适用与决策支持系统领域。在用户需求尚不明确的情况下,数据仓库的建模是从整合现有操作型数据开始的,分析业务系统的数据组织、关系模型,确定数据范围、主题,依次设计系统的概念模型、逻辑模型和物理模型;而在实际的项目实施当中,如在医院的数据仓库建设中,系统的初步需求还是需要首先了解和分析的。这为数据仓库建设提供了原始范围,以及最终为用户所接受提供保证。以下,我在设计医院数据仓库模型是从系统需求分析和HIS的数据分析开始的,采用三层模型设计的。 3 设计医院的数据仓库的数据模型 3.1 概念模型的设计 3.1.1 系统边界的确立,包括需求分析、数据来源等现有的医院数据是面向具体业务的,
建立多维数据集和关联规则分析
成都理工大学管理科学学院 教学实验报告 2013~2013学年第二学期 2.定义数据源: 为了让挖掘服务器能够正确地找到被挖掘的数据,需要对数据源进行设置,步骤如下: 步骤一:在解决方案资源管理器中,右击“数据源”文件夹,在弹出的快捷菜单中选择【新建数据源】命令,之后将会出现数据源向导,如下图所示:
步骤三:如下图所示,在“提供程序”下拉列表中选择分析合适的提供程序, Provider for SQL Server”选项;服务器名在下拉列表中选择网络中存在的 身份验证”单选按钮;选中“选择或输入一个数据库名”单选按钮,在下拉列表框中,选择或输入数据库名,本案例中我们选择 Adventure Works DW 示例数据库,作为挖掘时使用的数据库;设置完成后,单击【测试连接】按钮,如果连接成功,会弹出【连接测试成功】对话框;单击【确定】按钮。 步骤六: 在上一步中,单击【确定】按钮后,会重新切换到【选择如何定义连接】页面,点击【下一步】按钮,出现如下图所示的【模拟信息】页面;选中“默认值”单选按钮,单击【下一步】按钮,切换到下一个页面。 步骤七:在“数据源名称”框中输入数据源名称“销售分析数据源” 图所示:
步骤三:单击【下一步】按钮,切换到【选择表和视图】页面,如下图所示:在左侧“可用对象”列表框中,选择下列表,Dim Customer(客户维表 (产品维表),Dim Time(时间维表),FactInternet Sales(网上销售事实表) 步骤四:单击【下一步】按钮,切换到【完成向导】页面,如下图所示:在“名称”中输入“销售分析视图”,单击【完成】按钮,即可。
数据仓库的构建及其多维数据集分析
科技广场 2007.6 208 入 (Import 、导出 (Export 以及转换的服务。 DTS 中最常用的两大工具是DTS向导和 DTS设计器, 因为本文涉及的数据转换是由多个表取得数据并转换至目的数据库, 因此选择 DTS设计器。 将Northwind数据库中的数据转移到数据仓库的目的数据库中, 遵循以下步骤:①设置数据源;②设置数据目的地; ③设置转换方式;④将数据转移任务存储为一个包;⑤执行包进行实际数据转移。 在正式进行数据转换之前, 首先要为Northwind的数据仓库新建一个数据库Northwind_DW, 这样数据源和数据目的地分别为数据库Northwind和 Northwind_DW。然后激活DTS 设计器并创建转移数据包NorthwindToNorthwind_DW。接下来便可以进行事实表和维度表的数据转换任务了, 这个过程是将源数据库中的某些表中的字段抽取出来, 进行相应的组合和转换,
生成目的数据库中的事实表或维度表, 这些工作都可用SQL语句及VB转换脚本语句来完成。以事实表 Sales 为例, 在其转换数据任务属性中, 对应的 SQL 语句如下: SELECT e.EmployeeID,p.ProductID,s.SupplierID,c. CustomerID,o.OrderDate,od.Quantity,od.UnitPrice,od. Discount FROM Orders o,[Order Details]od,Employees e, Products p,Suppliers s,Customers c WHERE o.OrderID=od.OrderID AND o.EmployeeID=e. EmployeeID AND o.CustomerID=c.CustomerID AND od. ProductID=p.ProductID AND p.SupplierID=s.SupplierID 除了以上抽取出的字段外, 事实表Sales还包含一个度量值字段Total, 是将已抽取出的字段UnitPrice、 Discount、 Quantity进行组合转换而成, 对应的VB转换脚本语句如下 : Function Main( DTSDestination("Total"=DTSSource("UnitPrice" *D T S S o u r c e (" Q u a n t i t y " *(1. 0-D T S S o u r c e ("Discount" Main=DTSTransformStat_OK End Function 员工维度表Employee数据转换方法同事实表数据转换方法, 其它维度表数据 转换更容易, 方法基本相同, 只是在进行转换选项时, 不需要选择新建选项。 至此, 数据转换包设计完毕, 保存并执行, 便将数据由 Northwind数据库加载到Northwind_DW中。最后进行设置表的主键和外键工作。 3多维数据集分析 在分析数据时, 用户往往并不是以单一的维度为基准, 而是以多个维度为依据。譬如在Northwind的数据仓库中包括了员工、顾客、产品、供货商以及时间等 5个维度, 就会经常有查询某供应商于某年提供了多少金额的某产品或查询某员工于
数据仓库与数据挖掘课程设计报告书
目录 1. 绪论 (2) 1.1项目背景 (2) 1.2 提出问题 (2) 2 数据库仓库与数据集的概念介绍 (2) 2.1数据仓库 (2) 2.2数据集 (3) 3 数据仓库 (3) 3.1 数据仓库的设计 (3) 3.1.1数据仓库的概念模型设计 (3) 3.1.2数据仓库的逻辑模型设计 (3) 3.2 数据仓库的建立 (4) 3.2.1数据仓库数据集 (4) 3.2.2建立维表 (4) 4.数据挖掘操作 (5) 4.1数据预处理 (5) 4.1.1描述性数据汇总 (5) 4.2决策树 (5) 5、实验心得 (13) 6、大总结 (14)
1. 绪论 1.1项目背景 在现在大数据时代,各行各业需要对商品及相关关节的数据进行收集处理,尤其零售行业,于企业对产品的市场需求进行科学合理的分析,从而预测出将来的市场,制定出高效的决策,给企业带来经济收益。 1.2 提出问题 对于超市的商品的购买时期和购买数量的如何决定,才可以使销售量最大,不积压商品,不缺货,对不同时期季节和不同人群制定不同方案,使企业收益最大,通过数据挖掘对数据进行决策树分析,关联分析,顺序分析与决策分析等可以制定出最佳方案。 2 数据库仓库与数据集的概念介绍 2.1数据仓库 数据仓库是为企业所有级别的决策制定过程提供支持的所有类型数据的战略集合。它是单个数据存储,出于分析性报告和决策支持的目的而创建。为企业提供需要业务智能来指导业务流程改进和监视时间、成本、质量和控制。 数据仓库是决策系统支持(dss)和联机分析应用数据源的结构化数据环境。
数据仓库研究和解决从数据库中获取信息的问题。数据仓库的特征在于面向主题、集成性、稳定性和时变性。 2.2数据集 数据集是指一种由数据所组成的集合。Data set(或dataset)是一个数据的集合,通常以表格形式出现。每一列代表一个特定变量。每一行都对应于某一成员的数据集的问题。它列出的价值观为每一个变量,如身高和体重的一个物体或价值的随机数。每个数值被称为数据资料。对应于行数,该数据集的数据可能包括一个或多个成员。 3 数据仓库 3.1 数据仓库的设计 3.1.1数据仓库的概念模型设计 概念模型的设计是整个概念模型开发过程的三阶段。设计阶段依据概念模型分析以及分析过程中收集的任何数据,完成星型模型和雪花型模型的设计。如果仅依赖ERD,那只能对商品、销售、客户主题设计成如图所示的概念模型。这种模型适合于传统的数据库设计,但不适合于数据仓库的设计。 3.1.2数据仓库的逻辑模型设计 逻辑建模是数据仓库实施中的重要一环,因为它能直接反映出各个业务的需求,同时对系统的物理实施有着重要的指导作用,它的作用在于可以通过实体和关系勾勒出企业的数据蓝图,数据仓库的逻辑模型设计任务主要有:分析主题域,确定要装载到数据仓库的主题、确认粒度层次划分、确认数据分割策略、关系模式的定义和记录系统定义、确认数据抽取模型等。逻辑模型最终设计成果包