对k均值算法和硬C-均值算法的对比分析

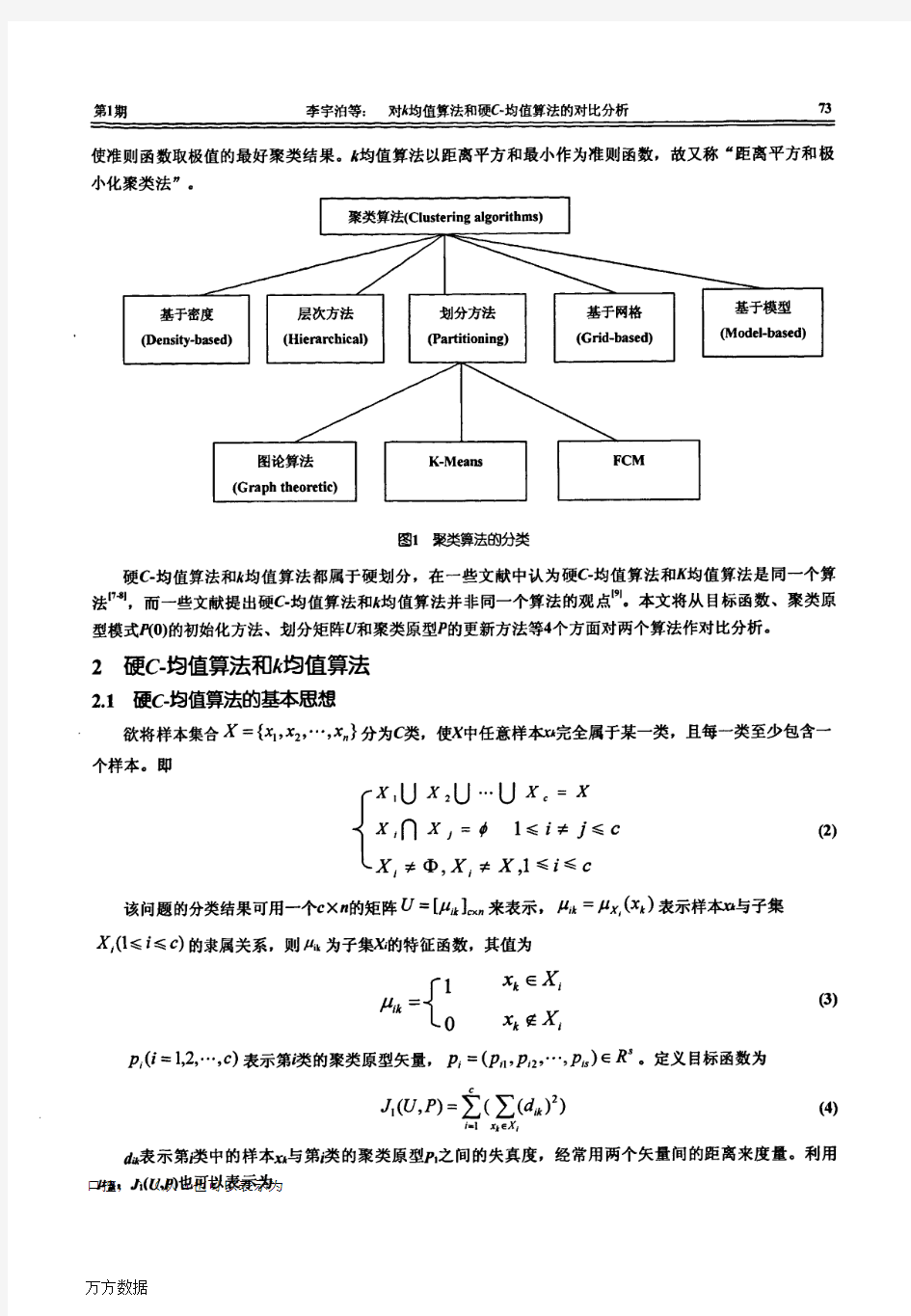
对k均值算法和硬C-均值算法的对比分析
作者:李宇泊, 李秦, LI Yu-bo, LI Qin
作者单位:兰州交通大学数理与软件工程学院,甘肃兰州,730070
刊名:
洛阳理工学院学报(自然科学版)
英文刊名:Journal of Luoyang Institute of Science and Technology 年,卷(期):2012,22(1)
本文链接:https://www.360docs.net/doc/d411373675.html,/Periodical_lygygdzkxxxb201201017.aspx
实验三 K-均值聚类算法实验报告
实验三 K-Means聚类算法 一、实验目的 1) 加深对非监督学习的理解和认识 2) 掌握动态聚类方法K-Means 算法的设计方法 二、实验环境 1) 具有相关编程软件的PC机 三、实验原理 1) 非监督学习的理论基础 2) 动态聚类分析的思想和理论依据 3) 聚类算法的评价指标 四、算法思想 K-均值算法的主要思想是先在需要分类的数据中寻找K组数据作为初始聚类中心,然后计算其他数据距离这三个聚类中心的距离,将数据归入与其距离最近的聚类中心,之后再对这K个聚类的数据计算均值,作为新的聚类中心,继续以上步骤,直到新的聚类中心与上一次的聚类中心值相等时结束算法。 实验代码 function km(k,A)%函数名里不要出现“-” warning off [n,p]=size(A);%输入数据有n个样本,p个属性 cid=ones(k,p+1);%聚类中心组成k行p列的矩阵,k表示第几类,p是属性 %A(:,p+1)=100; A(:,p+1)=0; for i=1:k %cid(i,:)=A(i,:); %直接取前三个元祖作为聚类中心 m=i*floor(n/k)-floor(rand(1,1)*(n/k)) cid(i,:)=A(m,:); cid; end Asum=0; Csum2=NaN; flags=1; times=1; while flags flags=0; times=times+1; %计算每个向量到聚类中心的欧氏距离 for i=1:n
for j=1:k dist(i,j)=sqrt(sum((A(i,:)-cid(j,:)).^2));%欧氏距离 end %A(i,p+1)=min(dist(i,:));%与中心的最小距离 [x,y]=find(dist(i,:)==min(dist(i,:))); [c,d]=size(find(y==A(i,p+1))); if c==0 %说明聚类中心变了 flags=flags+1; A(i,p+1)=y(1,1); else continue; end end i flags for j=1:k Asum=0; [r,c]=find(A(:,p+1)==j); cid(j,:)=mean(A(r,:),1); for m=1:length(r) Asum=Asum+sqrt(sum((A(r(m),:)-cid(j,:)).^2)); end Csum(1,j)=Asum; end sum(Csum(1,:)) %if sum(Csum(1,:))>Csum2 % break; %end Csum2=sum(Csum(1,:)); Csum; cid; %得到新的聚类中心 end times display('A矩阵,最后一列是所属类别'); A for j=1:k [a,b]=size(find(A(:,p+1)==j)); numK(j)=a; end numK times xlswrite('data.xls',A);
K-means算法简介
K-means聚类算法 K-means也是聚类算法中最简单的一种了,但是里面包含的思想却是不一般。最早我使用并实现这个算法是在学习韩爷爷那本数据挖掘的书中,那本书比较注重应用。看了Andrew Ng的这个讲义后才有些明白K-means后面包含的EM思想。 聚类属于无监督学习,以往的回归、朴素贝叶斯、SVM等都是有类别标签y的,也就是说样例中已经给出了样例的分类。而聚类的样本中却没有给定y,只有特征x,比如假设 宇宙中的星星可以表示成三维空间中的点集。聚类的目的是找到每个样本x潜在的类别y,并将同类别y的样本x放在一起。比如上面的星星,聚类后结果是一个个星团,星团里面的点相互距离比较近,星团间的星星距离就比较远了。 在聚类问题中,给我们的训练样本是,每个,没有了y。 K-means算法是将样本聚类成k个簇(cluster),具体算法描述如下: 1、随机选取k个聚类质心点(cluster centroids)为。 2、重复下面过程直到收敛 { 对于每一个样例i,计算其应该属于的类 对于每一个类j,重新计算该类的质心 } K是我们事先给定的聚类数,代表样例i与k个类中距离最近的那个类,的值 是1到k中的一个。质心代表我们对属于同一个类的样本中心点的猜测,拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,然后选取 距离最近的那个星团作为,这样经过第一步每一个星星都有了所属的星团;第二步对于
每一个星团,重新计算它的质心(对里面所有的星星坐标求平均)。重复迭代第一步和第二步直到质心不变或者变化很小。 下图展示了对n个样本点进行K-means聚类的效果,这里k取2。 K-means面对的第一个问题是如何保证收敛,前面的算法中强调结束条件就是收敛,可以证明的是K-means完全可以保证收敛性。下面我们定性的描述一下收敛性,我们定义畸变函数(distortion function)如下: J函数表示每个样本点到其质心的距离平方和。K-means是要将J调整到最小。假设当 前J没有达到最小值,那么首先可以固定每个类的质心,调整每个样例的所属的类别来让J函数减少,同样,固定,调整每个类的质心也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时,和c也同时收敛。(在理论上,可以有多组不同的和c值能够使得J取得最小值,但这种现象实际上很少见)。
模式识别最近邻和fisher分类matlab实验报告
一、Fisher 线性判别 Fisher 线性判别是统计模式识别的基本方法之一。它简单,容易实现,且计算量和存储量小,是实际应用中最常用的方法之一。Fisher 判别法Fisher 在1936年发表的论文中首次提出的线性判别法。Fisher 判别法的基本思想是寻找一个最好的投影,当特征向量x 从d 维空间映射到这个方向时,两类能最好的分开。这个方法实际上涉及到特征维数的压缩问题。 一维空间的Fisher 线性判别函数为: 2 1212 ()()F m m J w S S -= + (1) i m = ∑x N 1,i=1,2 (2) 2,1,)()(=--=∑∈i m x m x S T i x i i i ξ (3) 其中,1m 和2m 是两个样本的均值,1S ,2S 分别为各类样本的的类内离散度。投影方向w 为: )(211 m m S w w -=- (4) 12w S S S =+ (5) 在Fisher 判决函数中,分子反应了映射后两类中心的距离平方,该值越大,类间可分性越好;分母反应了两类的类内的离散度,其值越小越好;从总体上讲,()F J w 的值越大越好,在这种可分性评价标准下,使()F J w 达到最大值的w 即为最佳投影方向。
1.1、 Fisher线性判别实验流程图
1.2 Fisher线性判别mtalab代码 data=importdata('C:\Users\zzd\Desktop\data-ch5.mat'); data1=data.data; data2=https://www.360docs.net/doc/d411373675.html,bel; sample1=data1(1:25,:); sample2=data1(51:75,:); sample=[sample1 sample2]; sp_l=data2(26:75); test1=data1(26:50,:); test2=data1(76:100,:); test=[test1 test2]; lth=zeros(50,50); sample_m1=mean(sample1); sample_m2=mean(sample2); m1=sample_m1'; m2=sample_m2'; sb=(m1-m2)*(m1-m2)'; s1=zeros(2); for n=1:25 temp = (sample1(n,:)'-m1)*(sample1(n,:)'-m1)'; s1=s1+temp; end; s2=zeros(2); for n=1:25 temp = (sample2(n,:)'-m2)*(sample2(n,:)'-m2)'; s2 = s2+temp; end; sw=s1+s2; vw=inv(sw)*(m1-m2); a_m1 = vw'*m1; a_m2 = vw'*m2; w0 = (a_m1+a_m2)/2;
对数据进行聚类分析实验报告
对数据进行聚类分析实验报告 1.方法背景 聚类分析又称群分析,是多元统计分析中研究样本或指标的一种主要的分类方法,在古老的分类学中,人们主要靠经验和专业知识,很少利用数学方法。随着生产技术和科学的发展,分类越来越细,以致有时仅凭经验和专业知识还不能进行确切分类,于是数学这个有用的工具逐渐被引进到分类学中,形成了数值分类学。近些年来,数理统计的多元分析方法有了迅速的发展,多元分析的技术自然被引用到分类学中,于是从数值分类学中逐渐的分离出聚类分析这个新的分支。结合了更为强大的数学工具的聚类分析方法已经越来越多应用到经济分析和社会工作分析中。在经济领域中,主要是根据影响国家、地区及至单个企业的经济效益、发展水平的各项指标进行聚类分析,然后很据分析结果进行综合评价,以便得出科学的结论。 2.基本要求 用FAMALE.TXT、MALE.TXT和/或test2.txt的数据作为本次实验使用的样本集,利用C均值和分级聚类方法对样本集进行聚类分析,对结果进行分析,从而加深对所学内容的理解和感性认识。 3.实验要求 (1)把FAMALE.TXT和MALE.TXT两个文件合并成一个,同时采用身高和体重数据作为特征,设类别数为2,利用C均值聚类方法对数据进行聚类,并将聚类结果表示在二维平面上。尝试不同初始值对此数据集是否会造成不同的结果。 (2)对1中的数据利用C均值聚类方法分别进行两类、三类、四类、五类聚类,画出聚类指标与类别数之间的关系曲线,探讨是否可以确定出合理的类别数目。 (3)对1中的数据利用分级聚类方法进行聚类,分析聚类结果,体会分级聚类方法。。(4)利用test2.txt数据或者把test2.txt的数据与上述1中的数据合并在一起,重复上述实验,考察结果是否有变化,对观察到的现象进行分析,写出体会 4.实验步骤及流程图 根据以上实验要求,本次试验我们将分为两组:一、首先对FEMALE 与MALE中数据组成的样本按照上面要求用C均值法进行聚类分析,然后对FEMALE、MALE、test2中数据组成的样本集用C均值法进行聚类分析,比较二者结果。二、将上述两个样本用分即聚类方法进行聚类,观察聚类结果。并将两种聚类结果进行比较。 (1)、C均值算法思想
关于模糊c均值聚类算法
FCM模糊c均值 1、原理详解 模糊c-均值聚类算法fuzzy c-means algorithm (FCMA)或称(FCM)。在众多模糊聚类算法中,模糊C-均值(FCM)算法应用最广泛且较成功,它通过优化目标函数得到每个样本点对所有类中心的隶属度,从而决定样本点的类属以达到自动对样本数据进行分类的目的。 聚类的经典例子 然后通过机器学习中提到的相关的距离开始进行相关的聚类操作 经过一定的处理之后可以得到相关的cluster,而cluster之间的元素或者是矩阵之间的距离相对较小,从而可以知晓其相关性质与参数较为接近 C-Means Clustering: 固定数量的集群。 每个群集一个质心。 每个数据点属于最接近质心对应的簇。
1.1关于FCM的流程解说其经典状态下的流程图如下所示
集群是模糊集合。 一个点的隶属度可以是0到1之间的任何数字。 一个点的所有度数之和必须加起来为1。 1.2关于k均值与模糊c均值的区别 k均值聚类:一种硬聚类算法,隶属度只有两个取值0或1,提出的基本根据是“类内误差平方和最小化”准则,进行相关的必要调整优先进行优化看是经典的欧拉距离,同样可以理解成通过对于cluster的类的内部的误差求解误差的平方和来决定是否完成相关的聚类操作;模糊的c均值聚类算法:一种模糊聚类算法,是k均值聚类算法的推广形式,隶属度取值为[0 1]区间内的任何数,提出的基本根据是“类内加权误差平方和最小化”准则; 这两个方法都是迭代求取最终的聚类划分,即聚类中心与隶属度值。两者都不能保证找到问题的最优解,都有可能收敛到局部极值,模糊c均值甚至可能是鞍点。 1.2.1关于kmeans详解 K-means算法是硬聚类算法,是典型的基于原型的目标函数聚类方法的代表,它是数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则。K-means算法以欧式距离作为相似度测度,它是求对应某一初始聚类中心向量V最优分类,使得评价指标J最小。算法采用误差平方和准则函数作为聚类准则函数。 关于其优点:
数据挖掘实验报告
《数据挖掘》Weka实验报告 姓名_学号_ 指导教师 开课学期2015 至2016 学年 2 学期完成日期2015年6月12日
1.实验目的 基于https://www.360docs.net/doc/d411373675.html,/ml/datasets/Breast+Cancer+WiscOnsin+%28Ori- ginal%29的数据,使用数据挖掘中的分类算法,运用Weka平台的基本功能对数据集进行分类,对算法结果进行性能比较,画出性能比较图,另外针对不同数量的训练集进行对比实验,并画出性能比较图训练并测试。 2.实验环境 实验采用Weka平台,数据使用来自https://www.360docs.net/doc/d411373675.html,/ml/Datasets/Br- east+Cancer+WiscOnsin+%28Original%29,主要使用其中的Breast Cancer Wisc- onsin (Original) Data Set数据。Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 3.实验步骤 3.1数据预处理 本实验是针对威斯康辛州(原始)的乳腺癌数据集进行分类,该表含有Sample code number(样本代码),Clump Thickness(丛厚度),Uniformity of Cell Size (均匀的细胞大小),Uniformity of Cell Shape (均匀的细胞形状),Marginal Adhesion(边际粘连),Single Epithelial Cell Size(单一的上皮细胞大小),Bare Nuclei(裸核),Bland Chromatin(平淡的染色质),Normal Nucleoli(正常的核仁),Mitoses(有丝分裂),Class(分类),其中第二项到第十项取值均为1-10,分类中2代表良性,4代表恶性。通过实验,希望能找出患乳腺癌客户各指标的分布情况。 该数据的数据属性如下: 1. Sample code number(numeric),样本代码; 2. Clump Thickness(numeric),丛厚度;
数据挖掘实验报告三
实验三 一、实验原理 K-Means算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。 在数据挖掘中,K-Means算法是一种cluster analysis的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。 算法原理: (1) 随机选取k个中心点; (2) 在第j次迭代中,对于每个样本点,选取最近的中心点,归为该类; (3) 更新中心点为每类的均值; (4) j<-j+1 ,重复(2)(3)迭代更新,直至误差小到某个值或者到达一定的迭代步 数,误差不变. 空间复杂度o(N) 时间复杂度o(I*K*N) 其中N为样本点个数,K为中心点个数,I为迭代次数 二、实验目的: 1、利用R实现数据标准化。 2、利用R实现K-Meams聚类过程。 3、了解K-Means聚类算法在客户价值分析实例中的应用。 三、实验内容 依据航空公司客户价值分析的LRFMC模型提取客户信息的LRFMC指标。对其进行标准差标准化并保存后,采用k-means算法完成客户的聚类,分析每类的客户特征,从而获得每类客户的价值。编写R程序,完成客户的k-means聚类,获得聚类中心与类标号,并统计每个类别的客户数
四、实验步骤 1、依据航空公司客户价值分析的LRFMC模型提取客户信息的LRFMC指标。
2、确定要探索分析的变量 3、利用R实现数据标准化。 4、采用k-means算法完成客户的聚类,分析每类的客户特征,从而获得每类客户的价值。
五、实验结果 客户的k-means聚类,获得聚类中心与类标号,并统计每个类别的客户数 六、思考与分析 使用不同的预处理对数据进行变化,在使用k-means算法进行聚类,对比聚类的结果。 kmenas算法首先选择K个初始质心,其中K是用户指定的参数,即所期望的簇的个数。 这样做的前提是我们已经知道数据集中包含多少个簇. 1.与层次聚类结合 经常会产生较好的聚类结果的一个有趣策略是,首先采用层次凝聚算法决定结果
K-MEANS算法(K均值算法)
k-means 算法 一.算法简介 k -means 算法,也被称为k -平均或k -均值,是一种得到最广泛使用的聚类算法。 它是将各个聚类子集内的所有数据样本的均值作为该聚类的代表点,算法的主要思想是通过迭代过程把数据集划分为不同的类别,使得评价聚类性能的准则函数达到最优,从而使生成的每个聚类内紧凑,类间独立。这一算法不适合处理离散型属性,但是对于连续型具有较好的聚类效果。 二.划分聚类方法对数据集进行聚类时包括如下三个要点: (1)选定某种距离作为数据样本间的相似性度量 k-means 聚类算法不适合处理离散型属性,对连续型属性比较适合。因此在计算数据样本之间的距离时,可以根据实际需要选择欧式距离、曼哈顿距离或者明考斯距离中的一种来作为算法的相似性度量,其中最常用的是欧式距离。下面我给大家具体介绍一下欧式距离。 假设给定的数据集 ,X 中的样本用d 个描述属性A 1,A 2…A d 来表示,并且d 个描述属性都是连续型属性。数据样本x i =(x i1,x i2,…x id ), x j =(x j1,x j2,…x jd )其中,x i1,x i2,…x id 和x j1,x j2,…x jd 分别是样本x i 和x j 对应d 个描述属性A 1,A 2,…A d 的具体取值。样本xi 和xj 之间的相似度通常用它们之间的距离d(x i ,x j )来表示,距离越小,样本x i 和x j 越相似,差异度越小;距离越大,样本x i 和x j 越不相似,差异度越大。 欧式距离公式如下: (2)选择评价聚类性能的准则函数 k-means 聚类算法使用误差平方和准则函数来评价聚类性能。给定数据集X ,其中只包含描述属性,不包含类别属性。假设X 包含k 个聚类子集X 1,X 2,…X K ; {} |1,2,...,m X x m total ==() ,i j d x x =
Parzen窗估计与KN近邻估计实验报告
模式识别实验报告 题目:Parzen 窗估计与KN 近邻估计 学 院 计算机科学与技术 专 业 xxxxxxxxxxxxxxxx 学 号 xxxxxxxxxxxx 姓 名 xxxx 指导教师 xxxx 20xx 年xx 月xx 日 Parzen 窗估计与KN 近邻估计 装 订 线
一、实验目的 本实验的目的是学习Parzen窗估计和k最近邻估计方法。在之前的模式识别研究中,我们假设概率密度函数的参数形式已知,即判别函数J(.)的参数是已知的。本节使用非参数化的方法来处理任意形式的概率分布而不必事先考虑概率密度的参数形式。在模式识别中有躲在令人感兴趣的非参数化方法,Parzen窗估计和k最近邻估计就是两种经典的估计法。二、实验原理 1.非参数化概率密度的估计 对于未知概率密度函数的估计方法,其核心思想是:一个向量x落在区域R中的概率可表示为: 其中,P是概率密度函数p(x)的平滑版本,因此可以通过计算P来估计概率密度函数p(x),假设n个样本x1,x2,…,xn,是根据概率密度函数p(x)独立同分布的抽取得到,这样,有k个样本落在区域R中的概率服从以下分布: 其中k的期望值为: k的分布在均值附近有着非常显著的波峰,因此若样本个数n足够大时,使用k/n作为概率P的一个估计将非常准确。假设p(x)是连续的,且区域R足够小,则有: 如下图所示,以上公式产生一个特定值的相对概率,当n趋近于无穷大时,曲线的形状逼近一个δ函数,该函数即是真实的概率。公式中的V是区域R所包含的体积。综上所述,可以得到关于概率密度函数p(x)的估计为:
在实际中,为了估计x处的概率密度函数,需要构造包含点x的区域R1,R2,…,Rn。第一个区域使用1个样本,第二个区域使用2个样本,以此类推。记Vn为Rn的体积。kn为落在区间Rn中的样本个数,而pn (x)表示为对p(x)的第n次估计: 欲满足pn(x)收敛:pn(x)→p(x),需要满足以下三个条件: 有两种经常采用的获得这种区域序列的途径,如下图所示。其中“Parzen窗方法”就是根据某一个确定的体积函数,比如Vn=1/√n来逐渐收缩一个给定的初始区间。这就要求随机变量kn和kn/n能够保证pn (x)能收敛到p(x)。第二种“k-近邻法”则是先确定kn为n的某个函数,如kn=√n。这样,体积需要逐渐生长,直到最后能包含进x的kn个相邻点。
KNN算法实验报告
KNN算法实验报告 一试验原理 K最近邻(k-NearestNeighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。 该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决 定待分样本所属的类别。KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。 KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成正比。 该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量
并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进。该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。 二试验步骤 那么根据以上的描述,我把结合使用反余弦匹配和kNN结合的过程分成以下几个步骤: 1.计算出样本数据和待分类数据的距离 2.为待分类数据选择k个与其距离最小的样本 3.统计出k个样本中大多数样本所属的分类 4.这个分类就是待分类数据所属的分类 数学表达:目标函数值可以是离散值(分类问题),也可以是连续值(回归问题).函数形势为f:n维空间R—〉一维空间R。 第一步:将数据集分为训练集(DTrn)和测试集(DTES)。 第二步:在测试集给定一个实例Xq;在训练集(DTrn)中找到与这个实例Xq的K-最近邻子集{X1、、、、XK},即:DKNN。 第三步:计算这K-最近邻子集得目标值,经过加权平均: ^f(Xq)=(f(X1)+...+f(XK))/k作为f(Xq)的近似估计。改进的地方:对
K均值聚类算法优缺点
J.B.MacQueen 在 1967 年提出的K-means算法[22]到目前为止用于科学和工业应用的诸多聚类算法中一种极有影响的技术。它是聚类方法中一个基本的划分方法,常常采用误差平方和准则函数作为聚类准则函数,误差平方和准则函数定义为: (3-1)其中,是类中数据对象的均值,即,(j=1,2,…,n),是K个聚类中心,分别代表K个类。 K-means算法的工作原理:算法首先随机从数据集中选取 K个点作为初始聚类中心,然后计算各个样本到聚类中的距离,把样本归到离它最近的那个聚类中心所在的类。计算新形成的每一个聚类的数据对象的平均值来得到新的聚类中心,如果相邻两次的聚类中心没有任何变化,说明样本调整结束,聚类准则函数已经收敛。本算法的一个特点是在每次迭代中都要考察每个样本的分类是否正确。若不正确,就要调整,在全部样本调整完后,再修改聚类中心,进入下一次迭代。如果在一次迭代算法中,所有的样本被正确分类,则不会有调整,聚类中心也不会有任何变化,这标志着已经收敛,因此算法结束。 算法描述如下: 算法:K-means。划分的 K-means 算法基于类中对象的平均值。 输入:类的数目K和包含N个对象的数据库。 方法: ① 对于数据对象集,任意选取K个对象作为初始的类中心; ② 根据类中对象的平均值,将每个对象重新赋给最相似的类; ③ 更新类的平均值,即计算每个类中对象的平均值; ④ Repeat ②③; ⑤ 直到不再发生变化。 其中,初始聚类中心的选择对聚类结果的影响是很大的,如图3.1,图a是三个类的实际分布,图b是选取了好的初始聚类中心(+字标记的数据对象)得到的结果。图c是选取不好的初始聚类中心得到的结果,从中可以看到,选择初始聚类中心是很关键的。 a b c
模糊C均值聚类 及距离函数的优缺点
K-均值聚类分析是一种硬划分,它把每一个待识别的对象严格的划分到某一类中,具有非此即彼的性质。而实际上高光谱值目标在形态和类属方面存在着中介性,没有确定的边界来区分。因此需要考虑各个像元属于各个类别的隶属度问题,进行软划分,从而更好的区分。 设要进行聚类分析的图像像元数N ,图像像元集合{}N x x x X ,...,,21=,其中 {} T p k k k k x x x x ,...,,2 1=,p 为波段数。设把图像分为C 个类别,每个类别的聚类中心 ),...,,(21p i i i i v v v v =,聚类中心集合{}c v v v V ,...,,21=。用ik u 表示像元k x 隶属于以i v 为中心的类别i 的隶属度,定义隶属度矩阵U 为[]N C ik u U ?=。 矩阵U 中每一列的元素表示所对应的像元隶属于C 个类别中各个类的隶属度。满足一下约束条件: ???? ?????≤≤===>∑∑==10,...2,1;,...,2,1. (101) 1ik C i ik N k ik u N k C i u u 对隶属度ik u 进行了迷糊化,ik u 可取0和1之间的任意实数,这样一个像元可以同时隶 属于不同的类别,但其隶属度的总和总是等于1,这符合高光谱像元的实际情况。而属于硬聚类的K-均值聚类,其隶属度具有非此即彼的性质,隶属度ik u 只能取0或1。 定义目标函数J 为 ∑∑==?=N k C i ik m ik m d u V U J 11 2)()(),( 22)(i k ik v x d -=为Euclidean 距离;[)∞∈,1m 为模糊加权指数(当m=1时,同K- 均值的目标函数一致)。最优化的类就是使目标函数取最小值的类,如果一类中的所有点都 贴近于它们的类中心,则目标函数很小。 FCM 算法步骤: (1) 确定聚类数C ,加权指数m ,终止误差ε,最大迭代次数LOOP 。 (2) 初始化隶属度矩阵) 0(U (3) 开始循环,当迭代次数为IT (IT=0,1,2…,C )时,根据) (IT U 计算C-均值向量, 即C i u x u U N k N k m ik k m ik IT ,...,2,1],))(/()([1 1 ) (==∑∑== (4) 对k=1,2,…,N ,按以下公式更新) (IT U 为) 1(+IT U : 若i k v x ≠对所有的i v (i=1,2,…,C)满足,则对此k x 计算 C i v x d d u i k C j m jk ik ik ,...,2,1,,])([1112 =≠=-=-∑ 若对某一个i v ,有k x 满足i k v x =,则对应此k x ,令)(0;1i j u u jk ik ≠==。这样把聚 类中心与样本一致的情形去掉,把隶属度模糊化为0和1之间的实数。 (5) 若ε<+)1() (-IT IT U U 或IT>LOOP ,停止;否则置IT=IT+1,并返回第三步。 FCM 算法允许自由选取聚类个数,每一向量按其指定的隶属度]1,0[∈ik u 聚类到每一聚类中心。FCM 算法是通过最小化目标函数来实现数据聚类的。
算法实验报告
《算法设计与分析》上机实验报告
一、分治与递归 1、问题描述 编写程序,实现线性时间内选择n个元素的中位数的算法。并对于不同的n,测试平均时间效率。 2、问题分析 本问题属于线性选择问题的一个特例,可以使用分治法进行求解。其基本思想是模仿快速排序方法,对输入的数组进行划分,求出中位数所在的子数组,然后用递归的方法进行求解,最终可以求得问题的解。 3、算法设计 将n个输入元素根据随机选择的基准划分成2个子数组,a[p:r]被划分成a[p:i]和a[i+1:r]两组,使得a[p:i]中每个元素都不大于a[i+1:r]中元素。接着算法计算子数组a[p:i]中元素个数j,如果k<=j,则a[p:r]中第k个小元素落在子数组a[p:i]中元素均小于要找的第k小元素,因此要找的a[p:r]中第k小元素是a[i+1:r]中的第k-j小元素。 按照上述的方法递归的执行,直到当前数组中只剩下一个元素,就可以得到问题的解。 4、算法实现 #include"iostream.h" #include"stdlib.h" #include"time.h" #include
void main() { srand((unsigned int)time(NULL)); _timeb time0,time1; int n; cout << "请输入数组的长度:"; cin >> n; cout << "请输入数组的每一个数:" << endl; int *a=new int[n]; for(int i=0;i
C均值聚类实验报告
C 均值聚类实验报告 一、C 均值聚类的算法原理 聚类分析是指事先不知样本的类别,而利用样本的先验知识来构造分类器(无监督学习) 聚类准则函数 在样本相似性度量的基础上,聚类分析还需要一定的准则函数,才能把真正属于同一类的样本聚合成一个类的子集,而把不同类的样本分离开来。如果聚类准则函数选得好,聚类质量就会高。同时,聚类准则函数还可以用来评价一种聚类结果的质量,如果聚类质量不满足要求,就要重复执行聚类过程,以优化结果。在重复优化中,可以改变相似性度量,也可以选用新的聚类准则。 误差平方和准则(最常用的) 假定有混合样本集 ,采用某种相似性度量 被聚合成c 个分离开的子集 ,每个子集是一个类, 它们分别包 含 个 样本 。 为了衡量聚类的质量,采用误差平方和聚类准则函数 式中 为类中样本的均值: 是c 个子集合的中心,可以用来代表c 个类。 误差平方和 聚类准则函数是样本与集合中心的函数。在样本集X 给定的情况下, 其取值取决于c 个集合“中心”。 它描述n 个试验样本聚合成c 个类时,所产生的总误差平方和 越小越好。 误差平方和准则适用于各类样本比较密集且样本数目悬殊不大的样本分布。 C-均值聚类算法的核心思想是通过迭代把数据对象划分到不同的簇中,以求目标数最小化,从而使生成的簇尽可能地紧凑和独立。 首先,随机选取k 个对象作为初始的k 个簇的质心; 然后,将其余对象根据其与各个簇质心的距离分配到最近的簇;再求新形成的簇的质心。 12{,,...,}n X x x x =X c X X X ,.....,,21c n n n ,......,,21c J ∑∑==-= c j n k j k c j m x J 11 2 ||||j m ∑==j n j j j j x n m 1 1 c j ,....,2,1=j m c J c J
数据挖掘实验报告
数据挖掘实验报告 ——加权K-近邻法 一、 数据源说明 1. 数据理解 数据来自于天猫对顾客的BuyOrNot(买与不买),BuyDNactDN(消费活跃度),ActDNTotalDN(活跃度),BuyBBrand(成交有效度),BuyHit(活动有效度)这五个变量的统计。 数据分成两类数据,一类作为训练数据集,一类为测试数据集。 2.数据清理 现实世界的数据一般是不完整的、有噪声的和不一致的。数据清理例程试图填充缺失的值,光滑噪声并识别离群点,并纠正数据中的不一致。 a) 缺失值:当数据中存在缺失值是,忽略该元组 b) 噪声数据:本文暂没考虑。 二、 基于变量重要性的加权K-近邻法[1] 由于我们计算K-近邻法默认输入变量在距离测度中有“同等重要”的贡献,但情况并不总是如此。我们知道不同的变量对我们所要预测的变量的作用是不一定一样的,所以找出对输出变量分类预测有意义的重要变量对数据预测具有重要作用。同时也可以减少那些对输出变量分类预测无意义的输入变量,减少模型的变量。为此,采用基于变量重要性的K-近邻法,计算加权距离,给重要的变量赋予较高的权重,不重要的变量赋予较低的权重是必要的。 (1)算法思路: 我们引进1w 为第i 个输入变量的权重,是输入变量重要性(也称特征重要性),FI 函数,定义为:∑== p j i FI FI 1 ) i ()((i)w 。其中(i)FI 为第i 个输入变量的特征重要性, ∑=<1,1w )((i)i w 这里,(i)FI 依第i 个输入变量对预测误差的影响定义。设输入 变量集合包含p 个变量:p x x x x ,...,,,321。剔除第i 个变量后计算输入变量
实验三报告实验三-Kmeans算法实现
实验三报告实验三-Kmeans算法实现
北华大学开放实验报告 实验名称:实验三Kmeans算法实现 所属课程:模式识别 班级:信息10—1 学号:36 姓名:张慧
实验三、K_means算法实现 一、背景知识简介: Kmeans算法是一种经典的聚类算法,在模式识别中得到了广泛的应用,基于Kmeans的变种算法也有很多,模糊Kmeans、分层Kmeans 等。 Kmeans和应用于混合高斯模型的受限EM算法是一致的。高斯混合模型广泛用于数据挖掘、模式识别、机器学习、统计分析。Kmeans的迭代步骤可以看成E步和M步,E:固定参数类别中心向量重新标记样本,M:固定标记样本调整类别中心向量。K均值只考虑(估计)了均值,而没有估计类别的方差,所以聚类的结构比较适合于特征协方差相等的类别。 二、k-means聚类算法 k-means 算法接受参数 k ;然后将事先输入的n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。 K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。K-means算法的基本思想是:以空间中k个点
为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。 (1)算法思路: 首先从n个数据对象任意选择 k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用均方差作为标准测度函数. k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。 该算法的最大优势在于简洁和快速。算法的关键在于初始中心的选择和距离公式。 (2)算法步骤: step.1---初始化距离K个聚类的质心(随机产生) step.2---计算所有数据样本与每个质心的欧氏距离,将数据样本加入与其欧氏距离最短的那个质心的簇中(记录其数据样本的编号) step.3---计算现在每个簇的质心,进行更新,判断新质心是否与原质心相等,若相等,则迭代结束,若不相等,回到step2继续迭代。 (3)算法流程图
matlab实现Kmeans聚类算法
matlab实现Kmeans聚类算法 1.简介: Kmeans和应用于混合高斯模型的受限EM算法是一致的。高斯混合模型广泛用于数据挖掘、模式识别、机器学习、统计分析。Kmeans 的迭代步骤可以看成E步和M步,E:固定参数类别中心向量重新标记样本,M:固定均值只考虑(估计)了均值,而没有估计类别的方差,所以聚类的结构比较适合于特征协方差相等的类别。 Kmeans在某种程度也可以看成Meanshitf的特殊版本,Meanshift 是所以Meanshift可以用于寻找数据的多个模态(类别),利用的是梯度上升法。在06年的一篇CVPR文章上,证明了Meanshift方法是牛顿拉夫逊算法的变种。Kmeans和EM算法相似是指混合密度的形式已知(参数形式已知)情况下,利用迭代方法,在参数空间中搜索解。而Kmeans和Meanshift相似是指都是一种概率密度梯度估计的方法,不过是Kmean选用的是特殊的核函数(uniform kernel),而与混合概率密度形式是否已知无关,是一种梯度求解方式。 k-means是一种聚类算法,这种算法是依赖于点的邻域来决定哪些点应该分在点,也可以对高维的空间(3维,4维,等等)的点进行聚类,任意高维的空间都可以。 上图中的彩色部分是一些二维空间点。上图中已经把这些点分组了,并使用了不同的颜色对各组进行了标记。这就是聚类算法要做的事情。 这个算法的输入是: 1:点的数据(这里并不一定指的是坐标,其实可以说是向量)
2:K,聚类中心的个数(即要把这一堆数据分成几组) 所以,在处理之前,你先要决定将要把这一堆数据分成几组,即聚成几类。但并不是在所有情况下,你都事先就能知道需要把数据聚成几类的。意味着使用k-means就不能处理这种情况,下文中会有讲解。 把相应的输入数据,传入k-means算法后,当k-means算法运行完后,该算法的输出是: 1:标签(每一个点都有一个标签,因为最终任何一个点,总会被分到某个类,类的id号就是标签) 2:每个类的中心点。 标签,是表示某个点是被分到哪个类了。例如,在上图中,实际上有4中“标签”,每个“标签”使用不同的颜色来表示。所有黄色点我们可以用标签以看出,有3个类离的比较远,有两个类离得比较近,几乎要混合在一起了。 当然,数据集不一定是坐标,假如你要对彩色图像进行聚类,那么你的向量就可以是(b,g,r),如果使用的是hsv颜色空间,那还可以使用(h,s,v),当然肯定可以有不同的组合例如(b*b,g*r,r*b) ,(h*b,s*g,v*v)等等。 在本文中,初始的类的中心点是随机产生的。如上图的红色点所示,是本文随机产生的初始点。注意观察那两个离得比较近的类,它们几乎要混合在一起,看看算法是如何将它们分开的。 类的初始中心点是随机产生的。算法会不断迭代来矫正这些中心点,并最终得到比较靠5个中心点的距离,选出一个距离最小的(例如该点与第2个中心点的距离是5个距离中最小的),那么该点就归属于该类.上图是点的归类结果示意图. 经过步骤3后,每一个中心center(i)点都有它的”管辖范围”,由于这个中心点不一定是这个管辖范围的真正中心点,所以要重新计算中心点,计算的方法有很多种,最简单的一种是,直接计算该管辖范围内所有点的均值,做为心的中心点new_center(i). 如果重新计算的中心点new_center(i)与原来的中心点center(i)的距离大于一定的阈值(该阈值可以设定),那么认为算法尚未收敛,使用new_center(i)代替center(i)(如图,中心点从红色点
FCMClust(模糊c均值聚类算法MATLAB实现)
function [center, U, obj_fcn] = FCMClust(data, cluster_n, options) % FCMClust.m 采用模糊C均值对数据集data聚为cluster_n类 % 用法: % 1. [center,U,obj_fcn] = FCMClust(Data,N_cluster,options); % 2. [center,U,obj_fcn] = FCMClust(Data,N_cluster); % 输入: % data ---- nxm矩阵,表示n个样本,每个样本具有m的维特征值 % N_cluster ---- 标量,表示聚合中心数目,即类别数 % options ---- 4x1矩阵,其中 % options(1): 隶属度矩阵U的指数,>1 (缺省值: 2.0) % options(2): 最大迭代次数(缺省值: 100) % options(3): 隶属度最小变化量,迭代终止条件(缺省值: 1e-5) % options(4): 每次迭代是否输出信息标志(缺省值: 1) % 输出: % center ---- 聚类中心 % U ---- 隶属度矩阵 % obj_fcn ---- 目标函数值 % Example: % data = rand(100,2); % [center,U,obj_fcn] = FCMClust(data,2); % plot(data(:,1), data(:,2),'o'); % hold on; % maxU = max(U); % index1 = find(U(1,:) == maxU); % index2 = find(U(2,:) == maxU); % line(data(index1,1),data(index1,2),'marker','*','color','g'); % line(data(index2,1),data(index2,2),'marker','*','color','r'); % plot([center([1 2],1)],[center([1 2],2)],'*','color','k') % hold off; %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%%%%%%%%%% if nargin ~= 2 & nargin ~= 3, %判断输入参数个数只能是2个或3个 error('Too many or too few input arguments!'); end data_n = size(data, 1); % 求出data的第一维(rows)数,即样本个数 in_n = size(data, 2); % 求出data的第二维(columns)数,即特征值长度 % 默认操作参数 default_options = [2; % 隶属度矩阵U的指数 100; % 最大迭代次数 1e-5; % 隶属度最小变化量,迭代终止条件