第六章 提升算法
6.1 引言
当做重要决定时,大家可能都会考虑吸取多个专家而不是一个人的意见。机器学习处理问题时也是如此,这就是提升算法背后的思路,提升算法是对其它算法进行组合的一种方式,接下来我们将对提升算法,以及提升算法中最流行的一个算法AdaBoost 算法进行介绍,并对提升树以及简单的基于单层决策树的Adaboost 算法进行讨论。
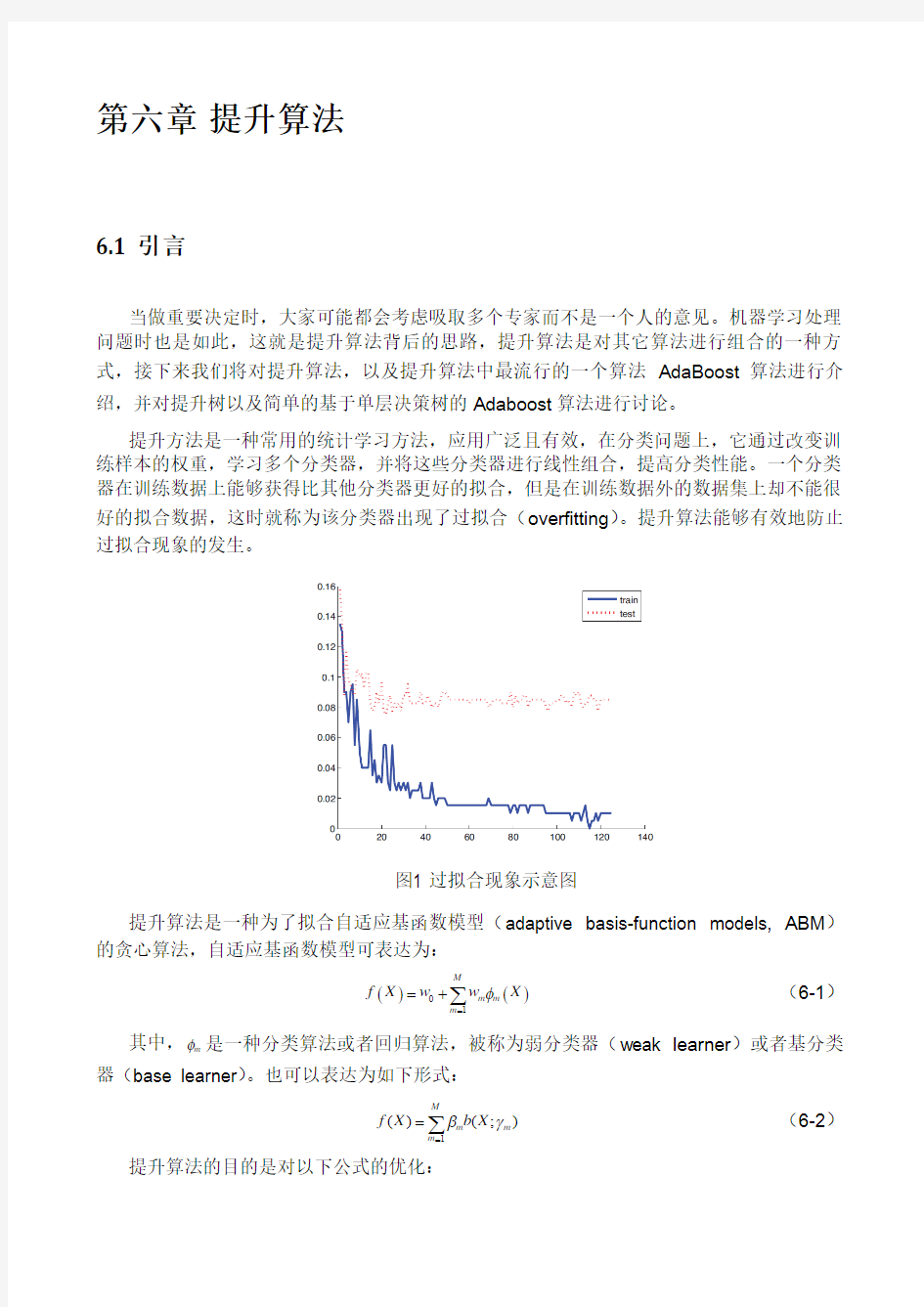
提升方法是一种常用的统计学习方法,应用广泛且有效,在分类问题上,它通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类性能。一个分类器在训练数据上能够获得比其他分类器更好的拟合,但是在训练数据外的数据集上却不能很好的拟合数据,这时就称为该分类器出现了过拟合(overfitting )。提升算法能够有效地防止过拟合现象的发生。
图1 过拟合现象示意图
提升算法是一种为了拟合自适应基函数模型(adaptive basis-function models, ABM )的贪心算法,自适应基函数模型可表达为:
()()01M
m m m f X w w X φ==+∑ (6-1)
其中,m φ是一种分类算法或者回归算法,被称为弱分类器(weak learner )或者基分类器(base learner )。也可以表达为如下形式:
1()(;)M
m m m f X b X βγ==∑ (6-2)
提升算法的目的是对以下公式的优化:
1
min (,())N
i i f
i L y f x =∑ (6-3)
其中,?(,)L y y 称为损失函数(loss function ),f 是ABM 模型。不同的损失函数有着不同
的性质,对应不同的提升算法,如表1所示。
将(2)式代入(3)式可得如下表达式:
,11min ,(;)m m
N
M
i m i m i m L y x βγβφγ==??
???
∑∑ (6-4) 因为学习的是加法模型,如果能够从前向后,每一步只学习一个基分类器及其系数,那
么就可以简化优化的复杂度,具体推导过程如下所示:
(),1
min ,(;)m m
N
i m i m i L y x βγβφγ=∑ (6-5)
表1 常见损失函数以及相应提升算法
名称 损失函数
导数
*f
算法 平方误差 21
(())2
i i y f x - ()i i y f x -
[]|i y x E
L2Boosting 绝对误差 ()i i y f x -
sgn(())
i i y f x -
(|)i median y x
Gradient boosting 指数损失 ()
exp ()i i y f x -
()
exp ()i i i y y f x --
1
log 21i i ππ- AdaBoost 对数损失
()log 1i i
y f e -+
i i y π-
1
log 21i i
ππ-
LogitBoost
01
()arg min (,(;))N
i i i f X L y f x γ
γ==∑ (6-6)
1,1
(,)argmin (,()(;))N
m m i m i i i L y f x x βγ
βγβφγ-==+∑ (6-7)
1()()(;)m m m m f X f X X βφγ-=+ (6-8)
算法不进行回溯对参数进行修改,因此该算法称为前向分步算法。
6.2 AdaBoost 算法
AdaBoost (Adaptive boosting )算法,也称为自适应提升算法。训练数据中的每个样本,并赋予其一个权重,这些权重构成向量D 。一开始,这些权重都初始化为相等值,首先
在训练数据上训练出一个弱分类器并计算该分类器的错误率,然后在同一数据集上再次训练弱分类器。再次训练分类器的过程中,将会重新调整每个样本的权重,其中上一次分对的样本权重会降低,而上一次分错的样本权重会提高。
图2 AdaBoost 算法示意图
给定一个二类分类的训练数据集1122{(,),(,),,(,)}N N T x y x y x y =,其中,每个样本点由实例
与标记组成,实例n i x R χ∈?,标记{1,1}i y Y ∈=-+,χ是实例空间,Y 是标记集合。损失函数可以表达为:
1,1
1
()exp[(()())]exp(())N N
m i m i i i m i i i i L y f x x w y x φβφβφ-===-+=-∑∑ (6-9)
其中,,1exp(())i m i m i w y f x --,{}1,1i y ∈-+,则可以有如下推导:
()
,,,,()
()
1
1
()(())i i i i N N
m i m i m i m i i i m
y x y x i i L e w e w e e w I y x e w β
β
ββ
βφ
φ
φφ---=≠===+=-≠+∑∑∑∑ (6-10)
其中,11
log
2m m m
err err β-=,,1,1(())
N
i m i m i i m N i m
i w I y x err w φ==≠=∑∑,m
err 称为分类误差率。则可以得到第
m 个分类器:
1()()()m m m f X f X X βφ-=+ (6-11)
计算第m+1个分类器的参数可以通过下式得到:
()(2(())1)2(()),1,,,m i m i m i m i m i m i m y x I y x I y x i m i m i m i m w w e w e w e e βφβφβφβ-≠-≠-+=== (6-12)
总结起来Adaboost 算法主要有以下7步。 1 1i w N = 2 for 1:m M =do
3 Fit a classifier ()m X φ to the training set using weights w
4 Compute ,11(())
N
i m i m i i m N i
i w I y x err w φ==≠=∑∑
5 Compute 1log (2)m
m m m m
err err ααβ-== 6 Set (())
m i m i I y x i i w w e α
φ≠←
7 Return 1()sgn ()M
m m m f x X αφ=?
?=??
∑ 算法结束条件是训练错误率为0或者弱分类器数目达到用户指定的值。在具体应用AdaBoost 算法时,可以将其总结为以下的一般流程:
(1) 收集数据:可以使用任意方法;
(2) 准备数据:依赖于所使用弱分类器的类型,这里k-近邻、决策树、朴素贝叶斯、逻辑
回归、支持向量机等任意分类算法都可以作为本部分弱分类器; (3) 分析数据:可使用任意方法;
(4) 训练算法:AdaBoost 算法大部分时间都用在训练上,分类器将多次在同一数据集上训练弱分类器; (5) 测试算法:计算分类错误率;
(6) 使用算法:同支持向量机类似,AdaBoost 算法预测两个类别中的一个,如果想应用多分类,需要做与支持向量机类似的相应修改。
6.3 提升树
分类与回归树(Classification and regression trees, CART )又称为决策树(decision tree ),使用分类数与回归树作为基本分类器的提升方法,称为提升树(Boosting tree )。
图3 决策树示意图
决策树模型将空间分为数个互不相交的区域,1,,j R j J =,每一个区域作为树的叶子节点,并为每个区域分配一个参数j γ:
()j j
x R f x γ∈?= (6-13)
因此决策树则可以表达为如下形式:
()()1;J
j j j T x I x R γ=Θ=∈∑ (6-14)
其中,1{,}J j j R γΘ=,该参数由最小化经验风险计算得到:
1arg min (,)j j
J
j j j x R L y γΘ
=∈Θ=∑
∑
(6-15)
决策树模型是一种传统的学习方法,易于被理解,相比较人工神经网络,我们能够清晰地了解如何构建决策树,而且决策树模型无信息丢失。但是决策树模型也存在不稳定的缺点,训练样本较小的变化会导致结果的较大差异。为解决这一问题,研究者主要通过提升算法来对决策树模型进行优化,即所谓的提升树(Boosting tree ),其基本算法思路为,构建多个决策树,多个决策树决策结果的加权平均对样本的变化不敏感。
提升树模型是一系列的决策树的和:
()1();M
M m m f x T x ==Θ∑ (6-16)
引入前向分步算法:
11?argmin (,()(;))m
N
m i m i i m
i L y f x T x -Θ=Θ=+Θ∑ (6-17) 已知1()m f x -求得1{,}m
J m jm jm R γΘ=,已知jm R 求jm γ:
1?arg min
(,())jm
i jm
jm i m i jm x R L y f x γγγ-∈=+∑
(6-18)
6.4 基于单层决策树的AdaBoost 算法
单层决策树(decision stump ,也称决策树桩)是一种简单的决策树,仅基于单个特征来做决策,由于这棵树只有一次分裂过程,因此它实际上就是一个树桩。利用Python 对单
层决策树进行实现,代码如下:
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq): retArray = ones((shape(dataMatrix)[0],1)) if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0 else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0 return retArray
def buildStump(dataArr,classLabels,D):
dataMatrix = mat(dataArr); labelMat = mat(classLabels).T m,n = shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClasEst = mat(zeros((m,1)))
minError = inf
for i in range(n):
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max();
stepSize = (rangeMax-rangeMin)/numSteps
for j in range(-1,int(numSteps)+1):
for inequal in ['lt', 'gt']:
threshVal = (rangeMin + float(j) * stepSize)
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)
errArr = mat(ones((m,1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T*errArr
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst
上述程序包含两个函数。第一个函数stumpClassfy()是通过阈值比较对数据进行分类的,所有的阈值一边的数据会分到类别-1,而在另一边的数据分到类别+1.该函数可以通过数组过滤来实现,首先将返回数组的全部元素设置为1,然后将所有不满足不等式要求的元素设置为-1,可以给予数据集中的任意元素进行比较,同时也可以将不等号在大于、小于之间切换。
第二个函数buildStump()将会遍历stumpClassfy()函数所有可能的输入,并找到数据集上最佳的单层决策树。在确保输入数据符合矩阵格式之后,整个函数就开始执行了,然后函数将构建一个称为bestStump的空字典,这个字典用语存储给定权重向量D时所得到的最佳单层决策树的相关信息。变量numSteps用于在特征的所有可能值上进行遍历。而变量minError则在一开始就初始化成正无穷大,之后用语寻找可能的最小错误率。
三层嵌套的for循环是程序最主要的部分。第一层for循环在数据集所有特征上遍历。考虑到数值型的特征,我们就可以通过计算最小值和最大值来了解应该需要多大的不畅。然后,第二层for循环再在这些值上遍历。甚至将阈值设置为整个取值范围之外也是可以的。因此在取值范围之外还应该有两个额外的步骤,最后一个for循环则是在大于和小于之间切换不等式。
上述单层决策树的生成函数是决策树的一个简化版本,即是所谓的弱学习器(弱分类器)。到现在为止,我们已经建立了单层决策树,并生成了程序,做好了过渡到完整AdaBoost算法,如下所示:
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m = shape(dataArr)[0]
D = mat(ones((m,1))/m) #init D to all equal
aggClassEst = mat(zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr,classLabels,D)
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))
bestStump['alpha'] = alpha
weakClassArr.append(bestStump)
expon = multiply(-1*alpha*mat(classLabels).T,classEst)
D = multiply(D,exp(expon))
D = D/D.sum()
aggClassEst += alpha*classEst
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
errorRate = aggErrors.sum()/m
print "total error:",errorRate
if errorRate == 0.0: break
return weakClassArr
伪代码可以简单总结为以下步骤:
对每次迭代:
利用buildStump( )函数找到最佳的单层决策树
将最佳单层决策树加入到单层决策树组
计算alpha
计算新的权重向量D
更新累积类别估计值
如果错误率等于0.0,则退出循环
该AdaBoost算法的输入参数包括数据集、类别标签以及迭代次数numIt,其中numI是在整个AdaBoost算法中唯一需要用户指定的参数。AdaBoost算法的核心在于for循环,该循环运行numIt次,或者知道训练错误率为0为止。循环中的第一件事就是利用前面介绍的buildStump()函数建立一个单层决策树,同时返回的还有最小的错误率以及估计的类别向量。
然后则需要计算的则是alpha值,该值会告诉总分类器本次单层决策树输出结果的权重,其中的语句max(error, 1e-16)用语确保在没有错误时,不会发生除零溢出,而后,alpha值加入到bestStump字典中,该字典又添加到列表中。该字典包含分类所需要的所有信息。接下来则是计算下一次迭代中的新权重向量D,在训练错误率为0时则提前结束for 循环。图4则为我们所得到的一组弱分类器及其权重。
图4 弱分类器
如图5所示,为不同弱分类器数,所得的分类结果,可以看到,弱分类器越多,在训练集上分类错误率越低,分类效果越好,但是并不是弱分类器越多,对测试数据的分类效果越好。
图5 不同数量弱分类器分类结果
6.5 小结
提升方法通过组合多个弱分类器的分类结果,获得了比简单的单分类器更好的分类结果。目前还存在利用不同分类器的集成方法,但是本章仅介绍了利用同一分类器的集成方法。
多个分类器组合可能会进一步凸显单分类器的不足,比如过拟合问题。如果分类器之间差别显著,那么多个分类器组合就可能会缓解这一问题。分类器之间的差别可以使算法本身
或者是应用于算法上的数据的不同。
决策树算法研究及应用概要
决策树算法研究及应用? 王桂芹黄道 华东理工大学实验十五楼206室 摘要:信息论是数据挖掘技术的重要指导理论之一,是决策树算法实现的理论依据。决 策树算法是一种逼近离散值目标函数的方法,其实质是在学习的基础上,得到分类规则。本文简要介绍了信息论的基本原理,重点阐述基于信息论的决策树算法,分析了它们目前 主要的代表理论以及存在的问题,并用具体的事例来验证。 关键词:决策树算法分类应用 Study and Application in Decision Tree Algorithm WANG Guiqin HUANG Dao College of Information Science and Engineering, East China University of Science and Technology Abstract:The information theory is one of the basic theories of Data Mining,and also is the theoretical foundation of the Decision Tree Algorithm.Decision Tree Algorithm is a method to approach the discrete-valued objective function.The essential of the method is to obtain a clas-sification rule on the basis of example-based learning.An example is used to sustain the theory. Keywords:Decision Tree; Algorithm; Classification; Application 1 引言 决策树分类算法起源于概念学习系统CLS(Concept Learning System,然后发展 到ID3
人工智能之机器学习常见算法
人工智能之机器学习常见算法 摘要机器学习无疑是当前数据分析领域的一个热点内容。很多人在平时的工作中都或多或少会用到机器学习的算法。这里小编为您总结一下常见的机器学习算法,以供您在工作和学习中参考。 机器学习的算法很多。很多时候困惑人们都是,很多算法是一类算法,而有些算法又是从其他算法中延伸出来的。这里,我们从两个方面来给大家介绍,第一个方面是学习的方式,第二个方面是算法的类似性。 学习方式 根据数据类型的不同,对一个问题的建模有不同的方式。在机器学习或者人工智能领域,人们首先会考虑算法的学习方式。在机器学习领域,有几种主要的学习方式。将算法按照学习方式分类是一个不错的想法,这样可以让人们在建模和算法选择的时候考虑能根据输入数据来选择最合适的算法来获得最好的结果。 监督式学习: 在监督式学习下,输入数据被称为训练数据,每组训练数据有一个明确的标识或结果,如对防垃圾邮件系统中垃圾邮件非垃圾邮件,对手写数字识别中的1,2,3,4等。在建立预测模型的时候,监督式学习建立一个学习过程,将预测结果与训练数据的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。监督式学习的常见应用场景如分类问题和回归问题。常见算法有逻辑回归(LogisTIc Regression)和反向传递神经网络(Back PropagaTIon Neural Network) 非监督式学习: 在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。常见的应用场景包括关联规则的学习以及聚类等。常见算法包括Apriori算法以及k-Means 算法。 半监督式学习: 在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预
决策树算法介绍(DOC)
3.1 分类与决策树概述 3.1.1 分类与预测 分类是一种应用非常广泛的数据挖掘技术,应用的例子也很多。例如,根据信用卡支付历史记录,来判断具备哪些特征的用户往往具有良好的信用;根据某种病症的诊断记录,来分析哪些药物组合可以带来良好的治疗效果。这些过程的一个共同特点是:根据数据的某些属性,来估计一个特定属性的值。例如在信用分析案例中,根据用户的“年龄”、“性别”、“收入水平”、“职业”等属性的值,来估计该用户“信用度”属性的值应该取“好”还是“差”,在这个例子中,所研究的属性“信用度”是一个离散属性,它的取值是一个类别值,这种问题在数据挖掘中被称为分类。 还有一种问题,例如根据股市交易的历史数据估计下一个交易日的大盘指数,这里所研究的属性“大盘指数”是一个连续属性,它的取值是一个实数。那么这种问题在数据挖掘中被称为预测。 总之,当估计的属性值是离散值时,这就是分类;当估计的属性值是连续值时,这就是预测。 3.1.2 决策树的基本原理 1.构建决策树 通过一个实际的例子,来了解一些与决策树有关的基本概念。 表3-1是一个数据库表,记载着某银行的客户信用记录,属性包括“姓名”、“年龄”、“职业”、“月薪”、......、“信用等级”,每一行是一个客户样本,每一列是一个属性(字段)。这里把这个表记做数据集D。 银行需要解决的问题是,根据数据集D,建立一个信用等级分析模型,并根据这个模型,产生一系列规则。当银行在未来的某个时刻收到某个客户的贷款申请时,依据这些规则,可以根据该客户的年龄、职业、月薪等属性,来预测其信用等级,以确定是否提供贷款给该用户。这里的信用等级分析模型,就可以是一棵决策树。在这个案例中,研究的重点是“信用等级”这个属性。给定一个信用等级未知的客户,要根据他/她的其他属性来估计“信用等级”的值是“优”、“良”还是“差”,也就是说,要把这客户划分到信用等级为“优”、“良”、“差”这3个类别的某一类别中去。这里把“信用等级”这个属性称为“类标号属性”。数据集D中“信用等级”属性的全部取值就构成了类别集合:Class={“优”,
机械优化设计复习总结.doc
1. 优化设计问题的求解方法:解析解法和数值近似解法。解析解法是指优化对象用数学方程(数学模型)描述,用 数学 解析方法的求解方法。解析法的局限性:数学描述复杂,不便于或不可能用解析方法求解。数值解法:优 化对象无法用数学方程描述,只能通过大量的试验数据或拟合方法构造近似函数式,求其优化解;以数学原理 为指导,通过试验逐步改进得到优化解。数值解法可用于复杂函数的优化解,也可用于没有数学解析表达式的 优化问题。但不能把所有设计参数都完全考虑并表达,只是一个近似的数学描述。数值解法的基本思路:先确 定极小点所在的搜索区间,然后根据区间消去原理不断缩小此区间,从而获得极小点的数值近似解。 2. 优化的数学模型包含的三个基本要素:设计变量、约束条件(等式约束和不等式约束)、目标函数(一般使得目 标 函数达到极小值)。 3. 机械优化设计中,两类设计方法:优化准则法和数学规划法。 优化准则法:x ;+, = c k x k (为一对角矩阵) 数学规划法:X k+x =x k a k d k {a k \d k 分别为适当步长\某一搜索方向一一数学规划法的核心) 4. 机械优化设计问题一般是非线性规划问题,实质上是多元非线性函数的极小化问题。重点知识点:等式约束优 化问 题的极值问题和不等式约束优化问题的极值条件。 5. 对于二元以上的函数,方向导数为某一方向的偏导数。 函数沿某一方向的方向导数等于函数在该点处的梯度与这一方向单位向量的内积。梯度方向是函数值变化最快的方 向(最速上升方向),建议用单位向暈表示,而梯度的模是函数变化率的最大值。 6. 多元函数的泰勒展开。 7. 极值条件是指目标函数取得极小值吋极值点应满足的条件。某点取得极值,在此点函数的一阶导数为零,极值 点的 必要条件:极值点必在驻点处取得。用函数的二阶倒数来检验驻点是否为极值点。二阶倒数大于冬,取得 极小值。二阶导数等于零时,判断开始不为零的导数阶数如果是偶次,则为极值点,奇次则为拐点。二元函数 在某点取得极值的充分条件是在该点岀的海赛矩阵正定。极值点反映函数在某点附近的局部性质。 8. 凸集、凸函数、凸规划。凸规划问题的任何局部最优解也就是全局最优点。凸集是指一个点集或一个区域内, 连接 英中任意两点的线段上的所有元素都包含在该集合内。性质:凸集乘上某实数、两凸集相加、两凸集的交 集仍是凸集。凸函数:连接凸集定义域内任意两点的线段上,函数值总小于或等于用任意两点函数值做线性内 插所得的值。数学表达:/[^+(l-a )x 2]机器学习常见算法分类汇总
机器学习常见算法分类汇总 ?作者:王萌 ?星期三, 六月25, 2014 ?Big Data, 大数据, 应用, 热点, 计算 ?10条评论 机器学习无疑是当前数据分析领域的一个热点内容。很多人在平时的工作中都或多或少会用到机器学习的算法。这里IT经理网为您总结一下常见的机器学习算法,以供您在工作和学习中参考。 机器学习的算法很多。很多时候困惑人们都是,很多算法是一类算法,而有些算法又是从其他算法中延伸出来的。这里,我们从两个方面来给大家介绍,第一个方面是学习的方式,第二个方面是算法的类似性。 学习方式 根据数据类型的不同,对一个问题的建模有不同的方式。在机器学习或者人工智能领域,人们首先会考虑算法的学习方式。在机器学习领域,有几种主要的学习方式。将算法按照学习方式分类是一个不错的想法,这样可以让人们在建模和算法选择的时候考虑能根据输入数据来选择最合适的算法来获得最好的结果。 监督式学习:
在监督式学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,如对防垃圾邮件系统中“垃圾邮件”“非垃圾邮件”,对手写数字识别中的“1“,”2“,”3“,”4“等。在建立预测模型的时候,监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。监督式学习的常见应用场景如分类问题和回归问题。常见算法有逻辑回归(Logistic Regression)和反向传递神经网络(Back Propagation Neural Network) 非监督式学习: 在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。常见的应用场景包括关联规则的学习以及聚类等。常见算法包括Apriori算法以及k-Means算法。 半监督式学习:
机械优化设计复合形方法及源程序
机械优化设计——复合形方法及源程序 (一) 题目:用复合形法求约束优化问题 ()()()2 22 1645min -+-=x x x f ;0642 22 11≤--=x x g ;01013≤-=x g 的最优解。 基本思路:在可行域中构造一个具有K 个顶点的初始复合形。对该复合形各顶点的目标函数值进行比较,找到目标函数值最大的顶点(即最坏点),然后按一定的法则求出目标函数值有所下降的可行的新点,并用此点代替最坏点,构成新的复合形,复合形的形状每改变一次,就向最优点移动一步,直至逼近最优点。 (二) 复合形法的计算步骤 1)选择复合形的顶点数k ,一般取n k n 21≤≤+,在可行域内构成具有k 个顶点的初始 复合形。 2)计算复合形个顶点的目标函数值,比较其大小,找出最好点x L 、最坏点x H 、及此坏点 x G.. 3)计算除去最坏点x H 以外的(k-1)个顶点的中心x C 。判别x C 是否可行,若x C 为可行点, 则转步骤4);若x C 为非可行点,则重新确定设计变量的下限和上限值,即令 C L x b x a ==,,然后转步骤1),重新构造初始复合形。 4)按式()H C C R x x x x -+=α计算反射点x R,必要时改变反射系数α的值,直至反射成 功,即满足式()()()()H R R j x f x f m j x g
数据挖掘决策树算法Java实现
import java.util.HashMap; import java.util.HashSet; import java.util.LinkedHashSet; import java.util.Iterator; //调试过程中发现4个错误,感谢宇宙无敌的调试工具——print //1、selectAtrribute中的一个数组下标出错 2、两个字符串相等的判断 //3、输入的数据有一个错误 4、selectAtrribute中最后一个循环忘记了i++ //决策树的树结点类 class TreeNode { String element; //该值为数据的属性名称 String value; //上一个分裂属性在此结点的值 LinkedHashSet childs; //结点的子结点,以有顺序的链式哈希集存储 public TreeNode() { this.element = null; this.value = null; this.childs = null; } public TreeNode(String value) { this.element = null; this.value = value; this.childs = null; } public String getElement() { return this.element; } public void setElement(String e) { this.element = e; } public String getValue() { return this.value; } public void setValue(String v) { this.value = v; } public LinkedHashSet getChilds() { return this.childs;
机器学习复习总结
机器学习复习总结 选择目标函数的表示选择函数逼近算法最终设计选择训练经验第一个关键属性,训练经验能否为系统的决策提供直接或间接的反馈第二个重要属性,学习器在多大程度上控制样例序列第三个重要属性,训练样例的分布能多好地表示实例分布,通过样例来衡量最终系统的性能最终设计执行系统用学会的目标函数来解决给定的任务鉴定器以对弈的路线或历史记录作为输入,输出目标函数的一系列训练样例。泛化器以训练样例为输入,产生一个输出假设,作为它对目标函数的估计。实验生成器以当前的假设作为输入,输出一个新的问题,供执行系统去探索。第二章一致,满足,覆盖的定义:一致:一个假设h与训练样例集合D一致,当且仅当对D中每一个样例都有h(x)=c(x),即Consistent(h,D)?("?D)h(x)=c(x)一个样例x在h (x)=1时称为满足假设h,无论x是目标概念的正例还是反例。当一假设能正确划分一个正例时,称该假设覆盖该正例。变型空间(version space):与训练样例一致的所有假设组成的集合,表示了目标概念的所有合理的变型,VS H,D={h?H|Consistent(h,D)}第三章决策树适用问题的特征:实例由“属性-值”对(pair)表示目标函数具有离散的输出值可能需要析取的描述训练数据可以包含错误训练数据可以包含缺少属性值的实例ID3算法特点:n 搜索完整的假设空间(也就是说,决
策树空间能够表示定义在离散实例上的任何离散值函数)n 从根向下推断决策树,为每个要加入树的新决策分支贪婪地选择最佳的属性。n 归纳偏置,优先选择较小的树观察ID3的搜索空间和搜索策略,认识到这个算法的优势和不足假设空间包含所有的决策树,它是关于现有属性的有限离散值函数的一个完整空间维护单一的当前假设(不同于第二章的变型空间候选消除算法)不进行回溯,可能收敛到局部最优每一步使用所有的训练样例,不同于基于单独的训练样例递增作出决定,容错性增强ID3和候选消除算法的比较ID3的搜索范围是一个完整的假设空间,但不彻底地搜索这个空间候选消除算法的搜索范围是不完整的假设空间,但彻底地搜索这个空间ID3的归纳偏置完全是搜索策略排序假设的结果,来自搜索策略候选消除算法完全是假设表示的表达能力的结果,来自对搜索空间的定义过度拟合:对于一个假设,当存在其他的假设对训练样例的拟合比它差,但事实上在实例的整个分布上表现得却更好时,我们说这个假设过度拟合训练样例定义:给定一个假设空间H,一个假设h?H,如果存在其他的假设h’?H,使得在训练样例上h的错误率比h’小,但在整个实例分布上h’的错误率比h小,那么就说假设h过度拟合训练数据导致过度拟合的原因 1、一种可能原因是训练样例含有随机错误或噪声 2、特别是当少量的样例被关联到叶子节点时,很可能出现巧合的规律性,使得一些属性恰巧可以很好地分割样例,但却与实
R语言与机器学习(2)决策树算法
算法二:决策树算法 决策树定义 首先,我们来谈谈什么是决策树。我们还是以鸢尾花为例子来说明这个问题。 观察上图,我们判决鸢尾花的思考过程可以这么来描述:花瓣的长度小于2.4cm 的是setosa(图中绿色的分类),长度大于1cm的呢?我们通过宽度来判别,宽度小于1.8cm的是versicolor(图中红色的分类),其余的就是virginica(图中黑色的分类)
我们用图形来形象的展示我们的思考过程便得到了这么一棵决策树: 这种从数据产生决策树的机器学习技术叫做决策树学习, 通俗点说就是决策树,说白了,这是一种依托于分类、训练上的预测树,根据已知预测、归类未来。 前面我们介绍的k-近邻算法也可以完成很多分类任务,但是他的缺点就是含义不清,说不清数据的内在逻辑,而决策树则很好地解决了这个问题,他十分好理解。从存储的角度来说,决策树解放了存储训练集的空间,毕竟与一棵树的存储空间相比,训练集的存储需求空间太大了。 决策树的构建 一、KD3的想法与实现 下面我们就要来解决一个很重要的问题:如何构造一棵决策树?这涉及十分有趣的细节。 先说说构造的基本步骤,一般来说,决策树的构造主要由两个阶段组成:第一阶段,生成树阶段。选取部分受训数据建立决策树,决策树是按广度优先建立直到每个叶节点包括相同的类标记为止。第二阶段,决策树修剪阶段。用剩余数据检验决策树,如果所建立的决策树不能正确回答所研究的问题,我们要对决策树进行修剪直到建立一棵正确的决策树。这样在决策树每个内部节点处进行属性值的比较,在叶节点得到结论。从根节点到叶节点的一条路径就对应着一条规则,整棵决策树就对应着一组表达式规则。
机械优化设计方法基本理论
机械优化设计方法基本理论 一、机械优化概述 机械优化设计是适应生产现代化要求发展起来的一门科学,它包括机械优化设计、机械零部件优化设计、机械结构参数和形状的优化设计等诸多内容。该领域的研究和应用进展非常迅速,并且取得了可观的经济效益,在科技发达国家已将优化设计列为科技人员的基本职业训练项目。随着科技的发展,现代化机械优化设计方法主要以数学规划为核心,以计算机为工具,向着多变量、多目标、高效率、高精度方向发展。]1[ 优化设计方法的分类优化设计的类别很多,从不同的角度出发,可以做出各种不同的分类。按目标函数的多少,可分为单目标优化设计方法和多目标优化设计方法按维数,可分为一维优化设计方法和多维优化设计方法按约束情况,可分为无约束优化设计方法和约束优化设计方法按寻优途径,可分为数值法、解析法、图解法、实验法和情况研究法按优化设计问题能否用数学模型表达,可分为能用数学模型表达的优化设计问题其寻优途径为数学方法,如数学规划法、最优控制法等 1.1 设计变量 设计变量是指在设计过程中进行选择并最终必须确定的各项独立参数,在优化过程中,这些参数就是自变量,一旦设计变量全部确定,设计方案也就完全确定了。设计变量的数目确定优化设计的维数,设计变量数目越多,设计空间的维数越大。优化设计工作越复杂,同时效益也越显著,因此在选择设计变量时。必须兼顾优化效果的显著性和优化过程的复杂性。 1.2 约束条件 约束条件是设计变量间或设计变量本身应该遵循的限制条件,按表达方式可分为等式约束和不等式约束。按性质分为性能约束和边界约束,按作用可分为起作用约束和不起作用约束。针对优化设计设计数学模型要素的不同情况,可将优化设计方法分类如下。约束条件的形式有显约束和隐约束两种,前者是对某个或某组设计变量的直接限制,后者则是对某个或某组变量的间接限制。等式约束对设计变量的约束严格,起着降低设计变量自由度的作用。优化设计的过程就是在设计变量的允许范围内,找出一组优化的设计变量值,使得目标函数达到最优值。
数据挖掘——决策树分类算法 (1)
决策树分类算法 学号:20120311139 学生所在学院:软件工程学院学生姓名:葛强强 任课教师:汤亮 教师所在学院:软件工程学院2015年11月
12软件1班 决策树分类算法 葛强强 12软件1班 摘要:决策树方法是数据挖掘中一种重要的分类方法,决策树是一个类似流程图的树型结构,其中树的每个内部结点代表对一个属性的测试,其分支代表测试的结果,而树的每个 叶结点代表一个类别。通过决策树模型对一条记录进行分类,就是通过按照模型中属 性测试结果从根到叶找到一条路径,最后叶节点的属性值就是该记录的分类结果。 关键词:数据挖掘,分类,决策树 近年来,随着数据库和数据仓库技术的广泛应用以及计算机技术的快速发展,人们利用信息技术搜集数据的能力大幅度提高,大量数据库被用于商业管理、政府办公、科学研究和工程开发等。面对海量的存储数据,如何从中有效地发现有价值的信息或知识,是一项非常艰巨的任务。数据挖掘就是为了应对这种要求而产生并迅速发展起来的。数据挖掘就是从大型数据库的数据中提取人们感兴趣的知识,这些知识是隐含的、事先未知的潜在有用的信息,提取的知识表示为概念、规则、规律、模式等形式。 分类在数据挖掘中是一项非常重要的任务。 分类的目的是学会一个分类函数或分类模型,把数据库中的数据项映射到给定类别中的某个类别。分类可用于预测,预测的目的是从历史数据记录中自动推导出对给定数据的趋势描述,从而能对未来数据进行预测。分类算法最知名的是决策树方法,决策树是用于分类的一种树结构。 1决策树介绍 决策树(decisiontree)技术是用于分类和预测 的主要技术,决策树学习是一种典型的以实例为基础的归纳学习算法,它着眼于从一组无次序、无规则的事例中推理出决策树表示形式的分类规则。它采用自顶向下的递归方式,在决策树的内部节点进行属性的比较,并根据不同属性判断从该节点向下的分支,在决策树的叶节点得到结论。所以从根到叶节点就对应着一条合取规则,整棵树就对应着一组析取表达式规则。 把决策树当成一个布尔函数。函数的输入为物体或情况的一切属性(property),输出为”是”或“否”的决策值。在决策树中,每个树枝节点对应着一个有关某项属性的测试,每个树叶节点对应着一个布尔函数值,树中的每个分支,代表测试属性其中一个可能的值。 最为典型的决策树学习系统是ID3,它起源于概念学习系统CLS,最后又演化为能处理连续属性的C4.5(C5.0)等。它是一种指导的学习方法,该方法先根据训练子集形成决策树。如果该树不能对所有给出的训练子集正确分类,那么选择一些其它的训练子集加入到原来的子集中,重复该过程一直到时形成正确的决策集。当经过一批训练实例集的训练产生一棵决策树,决策树可以根据属性的取值对一个未知实例集进行分类。使用决策树对实例进行分类的时候,由树根开始对该对象的属性逐渐测试其值,并且顺着分支向下走,直至到达某个叶结点,此叶结点代表的类即为该对象所处的类。 决策树是应用非常广泛的分类方法,目前有多种决策树方法,如ID3,C4.5,PUBLIC,
机械优化设计复习总结
10. 1. 优化设计问题的求解方法:解析解法和数值近似解法。解析解法是指优化对象用数学方程(数学模型)描述,用数学解析 方法的求解方法。解析法的局限性:数学描述复杂,不便于或不可能用解析方法求解。数值解法:优化对象无法用数学 方程描述,只能通过大量的试验数据或拟合方法构造近似函数式,求其优化解;以数学原理为指导,通过试验逐步改进 得到优化解。数值解法可用于复 杂函数的优化解,也可用于没有数学解析表达式的优化问题。但不能把所有设计参数都 完全考虑并表达,只是一个近似的数学描述。数值解法的基本思路:先确定极小点所在的搜索区间,然后根据区间消去 原理不断缩小此区间,从而获得极小点的数值近似解。 2. 优化的数学模型包含的三个基本要素:设计变量、约束条件(等式约束和不等式约束)、目标函数(一般使得目标函 数达到极小值)。 3. 机械优化设计中, 两类设计方法:优化准则法和数学规划法。 k 1 k k 优化准则法:X c X (为一对角矩阵) k 1 数学规划法:X k 1 k k k X k d ( k d 分别为适当步长某一搜索方向一一数学规划法的核心) 4. 机械优化设计问题一般是非线性规划问题, 实质上是多元非线性函数的极小化问题。 的极值问题和不等式约束优化问题的极值条件。 5. 对于二元以上的函数,方向导数为某一方向的偏导数。 重点知识点:等式约束优化问题 f | X o *kCOS i d i 1 X i 函数沿某一方向的方向导数等于函数在该点处的梯度与这一方向单位向量的内积。 速上升方向),建议用 单位向量 表示,而梯度的模是函数变化率的最大值。 6. 梯度方向是函数值变化最快的方向 (最 7. 8. 9. 多元函数的泰勒展开。 f X f x 0 T f X o -X T G X o 2 f X o f X i f X 2 X , X 2 1 2 X1 X 2 2f 2f 为X 2 2 f X 1 X 2 X 1 2 f X 2 -- 2 X 2 海赛矩阵: x o 2 f ~2 X 1 2 f 2 f X l X 2 X 1 X 2 2 f 2 X 2 (对称方 阵) 极值条件是指目标函数取得极小值时极值点应满足的条件。 某点取得极值, 要条件:极值点必在驻点处取得。用函数的二阶倒数来检验驻点是否为极值点。 导数等于零时,判断开始不为零的导数阶数如果是偶次,则为极值点, 在此点函数的一阶导数为零, 极值点的必 二阶倒数大于零,取得极小值 。二阶 奇次 则为拐点。二元函数在某点取得极值的充 分条件是在该点岀的海赛矩阵正定。 极值点反映函数在某点附近的局部性质 凸集、凸函数、凸规划。 凸规划问题的任何局部最优解也就是全局最优点 中任意两点 的线段上的所有元素都包含在该集合内。 凸函数:连接凸集定义域内任意两点的线段上, 。凸集是指一个点集或一个区域内,连接其 性质: 凸集乘上某实数、两凸集相加、两凸集的交集仍是凸集。 函数值总小于或等于用任意两点函数值做线性内插所得的值。 数学表 达:f ax, 1 a x 2 f X i f X 2 0 1,若两式均去掉等号,则 f X 称作严格凸函数。凸 函数同样满足倍乘, 加法和倍乘加仍为凸函数的三条基本性质。 优化问题。 等式约束优化问题的极值条件。两种处理方法:消元法和拉格朗日乘子法。也分别称作降维法和升维法。消元法 等式约束条件的一个变量表示成另一个变量的函数。减少了变量的个数。拉格朗日乘子法是通过增加变量 约束优化问题变成无约束优化问题,增加了变量的个数。 不等式约束优化问题的极值条件。不等式约束的多元函数极值的必要条件为库恩塔克条件。库恩塔克条件: 凸规划针对目标函数和约束条件均为凸函数是的约束 :将 将等式
数据挖掘决策树算法概述
决策树是分类应用中采用最广泛的模型之一。与神经网络和贝叶斯方法相比,决策树无须花费大量的时间和进行上千次的迭代来训练模型,适用于大规模数据集,除了训练数据中的信息外不再需要其他额外信息,表现了很好的分类精确度。其核心问题是测试属性选择的策略,以及对决策树进行剪枝。连续属性离散化和对高维大规模数据降维,也是扩展决策树算法应用范围的关键技术。本文以决策树为研究对象,主要研究内容有:首先介绍了数据挖掘的历史、现状、理论和过程,然后详细介绍了三种决策树算法,包括其概念、形式模型和优略性,并通过实例对其进行了分析研究 目录 一、引言 (1) 二、数据挖掘 (2) (一)概念 (2) (二)数据挖掘的起源 (2) (三)数据挖掘的对象 (3) (四)数据挖掘的任务 (3) (五)数据挖掘的过程 (3) (六)数据挖掘的常用方法 (3) (七)数据挖掘的应用 (5) 三、决策树算法介绍 (5) (一)归纳学习 (5) (二)分类算法概述 (5) (三)决策树学习算法 (6) 1、决策树描述 (7) 2、决策树的类型 (8) 3、递归方式 (8) 4、决策树的构造算法 (8) 5、决策树的简化方法 (9) 6、决策树算法的讨论 (10) 四、ID3、C4.5和CART算法介绍 (10) (一)ID3学习算法 (11) 1、基本原理 (11) 2、ID3算法的形式化模型 (13) (二)C4.5算法 (14) (三)CART算法 (17) 1、CART算法理论 (17) 2、CART树的分支过程 (17) (四)算法比较 (19) 五、结论 (24) 参考文献...................................................................................... 错误!未定义书签。 致谢.............................................................................................. 错误!未定义书签。
机器学习算法汇总:人工神经网络、深度学习及其它
学习方式 根据数据类型的不同,对一个问题的建模有不同的方式。在机器学习或者人工智能领域,人们首先会考虑算法的学习方式。在机器学习领域,有几种主要的学习方式。将算法按照学习方式分类是一个不错的想法,这样可以让人们在建模和算法选择的时候考虑能根据输入数据来选择最合适的算法来获得最好的结果。 监督式学习: 在监督式学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,如对防垃圾邮件系统中“垃圾邮件”“非垃圾邮件”,对手写数字识别中的“1“,”2“,”3“,”4“等。在建立预测模型的时候,监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。监督式学习的常见应用场景如分类问题和回归问题。常见算法有逻辑回归(Logistic Regression)和反向传递神经网络(Back Propagation Neural Network) 非监督式学习:
在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。常见的应用场景包括关联规则的学习以及聚类等。常见算法包括Apriori算法以及k-Means算法。 半监督式学习: 在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是模型首先需要学习数据的内在结构以便合理的组织数据来进行预测。应用场景包括分类和回归,算法包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。如图论推理算法(Graph Inference)或者拉普拉斯支持向量机(Laplacian SVM.)等。 强化学习:
机器学习 决策树(ID3)算法及案例
机器学习--决策树(ID3)算法及案例 1基本原理 决策树是一个预测模型。它代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,每个分支路径代表某个可能的属性值,每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。一般情况下,决策树由决策结点、分支路径和叶结点组成。在选择哪个属性作为结点的时候,采用信息论原理,计算信息增益,获得最大信息增益的属性就是最好的选择。信息增益是指原有数据集的熵减去按某个属性分类后数据集的熵所得的差值。然后采用递归的原则处理数据集,并得到了我们需要的决策树。 2算法流程 检测数据集中的每个子项是否属于同一分类: If是,则返回类别标签; Else 计算信息增益,寻找划分数据集的最好特 征 划分数据数据集 创建分支节点(叶结点或决策结点)
for每个划分的子集 递归调用,并增加返回结果 到分支节点中 return分支结点 算法的基本思想可以概括为: 1)树以代表训练样本的根结点开始。 2)如果样本都在同一个类.则该结点成为树叶,并记录该类。 3)否则,算法选择最有分类能力的属性作为决策树的当前结点. 4)根据当前决策结点属性取值的不同,将训练样本根据该属性的值分为若干子集,每个取值形成一个分枝,有几个取值形成几个分枝。匀针对上一步得到的一个子集,重复进行先前步骤,递归形成每个划分样本上的决策树。一旦一个属性只出现在一个结点上,就不必在该结点的任何后代考虑它,直接标记类别。 5)递归划分步骤仅当下列条件之一成立时停止: ①给定结点的所有样本属于同一类。 ②没有剩余属性可以用来进一步划分样本.在这种情况下.使用多数表决,将给定的结点转换成树叶,并以样本中元组个数最多的类别作为类别标记,同时也可以存放该结点样本的类别分布[这个主要可以用来剪枝]。 ③如果某一分枝tc,没有满足该分支中已有分类的样本,则以样本的多数类生成叶子节点。 算法中2)步所指的最优分类能力的属性。这个属性的选择是本算法种的关键点,分裂属性的选择直接关系到此算法的优劣。 一般来说可以用比较信息增益和信息增益率的方式来进行。 其中信息增益的概念又会牵扯出熵的概念。熵的概念是香农在研究信息量方面的提出的。它的计算公式是:
机械优化设计课程教学大纲
《机械优化设计》课程教学大纲 一.课程基本信息 开课单位:机械工程学院 英文名称:Mechanical Optimize Design 学时:总计48学时,其中理论授课36学时,实验(含上机)12学时 学分:3.0学分 面向对象:机械设计制造及其自动化,机械电子工程等本科专业 先修课程:高等数学,线性代数,计算机程序设计,工程力学,机械原理,机械设计 教材:《机械优化设计》,孙靖民主编,机械工业出版社,2012年第 5版 主要教学参考书目或资料: 1.《机械优化设计》,陈立周主编,上海科技出版社,1982年 2.《机械优化设计基础》,高健主编,机械工业出版社,2000年 3.其它教学参考数目在课程教学工作实施前另行确定 二.教学目的和任务 优化设计是60年代以来发展起来的一门新学科,它是将最优化方法和计算机技术结合、应用于设计领域而产生的一种现代设计方法。利用优化设计方法可以从众多的设计方案中寻找最佳方案,加快设计过程,缩短设计周期,从而大大提高设计效率和质量。优化设计方法目前已经在机械工程、结构工程、控制工程、交通工程和经济管理等领域得到广泛应用。在机械设计中采用最优化方法,可以加速产品的研发过程,提高产品质量,降低成本,从而达到增加经济效益的目的。学生通过学习《机械优化设计》课程,可以掌握优化设计的基本原理和方法,熟悉建立最优化问题数学模型的基本过程,初步具备对工程中的优化设计问题进行建模、编程和计算的应用能力,为以后从事有关的工程技术工作和科学研究工作打下一定的基础。 三.教学目标与要求 本门课程通过授课、计算机编程等教学环节,使学生了解优化设计的基本思想,优化设计在机械中的作用及其发展概况。初步掌握建立数学模型的方法,掌握优化方法和使用MATLAB优化工具箱能力。并具备一定的将机械工程问题转化为最优化问题并求解的应用能力 四.教学内容、学时分配及其基本要求 第一章优化设计概述(2学时) (一)教学内容 1、课程的性质、优化的含义;优化方法的发展与应用;机械优化设计的内容及目的;机械优化设计的一般过程 2、机械优化设计的基本概念和基本术语;优化设计的数学模型;优化问题的几何描述;优化设计的基本方法 (二)基本要求
生物数据挖掘-决策树实验报告
实验四决策树 一、实验目的 1.了解典型决策树算法 2.熟悉决策树算法的思路与步骤 3.掌握运用Matlab对数据集做决策树分析的方法 二、实验内容 1.运用Matlab对数据集做决策树分析 三、实验步骤 1.写出对决策树算法的理解 决策树方法是数据挖掘的重要方法之一,它是利用树形结构的特性来对数据进行分类的一种方法。决策树学习从一组无规则、无次序的事例中推理出有用的分类规则,是一种实例为基础的归纳学习算法。决策树首先利用训练数据集合生成一个测试函数,根据不同的权值建立树的分支,即叶子结点,在每个叶子节点下又建立层次结点和分支,如此重利生成决策树,然后对决策树进行剪树处理,最后把决策树转换成规则。决策树的最大优点是直观,以树状图的形式表现预测结果,而且这个结果可以进行解释。决策树主要用于聚类和分类方面的应用。 决策树是一树状结构,它的每一个叶子节点对应着一个分类,非叶子节点对应着在某个属性上的划分,根据样本在该属性上的不同取值将其划分成若干个子集。构造决策树的核心问题是在每一步如何选择适当的属性对样本进行拆分。对一个分类问题,从已知类标记的训练样本中学习并构造出决策树是一个自上而下分而治之的过程。 2.启动Matlab,运用Matlab对数据集进行决策树分析,写出算法名称、数据集名称、关键代码,记录实验过程,实验结果,并分析实验结果 (1)算法名称: ID3算法 ID3算法是最经典的决策树分类算法。ID3算法基于信息熵来选择最佳的测试属性,它选择当前样本集中具有最大信息增益值的属性作为测试属性;样本集的划分则依据测试属性的取值进行,测试属性有多少个不同的取值就将样本集划分为多少个子样本集,同时决策树上相应于该样本集的节点长出新的叶子节点。ID3算法根据信息论的理论,采用划分后样本集的不确定性作为衡量划分好坏的标准,用信息增益值度量不确定性:信息增益值越大,不确定性越小。因此,ID3算法在每个非叶节点选择信息增益最大的属性作为测试属性,这样可以得到当前情况下最纯的划分,从而得到较小的决策树。 ID3算法的具体流程如下: 1)对当前样本集合,计算所有属性的信息增益; 2)选择信息增益最大的属性作为测试属性,把测试属性取值相同的样本划为同一个子样本集; 3)若子样本集的类别属性只含有单个属性,则分支为叶子节点,判断其属性值并标上相应的符号,然后返回调用处;否则对子样本集递归调用本算法。 (2)数据集名称:鸢尾花卉Iris数据集 选择了部分数据集来区分Iris Setosa(山鸢尾)及Iris Versicolour(杂色鸢尾)两个种类。
几种机器学习算法原理入门教程
几种机器学习算法原理入门教程 一、机器学习的过程 机器学习的过程:从本质上来说,就是通过一堆的训练数据找到一个与理想函数(f)相接近的函数。 在理想情况下,对于任何适合使用机器学习的问题,在理论上都是会存在一个最优的函数让每个参数都有一个最合适的权重值,但在现实应用中不一定能这么准确得找到这个函数。所以,我们要去找与这个理想函数相接近的函数。只要是能够满足我们的使用的函数,我们就认为是一个好的函数。 这个训练数据的过程通常也被解释为: 在一堆的假设函数(Hypothesis set)中,它是包含了各种各样的假设,其中包括好的和坏的假设。 我们需要做的就是:从这一堆假设函数中挑选出它认为最好的假设函数(g)——这个假设函数是与理想函数(f)最接近的。
机器学习这个过程就像是:在数学上,我们知道了有一个方程和一些点的坐标,用这些点来求这个方程的未知项从而得出完整的方程。 但在机器学习上,我们往往很难解出来这个完整的方程是什么。所以,我们只能通过各种手段求最接近理想情况下的未知项取值,使得这个结果最接近原本的方程。 二、什么问题适合用机器学习解决 机器学习不是万能的,并不能解决所有的问题。 通过以上机器学习的过程可以看出来,实质上,机器学习是:通过已知经验找到规律来进行预测。 银行想知道应该发放多少贷款给某个客户时,可以根据过往成功放贷的数据找出每个贷款区间的人群特点、自身的房车资产状况等,再看看这个客户的特点符合哪个区间,以此去确定应该发放多少贷款,这就是适合用机器学习去解决的问题。
对于适合用机器学习解决的问题,台大的林轩田教授为我们总结了三个要素: 1.有规律可以学习 2.编程很难做到 3.有能够学习到规律的数据 只要满足这三个条件的问题,我们都可以挑选合适的算法去解决。 基于以上的条件,通常我们可以用机器学习解决三类问题: 1.预测(回归):根据已知数据和模型,预测不同客户应该发放的贷款 额度是多少 2.判别(分类):与预测有点类似,也是根据模型判别这个客户属于过 往哪一类客户的概率有多大 3.寻找关键因素:客户的属性非常多,通过模型我们可以找出对放贷影 响最大的因素是什么 三、几种常见的模型和算法
小晨精品06-机器学习_(决策树分类算法与应用)(优秀)
机器学习算法day04_决策树分类算法及应用课程大纲 课程目标: 1、理解决策树算法的核心思想 2、理解决策树算法的代码实现 3、掌握决策树算法的应用步骤:数据处理、建模、运算和结果判定
1. 决策树分类算法原理 1.1 概述 决策树(decision tree)——是一种被广泛使用的分类算法。 相比贝叶斯算法,决策树的优势在于构造过程不需要任何领域知识或参数设置 在实际应用中,对于探测式的知识发现,决策树更加适用 1.2 算法思想 通俗来说,决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话: 女儿:多大年纪了? 母亲:26。 女儿:长的帅不帅? 母亲:挺帅的。 女儿:收入高不? 母亲:不算很高,中等情况。 女儿:是公务员不? 母亲:是,在税务局上班呢。 女儿:那好,我去见见。 这个女孩的决策过程就是典型的分类树决策。 实质:通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见 假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么这个可以用下图表示女孩的决策逻辑
上图完整表达了这个女孩决定是否见一个约会对象的策略,其中: ◆绿色节点表示判断条件 ◆橙色节点表示决策结果 ◆箭头表示在一个判断条件在不同情况下的决策路径 图中红色箭头表示了上面例子中女孩的决策过程。 这幅图基本可以算是一颗决策树,说它“基本可以算”是因为图中的判定条件没有量化,如收入高中低等等,还不能算是严格意义上的决策树,如果将所有条件量化,则就变成真正的决策树了。 决策树分类算法的关键就是根据“先验数据”构造一棵最佳的决策树,用以预测未知数据的类别 决策树:是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。