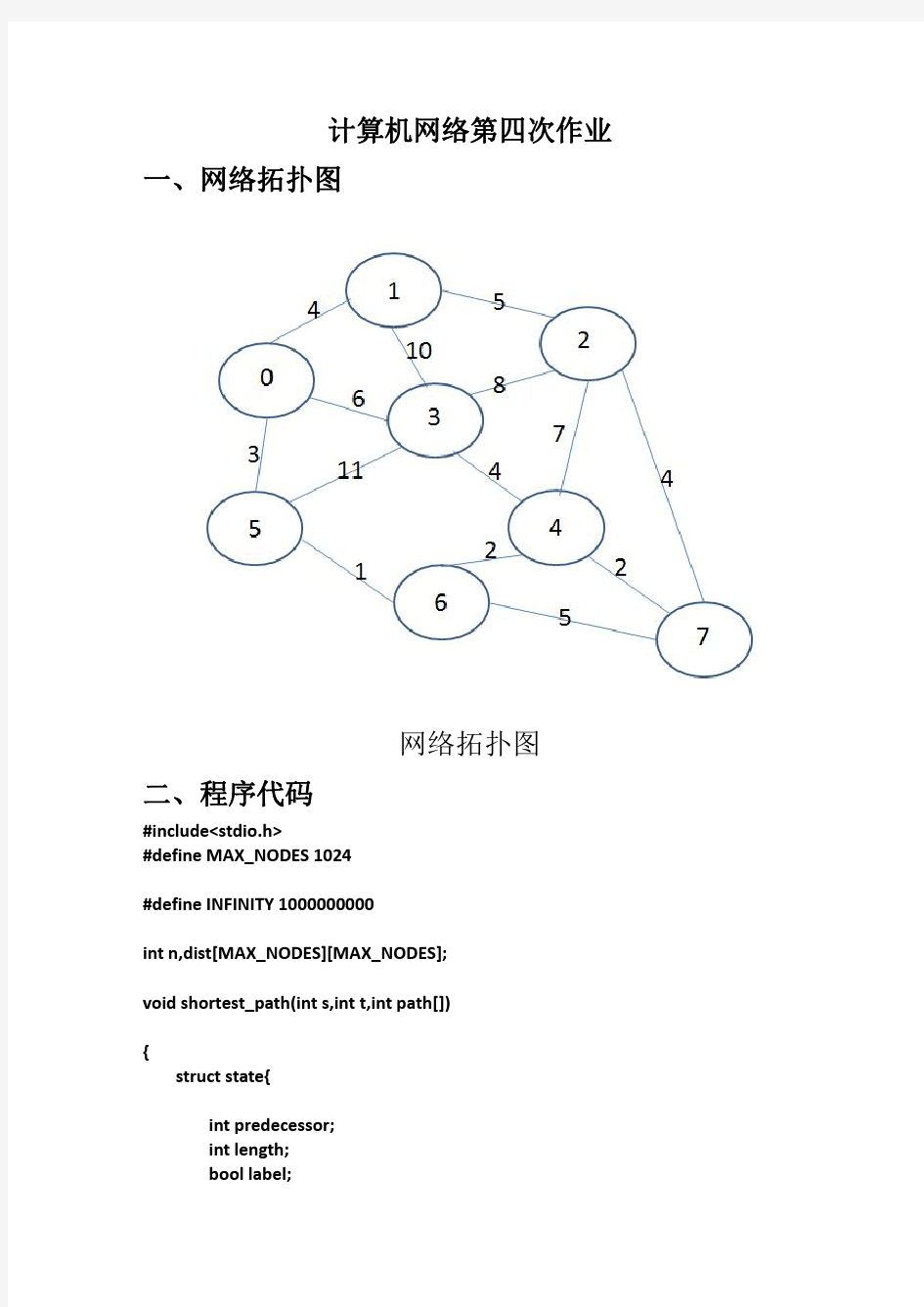
最短路径算法C语言实现

数据结构与算法C语言版期末复习题
《数据结构与算法》期末复习题 一、选择题。 1.在数据结构中,从逻辑上可以把数据结构分为 C 。 A.动态结构和静态结构B.紧凑结构和非紧凑结构 C.线性结构和非线性结构D.内部结构和外部结构 2.数据结构在计算机内存中的表示是指 A 。 A.数据的存储结构B.数据结构C.数据的逻辑结构D.数据元素之间的关系 3.在数据结构中,与所使用的计算机无关的是数据的 A 结构。 A.逻辑B.存储C.逻辑和存储D.物理 4.在存储数据时,通常不仅要存储各数据元素的值,而且还要存储 C 。 A.数据的处理方法B.数据元素的类型 C.数据元素之间的关系D.数据的存储方法 5.在决定选取何种存储结构时,一般不考虑 A 。 A.各结点的值如何B.结点个数的多少 C.对数据有哪些运算D.所用的编程语言实现这种结构是否方便。 6.以下说法正确的是 D 。 A.数据项是数据的基本单位 B.数据元素是数据的最小单位 C.数据结构是带结构的数据项的集合 D.一些表面上很不相同的数据可以有相同的逻辑结构 7.算法分析的目的是 C ,算法分析的两个主要方面是 A 。 (1)A.找出数据结构的合理性B.研究算法中的输入和输出的关系C.分析算法的效率以求改进C.分析算法的易读性和文档性 (2)A.空间复杂度和时间复杂度B.正确性和简明性 C.可读性和文档性D.数据复杂性和程序复杂性 8.下面程序段的时间复杂度是O(n2) 。 s =0; for( I =0; i RC4 加密算法 C 语言实现 代码文件名 RC4.cpp Encrypt.h (代码详见后文) 备注:将以上两个文件放在相同的路径(建议不要放在中文路径 下)编译执行!编译环境 Microsoft Visual C++ 6.0 C-Free 5.0 代码解释 RC4 加密算法是大名鼎鼎的RSA 三人组中的头号人物Ron Rivest 在1987 年设计的密钥长度可变的流加密算法簇。之所以称其为簇,是由于其核心部分的S-box 长度可为任意,但一般为256字节。该算法的速度可以达到DES 加密的10倍左右。 RC4 算法的原理很简单,包括初始化算法和伪随机子密码生成算法两大部分。假设S-box 长度和密钥长度均为为n。先来看看算法的初始化部分(用类C伪代码表示): for (i=0; i } 得到的子密码sub_k用以和明文进行xor运算,得到密文,解密过程也完全相同。 RC4加密算法在C++中的实现: RC4函数(加密/解密):其实RC4只有加密,将密文再加密一次,就是解密了。 GetKey函数:随机字符串产生器。 ByteToHex函数:把字节码转为十六进制码,一个字节两个十六进制。十六进制字符串非常适合在HTTP中传输。 HexToByte函数:把十六进制字符串,转为字节码。。 Encrypt函数:把字符串经RC4加密后,再把密文转为十六进制字符串返回,可直接用于传输。 Decrypt函数:直接密码十六进制字符串密文,再解密,返回字符串明文。 源代码 以下为Encrypt.h文件代码 #ifndef _ENCRYPT_RC4_ #defi ne _ENCRYPT_RC4_ #in clude C语言几种常见的排序方法 2009-04-2219:55 插入排序是这样实现的: 首先新建一个空列表,用于保存已排序的有序数列(我们称之为"有序列表")。 从原数列中取出一个数,将其插入"有序列表"中,使其仍旧保持有序状态。 重复2号步骤,直至原数列为空。 插入排序的平均时间复杂度为平方级的,效率不高,但是容易实现。它借助了"逐步扩大成果"的思想,使有序列表的长度逐渐增加,直至其长度等于原列表的长度。 冒泡排序 冒泡排序是这样实现的: 首先将所有待排序的数字放入工作列表中。 从列表的第一个数字到倒数第二个数字,逐个检查:若某一位上的数字大于他的下一位,则将它与它的下一位交换。 重复2号步骤,直至再也不能交换。 冒泡排序的平均时间复杂度与插入排序相同,也是平方级的,但也是非常容易实现的算法。 选择排序 选择排序是这样实现的: 设数组内存放了n个待排数字,数组下标从1开始,到n结束。 i=1 从数组的第i个元素开始到第n个元素,寻找最小的元素。 将上一步找到的最小元素和第i位元素交换。 如果i=n-1算法结束,否则回到第3步 选择排序的平均时间复杂度也是O(n²)的。 快速排序 现在开始,我们要接触高效排序算法了。实践证明,快速排序是所有排序算法中最高效的一种。它采用了分治的思想:先保证列表的前半部分都小于后半部分,然后分别对前半部分和后半部分排序,这样整个列表就有序了。这是一种先进的思想,也是它高效的原因。因为在排序算法中,算法的高效与否与列表中数字间的比较次数有直接的关系,而"保证列表的前半部分都小于后半部分"就使得前半部分的任何一个数从此以后都不再跟后半部分的数进行比较了,大大减少了数字间不必要的比较。但查找数据得另当别论了。 堆排序 堆排序与前面的算法都不同,它是这样的: 首先新建一个空列表,作用与插入排序中的"有序列表"相同。 找到数列中最大的数字,将其加在"有序列表"的末尾,并将其从原数列中删除。 重复2号步骤,直至原数列为空。 堆排序的平均时间复杂度为nlogn,效率高(因为有堆这种数据结构以及它奇妙的特征,使得"找到数列中最大的数字"这样的操作只需要O(1)的时间复杂度,维护需要logn的时间复杂度),但是实现相对复杂(可以说是这里7种算法中比较难实现的)。 一、基本算法 1.交换(两量交换借助第三者) 例1、任意读入两个整数,将二者的值交换后输出。 main() {int a,b,t; scanf("%d%d",&a,&b); printf("%d,%d\n",a,b); t=a; a=b; b=t; printf("%d,%d\n",a,b);} 【解析】程序中加粗部分为算法的核心,如同交换两个杯子里的饮料,必须借助第三个空杯子。 假设输入的值分别为3、7,则第一行输出为3,7;第二行输出为7,3。 其中t为中间变量,起到“空杯子”的作用。 注意:三句赋值语句赋值号左右的各量之间的关系! 【应用】 例2、任意读入三个整数,然后按从小到大的顺序输出。 main() {int a,b,c,t; scanf("%d%d%d",&a,&b,&c); /*以下两个if语句使得a中存放的数最小*/ if(a>b){ t=a; a=b; b=t; } if(a>c){ t=a; a=c; c=t; } /*以下if语句使得b中存放的数次小*/ if(b>c) { t=b; b=c; c=t; } printf("%d,%d,%d\n",a,b,c);} 2.累加 累加算法的要领是形如“s=s+A”的累加式,此式必须出现在循环中才能被反复执行,从而实现累加功能。“A”通常是有规律变化的表达式,s在进入循环前必须获得合适的初值,通常为0。例1、求1+2+3+……+100的和。 main() {int i,s; s=0; i=1; while(i<=100) {s=s+i; /*累加式*/ i=i+1; /*特殊的累加式*/ } printf("1+2+3+...+100=%d\n",s);} 【解析】程序中加粗部分为累加式的典型形式,赋值号左右都出现的变量称为累加器,其中“i = i + 1”为特殊的累加式,每次累加的值为1,这样的累加器又称为计数器。 C语言9种常用排序法 1.冒泡排序 2.选择排序 3.插入排序 4.快速排序 5.希尔排序 6.归并排序 7.堆排序 8.带哨兵的直接插入排序 9.基数排序 例子:乱序输入n个数,输出从小到大排序后的结果1.冒泡排序 #include for(i=0;i int i, j, n, a[100], t, temp; while(scanf("%d",&n)!=EOF) { for(i=0;i 2008-02-18 18:48 【程序1】 题目:有1、2、3、4个数字,能组成多少个互不相同且无重复数字的三位数?都是多少? 1.程序分析:可填在百位、十位、个位的数字都是1、2、3、4。组成所有的排列后再去 掉不满足条件的排列。 2.程序源代码: main() { int i,j,k; printf("\n"); for(i=1;i<5;i++) /*以下为三重循环*/ for(j=1;j<5;j++) for (k=1;k<5;k++) { if (i!=k&&i!=j&&j!=k) /*确保i、j、k三位互不相同*/ printf("%d,%d,%d\n",i,j,k); } } ============================================================== 【程序2】 题目:企业发放的奖金根据利润提成。利润(I)低于或等于10万元时,奖金可提10%;利润高 于10万元,低于20万元时,低于10万元的部分按10%提成,高于10万元的部分,可可提 成7.5%;20万到40万之间时,高于20万元的部分,可提成5%;40万到60万之间时高于 40万元的部分,可提成3%;60万到100万之间时,高于60万元的部分,可提成1.5%,高于 100万元时,超过100万元的部分按1%提成,从键盘输入当月利润I,求应发放奖金总数? 1.程序分析:请利用数轴来分界,定位。注意定义时需把奖金定义成长整型。 2.程序源代码: main() { long int i; int bonus1,bonus2,bonus4,bonus6,bonus10,bonus; scanf("%ld",&i); bonus1=100000*0.1;bonus2=bonus1+100000*0.75; bonus4=bonus2+200000*0.5; bonus6=bonus4+200000*0.3; bonus10=bonus6+400000*0.15; if(i<=100000) 一、设计思想 插入排序:首先,我们定义我们需要排序的数组,得到数组的长度。如果数组只有一个数字,那么我们直接认为它已经是排好序的,就不需要再进行调整,直接就得到了我们的结果。否则,我们从数组中的第二个元素开始遍历。然后,启动主索引,我们用curr当做我们遍历的主索引,每次主索引的开始,我们都使得要插入的位置(insertIndex)等于-1,即我们认为主索引之前的元素没有比主索引指向的元素值大的元素,那么自然主索引位置的元素不需要挪动位置。然后,开始副索引,副索引遍历所有主索引之前的排好的元素,当发现主索引之前的某个元素比主索引指向的元素的值大时,我们就将要插入的位置(insertIndex)记为第一个比主索引指向元素的位置,跳出副索引;否则,等待副索引自然完成。副索引遍历结束后,我们判断当前要插入的位置(insertIndex)是否等于-1,如果等于-1,说明主索引之前元素的值没有一个比主索引指向的元素的值大,那么主索引位置的元素不要挪动位置,回到主索引,主索引向后走一位,进行下一次主索引的遍历;否则,说明主索引之前insertIndex位置元素的值比主索引指向的元素的值大,那么,我们记录当前主索引指向的元素的值,然后将主索引之前从insertIndex位置开始的所有元素依次向后挪一位,这里注意,要从后向前一位一位挪,否则,会使得数组成为一串相同的数字。最后,将记录下的当前索引指向的元素的值放在要插入的位置(insertIndex)处,进行下一次主索引的遍历。继续上面的工作,最终我们就可以得到我们的排序结果。插入排序的特点在于,我们每次遍历,主索引之前的元素都是已经排好序的,我们找到比主索引指向元素的值大的第一个元素的位置,然后将主索引指向位置的元素插入到该位置,将该位置之后一直到主索引位置的元素依次向后挪动。这样的方法,使得挪动的次数相对较多,如果对于排序数据量较大,挪动成本较高的情况时,这种排序算法显然成本较高,时间复杂度相对较差,是初等通用排序算法中的一种。 选择排序:选择排序相对插入排序,是插入排序的一个优化,优化的前提是我们认为数据是比较大的,挪动数据的代价比数据比较的代价大很多,所以我们选择排序是追求少挪动,以比较次数换取挪动次数。首先,我们定义我们需要排序的数组,得到数组的长度,定义一个结果数组,用来存放排好序的数组,定义一个最小值,定义一个最小值的位置。然后,进入我们的遍历,每次进入遍历的时候我们都使得当前的最小值为9999,即认为每次最小值都是最大的数,用来进行和其他元素比较得到最小值,每次认为最小值的位置都是0,用来重新记录最小值的位置。然后,进入第二层循环,进行数值的比较,如果数组中的某个元素的值比最小值小,那么将当前的最小值设为元素的值,然后记录下来元素的位置,这样,当跳出循环体的时候,我们会得到要排序数组中的最小值,然后将最小值位置的数值设置为9999,即我们得到了最小值之后,就让数组中的这个数成为最大值,然后将结果数组result[]第主索引值位置上的元素赋值为最小值,进行下一次外层循环重复上面的工作。最终我们就得到了排好序的结果数组result[]。选择排序的优势在于,我们挪动元素的次数很少,只是每次对要排序的数组进行整体遍历,找到其中的最小的元素,然后将改元素的值放到一个新的结果数组中去,这样大大减少了挪动的次序,即我们要排序的数组有多少元素,我们就挪动多少次,而因为每次都要对数组的所有元素进行遍历,那么比较的次数就比较多,达到了n2次,所以,我们使用选择排序的前提是,认为挪动元素要比比较元素的成本高出很多的时候。他相对与插入排序,他的比较次数大于插入排序的次数,而挪动次数就很少,元素有多少个,挪动次数就是多少个。 希尔排序:首先,我们定义一个要排序的数组,然后定义一个步长的数组,该步长数组是由一组特定的数字组成的,步长数组具体得到过程我们不去考虑,是由科学家经过很长时间计算得到的,已经根据时间复杂度的要求,得到了最适合希尔排序的一组步长值以及计算 1.定积分近似计算: /*梯形法*/ double integral(double a,double b,long n) { long i;double s,h,x; h=(b-a)/n; s=h*(f(a)+f(b))/2; x=a; for(i=1;i } 3.素数的判断: /*方法一*/ for (t=1,i=2;i //插入排序法 void InsertSort() { int s[100]; int n,m,j,i=0,temp1,temp2; printf("请输入待排序的元素个数:"); scanf("%d",&n); printf("请输入原序列:"); for (i=0; i //堆排序 static a[8] = {0,25,4,36,1,60,10,58,}; int count=1; void adjust(int i,int n) { int j,k,r,done=0; k = r = a[i]; j = 2*i; while((j<=n)&&(done==0)) { if(j C语言常用算法集合 1.定积分近似计算: /*梯形法*/ double integral(double a,double b,long n) { long i;double s,h,x; h=(b-a)/n; s=h*(f(a)+f(b))/2; x=a; for(i=1;i if(n==1||n==2) *s=1; else{ fib(n-1,&f1); fib(n-2,&f2); *s=f1+f2; } } 3.素数的判断: /*方法一*/ for (t=1,i=2;i 字符串全排列算法C语言实现 问题描述: 输入一个字符串,打印出该字符串中字符的所有排列。 输入: 123 输出: 123 132 213 231 312 321 问题分析: 现象分析: 这种问题,从直观感觉就是用递归方法来实现即:把复杂问题逐渐简单化,进而得出具体代码实现。(如何发现一个问题可以使用递归方式来解决?经分析可以发现:M 个数的排列方法与N(N>M)个数的排列方法没有区别,处理方法与数据的个数没有关系。 处理方法的一致性,就可以采用递归)。 3个数(123)排列,第一位1不动,剩下两个数(23)的排列,只要相互颠倒一下,就可以出现关于1开头的所有排列 123 132 把2换到第一位,保持不动,剩下的两个数(13)的排列,只要相互颠倒一下,就可以出现关于2开头的所有排列 213 231 同理,把3换到第一位,可得到 312 321 扩展: 把3个数的所有排列,前面加一个4,就可以得到关于4开头的所有的排列4123 4132 4213 4231 4312 4321 若把4与后续数据中的任意一个数据交换,通过完成对后续三个数的全排列,就可以得到相应的数开头的四数的排列。 总结: 对4个数的排列,可以转换成首位不动,完成对3个数的排列 对3个数的排列,可以转换成首位不动,完成对2个数的排列 对2个数的排列,可以转换成首位不动,完成对1个数的排列 对于1个数,无排列,直接输出结果 算法实现说明: 对n个数的排列,分成两步: (1)首位不动,完成对n-1个数的排列, (2)循环将后续其他数换到首位,再次进行n-1个数的排列 注:排列完成后,最终的串要与原串相同 C语言代码实现: #include 基于C语言地多种排序方法地实现 1 引言 1.1 课题背景 排序问题源远流长,一直是数学地重要组成部分.随着各种信息地快速更新,排序问题也走进了其他领域以及我们地日常生活.如何高效地排序一直困扰着我们. 1.2 课程设计目地 排序是数学地重要组成部分,工作量大是其存在地问题.如何高效地排序?本程序就是解决这个问题而设计.程序中,把数列储存在数组中,采用插入排序等十种排序方法对数组元素进行排序,高效地解决了排序问题.本软件开发地平台为最新地微软公司出版地市面最新系统Windows 2000,而且可以作为自身地运行平台非常广泛,包括 Windows 98/2000/XP/Vista等等. 1.3课程设计内容 本程序把对数列地排序转化为对数组元素地排序,用户可以根据自己地实际问题选择系统提供地七种排序方法地任意一种进行排序.程序通过自身地判断以及处理实现排序.程序最后输出每趟排序及初始排序结果. 2 系统分析与设计方案 2.1 系统分析 设计一个排序信息管理系统,使之能够操作实现以下功能: 1) 显示需要输入地排序长度及其各个关键字 2) 初始化输入地排序序列 3) 显示可供选择地操作菜单 4) 显示输出操作后地移动次数和比较次数 5) 显示操作后地新序列 5) 可实现循环继续操 2.2 设计思路 通过定义C语言顺序表来存储排序元素信息,构造相关函数,对输入地元素进行相应地处理. [2] 2.3 设计方案 设计方案如图2.1所示 图2.1 设计方案 具体流程见图2.2 图 2.2 程序流程图 3功能设计 3.1 SqList顺序表 其中包括顺序表长度,以及顺序表.源代码如下:[1] typedef struct { KeyType key。 //关键字项 InfoType otherinfo。 //其他数据项 }RedType。 typedef struct { RedType r[MaxSize+1]。 //r[0]作为监视哨 int length。 //顺序表长度 }SqList。 3.2 直接插入排序 直接插入排序是将一个记录插入到已排好序地有序表中,从而得到一个新地、记录数增1地有序表 图3.1 直接插入排序示意图 将第i个记录地关键字r[i].key顺序地与前面记录地关键字r[i-1].key,r[i-2].key,……,r[1].key进行比较,把所有关键字大于r[i].key地记录依次后移一位,直到关键字小于或者等于r[i].key地记录 /* ===================================================================== ======== 相关知识介绍(所有定义只为帮助读者理解相关概念,并非严格定义): 1、稳定排序和非稳定排序 简单地说就是所有相等的数经过某种排序方法后,仍能保持它们在排序之前的相对次序,我们就 说这种排序方法是稳定的。反之,就是非稳定的。 比如:一组数排序前是a1,a2,a3,a4,a5,其中a2=a4,经过某种排序后为 a1,a2,a4,a3,a5, 则我们说这种排序是稳定的,因为a2排序前在a4的前面,排序后它还是在a4的前面。假如变成a1,a4, a2,a3,a5就不是稳定的了。 2、内排序和外排序 在排序过程中,所有需要排序的数都在内存,并在内存中调整它们的存储顺序,称为内排序; 在排序过程中,只有部分数被调入内存,并借助内存调整数在外存中的存放顺序排序方法称为外排序。 3、算法的时间复杂度和空间复杂度 所谓算法的时间复杂度,是指执行算法所需要的计算工作量。 一个算法的空间复杂度,一般是指执行这个算法所需要的内存空间。 ===================================================================== =========== */ /* ================================================ 功能:选择排序 输入:数组名称(也就是数组首地址)、数组中元素个数 ================================================ */ /* ==================================================== 算法思想简单描述: Warshall算法求传递闭包 例:A = { a, b, c, d ,e} , R 为A 上的关系, R = { { for(j=1;j<=n;j++) { scanf("%d",&A[i][j]); if(A[i][j]!=1&&A[i][j]) printf("There is an error"); } } for(i=1;i<=n;i++) { for(j=1;j<=n;j++) { for(k=1;k<=n;k++) { if(A[i][j]&&(A[i][k]||A[j][k])) A[i][k]=1; } } } printf("传递闭包的关系矩阵:\n"); for( i=1;i<=n;i++) { for(j=1;j<=n;j++) printf("%2d",A[i][j]); printf("\n"); } } #include printf("\n请输入该序列元素的个数\n"); scanf("%d", &pvector->n); pvector->record = (RecordNode*)malloc((sizeof(RecordNode))*(pvector->n)); printf("\n你要以什么方式创建序列?\n方式1:自动创建请输入1,方式2:手动创建请输入0\n"); scanf("%d", &k); if (k) { srand((int)time(0)); for (i = 0; i < pvector->n; i++) { if(pvector->n<100) pvector->record[i].key = randx(100); else if((pvector->n<1000)) pvector->record[i].key = randx(1000); else pvector->record[i].key = randx(pvector->n); } } else { printf("\n请输入%d个大小不一样的整数\n", pvector->n); 60.题目:古典问题:有一对兔子,从出生后第3个月 起每个月都生一对兔子,小兔 子长到第三个月后每个月又生一对兔子,假如兔子都不死,问每个月的兔子总 数 为多少? _________________________________________________________________ _ 程序分析:兔子的规律为数列1,1,2,3,5,8,13,21.... _________________________________________________________________ __ 程序源代码: main() { long f1,f2; int i; f1=f2=1; for(i=1;i<=20;i++) { printf("%12ld %12ld",f1,f2); if(i%2==0) printf("\n");/*控制输出,每行四个*/ f1=f1+f2;/*前两个月加起来赋值给第三个月*/ f2=f1+f2;/*前两个月加起来赋值给第三个月*/ } } 上题还可用一维数组处理,you try! 61.题目:判断101-200之间有多少个素数,并输出所有素数。 _________________________________________________________________ _ 1 程序分析:判断素数的方法:用一个数分别去除2到sqrt(这个数),如果能被 整 除,则表明此数不是素数,反之是素数。 _________________________________________________________________ __ 程序源代码: #include "math.h" main() { int m,i,k,h=0,leap=1; 线性方程组AX=B 的数值计算方法实验 一、 实验描述: 随着科学技术的发展,线性代数作为高等数学的一个重要组成部分, 在科学实践中得到广泛的应用。本实验的通过C 语言的算法设计以及编程,来实现高斯消元法、三角分解法和解线性方程组的迭代法(雅可比迭代法和高斯-赛德尔迭代法),对指定方程组进行求解。 二、 实验原理: 1、高斯消去法: 运用高斯消去法解方程组,通常会用到初等变换,以此来得到与原系数矩阵等价的系数矩阵,达到消元的目的。初等变换有三种:(a)、(交换变换)对调方程组两行;(b)、用非零常数乘以方程组的某一行;(c)、将方程组的某一行乘以一个非零常数,再加到另一行。 通常利用(c),即用一个方程乘以一个常数,再减去另一个方程来置换另一个方程。在方程组的增广矩阵中用类似的变换,可以化简系数矩阵,求出其中一个解,然后利用回代法,就可以解出所有的解。 2、选主元: 若在解方程组过程中,系数矩阵上的对角元素为零的话,会导致解出的结果不正确。所以在解方程组过程中要避免此种情况的出现,这就需要选择行的判定条件。经过行变换,使矩阵对角元素均不为零。这个过程称为选主元。选主元分平凡选主元和偏序选主元两种。平凡选主元: 如果()0p pp a ≠,不交换行;如果()0p pp a =,寻找第p 行下满足() 0p pp a ≠的第一 行,设行数为k ,然后交换第k 行和第p 行。这样新主元就是非零主元。偏序选主元:为了减小误差的传播,偏序选主元策略首先检查位于主对角线或主对角线下方第p 列的所有元素,确定行k ,它的元素绝对值最大。然后如果k p >,则交换第k 行和第p 行。通常用偏序选主元,可以减小计算误差。 3、三角分解法: 由于求解上三角或下三角线性方程组很容易所以在解线性方程组时,可将系数矩阵分解为下三角矩阵和上三角矩阵。其中下三角矩阵的主对角线为1,上三角矩阵的对角线元素非零。有如下定理: 如果非奇异矩阵A 可表示为下三角矩阵L 和上三角矩阵U 的乘积: A LU = (1) 则A 存在一个三角分解。而且,L 的对角线元素为1,U 的对角线元素非零。得到L 和U 后,可通过以下步骤得到X : (1)、利用前向替换法对方程组LY B =求解Y 。 (2)、利用回代法对方程组UX Y =求解X 。 4、雅可比迭代: 1、稳定排序和非稳定排序 简单地说就是所有相等的数经过某种排序方法后,仍能保持它们在排序之前的相对次序,我们就说这种排序方法是稳定的。反之,就是非稳定的。 比如:一组数排序前是a1,a2,a3,a4,a5,其中a2=a4,经过某种排序后为a1,a2,a4,a3,a5,则我们说这种排序是稳定的,因为a2排序前在a4的前面,排序后它还是在a4的前面。假如变成a1,a4,a2,a3,a5就不是稳定的了。 2、内排序和外排序在排序过程中,所有需要排序的数都在内存,并在内存中调整它们的存储顺序,称为内排序; 在排序过程中,只有部分数被调入内存,并借助内存调整数在外存中的存放顺序排序方法称为外排序。 3、算法的时间复杂度和空间复杂度 所谓算法的时间复杂度,是指执行算法所需要的计算工作量。 一个算法的空间复杂度,一般是指执行这个算法所需要的内存空间。 ================================================ 功能:选择排序 输入:数组名称(也就是数组首地址)、数组中元素个数 ==================================================== 算法思想简单描述: 在要排序的一组数中,选出最小的一个数与第一个位置的数交换; 然后在剩下的数当中再找最小的与第二个位置的数交换,如此循环 到倒数第二个数和最后一个数比较为止。 选择排序是不稳定的。算法复杂度O(n2)--[n的平方] ===================================================== void select_sort(int*x,int n) { int i,j,min,t; for(i=0;iRC4加密算法C语言实现
C语言几种常见的排序方法
非常全的C语言常用算法
C语言9种常用排序法
C语言经典算法100例(1---30)
几种排序算法的分析与比较--C语言
C语言常用算法集合
数据结构经典算法 C语言版
最新C语言常用算法集合汇总
补充全排列算法C语言实现
基于C语言的多种排序方法的实现
C语言常用排序算法
Warshall算法C语言实现
快速排序法(C语言)
c语言经典算法100例
线性方程组的数值算法C语言实现(附代码)
C语言常用排序算法