统计功效和效应值(学生用)

统计功效与效应大小
华中师范大学心理学院刘华山
一、统计功效(检验功效,效力,Power)
统计功效指某检验能够正确地拒绝一个错误的虚无假设的能力。用1-β表示。
或说:当总体实际上存在差异,应该拒绝虚无假设时,正确地拒绝虚无假设的概率,或不犯β错误的概率。它表示某个检验探查出实际存在的差异,正确拒绝虚无假设的能力。在实验设计中,统计功效反映了假设检验能够正确侦查到真实的处理效应的能力。
统计功效的大小取决于四个条件:
1.两总体差异。当两总体实有差异越大,或处理效应越大,则假设检验的统计功效越大;
2.显着性标准α。显着性标准α越大,则β错误越小,从而统计功效1-β越大;反之,α变小,1-β变小
3.检验的方向:当两总体差异一定,对于同样的显着性标准α,单侧检验比双侧检验的统计功效要大。
4.样本容量。样本容量越大,样本平均数分布的标准误越小,分布曲线越瘦削,统计功效越大。
二、效应量 (效应大小,Effect Size,ES )
效应量,反映处理效应大小的度量。其实,两样本平均数的差异就是一个效应量。效应量表示两个总体分布的重叠程度。ES越大,表示两总体重叠的程度越小,效应越明显。由计算出的ES大小,可由专门的表格中查出两样本分布的重叠的百分比。故效应量经常用两总体重叠的程度为指标,重叠的部分百分比越大,效应量越小。或以两个样本不重叠的程度为指标,不重叠的部分百分比越大,效应量越大。
三、效应量检验的功能
1.效应量有助于我们判断统计上显着差异是否有实际的意义
效应量检验,也就是要检验自变量作用的大小。它不同于差异显着性的检验。
统计显着性与实际显着性的区别:差异的统计显着性、相关的统计显着性只
是告诉你在特定的条件下,这差异、这相关系数是存在的、并不是完全由抽样误差造成的,但并不意味着这差异有实际意义。大样本比较容易获得统计显着性的结果,但这并不意味着差异是有意义的。
2.有些效应量,主要是有相关意义的效应量,如相关系数,点二列相关系数的平方,,可以反映自变量解释因变量变异的百分比。
3.在同一个实验中,如果有几个自变量,可以根据效应量大小把自变量的重要性排序。
4.在元分析中,将各个不同的相关研究进行概括分析的基础便是各个不同研究的效应量(的合成)。
5.效果量的计算还为改进研究设计、提高检验能力提供了根据。
APA出版手册第五版要求报告差异检验结果时一般要报告ES值。
美国心理学会1994 年发出通知,要求公开发表的研究报告包含效应量的测定结果。当具有统计上的显着性后,一定要计算效应量, 看你进行的研究是否有价值。
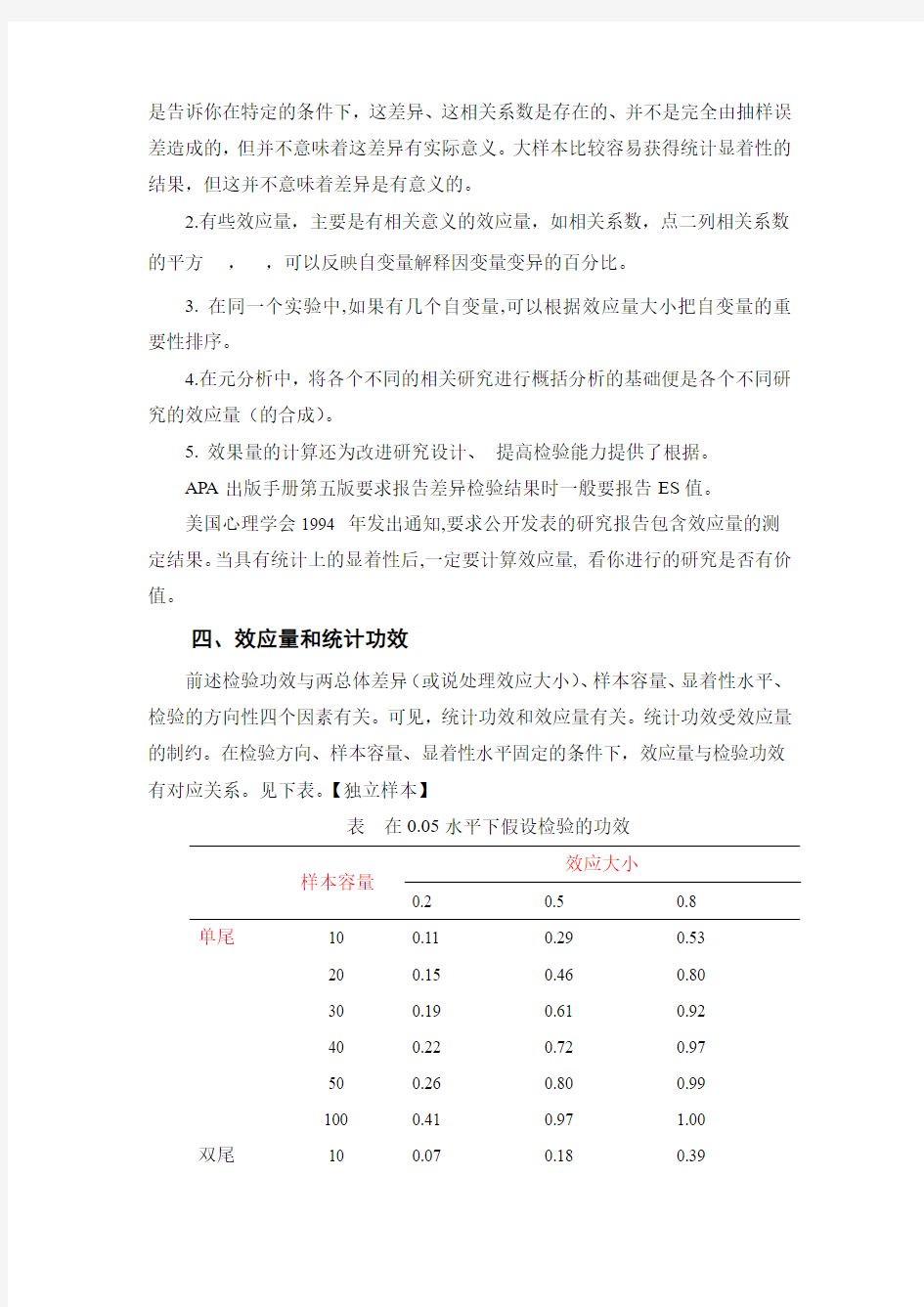
四、效应量和统计功效
前述检验功效与两总体差异(或说处理效应大小)、样本容量、显着性水平、检验的方向性四个因素有关。可见,统计功效和效应量有关。统计功效受效应量的制约。在检验方向、样本容量、显着性水平固定的条件下,效应量与检验功效有对应关系。见下表。【独立样本】
表在0.05水平下假设检验的功效
样本容量
效应大小
0.2 0.5 0.8
单尾10 0.11 0.29 0.53
20 0.15 0.46 0.80
30 0.19 0.61 0.92
40 0.22 0.72 0.97
50 0.26 0.80 0.99
100 0.41 0.97 1.00 双尾10 0.07 0.18 0.39
20 0.09 0.33 0.69 30 0.12 0.47 0.86 40 0.14 0.60 0.94 50 0.17 0.70 0.94
100
0.29
0.94
1.00
五、独立样本t 检验的效应大小
是一限制。
因为平均数对样本数据——,其中)即合成方差(以两样本自由度之和,本离差平方和之和即两样算术平方根,合成方差是两个样本合成方差的,而—.1,1除d s Cohen'.122112
12
122
2
1n df n df df df ss ss S S S X X p pooled p P
==++=
=
σ 上述效应量公式等价于
例:在大学一年级新生中选取10名双性化学生和20名非双性化学生,对他们施测自尊量表。10名双性化学生得分的平均数为,251=X 离差平方和SS 1=670;20名非双性化学生得分的平均数为,182=X 离差平方和SS 2=1010。问两组平均数有无差异?(设α=0.01)
已知,251=X SS 1=670; ,182=X SS 2=1010,则 平均数差异的样本分布的标准误为 求效应量
这说明由双性化与非双性化造成的差异还是较大的。 2.Cohen's d ⑴指标1 (2)指标2
t-t 检验值 df-t 检验自由度 3.Glass ’ estimator g ˊ
1X 为处理组的平均数,2X 为对照组平均数,2S 为对照组标准差。此公式
特点是用对照组方差代替合成方差。
本指标的使用范围同Cohen ′s d 指标。也有人将这里的效应量也称作d ,其
()2
121n n df n n t d +=
大小标准的判断也是0.2(小),0.5(中),0.8(大)。
4.Hedges' ?
(1)指标1 ?
这只是对Cohen's d的小的修正。
(2)指标2 g
分母根号内为两独立样本方差分析中的误差均方。
下表采用不同的两个公式计算效应量。前一种算法是以两样本方差的均值代替它们的联合方差。后一种算法是用方差分析组内方差的平方根作分母。本例求得的两个指标刚好相等。
5. 当对两独立组平均数之差进行检验时,也可用点二列相关系数
( point-biserial correlation coefficient ) 的平方作为效果量的指标。不过也可用作相关样本的效应量的指标、方差分析的效应量指标(见后)。其标准为:
0. 010 (效果小) ;0. 059 ( 效果中);0. 138 (效果大)。
的计算公式为:
用作独立样本时,;用作相关样本时,。
此公式也可用于相关样本的t检验。本式显示标准化平均差与相关系数间的转化。
6.对于两独立样本的平均数差异的检验,也可以对之作方差分析,用输出的
作效应量(例见后)。
六、效应量大小的标准
计算出效应量后,如何解释、评价效应量的大小呢?评价的标准是什么?有以下几种方法。
(一)为效应量规定数值标准
不同的效应量指标的评价标准是不同的。
1.Cohen(1988)定义d 效应量大小标准(解释)(两个独立样本的t检验)
d=0.2 小
d=0.5 中
d=0.8 大
2.作为效应量的相关系数的评价标准
根据Cohen的规定(1988,1992),相关系数0.10~0.29是小的效应;0.30~0.49是中等效应;等于或大于0.50是大的效应量。
3.卡方检验中效应量Φ系数的评价标准与自由度有关。(见后)
4.点二列相关系数平方的评价标准
0. 010 (效果小) ;0. 059 ( 效果中);0. 138 (效果大)。
5.总体效应量的评价标准
效果量标准是: 解释变异量 6%以下者,显示变量间关系微弱;解释变异量在6%以上到16%以下者,显示变量间属中等关系;解释变异量在16%以上者,显示变量间关系强。(Cohen J. 1982,1988)
6. 单因素方差分析中Cohen’s f的评价标准
根据Cohen的建议,f小于0.1为小的效应;f在0.25左右为中等效应;f大于0.4属于大的效应。
(二)用自变量解释因变量变异的百分比来评价
,,积差相关系数的平方等相关系数类效应量都可解释为:自变量可以解释因变量变异的百分比。
(三)用两总体重叠部分的百分比来评价
在两样本平均数差异的检验中,效应量可以用两个总体分布的重叠程度来解释。重叠部分比例越大,则效应量越小。
附表Cohen’s d与两个样本分布的不重叠部分百分比
Cohen的标准效应量Percentile Standing 不重叠部分百分比(%)
2.0 97.7 81.1
1.9 97.1 79.4
1.8 96.4 77.4
1.7 95.5 75.4
1.6 94.5 73.1
1.5 93.3 70.7
1.4 91.9 68.1
1.3 90.0 65.3
1.2 88 6
2.2
1.1 86 58.9
1.0 84 55.4
0.9 82 51.6
大0.8 79 47.4
0.7 76 43.0
0.6 73 38.2
中等0.5 69 33.0
0.4 66 27.4
0.3 62 21.3
小0.2 58 14.7
0.1 54 7.7
0.0 50 0.0
七、相关样本t检验的效应量
对照相关样本之差的检验的统计量,就知道S D的含义。
2.两相关样本的效应量
指标公式
本公式与前述两独立样本t检验的效应量公式。即Cohen's d 指标1
3.点二列相关系数的平方(同前)
八、2χ检验的效应量
(一)2χ检验的效应量
1. Φ系数
类别变量的相关系数Φ系数也代表了效应大小。Φ系数(Φ相关系数)的计算公式是(适用于两列二分变量间的相关):
2.Cramer’s φ(适用于两列多分类变量)
显然Φ系数是Cramer’s φ的特例。后者就是Cramer系数,或称克拉默系数V.
(二)2χ检验的效应量的评价标准
当df min=1时,Φ=0.10表示低的效应;Φ=0.30表示中等的效应;Φ=0.50表
示高的效应;
当df min =2时,Φ=0.07表示低的效应;Φ=0.21表示中等的效应;Φ=0.35表示高的效应;
当df min =3时,Φ=0.06表示低的效应;Φ=0.17表示中等的效应;Φ=0.29表示高的效应.。
九、方差分析中的效应量 (一)含义
方差分析中的效应量用以测量处理效应(主效应、交互效应)与自变量关系程度的指标,它们可以被看作是自变量与处理效应之间的相关系数,它的平方可以解释为因变量总变异中各种效应的解释比例。
(二)方差分析常用的四种效应量 ①Eta squared
②partial Eta squared
③omega squared
④the Intraclass correlation ρΙ?
和 是对样本中自变量和因变量关联程度的估计,是一个描述
统计量;而 和跨级相关 是总体中自变量与因变量关联程度的度量,是一个参数。每一个 都有一个对应的 。在一般情况下只要计算
就足够了。 永远小于 和 。
(三)四种效应量的计算
该表是以drive 和reward 为自变量,以performance 为因变量的二因素分析的结果.
2η的计算
2
ω
①含义
②公式
2
η的计算(SPSS)
在SPSS软件的方差分析部分,在选择窗口“option”中可以选择“estimates effect size”即可输出和。
2.偏2η的计算
①公式【某一效应的偏2η等于该效应的平方和除以该效应平方和与误差平方和的和所得的商。
3.Omega squared ω2的计算
Omega squared is an estimate of the dependent variance accounted for by the independent variable in the population for a fixed effects model.?The between-subjects, fixed effects。【用于固定效应模型】Note
Do not use this formula for repeated measures designs。【不能用于重复测量的方差分析设计。】
①公式
关于效果量的高低判断方面, Cohen( 1982, 1988) 提出的标准是: 解释变异量 6%以下者,显示变量间关系微弱;解释变异量在6%以上到16%以下者,显示变量间属中等关系;解释变异量在16%以上者,显示变量间关系强。(Cohen J. Statistical power and analysis for the behavioural sciences[ M] . Second dition , Hillsdalee, NJ: Erlbaum,1988.)
ρ的计算
4.跨级相关(Intraclass correlation)
I
①内涵
Because it is for a random effects model it is not commonly used in
psychology experiments.?【用于随机效应模型】
②公式
十、单因素方差分析的效应量与统计功效 (一)效应量的计算
f=
n
F
其中F 为样本F 统计量的观测值,n 为每组样本容量。 这个f 称为Cohen ’s f
(二)效应大小的判断
根据Cohen 的建议,f 小于0.1为小的效应;f 在0.25左右为中等效应;f 大于0.4属于大的效应。
例:一项实验欲研究阅读时间长短对儿童阅读能力的影响。将儿童随机分配到3种阅读条件下,第一组阅读时间为5分钟,第二组为15分钟,第3组为30分钟。两周后测量儿童的阅读能力,得分如下。
表 阅读测试得分表
第一组 第二组 第三组 (K=3)
10 15 10
14 20 12 (n=5)
12 17 6 8
8
12 11 15 10
11
15
10
方差分析结果为88.344.3)12,2(05.0=F <=F ,所以三组阅读测验平均分数无显着差异。
计算效应量:f=
40.083.05
44
.3>==n
F
, 可见,尽管方差分析的F 值不显着,效应分析却显示大的效应。
十一、回归或单因素方差分析中的效应量
1.Cohen's 2f
2
R
为确定系数。 Cohen, 1988提出效应量大小标准。2f ≤0.02,小,0.02<2f <0.15中,2f >0.3,大。
十二、 的应用
可以在两独立样本的t 检验、单因素方差分析、多因素方差分析、秩和
检验、克-瓦氏H 检验、单因素多相关组弗里德曼卡方检验中作为效应量指标使用。
(一) 用作两独立样本的t 检验中的效应量 此时仍需作方差分析,而不是作t 检验。
两种识记方法对回忆效果的影响的实验结果
Source SS
df Mean Square
F p
Eta Squared
识记方法 22.500 1
22.500 9.000 0.017 0. 529
误差 20.000 8 2. 500
总和
42.500 9
说明识记方法能解释回忆成绩变异量的53%。(指平方和的比例) (二) 用作单因素方差分析中的效应量 (三) 用作两因素方差分析中的效应量
(四) 用作秩和检验中的效应量(两独立样本的非参数检验) 秩和检验中效应量 的计算
设有两个独立组,每组5个被试。分别测量试验组对绿色信号灯的反应时,和对照组对蓝色信号灯的反应时。结果如下:
试验组 对照组 反应时 等级
反应时 等级
539 2 759 7 480 1 890 8 600
5
1105
10
R
R f 2
2
2
1-=
590 3 595 4 605 6 941 9 ΣR
17
38
先选定一组,算出其等级和ΣR 。 根据下式算出期望等级和
, 其中应是 为所选组的人数(较小的样本容量),N
是总人数。根据下式算出Z 值
再根据Z 求出
本例中求得ΣR=17, ,Z=-2.19, ,说明信号颜色能解释反应时变异的53%。
十三、逻辑斯蒂回归的效应量
Odds ratio (比值比,发生比之比,简写OR ) 在逻辑斯蒂回归中,)P (p 1称为发生比。
适于二个变量均是二分变量的情况,它也是逻辑斯蒂回归的效应量。 比值比的单位与Cohen ’d 不一样,因此同样的取值不是等价的。(见“六”中“二分变量的两独立组比较”)
十四、相关系数的效应量
相关系数的效应量指标,就是相关系数本身。皮尔逊积差相关系数r 及点二列相关系数这是用得应用最为广泛的效应量之一。
根据Cohen 的规定(1988,1992),0.10~0.29是小的效应;0.30~0.49是中等效应;等于或大于0.50是大的效应量。
另一个刻划两变量间关系强度大小的是确定系数。
十五、效应量的种类
(一)标准化的和非标准化的
⑴标准化效应测量(一般文献效应量常指此)
标准化的效应量例如,相关系数r、Cohen’s d、odds ratio、Hedges’s g、Glass’s Δ等。
⑵非标准化效应测量
例如:组间均值原始数值之差;非标准化回归系数等。
(二)利用样本统计量计算的,和不利用样本统计量计算出的
1.如果研究报告中没有报告统计量
例如当实验组与控制组的标准差相差不大时,有公式
2.如果研究报告中出现了统计量,则需视统计量的具体情况计算效应量。
(1)独立样本,研究结果以t表示时,其效应量:
(2)研究结果有2 表示时,其效应量为
(三)基于相关系数的效应量与基于标准化平均差的效应量
在相关设计中,一般采用相关系数作为效应量的指标;在实验组控制组设计中,一般采用标准化的平均差作为效应量的指标。二者可由点二列相关而得到转化。即t值可转化为点二列相关系数。
(四)不同检验方法所用的不同的效应量
(五)元分析理论的不同学者提出的不同的效应量
描述统计与推断统计
描述统计与推断统计-心理学统计与测量经典习题1 第一章描述统计 名词解释 1.描述统计(吉林大学2002研) 答:描述统计主要研究如何整理心理与教育科学实验或调查得来的大量数据,描述一组数据的全貌,表达一件事物的性质。具体内容有:数据如何分组,如何使用各种统计表与统计图的方法去描述一组数据的分组及分布情况,如何通过一组数据计算一些特征数,减缩数据,进一步显示与描述一组数据的全貌。 2.相关系数(吉林大学2002研) 答:相关系数是两列变量间相关程度的数字表现形式,或者说是表示相关程度的指标。作为样本的统计量用r表示,作为总体参数一般用ρ表示。相关系数不是等距的度量值,因此在比较相关程度时,只能说绝对值大者比绝对值小者相关更密切一些,而不能进行加减乘除。 3.差异系数(浙大2003研) 答:差异系数,又称变异系数、相对标准差等,它是一种相对差异量,为标准差对平均数的百分比。其公式如下: 常用于:①同一团体不同观测值离散程度的比较;②对于水平相差较大,但进行的是同一种观测的各种团体,进行观测值离散程度的比较。 4.二列相关(中科院2004研) 答:如果两列变量均属于正态分布,其中一列变量为等距或等比的测量数据,另一列变量虽然也是正态分布,但被人为地划分为两类。求这样两列变量的相关用二列相关。 5.集中量数与差异量数(浙大2000研,苏州大学2002研) 答:集中趋势和离中趋势是次数分布的两个基本特征。数据的集中趋势就是指数据分布中大量数据向某方向集中的程度,离中趋势是指数据分布中数据彼此分散的程度。用来描述一组数据这两种特点的统计量分别称为集中量数和差异量数。 6.中位数(南开大学2004研) 答:中位数,又称中点数,中数,是指位于一组数据中较大一半和较小一半中间位置的那个数,用Md或Mdn来表示。 7.品质相关(华东师大2002研)
高频变压器导线的趋肤效应
高频变压器导线的趋肤效应 1、趋肤效应 趋肤效应亦称为“集肤效应”。 交变电流通过导体时,由于感应作用引起导体截面上电流分布不均匀,愈近导体表面电流密度越大。这种现象称“趋肤效应”。趋肤效应使导体的有效电阻增加。当频率很高的电流通过导线时,可以认为电流只在导线表面上很薄的一层中流过,这等效于导线的截面减小,电阻增大。既然导线的中心部分几乎没有电流通过,就可以把这中心部分除去以节约材料。因此,在高频电路中可以采用空心导线代替实心导线。此外,为了削弱趋肤效应,在高频电路中也往往使用多股相互绝缘细导线编织成束来代替同样截面积的粗导线,这种多股线束称为辫线。 交变磁场会在导体内部引起涡流,电流在导体横截面上的分布不再是均匀的,这时,电流将主要地集中到导体表面。这种效应称为趋肤效应。 利用趋肤效应,在高频电路中可用空心铜导线代替实心铜导线以节约铜材。架空输电线中心部分改用抗拉强度大的钢丝。虽然其电阻率大一些,但是并不影响输电性能,又可增大输电线的抗拉强度。 2、高频变压器工作频率较高,一般在15-100kHz.因趋肤效应作用,变压器的导线粗细就受到一定限制。工作频率的提高,趋肤效应影响越大。因此,在设计绕组选择电流密度和线径时必须考虑趋肤效应引起的有效截面的减小。导线通有高频交变电流时,有效截面的减少可以用穿透深度来表示。穿透深度的意义是:由于趋肤效应,交变电流沿导线表面开始能达到的径向深度,用“Δ”表示,计算公式为:Δ——穿透深度(mm);ω——角频率,ω=2πf(rad/s); γ——电导率(S/m),当导线为铜线时,(S/m); μ——磁导率(H/m);铜的相对磁导率,;式中即为真空磁导率 H/m。 导体的穿透深度公式可以简化为:Δ=K×66.1/√f (mm), f是工作频率(Hz), K是常数对铜而言K=1。 铜导体的穿透深度(20 ℃) 3、高频变压器单股导线的最大线径<2Δ=2*66.1/√f (mm).假若工作频率f=30KHz时,最大线径为0.76mm ,所以选择0.8mm以上的导线就没有意义了. 4. 高频变压器线径
@2017.3.16-统计学-计量资料的统计描述方法
计量资料的统计描述方法 怎样表达一组数据? 描述计量资料的常用指标— A 、描述平均水平(中心位置): 均数X 、中位数和百分位数、几何均数G 、众数(mode ) B 、描述数据的分散程度: 标准差、四分位数间距、 变异系数、方差、全距 (一)均数mean 和标准差standard deviation 1. (算术)均数X 均数是描述一组计量资料平均水平或集中趋势的指标。 *直接计算公式: 应用条件:适用于对称分布,特别是正态分布资料。 2. 中位数(median )M 和百分位数(percentile ) A.中位数M 是将一组观察值从小到大排序后,居于中间位置的那个值或两个中间值的平均值。 应用条件: 12n X X X X X n n +++== ∑L
用于任何分布类型,包括偏态资料、两端数据无界限的资料。 计算: n 为奇数时-- n 为偶数时-- 9人数据:12,13,14, 14, 15, 15, 15, 17, 19天 B.百分位数 是将N 个观察值从小到大依次排列,再分成100等份,对应于X%位的数值即为第X 百分位数。中位数是第百分50位数。 四分位数间距(quartile range ) =第25百分位数(P25)~第75百分位数(P75)。 四分位数间距用于描述偏态资料的分散程度(代替标准差S ),包含了全部观察值的一半。 ) (天1552 19===+X X M 88451 22221415214.5() M X X X X ?? ==== ???+如果只调查了前八位中学生,则: +(+)(+)天
百分位数计算(频数表法): X L :第X 百分位数所在组段下限 L Σf :小于X L 各组段的累计频数 X i :第X 百分位数所在组段组距 n :总例数f x :所在组段频数 注:有的教材X= r ; L f ∑=C 例:求频数表的第25、第75百分位数(四分位数间距) 组段 频数f 累积频数∑f 56~ 2 2 59~ 5 7 62~ 12 19 ∑f 25 L 2565~ 15 34 P 25在此 68~ 25 59 71~ 26 85∑f 75 L 7574~ 19 104 P 75在此 77~ 15 119 80~ 10 129 83~85 1 130 合计 130 ① 确定Px 所在组段: P 25所在的组段:n X %=130×25%=32.5, 65~组最终的累积频数=34,32.5落在65~组段内;
什么叫趋肤效应
什么叫趋肤效应?趋肤效应的定义 对于每个电气参数,必须考虑其数值有效时的频率范围。传输线的串联电阻也不例外。与其他参数一样,它也是频率的函数。图4.10画出了RG-58/U和等效串联电阻与频率的函数曲线。图中采用对数坐标轴。图4.10以相同的坐标轴绘出了感抗WL的曲线。 当频率低于W=R/L时,电阻超过感抗,电缆表现为一个RC传输线。当频率高于W=R/L时,电缆是一个低损耗传输线。 当频率高于0.1MHZ时,串联电阻开始增大。这导致更多的衰减,但相位保持线性。这种电阻的增加称为趋肤效应(SKIN EFFECT)。 传播因数的实部和虚部((R+JWL)(JWC))1/2在图4.11中绘出,损耗单位为标培,相位单位为RAD(弧度)。1奈培等于8.69DB的损耗。图中显示了RC区域、固定衰减区域和趋肤效应区域。如图所示,相对于RC区域和趋肤效应区域,低损耗区域非常窄。 是什么导致了趋肤效应,它与导体外表层有什么关系呢? 1、趋肤效应的机理 在低频时,电流在导体内部的分布密度是均匀的。从导线的截面图看,中心和边缘区域电流的流量是相同的。 在高频时,导线表面的电流密度变大,而中心区域几乎没有电流流过。电流分布的变化如图4.12所示,低频时电流均匀地填满整个导线,高频时电流只从接近导线表面的地方流过。 为了形象地证明高频条件下电流的分布,首先假设导线纵向切成多层同心的长管,就像树桩上的年轮。 自然对称的形状可以阻止电流在环间流动,所以必须无误差地切割,所有电流绝对平行于导线的中心轴。 现在导线被切成许多环,我们可以分别考虑每个环的电感。靠近中心的环,像长而薄的管道,比外部的环有更大的电感。我们知道,在高频条件下,电流将从电感更低的通路流过。因此,高频条件下可以预计从外环通路流过的电流比内环更多。实际上正是如此。在高频条件下,绝大多数的电流聚集在靠近导体的外表面。
10第十章效应量和统计检验力-刘红云版心理统计教材课后习题
练习题 1.什么叫效应值?它在实际研究中有何作用? 2.Cohen d值是如何表达的?在单样本t检验、独立样本t检验和相关样本t检验中,d值的公式是如何变化的? 3.统计量r2描述了什么?它在实际研究中有何作用? 4.从一个均值为40的正态总体中选择一个n=16的样本。对样本施测,处理后,评价处理效应的大小。 a.假设总体的标准差为8,计算Cohen d系数来评价一个样本均值为?x=42的样本的效应大小; b.假设总体的标准差为2,计算Cohen d系数来评价一个样本均值为?x=42的样本的效应大小; c.假设总体的标准差为8,计算Cohen d系数来评价一个样本均值为?x=48的样本的效应大小; d.假设总体的标准差为2,计算Cohen d系数来评价一个样本均值为?x=48的样本的效应大小; 5.五年级学生的阅读成绩测验形成了一个均值为60,标准差为10的正态分布。一个研究者想要评价一个新的阅读项目。他对五年级学生的样本进行这个项目的培训,然后测量他们的阅读成绩。 a.假设研究者使用了一个n=16的样本,得到的测验分数均值为?x=62。使用α=0.05的假设检验来确定项目是否有显著的作用。用Cohen d系数来测量效应大小; b.现在假设研究者使用了一个n=100的样本,得到的测验分数均值为?x=62。再使用假设检验来评价项目效果的显著性,计算Cohen d系数来测量效应大小; c.比较a和b得到的结果,解释样本大小怎样随机影响假设检验和Cohen d系数的。 6.从一个均值为100的总体中得到一个随机样本,对样本施测。处理后,样本均值为?x=104,样本方差为S2=400。 a.假定样本包括n=16名被试,计算Cohen d系数和r2测量处理效应大小; b.假定样本包括n=25名被试,计算Cohen d系数和r2测量处理效应大小; c.比较在a和b部分得到的结果,样本量是如何影响效应大小的? 7.下图是垂直一水平错觉的一个例子。尽管两条线是一样长的,垂直的线看起来更长。为了考察这个错觉,一个研究者准备了一个例子,这个例子中两条线都是10英尺长。给每个被试展示这个例子,告诉他们水平线有10英尺长,然后让他们估计垂直线的长度。一个n=25的样本,估计的平均值为?x=12.2英尺,标准差为S=1.00。 a.使用0.01水平的单侧假设检验证明样本中的个体显著高估了线段的真实长度。(注
随机对照试验的meta分析方法之一:合并效应量计算
随机对照试验的meta分析方法之一:合并效应量计算 介绍metan命令的用法 数据来源: Example1: The following table gives data from 22 randomised controlled trials of streptokinase(链激酶) in the prevention of death following myocardial infarction.(心肌梗塞) 命令:describe 命令:generate alive1=pop1-deaths1
generate alive0=pop0-deaths0 metan deaths1 alive1 deaths0 alive0, rr xlab(.1,1,10) label(namevar=trialnam) 注意: generate用于产生新变量,Stata和RevMan不一样,需要的是治疗组有效数和无效数,以及对照组的有效数和无效数,而不是有效数和治疗总数或对照总数。metan就是Stata中Meta分析的命令。 deaths1 alive1 deaths0 alive0 就是四格表资料。 rr表示使用RR统计量。 xlab(.1,1,10)就是制定森林图中X轴的坐标,0.1~10,其中1是无效线。label(namevar=trialnam) 在森林图中用实验名称标识试验。
介绍meta命令的用法 The meta command uses inverse-variance weighting to calculate ?xed and random effects summary estimates, and, optionally, to produce a forest plot. The main difference in using the meta command (compared to the metan command) is that we require variables containing the effect estimate and its corresponding standard error for each study. meta是Stata进行Meta分析的另一个命令,meta命令和metan命令的区别在于meta使用的是一般倒方差法,需要输入效应量和效应量的标准误。 命令如下:generate alive1=pop1-deaths1 generate alive0=pop0-deaths0 generate logor=log((deaths1/alive1)/(deaths0/alive0)) generate selogor=sqrt((1/deaths1)+(1/alive1)+(1/deaths0)+(1/alive0)) meta logor selogor, eform graph(f) cline xline(1) xlab(.1,1,10) id(trialnam)
Excel 在描述统计中的应用
第三节Excel 在描述统计中的应用 在使用Excel 进行数据分析时,要经常使用到Excel 中一些函数和数据分析工具。其中,函数是Excel 预定义的内置公式。它可以接受被称为参数的特定数值,按函数的内置语法结构进行特定计算,最后返回一定的函数运算结果。例如,SUM 函数对单元格或单元格区域执行相加运算,PMT 函数在给定的利率、贷款期限和本金数额基础上计算偿还额。函数的语法以函数名称开始,后面是左圆括号、以逗号隔开的参数和右圆括号。参数可以是数字、文本、形如TRUE 或FALS E 的逻辑值、数组、形如#N/A 的错误值,或单元格引用。给定的参数必须能产生有效的值。参数也可以是常量、公式或其它函数。 Excel 还提供了一组数据分析工具,称为“分析工具库”,在建立复杂的统计分析时,使用现成的数据分析工具,可以节省很多时间。只需为每一个分析工具提供必要的数据和参数,该工具就会使用适宜的统计或数学函数,在输出表格中显示相应的结果。其中的一些工具在生成输出表格时还能同时产生图表。如果要浏览已有的分析工具,可以单击“工具”菜单中的“数据分析”命令。如果“数据分析”命令没有出现在“工具”菜单上,则必须运行“安装”程序来加载“分析工具库”。安装完毕之后,必须通过“工具”菜单中的“加载宏”命令,在“加载宏”对话框中选择并启动它。
一、描述统计工具 (一)简介:此分析工具用于生成对输入区域中数据的单变量分析,提供数据趋中性和易变性等有关信息。 (二)操作步骤: 1.用鼠标点击工作表中待分析数据的任一单元格。 2.选择“工具”菜单的“数据分析”子菜单。 3.用鼠标双击数据分析工具中的“描述统计”选项。 4.出现“描述统计”对话框,对话框内各选项的含义如下:输入区域:在此输入待分析数据区域的单元格范围。一般情况下Excel 会自动根据当前单元格确定待分析数据区域。分组方式:如果需要指出输入区域中的数据是按行还是按列排列,则单击“行”或“列”。 标志位于第一行/列:如果输入区域的第一行中包含标志项(变量名),则选中“标志位于第一行”复选框;如果输入区域的第一列中包含标志项,则选中“标志位于第一列”复选框;如果输入区域没有标志项,则不选任何复选框,Excel 将在输出表中生成适宜的数据标志。 均值置信度:若需要输出由样本均值推断总体均值的置信区间,则选中此复选框,然后在右侧的编辑框中,输入所要 使用的置信度。例如,置信度95%可计算出的总体样 本均值置信区间为10,则表示:在5%的显著水平下总 体均值的置信区间为( X -10, X +10)。
统计功效和效应值(讲稿子1)
统计功效与效应量 华中师范大学心理学院 刘华山 一、统计功效(检验功效,效力,Power ) 统计功效指某检验能够正确地拒绝一个错误的虚无假设的能力。用1-β表示。 或说:当总体实际上存在差异(备择假设H 1为真),应该拒绝虚无假设时,正确地拒绝虚无假设的概率,或不犯β错误的概率 。它表示某个检验探查出实际存在的差异,正确拒绝虚无假设的能力。在实验设计中,统计功效反映了假设检验能够正确侦查到真实的处理效应的能力。 统计功效的大小取决于四个条件: 1.两总体差异。当两总体实有差异越大,或处理效应越大,则假设检验的统计功效越大;(在α错误概率不变的情况下,1-β变大) 2.显著性标准α:也称显著性水平,是一个特定的值,一个决策标准。通过p 与α的决策比较,作出统计决策。 而当假设H 0是真实的时候,观察到的差异完全是由随机误差所致的概率称为观察概率p 。 显著性标准α越大,则β错误越小,从而统计功效1-β越大;反之,α变小,1-β变小 3.检验的方向:当两总体差异一定,对于同样的显著性标准α,单侧检验比双侧检验的统计功效要大。 4.样本容量。样本容量越大,样本平均数分布的标准误越小,分布曲线越瘦 ◆ 单总体检验 ◆ α错误的解释 ◆ β错误的解释 ◆ 统计功效1-β ◆ 决定统计功效的条件
削,统计功效越大。 二、效应量 (效应大小,Effect Size,ES ) 效应量,反映处理效应大小的度量。效应量表示两个总体分布的重叠程度。ES越大,表示两总体重叠的程度越小,效应越明显。其实,两样本平均数的差异本身就是一个效应量。由计算出的ES大小,可由专门的表格中查出两样本分布的重叠的百分比。故效应量经常用两总体重叠的程度为指标,重叠的部分百分比越大,效应量越小。或以两个样本不重叠的程度为指标,不重叠的部分百分比越大,效应量越大。 三、效应量检验的功能 1.效应量有助于我们判断统计上显著差异是否有实际的意义 已有统计显著性检验的条件下,检验效应大小的必要性: 统计显著性与实际显著性的区别:差异的统计显著性、相关的统计显著性只是告诉你在特定的条件下,这差异、这相关系数是存在的、并不是完全由抽样误差造成的,但并不意味着这差异有实际意义。统计量是否显著,是在一定条件下取得的,这条件与与上述统计功效的条件是一致的。也就是说差异是否显著受几个条件影响:一是实际差异的大小,或处理效应的大小(从t检验的待检验的统计量t的计算公式上可看出);二是要求的置信度1-α的大小(或说是指定的显著性水平);三是样本规模的大小,四是检验的方向。在降低对做结论的把握的要求、增大样本规模的条件下,一个完全没有实际意义的差异或处理效应可以取得统计显著的结果。 大样本比较容易获得统计显著性的结果,但这并不意味着差异是有意义的。例如如果有两个省的平均收入相差0.001元,由于样本规模达到几千万,这一微小差异在统计上一定是显著的。一个很容易的检测方法是在SPSS有关窗口下,将一套数据复制下来,再贴到原来的数据之后。这样以来,样本规模扩大了一倍。统计结果仍然保持原来的水平不变(数据的实际意义不变),但显著性水平得到了明显的提高。 由于样本容量影响显著性水平,故即使统计检验显著,仍然应检查有实际意义的有关指标,如典型相关系数的平方所代表的典型变量之间的共享方差比例到底有多大,以判断其有无实际意义。反过来,统计不显著时,也许是因为样本容
集肤效应及深度计算及涡流的相关知识
定义 集肤效应(skin effect)又叫趋肤效应,表皮效应,当交变电流通过导体时,电流将趋于导体表面流过,这种现象叫集肤效应。电流以较高的频率在导体中传导时,会聚集于导体表层,而非平均分布于整个导体的截面积中。频率越高,趋肤效用越显著。 原理 因为当导线流过交变电流时,根据楞次定律会在导线内部产生涡流,与导线中心电流方向相反,。由于导线中心较导线表面的磁链大,在导线中心处产生的电动势就比在导线表面附近处产生的电动势大。这样作用的结果,电流在表面流动,中心则无电流,这种由导线本身电流产生之磁场使导线电流在表面流动。 集肤效应是电磁学,涡流学(涡旋电流)的术语。这种现象是由通电铁磁性材料,靠近未通电的铁磁性材料,在未通电的铁磁性材料表面产生方向相反的磁场,有了磁场就会产生切割磁力线的电流,这个电流就是所谓的涡旋电流,这个现象就是集肤效应。 计算公式 我们可以计算交变电流集肤效应的深度:δ=1/sqrt(1/2*w*σ*μ) 其中,w是交流电频率,σ是导体电导率,μ是导体磁通率(相对磁导率)。 16MnC5按低碳合金钢σ为1.4*10-7欧/厘米;μ按500计算,w按目前使用的17kHz计算δ=1/sqrt(1/2*w*σ*μ) =13.68mm,目前齿套最厚处为9mm。 如用公式 则δ=δ=56.4 √(p/u r f)=1.23mm 涡流百度百科 涡流抑制 大块的导体在磁场中运动或处在变化的磁场中,都要产生感应电动势,形成涡流,引起较大
的涡流损耗。为减少涡流损耗,常将铁心用许多铁磁导体薄片(例如硅钢片)叠成,这些薄片被分开呈梯形状,表面涂有薄层绝缘漆或绝缘的氧化物。磁场穿过薄片的狭窄截面时,涡流被限制在沿各片中的一些狭小回路流过,这些回路中的净电动势较小,回路的长度较大,再由于这种薄片材料的电阻率大,这样就可以显著地减小涡流损耗。所以,交流电机、电器中广泛采用叠片铁心。 当然,在生产和生活中,有时也要避免涡流效应。如电机、变压器的铁芯在工作时会产生涡流,增加能耗,并导致变压器发热。要减少涡流,可采用的方法是把整块铁芯改成用薄片叠压的铁芯,增大回路电阻,削弱回路电流,减少发热损失。
功效和样本量
功效和样本量 一、概述: 使用Mini tab 的功效和样本数量功能在设计和运行试验之前(预期)或执行试验之后(回顾)评估功效和样本数量。 预期研究在收集数据之前使用以考虑设计敏感度。您要确保功效足够大,以检测出您确定为重要的差值(效应)。例如,您可以通过增大样本数量或采取措施降低错误方差来提高设计敏感度。 回顾研究在收集数据之后使用以帮助了解已执行的检验的功效。例如,假设您进行一项试验,但数据分析并未显示任何在统计意义上显著的结果。然后可以根据所希望检测到的最小差异(效应)计算功效。如果检测此差值的功效较低,则您可能要修改试验设计以提高功效并继续评估相同问题。但是,如果功效值较高,则您可能要断定不存在有意义的差值(效应),并停止试验。 什么是功效? 功效是当确实存在显著差值(效应)时能够将其认定的可能性。假设检验有四种可能的结果。结果取决于原假设(H。)为真还是假,以及您决定“否定”还是 “不能否定” H。。检验的功效就是当H。为假时正确地将其否定的概率。 这四种可能的结果总结如下: 原假设 决策直 /、假 不能否定H o正确决策类型II错误 p = 1p = 否定H o类型1错昔误正确决策 p =p = 1 当H。为真而却否定它时,就发生了类型I错误。发生类型I错误的概率(p)称为alpha (),有时称为检验的显著性水平。 当H。为假却没有否定它时,就发生了类型II错误。发生类型II错误的概率称为beta ()。 选择概率水平 当确定检验的和值的时候,应该考虑
发生错误的严重程度错误越严重,越希望少发生这种情况。因此, 应该向更严重的错误指定更小的概率值。 要检测的效应的量值功效是当H。为假时正确否定它的概率(p = 1 -)。理想状态下,您检测所关注的差值时要有高功效,检测没有意义的差值时要有低功效。 例如,假设您制造储存容器,并要评估一种潜在更耐高温的新型塑料。如果新型塑料将产品的平均熔点提高20°或更多,则这项支出就值得考虑。检验更多的样本可以增大检测出此类差异的机会,但是检验过多的样本会增加时间和费用,还可能检测到不重要的差异。您可以使用双样本t的功效和样本数量来估计检测具有足够功效的差值20。需要多少样本。 影响功效的因子 许多因子都影响功效: ,发生类型I错误的概率(也称为显著性水平)。当增大时,发生类型II错误()的概率减小。因此,当增大时,功效(等于1 ) 也随之增大。 ,总体的变异性(或试验变异性)。当减小时,功效也随之 减小。 效应的大小。当效应大小增大时,功效也随之增大。 样本数量。当样本数量增大时,功效也随之增大。 补充内容:估计标准误 对于“功效和样本数量”的计算,(总体标准差或试验变异性)的估计值取决 于您是否已经收集了数据。 预期研究在收集数据前进行,因此必须估计。您可以使用相关研究、初步研究或学科知识来估计。 回顾研究在数据收集后进行,因此可以使用数据估计。 对于单样本Z或单样本t,使用样本的标准差。
统计功效和效应值(讲稿1)
统计功效与效应量 华中师范大学心理学院刘华山 一、统计功效(检验功效,效力,Power) 统计功效指某检验能够正确地拒绝一个错误的虚无假设的能力。用1-β表示。 或说:当总体实际上存在差异(备择假设H1为真),应该拒绝虚无假设时,正确地拒绝虚无假设的概率,或不犯β错误的概率。它表示某个检验探查出实际存在的差异,正确拒绝虚无假设的能力。在实验设计中,统计功效反映了假设检验能够正确侦查到真实的处理效应的能力。 ◆单总体检验 ◆α错误的解释 ◆β错误的解释 ◆统计功效1-β ◆决定统计功效的条件 统计功效的大小取决于四个条件: 1.两总体差异。当两总体实有差异越大,或处理效应越大,则假设检验的统计功效越大;(在α错误概率不变的情况下,1-β变大) 2.显著性标准α:也称显著性水平,是一个特定的值,一个决策标准。通过p与α的决策比较,作出统计决策。 而当假设H0是真实的时候,观察到的差异完全是由随机误差所致的概率称为观察概率p。 显著性标准α越大,则β错误越小,从而统计功效1-β越大;反之,α变小,1-β变小 3.检验的方向:当两总体差异一定,对于同样的显著性标准α,单侧检验比双侧检验的统计功效要大。 4.样本容量。样本容量越大,样本平均数分布的标准误越小,分布曲线越瘦削,统计功效越大。
二、效应量 (效应大小,Effect Size,ES ) 效应量,反映处理效应大小的度量。效应量表示两个总体分布的重叠程度。ES越大,表示两总体重叠的程度越小,效应越明显。其实,两样本平均数的差异本身就是一个效应量。由计算出的ES大小,可由专门的表格中查出两样本分布的重叠的百分比。故效应量经常用两总体重叠的程度为指标,重叠的部分百分比越大,效应量越小。或以两个样本不重叠的程度为指标,不重叠的部分百分比越大,效应量越大。 三、效应量检验的功能 1.效应量有助于我们判断统计上显著差异是否有实际的意义 已有统计显著性检验的条件下,检验效应大小的必要性: 统计显著性与实际显著性的区别:差异的统计显著性、相关的统计显著性只是告诉你在特定的条件下,这差异、这相关系数是存在的、并不是完全由抽样误差造成的,但并不意味着这差异有实际意义。统计量是否显著,是在一定条件下取得的,这条件与与上述统计功效的条件是一致的。也就是说差异是否显著受几个条件影响:一是实际差异的大小,或处理效应的大小(从t检验的待检验的统计量t的计算公式上可看出);二是要求的置信度1-α的大小(或说是指定的显著性水平);三是样本规模的大小,四是检验的方向。在降低对做结论的把握的要求、增大样本规模的条件下,一个完全没有实际意义的差异或处理效应可以取得统计显著的结果。 大样本比较容易获得统计显著性的结果,但这并不意味着差异是有意义的。例如如果有两个省的平均收入相差0.001元,由于样本规模达到几千万,这一微小差异在统计上一定是显著的。一个很容易的检测方法是在SPSS有关窗口下,将一套数据复制下来,再贴到原来的数据之后。这样以来,样本规模扩大了一倍。统计结果仍然保持原来的水平不变(数据的实际意义不变),但显著性水平得到了明显的提高。 由于样本容量影响显著性水平,故即使统计检验显著,仍然应检查有实际意义的有关指标,如典型相关系数的平方所代表的典型变量之间的共享方差比例到底有多大,以判断其有无实际意义。反过来,统计不显著时,也许是因为样本容量太小。此时典型相关系数的平方仍然可以提供信息,以判断是否值得收集更多
数据的统计描述和分析
第十章 数据的统计描述和分析 数理统计研究的对象是受随机因素影响的数据,以下数理统计就简称统计,统计是以概率论为基础的一门应用学科。 数据样本少则几个,多则成千上万,人们希望能用少数几个包含其最多相关信息的数值来体现数据样本总体的规律。描述性统计就是搜集、整理、加工和分析统计数据,使之系统化、条理化,以显示出数据资料的趋势、特征和数量关系。它是统计推断的基础,实用性较强,在统计工作中经常使用。 面对一批数据如何进行描述与分析,需要掌握参数估计和假设检验这两个数理统计的最基本方法。 我们将用Matlab 的统计工具箱(Statistics Toolbox)来实现数据的统计描述和分析。 §1 统计的基本概念 1.1 总体和样本 总体是人们研究对象的全体,又称母体,如工厂一天生产的全部产品(按合格品及废品分类),学校全体学生的身高。 总体中的每一个基本单位称为个体,个体的特征用一个变量(如x )来表示,如一件产品是合格品记0=x ,是废品记1=x ;一个身高170(cm )的学生记170=x 。 从总体中随机产生的若干个个体的集合称为样本,或子样,如n 件产品,100名学生的身高,或者一根轴直径的10次测量。实际上这就是从总体中随机取得的一批数据,不妨记作n x x x ,,,21 ,n 称为样本容量。 简单地说,统计的任务是由样本推断总体。 1.2 频数表和直方图 一组数据(样本)往往是杂乱无章的,作出它的频数表和直方图,可以看作是对这组数据的一个初步整理和直观描述。 将数据的取值范围划分为若干个区间,然后统计这组数据在每个区间中出现的次数,称为频数,由此得到一个频数表。以数据的取值为横坐标,频数为纵坐标,画出一个阶梯形的图,称为直方图,或频数分布图。 若样本容量不大,能够手工作出频数表和直方图,当样本容量较大时则可以借助Matlab 这样的软件了。让我们以下面的例子为例,介绍频数表和直方图的作法。 例1 学生的身高和体重
第一讲 作用与作用效应
前言 一、本课程内容简介 结构的功能就是满足安全、适用和耐久,概括起来称为结构的可靠性。 结构的设计就是通过一定的设计方法确保结构在各种作用(荷载)作用下的可靠性。 本课程全面系统 地介绍了各种荷 载(作用)的概念 、原理和确定方 法;极限状态设 计法。 土木工程系黄林
二、教学内容与要求 本课程将讲授5章,其中第1到4章讲“作用”,第5章讲“设计方法”。 第1章作用与作用效应(了解)2节 第2章重力作用(熟悉)8节 第3章风荷载(熟悉)8节 第4章地震作用(熟悉)6节 第5章概率极限状态设计法(熟悉)6节 前言 土木工程系黄林 三、课程性质选修、考查 四、教学安排 第9到17周,共32学时 五、考试 本课程结束时进行 前言 六、参考资料 1.赵阳《荷载与结构设计方法》重庆大学出版社,2001 2.柳炳康《荷载与结构设计方法》武汉理工大学出版社,2003 3.建筑结构荷载规范GB50009-2012 4.公路桥涵设计通用规范JTG D60-2004 5.公路工程抗震规范JTG B02-2013 6.建筑抗震设计规范GB50011-2010 土木工程系黄林
第1讲作用与作用效应 本讲要点 1、作用与作用效应的概念 2、名词术语: 作用、作用效应、设计基准期、荷载(作用)标准值、荷载(作用)准永久值、荷载(作用)频遇值 为了您的美好前途,请认真听讲,谢谢!土木工程系黄林
1.1结构上的作用 结构:能承受作用并具有适当刚度 的由各连接部件有机结合而成的系 统,如桥梁结构、房屋建筑。 第1讲作用与作用效应 作用:施加在结构上的集中力或分布力和引起结构外加变形或约束变形的原因。 土木工程系黄林 第1讲作用与作用效应 1.1结构上的作用 1.按形式分类 直接作用:力;结构自重、车辆、人群、家具、设备等 间接作用:变形;砼收缩徐变、基础沉降、温度作用、地震等 2.按时间的变化分类 永久作用:不变或变化缓慢;结构自重、基础沉降可变作用:变化值不能忽略;车辆、人群、风荷载 偶然作用:出现时间不定,持续时间短但值很大;地震、船撞 3.按空间的变化分类 固定作用:空间位置固定;结构自重、固定设备荷载自由作用:空间位置不固定;车辆、人群4.按结构反应分类静态作用:结构加速度可忽略;结构自重、人群动态作用:结构加速度不能忽略;地震、车辆、风荷载(柔)土木工程系黄林士兵过桥 1849 法国 1906 沙皇俄国1831 英国
集肤深度概念及公式
集肤效应 1.解释 集肤效应(skin effect)又叫趋肤效应,当交变电流通过导体时,电流将集中在导体表面流过,这种现象叫集肤效应。电流或电压以频率较高的电子在导体中传导时,会聚集于导体表层,而非平均分布于整个导体的截面积中。频率越高,趋肤效用越显著。 因为当导线流过交变电流时,在导线内部将产生与电流方向相反的电动势。由于导线中心较导线表面的磁链大,在导线中心处产生的电动势就比在导线表面附近处产生的电动势大。这样作用的结果,电流在表面流动,中心则无电流,这种由导线本身电流产生之磁场使导线电流在表面流动。 集肤效应是电磁学,涡流学(涡旋电流)的术语。这种现象是由通电铁磁性材料,靠近未通电的铁磁性材料,在未通电的铁磁性材料表面产生方向相反的磁场,有了磁场就会产生切割磁力线的电流,这个电流就是所谓的涡旋电流,这个现象就是集肤效应。 2.影响及应用 在高频电路中可以采用空心导线代替实心导线。此外,为了削弱趋肤效应,在高频电路中也往往使用多股相互绝缘细导线编织成束来代替同样截面积的粗导线,这种多股线束称为辫线。在工业应用方面,利用趋肤效应可以对金属进行表面淬火。 考虑到交流电的集肤效应,为了有效地利用导体材料和便于散热,发电厂的大电流母线常做成槽形或菱形母线;另外,在高压输配
电线路中,利用钢芯铝绞线代替铝绞线,这样既节省了铝导线,又增加了导线的机械强度,这些都是利用了集肤效应这个原理。 集肤效应是在讯号线里最基本的失真作用过程之一,也有可能是最容意被忽略误解的。与一般讯号线的夸大宣传所言,集肤效应并不会改变所有的高频讯号,并且不会造成任何相关动能的损失。正好相反,集肤效应会因传导体的不同成分,在传递高频讯号时有不连贯的现象。同样地,在陈旧的线束传导体上,集肤效应助长讯号电流在多条线束上的交互跳动,对于声音造成刺耳的记号。 3. 集肤深度计算公式 δ 集肤效应频率(Hz) 角频率 δ=√2/(ωμξ)f=100000 ω =2πf 材名称铜铝 ω角频率628318 628318 μ(H/m) 磁导率 ξ(1/Ωm)电导率(20℃) .14 .05 δ集肤深度(mm)
数据的统计描述和分析
第十章数据的统计描述和分析 数理统计研究的对象是受随机因素影响的数据,以下数理统计就简称统计,统计是以概率论为基础的一门应用学科。 数据样本少则几个,多则成千上万,人们希望能用少数几个包含其最多相关信息的数值来体现数据样本总体的规律。描述性统计就是搜集、整理、加工和分析统计数据,使之系统化、条理化,以显示出数据资料的趋势、特征和数量关系。它是统计推断的基础,实用性较强,在统计工作中经常使用。 面对一批数据如何进行描述与分析,需要掌握参数估计和假设检验这两个数理统计的最基本方法。 我们将用Matlab的统计工具箱(Statistics Toolbox)来实现数据的统计描述和分析。 § 1 统计的基本概念 1.1总体和样本 总体是人们研究对象的全体,又称母体,如工厂一天生产的全部产品(按合格品及废品分类),学校全体学生的身高。 总体中的每一个基本单位称为个体,个体的特征用一个变量(如x)来表示,如 一件产品是合格品记X =0,是废品记x =1;一个身高170(cm)的学生记X = 170。 从总体中随机产生的若干个个体的集合称为样本,或子样,如n件产品,100名 学生的身高,或者一根轴直径的10次测量。实际上这就是从总体中随机取得的一批数 据,不妨记作x1,x2 ,L ,x n,n称为样本容量。 简单地说,统计的任务是由样本推断总体。 1.2频数表和直方图 一组数据(样本)往往是杂乱无章的,作出它的频数表和直方图,可以看作是对这组数据的一个初步整理和直观描述。 将数据的取值范围划分为若干个区间,然后统计这组数据在每个区间中出现的次数,称为频数,由此得到一个频数表。以数据的取值为横坐标,频数为纵坐标,画出一个阶梯形的图,称为直方图,或频数分布图。 若样本容量不大,能够手工作出频数表和直方图,当样本容量较大时则可以借助Matlab这样的软件了。让我们以下面的例子为例,介绍频数表和直方图的作法。 例1学生的身高和体重 学校随机抽取100名学生,测量他们的身高和体重,所得数据如表 身高体重身高体重身高体重身高体重身高体重 172 75 169 55 169 64 171 65 167 47 171 62 168 67 165 52 169 62 168 65 166 62 168 65 164 59 170 58 165 64 160 55 175 67 173 74 172 64 168 57 155 57 176 64 172 69 169 58 176 57 173 58 168 50 169 52 167 72 170 57 166 55 161 49 173 57 175 76 158 51 170 63 169 63 173 61 164 59 165 62 167 53 171 61 166 70 166 63 172 53 173 60 178 64 163 57 169 54 169 66 178 60 177 66 170 56 167 54 169 58 173 73 170 58 160 65 179 62 172 50
(完整版)统计功效和效应值(重要内容)
统计功效与效应大小 华中师范大学心理学院刘华山 一、统计功效(检验功效,效力,Power) 统计功效指某检验能够正确地拒绝一个错误的虚无假设的能力。用1-β表示。 或说:当总体实际上存在差异,应该拒绝虚无假设时,正确地拒绝虚无假设的概率,或不犯β错误的概率。在实验设计中,统计功效反映了假设检验能够正确侦查到真实的处理效应的能力。 统计功效的大小取决于四个条件: 1.两总体差异。 2.显著性标准α。 显著性标准α越大,则β错误越小,从而统计功效1-β越大。 3.检验的方向:当两总体差异一定,对于同样的显著性标准α,单侧检验比双侧检验的统计功效要大。 4.样本容量。样本容量越大,样本平均数分布的标准误越小,分布曲线越瘦削,统计功效越大。 二、效应量 (Effect Size,ES ) 效应量,反映处理效应大小的度量。其实,两样本平均数的差异就是一个效应量。效应量表示两个总体分布的重叠程度。ES越大,表示两总体重叠的程度越小,效应越明显。 三、效应量检验的功能 1.效应量有助于我们判断统计上显著差异是否有实际的意义。 2.有些效应量,如相关系数,点二列相关系数的平方r pb2,η2,可以反映自变量解释因变量变异的百分比。 3.在同一个实验中,如果有几个自变量,可以根据效应量大小对自变量的重 要性排序。 4.原分析的基础。在元分析中,将各个不同的相关研究进行概括分析的基础便是各个不同研究的效应量。
5. 效果量的计算还为改进研究设计、 提高检验能力提供了根据。 APA 出版手册第五版要求报告差异检验结果时一般要报告SE 值。 四、效应量和统计功效 前述检验功效与两总体差异(或说处理效应大小)、样本容量、显著性水平、检验的方向性四个因素有关。而两总体差异大小、两样本分布的重叠恰恰是与效应量有关的概念。可见,效应量和统计功效有关。统计功效受效应量的制约。在检验方向、样本容量、显著性水平固定的条件下,效应量与检验功效有对应关系。见下表。【独立样本】 表 在0.05水平下假设检验的功效 样本容量 效应大小 0.2 0.5 0.8 单尾 10 0.11 0.29 0.53 20 0.15 0.46 0.80 30 0.19 0.61 0.92 40 0.22 0.72 0.97 50 0.26 0.80 0.99 100 0.41 0.97 1.00 双尾 10 0.07 0.18 0.39 20 0.09 0.33 0.69 30 0.12 0.47 0.86 40 0.14 0.60 0.94 50 0.17 0.70 0.94 100 0.29 0.94 1.00 五、独立样本t 检验的效应大小 . 1,1除d s Cohen'.122112 12 122 1——,其中以两样本自由度之和 本离差平方和之和即两样算术平方根,合成方差是两个样本合成方差的,而—n df n df df df ss ss S S S X X p p P ==++= =
第2章统计数据的描述
第二章统计数据的描述 一、单项选择题 1.下列中,最粗略、计量层次最低的计量尺度是() A.间隔尺度 B.顺序尺度 C.比例尺度 D.列名尺度 2.将全国人口按“民族”划分为汉、白、彝、回、藏…..,这里使用的计量尺度是() A.比例尺度 B.列名尺度 C.间隔尺度 D.顺序尺度 3.某个人对某一事物的态度可以划分为非常同意、同意、保持中立、不同意、非常不同意,这里使用的计量尺度是() A.列名尺度 B.间隔尺度 C.顺序尺度 D.比例尺度 4.下列中,计量层次的最高、最精确的计量尺度是() A.比例尺度 B.间隔尺度 C.顺序尺度 D.列名尺度 5.下列调查方式中,只能调查一些最基本、最一般现象的调查方式是() A.抽样调查 B.重点调查和典型调查 C.统计报表 D.普查 6.实际中应用最为广泛的一种调查方式是() A.重点调查 B.统计报表 C.普查 D.抽样调查 7.某城市拟对占全市储蓄额4/5的几个大储蓄所进行调查,以了解全市储蓄的一般情况,则这种调查方式是() A.抽样调查 B.典型调查 C.重点调查 D.普查 8.一次性调查是指() A.只做过一次的调查 B.调查一次以后不再调查 C.间隔一段时间在进行一次调查 D.只隔一年就进行一次的调查 9.在统计分析中,对累积的次数分配用得最直接的是() A.供给曲线 B.需求曲线 C.洛伦茨曲线 D.边际需求曲线 10.专门用来衡量和反映收入分配平均程度的统计指标是() A.基尼系数 B.可决系数 C.相关系数 D.离散系数 11.一般认为,基尼系数在()之间是比较恰当的。
A.0.1— —0.4 C.— —0..8 12.一般认为,基尼系数等于( )是收入分配不公平的警戒线。 A.0.2 B.0.6 C. 利用公式计算众数的基本假定之一是众数组的频数在该组内呈( ) A.正态分布 分布 C.均匀分布 D.偏态分布 14.计算中位数时,假定中位数所在组的频数在该组内呈( ) A.左偏分布 B.正态分布 C.右偏分布 D.均匀分布 15.反映数据分布集中趋势的最主要的测度值是( ) A.众数 B.中位数 C.均值 D.几何平均数 16.各个变量值与均值的离差之和( ) A.大于0 B.小于0 C.等于0 D.等于一个不为0的常数 17.各个变量值与均值的离差平方和( ) A.为最大 B.为最小 C.为0 D.为一个不为0的常数 18.下列中,专门用来衡量众数代表性大小的离散程度测度值是( ) A.异众比率 B.四分位差 C.方差或标准差 D.极差 19.下列中,专门用来衡量中位数代表性大小的离散程度测度值是( ) A.方差和标准差 B.内距 C.异众比率 D.平均差 20.下列中,适用于列名数据的集中趋势测度值是( ) A.众数 B.中位数 C.均值 D.几何均值 21.描述数据离散程度最简单的测度值是( ) A.平均差 B.方差和标准差 C.极差 D.四分位差 22.经验法则表明,当一组数据呈对称分布时,大约有95%的数据在( )范围之内。 A.σ±X B.σ2±X C.σ3±X D.σ4±X 23.用来对两组数据的差异程度进行比较的统计分析指标是( ) A.基尼系数 B.标准差系数 C.相关系数 D.可决系数 24.测定数据分布偏斜程度需要计算( )