数据挖掘实验一

实验一准备Analysis Services 数据库
1. 实验目标
?复习SQL 语句以及SQL Server2008基本操作
?创建Analysis Services 项目
?创建数据源
?创建数据源视图
2. 实验要求
(1)按“实验内容”完成操作,并记录实验步骤;
(2)源代码记入实验结果,并说明实现的功能与效果;
(3)回答“问题讨论”中的思考题,并写出本次实验的心得体会;
(4)完成实验报告
(5)所有实验环节均独立完成,严禁抄袭他人实验结果。
3. 实验内容
复习SQL 语句以及SQL Server2008基本操作
根据Analysis Services 项目模板在Business Intelligence Development Studio 中创建SQL Server Analysis Services 项目。创建Analysis Services 项目后,再定义一个或多个数据源。然后,根据选自数据源的表和视图,定义名为“数据源视图”的元数据视图。
创建一个Analysis Services 项目,定义一个单个数据源,并向数据源视图添加一个表子集。包括以下任务:
(1)创建Analysis Services 项目
(2)创建数据源
(3)创建数据源视图
4. 实验步骤
(1)创建Analysis Services 项目
每个Microsoft SQL Server Analysis Services 项目都可为单个Analysis Services 数据库中的对象定义架构。Analysis Services 数据库包含挖掘结构和挖掘模型、联机分析处理(OLAP) 多维数据集和补充对象(例如数据源和数据源视图)。
本次实验将使用AdventureWorks2008R2DW2008 数据库。
默认情况下,Analysis Services 使用新项目的localhost实例。如果使用命名实例或者另一台服务器,则必须首先创建和打开该项目,然后更改实例名称。
创建Analysis Services 项目
1.打开Business Intelligence Development Studio。
2.在“文件”菜单上,指向“新建”,然后选择“项目”。
3.确保已选中“项目类型”窗格中的“商业智能项目”。
4.确保已选中“模板”窗格中的“Analysis Services 项目”。
5.在“名称”框中,将新项目命名为ASDataMining2008。
6.单击“确定”。
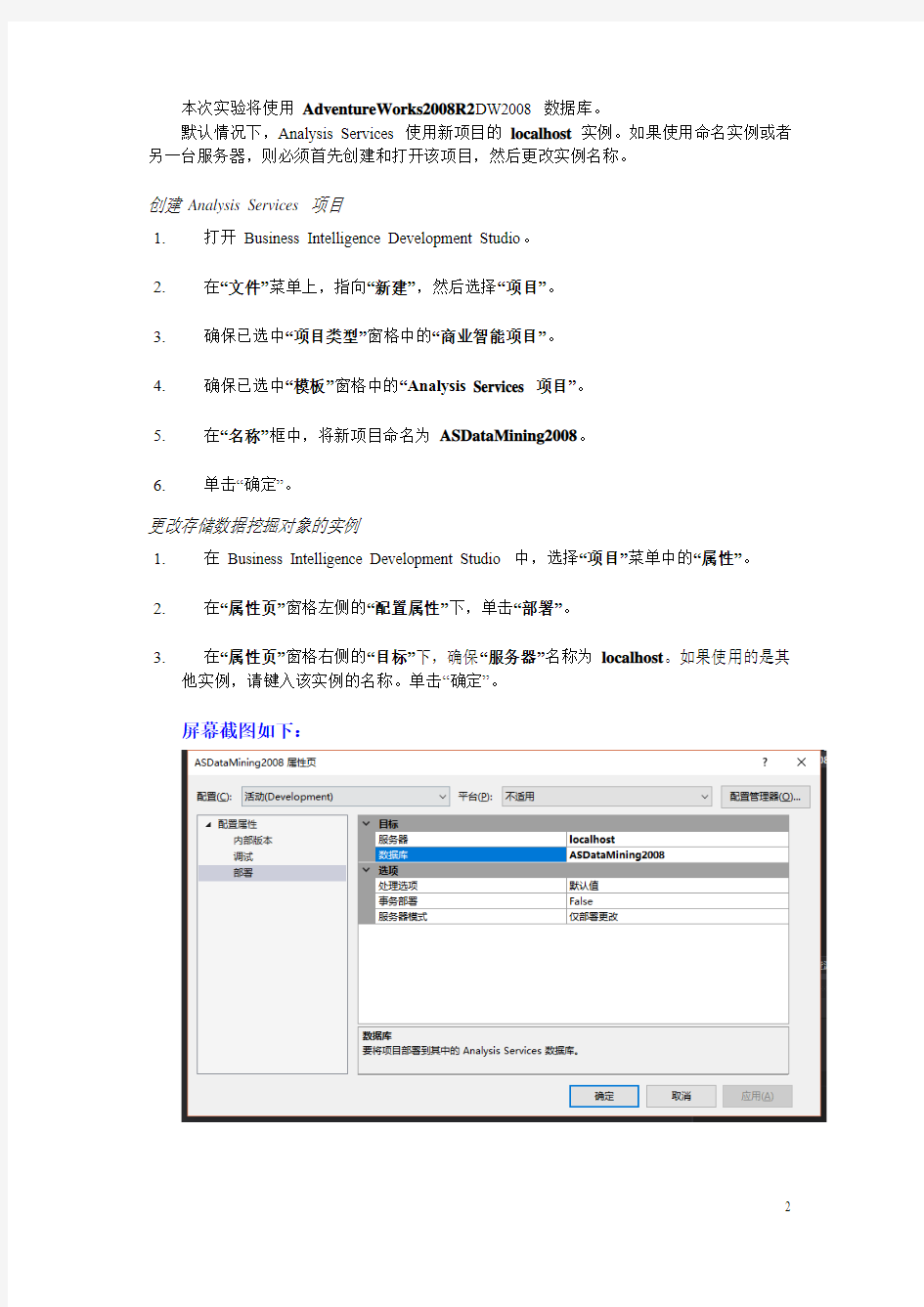
更改存储数据挖掘对象的实例
1.在Business Intelligence Development Studio 中,选择“项目”菜单中的“属性”。
2.在“属性页”窗格左侧的“配置属性”下,单击“部署”。
3.在“属性页”窗格右侧的“目标”下,确保“服务器”名称为localhost。如果使用的是其
他实例,请键入该实例的名称。单击“确定”。
屏幕截图如下:
(2)创建数据源
“数据源”是一种数据连接,在项目中保存和管理,并部署到Microsoft SQL Server Analysis Services 数据库。除了其他所有必需的连接属性外,数据源还包含源数据所在的服务器和数据库的名称。
创建数据源
1.在解决方案资源管理器中,右键单击“数据源”文件夹,然后选择“新建数据源”。
2.在“欢迎使用数据源向导”页面中,单击“下一步”按钮。
3.在“选择如何定义连接”页上,单击“新建”向数据库中添加连接。
4.在连接管理器中的“访问接口”列表中,选择“本机OLE DB\SQL Server Native
Client 10.0”。
5.在“服务器名称”框中,键入或选择安装了的服务器的名称。
例如,如果是在本地服务器上承载该数据库,请键入localhost。
6.在“登录到服务器”组中,选择“使用Windows 身份验证”。
重要提示:
7.在“选择或输入数据库名称”列表中,选择,然后单击“确定”。
8.单击“下一步”。
9.在“模拟信息”页中,单击“使用服务帐户”,再单击“下一步”。
10.在“完成向导”页中,请注意数据源名称默认为。
11.单击“完成”。
此时,解决方案资源管理器的“数据源”文件夹中将出现刚创建的新数据源。
屏幕截图如下:
(3)创建数据源视图
数据源视图是基于数据源生成的,定义用来填充数据仓库的数据的子集。通过数据源视图,您可以修改数据的结构,使它与项目的关系更密切。通过数据源视图,可以选择与特定项目相关的表,建立表之间的关系,并添加计算列和命名视图,而不必修改原始的数据源。
创建数据源视图
1.在解决方案资源管理器中,右键单击“数据源视图”并选择“新建数据源视图”。
2.在“欢迎使用数据源视图向导”页中,单击“下一步”。
3.在“选择数据源”页的“关系数据源”下方,选择在上一个任务中创建的
AdventureWorks2008R2 DW2008数据源。单击“下一步”。
注意:
4.在“选择表和视图”页上,选择下列对象,然后单击右箭头键,将它们包括在新数据
源视图中:
?ProspectiveBuyer (dbo) - 预期自行车购买者的表
?vTargetMail (dbo) - 有关以前的自行车购买者的历史数据的视图
5.单击“下一步”。
6.在“完成向导”页上,系统默认将数据源视图命名为Adventure Works DW2008。将该
名称更改为Targeted Mailing,然后单击“完成”。
新数据源视图随即在“Targeted Mailing.dsv [设计]”选项卡中打开。
屏幕截图如下
5. 实验结果及问题讨论
(1)请说明什么是SSAS的全称是什么?
SQL Server Analysis Service
(2)判断正误:在Analysis Services 项目或数据库中,可以根据一个或多个数据源生成多个数据源视图,并构造每一个数据源视图以满足不同解决方案的要求。
对
(3)基于SSAS的数据挖掘算法有什么?
ID3算法、C4.5算法、FM_CUBE算法等一系列算法。
附录1:报告封面格式
实验报告
姓名:沈承润
学号:1504030320
完成日期:2017-09-30
数据挖掘实验报告
《数据挖掘》Weka实验报告 姓名_学号_ 指导教师 开课学期2015 至2016 学年 2 学期完成日期2015年6月12日
1.实验目的 基于https://www.360docs.net/doc/f614736253.html,/ml/datasets/Breast+Cancer+WiscOnsin+%28Ori- ginal%29的数据,使用数据挖掘中的分类算法,运用Weka平台的基本功能对数据集进行分类,对算法结果进行性能比较,画出性能比较图,另外针对不同数量的训练集进行对比实验,并画出性能比较图训练并测试。 2.实验环境 实验采用Weka平台,数据使用来自https://www.360docs.net/doc/f614736253.html,/ml/Datasets/Br- east+Cancer+WiscOnsin+%28Original%29,主要使用其中的Breast Cancer Wisc- onsin (Original) Data Set数据。Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 3.实验步骤 3.1数据预处理 本实验是针对威斯康辛州(原始)的乳腺癌数据集进行分类,该表含有Sample code number(样本代码),Clump Thickness(丛厚度),Uniformity of Cell Size (均匀的细胞大小),Uniformity of Cell Shape (均匀的细胞形状),Marginal Adhesion(边际粘连),Single Epithelial Cell Size(单一的上皮细胞大小),Bare Nuclei(裸核),Bland Chromatin(平淡的染色质),Normal Nucleoli(正常的核仁),Mitoses(有丝分裂),Class(分类),其中第二项到第十项取值均为1-10,分类中2代表良性,4代表恶性。通过实验,希望能找出患乳腺癌客户各指标的分布情况。 该数据的数据属性如下: 1. Sample code number(numeric),样本代码; 2. Clump Thickness(numeric),丛厚度;
数据挖掘实验三报告
实验三:基于Weka 进行关联规则挖掘 实验步骤 1.利用Weka对数据集contact-lenses.arff进行Apriori关联规则挖掘。要求: 描述数据集;解释Apriori 算法及流程;解释Weka 中有关Apriori 的参数;解释输出结果 Apriori 算法: 1、发现频繁项集,过程为 (1)扫描 (2)计数 (3)比较 (4)产生频繁项集 (5)连接、剪枝,产生候选项集 (6)重复步骤(1)~(5)直到不能发现更大的频集 2、产生关联规则 (1)对于每个频繁项集L,产生L的所有非空子集; (2)对于L的每个非空子集S,如果 P(L)/P(S)≧min_conf(最小置信度阈值) 则输出规则“S=>L-S” Weka 中有关Apriori 的参数:
1. car 如果设为真,则会挖掘类关联规则而不是全局关联规则。 2. classindex 类属性索引。如果设置为-1,最后的属性被当做类属性。 3.delta 以此数值为迭代递减单位。不断减小支持度直至达到最小支持度或产生了满足数量要求的规则。 4. lowerBoundMinSupport 最小支持度下界。 5. metricType 度量类型。设置对规则进行排序的度量依据。可以是:置信度(类关联规则只能用置信度挖掘),提升度(lift),杠杆率(leverage),确信度(conviction)。 在Weka中设置了几个类似置信度(confidence)的度量来衡量规则的关联程度,它们分别是: a)Lift :P(A,B)/(P(A)P(B)) Lift=1时表示A和B独立。这个数越大(>1),越表明A和B存在于一个购物篮中不是偶然现象,有较强的关联度. b)Leverage :P(A,B)-P(A)P(B) Leverage=0时A和B独立,Leverage越大A和B的关系越密切
数据挖掘实验报告(一)
数据挖掘实验报告(一) 数据预处理 姓名:李圣杰 班级:计算机1304 学号:1311610602
一、实验目的 1.学习均值平滑,中值平滑,边界值平滑的基本原理 2.掌握链表的使用方法 3.掌握文件读取的方法 二、实验设备 PC一台,dev-c++5.11 三、实验内容 数据平滑 假定用于分析的数据包含属性age。数据元组中age的值如下(按递增序):13, 15, 16, 16, 19, 20, 20, 21, 22, 22, 25, 25, 25, 25, 30, 33, 33, 35, 35, 35, 35, 36, 40, 45, 46, 52, 70。使用你所熟悉的程序设计语言进行编程,实现如下功能(要求程序具有通用性): (a) 使用按箱平均值平滑法对以上数据进行平滑,箱的深度为3。 (b) 使用按箱中值平滑法对以上数据进行平滑,箱的深度为3。 (c) 使用按箱边界值平滑法对以上数据进行平滑,箱的深度为3。 四、实验原理 使用c语言,对数据文件进行读取,存入带头节点的指针链表中,同时计数,均值求三个数的平均值,中值求中间的一个数的值,边界值将中间的数转换为离边界较近的边界值 五、实验步骤 代码 #include
数据挖掘实验报告资料
大数据理论与技术读书报告 -----K最近邻分类算法 指导老师: 陈莉 学生姓名: 李阳帆 学号: 201531467 专业: 计算机技术 日期 :2016年8月31日
摘要 数据挖掘是机器学习领域内广泛研究的知识领域,是将人工智能技术和数据库技术紧密结合,让计算机帮助人们从庞大的数据中智能地、自动地提取出有价值的知识模式,以满足人们不同应用的需要。K 近邻算法(KNN)是基于统计的分类方法,是大数据理论与分析的分类算法中比较常用的一种方法。该算法具有直观、无需先验统计知识、无师学习等特点,目前已经成为数据挖掘技术的理论和应用研究方法之一。本文主要研究了K 近邻分类算法,首先简要地介绍了数据挖掘中的各种分类算法,详细地阐述了K 近邻算法的基本原理和应用领域,最后在matlab环境里仿真实现,并对实验结果进行分析,提出了改进的方法。 关键词:K 近邻,聚类算法,权重,复杂度,准确度
1.引言 (1) 2.研究目的与意义 (1) 3.算法思想 (2) 4.算法实现 (2) 4.1 参数设置 (2) 4.2数据集 (2) 4.3实验步骤 (3) 4.4实验结果与分析 (3) 5.总结与反思 (4) 附件1 (6)
1.引言 随着数据库技术的飞速发展,人工智能领域的一个分支—— 机器学习的研究自 20 世纪 50 年代开始以来也取得了很大进展。用数据库管理系统来存储数据,用机器学习的方法来分析数据,挖掘大量数据背后的知识,这两者的结合促成了数据库中的知识发现(Knowledge Discovery in Databases,简记 KDD)的产生,也称作数据挖掘(Data Ming,简记 DM)。 数据挖掘是信息技术自然演化的结果。信息技术的发展大致可以描述为如下的过程:初期的是简单的数据收集和数据库的构造;后来发展到对数据的管理,包括:数据存储、检索以及数据库事务处理;再后来发展到对数据的分析和理解, 这时候出现了数据仓库技术和数据挖掘技术。数据挖掘是涉及数据库和人工智能等学科的一门当前相当活跃的研究领域。 数据挖掘是机器学习领域内广泛研究的知识领域,是将人工智能技术和数据库技术紧密结合,让计算机帮助人们从庞大的数据中智能地、自动地抽取出有价值的知识模式,以满足人们不同应用的需要[1]。目前,数据挖掘已经成为一个具有迫切实现需要的很有前途的热点研究课题。 2.研究目的与意义 近邻方法是在一组历史数据记录中寻找一个或者若干个与当前记录最相似的历史纪录的已知特征值来预测当前记录的未知或遗失特征值[14]。近邻方法是数据挖掘分类算法中比较常用的一种方法。K 近邻算法(简称 KNN)是基于统计的分类方法[15]。KNN 分类算法根据待识样本在特征空间中 K 个最近邻样本中的多数样本的类别来进行分类,因此具有直观、无需先验统计知识、无师学习等特点,从而成为非参数分类的一种重要方法。 大多数分类方法是基于向量空间模型的。当前在分类方法中,对任意两个向量: x= ) ,..., , ( 2 1x x x n和) ,..., , (' ' 2 ' 1 'x x x x n 存在 3 种最通用的距离度量:欧氏距离、余弦距 离[16]和内积[17]。有两种常用的分类策略:一种是计算待分类向量到所有训练集中的向量间的距离:如 K 近邻选择K个距离最小的向量然后进行综合,以决定其类别。另一种是用训练集中的向量构成类别向量,仅计算待分类向量到所有类别向量的距离,选择一个距离最小的类别向量决定类别的归属。很明显,距离计算在分类中起关键作用。由于以上 3 种距离度量不涉及向量的特征之间的关系,这使得距离的计算不精确,从而影响分类的效果。
数据挖掘试验指导书
《商务数据分析》实验指导书(适用于国际经济与贸易专业) 江西财经大学国际经贸学院 编写人:戴爱明
目录 前言 (1) 实验一、SPSS Clementine 软件功能演练 (5) 实验二、SPSS Clementine 数据可视化 (9) 实验三、决策树C5.0 建模 (17) 实验四、关联规则挖掘 (30) 实验五、聚类分析(异常值检测) (38)
前言 一、课程简介 商务数据分析充分利用数据挖掘技术从大量商务数据中获取有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。数据挖掘的广义观点:数据挖掘就是从存放在数据库,数据仓库或其他信息库中的大量的数据中“挖掘”有趣知识的过程。数据挖掘,又称为数据库中知识发现(Knowledge Discovery in Database, KDD),因此,数据挖掘和数据仓库的协同工作,一方面,可以迎合和简化数据挖掘过程中的重要步骤,提高数据挖掘的效率和能力,确保数据挖掘中数据来源的广泛性和完整性。另一方面,数据挖掘技术已经成为数据仓库应用中极为重要和相对独立的方面和工具。 数据挖掘有机结合了来自多学科技术,其中包括:数据库、数理统计、机器学习、高性能计算、模式识别、神经网络、数据可视化、信息检索、图像与信号处理、空间数据分析等,这里我们强调商务数据分析所处理的是大规模数据,且其算法应是高效的和可扩展的。通过数据分析,可从数据库中挖掘出有意义的知识、规律,或更高层次的信息,并可以从多个角度对其进行浏览察看。所挖掘出的知识可以帮助进行商务决策支持。当前商务数据分析应用主要集中在电信、零售、农业、网络日志、银行等方面。
理工大学数据仓库与数据挖掘实验一
昆明理工大学信息工程与自动化学院学生实验报告 (2012 —2013 学年第 1 学期) 课程名称:数据库仓库与数据挖掘开课实验室: 2012 年10月 30日 一、上机目的 1.理解数据库与数据仓库之间的区别与联系; 2.掌握典型的关系型数据库及其数据仓库系统的工作原理以及应用方法; 3.掌握数据仓库建立的基本方法及其相关工具的使用。 二、上机内容 内容:以SQL Server为系统平台,设计、建立数据库,并以此为基础创建数据仓库。 要求:利用实验室和指导教师提供的实验软件,认真完成规定的实验项目,真实地记录实验中遇到的各种问题和解决的方法与过程,并绘出模拟实验案例的数据仓库模型。实验完成后,应根据实验情况写出实验报告。 三、所用仪器、材料(设备名称、型号、规格等或使用软件) 1台PC及SQL 2008软件 四、实验方法、步骤和截图(或:程序代码或操作过程) 采用SQL语句创建数据库,数据库命名为:DW。如图所示:
DW数据库中包含7张维表和一张事实表。7张维表分别为:订单方式维表、销售人员及销售地区维表、发货方式维表、订单日期维表、客户维表、订单状态维表、客户价值维表。建立7张维表语句和建立7张维表的ETL如下: 语句执行成功的结果如图所示:
DW数据库包含的事实表为FACT_SALEORDER。建立1张事实表语句和建立1张事实表的ETL如下: 三、建事实表 CREATE TABLE FACT_SALEORDER( SALEORDERID INT, TIME_CD V ARCHAR(8), STATUS INT, ONLINEORDERFLAG INT, CUSTOMERID INT, SALESPERSONID INT, SHIPMETHOD INT, ORDER_V ALUES INT, SUBTOTAL DECIMAL(10,2), TAXAMT DECIMAL(10,2), FREIGHT DECIMAL(10,2)) ----------------------------------- 四、事实表的ETL /* FACT_SALEORDER的ETL*/ TRUNCATE TABLE FACT_SALEORDER INSERT INTO FACT_SALEORDER SELECT SalesOrderID,CONVERT(CHAR(8),,112) , ,,ISNULL,0),ISNULL,0),,,,, FROM A, V_SUBTOTAL_V ALUES B WHERE >= AND <
数据挖掘实验报告三
实验三 一、实验原理 K-Means算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。 在数据挖掘中,K-Means算法是一种cluster analysis的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。 算法原理: (1) 随机选取k个中心点; (2) 在第j次迭代中,对于每个样本点,选取最近的中心点,归为该类; (3) 更新中心点为每类的均值; (4) j<-j+1 ,重复(2)(3)迭代更新,直至误差小到某个值或者到达一定的迭代步 数,误差不变. 空间复杂度o(N) 时间复杂度o(I*K*N) 其中N为样本点个数,K为中心点个数,I为迭代次数 二、实验目的: 1、利用R实现数据标准化。 2、利用R实现K-Meams聚类过程。 3、了解K-Means聚类算法在客户价值分析实例中的应用。 三、实验内容 依据航空公司客户价值分析的LRFMC模型提取客户信息的LRFMC指标。对其进行标准差标准化并保存后,采用k-means算法完成客户的聚类,分析每类的客户特征,从而获得每类客户的价值。编写R程序,完成客户的k-means聚类,获得聚类中心与类标号,并统计每个类别的客户数
四、实验步骤 1、依据航空公司客户价值分析的LRFMC模型提取客户信息的LRFMC指标。
2、确定要探索分析的变量 3、利用R实现数据标准化。 4、采用k-means算法完成客户的聚类,分析每类的客户特征,从而获得每类客户的价值。
五、实验结果 客户的k-means聚类,获得聚类中心与类标号,并统计每个类别的客户数 六、思考与分析 使用不同的预处理对数据进行变化,在使用k-means算法进行聚类,对比聚类的结果。 kmenas算法首先选择K个初始质心,其中K是用户指定的参数,即所期望的簇的个数。 这样做的前提是我们已经知道数据集中包含多少个簇. 1.与层次聚类结合 经常会产生较好的聚类结果的一个有趣策略是,首先采用层次凝聚算法决定结果
数据挖掘报告
哈尔滨工业大学 数据挖掘理论与算法实验报告(2016年度秋季学期) 课程编码S1300019C 授课教师邹兆年 学生姓名汪瑞 学号 16S003011 学院计算机学院
一、实验内容 决策树算法是一种有监督学习的分类算法;kmeans是一种无监督的聚类算法。 本次实验实现了以上两种算法。在决策树算法中采用了不同的样本划分方式、不同的分支属性的选择标准。在kmeans算法中,比较了不同初始质心产生的差异。 本实验主要使用python语言实现,使用了sklearn包作为实验工具。 二、实验设计 1.决策树算法 1.1读取数据集 本次实验主要使用的数据集是汽车价值数据。有6个属性,命名和属性值分别如下: buying: vhigh, high, med, low. maint: vhigh, high, med, low. doors: 2, 3, 4, 5more. persons: 2, 4, more. lug_boot: small, med, big. safety: low, med, high. 分类属性是汽车价值,共4类,如下: class values:unacc, acc, good, vgood 该数据集不存在空缺值。
由于sklearn.tree只能使用数值数据,因此需要对数据进行预处理,将所有标签类属性值转换为整形。 1.2数据集划分 数据集预处理完毕后,对该数据进行数据集划分。数据集划分方法有hold-out法、k-fold交叉验证法以及有放回抽样法(boottrap)。 Hold—out法在pthon中的实现是使用如下语句: 其中,cv是sklearn中cross_validation包,train_test_split 方法的参数分别是数据集、数据集大小、测试集所占比、随机生成方法的可
数据挖掘分类实验详细报告概论
《数据挖掘分类实验报告》 信息安全科学与工程学院 1120362066 尹雪蓉数据挖掘分类过程 (1)数据分析介绍 本次实验为典型的分类实验,为了便于说明问题,弄清数据挖掘具体流程,我们小组选择了最经典的决策树算法进行具体挖掘实验。 (2)数据准备与预处理 在进行数据挖掘之前,我们首先要对需要挖掘的样本数据进行预处理,预处理包括以下步骤: 1、数据准备,格式统一。将样本转化为等维的数据特征(特征提取),让所有的样 本具有相同数量的特征,同时兼顾特征的全面性和独立性 2、选择与类别相关的特征(特征选择) 3、建立数据训练集和测试集 4、对数据集进行数据清理 在本次实验中,我们选择了ILPD (Indian Liver Patient Dataset) 这个数据集,该数据集已经具有等维的数据特征,主要包括Age、Gender、TB、DB、Alkphos、Sgpt、Sgot、TP、ALB、A/G、classical,一共11个维度的数据特征,其中与分类类别相关的特征为classical,它的类别有1,2两个值。 详见下表: 本实验的主要思路是将该数据集分成训练集和测试集,对训练集进行训练生成模型,然后再根据模型对测试集进行预测。 数据集处理实验详细过程:
●CSV数据源处理 由于下载的原始数据集文件Indian Liver Patient Dataset (ILPD).csv(见下图)中间并不包含属性项,这不利于之后分类的实验操作,所以要对该文件进行处理,使用Notepad文件,手动将属性行添加到文件首行即可。 ●平台数据集格式转换 在后面数据挖掘的实验过程中,我们需要借助开源数据挖掘平台工具软件weka,该平台使用的数据集格式为arff,因此为了便于实验,在这里我们要对csv文件进行格式转换,转换工具为weka自带工具。转换过程为: 1、打开weka平台,点击”Simple CLI“,进入weka命令行界面,如下图所示: 2、输入命令将csv文件导成arff文件,如下图所示: 3、得到arff文件如下图所示: 内容如下:
数据挖掘实验三
实验三设计并构造AdventureWorks数据仓库实例 【实验要求】 在SQL Server 平台上,利用AdventureWorks数据库作为商业智能解决方案的数据源,设计并构造数据仓库,建立OLAP和数据挖掘模型,并以输出报表的形式满足决策支持的查询需求。 【实验内容】 步骤1:需求分析:以决策者的视角分析和设计数据仓库的需求; 步骤2:根据所设计的需求,确定本数据仓库的主题和主题与边界; 步骤3:设计并构造逻辑模型; 步骤4:进行数据转换和抽取,建立数据仓库:创建数据源,,建立OLAP和挖掘模型,使用多维数据集进行分析,建立数据挖掘结构和数据挖掘模型,创建报表。 【实验平台】 Win7操作系统,SQL Server 2005 【实验过程】 一、创建Analysis Services 项目 1.打开Business Intelligence Development Studio。 2.在“文件”菜单上,指向“新建”,然后选择“项目”。 3.确保已选中“模板”窗格中的“Analysis Services 项目”。 4.在“名称”框中,将新项目命名为AdventureWorks。 5. 单击“确定”。 二、创建数据库和数据源 1.运行AdventureWorks sql server 2005示例数据库.msi,然后用SQL Server Management Studio 附加数据库AdventureWorks_Data.mdf 。 (1)运行AdventureWorks sql server 2005示例数据库.msi
(2)用SQL Server Management Studio附加数据库AdventureWorks_Data.mdf
数据挖掘实验报告1
实验一 ID3算法实现 一、实验目的 通过编程实现决策树算法,信息增益的计算、数据子集划分、决策树的构建过程。加深对相关算法的理解过程。 实验类型:验证 计划课间:4学时 二、实验内容 1、分析决策树算法的实现流程; 2、分析信息增益的计算、数据子集划分、决策树的构建过程; 3、根据算法描述编程实现算法,调试运行; 4、对所给数据集进行验算,得到分析结果。 三、实验方法 算法描述: 以代表训练样本的单个结点开始建树; 若样本都在同一个类,则该结点成为树叶,并用该类标记; 否则,算法使用信息增益作为启发信息,选择能够最好地将样本分类的属性; 对测试属性的每个已知值,创建一个分支,并据此划分样本; 算法使用同样的过程,递归形成每个划分上的样本决策树 递归划分步骤,当下列条件之一成立时停止: 给定结点的所有样本属于同一类; 没有剩余属性可以进一步划分样本,在此情况下,采用多数表决进行 四、实验步骤 1、算法实现过程中需要使用的数据结构描述: Struct {int Attrib_Col; // 当前节点对应属性 int Value; // 对应边值 Tree_Node* Left_Node; // 子树 Tree_Node* Right_Node // 同层其他节点 Boolean IsLeaf; // 是否叶子节点 int ClassNo; // 对应分类标号 }Tree_Node; 2、整体算法流程
主程序: InputData(); T=Build_ID3(Data,Record_No, Num_Attrib); OutputRule(T); 释放内存; 3、相关子函数: 3.1、 InputData() { 输入属性集大小Num_Attrib; 输入样本数Num_Record; 分配内存Data[Num_Record][Num_Attrib]; 输入样本数据Data[Num_Record][Num_Attrib]; 获取类别数C(从最后一列中得到); } 3.2、Build_ID3(Data,Record_No, Num_Attrib) { Int Class_Distribute[C]; If (Record_No==0) { return Null } N=new tree_node(); 计算Data中各类的分布情况存入Class_Distribute Temp_Num_Attrib=0; For (i=0;i 数据分析与挖掘实验报告 《数据挖掘》实验报告 目录 1.关联规则的基本概念和方法 (1) 1.1数据挖掘 (1) 1.1.1数据挖掘的概念 (1) 1.1.2数据挖掘的方法与技术 (2) 1.2关联规则 (5) 1.2.1关联规则的概念 (5) 1.2.2关联规则的实现——Apriori算法 (7) 2.用Matlab实现关联规则 (12) 2.1Matlab概述 (12) 2.2基于Matlab的Apriori算法 (13) 3.用java实现关联规则 (19) 3.1java界面描述 (19) 3.2java关键代码描述 (23) 4、实验总结 (29) 4.1实验的不足和改进 (29) 4.2实验心得 (30) 1.关联规则的基本概念和方法 1.1数据挖掘 1.1.1数据挖掘的概念 计算机技术和通信技术的迅猛发展将人类社会带入到了信息时代。在最近十几年里,数据库中存储的数据急剧增大。数据挖掘就是信息技术自然进化的结果。数据挖掘可以从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的,人们事先不知道的但又是潜在有用的信息和知识的过程。 许多人将数据挖掘视为另一个流行词汇数据中的知识发现(KDD)的同义词,而另一些人只是把数据挖掘视为知识发现过程的一个基本步骤。知识发现过程如下: ·数据清理(消除噪声和删除不一致的数据)·数据集成(多种数据源可以组合在一起)·数据转换(从数据库中提取和分析任务相关的数据) ·数据变换(从汇总或聚集操作,把数据变换和统一成适合挖掘的形式) ·数据挖掘(基本步骤,使用智能方法提取数 据模式) ·模式评估(根据某种兴趣度度量,识别代表知识的真正有趣的模式) ·知识表示(使用可视化和知识表示技术,向用户提供挖掘的知识)。 1.1.2数据挖掘的方法与技术 数据挖掘吸纳了诸如数据库和数据仓库技术、统计学、机器学习、高性能计算、模式识别、神经网络、数据可视化、信息检索、图像和信号处理以及空间数据分析技术的集成等许多应用领域的大量技术。数据挖掘主要包括以下方法。神经网络方法:神经网络由于本身良好的鲁棒性、自组织自适应性、并行处理、分布存储和高度容错等特性非常适合解决数据挖掘的问题,因此近年来越来越受到人们的关注。典型的神经网络模型主要分3大类:以感知机、bp反向传播模型、函数型网络为代表的,用于分类、预测和模式识别的前馈式神经网络模型;以hopfield 的离散模型和连续模型为代表的,分别用于联想记忆和优化计算的反馈式神经网络模型;以art 模型、koholon模型为代表的,用于聚类的自组 通信与信息工程学院 课程设计说明书 课程名称: 数据仓库与数据挖掘课程设计题目: 超市商品销售分析及数据挖掘专业/班级: 电子商务(理) 组长: 学号: 组员/学号: 开始时间: 2011 年12 月29 日完成时间: 2012 年01 月 3 日 目录 1.绪论 (1) 1.1项目背景 (1) 1.2提出问题 (1) 2.数据仓库与数据集市的概念介绍 (1) 2.1数据仓库介绍 (1) 2.2数据集市介绍 (2) 3.数据仓库 (3) 3.1数据仓库的设计 (3) 3.1.1数据仓库的概念模型设计 (4) 3.1.2数据仓库的逻辑模型设计 (5) 3.2 数据仓库的建立 (5) 3.2.1数据仓库数据集成 (5) 3.2.2建立维表 (8) 4.OLAP操作 (10) 5.数据预处理 (12) 5.1描述性数据汇总 (12) 5.2数据清理与变换 (13) 6.数据挖掘操作 (13) 6.1关联规则挖掘 (13) 6.2 分类和预测 (17) 6.3决策树的建立 (18) 6.4聚类分析 (22) 7.总结 (25) 8.任务分配 (26) 数据挖掘实验报告 1.绪论 1.1项目背景 在商业领域中使用计算机科学与技术是当今商业的发展方向,而数据挖掘是商业领域与计算机领域的乔梁。在超市的经营中,应用数据挖掘技术分析顾客的购买习惯和不同商品之间的关联,并借由陈列的手法,和合适的促销手段将商品有魅力的展现在顾客的眼前, 可以起到方便购买、节约空间、美化购物环境、激发顾客的购买欲等各种重要作用。 1.2提出问题 那么超市应该对哪些销售信息进行挖掘?怎样挖掘?具体说,超市如何运用OLAP操作和关联规则了解顾客购买习惯和商品之间的关联,正确的摆放商品位置以及如何运用促销手段对商品进行销售呢?如何判断一个顾客的销售水平并进行推荐呢?本次实验为解决这一问题提出了解决方案。 2.数据仓库与数据集市的概念介绍 2.1数据仓库介绍 数据仓库,英文名称为Data Warehouse,可简写为DW或DWH,是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的,它并不是所谓的“大型数据库”。........ 2.2数据集市介绍 数据集市,也叫数据市场,是一个从操作的数据和其他的为某个特殊的专业人员团体服务的数据源中收集数据的仓库。....... 3.数据仓库 3.1数据仓库的设计 3.1.1数据库的概念模型 3.1.2数据仓库的模型 数据仓库的模型主要包括数据仓库的星型模型图,我们创建了四个 实验二:决策树 要求:实现决策树分类算法,在两种不同的数据集上(iris.txt 和wine.txt)比较算法的性能。有趣的故事介绍一下决策树。[白话决策树模 型](https://www.360docs.net/doc/f614736253.html,/shujuwajue/2441.html) 首先第一个数据集iris.txt。 iris数据集记录的是鸢尾植物。Scikit-learn自带了iris数据集。 其中iris.data记录的就是它的四个属性:萼片/花瓣的长和宽。一个150*4的矩阵。 Iris.target就是每一行对应的鸢尾植物的种类,一共有三种。 测试结果: 可以看到,本算法的性能大约是,准确率为0.673333333333。 附录-Python代码: import sys from math import log import operator from numpy import mean def get_labels(train_file): ''' 返回所有数据集labels(列表) ''' labels = [] for index,line in enumerate(open(train_file,'rU').readlines()): label = line.strip().split(',')[-1] labels.append(label) return labels def format_data(dataset_file): ''' 返回dataset(列表集合)和features(列表) ''' dataset = [] for index,line in enumerate(open(dataset_file,'rU').readlines()): line = line.strip() fea_and_label = line.split(',') dataset.append([float(fea_and_label[i]) for i in range(len(fea_and_label)-1)]+[fea_and_label[len(fea_and_label)-1]]) #features = [dataset[0][i] for i in range(len(dataset[0])-1)] #sepal length(花萼长度)、sepal width(花萼宽度)、petal length(花瓣长度)、petal width(花瓣宽度) features = ['sepal_length','sepal_width','petal_length','petal_width'] return dataset,features def split_dataset(dataset,feature_index,labels): ''' 按指定feature划分数据集,返回四个列表: @dataset_less:指定特征项的属性值<=该特征项平均值的子数据集 @dataset_greater:指定特征项的属性值>该特征项平均值的子数据集 @label_less:按指定特征项的属性值<=该特征项平均值切割后子标签集 @label_greater:按指定特征项的属性值>该特征项平均值切割后子标签集 ''' dataset_less = [] dataset_greater = [] label_less = [] label_greater = [] datasets = [] for data in dataset: datasets.append(data[0:4]) mean_value = mean(datasets,axis = 0)[feature_index] #数据集在该特征项的所有取值的平均值 for data in dataset: if data[feature_index] > mean_value: dataset_greater.append(data) label_greater.append(data[-1]) else: dataset_less.append(data) label_less.append(data[-1]) return dataset_less,dataset_greater,label_less,label_greater def cal_entropy(dataset): ''' 计算数据集的熵大小 ''' 数据挖掘实验报告-实验1-W e k a基础操作 学生实验报告 学院:信息管理学院 课程名称:数据挖掘 教学班级: B01 姓名: 学号: 实验报告 课程名称数据挖掘教学班级B01 指导老师 学号姓名行政班级 实验项目实验一: Weka的基本操作 组员名单独立完成 实验类型■操作性实验□验证性实验□综合性实验实验地点H535 实验日期2016.09.28 1. 实验目的和要求: (1)Explorer界面的各项功能; 注意不能与课件上的截图相同,可采用打开不同的数据文件以示区别。 (2)Weka的两种数据表格编辑文件方式下的功能介绍; ①Explorer-Preprocess-edit,弹出Viewer对话框; ②Weka GUI选择器窗口-Tools | ArffViewer,打开ARFF-Viewer窗口。(3)ARFF文件组成。 2.实验过程(记录实验步骤、分析实验结果) 2.1 Explorer界面的各项功能 2.1.1 初始界面示意 其中:explorer选项是数据挖掘梳理数据最常用界面,也是使用weka最简单的方法。 Experimenter:实验者选项,提供不同数值的比较,发现其中规律。 KnowledgeFlow:知识流,其中包含处理大型数据的方法,初学者应用较少。 Simple CLI :命令行窗口,有点像cmd 格式,非图形界面。 2.1.2 进入Explorer 界面功能介绍 (1)任务面板 Preprocess(数据预处理):选择和修改要处理的数据。 Classify(分类):训练和测试分类或回归模型。 Cluster(聚类):从数据中聚类。聚类分析时用的较多。 Associate(关联分析):从数据中学习关联规则。 Select Attributes(选择属性):选择数据中最相关的属性。 Visualize(可视化):查看数据的二维散布图。 (2)常用按钮 实验报告说明 本课程一共需要写两个实验报告: 实验报告一:基于人工神经网络的曲线拟合 实验目的:首先,熟悉人工神经网络的产生背景、算法的思想和原理以及步骤;其次,熟悉人工神经网络的Matlab工具箱;最后,通过对曲线的拟合的实验,熟练掌握神经网络的程序设计。 实验时间:第11周周二9-10节、第12周周二9-10节;学时:4 参考程序: 实验数据集文件名:data.mat %% 清空环境变量 clc clear %% 训练数据预测数据提取及归一化 %下载输入输出数据 load data input output %input 是2000行2列,output是1行2000列 %从1到2000间随机排序 k=rand(1,2000); %随机生成一个1行2000列的矩阵 [m,n]=sort(k); %对矩阵K排序,其中m表示从小到大的排序结果,n表示m中各数据的排序前的索引(位置结果) %产生训练数据和预测数据 input_train=input(n(1:1900),:)'; %input_train为2行1900列的训练的输入矩阵 output_train=output(n(1:1900)); %output_train为1行1900列的训练的输出矩阵 input_test=input(n(1901:2000),:)'; output_test=output(n(1901:2000)); %选连样本输入输出数据归一化 [inputn,inputps]=mapminmax(input_train); % mapminmax是对矩阵的行进行归一化处理,其中inputn为归一化后的数据矩阵,inputps是归一化后的结构体,包含最大值、最小值、平均值等信息 [outputn,outputps]=mapminmax(output_train); %% BP网络训练 % %初始化网络结构 net=newff(inputn,outputn,5); 数据预处理 一、实验原理 预处理方法基本方法 1、数据清洗 去掉噪声和无关数据 2、数据集成 将多个数据源中的数据结合起来存放在一个一致的数据存储中 3、数据变换 把原始数据转换成为适合数据挖掘的形式 4、数据归约 主要方法包括:数据立方体聚集,维归约,数据压缩,数值归约,离散化和概念分层等二、实验目的 掌握数据预处理的基本方法。 三、实验内容 1、R语言初步认识(掌握R程序运行环境) 2、实验数据预处理。(掌握R语言中数据预处理的使用) 对给定的测试用例数据集,进行以下操作。 1)、加载程序,熟悉各按钮的功能。 2)、熟悉各函数的功能,运行程序,并对程序进行分析。 对餐饮销量数据进统计量分析,求销量数据均值、中位数、极差、标准差,变异系数和四分位数间距。 对餐饮企业菜品的盈利贡献度(即菜品盈利帕累托分析),画出帕累托图。 3)数据预处理 缺省值的处理:用均值替换、回归查补和多重查补对缺省值进行处理 对连续属性离散化:用等频、等宽等方法对数据进行离散化处理 四、实验步骤 1、R语言运行环境的安装配置和简单使用 (1)安装R语言 R语言下载安装包,然后进行默认安装,然后安装RStudio 工具(2)R语言控制台的使用 1.2.1查看帮助文档 1.2.2 安装软件包 1.2.3 进行简单的数据操作 (3)RStudio 简单使用 1.3.1 RStudio 中进行简单的数据处理 1.3.2 RStudio 中进行简单的数据处理 2、R语言中数据预处理 (1)加载程序,熟悉各按钮的功能。 (2)熟悉各函数的功能,运行程序,并对程序进行分析 2.2.1 销量中位数、极差、标准差,变异系数和四分位数间距。 , 2.2.2对餐饮企业菜品的盈利贡献度(即菜品盈利帕累托分析),画出帕累托图。 时间序列的模型法和数据挖掘两种方法比较分析研究 实验目的:通过实验能对时间序列的模型法和数据挖掘两种方法的原理和优缺点有更清楚的认识和比较. 实验内容:选用1952-2006年的中国GDP,分别对之用自回归移动平均模型(ARIMA) 和时序模型的数据挖掘方法进行分析和预测,并对两种方法的趋势和预测结果进行比较并给出解 释. 实验数据:本文研究选用1952-2006年的中国GDP,其资料如下 日期国内生产总值(亿元)日期国内生产总值(亿元) 2006-12-312094071997-12-3174772 2005-12-311830851996-12-31 2004-12-311365151995-12-31 2003-12-311994-12-31 2002-12-311993-12-31 2001-12-311992-12-31 2000-12-31894041991-12-31 1999-12-31820541990-12-31 1998-12-31795531989-12-31 1988-12-311969-12-31 1987-12-311968-12-31 1986-12-311967-12-31 1985-12-311966-12-311868 1984-12-3171711965-12-31 1983-12-311964-12-311454 1982-12-311963-12-31 1981-12-311962-12-31 1980-12-311961-12-311220 1979-12-311960-12-311457 1978-12-311959-12-311439 1977-12-311958-12-311307 1976-12-311957-12-311068 1975-12-311956-12-311028 1974-12-311955-12-31910 1973-12-311954-12-31859 1972-12-311953-12-31824 1971-12-311952-12-31679 1970-12-31 表一 国内生产总值(GDP)是指一个国家或地区所有常住单位在一定时期内生产活动的最终成果。这个指标把国民经济全部活动的产出成果概括在一个极为简明的统计数字之中为评价和衡量国家经济状况、经济增长趋势及社会财富的经济表现提供了一个最为综合的尺度,可以说,它是影响经济生活乃至社会生活的最重要的经济指标。对其进行的分析预测具有重要的理论与现实意义。数据分析与挖掘实验报告
数据挖掘实验报告 超市商品销售分析及数据挖掘
数据挖掘实验2
数据挖掘实验报告-实验1-Weka基础操作
数据挖掘实验
数据挖掘实验报告一
数据挖掘实验报告(参考)