httrack模拟搜索引擎爬虫
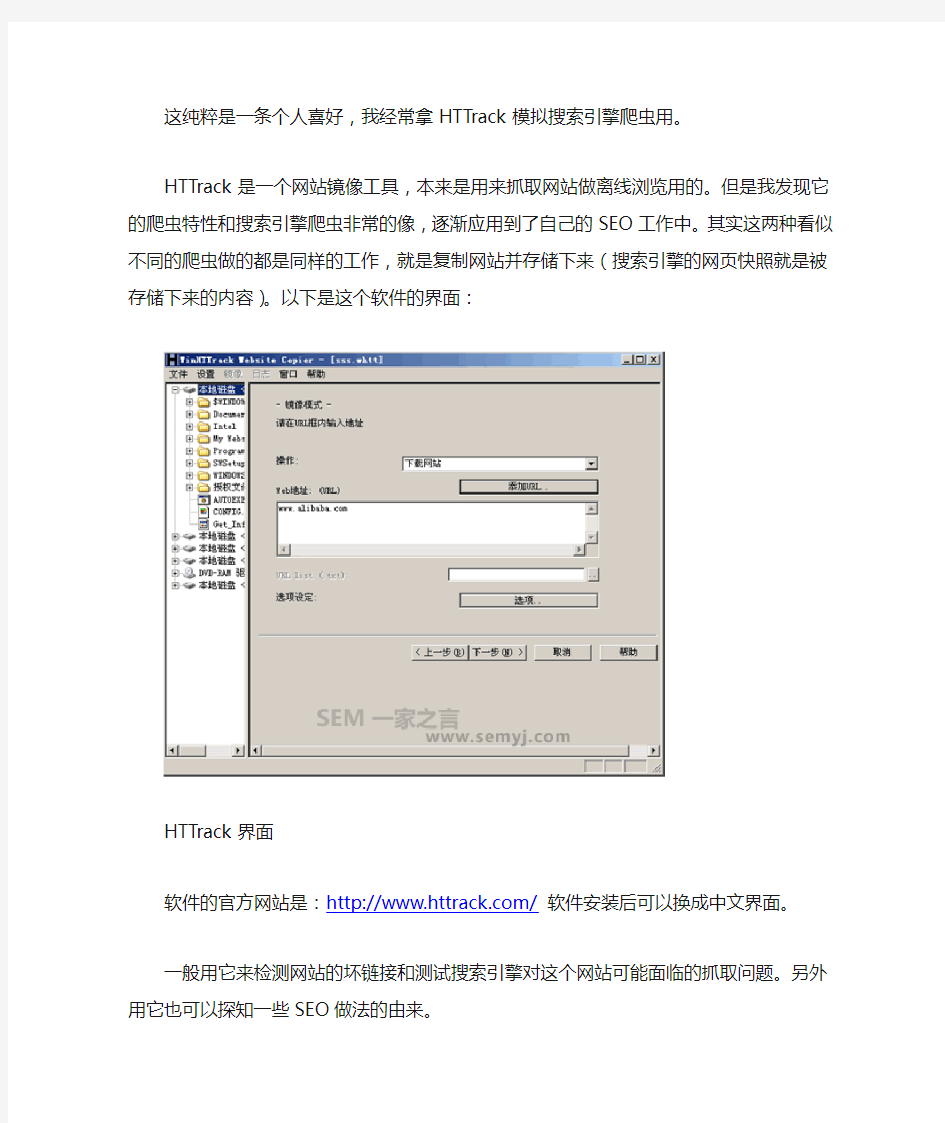

这纯粹是一条个人喜好,我经常拿HTTrack模拟搜索引擎爬虫用。
HTTrack是一个网站镜像工具,本来是用来抓取网站做离线浏览用的。但是我发现它的爬虫特性和搜索引擎爬虫非常的像,逐渐应用到了自己的SEO工作中。其实这两种看似不同的爬虫做的都是同样的工作,就是复制网站并存储下来(搜索引擎的网页快照就是被存储下来的内容)。以下是这个软件的界面:
HTTrack界面
软件的官方网站是:https://www.360docs.net/doc/0f9193663.html,/软件安装后可以换成中文界面。
一般用它来检测网站的坏链接和测试搜索引擎对这个网站可能面临的抓取问题。另外用它也可以探知一些SEO做法的由来。
软件的使用方法非常简单,在“Web地址”里填上URL就可以了。然后点“选项”,先看“扫描规则”
扫描规则
这样的扫描规则搜索引擎也一定会有的,比如不收录.exe文件,zip文件等等。然后不收录一些特定的跟踪链接,如 https://www.360docs.net/doc/0f9193663.html, 。你需要把一些搜索引擎爬虫不收录的特征加进去。
然后在“搜寻”里面,很多的特征都是现在搜索引擎爬虫的特征:
搜寻
搜索引擎不会接受cookie,所以取消“接收cookie”。
至于“解析java文件”,google 爬虫也会去解析java文件的。这是一个像HTTrack这样的通用爬虫都可以做到的事情。可能很多人还不知道,google会去试图解析javascript代码。如果你的页面上放很多javascript代码,就会使爬虫的停留时间增加,进而影响爬虫效率。这也可以算是为什么要把javascript 代码外调的另一个原因。
还有,有些javascript代码里面的URL,google爬虫是可以收录的,原因不明。这样做可能是因为有些内容很好的网站,很多链接就是喜欢用javascript来做的缘故吧。但是不代表你的链接可以用javascript来做。
HTTrack也同样能识别并遵守robots.txt文件。
至于url hacks ,就是让那种带 www和不带www的网址,如www.***.com和
***.com。以及有斜杠和无斜杠的网址,如http://www.***.com 和
www.***.com 能统一。
这种网站上URL不统一的状况爬虫程序其实能很简单的处理好。至于google为什么要网站所有者在webmaster tool 后台指定一下“首选域”,是因为有些网站 www.***.com 和***.com 指向不同的内容。所以google不能那么武断的就认为www.***.com 和***.com是同一个网站。
至于“流量控制”和“限制”,
流量控制
限制
里面可以设置“连接数”和“深度”什么的。我相信google也有这些设置,不然,google的《网站质量指南》里不会这么写“如果站点地图上的链接超过 100 个,则需要将站点地图拆分为多个网页。”
至于深度,有报告说,google抓取的最大深度是12。超时时间可以设为10秒。
还有其他“浏览器标识”和“预存区”也和搜索引擎爬虫一样的。
其他设置
下面用它来抓取一个网站,看看会有什么样的情况。
首先爬虫会去网站根目录下访问 robots.txt文件,如果碰到该网站的二级域名,还会去二级域名下访问robots.txt文件。这个和搜索引擎是一样的。
在抓取的时候,是多线程的,你可以实时的看到哪些URL正在被抓取以及速度怎么样。
很多人用它抓取完一个网站后会惊讶的发现有很多没什么SEO价值的页面在被
抓取。而这些“垃圾链接”竟然还是最先被抓取到的。可惜这个爬虫不支持nofollow属性,不然更加能模拟google爬虫。你还会用它发现很多死链接和超时的页面。
要是经常使用,你还会发现这个软件的一个规律,就是在抓取那些动态URL的时候,经常会产生重复抓取的现象,抓取URL类似
www.***.com/index.asp?=12345 这样页面会陷入到死循环当中。这个和早期的google爬虫又是一样的。由此判断,这应该是爬虫天生的一个弱点,可能它没办法实时的比较多个页面的内容,如果加上网页程序在处理URL ID的上遇到什么问题,就会重复抓取。也由此得出为什么要有URL静态化了。 URL的静态化与其叫静态化不如叫唯一化,其实只要给网页内容一个唯一的、结构不容易陷入死循环的URL即可,这就是静态化的本质。
google最新的声明不要静态化,是不希望爬虫从一种重复抓取陷入到另一种重复抓取才这样说的。其实google举例的那几种不好的静态化一般是不会发生的。只要你明白那些URL中的参数代表什么,还有不要把很多个参数直接rewrite
到静态化的URL里即可。
用这个软件,能让你直观的感受一个爬虫是怎么工作的。对于让一个新手正确认识爬虫有帮助。
这个软件的功能也差不多就这么多,要逼真的模拟搜索引擎爬虫,就要用《google 网站质量指南》里提到的Lynx。但是Lynx是一个页面一个页面检查的。以后会写一篇应用Lynx的文章。
更好的模拟google爬虫就要用GSA了。不应该说是模拟,而应该说它就是google 爬虫。
用HTTrack、Lynx和GSA,再配合服务器LOG日志里面的爬虫分析,会让你对爬虫的了解到达一个更高的水平。分析爬虫会让你得益很多的。很多都以后再讲。
网络爬虫工作原理
网络爬虫工作原理 1 聚焦爬虫工作原理及关键技术概述 网络爬虫是一个自动提取网页的程序,它为搜索引擎从Internet网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止,另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。 相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题: (1) 对抓取目标的描述或定义; (2) 对网页或数据的分析与过滤; (3) 对URL的搜索策略。 抓取目标的描述和定义是决定网页分析算法与URL搜索策略如何制订的基础。而网页分析算法和候选URL排序算法是决定搜索引擎所提供的服务形式和爬虫网页抓取行为的关键所在。这两个部分的算法又是紧密相关的。 2 抓取目标描述 现有聚焦爬虫对抓取目标的描述可分为基于目标网页特征、基于目标数据模式和基于领域概念3种。 基于目标网页特征的爬虫所抓取、存储并索引的对象一般为网站或网页。根据种子样本获取方式可分为: (1)预先给定的初始抓取种子样本; (2)预先给定的网页分类目录和与分类目录对应的种子样本,如Yahoo!分类结构等; (3)通过用户行为确定的抓取目标样例,分为: a) 用户浏览过程中显示标注的抓取样本; b) 通过用户日志挖掘得到访问模式及相关样本。 其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征,等等。现有的聚焦爬虫对抓取目标的描述或定义可以分为基于目标网页特征,基于目标数据模式和基于领域概念三种。 基于目标网页特征的爬虫所抓取、存储并索引的对象一般为网站或网页。具体的方法根据种子样本的获取方式可以分为:(1)预先给定的初始抓取种子样本;(2)预先给定的网页分类目录和与分类目录对应的种子样本,如Yahoo!分类结构等;(3)通过用户行为确定的抓取目标样例。其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征,等等。 基于目标数据模式的爬虫针对的是网页上的数据,所抓取的数据一般要符合一定的模式,或者可以转化或映射为目标数据模式。
httrack模拟搜索引擎爬虫
这纯粹是一条个人喜好,我经常拿HTTrack模拟搜索引擎爬虫用。 HTTrack是一个网站镜像工具,本来是用来抓取网站做离线浏览用的。但是我发现它的爬虫特性和搜索引擎爬虫非常的像,逐渐应用到了自己的SEO工作中。其实这两种看似不同的爬虫做的都是同样的工作,就是复制网站并存储下来(搜索引擎的网页快照就是被存储下来的内容)。以下是这个软件的界面: HTTrack界面 软件的官方网站是:https://www.360docs.net/doc/0f9193663.html,/软件安装后可以换成中文界面。 一般用它来检测网站的坏链接和测试搜索引擎对这个网站可能面临的抓取问题。另外用它也可以探知一些SEO做法的由来。 软件的使用方法非常简单,在“Web地址”里填上URL就可以了。然后点“选项”,先看“扫描规则”
扫描规则 这样的扫描规则搜索引擎也一定会有的,比如不收录.exe文件,zip文件等等。然后不收录一些特定的跟踪链接,如 https://www.360docs.net/doc/0f9193663.html, 。你需要把一些搜索引擎爬虫不收录的特征加进去。 然后在“搜寻”里面,很多的特征都是现在搜索引擎爬虫的特征: 搜寻 搜索引擎不会接受cookie,所以取消“接收cookie”。
至于“解析java文件”,google 爬虫也会去解析java文件的。这是一个像HTTrack这样的通用爬虫都可以做到的事情。可能很多人还不知道,google会去试图解析javascript代码。如果你的页面上放很多javascript代码,就会使爬虫的停留时间增加,进而影响爬虫效率。这也可以算是为什么要把javascript 代码外调的另一个原因。 还有,有些javascript代码里面的URL,google爬虫是可以收录的,原因不明。这样做可能是因为有些内容很好的网站,很多链接就是喜欢用javascript来做的缘故吧。但是不代表你的链接可以用javascript来做。 HTTrack也同样能识别并遵守robots.txt文件。 至于url hacks ,就是让那种带 www和不带www的网址,如www.***.com和 ***.com。以及有斜杠和无斜杠的网址,如http://www.***.com 和 www.***.com 能统一。 这种网站上URL不统一的状况爬虫程序其实能很简单的处理好。至于google为什么要网站所有者在webmaster tool 后台指定一下“首选域”,是因为有些网站 www.***.com 和***.com 指向不同的内容。所以google不能那么武断的就认为www.***.com 和***.com是同一个网站。 至于“流量控制”和“限制”, 流量控制
简析搜索引擎的网络爬虫技术
简析搜索引擎的网络爬虫技术 简析搜索引擎的网络爬虫技术 内容简介: 简析搜索引擎的网络爬虫技术 1 网络爬虫技术网络爬虫也称为文档抽取系统,是构成第三代搜索引擎系统的重要组成部分之一,主要由文档适配器与信息爬行器组成,文档适配器能够处理不同类型的文档,信息爬行器主要进行页面信息的收集工 论文格式论文范文毕业论文 简析搜索引擎的网络爬虫技术 1 网络爬虫技术网络爬虫也称为文档抽取系统,是构成第三代搜索引擎系统的重要组成部分之一,主要由文档适配器与信息爬行器组成,文档适配器能够处理不同类型的文档,信息爬行器主要进行页面信息的收集工作,文档抽取子系统首先根据配置文件的约定,定时产生信息爬行器对分布在网络上的信息节点进行遍历,然后调用对应的文档适配器来抽取网络文档信息。文档适配器能够抽取的页面文件种类繁多,能够对各种类型的文档以及多媒体文本信息等。信息爬行器为计算机程序的一个进程或线程,通常采用并发工作方式,以便能可能多、周期尽可能短地搜集网络节点的页面信息,同时还要避免死链接或无效链接。信息爬行器一般采用分布式并行计算技术来提高工作的广度与速度。 2 图的遍历算法网络爬虫在网络中执行信息收集的过程实际上就是一种图的遍历。图的遍历算法通常有两种方式: 即广度优先算法与深度优先算法。下面就具体介绍一下两种算法。通常深度优先算法使用的数据结构为栈,通过栈的出入特点进行搜索,其过程首先从该图的某个顶点或者子图出发,将所有属于该子图的顶点信息的链接地址(即URL,Universal Resoure Loator)进行压栈操作,待所有顶点都操作完成后,然后将栈
顶的元素取出,根据该元素的URL,访问该元素URL所指向的网络,然后将该页面的信息进行收集与分析,从而得到该页面内部的所有的URL连接信息,再将该页面所有的连接信息进行压栈,从而按照图的广度将图上所有的链接 进行展开操作,重复这些步骤就可以对图进行深度搜索遍历,达到遍历收集所有互联网信息资源的目的。深度优先搜索算法在展开页面链接时总是从栈顶进行展开,因此随着时间的增加,栈的深度也在不断增加,位于底部的元素可能会长时间不能进行处理,从而造成该算法陷入一个大的页面而不能继续展开遍历。为了避免这一问题,可以采用广度优先搜索算法,广度优先搜索算法是通过队列这种数据结构进行展开的,根据各个元素节点距离最初节点的层次对所有的网络节点进行遍历,从而对每个节点都能够在访问全网一次的时间内进行公平处理,克服了深度优先算法陷入局部节点的不足,也保证了不会漏掉队列后面的的元素,从而达到了公平对待互联网上所有节点资源的目的。在广度优先算法中,根据是否已经对节点进行访问,将爬行队列构造为两部分: 即待爬行队列与已爬行队列。待爬行队列主要存储需要进行访问的元素节点URL,而URL在队列中的先后顺序则体现了算法的爬行策略。而已爬行队列则主要存储已经访问过的URL,由于该队列的长度随着时间的增加不断增长,因此需要优化该队列的插入与查询操作;在网络爬虫的爬行过程中,不论是带爬行队列还是已爬行队列,都需要频繁进行插入与查询操作。因此,该队列数据结构的性能会直接影响搜索引擎的搜集性能。对爬行器来说,网页的采集与解析是核心工作。而爬行程序是否高效,主要取决于网页采集的效率。其过程分为5个步骤: 1) 将待爬行队列的第一个元素取出; 2)访问DNS服务器,对URL进行域名解析; 3)根据ROBOT网络协议,获取该URL服务器的权限; 4)若得到访问权限,则对服务器发出URL请求;
搜索引擎基本工作原理
搜索引擎基本原理 一.全文搜索引擎 在搜索引擎分类部分我们提到过全文搜索引擎从网站提取信息建立网页数据库的概念。搜索引擎的自动信息搜集功能分两种。一种是定期搜索,即每隔一段时间(比如Google一般是28天),搜索引擎主动派出“蜘蛛”程序,对一定IP地址范围内的互联网站进行检索,一旦发现新的网站,它会自动提取网站的信息和网址加入自己的数据库。 另一种是提交网站搜索,即网站拥有者主动向搜索引擎提交网址,它在一定时间内(2天到数月不等)定向向你的网站派出“蜘蛛”程序,扫描你的网站并将有关信息存入数据库,以备用户查询。由于近年来搜索引擎索引规则发生了很大变化,主动提交网址并不保证你的网站能进入搜索引擎数据库,因此目前最好的办法是多获得一些外部链接,让搜索引擎有更多机会找到你并自动将你的网站收录。 当用户以关键词查找信息时,搜索引擎会在数据库中进行搜寻,如果找到与用户要求内容相符的网站,便采用特殊的算法——通常根据网页中关键词的匹配程度,出现的位置/频次,链接质量等——计算出各网页的相关度及排名等级,然后根据关联度高低,按顺序将这些网页链接返回给用户。 二.目录索引 与全文搜索引擎相比,目录索引有许多不同之处。 首先,搜索引擎属于自动网站检索,而目录索引则完全依赖手工操作。用户提交网站后,目录编辑人员会亲自浏览你的网站,然后根据一套自定的评判标准甚至编辑人员的主观印象,决定是否接纳你的网站。 其次,搜索引擎收录网站时,只要网站本身没有违反有关的规则,一般都能登录成功。而目录索引对网站的要求则高得多,有时即使登录多次也不一定成功。
尤其象Yahoo!这样的超级索引,登录更是困难。(由于登录Yahoo!的难度最大,而它又是商家网络营销必争之地,所以我们会在后面用专门的篇幅介绍登录Yahoo雅虎的技巧) 此外,在登录搜索引擎时,我们一般不用考虑网站的分类问题,而登录目录索引时则必须将网站放在一个最合适的目录(Directory)。 最后,搜索引擎中各网站的有关信息都是从用户网页中自动提取的,所以用户的角度看,我们拥有更多的自主权;而目录索引则要求必须手工另外填写网站信息,而且还有各种各样的限制。更有甚者,如果工作人员认为你提交网站的目录、网站信息不合适,他可以随时对其进行调整,当然事先是不会和你商量的。 目录索引,顾名思义就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。如以关键词搜索,返回的结果跟搜索引擎一样,也是根据信息关联程度排列网站,只不过其中人为因素要多一些。如果按分层目录查找,某一目录中网站的排名则是由标题字母的先后顺序决定(也有例外)。 目前,搜索引擎与目录索引有相互融合渗透的趋势。原来一些纯粹的全文搜索引擎现在也提供目录搜索,如Google就借用Open Directory目录提供分类查询。而象 Yahoo! 这些老牌目录索引则通过与Google等搜索引擎合作扩大搜索范围。在默认搜索模式下,一些目录类搜索引擎首先返回的是自己目录中匹配的网站,如国内搜狐、新浪、网易等;而另外一些则默认的是网页搜索,如Yahoo。
搜索引擎中的网络爬虫搜索对策分析
搜索引擎中的网络爬虫搜索对策分析 进入互联网时代之后,网络融入到了现代人生活的各个方面,而搜索引擎之运用为人们的工作、学习与生活带来了非常大的好处。因此,实施对基于搜索引擎的网络爬虫技术的探究,对进一步提高搜索引擎的效率来说很有必要。本文在阐述网络爬虫原理的基础上,列举了网络爬虫的基本类别,并提出了搜索引擎中应用网络爬虫搜索的主要对策。 标签:搜索引擎;网络爬虫;对策 随着互联网技术的迅猛发展,网络为人们提供了极大的便利。然而,因为网络中的信息非常分散和无序,因此极难被充分运用。怎样在网络这一信息大海中迅速而又精准地找到最有效的信息,是用户们迫切需要解决的问题,而搜索引擎的产生很好地破解了该难题。搜索引擎主要是运用诸多网络站点中的信息,便于为用户们找到需要的信息。在搜索引擎当中,网络爬虫发挥了非常大的作用,是引擎全部数据之源头。爬虫设计之优劣将直接影响到引擎系统内容的丰富性与更新的及时性。 一、网络爬虫原理阐述 所谓网络爬虫,是指一种能够自动提取相关网页的程序,能够为搜索引擎从网络中下载所需要的网页,也是搜索引擎中极为重要的构成部份。爬虫从一个或者数个初始网页URL上起步,再分析这一URL的源文件,从而提取到新网页的链接,其后再运用新链接去找别的新链接,如此循环往复,一直到抓取与分析完全部网页。这可以说是一种理想的状态,然而事实上不可能抓取到网络中的全部网页。依据一项统计,最优秀的搜索引擎只能够抓取到40%的网页。原因是网络爬虫的抓取技术还存在着瓶颈,难以顾及到全部网页。同时,存储技术也存在一定的问题。依据每一网页平均为20K来计算,100亿个网页的规模为大小就是20万G,目前的存储技术还无法达到。 二、网络爬虫的基本类别 一是通用爬虫。其爬取的范围太大,而且对于爬取的顺序要求比较低,但对爬取的速度以及存储空间的要求相对较高。二是限定爬虫。主要是一种能够爬取使用者有兴趣的某类网页的程序。它并不需要爬取全部网页,只要爬取部分特定网页即可。工作原理是运用朴素贝叶斯法来训练文本分类器,其后使用该分类器以指导爬虫之偏好,在诸多爬虫队列中为用户选出其最有兴趣的那部分网页。三是主题爬虫。先明确一个或者多个不同的主题,再依据相关分析算法过滤出和主题没有关系的URL,并保留和主题存在关联的URL,并且把其放进等待队列之中,其后再用搜索策略从诸多等待的队列当中选取下一个需要进行抓取的URL,并且循环操作,一直到达成停止条件为止。 三、搜索引擎中应用网络爬虫搜索的主要对策
JAVA基于网络爬虫的搜索引擎设计与实现
本科毕业设计 题目:基于网络爬虫的搜索引擎设计与实现 系别: 专业:计算机科学与技术 班级: 学号: 姓名: 同组人: 指导教师:教师职称:协助指导教师:教师职称:
摘要 本文从搜索引擎的应用出发,探讨了网络蜘蛛在搜索引擎中的作用和地住,提出了网络蜘蛛的功能和设计要求。在对网络蜘蛛系统结构和工作原理所作分析的基础上,研究了页面爬取、解析等策略和算法,并使用Java实现了一个网络蜘蛛的程序,对其运行结果做了分析。 关键字:爬虫、搜索引擎
Abstract The paper,discussing from the application of the search engine,searches the importance and function of Web spider in the search engine.and puts forward its demand of function and design.On the base of analyzing Web Spider’s system strtucture and working elements.this paper also researches the method and strategy of multithreading scheduler,Web page crawling and HTML parsing.And then.a program of web page crawling based on Java is applied and analyzed. Keyword: spider, search engine
垂直搜索引擎系统介绍
SOPI垂直搜索引擎系统介绍 SOPI垂直搜索引擎2.0是一个从信息采集到分析到索引的整套解决方案,让你也可以轻松拥有一个搜索引擎。可以针用于行业垂直信息进行搜索,网站搜索等各类应用。 SOPI垂直搜索引擎系统的应用特点 ●外网搜索引擎:众多内容型网站为了保持数据的最新,不得不花费大量的人力进行内容 更新。SOPI 系统可以锁定需要的网站,进行定时采集此网站的最新内容;可以节省大量的人力成本,而且可以保证信息的全面性,同时结合搜索技术在海量的信息库中快速找到需要的信息。 ●高应用扩展性,可以根据用户需求快速配置成为不同类型的垂直搜索引擎,如成为商机 搜索、产品信息及其他各类需要的信息。只需普通技术人员便可以实现。 ●极少量的人工干预,系统管理员仅通过管理界面即可自动实现各类信息的搜索。大部分 工作由系统自动完成。 ●自动生成对网站的配置,提高工作效率及降低工作难度,垂直搜索引擎对不同网站进行 不同配置是必然的,本系统应用自动化技术将人工工作降到最低,将工作人员的技术要求降至最低。 ●可以从多个界而采集信息,系统进行自动合并,如从一个页面搜索产品信息,另一个网 页搜索公司信息,将两个页面的内容自动合并。 ●站内搜索引擎:可以轻松将内部网站的内容进行索引,为企业提供企业知识管理,或为 网站用户提供自身网站的搜索服务。 ●SOPI 搜索系统采用先进的索引机制,高效对全文进行索引及搜索,可以产生与百度和 GOOGLE 相同的准确结果,而且快速; SOPI搜索引擎系统的技术特点 ●使用与GOOGLE相同的数据库系统Oralce Berkeley DB嵌入式数据库,千万级数据状况 下操作数据仍保持在毫秒级,与使用ORACLE或SqlServer数据库性能提升数百倍。●系统结构的合理分离有利于分布式架构,适应未来大量的搜索工作,可以轻易在多服务 器环境中进行应用。 ●各子系统相互独立,任一子系统的停止运行不影响其他系统,有效保证稳定性;
搜索引擎爬虫外文翻译文献
搜索引擎爬虫外文翻译文献 (文档含中英文对照即英文原文和中文翻译) 译文: 探索搜索引擎爬虫 随着网络难以想象的急剧扩张,从Web中提取知识逐渐成为一种受欢迎的途径。这是由于网络的便利和丰富的信息。通常需要使用基于网络爬行的搜索引擎来找到我们需要的网页。本文描述了搜索引擎的基本工作任务。概述了搜索引擎与网络爬虫之间的联系。 关键词:爬行,集中爬行,网络爬虫 1.导言 在网络上WWW是一种服务,驻留在链接到互联网的电脑上,并允许最终用户访问是用标准的接口软件的计算机中的存储数据。万维网是获取访问网络信息的宇
宙,是人类知识的体现。 搜索引擎是一个计算机程序,它能够从网上搜索并扫描特定的关键字,尤其是商业服务,返回的它们发现的资料清单,抓取搜索引擎数据库的信息主要通过接收想要发表自己作品的作家的清单或者通过“网络爬虫”、“蜘蛛”或“机器人”漫游互联网捕捉他们访问过的页面的相关链接和信息。 网络爬虫是一个能够自动获取万维网的信息程序。网页检索是一个重要的研究课题。爬虫是软件组件,它访问网络中的树结构,按照一定的策略,搜索并收集当地库中检索对象。 本文的其余部分组织如下:第二节中,我们解释了Web爬虫背景细节。在第3节中,我们讨论爬虫的类型,在第4节中我们将介绍网络爬虫的工作原理。在第5节,我们搭建两个网络爬虫的先进技术。在第6节我们讨论如何挑选更有趣的问题。 2.调查网络爬虫 网络爬虫几乎同网络本身一样古老。第一个网络爬虫,马修格雷浏览者,写于1993年春天,大约正好与首次发布的OCSA Mosaic网络同时发布。在最初的两次万维网会议上发表了许多关于网络爬虫的文章。然而,在当时,网络i现在要小到三到四个数量级,所以这些系统没有处理好当今网络中一次爬网固有的缩放问题。 显然,所有常用的搜索引擎使用的爬网程序必须扩展到网络的实质性部分。但是,由于搜索引擎是一项竞争性质的业务,这些抓取的设计并没有公开描述。有两个明显的例外:股沟履带式和网络档案履带式。不幸的是,说明这些文献中的爬虫程序是太简洁以至于能够进行重复。 原谷歌爬虫(在斯坦福大学开发的)组件包括五个功能不同的运行流程。服务器进程读取一个URL出来然后通过履带式转发到多个进程。每个履带进程运行在不同的机器,是单线程的,使用异步I/O采用并行的模式从最多300个网站来抓取数据。爬虫传输下载的页面到一个能进行网页压缩和存储的存储服务器进程。然后这些页面由一个索引进程进行解读,从HTML页面中提取链接并将他们保存到不同的磁盘文件中。一个URL解析器进程读取链接文件,并将相对的网址进行存储,并保存了完整的URL到磁盘文件然后就可以进行读取了。通常情况下,因
简单学习网络爬虫(通用爬虫)
根据使用场景,网络爬虫可分通用爬虫和聚焦爬虫两种,今天广州中软卓越只讲通用爬虫。通用网络爬虫是捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分,主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。 通用搜索引擎(Search Engine)工作原理 通用网络爬虫是从互联网中搜集网页,采集信息,采集的网页信息用于为搜索引擎建立索引从而提供支持,决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的优劣直接影响着搜索引擎的效果。 步骤一:抓取网页 搜索引擎网络爬虫的基本工作流程如下: 1、首先选取一部分种子URL,将这些种子放入待抓取URL队列; 2、取出待抓取URL,解析DNS得到主机的IP,并将URL对应的网页下载下来,存储进已下载网页库中,再将这些URL放进已抓取URL队列。 3、将已抓取URL队列中的URL进行分析,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环.... 搜索引擎如何获取一个新网站的URL: 1、新网站向搜索引擎主动提交网址 2、在其他网站上设置新网站外链(尽可能处于搜索引擎爬虫爬取范围)
3、搜索引擎和DNS解析服务商(如DNSPod等)合作,新网站域名将被迅速抓取。 但是搜索引擎蜘蛛的爬行是被输入了一定的规则的,它需要遵从一些命令或文件的内容,如标注为nofollow的链接,或者是Robots协议。(Robots协议(也叫爬虫协议、机器人协议等),全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取) 步骤二:数据存储 搜索引擎通过爬虫爬取到的网页,将数据存入原始页面数据库。其中的页面数据与用户浏览器得到的HTML是一致的。搜索引擎蜘蛛在抓取页面的同时,也做一定的重复内容检测,一旦遇到访问权重很低的网站上有大量抄袭、采集或者复制的内容,很可能不再爬行。 步骤三:预处理 搜索引擎将爬虫抓取回来的页面,进行各种步骤的预处理。 提取文字→中文分词→消除噪音(比如版权声明文字、导航条、广告等……)→索引处理→链接关系计算→特殊文件处理→…… 除HTML文件外,搜索引擎通常还能抓取和索引以文字为基础的多种文件类型,如PDF、Word、WPS、XLS、PPT、TXT文件等。但目前搜索引擎还不能处理图片、视频、Flash这类非文字内容,也不能执行脚本和程序。 步骤四:提供检索服务,网站排名 搜索引擎在对信息进行组织和处理后,为用户提供关键字检索服务,将用户检索相关的信息展示给用户。同时会根据页面的PageRank值,也就是链接的访问量排名,来进行网站排名,Rank值高的网站在搜索结果中会排名较前,当然如果你有钱任性,也可以简单粗暴直接购买网站排名。
垂直搜索引擎技术指标
垂直搜索引擎技术指标 一、什么是垂直搜索 垂直搜索是针对某一个行业的专业搜索引擎,是搜索引擎的细分和延伸,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户。 垂直搜索引擎和普通的网页搜索引擎的最大区别是对网页信息进行了结构化信息抽取,也就是将网页的非结构化数据抽取成特定的结构化信息数据,好比网页搜索是以网页为最小单位,基于视觉的网页块分析是以网页块为最小单位,而垂直搜索是以结构化数据为最小单位。然后将这些数据存储到数据库,进行进一步的加工处理,如:去重、分类等,最后分词、索引再以搜索的方式满足用户的需求。 整个过程中,数据由非结构化数据抽取成结构化数据,经过深度加工处理后以非结构化的方式和结构化的方式返回给用户。 垂直搜索引擎的应用方向很多,比如企业库搜索、供求信息搜索引擎、购物搜索、房产搜索、人才搜索、地图搜索、mp3搜索、图片搜索……几乎各行各业各类信息都可以进一步细化成各类的垂直搜索引擎。 二、垂直搜索技术概述 垂直搜索技术主要分为两个层次:模板级和网页库级。 模板级是针对网页进行模板设定或者自动生成模板的方式抽取数据,对网页的采集也是针对性的采集,适合规模比较小、信息源少且稳定的需求,优点是快速实施、成本低、灵活性强,缺点是后期维护成本高,信息源和信息量小。 网页库级就是在信息源数量上、数据容量上检索容量上、稳定性可靠性上都是网页库搜索引擎级别的要求,和模板方式最大的区别是对具体网页不依赖,可针对任意正常的网页进信息采集信息抽取……。这就导致这种方式数据容量上和模板方式有质的区别,但是其灵活性差、成本高。当然模板方式和网页库级的方式不是对立的,这两者对于垂直搜索引擎来说是相互补充的,因为技术只是手段,目的是切反用户之需。本文谈及的技术主要是指网页库级别垂直搜索引擎技术。下图为垂直搜索引擎结构的拓扑图。
搜索引擎爬虫工作原理
搜索引擎爬虫工作原理 搜索引擎的处理对象是互联网网页,日前网页数量以百亿计,所以搜索引擎首先面临的问题就是:如何能够设计出高效的下载系统,以将如此海量的网页数据传送到本地,在本地形成互联网网页的镜像备份。 网络爬虫即起此作用,它是搜索引擎系统中很关键也根基础的构件。这里主要介绍与网络爬虫相关的技术,尽管爬虫技术经过几十年的发展,从整体框架上已相对成熟,但随着联网的不断发展,也面临着一些有挑战性的新问题。 版纳论坛下图所示是一个通用的爬虫框架流程。首先从互联网页面中精心选择一部分网页,以这些网页的链接地址作为种子URL,将这些种子URL放入待抓取URL队列中,爬虫从待抓取URL队列依次读取,并将URL通过DNS解析,把链接地址转换为网站服务器对应的IP地址。 然后将其和网页相对路径名称交给网页下载器,网页下载器负责页面内容的下载。对于下载到本地的网页,一方面将其存储到页面库中,等待建立索引等后续处理;另一方面将下载网页的URL放入已抓取URL队列中,这个队列记载了爬虫系统已经下载过的网页URL,以避免网页的重复抓取。对于刚下载的网页,从中抽取出所包含的所有链接信息,并在已抓取URL队列中检查,如果发现链接还没有被抓取过,则将这个URL放入待抓取URL队列末尾,在之后的抓取调度中会下载这个URL对应的网页。如此这般,形成循环,直到待抓取URL队列为审,这代表着爬虫系统已将能够抓取的网页尽数抓完,此时完成了一轮完整的抓取过程。
对于爬虫来说,往往还需要进行网页去重及网页反作弊。 上述是一个通用爬虫的整体流程,如果从更加宏观的角度考虑,处于动态抓取过程中的爬虫和互联网所有网页之间的关系,可以大致像如图2-2所身那样,将互联网页面划分为5个部分: 1.已下载网页集合:爬虫已经从互联网下载到本地进行索引的网页集合。 2.已过期网页集合:由于网页数最巨大,爬虫完整抓取一轮需要较长时间,在抓取过程中,很多已经下载的网页可能过期。之所以如此,是因为互联网网页处于不断的动态变化过程中,所以易产生本地网页内容和真实互联网网页不一致的情况。 3.待下载网页集合:即处于上图中待抓取URL队列中的网页,这些网页即将被爬虫下载。 4.可知网页集合:这些网页还没有被爬虫下载,也没有出现在待抓取URL队列中,不过通过已经抓取的网页或者在待抓取URL队列中的网页,总足能够通过链接关系发现它们,稍晚时候会被爬虫抓取并索引。
垂直搜索引擎是什么_垂直搜索引擎有哪些
垂直搜索引擎是什么_垂直搜索引擎有哪些 垂直搜索引擎是针对某一个行业的专业搜索引擎,是搜索引擎的细分和延伸,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户。垂直搜索是相对通用搜索引擎的信息量大、查询不准确、深度不够等提出来的新的搜索引擎服务模式,通过针对某一特定领域、某一特定人群或某一特定需求提供的有一定价值的信息和相关服务。其特点就是专、精、深,且具有行业色彩,相比较通用搜索引擎的海量信息无序化,垂直搜索引擎则显得更加专注、具体和深入。 什么是垂直搜索引擎垂直搜索是针对某一个行业的专业搜索引擎,是搜索引擎的细分和延伸,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户。 垂直搜索引擎和普通的网页搜索引擎的最大区别是对网页信息进行了结构化信息抽取,也就是将网页的非结构化数据抽取成特定的结构化信息数据,好比网页搜索是以网页为最小单位,基于视觉的网页块分析是以网页块为最小单位,而垂直搜索是以结构化数据为最小单位。然后将这些数据存储到数据库,进行进一步的加工处理,如:去重、分类等,最后分词、索引再以搜索的方式满足用户的需求。 整个过程中,数据由非结构化数据抽取成结构化数据,经过深度加工处理后以非结构化的方式和结构化的方式返回给用户。 垂直搜索引擎的应用方向很多,比如企业库搜索、供求信息搜索引擎、购物搜索、房产搜索、人才搜索、地图搜索、mp3搜索、图片搜索几乎各行各业各类信息都可以进一步细化成各类的垂直搜索引擎。 举个例子来说明会更容易理解,比如购物搜索引擎,整体流程大致如下:抓取网页后,对网页商品信息进行抽取,抽取出商品名称、价格、简介甚至可以进一步将笔记本简介细分成品牌、型号、CPU、内存、硬盘、显示屏、然后对信息进行清洗、去重、分类、分析比较、数据挖掘,最后通过分词索引提供用户搜索、通过分析挖掘提供市场行情报告。
搜索引擎蜘蛛爬虫原理
搜索引擎蜘蛛爬虫原理: 1、聚焦爬虫工作原理及关键技术概述 网络爬虫是一个自动提取网页的程序,它为搜索引擎从Internet网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止,另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。 相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题: (1) 对抓取目标的描述或定义; (2) 对网页或数据的分析与过滤; (3) 对URL的搜索策略。 抓取目标的描述和定义是决定网页分析算法与URL搜索策略如何制订的基础。而网页分析算法和候选URL排序算法是决定搜索引擎所提供的服务形式和爬虫网页抓取行为的关键所在。这两个部分的算法又是紧密相关的。 2、抓取目标描述 现有聚焦爬虫对抓取目标的描述可分为基于目标网页特征、基于目标数据模式和基于领域概念3种。 基于目标网页特征的爬虫所抓取、存储并索引的对象一般为网站或网页。根据种子样本获取方式可分为: (1)预先给定的初始抓取种子样本; (2)预先给定的网页分类目录和与分类目录对应的种子样本,如Yahoo!分类结构等; (3)通过用户行为确定的抓取目标样例,分为: a) 用户浏览过程中显示标注的抓取样本; b) 通过用户日志挖掘得到访问模式及相关样本。 其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征,等等。 现有的聚焦爬虫对抓取目标的描述或定义可以分为基于目标网页特征,基于目标数据模式和基于领域概念三种。 基于目标网页特征的爬虫所抓取、存储并索引的对象一般为网站或网页。 具体的方法根据种子样本的获取方式可以分为: (1)预先给定的初始抓取种子样本; (2)预先给定的网页分类目录和与分类目录对应的种子样本,如Yahoo!分类结构等; (3)通过用户行为确定的抓取目标样例。其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征,等等。 基于目标数据模式的爬虫针对的是网页上的数据,所抓取的数据一般要符合一定的模式,或者可以转化或映射为目标数据模式。
探索搜索引擎爬虫毕业论文外文翻译(可编辑)
外文译文正文: 探索搜索引擎爬虫随着网络难以想象的急剧扩张,从Web中提取知识逐渐成为一种受欢迎的途径。这是由于网络的便利和丰富的信息。通常需要使用基于网络爬行的搜索引擎来找到我们需要的网页。本文描述了搜索引擎的基本工作任务。概述了搜索引擎与网络爬虫之间的联系。 关键词:爬行,集中爬行,网络爬虫 导言在网络上是一种服务,驻留在链接到互联网的电脑上,并允许最终用户访问是用标准的接口软件的计算机中的存储数据。万维网是获取访问网络信息的宇宙,是人类知识的体现。搜索引擎是一个计算机程序,它能够从网上搜索并扫描特定的关键字,尤其是商业服务,返回的它们发现的资料清单,抓取搜索引擎数据库的信息主要通过接收想要发表自己作品的作家的清单或者通过“网络爬虫”、“蜘蛛”或“机器人”漫游互联网捕捉他们访问过的页面的相关链接和信息。 网络爬虫是一个能够自动获取万维网的信息程序。网页检索是一个重要的研究课题。爬虫是软件组件,它访问网络中的树结构,按照一定的策略,搜索并收集当地库中检索对象。本文的其余部分组织如下:第二节中,我们解释了Web爬虫背景细节。在第3节中,我们讨论爬虫的类型,在第4节中我们将介绍网络爬虫的工作原理。在第5节,我们搭建两个网络爬虫的先进技术。在第6节我们讨论如何挑选更有趣的问题。 调查网络爬虫网络爬虫几乎同网络本身一样古老。第一个网络爬虫,马修格雷浏览者,写于1993年春天,大约正好与首次发布的OCSA Mosaic网络同时发布。在最初的两次万维网会议上发表了许多关于网络爬虫的文章。然而,在当时,网络
i现在要小到三到四个数量级,所以这些系统没有处理好当今网络中一次爬网固有的缩放问题。显然,所有常用的搜索引擎使用的爬网程序必须扩展到网络的实质性部分。但是,由于搜索引擎是一项竞争性质的业务,这些抓取的设计并没有公开描述。有两个明显的例外:股沟履带式和网络档案履带式。不幸的是,说明这些文献中的爬虫程序是太简洁以至于能够进行重复。原谷歌爬虫(在斯坦福大学开发的)组件包括五个功能不同的运行流程。服务器进程读取一个URL出来然后通过履带式转发到多个进程。每个履带进程运行在不同的机器,是单线程的,使用异步I/O采用并行的模式从最多300个网站来抓取数据。爬虫传输下载的页面到一个能进行网页压缩和存储的存储服务器进程。然后这些页面由一个索引进程进行解读,从6>HTML页面中提取链接并将他们保存到不同的磁盘文件中。一个URL 解析器进程读取链接文件,并将相对的网址进行存储,并保存了完整的URL到磁盘文件然后就可以进行读取了。通常情况下,因为三到四个爬虫程序被使用,所有整个系统需要四到八个完整的系统。在谷歌将网络爬虫转变为一个商业成果之后,在斯坦福大学仍然在进行这方面的研究。斯坦福Web Base项目组已实施一个高性能的分布式爬虫,具有每秒可以下载50到100个文件的能力。Cho等人又发展了文件更新频率的模型以报告爬行下载集合的增量。互联网档案馆还利用多台计算机来检索网页。每个爬虫程序被分配到64个站点进行检索,并没有网站被分配到一个以上的爬虫。每个单线程爬虫程序读取到其指定网站网址列表的种子从磁盘到每个站点的队列,然后用异步I/O来从这些队列同时抓取网页。一旦一个页面下载完毕,爬虫提取包含在其中的链接。如果一个链接提到它被包含在页面中的网站,它被添加到适当的站点排队;否则被记录在磁盘。每隔一段时间,合并成一个批处理程序的具体地点的种子设置这些记录“跨网站”的网址,过滤掉进程
java课程设计—网络爬虫搜索引擎
课程设计 题目网络爬虫搜索引擎 学院管理学院 专业信息管理与信息系统 班级 姓名 指导教师王新 201 年7 月 4 日
课程设计任务书 学生姓名: 指导教师:王新工作单位:信息管理与信息系统系题目: 网络爬虫搜索引擎 初始条件: 合理应用Java相关知识与编程技能,结合UML面向对象设计,解决信息管理领域的实际问题,如学生成绩管理、学籍管理、图书借阅管理、自动存取款机、通信录管理、商品销售管理、医院门诊管理、火车订票管理、影院自动售票、世界杯足球比赛管理、人力资源管理、酒店前台管理、房产中介管理、停车收费管理等。 要求完成的主要任务:(包括课程设计工作量及其技术要求,以及说明书撰写 等具体要求) 1.进行需求分析,撰写需求文档,绘制用例图。 2.识别需求文档中的类,建模类,初步绘制类图(之后逐渐完善)。 3.确定、建模类的实例变量。 4.确定、建模类的方法。 5.若有需要,在系统中加入继承与多态。 6.将UML图转换成Java代码框架。 7.设计算法,若有复杂的数据结构需求,使用相应集合框架。 8.设计数据访问层,若有数据持久化需求,使用数据库/文件。 9.添加表示层,若程序运行在桌面,使用图形用户界面。 10.实现完整的系统,最终Java源代码至少在300行以上。 11.进行测试,并给出相应结果。 课程设计报告中要求详细描述思路、步骤、方法、实现、问题及解决过程、操作说明、测试及结果。 时间安排: 1.2014年6月23日课程设计选题、查阅资料 2.2014年6月24日~25日UML面向对象设计 3.2014年6月26日~7月1日Java程序设计与代码调试 4.2014年7月2日改进、完善、测试系统 5.2014年7月3日~7月4日上午撰写、提交课程设计报告 6.2014年7月4日下午课程设计答辩 指导教师签名:年月日 系主任(或责任教师)签名:年月日
搜索引擎蜘蛛采用什么抓取策略
搜索引擎蜘蛛采用什么抓取策略 搜索引擎蜘蛛简称爬虫,它的主要目的是抓取并下载互联网的网页到本地,同时与切词器、索引器一起共同对网页内容进行分词处理,建立索引数据库,促使最终形成用户查询的结果。即使对于商业搜索引擎来说,想要抓取互联网的所有网页也是一件很困难的事情,百度为什么没有Google强大?首先百度对于互联网上信息的抓取量与Google是无法相比的;其次对于爬虫的抓取速度和抓取效率也跟不上Google,这些不是说解决就能解决的,一些技术上的问题很可能会很长时间都无法获得解决。 虽然搜索引擎很难抓取到互联网上的所有网页,但是这也是它必然的目标,搜索引擎会尽量增加抓取数量。那么搜索引擎抓取采用的策略都有什么呢? 目前主要流行的策略有四个:宽度优先遍历策略、Partial PageRank策略、OPIC策略策略、大站优先策略。 一、宽度优先遍历策略 如图所示,宽度优先遍历策略就是将下载完成的网页中发现的链接逐一直接加入待抓取URL,这种方法没有评级网页的重要性,只是机械性地将新下载的网页中URL提取追加入待抓取URL。这种策略属于搜索引擎早期采用的抓取策略,效果很好,以后的新策略也都以这个为基准的。 上图遍历抓取路径:A-B-C-D-E-F G H I 二、Partial PageRank策略 Partial PageRank策略借鉴了PageRank算法的思想,对于已经下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每个页面的PageRank值,计算完之后,将待抓取URL 队列中的URL按照PageRank值的大小排列,并按照该顺序抓取页面。 通常搜索引擎会采取每当新下载网页达到一个N值后,就将所有下载过的网页计算一个新的PageRank(非完全PageRank值),然后将待抓取URL跟这个进行重新排序。这种方法的争议很大,有人说比宽度优先遍历策略的效果:也有人说这样与PageRank的完整值差别很大,依托这种值的排序不准确。 三、OPIC策略 OPIC策略更像是Partial PageRank策略进行的改进。OPIC策略与Partial PageRank策略大体结构上相同,类似与PageRank评级的网页重要性,每个网页都会有一个10分,然后分别传递给网页上的链接,最后10分清空。通过网页获得的分值高低,评级一个网页的重要性,优先下载获得评分高的URL。这种策略不需要每次都要对新抓取URL进行重新计算分值。
如何通过垂直搜索引擎构建自己的学术搜索引擎
如何通过垂直搜索引擎构建自己的学术搜索引擎 课题背景 随着因特网的发展,网上信息资源日益丰富且呈现出以下特点: (1)信息量大而且分散; (2)自治性强; (3)信息资源多种多样;(4)不一致和不完整性。 这些给信息挖掘带来了挑战。一方面使其实用性不断加强,越术越多的人从网上获取信息: 另一方面,人们经常会感到通过一般的搜索引擎难以找到自己想要的信息,对于具体专业或某一领域的内容尤其如此,如学术文献. 所以,要从Internet上获取有价值的专业信息,就必须有专门的搜索引擎来获取专业性的信息。 垂直搜索引擎是针对某一个行业的专业搜索引擎,是搜索引擎的细分和延伸,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户。垂直搜索是相对通用搜索引擎的信息量大、查询不准确、深度不够等提出来的新的搜索引擎服务模式,通过针对某一特定领域、某一特定人群或某一特定需求提供的有一定价值的信息和相关服务。其特点就是“专、精、深”,且具有行业色彩,相比较通用搜索引擎的海量信息无序化,垂直搜索引擎则显得更加专注、具体和深入。 学术搜索引擎 学术搜索引擎顾名思义就是搜索学术资源的引擎,资源以学术论文、国际会议、权威期刊、学者为主,随着新一代搜索引擎的快速发展,学术搜索引擎应具备个性化、智能化、数据挖掘分析、学术圈等特色。 2.3垂直搜索引擎的结构 本文根据常用的搜索结构, 有机地将分类目录式搜索引擎和基于查询串的搜索引擎结合起来,设计了一个垂直搜索引擎的体系结构,如图所示。 其各部分功能简述如下: l、爬虫软件:也称为spider,crawler和robot等,定向搜索各类信息前
垂直搜索引擎的研究与设计
第27卷第7期 计算机应用与软件 Vol 127No .72010年7月 Computer App licati ons and Soft w are Jul .2010 垂直搜索引擎的研究与设计 刘运强 (贵州大学计算机学院 贵州贵阳550025) 收稿日期:2009-10-09。贵州省科技计划工业攻关基金项目(黔科合GY 字[2008]3035);贵州省2008年省级信息化专项基金项目 (0830)。刘运强,硕士生,主研领域:数据库技术与软件工程。 摘 要 通过对垂直搜索引擎的原理和关键技术的研究,运用Lucene 等JAVA 开源工具设计并实现了一个手机信息检索系统。 对于构建垂直搜索引擎必须要面对和解决的一些关键问题进行了分析,并给出了解决方案,如防止重复爬取网页和专业词库的扩展等,具有较强的实用性。 关键词 搜索引擎 垂直搜索 爬虫 Lucene RESEARCH AND D ES I GN O F VERT I CAL SEARCH ENG I NE L iu Yunqiang (College of Co m puter Science,Guizhou U niversity,Guiyang 550025,Guizhou,China ) Abstract This paper p resents the design and i m p le mentati on of an infor mati on retrieval syste m f or mobile phones by app lying JAVA open -s ource t ools such as Lucene and thr ough studying the p rinci p les of vertical search engine and critical technol ogies .I n additi on,the analyses are made on s ome key p r oblem s which have t o encounter and res olve when constructing the vertical search engine .The s oluti ons pertaining t o these p r oble m s are given as well,for exa mp le,the p reventi on of cra wling sa me homepage repeatedly and the expansi on of s pecialised ter m s li 2brary .The system has high p racticality . Keywords Search engine Vertical search Sp ider Lucene 0 引 言 随着信息技术的快速发展,互联网已经成为人们获知信息的重要渠道。面对互联网如此庞大复杂的信息资源,仅依靠浏览器浏览的方式来获得我们所关心的信息是非常困难的,这就促使了网络搜索引擎的出现和快速发展。搜索引擎整合了众多网站的信息,将大量信息整合在一个平台上供用户检索,起到了信息导航的作用,已成为人们获取信息的有效工具。但是互联网的信息量呈爆炸趋势增长,每天都有数以万计的网页出现在互联网,使得搜索引擎对网络信息的覆盖率和搜索出结果的相关性、准确性在整体上呈下降趋势。检索出的结果集数量之多,经常都是几十万条甚至是几百万条记录,其中存在着大量的重复信息或是与检索主题无关的信息,要想从中快速、准确地找出所需要的信息变得越来越困难。人们需要更具有针对性、能快速准确定位信息的搜索引擎———垂直搜索引擎。 本文通过对垂直搜索引擎原理的深入了解,设计并实现了一个用于手机信息检索的垂直搜索引擎。与其它一些垂直搜索引擎的研究相比,本文更为深入和实际地研究了垂直搜索引擎亟待解决的关键问题,并给出了解决方案,通过手机垂直搜索引擎实例也很好地证明了方案的可行性和实用性。 1 垂直搜索引擎的原理和关键技术 1.1 垂直搜索引擎的原理 垂直搜索引擎是相对通用搜索引擎的信息量大、查询不准 确、深度不够等提出来的新的搜索引擎服务模式,通过针对某一特定领域、某一特定人群或某一特定需求提供的有一定价值的信息和相关服务[1]。其特点就是“专、精、深”,且具有行业色彩,相比较通用搜索引擎的海量信息无序化,垂直搜索引擎则显得更加专注、具体和深入。可以简单地把垂直搜索引擎说成是搜索引擎领域的行业化分工,它为用户提供的并不是上百甚至上千万相关网页,而是范围极为缩小、极具针对性的具体信息。 垂直搜索引擎通过网络爬虫在互联网上爬取某一特定领域的专业信息网页,并对爬取到的网页进行解析和处理,形成专业信息数据库,并对这些数据进行索引,形成索引库。用户在搜索引擎的客户端键人要查找的关键词,搜索引擎就会在索引库中找出与该关键词相匹配的摘要信息和URL,并将结果显示给用户,用户可根据输出的结果选择并访问相关站点。 1.2 垂直搜索引擎的关键技术 1.2.1 网络爬虫技术 网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。爬虫通常是从一个或若干初始网页的URL 开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL 放入队列,直到满足系统的一定停止条件。 网络爬虫的实现需要一个支持HTTP 协议的编程工具包,本文所使用的是H tt pClient,它是Apache 的一个开源项目,用来