语料库常用统计方法

常用统计分析方法
常用统计分析方法 排列图 因果图 散布图 直方图 控制图 控制图的重要性 控制图原理 控制图种类及选用 统计质量控制是质量控制的基本方法,执行全面质量管理的基本手段,也是CAQ系统的基础,这里简要介绍制造企业应用最广的统计质量控制方法。 常用统计分析方法与控制图 获得有效的质量数据之后,就可以利用各种统计分析方法和控制图对质量数据进行加工处理,从中提取出有价值的信息成分。 常用统计分析方法 此处介绍的方法是生产现场经常使用,易于掌握的统计方法,包括排列图、因果图、散布图、直方图等。 排列图 排列图是找出影响产品质量主要因素的图表工具.它是由意大利经济学家巴洛特(Pareto)提出的.巴洛特发现人类经济领域中"少数人占有社会上的大部分财富,而绝大多数人处于贫困状况"的现象是一种相当普遍的社会现象,即所谓"关键的少数与次要的多数"原理.朱兰(美国质量管理学家)把这个原理应用到质量管理中来,成为在质量管理中发现主要质量问题和确定质量改进方向的有力工具. 1.排列图的画法
排列图制作可分为5步: (1)确定分析的对象 排列图一般用来分析产品或零件的废品件数、吨数、损失金额、消耗工时及不合格项数等. (2)确定问题分类的项目 可按废品项目、缺陷项目、零件项目、不同操作者等进行分类。 (3)收集与整理数据 列表汇总每个项目发生的数量,即频数fi、项目按发生的数量大小,由大到小排列。最后一项是无法进一步细分或明确划分的项目统一称为“其它”。 (4)计算频数fi、频率Pi和累计频率Fi 首先统计频数fi,然后按(1)、(2)式分别计算频率Pi和累计频率Fi (1) 式中,f为各项目发生频数之和。 (2)
污染物排放j计算方法
工业污染物排放统计方法 一、工业污染物估算常用方法 工业企业环境统计工作中对废气、废水和固体废物及所含污染物产生量、排放量的计算通常采用三种方法,即实测法、物料衡算法和产排污系数法。 1、实测法 实测法是通过监测手段或国家有关部门认定的连续计量设施,测量废气、废水的流速、流量和废气、废水中污染物的浓度,用环保部门认可的测量数据来计算各种污染物的产生量和排放总量的统计计算方法。 G=KC i Q 式中:G——污染物产生量或排放量; Q——介质流量; C i——介质中i污染物浓度; K——单位换算系数。 浓度和流量的单位不一致时,单位换算系数K取不同的值。废水中污染物的浓度单位常取mg/L,系数K取10-3;废气中污染物的浓度一般取mg/L,系数K取10-6。 实测法的基础数据主要来自于环境监测站。监测数据是通过科学、合理地采集样品、分析样品而获得的。监测采集的样品是对监测的环境要素的总体而言,如采集的样品缺乏代表性,尽管测试分析很准确,不具备代表性的数据也毫无意义。 因受现有监测技术和监测条件的约束,实测法有一定的局限性。这主要是目前除了重点污染源有比较准确的监测数据外,其他多数非重点污染源不能得到有效的监测;而且很多重点污染源还未实现连续监测,监测结果的代表性有待提高。 例某炼油厂年排废水2万t,废水中废油浓度C油为500mg/L,COD浓度C COD为300mg/L,水未处理直接排放。计算该厂废油和COD的年排放量。 解:G油=K C油Q =10-6×500×2×104 =10(t) G COD=K C COD Q =10-6×300×2×104 =6(t) 例某冶炼厂排气筒截面0.4m2,排气平均流速12.5m/s,实测所排废气中SO2平均浓度12mg/m3,粉尘浓度8mg/L计算该排气筒每小时SO2和粉尘的排放量。 解:每小时废气流量Q=12.5×0.4×3600 = 1.8×104(m3/h) 每小时SO2排放量Gso2 = 10—6×12×1.8×104 = 0.216(kg/h) 每小时粉尘排放量G粉尘= 10—6×8×1.8×104 = 0.144((kg/h) 2、物料衡算法 物料衡算法是指根据物质质量守恒原理,对生产过程中使用的物料变化情况进行定量分析的一种方法。即: 投入物料量总和=产出物料量总和 =主副产品和回收及综合利用的物质量总和+排出系统外的废物质量这里的排出系统外的废物质量包括可控制与不可控制生产性废物及工艺过程的泄漏等物料流失。
科研常用的实验数据分析与处理方法
科研常用的实验数据分析与处理方法 对于每个科研工作者而言,对实验数据进行处理是在开始论文写作之前十分常见的工作之一。但是,常见的数据分析方法有哪些呢?常用的数据分析方法有:聚类分析、因子分析、相关分析、对应分析、回归分析、方差分析。 1、聚类分析(Cluster Analysis) 聚类分析指将物理或抽象对象的集合分组成为由类似的对象组成的多个类的分析过程。聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。聚类分析所使用方法的不同,常常会得到不同的结论。不同研究者对于同一组数据进行聚类分析,所得到的聚类数未必一致。 2、因子分析(Factor Analysis) 因子分析是指研究从变量群中提取共性因子的统计技术。因子分析就是从大量的数据中寻找内在的联系,减少决策的困难。因子分析的方法约有10多种,如重心法、影像分析法,最大似然解、最小平方法、阿尔发抽因法、拉奥典型抽因法等等。这些方法本质上大都属近似方法,是以相关系数矩阵为基础的,所不同的是相关系数矩阵对角线上的值,采用不同的共同性□2估值。在社会学研究中,因子分析常采用以主成分分析为基础的反覆法。
3、相关分析(Correlation Analysis) 相关分析(correlation analysis),相关分析是研究现象之间是否存在某种依存关系,并对具体有依存关系的现象探讨其相关方向以及相关程度。相关关系是一种非确定性的关系,例如,以X和Y 分别记一个人的身高和体重,或分别记每公顷施肥量与每公顷小麦产量,则X与Y显然有关系,而又没有确切到可由其中的一个去精确地决定另一个的程度,这就是相关关系。 4、对应分析(Correspondence Analysis) 对应分析(Correspondence analysis)也称关联分析、R-Q 型因子分析,通过分析由定性变量构成的交互汇总表来揭示变量间的联系。可以揭示同一变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系。对应分析的基本思想是将一个联列表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来。 5、回归分析 研究一个随机变量Y对另一个(X)或一组(X1,X2,…,Xk)变量的相依关系的统计分析方法。回归分析(regression analysis)是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法。运用十分广泛,回归分析按照涉及的自变量的多少,可分为一
《统计学原理》常用公式及计算题目分析
《统计学原理》常用公式汇总及计算题目分析 第三章统计整理 a) 组距=上限-下限 b) 组中值=(上限+下限)÷2 c) 缺下限开口组组中值=上限-1/2邻组组距 d) 缺上限开口组组中值=下限+1/2邻组组距 第四章综合指标 i. 相对指标 1. 结构相对指标=各组(或部分)总量/总体总量 2. 比例相对指标=总体中某一部分数值/总体中另一部分数值 3. 比较相对指标=甲单位某指标值/乙单位同类指标值 4. 强度相对指标=某种现象总量指标/另一个有联系而性质不同的 现象总量指标 5. 计划完成程度相对指标=实际数/计划数 =实际完成程度(%)/计划规定的完成程度(%) ii. 平均指标
1.简单算术平均数: 2.加权算术平均数或 iii. 变异指标 1.全距=最大标志值-最小标志值 2.标准差: 简单σ= ;加权σ= 3.标准差系数: 第五章抽样估计 1.平均误差: 重复抽样: 不重复抽样:
2.抽样极限误差 3.重复抽样条件下: 平均数抽样时必要的样本数目 成数抽样时必要的样本数目 4.不重复抽样条件下: 平均数抽样时必要的样本数目 第八章 指数分数 一、综合指数的计算与分析 ()() ()p x 2 2 2 2 x 2 p n (1)1N (2)p 1-p p 1-p (3)p 1-p μ= μ= σσ σδδ?? ?????→??→??→??→,最基本的是:若为:乘以-若不重复抽样类型抽样整为:若为群抽样: n N R r ??→??→
(1)数量指标指数 此公式的计算结果说明复杂现象总体数量指标综合变动的方向和程度。 ( - ) 此差额说明由于数量指标的变动对价值量指标影响的绝对额。 (2)质量指标指数 此公式的计算结果说明复杂现象总体质量指标综合变动的方向和程度。 ( - ) 此差额说明由于质量指标的变动对价值量指标影响的绝对额。 加权算术平均数指数= 加权调和平均数指数= (3)复杂现象总体总量指标变动的因素分析 相对数变动分析: = ×
SPC常用计算方法
SPC常用计算方法 SPC基础知识及常用计算方法 SPC基础知识 一、 SPC定义: 1、 SPC——统计制程管制:是指一套自制程中去搜集资料,并加以统计分析,从分析中去发气掘制程的异常,立即采取修正行动,使制程恢复正常的方法。 也就是说:品质不应再依赖进料及出货的抽样检验,而应该采取在生产过程中,认良好的管理方法,未获得良好的品质。 2、良好品质,必须做到下面几点: ①变异性低 ②耐用度 ③吸引力 ④合理的价格 3、变异的来源:大概来自5个方面: ①机器②材料③方法④环境⑤作业人员 应先从机器,材料方法,环境找变异,最后考虑人。 4、 SPC不是一个观念,而是要行动的 步骤一、确立制程流程——首先制程程序要明确,依据制程程序给制造流程图,并依据流程图订定工程品质管理表。 步骤二、决定管制项目——如果把所有对品质有影响的项目不论大小,轻重缓急一律列入或把客户不很重视的特性一并管制时,徒增管制成本浪费资料且得不赏失,反之如果重要的项目未加以管制时,则不能满足设计者,后工程及客户的需求,则先去管制的意义。 步骤三、实施标准化——欲求制程管制首先即得要求制程安定,例如:在风浪很大的船上比赛乒乓球,试部能否确定谁技高一筹,帮制程作业的安定是最重要的先决条件,所以对于制程上影响产品口质的重要原因,应先建立作业标准,并透过教育训练使作业能经标准进行。 步骤四、制程能力调查——为了设计、生产、销售客户满意且愿意购买的产品,制造该产品的制程能力务必符合客户的要求。因此制程的能力不足时,必顺进行制程能力的改善,而且在制程能力充足后还必须能继续,所以在品质管理的系统中制程能力的掌握很重要。 步骤五、管制图运用——SPC的一个基本工具就是管制图,而管制图又分计量值管制图与计数值管制图。 步骤六、问题分析解决——制程能力调查与管制图是可筛提供问题的原因系由遇原因或非机遇原因所造成,但无法告知你确切的原因为何及如何解决决问题?解决问题?而问题的解决技巧,在于依据事实找出造成变异的确切原因,并提此对策加以改善,及如何防止再发生。 步骤七、制程之继续管制——经过前6个步骤,人制程能力符合客户的要求,且管制图上的点未出管制界限时,则可将此管制界限沿有作为制程之继续管制,但当制程条件如有变动时,如机器,材料,方法等产生异动时,则须回到步骤三,不可沿原先之管制界限。 SPC的应用步骤其流程图如下: Ca制程准确度 Cp制程精密度 Cpk制程能力指数 二、管制图的运用 管制图的种类又依数值资料是计量值或计数值者,划分为二大类即计量值管制图与计数值管制图,计量值管制图不但只告诉你制程有问题了,还可以告诉你制程在什么地方出了问题,是中心值产生了问题还是变异量产生了问题。而在计量值管制图应用不便或应用时,则可采用计数值
词语搭配抽取的统计方法及计算机实现
词语搭配抽取的统计方法及计算机实现 邓耀臣王同顺 (上海交通大学外国语学院,上海200240 ) 摘要:计算机语料库的发展为词语搭配研究提供了新的方法。然而,也同样受到资源共享困难和语料分析工具不足的困惑。本文在简要介绍词语搭配抽取中常用的三种统计方法的基础上,重点提出一种将免费检索软件Wconcord和语言研究者较为熟悉的Visual Foxpro (VFP)编程技术相结合,计算词语搭配统计量,实现词语搭配自动抽取的方法并对这种方法的可行性和结果的可靠性进行了评估。 关键词:词语搭配;统计方法;计算机实现 Statistics in Collocation Extraction and Computer Implementation DENG Yaochen, WANG Tongshun (College of Foreign Studies, Shanghai Jiao Tong University, Shanghai 200240, China) Abstract: The development of computer corpora provides a new approach for collocation study. However, the corpus-based collocation study is restricted by difficulties in resource share and inefficiency of current analysis tools. This paper, on the basis of the introduction to three commonly-used statistics in collocation extraction, proposes a method to calculate the collocation measures and to extract collocations automatically by combining a free concordance software and Visual Foxpro. An evaluation test confirms its practicability and reliability. Key words: collocation, statistics, computer implementation 语料库语言学的发展为语言研究开辟了一个新的领域,词语搭配以其在语言产生、语言理解和语言学习中的重要作用无疑处于该领域的中心地位。然而,基于语料库的词语搭配研究也同样受到资源共享困难和语料分析工具不足的困惑。目前词语搭配研究中较为权威可靠的工具要么属于商业性软件,如WordSmith,Sara等,价格昂贵,不是一般的研究人员所能拥有;要么功能不全,如TACT仅提供Z-值并且对语料库的大小有严格限制,WordSmith 仅提供MI-值,只能抽取出显著性最高的10个搭配词。由此可见,现有工具远不能满足语料库深入研究的需要。本文在简要介绍词语搭配抽取中常用的三种统计方法的基础上,重点提出一种将免费检索软件Wconcord和语言研究者较为熟悉的Visual Foxpro(VFP)编程技术相结合,计算词语搭配统计量,实现词语搭配自动抽取的方法。通过与TACT和WordSmith 抽取结果的对比,对这种方法的可行性和结果的可靠性进行了评估。 1 词语搭配抽取的统计方法 词语搭配指的是词与词的结伴使用这种语言现象,是词语间的典型共现行为(Firth 作者简介:邓耀臣(1967—),男,汉,博士研究生。研究方向:语料库语言学与二语习得。 王同顺(1955—),男,汉,教授,博士生导师。研究方向:二语习得,大纲设计。
统计学常用公式汇总情况
统计学常用公式汇总 项目三 统计数据的整理与显示 组距=上限-下限 a) 组中值=(上限+下限)÷2 b) 缺下限开口组组中值=上限-邻组组距/2 c) 缺上限开口组组中值=下限+1/2邻组组距 例 按完成净产值分组(万元) 10以下 缺下限: 组中值=10—10/2=5 10—20 组中值=(10+20)/2=15 20—30 组中值=(20+30)/2=25 30—40 组中值=(30+40)/2=35 40—70 组中值=(40+70)/2=55 70以上 缺上限:组中值=70+30/2=85 项目四 统计描述 i. 相对指标 1. 结构相对指标=各组(或部分)总量/总体总量 2. 比例相对指标=总体中某一部分数值/总体中另一部分数值 3. 比较相对指标=甲单位某指标值/乙单位同类指标值 4. 动态相对指标=报告期数值/基期数值 5. 强度相对指标=某种现象总量指标/另一个有联系而性质不同的现 象总量指标 6. 计划完成程度相对指标K = 计划数 实际数 =%%计划规定的完成程度实际完成程度 7. 计划完成程度(提高率):K= %10011?++计划提高百分数实际提高百分数 计划完成程度(降低率):K= %10011?--计划提高百分数 实际提高百分数
ii. 平均指标 1.简单算术平均数: 2.加权算术平均数 或 iii. 变异指标 1. 全距=最大标志值-最小标志值 2.标准差: 简单σ= ; 加权 σ= 成数的标准差(1) p p p σ=-3.标准差系数: 项目五 时间序列的构成分析 一、平均发展水平的计算方法: (1)由总量指标动态数列计算序时平均数 ①由时期数列计算 n a a ∑= ②由时点数列计算 在连续时点数列的条件下计算(判断标志按日登记):∑ ∑=f af a 在间断时点数列的条件下计算(判断标志按月/季度/年等登记): 若间断的间隔相等,则采用“首末折半法”计算。公式为: 1 212 11 21-++++=-n a a a a a n n Λ
常用统计工具1
1. np ——在一容量为n 的样本中不合格品的数量,np 图的介绍见第Ⅲ章第2节。 2. P n ——样本容量恒定为n 时,不合格品数的平均数。 3. P ——一个样本中的不合格品率,p 图的介绍如见第Ⅲ单第1节。 4. P ——一系列样本中的平均不合格品率。 5. P P ——性能指数,通常定义为S LSL USL σ?6)(-。 6. PR ——性能比率,通常定义为) (?6LSL USL s -σ。 7. Ppk ——性能指数,通常定义为 S X USL σ?3-或S LSL X σ?3-的最小值。 8. Pz ——输出超过利益点的比例,这种利益点诸如特定的规范限值,与过程均值之差为z 个标准差 单位。 9. R ——子组的极差(最大值减去最小值);R 图的介绍见第Ⅱ章。 10. R ——一系列容量相等子组的平均极差。 11. R ——一系列容量相等子组的平均极差的均值。 12. R ~——一系列容量相等子组的极差的中位数极差。 13. S ——子组的样本标准差,S 图的介绍见第Ⅱ章第2节。 14. s ——过程的样本标准差,s 的介绍见第Ⅱ章第5节。 15. S ——一系列子组的平均样本标准差,如有必要可以按样本容量加权。 16. SL ——单边工程规范极限。 17. u ——一个样本中每单元不合格数,这个样本可能含有一个以上单位,u 图的介绍见第Ⅲ章第4节。 18. u ——样本中单位不合格数的平均值,样本的容量不必相等。 19. UCL ——上控制限,P R X UCL UCL UCL ,,等分别是均值、极差、不合格品率等的上控制限。 20. USL ——工程规范的上限。 21. X ——一个单值,是其它子组统计值的基础,单值图的讨论见第Ⅱ章第4节。 22. X ——一个子组内数值的平均数,X 图的讨论见第Ⅱ章第1节。 23. LCL ——下控制限。P R LCL LCL 、、X LCL 等分别是均值、极差、不合格品率等的下控制限。 24. LSL ——工程规范的下限。 25. MR ——主要用于单值图的一系列点的移动极差。 26. n ——一个子组内的单值的个数;子组的样本容量。 27. n ——平均子组样本容量。 28. X ——子组均值的均值(如有必要可按样本容量加权);测得的过程均值。 注:在本手册中,X 用作单值图的过程均值(第Ⅱ章第4节)尽管它仅代表一个水平的平均(单值点),以便避免与通常代表子组均值的X 相混淆。 29. X ~ ——一个子组的数值的中位数;中位数图的讨论见第Ⅱ章第3节。
基于语料库同义词辨析的一般方法
收稿日期:2005-3-28 作者简介:1.张继东(1965-),男,安徽安庆人,东华大学外语学院讲师,研究方向为语料库语言学;2.刘 萍 (1965-),女,安徽芜湖人,上海交通大学技术学院副教授,研究方向为语料库语言学与英语教学法。 基于语料库同义词辨析的一般方法 张继东1 ,刘 萍 2 (1.东华大学外语学院,上海200051;2.上海交通大学技术学院,上海200231) 摘 要:基于语料库的同义词辨析方法包括:(1)统计出同义词在语料库的不同语域中的词频分布差异;(2)以节点词的跨距为参照,统计同义词的显著搭配词,并计算同义词与其搭配词相互信息值(M I 值)以及Z 值;(3)通过观察检 索行中所呈现的同义词搭配特征,揭示出它们的类联结、搭配关系和语义韵等语言特征。 关键词:同义词;语料库;语域;搭配;语义韵 中图分类号:H31312 文献标识码:A 文章编号:10022722X (2005)0620049204 Corpus 2ba sed Approaches to the D i fferen ti a ti on of English Synony m s Z HANG J i 2dong 1 ,L I U Ping 2 (1.College of Foreign Languages,Donghua University,Shanghai,200051,China;2.Technical School,Shanghai J iao Tong University,Shanghai,200231,China ) Abstract:W ithin cor pus 2based app r oaches,synony m s can be differentiated with reference t o:1)their distributi ons a mong different registers;2)their significant coll ocates,and the M I value and Z score bet w een synony m s and their coll ocates;3)their coll ocati onal behavi ors and se mantic p r os odies with regard t o certain colligati onal fra me works .Synony m s thus differentiated will have significant pedagogical i m p licati ons . Key W ords:synony m;cor pora;register;coll ocati on;semantic p r os ody 0.引言 英语是世界上使用最广泛的语言之一,其词汇量极其庞大,其中同义词占有很大比例,是语言学习的难点。据统计,英语语言中同义词、近义词的数量约占总词汇量的60%以上(贺晓东,2003),它们通过词形、词义、结构或用法等方方面面的相同或相近构成了庞大的英语词汇体系,切实学懂、用熟同义词是突破英语词汇的重要环节,更是提高英语写作、阅读、会话等技能的关键。 传统的同义词辨析方法,多依赖于直觉经验,采用内省的定性方法,对同义词的词目意义条分缕析,然而,一般的语言学习者在实际的运用中似乎仍然难得要领。本文拟从语料库语言学的角度,通过对相关的语料库进行检索统计,发现同义词在不同语域中的词频分布差异,计算出词语搭配的不同相互信息值,通过观察检索行中所呈现的同义词搭配特征,揭示出它们不同的类联结、搭配关系和语义韵等语言特征。 1.基于英语语料库的同义词辨析111同义词在不同语域中词频分布差异 语域是人们在实际的语言活动中,出于交际的需要,或因其所从事的职业和兴趣相异,亦或因其话语发生的情景、说话的对象、地点和话题的不同而产生的一种言语变体,体现为语言中的不同语体风格、用语格调等。同义词由于其内在意义的差异,在不同的语域中往往会呈现出不同的分布特征,所以统计它们不同语域中的频率差异,有助于将它们区分开来。 为了说明同义词在不同语域中的分布频率对同义词的辨析具有宏观指导作用,本文选取了一组同义形容词:big 、great 、large,对《朗文英语口语和书面语语料库》(简称LGS W E )所提供的数据进行搜集,按会话、小说、新闻、学术文章四个语域进行分类。 big 、great 、large 之间的词义差异,学习者似乎能够直接从词典类工具书中就可以查询出来,但是 第28卷 第6期2005年11月解放军外国语学院学报 Journal of P LA University of Foreign Languages Vol .28 No .6Nov 12005
常用的数据统计方法
常用的数据统计方法 一、集中趋势分析 集中趋势反映一组资料中各数据所具有的共同特征,如资料中各数据聚集的位置或者一组数据的中心点等,可以是算术平均数、中位数、众数等。 ?算术平均数 算术平均数也可以称作均值,是数据集中趋势的最主要测度量。 (1)简单算术平均数。简单算术平均数的计算公式如下:(P2) ∑ = 求和符号 X = 每一变量 N = 样本量 例 1:已知某组织五类主要职工的月收入分别是 4000 、 5000 、 6000 、 10000 和15000 元,求这五类职工的平均月收入。 解: (元) 以上大小不等五个数值的月收入水平相互抵消的结果反映的该组织职工公众的平均月收入水平。从数据分布来看各个数据围绕 8000 元上下分布,算术平均数就是该组数据的中心值,反映了该组数据的集中趋势。 (2)加权算术平均数 如果是根据分组资料计算算术平均数,由于分组资料中每个数值出现的次数不同,所以要用次数做权数计算加权算术平均数。计算公式如下:
F = 权数(每一变量的次数或频率) ∑ F = N = 样本量 例 2:某组织有月收入 3000 元的公众 50 人, 5000 的 30 人, 7000 的 10 人,10000 的 8 人, 15000 的 2 人,求该组公众的平均月收入。 解: =480000/100=4800 (元) 可见该组公众的平均月收入不简单地等于(3000+5000+7000+10000+15000) /5 。从加权算术平均数的计算公式以及上例的计算过程及结果来看,算术平均数大小不仅受到各组变量数值大小的影响,而且还受各组变量权数大小的影响。 例 3:某组织公众周工资水平整理成分组资料如下表,试计算该组织公众周收入的平均值。 按工资分组工人数组中值 F M 100~200 10 150 200~300 30 250 300~400 40 350 400~500 20 450 合计 100 — 解:
病案室常用统计公式
病案室常用统计公式 治愈率%= [治愈人数(13)/出院病人数(12)] *100% 好转率%=[好转人数(14)/出院病人数(12)] *100% 病死率%=[死亡人数(16/出院病人数(12)] *100% 病床周转次数(次)=出院病人数“总计”(11)/平均开放病床数(20)病床工作日(日)=实际占用总床数(21)/平均开放病床数(20) 实际病床使用率=实际占用总床数(21)/实际开放总床数(19) 出院者平均出院日=出院者占用总床日数(22)/出院人数“总计”(11)疾病构成%=(实际数/合计总数)*100% 增减数=本次数-上次数 增减率%=(增减数/上次数)*100%
*实际开放总床日数:指年内医院各科每日夜晚12点开放病床数总和,不论该床是否被病人占用,都应计算在内。包括消毒和小修理等暂停使用的病床,超过半年的加床。不包括因病房扩建或大修而停用的病床及临时增设病床。 *实际占用总床日数:指医院各科每日夜晚12点实际占用病床数(即每日夜晚12点住院人数)总和。包括实际占用的临时加床在内。病人入院后于当晚12点前死亡或因故出院的病人, 作为实际占用床位1天进行统计,同时亦应统计“出院者占用总床日数”1天,入院及出院人数各1人。 *出院者占用总床日数:指所有出院人数的住院床日之总和。包括正常分娩、未产出院、住院经检查无病出院、未治出院及健康人进行人工流产或绝育手术后正常出院者的住院床日数。 *平均开放病床数=实际开放总床日数/本年日历日数(365)。 *病床使用率=实际占用总床日数/实际开放总床日数X100%。 *病床周转次数=出院人数/平均开放床位数。 *病床工作日=实际占用总床日数/平均开放病床数。 *出院者平均住院日=出院者占用总床日数/出院人数。 *病床周转率=每月(年)出院人数/科(院)床位数 *病床使用率是反映每天使用床位与实有床位的比率,即实际占用的总床日数与实际开放的总床日数之比。 *实际占用的总床日数应该从每天实际占床人数中累加得到,依据于各科室每日的动态报表中 *出院者占用总床日数是出院人数住院天数的总和,依据于出院病人病案中住院天数,实际占用的总床日数用来计算病床使用率和平均病床工作日 抗生素使用强度%=所有抗菌药物累计DDD数/同期收治患者人天数(<40) 住院患者抗菌药物使用率%=使用了抗菌药物的患者数/患者总数
环境统计6
第六次作业 1、分发统一的含铜0.100mg/L的样品到六个实验室,各实验室5次测定值如表1,试比较不同实验室之间是否存在显著性差异? 表1 6个实验室测定结果比较 实验室铜测定值(mg/L) 10.0980.0990.0980.1000.099 20.0990.1010.0990.0980.097 30.1010.1010.1010.1010.102 40.1000.1000.0970.0970.095 50.0980.0940.1020.1000.100 60.0980.0940.0980.0980.098解:单因素方差分析 (1)H0: 不同实验室之间不存在差异 H A:. 不同实验室之间存在差异。 (2)确定显著水平α=0.05 (3)计算 进行F 检验,P=0.017 由此判断组间差异极显著 为了确定各个实验室之间的差异是否显著,需要进行多重比较。结果表明3与1、2、4、5、6差异显著。其余差异不显著。 2、用3种方法测定水中硫酸盐含量,结果如表2,问3种方法测定结果是否有显著性差别?
表2 3种方法测定水中硫酸盐含量 甲法乙法丙法 279229210 334274285 303310117 378 198 解:组内观测次数不相等的方差分析 (1)H0: 3种方法测定结果没有显著性差别 H A: 3种方法测定结果有显著性差别 (2)确定显著水平α=0.05 (3)计算 进行F 检验,P=0.212 组间差异无显著性差异 3、某地区通过大量饮用水源调查得知,压力井细菌总数合格率为63%,先抽查压水井水样80份,细菌总数合格的58份,合格率为72.5%。问这批抽查水样的合格率与大量调查的合格率有无显著性差别? 解:进行适合性检验 (1)H0: 这批抽查水样的合格率与大量调查的合格率无差别。 H A:.这批抽查水样的合格率与大量调查的合格率有差别。 (2)确定显著水平α=0.05 (3)计算
语料库常用统计方法
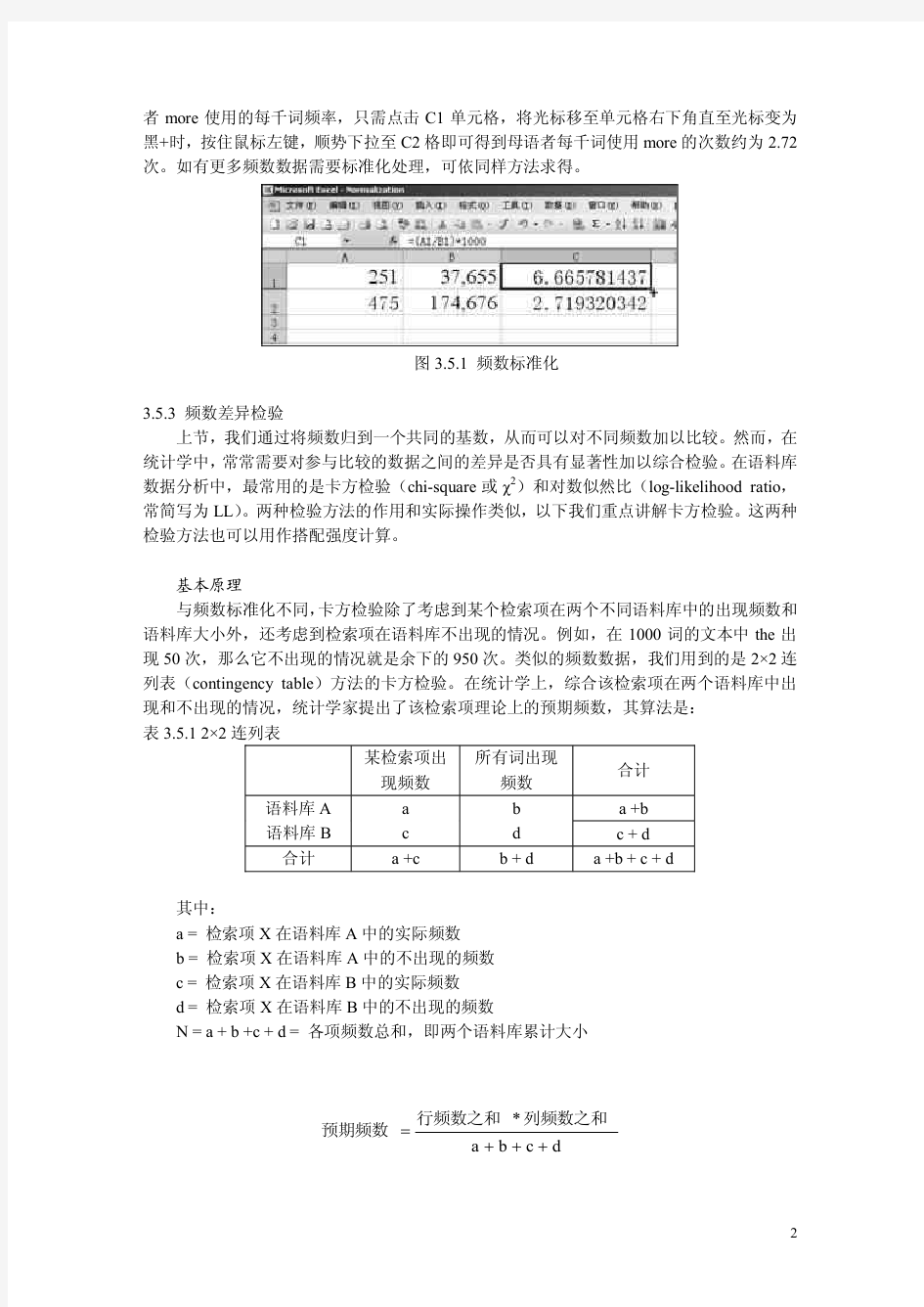
3.5语料库常用统计方法 第3章前几节对语料库应用中的几种主要技术做了介绍。通过语料检索、词表和主题词表的生成,可以得到一定数量的句子、词汇或结构。为能更好说明所得到的结果的真正意义,常常需要对它们加以统计学分析。本章主要介绍语料分析中的一些常用统计方法。 3.5.1 语料库与统计方法 介绍相关统计方法之前,首先需要了解为什么语料库应用中需要运用统计方法。在2.1节讲到文本采集时,我们知道文本或会话构成了最终的语料库样本。这些样本是通过一定的抽样方法获得的。研究中,我们需要描述这些样本的出现和分布情况。此外,我们还经常需要观察不同语言项目之间在一定语境中共同出现(简称共现)的概率;以及观察某个(些)语言项目在不同文本之间出现多少的差异性。这些需要借助统计学知识来加以描写和分析。 理论上说,几乎所有统计方法都可以用于语料库分析。本章只择其中一些常用方法做一介绍。我们更注重相关统计方法的实际应用,不过多探讨其统计学原理。这一章我们主要介绍语料分析中的频数标准化(normalization )、频数差异检验和搭配强度的计算方法。 3.5.2 频数标准化 基本原理 通常语料检索、词表生成结果中都会报告频数(frequency, freq 或raw frequency )。那么某词(如many )在某语料库中出现频数为100次说明什么呢?这个词在另一个语料库中出现频数为105次,是否可以说many 在第二个语料库中更常用呢?显然,不能因为105大于100,就认定many 在第二个语料库中更常用。这里大家很容易想到,两个语料库的大小未必相同。按照通常的思维,我们可以算出many 在两个语料库中的出现百分比,这样就可比了。这种情况下,我们是将many 在两个语料库中的出现频数归到一个共同基数100之上,即每100词中出现多少个many 。这里通过百分比得到的频率即是一种标准化频率。有些文献中标准化频率也称归一频率或标称频率,即基于一个统一基准得出的频率。 实例及操作 频数标准化,首先需要用某个(些)检索项的实际观察频数(原始频数,raw frequency )除以总体频数(通常为文本或语料库的总词数),这样得到每一个单词里会出现该检索项多少次。在频数标准化操作中,我们通常会在此基础上乘以1千(1万、1百万)得到平均每千(万、百万)词的出现频率。即: 1000?=总体频数 观测频数标准化频率(每千词) (注:观测频数即检索词项实际出现的次数;总体频数即语料库的大小或总形符数。) 例如,more 在中国学生的作文里出现251次,在英语母语者语料中出现475次。两个语料库的大小分别为37,655词次和174,676词次。我们可以根据上面的公式很容易计算出251和475对应的标准化频率。另外,我们还可以利用Excel 或SPSS 等工具来计算标准化频率。比如,可以将实际观察频数和语料库大小如图3.5.1输入相应的单元格,然后在C1单元格里输入=(A1/B1)*1000即可得到中国学生每千词使用more 约为6.67次。要得到母语
常用相关分析方法及其计算
二、常用相关分析方法及其计算 在教育与心理研究实践中,常用的相关分析方法有积差相关法、等级相关法、质量相关法,分述如下。 (一)积差相关系数 1. 积差相关系数又称积矩相关系数,是英国统计学家皮尔逊(Pearson )提出的一种计算相关系数的方法,故也称皮尔逊相关。这是一种求直线相关的基本方法。 积差相关系数记作XY r ,其计算公式为 ∑∑∑===----= n i i n i i n i i i XY Y y X x Y y X x r 1 2 1 2 1 ) ()() )(( (2-20) 式中i x 、i y 、X 、Y 、n 的意义均同前所述。 若记X x x i -=,Y y y i -=,则(2-20)式成为 Y X XY S nS xy r ∑= (2-21) 【 式中 n xy ∑称为协方差,n xy ∑的绝对值大小直观地反映了两列变量的一致性程 度。然而,由于X 变量与Y 变量具有不同测量单位,不能直接用它们的协方差 n xy ∑来表示两列变量的一致性,所以将各变量的离均差分别用各自的标准差 除,使之成为没有实际单位的标准分数,然后再求其协方差。即: ∑∑?= = )()(1Y X Y X XY S y S x n S nS xy r Y X Z Z n ∑?= 1 (2-22) 这样,两列具有不同测两单位的变量的一致性就可以测量计算。 计算积差相关系数要求变量符合以下条件:(1)两列变量都是等距的或等比的测量数据;(2)两列变量所来自的总体必须是正态的或近似正态的对称单峰分布;(3)两列变量必须具备一一对应关系。 2. 积差相关系数的计算
利用公式 (2-20)计算相关系数,应先求两列变量各自的平均数与标准差,再求离中差的乘积之和。在统计实践中,为方便使用数据库的数据格式,并利于计算机计算,一般会将(2-20)式改写为利用原始数据直接计算XY r 的公式。即: ∑∑∑∑∑∑∑---= 2 22 2) () (i i i i i i i i XY y y n x x n y x y x n r (2-23) (二)| (三)等级相关 在教育与心理研究实践中,只要条件许可,人们都乐于使用积差相关系数来度量两列变量之间的相关程度,但有时我们得到的数据不能满足积差相关系数的计算条件,此时就应使用其他相关系数。 等级相关也是一种相关分析方法。当测量得到的数据不是等距或等比数据,而是具有等级顺序的测量数据,或者得到的数据是等距或等比的测量数据,但其所来自的总体分布不是正态的,出现上述两种情况中的任何一种,都不能计算积差相关系数。这时要求两列变量或多列变量的相关,就要用等级相关的方法。 1. 斯皮尔曼(Spearman)等级相关 斯皮尔曼等级相关系数用R r 表示,它适用于两列具有等级顺序的测量数据,或总体为非正态的等距、等比数据。 斯皮尔曼等级相关的基本公式如下: ) 1(612 2--=∑n n D r R (2-24) 式中: Y X R R D -=____________对偶等级之差; n ____________对偶数据个数。 , 如不用对偶等级之差,而使用原始等级序数计算,则可用下式 )]1() 1(4[13+-+?-= ∑n n n R R n r Y X R (2-25) 式中: X R ___________X 变量的等级; Y R ____________Y 变量的等级; n ____________对偶数据个数。 (2-25)式要求∑∑=Y X R R ,∑∑=2 2Y X R R ,从而保证22Y X S S =。在观测变量中没有相同等级出现时可以保证这一条件。但是,在教育与心理研究实践中,搜集到的观测变量经常出现相同等级。在这种情况下,∑∑=Y X R R 的条件仍可得
环境影响评价 常用计算系数
环境影响评价必须掌握的方法 计算系数 烧一吨煤,产生1600×S%千克SO2,1万立方米废气;产生200千克烟尘。 烧一吨柴油,排放2000×S%千克SO2,1.2万立米废气;排放1千克烟尘。 烧一吨重油,排放2000×S%千克SO2,1.6万立米废气;排放2千克烟尘。 大电厂,烟尘治理好,去除率超98%,烧一吨煤,排放烟尘3-5千克。 普通企业,有治理设施的,烧一吨煤,排放烟尘10-15千克; 砖瓦生产,每万块产品排放40-80千克烟尘;12-18千克二氧化硫。 规模水泥厂,每吨水泥产品排放3-7千克粉尘;1千克二氧化硫。 乡镇小水泥厂,每吨水泥产品排放12-20千克粉尘;1千克二氧化硫。 【物料衡算公式】 1吨煤炭燃烧时产生的SO2量=1600×S千克;S含硫率,一般0.6-1.5%。若燃煤的含硫率为1%,则烧1吨煤排放16公斤SO2 。 1吨燃油燃烧时产生的SO2量=2000×S千克;S含硫率,一般重油 1.5-3%,柴油0.5-0.8%。若含硫率为2%,燃烧1吨油排放40公斤SO2 。 排污系数:燃烧一吨煤,排放0.9-1.2万标立方米燃烧废气,电厂可取小值,其他小厂可取大值。燃烧一吨油,排放1.2-1.6万标立方米废气,柴油取小值,重油取大值。 【城镇排水折算系数】 0.7~0.9,即用水量的70-90%。 【生活污水排放系数】采用本地区的实测系数。。 【生活污水中COD产生系数】60g/人.日。也可用本地区的实测系数。 【生活污水中氨氮产生系数】7g/人.日。也可用本地区的实测系数。使用系数进行计算时,人口数一般指城镇人口数;在外来较多的地区,可用常住人口数或加上外来人口数。 【生活及其他烟尘排放量】 按燃用民用型煤和原煤分别采用不同的系数计算: 民用型煤:每吨型煤排放1~2公斤烟尘 原煤:每吨原煤排放8~10公斤烟尘 【工业废气排放总量计算】 1.实测法 当废气排放量有实测值时,采用下式计算: Q年= Q时× B年/B时/10000 式中: Q年——全年废气排放量,万标m3/y; Q时——废气小时排放量,标m3/h;
16种常用的数据分析方法汇总
一、描述统计 描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:剔除法、均值法、最小邻居法、比率回归法、决策树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A 单样本t检验:推断该样本来自的总体均数μ与已知的某一总体均数μ0 (常为理论值或标准值)有无差别; B 配对样本t检验:当总体均数未知时,且两个样本可以配对,同对中的两者在可能会影响处理效果的各种条件方面扱为相似;
C 两独立样本t检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验 非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。 A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析 检査测量的可信度,例如调查问卷的真实性。 分类: 1、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度 2、内在信度;每个量表是否测量到单一的概念,同时组成两表的内在体项一致性如何,常用方法分半信度。 四、列联表分析 用于分析离散变量或定型变量之间是否存在相关。
统计学常用公式汇总
《统计学原理》常用公式汇总 组距=上限-下限组中值=(上限+下限)÷2 缺下限开口组组中值=上限-1/2邻组组距缺上限开口组组中值=下限+1/2邻组组距 111平均指标 1.简单算术平均数: 2.加权算术平均数 或 iii.变异指标 1.全距=最大标志值-最小标志值 2.标准差: 简单σ= ;加权σ= 3.标准差系数: 第五章抽样估计 1.平均误差:重复抽样: 不重复抽样: 2.抽样极限误差 3.重复抽样条件下:平均 数抽样时必要的样本数目 成数抽样时必要的样本数目 4.不重复抽样条件下:平均数抽样时必要的样本数目 第七章相关分析 1.相关系数 2.配合回归方程y=a+bx
3.估计标准误: 第八章指数分数一、综合指数的计算与分析 (1)数量指标指数 此公式的计算结果说明复杂现象总体数量指标综合变动的方向和程度。 ( - ) 此差额说明由于数量指标的变动对价值量指标影响的绝对额。 (2)质量指标指数 此公式的计算结果说明复杂现象总体质量指标综合变动的方向和程度。 ( - ) 此差额说明由于质量指标的变动对价值量指标影响的绝对额。 加权算术平均数指数= 加权调和平均数指数= (3)复杂现象总体总量指标变动的因素分析 相对数变动分析: = × 绝对值变动分析: - = ( - )×( - ) 第九章动态数列分析 一、平均发展水平的计算方法:
(1)由总量指标动态数列计算序时平均数 ①由时期数列计算 ②由时点数列计算 在间断时点数列的条件下计算: a.若间断的间隔相等,则采用“首末折半法”计算。公式为: b.若间断的间隔不等,则应以间隔数为权数进行加权平均计算。公式为: (2)由相对指标或平均指标动态数列计算序时平均数 基本公式为: 式中:代表相对指标或平均指标动态数列的序时平均数; 代表分子数列的序时平均数; 代表分母数列的序时平均数; 逐期增长量之和累积增长量 二. 平均增长量=─────────=───────── 逐期增长量的个数逐期增长量的个数 (1)计算平均发展速度的公式为: (2)平均增长速度的计算 平均增长速度=平均发展速度-1(100%)