数字验证码识别算法的研究与设计

数字验证码识别算法的研究和设计
王虎, 冯林, 孙宇哲
Wang Hu, Feng Lin, Sun Yuzhe
大连理工大学大学生创新院,大连116023
Institute of University Students’ Innovation, Dalian University of Technology, Dalian 116023, China
E-mail: wlys111@https://www.360docs.net/doc/5613068697.html,
Research and Design of Digital character-based CAPTCHA Recognition
Abstract:CAPTCHA Recognition can be used in multi-send technology. Digital character-based CAPTCHA Recognition, which is foundation of pattern recognition research, is a kind of OCR. In this paper, we proposed a CAPTCHA Recognition System based on simple distortion and its architecture is template matching. Hilditch thinning algorithm, circle structure searching algorithm and dynamic template analyzing algorithm is chose and the weigh of template is also used to improve the recognition accuracy. The advantage of the system is that the recognition precision is perfect.
Key words:Template matching, Weighted Template, dynamic template, grid feature, crossing points feature
摘要:验证码识别技术可以用于网站的群发软件,数字验证码识别是光学字符识别(OCR)的一种,是进行模式识别研究的基础。论文提出了以简单变形的数字字符为理论研究素材,将模板匹配作为基本框架的验证码识别系统。系统采用图像的Hilditch细化算法、环结构的搜索算法、活动模板分析算法,加入模板分量的权值。其优点在于能够对特定数字验证码精确识别,实验中识别准确率基本达到100%。
关键字:模板匹配,加权模板,活动模板,网格特征,交叉点特征
文章编号:文献标识码:A 中图分类号:TP391.43
引言
目前,网络上出现了很多以图片形式出现的基于文本的验证码。所谓验证码,就是将一串随机产生的字符,生成一幅图片,图片里随机的加入一些像素干扰、颜色干扰和形变干扰等等,以达到防止恶意注册等目的。有的验证码是无像素干扰的、大小固定的、质心位置居中,含有形变干扰的数字字符,我们称之为简单变形体。反之,我们称加入了更多干扰的字符为复杂变形体。
验证码千变万化,而当前的识别系统都具有很强针对性,只能够识别一种类型的验证码,而且验证码的技术不断发展,出现了更加复杂的基于图像的验证码系统[5],并且目前人工智能(机器智能)还远未赶上人类智能,但是对于给定的验证码系统,在获知其特点之后,基本能够以一定的准确率进行识别[6、7]。
基金项目: 国家自然科学基金( the National Foundation of China under Grant No.10471051 )。
作者简介: 王虎(1984-),学士,研究方向:计算机图形处理,模式识别与智能控制; 冯林(1969-),博士,教授,研究方向:图像压缩、配准及融合和演化算法; 孙宇哲(-),硕士,研究方向:.
目前,在公开的验证码识别算法中,只有一些简单的、识别率低的识别方法,且缺乏系统性,这不利于对日新月异的验证码的识别,因此我们需要一个系统、高准确率的算法。
本文讨论了图像的模板匹配算法,细化算法,网格特征、交叉点特征[1],并由此构架识别算法的基本框架。为了提高识别准确率,使用改进的活动模板部分结构分析算法[2],减弱了字符形变对识别系统的干扰;提出一种能较大地增强模板区分能力的加权模板。
1. 数字验证码识别
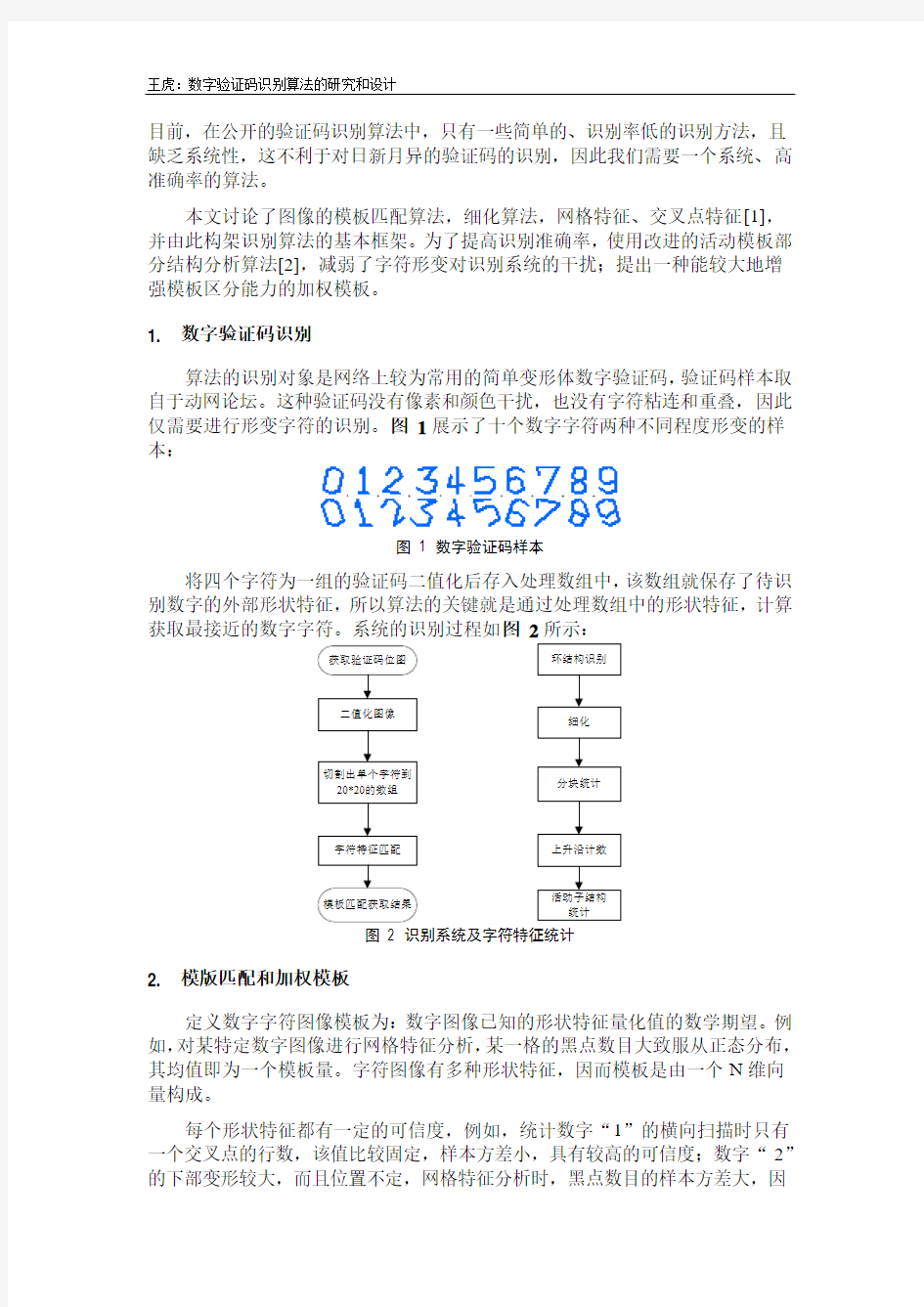
算法的识别对象是网络上较为常用的简单变形体数字验证码,验证码样本取自于动网论坛。这种验证码没有像素和颜色干扰,也没有字符粘连和重叠,因此仅需要进行形变字符的识别。图1展示了十个数字字符两种不同程度形变的样本:
图 1 数字验证码样本
将四个字符为一组的验证码二值化后存入处理数组中,该数组就保存了待识别数字的外部形状特征,所以算法的关键就是通过处理数组中的形状特征,计算获取最接近的数字字符。系统的识别过程如图2所示:
图 2 识别系统及字符特征统计
2. 模版匹配和加权模板
定义数字字符图像模板为:数字图像已知的形状特征量化值的数学期望。例如,对某特定数字图像进行网格特征分析,某一格的黑点数目大致服从正态分布,其均值即为一个模板量。字符图像有多种形状特征,因而模板是由一个N维向量构成。
每个形状特征都有一定的可信度,例如,统计数字“1”的横向扫描时只有一个交叉点的行数,该值比较固定,样本方差小,具有较高的可信度;数字“2”的下部变形较大,而且位置不定,网格特征分析时,黑点数目的样本方差大,因
而此模板分量不可信。特征权值就是某形状特征的可信度的量化,可信度高则权值高,可信度低则权值低。
模板向量的每个分量均对应一个权值,从而每个字符对应一个N 维的权值向量,由这两个向量共同决定该数字的特征模板,这两个向量便组成了加权模板。加权模版可以提高某特殊外形特征的权重,降低不可信外形特征的权重,从而更加准确的获得识别结果。此外,为了达到字符的总体均衡,也需要进行权值调整。
模板匹配时,由待识别的字符x 特征向量α和某个字符i N 的模板向量β与权值向量γ即可计算两者之间的差异度。计算公式如下:
()()∑=?-?-=n
k k k k k k i Diff 1γβαβα, n 为模版向量的长度。
10个模版对应10个i Diff 值,其中最小值对应的数字即可作为x 的识别结果。 模板分量的权值j γ是基于统计学方式计算得出的。在随机的N 个验证码样本(4*N 个字符样本)中,模板长度为M 的字符图像有如下几个参数:各个字符的个数)9,,1,0( =i N i ,各个字符某模板分量的样本均值),,1,0(M j Y j =、样本方差),,1,0(S 2j M j =,不同字符的同一分量样本均值的方差),,1,0(S 2j M j ='。其中,j Y 是该模板分量的期望值,作为某个字符模板分量j 的数值j β;2j S 展示了对应模板分量度对于该字符的可信度,是确定j γ的主要依据,2j S 越小,可信度越高;2j S '展示的是该模板对各个字符的区分能力,2j S '越大,模板的区分能力越强,该数值用于调整模板分量权值。
下面三个表格展示了模板分量权值的计算方式(0-4五个数字字符的六个分量):根据表格 3,表格 1到表格 2的影射:
模板法是本项目算法的基本框架,将各个数字字符的外形特征都统一到模板内部,然后进行一致的运算,降低了程序的复杂度,提高了开发效率。那么,如
何来构造一个好的模板呢?
3. 细化
图像细化就是把图像中的笔画细化成单像素的线条。它作为一种图像预处理技术出现,目的是提取源图像的骨架,即将原图像中线条宽度大于1个像素的线条细化成只有一个像素宽,形成“骨架”,形成骨架后便于分析图像特征,例如,进行网格特征统计、活动模板分析等。我们采用的是比较成熟的Hilditch细化算法。
4. 网格特征模板
网格特征模板是第一个外形模版,也是最简单、最基本的模板。先将20*20的图形分成4*4块,每块5*5个像素,然后统计各个网格中黑点个数。图像的网格分块如图 3所示:
图 3 细化字符以及原始字符图像分块
由于字符的基本形状一定,并且质心不动,字符的笔划经过每个网格的笔划数大致保持稳定。细化后的笔划是由单像素构成,各个网格的黑色像素不会受字符笔划的粗细而变化。对于模板期望值的计算,采用了统计的方法:选取1000个样本,计算各个字符在每个网格的平均黑点数,此数值即所求期望值。
5. 活动模板
对于部分数字,活动空间较大。经过形变后其某部分结构不定于某网格,即网格特征模板的可信度较低。例如数字"1",常常以正斜或者反斜的形态出现,倾斜角度也很不一定,因此容易出错。
本算法所使用的活动模板,是用一个小方块包围字符图形的某一部分,例如上、中、下部。虽然某些字符整体形变大,但是部分的形变却很小,从而具有较大的参考价值。例如,"7"的下部是很简单的一条斜线,可以用于区分数字"1"和数字"2",如图4所示:
图 4 部分结构示例
部分结构A的参数有,黑点个数,不均衡度等。不均衡度可分为水平不均衡度和垂直不均衡度,水平不均衡度就是A中各黑点到水平中心的坐标差值求和。A的水平不均衡度计算方法如下:
a) 计算A 的水平中心位置;
b) 对A 中各个黑点与水平中心的距离算术求和(规定中心左边的黑点距离为
负)。计算公式:∑-=)(x ix z c Balance ,其中ix c 为A 中第i 个黑点的横坐标,
x z 为中心的横坐标。
垂直不均衡度类似于水平不均衡度,即A 中各黑点到垂直中心的坐标差值求和。
6. 交叉点特征模板
实验中,我们发现分块黑点计数模板对于"2"、"3"、"5"、"7","1"、"2"、"7"和"3"、"5"、"6"、"9"这三组数据区分不到位。分析这些数字字符图像的特点,我们发现,使用直线切割字符图像的同一坐标位置所得的交叉点数目是不同的。沿第一组数据的纵向某两坐标进行切割,所得的交点数目不同,如图 5所示:
图 5 纵向两列交叉点数
7. 环结构
由于字符"6"、"8"、"9"图形相近,且字符"6"、"9"的部分变形体非常接近于字符"8",以至于上述方法容易出错。而这三个字符存在非常明显的特征——环结构。根据环结构的数目、位置,即可准确的区分"6"、"8"、"9"。由于只对三个字符具有区分作用,且不服从正态分布,所以我们没有将环结构作为模板,仅用于对识别结果进行调整。 8. 测试结果及其分析
注:后三项是与网格特征模板一起使用的效果
为实现高准确率,系统采用4个模板,在实验中各模板组合的有机系统的识别准确率为100%。但是系统优化后时间复杂度仍然很大,因此,在算法移植普通系统时可进行适当剪裁;对于高效系统,需要调整系统的结构方式,缩小搜索空间、优化搜索算法等。 9. 结论
简单变形体数字字符的识别,是字符识别的最基本理论研究。我们研究了网
格特征模板、活动模板、交叉点模板、环结构模板以及其综合而成的有机整体。
进一步研究发现,基于文本的复杂验证码字符图像只是加入了噪声、字符缩放、重叠处理等技术。因此只须对此类验证码使用去噪、分割、归一化等处理后,再使用本系统的技术,也可得出结果。
此外,本项目只是在模式识别领域进行的小小尝试,使用的技术也是最基础、较为简单的技术。但是对于初学者进一步理解模式识别技术,它具有较好的指导意义。同时,本项目的算法易于理解,易于扩展、移植,可以很方便地运用到其它种类的模式识别中去。
10. 参考文献
[1]张宏林.Visual C++ 数字图像模式识别技术及工程实践[M].北京:人民邮电
出版社,2003.
[2]肖旭红,戴汝为.一种活动模板子结构引导的联机手写汉字识别方法[J].自
动化学报,1998,第24卷(4): 469-475.
[3]胡爱明,周孝宽.车牌图像的快速匹配识别方法[J].计算机工程与应
用,2003,(07) :90-110.
[4]李弟平,罗三定.一种基于几何特征的改进模板匹配算法[J]. 电脑知识与技
术, 2006,(17):118-120.
[5]Ritendra Datta, Jia Li, James Z. Wang R. Datta, J. Li, and J. Wang.
IMAGINATION: A robust image-based captcha generation system.
Proceedings of the ACM Multimedia Conference, November 2005:331-334.
[6]六安网络.验证码识别技术.https://www.360docs.net/doc/5613068697.html,/captcha/.
[7]Qqwwee_COM.验证码识别. https://www.360docs.net/doc/5613068697.html,/qqwwee_com/.
验证码识别常用算法
验证码识别常用算法 图像处理(验证码识别)程序中常用算法:灰度,二值化,去噪(1*1像素或者3*3像素等) 代码: view plaincopy to clipboardprint? //灰度 private void btnGray_Click(object sender, EventArgs e) { try { int Height = this.picBase.Image.Height; int Width = this.picBase.Image.Width; Bitmap newbitmap = new Bitmap(Width, Height); Bitmap oldbitmap = (Bitmap)this.picBase.Image; Color pixel; for (int x = 0; x < Width; x++) { for (int y = 0; y < Height; y++) { pixel = oldbitmap.GetPixel(x, y); newbitmap.SetPixel(x, y, Gray(pixel)); } } this.picBase.Image = newbitmap; } catch (Exception err) { MessageBox.Show("灰度化失败原因:" + err.Message); } } //灰度化算法 protected static Color Gray(Color c) { int rgb = Convert.ToInt32((double)(((0.3 * c.R) + (0.59 * c.G)) + (0.11 * c.B))); return Color.FromArgb(rgb, rgb, rgb); } //灰度 private void btnGray_Click(object sender, EventArgs e) { try { int Height = this.picBase.Image.Height; int Width = this.picBase.Image.Width; Bitmap newbitmap = new Bitmap(Width, Height); Bitmap oldbitmap = (Bitmap)this.picBase.Image; Color pixel; for (int x = 0; x < Width; x++) { for (int y = 0; y < Height; y++) { pixel = oldbitmap.GetPixel(x, y);
图片验证码识别打码软件使用教程
图片验证码识别打码软件 使用教程 目录 一、简介 (2) 二、运行原理 (2) 三、菜单功能 (3) 四、使用流程 (6) 五、注意事项 (9)
一、简介 其实图片验证码识别打码软件是依托一个验证码自动识别平台,根据用户及软件开发者的需求进行平台对接之后自动将软件遇到的验证码进行自动的识别,从而减少验证码给双眼带来的压力,节省验证码识别的时间。其中可以自动识别输入的验证码有数字,字母,数字字母组合,汉字等,但是特殊类型的需要与客服沟通。在目前国内已有的验证码识别的技术的基础上,加入验证码题库,大大提高了验证码识别的准确率。像比较常见的就是对接好答题吧打码平台进行电脑打码。 二、运行原理 1、答题打码平台开发研究要重点研究了用于字符识别的BP神经网络、卷积神经网络和形状上下文算法,给出详细的推导。 2、采用分段线性变换去除图像模糊,利用局部OSTU二值化,得到了比全局阈值更好的分割结果。对传统的投影分割法改进,提出了极小值分割算法,有效解决了验证码字符粘连的问题。并采用简化后的卷积神经网络进行字符训练和识别,达到了99.1%的高识别率。 3、聚类算法和竖直投影结合的方式完成分割,解决了字符叠加和粘连的难题。对单个字符以简化后的卷积神经网络进行训练和识别,识别率达到了53%。 4.对已有的难以分割的验证码,提出了基于形状上下文整体识别
验证码的方法,破解率达到了27.7%。这种整体识别的思想也给其 他较难分割的验证码提供了一个新的识别思路。 三、菜单功能 1、识别测试 在对接操作之前,让用户进行免费测试了解平台的识别准确率的 窗口。将用户名,密码进行填写之后上传测试的图片验证码就可以进 行测试识别。(ps:在线识别测试只支持普通英文、数字或者汉字验 证码,选择题及特殊类型请联系客服) 2、VIP体系 详细介绍了不同的VIP等级享受的福利不一样。基本上是充值的 越多,送的也就越多。一般来说,识别验证码的价格是十分的划算的。 3、价格类型 1)识别验证码类型 纯数字,纯英文字母,字母数字组合,纯汉字,数字英文汉字 三混合。 2)价格详情 1.纯数字 编码类型白天收费点数夜间收费点数超时时间44位纯数字10.0014.0060 61位纯数字10.0012.0060
按键精灵 识别验证码 一般的验证码通杀
Function body(a,b,c) dim aa aa=a aa=mid(aa,instr(aa,b) len(b)) body=left(aa,instr(aa,c)-1) End Function Public Function StringToBytes(ByVal strData, ByVal strCharset) Dim objFile Set objFile = CreateObject("ADODB.Stream") objFile.Type = adTypeText objFile.Charset = strCharset objFile.Open objFile.WriteText strData objFile.Position = 0 objFile.Type = adTypeBinary If UCase(strCharset) = "UNICODE" Then objFile.Position = 2 'delete UNICODE BOM ElseIf UCase(strCharset) = "UTF-8" Then objFile.Position = 3 'delete UTF-8 BOM End If StringToBytes = objFile.Read(-1) objFile.Close Set objFile = Nothing End Function Private Function GetFileBinary(ByVal strPath) Dim objFile Set objFile = CreateObject("ADODB.Stream") objFile.Type = adTypeBinary objFile.Open objFile.LoadFromFile strPath GetFileBinary = objFile.Read(-1) objFile.Close Set objFile = Nothing End Function
基于目标检测方法的验证码识别方法及系统与制作流程
图片简介: 本技术涉及一种基于目标检测方法的验证码识别方法及系统,其中方法包括:A.收集不同形状的滑块图片并建立数据集,通过selenium库操控浏览器进行网页请求操作,并进行模拟登陆,对验证码图片进行截图;B.对滑块图片进行RGBA四通道转透明通道处理,得到不透明滑块图片,对带缺口的验证码图片进行灰色处理;C.通过OpenCV中的函数对图片进行匹配,计算出不透明滑块图片和带缺口的验证码图片缺口处的坐标,得到滑块图片的位移量; D.通过selenium库模拟鼠标,按照先快后慢的人工滑动规律移动滑块图片,对验证码进行解析。为在各大网站收集数据做前期准备工作,实现自动识别滑动拼图验证码,提高验证码识别的准确率。 技术要求
1.一种基于目标检测方法的验证码识别方法,其特征包括: A.收集不同形状的滑块图片并建立滑块图片数据集,通过selenium库操控浏览器进行网页请求操作,并进行模拟登录,对带缺口的验证码图片进行截图,提取带缺口的验证码图片; B.对数据集中的滑块图片进行RGBA四通道转透明通道处理,得到不透明滑块图片,对所提取的带缺口的验证码图片进行灰色处理; C.通过OpenCV的matchTemaplate函数对所述不透明滑块图片和所述带缺口的验证码图片进行匹配,设置相似度阀值,通过OpenCV中的cv2.TM_CCOEFF_NORMED得到与带缺口的验证码图片最相匹配的不透明滑块图片,计算出不透明滑块图片和带缺口的验证码图片缺口处的坐标,得到不透明滑块图片移动到带缺口的验证码图片缺口处的位移量distance; D.通过selenium库模拟鼠标点击所述滑块图片,并保持模拟鼠标按键的点压状态,按照先快后慢的人工滑动规律移动所述滑块图片,实现将滑块图片移动到所述带缺口的验证码图片的缺口处进行验证码解析。 2.根据权利要求1所述的一种基于目标检测方法的验证码识别方法,其特征在于:步骤B 中,对所述的滑块图片和带缺口的验证码图片进行处理时,对滑块图片进行RGBA四通道转透明通道处理,将RGB三通道的数值设为0,透明通道“A”的数值设置为220,仅保留滑块图的边缘部分;对所述带缺口的验证码图片进行RGB三通道转单通道的灰度处理。 3.根据权利要求1所述的一种基于目标检测方法的验证码识别方法,其特征在于:步骤D 中,所述进行验证码解析的步骤包括: D1.设置阈值mid=distance×3/4,初始滑块位置current=0,时刻t=0.2,初始速度V=0,加速度a=0; D2.初始滑块位置current小于位移量distance时,进入循环: 若当前滑块位置current小于阀值mid时, a=2; 若当前滑块位置current大于阀值mid时, a=-3;
验证码的作用
验证码的作用 验证码的作用:有效防止这种问题对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试,实际上是用验证码是现在很多网站通行的方式(比如招商银行的网上个人银行,腾讯的QQ社区),我们利用比较简易的方式实现了这个功能。虽然登陆麻烦一点,但是对社区还来说这个功能还是很有必要,也很重要。但我们还是提醒大家主要保护自己的密码,尽量使用混杂了数字、字母、符号在内的6位以上密码,不要使用诸如1234之类的简单密码或者与用户名相同、类似的密码。不要因为只是来iclub问问问题,就随意设置密码,保护你自己的密码也是保护你自己,免得你的账号给人盗用给自己带来不必要的麻烦。~ (1).验证码一般是防止批量注册的,人眼看起来都费劲,何况是机器。二像百度贴吧未登录发贴要输入验证码大概是防止大规模匿名回帖的发生目前,不少网站为了防止用户利用机器人自动注册、登录、灌水,都采用了验证码技术。所谓验证码,就是将一串随机产生的数字或符号,生成一幅图片,图片里加上一些干扰象素(防止OCR),由用户肉眼识别其中的验证码信息,输入表单提交网站验证,验证成功后才能使用某项功能。 (2).一般注册用户ID的地方以及各大论坛都要要输入验证码 (3).常见的验证码 1,四位数字,随机的一数字字符串,最原始的验证码,验证作用几乎为零。 2,CSDN网站用户登录用的是GIF格式,目前常用的随机数字图片验证码。图片上的字符比较中规中矩,验证作用比上一个好。没有基本图形图像学知识的人,不可破!可惜读取它的程序,在CSDN使用它的第一天,好像就在论坛里发布了,真是可怜! 3,QQ网站用户登录用的是PNG格式,图片用的随机数字+随机大写英文字母,整个构图有点张扬,每刷新一次,每个字符还会变位置呢!有时候出来的图片,人眼都识别不了,厉害啊… 4,MS的hotmail申请时候的是BMP格式, 随机数字+随机大写英文字母+随机干扰像素+随机位置。 5,Google的Gmail注册时候的是JPG格式,随机英文字母+随机颜色+随机位置+随机长度。6,其他各大论坛的是XBM格式,内容随机。 (4)意义:不少网站为了防止用户利用机器人自动注册、登录、灌水,都采用了验证码技术。所谓验证码,就是将一串随机产生的数字或符号,生成一幅图片,图片里加上一些干扰象素(防止OCR),由用户肉眼识别其中的验证码信息,输入表单提交网站验证,验证成功后才能使用某项功能。
验证码新技术趋势
0x00 简介 验证码作为一种辅助安全手段在Web安全中有着特殊的地位,验证码安全和web应用中的众多漏洞相比似乎微不足道,但是千里之堤毁于蚁穴,有些时候如果能绕过验证码,则可以把手动变为自动,对于Web安全检测有很大的帮助。 全自动区分计算机和人类的图灵测试(英语:Completely Automated Public Turing test to tell Computers and Humans Apart,简称CAPTCHA),俗称验证码,是一种区分用户是计算机和人的公共全自动程序。在CAPTCHA测试中,作为服务器的计算机会自动生成一个问题由用户来解答。这个问题可以由计算机生成并评判,但是必须只有人类才能解答。由于计算机无法解答CAPTCHA的问题,所以回答出问题的用户就可以被认为是人类。(from wikipedia) 大部分验证码的设计者都不知道为什么要用到验证码,或者对于如何检验验证码的强度没有任何概念。大多数验证码在实现的时候只是把文字印到背景稍微复杂点的图片上就完事了,程序员没有从根本上了解验证码的设计理念。 验证码的形式多种多样,先介绍最简单的纯文本验证码。 纯文本验证码 纯文本,输出具有固定格式,数量有限,例如: ?1+1=? ?本论坛的域名是? ?今天是星期几? ?复杂点的数学运算
这种验证码并不符合验证码的定义,因为只有自动生成的问题才能用做验证码,这种文字验证码都是从题库里选择出来的,数量有限。破解方式也很简单,多刷新几次,建立题库和对应的答案,用正则从网页里抓取问题,寻找匹配的答案后破解。也有些用随机生成的数学公式,比如随机数 [+-*/]随机运算符随机数=?,小学生水平的程序员也可以搞定…… 这种验证码也不是一无是处,对于很多见到表单就来一发的spam bot来说,实在没必要单独为了一个网站下那么大功夫。对于铁了心要在你的网站大量灌水的人,这种验证码和没有一样。 下面讲的是验证码中的重点,图形验证码。 图形验证码 先来说一下基础: 识别图形验证码可以说是计算机科学里的一项重要课题,涉及到计算机图形学,机器学习,机器视觉,人工智能等等高深领域…… 简单地说,计算机图形学的主要研究内容就是研究如何在计算机中表示图形、以及利用计算机进行图形的计算、处理和显示的相关原理与算法。图形通常由点、线、面、体等几何元素和灰度、色彩、线型、线宽等非几何属性组成。计算机涉及到的几何图形处理一般有2维到n维图形处理,边界区分,面积计算,体积计算,扭曲变形校正。对于颜色则有色彩空间的计算与转换,图形上色,阴影,色差处理等等。 在破解验证码中需要用到的知识一般是像素,线,面等基本2维图形元素的处理和色差分析。常见工具为: ?支持向量机(SVM) ?OpenCV ?图像处理软件(Photoshop,Gimp…) ?Python Image Library
php实现验证码的识别(初级篇)
近期研究一些突破验证码方面的知识,记录下来。一方面算是对这几天学习知识的总结帮助自己理解;另一方面希望对研究这方面的技术同学有所帮助;另外也希望引起网站管理者的注意,在提供验证码时多些考虑进去。由于刚刚接触这方面的知识,理解比较浅显,有错误再所难免,欢迎拍砖。 验证码的作用:有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试。其实现代的验证码一般是防止机器批量注册的,防止机器批量发帖回复。目前,不少网站为了防止用户利用机器人自动注册、登录、灌水,都采用了验证码技术。 所谓验证码,就是将一串随机产生的数字或符号,生成一幅图片,图片里加上一些干扰象素(防止OCR),由用户肉眼识别其中的验证码信息,输入表单提交网站验证,验证成功后才能使用某项功能。 我们最常见的验证码 1,四位数字,随机的一数字字符串,最原始的验证码,验证作用几乎为零。 2,随机数字图片验证码。图片上的字符比较中规中矩,有的可能加入一些随机干扰素,还有一些是随机字符颜色,验证作用比上一个好。没有基本图形图像学知识的人,不可破!3,各种图片格式的随机数字+随机大写英文字母+随机干扰像素+随机位置。 4,汉字是注册目前最新的验证码,随机生成,打起来更难了,影响用户体验,所以,一般应用的比较少。 简单起见,我们这次说明的主要对象是第2种类型的,我们先看几种网上比较常见的这种验证码的图片. (不知道怎么搞的,CSDN又不能上传图片了,我把这四种图片放到下载包中了,可以下载下来对比察看) 这四种样式,基本上能代表2中所提到的验证码类型,初步看起来第一个图片最容易破解,第二个次之,第三个更难,第四个最难。 真实情况那?其实这三种图片破解难度相同。 第一个图片,最容易,图片背景和数字都使用相同的颜色,字符规整,字符位置统一。 第二个图片,看似不容易,其实仔细研究会发现其规则,背景色和干扰素无论怎么变化,验证字符字符规整,颜色相同,所以排除干扰素非常容易,只要是非字符色素全部排除即可。第三个图片,看似更复杂,处理上面提到背景色和干扰素一直变化外,验证字符的颜色也在变化,并且各个字符的颜色也各不相同。看似无法突破这个验证码,本篇文章,就一这种类型验证码为例说明,第四个图片,同学们自己搞。 第四个图片,除了第三个图片上提到的特征外,又在文字上加了两条直线干扰率,看似困难其实,很容易去掉。 验证码识别一般分为以下几个步骤:
验证码识别原理及实现方法
验证码识别原理及实现方法 验证码的作用:有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试。其实现代的验证码一般是防止机器批量注册的,防止机器批量发帖回复。目前,不少网站为了防止用户利用机器人自动注册、登录、灌水,都采用了验证码技术。 所谓验证码,就是将一串随机产生的数字或符号,生成一幅图片,图片里加上一些干扰象素(防止OCR),由用户肉眼识别其中的验证码信息,输入表单提交网站验证,验证成功后才能使用某项功能。 我们最常见的验证码 1,四位数字,随机的一数字字符串,最原始的验证码,验证作用几乎为零。 2,随机数字图片验证码。图片上的字符比较中规中矩,有的可能加入一些随机干扰素,还有一些是随机字符颜色,验证作用比上一个好。没有基本图形图像学知识的人,不可破! 3,各种图片格式的随机数字+随机大写英文字母+随机干扰像素+随机位置。 4,汉字是注册目前最新的验证码,随机生成,打起来更难了,影响用户体验,所以,一般应用的比较少。 简单起见,我们这次说明的主要对象是第2种类型的,我们先看几种网上比较常见的这种验证码的图片. 这四种样式,基本上能代表2中所提到的验证码类型,初步看起来第一个图片最容易破解,第二个次之,第三个更难,第四个最难。 真实情况那?其实这三种图片破解难度相同。 第一个图片,最容易,图片背景和数字都使用相同的颜色,字符规整,字符位置统一。 第二个图片,看似不容易,其实仔细研究会发现其规则,背景色和干扰素无论怎么变化,验证字符字符规整,颜色相同,所以排除干扰素非常容易,只要是非字符色素全部排除即可。 第三个图片,看似更复杂,处理上面提到背景色和干扰素一直变化外,验证字符的颜色也在变化,并且各个字符的颜色也各不相同。看似无法突破这个验证码,本篇文章,就一这种类型验证码为例说明,第四个图片,同学们自己搞。 第四个图片,除了第三个图片上提到的特征外,又在文字上加了两条直线干扰率,看似困难其实,很容易去掉。 验证码识别一般分为以下几个步骤: 1.取出字模 2.二值化 3.计算特征 4.对照样本 1:取出字模 识别验证码,毕竟不是专业的OCR识别,并且,由于各个网站的验证码各不相同,所以,最常见的方法就是就是建立这个验证码的特征码库。去字模时,我们需要多下载几张图片,使这些图片中,包括所有的字符,我们这里的字母只有图片,所以,只要收集到包括0-9的图片即可。 2:二值化 二值化就是把图片上的验证数字上每个象素用一种数字表示1,其他部分用0表示。这样就可以计算出每个数字字模,记录下这些字模来,当作key即可。
数字图像__验证码识别
一、数字图像处理基础 一幅图像可以定义为一个二维数组f(x,y),这里x,y是空间坐标,而在任何一对空间坐标(x,y)上的幅值f称为该点图像的强度或灰度。当x,y和幅值f为有限的、离散的数值时,称该图像为数字图像。 自然界呈现在人眼中的图像是连续的模拟信号,在计算机处理前,必须用图像传感器把光信号转换为表示亮度的电信号,再通过取样和量化得到一副数字图像。取样是对图像在坐标上进行离散化的过程,每一个取样点称为一个像素。量化是对图像灰度上的离散化过程。取样后将得到M*N个像素,每个像素量化得到一个灰度值L,以L表示灰度值的允许取值范围,则数字图像存储需要的比特数b可以表示为: 图像的灰度值取值范围被称为图像的动态范围。把占有灰度级全部有效段的图像称为高动态范围图像,高动态范围图像有较高的对比度。相反,地动态范围的图像看上去是冲淡了的灰暗格调。 二、图像的预处理: 主要是对图像进行灰度化、二值化、抑噪(滤波)等技术。 1、图像的灰度化 RGB系统中一个颜色值由3个分量组成,这样的图像称为彩色图像,RGB系统称为颜色空间模型。常见的颜色空间模型还有HSI、CMYK 等。如果一幅图像的颜色空间是一维的(一个颜色值只有一个颜色分
量),则这幅图像就是一副灰度图。在位图图像中,一般以R=G=B来显示灰度图像。 图 1 原始图片 常用的灰度化方法有以下三种: (2.1) (2.2) (2.3) 其中,公式(2.1)的方法来源于I色彩空间中I分量的计算公式,公式(2.2)来源于NTSC色彩空间中Y分量的计算公式。公式(2.3)是基于采用保留最小亮度(黑色)的方法。 图 2 用公式2.2灰度化后的图片 RGB彩色图像可以看成是由3副单色的灰度图像构成的,可以直 接取RGB通道中的任一个通道得到灰度化图像,如,前提是图像中目标像素的亮度信息主要分布在B通道上,否则灰度化结果将是亮度信息的大量丢失。灰度图像又叫亮度图像,由归一化的取值表示亮度,最大取值表示白色,最小取值表示黑色。
数字验证码识别算法的研究与设计
数字验证码识别算法的研究和设计 王虎, 冯林, 孙宇哲 Wang Hu, Feng Lin, Sun Yuzhe 大连理工大学大学生创新院,大连116023 Institute of University Students’ Innovation, Dalian University of Technology, Dalian 116023, China E-mail: wlys111@https://www.360docs.net/doc/5613068697.html, Research and Design of Digital character-based CAPTCHA Recognition Abstract:CAPTCHA Recognition can be used in multi-send technology. Digital character-based CAPTCHA Recognition, which is foundation of pattern recognition research, is a kind of OCR. In this paper, we proposed a CAPTCHA Recognition System based on simple distortion and its architecture is template matching. Hilditch thinning algorithm, circle structure searching algorithm and dynamic template analyzing algorithm is chose and the weigh of template is also used to improve the recognition accuracy. The advantage of the system is that the recognition precision is perfect. Key words:Template matching, Weighted Template, dynamic template, grid feature, crossing points feature 摘要:验证码识别技术可以用于网站的群发软件,数字验证码识别是光学字符识别(OCR)的一种,是进行模式识别研究的基础。论文提出了以简单变形的数字字符为理论研究素材,将模板匹配作为基本框架的验证码识别系统。系统采用图像的Hilditch细化算法、环结构的搜索算法、活动模板分析算法,加入模板分量的权值。其优点在于能够对特定数字验证码精确识别,实验中识别准确率基本达到100%。 关键字:模板匹配,加权模板,活动模板,网格特征,交叉点特征 文章编号:文献标识码:A 中图分类号:TP391.43 引言 目前,网络上出现了很多以图片形式出现的基于文本的验证码。所谓验证码,就是将一串随机产生的字符,生成一幅图片,图片里随机的加入一些像素干扰、颜色干扰和形变干扰等等,以达到防止恶意注册等目的。有的验证码是无像素干扰的、大小固定的、质心位置居中,含有形变干扰的数字字符,我们称之为简单变形体。反之,我们称加入了更多干扰的字符为复杂变形体。 验证码千变万化,而当前的识别系统都具有很强针对性,只能够识别一种类型的验证码,而且验证码的技术不断发展,出现了更加复杂的基于图像的验证码系统[5],并且目前人工智能(机器智能)还远未赶上人类智能,但是对于给定的验证码系统,在获知其特点之后,基本能够以一定的准确率进行识别[6、7]。 基金项目: 国家自然科学基金( the National Foundation of China under Grant No.10471051 )。 作者简介: 王虎(1984-),学士,研究方向:计算机图形处理,模式识别与智能控制; 冯林(1969-),博士,教授,研究方向:图像压缩、配准及融合和演化算法; 孙宇哲(-),硕士,研究方向:.
验证码自动识别的应用
验证码自动识别的应用一、验证码的由来 智能时代的到来给我们的生活带来了很多的新鲜词,“验证码”便是在这样的背景之下诞生的。 垃圾评论和垃圾邮件可以轻松通过任何一个网站的注册程序,通过各种方式轰炸人民群众的眼球。 最先想要解决这一问题的是雅虎——作为互联网时代早期最重要的免费邮件提供商,他们一方面要解决用户们每天遇到的数以百计的垃圾邮件轰炸,另一方面,他们自己的免费邮箱,恰恰又是垃圾邮件的最爱耗费无数资源所阻止的垃圾邮件,都来自于自己的服务器。这让雅虎开始认真考虑如何解决人机辨识问题。(摘自网络文章) 二、验证码识别技术的背景 在国内验证码识别技术还是在摸索阶段,但是却无法阻挡它的发展。2009年,A.A. Chandavale等针对EZ-Gimpy 的四类验证码分别进行了识别。2008年,Jeff Yan等人以高达90%以上的识别率破解了微软先前的验证码。2005年,
Edward Aboufadel,Julia Olsen和Jesse Windle通过将字符旋转至水平并对单个字符应用Harr小波滤波结果作为特征,以接近100%的识别率破解了the Holiday Inn Priority Club的验证码。【摘自:验证码识别技术研究】 三、验证码识别技术的技术原理 为简单起见,破解说明主要针对是第2种类型的,先来看看网上常见的这种验证码的图片: 一种,最容易,图片背景和数字都使用相同的颜色,字符规整,字符位置统一。 二种,看似不容易,其实仔细研究会发现其规则,背景色和干扰素无论怎么变化,验证字符字符规整,颜色相同,所以排除干扰素非常容易,只要是非字符色素全部排除即可。 三种,看似更复杂,处理上面提到背景色和干扰素一直变化外,验证字符的颜色也在变化,并且各个字符的颜色也各不相同。 四种,除了第三个图片上提到的特征外,又在文字上加了两
C#源代码,数字识别,特征识别,新浪数字,验证码识别
using System; using System.Collections.Generic; using https://www.360docs.net/doc/5613068697.html,ponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Windows.Forms; namespace测试数字提取 { public partial class Form1 : Form { public Form1() { InitializeComponent(); } //新浪微博数字识别,根据rgb红色分量150一下的识别 //下面是每个数字的特征 class NewNumber { static int[,] _num1 = new int[9, 7] {{0,0,0,0,1,0,0},{0,0,0,1,1,0,0},{0,0,1,0,1,0,0},{0,0,0,0,1,0,0},{0,0,0,0,1,0,0}, {0,0,0,0,1,0,0},{0,0,0,0,1,0,0},{0,0,0,0,1,0,0},{0,0,0,0,1,0,0}}; static int[,] _num2 = new int[9, 7] {{0,0,1,1,1,1,0},{0,1,0,0,0,1,0},{0,1,0,0,0,0,1},{0,0,0,0,0,1,0},{0,0,0,0,0,1,0}, {0,0,0,1,1,0,0},{0,0,1,1,0,0,0,},{0,1,1,0,0,0,0},{0,1,1,1,1,1,1}}; static int[,] _num3 = new int[9, 7] {{0,0,1,1,1,0,0},{0,1,0,0,0,1,0},{0,0,0,0,0,1,0},{0,0,0,0,0,1,0},{0,0,0,1,1,0,0}, {0,0,0,0,0,1,0},{0,0,0,0,0,0,1},{0,1,0,0,0,1,0},{0,0,1,1,1,0,0}}; static int[,] _num4 = new int[9, 7] {{0,0,0,0,0,1,0},{0,0,0,0,1,1,0},{0,0,0,1,1,0,0},{0,0,0,0,0,1,0},{0,0,1,0,0,1,0}, {0,1,0,0,0,1,0},{0,1,1,1,1,1,1},{0,0,0,0,0,1,0},{0,0,0,0,0,1,0}}; static int[,] _num5 = new int[9, 7] {{0,0,1,1,1,1,0},{0,0,1,0,0,0,0},{0,0,0,0,0,0,0},{0,1,1,1,1,1,0},{0,1,0,0,0,0,0}, {0,0,0,0,0,0,1},{0,0,0,0,0,0,1},{0,1,0,0,0,0,0},{0,0,1,1,1,0,0}}; static int[,] _num6 = new int[9, 7] {{0,0,0,1,1,0,0},{0,0,1,0,0,1,0},{0,1,0,0,0,0,0},{0,1,0,1,1,0,0},{0,1,1,0,0,1,0}, {0,1,0,0,0,1,0},{0,1,0,0,0,1,0},{0,0,1,0,0,1,0},{0,0,1,1,1,0,0}}; static int[,] _num7 = new int[9, 7] {{0,1,1,1,1,1,1},{0,0,0,0,0,1,0},{0,0,0,0,1,0,0},{0,0,0,0,1,0,0},{0,0,0,1,0,0,0}, {0,0,0,1,0,0,0},{0,0,0,1,0,0,0},{0,0,0,0,0,0,0},{0,0,1,0,0,0,0}}; static int[,] _num8 = new int[9, 7] {{0,0,1,1,1,0,0},{0,1,0,0,0,1,0},{0,1,0,0,0,1,0},{0,1,0,0,0,1,0},{0,0,1,1,1,0,0}, {0,1,0,0,0,1,0},{0,1,0,0,0,1,0},{0,1,0,0,0,1,0},{0,0,1,1,1,0,0}}; static int[,] _num9 = new int[9, 7] {{0,0,1,1,1,0,0},{0,1,1,0,0,1,0},{0,1,0,0,0,1,0},{0,1,0,0,0,1,0},{0,1,1,0,0,1,0}, {0,0,1,1,1,0,0},{0,0,0,0,0,1,0},{0,1,0,0,0,1,0},{0,0,1,1,1,0,0}}; static int[,] _num0 = new int[9, 7]
Python用KNN算法实现验证码识别
Python用KNN算法实现验证码识别 作为一名爬虫爱好者,把互联网作为数据库的同时总会遇到很多坑,其中一个就是验证码,设置验证码一大理由就是为了限制你乱爬,不过对于很多简单的验证码,破解还是相当容易的。比如类似下面这种。最简单的办法是直接用pytesseract库,具体方法请自行搜索。当然如果不想用它,自己来写一个识别算法也并不难。可以用机器学习里面比较基础的KNN算法。 先来介绍一下这个KNN算法,他全称叫K最近邻(kNN, k-NearestNeighbor),所谓K最近邻,就是离谁最近,是谁的可能性就更大。什么意思,举个例子就明白了。 我现在已经统计了一组手机数据,方便起见,假设只有高端机和低端机两个分类,如下:此时如果有一个新手机T(1500元,15小时),该怎么判断是什么手机呢?我把它们放到同一个坐标系中去比较一下。它并不能很好地跟已知数据完全重合,但不要紧,可以算一下它与其他手机的距离。经过计算,与T的距离D就是这么简单。当然了,这里面只是举个例子所以数据量比较小,当数据量足够大时,比如有200台低端机和300台高端机,选出最接近的200个数据,其中哪种机器多就归到哪种,得出的结论就会比较准确。这就是最简单的KNN算法,离哪个近,就把它归类为哪个种类。这
是二维,还可以再加个“像素”属性,变为三维,仍然可以求最近距离。拓展到N个属性也是一样的道理。基本原理就是这样,下面来介绍如何识别验证码,以下代码基于Python3 还是这张验证码,我们把它放大一点可以看到,其实他就是一个一个的像素点构成的。 里面颜色太多不好操作,首先把这张图变成黑白的from PIL import Image#引入Image类 im = Image.open('图片路径')#打开图片 im=im.convert('1')#原来图片是彩色的,这里把图片转换成模式'1',即黑白的 im.show()#显示图片 于是我们就得到了这么一张图 可以把每个点的颜色转变成0和1,并打印出来for i in range(im.size[1]): temp=[] for j in range(im.size[0]): pos=(j,i) col=im.getpixel(pos) #获取某坐标的点的颜色,黑色为0,白色为255,为了显示规程,把它转变成1了 if col==255: col=1
图像识别解决方案(验证码)
图像识别解决方案(验证码) 篇一:用于验证码图片识别的类 用于验证码图片识别的类(C#源码) 最近写了几个网站的验证码图片自动识别程序,尽管每个网站的验证码图片都不相同,识别的方法有所差别。但写得多了,也总结出不少相同之处。今天抽空封装出一个基础类来,发现可以很好地重复利用,编写不同的验证码识别程序,效率提高了不少。好东东不能独享,现放出来供大家共同研究,请网友们妥善用之。 封装后的类使用很简单,针对不同的验证码,相应继承修改某些方法,即可简单几句代码就可以实现图片识别了:GrayByPixels(); //灰度处理 GetPicValidByValue(128, 4); //得到有效空间 Bitmap[] pics = GetSplitPics(4, 1); //分割 string code = GetSingleBmpCode(pics[i], 128);//得到代码串 using System; using ; using
using ; using ; using ; using ; namespace BallotAiying2 { class UnCodebase { public Bitmap bmpobj; public UnCodebase(Bitmap pic) { bmpobj = new Bitmap(pic); //转换为Format32bppRgb
/// /// 根据RGB,计算灰度值 /// /// Color值 /// 灰度值,整型 private int GetGrayNumColor( posClr) { return ( * 19595 + * 38469 + posClr .B * 7472) >> 16; } /// /// 灰度转换,逐点方式 /// public void GrayByPixels() { for (int i = 0; i { for (int
易语言验证码识别源码
模拟精灵是首个公开最有效的验证码识别技术的软件, 使用模拟精灵制作了大量的免费、商用群发软件,对很多复杂BT的验证码都能成功的识别。但是验证码仍然需要精湛的技术与足够的耐心。请牢记这一点。 验证码识别不适合浮躁的人去做。 验证码识别是一项特殊的技术,任何一个公开的验证码识别代码都会很快的失效。 因为代码的公开后相关网站都会很快的更改验证码。 所以下面我只会介绍其原理。 在这里讨论验证码识别技术纯粹基于技术研究目的。 公开此技术也是为了让更多的网站采取更有效的防范措施。 禁止任何人利用这里介绍的验证码识别技术滥发垃圾信息。 本文介绍的验证码识别适用于比较复杂的图片验证码,也是大多数网站采用的方法。 有一些网站的验证码极简单,例如在网页中直接显示验证码字符而不是图片,或者图片的文件名直接就是验证码上的字符。 或者有其他规律可循,或者有其他明显的漏洞可以利用(例如通过改写访问验证码页面的源代码使验证码不刷新)。 这一类的验证码识别极其简单,只要熟练掌握web库、element库的函数即可,不需要使用下面介绍的方法。 一、下载验证码样本 打开c:\test文件夹,选“查看缩略图”, 然后重复运行下面的LAScript脚本,每运行一次,就查看c:\test下自动生成的图片,把图片上的字符改为文件名. 例如图片上面显示5,就把文件名改为5.jpg. 如果变化比较复杂的验证码,可以对每个字符多用几个样本,第一个字符为验证码字符,第二个字符可以为任意字符。 例如:5a.jpg , 5b.jpg , 5c.jpg ...........等等。 样本多就会识别能力就越强。 img = image.new(); --下载图像,没有后缀名要显示指定*.bmp格式 img:getURL("http://www.***.com/test.asp","*.png"); assert(img:ok(),"下载验证码失败"); img:Crop(4 ,3 , 56 ,18 ) img:save("c:\\test\\test.jpg") --保存到硬盘 --折分图片,指定一行四列
验证码识别技术
验证码识别技术 模拟精灵是首个公开最有效的验证码识别技术的软件, 使用模拟精灵制作了大量的免费、商用群发软件,对很多复杂BT的验证码都能成功的识别。 但是验证码仍然需要精湛的技术与足够的耐心。请牢记这一点。 验证码识别不适合浮躁的人去做。 验证码识别是一项特殊的技术,任何一个公开的验证码识别代码都会很快的失效。 因为代码的公开后相关网站都会很快的更改验证码。 所以下面我只会介绍其原理。 在这里讨论验证码识别技术纯粹基于技术研究目的。 公开此技术也是为了让更多的网站采取更有效的防范措施。 禁止任何人利用这里介绍的验证码识别技术滥发垃圾信息。 本文介绍的验证码识别适用于比较复杂的图片验证码,也是大多数网站采用的方法。 有一些网站的验证码极简单,例如在网页中直接显示验证码字符而不是图片,或者图片的文件名直接就是验证码上的字符。 或者有其他规律可循,或者有其他明显的漏洞可以利用(例如通过改写访问验证码页面的源代码使验证码不刷新)。 这一类的验证码识别极其简单,只要熟练掌握web库、element库的函数即可,不需要使用下面介绍的方法。 一、下载验证码样本 打开c:\test文件夹,选“查看缩略图”, 然后重复运行下面的LAScript脚本,每运行一次,就查看c:\test下自动生成的图片,把图片上的字符改为文件名. 例如图片上面显示5,就把文件名改为5.jpg. 如果变化比较复杂的验证码,可以对每个字符多用几个样本,第一个字符为验证码字符,第二个字符可以为任意字符。 例如:5a.jpg , 5b.jpg , 5c.jpg ...........等等。 样本多就会识别能力就越强。 img = image.new(); --下载图像,没有后缀名要显示指定*.bmp格式 img:getURL("http://www.***.com/test.asp","*.png"); assert(img:ok(),"下载验证码失败"); img:Crop(4 ,3 , 56 ,18 ) img:save("c:\\test\\test.jpg") --保存到硬盘
易语言自动识别验证码教程
易语言自动识别验证码教程 一、验证码识别流程 图像二值化-分割图片-取图片特征-将特征和特征库比较获取 图片对应内容-识别完毕 当然,这些步骤不是必须的,不过事实上现在大部分的识别顺序都是如此。 我来简单解释下 图像二值化:将图片的背景内容和文本内容分离。如果不分离图片内容的话程序无法正确的获取文本的特征(特征越精确越好)分割图片:将图片内的验证码文本分开。比如ABCD验证码,将至分成带有ABCD的四张图片分开取图片特征。这样方便后续的特征码判断(基本上大部分识别算法都要求分割图片) 取图片特征:这个过程是比较抽象的。稍后再解释。本教程只教最基本的识别方法,主要还是给大家思路 对比特征:这个不解释了。假设图片特征获取到2fz4fs23fs31。并且这个特征意味着图片值为1,那么假设以后识别到特征为 2fz4fs23fs31 就意味着图片内容是1 特征还是要自己获取的。而且更具不同的算法,特征也不同。有的算法就可以识别倾斜图片,有的算法就只能识别规则图片。所谓特
征算法还是要后续自己学习甚至是自己写出一个算法的。 二、易语言 易语言是一个自主开发,适合国情,不同层次不同专业的人员易学易用的汉语编程语言。易语言降低了广大电脑用户编程的门槛,尤其是根本不懂英文或者英文了解很少的用户,可以通过使用本语言极其快速地进入Windows程序编写的大门。易语言汉语编程环境是一个支持基于汉语字、词编程的、全可视化的、跨主流操作系统平台的编程工具环境;拥有简、繁汉语以及英语、日语等多语种版本;能与常用的编程语言互相调用;具有充分利用API,COM、DLL、OCX组件,各种主流数据库,各种实用程序等多种资源的接口和支撑工具。 三、易语言自动识别验证码的使用教程 (本文以答题吧打码平台作为演示示例) 1.注册一个属于自己的个人账号;