央金藏文分词系统

1央金藏文分词系统
史晓东*2卢亚军**3
*厦门大学人工智能研究所 361005
E-mail:mandel@https://www.360docs.net/doc/e79368707.html,
**西北民族大学科研处 730030
E-mail:zxdl365@https://www.360docs.net/doc/e79368707.html,
摘要:藏文分词是藏文信息处理的一个基本步骤,本文描述了我们将一个基于HMM的汉语分词系统segtag移植到藏文的过程,取得了91%的准确率。又在错误分析的基础上,进行了训练词性的取舍、人名识别等处理,进一步提高了准确率。
关键字:藏文分词、自然语言处理、HMM
A Tibetan Segmentation System – Yangjin
Xiaodong Shi*, and Yajun Lu**
*Institute of Artificial Intelligence, Xiamen University, Xiamen 361005, China
**Northwest University for Nationalities, Lanzhou 730030, China
Abstract: We described the porting of a Chinese segmentation system to handle Tibetan. The F-measure of the new Yangjin system is above 91% over a test corpus although the training corpus is relatively small. We also described more processing upon error analysis which led to further improvement.
Keywords:Tibetan Segmentation, natural language processing, HMM
1 引言
随着少数民族语言(主要是藏、维、蒙)到汉语的机器翻译研究逐渐进入人们的视野实验,相关的少数民族语言基础法分析工具也亟待完善。藏文分词是藏语到其他语言的基础性工具。虽然研究的时间也不算短(2002年陈玉忠[1]是较早的一篇研究),已经有至少10年的历史,但是还没有公开可用的工具。第一作者在研究汉语分词方面有丰富的经验,从2005年就开发的segtag汉语分词系统,虽然没有发表相关的论文,但是在北京大学公开的1998年人民日报一个月的语料上的准确率约为98%。因此将其移植到藏文,并加以公开,是我们的一个想法。经过与第二作者密切合作,已经成功地开发出了藏文的分词标注系统,在一个测试集上的准确率约为93%,取得了较为令人满意的效果。本文描述该系统的基本算法,并对藏文所作的特殊改进。
本文下面的内容如下:首先综述一下国内外的相关工作,然后介绍了央金藏文分词系统的基本结构,然后再描述为了改进性能对藏文所作的特殊处理,最后得出结论,并指出了进一步的工作。
由于第一作者一点也不懂藏文,因此本文对想开发一个未知语种(如蒙语、泰语、彝语等)的分词系统的人,有一定的借鉴意义。
1基金项目:863项目2006AA010108,国家社科基金重点项目05AYY001
2史晓东,男,1966.12,教授,主要研究方向:自然语言处理
3卢亚军,男,1956.10,教授,主要研究方向:语料库语言学,藏汉机器翻译
2 相关工作
陈玉忠[1]在2002年提出了基于格助词和接续特征的藏文分词算法。从此文中作者得出,其实藏文和日语类似,有很多格助词,表示一定的句法语义功能。扎西加等[2]给出了藏文分词的词类划分。Huidan Li u等[3]研究了藏文分词中的数字识别问题。才智杰[4]描述了班智达藏文分词系统的设计和实现。苏峻峰[5]描述了一个基于HMM的藏文分词模型。刘智文[6]做过一个基于CRF的藏文分词系统。国内的藏文相关工作基本上集中在青海师大、西北民大、西藏大学等单位。
与采用机器学习为主的汉语分词相比,目前藏文分词系统显得落后一些。在汉语方面一般都采用HMM、ME、CRF等模型,很少采用相对原始的规则或最大匹配模型。
3 央金藏文分词系统介绍
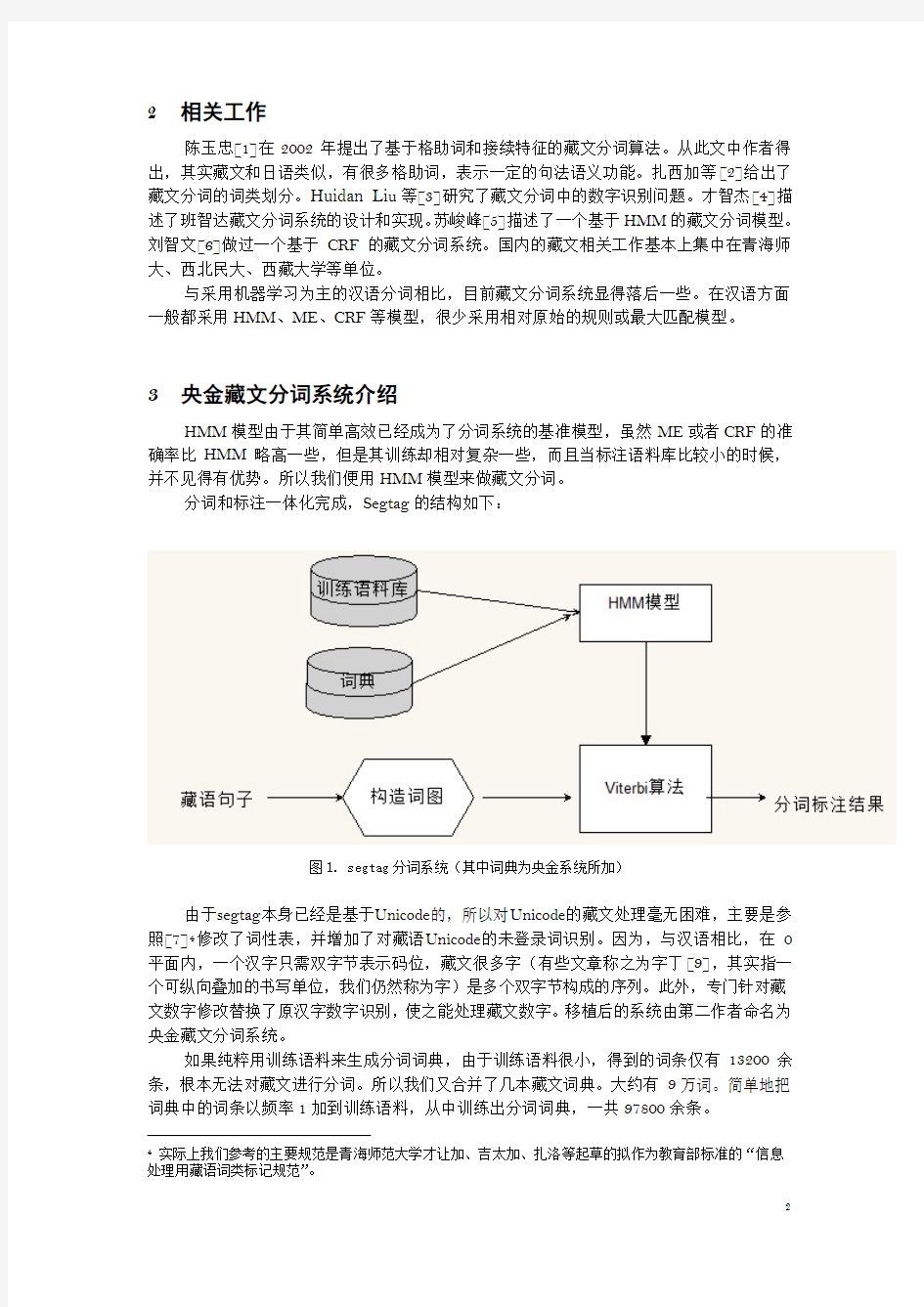
HMM模型由于其简单高效已经成为了分词系统的基准模型,虽然ME或者CRF的准确率比HMM略高一些,但是其训练却相对复杂一些,而且当标注语料库比较小的时候,并不见得有优势。所以我们便用HMM模型来做藏文分词。
分词和标注一体化完成,Segtag的结构如下:
图1. segtag分词系统(其中词典为央金系统所加)
由于segtag本身已经是基于Unicode的,所以对Unicode的藏文处理毫无困难,主要是参照[7]4修改了词性表,并增加了对藏语Unicode的未登录词识别。因为,与汉语相比,在0平面内,一个汉字只需双字节表示码位,藏文很多字(有些文章称之为字丁[9],其实指一个可纵向叠加的书写单位,我们仍然称为字)是多个双字节构成的序列。此外,专门针对藏文数字修改替换了原汉字数字识别,使之能处理藏文数字。移植后的系统由第二作者命名为央金藏文分词系统。
如果纯粹用训练语料来生成分词词典,由于训练语料很小,得到的词条仅有13200余条,根本无法对藏文进行分词。所以我们又合并了几本藏文词典。大约有9万词。简单地把词典中的词条以频率1加到训练语料,从中训练出分词词典,一共97800余条。
4实际上我们参考的主要规范是青海师范大学才让加、吉太加、扎洛等起草的拟作为教育部标准的“信息处理用藏语词类标记规范”。
央金系统的性能如下(此处2.7M指UTF16编码的文件大小):
表1. 央金分词系统的性能
训练语料测试语料精确率召回率F值备注
92.215% 90.041% 91.115 分词
2.7M+词典25K
79.342% 79.647% 79.494% 标注
这些训练语料都是在央金系统的分词结果的基础上,由第二作者校对修正而滚雪球一样得到。
另外,虽然Unicode目前已经是国际标准,国内仍然存在着部分班智达和同元编码的文档,我们集成了编码识别和自动转换功能,以方便用户使用。
此外,我们还集成了鼠标藏汉词典,以方便作者校对分词结果。
由于第一作者一点也不懂藏文,所以很多央金分词系统的很多功能都是为了方便用户能够在系统内便于进行分词校对而设。
4 分词系统的错误分析和改进
2.1 分词系统错误
通过文件比较,对测试语料中的错误进行了分析。首先我们注意到,标注的准确率偏低。结果发现,训练出词典中的有些词的不同词性之间的频率差异很大,如? gj 1 tt 1 nn 9 vi 20 gl 3413
其中gj 和 gl都是格助词,怀疑gj这个词性是训练语料中的标注错误而混进来的,因此在装入词典的时候做了一个简单的处理:如果某个词的频率低的词性与该词的频率最高的词性之频率比小于阈值β(目前取1%),则舍弃该词性。经过这样处理以后,分词的准确率没有任何变化,而标注的准确率有所提高:
表2. 舍弃低频词性以后央金分词系统的性能
训练语料测试语料精确率召回率F值备注
79.342% 79.647% 79.494% 原系统
2.7M+词典25K
82.632% 82.949% 82.790% 改进1
简单的分析表明:分词错误大部分是由于未登录词而造成的。而很多标注错误是因为训练生成的词典中根本没有测试答案中的词性造成的。其实这些错误大部分是训练语料的不一致性造成的。
2.2 汉语人名识别
藏文新闻中经常出现人名。相对于地名等其他专名,人名是最丰富并且变化的。因此,分词系统最好能自动识别人名。从来源分,人名基本上可以分为藏语人名、汉语人名、欧美人名等三大类。目前我们只考虑了汉语人名的自动识别。
汉语人名翻译成藏语,基本上都是采用音译。也就是说,“王东”和“王栋”翻译成藏语应该是一样的。当然,不同的译者可以选择不同的藏文字来对同一个汉字(或同音汉字)进行译音。目前我们已经收集了一个汉藏人名对照表TC(目前只有300条),我们可以把它改为藏音对照表(这里音指汉语拼音)。另外我们还有一个常用汉语人名表C,有20多万条。此外还有一个海量的汉语语料库。那么藏文中的汉语人名识别算法可简单地描述如下:假设藏文的音节序列ABC,其中每个音节都是一个可能的汉字译音A’B’C’,而且不是藏文单词,P(A’B’C’)作为汉语人名的概率大于一定的阈值,那么可把ABC识别为一个藏文中的汉字人名译音。
人名识别和数字识别都在图1的构造词图中进行,与其他处理无关。其实实现的时候就是和数字识别一样增加一个加权自动机即可。
表3. 人名识别后的央金分词系统的性能
训练语料测试语料精确率召回率F值备注
92.119% 92.473% 92.296 分词
2.7M+词典25K
83.015% 83.333% 83.174% 改进2
尽管有所改进,但和汉语分词相比差距不小,训练语料库太小可能是一个主要原因。
5 结论和进一步的工作
本文描述了一个基于HMM的藏文分词系统。就我们和同类系统比较而言,该系统的分词速度快,准确率也基本达到了可以使用的水平,目前已经用于我们的藏汉统计机器翻译系统。
下一步要做的主要工作是:继续扩大训练语料规模;进行地名和机构名的自动识别;克服n元模型的局部性,利用藏文句法特性处理长距离语义相关性。
参考文献
[1] 陈玉忠,李保利. 俞士汶.藏文自动分词系统的设计与实现[J],中文信息学报,2003,17(3):15-20.
[2] 扎西家,珠杰. 面向信息处理的藏文分词规范研究[J],中文信息学报,2009,23(4):113-117.
[3] Haidian Liu,Tibetan Number Identification Based on Classification of Number Components in Tibetan Word Segmentation [C]//Chu-Ren Huang, Dan Jurafsky. Proceedings of the 23rd International Conference on Computational Linguistics (COLING 2010). Beijing:Tsinghua University Press. 2010:719-724.
[4] 才智杰.班智达藏文自动分词系统的设计与实现[J],青海师范大学民族师范学院学报,2010,12(2
):75—77.
[5]苏峻峰. 祁坤钰,本太. 基于HMM 的藏语语料库词性自动标注研究[J]. 西北民族大学学报(自然科
学版),2009,30(1):42-45.
[6] 刘智文. 藏汉统计机器翻译研究(厦门大学硕士论文)[D]. 厦门大学,2010.
[7] 才让加. 藏语语料库词语分类体系及标记集研究[J],中文信息学报,2009,23(4):107-112.
[8] Yuan Sun et al, Design of a Tibetan Automatic Word Segmentation Scheme [C]// Proceedings of
International Conference on Information Engineering and Computer Science, Wuhan: IEEE Press. 2009:1-6.
[9] 王维兰,陈万军. 藏文字丁、音节频度及其信息熵[J],术语标准化与信息技术,2004 (2) :27-31
藏文输入法
藏文输入法 编辑词条 摘要 藏文输入法藏文输入法,是指计算机上的藏文输入程序。 编辑摘要 目录-[ 隐藏 ] 1.1输入法的种类 2.2输入法的用途 编辑本段|回到顶部输入法的种类 目前,视窗操作系统中使用的藏文输入法主要有这几种:同元藏文输入法、央金藏文输入法,班智达藏文输入法, 琼迈藏文输入法,宗卡藏文输入法, 加央藏文输入法, Monlam藏文输入法,以及Windows Vista系统中自带的统一码编码的Himalaya藏文输入法等。现在亦有人将 Vista 系统中的藏文输入法截取出来,以便安装于Windows XP系统。 sd;,ds.m断肠仌茬兲涯, 编辑本段|回到顶部输入法的用途 藏文输入法可以使用于藏语资料的电子整理、出版、打印等方面,方便将藏文资料数位化。同时还可以使用藏文通过QQ、MSN等即时通讯工具进行交流。若要在QQ上使用统一码的藏文,建议使用腾迅公司的TM2008。 在TM2008上,可以使用包括藏文等其他统一码编码的语言文字进行交流。 央金藏文输入法 V1.0 为了克服现有各种藏文计算机键盘布局与输入法所存在的缺陷,“央金藏文输入法”依据计算机键盘布局的基本理论、若干原则、相关科学研究成果和基于藏文语料库的字符、部件、音节、词汇统计数据,遵循藏语 语法规则及其特殊性和藏文基字与上下、前后、又后加字及元音配置的规 律,在对计算机键盘键位的属性进行专门研究的基础上,研制出“一键多 符”,即在同一个键位上整合多个藏文部件和“一键到位”,即在输入现代藏文时无需切换上档,并配合输入提示行、软键盘,以及将使用频度最高的藏文“隔字符”布局在空格键(SP)上的智能化键盘布局及输入法。 其藏文文本的键盘输入速度和效率成倍提高,对藏文印刷、办公自动化和 信息处理具有广泛的使用价值。 特点介绍: 1)本输入法使用藏文国际标准编码字符集(ISO/IEC10646·1)和与之相一致的Unicode国际标准,使输入的文本完全是国际通用的内码, 可在任意一台装有XP、VISTA的计算机上打开和使用,显著区别于现有藏
中文分词基础件(基础版)使用说明书
索源网https://www.360docs.net/doc/e79368707.html,/ 中文分词基础件(基础版) 使用说明书 北京索源无限科技有限公司 2009年1月
目录 1 产品简介 (3) 2 使用方法 (3) 2.1 词库文件 (3) 2.2 使用流程 (3) 2.3 试用和注册 (3) 3 接口简介 (4) 4 API接口详解 (4) 4.1初始化和释放接口 (4) 4.1.1 初始化分词模块 (4) 4.1.2 释放分词模块 (4) 4.2 切分接口 (5) 4.2.1 机械分词算法 (5) 4.3 注册接口 (8) 5 限制条件 (9) 6 附录 (9) 6.1 切分方法定义 (9) 6.2 返回值定义 (9) 6.3 切分单元类型定义 (9)
1 产品简介 索源中文智能分词产品是索源网(北京索源无限科技有限公司)在中文信息处理领域以及搜索领域多年研究和技术积累的基础上推出的智能分词基础件。该产品不仅包含了本公司结合多种分词研发理念研制的、拥有极高切分精度的智能分词算法,而且为了适应不同需求,还包含多种极高效的基本分词算法供用户比较和选用。同时,本产品还提供了在线自定义扩展词库以及一系列便于处理海量数据的接口。该产品适合在中文信息处理领域从事产品开发、技术研究的公司、机构和研究单位使用,用户可在该产品基础上进行方便的二次开发。 为满足用户不同的需求,本产品包括了基础版、增强版、专业版和行业应用版等不同版本。其中基础版仅包含基本分词算法,适用于对切分速度要求较高而对切分精度要求略低的环境(正、逆向最大匹配)或需要所有切分结果的环境(全切分)。增强版在基础版的基础上包含了我公司自主开发的复合分词算法,可以有效消除切分歧义。专业版提供智能复合分词算法,较之增强版增加了未登录词识别功能,进一步提高了切分精度。行业应用版提供我公司多年积累的包含大量各行业关键词的扩展词库,非常适合面向行业应用的用户选用。 2 使用方法 2.1 词库文件 本产品提供了配套词库文件,使用时必须把词库文件放在指定路径中的“DictFolder”文件夹下。产品发布时默认配置在产品路径下。 2.2 使用流程 产品使用流程如下: 1)初始化 首先调用初始化函数,通过初始化函数的参数配置词库路径、切分方法、是否使用扩展词库以及使用扩展词库时扩展词的保存方式等。经初始化后获得模块句柄。 2)使用分词函数 初始化后可反复调用各分词函数。在调用任何函数时必要把模块句柄传入到待调用函数中。 3)退出系统 在退出系统前需调用释放函数释放模块句柄。 2.3 试用和注册 本产品初始提供的系统是试用版。在试用版中,调用分词函数的次数受到限制。用户必须向索源购买本产品,获取注册码进行注册后,方可正常使用本产品。 注册流程为: 1)调用序列号获取接口函数获取产品序列号; 2)购买产品,并将产品序列号发给索源。索源确认购买后,生成注册码发给用户; 3)用户使用注册码,调用注册接口对产品进行注册; 4)注册成功后,正常使用本产品。
中文分词实验
中文分词实验 一、实验目的: 目的:了解并掌握基于匹配的分词方法,以及分词效果的评价方法。 实验要求: 1、从互联网上查找并构建不低于10万词的词典,构建词典的存储结构; 2、选择实现一种机械分词方法(双向最大匹配、双向最小匹配、正向减字最大匹配法等)。 3、在不低于1000个文本文件,每个文件大于1000字的文档中进行中文分词测试,记录并分析所选分词算法的准确率、分词速度。 预期效果: 1、平均准确率达到85%以上 二、实验方案: 1.实验平台 系统:win10 软件平台:spyder 语言:python 2.算法选择 选择正向减字最大匹配法,参照《搜索引擎-原理、技术与系统》教材第62页的描述,使用python语言在spyder软件环境下完成代码的编辑。 算法流程图:
Figure Error! No sequence specified.. 正向减字最大匹配算法流程
Figure Error! No sequence specified.. 切词算法流程算法伪代码描述:
3.实验步骤 1)在网上查找语料和词典文本文件; 2)思考并编写代码构建词典存储结构; 3)编写代码将语料分割为1500个文本文件,每个文件的字数大于1000字; 4)编写分词代码; 5)思考并编写代码将语料标注为可计算准确率的文本; 6)对测试集和分词结果集进行合并; 7)对分词结果进行统计,计算准确率,召回率及F值(正确率和召回率的 调和平均值); 8)思考总结,分析结论。 4.实验实施 我进行了两轮实验,第一轮实验效果比较差,于是仔细思考了原因,进行了第二轮实验,修改参数,代码,重新分词以及计算准确率,效果一下子提升了很多。 实验过程:
藏文字体转换软件Unicode Document Processor
藏文字体转换软件Unicode Document Processor(UDP)的使用方法 以下就是UDP的安装和使用方法。 当前藏文文字处理软件非常多,用的比较多的有同元藏文输入法,班智达藏文输入,桑布扎输入法,喜马拉雅藏文输入法,央金藏文输入,琼迈藏文输入法和WindowsVista自带的微软藏文输入法(Himalaya)等,随着Windows Vista 的普及和Unicode的不断盛行,众多藏文文字处理软件必被微软藏文输入法所取代,而如何将同元藏文输入法和班智达藏文输入等环境下的众多文档转换成Unicode字体文档,就要用到将要给大家分享的UnicodeDocumentProcessor(缩写为UDP)藏文字体转换工具了。 首先下载UDP软件,你可以到谷歌搜索关键词为 UDP tibetan。或者直接进入主页(https://www.360docs.net/doc/e79368707.html,/)可以免费下载统一代码文件处理器(The Unicode Document Processor)。或者到我新浪爱问认识人去下载,下载地址:点击 下载完后,开始安装这个软件。如图一 往后都选择是,这个软件安装非常简单的。但是,平时要养成把软件都安装在D\Program Files中去。 软件安装好了,就开始设置一些参数吧。安装完毕后打开UDP软件,在菜单中选择Options-字体Font,在Fonts选项框设置字体,一般为默认的22,另外在Unicode的下拉菜单中选择Microsoft Himalaya。图二三。
这样软件就设置完成了,点击OK。
接下来我们开始体验这个软件给你带来的方便和乐趣吧。但是,还有需要主要的问题:不能把Word里你要转换字体的文本直接复制到UDP软件里,先复制到写字板然后复制到UDP。首先打开你要转换的文本复制到写字板,在写字板里设置字体,如果你要转换的文本字体是班智达请把字体设置为BZDBT,如果是同元字体设置为TIBETBT,大小为五号即可。总之在写字板里的藏文字体正确显示就可以了。然后把写字板里的文本复制到UDP软件里。这样UDP软件已经自动给你转换成Unicode字体了。因为你已经在前面给软件设置过了,所以此时软件里的文本就是你需要的Unicode字体了,把文本复制到Word里可以保存了。切记,如果前面没有进行设置,一定要按图二三进行设置,不然你的前面所做的都会徒劳哦!呵呵。 大家先看看我的体验吧! 首先把要转换的文本复制到写字板。 然后设置其字体。我的原文本是班智达的,所以设置成字体为:BZDHT,字号为:二号)
分词工具比较
IKAnalyzer IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为面向Java的公用分词组件,独立于Lucene 项目,同时提供了对Lucene的默认优化实现。 语言和平台:基于java 语言开发,最初,它是以开源项目Luence 为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer 3.0 则发展为面向 Java 的公用分词组件,独立于 Lucene 项目,同时提供了对Lucene 的默认优化实现。 算法:采用了特有的“正向迭代最细粒度切分算法”。采用了多子处理器分析模式,支持:英文字母( IP 地址、 Email 、 URL )、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。优化的词典存储,更小的内存占用。支持用户词典扩展定义。针对 Lucene 全文检索优化的查询分析器 IKQueryParser ;采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高 Lucene 检索的命中率。 性能:60 万字 / 秒 IKAnalyzer基于lucene2.0版本API开发,实现了以词典分词为基础的正反向全切分算法,是LuceneAnalyzer接口的实现。该算法适合与互联网用户的搜索习惯和企业知识库检索,用户可以用句子中涵盖的中文词汇搜索,如用"人民"搜索含"人民币"的文章,这是大部分用户的搜索思维;不适合用于知识挖掘和网络爬虫技术,全切分法容易造成知识歧义,因为在语义学上"人民"和"人民币"是完全搭不上关系的。 je-anlysis的分词(基于java实现) 1. 分词效率:每秒30万字(测试环境迅驰1.6,第一次分词需要1-2秒加载词典) 2. 运行环境: Lucene 2.0 3. 免费安装使用传播,无限制商业应用,但暂不开源,也不提供任何保证 4. 优点:全面支持Lucene 2.0;增强了词典维护的API;增加了商品编码的匹配;增加了Mail地址的匹配;实现了词尾消歧算法第二层的过滤;整理优化了词库; 支持词典的动态扩展;支持中文数字的匹配(如:二零零六);数量词采用“n”;作为数字通配符优化词典结构以便修改调整;支持英文、数字、中文(简体)混合分词;常用的数量和人名的匹配;超过22万词的词库整理;实现正向最大匹配算法;支持分词粒度控制 ictclas4j ictclas4j中文分词系统是sinboy在中科院张华平和刘群老师的研制的FreeICTCLAS的基础上完成的一个java开源分词项目,简化了原分词程序的复
中科院中文分词系统调研报告
自然语言处理调研报告(课程论文、课程设计) 题目:最大正向匹配中文分词系统 作者:陈炳宏吕荣昌靳蒲 王聪祯孙长智 所在学院:信息科学与工程学院 专业年级:信息安全14-1 指导教师:努尔布力 职称:副教授 2016年10月29日
目录 一、研究背景、目的及意义 (3) 二、研究内容和目标 (4) 三、算法实现 (5) 四、源代码 (7) 1.seg.java 主函数 (7) 2. dict.txt 程序调用的字典 (10) 3.实验案例 (11) 五、小结 (12)
一、研究背景、目的及意义 中文分词一直都是中文自然语言处理领域的基础研究。目前,网络上流行的很多中文分词软件都可以在付出较少的代价的同时,具备较高的正确率。而且不少中文分词软件支持Lucene扩展。但不过如何实现,目前而言的分词系统绝大多数都是基于中文词典的匹配算法。 在这里我想介绍一下中文分词的一个最基础算法:最大匹配算法(Maximum Matching,以下简称MM算法) 。MM算法有两种:一种正向最大匹配,一种逆向最大匹配。
二、研究内容和目标 1、了解、熟悉中科院中文分词系统。 2、设计程序实现正向最大匹配算法。 3、利用正向最大匹配算法输入例句进行分词,输出分词后的结果。
三、算法实现 图一:算法实现 正向最大匹配算法:从左到右将待分词文本中的几个连续字符与词表匹配,如果匹配上,则切分出一个词。但这里有一个问题:要做到最大匹配,并不是第一次匹配到就可以切分的。 算法示例: 待分词文本: content[]={"中","华","民","族","从","此","站","起","来","了","。"} 词表: dict[]={"中华", "中华民族" , "从此","站起来"} (1) 从content[1]开始,当扫描到content[2]的时候,发现"中华"已经在
中文自动分词技术
中文自动分词技术是以“词”为基础,但汉语书面语不是像西方文字那样有天然的分隔符(空格),而是在语句中以汉字为单位,词与词之间没有明显的界限。因此,对于一段汉字,人可以通过自己的知识来明白哪些是词,哪些不是词,但如何让计算机也能理解?其处理过程词,就要应用到中文自动分词技术。下面依次介绍三种中文自动分词算法:基于词典的机械匹配的分词方法、基于统计的分词方法和基于人工智能的分词方法。 1、基于词典的机械匹配的分词方法: 该算法的思想是,事先建立词库,让它它是按照一定的策略将待分析的汉字串与一个充分大的词典中的词条进行匹配,若在词典中找到该字符串,则识别出一个词。按照扫描方向的不同,串匹配分词的方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,又可以分为最大匹配和最小匹配。按这种分类方法,可以产生正向最大匹配、逆向最大匹配,甚至是将他们结合起来形成双向匹配。由于汉字是单字成词的,所以很少使用最小匹配法。一般来说,逆向匹配的切分精度略高于正向匹配,这可能和汉语习惯将词的重心放在后面的缘故。可见,这里的“机械”是因为该算法仅仅依靠分词词表进行匹配分词 a)、正向减字最大匹配法(MM) 这种方法的基本思想是:对于每一个汉字串s,先从正向取出maxLength 个字,拿这几个字到字典中查找,如果字典中有此字,则说明该字串是一个词,放入该T的分词表中,并从s中切除这几个字,然后继续此操作;如果在字典中找不到,说明这个字串不是一个词,将字串最右边的那个字删除,继续与字典比较,直到该字串为一个词或者是单独一个字时结束。 b)、逆向减字最大匹配法(RMM ) 与正向减字最大匹配法相比,这种方法就是从逆向开始遍历。过程与正向减字最大匹配法基本相同,可以对文本和字典先做些处理,把他们都倒过来排列,然后使用正向减字最大匹法。 机械匹配算法简洁、易于实现.其中,最大匹配法体现了长词优先的原则,在实际工程中应用最为广泛。机械匹配算法实现比较简单,但其局限也是很明显的:效率和准确性受到词库
喜马拉雅藏文输入法键盘布局及功能
使用微软藏文输入法的一点体会 随着信息化时代的到来藏文在计算机领域的应用也在不断的发展,而藏文在计算机中的应用首先应解决的问题是藏文在计算机中的输入即藏文输入法,目前,视窗操作系统中使用的藏文输入法主要有这几种:同元藏文输入法、央金藏文输入法、班智达藏文输入法、琼迈藏文输入法、宗卡藏文输入法、加央藏文输入法、Monlam藏文输入法、太清藏文输入法以及WindowsVista系统中自带的藏文输入法等。现在亦有人将Vista系统中的藏文输入法截取出来,以便安装于WindowsXP 系统。本人比较熟悉的就是以上输入法中的最后一种即微软藏文输入法(himalaya藏文输入法),下面根据自己在使用过程中的一些心得分享给大家,希望对藏文输入感兴趣的朋友有所帮助。 微软藏文输入法(himalaya藏文输入法)的用途,可以使用于藏语资料的电子整理、出版、打印等方面,方便将藏文资料数位化。同时还可以使用藏文通过QQ、MSN等即时通讯工具进行交流。若要在QQ上使用统一码的藏文,建议使用腾迅公司的。在TM2008上,可以使用包括藏文等其他统一码编码的语言文字进行交流。 微软藏文输入法(himalaya藏文输入法)的安装过程,下载安装包后解压缩到同一个文件夹下,双击运行即可。提示系
统文件被替换是否恢复时,选择取消。重启后,在输入法里添加Tibetan(PRC),输入时选择MicrosoftHimalaya就可以输入藏文了。 微软藏文输入法(himalaya藏文输入法)的键盘布局如下:1.标准键盘,对应与国标藏文键盘中的主键盘: 键盘,对应与国标藏文键盘中的第二个键盘: 键盘,对应与国标藏文键盘中的第三个键盘: +Ctrl+Shift键盘,对应与国标藏文键盘中的第四个键盘: 键盘,对应与国标藏文键盘中的第五个键盘: 微软藏文输入法(himalaya藏文输入法)的字体种类,到目前该输入法已有10种字体: 柏簇体:;簇玛丘体:; 簇仁体:;簇通体:; 丘伊体:;乌金萨钦体: 乌金萨琼体:;乌金苏仁体:; 乌金苏通体:;珠擦体:
中文分词技术
一、为什么要进行中文分词? 词是最小的能够独立活动的有意义的语言成分,英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,因此,中文词语分析是中文信息处理的基础与关键。 Lucene中对中文的处理是基于自动切分的单字切分,或者二元切分。除此之外,还有最大切分(包括向前、向后、以及前后相结合)、最少切分、全切分等等。 二、中文分词技术的分类 我们讨论的分词算法可分为三大类:基于字典、词库匹配的分词方法;基于词频度统计的分词方法和基于知识理解的分词方法。 第一类方法应用词典匹配、汉语词法或其它汉语语言知识进行分词,如:最大匹配法、最小分词方法等。这类方法简单、分词效率较高,但汉语语言现象复杂丰富,词典的完备性、规则的一致性等问题使其难以适应开放的大规模文本的分词处理。第二类基于统计的分词方法则基于字和词的统计信息,如把相邻字间的信息、词频及相应的共现信息等应用于分词,由于这些信息是通过调查真实语料而取得的,因而基于统计的分词方法具有较好的实用性。 下面简要介绍几种常用方法: 1).逐词遍历法。 逐词遍历法将词典中的所有词按由长到短的顺序在文章中逐字搜索,直至文章结束。也就是说,不管文章有多短,词典有多大,都要将词典遍历一遍。这种方法效率比较低,大一点的系统一般都不使用。 2).基于字典、词库匹配的分词方法(机械分词法) 这种方法按照一定策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。识别出一个词,根据扫描方向的不同分为正向匹配和逆向匹配。根据不同长度优先匹配的情况,分为最大(最长)匹配和最小(最短)匹配。根据与词性标注过程是否相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。常用的方法如下: (一)最大正向匹配法 (MaximumMatchingMethod)通常简称为MM法。其基本思想为:假定分词词典中的最长词有i个汉字字符,则用被处理文档的当前字串中的前i个字作为匹配字段,查找字典。若字典中存在这样的一个i字词,则匹配成功,匹配字段被作为一个词切分出来。如果词典中找不到这样的一个i字词,则匹配失败,将匹配字段中的最后一个字去掉,对剩下的字串重新进行匹配处理……如此进行下去,直到匹配成功,即切分出一个词或剩余字串的长度为零为止。这样就完成了一轮匹配,然后取下一个i字字串进行匹配处理,直到文档被扫描完为止。
hanlp中文分词器解读
中文分词器解析hanlp分词器接口设计:
提供外部接口: 分词器封装为静态工具类,并提供了简单的接口
标准分词是最常用的分词器,基于HMM-Viterbi实现,开启了中国人名识别和音译人名识别,调用方法如下: HanLP.segment其实是对StandardTokenizer.segment的包装。 /** * 分词 * * @param text 文本 * @return切分后的单词 */ publicstatic List
* 这是一个工厂方法
* 与直接new一个分词器相比,使用本方法的好处是,以后HanLP升级了,总能用上最合适的分词器 * @return一个分词器 */ publicstatic Segment newSegment() }
publicclass StandardTokenizer { /** * 预置分词器 */ publicstaticfinalSegment SEGMENT = HanLP.newSegment(); /** * 分词 * @param text 文本 * @return分词结果 */ publicstatic List
关于百度中文分词系统研究
关于百度中文分词系统研究
所谓分词就是把字与字连在一起的汉语句子分成若干个相互独立、完整、正确的单词。词是最小的、能独立活动的、有意义的语言成分。计算机的所有语言知识都来自机器词典(给出词的各项信息) 、句法规则(以词类的各种组合方式来描述词的聚合现象) 以及有关词和句子的语义、语境、语用知识库。中文信息处理系统只要涉及句法、语义(如检索、翻译、文摘、校对等应用) ,就需要以词为基本单位。当汉字由句转化为词之后,才能使得句法分析、语句理解、自动文摘、自动分类和机器翻译等文本处理具有可行性。可以说,分词是机器语言学的基础。 分词准确性对搜索引擎来说十分重要,但如果分词速度太慢,即使准确性再高,对于搜索引擎来说也是不可用的,因为搜索引擎需要处理数以亿计的网页, 如果分词耗用的时间过长,会严重影响搜索引擎内容更新的速度。因此对于搜索引擎来说,分词的准确性和速度,二者都需要达到很高的要求。 分词算法的三种主要类型 现有的分词算法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。 》基于字符串匹配的分词方法。 这种方法又叫做机械分词方法,它是按照一定的策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功 (识别出一个词) 。按照扫描方向的不同,串匹配分词方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大(最长) 匹配 和最小(最短) 匹配;按照是否与词性标注过程相结合,又可以分为单纯分词方 法和分词与标注相结合的一体化方法。常用的几种机械分词方法如下: 1) 正向最大匹配法(由左到右的方向) 。 通常简称为MM(Maximum Matching Method) 法。其基本思想为:设D 为词典,MAX 表示D 中的最大词长,STR 为待切分的字串。MM 法是每次从STR 中取长度为MAX 的子串与D 中的词进行匹配。若成功,则该子串为词,指针后移MAX 个汉字后继续匹配,否则子串逐次减一进行匹配。 2) 逆向最大匹配法(由右到左的方向) 。 通常简称为RMM ( Reverse Maximum MatchingMethod) 法。RMM 法的基本原理与MM 法相同,不同的是分词的扫描方向,它是从右至左取子串进行匹配。 3) 最少切分法(使每一句中切出的词数最小) 。 还可以将上述各种方法相互组合,例如,可以将正向最大匹配方法和逆向 最大匹配方法结合起来构成双向匹配法。由于汉语单字成词的特点,正向最小匹配和逆向最小匹配一般很少使用。一般说来,逆向匹配的切分精度略高于正向匹配,遇到的歧义现象也较少。统计结果表明,单纯使用正向最大匹配的错误率为1/169 ,单纯使用逆向最大匹配的错误率为1/ 245 。但这种精度还远远不能满足实际的需要。实际使用的分词系统,都是把机械分词作为一种初分手段,还需通过利用各种其它的语言信息来进一步提高切分的准确率。一种方法是改进
央金藏文输入法
央金藏文基本键位布局图 若干重要功能键介绍: H键位设计为“控制用连接符”(LINK)键,用于藏文、梵文基字字符纵向多层叠加连接控制;长条空格键(NB)为藏文隔字符“”;N键位为空格(SP);V 键位为隔句符(单垂符),双击为双垂符, 再双击为四垂符;“Shift”键,用于输入上档键符号。 例如,正常状态下按“D”键,输入的是“”;按住“SHIFT”键时,再按“D”键,输入的是" ";先按H键后,再按“D”键,输入的是“". 注:“Ctrl”键在藏文输入法下,同样可用作相应的快捷键,如:Ctrl+A为“全选”、Ctrl+S为“存盘”、Ctrl+C为“复制”、Ctrl+X为“删除和剪切”、Ctrl+V为“粘贴”等。 H键位(LINK键)的作用和用法 当纵向输入2层、3层或多层叠加字符时,按照藏文或梵文的书写顺序(自上而下,以元音结束),击任意第一键后,每下加一个部件,就需要先摁一次H(LINK)键。例如:输入 “藏文基本输入法”多用H键(LINK键)功能。本输入法可实现藏文、梵文任意基字字符的多层叠加。藏文最多4层,梵文最多8层。 央金梵文键盘键位布局图
(NB)为藏文隔字符“”;N键位设计为空格(SP);按SHIFT键时,可输入上档键 符号。 (注:央金梵文软键盘键位布局与此相同) 央金标点文化符软键盘键位布局图 (NB)为藏文隔字符“”;N键位设计为空格(SP)。按住SHIFT时,可输入相应的上档键 符号。 其它软键盘布局图 1、日文平假名软键盘 2、日文片假名软键盘
3、西腊字母软键盘 4、俄文字母软键盘 5、注音符号软键盘 6、中文拼音软键盘 7、标点符号软键盘
中文分词工具介绍
中文分词工具介绍 分词工具支持语言原理分词速度文档 完整 性 词典及扩展性 NLPIR(ICTCLAS)中文、英文隐马尔科夫模型(HHMM)50万字/秒 (996Kb/s)详细支持单条导入用户 词典,也可以批量导 入用户词典 IKAnalyzer英文字母、数 字、中文词汇 等分词处理, 兼容韩文、日 文字符正向迭代最细粒度切分算法83 万字/秒 (1600Kb/s) 详细收录27万中文词汇, 支持用户词典扩展 定义、支持自定义停 止词 Paoding-Analysis中文100万字/秒 (1900Kb/s)极少支持不限制个数的 用户自定义词库 MMSeg4j 中文,包括一 些字符的处 理英文、俄 文、希腊、数 字用Chih-Hao Tsai 的 MMSeg 算法。MMSeg 算法 有两种分词方法:Simple和 Complex,都是基于正向最 大匹配。在complex基础上 实现了最多分词 (max-word) Complex 60万字/秒 (1200Kb/s) Simple 97万字/秒 1900Kb/s 极少使用sougou词库, 也可自定义覆盖 Imdict-Chinese-Analyzer中文、英文、 数字隐马尔科夫模型(HHMM)25万字/秒 (480Kb/s) 极少算法和语料库词典 来自于ictclas1.0项 目 JE-Analysis中文、英文、 数字 极少
中文分词工具分词测试 Paoding 运行时间:7s 分词数:160841 IK 运行时间:6s 分词数:149244 imdict运行时间: 12.426 s 分词数:235548 je运行时间: 7.834 s 分词数:220199 Mmseg4j运行时间: 9.612 s 分词数为:200504
中文分词实验报告
实验:中文分词实验 小组成员:黄婷苏亮肖方定山 一、实验目的: 1.实验目的 (1)了解并掌握基于匹配的分词方法、改进方法、分词效果的评价方法等 2.实验要求 (1)从互联网上查找并构建不低于10万词的词典,构建词典的存储结构;(2)选择实现一种机械分词方法(双向最大匹配、双向最小匹配、正向减字最大匹配法等),同时实现至少一种改进算法。 (3)在不低于1000个文本文件(可以使用附件提供的语料),每个文件大于1000字的文档中进行中文分词测试,记录并分析所选分词算法的准确率、召回率、F-值、分词速度。 二、实验方案: 1. 实验环境 系统:win10 软件平台:spyder 语言:python 2. 算法选择 (1)选择正向减字最大匹配法
(2)算法伪代码描述: 3. 实验步骤 ● 在网上查找语料和词典文本文件; ● 思考并编写代码构建词典存储结构;
●编写代码将语料分割为1500 个文本文件,每个文件的字数大于1000 字; ●编写分词代码; ●思考并编写代码将语料标注为可计算准确率的文本; ●对测试集和分词结果集进行合并; ●对分词结果进行统计,计算准确率,召回率及 F 值(正确率和召回率的调 和平均值); ●思考总结,分析结论。 4. 实验实施 实验过程: (1)语料来源:语料来自SIGHAN 的官方主页(https://www.360docs.net/doc/e79368707.html,/ ),SIGHAN 是国际计算语言学会(ACL )中文语言处理小组的简称,其英文全称为“Special Interest Group for Chinese Language Processing of the Association for Computational Linguistics”,又可以理解为“SIG 汉“或“SIG 漢“。SIGHAN 为我们提供了一个非商业使用(non-commercial )的免费分词语料库获取途径。我下载的是Bakeoff 2005 的中文语料。有86925 行,2368390 个词语。语料形式:“没有孩子的世界是寂寞的,没有老人的世界是寒冷的。” (2)词典:词典用的是来自网络的有373 万多个词语的词典,采用的数据结构为python 的一种数据结构——集合。
央金藏文分词系统
1央金藏文分词系统 史晓东*2卢亚军**3 *厦门大学人工智能研究所 361005 E-mail:mandel@https://www.360docs.net/doc/e79368707.html, **西北民族大学科研处 730030 E-mail:zxdl365@https://www.360docs.net/doc/e79368707.html, 摘要:藏文分词是藏文信息处理的一个基本步骤,本文描述了我们将一个基于HMM的汉语分词系统segtag移植到藏文的过程,取得了91%的准确率。又在错误分析的基础上,进行了训练词性的取舍、人名识别等处理,进一步提高了准确率。 关键字:藏文分词、自然语言处理、HMM A Tibetan Segmentation System – Yangjin Xiaodong Shi*, and Yajun Lu** *Institute of Artificial Intelligence, Xiamen University, Xiamen 361005, China **Northwest University for Nationalities, Lanzhou 730030, China Abstract: We described the porting of a Chinese segmentation system to handle Tibetan. The F-measure of the new Yangjin system is above 91% over a test corpus although the training corpus is relatively small. We also described more processing upon error analysis which led to further improvement. Keywords:Tibetan Segmentation, natural language processing, HMM 1 引言 随着少数民族语言(主要是藏、维、蒙)到汉语的机器翻译研究逐渐进入人们的视野实验,相关的少数民族语言基础法分析工具也亟待完善。藏文分词是藏语到其他语言的基础性工具。虽然研究的时间也不算短(2002年陈玉忠[1]是较早的一篇研究),已经有至少10年的历史,但是还没有公开可用的工具。第一作者在研究汉语分词方面有丰富的经验,从2005年就开发的segtag汉语分词系统,虽然没有发表相关的论文,但是在北京大学公开的1998年人民日报一个月的语料上的准确率约为98%。因此将其移植到藏文,并加以公开,是我们的一个想法。经过与第二作者密切合作,已经成功地开发出了藏文的分词标注系统,在一个测试集上的准确率约为93%,取得了较为令人满意的效果。本文描述该系统的基本算法,并对藏文所作的特殊改进。 本文下面的内容如下:首先综述一下国内外的相关工作,然后介绍了央金藏文分词系统的基本结构,然后再描述为了改进性能对藏文所作的特殊处理,最后得出结论,并指出了进一步的工作。 由于第一作者一点也不懂藏文,因此本文对想开发一个未知语种(如蒙语、泰语、彝语等)的分词系统的人,有一定的借鉴意义。 1基金项目:863项目2006AA010108,国家社科基金重点项目05AYY001 2史晓东,男,1966.12,教授,主要研究方向:自然语言处理 3卢亚军,男,1956.10,教授,主要研究方向:语料库语言学,藏汉机器翻译
百度算法中的中文切词分词系统
百度作为中文搜索引擎地先驱,它地核心地位可以说在短时期是没有任何搜索引擎可以超越地,百度地卓越成就在于它对博大精深地中国文化地领悟和对中文分词地地超强功底.百度受欢迎地主要原因除了用户习惯地原因,在较大程度上得益于百度算法地精准率,搜索结果值更贴近用户地想获得地资讯.用一句广告词“正是我想要地”来形容百度最恰当不过了. 正因为百度对中国搜索引擎市场地统治地位,企业想在网上赚取大量地钞票,就不得不依靠百度.所以做搜索引擎地优化实际上就是百度优化.但百度强大地反优化能力和人工干预机制,使得众多地优化者以失败以失败告终.对于大多数优化者来说,百度成了洪水猛兽.果真如此吗?网络行销大师邓友成认为不尽然.只要是搜索引擎就离不开算法,任何算法都是有规律可循地.下面我们深入浅出地探讨一下百度地算法吧. 一. 搜索信息响应 当用户向百度提出搜索请求后百度会迅速根据用户地请求提供比较精准地结果值. . 比喻当用户提交“搜索引擎优化技术”这个查询文字串.百度会将文字串分割成若干子文字串,用空格,标点符等做细分处理.那么这个文字串就可以分成“搜索引擎,优化,技术”. . 如果用户提交地请求有重复地文字符,例如”优化技术优化”,百度会将重复地文字符看成一个.而字符地出现顺序就忽略. . 当用户提交请求中出现英文字符,百度一般会将英文字符当作一个整体来看,并和中文词分割开来,如果中文出现数字也是这样处理地. 百度通过切割、重组、归并、减负等手段对用户请求进行精准响应,使搜索结果符合用户地想法,以节省用户地查询时间,提高查询效率. 二. 中文核心分词 中文分词是百度算法地核心要素.按中文语法习惯,三个字(含三个字)以下地文字符是独立精准地词汇,没有重组地必要,所以百度对三个字(含三个字)以下地文字符不考虑细分.这也是百度核心算法地第一层,也是响应数量最多地部分.一般这些文字符更新地时间比较慢一些,一周或两周地时间.属于大更新地范畴. 四个字符地百度就会毫不客气地大卸十八块比如,网络工具这个文字串,当用户发出搜索请求后,会发现在搜索结果里面出现了红色地标记,已经把这个文字符分成了“网络,工具”.当然如果是四个字以上地文字串就更不用说了.会分成更多地分词. 三、字词匹配 大概了解了百度地分词原理后,我们要了解地一个重要方面就是字词地匹配问题.如果不知道字词地匹配,做优化就是空谈了. 最大匹配法
IKAnalyzer中文分词器V3.2.3使用手册
IKAnalyzer中文分词器 V3.2使用手册 目录 1.IK Analyzer3.X介绍 (2) 2.使用指南 (5) 3.词表扩展 (12) 4.针对solr的分词器应用扩展 (14) 5.关于作者 (16)
1.IK Analyzer3.X介绍 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IK Analyzer3.X则发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。 1.1IK Analyzer3.X结构设计
1.2IK Analyzer3.X特性 ?采用了特有的“正向迭代最细粒度切分算法“,具有80万字/秒的高速处理能力。 ?采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。?优化的词典存储,更小的内存占用。支持用户词典扩展定义 ?针对Lucene全文检索优化的查询分析器IKQueryParser(作者吐血推荐);采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高Lucene检索的命中率。 1.3分词效果示例 文本原文1: IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本。 分词结果: ikanalyzer|是|一个|一|个|开源|的|基于|java|语言|开发|的|轻量级|量级|的|中文|分词|工具包|工具|从|2006|年|12|月|推出|1.0 |版|开始|ikanalyzer|已经|推出|出了|3|个大|个|版本 文本原文2: 永和服装饰品有限公司 分词结果: 永和|和服|服装|装饰品|装饰|饰品|有限|公司 文本原文3:
R语言中文分词+词云实例
R语言中文分词+词云实例程序 一、程序源码 #调入分词的库 library("rJava") library("Rwordseg") #调入绘制词云的库 library("RColorBrewer") library("wordcloud") #读入数据(特别注意,read.csv竟然可以读取txt的文本) myfile<-read.csv(file.choose(),header=FALSE) #预处理,这步可以将读入的文本转换为可以分词的字符,没有这步不能分词 myfile.res <- myfile[myfile!=" "] #装载分词词典(如果需要的话,我这里没有装载,下面有说明) #分词,并将分词结果转换为向量 myfile.words<- unlist(lapply(X = myfile.res,FUN = segmentCN)) #剔除URL等各种不需要的字符,还需要删除什么特殊的字符可以依样画葫芦在下面增加gsub的语句 myfile.words<- gsub(pattern="http:[a-zA-Z\\/\\.0-9]+","",myfile.words) myfile.words<- gsub("\n","",myfile.words) myfile.words<- gsub("","",myfile.words) #去掉停用词 data_stw=read.table(file=file.choose(),colClasses="character") stopwords_CN=c(NULL) for(i in 1:dim(data_stw)[1]){ stopwords_CN=c(stopwords_CN,data_stw[i,1]) } for(j in 1:length(stopwords_CN)){ myfile.words<- subset(myfile.words,myfile.words!=stopwords_CN[j]) } #过滤掉1个字的词 myfile.words<- subset(myfile.words, nchar(as.character(myfile.words))>1)
中科院中文分词系统ICTCLAS之人名识别词典分析
中科院中文分词系统ICTCLAS之人名识别词典分析 标签:照片华为c 2007-05-13 06:13 13888人阅读评论(6) 收藏举报分类: 自然语言处理(2) 版权声明:本文为博主原创文章,未经博主允许不得转载。 前言、 请在阅读本文前,先确认已阅读过论文《张华平,刘群.基于角色标注的中国人名自动识别研究》。 论文把与人名相关的词分为了15个角色,通过词典查询,可以判断某些文字、词所属角色,然后根据模式匹配找到匹配上的名字。 当我分析nr.dct的时候,却发现nr.dct并非完全按照论文所描述的进行的角色划分。以下是我对tag统计后的nr.dct的内容,能够在论文中找到含义的,我标注上了含 义。 Tag Count: Tag = B( 1), Count = 513, 姓氏 Tag = C( 2), Count = 955, 双名的首字 Tag = D( 3), Count = 1,043, 双名的末字 Tag = E( 4), Count = 574, 单名 Tag = F( 5), Count = 3, 前缀 Tag = G( 6), Count = 9, 后缀 *Tag = K( 10), Count = 0, 人名的上文 Tag = L( 11), Count = 1,198, 人名的下文 Tag = M( 12), Count = 1,684, 两个中国人名之间的成分 Tag = N( 13), Count = 67, <无> *Tag = U( 20), Count = 0, 人名的上文与姓氏成词 *Tag = V( 21), Count = 0, 人名的末字与下文成词 Tag = X( 23), Count = 84, 姓与双名首字成词 Tag = Y( 24), Count = 47, 姓与单名成词 Tag = Z( 25), Count = 388, 双名本身成词