感知器算法有代码

基于模式识别的判别函数分类器的
设计与实现
摘要:本文主要介绍了模式识别中判别函数的相关概念和感知器算法的原理及特点,并例举实例介绍感知器算法求解权向量和判别函数的具体方法,最后按照线性函数判决函数的感知算法思想结合数字识别,来进行设计,通过训练数字样本(每个数字样本都大于120),结合个人写字习惯,记录测试结果,最后通过matlab编码来实现感知器的数字识别。
关键字:模式识别判别函数感知器 matlab
1 引言
模式识别就是通过计算机用数学技术方法来研究模式的自动处理和识别。对于人类的识别能力我们是非常熟悉的。因为我们在早些年就已经会开发识别声音、脸、动物、水果或简单不动的东西的技术了。在开发出说话技术之前,一个象球的东西,甚至看上去只是象个球,就已经可以被识别出来了。所以除了记忆,抽象和推广能力是推进模式识别技术的关键技术。最近几年我们已可以处理更复杂的模式,这种模式可能不是直接基于通过感知器观察出来的随着计算机技术的发展,人类对模式识别技术提出了更高的要求。
本文第二节介绍判别函数分类器,具体介绍了判别函数的概念、特点以及如何确定判别函数的正负;第三节介绍了感知器的概念、特点并用感知器算法求出将模式分为两类的权向量解和判别函数,最后用matlab实现感知判别器的设计。
2 判别函数分类器
2.1 判别函数概念
直接用来对模式进行分类的准则函数。若分属于ω1,ω2的两类模式可用一方程d(X) =0来划分,那么称d(X) 为判别函数,或称判决函数、决策函数。如,
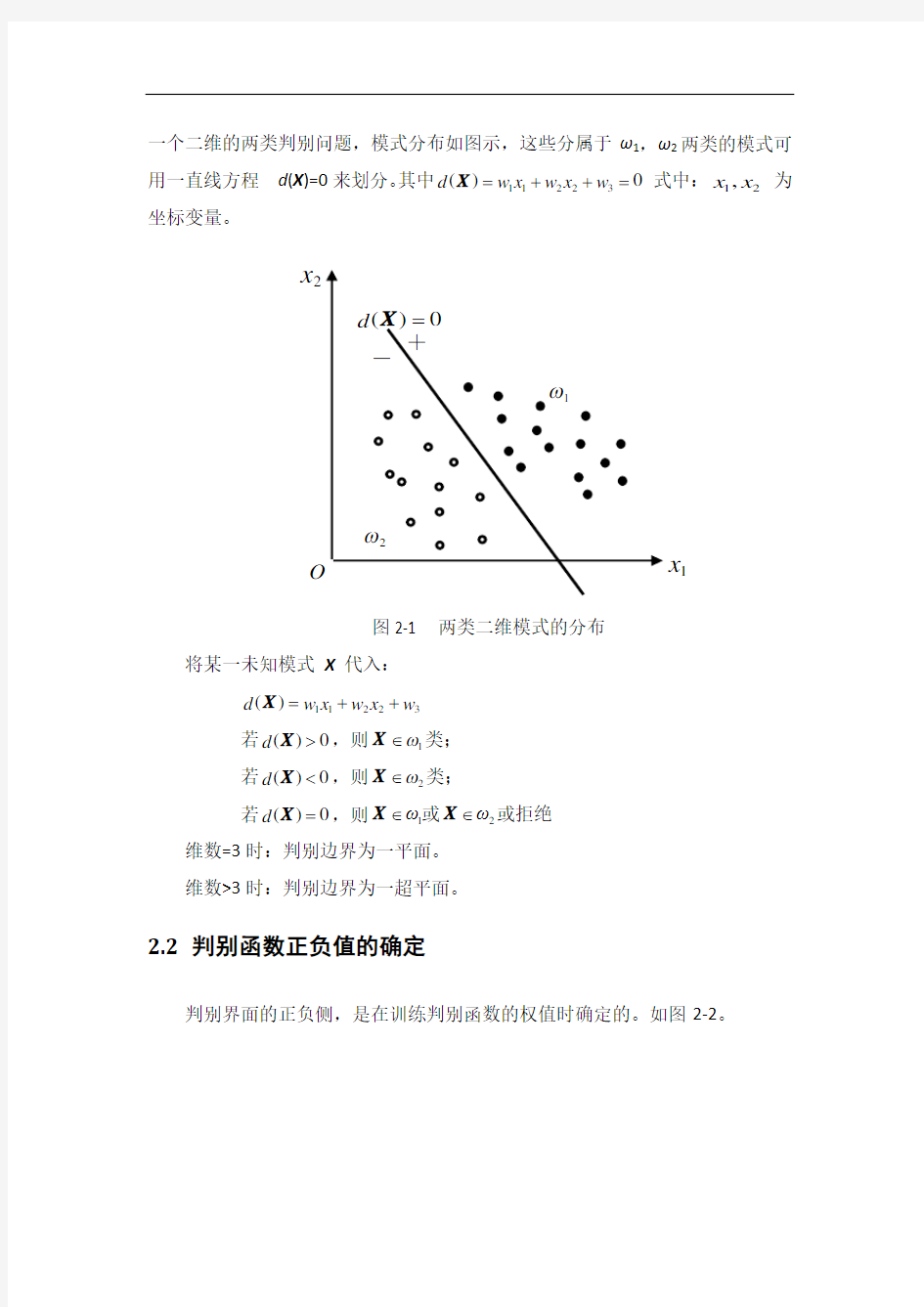
一个二维的两类判别问题,模式分布如图示,这些分属于ω1,ω2两类的模式可用一直线方程 d (X )=0来划分。其中0)(32211=++=w x w x w d X 式中: 21,x x 为坐标变量。
图2-1 两类二维模式的分布
将某一未知模式 X 代入: 32211)(w x w x w d ++=X 若0)(>X d ,则1ω∈X 类; 若0)( 若0)(=X d ,则21ωω∈∈X X 或或拒绝 维数=3时:判别边界为一平面。 维数>3时:判别边界为一超平面。 2.2 判别函数正负值的确定 判别界面的正负侧,是在训练判别函数的权值时确定的。如图2-2。 2x 1x 图2-2 判别函数正负的确定 图中 d (X )=0表示的是一种分类的标准,它可以是1、2、3维的,也可以是更高维的。 2.3 确定判别函数的两个因素 1)判决函数d (X )的几何性质。它可以是线性的或非线性的函数,维数在特征提取时已经确定。 已知三维线性分类 —— 判决函数的性质就确定了判决函数的形式: 4332211)(w x w x w x w d +++=X 非线性判决函数,其示意图如图2-3所示: 图:2-3 非线性判决函数图示 1 x 0 2x 1 x 2x 1x 2)判决函数d (X )的系数,由所给模式样本确定的。 3感知器算法设计与实现 对一种分类学习机模型的称呼,属于有关机器学习的仿生学领域中的问题,由于无法实现非线性分类而下马。但“赏罚概念( reward-punishment concept )” 得到广泛应用,感知器算法就是一种赏罚过程。 3.1 感器算法原理及特点 3.1.1 感知器算法原理 两类线性可分的模式类 21,ωω,设 X W X d T )(=其中, []T 121,,,,+=n n w w w w W ,[]T 211,,,,n x x x =X 应具有性质 (3-1) 对样本进行规范化处理,即ω2类样本全部乘以(-1),则有: 2) -(3 0)(T >=X W X d 感知器算法通过对已知类别的训练样本集的学习,寻找一个满足上式的权向量。 感知器算法步骤: (1)选择N 个分属于ω1和 ω2类的模式样本构成训练样本集{ X1 ,…, XN }构成增广向量形式,并进行规范化处理。任取权向量初始值W(1),开始迭代。迭代次数k=1。 (2)用全部训练样本进行一轮迭代,计算W T (k )X i 的值,并修正权向量。 分两种情况,更新权向量的值: 1. (),若0≤T i k X W 分类器对第i 个模式做了错误分类,权向量校正为: ()()i c k k X W W +=+1 ?? ?∈<∈>=2 1 T ,0,0)(ωωX X X W X 若若d c :正的校正增量。 2. 若(), 0T >i k X W 分类正确,权向量不变:()()k k W W =+1,统一写为: ()()()()(),01, T k T k k k k k k C k ?≥? +=? + X (3-3) (3)分析分类结果:只要有一个错误分类,回到(2),直至对所有样本正确分类。 感知器算法是一种赏罚过程: 分类正确时,对权向量“赏”——这里用“不罚”,即权向量不变; 分类错误时,对权向量“罚”——对其修改,向正确的方向转换。 3.1.2 感知算法特点--收敛性 收敛性:经过算法的有限次迭代运算后,求出了一个使所有样本都能正确分类的W ,则称算法是收敛的。感知器算法是在模式类别线性可分条件下才是收敛的。 3.1.3 感知器算法用于多类情况 采用多类情况3的方法时,应有: 若i ω∈X ,则(),,)(i j d d j i ≠?>X X M j ,,1 = 对于M 类模式应存在M 个判决函数: {}M i d i ,,1, =,,,,, 算法主要内容: 设有M 中模式类别:M ωωω,,,21 设其权向量初值为: ()M j j ,,1,1 =W 训 练样本为增广向量形式,但不需要规范化处理。第K 次迭代时,一个属于ωi 类的模式样本X 被送入分类器,计算所有判别函数 ()()M j k k d j j ,,1,T ==X W (3-4) 分二种情况修改权向量: ① 若()()M j i j k d k d j i ,,2,1;, =≠?>,则权向量不变; ()()M j k k j j ,,2,1, 1 ==+W W ② 若第L 个权向量使()()k d k d l i ≤,则相应的权向量作调整,即: ()()()()()()? ?? ??≠=+-=++=+l i j k k c k k c k k j j l l i i ,,111W W X W W X W W (3-5) 其中c 为正的校正增量,只要模式类在情况3判别函数时是可分的,则经过有限次迭代后算法收敛。 3.2 实例说明 为了说明感知器算法的具体实现,下面举出实例加以说明: 已知两类训练样本 :1ω[]T 10,0=X []T 21,0= X :2ω[]T 30 ,1=X []T 41 ,1=X 用感知器算法求出将模式分为两类的权向量解和判别函数。 解:所有样本写成增广向量形式;进行规范化处理,属于ω2的样本乘以(-1)。 []T 11,0,0=X []T 21,1,0=X []T 31,0,1--=X []T 41,1,1---=X 任取W (1)=0,取c =1,迭代过程为: 第一轮: []0,1000,0,0)1(1T =??????????=X W [] T 11,0,0)1()2(, 0=+=≤X W W 故 []1,1101,0,0)2(2T =???? ??????=X W [] T 1,0,0)2()3(, 0==>W W 故 []-1,1-01-1,0,0)3(3T =??????????=X W []T 30,0,1-)3()4(, 0=+=≤X W W 故 []1,1-1-1-0,0,1-)4(4T =???? ??????=X W [] T 0,0,1-)4()5(, 0==>W W 故 有两个W T (k )X i ≤0的情况(错判),进行第二轮迭代。 第二轮: []T 11T 1,0,1-)5()6(,00)5(=+=≤=X W W X W 故 [] T 2T 1,0,1-(6))7(, 01)6(==>=W W X W 故 []T 33T 0,0,2-)7()8(, 00)7(=+=≤=X W W X W 故 [] T 4T 0,0,2-)8()9(, 02)8(==>=W W X W 故 第三轮: [] T 11T 1,0,2-)9()10(, 00)9(=+=≤=X W W X W 故 (10))11(,01)10(2T W W X W =>=故 )11()12(, 01)11(3T W W X W =>=故 )12()13(, 01)12(4T W W X W =>=故 第四轮: )13()14(,01)13(1T W W X W =>=故 (14) )15(,01)14(2T W W X W =>=故 )15()16(, 01)15(3T W W X W =>=故 )16()17(, 01)16(4T W W X W =>=故 该轮迭代的分类结果全部正确,故解向量[]T 1,0,2-=W 相应的判别函数为:12)(1+=x d X 图3-1 判决函数示意图 判别界面d (X )=0如图示。当c 、W (1)取其他值时,结果可能不一样,所以感 x 3()1,02X 1x ()0,01X 知器算法的解不是单值的。 3.3 matlab的感知器算法设计与实现 本设计是按照线性函数判决函数的感知算法思想结合数字识别,来进行设计,通过训练数字样本(每个数字样本都大于120),结合个人写字习惯,记录测试结果,最后通过matlab编码来实现感知器的数字识别。 3.3.1 Matlab代码设计 function y=jiangcheng(sample) clc; load templet pattern; w=zeros(26,10); d=[]; maxpos=0; maxval=0; f=1; n=[];m=[]; %依次输入样本 for j=1:100 for i=1:10 f=1; pattern(i).feature(26,j)=1; for k=1:10 m=pattern(i).feature(:,j); d(k)=w(:,k)*m; end %判断是否为最大值,如果是,f=1,否则f=0; for=1:10 if k=i if d(i)<=d(k) I=0; end end end %修正权值 if f for k=1:10 if k==i w(:,k)=w(:,k)+pattern(i).feature(:,j); else w(:,k)=w(:,k)-pattern(i).feature(:,j); end end end end end sample(26)=1; h=[]; %计算各类别的判别函数 for k=1:10 h(k)=w(:k)'*sample'; end [maxval,maxpos]=max(h); y=maxpos-1; 3.3.2 matlab实现 首先通过,手写输入0-9个数字的训练样例各130个,如下图所示: 图3-2 数字训练样品 训练样本准备好后,进行数字识别测试,其测验如下: 图3-3 数字测验结果正确样例 图3-4 数字测试不正确样例 3.3.3 设计结果分析 通过多次手写验证测试,有65%通过,其结果如节显示,由于模式识别的算法复杂,步骤较多,实现起来有一定的难度。为了使样品库少一些,将精力着重放在算法的理解及编程实现上,此次设计用的是6x6的设计模板,这个比较小,其对测试结果的正确性起着确定性的作用。故增大设计模板以及提高算法的精确度可以使计算更为准确。 参考文献: 1.《模式识别与智能计算的MATLAB实现》许国根、贾瑛编著,北京航空航天大学出版社; 2.《模式识别与智能计算Matlab技术实现》杨淑莹著,电子工业出版社;3.《Matlab从入门到精通》胡晓东、董晨辉著,人民邮电出版社; 4.《模式识别第二版》边肇祺著,清华大学出版社; 5.《模式识别第四版》西奥多里德斯,电子工业出版社。 感知器算法求判别函数 一、 实验目的 掌握判别函数的概念和性质,并熟悉判别函数的分类方法,通过实验更深入的了解判别函数及感知器算法用于多类的情况,为以后更好的学习模式识别打下基础。 二、 实验内容 学习判别函数及感知器算法原理,在MATLAB 平台设计一个基于感知器算法进行训练得到三类分布于二维空间的线性可分模式的样本判别函数的实验,并画出判决面,分析实验结果并做出总结。 三、 实验原理 3.1 判别函数概念 直接用来对模式进行分类的准则函数。若分属于ω1,ω2的两类模式可用一方程d (X ) =0来划分,那么称d (X ) 为判别函数,或称判决函数、决策函数。如,一个二维的两类判别问题,模式分布如图示,这些分属于ω1,ω2两类的模式可用一直线方程 d (X )=0来划分。其中 0)(32211=++=w x w x w d X (1) 21,x x 为坐标变量。 将某一未知模式 X 代入(1)中: 若0)(>X d ,则1ω∈X 类; 若0)( 类学习机模型的称呼,属于有关机器学习的仿生学领域中的问题,由于无法实现非线性分类而下马。但“赏罚概念( reward-punishment concept )” 得到广泛应用,感知器算法就是一种赏罚过程[2]。 两类线性可分的模式类 21,ωω,设X W X d T )(=其中,[]T 1 21,,,,+=n n w w w w ΛW ,[]T 211,,,,n x x x Λ=X 应具有性质 (2) 对样本进行规范化处理,即ω2类样本全部乘以(-1),则有: (3) 感知器算法通过对已知类别的训练样本集的学习,寻找一个满足上式的权向量。 感知器算法步骤: (1)选择N 个分属于ω1和 ω2类的模式样本构成训练样本集{ X1 ,…, XN }构成增广向量形式,并进行规范化处理。任取权向量初始值W(1),开始迭代。迭代次数k=1。 (2)用全部训练样本进行一轮迭代,计算W T (k )X i 的值,并修正权向量。 分两种情况,更新权向量的值: 1. (),若0≤T i k X W 分类器对第i 个模式做了错误分类,权向量校正为: ()()i c k k X W W +=+1 c :正的校正增量。 2. 若(),0T >i k X W 分类正确,权向量不变:()()k k W W =+1,统一写为: ???∈<∈>=21T ,0,0)(ωωX X X W X 若若d 机器学习入门- 感知器(PERCEPTRON) POSTED IN 学术_STUDY, 机器学习 本文是基于马里兰大学教授Hal Dame III(Blogger)课程内容的笔记。 感知器(Perceptron)这个词会成为Machine Learning的重要概念之一,是由于先辈们对于生物神经学科的深刻理解和融会贯通。 对于神经(neuron)我们有一个简单的抽象:每个神经元是与其他神经元连结在一起的,一个神经元会受到多个其他神经元状态的冲击,并由此决定自身是否激发。(如下图) Neuron Model (From Wikipedia) 这玩意儿仔细想起来可以为我们解决很多问题,尤其是使用决策树和KNN算法时解决不了的那些问题: ?决策树只使用了一小部分知识来得到问题的答案,这造成了一定程度上的资源浪费。 ?KNN对待数据的每个特征值都是一样的,这也是个大问题。比如一组数据包含100种特征值,而只有其中的一两种是起最重要作用的话,其他的特征值就变成了阻碍我们找到最好答案的噪声(Noise)。 根据神经元模型,我们可以设计这样一种算法。对于每种输入值(1 - D),我们计算一个权重。当前神经元的总激发值(a)就等于每种输入值(x)乘以权重(w)之和。 neuron sum 我们还可以推导出以下几条规则: ?如果当前神经元的某个输入值权重为零,则当前神经元激发与否与这个输入值无关?如果某个输入值的权重为正,它对于当前神经元的激发值a 产生正影响。反之,如果权重为负,则它对激发值产生负影响。 接下来我们要将偏移量(bias)的概念加入这个算法。有时我们希望我们的神经元激发量a 超过某一个临界值时再激发。在这种情况下,我们需要用到偏移量b。 neuron sum with bias 偏移量b 虽然只是附在式子后面的一个常数,但是它改变了几件事情: ?它定义了神经元的激发临界值 ?在空间上,它对决策边界(decision boundary) 有平移作用,就像常数作用在一次或二次函数上的效果。这个问题我们稍后再讨论。 在了解了神经元模型的基本思路之后,我们来仔细探讨一下感知器算法的具体内容。 感知器算法虽然也是二维分类器(Binary Classifier),但它与我们所知道的决策树算法和KNN都不太一样。主要区别在于: ?感知器算法是一种所谓“错误驱动(error-driven)”的算法。当我们训练这个算法时,只要输出值是正确的,这个算法就不会进行任何数据的调整。反之,当输出值与实际值异号,这个算法就会自动调整参数的比重。 ?感知器算法是实时(online)的。它逐一处理每一条数据,而不是进行批处理。 perceptron algorithms by Hal Dame III 感知器算法实际上是在不断“猜测”正确的权重和偏移量: ?首先,感知器算法将所有输入值的权重预设为0。这意味着,输入值预设为对结果不产生任何影响。同时,偏移量也被预设为0。 ?我们使用参数MaxIter。这个参数是整个算法中唯一一个超参数(hyper-parameter)。 这个超参数表示当我们一直无法找到准确答案时,我们要最多对权重和偏移量进行几次优化。 感知器的学习算法 1.离散单输出感知器训练算法 设网络输入为n 维向量()110-=n x x x ,,, X ,网络权值向量为()110-=n ωωω,,, W ,样本集为(){}i i d ,X ,神经元激活函数为f ,神经元的理想输出为d ,实际输出为y 。 算法如下: Step1:初始化网络权值向量W ; Step2:重复下列过程,直到训练完成: (2.1)对样本集中的每个样本()d ,X ,重复如下过程: (2.1.1)将X 输入网络; (2.1.2)计算)(T =WX f y ; (2.1.3)若d y ≠,则当0=y 时,X W W ?+=α;否则X W W ?-=α。 2.离散多输出感知器训练算法 设网络的n 维输入向量为()110-=n x x x ,,, X ,网络权值矩阵为{}ji n m ω=?W ,网络理想输出向量为m 维,即()110-=m d d d ,,, D ,样本集为(){}i i D X ,,神经元激活函数为f , 网络的实际输出向量为()110-=m y y y ,,, Y 。 算法如下: Step1:初始化网络权值矩阵W ; Step2:重复下列过程,直到训练完成: (2.1)对样本集中的每个样本()D X ,,重复如下过程: (2.1.1)将X 输入网络; (2.1.2)计算)(T =XW Y f ; (2.1.3)对于输出层各神经元j (110-=m j ,,, )执行如下操作: 若j j d y ≠,则当0=j y 时,i ji ji x ?+=αωω,110-=n i ,,, ; 否则i ji ji x ?-=αωω,110-=n i ,,, 。 感知器算法实验--1 一.实验目的 1.理解线性分类器的分类原理。 2.掌握感知器算法,利用它对输入的数据进行 分类。 3.理解BP算法,使用BP算法对输入数据进 行分类。 二. 实验原理 1.感知器算法 感知器算法是通过训练模式的迭代和学习算法,产生线性可分的模式判别函数。感知器算法就是通过对训练模式样本集的“学习”得出判别函数的系数解。在本次实验中,我们主要是采用硬限幅函数进行分类。 感知器的训练算法如下: 设输入矢量{x1,x2,…,x n}其中每一个模式类别已知,它们分别属于ω1类和ω2类。 (1)置步数k=1,令增量ρ为某正的常数,分别赋给初始增广权矢量w(1)的各分量较小的任意值。 (2)输入训练模式x k,计算判别函数值 w T(k) x k。 (3)调整增广权矢量,规则是: a.如果x k ∈ω1和w T (k) x k ≤0,则w(k+1)=w(k)+ ρx k ; b.如果x k ∈ω2和w T (k) x k ≥0,则w(k+1)=w(k)-ρx k ; c.如果x k ∈ω1和w T (k) x k >0,或x k ∈ω2和w T (k) x k <0,则w(k+1)=w(k) (4)如果k 感知器的训练算法实例 将属于ω2的训练样本乘以(-1),并写成增广向量的形式。 x①=(0 0 1)T, x②=(0 1 1)T, x③=(-1 0 -1)T, x④=(-1 -1 -1)T 第一轮迭代:取C=1,w(1)= (0 0 0)T 因w T(1)x①=(0 0 0)(0 0 1)T=0≯0,故w(2)=w(1)+x①=(0 0 1)T 因w T(2)x②=(0 0 1)(0 1 1)T=1>0,故w(3)=w(2)=(0 0 1)T 因w T(3)x③=(0 0 1)(-1 0 -1)T=-1≯0,故w(4)=w(3)+x③=(-1 0 0)T 因w T(4)x④=(-1 0 0)(-1 -1 -1)T=1>0,故w(5)=w(4)=(-1 0 0)T 这里,第1步和第3步为错误分类,应“罚”。 因为只有对全部模式都能正确判别的权向量才是正确的解,因此需进行第二轮迭代。 第二轮迭代: 因w T(5)x①=(-1 0 0)(0 0 1)T=0≯0,故w(6)=w(5)+x①=(-1 0 1)T 因w T(6)x②=(-1 0 1)(0 1 1)T=1>0,故w(7)=w(6)=(-1 0 1)T 因w T(7)x③=(-1 0 1)(-1 0 -1)T=0≯0,故w(8)=w(7)+x③=(-2 0 0)T 因w T(8)x④=(-2 0 0)(-1 -1 -1)T=2>0,故w(9)=w(8)=(-2 0 0)T 需进行第三轮迭代。 第三轮迭代: 因w T(9)x①=(-2 0 0)(0 0 1)T=0≯0,故w(10)=w(9)+x①=(-2 0 1)T 模式识别第三章 感知器算法 一.用感知器算法求下列模式分类的解向量w : })0,1,1(,)1,0,1(,)0,0,1(,)0,0,0{(:1T T T T ω })1,1,1(,)0,1,0(,)1,1,0(,)1,0,0{(:2T T T T ω 将属于2ω的训练样本乘以(-1),并写成增广向量的形式: T x )1,0,0,0(1 =,T x )1,0,0,1(2=,T x )1,1,0,1(3=,T x )1,0,1,1(4 = T x )1,1-,0,0(5-=,T x )1,1-,1-,0(6-=,T x )1,0,1-,0(7-=,T x )1,1-,1-,1-(8-= 第一轮迭代:取1=C ,T )0,0,0,0()1(=ω 因0)1,0,0,0)(0,0,0,0()1(1==T T x ω不大于0,故T x )1,0,0,0()1()2(1=+=ωω 因1)1,0,0,1)(1,0,0,0()2(2==T T x ω大于0,故T )1,0,0,0()2()3(==ωω 因1)1,1,0,1)(1,0,0,0()3(3==T T x ω大于0,故T )1,0,0,0()3()4(==ωω 因1)1,0,1,1)(1,0,0,0()4(4==T T x ω大于0,故T )1,0,0,0()4()5(==ωω 因1)1,1-,0,0)(1,0,0,0()5(5-=-=T T x ω不大于0,故T x )0,1-,0,0()5()6(5 =+=ωω 因1)1,1-,1-,0)(0,1-,0,0()6(6=-=T T x ω大于0,故T )0,1-,0,0()6()7(==ωω 因0)1,0,1-,0)(0,1-,0,0()7(7=-=T T x ω不大于0,故T x )1-,1-,1,0()7()8(7-=+=ωω 因3)1,1-,1-,1-)(1-,1-,1,0()8(8=--=T T x ω大于0,故T )1-,1-,1,0()8()9(-==ωω 第二轮迭代: 因1)1,0,0,0)(1-,1-,1,0()9(1-=-=T T x ω不大于0,故T x )0,1-,1,0()9()10(1-=+=ωω 因0)1,0,0,1)(0,1-,1-,0()10(2==T T x ω不大于0,故T x )1,1,1,1()10()11(2--=+=ωω 因1)1,1,0,1)(1,1,1,1()11(3=--=T T x ω大于0,故T )1,1,1,1()11()12(--==ωω 因1)1,0,1,1)(1,1,1,1()12(4=--=T T x ω大于0,故T )1,1,1,1()12()13(--==ωω —190 — 感知器学习算法研究 刘建伟,申芳林,罗雄麟 (中国石油大学(北京)自动化研究所,北京 102249) 摘 要:介绍感知器学习算法及其变种,给出各种感知器算法的伪代码,指出各种算法的优点。给出感知器算法在线性可分和线性不可分情况下的误差界定理,讨论各种感知器学习算法的误差界理论,给出各种算法的误差界。介绍感知器学习算法在在线优化场景、强化学习场景和赌博机算法中的应用,并对未解决的问题进行讨论。 关键词:感知器;错误界;赌博机算法;强化学习 Reserch on Perceptron Learning Algorithm LIU Jian-wei, SHEN Fang-lin, LUO Xiong-lin (Research Institute of Automation, China University of Petroleum, Beijing 102249) 【Abstract 】This paper introduces some perceptron algorithms and their variations, gives various pseudo-codes, pionts out advantage among algorithms. It gives mistake bound’s theorems of perceptrons algorithm in linearly separable and unlinearly separable situation. It studies their mistake bounds and works out their bounds. It shows their various applications in the online optimization, reinforcement learning and bandit algorithm, and discusses the open problems. 【Key words 】perceptron; mistake bound; bandit algorithm; reinforcement learning 计 算 机 工 程Computer Engineering 第36卷 第7期 Vol.36 No.7 2010年4月 April 2010 ·人工智能及识别技术·文章编号:1000—3428(2010)07—0190—03 文献标识码:A 中图分类号:TP18 感知器算法[1]由Rosenblatt 提出,其主要功能是通过设计分类器来判别样本所属的类别;通过对训练样本集的学习,从而得到判别函数权值的解,产生线性可分的样本判别函数。该算法属于非参数算法,优点是不需要对各类样本的统计性质作任何假设,属于确定性方法。 1 感知器的主要算法 1.1 感知器算法 感知器算法是非常好的二分类在线算法。该算法求取一个分离超平面,超平面由n w R ∈参数化并用来预测。对于一 个样本x ,感知器算法通过计算?,y w x =预测样本的标签。最终的预测标签通过计算()?sign y 来实现。算法仅在预测错误时修正权值w 。如果正确的标签是1y =,那么权值修正为 w x +;如果1y =?,权值变为w x ?,可以总结为w w yx ←+; 需要注意的是在预测后,尽管算法不能保证修正后的预测准 则会正确分类目前的样本,但在目前样本上的分离超平面的间隔会增加,即算法是保守的不是主动的,感知器算法伪代码如下: Initialize: Set w 1=0 For: i=1, 2,…,m Get a new instance x i Predict i i i ?y =w ,x Get a new label y i Compute L=L(w i ,(x i , y i )) Update: If L=0, w i+1=w i If L=1, w i+1=w i +y i x i Output: m h(x)=w ,x 支持向量机(SVM)也是使用超平面来分类的,但SVM 中 的超平面要求每类数据与超平面距离最近的向量与超平面之间的间隔最大,而感知器不需要间隔最大化。 1.2 平均感知器 平均感知器[2](Averaged Perceptron, AP)算法和感知器算法的训练方法一样。不同的是每次训练样本i x 后,保留先前训练权值{}12,,,n w w w ",训练结束后平均所有权值即 1n i i w w n ==∑ 最终用平均权值作为最终判别准则的权值。平均感知器 算法伪代码如下: Initialization: (w 1, w 2,…, w n )=0 For i=1,2,…, n Receive d i x R ∈, {}i y 1,1+?∈ Predict: ()i t t ?y =sign w x ? Receive correct lable: {}i y 1,1∈+? Update i+1i i i w =w +y x Output n i i=1w=w /n ∑ 参数平均化可以克服由于学习速率过大所引起的训练过 程中出现的震荡现象。 1.3 信任权感知器 信任权(Confidence Weighted, CW)学习[3]是一种新的在线学习算法,它使每个学习参数有个信任度。较小信任度的参数得到更大的更频繁的修正。参数信任权用参数向量的高斯分布表示。每训练一次样本就修正一次参数信任权使样本 作者简介:刘建伟(1966-),男,副研究员、博士,主研方向:机器学习;申芳林,硕士;罗雄麟,教授、博士生导师 收稿日期:2009-08-12 E-mail :shenfanglin@https://www.360docs.net/doc/ec9493207.html, 感知器算法作业: 图为二维平面中的4个点,x 1, x 2∈ω1 ,x 3,x 4∈ω2 ,设计使用感知器算法的线性分类器,步长参数设为1. 解:由题知: 112:[1,0][0,1]T T X X ω=-=234:[01][10]T T X X ω=-=,, 所有样本写成增广向量形式,进行规范化处理,属于2ω的样本乘以-1 12[1,0,1][0,1,1]T T X X =-=34[011][101]T T X X =-=--,,,, 步长c=1,任取(1)[0,0,0]T W = 第一轮迭代: 11(1)[0,0,0]0=001T W X -????=≤?????? , ,故1(2)(1)[1,0,1]T W W X =+=- 20(2)[1,0,1]1=101T W X ????=-?????? ,>,故(3)(2)[1,0,1]T W W ==- 30(3)[1,0,1]1=101T W X ????=--≤????-?? ,,故3(4)(3)[1,1,0]T W W X =+=- 41(4)[1,1,0]0=101T W X -????=-????-?? ,>,故(5)(4)[1,1,0]T W W ==- 第二轮迭代: 1x 2x 3x 4x 11(5)[1,1,0]0=101T W X -????=-?????? ,>,故(6)(5)[1,1,0]T W W ==- 20(6)[1,1,0]1=101T W X ????=-?????? ,>,故(7)(6)[1,1,0]T W W ==- 30(7)[1,1,0]1=101T W X ????=-????-?? ,>,故(8)(7)[1,1,0]T W W ==- 41(8)[1,1,0]0=101T W X -????=-????-?? ,>,故(9)(8)[1,1,0]T W W ==- 该轮迭代的分类结果全部正确,故解向量[1,1,0]T W =- 相应的判别函数为12()d X x x =-+ function Perceptron %UNTITLED Summary of this function goes here % Detailed explanation goes here X=[-1 0 0 -1;0 1 1 0;1 1 -1 -1]; W1=[0 0 0]'; t=0; s=1; while s>0 s=0; for i=1:4 if W1'*X(:,i)<=0; W1=W1+X(:,i); s=s+1; else W1=W1+0; s=s+0; end end t=t+1; end fprintf('迭代次数为',t) 习题四 已知两类训练样本为 w 1: (0, 0, 0)T , (1, 0, 0,)T , (1, 0, 1)T , (1, 1, 0)T w 2: (0, 0, 1)T , (0, 1, 1,)T , (0, 1, 0)T , (1, 1, 1)T 设 W (1) = (-1,-2,-2,0)T ,用感知机算法求解判别函数,并绘出判别界面。 解:将属于2w 的训练样本乘以(1)-,并写成增广向量的形式 x1=[0 0 0 1]',x2=[1 0 0 1]',x3=[1 0 1 1]',x4=[1 1 0 1]'; x5=[0 0 -1 -1]',x6=[0 -1 -1 -1]',x7=[0 -1 0 -1]',x8=[-1 -1 -1 -1]'; 迭代选取1C =,(1)(0,0,0,0)w '=,则迭代过程中权向量w 变化如下: (2)(0 0 0 1)w '=;(3)(0 0 -1 0)w '=;(4)(0 -1 -1 -1)w '=;(5)(0 -1 -1 0)w '=;(6)(1 -1 -1 1)w '=;(7)(1 -1 -2 0)w '=;(8)(1 -1 -2 1)w '=;(9)(2 -1 -1 2)w '=; (10)(2 -1 -2 1)w '=;(11)(2 -2 -2 0)w '=;(12)(2 -2 -2 1)w '=;收敛 所以最终得到解向量(2 -2 -2 1)w '=,相应的判别函数为123()2221d x x x x =--+。 第八次迭代:以2x 为训练样本,123(8)1,(8)0,(8)2d d d =-==-,故 112233(9)(8),(9)(8),(9)(8)w w w w w w === 由于第六、七、八次迭代中对312,,x x x 均以正确分类,故权向量的解为: 1.具体应用背景的介绍 感知器是由美国计算机科学家罗森布拉特(F.Roseblatt)于1957年提出的。感知器可谓是最早的人工神经网络。单层感知器是一个具有一层神经元、采用阈值激活函数的前向网络。通过对网络权值的训练,可以使感知器对一组输人矢量的响应达到元素为0或1的目标输出,从而实现对输人矢量分类的目的。 2.分类器设计方法概述及选择依据分析 分类器设计方法概述 感知器是由具有可调节的键结值以及阈值的单一个类神经元所组成,它是各种类神经网络中,最简单且最早发展出来的类神经网络模型,通常被用来作为分类器使用。感知器的基本组成元件为一个具有线性组合功能的累加器,后接一个硬限制器而成,如下图所示: 单层感知器是一个具有一层神经元、采用阈值激活函数的前向网络。通过对网络权值的训练,可以使感知器对一组输入矢量的响应达到元素为0或1的目标输出,从而达到对输入矢量分类的目的。 分类的判断规则是:若感知器的输出为1,则将其归类于C1类;若感知器的输出为0,则将其归类于C2类。判断规则所划分的只有两个判断区域,我们将作为分类依据的超平面定义如下: 感知器分类是通过训练模式的迭代和学习算法,产生线性或非线性可分的模式判别函数。它不需要对各类训练模式样本的统计性质作任何假设,所以是一种确定性的方法。比如固定增量逐次调整算法、最小平方误差算法。 要使前向神经网络模型实现某种功能,必须对它进行训练,让他学会要做的事情, 并把所学到的知识记忆在网络的权值中。人工神经网络的权值的确定不是通过计算,而是通过网络自身的训练来完成的。 感知器的训练过程如下:在输入矢量X的作用下,计算网络的实际输出A 与相应的目标矢量T进行比较,检查A是否等于T,然后比较误差T-A,根据学习规则进行权值和偏差的调整;重新计算网络在新权值作用下的输入,重复权值调整过程,知道网络的输出A等于目标矢量T或训练次数达到事先设置的最大值时结束训练。 感知器设计训练的步骤如下: (1)对于所要解决的问题,确定输入矢量X,目标矢量T,并由此确定各矢量的维数以及确定网络结构大小的参数:r(表示输入矢量维数,神经元的权值向量维数),s(表示一个输入矢量所对应的输出矢量的维数,或者表示神经元个数),p(表示输入矢量组数,)。 (2)参数初始化:赋给权值矢量W在(-1,1)的随机非0初始值;给出最大循环次数max_epcho。 (3)网络表达式:根据输入矢量X以及最新权矢量W,计算网络输出矢量A。(4)检查输出矢量A与目标矢量T是否相同,如果是,或已达到自大循环次数,训练结束,否则转入(5)。 (5)学习:根据感知器的学习规则调整权矢量,并返回(3)。 步骤一:网络初始化 以随机的方式产生乱数,令w(0)为很小的实数,并且将学习循环n设定为1。步骤二:计算网络输出值 选择依据分析 1.准确率:模型正确预测新数据类标号的能力。 2.速度:产生和使用模型花费的时间。 3.健壮性:有噪声数据或空缺值数据时模型正确分类或预测的能力。 4.伸缩性:对于给定的大量数据,有效地构造模型的能力。 5.可解释性:学习模型提供的理解和观察的层次。 3.感知算法原理及算法步骤 感知器基本原理: 基于模式识别的判别函数分类器的设计 与实现 摘要:本文主要介绍了模式识别中判别函数的相关概念和感知器算法的原理及特点,并例举实例介绍感知器算法求解权向量和判别函数的具体方法,最后按照线性函数判决函数的感知算法思想结合数字识别,来进行设计,通过训练数字样本(每个数字样本都大于120),结合个人写字习惯,记录测试结果,最后通过matlab 编码来实现感知器的数字识别。 关键字:模式识别 判别函数 感知器 matlab 1 引言 模式识别就是通过计算机用数学技术方法来研究模式的自动处理和识别。对于人类的识别能力我们是非常熟悉的。因为我们在早些年就已经会开发识别声音、脸、动物、水果或简单不动的东西的技术了。在开发出说话技术之前,一个象球的东西,甚至看上去只是象个球,就已经可以被识别出来了。所以除了记忆,抽象和推广能力是推进模式识别技术的关键技术。最近几年我们已可以处理更复杂的模式,这种模式可能不是直接基于通过感知器观察出来的随着计算机技术的发展,人类对模式识别技术提出了更高的要求。 本文第二节介绍判别函数分类器,具体介绍了判别函数的概念、特点以及如何确定判别函数的正负; 第三节介绍了感知器的概念、特点并用感知器算法求出将模式分为两类的权向量解和判别函数,最后用matlab 实现感知判别器的设计。 2 判别函数分类器 2.1 判别函数概念 直接用来对模式进行分类的准则函数。若分属于ω1,ω2的两类模式可用一方程d (X ) =0来划分,那么称d (X ) 为判别函数,或称判决函数、决策函数。如,一个二维的两类判别问题,模式分布如图示,这些分属于ω1,ω2两类的模式可用一直线方程 d (X )=0来划分。其中0)(32211=++=w x w x w d X 式中: 21,x x 为坐标变量。 图2-1 两类二维模式的分布 将某一未知模式 X 代入: 若0)(>X d ,则1ω∈X 类; 若0)( 单层感知器实现逻辑‘与’功能 1.感知器实现逻辑‘与’功能的学习算法 单层感知器,即只有一层处理单元的感知器。 感知器结构如下图所示: 图1:感知器结构 表1:与运算的真值表 x 1 【 x 2 y 0 0 0 0 1 0 1 0 ) 1 1 1 分界线的方程(w 1x 1+w 2x 2-T=0)可以为: +输入为k x 1、k x 2,输出为yk 。当k x 1和k x 2均为1时,yk 为1,否则yk 为0。 设阈值θ=,训练速率系数η=,初始设置加权为058.0) 0(1=w ,065.0) 0(2=w 。 由于只有一个输出,得加权修正公式为: k k i i x n w n w ηδ+=+)()1( k k k y T -=δ - 第一步:w(0)=, ,加入x 1=(0, 0),05.01221 111-=-+=θx w x w s ,则y 1=0。由 于T 1=0,δ1= T 1- y 1=0,故w(1)=, 第二步:加入x 2=(0, 1),015.02 222112 =-+=θx w x w s ,则y 2=1。由于T 2=0, 则δ2= T 2- y 2=-1,故 w(2)=w(1)+(-1)x 2=, 第三步:加入x 3=(1, 0),008.03 223113=-+=θx w x w s ,则y 3=1。由于T 3=0,则δ3= T 3- y 3=-1,故 w(3)=w(2)+(-1)x 3=, 第四步:加入x 4=(1, 1),033.04 224114=-+=θx w x w s ,则y 4=1。由于T 4=1, 则δ4= T 4- y 4=0,故w(4)=w(3)=, 第五步:加入x 1=(0, 0),S 1=,则y 1=0。由于T 1=0,δ1=0,故w(5)=, 第六步:加入x 2=(0, 1),S 2=,则y 2=0。由于T 2=0,δ2=0,故w(6)=, 第七步:加入x 3=(1, 0),S 3=,则y 3=0。由于T 3=0,δ3=0,故w(7)=, 第八步:加入x 4=(1, 1),S 4=,则y 4=1。由于T 4=1,δ4=0,故w(8)=, 】 所以:w=, 2.用Matlab 实现‘与’逻辑的程序 function yu(); close all; rand('state',sum(100*clock)) X=[-1 0 0;-1 0 1;-1 1 0;-1 1 1]'; d=[0 0 0 1]; h=; $ p=4; epoch=100; T=; W=rand(1,3); W(1)=T; W1=[]; W2=[]; err=[]; k=0; for i=1:epoch 《 s=0; for j=1:p 计算智能作业一 感知器分类 题目: 设有两个模式集合Ω1={(0,1),(0,2),(1,1)},Ω2={(2,0),(3,0),(3,1)},试用感知器算法求出这两个模式类的分类判别函数g(x),试问当权值向量w取不同初值时,对训练结果有影响否,为什么? 算法: 感知器权值调整的学习算法 W k n0+1=W k n0+2ηt q?y r n0?x k n0 实现方法: 设w1x1+w2x2+b=0,x1和x2为样本点的坐标;w1和w2为权值,由计算机随机产生;t q 为期望输出,取1,1,1,?1?,1,?1T;y r为实际输出;学习率为q。 实验结果: 随机产生了三组w值,用蓝线表示迭代过程,红线表示最终分类结果。 g x=-3.53x1+3.68x2-5.20 g x=-5.65x1-2.01x2+8.05 g x=-2.48x1-7.28x2-1.37 实验代码: %感知器先行分类问题程序代码 x=[0,0,1,2,3,3]; y=[1,2,1,0,0,1]; w=10*(2*rand(1,3)-1); b=w(3); %w1,w2,b取-10到10之间的随机数 q=1;%学习率设为1 t=[1,1,1,-1,-1,-1];%期待输出,1为一类,-1为另一类syms p; syms l; for j=1:3%画出一个样本中三个待分类的点 plot(x(j),y(j),'sb');hold on; end for j=4:6%画出另一个样本中三个待分类的点 plot(x(j),y(j),'ok');hold on; end while (p~=w(1)||l~=w(2)) p=w(1);l=w(2); for i=1:6 z=t(i)*(x(i)*w(1)+y(i)*w(2)+b); if z<=0 w(1)=w(1)+q*x(i)*t(i);%?感知器学习算法 w(2)=w(2)+q*y(i)*t(i); b=b+t(i); end title('感知器线性分类结果'); axis([0,5,-1,5]); h=[-1:0.1:5]; g=[0:0.1:5]; k=-w(1)/w(2); m=-b/w(2); h=k*g+m; line(g,h); hold on;%将每一次迭代的直线都画出来 end end plot(g,h,'r'); hold on;%将最终分类结果用红色表示 结论分析: 实验中权值由计算机随机生成,初始权值越接近最终分类的结果,则训练次数越少。权值的不同选择会影响最终分类的结果与训练所耗费的时间,但是不会影响结果的生成,也就是对于线性可分的问题,感知器学习算法是一定找到分类结果的。在实验中,改变学习率的值,做了如下比较: 增加学习率有提高学习效率,减少训练时间的作用。 题:用感知器算法实现样本分类,编写BASE程序。样本X1=[0,0];X2=[0,-1]; X3=[-1,0];X4=[-1,-1]。(1)X1,X2为ω1;X3,X4为ω2。(2)X1,X4为ω1;X2,X3为ω2。计算各权值向量。 解: 1、单个感知器算法步骤。 设给定一个训练模式集{x1,x2,……,x n},其中每个样本的模式类别已知,类别为ω1或ω2。其算法步骤如下: (1)将全部训练样本写成增广向量形式,并进行规范化处理。 (2)任取定初始权向量值W和增量常数c,开始进行迭代。 (3)输入训练样本x i,计算判别函数W k x i。 (4)调整权向量,若W k x i>0,表明分类正确,权向量不变,并将迭代次数加1;若W k x i<0,表明分类错误,计算分类错误次数的变量加1,权向量W k+1=W k+cx i,并将迭代次数加1。 (5)在1轮迭代完成后分类错误次数的变量需置0,并进行下一轮的迭代,直至分类错误次数为0时迭代截止,此时的权值向量即为所求。 2、二元样本、单个感知器算法程序。 function[W k]=PA(X,W,c,classes) %X为训练样本形成的矩阵,训练样本的个数为N;W为权向量;c为校正增量 %classes为各训练样本的类别且为一个N维向量,ω1类用1表示,ω2类用-1表示, [N,n]=size(X);%训练样本的大小N*n,N即训练样本的个数,n即每个训练样本的维数 A=ones(N,1); X1=[X A];%将训练样本写成增广向量形式 %对训练样本规范化 for i=1:N X1(i,:)=classes(i)*X1(i,:); 感知器算法 & BP 算法实验 硕633 3106036072 赵杜娟 一. 实验目的 1. 理解线性分类器的分类原理。 2. 掌握感知器算法,利用它对输入的数据进行分类。 3. 理解BP 算法,使用BP 算法对输入数据进行分类。 二. 实验原理 1. 感知器算法 感知器算法是通过训练模式的迭代和学习算法,产生线性可分的模式判别函数。感知器算法就是通过对训练模式样本集的“学习”得出判别函数的系数解。在本次实验中,我们主要是采用硬限幅函数进行分类。 感知器的训练算法如下: 设输入矢量X x x x N =??????12,,...... , 加权矢量W w w w N =????? ?12,,......,则神经元 的输出可通过下式来计算 (1) 这里对于训练结束我们判断的依据是实际输出值与理想预期值之间误差的均方值最小。定义()()()εk d k y k =-,它的均方值记作()E k []ε 2 ,令()()ξεk E k =[]2, 则可以推出 ()()()[]ξk E d k WE X T X W T E d k X W T =??????-??????-22 (2) 可证存在最佳的加权矢量W * ,使()ξk 达到最小。解得 ()[]W E d k X E X T X *=????? ?-1 (3) 式(3)给出了求最佳加权矢量的方法,但是需要做大量的统计计算,并且需要解决高阶矩阵求逆的问题,这些都是非常困难的。于是我们给出一种递推求解的方法: 在给定初始权值后,以这种方法可以得到递推公式: ()()[] W k W k E k X k ()()+=+12αε (4) 用这种方法虽然可以保证求得严格的最佳解,且避开了矩阵求逆的困难,但学习过程中的每一步仍需完成大量的统计计算。 2.BP 算法 由于硬限幅函数是非可微函数,不能实现多层神经网络的一种有效的LMS 学习算法。而BP 算法中所用到的是Sigmoid 型函数,它既具有完成分类所需的非线性特性,又具有实现LMS 算法所需的可微特性。采用S 型函数的神经元的输入和输出之间的关系为: u s e u f -+= 11 )( (5) 采用了S 型函数就可将用于单神经元的LMS 学习算法适当推广,得到一种适用于前向多层神经网络的有效学习算法。 我们现在研究一个采用S 型函数的前向三层神经网络来说明其原理。 对于训练样本p,它的输入是N 维矢量X ,X=],,[1,10-N p p p x x x ,网络的第一,二,三层分别包括J ,K ,M 个神经元,它的总输出是一个M 维矢量,Y=],,[1,10-M p p p y y y ,第i 层到第i+1层之间的权重系数用) 1(+i nj w 来表示。可设前向三层神经网络输出各个分量的理想 值是pi d ,i=0,1,……M-1,而这些分量的实际值是) 3(pi pi o y =, i=0,1,……M-1,理想值和实际值之间的误差是 ) (pi pi pi y d -=ε。各输出误差的平方和可以表示为: ∑-== 1 2 M i pi p E ε (6) 现在我们希望改变网络中的各个加权系数) (l ij w ,使得p E 尽可能的减小。为此我们可以 采取最陡下降算法的公式来调整权重系数) (l ij p w ?。公式如下: ,)() (l ij p l ij p w E a w ??? -=? 式中的a 是学习的步幅,它应随学习过程而变化。 对于通用神经层,它的各个输出)(l pL o 与各个输入) 1(-l pL o 之间的关系可以表示为: ∑-=--==1 ) () 1()()()(),(L j l i l pj l ij l pi l pi s l pi O w I I f o θ #include模式识别感知器算法求判别函数
机器学习入门 - 感知器
感知器的学习算法
感知器算法实验--1
感知器的训练算法实例
模式识别第三章-感知器算法
感知器学习算法研究
感知器算法 作业
感知机算法习题
感知器
感知器算法
单层感知器实现逻辑‘与’功能
计算智能,感知器分类问题实验报告
模式识别中感知器算法
感知器算法实验
感知器算法(c语言版)