CAPWAP隧道技术白皮书

CAPWAP白皮书
一、CAPW AP简介:
CAPW AP协议目前仍属于IETF-RFC草案,全称:Control And Provisioning of Wireless Access Point Protocol(无线接入点控制与配置协议),该协议用于无线终端接入点(WTP)和无线网络控制器(AC)之间的通信交互,实现了对于AC关联的所有WTP的控制管理和数据转发。目前,CAPW AP通信数据类型总体上可以分为两类:
●CAPW AP控制隧道中传输的CAPW AP控制报文
●CAPW AP数据隧道中传输的CAPW AP数据报文
目前CAPWAP功能的实现都是基于3层网络传输模式下,即所有的CAPW AP报文都被封装成UDP报文格式在IP网路中传输,而CAPW AP隧道就是由AC的接口IP地址和WTP 的IP地址来维护的。
注:此文档对CAPW AP的讨论基于CAPW AP-IETF Draft 10
二、CAPW AP隧道建立
本文档将详细介绍CAPW AP控制隧道和数据隧道的建立过程,以及CAPW AP控制报文和数据报文帧格式。
图一、CAPW AP隧道建立框架图
其中WTP和AC处在不同网段:
AC接口IP :192.168.1.17
WTP1 IP :192.169.10.12
WTP2 IP :220.200.20.36
WTP3 IP :10.39.35.40
STA IP :192.168.20.88
AC与WTPs之间建立起两条通信隧道用于数据处理和转发,下面分别介绍两条CAPW AP 隧道
三、CAPW AP状态机
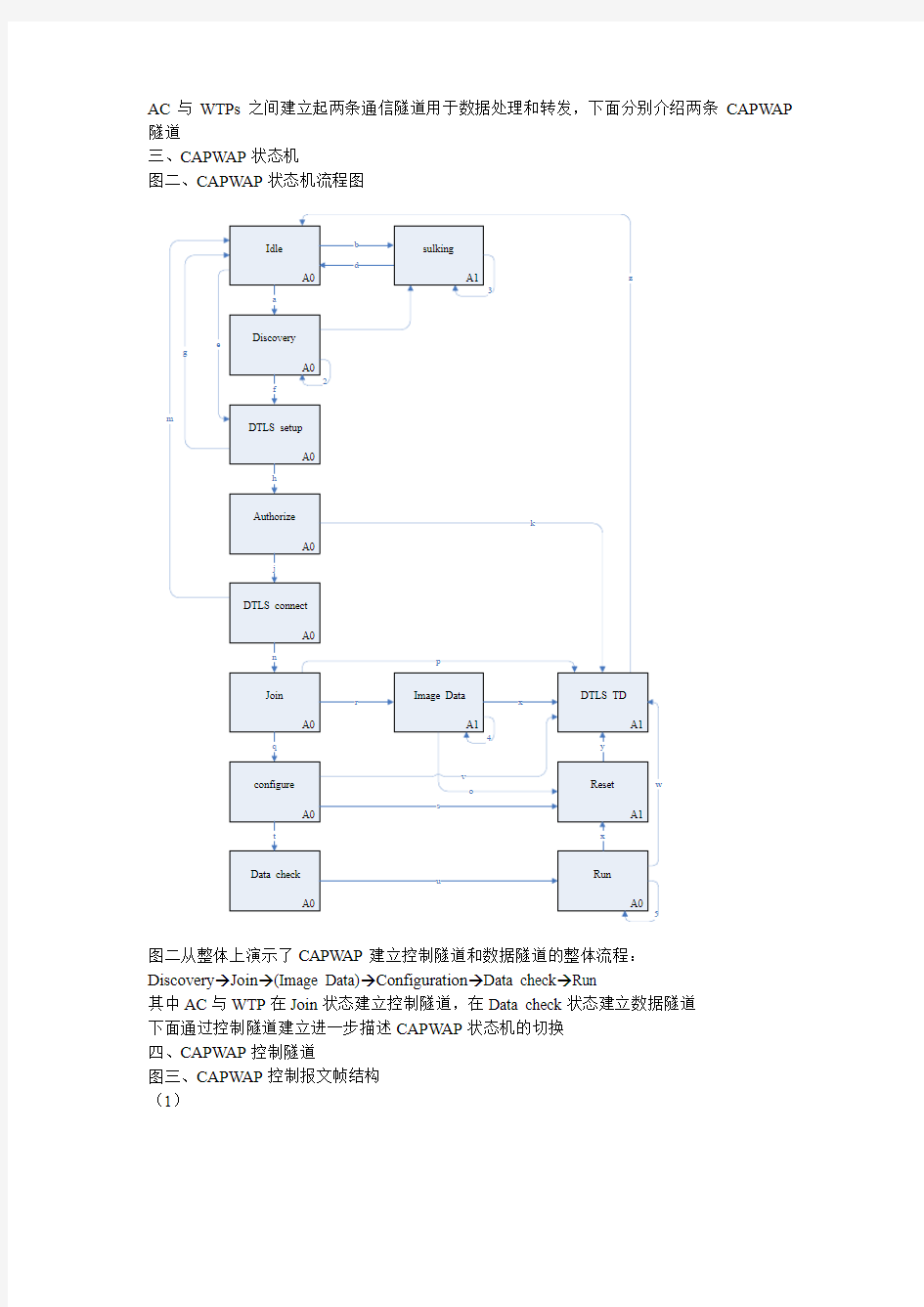
图二、CAPW AP状态机流程图
图二从整体上演示了CAPWAP建立控制隧道和数据隧道的整体流程:
Discovery→Join→(Image Data)→Configuration→Data check→Run
其中AC与WTP在Join状态建立控制隧道,在Data check状态建立数据隧道
下面通过控制隧道建立进一步描述CAPW AP状态机的切换
四、CAPW AP控制隧道
图三、CAPW AP控制报文帧结构
(1)
(2)
图三(1)为CAPW AP控制报文的Discovery帧结构,由于它完成的是查找现有AC的过程,此时控制隧道还未建立,所以它是所有控制报文中唯一非加密数据报文
图三(2)为CAPW AP控制报文帧格式,由于控制隧道是DTLS链接,所以所有CAPWAP 控制报文都会被封装在DTLS中,保证控制隧道的安全,其中Control Header用来描述该报文的作用,Message Element则是实现控制配置目的的参数
图四、CAPW AP控制隧道建立交互流程图
1、Discovery状态
该状态是一个WTP发现可关联AC的过程,在前期WTP可以通过1)读取静态配置文件中AC IP列表2)通过DNS域名解析3)DHCP返回AC IP列表4)广播等方式发送Discovery request,查找当前可关联的AC,当AC收到Discovery request,会发送Discovery response 作为响应。
2、Join状态
该状态是AC与WTP建立控制通道的交互过程,并在此交互过程中,AC检查WTP当前版本,如果WTP的版本无法与AC要求的相匹配,WTP和AC会进入Image Data状态做固件升级,来更新WTP版本;如果WTP版本符合要求,则进入configuration状态
3、Image Data状态
Image Data状态是AC对WTP升级的过程,以便WTP的版本可正常关联AC
4、Configuration状态
该状态用于做WTP的现有配置和AC设定配置的匹配检查,WTP发送configuration request 到AC,里面包含现有WTP配置,当WTP当前配置与AC要求不符实,AC会通过configuration response通知WTP,WTP根据response内容对自身配置做重新设置。
5、Run状态
当WTP进入Run状态,说明WTP与AC的控制和数据通道建立已成功,用户可根据需要,对指定的WTP做配置设置,如创建WLAN、Channel设置、Txpower设置等等,并可实时监控WTP的运行状态。
五、CAPW AP数据隧道
图五、CAPW AP数据帧格式
(1)
(2)
图五(1)为非加密的CAPW AP数据报文格式,由于它是非加密的,所以这种数据报文只能应用在wireless payload内的无线帧已做过安全加密的基础之上,如(WEP、802.1X、WPA 等等)具体内容请参看WLAN身份验证和数据加密白皮书。
图五(2)为加密CAPWAP数据报文帧格式,由于这种数据隧道是建立在DTLS基础之上的,所以安全性和保密性更高。
通过CAPW AP数据隧道,上网用户的无线数据在WTP中被封装在CAPW AP数据报文里提交AC,AC负责实现用户的数据转发。
综述:
AC通过使用CAPWAP协议与WTP建立控制、数据隧道,可以有效解决公司、企业、工厂、学校、医院等的复杂环境下网络难于管理和布置,上网安全性低,对周边网络环境影响抵抗差,预防网络攻击能力不足,接入用户统计管理难等等一系列问题,是当前大中小型企业以及复杂环境下提供上网服务的完美解决方案
工作流引擎技术白皮书
工作流引擎 产品功能介绍V0.07
目录 1.1工作流引擎简介 (4) 1.1.1产生背景 (4) 1.1.2发展阶段 (5) 1.1.2.1EDF(电子数据流)阶段 (5) 1.1.2.2TPF(事务处理流)阶段 (5) 1.1.2.3IMF(整体集成管理流)阶段 (5) 1.1.2.4CPF(知识共享和持续改进)阶段 (6) 1.1.3主要特点 (6) 1.1.4流程定义和运行 (7) 1.1.5流程运转模式 (7) 1.1.6工作流引擎不等于OA系统 (9) 1.2XX工作流引擎 (10) 1.2.1XX工作流引擎简介 (10) 1.2.2产品设计 (11) 1.2.2.1工作流是XX电子政务平台的组件之一 (11) 1.2.2.2工作流引擎设计思想 (12) 1.2.2.3工作流引擎产品架构 (14) 1.2.3产品功能 (15) 1.2.3.1支持流程运转模式 (15) 1.2.3.2设计工具 (19) 1.2.3.3控制平台 (21) 1.2.3.4任务列表 (22) 1.2.3.5流程与用户 (24) 1.2.3.6工作流数据 (25) 1.2.3.7事务处理 (26) 1.2.3.8异常处理 (26) 1.2.4产品安全能力 (26) 1.2.5产品集成扩展 (26)
1.2.6运行环境 (27) 1.3XX工作流引擎适应复杂应用的要求 (27) 1.3.1多机构联合作业 (28) 1.3.2流程的定义集中管理 (29) 1.3.3嵌套子流程和和引用子流程 (29) 1.4XX工作流应用实施方法 (29) 1.4.1点面结合,全面推进 (29) 1.4.2分步实施,适当激励 (30) 1.4.3持续改进,形成文化 (30) 1.5XX工作流引擎成功案例 (30) 1.5.1广州移动广州公务机管理系统 (31) 1.5.1.1实现功能 (31) 1.5.1.2实施效果 (32) 1.5.2广州外经贸网上政务-发文管理 (33) 1.5.2.1实现功能 (33) 1.5.2.2实施效果 (35)
工作流引擎技术白皮书
工作流引擎产品功能介绍
目录
1.1工作流引擎简介 1.1.1产生背景 随着我国信息化建设的不断深入,越来越多的政府部门和企事业单位都清醒地认识到信息化对于自身的生存与发展的重要性,以IT 系统建设为基础提高工作效率,增强竞争能力,已经成为共识。 在过去的若干年中,许多企业以当时的IT 发展水平为基础,针对不同的业务需求搭建了种类繁多的应用系统。回顾这一阶段,我们可以发现长期以来IT 系统的建设一直跟随着技术的革新和业务需求的增长而被动地发展着。不论技术手段如何变化,企业仍旧习惯于沿着功能分析的思路为特定的需求开发专有应用。随着时间的推移,企业内部逐渐积累了许多相互孤立的筒仓式应用系统。不可否认,正是这些应用系统共同构成了当今企业的主要IT 运行环境并有效地支撑了企业早期的业务发展,但是我们也必须清醒地认识到,在这些缺乏前期规划、互连性极差的应用系统之间信息不能被有效地共享且难于保持一致,业务过程也无法顺畅地流转,它们是造成“信息孤岛”现象的根源。一些企业也曾经尝试采用整理、合并各种需求、统一数据接口、规范业务过程等方式来降低集成的复杂度,但是在经过一番实践后,人们又发现仅仅依靠规范静态信息的交换格式,集合局部的需求等方法并不足以支持更大范围内的应用整合。因此当前的企业迫切需要一个能够支持在不同的应用系统之间完成协作任务的具有前瞻性的应用集成框架。 当前,企业面对的是一个多变且难以预测的市场,要在这样的环境中生存和
发展,就必需具备对外部变化做出迅速响应的能力。同样,政府部门也面临着转变工作职能,适应市场经济发展要求的压力,需要不断地为大众提供各种高效的公共服务。各项独立调查表明: 对业务系统和IT 基础设施进行快速调整和扩展一直是政府部门和企事业单位应对外部环境变化的重要手段。然而在早期的IT 系统设计过程中,人们往往更加关注于系统的稳定性而不是迅速应对变化的能力,原先那种僵硬的基于硬编码实现的系统功能扩展和集成方式已远远不能满足要求。“采用什么样的技术来搭建能够实现跨部门、跨企业、跨地理范围的支持流程协作和流程自动化的IT 基础设施”,“如何能够从被动地应对变化到预见变化进而实现前瞻性地主动变化”…这些都是当前每一个政府部门和企事业单位必须面对的挑战。 通过工作流系统把各业务部门的孤立应用系统整合起来是IT技术发展的必然趋势,而我国从上实际八十年代大量建设基础信息系统至今,工作流技术的发展可以分成以下几个阶段。 1.1.2发展阶段 1.1. 2.1EDF(电子数据流)阶段 此阶段的工作流在信息技术中的应用,仅着眼于利用信息技术减轻人们在流程中的计算强度最主要的特点是仅对企业单项业务进行处理,基本不涉及管理的内容。国内最早成功的产品是财务管理产品,为了配合产生正确的数据,可能要设计一个流程用来协调多个会计统计帐目。 此阶段仅仅停留在诸如文档处理、公文流转以及信息发布等这些简单的业务
大数据处理及分析理论方法技术
大数据处理及分析理论方法技术 (一)大数据处理及分析建设的过程 随着数据的越来越多,如何在这些海量的数据中找出我们需要的信息变得尤其重要,而这也是大数据的产生和发展原因,那么究竟什么是大数据呢?当下我国大数据研发建设又有哪些方面着力呢? 一是建立一套运行机制。大数据建设是一项有序的、动态的、可持续发展的系统工程,必须建立良好的运行机制,以促进建设过程中各个环节的正规有序,实现统合,搞好顶层设计。 二是规范一套建设标准。没有标准就没有系统。应建立面向不同主题、覆盖各个领域、不断动态更新的大数据建设标准,为实现各级各类信息系统的网络互连、信息互通、资源共享奠定基础。
三是搭建一个共享平台。数据只有不断流动和充分共享,才有生命力。应在各专用数据库建设的基础上,通过数据集成,实现各级各类指挥信息系统的数据交换和数据共享。 四是培养一支专业队伍。大数据建设的每个环节都需要依靠专业人员完成,因此,必须培养和造就一支懂指挥、懂技术、懂管理的大数据建设专业队伍。 (二)大数据处理分析的基本理论 对于大数据的概念有许多不同的理解。中国科学院计算技术研究所李国杰院士认为:大数据就是“海量数据”加“复杂数据类型”。而维基百科中的解释为:大数据是由于规模、复杂性、实时性而导致的使之无法在一定时间内用常规软件工具对其进行获取、存储、搜索、分享、分析、可视化的数据集合。 对于“大数据”(Bigdata)研究机构Gartner给出了这样的定义。“大数据”是需要新处理模式才能具有更强的决
图2.1:大数据特征概括为5个V (三)大数据处理及分析的方向 众所周知,大数据已经不简简单单是数据大的事实了,而最重要的现实是对大数据进行分析,只有通过分析才能获取很多智能的,深入的,有价值的信息。那么越来越多的应用涉及到大数据,而这些大数据的属性,包括数量,速度,多样性等等都是呈现了大数据不断增长的复杂性,所以大数据的分析方法在大数据领域就显得尤为重要,可以说是决定
BP神经网络实验——【机器学习与算法分析 精品资源池】
实验算法BP神经网络实验 【实验名称】 BP神经网络实验 【实验要求】 掌握BP神经网络模型应用过程,根据模型要求进行数据预处理,建模,评价与应用; 【背景描述】 神经网络:是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型。BP神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络,是目前应用最广泛的神经网络。其基本组成单元是感知器神经元。 【知识准备】 了解BP神经网络模型的使用场景,数据标准。掌握Python/TensorFlow数据处理一般方法。了解keras神经网络模型搭建,训练以及应用方法 【实验设备】 Windows或Linux操作系统的计算机。部署TensorFlow,Python。本实验提供centos6.8环境。 【实验说明】 采用UCI机器学习库中的wine数据集作为算法数据,把数据集随机划分为训练集和测试集,分别对模型进行训练和测试。 【实验环境】 Pyrhon3.X,实验在命令行python中进行,或者把代码写在py脚本,由于本次为实验,以学习模型为主,所以在命令行中逐步执行代码,以便更加清晰地了解整个建模流程。 【实验步骤】 第一步:启动python: 1
命令行中键入python。 第二步:导入用到的包,并读取数据: (1).导入所需第三方包 import pandas as pd import numpy as np from keras.models import Sequential from https://www.360docs.net/doc/2b7574831.html,yers import Dense import keras (2).导入数据源,数据源地址:/opt/algorithm/BPNet/wine.txt df_wine = pd.read_csv("/opt/algorithm/BPNet/wine.txt", header=None).sample(frac=1) (3).查看数据 df_wine.head() 1
云计算白皮书
天云科技云计算白皮书 目录 1 概述3 1.1云计算的概念3 1.2云计算的特点4 1.3云计算的分类5 1.4云计算实现机制6 1.5云计算发展现状8 2 云计算应用方向与实例10 2.1基础设施租用10 2.2海量数据管理12 2.3在线软件服务12 2.4云安全应用14 3 云计算优势分析17 3.1性价比优势17 3.2应用优势20 3.3可靠性优势20 3.4安全性优势21 4 云计算发展趋势22 4.1云计算的历史定位22 4.2云计算与3G和物联网25 4.3云计算与网格融合发展25 5 云计算演进策略28 5.1云计算带来的变革28 5.1.1 机遇28 5.1.2 挑战29 5.2政府部门的演进策略31 5.3运营商的演进策略33 5.4典型行业的演进策略34 5.4.1 能源行业35 5.4.2 服务行业35
5.4.3 教育行业36 5.4.4 医疗行业37 6 天云科技与云计算38 6.1 我们的使命39 6.2 我们的团队39 6.3 服务和产品39 6.4 推动形成云产业链40
1 概述 “云计算”这个词汇是Google CEO埃里克·施密特于2006年8月9日在搜索引擎战略会议上的演讲中首次提到。2007年第3季度,这个词汇开始引起广泛关注,随后公众对这个词的搜索量呈爆炸式增长。一时间,众说纷芸,有人称之为炒作,有人猛烈抨击,有人迅速转型,有人大声叫好。经过短短的几年发展,云计算已经形成了雷霆万钧的势能和横扫千军的动能。Google、Amazon、IBM与微软等互联网与IT巨头纷纷把云计算作为自己未来的核心战略。更重要的是在硅谷近百家新型云计算创新企业正在兴起,业务范围涉及从硬件、软件到应用的各个领域;这些企业创新的势头及其目标定位颇像三十年前个人计算机及十五年前互联网刚刚出现的时候,具有创新精神的小公司迅速而大量涌现,这些公司在刚成立时便立志从技术、服务、商业模式等方面挑战与颠覆现有的IT产业格局。 1.1 云计算的概念 然而,对于到底什么是云计算,至少可以找到100种解释,目前还没有公认的定义。本白皮书给出一种参考定义: 云计算是一种商业计算模型,它将计算任务分布在大量计算机构成的资源池上,使用户能够按需获取计算力、存储空间和信息服务。 这种资源池称为“云”。“云”是一些可以自我维护和管理的虚拟计算资源,通常是一些大型服务器集群,包括计算服务器、存储服务器和宽带资源等。云计算将计算资源集中起来,并通过专门软件实现自动管理,无需人为参与。用户可以动态申请部分资源,支持各种应用程序的运转,无需为烦琐的细节而烦恼,能够更加专注于自己的业务,有利于提高效率、降低成本和技术创新。云计算的核心理念是资源池,这与早在2002年刘鹏教授提出的网格计算池(Computing Pool)的概念非常相似。网格计算池将计算和存储资源虚拟成为一个可以任意组合分配的集合,池的规模可以动态扩展,分配给用户的处理能力可以动态回收重用。这种模式能够大大提高资源的利用率,提升平台的服务质量。 之所以称为“云”,是因为它在某些方面具有现实中云的特征:云一般都较大;云的规模可以动态伸缩,它的边界是模糊的;云在空中飘忽不定,无法也无需确定它的具体位置,但它确实存在于某处。之所以称为“云”,还因为云计算的鼻祖之一亚马逊公司将大家曾经称为网格计算的东西,取了一个新名称“弹性计算云”(Elastic Computing Cloud),并取得了商业上的成功。 云计算是并行计算(Parallel Computing)、分布式计算(Distributed Computing)和网格计算(Grid Computing)的发展,或者说是这些计算科学概念的商业实现。云计算是虚拟化(Virtualization)、效用计算(Utility Computing)、将基础设施作为服务IaaS (Infrastructure as a Service)、将平台作为服务PaaS(Platform as a Service)和将软件作为服务SaaS(Software as a Service)等概念混合演进并跃升的结果。
大数据采集技术概述
智慧IT 大数据采集技术概述 技术创新,变革未来
大数据中数据采集概念 数据采集(DAQ):又称数据获取,是指从传感器和其它待测设备等模拟和数字被测单元中自动及被动采集信息的过程。 数据分类新一代数据体系中,将传统数据体系中没有考虑过的新数据源进行归纳与分类,可将其分为线上行为数据与内容数据两大类。 在大数据领域,数据采集工作尤为重要。目前主流以实时采集、批量采集、ETL相关采集等
大数据的主要来源数据 ?线上行为数据:页面数据、交互数据、表单数据、会话数据等。 ?内容数据:应用日志、电子文档、机器数据、语音数据、社交媒体数据等。 ?大数据的主要来源: 1)商业数据 2)互联网数据 3)传感器数据 4)软件埋点数据等
数据源 分析数据、清洗数据时候。首先弄清除数据的来源。 数据的所有来源是程序。比如:web程序、服务程序等。 数据的形态 两种:日志文件、数据流。 对比: 由于数据流的接口要求比较高。比如有些语言不支持写入kafka。 队列跨语言问题。所以日志文件是主要形态。数据流的用于实时分析较好。 日志文件好处:便于分析、便于跨平台、跨语言。 调试代码注意。 常用的日志文件输出工具log4j。写程序时尽量别写system.out。
互联网日志采集统计常见指标 1、UGC : User Generated Content,也就是用户生成的内容。 2、UV:(unique visitor),指访问某个站点或点击某条新闻的不同IP地址 的人数。现已引申为各个维度的uv泛称。 3、PV:(pageview),即页面浏览量,或点击量。 4、DAU : daily active user,日活跃用户数量、MAU : 月活跃用户量 5、ARPU : Average Revenue Per User 即每用户平均收入,用于衡量 电信运营商和互联网公司业务收入的指标。 6、新增用户数、登录用户数、N日留存(率)、转换率。
数据挖掘常用资源及工具
资源Github,kaggle Python工具库:Numpy,Pandas,Matplotlib,Scikit-Learn,tensorflow Numpy支持大量维度数组与矩阵运算,也针对数组提供大量的数学函数库 Numpy : 1.aaa = Numpy.genfromtxt(“文件路径”,delimiter = “,”,dtype = str)delimiter以指定字符分割,dtype 指定类型该函数能读取文件所以内容 aaa.dtype 返回aaa的类型 2.aaa = numpy.array([5,6,7,8]) 创建一个一维数组里面的东西都是同一个类型的 bbb = numpy.array([[1,2,3,4,5],[6,7,8,9,0],[11,22,33,44,55]]) 创建一个二维数组aaa.shape 返回数组的维度print(bbb[:,2]) 输出第二列 3.bbb = aaa.astype(int) 类型转换 4.aaa.min() 返回最小值 5.常见函数 aaa = numpy.arange(20) bbb = aaa.reshape(4,5)
numpy.arange(20) 生成0到19 aaa.reshape(4,5) 把数组转换成矩阵aaa.reshape(4,-1)自动计算列用-1 aaa.ravel()把矩阵转化成数组 bbb.ndim 返回bbb的维度 bbb.size 返回里面有多少元素 aaa = numpy.zeros((5,5)) 初始化一个全为0 的矩阵需要传进一个元组的格式默认是float aaa = numpy.ones((3,3,3),dtype = numpy.int) 需要指定dtype 为numpy.int aaa = np 随机函数aaa = numpy.random.random((3,3)) 生成三行三列 linspace 等差数列创建函数linspace(起始值,终止值,数量) 矩阵乘法: aaa = numpy.array([[1,2],[3,4]]) bbb = numpy.array([[5,6],[7,8]]) print(aaa*bbb) *是对应位置相乘 print(aaa.dot(bbb)) .dot是矩阵乘法行乘以列 print(numpy.dot(aaa,bbb)) 同上 6.矩阵常见操作
HC大数据产品技术白皮书
H3C大数据产品技术白皮书杭州华三通信技术有限公司 2020年4月
目录 1 H3C大数据产品介绍 (1) 1.1产品简介 (1) 1.2产品架构 (1) 1.2.1 数据处理 (2) 1.2.2 数据分层 (3) 1.3产品技术特点 (4) 先进的混合计算架构 (4) 高性价比的分布式集群 (4) 云化ETL (5) 数据分层和分级存储 (5) 数据分析挖掘 (6) 数据服务接口 (6)
可视化运维管理 (7) 1.4产品功能简介 (7) 管理平面功能: (12) 业务平面功能: (14) 2DataEngine HDP核心技术 (15) 3DataEngine MPP Cluster核心技术 (16) 3.1MPP + Shared Nothing架构 (16) 3.2核心组件 (16) 3.3高可用 (17) 3.4高性能扩展能力 (18) 3.5高性能数据加载 (18) 3.6OLAP函数 (19) 3.7行列混合存储 (19)
1H3C大数据产品介绍 1.1产品简介 H3C大数据平台采用开源社区Apache Hadoop2.0和MPP分布式数据库混合计算框架为用户提供一套完整的大数据平台解决方案,具备高性能、高可用、高扩展特性,可以为超大规模数据管理提供高性价比的通用计算存储能力。H3C大数据平台提供数据采集转换、计算存储、分析挖掘、共享交换以及可视化等全系列功能,并广泛地用于支撑各类数据仓库系统、BI 系统和决策支持系统帮助用户构建海量数据处理系统,发现数据的内在价值。 1.2产品架构 H3C大数据平台包含4个部分: 第一部分是运维管理,包括:安装部署、配置管理、主机管理、用户管理、服务管理、监控告警和安全管理等。 第二部分是数据ETL,即获取、转换、加载,包括:关系数据库连接Sqoop、日志采集Flume、ETL工具 Kettle。
大数据关键技术(一)——数据采集知识讲解
大数据开启了一个大规模生产、分享和应用数据的时代,它给技术和商业带来了巨大的变化。 麦肯锡研究表明,在医疗、零售和制造业领域,大数据每年可以提高劳动生产率0.5-1个百 分点。 大数据技术,就是从各种类型的数据中快速获得有价值信息的技术。大数据领域已经涌现出 了大量新的技术,它们成为大数据采集、存储、处理和呈现的有力武器。 大数据关键技术 大数据处理关键技术一般包括:大数据采集、大数据预处理、大数据存储及管理、大数据分 析及挖掘、大数据展现和应用(大数据检索、大数据可视化、大数据应用、大数据安全等)。 然而调查显示,未被使用的信息比例高达99.4%,很大程度都是由于高价值的信息无法获取 采集。 如何从大数据中采集出有用的信息已经是大数据发展的关键因素之一。 因此在大数据时代背景下,如何从大数据中采集出有用的信息已经是大数据发展的关键因素 之一,数据采集才是大数据产业的基石。那么什么是大数据采集技术呢?
什么是数据采集? ?数据采集(DAQ):又称数据获取,是指从传感器和其它待测设备等模拟和数字被测单元中自动采集信息的过程。 数据分类新一代数据体系中,将传统数据体系中没有考虑过的新数据源进行归纳与分类,可将其分为线上行为数据与内容数据两大类。 ?线上行为数据:页面数据、交互数据、表单数据、会话数据等。 ?内容数据:应用日志、电子文档、机器数据、语音数据、社交媒体数据等。 ?大数据的主要来源: 1)商业数据 2)互联网数据 3)传感器数据
数据采集与大数据采集区别 传统数据采集 1. 来源单一,数据量相对于大数据较小 2. 结构单一 3. 关系数据库和并行数据仓库 大数据的数据采集 1. 来源广泛,数据量巨大 2. 数据类型丰富,包括结构化,半结构化,非结构化 3. 分布式数据库
技术白皮书模板
XXXX 技术白皮书 XX技术股份有限公司 XXXX 2011年1月 目录 第一章概述 3 第二章平台架构 4 2.1平台整体架构 4 2.2平台技术架构 4 第三章平台特点 5 3.1 稳定性 5 3.2 设备接入全面 5 3.3 智能 5 3.4 易用性 5 3.5 扩展性 5
3.6 开放性 5 3.7 标准性 5 3.8 组件化 5 3.9 传输能力 5 3.10 多级级联 5 第四章平台特色功能 5 3.1 特色功能一 5 3.2特色功能二 5 3.3特色功能三 5 3.4特色功能四 6 3.5特色功能五 6 3.6特色功能六 6 第五章平台技术参数 6 5.1服务器端配置要求 6 5.2管理员客户端配置要求 6 5.3操作员客户端配置要求 6 5.4 单服务器性能指标 6
5.5 客户端性能指标 6 第六章行业案例 6 6.1 案例概述 6 6.2 案例特点 6 6.3 案例网络结构图 6 6.4 案例图例 6 第一章概述 第二章平台架构 2.1平台整体架构 2.2平台技术架构 第三章平台特点
3.1 稳定性 3.2 设备接入全面 3.3 智能 3.4 易用性 3.5 扩展性 3.6 开放性 3.7 标准性 3.8 组件化 3.9 传输能力 3.10 多级级联 第四章平台特色功能 3.1 特色功能一 3.2特色功能二 3.3特色功能三 3.4特色功能四 3.5特色功能五 3.6特色功能六 第五章平台技术参数
5.1服务器端配置要求 5.2管理员客户端配置要求5.3操作员客户端配置要求5.4 单服务器性能指标 5.5 客户端性能指标 第六章行业案例 6.1 案例概述 6.2 案例特点 6.3 案例网络结构图 6.4 案例图例
题库深度学习面试题型介绍及解析--第7期
1.简述激活函数的作用 使用激活函数的目的是为了向网络中加入非线性因素;加强网络的表示能力,解决线性模型无法解决的问题 2.那为什么要使用非线性激活函数? 为什么加入非线性因素能够加强网络的表示能力?——神经网络的万能近似定理 ?神经网络的万能近似定理认为主要神经网络具有至少一个非线性隐藏层,那么只要给予网络足够数量的隐藏单元,它就可以以任意的精度来近似任何从一个有限维空间到另一个有限维空间的函数。 ?如果不使用非线性激活函数,那么每一层输出都是上层输入的线性组合;此时无论网络有多少层,其整体也将是线性的,这会导致失去万能近似的性质 ?但仅部分层是纯线性是可以接受的,这有助于减少网络中的参数。3.如何解决训练样本少的问题? 1.利用预训练模型进行迁移微调(fine-tuning),预训练模型通常在特征上拥有很好的语义表达。此时,只需将模型在小数据集上进行微调就能取得不错的效果。CV 有 ImageNet,NLP 有 BERT 等。 2.数据集进行下采样操作,使得符合数据同分布。
3.数据集增强、正则或者半监督学习等方式来解决小样本数据集的训练问题。 4.如何提升模型的稳定性? 1.正则化(L2, L1, dropout):模型方差大,很可能来自于过拟合。正则化能有效的降低模型的复杂度,增加对更多分布的适应性。 2.前停止训练:提前停止是指模型在验证集上取得不错的性能时停止训练。这种方式本质和正则化是一个道理,能减少方差的同时增加的偏差。目的为了平衡训练集和未知数据之间在模型的表现差异。 3.扩充训练集:正则化通过控制模型复杂度,来增加更多样本的适应性。 4.特征选择:过高的特征维度会使模型过拟合,减少特征维度和正则一样可能会处理好方差问题,但是同时会增大偏差。 5.你有哪些改善模型的思路? 1.数据角度 增强数据集。无论是有监督还是无监督学习,数据永远是最重要的驱动力。更多的类型数据对良好的模型能带来更好的稳定性和对未知数据的可预见性。对模型来说,“看到过的总比没看到的更具有判别的信心”。 2.模型角度
Pentaho 开放源码的商业智能平台技术白皮书
Pentaho 开放源码的商业智能平台 技术白皮书 摘要 所有组织都希望在业务过程和总性能中通过改善效率和有效性来提高收入,降低成本,达到改善收益的目的。而商业智能(BI) 软件供应商声称他们有相应技术来满足这种需求。 这些软件供应商销售用于构建这些解决方案(Solution)的产品或工具,但很少关注客户 面临的真正问题。客户为了新需求,而不断去联系新的供应商,买进新的工具,聘请新的顾问。最终,公司的BI initiative 变成了众多相互独立的解决方案(Solution),为了维护和协调它们,需要使用各种昂贵的调度管理程序来整合各个方案。 在现有方案中,每为解决一个特定问题,就设计一个应用平台,这样在实际应用中,一个业务问题被分割成许多单独的任务,如报表,分析,数据挖掘,工作流等等,而没有应用负责初始化,管理,验证或调整结果,最终需要人手动的来弥补这些不足。 这个白皮书描述了Pentaho 商业智能平台:一个面向解决方案(Solution)的BI 平台,其将开放源码组件/公开标准和流程驱动引擎集成在一起。它显示了这个BI 平台如何通过将BI 和工作流/流程管理相结合,并对之进行改善,并以开放源码的形式发布平台来解决BI 问题。 问题描述 传统的商业智能(BI) 工具昂贵、复杂,并且在效率和性能方面具有很大不足,难于让 企业获得真正益处。各个软件供应商均承诺其BI 将提供整合,分析和报表等必要功能, 将数据转换成蕴涵价值的知识,使管理者得到更及时有用的决策信息。不幸的是,这种 BI 系统和报表系统几乎并没有什么太大的差别,仅仅如此是不能满足需求的。 当传送一个报表,或遇到一个特定情形时,需要触发一些特定的应对操作:重新响应决 策,并需要发现引发这些变化的原因,或启动一个特定流程。在这些案例中,信息展示, 分析和传送(BI) 是一个较大流程里的一部分。我们需要这样的流程来解决商业问题。 (译者注:作者强调业务流程是商业问题的关键。BI只是业务流程的一部分。) 为澄清: 通常一个商业问题的解决方案(Solution)是一个包含商业智能(BI) 的流程。
产品的解决方案技术白皮书模板.doc
一、背景概述 (2) 1、研发背景 (2) 2、产品定位 (2) 二、产品方案功能介绍 (2) 1、设计理念 (2) 2、系统拓扑图 (2) 3、系统构架描述 (2) 4、系统功能介绍 (2) 5、产品方案规格 (2) 四、产品方案应用介绍 (3) 1、应用模式 (3) 2、应用流程 (3) 3、应用环境 (3) 五、产品方案特性介绍 (3) 1、技术特性 (3) 2、应用特性 (3) 3、系统特性 (3) 六、产品方案技术介绍 (3) 1、相关技术 (3) 2、技术指标 (4) 七、产品方案测评数据 (4) 八、实施运维方式说明 (4) 九、售后服务方式说明 (4)
一、背景概述 1、研发背景 介绍用户需求背景、该产品所在行业信息化建设背景、产品所涉及的相关政策简述等,以说明该产品的研发背景,以及满足的客户需求。 2、产品定位 为了满足客户以上需求,该产品具有什么功能,能够解决什么问题。 二、产品方案功能介绍 1、设计理念 该产品方案的设计思路。 2、系统拓扑图 使用统一的图标,制作系统拓扑图。 3、系统构架描述 按照系统的构成,分类对系统进行描述。 4、系统功能介绍 详细阐述系统的主要功能。 5、产品方案规格 产品方案不同的规格介绍,或者对产品方案技术规格的介绍。
四、产品方案应用介绍 1、应用模式 该产品方案包括的应用模式类型,或者针对不同类型客户的解决方案。 2、应用流程 该产品方案的应用流程。 3、应用环境 描述该产品所运行的应用环境。 五、产品方案特性介绍 1、技术特性 主要是性能先进性、功能齐全性、系统兼容性、技术稳定性等。 2、应用特性 主要是部署灵活性、可扩展性、管理方便性、易用性等。 3、系统特性 对系统的主要特性进行描述,根据产品不同和竞争优势的不同而不同。 六、产品方案技术介绍 1、相关技术 主要应用技术的介绍,以及该技术的优势。
工业互联网平台技术白皮书
工业互联网平台技术白皮书
目录 一、工业互联网平台的整体态势 (1) (一)全球工业互联网平台保持活跃创新态势 (1) (二)我国工业互联网平台呈现蓬勃发展良好局面 (1) (三)工业互联网平台整体仍处于发展初期 (2) 二、工业互联网平台的应用路径 (3) (一)平台应用场景逐步聚焦,国内外呈现不同发展特点 (3) (二)我国平台应用进展迅速,大中小企业协同推进 (5) 1.平台应用全面开展,模式创新与跨界融合成为我国特色.5 2.我国大中小企业基于平台并行推进创新应用与能力普及.7 (三)平台应用发展层次与价值机理逐步清晰 (9) 1.由单点信息化走向跨域智能化,应用呈现三大发展层次.9 2.数据分析深度与工业机理复杂度决定平台应用优化价值和 发展热度 (12) (四)垂直行业平台应用走向纵深 (13) 1.高端装备行业重点围绕产品全生命周期开展平台应用.. 13 2.流程行业以资产、生产、价值链的复杂与系统性优化为应用 重点 (15) 3.家电、汽车等行业侧重于规模化定制、质量管理与产品后服 务应用 (17)
4.制药、食品等行业的平台应用以产品溯源与经营管理优化为 重点 (18) 5.电子信息制造业重点关注质量管理与生产效率提升 (19) 三、工业互联网平台的技术进展 (20) (一)边缘功能重心由接入数据向用好数据演进 (22) 1.数据接入由定制化方案走向平台通用服务 (22) 2.边缘数据分析从简单规则向复杂分析延伸 (23) 3.通用IT 软硬件架构向边缘侧下沉,为边缘应用创新提供更 好载体和环境 (24) (二)模型的沉淀、集成与管理成平台工业赋能的核心能力. 26 1.信息模型规范统一成为平台提升工业要素管理水平的关键 (26) 2.机理模型、数据模型、业务模型加速沉淀,工业服务能力不 断强化 (27) 3.多类模型融合集成,推动数字孪生由概念走向落地 (28) (三)数据管理与分析从定制开发走向成熟商业方案 (29) 1.平台聚焦工业特色需求,强化工业数据管控能力 (29) 2.实时分析与人工智能成为平台数据分析技术的创新热点. 30 3.平台贴近工业实际,完善工具不断提高工业数据易用性. 31 (四)平台架构向资源灵活组织、功能封装复用、开发敏捷高效加速演进 (32) 1.容器、微服务技术演进大幅提升平台基础架构灵活性.. 32
人工智能实践:Tensorflow笔记 北京大学 7 第七讲卷积网络基础 (7.3.1) 助教的Tenso
Tensorflow笔记:第七讲 卷积神经网络 本节目标:学会使用CNN实现对手写数字的识别。 7.1 √全连接NN:每个神经元与前后相邻层的每一个神经元都有连接关系,输入是特征,输出为预测的结果。 参数个数:∑(前层×后层+后层) 一张分辨率仅仅是28x28的黑白图像,就有近40万个待优化的参数。现实生活中高分辨率的彩色图像,像素点更多,且为红绿蓝三通道信息。 待优化的参数过多,容易导致模型过拟合。为避免这种现象,实际应用中一般不会将原始图片直接喂入全连接网络。 √在实际应用中,会先对原始图像进行特征提取,把提取到的特征喂给全连接网络,再让全连接网络计算出分类评估值。
例:先将此图进行多次特征提取,再把提取后的计算机可读特征喂给全连接网络。 √卷积Convolutional 卷积是一种有效提取图片特征的方法。一般用一个正方形卷积核,遍历图片上的每一个像素点。图片与卷积核重合区域内相对应的每一个像素值乘卷积核内相对应点的权重,然后求和,再加上偏置后,最后得到输出图片中的一个像素值。 例:上面是5x5x1的灰度图片,1表示单通道,5x5表示分辨率,共有5行5列个灰度值。若用一个3x3x1的卷积核对此5x5x1的灰度图片进行卷积,偏置项
b=1,则求卷积的计算是:(-1)x1+0x0+1x2+(-1)x5+0x4+1x2+(-1)x3+0x4+1x5+1=1(注意不要忘记加偏置1)。 输出图片边长=(输入图片边长–卷积核长+1)/步长,此图为:(5 – 3 + 1)/ 1 = 3,输出图片是3x3的分辨率,用了1个卷积核,输出深度是1,最后输出的是3x3x1的图片。 √全零填充Padding 有时会在输入图片周围进行全零填充,这样可以保证输出图片的尺寸和输入图片一致。 例:在前面5x5x1的图片周围进行全零填充,可使输出图片仍保持5x5x1的维度。这个全零填充的过程叫做padding。 输出数据体的尺寸=(W?F+2P)/S+1 W:输入数据体尺寸,F:卷积层中神经元感知域,S:步长,P:零填充的数量。 例:输入是7×7,滤波器是3×3,步长为1,填充为0,那么就能得到一个5×5的输出。如果步长为2,输出就是3×3。 如果输入量是32x32x3,核是5x5x3,不用全零填充,输出是(32-5+1)/1=28,如果要让输出量保持在32x32x3,可以对该层加一个大小为2的零填充。可以根据需求计算出需要填充几层零。32=(32-5+2P)/1 +1,计算出P=2,即需填充2
大数据采集技术和预处理技术
现如今,很多人都听说过大数据,这是一个新兴的技术,渐渐地改变了我们的生活,正是由 于这个原因,越来越多的人都开始关注大数据。在这篇文章中我们将会为大家介绍两种大数 据技术,分别是大数据采集技术和大数据预处理技术,有兴趣的小伙伴快快学起来吧。 首先我们给大家介绍一下大数据的采集技术,一般来说,数据是指通过RFID射频数据、传 感器数据、社交网络交互数据及移动互联网数据等方式获得的各种类型的结构化、半结构化 及非结构化的海量数据,是大数据知识服务模型的根本。重点突破高速数据解析、转换与装 载等大数据整合技术设计质量评估模型,开发数据质量技术。当然,还需要突破分布式高速 高可靠数据爬取或采集、高速数据全映像等大数据收集技术。这就是大数据采集的来源。 通常来说,大数据的采集一般分为两种,第一就是大数据智能感知层,在这一层中,主要包 括数据传感体系、网络通信体系、传感适配体系、智能识别体系及软硬件资源接入系统,实 现对结构化、半结构化、非结构化的海量数据的智能化识别、定位、跟踪、接入、传输、信 号转换、监控、初步处理和管理等。必须着重攻克针对大数据源的智能识别、感知、适配、 传输、接入等技术。第二就是基础支撑层。在这一层中提供大数据服务平台所需的虚拟服务器,结构化、半结构化及非结构化数据的数据库及物联网络资源等基础支撑环境。重点攻克 分布式虚拟存储技术,大数据获取、存储、组织、分析和决策操作的可视化接口技术,大数 据的网络传输与压缩技术,大数据隐私保护技术等。 下面我们给大家介绍一下大数据预处理技术。大数据预处理技术就是完成对已接收数据的辨析、抽取、清洗等操作。其中抽取就是因获取的数据可能具有多种结构和类型,数据抽取过 程可以帮助我们将这些复杂的数据转化为单一的或者便于处理的构型,以达到快速分析处理 的目的。而清洗则是由于对于大数并不全是有价值的,有些数据并不是我们所关心的内容, 而另一些数据则是完全错误的干扰项,因此要对数据通过过滤去除噪声从而提取出有效数据。在这篇文章中我们给大家介绍了关于大数据的采集技术和预处理技术,相信大家看了这篇文 章以后已经知道了大数据的相关知识,希望这篇文章能够更好地帮助大家。
“网络预警”系统产品技术白皮书
IP网络运维经管系统 为企业的网络和关键应用保驾护航 “网络预警”系统产品技术 白皮书
嘉锐世新科技(北京)有限公司 目录
1、概述 “网络”的迅速发展已经成为人们办公、日常生活中不可缺少的一部分,一旦网络出现问题将导致无法正常办公,甚至网站内容被篡改等将产生不良影响等。 网络机房,作为企业或政府“网络心脏”,网络机房的重要性越来越被信息部门重视,在以往的建设中网络中心领导注重外网的攻击,内网的经管等部分,设立防火墙,上网行为经管等设备保证网络的正常运行,往往忽视了网络运维中的网络预警。 预警,听到这个名词大多会理解为,消防、公安、天气、山体滑坡等,非专业人士很少人知道网络也可以“预警”,网络预警是建立在正常网络运行状态下所占用的网络带宽,CPU的使用率、温度,内存的使用率等,根据常规值设定阀值,一但产生大的变化超过阀值将产生报警,自动通知网络经管人员,及时准确的定位到某台设备、某个端口出现故障,网络经管人员免去繁琐的检查工作,一免影响网络的正常运行。 现在市场上以有众多的网络预警产品,各家都有相应的优缺点,我公司所提供的产品相比其他家的优势为: 1.专业硬件系统,没有纯软件产品的部署和维护烦恼;
集网络设备、服务器、应用系统监控经管、机房环境监控、内网流量分析经管于一身,不需单独投资各个系统; 2.网络日志服务子系统,可收集所有网络设备的运行log,易于查询,永久保存; 3.独创的集成VPN功能,轻松监控和经管远端局域网内的服务器; 4.监控历史记录、性能曲线、报表等非常详尽; 5.全中文web经管方式,智能式向导配置,更易于使用和符合国内网络经管人员使用习惯; 6.独创远程协助功能,轻松获取专业技术服务; 7.同比其它的国际品牌有较高的性价比。 2、“网络预警”产品结构及主要功能 “网络预警”系统由IP网络监控报警主系统和流量分析经管、VPN和防火墙、日志储存服务等多个子系统组成。 系统以实用设计为原则,运行于安全可靠的Linux操作系统,采用多层高性能架构设计,可经管上万个监控对象。采用中文WEB架构,全面支持SNMP、WMI 和IPMI协议,提供昂贵的高端网管产品才具有的丰富功能,操作简单,是追求实用和高性价比的企业用户、政府、事业单位以及IDC服务提供商为用户提供增值服务的首选产品。 IP网络监控预警主系统
人工智能实践:Tensorflow笔记 北京大学 4 第四讲神经网络优化 (4.6.1) 助教的Tenso
Tensorflow笔记:第四讲 神经网络优化 4.1 √神经元模型:用数学公式表示为:f(∑i x i w i+b),f为激活函数。神经网络是以神经元为基本单元构成的。 √激活函数:引入非线性激活因素,提高模型的表达力。 常用的激活函数有relu、sigmoid、tanh等。 ①激活函数relu: 在Tensorflow中,用tf.nn.relu()表示 r elu()数学表达式 relu()数学图形 ②激活函数sigmoid:在Tensorflow中,用tf.nn.sigmoid()表示 sigmoid ()数学表达式 sigmoid()数学图形 ③激活函数tanh:在Tensorflow中,用tf.nn.tanh()表示 tanh()数学表达式 tanh()数学图形 √神经网络的复杂度:可用神经网络的层数和神经网络中待优化参数个数表示 √神经网路的层数:一般不计入输入层,层数 = n个隐藏层 + 1个输出层
√神经网路待优化的参数:神经网络中所有参数w 的个数 + 所有参数b 的个数 例如: 输入层 隐藏层 输出层 在该神经网络中,包含1个输入层、1个隐藏层和1个输出层,该神经网络的层数为2层。 在该神经网络中,参数的个数是所有参数w 的个数加上所有参数b 的总数,第一层参数用三行四列的二阶张量表示(即12个线上的权重w )再加上4个偏置b ;第二层参数是四行两列的二阶张量()即8个线上的权重w )再加上2个偏置b 。总参数 = 3*4+4 + 4*2+2 = 26。 √损失函数(loss ):用来表示预测值(y )与已知答案(y_)的差距。在训练神经网络时,通过不断改变神经网络中所有参数,使损失函数不断减小,从而训练出更高准确率的神经网络模型。 √常用的损失函数有均方误差、自定义和交叉熵等。 √均方误差mse :n 个样本的预测值y 与已知答案y_之差的平方和,再求平均值。 MSE(y_, y) = ?i=1n (y?y_) 2n 在Tensorflow 中用loss_mse = tf.reduce_mean(tf.square(y_ - y)) 例如: 预测酸奶日销量y ,x1和x2是影响日销量的两个因素。 应提前采集的数据有:一段时间内,每日的x1因素、x2因素和销量y_。采集的数据尽量多。 在本例中用销量预测产量,最优的产量应该等于销量。由于目前没有数据集,所以拟造了一套数据集。利用Tensorflow 中函数随机生成 x1、 x2,制造标准答案y_ = x1 + x2,为了更真实,求和后还加了正负0.05的随机噪声。 我们把这套自制的数据集喂入神经网络,构建一个一层的神经网络,拟合预测酸奶日销量的函数。
Oracle BPM技术白皮书
ORACLE BPM产品介绍 目录 1.业务流程生命周期及方法论 (2) 1.1流程建模 (3) 1.2流程仿真 (3) 1.3流程开发及系统集成 (4) 1.4流程运行 (4) 1.5流程监控和优化 (5) 2.业务流程管理平台 (5) 2.1统一的SOA架构 (8) 2.2业务流程建模 (11) 2.2.1设计阶段流程建模 (11) 2.2.2运行阶段调整流程 (13) 2.3流程模拟仿真 (14) 2.4灵活的业务流程模式 (16) 2.5人工流程和流程操作 (18) 2.5.1基于角色设计人工流程 (18) 2.5.2任务列表和流程交互操作 (19) 2.5.3基于流程进行协作 (22) 2.6自动化流程表单设计 (24) 2.7用户管理和安全 (26) 2.8灵活的业务规则 (26) 2.9灵活、可靠的流程运行 (28) 2.9.1流程版本 (28) 2.9.2异常流程 (28) 2.10实时流程监控和优化 (29) 2.11统一业务流程管理 (34)
1.业务流程生命周期及方法论 Oracle BPM为应用支撑架构中的业务流程管理平台提供了面向电子政务业务的平台,它提供涵盖从流程建模、开发、执行、优化的各个方面完整的流程生命周期支持。面向业务的流程可以覆盖人与人、应用与应用以及人与应用的各种资源和服务。它不但实现业务流程的自动化,并完成了从执行到监控和优化的整个业务流程生命期。业务流程生命周期主要包括设计期和运行期。 图:业务流程生命周期 业务流程管理是跨组织结构,跨系统,跨应用的软件和方法论,从而实现自动化管理,优化动态业务,产生真正的业务价值。针对业务流程管理,ORACLE 提供了成熟的BPM解决方案声明周期管理,依照此种方式构建BPM系统,将最大化的降低系统开发部署开销。